
طبقه بندی متن (Text Classification) فرایند طبقهبندی متون در کلاسهای ازپیشتعیینشده ازطریق برچسبگذاری آنهاست. اساساً متن میتواند یک منبع اطلاعاتی بسیار غنی باشد، اما بهدلیل ماهیت غیرساختاری، استخراج اطلاعات از آن دشوار و وقتگیر است. بهلطف پیشرفتهای اخیر در پردازش زبان طبیعی (NLP) و یادگیری ماشین (ML) که هر دو در حوزهی هوش مصنوعی (AI) قرار دارند، مرتبسازی دادههای متنی آسانتر شده است.
- 1. چرا طبقه بندی متن مهم است؟
- 2. طبقه بندی متن (Text Classification) چیست؟
- 3. طبقه بندی متن چطور کار میکند؟
- 4. کاربردهای طبقه بندی متن
- 5. خلاصه مطالب
- 6. آموزش دیتا ساینس در کلاسهای آنلاین علم داده کافهتدریس
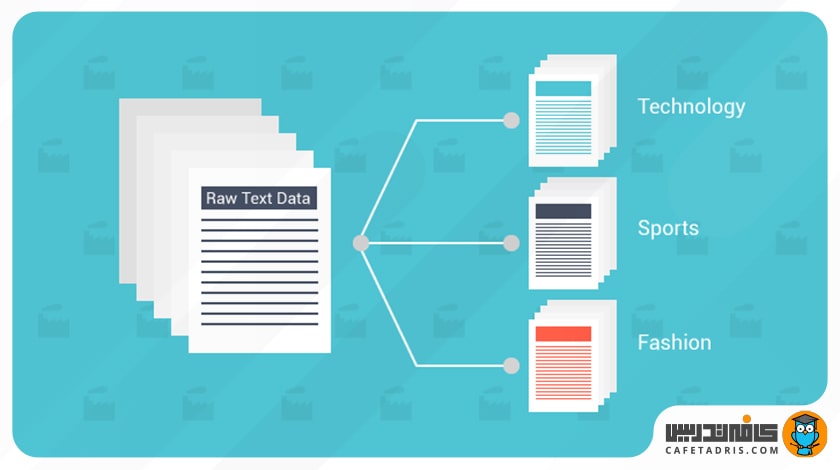
چرا طبقه بندی متن مهم است؟
طبق آمار حدود هشتاد درصد از کل دادههای موجود بدون ساختار هستند و متن یکی از متداولترین انواع دادههای بدون ساختار است. بهدلیل ماهیت نامرتب متن، تجزیهوتحلیل، درک، سازماندهی و مرتبسازی دادههای متنی کاری دشوار و زمانبر است؛ بنابراین اکثر شرکتها در استفاده از آن بهشکل مناسب و بهینه ناکام میمانند.
اینجاست که طبقه بندی متن (Text Classification) با استفاده از یادگیری ماشین (Machine Learning/ ML) مطرح میشود. با استفاده از طبقهبندی متن شرکتها میتوانند بهصورت خودکار هر نوع متنی را مانند ایمیل، اسناد حقوقی، رسانههای اجتماعی، چتباتها، نظرسنجیها و موارد دیگر بهروشی سریع و مقرونبهصرفه مرتب و سازماندهی کنند.
این فرایند به شرکتها امکان میدهد تا در زمان لازم برای تجزیهوتحلیل دادههای متنی صرفهجویی کنند، فرایندهای تجاری را بهصورت خودکار انجام دهند و تصمیمهای تجاری خود را مبتنی بر دادههای بهدستآمده اتخاذ کنند. در این مقاله قصد داریم با تکنیک طبقهبندی متن آشنا شویم و روشهای مورداستفاده در آن و برخی از کاربردهای متنوع آن را بررسی کنیم.
طبقه بندی متن (Text Classification) چیست؟
طبقه بندی متن یکی از روشهای یادگیری ماشین است که مجموعهای از کلاسهای ازپیشتعریفشده را به متن اختصاص میدهد. طبقهبندیکنندههای متن میتوانند برای سازماندهی و طبقهبندی هر نوع متنی، مانند اسناد، مطالعات پزشکی یا هر متنی که در اینترنت وجود دارد، استفاده شود.
برای مثال، با استفاده از تکنیک طبقهبندی متن میتوانیم مقالهها را براساس موضوعشان یا نظر افراد درمورد یک محصول را براساس مثبت یا منفیبودن آنها طبقهبندی کنیم. طبقه بندی متن یکی از وظایف اساسی در پردازش زبان طبیعی (Processing Natural Language / NLP) با کاربردهای گستردهای مانند تجزیهوتحلیل احساسات (Sentiment Analysis)، برچسبگذاری موضوع (Topic Labeling) و تشخیص هرزنامه (Spam Detection) است.
یادگیری ماشین (Machine Learning) چیست و چگونه کار میکند؟
تا اینجا متوجه شدیم طبقهبندی متن به چه معناست و مثالهایی از کاربرد آن را نیز برشمردیم. حال لازم است با نحوهی کار تکنیک طبقهبندی متن آشنا شویم.

طبقه بندی متن چطور کار میکند؟
طبقهبندی متن را میتوان به دو روش دستی یا خودکار انجام داد.
طبقه بندی دستی متن
طبقهبندی دستی متن حاشیهنویسی انسانی (human annotator) را دربرمیگیرد که یک یا چند شخص محتوای (مثلا کارشناس آن حوزه) متن را تفسیر می کنند و براساس آن متن را طبقهبندی میکنند. این روش میتواند نتایج خوبی به همراه داشته باشد، اما وقت گیر و گران است.
طبقهبندی خودکار متن
طبقهبندی خودکار متن از یادگیری ماشین (ML)، پردازش زبان طبیعی (NLP) و دیگر تکنیکهای هوش مصنوعی (AI) برای طبقهبندی خودکار متن بهشیوهای سریعتر، مقرونبهصرفهتر و دقیقتر استفاده میکند.
رویکردهای بسیاری برای طبقهبندی خودکار متن وجود دارد، اما همه آنها تحت سه نوع سیستم اصلی قرار میگیرند:
- سیستمهای مبتنی بر قانون (Rule-based)
- سیستمهای مبتنی بر یادگیری ماشین (Machine Learning-based)
- سیستمهای ترکیبی (Hybrid)
در ادامه هر یک از این سیستمها را توضیح خواهیم داد.
سیستمهای مبتنی بر قانون (Rule-based)
رویکردهای مبتنی بر قانون، با استفاده از مجموعهای از قوانین زبانی دستنویس، متن را در گروههای سازمانیافته طبقهبندی میکنند. این قوانین به سیستم دستور میدهند تا از عناصر معنایی مرتبط با متن برای شناسایی دستههای مربوط براساس محتوای آن استفاده کند. هر قانون از یک الگو (Pattern) و یک دسته یا کلاس پیشبینیشده (Predicted Category) تشکیل شده است.
نحوه کار سیستمهای مبتنی بر قانون
برای درک بهتر این مساله این مثال را در نظر بگیرید: فرض کنید میخواهید مقالههای خبری را به دو گروه ورزش و سیاست طبقهبندی کنید. در ابتدا شما باید دو فهرست از کلمهها را تعریف کنید که مشخصکننده هر گروه هستند (برای مثال، کلمههای مربوط به ورزش، مانند فوتبال، بسکتبال و غیره، و کلمات مربوط به سیاست، مانند دونالد ترامپ، هیلاری کلینتون، پوتین، و غیره).
در مرحله بعد وقتی میخواهیم متن ورودی جدید را طبقهبندی کنیم باید تعداد کلمههای مربوط به ورزش را بشماریم که در متن هستند و همین کار را برای کلمههای مرتبط با سیاست نیز انجام دهیم. اگر تعداد کلمههای مربوط به ورزش از تعداد کلمههای مرتبط با سیاست بیشتر باشد، متن در دستهی ورزشی و در غیر این صورت، در دستهی سیاسی طبقهبندی میشود.
معایب سیستمهای مبتنی بر قانون
سیستمهای مبتنی بر قانون (Rule-based) برای انسان درکپذیر هستند و میتوانند با گذشت زمان بهبود یابند، اما معایبی هم دارند؛ برای مثال، این سیستمها به دانش عمیقی در حوزهی مدنظر نیاز دارند؛ علاوهبراین زمانبر هستند؛ زیرا ایجاد قوانین برای یک سیستم پیچیده بسیار چالشبرانگیز است و معمولاً به تجزیهوتحلیل و آزمایشهای زیادی نیاز دارد؛ همچنین نگهداری (Maintaining) سیستمهای مبتنی بر قانون دشوار است؛ زیرا افزودن قوانین جدید میتواند بر نتایج قوانین قبلی تأثیر بگذارد.
بعد از سیستمهای مبتنی بر قانون (Rule-based) لازم است با روش دیگری که در طبقه بندی متن (Text Classification) از آن استفاده میکنیم، یعنی سیستمهای مبتنی بر یادگیری ماشین (Machine Learning-based)، آشنا شویم.

سیستمهای مبتنی بر یادگیری ماشین (Machine Learning-based)
بهجای تکیه بر قوانین دستنویس، طبقهبندی متن مبتنی بر یادگیری ماشین (Machine Learning-based) یاد میگیرد که براساس مشاهدههای گذشته متن را طبقهبندی کند. با استفاده از مثالهای از پیش برچسبزدهشده بهعنوان دادههای آموزشی، الگوریتمهای یادگیری ماشین میتوانند ارتباطات مختلف میان متن را بیاموزند و برای یک ورودی خاص یک برچسب خاص را تعیین کنند. «برچسب» همان کلاس یا دستهی مدنظر است که هر متن ورودی میتواند در یک دستهی خاص قرار بگیرد.
اما چطور سیستمهای مبتنی بر یادگیری ماشین (Machine Learning-based) کار طبقهبندی متن (Text Classification) را انجام میدهند؟
نحوه کار سیستمهای مبتنی بر یادگیری ماشین
اولین قدم برای آموزش یک طبقهبندیکنندهی متن که بر یادگیری ماشین مبتنی است استخراج ویژگی (Feature Extraction) است. در این فرایند از روشی استفاده میشود تا هر متن را بهشکل یک بردار به نمایش عددی تبدیل کنیم؛ زیرا کامپیوتر قادر به درک متن بهشکلی که ما میبینیم نیست. یکی از روشهای متداول روش صندوقچهی کلمات (Bag of Words) است که بردار تعداد تکرار یک کلمه را در یک فرهنگ لغت ازپیشتعریفشده نشان می دهد.
طرز کار سیستمهای مبتنی بر یادگیری ماشین با فرهنگ لغت
فرض کنیم که فرهنگ لغت ما این کلمات را دارد:
{This, is, the, not, awesome, bad, basketball}
حال ما میخواهیم جمله «This is awesome» را به بردار عددی تبدیل کنیم. بردار آن بهاین شکل خواهد بود:
(0, 0, 1, 0, 0, 1, 1)
یعنی بهجای هر یک از کلمههای فرهنگ لغت که در این جمله ورودی وجود را دارد 1 و بهجای آن کلمههایی که وجود ندارد 0 میگذاریم.
تا اینجا متن ورودی را به بردار تبدیل کردیم. در مرحلهی بعد به الگوریتم یادگیری ماشین تعدادی داده آموزشی داده میشود که این دادهها بردارهای ویژگی و برچسب را دربرمیگیرند؛ یعنی بردار هر متن بههمراه کلاسی که به آن متعلق است به الگوریتم داده میشود تا با آنها آموزش ببیند و مدل طبقهبندی را ایجاد کند.
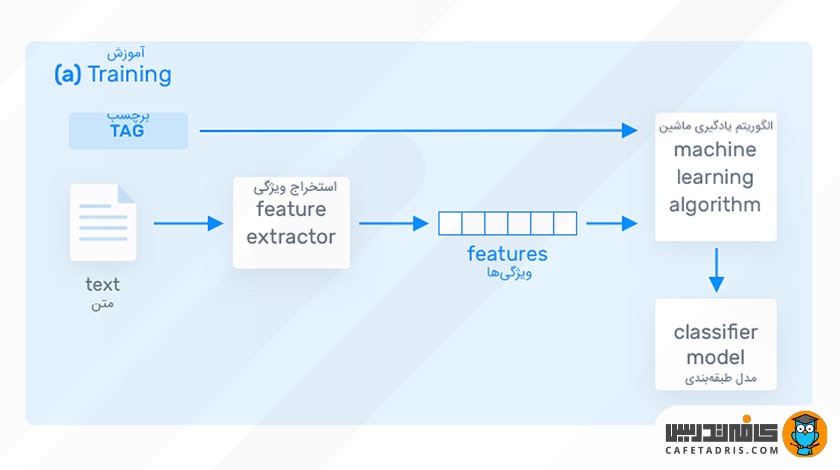
هنگامی که مدل یادگیری ماشین با نمونههای آموزشی کافی آموزش داده شود میتواند دادههای جدیدی را بهعنوان ورودی دریافت و شروع به پیشبینی کلاس هر یک از آنها کند.
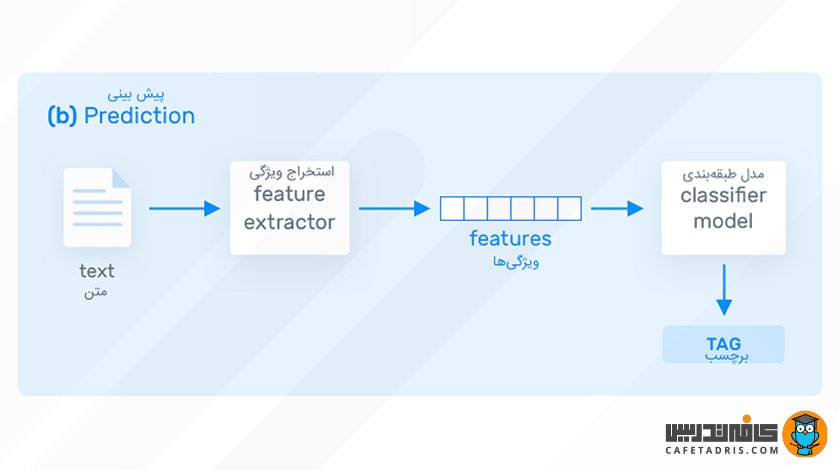
طبقه بندی متن (Text Classification) مبتنی بر یادگیری ماشین معمولاً بسیار دقیقتر از سیستمهای مبتنی بر قانون است؛ همچنین نگهداری (Maintaining) سیستم طبقهبندی با یادگیری ماشین آسانتر است و همیشه میتوانیم برچسبهای جدیدی به نمونهها بزنیم و مدل را با آنها آموزش دهیم.
و اما برویم سراغ آخرین سیستمهای طبقهبندی متن، یعنی سیستمهای ترکیبی.
سیستمهای ترکیبی (Hybrid Systems)
سیستمهای ترکیبی (Hybrid Systems) برای بهبود نتایج یک طبقهبندیکنندهی مبتنی بر یادگیری ماشین را با یک سیستم مبتنی بر قانون ترکیب میکنند.
حال که با روشهای مورد استفاده در طبقهبندی متن (Text Classification)آشنا شدیم، بهتر است به برخی از کاربردهای این تکنیک نگاهی بیندازیم:
کاربردهای طبقه بندی متن
طبقهبندی متن هزاران کاربرد دارد و برای طیف وسیعی از وظایف اعمال میشود. خیلی از نرمافزارهایی که امروزه با آنها کار میکنیم از تکنیک طبقهبندی متن استفاده میکنند؛ برای مثال، میتوانیم به فیلترکردن ایمیلهای اسپم (Email Spam Filtering) اشاره کنیم. بازاریابان، مدیران محصولات، مهندسان و فروشندگان برای اتوماسیون فرایندهای تجاری و صرفهجویی در صدها ساعت پردازش دستی اطلاعات از طبقهبندیکنندهها استفاده میکنند. در این بخش به سه نمونه از مهمترین کاربردهای طبقهبندی متن اشاره میکنیم.
شناسایی مشکلات فوری (Detecting Urgent Issues)
فقط در توئیتر کاربران هر روز پانصدمیلیون توییت ارسال می کنند. بررسیها نشان میدهد 83 درصد از مشتریانی که در شبکههای اجتماعی اظهارنظر یا شکایت میکنند انتظار پاسخ در همان روز را دارند و ۱۸ درصد انتظار دارند بلافاصله پاسخی دریافت کنند.
با کمک تکنیک طبقهبندی متن مشاغل میتوانند مقدار زیادی اطلاعات را با استفاده از تکنیکهایی مانند تجزیهوتحلیل احساسات مبتنی بر جنبه (Aspect-based Sentiment Analysis) به دست آورند تا بفهمند مردم دربارهی چه چیزی صحبت میکنند؛ برای مثال، یک مشتری درمورد یک مشکل یا خرابی خیلی مهم اعتراض میکند که ممکن است به این بینجامد که تعداد زیادی مشتری را از دست بدهند. در این حالت مشاغل خیلی راحتتر میتوانند این مسائل را مدیریت کنند.
اتوماسیون فرایندهای پشتیبانی مشتری
ایجاد یک تجربهی کاربری خوب یکی از اساسیترین مسائل یک شرکت در حال رشد است.
درواقع زمانی که مشتری تجربهی خوبی از استفاده از خدمات یک شرکت را دارد قطعاً بار دیگر از خدمات آن استفاده میکند، اما اگر تجربهی ضعیفی از خرید یا استفاده از خدمات شرکت داشته باشد، بهاحتمال خیلی زیاد دیگر آن را تکرار نخواهد کرد.
طبقهبندی متن میتواند با اتوماتیککردن کارها به تیمهای پشتیبانی مشتری امکان دهد تا تجربهی کاربری بهتری را برای مشتری فراهم کنند و وقتشان را برای کارهای مهم دیگر صرف کنند.
شنیدن صدای مشتری (VoC/Voice of Customer)
شرکتها از نظرسنجیهایی مانند Net Promoter Score برای گوشکردن به صدای مشتریان خود استفاده می کنند.
اطلاعات جمعآوریشده هم کیفی و هم کمّی است و بااینکه آمارهای NPS بهراحتی تجزیهوتحلیلپذیر هستند، اما پاسخهای Open-ended (پاسخهایی که مشتریان در نظرسنجیها میدهند و جوابشان کیفی است و فقط به بله یا خیر خلاصه نمیشود) به تجزیهوتحلیل عمیقتری با استفاده از تکنیکهای طبقهبندی متن نیاز دارد. بهجای اعتماد به انسان برای تجزیهوتحلیل دادههای مشتری میتوانیم بهسرعت بازخورد مشتری را با یادگیری ماشین پردازش کنیم. مدلهای طبقهبندی به ما کمک میکنند تا نتایج نظرسنجی را برای اطلاعاتی از این دست استفاده کنیم:
- مردم درمورد محصول یا خدمات ما چه چیزی دوست دارند؟
- چه چیزی را باید بهبود ببخشیم؟
- چه چیزی باید تغییر دهیم؟
با تجزیهوتحلیل این اطلاعات تیمها میتوانند آگاهانهتر تصمیم بگیرند، بدون اینکه مجبور شوند ساعتها بهصورت دستی هر یک از پاسخهای مشتریان را تجزیهوتحلیل کنند.
با کاربردهای یادگیری ماشین بیشتر آشنا شوید:
۹ کاربرد یادگیری ماشین در زندگی روزمره را بشناسید!
خلاصه مطالب
در این مطلب تکنیک طبقهبندی متن را معرفی کردیم و دیدیم که روشهای مرسوم کاربردی در این حوزه چیست؛ همچنین با بعضی از کاربردهای آن آشنا شدیم.
همانطور که دیدیم طبقهبندی متن سلاحی مخفی برای ساخت سیستمهای پیشرفته و سازماندهی اطلاعات تجاری محسوب میشود. تبدیل دادههای متنی به دادههای کمی برای بهدستآوردن بینش عملی و هدایت تصمیمهای تجاری فوقالعاده مفید است؛ همچنین خودکارکردن کارهای دستی و تکراری کمک میکند تا در وقت صرفهجویی و کارهای بیشتری را مدیریت کنیم.
آموزش دیتا ساینس در کلاسهای آنلاین علم داده کافهتدریس
یکی از بهترین روشهای یادگیری علم داده و یادگیری ماشین شرکت در کلاسهای آنلاین است. کلاسهای آنلاین به شما امکان میدهد بهصورت کاملاً پویا و تعاملی شرایط کلاسهای حضوری را تجربه کنید، اما بهصورت چشمگیری بتوانید زمان خود را ذخیره کنید.
کلاسهای آنلاین آموزش علم داده کافهتدریس بهصورت مقدماتی و پیشرفته برگزار میشود و مبتنی بر پروژههای واقعی علم داده است و بهشکل کارگاهی برگزار میشود.
برای آشنایی با کلاسهای آنلاین آموزش علم داده کافهتدریس و مشاورهی رایگان برای یادگیری دیتا ساینس و ماشین لرنینگ روی این لینک کلیک کنید:
1.طبقهبندی متن چرا اهمیت دارد؟
حدود هشتاد درصد از کل دادهها بدون ساختار هستن و متن یکی از انواع دادههای بدون ساختارهست. بهدلیل تجزیهوتحلیل، درک، سازماندهی و مرتبسازی دادههای متنی کاری هست که زمان زیادی می بره که باعث میشه اکثر شرکتها در استفاده از آن بهشکل مناسب استفاده کنند
2.طبقهبندی متن چطور عمل میکند؟
طبقهبندی دستی متن
طبقهبندی خودکار متن
3.طبقهبندی متن بهزبان ساده یعنی چه؟
طبقه بندی متن به زبان ساده یعنی زمان لازم برای تجزیهوتحلیل دادههای متنی صرفهجویی بشه و فرایندهای تجاری را بهصورت خودکار انجام بدن و تصمیمهای تجارشرکت رو بر اساس دادههای بهدستآمده نتیجه گیری کننئد
من دوره علم 2 رو شرکت کردم حسابی هیجان دارم که شروع بشه .ممنون از سایت خوبتون
سپاس از اشتراک نظر شما دوست عزیز
سلام من دانش آموز پایه نهم هستم که در ریاضیات و آماری که شما در مباحث فرمودید خیلی حرفه ای هستم اما قسمت پایتون رو بلد نیستم به نظرتون می تونم تو این دوره شرکت کنم ؟
سلام، در دوره ۱ ویدیوی پیشنیاز پایتون هم در اختیارتون قرار میگیره که با سینتکسهای کلی پایتون آشنا میشین و در طول دوره با حل تمرین و انجام پروژهها بیشتر و بهتر پایتون رو یاد میگیرین. بنابراین بله شما میتونین تو این دوره شرکت کنین.
کانال آموزشی هم دارید ؟
بله دوست عزیز، لینک کانال علم داده : https://t.me/DSLanders
سلام ادمین عزیز دوره هاتون پشتیبانی آموزشی هم داره که در کانال و گروهی بچه ها در ارتباط باشن؟
سلام، بله دوست عزیز، دورهها گروههای مختص خودشون رو دارن که افراد میتونن با هم تعامل داشته باشن.
درآمد کسانی که در حوزه دیتا کار میکنند چفدر هست ؟
برای پاسخ به این سوال باید خیلی از عوامل رو در نظر گرفت، مثل کشور مورد نظر، سازمانی که توش کار میکنن و وظیفهای که بر عهده دارن. پیشنهاد میکنم این مقاله رو مطالعه کنین: http://ctdrs.ir/ds0051
خدا قوت نماز و روزه هاتون قبول
شما کلاس آموزشی هوش مصنوعی ویژه رشته کامپیوتر هم دارید ؟
کلاسهای آنلاین علم داده شامل مباحث هوشمصنوعی میشه که البته لزوما ویژهی رشتهی کامپیوتر نیست. اما اگر رشتهتون مرتبط باشه خب نکته مثبتی محسوب میشه. برای مشاهده کلاسهای علم داده میتونین به این لینک مراجعه کنین: https://cafetadris.com/datascience
سلام دوره علم داده 1 رو از کجا می تونم ثبت نام کنم ؟
سلام، از طریق لینک برای ثبتنام اقدام کنین: http://ctdrs.ir/cr10629
سلام خسته نباشید تیم قوی کافه تدریس
میشه لطفا در رابطه با یادگیری تقویتی هم مقاله بذارید ؟
سلام، دوست عزیز از طریق این لینک میتونین مطلب یادگیری تقویتی رو مطالعه کنین : http://ctdrs.ir/ds0013