
{kind=link}
مدل ترنسفورمر (Transformer Model) یا مدل انتقالی یک مدل یادگیری عمیق (Deep Learning) است که از مکانیزم توجه (Attention Mechanism) استفاده میکند. این مدل برای اولین بار در سال ۲۰۱۷ معرفی شد. مدل ترنسفورمر (Transformer Model) بهطور معمول در تحقیقات پردازش زبان های طبیعی (NLP / Natural Language Processing) استفاده میشود. در این مطلب تلاش کردهایم تا با بیانی ساده، مدل ترنسفورمر را توضیح دهیم.

ساختار مدل ترنسفورمر (Transformer Model)
اگر در نظر بگیریم که کار مدنظر در اینجا ترجمهی متن است، پس یک مدل ترنسفورمر یا مدل انتقالی در ورودی جملهای را دریافت و در خروجی ترجمهی آن را تحویل میدهد. شکل ۱ نمایی از یک مدل ترنسفورمر (Transformer Model) را نمایش میدهد.
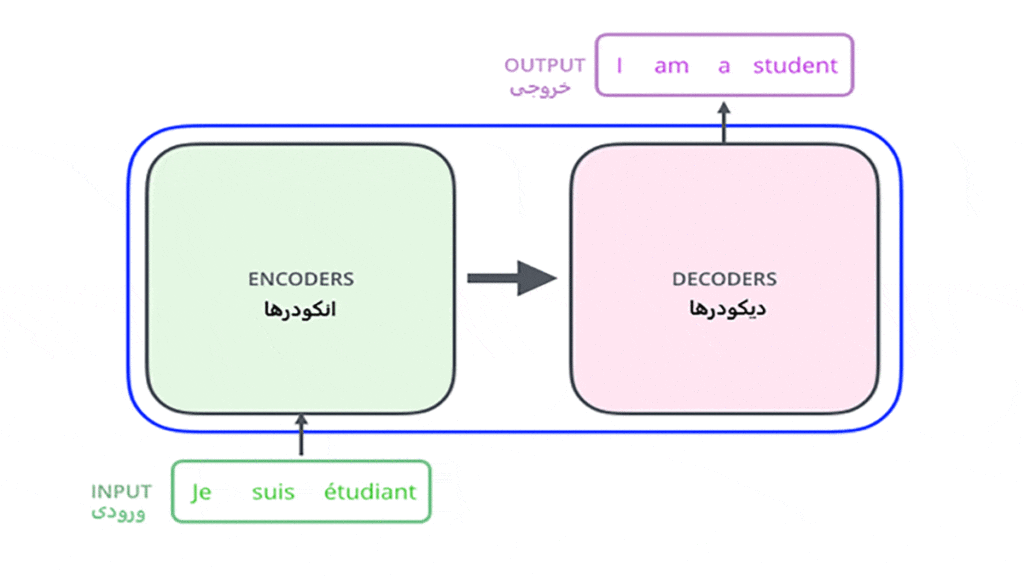
همانطور که در شکل میبینید، این مدل دستهای انکودر (Encoder) و دیکودر (Decoder) دارد که با هم در ارتباط هستند. در مقالهی اصلی تعداد این انکودر و دیکودر ها ۶ در نظر گرفته شده است که البته میتوان هر تعدادی را در نظر گرفت، اما باید در نظر بگیریم که تعداد انکودر و دیکودرها برابر است. ساختار تمامی انکودرها مشابه یکدیگر است و ساختار دیکودرها نیز مشابه هم است.
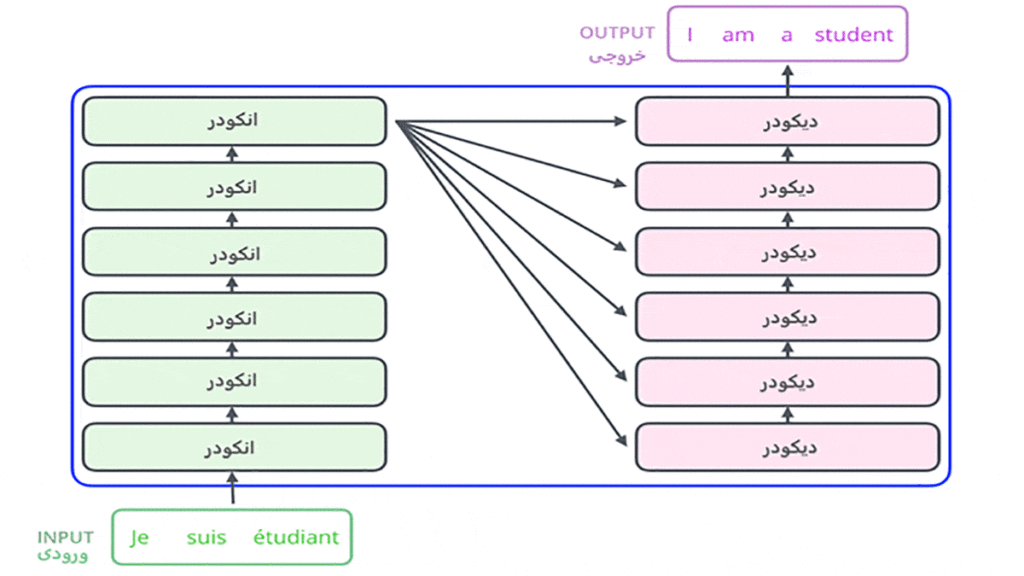
حال ساختار انکودرها و سپس ساختار دیکوردها را بهصورت جداگانه بررسی میکنیم تا با جزئیات مدل ترنسفورمر بیشتر آشنا شویم.
ساختار انکودر در مدل ترنسفورمر
هر انکودر دو زیرلایهی مجزا دارد که لایهی اول لایه Self-Attention و لایهی دوم یک شبکه عصبی پیشخور (Feedforward Neural Network) است.
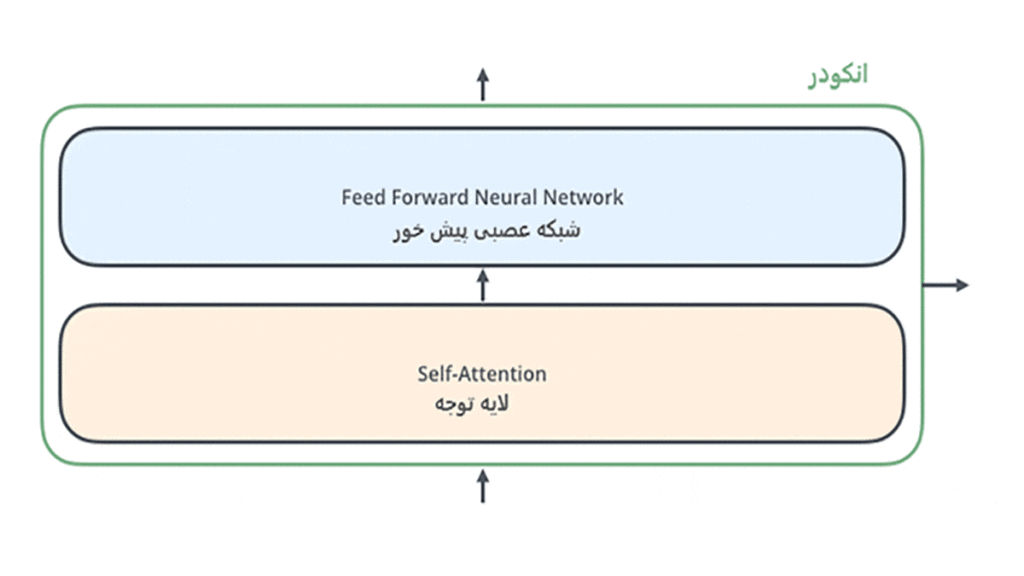
ورودی انکودر ابتدا از یک لایهی Self-Attention عبور میکند که به انکودر کمک میکند تا در حین انکودکردن یک کلمه به کلمههای دیگر موجود در جمله هم توجه کند. خروجی لایهی Self-Attention به یک لایهی شبکهی عصبی پیشخور وارد میشود.
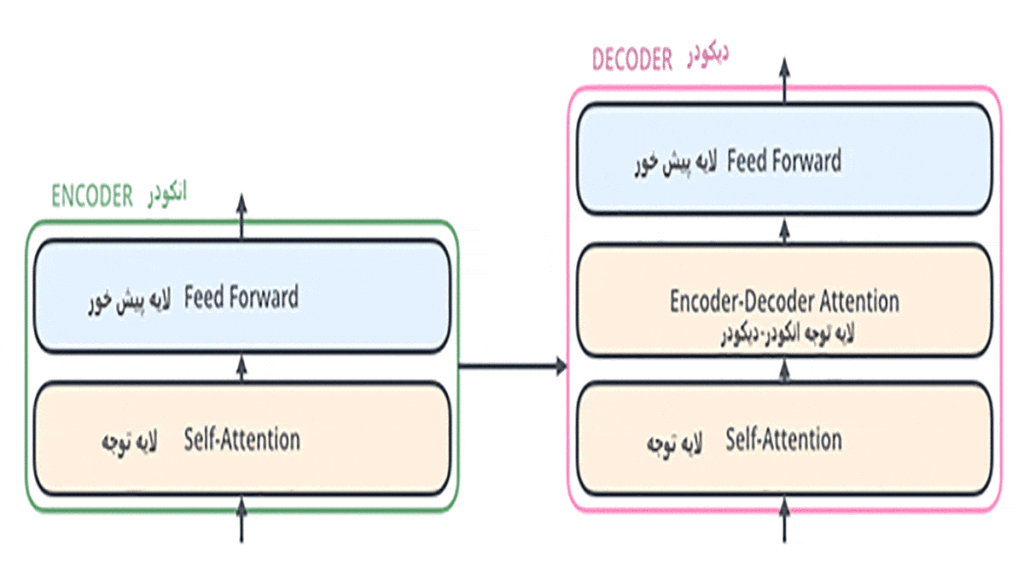
ساختار دیکودر در مدل ترنسفورمر
هر دیکودر نیز دو لایهی Self-Attention و شبکهی عصبی پیشخور دارد، با این تفاوت که در دیکودرهای لایه توجه دیگری بهنام Encoder-Decoder Attention وجود دارد که به دیکودر کمک میکند تا روی کلمههای مرتبط تمرکز کند. درواقع این لایه دقیقاً همان کاری را میکند که سازوکار توجه در مدل های ترتیبی (Seq2Seq Models) انجام میدهد.
حال که ساختار کلی مدل ترنسفورمر (Transformer Model) را بررسی کردیم، به توضیح جزئیات بیشتر دربارهی آن میپردازیم.
جزئیات ساختار یک مدل ترنسفورمر
در پردازش زبانهای طبیعی اولین قدم تبدیل کلمات ورودی به بردار است تا برای ماشین فهمیدنی باشد. این کار را الگوریتمهای تعبیه کلمات (Word Embedding) انجام میدهند.
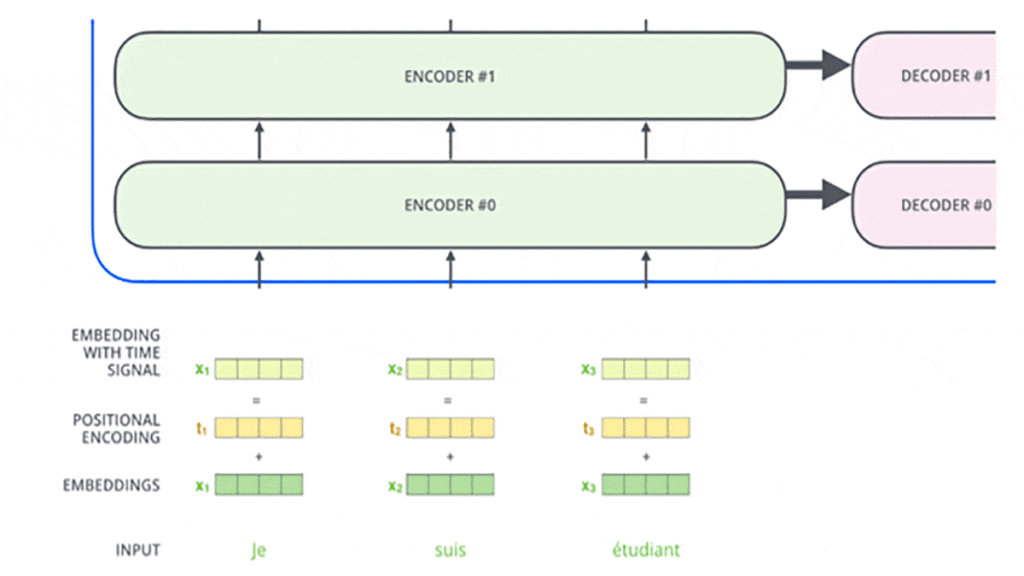
تعبیهی کلمات در مدل ترنسفورمر فقط در اولین انکودر (پایین ترین انکودر) صورت میگیرد. همهی انکودرها فهرستی از بردارها به سایز ۵۱۲ را دریافت میکنند که در اولین انکودر همان بردار تعبیه است و در انکودرهای دیگر بردار خروجی انکودر قبلی است. اندازهی این فهرست یک هایپرپارامتر است که براساس بلندترین جملهی موجود در مجموعهی دادهها مشخص میشود.
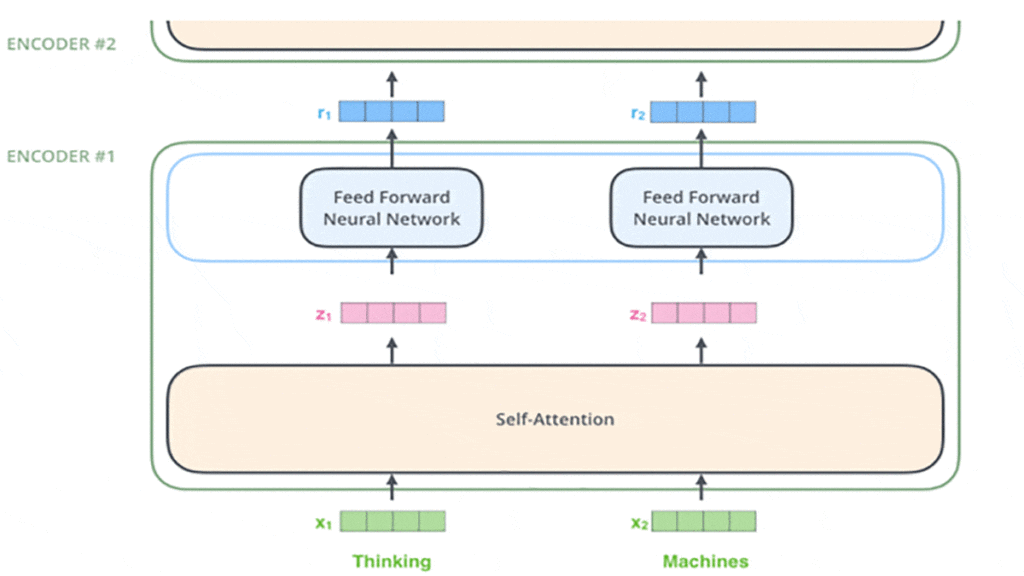
بعد از اینکه هر کلمهی ورودی را به بردار مدنظر تبدیل کردیم و بهاصطلاح بعد از فرایند تعبیه، هر یک از دو زیرلایهی موجود در انکودرها عبور میکنند. در اینجا این نکته مهم است که این کلمات بهطور موازی وارد انکودر میشوند که این یکی از ویژگیهای متمایزکننده مدل ترنسفورمر (Transformer Model) محسوب میشود.
نکته ای که در اینجا باید به آن توجه کنیم این است که در مدل ترنسفورمر ترتیب کلمات ورودی با انکودینگ موقعیتی (Positional Encoding) مدنظر قرار میگیرد. بهاین شکل که در مدل ترنسفورمر به هر بردار تعبیهی ورودی یک بردار دیگر هم اضافه میشود. این بردار درواقع یک الگوی مشخص را که مدل یاد میگیرد دنبال میکنند و این به مدل کمک میکند تا موقعیت هر کلمه یا فاصلهی موجود بین کلمههای مختلف را در توالی ورودی تشخیص دهد.
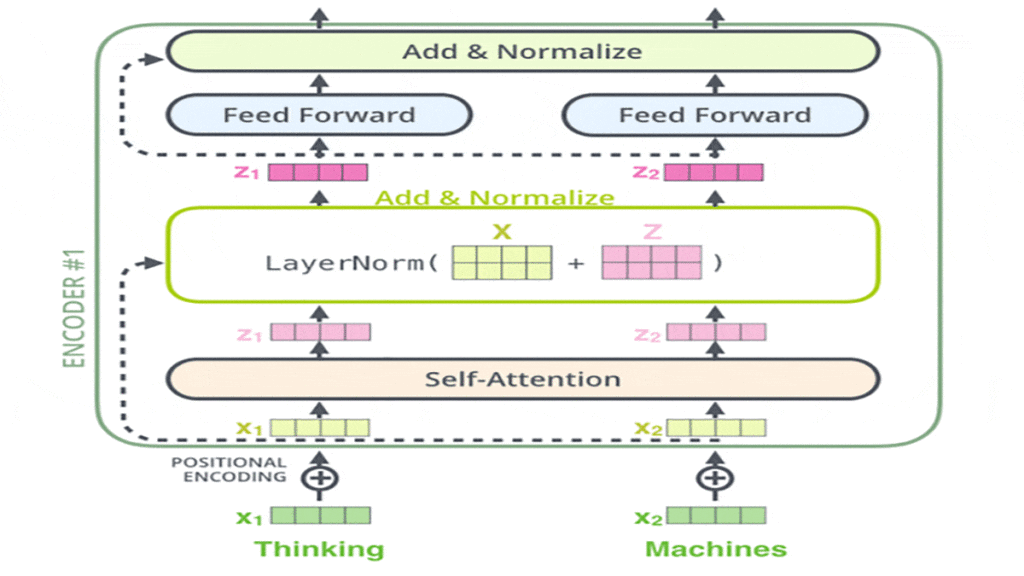
حال اگر عمیقتر به ساختار مدل ترنسفورمر (Transformer Model) توجه کنیم باید به این نکته نیز اشاره کنیم که هر زیرلایه موجود در انکودر و دیکودر یک اتصال دیگر نیز دارند و درواقع هر یک دارای یک گام نرمالیزهکردن لایه (Layer-Normalization Step) هستند.
شکل کلی یک مدل ترنسفورمر با دو انکودر و دو دیکودر بهاین صورت خواهد بود:
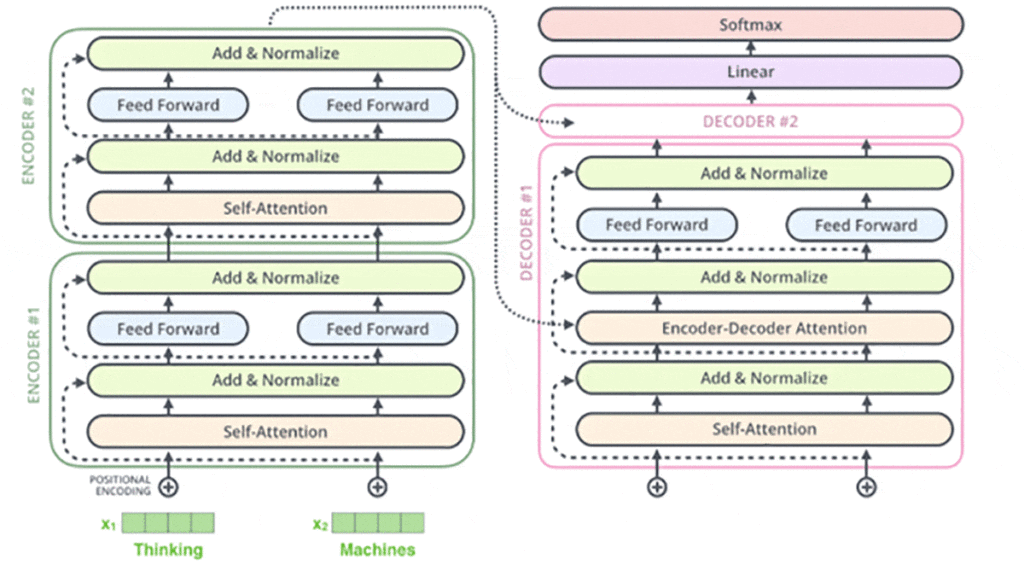
حالا نحوهی کار بخش انکودر و دیکودر را بررسی میکنیم.
نحوهی کار یک مدل ترنسفورمر
در ابتدا انکودر شروع به پردازش توالی ورودی میکند و خروجی آخرین لایهی انکودر به دو بردار توجه K و V تبدیل میشود ( شکل ۱۰). این دو بردار در لایهی Encoder-Decoder Attention هر دیکودر استفاده میشوند تا به دیکودر کمک کنند به کلمات مرتبط و مناسب در توالی توجه کند. در شکلهای زیر در مثالی این مرحلهها را در بخش انکودر مشاهده میکنید:
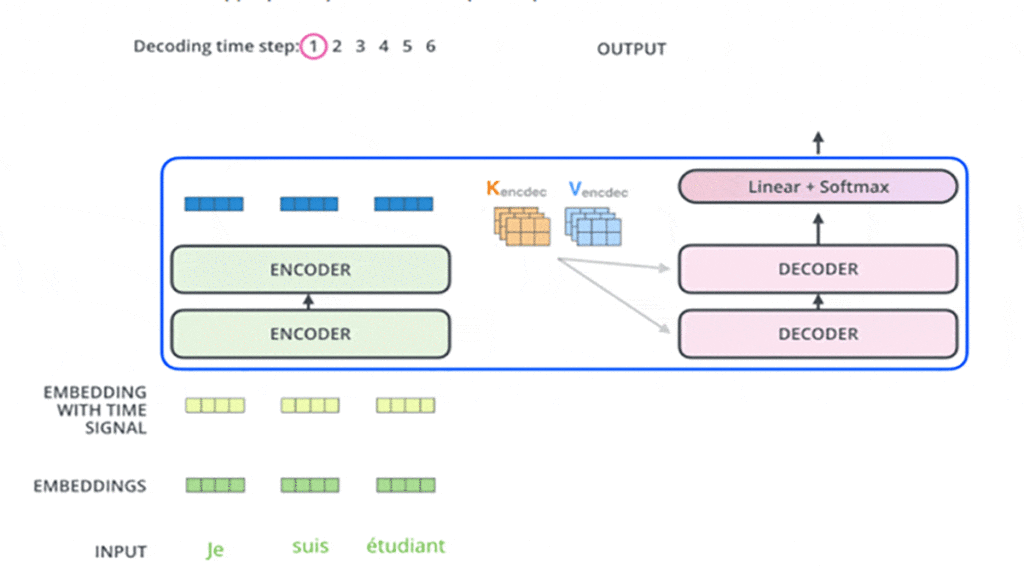
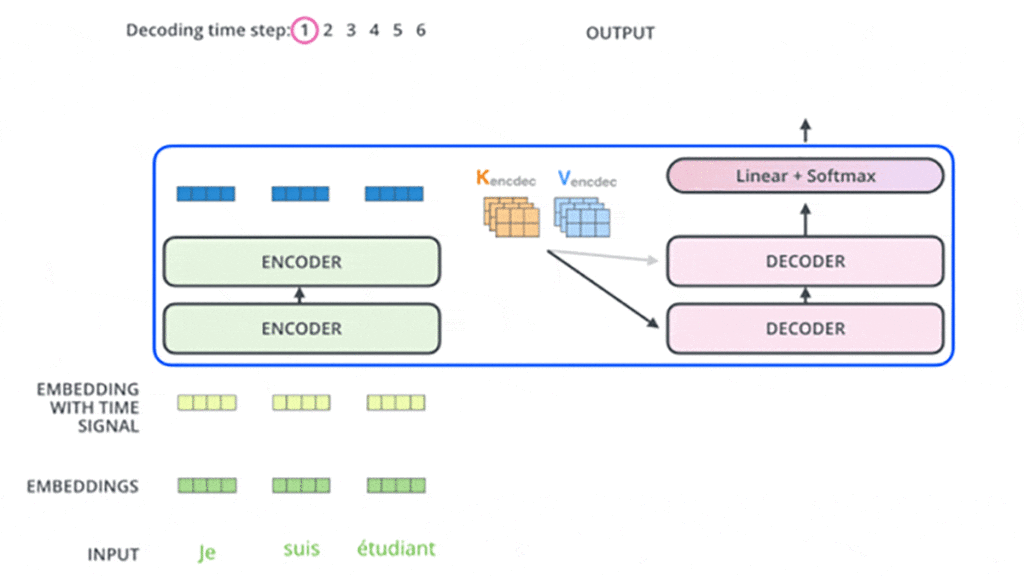
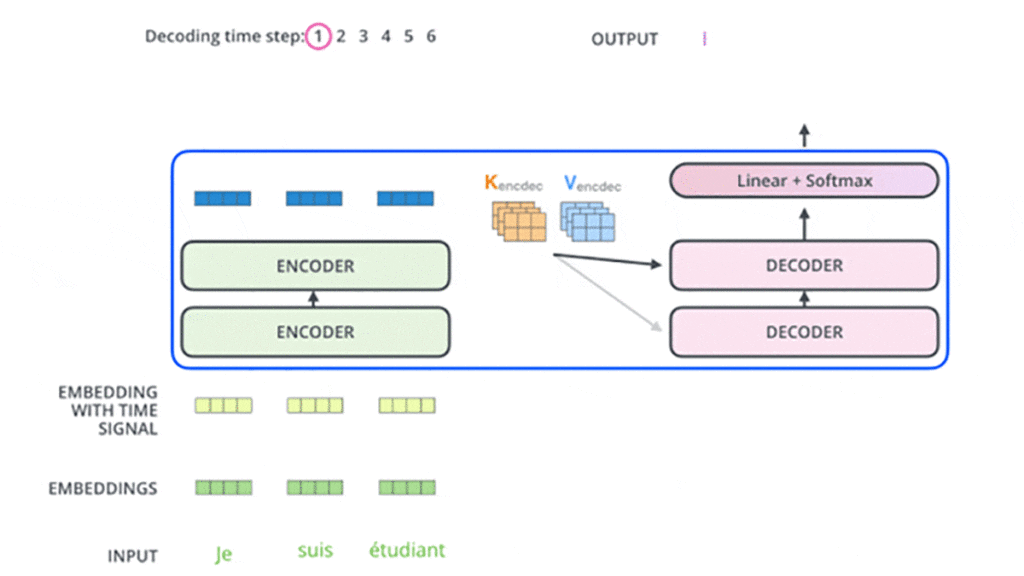
این مراحل انجام میشود تا زمانی که دیکودر در آخر یک خروجی ارائه کند که نشان میدهد کار دیکودر تمام شده است. هر خروجی که در هر گام زمانی ایجاد میشود در گام زمانی بعدی به اولین دیکودر وارد میشود و مرحلهبهمرحله به دیکودرهای بعدی وارد میشود. در اینجا، همانند کاری که در ورودی بخش انکودر انجام دادیم، هر ورودی بخش دیکودر تعبیه و انکودینگ موقعیتی هم به آن اضافه میشود تا موقعیت هر کلمهی ورودی مشخص شود. در شکلهای این مرحلهها را که در بخش دیکودر اتفاق میافتد در گامهای زمانی مختلف مشاهده میکنید:
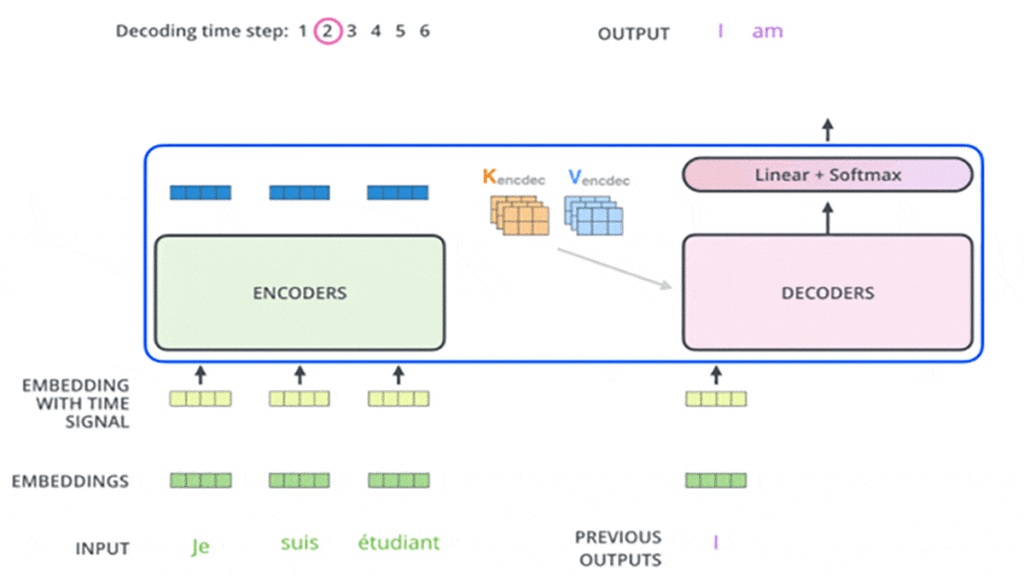
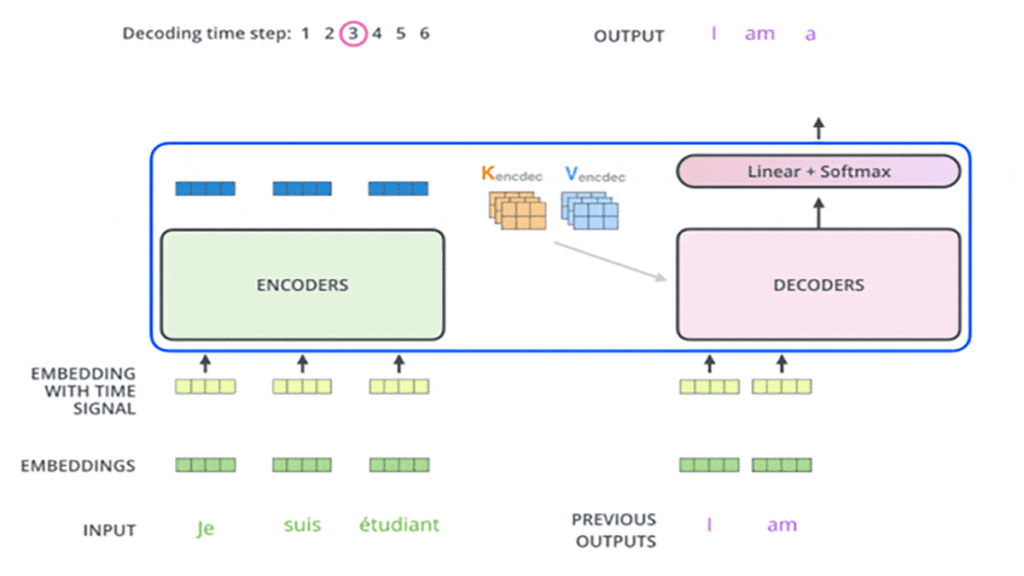
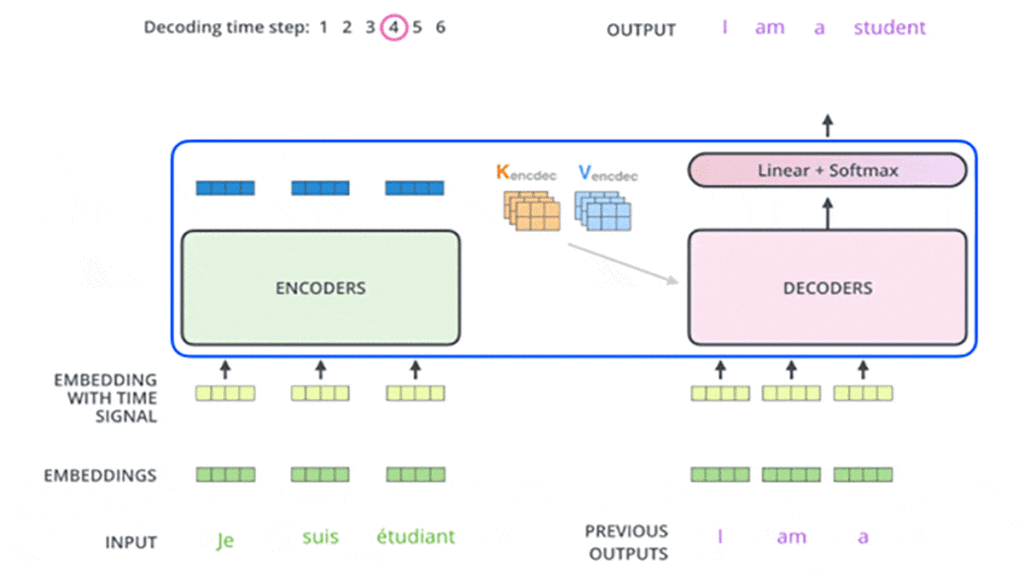
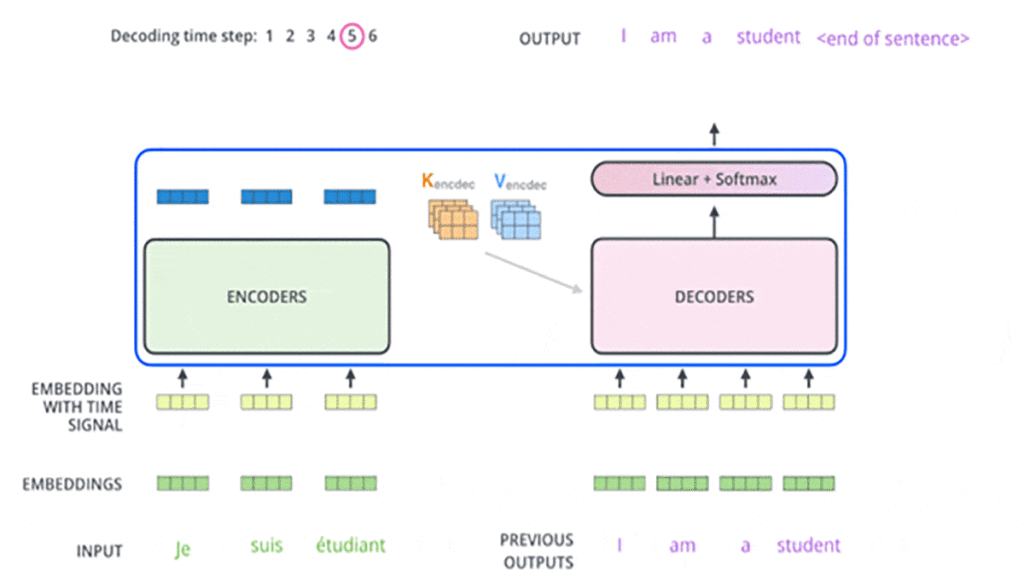
در دیکودرها لایههای Self-Attention عملکرد متفاوتی در مقایسه با لایههای Self-Attention در انکودرها دارند، بهاین شکل آنها فقط اجازهی دسترسی به موقعیتهای قبلی در توالی خروجی را دارند و نه بعدی. این کار با عملیات پنهانکردن یا مسککردن (Masking) موقعیتهای بعدی انجام میشود.
لایهی سافتمکس (Softmax)
از آنجا که خروجی دستهای دیکودر یک بردار است و لازم است این بردار به کلمات تبدیل شوند، درنهایت یک لایهی سافتمکس (Softmax) و خطی داریم تا این کار را انجام دهد. لایهی خطی یک شبکهی عصبی کاملاً متصل (Fully Connected Neural network) است که بردار خروجی بخش دیکودر را به یک بردار بسیار بزرگتر بهنام logits تبدیل میکند که اندازهی آن برابر با تعداد کلماتی است که مدل یاد گرفته است؛ برای مثال، اگر مدل ۲۰هزار کلمه را یاد گرفته باشد، پس بردار logits ۲۰هزار سلول دارد که هر یک از آنها عدد یا امتیاز هر کلمه را مشخص میکند. بهکمک همین بردار ما قادر به تفسیر خروجی مدل با لایهی خطی هستیم.
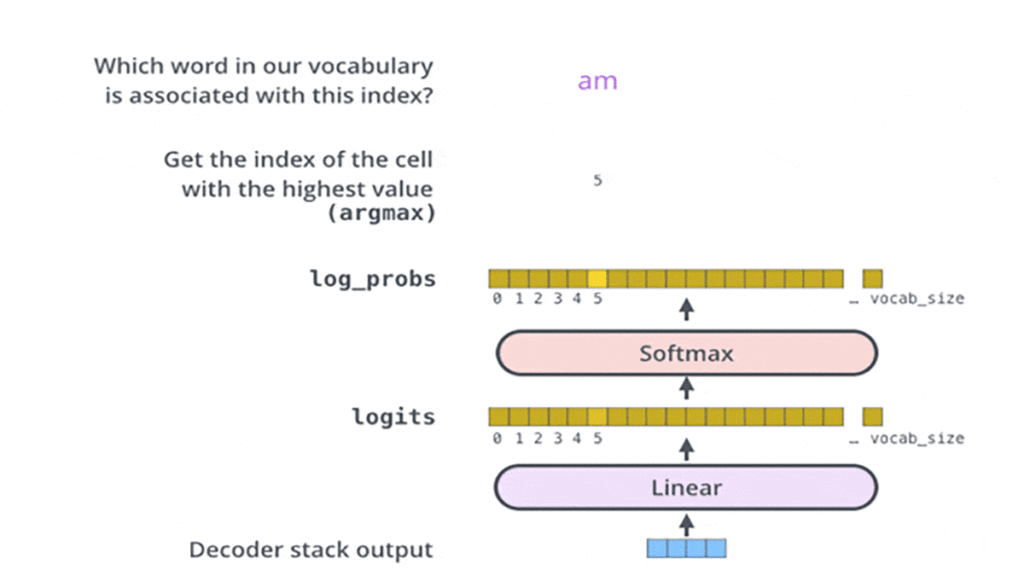
لایهی سافتمکس در آخر این امتیازها را به احتمالات تبدیل میکند، بهطوری که همه مثبت باشند و جمع آنها با هم ۱ باشد. سلولی که بالاترین احتمال را داشته باشد انتخاب و کلمهی مرتبط با آن در خروجی در آن گام زمانی نشان داده میشود.
حرف آخر
با ورود مدل ترنسفورمر (Transformer Model) انقلابی در معماری انکودرـدیکودر شکل گرفت. قبل از مدل ترنسفورمر، شبکهی عصبی بازگشتی (RNN / Recurrent Neural Network) و انواع جدیدتر آن، یعنی LSTM و GRU، در پردازش دادههای ترتیبی (Sequential Data) استفاده میشدند. با ظهور مدل ترنسفورمر که در ساختار خود از مکانیزم توجه (Attention Mechanism) استفاده میکند، شبکههای RNN، LSTM و GRU جایگزین شدهاند و حالا در زمینه پردازش دادههای ترتیبی، مدل ترنسفورمر حرف اول را میزند.
یادگیری دیتا ساینس با کلاسهای آنلاین آموزش علم داده کافهتدریس
اگر به یادگیری دیتا ساینس و ماشین لرنینگ علاقه دارید، کلاسهای آنلاین آموزش علم داده کافهتدریس به شما امکان میدهد در هر نقطهی جغرافیایی به بروزترین و جامعترین آموزش علم داده دسترسی داشته باشید.
کلاسهای آنلانی آموزش علم داده کافهتدریس بهصورت تعاملی و پویا و کارگاهی و براساس کار روی پروژههای واقعی علم داده برگزار میشود و صفر تا صد مباحث آموزشی را دربرمیگیرد.
برای آشنایی بیشتر با کلاسهای آنلاین آموزش علم داده کافهتدریس و مشاورهی رایگان برای شروع یادگیری روی این لینک کلیک کنید:
لایهی سافتمکس در نحوهی کار مدل ترنسفورمر چگونه عمل میکند؟
ز آنجا که خروجی دستهای دیکودر یک بردار است و لازم است این بردار به کلمات تبدیل شوند، درنهایت یک لایهی سافتمکس (Softmax) و خطی داریم تا این کار را انجام دهد. لایهی خطی یک شبکهی عصبی کاملاً متصل (Fully Connected Neural network) است که بردار خروجی بخش دیکودر را به یک بردار بسیار بزرگتر بهنام logits تبدیل میکند که اندازهی آن برابر با تعداد کلماتی است که مدل یاد گرفته است؛ برای مثال، اگر مدل ۲۰هزار کلمه را یاد گرفته باشد، پس بردار logits ۲۰هزار سلول دارد که هر یک از آنها عدد یا امتیاز هر کلمه را مشخص میکند. بهکمک همین بردار ما قادر به تفسیر خروجی مدل با لایهی خطی هستیم.
انکودر در مدل ترنسفورمر چه نقشی ایفا میکند؟
قبل از مدل ترنسفورمر، شبکهی عصبی بازگشتی (RNN / Recurrent Neural Network) و انواع جدیدتر آن، یعنی LSTM و GRU، در پردازش دادههای ترتیبی (Sequential Data) استفاده میشدند. با ظهور مدل ترنسفورمر که در ساختار خود از مکانیزم توجه (Attention Mechanism) استفاده میکند، شبکههای RNN، LSTM و GRU جایگزین شدهاند و حالا در زمینه پردازش دادههای ترتیبی، مدل ترنسفورمر حرف اول را میزند.
مدل ترنسفورمر چه ساختاری دارد؟
تعبیهی کلمات در مدل ترنسفورمر فقط در اولین انکودر (پایین ترین انکودر) صورت میگیرد. همهی انکودرها فهرستی از بردارها به سایز ۵۱۲ را دریافت میکنند که در اولین انکودر همان بردار تعبیه است و در انکودرهای دیگر بردار خروجی انکودر قبلی است. اندازهی این فهرست یک هایپرپارامتر است که براساس بلندترین جملهی موجود در مجموعهی دادهها مشخص میشود.
سوال ۳:
کار ترانسفومر، ترجمهی متن است، یک مدل ترنسفورمر یا مدل انتقالی در ورودی جملهای را دریافت و در خروجی ترجمهی آن را تحویل میدهد. این مدل دستهای انکودر و دیکودر دارد که با هم در ارتباط هستند.
تعداد آن ها 6 و باید با هم برابر باشد
سوال ۲:
هر انکودر دو زیرلایهی مجزا دارد که لایهی اول لایه Self-Attention و لایهی دوم یک شبکه عصبی پیشخور است.
تشکیلدهندهی هر انکودر
ورودی انکودر ابتدا از یک لایهی Self-Attention عبور میکند که به انکودر کمک میکند تا در حین انکودکردن یک کلمه به کلمههای دیگر موجود در جمله هم توجه کند. خروجی لایهی Self-Attention به یک لایهی شبکهی عصبی پیشخور وارد میشود
سوال۱:
آنجا که خروجی دستهای دیکودر یک بردار است و لازم است این بردار به کلمات تبدیل شوند، درنهایت یک لایهی سافتمکس (Softmax) و خطی داریم تا این کار را انجام دهد. لایهی خطی یک شبکهی عصبی کاملاً متصل است که بردار خروجی بخش دیکودر را به یک بردار بسیار بزرگتر بهنام logits تبدیل میکند که اندازهی آن برابر با تعداد کلماتی است که مدل یاد گرفته است
مقاله بسیار مفید و خلاصه ای بود. ممنون از نویسنده محترم
ممنون از توجه شما