
ما در زمان خاصی از تاریخ زندگی میکنیم که پیشرفتهای چشمگیری در حوزه هوش مصنوعی در حال رخدادن است. در میان این پیشرفتها مدلهای زبانی کوچکتر و درعینحال بسیار کارآمد مانند Vicuna ،Koala ،Alpaca و StableLM را مییابیم که به حداقل منابع محاسباتی نیاز دارند و درعینحال نتایجی همتراز با ChatGPT ارائه میدهند. آنچه آنها را به هم پیوند میدهد این است که پایهواساس همه آنها مدلهای LLaMA متا هوش مصنوعی است. در این مطلب با مدلهای LLaMA متا هوش مصنوعی آشنا میشویم، عملکرد آنها را بررسی میکنیم و چالشها و درمورد محدودیتهایشان بحث میکنیم.
- 1. LLaMA چیست؟
- 2. LLaMA متا چگونه کار میکند؟
- 3. چالشها و محدودیتهای LLaMA چیست؟
- 4. نکته پایانی
-
5.
پرسشهای متداول
- 5.1. LLaMA مدلهای زبانی چگونه با GPT-3 و دیگر مدلهای پیشرفته مقایسه میشوند؟
- 5.2. چگونه LLaMA میتواند بر کاهش منابع محاسباتی در زمینه تحقیقات AI موثر باشد؟
- 5.3. محدودیتهای مدلهای LLaMA در مقایسه با مدلهای بزرگتر چیست؟
- 5.4. LLaMA در چه زمینههای کاربردی میتواند موثر باشد؟
- 5.5. چگونه LLaMA میتواند در حوزههای غیر زبان انگلیسی به پیشرفت کمک کند؟
- 6. یادگیری ماشین لرنینگ را از امروز شروع کنید!
LLaMA چیست؟
LLaMA مخفف Large Language Model Meta AI است و مجموعهای از پیشرفتهترین مدلهای زبانی پایه را دربرمیگیرد که بین ۷ تا ۶۵ میلیارد پارامتر دارند. این مدلها از نظر اندازه کوچک هستند و درعینحال عملکرد استثنایی را ارائه میکنند،
مدلهای زبانی LLaMA بهطور چشمگیری قدرت محاسباتی و منابع موردنیاز برای آزمایش روشهای جدید، اعتبارسنجی کار دیگران و کشف موارد استفاده نوآورانه را کاهش میدهند.
مدلهای پایه LLaMA روی مجموعه دادههای بدون برچسب بزرگ آموزش داده شدهاند که آنها را برای تنظیم دقیق (Fine-tunnig) در انواع وظایف ایدهآل میکند. این مدل روی منابع زیر آموزش داده شده است:
- CommonCrawl ۶۷%
- ۱۵٪ C4
- ۴.۵٪ GitHub
- ۴.۵٪ ویکی پدیا
- ۴.۵٪ کتاب
- ۲.۵٪ ArXiv
- ۲٪ StackExchange
تنوع گسترده مجموعه دادهها این مدلها را برای دستیابی به عملکرد پیشرفتهای که با مدلهای با عملکرد برتر، یعنی Chinchilla-70B و PaLM-540B، رقابت میکند توانمند کرده است.
LLaMA متا چگونه کار میکند؟
LLaMA یک مدل زبانی اتورگرسیو (auto-regressive language model) است که روی معماری ترنسفورمر ساخته شده است. مانند دیگر مدلهای زبانی برجسته، LLaMA با گرفتن دنبالهای از کلمهها بهعنوان ورودی و پیشبینی کلمه بعدی و تولید متن بهصورت بازگشتی عمل میکند.
پیشنهاد میکنیم درباره مدل ترنسفورمر (Transformer Model) یا مدل انتقالی هم مطالعه کنید.
چیزی که LLaMA را متمایز میکند آموزش آن روی مجموعه گستردهای از دادههای متنی در دسترس عموم است که زبانهای متعددی مانند بلغاری، کاتالان، چک، دانمارکی، آلمانی، انگلیسی، اسپانیایی، فرانسوی، کرواتی، مجارستانی، ایتالیایی، هلندی، لهستانی، پرتغالی، رومانیایی، روسی، اسلوونیایی، صربی، سوئدی و اوکراینی را شامل است. مدلهای LLaMA در چندین اندازه موجود هستند: با ۷، ۱۳، ۳۳ و ۶۵ میلیارد پارامتر که میتوانید در Hugging Face به آنها دسترسی داشته باشید.
چالشها و محدودیتهای LLaMA چیست؟
درست مانند دیگر مدلهای زبانی بزرگ، LLaMA نیز از توهم رنج میبرد، یعنی میتواند اطلاعات واقعی اشتباه تولید کند؛ این اطلاعات درواقع درست نیستند، اما مدل طوری آنها را بیان میکند که به نظر کاملاً درست و منطقی میآیند.
بهجز این مشکل میتوان به چالشهای دیگری هم اشاره کرد:
- از آنجا که اغلب مجموعه داده موجود متن انگلیسی را دربرمیگیرد مهم است که توجه کنیم که عملکرد مدل در زبانهایی غیر از انگلیسی ممکن است نسبتاً پایینتر باشد.
- هدف اصلی مدلهای LLaMA برای کاربردهای تحقیقاتی (غیرتجاری) است. هدف از انتشار این مدلها تسهیل کار پژوهشگران در ارزیابی و رسیدگی به موضوعهایی مانند سوگیریها، خطرات، تولید محتوای سمی یا مضر و توهمات است.
- LLaMA یک مدل پایه است و نباید برای ایجاد برنامههای کاربردی بدون ارزیابی ریسک آن استفاده شود.
- LLaMA در استدلال ریاضی و دانش این حوزه خوب نیست.
بهطور کلی، طبق نتایجی که در مقاله تحقیقاتی منتشر شده است، LLaMa، در مقایسه با GPT-3، در تست صداقت یا truthfulness مورداستفاده در اندازهگیری عملکرد بهتری دارد. بااینحال، همانطور که نتایج نشان میدهد، LLMها هنوز از نظر صداقت به بهبود نیاز دارند:
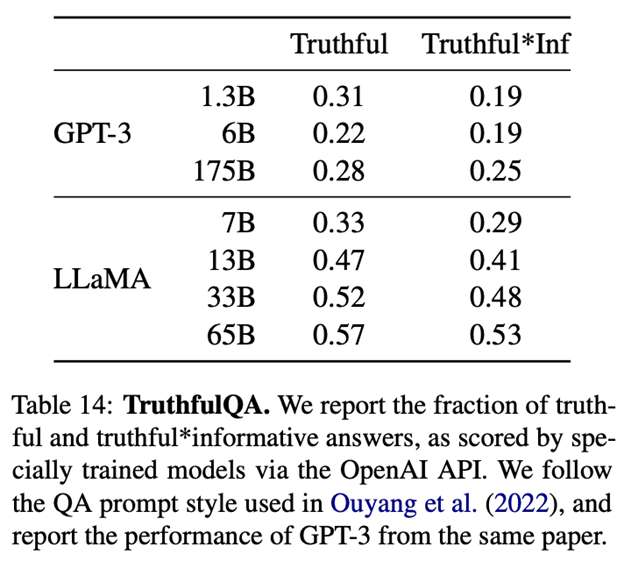
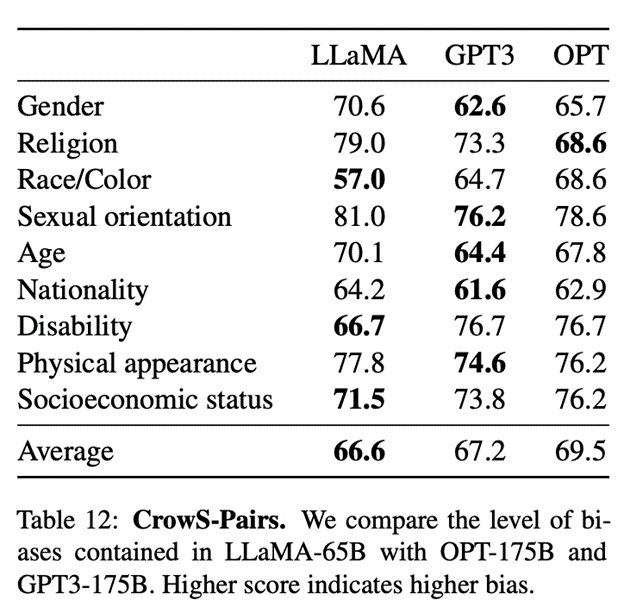
همینطور طبق گزارش این مقاله، مدل LLaMa با اندازه پارامتر ۶۵ میلیارد در مقایسه با مدل GPT3 سوگیری کمتری را نشان میدهد:
نکته پایانی
مدلهای LLaMA موجی انقلابی در توسعه هوش مصنوعی منبعباز ایجاد کردهاند. با پیشیگرفتن مدل پایه کوچکتر LLaMA-13B از قابلیتهای GPT-3 و LLaMA-65B، عملکرد قابلمقایسه با مدلهای پیشرفته مانند Chinchilla-70B و PaLM-540B، این پیشرفتها پتانسیل دستیابی آیندهای بهتر برای این مدلها را نشان داده است.

پرسشهای متداول
LLaMA مدلهای زبانی چگونه با GPT-3 و دیگر مدلهای پیشرفته مقایسه میشوند؟
LLaMA با کمترین پارامترها (۷ تا ۶۵ میلیارد) عملکردی مشابه با GPT-3 ارائه میکند؛ بااینحال از نظر توهم و سوگیری LLaMA پیشرفتهایی در مقایسه با GPT-3 کرده است، بهخصوص در نسخه ۶۵ میلیاردی که سوگیری کمتری نشان میدهد.
چگونه LLaMA میتواند بر کاهش منابع محاسباتی در زمینه تحقیقات AI موثر باشد؟
با اندازه کوچکتر و کارایی بالا، LLaMA امکان اجرای آزمایشهای AI را با منابع محدودتر فراهم میکند. این مدلها به پژوهشگران اجازه میدهند تا با کمترین هزینههای سختافزاری، ارزیابیها و تحقیقات خود را انجام دهند.
محدودیتهای مدلهای LLaMA در مقایسه با مدلهای بزرگتر چیست؟
اگرچه LLaMA در مواردی مانند صداقت و کاهش توهم بهبود یافته، اما در استدلال ریاضی و درک مفاهیم پیچیده تخصصی، هنوز با چالشهایی روبهرو است. همچنین عملکرد آن در زبانهای غیرانگلیسی ممکن است محدودتر باشد.
LLaMA در چه زمینههای کاربردی میتواند موثر باشد؟
LLaMA بیشتر برای کاربردهای تحقیقاتی مناسب است، بهویژه در زمینههایی که نیازمند بررسی سوگیریها، توهمات و تولید محتوای مضر هستند. این مدلها برای ارزیابی و توسعه استراتژیهای جدید در AI مفید هستند، اما برای برنامههای کاربردی تجاری بدون ارزیابی ریسک نباید استفاده شوند.
چگونه LLaMA میتواند در حوزههای غیر زبان انگلیسی به پیشرفت کمک کند؟
LLaMA، با پشتیبانی از چندین زبان، فرصتی برای بهبود فهم ماشینی زبانهای کمتر موردتوجه میآفریند. این مدلها میتوانند بر تحلیل و پردازش زبانهای گوناگون مؤثر باشند که این امر به توسعه فناوریهای هوش مصنوعی در محیطهای چندزبانه کمک خواهد کرد و به ارتقای دسترسی عادلانه به فناوریهای AI در سراسر جهان میانجامد.
یادگیری ماشین لرنینگ را از امروز شروع کنید!
دنیای دادهها جذاب است. دانستن دیتا ساینس یا علم داده، توانایی تحلیل داده یا بازاریابی مبتنی بر داده شما را برای فرصتهای شغلی بسیاری مناسب میکند. فارغ از رشته و پیشزمینه تحصیلی و شغلی، شما میتوانید از همین حالا یادگیری دیتا ساینس را شروع کنید و از سطح مقدماتی تا پیشرفته آن را بیاموزید. اگر دوست دارید به این حوزه وارد شوید، پیشنهاد میکنیم با کلیک روی این لینک قدم اول را همین حالا بردارید.
مشاوران کافهتدریس به شما کمک میکنند مسیر یادگیری برای ورود به این حوزه را شروع کنید: