

شبکه عصبی بازگشتی (RNN) چیست و چه کاربردهایی دارد؟ در این مطلب بهصورت مفصل دربارهی شبکهی عصبی بازگشتی صحبت کردهایم، تفاوت آن را با شبکه عصبی سنتی تعریف کردهایم و ساختار شبکه عصبی بازگشتی (RNN) را توضیح دادهایم.


شبکه عصبی بازگشتی و شبکه عصبی سنتی
ما طبق چیزهایی که در ذهنمان داریم و یاد گرفتهایم شروع به فکرکردن دربارهی مسائل جدید میکنیم؛ مثلاً وقتی شروع به خواندن این مقاله میکنیم هر کلمه را طبق مفهومی میشناسیم که قبلاً یاد گرفتهایم. درواقع افکار ما کاملاً پیوسته هستند؛ یعنی از یافتههای قبلیمان در مسائل جدیدی استفاده میکنیم که با آنها برخورد میکنیم.
اما شبکهی عصبی سنتی (Traditional Neural Network) نمیتواند اینطور کار کند. خود این مشکل محسوب میشود. چرا؟ بیاییم با هم مثالی را در نظر بگیریم. فرض کنیم شروع به دیدن فیلمی میکنیم. همینطور که فیلم پیش میرود، ما بیشتر و بیشتر میفهمیم چه اتفاقاتی در حال رخدادن است؛ چون یادمان است که از اول فیلم تا الان چه اتفاقاتی رخ داده است. این برای ما که افکار پیوستهای داریم میتواند کار راحتی باشد، اما شبکهی عصبی وقتی دربارهی اتفاقهای قبلی فیلم اطلاعاتی ندارد، چطور میتواند از استدلالش استفاده کند تا اتفاقهایی را که در حال انجامشدن است درک کند؟ اینجاست که بحث شبکه عصبی بازگشتی (RNN) مطرح میشود.
شبکه عصبی بازگشتی (RNN)
شبکهی RNN نوعی شبکهی عصبی است که ساختارش بهشکلی طراحی شده است که امکان مدلکردن دادههای ترتیبی را بدهد؛ اما دادههای ترتیبی چه دادههایی هستند؟ بهتر است با هم آزمایشی کوچک انجام بدهیم.
ما در اینجا تصویری ثابت از یک توپ در حال حرکت داریم:

حال میخواهیم جهت حرکت این توپ را پیشبینی کنیم، اما با اطلاعاتی که در تصویر بالا داریم به نظرتان ممکن است؟ میتوانیم حدس بزنیم، اما جوابمان در هر صورت فقط یک حدس است و هیچ پایهواساس منطقی ندارد. تا زمانی که ندانیم توپ قبلاً کجا بوده است، نمیتوانیم بفهمیم جهت حرکتش به کدام سمت است. حال اگر چندین تصویر از موقعیت توپ تو زمانهای مختلف داشته باشیم، چطور؟


الان میتوانیم تشخیص بدهیم جهت حرکت توپ به چه سمتی است؛ این دقیقاً همان توالی است که دربارهاش صحبت کردیم. دادههای ترتیبی میتوانند شکلهای مختلفی داشته باشند؛ برای مثال، صدا یک دادهی ترتیبی محسوب میشود که میتوانیم آن را به چندین اسپکتروگرام صدا (Audio Spectrogram) تقسیم و به یک شبکهی RNN وارد کنیم.

متن هم نوع دیگری از دادههای ترتیبی است که میتوانیم آن را به توالیای از کلمات یا توالی از حروف بشکنیم.
همانطور که گفتیم شبکه عصبی بازگشتی (RNN) در پردازش دادههای ترتیبی خیلی خوب عمل میکند، اما چطور این کار را انجام میدهد؟

شبکه عصبی بازگشتی (RNN) چطور عمل میکند؟
دلیل عملکرد خوب شبکه عصبی بازگشتی این است که از مفهومی بهنام حافظهی ترتیبی (Sequential Memory) استفاده میکند. برای اینکه این مفهوم را بهتر درک کنیم الفبا را در ذهنتان به یاد بیاورید و سعی کنید از اول حروف الفبا را بگویید. به نظر کار آسانی است. چون بارها و بارها این توالی را آموزش دادهایم. حال سعی کنید حروف الفبا رو از آخر به اول بگویید؛ به نظر سخت شد؛ اینطور نیست؟ دلیلش این است که ما کمتر این توالی را به ذهنمدن آموزش دادهایم. این دقیقاً معنی حافظهی ترتیبی است. حافظهی ترتیبی سازوکاری است که به ذهنمان کمک میکند تا الگوهای توالی را تشخیص دهیم.
تا اینجا فهمیدیم که شبکه عصبی بازگشتی (RNN) هم از مفهوم حافظهی ترتیبی استفاده میکند، اما چطور؟
بهتر است برای جوابدادن به این سؤال ساختار شبکهی RNN را بررسی کنیم.
ساختار شبکهی عصبی بازگشتی (RNN)
بیایید از شبکه عصبی سنتی شروع کنیم. شبکه عصبی سنتی لایهی ورودی (Input Layer)، لایهی نهان (Hidden Layer) و لایهی خروجی (Output Layer) دارد.
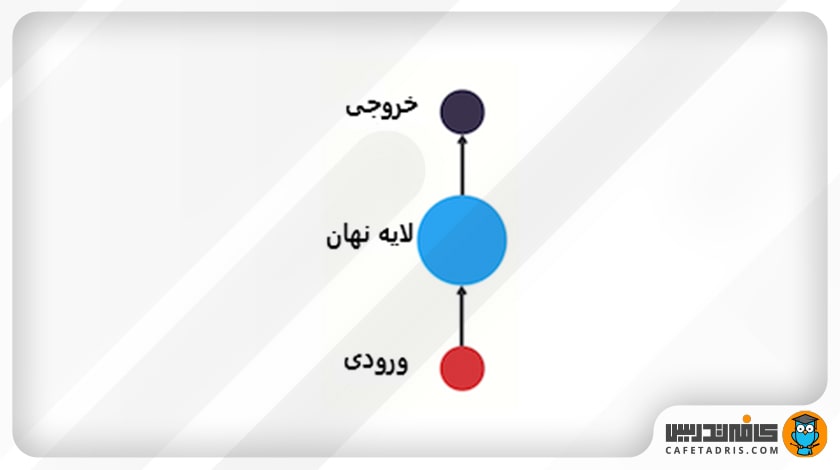
اما چطور میتوانیم کاری کنیم که این شبکه از اطلاعات قبلی استفاده کند تا روی اطلاعات جدیدی که به دست میآورد تأثیر بگذارد؟ چطور است یک حلقه به این شبکه اضافه کنیم تا این کار را برایمان انجام دهد؟
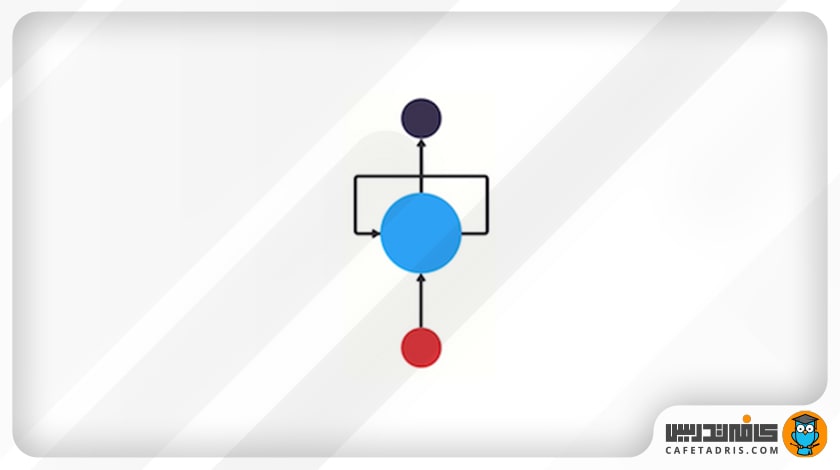
شکل بالا دقیقاً ساختار شبکه RNN نشان میدهد. این شبکه یک سازوکار حلقه دارد که مانند یک آزادراه عمل میکند و اجازه میدهد اطلاعات از گامی به گامی دیگر منتقل شود.
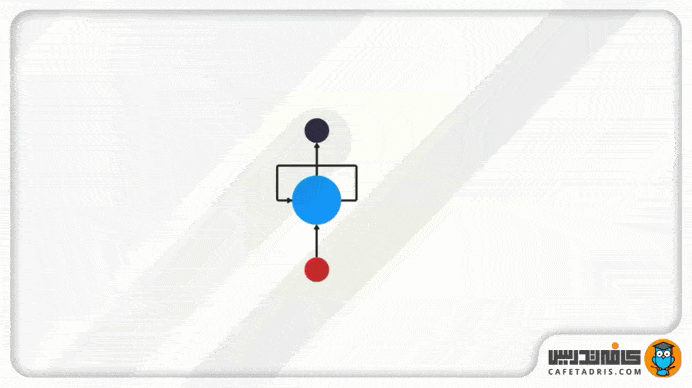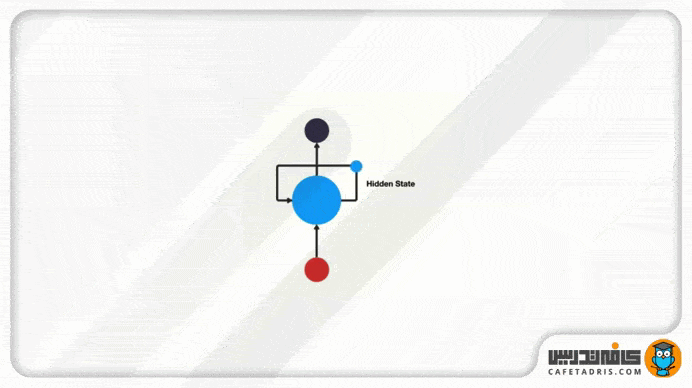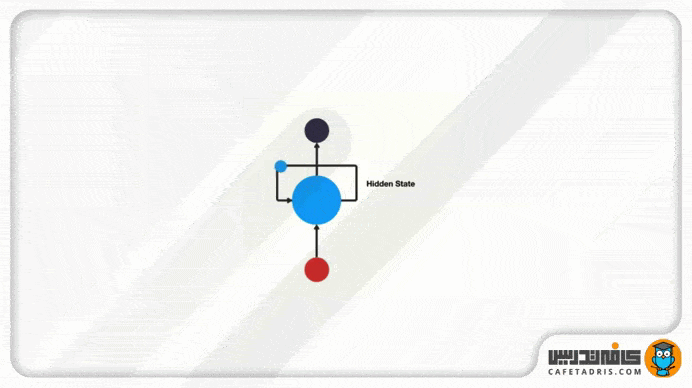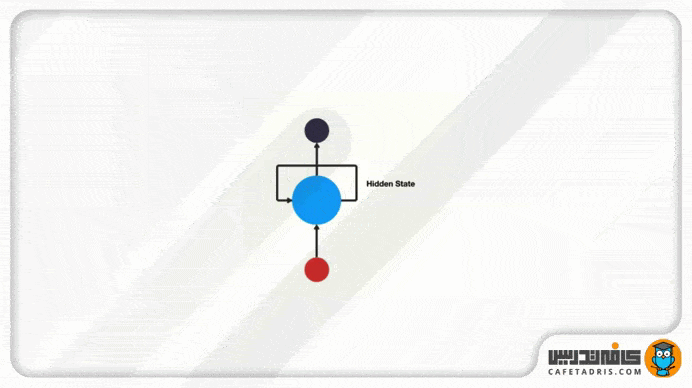
این اطلاعات درواقع همان حالت نهان (Hidden State) هستند که ورودیهای قبلی را نمایش میدهند.
ساختار و عملکرد شبکه RNN
این شکل ساختار دقیقتر شبکه عصبی بازگشتی (RNN) را نشان میدهد:
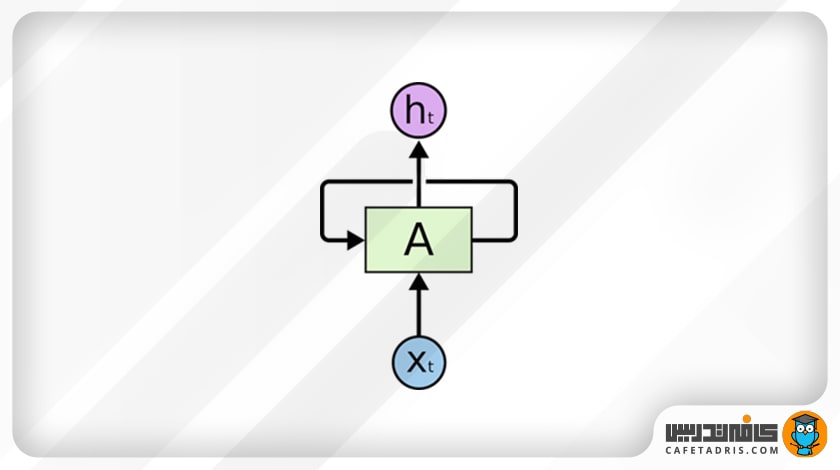
در اینجا A تعدادی شبکهی عصبی است که xt را بهعنوان ورودی میگیرد و با توجه به آن خروجی ht را به ما میدهد. حلقهای هم در شکل میبینیم که اطلاعات را از گامی به گام بعدی منتقل میکند. بهطور کلی، شبکهی عصبی بازگشتی (RNN) خیلی فرق چندانی با شبکهی عصبی معمولی ندارد. این شبکه زنجیرهای از شبکهای مشابه است که هر یک اطلاعات را به بعدی منتقل میکند. بهتر است برای درک بهتر این موضوع به این شکل نگاهی بیندازیم:
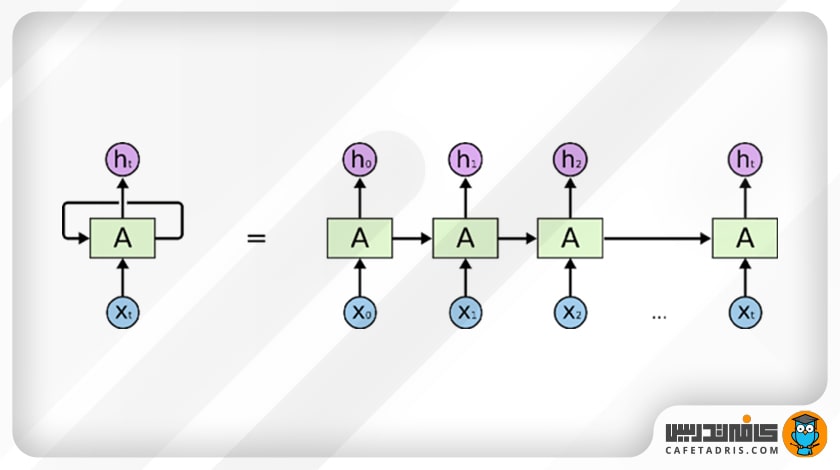
در این شکل حلقه را باز کردهایم تا بهتر بتوانیم ساختار این شبکه را درک کنیم. همانطور که در شکل مشخص است، این شبکه اول ورودی x0 را از توالی ورودیها میگیرد و خروجی h0 را تولید میکند که این خروجی بههمراه x1 در گام بعدی به شبکه وارد میشوند. همینطور خروجی h1 بههمراه x2 با هم در گام بعدی به شبکه وارد میشوند و این قضیه بههمین شکل ادامه دارد تا به خروجی نهایی برسیم. این کار به شبکه کمک میکند تا در حین آموزش مفهوم (Context) را به یاد داشته باشد.
بهدلیل ساختار زنجیرهای شبکهی RNN، این شبکه میتواند برای کار با توالیها و فهرستها استفاده شود. درواقع هر زمان که مدلی به مفهوم (Context) نیاز داشته باشد تا بتواند براساس ورودی خروجی مدنظر را تولید کند شبکهی RNN استفاده میشود؛ برای مثال، میتوانیم به کاربرد شبکهی RNN در پیشبینی کلمهی بعدی (New Word Prediction)، عنوانبندی عکس (Image Captioning)، تشخیص گفتار (Speech Recognition)، تشخیص آنومالی سریهای زمانی (Time Series Anomaly Detection) و پیشبینی بازار سهام (Stock Market Prediction) اشاره کنیم.
حال میخواهیم بهشکل خیلی ساده به یکی از موارد استفاده شبکه عصبی بازگشتی (RNN) اشاره کنیم و بگوییم چطور کار میکنه.
کاربرد شبکه عصبی بازگشتی و طرز عملکرد آن
فرض کنیم میخواهیم یک چتبات (Chatbot) بسازیم؛ مثلا این چتبات میتواند هدف متنی را که کاربر وارد کرده است مشخص کند؛ یعنی برای مثال، اگر متنی را وارد کنیم، چتبات تشخیص بدهد ما داریم از آن دربارهی آبوهوا سؤال میکنیم.

برای حل این مسئله لازم است که توالی متن ورودی را با استفاده از شبکه عصبی بازگشتی (RNN) پردازش (Encode) کنیم و بعد خروجی را یه شبکه Feed Forward بدهیم تا خروجی را طبقهبندی کند.
کاربر این جمله را تایپ میکند:
What time is it?
(ساعت چند است؟)
ما باید این جمله را به کلمهها بشکنیم. چون شبکهی RNN بهصورت ترتیبی کار میکند، در هر گام یک کلمه را به آن بدهیم.

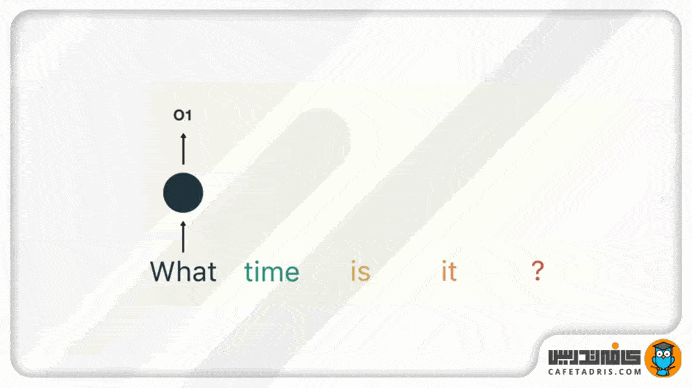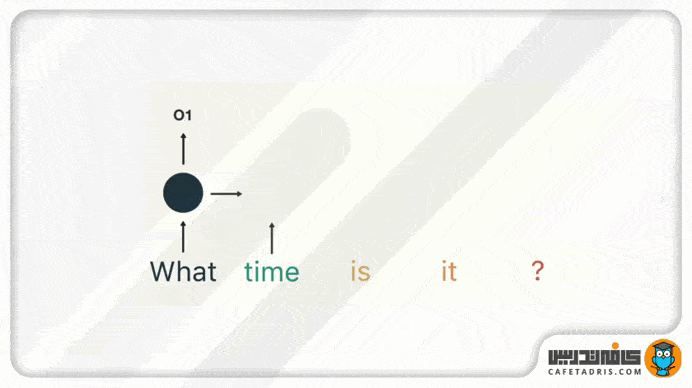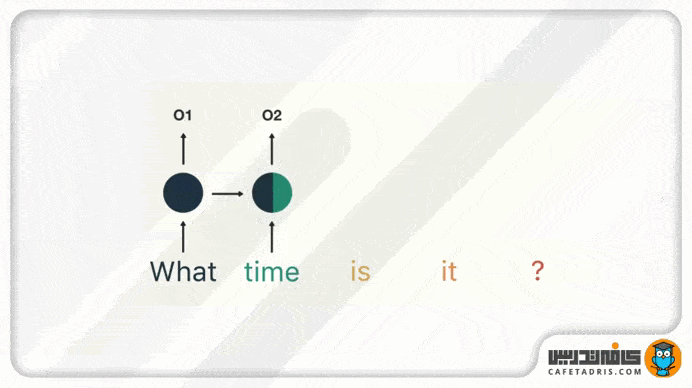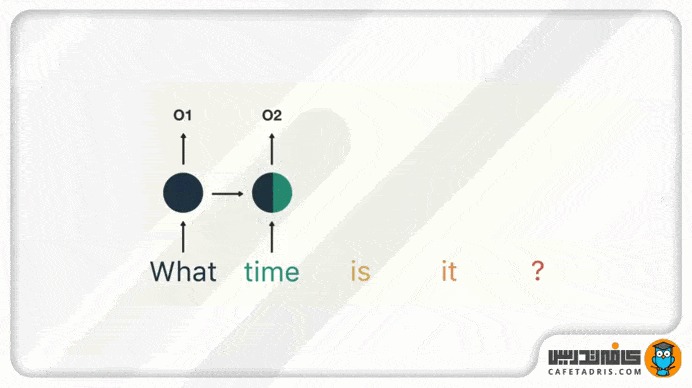
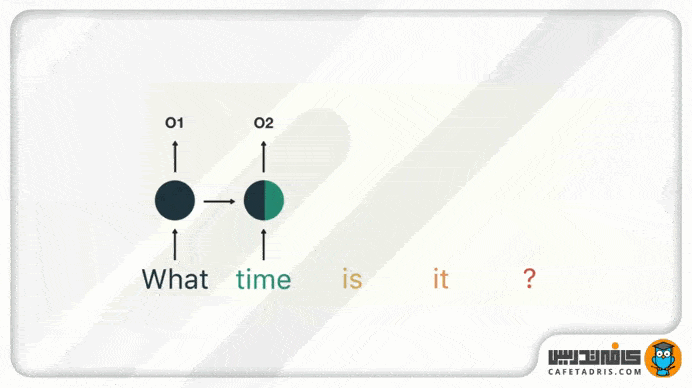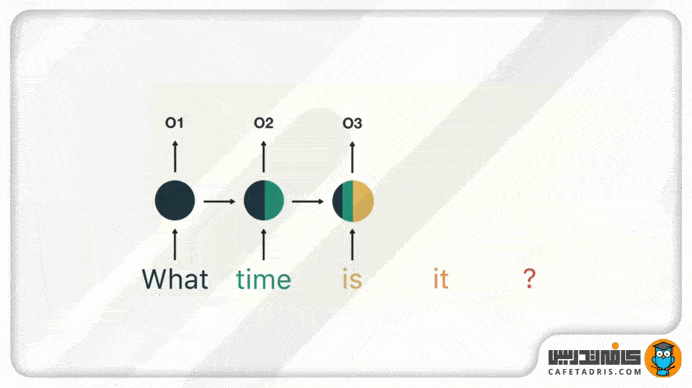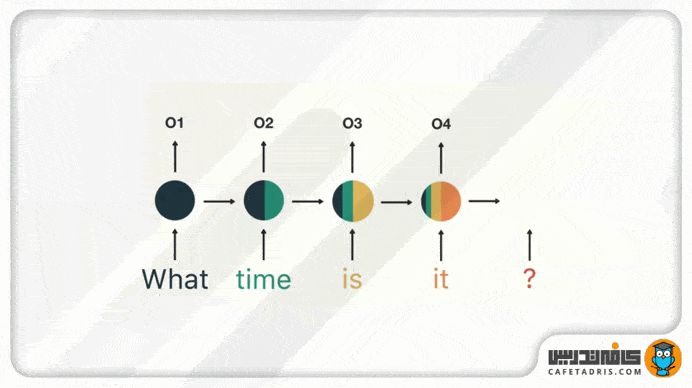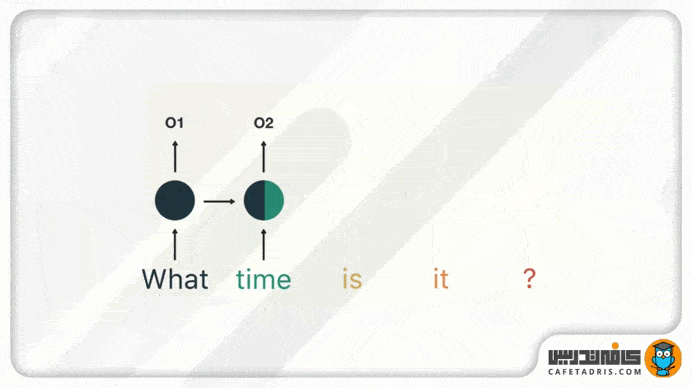
در گام اول کلمهی «what» را به شبکه میدهیم تا پردازش کند و به ما خروجی بدهد. خوب است که اینجا به این نکته اشاره کنیم که خود کلمهها بهاین شکل که ما میبینیم به شبکه وارد نمیشوند، بلکه بردار کلمهها وارد میشوند تا برای کامپیوتر فهمیدنی باشند.
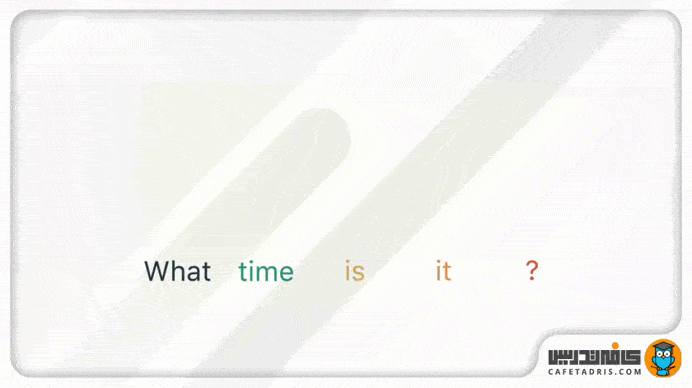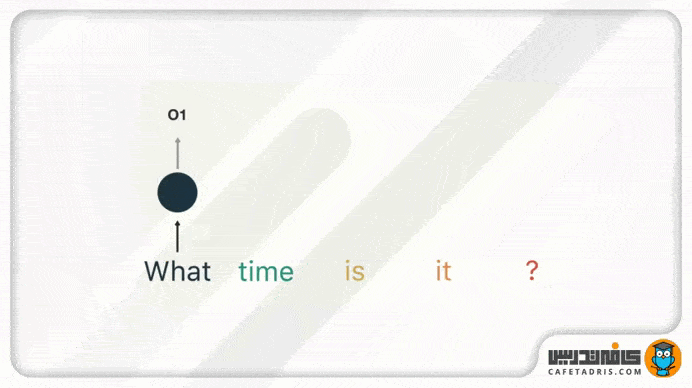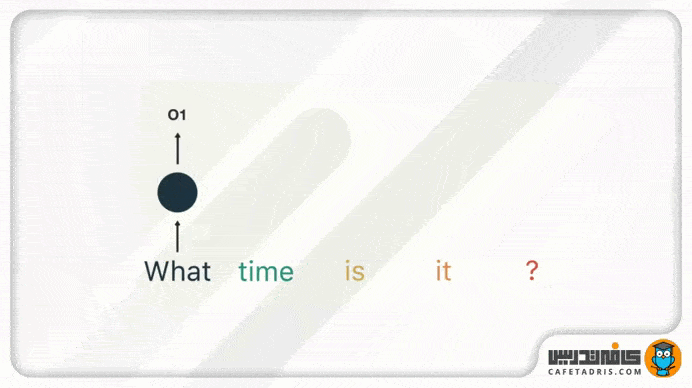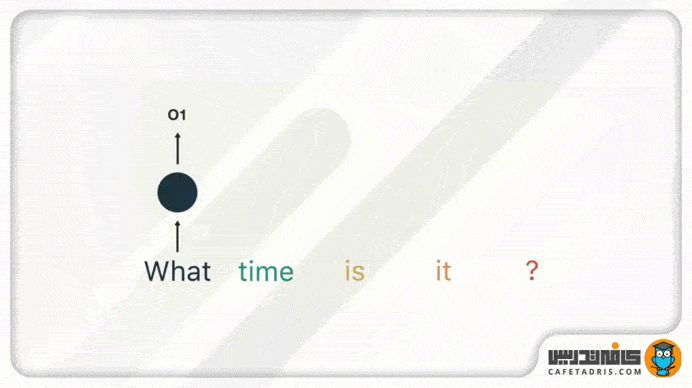
در گام بعدی کلمهی «time» را بههمراه حالت پنهان (Hidden State) مرحلهی قبل به شبکه میدهیم. حال شبکهی RNN اطلاعات لازم دربارهی هر دو کلمهی «what» و «time» را دارد.
این فرایند همینطور ادامه پیدا میکند تا زمانیکه به آخر جمله برسیم. درنهایت میبینیم که شبکهی RNN اطلاعات مربوط به تمامی کلمههای موجود در جمله را پردازش کرده است.
برای آشنایی بیشتر با کاربرد شبکههای عصبی مطلب با کاربردهای شبکه عصبی کانولوشنی (CNN) آشنا شوید! را مطالعه کنید.
انواع شبکههای عصبی بازگشتی
شبکههای عصبی بازگشتی (RNN) نوعی شبکه عصبی هستند که قادر به پردازش دادههای متوالی مانند دادههای سری زمانی، متن و گفتار هستند. انواع مختلفی از RNN وجود دارد که در طول سالها توسعه یافتهاند، از جمله:
RNNهای Vanilla: سادهترین نوع RNN است که ورودی فعلی و حالت پنهان قبلی را به عنوان ورودی میگیرد و خروجی فعلی و حالت پنهان بعدی را به عنوان خروجی تولید میکند.
شبکههای حافظه کوتاه مدت بلند مدت (LSTM): نوعی از RNN که دارای یک سلول حافظه داخلی و سه گیت (گیت ورودی، گیت فراموشی و گیت خروجی) است که جریان اطلاعات را کنترل میکند. شبکه LSTMها برای جلوگیری از مشکل محوشدگی گرادیان (Vanishing Gradient) که میتواند هنگام آموزش شبکههای عصبی عمیق رخ دهد، طراحی شده است.
شبکههای واحد بازگشتی گیتی (GRU): این شبکه شبیه به LSTM است، اما با معماری ساده شده که گیتهای فراموشی و ورودی را در یک گیت به روز رسانی واحد ترکیب میکند. شبکه GRU از نظر محاسباتی کارآمدتر از LSTMها هستند و آموزش آن ها آسانتر است.
RNNهای دوطرفه یا Bidirectional RNNs: نوعی از RNN که توالی ورودی را در دو جهت رو به جلو و عقب پردازش میکند و به شبکه اجازه میدهد هنگام پیش بینی، اطلاعات گذشته و آینده را در نظر بگیرد.
RNNهای انکودر-دیکودر : نوعی از معماری RNN که معمولاً در مدلهای sequence to sequence مانند ترجمه ماشینی و تشخیص گفتار استفاده میشود. انکودر توالی ورودی را پردازش میکند و یک نمایش برداری با طول ثابت تولید میکند که سپس برای تولید دنباله خروجی به دیکودر وارد میشود.
RNNهای مبتنی بر توجه (Attention-base RNNs): نوعی از معماری RNN که از مکانیزم توجه برای تمرکز بر مرتبط ترین بخشهای دنباله ورودی هنگام انجام پیشبینیها استفاده میکند. این کار به شبکه اجازه میدهد تا به طور انتخابی به بخشهای مختلف توالی ورودی بسته به زمینه فعلی توجه کند.
یادگیری دیتا ساینس با کلاسهای آنلاین آموزش علم داده کافهتدریس
اگر به یادگیری علم داده علاقه دارید، کلاسهای آنلاین علم داده کافهتدریس به شما کمک میکند در هر نقطهی جغرافیایی به بهروزترین و جامعترین آموزش دیتا ساینس دسترسی داشته باشید و علم داده را بهصورت کارگاهی و در قالب کار عملی روی پروژههای واقعی دیتا ساینس یاد بگیرید.
برای آشنایی با کلاسهای آنلاین آموزش علم داده کافهتدریس و مشاورهی رایگان برای شروع یادگیری یا ورود به بازار کار روی این لینک کلیک کنید: