
در توسعه نرمافزارهای مدرن، APIها (رابطهای برنامهنویسی کاربردی) نقش حیاتی ایفا میکنند. APIها ستون فقرات توسعه نرمافزار مدرن هستند که ارتباط و یکپارچهسازی بدون نقص بین سیستمهای نرمافزاری مختلف را ممکن میسازند. این مقاله به اهمیت APIها میپردازد و بر نقش آنها در تسهیل ارتباط بین سیستمهای نرمافزاری مختلف برای ایجاد برنامههای مقیاسپذیر، قابل نگهداری و کارآمد تأکید دارد. پکیج Requests فرآیند ارسال درخواستهای HTTP و مدیریت پاسخها را ساده میکند و آن را به ابزاری محبوب برای توسعهدهندگان پایتون تبدیل مینماید. این مقاله ویژگیهای کلیدی پکیج Requests از جمله فشردهسازی خودکار، پشتیبانی از اتصالات متعدد، مدیریت جلسه و مستندات گسترده را بررسی میکند.
- 1. مرور کلی بر APIها
- 2. اهمیت APIها در توسعه نرمافزارهای مدرن
- 3. ارتباط بین سیستمهای نرمافزاری با استفاده از APIها
- 4. معرفی پکیج Requests در پایتون
- 5. استفاده از پکیج Requests
- 6. ویژگیهای پیشرفته پکیج Requests
- 7. کاربردهای دنیای واقعی و مطالعات موردی
- 8. مقایسه با سایر کتابخانههای HTTP
- 9. روندهای آینده در توسعه API
- 10. جمعبندی
-
11.
پرسشهای متداول
- 11.1. پکیج Requests چه ویژگیهای کلیدی دارد که آن را از سایر کتابخانههای HTTP متمایز میکند؟
- 11.2. چه تفاوتی بین درخواستهای GET و POST در پکیج Requests وجود دارد؟
- 11.3. چگونه میتوان کوکیها را در پکیج Requests مدیریت کرد؟
- 11.4. چگونه میتوان دادههای JSON را با استفاده از پکیج Requests تجزیه کرد؟
- 11.5. چگونه میتوان خطاهای رایج در پکیج Requests را مدیریت کرد؟
- 12. یادگیری ماشین لرنینگ را از امروز شروع کنید!
مرور کلی بر APIها
APIها یا رابطهای برنامهنویسی کاربردی، بخش اساسی توسعه نرمافزارهای مدرن هستند. آنها مجموعهای از قوانین و پروتکلها را برای ساخت و تعامل با برنامههای نرمافزاری تعریف میکنند. با تسهیل ارتباط بین سیستمهای نرمافزاری مختلف، APIها به توسعهدهندگان امکان میدهند تا بدون نیاز به اختراع دوباره چرخ، امکانات متنوعی را ادغام کنند. در اصل، APIها به اجزای مختلف نرمافزاری اجازه میدهند تا با هم صحبت کنند و این امکان را فراهم میکنند تا سیستمهای پیچیده با کارایی بالا ساخته شوند.
همچنین بخوانید: استخراج داده با پایتون – راهنمای جامع برای بهرهبرداری از APIها
اهمیت APIها در توسعه نرمافزارهای مدرن
APIها با ایجاد قابلیت همکاری بین برنامههای نرمافزاری مختلف، نقش حیاتی در اکوسیستم دیجیتال ایفا میکنند. آنها ستون فقرات خدمات وب هستند و امکان تبادل دادهها و امکانات را بهصورت یکپارچه بین برنامهها فراهم میکنند. این قابلیت همکاری برای ایجاد سیستمهای مقیاسپذیر، قابلنگهداری و مقاوم بسیار مهم است. برای مثال، APIها به توسعهدهندگان امکان میدهند تا خدمات شخص ثالث مانند درگاههای پرداخت، پلتفرمهای شبکههای اجتماعی و خدمات ابری را در برنامههای خود ادغام کنند و به این ترتیب، امکانات و تجربه کاربری را ارتقا دهند.

ارتباط بین سیستمهای نرمافزاری با استفاده از APIها
ارتباط بین سیستمهای نرمافزاری با استفاده از APIها معمولاً شامل ارسال درخواستها و دریافت پاسخها میشود. یک مشتری (کلاینت) یک درخواست API به سرور ارسال میکند و سرور این درخواست را پردازش کرده و پاسخ مناسب را برمیگرداند. این چرخه “درخواست-پاسخ” پایه و اساس بیشتر تعاملات API را تشکیل میدهد. APIها از پروتکلهای مختلفی برای ارتباط استفاده میکنند که HTTP (Hypertext Transfer Protocol) رایجترین آنهاست. APIهای مبتنی بر HTTP که اغلب به عنوان وب APIها یا APIهای RESTful شناخته میشوند، به دلیل سادگی و همهگیر بودن خود بسیار مورد استفاده قرار میگیرند.
معرفی پکیج Requests در پایتون
تاریخچه و توسعه پکیج Requests
پکیج Requests پایتون توسط Kenneth Reitz توسعه داده شد و اولین بار در سال 2011 منتشر شد. این پکیج برای ارائه راهی سادهتر و کاربرپسندتر برای ارسال درخواستهای HTTP در پایتون ایجاد شد. قبل از Requests، توسعهدهندگان مجبور بودند از کتابخانههای سطح پایینتری مانند http.client یا urllib استفاده کنند که اغلب پیچیده و دشوار بودند. Requests هدف داشت که این فرآیند را ساده کند و ارسال درخواستهای HTTP و مدیریت پاسخها را آسانتر سازد.

برای مطالعه بیشتر کلیک کید: کاربرد پایتون در علم داده کجاست و چگونه از آن استفاده میشود؟
ویژگیهای کلیدی پکیج Requests
پکیج Requests دارای ویژگیهای کلیدی متعددی است که به محبوبیت آن کمک کردهاند:
- سادهسازی (Simplicity): پکیج Requests پیچیدگیهای ارسال درخواستهای HTTP را کاهش داده و یک API تمیز و ساده ارائه میدهد.
- فشردهسازی خودکار (Automatic Decompression): این پکیج از مدیریت خودکار محتوای فشرده، مانند gzip و deflate پشتیبانی میکند.
- مدیریت اتصالات (Connection Pooling): پکیج Requests از مدیریت اتصالات پشتیبانی میکند که میتواند با استفاده مجدد از اتصالات، عملکرد را بهبود بخشد.
- جلسات (Sessions): این پکیج اشیاء جلسات را برای اتصالات مداوم فراهم میکند که امکان نگهداری کوکیها و تنظیمات را در بین چندین درخواست فراهم میکند.
- مستندات گسترده (Extensive Documentation): کتابخانه دارای مستندات کاملی است که حتی برای مبتدیان نیز قابل دسترسی است.
- پشتیبانی جامعه (Community Support): با داشتن جامعهای بزرگ و فعال، توسعهدهندگان میتوانند منابع و پشتیبانی زیادی پیدا کنند.
محبوبیت و پشتیبانی جامعه
از زمان تأسیس، پکیج Requests محبوبیت زیادی در میان توسعهدهندگان پایتون کسب کرده است. این پکیج به طور گسترده در برنامههای مختلفی، از جمله web scraping، تعاملات API، تست و اتوماسیون استفاده میشود. این پکیج دائما به روزرسانی میشود و دارای جامعهای قوی است که به توسعه و پشتیبانی آن کمک میکند. این پذیرش گسترده و مشارکت جامعهای، اطمینان میدهد که پکیج Requests ابزاری قابل اعتماد و بهروز برای ارسال درخواستهای HTTP در پایتون باقی میماند.
استفاده از پکیج Requests
نصب و ایمپورت پکیج Requests
برای استفاده از پکیج Requests ابتدا باید آن را نصب کنیم. برای این منظور میتوانیم از pip، که مختص نصب پکیجهای پایتون است، استفاده کنیم:
!pip install requests
پس از نصب، میتوانیم این پکیج را در اسکریپت پایتون خود ایمپورت کنیم:
import requests
انجام درخواستهای HTTP ساده
GET Requests
درخواست GET برای بازیابی دادهها از سرور استفاده میشود. در اینجا یک مثال ساده از انجام یک درخواست GET با استفاده از پکیج Requests آورده شده است:
response = requests.get('https://api.example.com/data')
print(response.status_code)
print(response.json())
POST Requests
درخواست POST برای ارسال دادهها به سرور استفاده میشود. در اینجا نحوه انجام یک درخواست POST آمده است:
data = {'key': 'value'}
response = requests.post('https://api.example.com/data', json=data)
print(response.status_code)
print(response.json())
PUT Requests
درخواست PUT برای بهروزرسانی دادهها در سرور استفاده میشود. در اینجا یک مثال آمده است:
data = {'key': 'new_value'}
response = requests.put('https://api.example.com/data/1', json=data)
print(response.status_code)
print(response.json())
DELETE Requests
درخواست DELETE برای حذف دادهها از سرور استفاده میشود. در اینجا نحوه انجام یک درخواست DELETE با استفاده از پکیج Requests آمده است:
response = requests.delete('https://api.example.com/data/1')
print(response.status_code)
مدیریت پاسخها
تجزیه دادههای JSON
بیشتر APIها دادهها را به فرمت JSON برمیگردانند. ما میتوانیم بهراحتی پاسخهای JSON را با پکیج Requests تجزیه کنیم:
response = requests.get('https://api.example.com/data')
data = response.json()
print(data)
دسترسی به هدرها
میتوانیم با استفاده از ویژگی headers به هدرهای پاسخ دسترسی پیدا کنیم:
response = requests.get('https://api.example.com/data')
print(response.headers)
کدهای وضعیت و معانی آنها
کدهای وضعیت HTTP نتیجه درخواست HTTP را نشان میدهند. در اینجا چند کد وضعیت رایج آمده است:
- 200 OK: درخواست موفقیتآمیز بود.
- 201 Created: درخواست موفقیتآمیز بود و منبعی ایجاد شد.
- 400 Bad Request: درخواست نامعتبر بود.
- 401 Unauthorized: نیاز به احراز هویت دارد و درخواست موفقیت آمیز نبود.
- 404 Not Found: منبع درخواست شده پیدا نشد.
- 500 Internal Server Error: خطایی در سرور رخ داده است.
مدیریت خطاها
خطاها و استثناهای رایج
پکیج Requests ممکن است برای خطاهای مختلف استثناهایی را ایجاد کند. برخی از استثناهای رایج شامل موارد زیر است:
- requests.exceptions.RequestException: یک کلاس پایه برای همه استثناها.
- requests.exceptions.HTTPError: برای خطاهای مربوط به HTTP ایجاد میشود.
- requests.exceptions.ConnectionError: برای خطاهای مربوط به اتصال ایجاد میشود.
- requests.exceptions.Timeout: زمانی که یک درخواست به زمانبندی تعیینشده برسد ایجاد میشود.
تکرار درخواستها
میتوان از پکیج Requests همراه با کتابخانههای شخص ثالث مانند requests.adapters.HTTPAdapter و urllib3.util.retry.Retry برای پیادهسازی منطق تکرار برای درخواستهای ناموفق استفاده شود. منظور از third-party libraries یا کتابخانههای شخص ثالث در پایتون، کتابخانههایی هستند که توسط توسعهدهندگان مستقل یا سازمانهای خارج از پروژه اصلی پایتون توسعه یافتهاند. این کتابخانهها به عنوان افزونههای اضافی به زبان پایتون اضافه میشوند تا قابلیتها و امکانات بیشتری به زبان اضافه کنند. در اینجا یک مثال آمده است:
from requests.adapters import HTTPAdapter
from urllib3.util.retry import Retry
session = requests.Session()
retry = Retry(connect=3, backoff_factor=0.5)
adapter = HTTPAdapter(max_retries=retry)
session.mount('http://', adapter)
session.mount('https://', adapter)
response = session.get('https://api.example.com/data')
print(response.status_code)
در کد بالا، کلاس Retry از کتابخانه urllib3 برای تنظیم مکانیزم Retry برای درخواستهای HTTP استفاده شده است. HTTPAdapter این منطق تکرار را به هر دو درخواست HTTP و HTTPS نصب میکند. پارامترهای Retry(connect=3, backoff_factor=0.5) به معنای زیر هستند:
- connect=3: این پارامتر تعداد دفعاتی را که تلاش برای برقراری ارتباط مجدد در صورت وقوع خطای اتصال انجام میشود را مشخص میکند. در اینجا مقدار ۳ تعیین شده، یعنی اگر تلاش اول برای اتصال به سرور شکست بخورد، تا سه بار دیگر تلاش خواهد شد.
- backoff_factor=0.5: این پارامتر مدت زمان صبر بین هر تلاش مجدد را تعیین میکند. مدت زمان صبر برای هر تلاش مجدد به صورت تصاعدی افزایش مییابد زیر محاسبه میشود.
{backoff factor} * (2 ** (retry number – 1))
به عنوان مثال، پس از تلاش اول، دوم و سوم به ترتیب مدت زمان صبر برابر با 0.5، 1 و 2 ثانیه خواهد بود. این مکانیزم باعث میشود که اگر تلاشهای اولیه برای برقراری اتصال با سرور با مشکل مواجه شدند، زمان مناسبی برای صبر و تلاش مجدد وجود داشته باشد که میتواند در شرایطی که مشکلات موقت شبکه وجود دارد مفید باشد.
ویژگیهای پیشرفته پکیج Requests
جلسات و اتصالات پایدار
جلسات (Sessions) این امکان را میدهند تا پارامترهای خاصی بین درخواستها نگه داری شوند. این امر میتواند برای نگهداری کوکیها یا هدرها بین درخواستها مفید باشد. در اینجا یک مثال آمده است:
session = requests.Session()
session.headers.update({'Authorization': 'Bearer YOUR_ACCESS_TOKEN'})
response = session.get('https://api.example.com/data')
print(response.status_code)
در ادامه به توضیح کد بالا میپردازیم:
- در ابتدا یک شیء از نوع Session از کتابخانه requests ایجاد میشود. شیء Session اجازه میدهد تا پارامترها و تنظیمات مشترک (مثل هدرها) برای چندین درخواست HTTP تنظیم شوند. این امر باعث افزایش کارایی و کاهش تکرار کد میشود.
- هدرهای پیشفرض برای این شیء Session را بهروزرسانی میکند. در اینجا، هدر Authorization با مقدار Bearer YOUR_ACCESS_TOKEN تنظیم شده است. این هدر معمولاً برای احراز هویت در برابر APIها استفاده میشود. YOUR_ACCESS_TOKEN باید با یک توکن معتبر جایگزین شود که به شما اجازه دسترسی به دادههای API را میدهد.
- یک درخواست GET به آدرس مشخص شده ارسال میشود. با استفاده از شیء Session، هدرهای پیشفرض (شامل هدر احراز هویت) به درخواست اضافه میشوند.
این کد به طور کلی برای ارسال درخواستهای احراز هویت شده به APIها استفاده میشود و با استفاده از شیء Session، مدیریت هدرها و سایر تنظیمات به صورت متمرکز و کارآمدتر انجام میشود.
مدیریت کوکیها
پکیج Requests مدیریت کوکیها را آسان میکند. در اینجا نحوه ارسال و دریافت کوکیها آمده است:
# Sending cookies
cookies = {'session_id': '12345'}
response = requests.get('https://api.example.com/data', cookies=cookies)
print(response.text)
# Receiving cookies
response = requests.get('https://api.example.com/data')
print(response.cookies['session_id'])
درخواستهای جریانی
برای درخواستهای با حجم داده زیاد، ممکن است لازم باشد پاسخ را به صورت جریانی (Streaming) دریافت کنیم تا از بارگذاری آن به طور کامل در حافظه جلوگیری کنیم. در اینجا نحوه انجام این کار آمده است:
response = requests.get('https://api.example.com/largefile', stream=True)
with open('largefile.zip', 'wb') as file:
for chunk in response.iter_content(chunk_size=1024):
if chunk:
file.write(chunk)
در ادامه به توضیح کد بالا میپردازیم:
- ابتدا یک درخواست GET به آدرس مشخص شده با استفاده از پارامتر stream=True ارسال میشود. با فعالسازی این پارامتر، پاسخ به صورت تدریجی دریافت میشود و به یکباره در حافظه بارگذاری نمیشود. این امر برای دانلود فایلهای بزرگ مفید است زیرا از مصرف زیاد حافظه جلوگیری میکند.
- در ادامه یک فایل جدید به نام largefile.zip در حالت باینری (wb) برای نوشتن باز میشود. لازم به ذکر است که استفاده از with برای مدیریت خودکار باز و بسته شدن فایلها کاربرد دارد.
- حلقه for به کار رفته، پاسخ دریافتی از سرور را به صورت بخشهای کوچک با اندازه 1024 بایت (1 کیلوبایت) پیمایش میکند. متد iter_content دادهها را به صورت قطعات (چانکها) کوچک برمیگرداند.
- در ادامه این کد بررسی میشود که چانک خالی نباشد. این بررسی ضروری است تا از نوشتن چانکهای خالی جلوگیری شود..
- نهایتا چانک دریافت شده را در فایل محلی (largefile.zip) مینویسد.
سفارشیسازی هدرها و پارامترها
پکیج Requests این قابلیت را دارد که به کمک آن میتوان هدرها و پارامترها را برای کنترل رفتار درخواستهای HTTP سفارشیسازی کرد. کد زیر بیانگر این امر است:
headers = {'User-Agent': 'my-app/0.0.1'}
params = {'key1': 'value1', 'key2': 'value2'}
response = requests.get('https://api.example.com/data', headers=headers, params=params)
print(response.text)
آپلود فایلها
آپلود فایلها با استفاده از پکیج Requests بسیار ساده است. در اینجا یک مثال آمده است:
files = {'file': open('report.csv', 'rb')}
response = requests.post('https://api.example.com/upload', files=files)
print(response.status_code)
کاربردهای دنیای واقعی و مطالعات موردی
اتوماسیون تعاملات وب (Automating Web Interactions)
پکیج Requests میتواند برای تعامل با سرویسهای وب مورد استفاده قرار گیرد. برای مثال، میتوان مطابق قطعه کد زیر، فرآیند ورود به یک وبسایت و استخراج دادهها را اتوماسیون نمود:
login_data = {'username': 'myusername', 'password': 'mypassword'}
session = requests.Session()
session.post('https://example.com/login', data=login_data)
response = session.get('https://example.com/profile')
print(response.text)
این قطعه کد برای ورود به یک وبسایت و سپس دسترسی به صفحه پروفایل کاربر استفاده میشود. در اینجا توضیح مختصری از هر بخش کد آمده است:
- یک دیکشنری (dictionary) شامل اطلاعات ورود (نام کاربری و رمز عبور) ایجاد میکند. این اطلاعات برای ورود به سایت مورد استفاده قرار میگیرد.
- یک شیء از نوع Session از کتابخانه requests ایجاد میشود. این شیء برای حفظ کوکیها و سایر اطلاعات جلسه (session) بین درخواستها استفاده میشود.
- یک درخواست POST به آدرس مدنظر ارسال میکند. دادههای ورود (نام کاربری و رمز عبور) به عنوان پارامترهای این درخواست ارسال میشوند. این مرحله کاربر را وارد سایت میکند و اطلاعات جلسه (session) مانند کوکیها را در شیء Session ذخیره میکند.
- سپس یک درخواست GET به آدرس مدنظر ارسال میشود. با استفاده از شیء Session، کوکیهای احراز هویت شده و سایر اطلاعات جلسه به درخواست اضافه میشوند، بنابراین سرور درخواست را به عنوان یک کاربر وارد شده شناسایی میکند.
قطعه کد بالا معمولاً برای انجام عملیات ورود (login) و سپس دسترسی به صفحات یا دادههای محافظت شده در یک وبسایت استفاده میشود. با استفاده از شیء Session، اطلاعات جلسه بین درخواستها حفظ میشود و نیازی به ارسال مجدد اطلاعات ورود در هر درخواست نیست. این روش برای اسکریپتهای اتوماسیون وب و تستهای خودکار مفید است.
استخراج دادهها از APIها
APIها به طور گستردهای برای استخراج دادهها در پروژههای علم داده استفاده میشوند. در اینجا مثالی از استخراج دادهها از یک API عمومی آورده شده است:
response = requests.get('https://api.exchangerate-api.com/v4/latest/USD')
data = response.json()
print(f"Exchange rate from USD to EUR: {data['rates']['EUR']}")
این کد یک درخواست GET به API نرخ ارز ارسال میکند تا نرخ تبدیل دلار آمریکا (USD) به یورو (EUR) را دریافت کند و سپس آن را چاپ میکند.
ادغام با سرویسهای شخص ثالث
پکیج Requests میتواند برای ادغام با سرویسهای شخص ثالث مانند پلتفرمهای رسانه اجتماعی، درگاههای پرداخت و موارد دیگر مورد استفاده قرار گیرد:
data = {
'message': 'Hello, world!',
'access_token': 'YOUR_ACCESS_TOKEN'
}
response = requests.post('https://graph.facebook.com/v11.0/me/feed', data=data)
print(response.status_code)
این کد یک درخواست POST به API فیسبوک ارسال میکند تا پیام “Hello, world!” را با استفاده از یک توکن دسترسی (access token) به صفحه اصلی کاربر ارسال میکند.
مطالعه موردی: استفاده از Requests در یک پروژه علم داده
تصور کنید یک پروژه علم داده که نیاز به جمعآوری و تحلیل دادههای هواشناسی از یک API دارد. میتوانید از پکیج Requests برای دریافت این دادهها و سپس پردازش آنها برای تحلیل بیشتر استفاده کنید:
# Define the URL and API key
# Replace 'YOUR_API_KEY' with your actual API key
url = 'https://api.weatherapi.com/v1/current.json'
api_key = 'YOUR_API_KEY'
query = 'London'
# Make the request
response = requests.get(url, params={'key': api_key, 'q': query})
# Check if the request was successful
if response.status_code == 200:
try:
# Attempt to parse the JSON response
weather_data = response.json()
print(f"Current temperature in {query}: {weather_data['current']['temp_c']}°C")
except ValueError as e:
print(f"Error decoding JSON: {e}")
else:
print(f"Request failed with status code {response.status_code}")
این کد با استفاده از کلید API و نام شهر لندن، یک درخواست به API هواشناسی ارسال میکند، دمای فعلی لندن را از پاسخ JSON دریافت و نمایش میدهد، و در صورت وقوع خطاها آنها را مدیریت میکند.
همچنیین بخوانیدکاربردهای عملی علم داده در زمینههای مختلف چیست؟
مقایسه با سایر کتابخانههای HTTP
http.client
http.client یک کلاینت پروتکل HTTP در سطح پایین است که در کتابخانه استاندارد پایتون قرار دارد و ابزارهای بنیادی برای ساخت درخواستهای HTTP را فراهم میکند. این ماژول امکان کنترل دقیق بر ساخت درخواستها و مدیریت پاسخها را فراهم میآورد و یک رویکرد جزئینگرانه به ارتباطات HTTP ارائه میدهد. http.client برای توسعهدهندگانی ایدهآل است که نیاز به پیادهسازی پروتکلهای HTTP سفارشی دارند یا کنترل کامل بر چرخه درخواست/پاسخ (I/O) HTTP نیاز دارند. با این حال، این کنترل به قیمت پیچیدگی و فراوانی کد تمام میشود، چرا که توسعهدهندگان باید بسیاری از جنبههای فرآیند درخواست را که در کتابخانههای سطح بالاتر انتزاع شدهاند، به صورت دستی مدیریت کنند. علیرغم پیچیدگی آن، http.client همچنان ابزاری حیاتی برای انجام وظایف نیازمند به عملیات جزئی HTTP باقی میماند.
مزایا:
- بدون نیاز به وابستگیهای خارجی.
- کنترل بیشتر بر فرآیند درخواست و پاسخ.
معایب:
- پر از کد (Verbosity) و کمتر کاربرپسند.
- نیاز به کدنویسی بیشتر برای دستیابی به همان عملکرد Requests.
urllib
urllib یک ماژول جامع برای کار با URLها در کتابخانه استاندارد پایتون است که رابطی سطح بالاتر برای انجام درخواستهای HTTP نسبت به http.client ارائه میدهد. این ماژول فرآیند باز کردن و خواندن URLها، مدیریت کدگذاری URL و مدیریت هدرهای HTTP را ساده میکند. urllib به چند زیرماژول مانند urllib.request، urllib.parse، urllib.error و urllib.robotparser تقسیم شده است که هر کدام هدف خاصی در دستکاری URL و مدیریت درخواستهای HTTP دارند. در حالی که urllib استفاده آسانتری نسبت به http.client دارد، هنوز نیاز به کد تکراری بیشتری دارد و دارای منحنی یادگیری نسبتاً بالاتری نسبت به کتابخانههای مدرنتر مانند Requests است. با این حال، urllib در سناریوهایی که نیاز به کنترل دقیق و اجتناب از وابستگیهای خارجی وجود دارد، ارزشمند است.
مزایا:
- بخشی از کتابخانه استاندارد پایتون.
- استفاده آسانتر نسبت به http.client.
معایب:
- پیچیدهتر از Requests.
- API کمتر شهودی.
aiohttp
aiohttp یک چارچوب پیشرفته غیرهمزمان HTTP کلاینت/سرور است که برای کتابخانه asyncio پایتون طراحی شده و امکان مدیریت کارآمد درخواستهای HTTP همزمان را فراهم میآورد. این ماژول از عملیات کلاینت و سرور پشتیبانی میکند و برای وظایف مختلف وب کاربرد دارد. aiohttp از قابلیتهای asyncio پایتون برای انجام درخواستهای غیرمسدودکننده HTTP استفاده میکند که میتواند به طور قابل توجهی عملکرد را در برنامههای I/Oمحور بهبود بخشد، چرا که چندین درخواست را به طور همزمان بدون انتظار برای تکمیل هر کدام مدیریت میکند. این رویکرد غیرهمزمان، تأخیر را کاهش میدهد و پاسخگویی برنامههایی که به شدت به ارتباطات HTTP وابسته هستند را افزایش میدهد. با این حال، استفاده از aiohttp نیاز به آشنایی با پارادایمهای برنامهنویسی غیرهمزمان دارد که این امر دارای پیچیدگی بیشتری به منظور راهاندازی و استفاده از آن نسبت به سایر کتابخانهها میافزاید.
مزایا:
- غیرهمزمان، که میتواند کارایی را در برنامههای I/Oمحور بهبود بخشد.
- مدرن و دارای ویژگیهای غنی.
معایب:
- نیاز به درک برنامهنویسی غیرهمزمان.
- راهاندازی پیچیدهتر نسبت به پکیج Requests.
تحلیل مقایسهای ویژگیها
جدول زیر ویژگیهای کلیدی این کتابخانهها را مقایسه میکند:
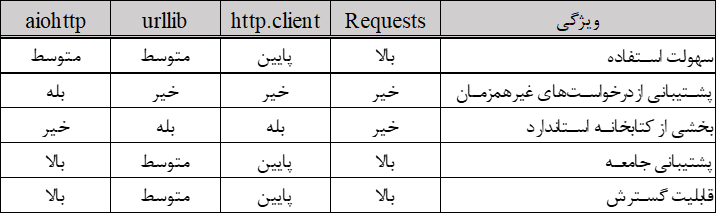
از نظر عملکرد، aiohttp میتواند در سناریوهایی که نیاز به عملیات I/O همزمان زیادی دارند، به دلیل ماهیت غیرهمزمان خود عملکرد بهتری داشته باشد. Requests، اگرچه غیرهمزمان نیست، اما بهینهسازی شده و برای بیشتر موارد استفاده رایج مناسب است. http.client و urllib به طور کلی به دلیل پیادهسازی سطح پایینتر و verbosity کندتر هستند.
روندهای آینده در توسعه API
ظهور GraphQL و APIهای ناهمگام
GraphQL که بهعنوان جایگزینی برای REST توسط فیسبوک توسعه یافته است، به مشتریان اجازه میدهد دادههای خاصی را درخواست کنند و مشکلات مربوط به دریافت بیش از حد یا کمتر از حد دادهها را به حداقل میرساند. زبان پرسشگری انعطافپذیر و ابزارهای توسعه قوی آن، این تکنولوژی به ابزاری محبوب تبدیل کردهاست. همزمان، APIهای ناهمگام به دلیل توانایی در مدیریت همزمان چندین درخواست، برای برنامههای I/Oمحور محبوبیت پیدا کردهاند. فناوریهایی مانند aiohttp در پایتون و الگوهای async/await در زبانهای مختلف، پیادهسازی این عملیاتها را تسهیل میکنند که برای برنامههای بلادرنگ و با حجم بالا ضروری هستند.
امنیت پیشرفته و معماریهای بدون سرور
با افزایش تهدیدات سایبری، امنیت API به اولویتی مهم تبدیل شده است. پیادهسازی استانداردهایی مانند OAuth 2.0، OpenID Connect و مدلهای امنیتی Zero Trust به روشهای معمول برای حفاظت از تعاملات API تبدیل شدهاند. از سویی دیگر، رایانش بدون سرور در حال تحول در توسعه API است. پلتفرمهایی مانند AWS Lambda، Azure Functions و Google Cloud Functions به توسعهدهندگان امکان میدهند APIهایی را بسازند و مستقر کنند که بدون نیاز به مدیریت زیرساخت سرور، ارائه مقیاسپذیری، کاهش هزینههای عملیاتی و مدلهای پرداخت بر اساس استفاده باشند. این روند برای تیمها و استارتاپهایی که به دنبال مدیریت کارآمد منابع هستند، بسیار جذاب است.
جمعبندی
پکیج Requests یک ابزار قدرتمند و کاربرپسند برای ارسال درخواستهای HTTP در پایتون است. این ابزار فرآیند ارسال درخواستها و مدیریت پاسخها را ساده میکند و حتی برای افرادی که تازه با پایتون آشنا شدهاند، قابل دسترس است. پکیج Requests پایتون به دلیل سادگی و قوی بودن، همچنان یک راهحل محبوب برای بسیاری از توسعهدهندگان است. چه در حال ساخت یک اسکریپت کوچک باشید و چه یک برنامه بزرگ، Requests میتواند به شما در تعامل با سرویسهای وب به راحتی کمک کند.
برای دسترسی به کد نوتبوک این بلاگ اینجا کلیک کنید.

پرسشهای متداول
پکیج Requests چه ویژگیهای کلیدی دارد که آن را از سایر کتابخانههای HTTP متمایز میکند؟
پکیج Requests به دلیل ویژگیهایی مانند سادگی استفاده، مدیریت خودکار اتصالات و جلسات، پشتیبانی از فشردهسازی خودکار و مستندات گسترده مشهور است. این ویژگیها باعث میشود تا توسعهدهندگان پایتون با استفاده از این پکیج به راحتی و با کارایی بالا درخواستهای HTTP خود را مدیریت کنند.
چه تفاوتی بین درخواستهای GET و POST در پکیج Requests وجود دارد؟
درخواستهای GET برای بازیابی دادهها از سرور و درخواستهای POST برای ارسال دادهها به سرور استفاده میشوند. درخواستهای POST معمولاً برای ارسال دادههای فرم یا بارگذاری فایلها استفاده میشوند، در حالی که درخواستهای GET بیشتر برای دسترسی به منابع و دریافت اطلاعات به کار میروند.
چگونه میتوان کوکیها را در پکیج Requests مدیریت کرد؟
با استفاده از شی Session از این پکیج، میتوان کوکیها را بین درخواستها نگه داری کرد. این کار به ما امکان میدهد تا به صورت مداوم اطلاعات جلسه را حفظ کنیم و از ارسال مجدد کوکیها در هر درخواست جلوگیری کنیم.
چگونه میتوان دادههای JSON را با استفاده از پکیج Requests تجزیه کرد؟
پس از دریافت پاسخ از سرور، میتوان با استفاده از متد ()json دادههای JSON را تجزیه کرد. این متد دادهها را به فرمت قابل استفاده در پایتون تبدیل میکند و به ما این امکان را میدهد تا به راحتی به مقادیر و ساختار دادهها دسترسی پیدا کنیم.
چگونه میتوان خطاهای رایج در پکیج Requests را مدیریت کرد؟
برای مدیریت خطاها میتوان از استثناهای تعریفشده در پکیج Requests مانند HTTPError، ConnectionError و Timeout استفاده کنیم. این استثناها به ما امکان میدهند تا خطاهای مختلف را شناسایی و به صورت مناسب با آنها برخورد کنیم.
یادگیری ماشین لرنینگ را از امروز شروع کنید!
دنیای دادهها جذاب است و دانستن علم داده، توانایی تحلیل داده، یا بازاریابی مبتنی بر داده، شما را برای فرصتهای شغلی بسیاری مناسب میکند. فارغ از رشته و پیشزمینه، میتوانید حالا شروع کنید و از سطح مقدماتی تا پیشرفته بیاموزید. اگر دوست دارید به این حوزه وارد شوید، پیشنهاد میکنیم با کلیک روی این لینک قدم اول را همین حالا بردارید.
مشاوران کافهتدریس به شما کمک میکنند مسیر یادگیری برای ورود به این حوزه را شروع کنید: