
ترنسفورمرها (Transformers)، به عنوان یکی از پیشرفتهترین مدلهای یادگیری عمیق، نقش مهمی در تحول پردازش زبان طبیعی ایفا کردهاند. این مدلها با مکانیزم توجه خود قابلیت پردازش موازی دادهها و مدیریت وابستگیهای بلندمدت را دارند. PyTorch، به عنوان یک کتابخانه متنباز و قدرتمند، امکان پیادهسازی و استفاده از ترنسفورمرها را به سادگی فراهم کرده است. در این مقاله، به بررسی نحوه پیادهسازی مدلهای ترنسفورمر با PyTorch و کاربردهای متنوع آنها در زمینههایی مانند ترجمه ماشینی، پردازش زبان طبیعی و تشخیص گفتار میپردازیم تا خوانندگان با قابلیتها و تواناییهای این مدلها و ابزارهای مرتبط آشنا شوند.
- 1. ترنسفورمر چیست؟
- 2. PyTorch و ترنسفورمرها
- 3. ساخت یک مدل ترنسفورمر با PyTorch
-
4.
پیادهسازی یک مدل ترنسفورمر با PyTorch
- 4.1. تعریف بلوک توجه چندسر
- 4.2. تعریف بلوک پیشخور
- 4.3. تعریف بلوکهای رمزگذاری موضعی
- 4.4. ساخت بلوک رمزگذار
- 4.5. ساخت بلوک رمزگشا
- 4.6. ساخت بلوک ترنسفورمر
- 4.7. پیشپردازش و آمادهسازی دادهها
- 5. استفاده از مدلهای ترنسفورمر پیشآموزشدیده با Hugging Face
- 6. جمعبندی درباره مدلهای ترنسفورمر با PyTorch
-
7.
سوالات متداول
- 7.1. چگونه میتوان از ترنسفورمرها برای بهبود مدلهای ترجمه ماشینی استفاده کرد؟
- 7.2. مکانیزم توجه چندسر چگونه در مدلهای ترنسفورمر کار میکند؟
- 7.3. پیادهسازی ترنسفورمر با PyTorch چه مزایایی دارد؟
- 7.4. چرا مدلهای ترنسفورمر در تحلیل احساسات موثر هستند؟
- 7.5. چگونه میتوان مدلهای ترنسفورمر را برای تولید خودکار متن آموزش داد؟
- 8. یادگیری ماشین لرنینگ را از امروز شروع کنید!
ترنسفورمر چیست؟
مدل ترنسفورمر برای اولین بار در سال ۲۰۱۷ توسط تیم تحقیقاتی گوگل معرفی شد. مقاله معروف Attention is All You Need این مدل را به جهان معرفی کرد و نشان داد که با استفاده از مکانیزم توجه (Attention Mechanism)، میتوان به دقتهای بیسابقهای در پردازش زبان طبیعی دست یافت. ترنسفورمرها از ساختار منحصربهفرد خود برای پردازش موازی دادهها بهره میبرند و برخلاف مدلهای سنتی مانندRNN ها که به ترتیب زمان پردازش میشوند، قادراند دادهها را به صورت موازی پردازش کنند. این ویژگی باعث شده تا ترنسفورمرها بتوانند وابستگیهای بلندمدت در دادهها را بهتر مدیریت کنند و کارایی بالاتری در وظایف مختلف یادگیری عمیق داشته باشند.
پیشنهاد میکنیم این ویدئوی یوتیوب را که رضا شکرزاد در آن بهطور کامل مقاله ترنسفورمرها را بررسی کرده نیز تماشا کنید.
یکی از مهمترین اجزای ترنسفورمرها، مکانیزم توجه یا بهطور خاص، مکانیزم خود-توجه (Self-Attention) است که به مدل اجازه میدهد تا به تمام بخشهای ورودی نگاه کرده و اهمیت هر بخش را برای تولید خروجی محاسبه کند. این مکانیزم یک طرح وزندهی است که به مدل اجازه میدهد هنگام تولید خروجی به بخشهای مختلف ورودی توجه کند. درواقع، مکانیزم خود-توجه به مدل اجازه میدهد که کلمات یا ویژگیهای مختلف در توالی ورودی را در نظر بگیرد و به هر یک وزنی اختصاص دهد که نشاندهنده اهمیت آن برای تولید یک خروجی مشخص است.
برای مثال، در ترجمه یک جمله، هنگام ترجمه یک کلمه خاص، مدل ممکن است وزنهای توجه بیشتری به کلماتی که به صورت دستوری یا معنایی با کلمه هدف مرتبط هستند، اختصاص دهد. این فرآیند به ترنسفورمر این امکان را میدهد که وابستگیها بین کلمات یا ویژگیها را بدون توجه به فاصله آنها از یکدیگر در توالی به دست آورد.
ترنسفورمرها از چه بخشهایی تشکیل شدهاند؟
ترنسفورمرها از دو بخش اصلی به نامهای انکودر (Encoder) و دکودر (Decoder) تشکیل شدهاند. انکودر وظیفه دارد ورودیها را به یک نمایش داخلی تبدیل کند، در حالی که دکودر از این نمایش داخلی برای تولید خروجیها استفاده میکند. هر دو بخش از مکانیزم توجه بهره میبرند که به مدل اجازه میدهد تمرکز خود را بر روی بخشهای مهمتر ورودی یا خروجی تنظیم کند.
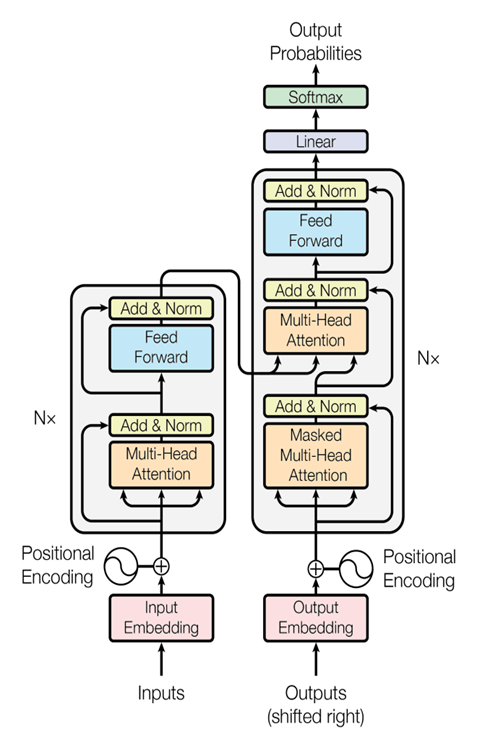
برای آشنایی بیشتر با ترنسفورمرها مقاله ترنسفورمر چیست؟ را بخوانید.
پس از معرفی، ترنسفورمرها بهسرعت جایگزین مدلهای قدیمیتر مانند RNN شده و به استاندارد جدیدی در یادگیری عمیق و پردازش زبان طبیعی تبدیل شدند. این مدلها در بسیاری از وظایف مانند ترجمه ماشینی، تولید متن، خلاصهسازی و پاسخ به سوالات به کار گرفته شده و نتایج بسیار بهتری نسبت به مدلهای پیشین به دست آوردهاند. از زمان معرفیشان تاکنون، ترنسفورمرها بهبودهای بسیاری داشته و نسخههای پیشرفتهتری از آنها مانند BERT و GPT نیز معرفی شدهاند که هر کدام قابلیتها و کاربردهای جدیدی را به ارمغان آوردهاند.
PyTorch و ترنسفورمرها
PyTorch یک کتابخانه متنباز برای یادگیری عمیق است که توسط فیسبوک توسعه داده شده است. این کتابخانه به دلیل سادگی در استفاده، انعطافپذیری بالا و پشتیبانی قوی از GPU ها، به یکی از محبوبترین ابزارها در میان پژوهشگران و توسعهدهندگان تبدیل شده است. پایتورچ امکان تعریف، آموزش و ارزیابی مدلهای پیچیده یادگیری عمیق از جمله ترنسفورمرها را با کمترین دردسر فراهم میکند.
برای آشنایی بیشتر با پایتورچ مقاله آشنایی کامل با کتابخانه PyTorch را بخوانید.
کاربردهای ترنسفورمر با PyTorch
همانطور که اشاره کردیم، مدلهای ترنسفورمر در حوزههای مختلفی از پردازش زبان طبیعی و یادگیری عمیق به کار گرفته میشوند. پایتورچ به عنوان یکی از ابزارهای قدرتمند یادگیری عمیق، امکان پیادهسازی و استفاده از ترنسفورمرها را به راحتی فراهم کرده است. در این بخش به برخی از کاربردهای اصلی ترنسفورمرها با استفاده از پایتورچ میپردازیم.
ترجمه ماشینی
یکی از برجستهترین کاربردهای ترنسفورمر، ترجمه ماشینی است. مدلهای ترنسفورمر به دلیل توانایی بالا در درک وابستگیهای بلندمدت و ساختار جملات، در ترجمه متون از یک زبان به زبان دیگر بسیار مؤثر هستند. با استفاده از پایتورچ، میتوان مدلهای ترجمه ماشینی قدرتمندی ساخت که دقت و سرعت بالایی دارند. این مدلها قادرند ترجمههای طبیعی و دقیقتری نسبت به مدلهای سنتی ارائه دهند.
پردازش زبان طبیعی
ترنسفورمرها در پردازش زبان طبیعی (NLP) نیز کاربردهای گستردهای دارند. از جمله این کاربردها میتوان به تحلیل متون، استخراج مفاهیم و معانی، خلاصهسازی متون، پاسخ به سوالات و تولید خودکار متون اشاره کرد. پایتورچ با ارائه ابزارهای مناسب، به پژوهشگران و توسعهدهندگان این امکان را میدهد که مدلهای پیچیده NLP را به سادگی پیادهسازی و اجرا کنند.
تشخیص گفتار
ترنسفورمرها همچنین در تشخیص گفتار کاربردهای فراوانی دارند. این مدلها میتوانند گفتار انسان را به متن تبدیل کنند و در کاربردهای مختلفی مانند دستیارهای صوتی، سیستمهای پاسخگویی خودکار و تبدیل گفتار به متن استفاده شوند. پایتورچ با پشتیبانی از ترنسفورمرها، به توسعهدهندگان این امکان را میدهد که مدلهای تشخیص گفتار با دقت بالا ایجاد کنند.
تولید خودکار متن
یکی دیگر از کاربردهای ترنسفورمرها، تولید خودکار متن است. مدلهای ترنسفورمر مانند GPT قادر هستند متون جدیدی تولید کنند که از نظر زبان و سبک به متون انسانی بسیار نزدیک هستند. این مدلها میتوانند برای تولید محتوای متنی، نوشتن مقالات، داستانسرایی و حتی ایجاد مکالمات خودکار در چتباتها به کار روند.
تحلیل احساسات
مدلهای ترنسفورمر میتوانند احساسات موجود در متون را تحلیل کرده و تشخیص دهند. این کاربرد در زمینههایی مانند تحلیل نظرات کاربران، بررسی بازخوردها و شناسایی احساسات مثبت، منفی و خنثی بسیار مفید است. پایتورچ ابزارهای مناسبی برای پیادهسازی مدلهای تحلیل احساسات ارائه میدهد که میتوانند دقت بالایی در این زمینه داشته باشند.
پاسخ به سوالات
ترنسفورمرها میتوانند به سوالات کاربران پاسخ دهند. این کاربرد در سیستمهای جستجوی اطلاعات، چتباتها و دستیارهای هوشمند بسیار مؤثر است. مدلهای ترنسفورمر با درک سوالات و استخراج پاسخهای مناسب از متون موجود، به کاربران کمک میکنند به سرعت به اطلاعات مورد نیاز خود دست یابند.
ساخت یک مدل ترنسفورمر با PyTorch
ساخت مدلهای ترنسفورمر با استفاده از پایتورچ به چندین مرحله تقسیم میشود:
تعریف بلوکهای پایهای ترنسفورمر
ترنسفورمر از چندین بلوک پایهای تشکیل شده است که شامل توجه چندسر (Multi-Head Attention)، شبکههای پیشخور موضعی (Position-Wise Feed-Forward Networks) و کدگذاری موضعی (Positional Encoding) میباشد. هر یک از این بلوکها باید به صورت جداگانه برای مدل تعریف شوند.
ساخت بلوک رمزگذار
بلوک رمزگذار (Encoder Block) مسئول پردازش ورودیها و تولید بازنماییهای داخلی است. این بلوک شامل لایههای توجه چندسر و شبکههای پیشخور موضعی است که به ترتیب پردازش میشوند. این ترکیب به مدل کمک میکند تا ویژگیهای پیچیدهای از ورودیها استخراج کرده و ترتیب توکنها را در دنباله در نظر بگیرد.
ساخت بلوک رمزگشا
بلوک رمزگشا (Decoder Block) مسئول تولید خروجیها بر اساس بازنماییهای داخلی تولید شده توسط رمزگذار است. این بلوک نیز شامل لایههای توجه چندسر و شبکههای پیشخور موضعی است. علاوه بر این، بلوک رمزگشا به بازنماییهای تولید شده توسط رمزگذار نیز توجه میکند تا اطلاعات ورودی را به خروجی مرتبط تبدیل کند.
ترکیب لایههای رمزگذار و رمزگشا
در نهایت، لایههای رمزگذار و رمزگشا با هم ترکیب میشوند تا شبکه ترنسفورمر کامل ساخته شود. این شبکه میتواند برای وظایف مختلفی مانند ترجمه ماشینی، پردازش زبان طبیعی و غیره استفاده شود. ترکیب این بلوکها به مدل اجازه میدهد تا با استفاده از مکانیزم توجه و پردازش توالی، روابط پیچیده بین ورودیها و خروجیها را یاد بگیرد و عملکرد بهتری در انجام وظایف مختلف داشته باشد.
پیادهسازی یک مدل ترنسفورمر با PyTorch
برای ساخت یک مدل ترنسفورمر با PyTorch ابتدا لازم است کتابخانههای مورد نیاز را فراخوانی کنیم:
import torch
import torch.nn as nn
import torch.optim as optim
import torch.utils.data as data
import math
تعریف بلوک توجه چندسر
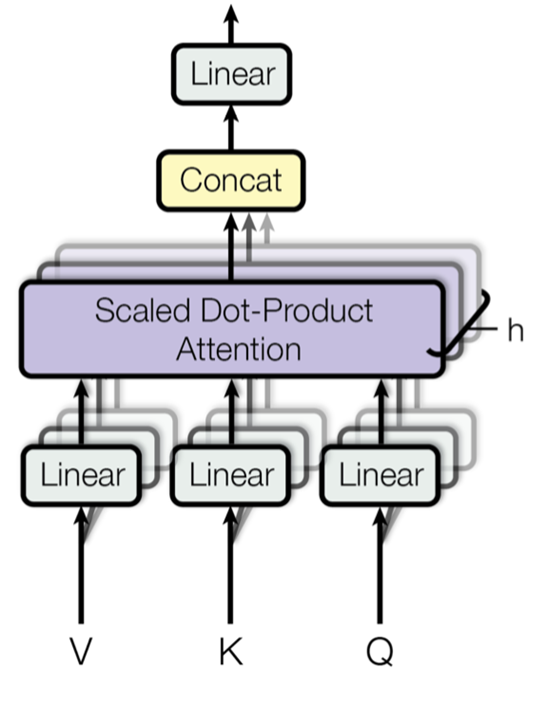
مکانیزم توجه چندسر (Multi-Head Attention) ارتباط بین هر جفت از موقعیتها را در یک دنباله محاسبه میکند. این مکانیزم شامل چندین سر توجه یا attention head است که جنبههای مختلف دنباله ورودی را درک و تحلیل میکنند. برای تعریف این بلوکها، ابتدا یک کلاس MultiHeadAttention که از nn.Module ارثبری میکند میسازیم:
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super(MultiHeadAttention, self).__init__()
# Ensure that the model dimension (d_model) is divisible by the number of heads
assert d_model % num_heads == 0, "d_model must be divisible by num_heads"
# Initialize dimensions
self.d_model = d_model # Model's dimension
self.num_heads = num_heads # Number of attention heads
self.d_k = d_model // num_heads # Dimension of each head's key, query, and value
# Linear layers for transforming inputs
self.W_q = nn.Linear(d_model, d_model) # Query transformation
self.W_k = nn.Linear(d_model, d_model) # Key transformation
self.W_v = nn.Linear(d_model, d_model) # Value transformation
self.W_o = nn.Linear(d_model, d_model) # Output transformation
که در آن:
- d_model ابعاد ورودی است.
- num_heads تعداد سرهای توجه برای تقسیم ورودی به آنهاست.
تابع __init__ این کلاس ابتدا بررسی میکند که ابعاد ورودی مدل قابل تقسیم بر تعداد سرهای توجه باشد. سپس لایههای کاملا متصل مربوط به ماتریسهای کوئری (Query)، کلید (Key)، مقدار (Value) و همچنین خروجی (Output) را تعریف میکند.
این لایههای کاملا متصل همان لایههای Linear در شکل زیر هستند که قسمتی از جزوه تدریس مبحث ترنسفورمرها در کلاس علم داده رضا شکرزاد است:
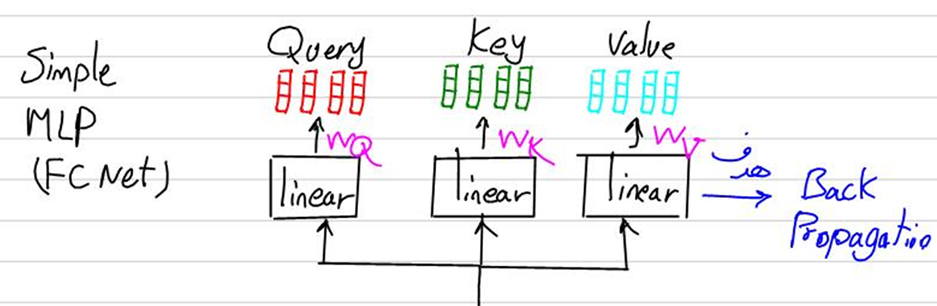
چرا تعداد نورونهای ورودی و خروجی این لایههای خطی برابر با d_model تنظیم میشود؟
این تنظیم باعث حفظ سازگاری ابعادی در طول مدل میشود، به طوری که خروجی هر مرحله به راحتی ورودی مرحله بعدی باشد. درواقع، برای ادغام سرهای توجه، هر سر توجه به طور جداگانه بردارهای Key، Query و Value را با ابعاد d_k پردازش میکند و سپس خروجیهای همه سرهای توجه ترکیب شده تا یک خروجی نهایی واحد با بعد d_model تولید شود. همچنین، ابعاد d_model به گونهای انتخاب شده است که نماینده ویژگیهای معنایی مهم در دادهها باشد و با حفظ این ابعاد در ورودی و خروجی لایههای خطی، اطلاعات معنایی مهم حفظ میشوند و مدل میتواند با کارایی بیشتری یادگیری کند.
به عنوان مثال، اگر d_model برابر با ۵۱۲ و تعداد سرهای توجه num_heads برابر با ۸ باشد، d_k برابر با ۶۴ خواهد بود و لایههای خطی باید تبدیلهایی را انجام دهند که ورودی با بعد ۵۱۲ را به بعد ۵۱۲ تبدیل کنند، سپس به ۸ سر تقسیم شده و هر سر ورودیهایی با بعد ۶۴ دریافت کند و پس از پردازش توسط سرها، خروجیها با هم ترکیب شده و دوباره به بعد ۵۱۲ برگردند. به این ترتیب، تنظیم ورودی و خروجی لایههای خطی با d_model این فرایند را به درستی انجام میدهد و سازگاری ابعادی را در سراسر مدل حفظ میکند.
محاسبه نمرات توجه
یکی دیگر از توابع این کلاس برای پیادهسازی ترنسفورمر با PyTorch تابع scaled_dot_product_attention است:
def scaled_dot_product_attention(self, Q, K, V, mask=None):
# Calculate attention scores
attn_scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.d_k)
# Apply mask if provided (useful for preventing attention to certain parts like padding)
if mask is not None:
attn_scores = attn_scores.masked_fill(mask == 0, -1e9)
# Softmax is applied to obtain attention probabilities
attn_probs = torch.softmax(attn_scores, dim=-1)
# Multiply by values to obtain the final output
output = torch.matmul(attn_probs, V)
return output
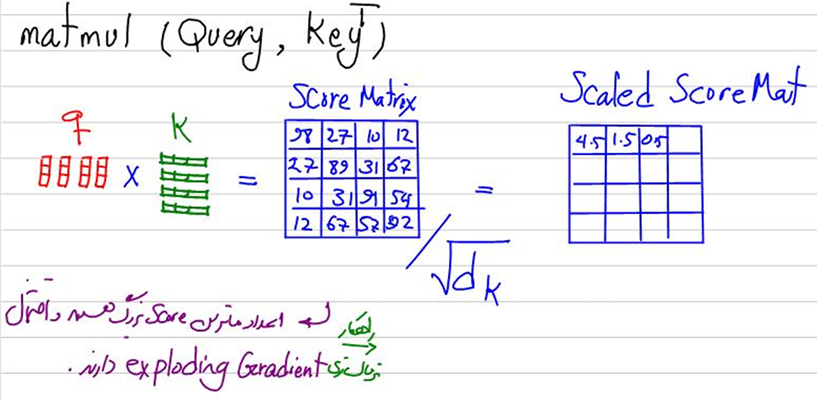
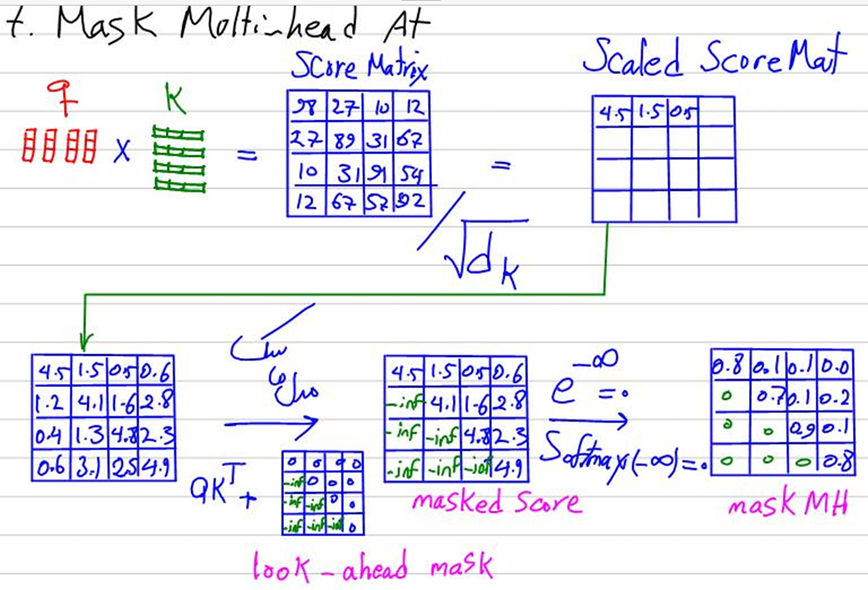
در این تابع ابتدا ماتریس نمرات توجه (Attention Scores) را با استفاده از حاصل ضرب نقطهای بین ماتریس کوئریها (Q) و ترانهادهی ماتریس کلیدها (K) محاسبه میکنیم. این حاصل ضرب نقطهای (torch.matmul) منجر به تولید یک ماتریس میشود که هر عنصر آن نشاندهنده همبستگی یا تشابه بین یک کوئری خاص و یک کلید خاص است. سپس، برای جلوگیری از بزرگ شدن نمرات توجه و کنترل مقدار آنها، این نمرات را بر جذر بُعد کلید (d_k) تقسیم میکنیم. این مقیاسبندی کمک میکند تا نمرات توجه به صورت متعادل و قابل مقایسه باقی بمانند.
این قسمت نیز در کلاس علم داده رضا شکرزاد بهصورت کامل تدریس شده است:
اعمال ماسک
در این تابع همچنین درصورت برقراری شرط None نبودن متغیر mask، برخی از نمرات توجه را از بین میبریم. بهعنوان مثال، در مدلهای زبانی، این کار میتواند برای جلوگیری از توجه به مکانهای پدشده یا برای حفظ اطلاعات آینده در مراحل پیشبینی استفاده شود.
برای انجام این کار، ماتریس نمرات توجه (Q.KT) را با ماتریس mask جمع میکنیم که در تمام درایههای آن صفر قرار گرفته بهجز درایههایی که میخواهیم درایه متناظرشان در ماتریس نمرات توجه، حذف گردند. در آن درایهها از ماتریس mask، بهجای صفر یک عدد منفی بسیار بزرگ قرار میدهیم و بهاینترتیب در خروجی، ماتریسی خواهیم داشت که برخی درایههای آن بهعلت جمع شدن با صفر بیتغییر میمانند و برخی دیگر بهعلت جمع شدن با یک عدد بسیار منفی، به منفی بینهایت میل میکنند.
محاسبه وزنهای توجه
درادامه، نمرات توجه را از یک تابع softmax عبور میدهیم. تابع softmax نمرات توجه را به مقادیر بین ۰ و ۱ تبدیل میکند، به طوری که مجموع این مقادیر در طول یک بُعد مشخص (معمولاً بعد آخر) برابر با ۱ است. این احتمالات وزنهای توجه (Attention weights) نامیده میشوند و نشاندهنده میزان توجه هر کوئری به هر کلید هستند. رضا شکرزاد در کلاس علم داده درمورد این قسمت نیز صحبت کرده است:
محاسبه خروجی
درپایان این تابع، خروجی نهایی توجه را با ضرب ماتریس وزنهای توجه در ماتریس مقادیر (V) محاسبه میکنیم. این مرحله منجر به تولید یک ماتریس خروجی میشود که ترکیبی از مقادیر مختلف با وزندهی بر اساس توجههای محاسبه شده است. به عبارت دیگر، هر عنصر در خروجی توجه ترکیبی از مقادیر مختلف است که با توجه به وزنهای محاسبه شده از مرحله قبل، وزندهی شدهاند.
تقسیم سرهای توجه
درادامه تابع split_heads را در کلاس MultiHeadAttentions تعریف میکنیم:
def split_heads(self, x):
# Reshape the input to have num_heads for multi-head attention
batch_size, seq_length, d_model = x.size()
return x.view(batch_size, seq_length, self.num_heads, self.d_k).transpose(1, 2)
این متد در مدل توجه چندسر (Multi-Head Attention) ابعاد ورودی x را تغییر میدهد تا مدل بتواند چندین سر توجه را به طور همزمان پردازش کند و محاسبات موازی را امکانپذیر سازد. برای این منظور، ابتدا ابعاد ورودی شامل batch_size (تعداد نمونهها در هر دسته)، seq_length (طول دنباله) و d_model (بعد مدل) استخراج میشود. سپس با استفاده از دستور view، شکل ورودی به (batch_size, seq_length, num_heads, d_k) تغییر داده میشود. همانطور که قبلا گفتیم، d_k برابر با مقدار صحیح تقسیم d_model بر num_heads است. در نهایت، با استفاده از دستور transpose، ابعاد دوم و سوم جابجا میشوند تا شکل نهایی ورودی به صورت (batch_size, num_heads, seq_length, d_k) درآید. این تغییر شکل و جابجایی ابعاد به مدل اجازه میدهد تا ورودیها را به طور همزمان و موازی برای هر سر توجه جداگانه پردازش کند، که منجر به افزایش کارایی و دقت مدل در درک ویژگیهای پیچیدهتر دادهها میشود.
ترکیب سرهای توجه
تابع یا متد بعدی این کلاس، combined_heads است:
def combine_heads(self, x):
# Combine the multiple heads back to original shape
batch_size, _, seq_length, d_k = x.size()
return x.transpose(1, 2).contiguous().view(batch_size, seq_length, self.d_model)
با این متد بعد از اعمال مکانیزم توجه به هر سر به صورت جداگانه، نتایج را دوباره باهم ترکیب میکنیم تا به یک تنسور واحد با ابعاد (batch_size, seq_length, d_model) برسیم. این مرحله، نتیجه را برای پردازشهای بعدی آماده میکند.
تابع forward
آخرین تابع کلاس MultiHeadAttention برای استفاده در مدل ترنسفورمر با PyTorch تضمین میکند که تمام مراحل محاسباتی چندسر توجه به درستی و بهترتیب مناسبی انجام شوند:
def forward(self, Q, K, V, mask=None):
# Apply linear transformations and split heads
Q = self.split_heads(self.W_q(Q))
K = self.split_heads(self.W_k(K))
V = self.split_heads(self.W_v(V))
# Perform scaled dot-product attention
attn_output = self.scaled_dot_product_attention(Q, K, V, mask)
# Combine heads and apply output transformation
output = self.W_o(self.combine_heads(attn_output))
return output
در این تابع ابتدا ماتریسهای کوئری (Q)، کلید (K) و مقدار (V) را از طریق لایههای خطی که قبلا تعریفشان کردیم، عبور میدهیم تا به ابعاد مناسب تبدیل شوند. سپس، این تنسورها را با استفاده از متد split_heads به چندین سر تقسیم میکنیم تا محاسبات توجه بهصورت موازی انجام شود.
در مرحله بعد، متد scaled_dot_product_attention را برای هر سر فراخوانی میکنیم تا وزنهای توجه محاسبه و در ماتریس مقادیر (V) ضرب داخلی شوند. بعد از اعمال مکانیزم توجه، نتایج هر سر را با استفاده از متد combine_heads دوباره به یک تنسور واحد تبدلی میکنیم. در نهایت، این تنسور ترکیبشده را از طریق یک لایه خطی خروجی عبور میدهیم تا نتیجه نهایی آماده شود.
این متد به طور کامل مکانیزم توجه چندسر را پیادهسازی میکند و به مدل اجازه میدهد تا روابط مختلف دادههای ورودی را در مقیاسهای مختلف کشف کند.
تعریف بلوک پیشخور
بلوک پیشخور (FeedForward) کلاس دیگری است که باید برای پیادهسازی مدل ترنسفورمر با PyTorch تعریف کنیم. نام این کلاس را PositionWiseFeedForward میگذاریم که آن هم از nn.Module ارثبری میکند:
class PositionWiseFeedForward(nn.Module):
def __init__(self, d_model, d_ff):
super(PositionWiseFeedForward, self).__init__()
self.fc1 = nn.Linear(d_model, d_ff)
self.fc2 = nn.Linear(d_ff, d_model)
self.relu = nn.ReLU()
که در آن:
- d_model بعد ورودی و خروجی مدل و نشاندهنده تعداد ویژگیهایی است که مدل در هر لحظه از زمان پردازش میکند.
- d_ff بعد لایه داخلی در شبکه پیشخور و نشاندهنده تعداد واحدهای نورونی در لایه مخفی شبکه پیشخور است.
- self.fc1 یک لایه کاملاً متصل (خطی) است که ابعاد ورودی آن برابر با d_model و ابعاد خروجی آن برابر با d_ff است.
- self.fc2 یک لایه خطی که ابعاد ورودی آن برابر با d_ff و ابعاد خروجی آن برابر با d_model است.
- self.relu تابع فعالساز ReLU (واحد خطی اصلاحشده) است، که غیرخطی بودن را بین دو لایه خطی معرفی میکند. این تابع فعالسازی به مدل کمک میکند تا روابط پیچیدهتری را یاد بگیرد.
متد forward را در این کلاس بهصورت زیر تعریف میکنیم:
def forward(self, x):
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
return x
این متد در کلاس PositionWiseFeedForward به این صورت عمل میکند که ابتدا ورودی x را از طریق اولین لایه خطی (fc1) عبور میدهد تا به فضای ویژگی با ابعاد d_ff تبدیل شود. سپس خروجی fc1 را از تابع فعالسازی ReLU عبور میدهد. بعد از این مرحله، خروجی از طریق دومین لایه خطی (fc2) عبور میکند تا به ابعاد اصلی d_model بازگردد. سپس نتیجه بهعنوان خروجی نهایی بازگردانده میشود.
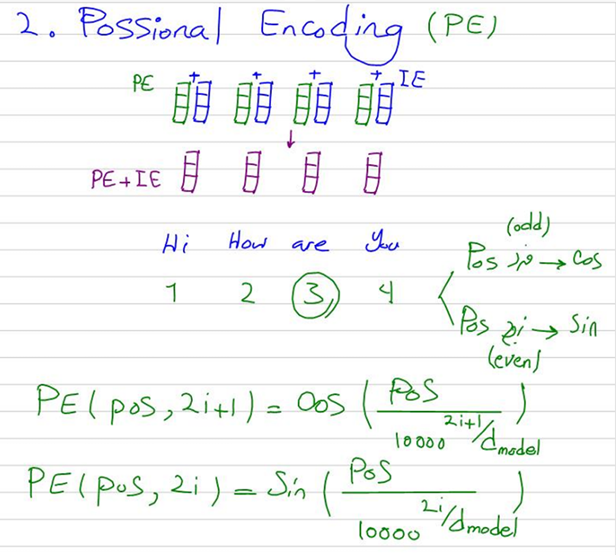
تعریف بلوکهای رمزگذاری موضعی
رمزگذاری موضعی (Positional Embedding) اطلاعات موقعیت را به ورودیهای مدل اضافه میکند تا مدل بتواند ترتیب توکنها را در دنباله درک کند. این کلاس نیز از nn.Module ارثبری کرده و آن را بهصورت زیر تعریف میکنیم:
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_seq_length):
super(PositionalEncoding, self).__init__()
pe = torch.zeros(max_seq_length, d_model)
position = torch.arange(0, max_seq_length, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * -(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
self.register_buffer('pe', pe.unsqueeze(0))
که در آن:
- d_model بعد ورودی مدل است و تعداد ویژگیهایی را که مدل در هر زمان پردازش میکند نشان میدهد.
- max_seq_length حداکثر طول دنباله است که برای آن رمزگذاریهای موضعی از پیش محاسبه میشوند.
- pe یک تنسور تمام صفر است که با رمزگذاریهای موضعی پر خواهد شد.
- position یک تنسور حاوی اندیسهای موقعیت برای هر موقعیت در دنباله است.
- div_term یک عبارت است که برای مقیاسبندی اندیسهای موقعیت به روش خاصی استفاده میشود.
- تابع سینوس بر روی اندیسهای زوج و تابع کسینوس بر روی اندیسهای فرد تنسور pe اعمال میشود.
- pe به عنوان یک بافر ثبت میشود که به این معناست که بخشی از وضعیت ماژول خواهد بود اما به عنوان یک پارامتر قابل آموزش در نظر گرفته نمیشود.
متد forward را در این کلاس بهصورت زیر تعریف میکنیم:
def forward(self, x):
return x + self.pe[:, :x.size(1)]
این تابع رمزگذاریهای موضعی را به ورودی x اضافه میکند تا مدل بتواند از اطلاعات موقعیت توکنها استفاده کند.
در تصویر زیر میتوانید جزوه مربوط به تدریس این مبحث را در کلاس علم داده رضا شکرزاد ببینید و درک بهتری از آن داشته باشید:
ساخت بلوک رمزگذار
رمزگذار بخش نخست معماری ترنسفورمرها است. یک بلوک رمزگذار شامل چندین لایه است که به طور متوالی اعمال میشوند. این بلوکها بخش مهمی از معماری مدل ترنسفورمر هستند و شامل مکانیزمهای توجه چندسر (Multi-Head Attention) و شبکههای عصبی پیشخور (Feed-Forward Neural Network) میباشند.
در ادامه، نحوه ساخت یک بلوک رمزگذار در PyTorch را میبینید که از کلاس nn.Module ارثبری میکند:
class EncoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout):
super(EncoderLayer, self).__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads)
self.feed_forward = PositionWiseFeedForward(d_model, d_ff)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
که در آن:
- d_model بعد ورودی مدل است.
- num_heads تعداد سرهای توجه در مکانیزم توجه چندسر است.
- d_ff بعد لایه داخلی در شبکه عصبی پیشخور است.
- dropout نرخ دراپاوت برای جلوگیری از بیشبرازش مدل است.
با تابع __init__ کلاس EncoderBlock را مقداردهی اولیه میکنیم. این اجزا شامل مکانیزم توجه چندسر، شبکه پیشخور موضعی، لایههای نرمالسازی و لایه دراپاوت هستند که همگی برای پردازش و استخراج ویژگیهای معنادار از دنباله ورودی به کار میروند. این تنظیمات به مدل ترنسفورمر کمک میکند تا به طور مؤثری از اطلاعات موقعیت و ویژگیهای پیچیده دنباله ورودی استفاده کند.
در ادامه، در این کلاس متد forward را نیز بهشکل زیر تعریف میکنیم:
def forward(self, x, mask):
# Self-attention + Residual Connection + Layer Norm
attn_output = self.self_attn(x, x, x, mask)
x = self.norm1(x + self.dropout(attn_output))
# Feed Forward + Residual Connection + Layer Norm
ff_output = self.feed_forward(x)
x = self.norm2(x + self.dropout(ff_output))
return x
که در آن:
- x ورودی به لایه رمزگذار است.
- mask ماسک اختیاری برای نادیده گرفتن بخشهای خاصی از ورودی است.
متد forward در کلاس EncoderBlock جایی است که محاسبات اصلی برای پردازش دنباله ورودی در آن انجام میشود. این متد شامل چندین مرحله است که آنها را بهترتیب توضیح میدهیم:
اعمال توجه چندسر
در خط اول این تابع، ورودی x را بهعنوان هر سه ماتریس کوئری، کلید و مقدار به مکانیزم توجه چندسر (self.self_attn) میدهیم. متغیر ماسک (mask) را نیز به این مکانیزم میدهیم تا همانطور که توضیح دادیم، درصورت تمایل، توجه مدل به برخی از مکانها محدود شود. البته در مقاله اصلی، مکانیزم توجه بخش رمزگذار بدون ماسک انجام میشود. نتیجه این مرحله یک تنسور (attn_output) است که خروجی مکانیزم توجه چندسر را نگه میدارد.
لایه نرمالسازی اول
در این قسمت، خروجی مکانیزم توجه چندسر (attn_output) را با ورودی اصلی (x) جمع میکنیم تا یک اتصال باقیمانده (Residual Connection) ایجاد شود. سپس، یک لایه دراپاوت (self.dropout) بر روی حاصل این جمع اعمال میکنیم تا از بیشبرازش جلوگیری شود. نتیجه حاصل از این عملیات را توسط لایه نرمالسازی (self.norm1) نرمال میکنیم تا همواری و پایداری بیشتری در آموزش مدل ایجاد شود.
برای درک دقیقتر اتفاقی که در لایه نرمالسازی میافتد، میتوانید به عکس زیر که بخشی از جزوه کلاس علم داده رضا شکرزاد در تدریس این مبحث است، مراجعه نمایید:
اعمال شبکه پیشخور
در این مرحله، ورودی نرمالسازیشده (x) را به شبکه پیشخور (self.feed_forward) میدهیم تا ویژگیهای پیچیدهتری استخراج شود. نتیجه این مرحله یک تنسور (ff_output) است که خروجی شبکه پیشخور را نگه میدارد.
لایه نرمالسازی دوم
درادامه، خروجی شبکه پیشخور (ff_output) را با ورودی نرمالسازیشده قبلی (x) جمع میکنیم تا یک اتصال باقیمانده دیگر ایجاد شود. سپس، یک لایه دراپاوت دیگر بر روی این جمع اعمال میشود و نتیجه حاصل توسط لایه نرمالسازی بعدی (self.norm2) نرمال میکنیم.
ساخت بلوک رمزگشا
رمزگشا بخش دوم معماری ترنسفورمرها است. یک بلوک رمزگشا شامل چندین لایه است که به طور متوالی اعمال میشوند. این بلوکها بخش مهمی از معماری مدل ترنسفورمر هستند و شامل مکانیزمهای توجه چندسر (Multi-Head Attention) و شبکههای عصبی پیشخور (Feed-Forward Neural Network) میباشند.
در ادامه، نحوه ساخت یک بلوک رمزگشا را در PyTorch میبینید که از کلاس nn.Module ارثبری میکند:
class DecoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout=0.1):
super(DecoderLayer, self).__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads)
self.enc_dec_attn = MultiHeadAttention(d_model, num_heads)
self.feed_forward = PositionWiseFeedForward(d_model, d_ff)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
که در آن:
- d_model بعد ورودی مدل است.
- num_heads تعداد سرهای توجه در مکانیزم توجه چندسر است.
- d_ff بعد لایه داخلی در شبکه عصبی پیشخور است.
- dropout نرخ دراپاوت برای جلوگیری از بیشبرازش مدل است.
با تابع __init__ کلاس DecoderBlock را مقداردهی اولیه میکنیم. این اجزا شامل مکانیزم توجه چندسر، مکانیزم توجه به رمزگذار، شبکه پیشخور موضعی، لایههای نرمالسازی و لایه دراپاوت هستند که همگی برای پردازش و استخراج ویژگیهای معنادار از دنباله ورودی به کار میروند. این تنظیمات به مدل ترنسفورمر کمک میکند تا به طور مؤثری از اطلاعات موقعیت و ویژگیهای پیچیده دنباله ورودی و بازنماییهای داخلی تولید شده توسط رمزگذار استفاده کند.
در ادامه، در این کلاس متد forward را نیز بهشکل زیر تعریف میکنیم:
def forward(self, x, enc_output, src_mask, tgt_mask):
# Self-attention + Residual Connection + Layer Norm
attn_output = self.self_attn(x, x, x, tgt_mask)
x = self.norm1(x + self.dropout(attn_output))
# Encoder-Decoder attention + Residual Connection + Layer Norm
enc_dec_attn_output = self.enc_dec_attn(x, enc_output, enc_output, src_mask)
x = self.norm2(x + self.dropout(enc_dec_attn_output))
# Feed Forward + Residual Connection + Layer Norm
ff_output = self.feed_forward(x)
x = self.norm3(x + self.dropout(ff_output))
return x
که در آن:
- x ورودی به لایه رمزگشا است.
- enc_output خروجی رمزگذار مربوطه است.
- src_mask ماسک منبع برای نادیده گرفتن بخشهای خاصی از خروجی رمزگذار است.
- tgt_mask ماسک هدف برای نادیده گرفتن بخشهای خاصی از ورودی رمزگشا است.
متد forward در کلاس DecoderBlock جایی است که محاسبات اصلی برای پردازش دنباله ورودی و بازنماییهای رمزگذار انجام میشود. این متد شامل چندین مرحله است که بهترتیب توضیح داده میشوند:
اعمال توجه چندسر
در خط اول این تابع، ورودی x را بهعنوان هر سه ماتریس کوئری، کلید و مقدار به مکانیزم توجه چندسر (self.self_attn) میدهیم. ماسک هدف (tgt_mask) نیز به این مکانیزم داده میشود تا توجه مدل به برخی از مکانها محدود شود. نتیجه این مرحله یک تنسور (attn_output) است که خروجی مکانیزم توجه چندسر را نگه میدارد.
لایه نرمالسازی اول
در این قسمت، خروجی مکانیزم توجه چندسر (attn_output) را با ورودی اصلی (x) جمع میکنیم تا یک اتصال باقیمانده ایجاد شود. سپس، یک لایه دراپاوت (self.dropout) بر روی این جمع اعمال میکنیم تا از بیشبرازش جلوگیری شود. نتیجه حاصل از این عملیات را توسط لایه نرمالسازی (self.norm1) نرمالسازی میکنیم.
اعمال مکانیزم توجه به خروجی رمزگذار
در این مرحله، ورودی نرمالسازیشده (x) را بهعنوان ماتریس کوئری و خروجی لایه رمزگذار (enc_output) را هم بهعنوان ماتریس کلید و هم ماتریس مقدار به مکانیزم توجه چندسر رمزگذار-رمزگشا (self.enc_dec_attn) میدهیم. دراینجا ماسک ورودی (src_mask) نیز درصورت تمایل به این مکانیزم داده میشود. البته در مقاله اصلی، در این قسمت از ماسک استفاده نشده است. نتیجه این مرحله یک تنسور (enc_dec_attn_output) است که خروجی توجه رمزگذار-رمزگشا را نگه میدارد.
لایه نرمالسازی دوم
درادامه، خروجی توجه رمزگذار-رمزگشا (enc_dec_attn_output) را با ورودی نرمالسازیشده مرحله قبلی (x) جمع میکنیم تا یک اتصال باقیمانده دیگر ایجاد شود. سپس، یک لایه دراپاوت بر روی این حاصل جمع اعمال میشود و نتیجه حاصل توسط لایه نرمالسازی بعدی (self.norm2) نرمالسازی میشود.
اعمال شبکه پیشخور
در این مرحله، ورودی نرمالسازیشده را به شبکه پیشخور (self.feed_forward) میدهیم تا ویژگیهای پیچیدهتری استخراج کند. نتیجه این مرحله یک تنسور (ff_output) است که خروجی شبکه پیشخور را نگه میدارد.
لایه نرمالسازی سوم
در نهایت، خروجی شبکه پیشخور (ff_output) را با ورودی نرمالسازیشده قبلی (x) جمع میکنیم تا یک اتصال باقیمانده دیگر ایجاد شود. سپس، یک لایه دراپاوت نیز بر روی این حاصل جمع اعمال میشود و نتیجه توسط لایه نرمالسازی بعدی (self.norm3) نرمالسازی میشود.
ساخت بلوک ترنسفورمر
بعد از ساخت تمامی بلوکهای پایه که در بخشهای قبل به آن اشاره شد، حال نوبت به ساخت یک بلوک ترنسفورمر با PyTorch میرسد. یک بلوک ترنسفورمر شامل بخش رمزگذار و بخش رمزگشا است که با هم کار میکنند تا ورودیها را پردازش و خروجیهای مناسب را تولید کنند.
درادامه، نحوه ساخت یک بلوک ترنسفورمر را میبینید. مانند سایر بلوکها، این بلوک نیز از کلاس nn.Module ارثبری میکند:
class Transformer(nn.Module):
def __init__(self, src_vocab_size, tgt_vocab_size, d_model, num_heads, num_layers, d_ff, max_seq_length, dropout):
super(Transformer, self).__init__()
self.encoder_embedding = nn.Embedding(src_vocab_size, d_model)
self.decoder_embedding = nn.Embedding(tgt_vocab_size, d_model)
self.positional_encoding = PositionalEncoding(d_model, max_seq_length)
self.encoder_layers = nn.ModuleList([EncoderLayer(d_model, num_heads, d_ff, dropout) for _ in range(num_layers)])
self.decoder_layers = nn.ModuleList([DecoderLayer(d_model, num_heads, d_ff, dropout) for _ in range(num_layers)])
self.fc = nn.Linear(d_model, tgt_vocab_size)
self.dropout = nn.Dropout(dropout)
که در آن:
- src_vocab_size اندازه واژگان متن ورودی است.
- tgt_vocab_size اندازه واژگان متن هدف است.
- d_model بعد ورودی مدل است.
- num_heads تعداد سرهای توجه در مکانیزم توجه چندسر است.
- num_layers تعداد لایههای رمزگذار و رمزگشا است.
- d_ff بعد لایه داخلی در شبکه عصبی پیشخور است.
- max_seq_length حداکثر طول دنباله برای رمزگذاریهای موضعی است.
- dropout نرخ دراپاوت برای جلوگیری از بیشبرازش مدل است.
ایجاد لایههای تعبیهسازی
با تابع __init__ کلاس Transformer را مقداردهی اولیه میکنیم. در دو خط اول این تابع، دو لایه تعبیه (Embedding) برای ورودیهای رمزگذار و رمزگشا تعریف میکنیم. تعبیهسازی فرآیندی است که در آن هر کلمه یا توکن به یک بردار عددی تبدیل میشود که نمایانگر ویژگیهای معنایی و نحوی کلمه است.
استفاده از رمزگذاری موضعی
در خط بعدی از کلاس رمزگذاری موضعی (Positional Encoding) استفاده میکنیم. همانطور که گفتیم، از آنجا که مدل ترنسفورمر به طور ذاتی ترتیب توکنها را در دنباله ورودی درک نمیکند، این رمزگذاری به مدل کمک میکند تا ترتیب و موقعیت هر توکن را در دنباله بفهمد.
ایجاد لایههای کدگذار و کدگشا
همانطور که در تصویر مربوط به معماری یک مدل ترنسفورمر میبینید، بعد از محاسبه بردارهای تعبیه، نوبت به تعریف لایههای کدگذار (Encoder Layers) میرسد. در اینجا، هر لایه رمزگذار به عنوان یک بلوک مجزا تعریف میشود و مجموعهای از این بلوکها به صورت متوالی برای ایجاد بخش رمزگذار مدل ترنسفورمر استفاده میشود. ModuleList یک کلاس در PyTorch است که لیستی از ماژولها (لایهها) را نگه میدارد. دلیل استفاده از این کلاس، این است که میخواهیم بهتعداد num_layers لایه کدگذار تعریف کنیم. بهاینترتیب این بخش از تابع، یک لیست از لایههای رمزگذار ایجاد میکند.
هر بار که حلقه for اجرا میشود، یک نمونه جدید از EncoderLayer با پارامترهای d_model (بعد مدل)، num_heads (تعداد سرهای توجه)، d_ff (بعد لایه داخلی شبکه پیشخور)، و dropout (نرخ دراپاوت) ایجاد میشود. این حلقه به تعداد num_layers بار اجرا میشود و در نتیجه لیستی از EncoderLayerها ایجاد میشود.
همین کار را برای ایجاد لایهها رمزگشا نیز انجام میدهیم. سپس یک لایه خطی نهایی تعریف میکنیم که وظیفه تبدیل خروجی رمزگشا به فضای واژگان هدف را دارد.
تابع تولید ماسک
با تابع generate_mask ماسکهای لازم برای ورودیهای منبع و هدف را در مدل ترنسفورمر تولید میکنیم:
def generate_mask(self, src, tgt):
src_mask = (src != 0).unsqueeze(1).unsqueeze(2)
tgt_mask = (tgt != 0).unsqueeze(1).unsqueeze(3)
seq_length = tgt.size(1)
nopeak_mask = (1 - torch.triu(torch.ones(1, seq_length, seq_length), diagonal=1)).bool()
tgt_mask = tgt_mask & nopeak_mask
return src_mask, tgt_mask
ماسک منبع (src_mask) به مدل ترنسفورمر با PyTorch کمک میکند تا پدینگها را در ورودی منبع نادیده بگیرد و ماسک هدف (tgt_mask) به مدل کمک میکند تا هم پدینگها را در ورودی هدف نادیده بگیرد و هم از نگاه به توکنهای آینده جلوگیری کند. این ماسکها برای بهینهسازی فرآیند توجه و جلوگیری از بیشبرازش به کار میروند
تابع forward
متد forward در مدل ترنسفورمر با PyTorch ورودیهای منبع و هدف را پردازش میکند تا خروجیهای مناسب تولید شود. این متد را بهصورت زیر تعریف میکنیم:
def forward(self, src, tgt):
# Generate masks for the source and target sequences
src_mask, tgt_mask = self.generate_mask(src, tgt)
# Embed the source sequence and apply dropout and positional encoding
src_embedded = self.dropout(self.positional_encoding(self.encoder_embedding(src)))
# Embed the target sequence and apply dropout and positional encoding
tgt_embedded = self.dropout(self.positional_encoding(self.decoder_embedding(tgt)))
# Pass the embedded source sequence through the encoder layers
enc_output = src_embedded
for enc_layer in self.encoder_layers:
enc_output = enc_layer(enc_output, src_mask)
# Pass the embedded target sequence through the decoder layers using encoder output
dec_output = tgt_embedded
for dec_layer in self.decoder_layers:
dec_output = dec_layer(dec_output, enc_output, src_mask, tgt_mask)
# Apply the final fully connected layer to the decoder output to get the final output
output = self.fc(dec_output)
return output
که در آن:
- src یا ورودی منبع (Source Input) دنباله ورودی اصلی است که بهبخش رمزگذار میدهیم. این ورودی معمولاً یک دنباله از توکنها (مانند کلمات) است که باید توسط مدل پردازش شود.
- trg یا ورودی هدف (Target Input) نیز دنباله ورودیای است که به بخش رمزگشا میدهیم. این ورودی معمولاً دنبالهای از توکنهاست که مدل باید آنها را پیشبینی کند یا آنها را تکمیل کند.
تولید ماسک
در این مرحله، ماسکهای منبع و هدف را تولید میکنیم تا بخشهای غیرمهم یا پد شده ورودی و خروجی نادیده گرفته شوند. منظور از خروجی، خروجی رمزگذار (Encoder Output) یا بازنمایی برداری ورودی منبع پس از پردازش توسط لایههای رمزگذار است که بهعنوان ورودی به مکانیزم توجه رمزگشا داده میشود.
توجه کنید mask کردن در ادبیات ترنسفورمرها برای ورودیهای مکانیزم توجه معنی دارد. یعنی ما میتوانیم هر چیزی که به یک بلوک توجه چندسر وارد میشود را mask کنیم. با توجه به شکل معماری ترنسفورمرها، درمییابیم که در سه قسمت، مکانیزم توجه بهکاررفته که ورودی یکی از آنها، خروجی لایه کدگذار است.
تعبیهسازی ورودی منبع
در این بخش با self.encoder_embedding(src) ورودی منبع را به بردارهای تعبیه تبدیل و با self.positional_encoding اطلاعات موقعیت هر کلمه را به بردارهای تعبیه اضافه میکنیم. درنهایت روی خروجی، یک لایه دراپاوت میزنیم تا از بیشبرازش جلوگیری کنیم.
تعبیهسازی ورودی هدف
در این بخش با self.decoder_embedding(tgt) ورودی هدف را به بردارهای تعبیه تبدیل و با self.positional_encoding اطلاعات موقعیت هر کلمه را به بردارهای تعبیه اضافه میکنیم. درنهایت روی خروجی، یک لایه دراپاوت میزنیم تا از بیشبرازش جلوگیری کنیم.
عبور از لایههای رمزگذار
در مرحله بعد، ورودی تعبیهسازیشده منبع از طریق لایههای رمزگذار عبور میدهیم. self.encoder_layers لیستی از لایههای رمزگذار است که در تابع __init__ آن را در یک ModuleList تعریف کردیم. این لیست شامل چندین نمونه از کلاس EncoderLayer است. با یک حلقه for، هر لایه رمزگذار را بهترتیب روی دادههای ورودی اعمال میکنیم. این دادههای ورودی ابتدا بردارهای تعبیه ورودی منبع هستند و بعد از هر پردازش از طریق لایه کدگذار، بهعنوان ورودی مرحله بعد استفاده میشوند.
عبور از لایههای رمزگشا
کارهایی را که با لایههای کدگذار انجام دادیم، درادامه با لایههای کدگشا نیز انجام میدهیم. بهاینترتیب که ورودی تعبیهسازیشده هدف را از طریق لایههای رمزگشا عبور میدهیم و بعد از هر پردازش از طریق هر لایه رمزگشا، از آنها بهعنوان ورودی مرحله بعد استفاده میکنیم.
لایه خطی نهایی برای تولید خروجی
خروجی نهایی با استفاده از یک لایه خطی (کاملا متصل) تولید میشود که احتمال مشاهده هر کلمه در واژگان هدف را محاسبه میکند و به مدل اجازه میدهد تا کلمه بعدی را پیشبینی کند.
پیشپردازش و آمادهسازی دادهها
در این مثال ما یک مجموعهداده ساختگی و عددی برای آموزش مدل ترنسفورمر با PyTorch که ساختیم، ایجاد خواهیم کرد. با این حال، در یک پروژه واقعی، از یک مجموعهداده متنی استفاده میشود که نیازمند پیشپردازش، پاکسازی و … برای هر دو زبان منبع و هدف خواهد بود.
پیش از ساخت این داده مصنوعی، لازم است تعدادی از پارامترهای مدل را تعریف کنیم. این اعداد معماری و رفتار مدل ترنسفورمر را تعریف میکنند:
# Initialize parameters
src_vocab_size = 5000
tgt_vocab_size = 5000
d_model = 512
num_heads = 8
num_layers = 6
d_ff = 2048
max_seq_length = 100
dropout = 0.1
- src_vocab_size اندازه واژگان برای دادههای منبع است.
- tgt_vocab_size اندازه واژگان برای دادههای هدف است.
- d_model ابعاد بردارهای تعبیه مدل است.
- num_heads تعداد سرهای توجه در مکانیزم توجه چندسر است.
- num_layers تعداد لایهها برای هر دو بخش رمزگذار و رمزگشا است.
- d_ff ابعاد لایه درونی در شبکه پیشخور است.
- max_seq_length حداکثر طول دنباله برای رمزگذاری موقعیتی است.
- dropout نرخ دراپاوت برای جلوگیری از بیشبرازش است.
تولید داده
با کد زیر میتوانیم داده ساختگی خود را بهصورت تصادفی تولید کنیم:
# Generate random sample data
src_data = torch.randint(1, src_vocab_size, (64, max_seq_length)) # (batch_size, seq_length)
tgt_data = torch.randint(1, tgt_vocab_size, (64, max_seq_length)) # (batch_size, seq_length)
- src_data اعداد صحیح تصادفی بین ۱ و src_vocab_size و نمایانگر یک بسته (Batch) از دادههای منبع با سایز (64, max_seq_length) هستند.
- tgt_data اعداد صحیح تصادفی بین ۱ و tgt_vocab_size و نمایانگر یک بسته (Batch) از دادههای هدف با سایز (64, max_seq_length) هستند.
این اعداد تصادفی میتوانند به عنوان ورودی به مدل ترنسفورمر استفاده شوند و شبیهسازی یک بسته داده با ۶۴ نمونه و دنبالههایی با طول ۱۰۰ را انجام دهند.
آموزش مدل
در مرحله بعد، مدل ترنسفورمر با PyTorch را با استفاده از دادههای تولیدشده آموزش میدهیم. برای انجام این کار ابتدا لازم است یک نمونه (Instance) از مدل ترنسفورمرمان بسازیم:
transformer = Transformer(src_vocab_size, tgt_vocab_size, d_model, num_heads, num_layers, d_ff, max_seq_length, dropout)
حال نوبت به تعریف تابع هزینه و بهینهساز میرسد که ما از تابع هزینه کراس انتروپی و بهینهساز Adam استفاده میکنیم:
criterion = nn.CrossEntropyLoss(ignore_index=0)
optimizer = optim.Adam(transformer.parameters(), lr=0.0001, betas=(0.9, 0.98), eps=1e-9)
اکنون همه چیز آماده است تا مدل را آموزش دهیم. ابتدا باید مدل را در حالت آموزش قرار دهیم. سپس در هر epoch، ابتدا باید گرادیانها را صفر کنیم، دادههای منبع و دادههای هدف (به جز آخرین توکن در هر دنباله) را به مدل ترنسفورمر بدهیم و با استفاده از تابع هزینه، اختلاف بین پیشبینیهای مدل و دادههای هدف (به جز اولین توکن در هر دنباله) را محاسبه میکنیم. در پایان با تابع loss.backward گرادیانهای تابع هزینه را نسبت به پارامترهای مدل محاسبه میکنیم و با optimizer.step پارامترهای مدل را با استفاده از گرادیانهای محاسبهشده بهروزرسانی میکنیم:
transformer.train()
for epoch in range(100):
optimizer.zero_grad()
output = transformer(src_data, tgt_data[:, :-1])
loss = criterion(output.contiguous().view(-1, tgt_vocab_size), tgt_data[:, 1:].contiguous().view(-1))
loss.backward()
optimizer.step()
print(f"Epoch: {epoch+1}, Loss: {loss.item()}")
ارزیابی مدل
برای ارزیابی مدل ترنسفورمر با PyTorch نیز به همان ترتیبی که دادههای آموزشی را تولید کردیم، مجموعه داده ساختگی خود را میسازیم. بعد مدل را در حالت ارزیابی قرار میدهیم. سپس دادههای منبع و دادههای هدف ارزیابی (به جز آخرین توکن در هر دنباله) را به مدل ترانسفورمر میدهیم و با استفاده از تابع هزینه، اختلاف بین پیشبینیهای مدل و دادههای هدف ارزیابی (به جز اولین توکن در هر دنباله) را محاسبه میکنیم. در طول این مرحله، محاسبه گرادیانها غیرفعال میشود تا مصرف حافظه کاهش یافته و محاسبات سریعتر انجام شود. در پایان، مقدار تابع هزینه را برای دادههای ارزیابی چاپ میکنیم:
# Generate validation data
val_src_data = torch.randint(1, src_vocab_size, (64, max_seq_length)) # (batch_size, seq_length)
val_tgt_data = torch.randint(1, tgt_vocab_size, (64, max_seq_length)) # (batch_size, seq_length)
# Evaluation mode
transformer.eval()
with torch.no_grad():
val_output = transformer(val_src_data, val_tgt_data[:, :-1])
val_loss = criterion(val_output.contiguous().view(-1, tgt_vocab_size), val_tgt_data[:, 1:].contiguous().view(-1))
print(f"Validation Loss: {val_loss.item()}")
همانطور که میبینید ترنسفورمرها ساختار پیچیدهای دارند و بههمین دلیل تنظیم و آموزش آنها نیز کار دشواری است. این پیچیدگی ناشی از تعداد زیادی پارامترها و لایههای مختلف است که در مدلهای ترنسفورمر وجود دارند. هر یک از این لایهها و پارامترها نیاز به تنظیم دقیق و بهینهسازی دارند تا مدل بتواند به خوبی از عهده وظایفی که به آن سپرده شده، برآید.
در نتیجه، برای کسانی که به دنبال استفاده از ترنسفورمر با PyTorch هستند، بهرهگیری از ابزارها و منابع مناسب بسیار مهم است. Hugging Face یکی از این ابزارها است. Hugging Face یک پلتفرم منبعباز پیشرو در زمینه پردازش زبان طبیعی و یادگیری ماشینی است. این مجموعه با توسعه کتابخانه Transformers و ارائه مدلهای از پیش آموزشدیده، فرآیند کار با ترنسفورمرها را به طور قابل توجهی سادهتر کرده است. با استفاده از منابع و ابزارهای ارائهشده توسط Hugging Face، محققان و توسعهدهندگان میتوانند به سرعت و با سهولت بیشتری مدلهای ترنسفورمر را پیادهسازی و بهینهسازی کنند.
برای آشنایی بیشتر با این پلتفرم پیشنهاد میکنیم مقاله پلتفرم Hugging Face چیست و چه کاربردهایی دارد؟ را بخوانید.
استفاده از مدلهای ترنسفورمر پیشآموزشدیده با Hugging Face
در این قسمت نحوه استفاده از مدلهای پیشآموزشدیده ترنسفورمر را با کتابخانه Transformers بررسی خواهیم کرد و مراحل مختلف پیادهسازی آنها را به شما نشان خواهیم داد. درواقع ما میخواهیم با کمک مدل از پیشآموزشدیده BERT نظرات کاربران سایت IMDB را طبقهبندی کنیم و این کار را با استفاده از مدلهای موجود در پلتفرم Hugging Face انجام خواهیم داد.
برای این منظور ابتدا کتابخانههای مورد نیاز را فراخوانی میکنیم:
# nlp
import nltk
nltk.download('stopwords')
from nltk.corpus import stopwords
nltk.download("wordnet")
nltk.download('omw-1.4')
from nltk.corpus import wordnet as wn
nltk.download('punkt')
from nltk.tokenize import word_tokenize
# pytorch
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader, Dataset
from transformers import BertTokenizer, BertModel
# others
import os
import re
import requests
import numpy as np
import matplotlib.pyplot as plt
from sklearn.manifold import TSNE
from sklearn.model_selection import train_test_split
بارگذاری دادههای IMDB
در قسمت بعد باید مجموعه داده نقد و بررسی فیلمهای سایت IMDB را بارگذاری کنیم. این مجموعه داده شامل نظرات مثبت و منفی کاربران است که از دو فایل متنی به دست میآیند. تابع download_imdb_data نقدهای مثبت و منفی را از URL های مشخص شده دانلود میکند، آنها را به نقدهای جداگانه تقسیم کرده و در یک لیست به نام reviews ترکیب میکند. برچسبهای متناظر (۱ برای نقدهای مثبت و ۰ برای نقدهای منفی) ایجاد شده و در لیست labels ذخیره میشوند. این تابع در نهایت دو لیست reviews و labels را برمیگرداند:
# Load IMDB dataset
def download_imdb_data():
pos_url = 'https://raw.githubusercontent.com/dennybritz/cnn-text-classification-tf/master/data/rt-polaritydata/rt-polarity.pos'
neg_url = 'https://raw.githubusercontent.com/dennybritz/cnn-text-classification-tf/master/data/rt-polaritydata/rt-polarity.neg'
pos_reviews = requests.get(pos_url).text.split('\n')
neg_reviews = requests.get(neg_url).text.split('\n')
reviews = pos_reviews + neg_reviews
labels = [1] * len(pos_reviews) + [0] * len(neg_reviews)
return reviews, labels
reviews, labels = download_imdb_data()
پیشپردازش متون
در این بخش باید یک تابع برای پاکسازی و پیشپردازش دادههای متنی تعریف کنیم. این تابع با استفاده از کتابخانه nltk جمله ورودی را به صورت زیر پردازش میکند:
stop_words = stopwords.words('english')
def clean_text(sentence):
sentence = str(sentence).lower()
sentence = re.sub('[^a-z]',' ',sentence)
sentence = word_tokenize(sentence)
sentence = [i for i in sentence if i not in stop_words]
sentence = [i for i in sentence if len(i)>2]
sentence = ' '.join(sentence)
return sentence
که در آن:
- جمله به حروف کوچک تبدیل میشود تا تفاوت حروف بزرگ و کوچک از بین برود.
- تمامی کاراکترهای غیر حرفی (مانند اعداد و نشانهها) با یک فضای خالی جایگزین میشوند.
- جمله به توکنهای جداگانه تقسیم میشود.
- کلماتی که در لیست کلمات توقف (stopwords) قرار دارند، حذف میشوند.
- کلماتی که طول آنها کمتر از ۳ حرف است، حذف میشوند.
- توکنهای باقیمانده دوباره به یک جمله تبدیل میشوند.
- در نهایت، جمله پاکسازی شده توسط تابع برگردانده میشود.
پیش از اعمال این تابع روی مجموعه نظرات، آنها را به دو بخش آموزشی و آزمایشی تبدیل میکنیم:
# Train Test Split
X_train, X_val, y_train, y_val = train_test_split(reviews, labels, test_size=0.2, random_state=42)
# Apply clean text on the reviews
for i in range(len(X_train)):
X_train[i] = clean_text(X_train[i])
حال تابع clean_text را روی نظرات اعمال میکنیم:
for i in range(len(X_val)):
X_val[i] = clean_text(X_val[i])
ایجاد کلاس MyDataset
کد زیر یک کلاس به نام MyDataset تعریف میکند که از کلاس Dataset کتابخانه torch.utils.data ارثبری میکند. این کلاس برای مدیریت دادههای ورودی به مدلهای یادگیری ماشین طراحی شده است:
class MyDataset(Dataset):
def __init__(self, encoded, label):
self.input_ids = encoded['input_ids']
self.attention_mask = encoded['attention_mask']
self.label = label
def __getitem__(self, index):
ids = self.input_ids[index]
masks = self.attention_mask[index]
lbls = self.label[index]
return ids, masks, lbls
def __len__(self):
return len(self.input_ids)
این کلاس ۳ متد اصلی دارد که در ادامه آنها را توضیح میدهیم:
- __init__: این متد سازنده کلاس است و در هنگام ایجاد یک نمونه جدید از MyDataset فراخوانی میشود. ورودیهای این متد encoded (یک دیکشنری حاوی input_ids و attention_mask) و label (برچسبهای مربوط به دادهها) هستند که بهعنوان ویژگیهای کلاس برگردانده میشوند.
- __getitem__: این متد برای دسترسی به یک نمونه از دادهها استفاده میشود. ورودی آن یک شاخص (index) است که مشخص میکند کدام نمونه باید بازگردانده شود.
- __len__: این متد تعداد کل نمونههای موجود در دیتاست را با استفاده از طول input_ids بازمیگرداند.
Tokenize کردن متن پاکسازیشده
در این قسمت با استفاده کتابخانه transformers، توکنایزر BERT را که یکی از معروفترین مدلهای پیشآموزشدیده برای پردازش زبان طبیعی است، بارگذاری میکنیم:
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
کد بالا یک توکنایزر BERT را بارگذاری میکند که از مدل bert-base-uncased استفاده میکند. این توکنایزر مسئول تبدیل متن خام به توکنهایی است که مدل BERT میتواند با آنها کار کند. بخش uncased در اسم آن به این معناست که تفاوت بین حروف بزرگ و کوچک در نظر گرفته نمیشود.
سپس خود مدل BERT را بارگذاری میکنیم که آن نیز از مدل bert-base-uncased استفاده میکند:
embedder = BertModel.from_pretrained('bert-base-uncased', output_hidden_states=True)
پارامتر output_hidden_states=True در این کد به مدل میگوید که وضعیتهای پنهان (hidden states) را در هر لایه بازگرداند. این وضعیتهای پنهان میتوانند بهعنوان بردارهای تعبیه کلمات متن نظرات استفاده شوند.
در پایان مدل BERT را در حالت ارزیابی قرر میدهیم تا برخی از رفتارهای مدل که مخصوص آموزش هستند، غیرفعال شوند. این کار باعث میشود که مدل در حین پیشبینی پایدارتر و قابل اعتمادتر باشد:
embedder.eval()
حال باید با استفاده از توکنایزر تعریفشده، مجموعه داده آموزشی را توکنایز کنیم:
# Make Train dataset
train_encoded = tokenizer(X_train, padding=True, truncation=True, max_length=100, return_tensors='pt')
دلیل استفاده از هر یک از پارامترهای این تابع را در ادامه توضیح خواهیم داد:
- padding=True برای اطمینان از یکنواخت بودن طول توکنها است.
- max_length=100 حداکثر طول توکنها است.
- truncation=True برای قطع کردن توکنها است (در صورتی که طول آنها بیش از ۱۰۰ باشد).
- ‘return_tensors=’pt برای بازگرداندن خروجی به صورت tensorهای PyTorch است.
سپس باید با دادههای توکنایز شده (train_encoded) و برچسبها (y_train) دیتاست آموزشی را با استفاده از کلاس MyDataset بسازیم:
trainset = MyDataset(train_encoded, y_train)
درنهایت دادههای آموزشی با استفاده از کلاس DataLoader بارگذاری میشوند. این کلاس مسئول مدیریت دستههای (batch) داده برای آموزش مدل است:
train_loader = DataLoader(trainset, batch_size=16)
همه این کارها را باید برای مجموعه داده ارزیابی نیز انجام دهیم:
# Make validation dataset
val_encoded = tokenizer(X_val, padding=True, truncation=True, max_length=100, return_tensors='pt')
valset = MyDataset(val_encoded, y_val)
val_loader = DataLoader(valset, batch_size=16)
تعریف مدل
درادامه یک کلاس به نام Classifier تعریف میکنیم که از کلاس nn.Module در PyTorch ارثبری میکند. این کلاس یک مدل شبکه عصبی برای طبقهبندی متن است که از مدل BERT به عنوان بخش تعبیهکننده (embedder) استفاده میکند:
class Classifier(nn.Module):
def __init__(self, embedder):
super(Classifier, self).__init__()
self.bert = embedder
self.drop1 = nn.Dropout()
self.fc1 = nn.Linear(768, 8)
self.drop2 = nn.Dropout(0.8)
self.batch1 = nn.BatchNorm1d(8)
self.fc2 = nn.Linear(8, 1)
self.batch2 = nn.BatchNorm1d(1)
self.sigmoid = nn.Sigmoid()
متد __init__ سازنده کلاس است که در هنگام ایجاد یک نمونه جدید از Classifier فراخوانی میشود و ورودی آنembedder است. در این تابع:
- self.bert مدل BERT را ذخیره میکند که به عنوان ورودی به این کلاس داده شده است.
- self.drop1 یک لایه دراپاوت برای کاهش بیشبرازش با نرخ پیشفرض ۰.۵ است.
- self.fc1 یک لایه کاملا متصل با ۷۶۸ نورون ورودی (ابعاد بردارهای تعبیه BERT) و ۸ نورون خروجی است.
- self.drop2 یک لایه دراپاوت دیگر با نرخ ۰.۸ است.
- self.batch1 یک لایه نرمالسازی دستهای یا Batch Normalization است.
- self.fc2 یک لایه کاملا متصل دیگر با ۸ نورون ورودی و ۱ نورون خروجی است.
- self.batch2 لایه نرمالسازی دستهای دیگر است.
- self.sigmoid یک تابع فعالسازی سیگموید برای تبدیل خروجی به یک مقدار بین ۰ و ۱
حال باید متد forward را به این کلاس اضافه کنیم. این متد مشخص میکند که دادهها چگونه از طریق لایههای مختلف مدل عبور میکنند:
def forward(self, input_ids, attention_mask):
x = self.bert(input_ids, attention_mask)[1]
x = self.drop1(x)
x = self.fc1(x)
x = self.drop2(x)
x = self.batch1(x)
x = self.fc2(x)
x = self.batch2(x)
x = self.sigmoid(x)
return x
متد آخر، get_embeddings است که برای استخراج تعبیهها (embeddings) از مدل BERT استفاده میشود. بعدا از این تابع برای استخراج بردارهای تعبیههای برت و نمایش آنها در دو بعد بهواسطه t-SNE استفاده میکنیم:
def get_embeddings(self, input_ids, attention_mask):
# Extract embeddings from BERT
with torch.no_grad():
embeddings = self.bert(input_ids, attention_mask=attention_mask)[1]
return embeddings
در پایان یک نمونه از کلاس مدل خود میسازیم و آن را در متغیر model قرار میدهیم:
model = Classifier(embedder)
حال با کد زیر مدل را به GPU (درصورت موجودبودن) منتقل میکنیم:
# Transport model to GPU
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
model = model.to(device)
تنظیم تابع هزینه، بهینهساز و پارامترهای آموزش
حال نوبت به تعیین تابع هزینه و بهینهساز میرسد. برای تابع هزینه از باینری کراسانتروپی (Binary Cross-Entropy Loss) استفاده میکنیم که برای مسائل طبقهبندی دودویی مناسب است. همچنین بهینهساز AdamW را برای بهروزرسانی وزنهای مدل با نرخ یادگیری مشخص تنظیم میکنیم:
# Loss function and Optimizer
criterion = nn.BCELoss().to(device)
optimizer = optim.AdamW(model.parameters(), lr=27e-6)
سپس چند پارامتر پارامتر را برای آموزش مدل تنظیم میکنیم. با num_epochs تعداد کل دورههای (epochs) آموزش مدل را به ۲۰ تعیین میکنیم. با patience تعداد دورههایی که مدل میتواند بدون بهبود در خطای ارزیابی به کار خود ادامه دهد را مشخص میکنیم، یعنی اگر به مدت ۵ دوره متوالی بهبودی مشاهده نشود، فرایند آموزش متوقف میشود. با best_val_loss بهترین مقدار خطای ارزیابی اولیه و با best_epoch بهترین دوره را مقداردهی اولیه میکنیم. همه این پارامترها در اجرای مکانیزم توقف زودهنگام استفاده خواهند شد:
num_epochs = 20
patience = 5 # Number of epochs to wait before stopping training
best_val_loss = float('inf')
best_epoch = 0
آموزش مدل
دراین مرحله ابتدا مدل را بهحالت آموزش میبریم (model.train). سپس دادههای آموزشی را به GPU منتقل میکنیم و بعد از صفر کردن گرادیانها در هر مرحله، پیشبینی مدل را در متغیر outputs میریزیم. درادامه باید خطای بین پیشبینی مدل و برچسبها را محاسبه و با استفاده از عملیات پسانتشار (backpropagation) گرادیانها را محاسبه و وزنهای مدل را بهروزرسانی کنیم. درپایان، مجموع خطاهای آموزش در طول هر دوره را جمعآوری و میانگینگیری میکنیم تا میانگین خطای آموزش محاسبه شود. این فرآیند برای هر دوره تکرار میشود تا مدل به طور کامل آموزش داده شود:
# Lists to store loss values
train_losses = []
val_losses = []
for epoch in range(num_epochs):
# Train phase
model.train()
# Initialize the epoch loss
epoch_train_loss = 0
# Iterate over train dataset batches
for train_input_ids, train_attention_mask, train_labels in train_loader:
# Transfer data to cuda
train_input_ids = train_input_ids.to(device)
train_attention_mask = train_attention_mask.to(device)
train_labels = train_labels.to(device)
# Clear the gradients
optimizer.zero_grad()
# Prediction of the model
outputs = torch.flatten(model(train_input_ids, train_attention_mask))
# Calculate loss between labels and model predictions
loss = criterion(outputs, train_labels.float())
# Backpropagation
loss.backward()
# Update weights
optimizer.step()
epoch_train_loss += loss.item()
epoch_train_loss /= len(train_loader)
train_losses.append(epoch_train_loss)
ارزیابی مدل
برای ارزیابی عملکرد مدل ترنسفورمر با PyTorch نیز، در پایان هر دوره آموزشی، مدل را به حالت ارزیابی برده (model.eval) و مجددا دادههای ورودی را به GPU منتقل میکنیم. سپس پیشبینیهای مدل را برای دادههای ارزیابی تولید و با استفاده از torch.no_grad، کاری میکنیم که محاسبات گرادیان انجام نشود، که این امر باعث کاهش مصرف حافظه و افزایش سرعت پردازش میشود. درپایان خطای ارزیابی برای هر دسته از دادههای ارزیابی محاسبه و جمعآوری میشود و در نهایت، میانگین خطای آن برای کل دادههای ارزیابی محاسبه میشود:
# Validation phase
model.eval()
epoch_val_loss = 0
with torch.no_grad():
for val_input_ids, val_attention_mask, val_labels in val_loader:
val_input_ids = val_input_ids.to(device)
val_attention_mask = val_attention_mask.to(device)
val_labels = val_labels.to(device)
val_outputs = torch.flatten(model(val_input_ids, val_attention_mask))
loss = criterion(val_outputs, val_labels.float())
epoch_val_loss += loss.item()
epoch_val_loss /= len(val_loader)
val_losses.append(epoch_val_loss)
print(f'Epoch [{epoch + 1}/{num_epochs}], Training Loss: {epoch_train_loss:.4f}, Validation Loss: {epoch_val_loss:.4f}')
توقف زودهنگام
بعد از قسمت ارزیابی، بهکمک مکانیزم توقف زودهنگام (Early Stopping) میتوانیم از بیشبرازش (Overfitting) مدل جلوگیری کنیم. بهاینصورت که در هر دوره وزنهای مدلی که تا آن لحظه کمترین خطای ارزیابی را داشته در مسیر مشخصشده ذخیره میکنیم و همچنین اگر عملکرد مدل (در اینجا ما خطای ارزیابی را ملاک قراردادیم) برای چند دوره متوالی بهبود نیافت، آموزش مدل را متوقف میکنیم:
# Check if the validation loss improved for Early stopping
if epoch_val_loss < best_val_loss:
best_val_loss = epoch_val_loss
best_epoch = epoch
# Save the best model
torch.save(model.state_dict(), os.path.join(model_dir, 'best_model.pth'))
print(f'Best model saved at epoch {epoch + 1}')
درواقع با شرط epoch – best_epoch > patience بررسی میکنیم که اگر تعداد دورههایی که مدل بدون بهبود در خطای ارزیابی آموزش دیده بیشتر از مقدار patience شد، حلقه آموزش را با دستور break متوقف کنیم:
# Check early stopping condition
if epoch - best_epoch > patience:
print(f'Early stopping at epoch {epoch + 1}')
break
محاسبه دقت مدل
حال برای محاسبه دقت مدلمان، ابتدا بهترین مدل آموزشدیده را بارگذای میکنیم:
# Load the best model
model.load_state_dict(torch.load(os.path.join(model_dir, 'best_model.pth')))
print('Best model loaded.')
سپس مدل را در حالت ارزیابی قرارداده، دو لیست برای ذخیره مقادیر پیشبینیها و برچسبها ایجاد و سپس محاسبات گرادیان را غیر فعال میکنیم. دادهها را به GPU منتقل میکنیم و پیشبینی مدل را در متغیر outputs ذخیره میکنیم. درادامه نیز با کد predicted_classes = (outputs > 0.5).float پیشبینیها را به کلاسهای باینری تبدیل میکنیم. بهاینصورت که اگر خروجی مدل بزرگتر از ۰.۵ شد، آن را در کلاس مثبت و در غیر این صورت به کلاس منفی قرار میدهیم و آن را به لیست مربوطهاش اضافه میکنیم. درپایان نیز با محاسبه تعداد پیشبینیهای درست مدل و تقسیم آن بر کل دادههای ارزیابی، دقت آن را بهدست میآوریم:
# Prediction phase
model.eval()
all_predictions = []
all_labels = []
with torch.no_grad():
for test_input_ids, test_attention_mask, test_labels in val_loader:
test_input_ids = test_input_ids.to(device)
test_attention_mask = test_attention_mask.to(device)
test_labels = test_labels.to(device)
outputs = model(test_input_ids, test_attention_mask)
predicted_classes = (outputs > 0.5).float()
all_predictions.extend(predicted_classes.cpu().numpy())
all_labels.extend(test_labels.cpu().numpy())
correct_predictions = (np.array(all_predictions).flatten() == np.array(all_labels)).sum()
accuracy = correct_predictions / len(all_labels)
print(f'Accuracy: {accuracy:.4f}')
Accuracy: 0.8425
درنهایت مدل ما توانست با دقت ۸۴ درصد نظرات کاربران سایت IMDB را طبقهبندی کند.
ترسیم بردارهای تعبیه BERT در دو بُعد
برای فهم بهتر الگوها و توزیع دادهها در فضای تعبیه برداریای که BERT ساخته است، با استفاده از کد زیر بردارهای تعبیه را از دادههای آموزشی استخراج کرده، با استفاده از t-SNE ابعاد آنها را کاهش داده و در یک نمودار دو بعدی رسم میکنیم:
embeddings = []
labels = []
for text, label in zip(X_train, y_train):
encoded = tokenizer(text, padding=True, truncation=True, max_length=100, return_tensors='pt')
ids = encoded['input_ids'].to(device)
mask = encoded['attention_mask'].to(device)
embedding = model.get_embeddings(ids, mask)
if isinstance(embedding, torch.Tensor):
embedding = embedding.detach().cpu().numpy()
embeddings.append(embedding)
labels.append(label)
# Combine embeddings
embeddings = np.vstack(embeddings)
labels = np.array(labels)
# Reduce dimensions using t-SNE with lower perplexity
perplexity = min(5, len(embeddings) - 1)
tsne = TSNE(n_components=2, perplexity=perplexity, random_state=42)
embeddings_2d = tsne.fit_transform(embeddings)
plt.figure(figsize=(10, 8))
for label in np.unique(labels):
indices = np.where(labels == label)
plt.scatter(embeddings_2d[indices, 0], embeddings_2d[indices, 1], label=f'Class {label}', marker='^' if label == 0 else 'o')
plt.title('t-SNE visualization of embeddings')
plt.xlabel('t-SNE dimension 1')
plt.ylabel('t-SNE dimension 2')
plt.legend()
plt.show()
خروجی کد بالا بهصورت زیر است:
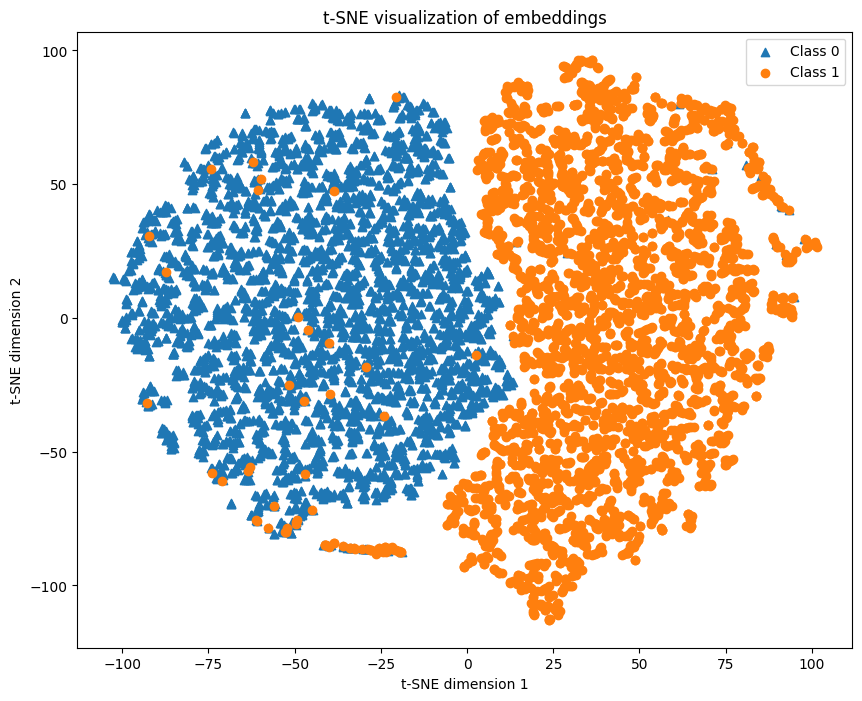
این نمودار نشان میدهد که کلاسهای مثبت و منفی در فضای بردارهای تعبیه بهخوبی ازهم جدا شدهاند. این یعنی مدل برت بهعنوان استخراجکننده بردارهای تعبیه (embedder) از متن، بهخوبی توانسته تفاوتهای بین این دو کلاس را منعکس کند و نهایتا کار مدل طبقهبندیکننده (Classifier) را برای تفکیک این دو کلاس آسان کرده است. دستهی دادههای آبی رنگ (کلاس ۰ یا منفی) عمدتاً در سمت چپ نمودار قرار دارند و دستهی دادههای نارنجی رنگ (کلاس یک یا مثبت) عمدتاً در سمت راست نمودار قرار گرفتهاند. جدا بودن این دو کلاس در نمودار t-SNE بیانگر قدرت مدل در تمایز بین این دو دسته است.
مجموعه کامل کدهایی این بخش را میتوانید در این ریپازیتوری از گیتهاب مشاهده کنید.
جمعبندی درباره مدلهای ترنسفورمر با PyTorch
ترنسفورمرها با مکانیزمهای پیشرفتهای مانند توجه چندسر و پردازش موازی، توانستهاند انقلابی در حوزه پردازش زبان طبیعی و یادگیری عمیق ایجاد کنند. این مدلها با دقت و کارایی بالای خود، در کاربردهای مختلفی از ترجمه ماشینی گرفته تا تولید خودکار متن و تشخیص گفتار، عملکرد بینظیری را به نمایش گذاشتهاند. کتابخانه PyTorch نیز بهعنوان ابزاری قدرتمند و انعطافپذیر، امکان پیادهسازی و بهینهسازی این مدلها را برای پژوهشگران فراهم کرده است.
ما در این مقاله، به بررسی ساختار و عملکرد ترنسفورمرها و پیادهسازی آنها با استفاده از کتابخانه PyTorch پرداختیم. با تحلیل و بررسی هر یک از مراحل و اجزای مختلف این مدلها، نحوهی اعمال توجه، نرمالسازی و پیشخور کردن دادهها را توضیح دادیم. همچنین، نشان دادیم که چگونه میتوان از این مدلها برای بهبود عملکرد در وظایف مختلف پردازش زبان طبیعی استفاده کرد. امیدواریم که این مقاله توانسته باشد به درک بهتر و عمیقتر شما از ترنسفورمرها و نحوهی پیادهسازی آنها کمک کند.

سوالات متداول
چگونه میتوان از ترنسفورمرها برای بهبود مدلهای ترجمه ماشینی استفاده کرد؟
مدلهای ترنسفورمر با استفاده از مکانیزم توجه توانایی درک و مدیریت وابستگیهای بلندمدت در جملات را دارند. این ویژگی باعث میشود ترجمههای دقیقتری نسبت به مدلهای سنتی مانند RNNها ارائه دهند. در پیادهسازی با PyTorch، میتوان از ماژولهای آماده برای ساخت و آموزش مدلهای ترجمه ماشینی استفاده کرد.
مکانیزم توجه چندسر چگونه در مدلهای ترنسفورمر کار میکند؟
مکانیزم توجه چندسر (Multi-Head Attention) به مدل اجازه میدهد تا از چندین جنبه مختلف به دادهها توجه کند. هر سر توجه (Attention Head) به بخشهای مختلفی از ورودی نگاه میکند و سپس نتایج این توجهها با هم ترکیب میشوند تا یک خروجی جامع تولید شود. این فرآیند باعث میشود مدل بتواند وابستگیهای پیچیده بین دادهها را بهتر درک کند.
پیادهسازی ترنسفورمر با PyTorch چه مزایایی دارد؟
PyTorch یک کتابخانه متنباز و انعطافپذیر است که توسط فیسبوک توسعه داده شده است. این کتابخانه با پشتیبانی قوی از GPUها و قابلیت دیباگ آسان، فرآیند آموزش و ارزیابی مدلهای پیچیده مانند ترنسفورمرها را ساده میکند. همچنین، مستندات جامع و جامعه کاربری فعال PyTorch به توسعهدهندگان کمک میکند تا به سرعت به مشکلات خود پاسخ دهند.
چرا مدلهای ترنسفورمر در تحلیل احساسات موثر هستند؟
مدلهای ترنسفورمر به دلیل تواناییشان در مدیریت وابستگیهای طولانیمدت و توجه به جزئیات مختلف متن، در تحلیل احساسات (Sentiment Analysis) بسیار موثر هستند. این مدلها میتوانند با توجه به کلمات کلیدی و زمینههای مختلف، احساسات مثبت، منفی و خنثی را به دقت تشخیص دهند. PyTorch ابزارهای مناسبی برای پیادهسازی این مدلها فراهم کرده است.
چگونه میتوان مدلهای ترنسفورمر را برای تولید خودکار متن آموزش داد؟
مدلهای ترنسفورمر مانند GPT با استفاده از دادههای بزرگ و متنوع، توانایی تولید متونی با سبک و سیاق انسانی را دارند. برای آموزش این مدلها، ابتدا نیاز است دادههای متنی مناسب جمعآوری و پیشپردازش شوند. سپس با استفاده از ابزارهای موجود مانند PyTorch، مدل ترنسفورمر طراحی و آموزش داده میشود تا بتواند متونی با کیفیت بالا و طبیعی تولید کند.
یادگیری ماشین لرنینگ را از امروز شروع کنید!
دنیای دادهها جذاب است و دانستن علم داده، توانایی تحلیل داده، یا بازاریابی مبتنی بر داده، شما را برای فرصتهای شغلی بسیاری مناسب میکند. فارغ از رشته و پیشزمینه، میتوانید حالا شروع کنید و از سطح مقدماتی تا پیشرفته بیاموزید. اگر دوست دارید به این حوزه وارد شوید، پیشنهاد میکنیم با کلیک روی این لینک قدم اول را همین حالا بردارید.
مشاوران کافهتدریس به شما کمک میکنند مسیر یادگیری برای ورود به این حوزه را شروع کنید: