

آیا تا به حال در پروژههای یادگیری ماشین خود به الگوریتمی نیاز داشتهاید که هم سریع باشد و هم دقت بالایی داشته باشد؟ مدل Catboost دقیقاً همان چیزی است که به دنبالش هستید. این الگوریتم که توسط شرکت Yandex توسعه داده شده، در سالهای اخیر به یکی از ابزارهای محبوب در میان دانشمندان داده و مهندسان یادگیری ماشین تبدیل شده است. در این مقاله، به بررسی جامع Catboost در یادگیری ماشین قدرتمند خواهیم پرداخت و شما را با کاربردها، مزایا، نحوه استفاده و تنظیمات آن آشنا خواهیم کرد.
- 1. Catboost چیست؟
- 2. چرا Catboost مهم است؟
- 3. کاربردهای Catboost
- 4. تبدیل ویژگیهای دستهبندیشده با کدگذاری مبتنی بر هدف
- 5. ایجاد درختهای تصمیمگیری
- 6. پیادهسازی Catboost در پایتون
- 7. مقایسه Catboost با دیگر الگوریتمها
- 8. مزایا و معایب Catboost
- 9. کلام آخر درباره Catboost
-
10.
سوالات متداول
- 10.1. چگونه Catboost از دادههای دستهبندیشده استفاده میکند؟
- 10.2. تفاوتهای اصلی بین Catboost و دیگر الگوریتمهای Boosting مانند XGBoost و LightGBM چیست؟
- 10.3. مزایای استفاده از Catboost در صنایع مختلف چیست؟
- 10.4. چگونه Catboost با تکنیک Ordered Boosting دقت مدل را بهبود میبخشد؟
- 10.5. چه تنظیماتی برای بهینهسازی عملکرد Catboost در پروژههای یادگیری ماشین پیشنهاد میشود؟
- 11. یادگیری ماشین لرنینگ را از امروز شروع کنید!


Catboost چیست؟
Catboost، کوتاه شدهی Categorical Boosting، یک الگوریتم یادگیری ماشین است که به طور خاص برای کار با دادههای دستهای (Categorical data) طراحی شده است. این الگوریتم بر پایهی تکنیکهای Boosting استوار است و به گونهای طراحی شده که با حداقل نیاز به پیشپردازش دادهها کار کند. Boosting یکی از روشهای اصلی برای بهبود دقت مدلهای یادگیری ماشین است که با ترکیب چندین مدل ضعیف به یک مدل قویتر انجام میشود. Catboost این فرآیند را با دقت بیشتری انجام میدهد و به همین دلیل محبوبیت زیادی پیدا کرده است.
چرا Catboost مهم است؟
Catboost با ارائهی دقت بالا و سرعت پردازش فوقالعاده، به یکی از ابزارهای کلیدی در یادگیری ماشین تبدیل شده است. برخی از مزایای اصلی این الگوریتم عبارتند از کاهش احتمال بیشبرازش (Overfitting)، قابلیت پردازش دادههای دستهای بدون نیاز به پیشپردازش زیاد، و دقت بالا و سرعت پردازش سریع. با استفاده از Catboost، میتوانید مدلهای یادگیری ماشین با عملکرد بهتری ایجاد کنید که در زمان کمتری آموزش داده میشوند و دقت بالاتری دارند.
کاربردهای Catboost
Catboost در بسیاری از صنایع و حوزهها کاربرد دارد. در بازاریابی، از این الگوریتم برای پیشبینی رفتار مشتریان و تحلیل دادههای بازاریابی استفاده میشود. در حوزه مالی، Catboost میتواند برای تحلیل ریسک و پیشبینی قیمت سهام مورد استفاده قرار گیرد. در صنعت سلامت، این الگوریتم برای پیشبینی بیماریها و تحلیل دادههای پزشکی بسیار مفید است. همچنین در تجارت الکترونیک، از Catboost برای توصیه محصولات و تحلیل دادههای فروش استفاده میشود. به طور کلی، هر جا که نیاز به تحلیل دادههای دستهای و پیشبینی دقیق وجود دارد، Catboost میتواند یک ابزار بسیار کارآمد باشد.
تبدیل ویژگیهای دستهبندیشده با کدگذاری مبتنی بر هدف
Catboost از یک روش به نام کدگذاری مبتنی بر هدف (Target-Based Encoding) برای تبدیل ویژگیهای دستهبندیشده (Categorical Feature) استفاده میکند. این روش هر ویژگی Categorical را به یک عدد بر اساس مقادیر هدف (Target Values) تبدیل میکند. این کار به مدل کمک میکند تا اطلاعات مفیدتری از دادههای دستهبندی استخراج کند. اما کدگذاری مبتنی بر هدف چیست؟
کدگذاری مبتنی بر هدف
کدگذاری مبتنی بر هدف، روشی برای تبدیل ویژگیهای دستهبندی به مقادیر عددی است که در آن هر مقدار دستهبندی بر اساس ارتباط آن با متغیر هدف (Target Variable) به یک عدد تبدیل میشود. این روش به طور خاص در Catboost برای استفاده بهتر از اطلاعات موجود در دادههای دستهبندی به کار گرفته میشود و کمک میکند تا مدلهای دقیقتر و کارآمدتری ایجاد شوند.
فرآیند کدگذاری مبتنی بر هدف شامل مراحل زیر است:
شناسایی ویژگی دستهبندی و مقدار هدف
فرض کنید ویژگی دستهبندی «رنگ» (مثلاً رنگ ماشین) و مقدار هدف «قیمت» (مثلاً قیمت ماشین) باشد. رنگ شامل مقادیر مختلفی مانند «قرمز»، «سبز»، و «آبی» است و ما میخواهیم ببینیم هر یک از این رنگها به طور میانگین با چه قیمتی همراه هستند.
محاسبه میانگین مقدار هدف برای هر دسته
برای هر مقدار دستهبندی (مثلاً هر رنگ)، میانگین مقادیر هدف (قیمتها) محاسبه میشود. این میانگین نشاندهنده تاثیر هر مقدار دستهبندی بر متغیر هدف است:
\large \text{Mean for category } c \ = \ \frac{\sum_{i=1}^{N_c} \ \text{Target value } i}{N_c}
که در آن Nc تعداد نمونههایی (Samples) است که دارای مقدار دستهبندیشده c هستند. عبارت صورت کسر نیز مجموع مقدار هدف برای نمونههای متعلق به این دسته است.
کدگذاری ویژگیهای دستهبندی با مقادیر میانگین
پس از محاسبه میانگین، هر مقدار دستهبندی با مقدار میانگین مربوط به خود جایگزین میشود. این کار باعث میشود که مدل بتواند از اطلاعاتی که در رابطه با تاثیر هر مقدار دستهبندی بر مقدار هدف وجود دارد، استفاده کند.
مثال عملی
فرض کنید دادههای زیر را داریم:
| رنگ | قیمت |
| قرمز | ۱۰ |
| سبز | ۱۵ |
| قرمز | ۱۲ |
| آبی | ۸ |
| سبز | ۱۷ |
ابتدا میانگین را برای هر رنگ محاسبه میکنیم:
- میانگین قیمت برای قرمز:
۲/(۱۰ + ۱۲) - میانگین قیمت برای سبز:
۲/(۱۵ + ۱۷) - میانگین قیمت برای آبی:
۸/۱
در نتیجه، جدول دادهها به صورت زیر تبدیل میشود:
| رنگ (کدگذاری شده) | قیمت |
| ۱۱ | ۱۰ |
| ۱۶ | ۱۵ |
| ۲۲ | ۱۲ |
| ۸ | ۸ |
| ۱۶ | ۱۷ |
ایجاد درختهای تصمیمگیری
Catboost یک نوع الگوریتم Boosting است که برای ساخت مدل خود از درختهای تصمیمگیری استفاده میکند. این درختها با تقسیم فضای ویژگیها (Features) به نواحی کوچکتر بر اساس یک سری قوانین، ساختاری شبیه به درخت ایجاد میکنند که هر گره داخلی نمایانگر یک تصمیم بر اساس یک ویژگی است و هر گره برگ، به خروجی یا مقدار نهایی میرسد.
Boosting
Boosting یک روش یادگیری گروهی (Ensemble Learning) است. که با ترکیب مدلهای ضعیف (Weak Learners) به یک مدل قوی، سعی در بهبود دقت پیشبینی دارد. در این روش، هر مدل جدید سعی میکند خطاهای مدل قبلی را اصلاح کند. در نهایت، پیشبینی نهایی با ترکیب پیشبینیهای تمام مدلها به دست میآید.

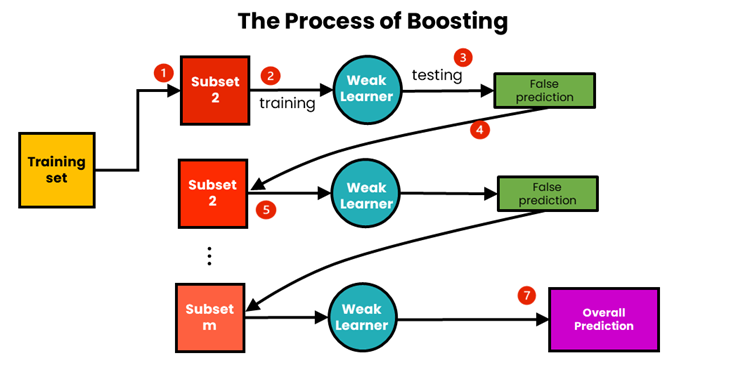
Gradient Boosting
Gradient Boosting یک نوع خاص از Boosting است که از روش گرادیان کاهشی برای بهینهسازی مدل استفاده میکند. در این روش، هر مدل ضعیف بهطور متوالی آموزش داده میشود تا خطاهای مدل فعلی کاهش یابد. به عبارت دیگر، هدف این است که یک مدل جدید با استفاده از گرادیان تابع زیان (Loss Function) برای تصحیح خطاهای مدلهای قبلی ساخته شود.

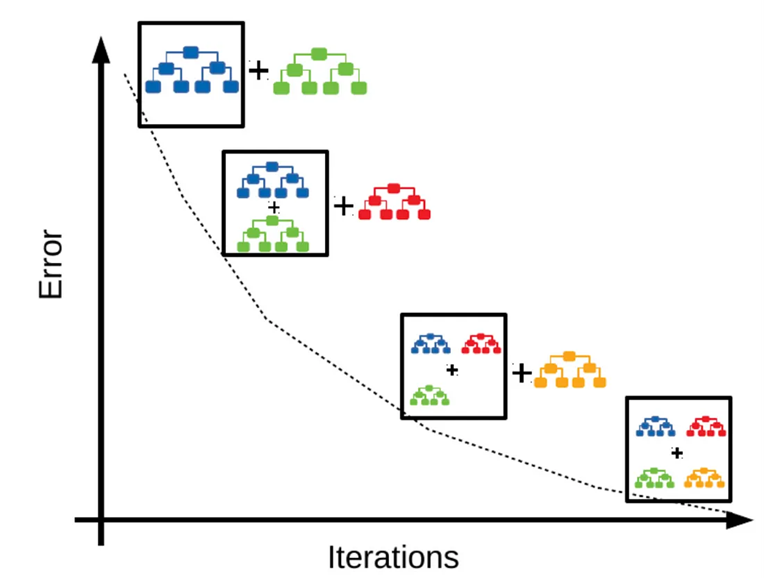
گرادیان بوستینگ روی درختهای تصمیمگیری
گرادیان بوستینگ روی درختهای تصمیمگیری (GBDT یا Gradient Boosting on Decision Tree) با هدف بهینهسازی تابع هزینه، یادگیرندههای ضعیف (درختهای تصمیمگیری ساده) را آموزش میدهد. برای اجرای این مدل مراحل زیر طی میشود:
ساخت مدل ابتدایی
ابتدا مدل با یک مقدار ثابت (مثلاً میانگین متغیر هدف) مقداردهی اولیه میشود. این مدل ابتدایی معمولاً خیلی ساده است و دقت کمی دارد.
آموزش درختهای ضعیف
آموزش درختهای ضعیف به این معناست که ما درختهای سادهای را به ترتیب آموزش میدهیم تا خطاهای مدل فعلی را کمینه کنند. فرمول آموزش یادگیرندههای ضعیف به این صورت است:
\large h_t(x) = \arg\min_h \sum_i L(y_i, F_{t-1}(x_i) + h(x_i))
که در آن:
- yi مقدار واقعی هدف برای نمونه i است.
- Ft−1(xi) خروجی مدل ترکیبی فعلی برای نمونه i است.
- h(xi) خروجی یادگیرنده ضعیف جدید برای نمونه i است.
این فرمول میگوید که یادگیرنده جدید ht(x) باید به گونهای آموزش داده شود که تابع خطا L(yi, Ft−1(xi)+h(xi)) را کمینه کند. به عبارت دیگر، یادگیرنده جدید باید به نحوی آموزش ببیند که خطاهای مدل فعلی را کم کند.
بررسی جزئیات فرمول
- انتخاب یادگیرنده جدید: در پیدا کردن یادگیرنده جدید ht(x)، به دنبال درختی هستیم که وقتی به مدل فعلی اضافه شود، مجموع خطاها را کاهش دهد.
- کمینه کردن تابع هزینه: تابع خطا یا هزینه L معیاری برای اندازهگیری تفاوت بین پیشبینی مدل و مقدار واقعی است. در اینجا، هدف این است که یادگیرنده (درخت) جدید طوری آموزش ببیند که این تفاوتها (خطاها) کمینه شود. این تابع هزینه میتواند به صورتهای مختلفی تعریف شود، مثلاً به صورت تابع میانگین مربعات خطا یا هوبر.
برای آشنایی بیشتر با توابع هزینه، این مقاله را مطالعه نمایید: تابع هزینه یا Loss Function چیست؟
بهروز رسانی مدل ترکیبی
پس از پیدا کردن یادگیرنده جدید (همان ht(x))، مدل ترکیبی به روز میشود. به عبارت دیگر، ما به تدریج و مرحله به مرحله مدل را با افزودن مدلهای کوچکتر (یادگیرندههای ضعیف) بهبود میبخشیم:
\large F_t(x) = F_{t-1}(x) + \gamma_t h_t(x)
که در آن:
- Ft(x) مدل جدید است.
- Ft-1(x) مدل فعلی است.
- γt نرخ یادگیری است. این پارامتر تعیین میکند که چقدر باید به مدل جدید اعتماد کنیم. نرخ یادگیری کوچکتر باعث میشود مدل به صورت آرامتر و پایدارتر بهبود یابد.
- ht(x) یادگیرنده ضعیف جدید است. این یادگیرنده جدید یک مدل ساده (مانند یک درخت تصمیمگیری کوچک) است که هدف آن بهبود مدل فعلی است.
وزندهی به درختها
هر درخت بر اساس عملکرد خود یک وزن میگیرد که بر نحوه تاثیر آن بر پیشبینی نهایی تاثیر میگذارد. در ابتدا، هر درخت وزنی به صورت پیشفرض دریافت میکند که میتواند ثابت باشد. این وزنها به مرور زمان با توجه به عملکرد هر درخت تنظیم میشوند. درواقع بعد از ساخت هر درخت، خطای پیشبینی آن درخت بر روی دادههای آموزشی ارزیابی میشود. هر چه درخت عملکرد بهتری در کاهش خطا داشته باشد، وزن بالاتری به آن تعلق میگیرد، در حالی که درختهایی که عملکرد ضعیفتری دارند، وزن کمتری میگیرند.
پیشبینی نهایی
پیشبینی نهایی شامل مجموع پیشبینیهای وزنی تمامی درختها است که منجر به یک مدل قوی و دقیق میشود که عملکرد خوبی بر روی دادههای جدید دارد.
برای درک بهتر نحوه عملکرد Catboost در یادگیری ماشین میتوانید به این ویدئو در یوتیوب مراجعه کنید.
پیادهسازی Catboost در پایتون
در این بخش میخواهیم با استفاده از مدل Catboost پیشبینی کنیم که آیا ممکن است سرطان تیروئید تمایزیافته (یک نوع از سرطان تیرویید) یک فرد برگردد یا خیر.
نصب و راهاندازی
برای نصب کتابخانه Catboost در محیط گوگل کلب کد زیر را اجرا میکنیم:
!pip install catboost
فراخوانی کتابخانهها
کتابخانههای لازم برای انجام این پروژه به شرح زیر است:
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore')
from catboost import CatBoostClassifier
from sklearn.metrics import accuracy_score, f1_score
from sklearn.model_selection import train_test_split, GridSearchCV
خواندن مجموعهداده
با استفاده از کتابخانه pandas مجموعهداده «بازگشت سرطان تیروئید تمایزیافته» را میخوانیم و برای نمونه ۵ تا از آنها را نمایش میدهیم:
data = pd.read_csv('Thyroid_Diff.csv')
data.sample(5)
خروجی کد بالا به شکل زیر است:

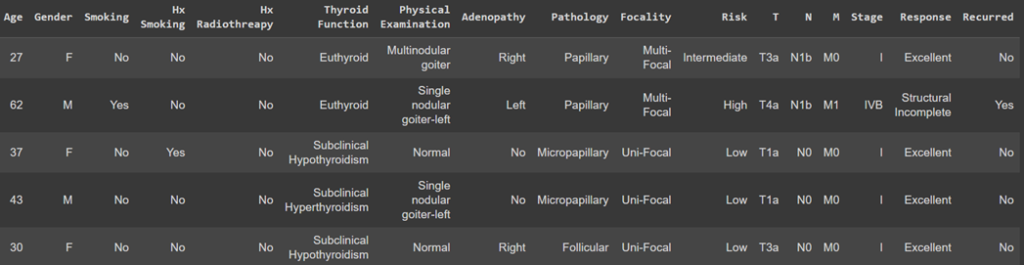
تقسیم مجموعهداده به دادههای آموزشی و آزمایشی
برای این کار ابتدا ستون برچسب (Label) را از مابقی مجموعهداده جدا میکنیم و سپس با تابع train_test_split دادههای آمزشی و آزمایشی را تفکیک مینماییم:
X = data.drop(['Recurred'], axis=1)
y = data['Recurred']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
ایجاد مدل
در قطعه کد زیر، ابتدا یک مدل CatboostClassifier با پارامترهای مورد نظر ایجاد میکنیم:
model = CatBoostClassifier(
depth=6,
verbose=0,
n_estimators=100,
learning_rate=0.1,
simple_ctr='Counter',
cat_features=cat_cols,
combinations_ctr='Counter',
loss_function='Logloss',
early_stopping_rounds=10
)
تنظیمات و هایپرپارامترها
تنظیم هایپرپارامترها میتواند تأثیر زیادی بر عملکرد مدل داشته باشد. برخی از مهمترین هایپرپارامترهای Catboost عبارتاند از تعداد تکرارها، نرخ یادگیری و عمق درختهای تصمیم. برای تنظیم بهینه این پارامترها، میتوانید از تکنیکهای مختلفی مانند جستجوی شبکهای (Grid Search) یا جستجوی تصادفی (Random Search) استفاده کنید. تنظیم صحیح این پارامترها میتواند به طور قابل توجهی عملکرد مدل شما را بهبود بخشد.
عمق (depth)
این پارامتر حداکثر عمق درختهای تصمیمگیری را کنترل میکند. یک درخت عمیقتر میتواند الگوهای پیچیدهتری را شناسایی کند اما ممکن است منجر به مشکل بیشبرازش شود.
تعداد درختان (n_estimators)
این پارامتر تعداد کل درختانی که در مدل Catboost استفاده میشود را نشان میدهد. هرچه تعداد درختان بیشتر باشد، مدل پیچیدگی بیشتری پیدا میکند و ممکن است بتواند الگوهای پیچیدهتری را یاد بگیرد یا منجر به بیشبرازش شود.
تعداد تکرارها (iterations)
این پارامتر تعداد کل تکرارهای تقویت (boosting) را تعیین میکند که در واقع تعداد درختها در مجموعه یادگیرنده است. در اینجا این مقدار را به ۵۰۰ تنظیم کردیم که به این معنی است که فرآیند آموزش ۵۰۰ درخت تصمیمگیری ایجاد خواهد کرد (تعداد تکرارها).
نرخ یادگیری (learning_rate)
این پارامتر اندازه گام را برای یادگیری الگوریتم تقویت گرادیان تعیین میکند که سهم هر درخت را در پیشبینی نهایی تنظیم میکند. یک نرخ یادگیری کمتر معمولاً منجر به مدل مقاومتر میشود اما به تعداد تکرارهای بیشتری نیاز دارد.
آمار هدف طبقه بندیشده ساده (simple_ctr) و مرکب (combinations_ctr)
در مدل Catboost، پارامترهای simple_ctr (Simple Categorical Target Statistics) وcombinations_ctr (Combinations Categorical Target Statistics) برای بهبود کارایی و دقت مدل هنگام کار با ویژگیهای (Features) دستهبندیشده استفاده میشوند. این پارامترها مشخص میکنند که چگونه ارزش ویژگیهای دستهبندیشده به اعداد تبدیل شوند تا مدل بتواند با آنها کار کند.
تابع زیان (loss_function)
این پارامتر تابع زیان مورد استفاده برای بهینهسازی مدل در طول آموزش را مشخص میکند. در اینجا به دلیل انجام دستهبندی دوکلاسه، آن را به Logloss تنظیم کردهایم.
توقف زودهنگام (early_stopping_rounds)
این پارامتر توقف زودهنگام در طول آموزش را فعال میکند. این پارامتر تعداد کل تکرارهایی را مشخص میکند که در صورت عدم بهبود معیار اعتبارسنجی، آموزش متوقف میشود. ما آن را به ۱۰ تنظیم کردهایم که به این معنی است که اگر معیار اعتبارسنجی برای ۱۰ تکرار متوالی بهبود نیابد، آموزش زودهنگام متوقف خواهد شد.
اجرای فرآیند آموزش
بعد از تعریف مدل، حال باید آن را با کد زیر روی دادههای آموزش Train کنیم:
model.fit(X_train, y_train, eval_set=(X_test, y_test))
با این کد، مدل با استفاده از دادههای آموزشی آموزش داده میشود و عملکرد آن بر روی دادههای آزمون در هر دور ارزیابی میشود. اگر مدل در طی ۱۰ دور بهبود نیابد، آموزش متوقف میشود تا از بیشبرازش جلوگیری شود.
تحلیل نتایج ارزیابی طی آموزش مدل
در بخش بعدی، نتایج ارزیابی مدل در طول فرآیند آموزش استخراج و تجزیه و تحلیل میشود. این کار به ما کمک میکند تا نحوه عملکرد مدل را در هر مرحله از آموزش مشاهده کنیم و تغییرات در تابع هزینه (Loss Function) را بررسی کنیم:
# Retrieve the evaluation results from the trained CatBoost model
evals_result = model.get_evals_result()
# Extract the training loss (Logloss) values over the training process
train_loss = evals_result['learn']['Logloss']
# Extract the validation loss (Logloss) values over the validation process
test_loss = evals_result['validation']['Logloss']
برای رسم نمودارهای تابع هزینه فرایندهای آموزش و آزمایش در هر تکرار (Iteration) از کتابخانه matplotlib بهصورت زیر استفاده میکنیم:
# Generate an array of iteration numbers, ranging from 1 to the total number of training iterations
iterations = np.arange(1, len(train_loss) + 1)
# Plot the training loss values against iterations, with a blue line
plt.plot(iterations, train_loss, label='Training Loss', color='blue')
# Plot the validation loss values against iterations, with a green line
plt.plot(iterations, test_loss, label='Validation Loss', color='green')
plt.xlabel('Iteration')
plt.ylabel('Loss')
plt.title('CatBoost Training Progress')
plt.legend()
plt.grid()
plt.show()
خروجی کد بالا بهشکل زیر است:

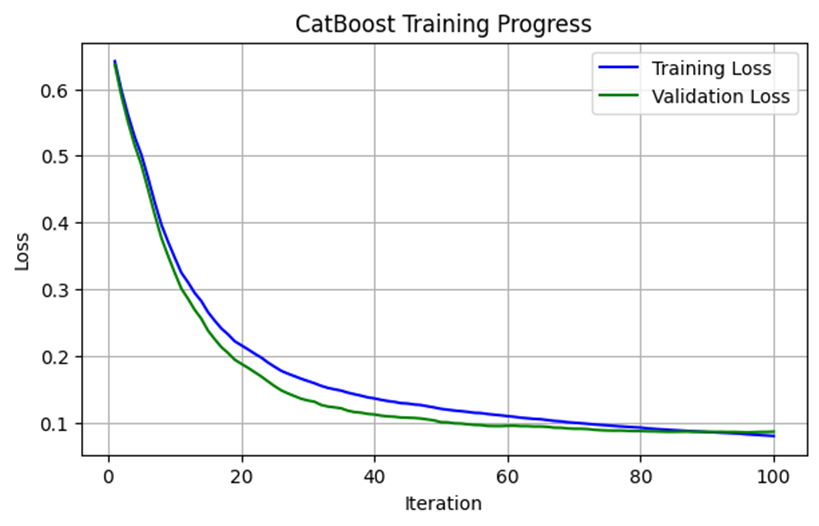
این نمودار نشان میدهد که مدل Catboost ما به درستی آموزش دیده و عملکرد خوبی بر روی هر دو مجموعه دادههای آموزشی و آزمایش دارد. کاهش پیوسته تابع هزینه و فاصله کم بین خطای آموزش و آزمایش، نشان میدهد که مدل به خوبی در حال یادگیری و تعمیمدهی است و مشکلی از نظر بیشبرازش یا کمبرازش ندارد.
ارزیابی مدل
در این بخش از کد، مدل Catboost ما که آموزش دیده برای پیشبینی مقادیر برچسب برای مجموعه دادههای آزمایش (X_test) استفاده میشود. سپس، معیارهای دقت (accuracy) و امتیاز F1 (F1-score) مدل محاسبه و چاپ میشوند:
# Predict the target values for the test set
y_pred = model.predict(X_test)
# Calculate Accuracy and F1-score of the model
accuracy = accuracy_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred, average='weighted')
# Print the Accuracy and F1-score
print(f"Accuracy: {accuracy}")
print(f"F1-Score: {f1}")
با اجرای کدهای بالا میبینید که دقت مدل آموزشدیده بهصورت زیر است:

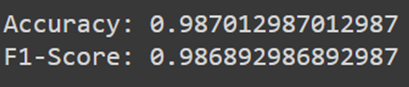
این نتایج نشان میدهد که مدل ما با دقت ۹۸.۷ درصد دادههای آزمایش را پیشبینی میکند.
مجموعه کامل کدهای استفاده شده در این مطلب، از گیتهاب ریپوزیتوری CatBoost قابل دسترسی است.
مقایسه Catboost با دیگر الگوریتمها
Catboost در مقایسه با دیگر الگوریتمهای Boosting مانند XGBoost و LightGBM دارای مزایای منحصربهفردی است که میتواند در پروژههای مختلف، عملکرد بهتری ارائه دهد. یکی از این مزایا، قابلیت کار با دادههای دستهای (Categorical Data) بدون نیاز به پیشپردازشهای پیچیده و زمانبر است که گفتیم با روش کدگذاری مبتنی بر هدف انجام میشود. در دیگر الگوریتمها مانند XGBoost و LightGBM، دادههای دستهای باید به صورت عددی کدگذاری شوند که این کار میتواند باعث از دست رفتن اطلاعات و افزایش پیچیدگی دادهها شود. در حالی که Catboost به طور خودکار این دادهها را پردازش میکند و نیازی به تکنیکهایی مانند One-Hot Encoding ندارد.
ویژگی دیگری که Catboost را متمایز میکند، استفاده از تکنیک Ordered Boosting است. این تکنیک به کاهش overfitting کمک میکند و به طور مؤثری دقت مدل را افزایش میدهد.
Ordered Boosting
Ordered Boosting یک نوع Gradient Boosting است که به طور خاص در الگوریتم Catboost به کار میرود. این روش به منظور جلوگیری از بیشبرازش (overfitting) طراحی شده است. درOrdered Boosting ، برای هر داده، مدل تنها از دادههایی که قبل از آن داده دیده شدهاند، برای ارزیابی استفاده میکند. توجه کنید که در روش Gradient Boosting، گرادیانها بر اساس همان دادههایی که مدل فعلی بر روی آنها ساخته شده است، محاسبه میشوند که واضحا این امر بیشبرازش را در پی خواهد داشت.
از نظر سرعت آموزش نیز، Catboost در بسیاری از موارد سریعتر از رقبای خود عمل میکند. این سرعت بالا به دلیل بهینهسازیهای مختلفی است که در الگوریتم Catboost انجام شده است. به عنوان مثال، این الگوریتم از GPU برای تسریع فرآیند آموزش استفاده میکند و قابلیت پردازش موازی دادهها را دارد که باعث کاهش زمان آموزش میشود.
در مجموع، اگرچه الگوریتمهای دیگری مانند XGBoost و LightGBM نیز در حوزههای خاصی برتری دارند، Catboost به دلیل ویژگیهای منحصربهفرد خود میتواند در بسیاری از پروژهها گزینه بهتری باشد، به ویژه در مواقعی که با دادههای دستهای کار میکنید و یا نیاز به سرعت بالا در فرآیند آموزش دارید.
مزایا و معایب Catboost
هر الگوریتم یادگیری ماشین، مزایا و معایب خاص خود را دارد و Catboost نیز از این قاعده مستثنی نیست. برخی از مزایای برجسته Catboost عبارتند از:
دقت بالا
به دلیل استفاده از تکنیکهای خاص مانند Ordered Boosting، Catboost میتواند مدلی با دقت بالا ایجاد کند که کمتر در معرض overfitting قرار دارد. این ویژگی، به خصوص در پروژههایی که دادههای پیچیده و حجیم دارند، بسیار حائز اهمیت است.
سرعت پردازش سریع
Catboost به طور کلی دارای سرعت بالاتری در فرآیند آموزش نسبت به دیگر الگوریتمهای Boosting است. این سرعت بالا به دلیل استفاده از بهینهسازیهای مختلف و قابلیت پردازش موازی دادههاست که باعث میشود زمان آموزش به طور قابل توجهی کاهش یابد.
قابلیت کار با دادههای دستهای
یکی از مزیتهای کلیدی Catboost، توانایی کار با دادههای دستهای (Categorical) بدون نیاز به پیشپردازشهای پیچیده است. این قابلیت باعث کاهش زمان و هزینههای مرتبط با آمادهسازی دادهها میشود و به مدل اجازه میدهد تا به شکلی کارآمدتر با دادههای دستهای کار کند.
با این حال، Catboost نیز معایب خود را دارد که باید در نظر گرفته شود:
نیاز به تنظیم دقیق هایپرپارامترها
برای دستیابی به بهترین عملکرد، Catboost نیاز به تنظیم دقیق هایپرپارامترها دارد. این فرآیند میتواند زمانبر و پیچیده باشد و نیازمند تجربه و دانش کافی در زمینه تنظیم هایپرپارامترهاست.
مصرف بالای حافظه
یکی از چالشهای Catboost مصرف بالای حافظه است که میتواند در پروژههای بزرگ و با دادههای حجیم مشکلساز شود. این موضوع به خصوص زمانی که با منابع محدود سختافزاری روبرو هستید، اهمیت بیشتری پیدا میکند.
مناسب نبودن برای همه پروژهها
در برخی از پروژهها و کاربردها، ممکن است الگوریتمهای دیگری مانند XGBoost یا LightGBM عملکرد بهتری داشته باشند. به عنوان مثال، در پروژههایی که نیاز به مدلهای بسیار ساده و سریع دارید، شاید استفاده از Catboost مناسب نباشد و بهتر است الگوریتمی سادهتر و سبکتر را انتخاب کنید.
کلام آخر درباره Catboost
Catboost بهعنوان یک الگوریتم قدرتمند و کارآمد، قابلیتها و مزایای منحصر به فردی دارد که آن را از دیگر الگوریتمها متمایز میکند. این الگوریتم برای پردازش دادههای دستهای مناسب است و با دقت و سرعت بالا، به یکی از ابزارهای محبوب در میان دانشمندان داده تبدیل شده است. با استفاده از تکنیکهای بهینهسازی و وزندهی مناسب به درختها، Catboost نه تنها دقت بالایی را در پیشبینیها ارائه میدهد بلکه از مشکلاتی نظیر بیشبرازش نیز جلوگیری میکند. با تنظیم دقیق هایپرپارامترها و استفاده از روشهای مناسب، میتوانید مدلهایی با دقت بالا و کارایی مناسب ایجاد کنید که در پروژههای مختلف قابل استفاده هستند.


سوالات متداول
چگونه Catboost از دادههای دستهبندیشده استفاده میکند؟
Catboost از روش کدگذاری مبتنی بر هدف (Target-Based Encoding) برای تبدیل ویژگیهای دستهبندیشده به مقادیر عددی استفاده میکند. این روش با محاسبه میانگین مقادیر هدف (Target Values) برای هر دسته، ویژگیهای دستهبندی را به اعدادی تبدیل میکند که مدل بتواند از آنها استفاده کند.
تفاوتهای اصلی بین Catboost و دیگر الگوریتمهای Boosting مانند XGBoost و LightGBM چیست؟
Catboost بهطور خودکار دادههای دستهبندیشده را پردازش میکند و نیازی به کدگذاری پیچیدهای مانند One-Hot Encoding ندارد. همچنین، Catboost از تکنیک Ordered Boosting استفاده میکند که به کاهش بیشبرازش کمک میکند و دقت مدل را افزایش میدهد. این ویژگیها Catboost را از دیگر الگوریتمهای Boosting متمایز میکند.
مزایای استفاده از Catboost در صنایع مختلف چیست؟
Catboost در صنایع مختلف مانند بازاریابی، مالی، سلامت و تجارت الکترونیک کاربرد دارد. در بازاریابی، برای پیشبینی رفتار مشتریان و تحلیل دادههای بازاریابی استفاده میشود. در حوزه مالی، میتواند برای تحلیل ریسک و پیشبینی قیمت سهام استفاده شود. در صنعت سلامت، برای پیشبینی بیماریها و تحلیل دادههای پزشکی مفید است. در تجارت الکترونیک، برای توصیه محصولات و تحلیل دادههای فروش کاربرد دارد.
چگونه Catboost با تکنیک Ordered Boosting دقت مدل را بهبود میبخشد؟
در تکنیک Ordered Boosting، برای هر داده، مدل تنها از دادههایی که قبل از آن داده دیده شدهاند برای ارزیابی استفاده میکند. این روش به جلوگیری از بیشبرازش کمک میکند و دقت مدل را بهبود میبخشد. در روشهای معمول Gradient Boosting، گرادیانها بر اساس همان دادههایی که مدل فعلی بر روی آنها ساخته شده، محاسبه میشوند که این امر میتواند باعث بیشبرازش شود.
چه تنظیماتی برای بهینهسازی عملکرد Catboost در پروژههای یادگیری ماشین پیشنهاد میشود؟
برای بهینهسازی عملکرد Catboost، تنظیم هایپرپارامترهایی مانند عمق درخت (Depth)، تعداد تکرارها (Iterations)، نرخ یادگیری (Learning Rate)، و تعداد درختان (n_estimators) اهمیت دارد. همچنین، استفاده از تکنیکهای جستجوی شبکهای (Grid Search) یا جستجوی تصادفی (Random Search) برای یافتن مقادیر بهینه این پارامترها میتواند به بهبود عملکرد مدل کمک کند.
یادگیری ماشین لرنینگ را از امروز شروع کنید!
دنیای دادهها جذاب است و دانستن علم داده، توانایی تحلیل داده، یا بازاریابی مبتنی بر داده، شما را برای فرصتهای شغلی بسیاری مناسب میکند. فارغ از رشته و پیشزمینه، میتوانید حالا شروع کنید و از سطح مقدماتی تا پیشرفته بیاموزید. اگر دوست دارید به این حوزه وارد شوید، پیشنهاد میکنیم با کلیک روی این لینک قدم اول را همین حالا بردارید.
مشاوران کافهتدریس به شما کمک میکنند مسیر یادگیری برای ورود به این حوزه را شروع کنید:
<p><a class=”call-to-btn” href=”https://cafetadris.com/datascience” target=”_blank” rel=”noopener noreferrer” data-wplink-edit=”true”>دوره جامع دیتا ساینس و ماشین لرنینگ</a></p>