

شبکه عصبی LSTM یا حافظه کوتاهمدت طولانی (Long-Short Term Memory) نوعی خاص از شبکه عصبی بازگشتی (RNN / Recurrent Neural Network) محسوب میشود. پس برای اینکه بتوانیم نحوه کار شبکه LSTM را درک کنیم لازم است با شبکه عصبی RNN آشنا شیم. در این مطلب بهصورت مختصر درباره شبکه RNN صحبت کردهایم و سپس به شبکه عصبی حافظه کوتاهمدت طولانی و نحوه کارش پرداختهایم.


معرفی شبکههای عصبی مصنوعی
شبکههای عصبی مصنوعی (ANN) نوعی الگوریتم یادگیری ماشین هستند که برای ساخت آنها از ساختار و عملکرد مغز انسان الهام گرفته شده است. شبکه های عصبی مصنوعی متشکل از گرههای به هم پیوسته یا نورونهای مصنوعی هستند که اطلاعات را پردازش میکنند و یاد میگیرند بر اساس دادههای ورودی پیش بینی کنند. اتصالات بین گرهها دارای وزن هستند و وزنها در طول پردازش داده، برای بهبود دقت پیش بینیها تنظیم میشوند.
شبکه های عصبی مصنوعی به طور گسترده در کاربردهای مختلفی مانند تشخیص تصویر، تشخیص گفتار و پردازش زبان طبیعی استفاده میشوند. یکی از نقاط قوت ANN ها توانایی آنها در یادگیری الگوهای پیچیده در مجموعه داده های بزرگ بدون برنامه ریزی صریح است. آنها همچنین میتوانند از مثالها یاد بگیرند و با موقعیتهای جدید تطبیق پیدا کنند، که آنها را برای کارهایی که شامل محیطهای نامشخص یا پویا هستند، مناسب میکند.
با این حال، ANN ها همچنین میتوانند از نظر محاسباتی گران باشند و برای دستیابی به دقت بالا به مقادیر زیادی از دادههای آموزشی نیاز دارند. علاوه بر این، تفسیر عملکرد درونی شبکههای عصبی مصنوعی میتواند دشوار باشد، که میتواند درک نحوه تصمیمگیری یا شناسایی سوگیریهای بالقوه در پیشبینیهایشان را دشوار کند. با وجود این چالشها، شبکههای عصبی مصنوعی همچنان یک حوزه تحقیقاتی فعال هستند و به پیشرفتهای قابل توجهی در یادگیری ماشین و هوش مصنوعی منجر شدهاند.
انواع شبکههای عصبی مصنوعی
در این بخش برخی از رایج ترین انواع شبکه عصبی مصنوعی (ANN) که هر کدام ساختار و عملکرد منحصر به فرد خود را دارند، معرفی خواهیم کرد.
شبکههای عصبی پیشخور (Feed-Forward Neural Networks): این نوع شبکه، ابتدایی ترین نوع شبکه عصبی مصنوعی است که در آن اطلاعات تنها در یک جهت جریان دارد، از گرههای ورودی به گره های خروجی. این شبکهها برای کارهایی مانند طبقه بندی، رگرسیون و تشخیص الگو استفاده میشوند.
شبکههای عصبی تکرارشونده (Recurrent Neural Networks): این شبکهها دارای یک حلقه بازخورد هستند که به آنها اجازه میدهد اطلاعات ورودیهای قبلی را ذخیره کنند که آنها را برای کارهایی مانند پیشبینی توالی، مدلسازی زبان و تشخیص گفتار مناسب میکند.
شبکههای عصبی کانولوشنی (CNNs): این شبکهها برای پردازش دادهها با توپولوژی شبکهای مانند تصاویر و ویدئوها طراحی شدهاند. آنها از یک سری لایههای کانولوشن برای استخراج ویژگیها از دادههای ورودی استفاده میکنند و معمولاً برای تشخیص تصویر، تشخیص اشیا و تجزیه و تحلیل ویدیو استفاده میشوند.

شبکه عصبی بازگشتی (RNN) چیست؟
شبکه عصبی RNN نوعی شبکه عصبی است که حافظه داخلی دارد؛ بهعبارت دیگر، این شبکه یک شبکه عصبی معمولی است که در ساختارش حلقهای دارد که ازطریق آن در هر گام (Step) خروجی گام قبلی، بههمراه ورودی جدید، به شبکه وارد میشود. این حلقه به شبکه کمک میکند تا اطلاعات قبلی را در کنار اطلاعات جدید داشته باشد و بتواند براساس این اطلاعات خروجی مدنظر را به ما بدهد. این ویژگی شبکه RNN این امکان را میدهد که بتوانیم با دادههای ترتیبی (Sequential Data)، مانند متن، صدا و غیره، کار کند.
سؤالی که پیش میآید این است که چرا با وجود شبکه عصبی RNN، شبکه LSTM به وجود آمده است؟
دلیل اصلی این است که شبکه عصبی RNN در مسائلی که نیاز باشد حافظه بلندمدت داشته باشد نمیتواند خیلیخوب عمل کند؛ برای مثال، اگه بخواهیم کلمه آخر («sky») را در این جمله پیشبینی کند این کار را بهخوبی انجام میدهد؛ چون با داشتن اطلاعات کلمات همین یک جمله میتواند بهراحتی کلمه آخر را پیشبینی کند:
“.The clouds are in the sky”
«ابرها در آسمان هستند.»
اما اگر بخواهیم کلمه آخر («French») را در این پاراگراف پیشبینی کند، متأسفانه از پس این کار برنمیآید؛ چون برای پیشبینی این کلمه نیاز دارد اطلاعات مربوط به کلمات خیلی قبلتر را هم در اختیار داشته باشد:
“.I grew up in France. …. I speak fluent French”
«من در فرانسه بزرگ شدم. … من خوب فرانسوی صحبت میکنم.»
درواقع هر قدر فاصله میان کلمهای که باید پیشبینی کند و اطلاعات قبلی که به آن نیاز دارد برای این پیشبینی زیادتر شود، شبکه RNN توانایی یادگیری آنها را از دست میدهد؛ پس بهطور کلی میتوانیم بگوییم شبکه RNN حافظه کوتاهمدت خوبی دارد، اما حافظه بلندمدت نه. دلیل این موضوع مفهومی بهنام محوشدگی گرادیان (Vanishing Gradient) است.
شبکه عصبی LSTM چیست؟
همانطور که قبلاً اشاره کردیم، شبکه LSTM یا Long-Short Term Memory نوع خاصی از شبکه RNN است که مشکل حافظه بلندمدت شبکه RNN را حل میکند. شبکه LSTM سازوکارهایی داخلی بهاسم گیت (Gate) دارد. این گیتها جریان اطلاعات را کنترل میکنند؛ همینطور مشخص میکنند چه دادههایی در توالی مهم هستند و باید همچنان حفظ بشوند و چه دادههایی باید حذف بشوند؛ بهاین شکل، شبکه اطلاعات مهم را در طول زنجیره توالی عبور میدهد تا خروجی مدنظر را داشته باشیم.
در این شکل ساختار یک شبکه عصبی LSTM را میبینیم:
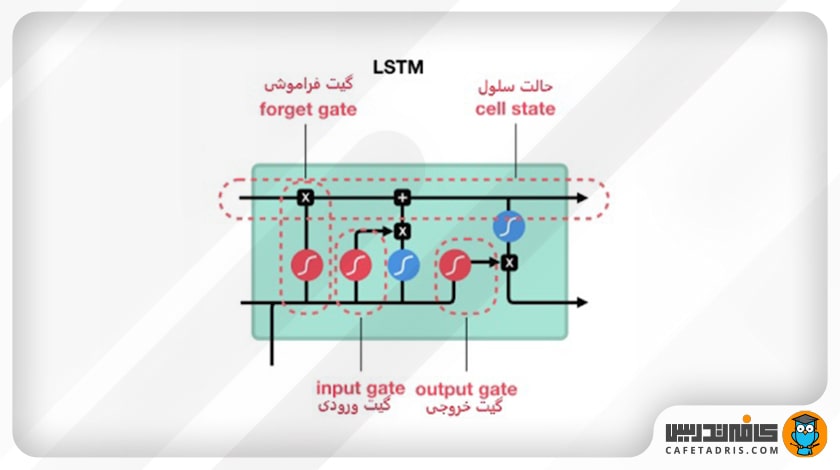

همانطور که در شکل مشخص است، شبکه LSTM چندین عملیات مختلف در ساختار داخلیاش دارد. این عملیات به شبکه LSTM کمک میکند اطلاعات را حفظ یا فراموش کند. برای درک نحوه کار این شبکه گامبهگام این عملیات را با هم بررسی میکنیم.
مفهوم اصلی شبکه LSTM
مفهوم اصلی شبکه LSTM همان cell state و گیتهای همراهش است؛ درواقع cell state مانند آزادراهی عمل میکند که اطلاعات را در طول زنجیره توالی جلو میبرد. میتوانیم به cell state بهعنوان حافظه شبکه نگاه کنیم. گیتها اطلاعات را در cell state بهروز نگه میدارند. این گیتها شبکههای عصبی مختلفی هستند که تصمیم میگیرند چه اطلاعاتی به cell state وارد بشوند. این گیتها در طول آموزش شبکه یاد میگیرند چه اطلاعاتی باید حفظ یا فراموش شوند.
قبل از اینکه درباره گیتهای شبکه LSTM صحبت کنیم، لازم است بهصورت مختصر دو تابع فعالسازیای را توضیح دهیم که در ساختار این شبکه وجود دارد تا با عملکردشان بهتر آشنا شویم.
تابع فعالساز تانژانت هایپربولیک (Tanh)
این تابع کمک میکند تا مقادیری که در طول شبکه در جریان دهستن تعدیل (regulate) شوند. تابع Tanh تمامی مقادیر را به بازه -۱ تا ۱ میبرد.


دلیل این کار این است که عملیات ریاضی مختلفی در طول شبکه روی بردارها انجام میشود؛ برای مثال، فک کنیم اگر یک مقدار در طول شبکه بارها در عددی مانند ۳ ضرب شود، در این صورت میتوانیم فکر کنیم مقادیر چقدر میتوانند بزرگ شوند.

تابع Tanh مقادیر شبکه را میان بازه -۱ تا ۱ قرار میدهد تا مقدار خروجی شبکه هم تعدیل شود. همانطور که در این شکل میبینیم، مقادیر با استفاده از تابع Tanh در یک بازه مشخص (-۱ تا ۱) باقی میمانند:

تابع فعالساز سیگموید (Sigmoid)
یکی دیگر از توابع فعالساز که در ساختار شبکه عصبی LSTM وجود دارد تابع سیگموید (Sigmoid) است. این تابع مانند تابع Tanh عمل میکند با این تفاوت که مقادیر را میان بازه صفر تا ۱ قرار میدهد. دلیل این کار این است که با بردن مقادیر در این بازه میتوانیم در زمان بهروزرسانی یا فراموشکردن داده از آن استفاده کنیم؛ چون هر عددی که در صفر ضرب شود نتیجه صفر میشود و این یعنی آن داده باید فراموش شود و هر عددی که در ۱ ضرب شود برابر با خودش میشود و این یعنی آن داده باید حفظ شود؛ بهاین شکل شبکه یاد میگیرد کدام اطلاعات را فراموش و کدام را حفظ کند.


حال لازم است با گیتهای موجود در ساختار شبکه عصبی LSTM آشنا شویم. این شبکه سه گیت دارد: گیت فراموشی (forget gate)، گیت ورودی (input gate) و گیت خروجی (output gate).
گیتهای موجود در ساختار شبکه عصبی LSTM
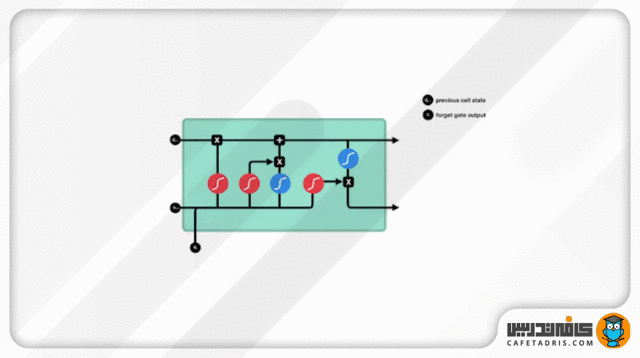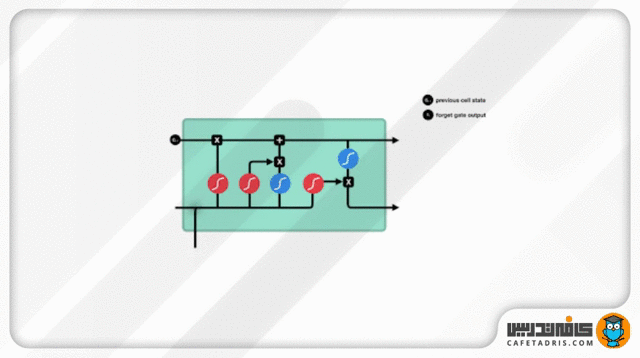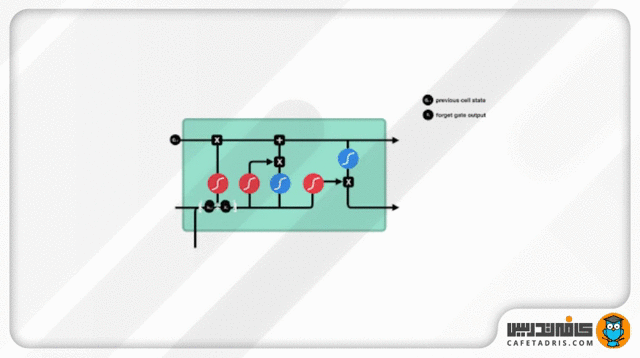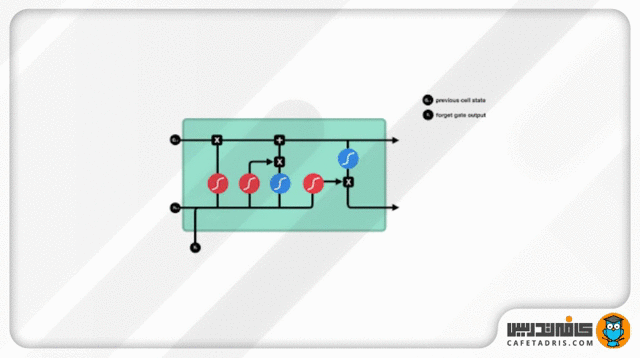
گیت فراموشی (Forget Gate)
این گیت تصمیم میگیرد کدام اطلاعات حفظ و کدام فراموش شود. اطلاعات ورودی گام جدید بههمراه اطلاعات حالت نهان (Hidden State) گام قبلی به این گیت وارد میشوند و از تابع Sigmoid عبور میکنند. خروجی این تابع، همانطور که قبلاً گفتیم، میان صفر تا ۱ است. هر قدر عدد خروجی به صفر نزدیکتر باشد یعنی باید اطلاعات فراموش شود و هر قدر به ۱ نزدیکتر باشد یعنی باید حفظ شود.
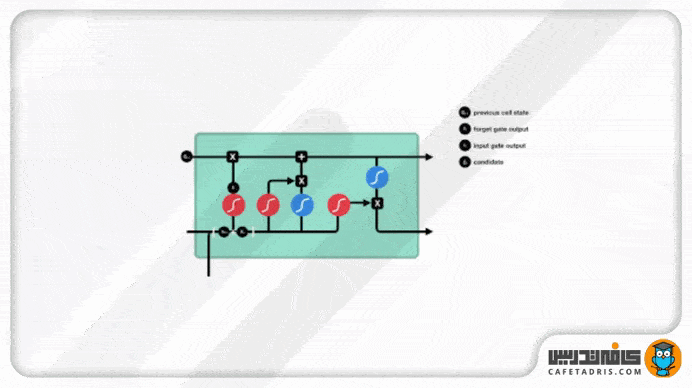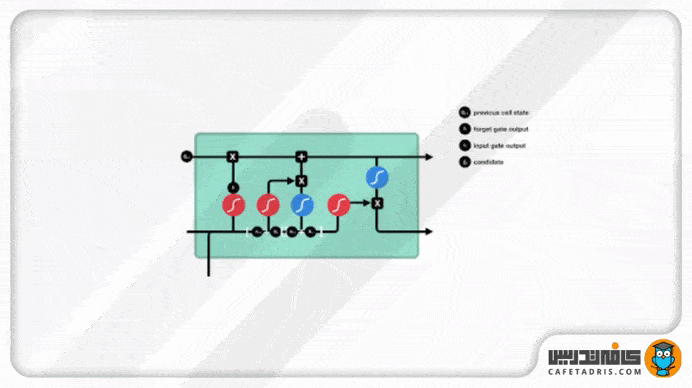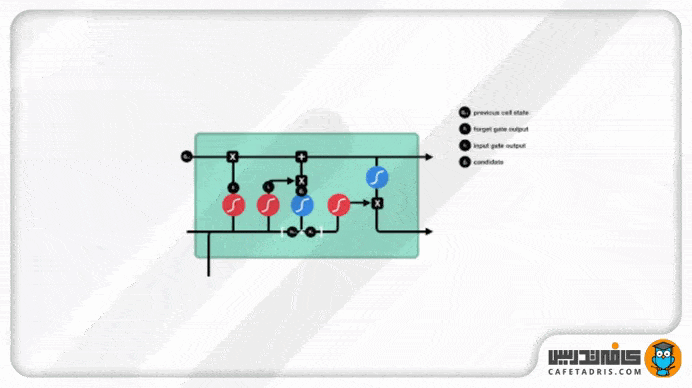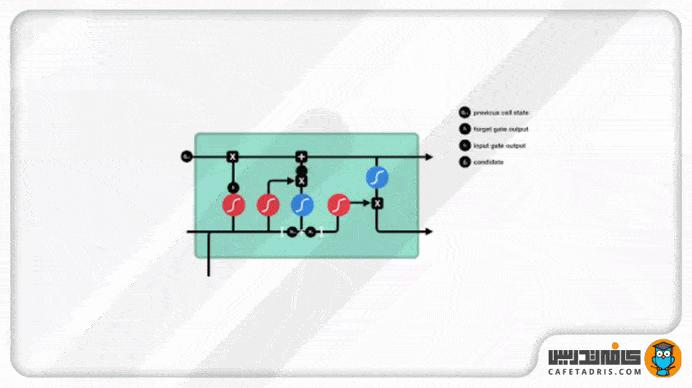
گیت ورودی (Input Gate)
این گیت برای بهروزرسانی مقادیر (اطلاعات) موجود در cell state تعبیه شده است. اطلاعات ورودی گام جدید، بههمراه اطلاعات hidden state گام قبلی، به این گیت وارد میشوند و از تابع Sigmoid عبور میکنند تا این تابع تصمیم بگیرد کدام اطلاعات (نزدیک به صفر) دور انداخته و کدوم (نزدیک به ۱) بهروزرسانی شوند. همچنین اطلاعات ورودی گام جدید، بههمراه اطلاعات hidden state گام قبلی، یه تابع Tanh وارد میشوند تا مقادیرشان میان -۱ تا ۱ قرار بگیرد. درنهایت خروجی تابع Sigmoid و Tanh با هم ضرب میشوند تا تابع Sigmoid تصمیم بگیرد چه مقادیری از خروجی تابع Tanh باید حفظ شوند.
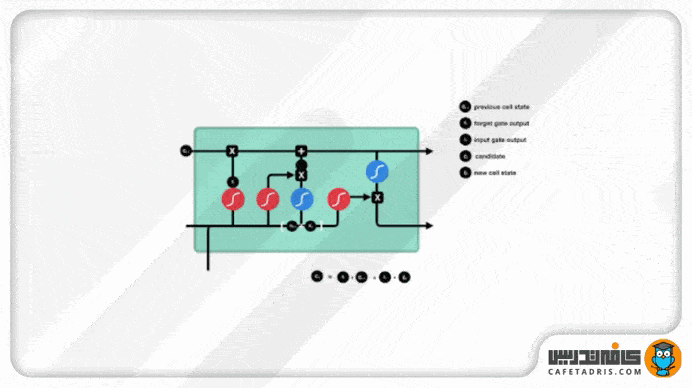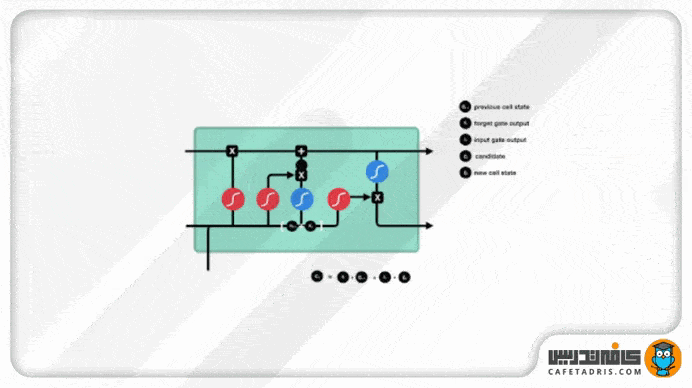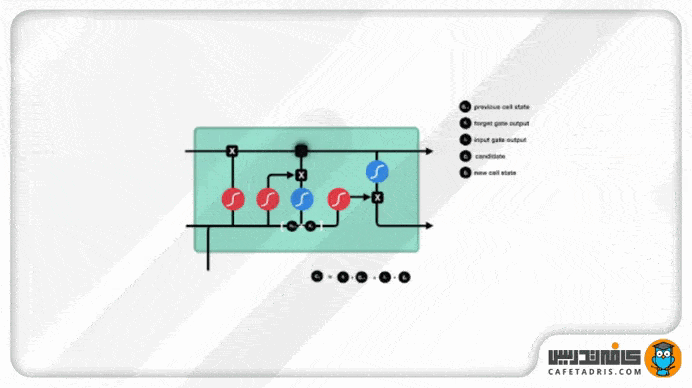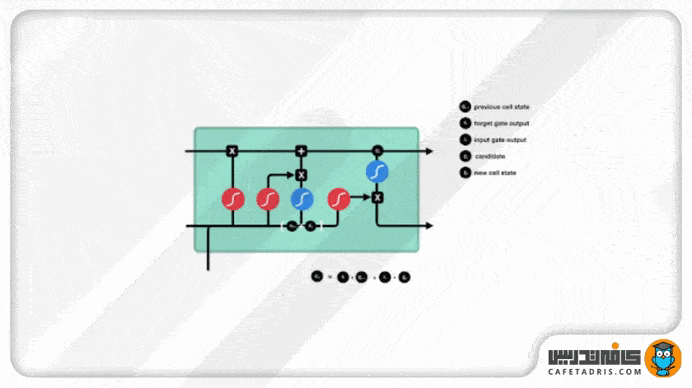
حالت سلول (Cell State)
حال میتوانیم با اطلاعات خروجی از گیت فراموشی و ورودی مقادیر cell state را آپدیت کنیم؛ بهاین شکل که اول مقدار cell state در خروجی گیت فراموشی ضرب در نقطهای (Pointwise Multiplication) میشود. در این قسمت هر مقداری در cell state که با مقدار نزدیک به صفر خروجی گیت فراموشی ضرب شود، فراموش میشود یا بهزبان دیگه کنار گذاشته میشود. بعد از این مرحله مقدار cell state با خروجی گیت ورودی جمع نقطهای (Pointwise Addition) میشود که مقدار cell state با مقادیر جدیدی که شبکه تشخیص داده است لازم هستند بهروزرسانی شوند. در پایان این مرحله مقادیر cell state بهروزرسانی شدهاند و جدید هستند.
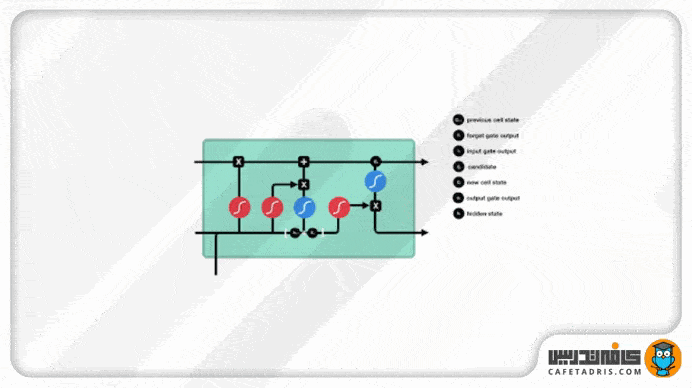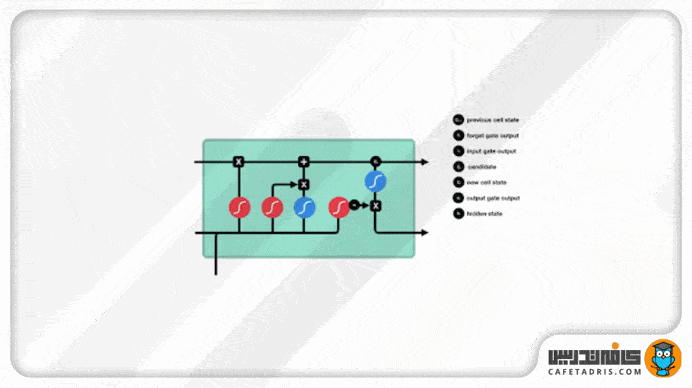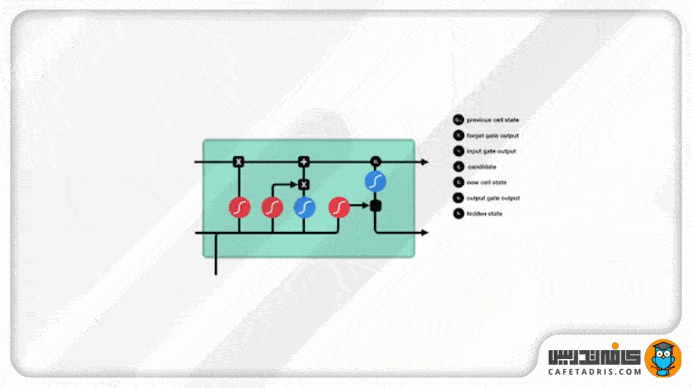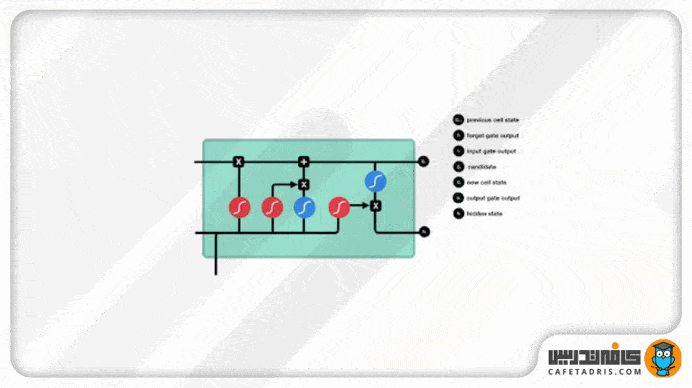
گیت خروجی (Output Gate)
این گیت درنهایت تصمیم میگیرد که hidden state بعدی ( گام بعدی) چه مقداری باشد. همانطور که میدانیم، hidden state اطلاعات ورودیهای قبلی را همراه خودش دارد. اول اطلاعات ورودی گام جدید بههمراه اطلاعات hidden state گام قبلی یه تابع Sigmoid وارد میشوند. مقدار آپدیتشده cell state به تابع Tanh وارد میشود. خروجی این دو تابع با هم ضرب میشود تا تصمیم گرفته شود hidden state چه اطلاعاتی را با خودش به گام بعدی ببرد. درنهایت cell state جدید و hidden state جدید به گام زمانی بعدی منتقل میشوند.
خلاصه مطالب درباره شبکه عصبی LSTM
شبکههای RNN، بااینکه برای پردازش دادههای ترتیبی ساخته شدهاند و در برخی موارد ممکن است عملکرد خوبی داشته باشند، مشکل حافظه کوتاهمدت دارند؛ بههمین دلیل نوع دیگری از این شبکهها بهاسم شبکه LSTM به میدان وارد شده است تا با حل این مشکل به تحقیقات در زمینههایی مانند تشخیص گفتار، پردازش زبان طبیعی و غیره کمک بزرگی کند.
البته ناگفته نماند که بعد از شبکه LSTM، مدل دیگری از این شبکه بهنام GRU هم معرفی شده است که در مقایسه با مدل LSTM تغییرات کوچکی کرده است.
پیشنهاد میکنیم برای اطلاعات بیشتر با با شبکه عصبی کانولوشنی CNN بیشتر آشنا شوید.