
یادگیری بدون ناظر (Unsupervised Learning) یکی از تکنیکهای یادگیری ماشین (Machine Learning) است که در آن کاربر نیازی به نظارت بر مدل ندارد؛ درعوض، خود مدل، بهتنهایی، برای کشف الگوها و اطلاعاتی که در داده وجود دارد کار میکند؛ بهعبارت دیگر، این تکنیک عمدتاً با دادههای بدون برچسب سروکار دارد.
- 1. مقدمه
- 2. یادگیری ماشین چیست؟
- 3. یادگیری بدون ناظر (Unsupervised Learning) چیست؟
- 4. یادگیری بانظارت و بدون نظارت
- 5. سه وظیفهی اصلی یادگیری بدون ناظر
- 6. مزایای استفاده از یادگیری بدون ناظر
- 7. معایب استفاده از یادگیری بدون ناظر
- 8. یادگیری نظارت شده در مقابل یادگیری بدون نظارت: کدام یک برای کار موردنظر شما بهتر است؟
- 9. خلاصهی مطالب
- 10. هفتخوان: مطالعه کن، نظر بده، جایزه بگیر!
- 11. هفتخوانپلاس
مقدمه
امروزه هم جامعهی هوش مصنوعی (Artificial Intelligence) و هم عموم مردم به یادگیری عمیق (Deep Learning) بسیار توجه میکنند، اما اخیراً محققان تردید کردهاند که یادگیری عمیق واقعاً بتواند آیندهی هوش مصنوعی باشد.
تکنیکهای برجستهی یادگیری عمیق که امروزه استفاده میشود، همه، به یادگیری با ناظر (Supervised Learning) متکی هستند؛ با وجود این، کاملاً واضح میبینیم که انسانها چیزها، الگوها و مفاهیم را بدون نظارت خاصی یاد میگیرند. بهتعبیری، یادگیری ما کاملاً بدون نظارت است، اما هنوز یادگیری بدون ناظر بهاندازهی یادگیری باناظر محل توجه نبوده است؛ شاید دلیل آن به دشواربودن حل مسائل بهاین روش و نتایج نامطلوب آن بازگردد.
در این مطلب قصد داریم یادگیری بدون ناظر را معرفی کنیم، با سه وظیفهی اصلی آن آشنا شویم و در آخر به مزایا و معایب آن نگاهی بیندازیم.
یادگیری ماشین چیست؟
امروزه فناوریهای هوشمند در همه جا وجود دارد و تقریباً در تمام جنبههای زندگی روزمره ما نفوذ کرده است. مصرفکنندگان انتظار دارند اطلاعات بیشتر، اتوماسیون بیشتر، سریعتر، همه با کلیک یک دکمه انجام شود. برای چنین کاری و برآورده کردن نیازهای مصرفکنندگان، شرکتها باید به انطباق و پیادهسازی جدیدترین فناوریها ادامه دهند، در غیر این صورت خطر عقب افتادن آنها از این روند غیرقابل انکار، وجود دارد.
پیشرفت هوش مصنوعی (AI) در حوزهی تجاری این نیاز را تشدید کرده است. در حال حاضر سیستمهای امنیتی میتوانند اسکن اثر انگشت و صورت را به دادههای بیومتریک تبدیل کنند تا قفل درها و گوشیهای هوشمند را باز کنند. سیستمهای بانکی میتوانند الگوهای خرید غیرمعمول را شناسایی کرده و به طور خودکار پیامی برای تأیید انسانی تراکنشها ارسال کنند. دستیارهای صوتی در تلفنهای هوشمند از پردازش زبان طبیعی برای پردازش صدا و پاسخ دادن به طیف گستردهای از درخواستهای افراد استفاده میکنند. همه این فناوریهای قابل توجه به طور مداوم با استفاده از الگوریتمهای یادگیری ماشین (ML) امکانپذیر و پیشرفتهتر میشوند.
یادگیری ماشین (Machine Learning) زیر مجموعهای از هوش مصنوعی (Artificial Intelligence) است. به طور خاص، ماشینلرنینگ یک برنامه کاربردی در هوش مصنوعی است که به سیستمها توانایی یادگیری و بهبود از روی دادهها را میدهد. همانطور که انسانها از تجربیات روزمره یاد میگیرند، ML به تدریج پیشبینیها و دقت کار خود را در چندین تکرار بهبود میبخشد. دادههای آموزشی برای مدلهای ماشینلرنینگ از دستگاههای IoT، جمعآوریشده از تراکنشها یا ثبتشده در رسانههای اجتماعی ارائه میشوند. تکنیکهای علم داده به غربال کردن، طبقه بندی و گروهبندی اطلاعات بر اساس پارامترهای مختلف برای این ماشینها / مدلها کمک میکنند. با پردازش و ترکیب دادهها، ماشینلرنینگ میتواند مدلهایی ایجاد کند که الگوهای رفتاری خاص انسان را به دقت پیشبینی کرده و پاسخها را بر این اساس آغاز کند. به عنوان مثال، هنگامی که مشتری برای خرید تلفن همراه بعدی خود به صورت آنلاین جستجو میکند و انتخابهای خود را محدود کرده است، سایت به آنها مقایسه با سایر تلفنها یا لوازم جانبی این تلفنها را ارائه میدهد که خریداران میتوانند همزمان آن محصولات را نیز تهیه کنند. این مدل پاسخ، از دادههایی ایجاد میشود که از خریدهای مشابه قبلی پردازش شدهاند و ماشین را قادر میسازد مدلی ایجاد کند که به مشتریان جدید کمک میکند تا انتخابهای مشابه و آگاهانه داشته باشند.
یادگیری بدون ناظر (Unsupervised Learning) چیست؟
یادگیری بدون ناظر (Unsupervised Learning) یا یادگیری بدون نظارت که بهعنوان یادگیری ماشین بدون ناظر (Unsupervised Machine Learning) نیز شناخته میشود، از الگوریتمهای یادگیری ماشین برای تجزیهوتحلیل و خوشهبندی مجموعهی دادههای بدون برچسب (Unlabeled) استفاده میکند. این الگوریتمها، بدون نیاز به دخالت انسان، الگوهای پنهان یا گروههای مختلف موجود در دادهها را کشف میکنند.
بیایید مثالی از یادگیری بدون ناظر را برای درک بهتر با هم بررسی کنیم.

در خانوادهای که یک نوزاد و یک سگ خانگی دارند نوزاد این سگ را میشناسد، بدون اینکه از قبل به او چیزی گفته باشند. چند هفته بعد، یک دوست خانوادگی یک سگ را بههمراه خود به خانهی آنان میآورد که شروع به بازی با نوزاد میکند. نوزاد خانواده این سگ را قبلاً ندیده است، اما ویژگیهای بسیاری را که به سگها مربوط است تشخیص میدهد (برای مثال، گوشها، چشمها، راهرفتن روی چهار پا) و بههمین دلیل میداند که این موجود مانند سگ خانگی خودشان است. او حیوان جدید را بهعنوان یک سگ تشخیص میدهد.
این دقیقاً مثالی از یک یادگیری بدون ناظر است؛ بهاین معنا که به ما آموزش داده نمیشود، اما از دادهها یاد میگیریم که در این مورد نوزاد دادههای مربوط به یک سگ را یاد گرفته است. اگر این یادگیری باناظر بود، دوست خانوادگی آنان به نوزاد میگفت که این یک سگ است تا یاد بگیرد.
یادگیری بانظارت و بدون نظارت
یادگیری ماشین دارای سه نوع الگوریتم – با نظارت (Supervised Learning)، بدون نظارت (Unsupervised Learning) و تقویتی (Reinforcement Learning) است. در یادگیری تقویتی، ماشینها برای ایجاد توالیای از تصمیمات آموزش داده میشوند و معمولا در حوزه رباتیک مورد استفاده قرار میگیرند. اما پرکاربردترین الگوریتمهای یادگیری ماشین یادگیری با نظارت و بدون نظارت هستند که یک تفاوت اساسی باهم دارند. یادگیری با نظارت از مجموعه دادههای برچسبدار استفاده میکند، در حالی که یادگیری بدون نظارت از مجموعه دادههای بدون برچسب استفاده میکند. منظور از “برچسب” این است که دادهها قبلا با پاسخ مناسب برچسبگذاری شدهاند و کلاس آنها یا خروجی آنها مشخص است. مدل ماشینلرنینگ از این دادهها و خروجی مختص آنها یاد میگیرد که برای دادههای آینده چه خروجیای را در نظر بگیرد.
برای آشنایی با یادگیری با ناظر این مطلب را مطالعه کنید:
یادگیری با ناظر (Supervised Learning) چیست؟
تفاوت اصلی بین یادگیری نظارتشده و یادگیری بدون نظارت
تمایز اصلی بین این دو رویکرد یادگیری ماشین، استفاده از مجموعه دادههای برچسبدار است. به بیان ساده، یادگیری نظارت شده (Supervised Learning) از دادههای ورودی و خروجی برچسب دار استفاده میکند، در حالی که یادگیری بدون نظارت (Unsupervised Learning) این کار را نمیکند.
در یادگیری نظارت شده، الگوریتم از مجموعه دادههای آموزشی که دارای برچسب هستند، یعنی خروجی آنها مشخص است، یاد میگیرد. به این شکل که پیشبینیهای مکرر بر روی دادهها انجام داده و سعی میکند با مقایسه خروجی خود با خروجی واقعی، پاسخ صحیح را یاد بگیرد. مدلهای یادگیری نظارت شده نسبت به مدلهای یادگیری بدون نظارت دقیقتر هستند، اما برای برچسبگذاری مناسب دادهها به مداخله انسانی نیاز دارند. به عنوان مثال، یک مدل یادگیری نظارت شده میتواند مدت زمان رفت و آمد شما را بر اساس زمان روز، شرایط آب و هوایی و غیره پیش بینی کند. اما ابتدا باید آن را آموزش دهید تا بداند که هوای بارانی زمان رانندگی را افزایش میدهد.
در مقابل، مدلهای یادگیری بدون نظارت، به تنهایی برای کشف ساختار ذاتی دادههای بدون برچسب کار میکنند. توجه داشته باشید که آنها هنوز به مداخله انسانی برای اعتبارسنجی متغیرهای خروجی نیاز دارند. به عنوان مثال، یک مدل یادگیری بدون نظارت میتواند تشخیص دهد که خریداران آنلاین اغلب گروههایی از محصولات را به طور همزمان باهم خریداری میکنند. با این حال، یک تحلیلگر داده باید در نهایت تأیید کند که آیا منطقی است که موتور توصیهگر به طور مثال، لباسهای کودک را با پوشک، سس کچاپ و فنجان چای دستهبندی کند یا خیر. این تفاوت، یعنی دادههای برچسبدار مهمترین و اصلیترین تفاوت بین یادگیری بدون نظارت و نظارتشده است. اما تفاوتهای دیگری نیز بین این دو نوع یادگیری ماشین وجود دارد که در ادامه قصد داریم به آنها بپردازیم.
سایر تفاوتهای کلیدی بین یادگیری نظارتشده و بدون نظارت
اهداف
در یادگیری نظارتشده (Supervised Learning)، هدف پیشبینی نتایج برای دادههای جدید است و شما از قبل از نوع نتایجی که باید انتظار داشته باشید اطلاع دارید. اما در یک الگوریتم یادگیری بدون نظارت(Unsupervised Learning) ، هدف این است که از حجم زیادی از دادههای جدید بینش به دست آوریم. در این حالت، الگوریتم خودش تعیین میکند که چه چیزی در مجموعه داده موردنظر متفاوت یا جالب است و چه الگوهایی در آن وجود دارد که باید مورد توجه قرار گیرد.
کاربردها
به طور کلی یادگیری نظارت شده و یادگیری بدون ناظر با توجه به نوع یادگیری که دارند، کاربردهای متفاوتی هم دارند. به طور مثال، مدلهای یادگیری نظارتشده برای تشخیص هرزنامه (Spam filtering)، تجزیه و تحلیل احساسات(Sentiment Analysis)، پیش بینی آب و هوا و پیش بینی قیمت محصولات مختلف و موارد دیگر ایده آل هستند. در مقابل، یادگیری بدون نظارت برای تشخیص ناهنجاری (Anomaly Detection)، موتورهای توصیهگر، ویژگیهای مشتری و تصویربرداری پزشکی مناسب است.
پیچیدگی
تفاوت دیگری که بین یادگیری بدون نظارت و نظارت شده وجود دارد، میزان پیچیدگی آنهاست. یادگیری نظارت شده روشی ساده برای یادگیری ماشین (Machine Learning) است که معمولاً از طریق استفاده از ابزارهایی مانند زبانهای برنامهنویسی R یا Python محاسبه میشود. در یادگیری بدون نظارت، به ابزارهای قدرتمندی برای کار با مقادیر زیادی از دادههای طبقه بندی نشده یا بدون برچسب نیاز داریم. مدلهای یادگیری بدون نظارت از نظر محاسباتی پیچیدهتر هستند، زیرا به مجموعه آموزشی بزرگی برای تولید نتایج مورد نظر نیاز دارند.
اشکالات
هر دو نوع یادگیری ماشین، چه نظارتشده و چه بدون نظارت، با وجود جنبههای مثبت و کارایی، نکات منفی مختص به خود را نیز دارند. به طور مثال، آموزش مدلهای یادگیری تحت نظارت ممکن است زمانبر باشد و برچسبهای متغیرهای ورودی و خروجی نیاز به تخصص انسانی دارد. در همین حال، روشهای یادگیری بدون نظارت میتوانند نتایج بسیار نادرستی داشته باشند، مگر اینکه مداخله انسانی برای اعتبارسنجی متغیرهای خروجی داشته باشیم تا بتوانیم از درستی خروجیهای مدل، اطمینان حاصل کنیم.
حال که با مفهوم یادگیری بدون ناظر و تفاوت آن با یادگیری باناظر آشنا شدیم. اکنون لازم است ببینیم یادگیری بدون ناظر چه وظایفی را دارد و هر وظیفه از چه الگوریتمهایی استفاده میکند.
سه وظیفهی اصلی یادگیری بدون ناظر
از مدلهای یادگیری بدون ناظر برای سه وظیفهی اصلی خوشهبندی (Clustering)، اتحاد (Association) و کاهش ابعاد (Dimensionality Reduction) استفاده میشود. در این بخش با هر یک از آنها آشنا خواهیم شد و الگوریتمها و رویکردهای رایج برای انجامدادنشان را معرفی خواهیم کرد.
خوشهبندی (Clustering)
خوشهبندی یک تکنیک دادهکاوی (Data Mining) است که دادههای بدون برچسب را براساس شباهتها یا تفاوتهای آنها گروهبندی میکند. الگوریتمهای خوشهبندی را میتوان در چند نوع انحصاری (Exclusive)، همپوشان (Overlapping)، سلسلهمراتبی (Hierarchical) و احتمالی (Probabilistic) دستهبندی کرد.
خوشهبندی انحصاری (Exclusive Clustering)
خوشهبندی انحصاری نوعی گروهبندی است. شرطش هم آن است که هر داده فقط در یک خوشه میتواند وجود داشته باشد. به این نوع «خوشهبندی سخت» نیز گفته میشود. الگوریتم خوشهبندی K-means نمونهای از خوشهبندی انحصاری است.
خوشهبندی K-means نمونهای از روش خوشهبندی انحصاری است که در آن نقاط داده به K گروه اختصاص مییابند. در این خوشهبندی K تعداد خوشهها را براساس فاصله از مرکز هر گروه نشان میدهد. نزدیکترین نقاط داده به یک مرکز دادهی مشخص در همان گروه قرار میگیرند. مقدار K بزرگتر نشاندهندهی گروهبندیهای کوچکتر با دانهبندی (granularity ) بیشتر خواهد بود، درحالیکه مقدار K کوچکتر گروهبندیهای بزرگتر و دانهبندی (granularity ) کمتری خواهد داشت.
خوشهبندی همپوشان (Overlapping Clustering)
خوشهبندی همپوشان با خوشهبندی انحصاری از این نظر تفاوت دارد که اجازه میدهد نقاط داده به چند خوشه با درجهی جداگانه عضویت تعلق داشته باشند. خوشهبندی K-means نرم یا فازی (Soft K-means / Fuzzy K-means) نمونهای از خوشهبندی همپوشان است.
خوشهبندی سلسلهمراتبی (Clustering Hierarchical)
خوشهبندی سلسلهمراتبی، یک الگوریتم خوشهبندی بدون ناظر است که میتواند به دو روش طبقهبندی شود: تجمیعی (Agglomerative) یا تقسیمکننده (Divisive).
خوشهبندی تجمیعی
خوشهبندی تجمیعی «رویکرد پایینبهبالا» دارد؛ یعنی نقاط دادهی آن در ابتدا بهصورت گروههای جداگانه در نظر گرفته میشوند و سپس براساس شباهتهای موجود کنار هم قرار میگیرند تا زمانی که یک خوشه حاصل شود. برای اندازهگیری شباهت معمولاً از چهار روش مختلف استفاده میشود:
- پیوند ایزولهساز (Ward Linkage): این روش فاصله میان دو خوشه را با افزایش مجموع مربع خوشهها پس از ادغام آنها تعریف میکند.
- پیوند میانگین (Average Linkage): این روش با میانگین فاصلهی میان دو داده در هر خوشه تعریف میشود.
- پیوند کامل یا حداکثر (Complete / maximum linkage): این روش با حداکثر فاصله میان دو داده در هر خوشه تعریف میشود.
- پیوند منفرد یا حداقل (Single / minimum linkage): این روش با حداقل فاصله میان دو نقطه در هر خوشه تعریف میشود. بهتر است بدانیم که فاصلهی اقلیدسی متداولترین معیاری است که برای محاسبهی این فاصلهها استفاده میشود.
خوشهبندی تقسیمکننده
این نوع خوشهبندی میتواند بهعنوان نقطهی مقابل خوشهبندی تجمیعی تعریف شود که رویکرد از بالابهپایین را در پیش میگیرد. در این حالت، یک خوشه داده براساس تفاوتهای موجود میان نقاط داده تقسیم میشود. بااینکه معمولاً از خوشهبندی تقسیمکننده استفاده نمیشود، هنوز هم در چارچوب خوشهبندی سلسلهمراتبی قابل ذکر است.
فرایند خوشهبندیهای سلسلهمراتبی معمولاً با استفاده از یک دندروگرام (Dendrogram)، نموداری درختمانند که ادغام یا تقسیم نقاط داده را در هر تکرار ثبت میکند، نمایش داده میشود.
خوشهبندی تقسیمکننده (Divisive) میتواند بهعنوان نقطهی مقابل خوشهبندی تجمیعی تعریف شود که رویکرد از بالابهپایین را در پیش میگیرد. در این حالت، یک خوشه داده براساس تفاوتهای موجود میان نقاط داده تقسیم میشود. بااینکه معمولاً از خوشهبندی تقسیمکننده استفاده نمیشود، هنوز هم در چارچوب خوشهبندی سلسلهمراتبی قابل ذکر است. فرایند خوشهبندیهای سلسلهمراتبی معمولاً با استفاده از یک دندروگرام (Dendrogram)، نموداری درختمانند که ادغام یا تقسیم نقاط داده را در هر تکرار ثبت میکند، نمایش داده میشود.
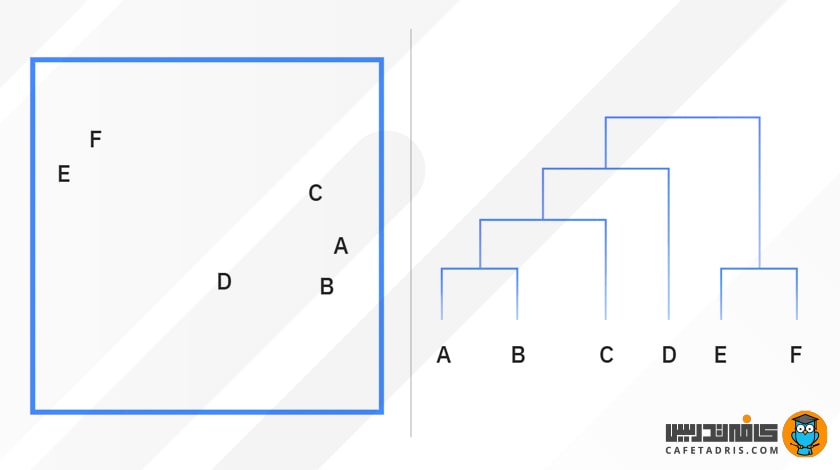
شکل بالا یک نمودار دندروگرام (Dendrogram) را نشان میدهد که اگر فرایند را از پایینبهبالا بررسی کنیم درواقع نشاندهندهی خوشهبندی تجمیعی است و اگر از بالابهپایین بررسی کنیم، خوشهبندی تقسیمکننده را نمایش میدهد.
خوشهبندی احتمالی (Probabilistic Clustering)
خوشهبندی احتمالی تکنیکی بدون ناظر است که در آن نقاط داده براساس احتمال متعلق بودن آنها به یک خوشهی خاص خوشهبندی میشوند. مدل گاوسی مخلوط (Gaussian Mixture Models) یکی از متداولترین روشهای خوشهبندی احتمالی است. یک مدل مخلوط گاوسی یک مدل احتمالی است که فرض میکند تمامی نقاط داده از مخلوط تعداد محدودی از توزیعهای گاوسی با پارامترهای ناشناخته تولید میشوند.
همبستگی (Association Rules / Association)
همبستگی یا Association روشی مبتنی بر قانون (Rule-based) برای یافتن روابط میان متغیرها در یک مجموعهی داده مشخص است. این روش بهطور مکرر برای تجزیهوتحلیل سبد بازار استفاده میشود و به شرکتها این امکان را میدهد تا روابط میان محصولات مختلف را بهتر درک کنند.
درک عادات مصرفی مشتریان مشاغل را قادر میکند تا استراتژیهای فروش متقابل و موتورهای پیشنهادی بهتری را ایجاد کنند؛ برای مثال، اگر در وبسایت دیجیکالا محصولی را انتخاب کنیم یا در سبد خرید خود قرار دهیم، پیشنهادهای دیگری با این جمله دریافت میکنیم: «خریداران این محصول این محصولات را نیز خریداری کردهاند». تعداد الگوریتمهای مورداستفاده برای این کار خیلی زیاد نیست، ازجمله Eclat، FP-Growth و Apriori ؛ معروفترین آنها الگوریتم Apriori است که بیشتر از باقی استفاده میشود.
کاهش ابعاد (Dimension Reduction)
با اینکه دادههای بیشتر بهطور کلی نتایج دقیقتری به همراه دارند، میتوانند روی عملکرد الگوریتمهای یادگیری ماشین تأثیر منفی بگذارند؛ برای مثال، میتوانند مشکل Overfitting را ایجاد کنند؛ علاوهبراین حجم دادهی زیاد میتواند نمایش مجموعه داده را دشوارتر کند.
کاهش ابعاد تکنیکی است که وقتی تعداد ویژگیها یا ابعاد یک مجموعهی داده بسیار زیاد باشد استفاده میشود. این تکنیک تعداد دادههای ورودی را بهاندازهای که کنترلشدنی باشند کاهش میدهد و درعینحال یکپارچگی مجموعهی داده را تا حد ممکن حفظ میکند.
تکنیک کاهش ابعاد معمولاً در مرحلهی پیشپردازش داده انجام میشود و متدهای مختلفی ازجمله آنالیز مؤلفهی اصلی (PCA)، تجزیهی مقادیر منفرد (SVD) و اتوانکدرها (Autoencoders) برای این کار وجود دارد.
تا اینجا با یادگیری بدون ناظر و وظایف آن آشنا شدیم. در ادامه به برخی از نکات مثبت و منفی این روش خواهیم پرداخت.
برای آشنایی بیشتر با یادگیری ماشین این مطلب را مطالعه کنید:
یادگیری ماشین به زبان ساده به چه معناست و چه مراحلی دارد؟
مزایای استفاده از یادگیری بدون ناظر
مزایای استفاده از یادگیری بدون موارد را میتوان بهصورت کلی اینطور برشمرد:
- یادگیری ماشین بدون ناظر همه نوع الگوی ناشناخته را در دادهها پیدا میکند؛
- روشهای بدون ناظر به ما در یافتن ویژگیهایی که میتوانند برای دستهبندی دادهها مفید باشند کمک میکند؛
- یادگیری بدون ناظر در لحظه و بهصورت بیدرنگ (Real-time) انجام میشود؛ بنابراین تمامی دادههای ورودی در حین یادگیری تجزیهوتحلیل و برچسبگذاری میشوند؛
- یافتن دادههای بدون برچسب راحتتر از دادههای برچسبدار است که به مداخلهی انسانی نیاز دارند.
معایب استفاده از یادگیری بدون ناظر
بهصورت کلی معایب استفاده از یادگیری بدون ناظر از این قرار است:
- نمیتوان اطلاعات زیادی دربارهی نحوهی مرتبسازی داده و طبقهبندی آنها در خروجی به دست آورد؛ زیرا یافتن الگوهای پنهان در داده و برچسبگذاری آنها با ماشین انجام میشود؛
- دقت خروجی یادگیری بدون ناظر کم است؛ زیرا کار برچسبگذاری داده را خود ماشین، بهتنهایی، انجام میدهد و دخالت انسانی در آن وجود ندارد؛
- هیچ دانش قبلی در روش یادگیری ماشین بدون ناظر وجود ندارد؛ علاوهبراین، تعداد کلاسها نیز مشخص نیست. این امر به ناتوانی در تعیین نتایج حاصل از تجزیهوتحلیل میانجامد.
پرسشهای متداول دربارهی علم داده را اینجا پیدا کنید:
پرسشهای متداول یادگیری ماشین که باید پاسخشان را بدانید!
یادگیری نظارت شده در مقابل یادگیری بدون نظارت: کدام یک برای کار موردنظر شما بهتر است؟
انتخاب یک رویکرد مناسب برای تسک موردنظر، بستگی به ساختار و حجم دادههای شما و همچنین مورد استفاده دارد. برای تصمیم گیری در مورد اینکه چه نوع رویکرد یادگیری ماشین، یعنی یادگیری نظارت شده یا بدون نظارت را برای کارتان انتخاب کنید، بهتر است موارد زیر را در نظر داشته باشید:
داده های ورودی خود را ارزیابی کنید!
آیا داده های شما برچسبدار (Labeled Data) هستند یا بدون برچسب؟ آیا کارشناسانی در اختیار دارید که بتوانند در صورت نیاز دادهها را برایتان برچسبگذاری کنند؟
اهداف خود را مشخص کنید!
آیا یک مسئله تکرار شونده و کاملاً تعریف شده برای بررسی دارید؟ یا اینکه الگوریتم نیاز به پیشبینی مسائل جدید دارد؟
گزینههای خود را برای الگوریتمها مرور کنید!
آیا الگوریتمهایی با همان ابعاد مورد نیاز شما (یعنی تعداد characteristic feature, attribute و) وجود دارد؟ آیا این الگوریتمها میتوانند حجم و ساختار داده شما را پشتیبانی کنند؟
به طور کلی، طبقهبندی کلان دادهها یا Bigdata میتواند یک چالش واقعی در یادگیری نظارت شده باشد، اما از سوی دیگر، نتایج آن بسیار دقیق و قابل اعتماد هستند. در مقابل، یادگیری بدون نظارت میتواند حجم زیادی از دادهها را به شکل بلادرنگ (Real-time) مدیریت کند. اما، عدم شفافیت در مورد نحوه خوشهبندی (Clustering) دادهها و خطر نتایج نادرست در این نوع الگوریتم وجود دارد. به همین دلیل است که نوع دیگری از یادگیری ماشین به نام یادگیری نیمه نظارتی یا semi-supervised learning هم وجود دارد.
یادگیری نیمهنظارتی، ترکیبی از مزایای دو نوع یادگیری قبلی
اگر نمی توانید در مورد استفاده از یادگیری نظارت شده یا بدون نظارت تصمیم بگیرید، یادگیری نیمه نظارت شده یک راهحل خوب است که در آن از یک مجموعه داده آموزشی با دادههای برچسب دار و بدون برچسب استفاده میکنید. این نوع یادگیری به ویژه زمانی مفید است که استخراج فیچرهای مرتبط از دادهها دشوار است و حجم داده زیادی دارید. یادگیری نیمه نظارتی برای تصاویر پزشکی ایده آل است، زیرا در آن، مقدار کمی از دادههای آموزشی میتواند منجر به بهبود قابل توجهی در دقت مدل شود. برای مثال، یک رادیولوژیست میتواند زیرمجموعه کوچکی از سی تی اسکنها را برای تومورها یا بیماریهای دیگر برچسبگذاری کند تا دستگاه بتواند با دقت بیشتری پیشبینی کند که کدام بیماران ممکن است به مراقبت پزشکی بیشتری نیاز داشته باشند.
برای مطالعه بیشتر در مورد یادگیری نیمهنظارتی، روی لینک زیر کلیک کنید:
یادگیری نیمهنظارتی چیست؟
خلاصهی مطالب
در این مطلب یادگیری بدون ناظر، یکی از تکنیکهای یادگیری ماشین، را معرفی کردیم. همینطور دانستیم که در یادگیری بدون ناظر به نظارت روی مدل نیازی نیست و خود مدل با پیداکردن الگوهای موجود در داده، دادهها را برچسبگذاری و در یک گروه خاص طبقهبندی میکند؛ علاوهبراین با سه نوع اصلی یادگیری بدون ناظر، یعنی خوشه بندی، اتحاد و کاهش ابعاد، آشنا شدیم.
بهطور کلی میتوان گفت تکنیکهای یادگیری ماشین، نهتنها یکی از پرطرفدارترین مباحث علوم داده محسوب میشوند، در تصمیم گیریهای مبتنی بر داده (Data-driven decision making) نقش مهمی دارند. این نوع تصمیمها در موفقیت تجارتها نقش بسیار مهمی دارند.
آموزش علم داده و یادگیری ماشین با کلاسهای آنلاین کافهتدریس
اگر به یادگیری علم داده و ماشینلرنینگ علاقه دارید، کلاسهای آنلاین آموزش علم داده کافهتدریس به شما امکان میدهد در هر نقطهی جغرافیایی به بهروزترین و جامعترین آموزش دسترسی داشته باشید.
کلاسهای آنلاین آموزش علم داده کافهتدریس مبتنی بر پروژههای واقعی علم داده است و بهصورت کاملاً تعاملی برگزار میشود.
برای آشنایی با کلاسهای آنلاین آموزش علم داده کافهتدریس و مشاورهی رایگان روی این لینک کلیک کنید:
کلاسهای آنلاین علم داده کافهتدریس

هفتخوان: مطالعه کن، نظر بده، جایزه بگیر!
هفتخوان مسابقهی وبلاگی کافهتدریس است. شما با پاسخ به چند پرسش دربارهی مطلبی که همین حالا مطالعه کردهاید، فرصت شرکت در قرعهکشی جایزه نقدی و کلاس رایگان کافهتدریس را پیدا خواهید کرد.
جوایز هفتخوان
- ۱,۵۰۰,۰۰۰ تومان جایزه نقدی
- ۳ کلاس رایگان ۵۰۰,۰۰۰ تومانی
پرسشهای مسابقه
برای شرکت در هفتخوان کافهتدریس در کامنت همین مطلب به این پرسشها پاسخ دهید:
- یکی از مزایای استفاده از یادگیری بدون ناظر چیست؟
- دو نوع خوشهبندی را که در یادگیری بدون ناظر مورد استفاده قرار میگیرند، نام ببرید.
- سه وظیفهی اصلی یادگیری بدون ناظر کدامند؟
هفتخوانپلاس
برای بالابردن شانستان میتوانید این مطلب را هم مطالعه کنید و به پرسشهای آن پاسخ دهید:
سلام وقت بخیر.میشه یه کتاب هم معرفی کنین برای pattern recognition؟
سلام، در این مورد کتابی رو در کانال تلگرام علم داده معرفی کردیم: https://t.me/DSLanders/181
سلام
Association جز یادگیری بدون نظارت نیست. اصلا یادگیری در این حوزه اتفاق نمی افته بلکه کاوش دانش رخ میدم. همنطور در کاهش ابعاد شما نمیتوانید بگید pca روش یادگیری است. در عوض تشخیص بی نظمی جز یادگیری بدون نظارت است که اینجا بررسی نشده. واقعا به صرف اینکه یک سایت به زبان انگلیسی مطلبی رو مینویسد لزوما درستی انرا تضمین نمیکند.
سلام، دوست عزیز در مورد اینکه مطمئن بشین Association Rules یکی از تکنیکهای یادگیری بدون ناظر یا Unsupervised Learning است، کتاب Data mining، a knowledge discovery approach بخش ۴ فصل ۱۰ با عنوان Unsupervised Learning: Association Rules رو مطالعه کنین لطفا. در این لینک هم میتونین بخش Introduction این مبحث رو بخونین: https://link.springer.com/chapter/10.1007/978-0-387-36795-8_10
یادگیری ماشین از جمله موضوعاتی هست که خیلی مورد توجه قرار گرفته . ممنون از شما که در این زمینه اطلاعات لازم رو در اختیار کاربرانتون میذارید
با توجه به اینکه فرمودید دقت خروجی یادگیری بدون ناظر کم است؛ پس خروجی که از این روش به دست میاد خروجی قابل اتکایی نخواهد بود درسته ؟ پس ضرورت استفاده از این روش چی هست ؟
اینکه دقت این روش نسبت به یادگیری باناظر کمتره، لزوما اون رو بلااستفاده نمیکنه. مزایایی هم داره این روش که تو مقاله بهش اشاره کردیم. لطفا بخش مزایای یادگیری بدون ناظر رو بار دیگه مطالعه کنین.
سلاااااام استاد شکرزاد نویسنده مقاله ها هستند ؟ مقاله ها عالی تهیه شدند کمتر کسی Unsupervised Learning رو به این خوبی توضیح داده
ممنون از توجه شما
چه مطالب خوبی در رابطه با یادگیری ماشین بدون ناظر گذاشتید تو هیچ منبعی انقدر روان توضیح ندادند
ممنون از توجهتون