
کتابخانه PyTorch به عنوان یکی از ابزارهای پیشرو در حوزه یادگیری عمیق، به دلیل طراحی کاربرپسند و قدرت بالای خود، توجه بسیاری از توسعهدهندگان را به خود جلب کرده است. PyTorch که توسط تیم تحقیقاتی هوش مصنوعی فیسبوک توصعه یافته، به دلیل انعطافپذیری و سادگی در پیادهسازی مدلهای پیچیده، انتخابی ایدهآل برای افرادی است که به دنبال آزمایش و بهینهسازی مدلهای یادگیری عمیق هستند. این کتابخانه، با ارائه امکاناتی همچون گرافهای محاسباتی پویا و پشتیبانی قوی از پردازندههای گرافیکی (GPU)، فرآیند توسعه و آموزش مدلها را بهطور قابل توجهی تسهیل میکند. با ما همراه باشید تا با این کتابخانه کاربردی آشنا شوید.
- 1. یادگیری عمیق چیست؟
- 2. تاریخچه PyTorch
- 3. PyTorch و برنامهنویسی پویای محاسباتی
- 4. چرا کتابخانه PyTorch محبوب شده است؟
- 5. آموزش نحوه استفاده از PyTorch
- 6. جدول دستورات مهم در PyTorch
- 7. جمعبندی درباره کتابخانه PyTorch
-
8.
سوالات متداول
- 8.1. چگونه میتوان با استفاده از PyTorch مدلهای پیچیده یادگیری عمیق را پیادهسازی کرد؟
- 8.2. چه تفاوتی بین PyTorch و سایر کتابخانههای یادگیری عمیق مانند TensorFlow وجود دارد؟
- 8.3. چگونه میتوان از کتابخانه PyTorch برای پردازش تصویر و ترجمه ماشینی استفاده کرد؟
- 8.4. چگونه میتوان با استفاده از کتابخانه PyTorch مدلهای یادگیری عمیق را بر روی GPU آموزش داد؟
- 8.5. چگونه میتوان از قابلیت Autograd در PyTorch برای محاسبه خودکار گرادیانها استفاده کرد؟
- 9. یادگیری ماشین لرنینگ را از امروز شروع کنید!
یادگیری عمیق چیست؟
یادگیری عمیق شاخهای از یادگیری ماشین (Machine Learning) است که به مدلسازی از طریق شبکههای عصبی مصنوعی (Artificial Neural Networks) با تعداد زیادی لایه میپردازد. هدف اصلی یادگیری عمیق، استخراج ویژگیها و یادگیری الگوهای پیچیده از دادهها است. این تکنیکها در کاربردهای متنوعی مانند تشخیص تصویر، ترجمهی ماشینی، تشخیص گفتار و بسیاری دیگر مورد استفاده قرار میگیرند.
پیشنهاد میکنیم برای آشنایی بیشتر با این حوزه، مقاله یادگیری عمیق چیست؟ را مطالعه نمایید.
تاریخچه PyTorch
PyTorch یک فریمورک متنباز یادگیری عمیق است که توسط تیم تحقیقاتی هوش مصنوعی فیسبوک (FAIR) توسعه یافته است. این فریمورک در سال ۲۰۱۶ معرفی شد و به سرعت توانست جایگاه ویژهای در جامعه یادگیری عمیق پیدا کند. در این بخش، به بررسی تاریخچه PyTorch و نقاط عطف مهم آن خواهیم پرداخت.
پیشینه Torch
پیش از معرفی کتابخانه PyTorch، فیسبوک از یک فریمورک به نام Torch استفاده میکرد. Torch یک فریمورک یادگیری عمیق بود که به زبان Lua نوشته شده بود و توسط محققان و توسعهدهندگان در پروژههای مختلف استفاده میشد. با وجود قدرت و انعطافپذیری Torch، استفاده از آن برای بسیاری از کاربران دشوار بود زیرا Lua زبان برنامهنویسی محبوبی نبود.
آغاز توسعه PyTorch
در اوایل سال ۲۰۱۶، تیم FAIR تصمیم گرفت یک فریمورک جدید را بر اساس تجربهها و درسهای آموخته شده از Torch توسعه دهد. هدف اصلی این تیم ایجاد یک ابزار قدرتمند، انعطافپذیر و آسان برای استفاده بود که بتواند به راحتی توسط محققان مورد استفاده قرار گیرد. از آنجایی که زبان پایتون بین این توسعهدهندگان محبوبیت زیادی داشت، تصمیم گرفته شد که فریمورک جدید به زبان پایتون نوشته شود.
معرفی PyTorch
PyTorch در اکتبر ۲۰۱۶ به صورت رسمی معرفی شد. این فریمورک با استقبال گستردهای از سوی جامعه یادگیری عمیق مواجه شد. از ویژگیهای برجسته PyTorch میتوان به رابط کاربری ساده و پایتونی، سیستم مشتقگیری خودکار (Autograd) و پشتیبانی از پردازش موازی با استفاده از GPU اشاره کرد. PyTorch به محققان این امکان را میداد که به سرعت مدلهای پیچیده خود را پیادهسازی و آزمایش کنند.
ترکیب با Caffe2
در ماه می ۲۰۱۸، فیسبوک اعلام کرد که PyTorch و Caffe2 را ترکیب کرده و یک فریمورک یکپارچه به نام PyTorch 1.0 را ایجاد خواهد کرد. این ترکیب باعث شد تا کاربران بتوانند از مزایای هر دو فریمورک در یک ابزار واحد بهرهمند شوند. PyTorch 1.0 شامل قابلیتهایی مانند کارایی بالاتر، سازگاری بهتر با سایر ابزارها و پشتیبانی از استقرار مدلها در محیطهای تولیدی بود.
نسخههای مهم کتابخانه PyTorch
از زمان معرفی اولیه، PyTorch نسخههای مختلفی را منتشر کرده است که هر کدام شامل بهبودها و ویژگیهای جدیدی بودهاند. برخی از نسخههای مهم PyTorch عبارتند از:
- PyTorch 0.1 (اکتبر ۲۰۱۶): نسخه اولیه PyTorch که با استقبال گستردهای مواجه شد و به سرعت به یکی از ابزارهای محبوب در جامعه یادگیری عمیق تبدیل شد.
- PyTorch 1.0 (دسامبر ۲۰۱۸): این نسخه شامل بهبودهای عملکردی، اضافه شدن ویژگیهای جدید و سازگاری بهتر با دیگر ابزارها و فریمورکها بود. نسخه 1.0 همچنین شامل PyTorch Hub بود که به کاربران این امکان را میداد که مدلهای از پیش آموزشدیده را به راحتی بارگذاری و استفاده کنند.
- PyTorch 1.2 (آگوست ۲۰۱۹): در این نسخه، بهبودهای بیشتری در زمینه عملکرد و کارایی صورت گرفت و ویژگیهای جدیدی مانند پشتیبانی بهتر از TensorBoard و بهبودهای در Autograd معرفی شد.
- PyTorch 1.5 (آوریل ۲۰۲۰): این نسخه شامل بهبودهای بیشتری در زمینه ارزیابی مدلها، پشتیبانی از ONNX (Open Neural Network Exchange) و بهبودهای در زمینه بهینهسازی مدلها بود.
- PyTorch 1.7 (اکتبر ۲۰۲۰): در این نسخه، بهبودهای متعددی در زمینه عملکرد و کارایی صورت گرفت و ویژگیهای جدیدی مانند PyTorch Mobile معرفی شد که امکان استفاده از PyTorch در دستگاههای موبایل را فراهم میکرد.
همکاری با سایر سازمانها
توسعه کتابخانه PyTorch تنها به تیم FAIR محدود نمیشود. بسیاری از شرکتها و سازمانهای بزرگ مانند NVIDIA، Microsoft، Google و Amazon نیز به توسعه و بهبود PyTorch کمک کردهاند. این همکاریها باعث شده است تا این فریمورک به یکی از جامعترین و قویترین فریمورکهای یادگیری عمیق تبدیل شود.
پذیرش در جامعه دانشگاهی و صنعتی
کتابخانه PyTorch به سرعت توسط جامعه آکادمیک دانشگاه و صنعت پذیرفته شد. امروزه محققان و دانشمندان داده از PyTorch برای انجام تحقیقات و توسعه مدلهای پیشرفته استفاده میکنند. همچنین بسیاری از شرکتهای فناوری بزرگ از این فریمورک برای توسعه و استقرار مدلهای یادگیری عمیق در محصولات و خدمات خود بهره میبرند. کتابخانه PyTorch به دلیل سهولت استفاده، انعطافپذیری بالا و پشتیبانی قوی از GPUها به یکی از ابزارهای اصلی در حوزه یادگیری عمیق تبدیل شده است.
PyTorch از زمان معرفی تاکنون به یکی از محبوبترین و قدرتمندترین فریمورکهای یادگیری عمیق تبدیل شده است. با توجه به تاریخچه توسعه، نسخههای مختلف و همکاریهای گسترده با سایر سازمانها، کتابخانه PyTorch توانسته است جایگاه ویژهای در جامعه تحقیقاتی و صنعتی پیدا کند. این فریمورک با ارائه ابزارهای قدرتمند و انعطافپذیر به محققان و توسعهدهندگان این امکان را میدهد تا به سرعت مدلهای پیچیده خود را پیادهسازی و بهینهسازی کنند و به نتایج بهتری دست یابند.
PyTorch و برنامهنویسی پویای محاسباتی
یکی از ویژگیهای برجسته کتابخانه PyTorch که آن را از سایر کتابخانههای یادگیری عمیق متمایز میکند، استفاده از برنامهنویسی پویای محاسباتی یا گرافهای محاسباتی پویا (Dynamic Computational Graph) است. در ادامه، به تفصیل توضیح میدهیم که این ویژگی چیست و چگونه توسعه و پیادهسازی مدلهای یادگیری عمیق را آسانتر میکند.
گراف محاسباتی چیست؟
گراف محاسباتی (Computational Graph) نمایشی است که فرآیند محاسباتی یک مدل یادگیری عمیق را به صورت یک گراف از گرهها و لبهها نشان میدهد. در این گراف، هر گره نشاندهنده یک عملیات ریاضی است و هر لبه ورودیها و خروجیهای این عملیاتها را نشان میدهد. برای درک بهتر نحوه ساخت گراف محاسباتی، باید به بررسی اجزای تشکیلدهنده این گراف بپردازیم:
- گرهها (Nodes): هر گره در گراف محاسباتی نماینده یک عملیات ریاضی است. این عملیاتها میتوانند شامل جمع، ضرب، اعمال توابع فعالسازی (Activation Functions) و دیگر عملیاتهای ریاضی باشند.
- لبهها (Edges): هر لبه نشاندهنده ورودی و خروجیهای عملیاتهاست. به عبارتی، لبهها دادهها را بین گرهها انتقال میدهند.
- تنسورها (Tensors): تنسورها واحدهای دادهای هستند که در گراف محاسباتی جریان مییابند. این تنسورها میتوانند مقادیر عددی یا ماتریسهای چندبعدی باشند که در طول اجرای مدل بهروزرسانی میشوند.
گراف محاسباتی پویا در PyTorch
PyTorch از گرافهای پویا برای ساخت و مدیریت عملیاتهای محاسباتی استفاده میکند. این گرافها به صورت دینامیک در زمان اجرا ساخته میشوند و به کاربران اجازه میدهند تا بهراحتی مدلهای پیچیده را پیادهسازی کنند. این انعطافپذیری مزایای متعددی دارد:
توسعه و آزمایش سریعتر
شما میتوانید به سرعت تغییرات مختلفی در مدل خود اعمال کنید و نتایج آنها را به سرعت مشاهده کنید. این ویژگی برای تحقیقات و آزمایش مدلهای جدید بسیار حیاتی است، زیرا نیاز به تعریف مجدد گراف و اجرای کامل مدل را از بین میبرد.
سهولت در دیباگ کردن
با استفاده از گرافهای پویا، میتوان هر مرحله از عملیات را به دقت بررسی کرد و خطاها را به راحتی پیدا و برطرف کرد. این کار مشابه برنامهنویسی معمولی در پایتون است و به همین دلیل برای توسعهدهندگان پایتون بسیار ساده و آشنا است.
انعطافپذیری بالا در تعریف مدلهای پیچیده
برای مدلهای پیچیدهتر که ممکن است شامل حلقهها، شرطها و ساختارهای پیچیده باشند، گرافهای پویا امکان تعریف و تغییر ساختار مدل را به راحتی فراهم میکنند. این ویژگی برای مدلهایی که ساختار آنها ممکن است بر اساس دادههای ورودی تغییر کند، بسیار مهم است.
استفاده بهینه از حافظه
در گرافهای پویا، محاسبات فقط در صورت نیاز انجام میشوند و حافظه به طور کارآمدتری مدیریت میشود، زیرا فقط دادهها و عملیاتهای مورد نیاز در حافظه نگهداری میشوند.
نحوه ساخت گرافهای محاسباتی PyTorch
همانطور که گفتیم، در کتابخانه PyTorch گرافهای محاسباتی به صورت پویا و در زمان اجرا ساخته میشوند. این به این معناست که هر زمان که یک عملیات ریاضی روی تنسورهایی که مشخصه requires_grad=True دارند انجام میشود، PyTorch به طور خودکار یک گره جدید در گراف محاسباتی ایجاد میکند. این گرهها شامل اطلاعات مربوط به نوع عملیات (مانند جمع، ضرب و غیره)، ورودیها و خروجیهای عملیات هستند. با انجام هر عملیات، گراف محاسباتی به تدریج ساخته میشود و شامل تمام گرهها و لبههایی است که نمایانگر روابط و دادههای جریان یافته بین عملیاتهای مختلف میباشند. هنگامی که تابع backward فراخوانی میشود، کتابخانه PyTorch از این گراف برای محاسبه گرادیانها استفاده میکند. این سیستم پویا به کاربران اجازه میدهد تا مدلهای پیچیده را به سادگی و انعطافپذیری بالا پیادهسازی و بهینهسازی کنند.
چرا کتابخانه PyTorch محبوب شده است؟
چند دلیل اصلی برای محبوبیت PyTorch در بین توسعهدهندگان هوش مصنوعی عبارت است از:
انعطافپذیری و سادگی
PyTorch به دلیل استفاده از گرافهای محاسباتی پویا و شباهت به برنامهنویسی پایتون، به توسعهدهندگان این امکان را میدهد که بهراحتی مدلهای خود را تغییر داده و بهینهسازی کنند. این ویژگی به خصوص برای تحقیقات و آزمایشهای سریع بسیار مفید است، زیرا توسعهدهندگان میتوانند مدلهای جدید را به سرعت پیادهسازی و آزمایش کنند بدون اینکه نیاز به تغییرات اساسی در کد داشته باشند. ساختار برنامهنویسی کتابخانه PyTorch به توسعهدهندگان اجازه میدهد که با استفاده از کدهای ساده و قابل فهم، مدلهای پیچیدهای را ایجاد و مدیریت کنند.
کارایی بالا
این کتابخانه برای محاسبات ماتریسی و برداری بهینه شده است و از پردازندههای گرافیکی (GPU) برای افزایش سرعت محاسبات استفاده میکند. کتابخانه PyTorch از تکنولوژی CUDA برای بهرهگیری از قدرت پردازشی بالای GPUها استفاده میکند که باعث میشود فرآیند آموزش مدلهای بزرگ و پیچیده با سرعت بسیار بیشتری انجام شود. این ویژگی به خصوص برای آموزش مدلهای یادگیری عمیق که نیاز به محاسبات سنگین دارند بسیار حیاتی است.
ادغام آسان با سایر کتابخانهها
این کتابخانه به راحتی با سایر کتابخانهها و ابزارهای پایتون ادغام میشود و امکانات گستردهای برای توسعهدهندگان فراهم میکند. PyTorch با کتابخانههایی مانندNumPy ، SciPy و matplotlib به خوبی سازگار است و این سازگاری باعث میشود که توسعهدهندگان بتوانند به راحتی از ابزارها و تکنیکهای موجود در این کتابخانهها در کنار PyTorch استفاده کنند. همچنین، PyTorch با کتابخانههای تخصصی مانند TorchVision برای پردازش تصاویر و TorchText برای پردازش متون نیز ادغام شده است که امکانات بیشتری برای توسعهدهندگان فراهم میکند.
منبع باز بودن
PyTorch به صورت منبع باز (Open Source) در دسترس است، که امکان استفاده، تغییر و بهبود آن توسط همهی کاربران را فراهم میکند. این ویژگی باعث میشود که جامعه بزرگی از توسعهدهندگان و محققان بتوانند به بهبود و ارتقای کتابخانه PyTorch کمک کنند. علاوه بر این، منابع آموزشی و مستندات جامعی که توسط جامعه کاربری PyTorch تهیه شده است، به توسعهدهندگان کمک میکند تا به سرعت با این ابزار قدرتمند آشنا شوند و از آن در پروژههای خود استفاده کنند.
جامعه فعال و پشتیبانی قوی
PyTorch دارای یک جامعه فعال و پویا از توسعهدهندگان است که به طور مداوم به توسعه و بهبود این فریمورک کمک میکنند. این جامعه بزرگ باعث میشود که توسعهدهندگان بتوانند از تجربیات و دانش دیگران بهرهمند شوند و مشکلات خود را سریعتر حل کنند. علاوه بر این، تیم توسعهدهنده PyTorch در فیسبوک نیز به طور مداوم به بهبود و ارتقای این فریمورک میپردازد و به سوالات و مشکلات کاربران پاسخ میدهد.
پشتیبانی از آموزش و استنتاج
PyTorch نه تنها برای آموزش مدلهای یادگیری عمیق، بلکه برای استنتاج نیز بسیار مناسب است. این فریمورک ابزارهایی را فراهم میکند که توسعهدهندگان بتوانند مدلهای خود را پس از آموزش به راحتی در محیطهای تولیدی استفاده کنند. این ویژگی باعث میشود که کتابخانه PyTorch برای توسعهدهندگان صنعتی نیز جذاب باشد، زیرا میتوانند مدلهای خود را با همان ابزارهایی که برای آموزش استفاده کردهاند، در محیطهای تولیدی نیز به کار بگیرند.
آموزش نحوه استفاده از PyTorch
برای شروع کار با PyTorch، اولین قدم نصب آن است. مراحل نصب این پکیج، بسیار ساده است و شما میتوانید با استفاده از pip یا conda این کتابخانه را نصب کنید. ابتدا باید اطمینان حاصل کنید که Python و pip بر روی سیستم شما نصب شدهاند. سپس با اجرای دستور pip install torch یا conda install pytorch میتوانید پایتورچ را نصب کنید:
pip install torch
سپس همه کتابخانههای لازم را فراخوانی میکنیم:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader, Dataset
import matplotlib.pyplot as plt
مفاهیم پایهای PyTorch
یکی از مفاهیم اصلی در PyTorch، Tensor است. Tensorها شبیه به آرایهها یا ماتریسهای چندبعدی هستند که برای ذخیره دادهها استفاده میشوند. اما چرا Tensorها اینقدر مهم هستند؟ به دلیل اینکه تمامی عملیاتهای محاسباتی در PyTorch بر روی Tensorها انجام میشود. برای ساخت تنسور در پایتورچ از کد زیر استفاده میکنیم:
# Create a 1D tensor
x = torch.tensor([1, 2, 3])
print(f'Tensor: {x}')
print(f'Tensor shape: {x.shape}')
Tensor: tensor([1, 2, 3])
Tensor shape: torch.Size([3])
برای ساخت یک تنسور تمام صفر از کد زیر استفاده میکنیم:
# Create a 2D tensor of zeros
zeros_tensor = torch.zeros((2, 3))
print('Zeros Tensor:')
print(zeros_tensor)
Zeros Tensor:
tensor([[0., 0., 0.],
[0., 0., 0.]])
همچنین با دستور زیر میتوان یک تنسور با مقادیر تصادفی ایجاد کرد:
# Create a random tensor
x = torch.rand(size=(3, 4))
print(f'Random Tensor:\n{x}')
Random Tensor:
tensor([[0.4312, 0.4909, 0.3876, 0.3121],
[0.0252, 0.6488, 0.4683, 0.2340],
[0.0421, 0.1277, 0.7409, 0.0853]])
در PyTorch میتوانید تنسورها را با ابعاد مختلف ایجاد کنید:
# Create a 2D tensor
x = torch.tensor([[1, 2, 3], [4, 5, 6]])
print(f'Tensor:\n{x}')
Tensor:
tensor([[1, 2, 3],
[4, 5, 6]])
همچنین میتوانید تنسورها را تغییر شکل دهید و عملیاتهای ریاضی مختلفی روی آنها انجام دهید:
# Reshape the tensor
x_reshaped = x.view(3, 2)
print(f'Reshaped Tensor:\n{x_reshaped}')
Reshaped Tensor:
tensor([[1, 2],
[3, 4],
[5, 6]])
# Summation operation
y = torch.tensor([[1, 1, 1], [1, 1, 1]])
z = x + y
print(f'Sum of two tensors:\n {z}')
Sum of two tensors:
tensor([[2, 3, 4],
[5, 6, 7]])
Autograd در PyTorch
Autograd یکی از قابلیتهای مهم کتابخانه PyTorch است که امکان محاسبه خودکار گرادیانها را فراهم میکند. این ویژگی به ویژه در فرآیند آموزش مدلهای یادگیری عمیق بسیار مفید است. Autograd با دنبال کردن تمامی عملیاتهایی که بر رویTensorها انجام میشود، میتواند به صورت خودکار گرادیانها را محاسبه کند:
# Create a computational graph to calculate gradients in BackPropagation
x = torch.tensor([1.0, 2.0, 6.0], requires_grad=True)
# Mathematical calculus
y = x * 2
z = y.mean()
# Calculate Gradient
z.backward()
print(x.grad)
tensor([0.6667, 0.6667, 0.6667])
ساختارهای داده در PyTorch
در PyTorch، کلاسهای Dataset و DataLoader ابزارهای بسیار مهمی برای مدیریت و پردازش دادهها برای قراردادن آنها در اختیار مدل هستند. Dataset یک کلاس پایه در PyTorch است که برای نگهداری و مدیریت مجموعه دادهها استفاده میشود. این کلاس به شما اجازه میدهد که دادههای خود را در یک قالب قابل دسترس و سازماندهی شده ذخیره کنید. برای استفاده از Dataset، باید یک کلاس سفارشی ایجاد کنید که از torch.utils.data.Dataset ارثبری و سه متد اصلی زیر را پیادهسازی کند:
- __init__: این یک متد سازنده در کلاس Dataset است که برای مقداردهی اولیه به دادهها و تنظیمات مورد نیاز استفاده میشود. این متد به شما اجازه میدهد تا دادهها را به صورت دلخواه در کلاس Dataset ذخیره و آماده کنید.
- __len__: این متد باید تعداد نمونههای موجود در مجموعه داده را برگرداند.
- __getitem__: این متد باید یک نمونه داده و برچسب مربوط به آن را بر اساس اندیسی که به آن داده میشود، برگرداند.
# Dataset and Dataloader
class MyDataset(Dataset):
def __init__(self, X, y):
self.X = X
self.y = y
self.len = self.X.shape[0]
def __getitem__(self, index):
return self.X[index], self.y[index]
def __len__(self):
return self.len
DataLoader نیز یک کلاس پایه دیگر در PyTorch است که برای بارگذاری دادهها به مدلها در دستههای کوچکتر استفاده میشود. DataLoader با استفاده از یک Dataset، دادهها را به صورت دستههای (batch) کوچکتر تقسیم میکند و به مدل میفرستد. این فرایند باعث میشود که بتوانیم به طور موثری با دادههای بزرگ کار کنیم و مدلها را راحتتر آموزش دهیم.
برای انجام ادامه کار یک مجموعه داده مصنوعی با نقاط رندوم تولید میکنیم. برچسبها را روی همان نقاط و بهصورت تابع y=x3+ 2 تولید میکنیم و بهاین ترتیب در ادامه با حل یک مسئله رگرسیون مواجه خواهیم بود:
# Make train data
X_train = torch.rand(size=(50, 1))
y_train = X_train**3 + 2
# Make validation data
X_val = torch.rand(size=(20, 1))
y_val = X_val**3 + 2
درادامه با استفاده از کد زیر یک کلاس سفارشی به نام MyDataset تعریف میکنیم که از کلاس پایه torch.utils.data.Dataset ارثبری کرده و دادهها و برچسبها (Labels) را مدیریت میکند. سپس برای هر دو مجموعه داده تصادفیای که بهعنوان دادههای آموزش (X_train و y_train) و ارزیابی (X_val و y_val) ایجاد کردیم، یک DataLoader ایجاد میکنیم که دادهها را به صورت دستههای کوچکتر (batch) و به صورت تصادفی (با shuffle) بارگذاری میکند، به طوری که دادههای آموزشی و ارزیابی برای مدل به طور موثر مدیریت و استفاده شوند:
# Make train loader
trainset = MyDataset(X_train, y_train)
train_loader = DataLoader(trainset, batch_size=4, shuffle=True)
# Make test loader
valset = MyDataset(X_val, y_val)
val_loader = DataLoader(valset, batch_size=4, shuffle=True)
ساخت یک مدل شبکه عصبی در PyTorch
برای استفاده از مدلهای شبکه عصبی در PyTorch نیز باید یک کلاس سفارشی ایجاد کنید که از nn.Module ارثبری و دو متد اصلی زیر را پیادهسازی کند:
- __init__: این یک متد سازنده است و برای تعریف و مقداردهی اولیه لایههای شبکه عصبی استفاده میشود. در اینجا، شما لایههای مختلف مانند لایههای خطی (fully connected) و توابع فعالسازی را تعریف میکنید.
- forward: این متد نحوه عبور دادهها از طریق لایههای شبکه عصبی را مشخص میکند. در اینجا، شما مراحل پردازش دادهها را از طریق لایهها، توابع فعالسازی و دیگر عملیات تعیین میکنید.
در کد زیر یک مدل شبکه عصبی چندلایه (MLP) ساده را برای پیشبینی تابع y = X3 + 2 تعریف میکنیم. کلاس SimpleModel از nn.Module ارثبری میکند و شامل دو لایه کاملا متصل (fully connected) و یک تابع فعالسازی ReLU است. در متد سازنده __init__، با استفاده از لایه اول (fc1) دادهها را از اندازه ورودی به ۱۵ نورون نگاشت میکنیم و با لایه دوم (fc2) دادهها را از ۱۵ نورون به اندازه خروجی نگاشت میکنیم. در متد forward، ابتدا دادهها را از لایه اول عبور میدهیم، سپس تابع فعالساز ReLU را روی آنها اعمال میکنیم. در نهایت دادهها را از لایه دوم عبور میدهیم تا خروجی نهایی تولید شود و یک نمونه (Instance) از مدل ایجاد میکنیم و آن را در متغیر model میریزیم:
# MLP for predicting y= x^3 + 2 line
class SimpleModel(nn.Module):
def __init__(self, input_size, output_size):
super(SimpleModel, self).__init__()
self.fc1 = nn.Linear(input_size, 15)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(15, output_size)
def forward(self, x):
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
return x
نحوه آموزش و ارزیابی مدل در PyTorch
برای اجرای مرحله آموزش در پایتورچ، مدل در حالت آموزش قرار میگیرد. برای هر دسته، ابتدا گرادیانها صفر شده، خروجیهای مدل محاسبه و خطا بین خروجی و مقدار واقعی اندازهگیری میشود. سپس گرادیانها به عقب منتشر شده (Backpropagate) و پارامترهای مدل بهروزرسانی میشوند. مقدار خطای آموزشی برای هر epoch محاسبه و ذخیره میشود. در فاز ارزیابی، مدل در حالت ارزیابی قرار میگیرد و بدون محاسبه گرادیان، خطای مدل بر روی دادههای ارزیابی محاسبه و ذخیره میشود. خطاهای آموزشی و ارزیابی برای هر epoch ذخیره شده و به صورت دورهای نتایج چاپ میشوند. با این روش امکان بررسی و پیگیری عملکرد مدل در طول زمان فراهم میشود.
برای انجام کارهای بالا ابتدا با تعیین ابعاد متناظر با مجموعهدادهمان، مدل ساختهشده را تعریف میکنیم و آن را در متغیر model میریزیم:
input_size, output_size = X_train.shape[1], y_train.shape[1]
model = SimpleModel(input_size, output_size)
آموزش مدل
میتوان از کدی که در ادامه آمده، برای فرآیند آموزش یک مدل یادگیری عمیق در پایتورچ استفاده کرد. برای این کار ابتدا تابع هزینه (Loss Function) میانگین مربعات خطا (MSE) و بهینهساز (Optimizer) گرادیان نزولی تصادفی (SGD) را با نرخ یادگیری ۰.۰۱ و تکانه ۰.۹ تعریف میکنیم:
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
برای آشنایی با انواع بهینهساز به این مقاله مراجعه نمایید: عملکرد بهینه سازها در یادگیری عمیق چگونه است و کدامیک برای مدل شما بهتر است؟
برای آشنایی با انواع تابع هزینه مقاله تابع هزینه یا Loss Function چیست؟ را مطالعه کنید.
سپس دو لیست برای ذخیره مقدار خطاهای آموزشی و ارزیابی ایجاد میکنیم:
# Lists to store loss values
train_losses = []
val_losses = []
طی ۲۵ epoch، در مرحله آموزش، با استفاده از model.train مدل را در حالت آموزش قرار میدهیم و برای هر دسته از دادههای آموزشی، بهکمک optimizer.zero_grad ابتدا گرادیانها را صفر کرده، پیشبینی مدل را در outputs قرار داده و با استفاده از تابع هزینه گفتهشده، خطای بین مقدار پیشبینیشده و مقدار واقعی را محاسبه میکنیم. سپس عملیات پسانتشار را با استفاده از loss.backward انجام داده و با optimizer.step پارامترهای مدل را بهروزرسانی میکنیم. خطای کل آموزشی برای هر epoch محاسبه و ذخیره میشود:
for epoch in range(25):
model.train() # Train mode
# Initialize training loss for the epoch
epoch_train_loss = 0
# Loop over each batch in the training loader
for X_train, y_train in train_loader:
# Clear previous gradients
optimizer.zero_grad()
# Forward pass
outputs = model(X_train)
# Compute loss
loss = criterion(outputs, y_train)
# Backward pass
loss.backward()
# Update model parameters
optimizer.step()
epoch_train_loss += loss.item()
# Average training loss for the epoch
epoch_train_loss /= len(train_loader)
train_losses.append(epoch_train_loss)
ارزیابی مدل
در مرحله ارزیابی نیز، با دستور model.eval مدل را در حالت ارزیابی قرار داده و بدون محاسبه گرادیان، میزان خطای آن را بر روی دادههای ارزیابی محاسبه و ذخیره میکنیم. همچنین برای بررسی و پیگیری عملکرد مدل، بعد از هر پنج epoch، مقدار خطاهای آموزشی و ارزیابی را چاپ میکنیم:
model.eval() # Validation mode
# Initialize validation loss for the epoch
epoch_val_loss = 0
# Disable gradient calculation
with torch.no_grad():
for X_val, y_val in val_loader:
# Forward pass
val_outputs = model(X_val)
loss = criterion(val_outputs, y_val)
epoch_val_loss += loss.item()
# Average validation loss for the epoch
epoch_val_loss /= len(val_loader)
val_losses.append(epoch_val_loss)
# Print losses every 5 epochs
if (epoch+1) % 5 == 0:
print(f'Epoch [{epoch+1}/25], Training Loss: {epoch_train_loss:.4f}, Validation Loss: {epoch_val_loss:.4f}')
Epoch [5/25], Training Loss: 0.0131, Validation Loss: 0.0133
Epoch [10/25], Training Loss: 0.0116, Validation Loss: 0.0123
Epoch [15/25], Training Loss: 0.0100, Validation Loss: 0.0114
Epoch [20/25], Training Loss: 0.0103, Validation Loss: 0.0105
Epoch [25/25], Training Loss: 0.0098, Validation Loss: 0.0098
رسم نمودار مقدار خطا در مقابل تعداد Epochها
با استفاده از قطعه کد زیر میتوان بهراحتی این نمودار را رسم کرد و مطمئن شد که مدل دچار بیشبرازش یا کمبرازش نشده است:
plt.figure(figsize=(8, 5))
plt.plot(range(1, 26), train_losses, label='Training Loss')
plt.plot(range(1, 26), val_losses, label='Validation Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.show()
نمودار مربوط به مدل ما بهشکل زیر درآمده است:
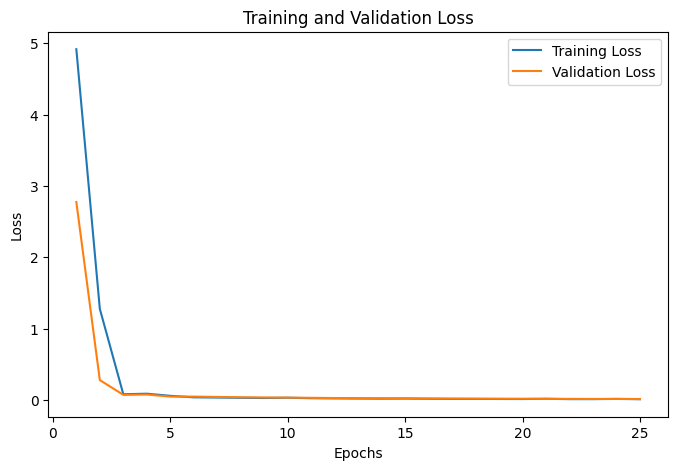
این نمودار نشان میدهد که مدل در ابتدا خطای بالایی دارد، اما با افزایش تکرارها (Epochs)، هر دو منحنی خطای آموزش (آبی) و ارزیابی (نارنجی) به سرعت کاهش مییابند. پس از چند تکرار، خطاها به سطح ثابتی میرسند که نشاندهنده یادگیری مؤثر مدل و عدم بیشبرازش (Overfitting) است.
مجموعه کامل کدهای بالا را میتوانید در این ریپازیتوری از گیتهاب مشاهده نمایید.
حال که با مقدمات کتابخانه PyTorch آشنا شدید، وقت آن است که پروژههای جذابتری را با این کتابخانه پیادهسازی کنید. برای این منظور ما برای شما مجموعه مقالات زیر را نیز فراهم کردهایم:
جدول دستورات مهم در PyTorch
برای کار با PyTorch، دستورات و توابع متعددی وجود دارند که هر یک برای انجام عملیات خاصی به کار میروند. در این جدول، به بررسی ۳۰ دستور مهم و پرکاربرد در کتابخانه PyTorch میپردازیم که توسعهدهندگان میتوانند از آنها برای ایجاد و مدیریت مدلهای یادگیری عمیق خود استفاده کنند. این دستورات شامل ایجاد و عملیات روی تنسورها، تعریف مدلهای شبکه عصبی، بهینهسازی مدلها و مدیریت دادهها میشوند. با آشنایی و استفاده از این دستورات، میتوانید به طور موثری با PyTorch کار کنید و مدلهای یادگیری عمیق خود را بهینهسازی کنید:
| ردیف | دستور | توضیحات |
| ۱ | torch.tensor | ایجاد یک تنسور از دادههای موجود |
| ۲ | torch.zeros | ایجاد یک تنسور با تمام مقادیر صفر |
| ۳ | torch.ones | ایجاد یک تنسور با تمام مقادیر یک |
| ۴ | torch.randn | ایجاد یک تنسور با مقادیر تصادفی از توزیع نرمال |
| ۵ | torch.full | ایجاد یک تنسور با یک مقدار ثابت |
| ۶ | torch.cat | الحاق (ترکیب) دو یا چند تنسور در امتداد یک محور مشخص |
| ۷ | torch.stack | پشته کردن تنسورها در امتداد یک بعد جدید |
| ۸ | torch.reshape | تغییر شکل تنسور بدون تغییر دادهها |
| ۹ | torch.view | تغییر شکل تنسور با تغییر نمای آن |
| ۱۰ | torch.transpose | جابجایی ابعاد تنسور |
| ۱۱ | torch.matmul | ضرب ماتریسی دو تنسور |
| ۱۲ | torch.mm | ضرب ماتریسی ساده دو تنسور دو بعدی |
| ۱۳ | torch.bmm | ضرب ماتریسی دستهای از تنسورهای سهبعدی |
| ۱۴ | torch.add | جمع دو تنسور |
| ۱۵ | torch.sub | تفریق دو تنسور |
| ۱۶ | torch.mul | ضرب عنصر به عنصر دو تنسور |
| ۱۷ | torch.div | تقسیم عنصر به عنصر دو تنسور |
| ۱۸ | torch.mean | محاسبه میانگین عناصر تنسور |
| ۱۹ | torch.sum | محاسبه مجموع عناصر تنسور |
| ۲۰ | torch.max | پیدا کردن مقدار بیشینه در تنسور |
| ۲۱ | torch.min | پیدا کردن مقدار کمینه در تنسور |
| ۲۲ | torch.argmax | پیدا کردن اندیس عنصر با بیشترین مقدار در یک تنسور |
| ۲۳ | torch.argmin | پیدا کردن اندیس عنصر با کمترین مقدار در یک تنسور |
| ۲۴ | torch.exp | محاسبه نمای (e^x) هر عنصر در تنسور |
| ۲۵ | torch.log | محاسبه لگاریتم طبیعی (ln) هر عنصر در تنسور |
| ۲۶ | torch.nn.Module | کلاس پایه برای تعریف مدلهای شبکه عصبی |
| ۲۷ | torch.optim.SGD | بهینهساز گرادیان نزولی تصادفی (Stochastic Gradient Descent) |
| ۲۸ | torch.nn.CrossEntropyLoss | تابع هزینه برای طبقهبندی چندکلاسی |
| ۲۹ | torch.utils.data.Dataset | کلاس پایه برای نگهداری مجموعه دادهها |
| ۳۰ | torch.utils.data.DataLoader | ابزاری برای بارگذاری دادهها به مدلها در دستههای کوچکتر |
جمعبندی درباره کتابخانه PyTorch
کتابخانه PyTorch با ارائه امکانات گسترده و انعطافپذیری بالا، به یکی از محبوبترین و پرکاربردترین ابزارها در زمینه یادگیری عمیق تبدیل شده است. یکی از ویژگیهای برجسته PyTorch استفاده از گرافهای محاسباتی پویاست که توسعه و پیادهسازی مدلهای یادگیری عمیق را بسیار سادهتر و کارآمدتر میکند. همچنین، این فریمورک با بهرهگیری از پردازندههای گرافیکی (GPU) و تکنولوژی CUDA، امکان آموزش مدلهای بزرگ و پیچیده را با سرعت بالا فراهم میسازد.
از دیگر ویژگیهای مهم PyTorch، میتوان به سادگی و شباهت زیاد آن به زبان برنامهنویسی پایتون اشاره کرد که باعث میشود توسعهدهندگان بتوانند به راحتی مدلهای خود را تغییر داده و بهینهسازی کنند. همچنین، جامعه فعال و پویا، منبع باز بودن و پشتیبانی قوی از سوی تیم توسعهدهنده و سازمانهای بزرگ دیگر، باعث شده است که PyTorch به یکی از ابزارهای اصلی در حوزه یادگیری عمیق تبدیل شود.

سوالات متداول
چگونه میتوان با استفاده از PyTorch مدلهای پیچیده یادگیری عمیق را پیادهسازی کرد؟
با استفاده از PyTorch میتوان مدلهای پیچیده یادگیری عمیق را با بهرهگیری از گرافهای محاسباتی پویا (Dynamic Computational Graphs) پیادهسازی کرد. این ویژگی به توسعهدهندگان امکان میدهد تا مدلها را در زمان اجرا به سادگی تغییر دهند و بهینهسازی کنند. برای شروع، باید با تعریف تنسورها (Tensors) و استفاده از ماژول nn.Module برای ساختاردهی مدلها آشنا شوید.
چه تفاوتی بین PyTorch و سایر کتابخانههای یادگیری عمیق مانند TensorFlow وجود دارد؟
یکی از تفاوتهای اصلی بین PyTorch و TensorFlow در نحوه ساخت و مدیریت گرافهای محاسباتی است. PyTorch از گرافهای پویا استفاده میکند که در زمان اجرا ساخته میشوند، در حالی که TensorFlow از گرافهای ثابت (Static Computational Graphs) استفاده میکند. این تفاوت باعث میشود PyTorch برای توسعه و آزمایش مدلهای جدید سریعتر و انعطافپذیرتر باشد.
چگونه میتوان از کتابخانه PyTorch برای پردازش تصویر و ترجمه ماشینی استفاده کرد؟
برای پردازش تصویر، PyTorch دارای کتابخانه تخصصی TorchVision است که شامل ابزارها و مدلهای پیشآماده برای کار با تصاویر میباشد. برای ترجمه ماشینی و پردازش متن، میتوان از کتابخانه TorchText استفاده کرد که ابزارهای مختلفی برای مدیریت و پیشپردازش دادههای متنی ارائه میدهد. این کتابخانهها به توسعهدهندگان امکان میدهند تا به سادگی مدلهای یادگیری عمیق را برای کاربردهای مختلف پیادهسازی کنند.
چگونه میتوان با استفاده از کتابخانه PyTorch مدلهای یادگیری عمیق را بر روی GPU آموزش داد؟
برای آموزش مدلهای یادگیری عمیق با استفاده از PyTorch بر روی GPU، ابتدا باید مطمئن شوید که PyTorch با پشتیبانی از CUDA نصب شده است. سپس، با استفاده از دستور to(device) که در آن device معمولاً cuda میباشد، تنسورها و مدلهای خود را به دستگاه GPU انتقال دهید.
چگونه میتوان از قابلیت Autograd در PyTorch برای محاسبه خودکار گرادیانها استفاده کرد؟
قابلیت Autograd در PyTorch امکان محاسبه خودکار گرادیانها را فراهم میکند. برای استفاده از این قابلیت، کافی است تنسورهایی با مشخصه requires_grad=True تعریف کنید. سپس با انجام عملیات ریاضی روی این تنسورها، گراف محاسباتی به طور خودکار ساخته میشود. با فراخوانی تابع backward، کتابخانه PyTorch به صورت خودکار گرادیانها را محاسبه میکند که در فرآیند آموزش مدلها برای بهروزرسانی وزنها استفاده میشود.
یادگیری ماشین لرنینگ را از امروز شروع کنید!
دنیای دادهها جذاب است و دانستن علم داده، توانایی تحلیل داده، یا بازاریابی مبتنی بر داده، شما را برای فرصتهای شغلی بسیاری مناسب میکند. فارغ از رشته و پیشزمینه، میتوانید حالا شروع کنید و از سطح مقدماتی تا پیشرفته بیاموزید. اگر دوست دارید به این حوزه وارد شوید، پیشنهاد میکنیم با کلیک روی این لینک قدم اول را همین حالا بردارید.
مشاوران کافهتدریس به شما کمک میکنند مسیر یادگیری برای ورود به این حوزه را شروع کنید: