
{kind=link}
شبکه BERT چیست و چطور پدید آمد؟ چگونه در حوزه پردازش زبانهای طبیعی یا همان NLP انقلاب کرده است؟ در این مطلب بهصورت مفصل مدل BERT را معرفی کردهایم، از سرآغازش گفتهایم، آن را شرح دادهایم و نشان دادهایم چگونه حوزهی پردازش زبانهای طبیعی را متحول کرده است.
شبکه BERT چیست و چطور پدید آمد؟
زمانی که برای اولین بار یک شبکه عصبی پیچشی (Convolutional Neural Network) در مسابقه ImageNet برنده شد، توجه همگان به مبحث یادگیری ماشین و در ادامه یادگیری عمیق جلب شد. دیگر همگان راهحل تمامی مشکلها را در این زمینه جستوجو میکردند، ولی فراموش میکردند که مسابقهی ImageNet دادهی عظیمی در اختیار شرکتکنندگان قرار میدهد و برگبرندهی شبکههای عمیق نیز همین دادهی زیاد است، درصورتیکه برای خیلی از مشکلات این حجم از اطلاعات در دسترس نیست.
از طرفی آموزش یک شبکهی عمیق با دادهی زیاد از دست همه ساخته نیست؛ زیرا این کار به قدرت پردازشی زیادی نیاز دارد.
اینجا بود که استفاده از مدلهای ازقبلآموزشدیده (Pre-trained Models) به کمک افرادی آمد که داده و قدرت پردازشی محدودی داشتند. شبکههایی که با دادهی مسابقهی Imagenet آموزش داده شدهاند در اختیار همه قرار داده شد و دیگر نیازی نبود که تمامی مسیر را از اول طی کنیم. در این حالت کافی است که یک شبکه را با استفاده از دو روش استخراج ویژگی (Feature Extraction) و تنظیم دقیق (Fine-tuning) برای کار خودمان اختصاصی کنیم.
ولی اگر مسئله ما به تصویر مربوط نباشد، چطور؟ دادهی به این عظیمی برای متن را از کجا بیاوریم؟ چگونه شبکه را آموزش دهیم؟
سرآغاز شبکه BERT چیست
برای استفاده از مدلهای از قبل آموزشدیده در مسائلی که با متن سروکار دارند، ابتدا به سراغ مدلهای تعبیهی کلمات (Word Embedding) رفتیم که به ما کمک و تغییر محسوسی در دقت شبکهها ایجاد کردند، ولی عمیق نبودند و حاوی اطلاعات کمی بودند؛ درواقع کمک آنها مؤثر ولی محدود بود.
در سال ۲۰۱۸ این مسیر برای مسئلههای متنی یا بهطور دقیقتر پردازش زبان های طبیعی (Natural Language Processing) نیز در دسترس قرار گرفت. مهندسان گوگل مدل بزرگی با دادهی زیاد را آموزش دادند و آن را در دسترس همه قرار دادند. حالا یک مدل بسیار قدرتمند برای بهرهگیری در مسائل متنی در اختیار داریم؛ این مدل BERT نام دارد.
برای آشنایی با مدل ترنسفورمر این مطلب را مطالعه کنید:
مدل ترنسفورمر (Transformer Model) یا مدل انتقالی چیست؟
مدل شبکه BERT چیست؟
در پاسخ به پرسش شبکه BERT چیست باید به مدل آن بپردازیم. مدل شبکه BERT یا Bidirectional Encoder Representations from Transforme در دو اندازهی متفاوت آموزش داده شده است: BERTBASE و BERTLARGE.
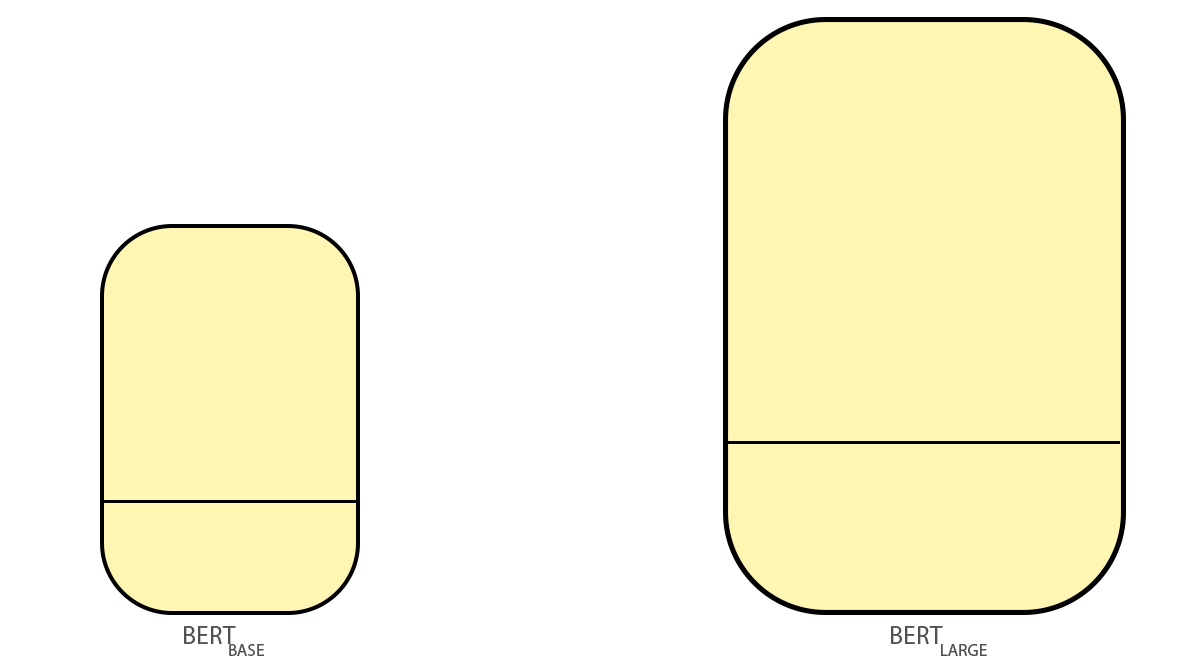
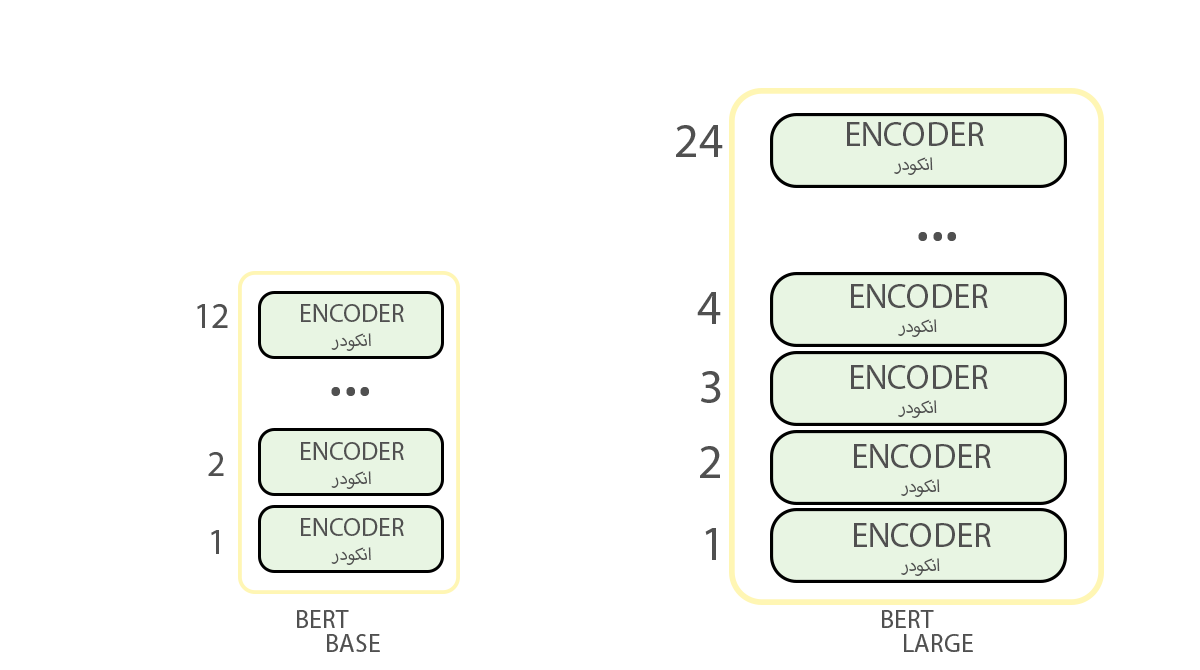
مدل BERT درواقع دستهای از انکودرهای مدل ترنسفورمر (Transformer Model) است که آموزش دیدهاند. هر دو مدل BERT تعداد زیادی لایهی انکودر دارند.
مدل شبکه BERTBASE شامل ۱۲ لایه انکودر (در مقالهی اصلی Transformer Blocks نامیده میشوند) و مدل بزرگتر که همان مدل BERTLARGE است شامل ۲۴ لایه انکودر است. مدل پایه در مجموع ۱۱۰میلیون پارامتر و مدل بزرگ ۳۴۵میلیون پارامتر دارد. آموزش هر یک از آنها چهار روز زمان برده است. مدل پایه ۷۶۸ و مدل بزرگتر ۱۰۲۴ نود پنهان در لایهی شبکه پیشخور خود دارند و تعداد لایههای توجه در اولی ۱۲ و در دومی ۱۶ است.
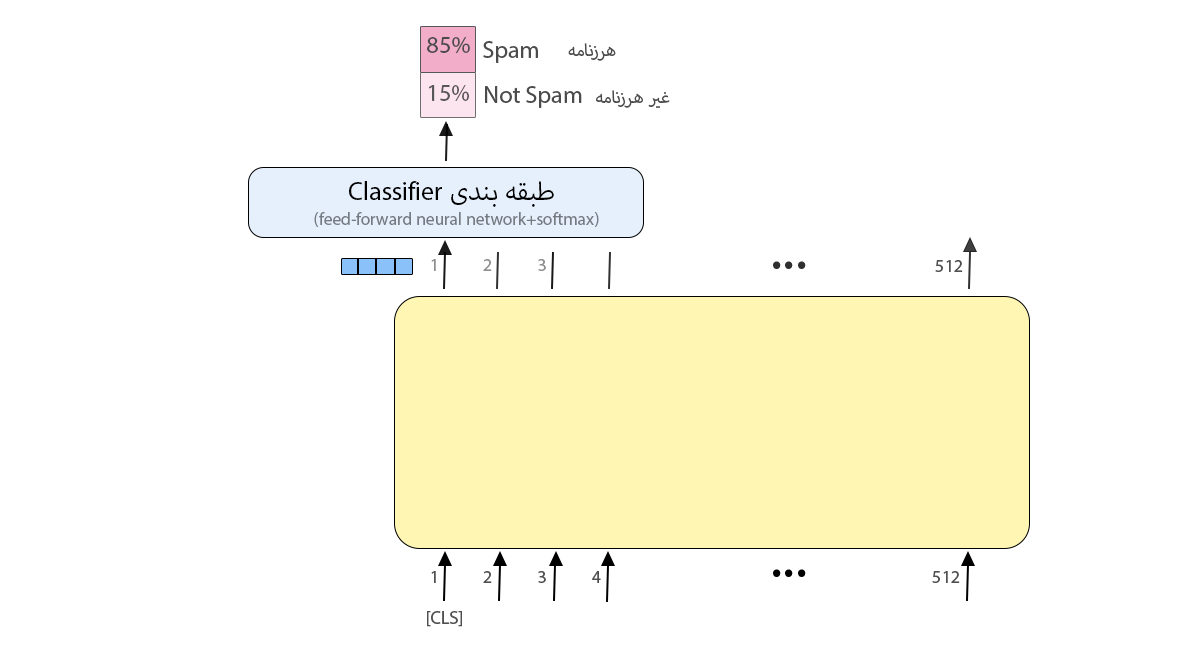
اولین توکن ورودی با یک توکن خاص بهنام CLS به مدل وارد میشود و دقیقاً مانند بخش انکودر مدل ترنسفورمر که در بخش قبلی دربارهی آن صحبت شد، مدل BERT توالی از کلمات را در ورودی دریافت میکند. اینها در طول لایههای انکودر موجود حرکت میکنند. هر لایهی انکودر یک لایهی Self-Attention و یک لایهی شبکهی پیشخور را شامل است که ورودیها از آنها میگذرند و سپس به لایهی انکودر بعدی وارد میشوند.
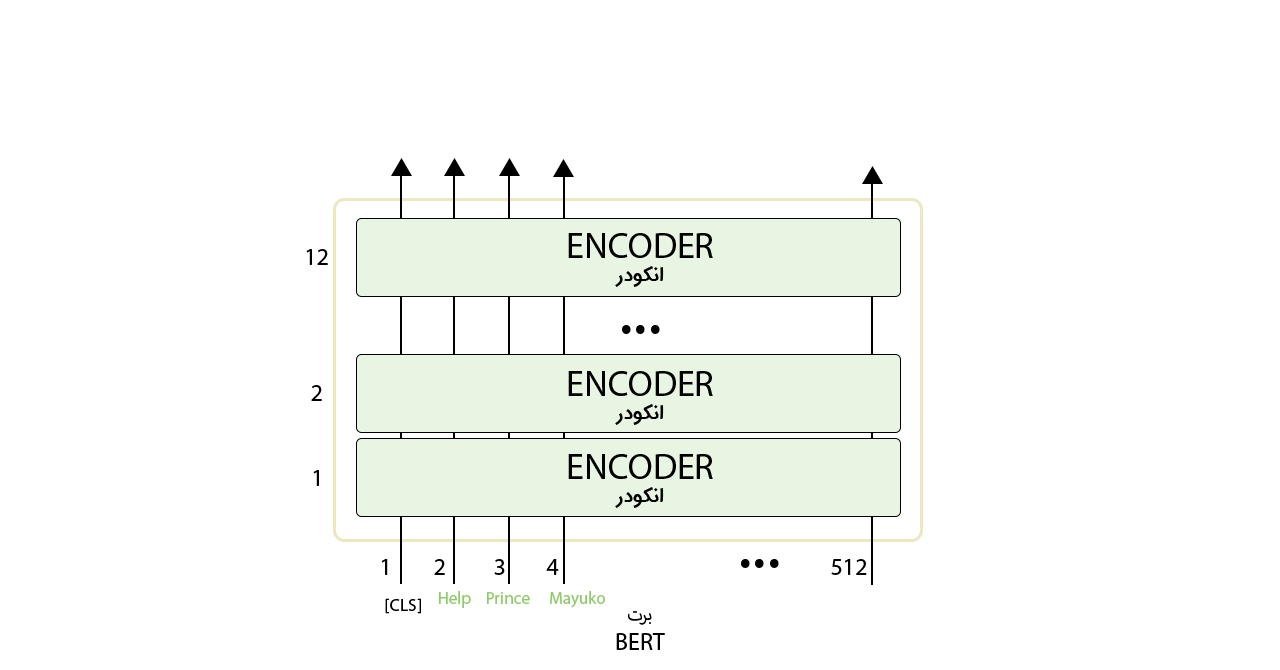
هر موقعیت یک بردار بهاندازهی نودهای لایهی پنهان را در خروجی ارائه میکند؛ برای مثال در مدل BERTBASE اندازهی لایهی پنهان ۷۶۸ است؛ پس در خروجی بردارهایی بهاندازهی ۷۶۸ خواهیم داشت. در مسئلهی طبقهبندی فقط بردار خروجی اول محل تمرکز ماست که ورودی آن همان توکن CLS بود.
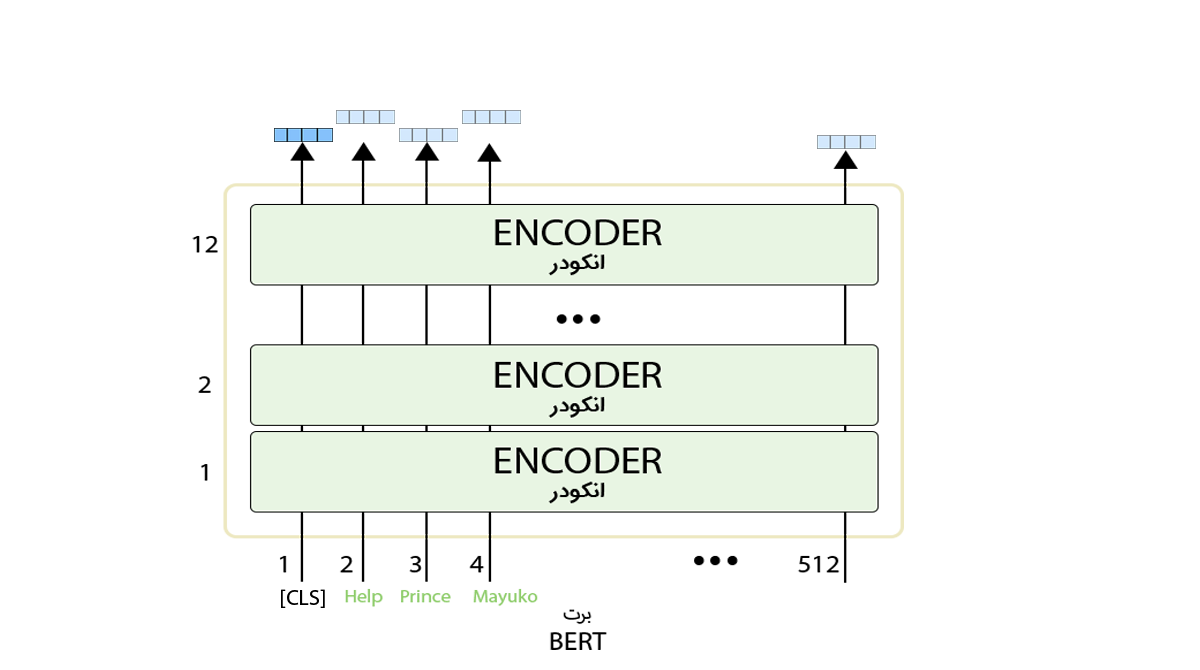
این بردار خروجی در مسئلهی طبقهبندی بهعنوان ورودی به لایهی طبقهبندی وارد میشود تا نتیجه را در خروجی نمایش دهد.
آموزش مدل BERT
برای آموزش BERT از این دو روش استفاده شده است:
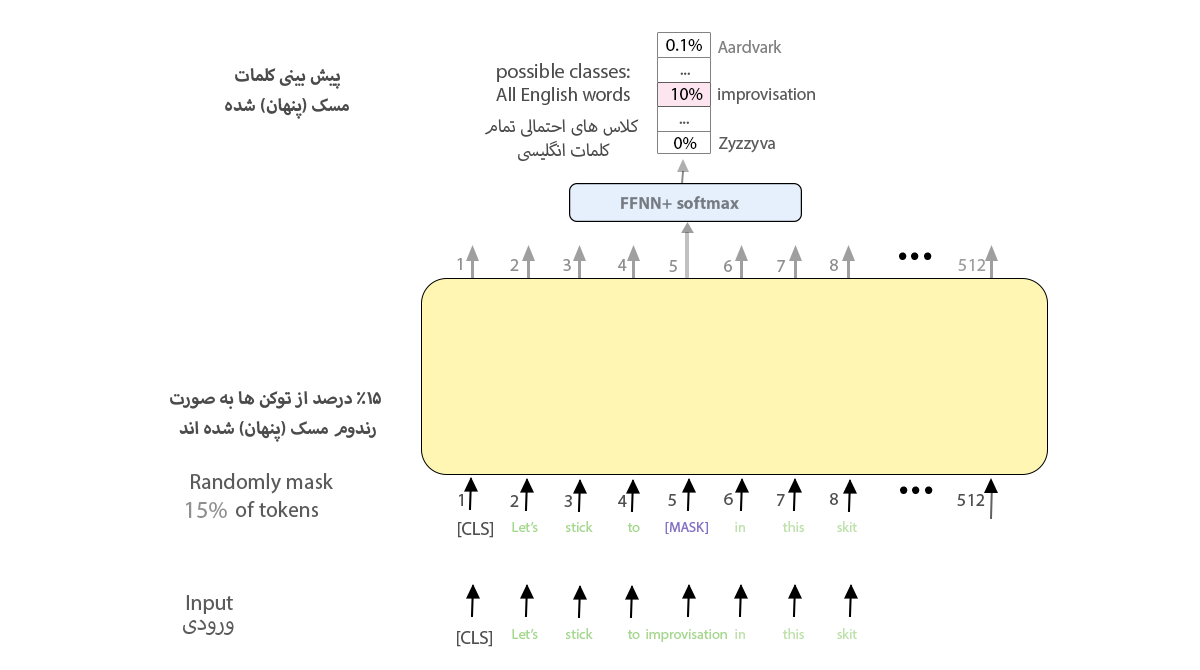
۱. مدل زبانی نقابدار (Masked Language Model)
۱۵ درصد لغات متن با توکن [MASK] جایگزین و به ورودی BERT داده میشوند. یک لایهی طبقهبندی بهاندازهی تعداد لغات بههمراه لایهی سافتمکس به خروجیِ انکودر اضافه میشود. در این روش باید لغات حذفشده را مدل حدس بزند. آموزش این شبکهی دوسویه (Bidirectional Network) است و به کلمات قبلی و بعدی حساس است.
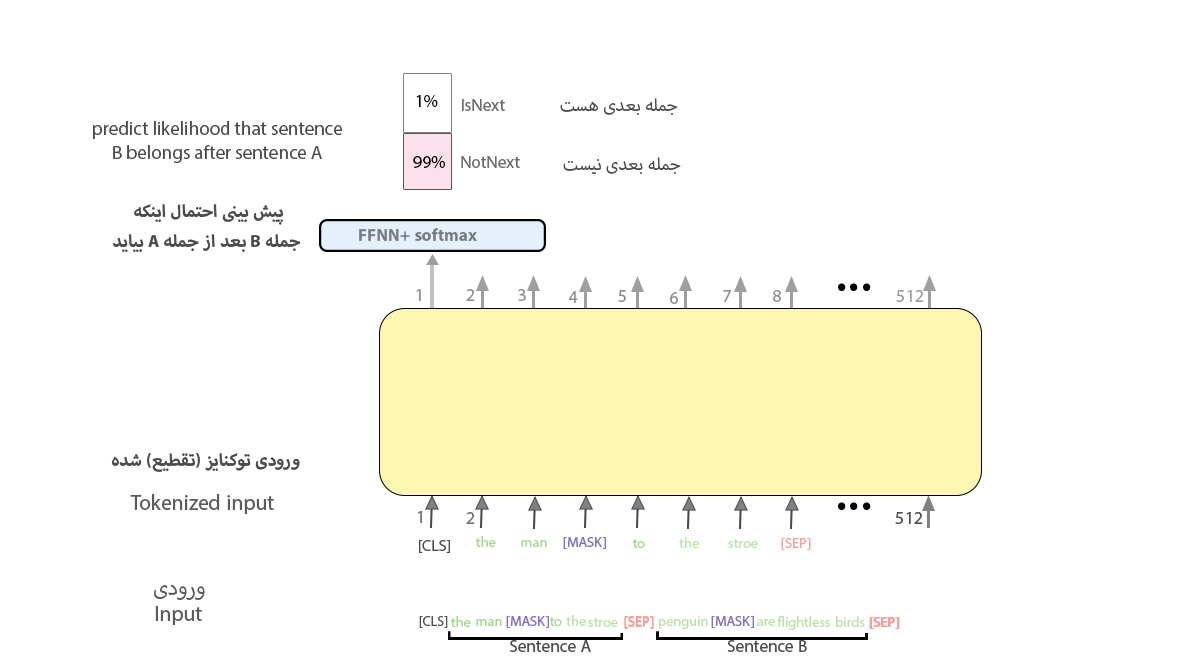
۲. پیشبینی جملهی بعدی (Next Sentence Prediction / NSP)
بهمنظور اینکه مدل BERT کارایی بهتری را در تشخیص ارتباط میان جملات داشته باشد، به مرحلهی آموزش تسک دیگری نیز اضافه شد که در آن وظیفهی مدل این بار این است که یاد بگیرد این دو جمله دو جملهی متوالی هستند یا نه. در ورودی دو جمله را توکن [SEP] از هم جدا میکند.
روشهای استفاده از مدل شبکه برت (BERT)
به دو روش میتوان از BERT استفاده کرد:
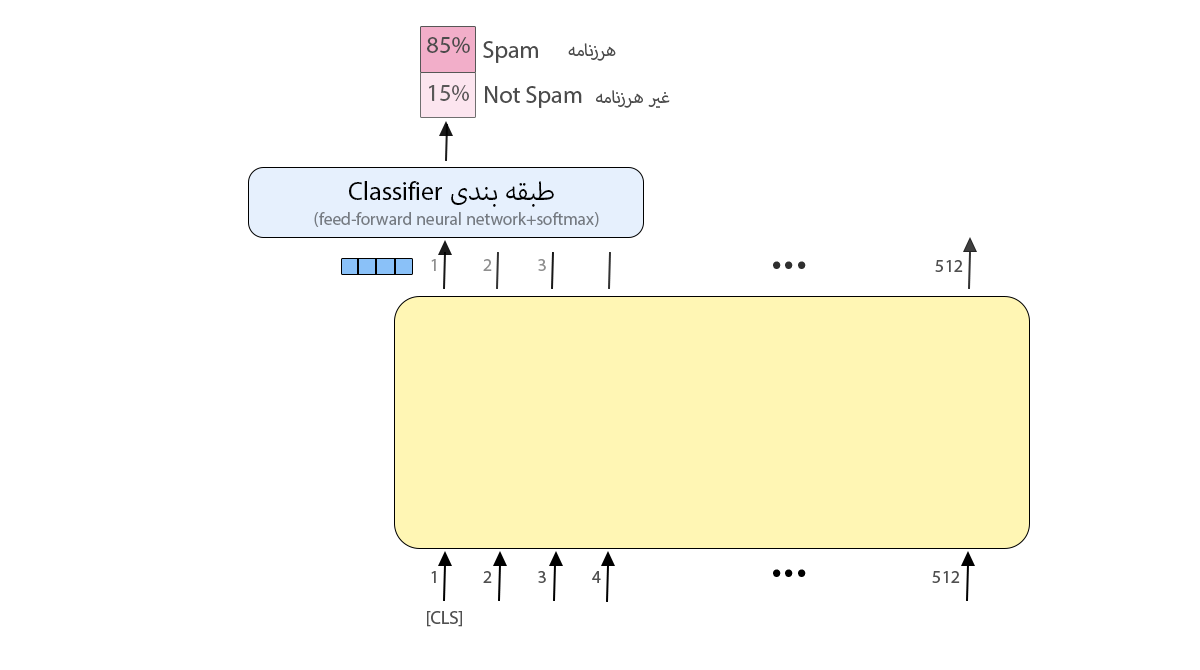
۱. تنظیم دقیق (Fine-tuning)
ورودی این مدل یک فهرست به طول ۵۱۲ توکن است. این توکنها از ۱۲ لایه (در مدل پایه) میگذرند و در انتها یک بردار با طول ۷۶۸ (در مدل پایه) بهعنوان خروجی برگردانده میشود. این بردار ورودی مدل دیگری برای مسئلهی خودمان میتواند باشد؛ مثلاً در شکل ۸ از مدل برت برای تشخیص مثبت یا منفیبودن جمله استفاده شده است. خروجی مدل برت به یک لایهی طبقهبندیکننده (شبکهی پیشخور و تابع سافتمکس) وارد میشود تا احتمال هر کلاس را به ما بدهد.
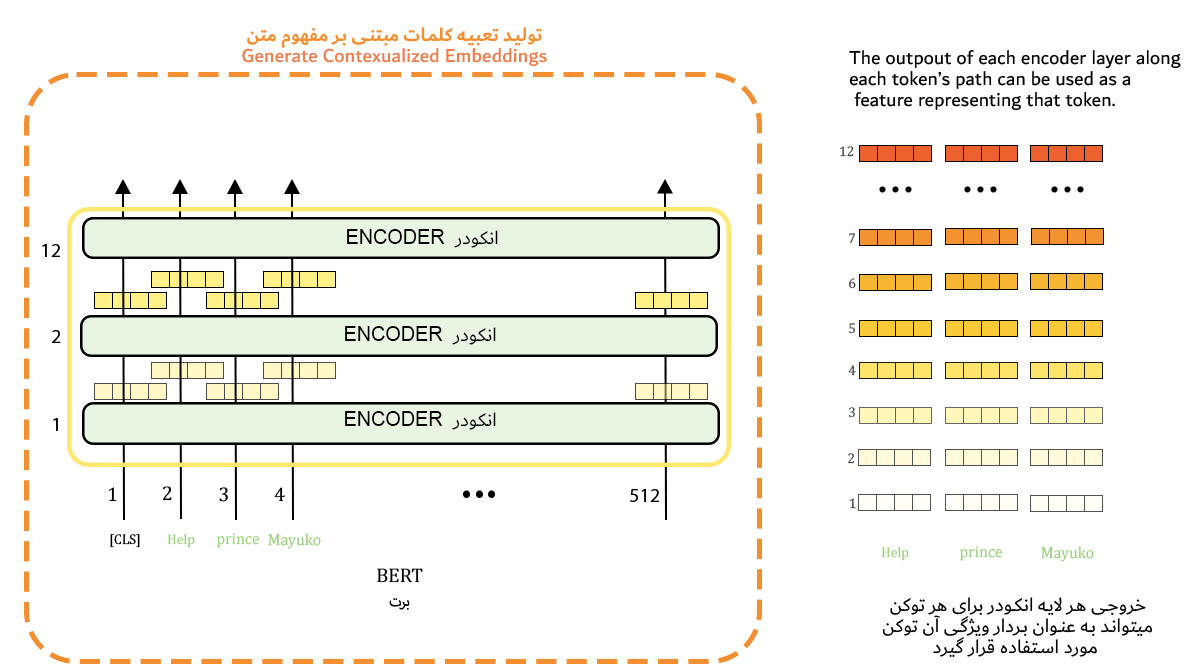
۲. استخراج ویژگی (Feature Extraction)
علاوه بر Fine-tuning به روش استخراج ویژگی هم میتوان از مدل BERT استفاده کرد. بهصورتیکه خروجی لایههای میانی انکودر را بهعنوان تعبیهی کلمات در نظر بگیریم و مدل خود را با آنها آموزش دهیم. در مدلهای تعبیهی کلمات قبلی مانند GloVe و Word2vec به هر کلمه یک بردار ویژگی اختصاص مییابد.
برای مثال، به معنای کلمهی «خودرو» در این دو جمله توجه کنید:
- سرخس گیاهی خودرو است.
- صنعت خودرو با مشکل مواجه شده است.
این دو کلمه درواقع دو کلمهی متفاوت با نوشتار مشابه هستند که در مدلهای تعبیه کلمات بردار یکسانی برای هر دو در نظر گرفته میشود؛ یا مثلاً در متنی زن و مرد را مقایسه میکند این دو کلمه در مقابل هم استفاده میشود، درصورتیکه در متن دیگری هر دو کلمه میتوانند به گونهی انسان اشاره کنند و کاربرد بسیار نزدیکی داشته باشند. مثالهای دیگری نیز برای نشاندادن ضعف مدلهای تعبیهی کلمات وجود دارد. در BERT قسمت بزرگی از متن همزمان به مدل داده میشود و برای تولید بردار هر کلمه، به کلمههای قبلی و بعدی نیز توجه میشود؛ مثلاً در این جملهها تأثیر «صنعت» و «گیاه» روی کلمهی «خودرو» متفاوت خواهد بود و درنتیجه بردارهای متفاوتی برای این کلمه تولید خواهد شد. این روش، در مقایسه با Fine-tuning، متناسب با مسئله میتواند بهتر یا بدتر باشد.
حرف آخر در پاسخ به پرسش شبکه BERT چیست
BERT یک مدل زبانی بسیار قدرتمند است که نقطهعطفی در حوزهی پردازش زبانهای طبیعی (NLP / Natural Language Processing) محسوب میشود. مدل برت امکان استفاده از تکنیک یادگیری انتقالی (Transfer Learning) را در حوزهی پردازش زبانهای طبیعی به وجود آورد و در بسیاری از تسکهای این حوزه عملکرد خوبی را ارائه کرده است. بیشک در آینده طیف گستردهای از کاربردهای عملی را برایمان فراهم خواهد کرد.
یادگیری دیتا ساینس با کلاسهای آنلاین آموزش علم داده کافهتدریس
کافهتدریس کلاسهای آنلاین آموزش علم داده را برگزار میکند. این کلاسها بهصورت پویا و تعاملی برگزار میشود و شکل کارگاهی دارد. مبنای آن کار روی پروژههای واقعی علم داده است. همچنین تمامی پیشنیازها و مباحث علم داده را پوشش میدهد.
بهاین ترتیب شرکت در کلاسهای آنلاین آموزش علم داده کافهتدریس به شما امکان میدهد از هر نقطهی جغرافیایی به بهروزترین و جامعترین آموزش دیتا ساینس و ماشین لرنینگ دسترسی داشته باشید و صفر تا صد مباحث را بیاموزید.
برای آشنایی بیشتر با کلاسهای آنلاین آموزش علم داده کافهتدریس و مشاورهی رایگان برای شروع یادگیری روی این لینک کلیک کنید:
دوره جامع آموزش علم داده (Data Science)

هفتخوان: مطالعه کن، نظر بده، جایزه بگیر!
هفتخوان مسابقهی وبلاگی کافهتدریس است. شما با پاسخ به چند پرسش دربارهی مطلبی که همین حالا مطالعه کردهاید، فرصت شرکت در قرعهکشی جایزه نقدی و کلاس رایگان کافهتدریس را پیدا خواهید کرد.
جوایز هفتخوان
- ۱,۵۰۰,۰۰۰ تومان جایزه نقدی
- ۳ کلاس رایگان ۵۰۰,۰۰۰ تومانی
پرسشهای مسابقه
برای شرکت در هفتخوان کافهتدریس در کامنت همین مطلب به این پرسشها پاسخ دهید:
- شبکه BERT برای چه منظوری ایجاد شده و چگونه به پدید آمدن آن پرداخته شده است؟
- دو بخش اصلی آموزش مدل BERT چه نام دارند و چگونه به توضیح آنها پرداخته شده است؟
- توضیح دهید چگونه میتوان از مدل شبکه BERT در پروژههای مختلف پردازش زبان طبیعی استفاده کرد و دو روش استفاده از آن چیست؟
هفتخوانپلاس
برای بالابردن شانستان میتوانید این مطلب را هم مطالعه کنید و به پرسشهای آن پاسخ دهید: