
امروز با یکی دیگر از فصلهای تجربیات ما در مسابقات Kaggle همراه شما هستیم. پس از بررسی مراحل انجام اولین مسابقه ما درباره پیشبینی سن صدفها، این بار با یک چالش جدید روبرو هستیم: پیشبینی احتمال وقوع سیل با استفاده از مدلهای رگرسیون. در این مقاله، تجربیات خود را از سری مسابقات Kaggle Playground فصل ۴، قسمت ۵ با شما به اشتراک میگذاریم. به بررسی پیچیدگیهای پیشبینی سطح سیل و استراتژیهایی که برای بهبود مدلهای خود، بهویژه با استفاده از کتابخانه Optuna ، به کار بردهایم، خواهیم پرداخت.
- 1. رقابت و توضیحات مجموعهداده سیل
- 2. تحلیل اکتشافی دادهها (EDA)
- 3. پیشپردازش داده
- 4. مهندسی ویژگی
- 5. انتخاب، آموزش و بهبود مدل با کتابخانه Optuna
- 6. ارزیابی مدل: بررسی عمیق R² و RMSE
- 7. فرآیند ارسال: راهبردهای موثر برای رقابت در Kaggle
- 8. درسهای کلیدی آموخته شده
- 9. نتیجهگیری: یادگیری از طریق چالشهای علم داده
- 10. یادگیری ماشین لرنینگ را از امروز شروع کنید!

تیم ما، به همراه راهنمایی استادمان رضا شکرزاد، این مسابقه را با هدف پیشبینی احتمال وقوع سیل و ساخت یک مدل قابل اعتماد آغاز کرد. ما از ابزارهای پیشرفتهای مانند کتابخانه Optuna برای بهینهسازی هایپرپارامترها استفاده کردیم و ویژگیهای آماری خاصی را برای بهبود مدلهای رگرسیون خود ایجاد کردیم.
در ادامه مروری بر روش کار ما، درسهایی که آموختیم و دیدگاههای منحصربهفردی که به دست آوردیم، آورده شده است.
رقابت و توضیحات مجموعهداده سیل
درباره مسابقه و بیان مسئله
در مسابقه “رگرسیون با مجموعه دادههای پیشبینی سیل”، وظیفه ما توسعه مدلی است که بتواند بهطور دقیق احتمال وقوع سیل را بر اساس عوامل مختلف پیشبینی کند. این چالش فرصتی عالی برای بهکارگیری و بهبود مهارتهای یادگیری ماشین ما، در پیشبینی یک بلای طبیعی بحرانی است که بسیاری از مناطق جهان را تحت تأثیر قرار میدهد. مسابقه از R2 برای ارزیابی مدلها استفاده میکند که میزان تطابق پیشبینیهای ما با احتمال واقعی وقوع سیل را اندازهگیری میکند.
تشخیص و پیشبینی سیل برای مدیریت و کاهش اثرات بلایای طبیعی بسیار حیاتی است. به طور سنتی، پیشبینی سیل نیاز به پایش گسترده محیطی و تحلیل دادهها دارد که اغلب نیازمند ورودیهای دستی قابل توجه و ارزیابی در زمان واقعی است. این مسابقه فرآیند را با استفاده از عوامل محیطی برای پیشبینی احتمال وقوع سیل ساده میکند و یک رویکرد کارآمد برای پیشبینی سیل ارائه میدهد.
درک مجموعه دادهها
مجموعه دادههای این مسابقه، شامل مجموعههای آموزشی و آزمایشی (train & test)، از یک مدل یادگیری عمیق که بر روی دادههای عوامل پیشبینی سیل آموزش دیده، تولید شده است. این مجموعه داده شامل ۲۲ ویژگی (Feature) است که همگی در ریسک وقوع سیل تأثیرگذار هستند:
- id: شناسه منحصربهفرد برای هر مشاهده.
- MonsoonIntensity: شدت بارشهای موسمی.
- TopographyDrainage: کارایی زهکشی بر اساس توپوگرافی منطقه.
- RiverManagement: مدیریت رودخانهها و جریانهای آنها.
- Deforestation: نرخ جنگلزدایی.
- Urbanization: سطح توسعه شهری.
- ClimateChange: شاخصهای تأثیر تغییرات آب و هوایی.
- DamsQuality: کیفیت و وضعیت سدها.
- Siltation: میزان رسوبگذاری در بستر رودخانهها و مخازن.
- AgriculturalPractices: استفاده از زمین و سیستمهای آبیاری در کشاورزی.
- Encroachments: تصرف غیرقانونی زمینها و منابع آبی.
- IneffectiveDisasterPreparedness: آمادگی ناکافی برای بلایای طبیعی.
- DrainageSystems: وضعیت سیستمهای زهکشی و فاضلاب.
- CoastalVulnerability: آسیبپذیری مناطق ساحلی در برابر سیل.
- Landslides: خطر زمینلغزش.
- Watersheds: وضعیت حوضههای آبریز.
- DeteriorationOfInfrastructure: تخریب زیرساختها.
- PopulationScore: تراکم جمعیت و عوامل مرتبط.
- WetlandLoss: از دست رفتن تالابها و شرایط منابع آبی.
- InadequatePlanning: برنامهریزی ناکافی و مدیریت مشکلات.
- PoliticalFactors: تأثیرات سیاسی بر ریسک سیل.
- FloodProbability: احتمال وقوع سیل (متغیر هدف).
با استفاده از این مجموعه داده، هدف ما ساخت یک مدل رگرسیون قوی است که بتواند احتمال وقوع سیل را بهطور مؤثر پیشبینی کند. با تحلیل این ویژگیها، میتوانیم به نتایج ارزشمندی در مورد اینکه کدام عوامل بیشترین تأثیر را بر ریسک سیل دارند، دست یابیم و چگونه میتوانیم بهتر برای سیلها آماده شده و از پیامدهای آنها کاسته شود.
تحلیل اکتشافی دادهها (EDA)
در این بخش، به تحلیل اکتشافی دادههای (Exploratory data analysis – EDA) مجموعه داده پیشبینی سیل میپردازیم، ساختار دادهها و توزیعهای رسم شده را بررسی کرده و روابط ویژگیها را تحلیل کردیم تا به نتایج ارزشمندی دست یابیم.
بررسی توزیع و نرمال بودن دادهها
ابتدا با رسم هیستوگرام (Histogram) برای هر ویژگی، توزیع آنها را بررسی کردیم. در بررسیهایمان، توزیعهایی نزدیک به نرمال برای تمامی ویژگیها مشاهده شد که فرآیند پیشپردازش را سادهتر کرد. یکنواختی در توزیع دادهها نشاندهنده کم بودن تعداد دادههای پرت می باشد. به عبارتی مجموعه دادهای با رفتار مناسب را نشان می دهد که با فرضیات مدلهای رگرسیون ما همخوانی داشت.
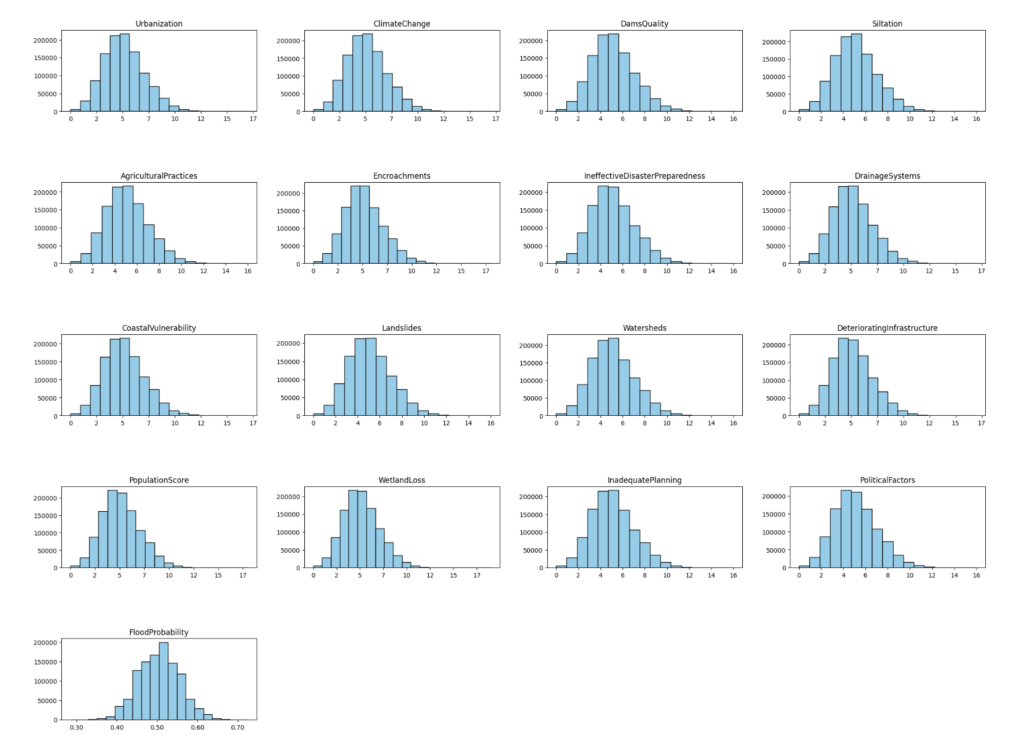
- نتیجه این بخش: تشخیص توزیع نرمال ویژگیها میتواند فرآیند پیشپردازش را سادهتر کند و سازگاری مدل را بدون نیاز به تبدیلهای پیچیده بهبود بخشد. عبارت سازگاری مدل، به معنای تطابق یا همخوانی مدل با دادههای ورودی و مسئلهی پیش رو است. در واقع، اگر ویژگیها دارای توزیع نزدیک به نرمال باشند، مدلهای رگرسیون و یادگیری ماشین که بر اساس فرضیات نرمالیته ساخته شدهاند، بهتر عمل میکنند.
تحلیل دادههای پرت
ما با استفاده از نمودارهای جعبهای (Boxplots) مجموعه داده را برای دادههای پرت (Outliers) بررسی کردیم. هرچند که ما تعداد بسیار کمی از دادههای پرت را شناسایی کردیم، اما پرداختن به این دادههای پرت (حذف و یا تغییر مقادیرشان) باعث بهبود عملکرد مدل ما نشد. در واقع، دقت پیشبینی ما را کاهش داد. به همین دلیل، تصمیم گرفتیم که دادههای پرت را به صورت فعلی حفظ کنیم. در بخش زیر، نتیجه تحلیل دادههای پرت ما نمایش داده شده است.
Column MonsoonIntensity outliers = 0.83% (9244 out of 1117957)
Column TopographyDrainage outliers = 0.86% (9575 out of 1117957)
Column RiverManagement outliers = 2.65% (29617 out of 1117957)
Column Deforestation outliers = 2.53% (28235 out of 1117957)
Column Urbanization outliers = 0.82% (9184 out of 1117957)
Column ClimateChange outliers = 0.78% (8702 out of 1117957)
Column DamsQuality outliers = 2.78% (31097 out of 1117957)
Column Siltation outliers = 0.81% (9079 out of 1117957)
Column AgriculturalPractices outliers = 0.81% (9006 out of 1117957)
Column Encroachments outliers = 2.79% (31141 out of 1117957)
Column IneffectiveDisasterPreparedness outliers = 0.80% (8945 out of 1117957)
Column DrainageSystems outliers = 2.69% (30060 out of 1117957)
Column CoastalVulnerability outliers = 0.91% (10209 out of 1117957)
Column Landslides outliers = 0.79% (8865 out of 1117957)
Column Watersheds outliers = 0.83% (9245 out of 1117957)
Column DeterioratingInfrastructure outliers = 0.80% (8971 out of 1117957)
Column PopulationScore outliers = 0.83% (9290 out of 1117957)
Column WetlandLoss outliers = 2.64% (29499 out of 1117957)
Column InadequatePlanning outliers = 0.83% (9299 out of 1117957)
Column PoliticalFactors outliers = 0.87% (9707 out of 1117957)
Column FloodProbability outliers = 0.50% (5579 out of 1117957)
- نتیجه این بخش: گاهی اوقات، پرداختن به دادههای پرت میتواند به طرز منفی بر عملکرد مدل تأثیر بگذارد. بسیار مهم است که اثرات پردازش دادههای پرت را در مجموعه داده خاص خود آزمایش و اعتبارسنجی کنید.
تحلیل مقادیر منحصر به فرد
ما در مرحلهی بعدی، مقادیر منحصر به فرد در هر ویژگی و فراوانی آنها را ارزیابی کردیم. این مرحله به ما کمک کرد تا برخی از متغیرهای دارای طبیعت دستهای (Categorical) را درک کنیم و اطمینان حاصل کنیم که هیچ ورودی نادرست یا غیرمنتظرهای وجود ندارد.
- نتیجه این بخش: بررسی مقادیر منحصر به فرد یک بررسی اولیه سریع را فراهم میکند و به شناسایی هر گونه نقص یا نیازهای پیشپردازش برای ویژگیهای دستهای (Categorical) کمک میکند.
همبستگی و روابط ویژگیها
ما با استفاده از یک نمودار Heatmap، همبستگی (Correlation) بین ویژگیها و متغیر هدف را بررسی کردیم. تحلیل نشان داد که همه ویژگیها فقط همبستگی متوسطی با متغیر هدف، “FloodProbability” داشتند، که مقادیر آن بین 0.17 تا 0.19 بود. این نشان میدهد که هر یک از ویژگیها به تنهایی قدرت پیشبینی بالایی ندارند، اما به طور کلی، هنگام استفاده از آنها به صورت تجمعی در مدل، هنوز میتوانند به تحلیلهای ارزشمندی منجر شوند.
مقادیر همبستگی بین هر ویژگی و متغیر هدف، FloodProbability:
Encroachments 0.463551
TopographyDrainage 0.458728
InadequatePlanning 0.455136
PopulationScore 0.451415
Watersheds 0.450488
Siltation 0.449248
MonsoonIntensity 0.444528
DeterioratingInfrastructure 0.444167
IneffectiveDisasterPreparedness 0.443369
Urbanization 0.442168
DrainageSystems 0.441420
DamsQuality 0.441402
CoastalVulnerability 0.439917
PoliticalFactors 0.437561
WetlandLoss 0.437045
Deforestation 0.434314
ClimateChange 0.429403
RiverManagement 0.426491
Landslides 0.425099
AgriculturalPractices 0.421145
FloodProbability 0.047226
dtype: float64
- نتیجه این بخش: حتی همبستگیهای متوسط در چند ویژگی میتواند به طور کلی به بهبود پیشبینیهای مدل کمک کند. ارزیابی روابط میان ویژگیها به درک تأثیرات ممکن هر ویژگی کمک میکند، که منجر به انتخاب و مهندسی بهتر ویژگیها میشود.
پیشپردازش داده
پیشپردازش داده به طور موثر برای آمادهسازی مجموعه داده برای مدلسازی بسیار حیاتی است. در ادامه، به بررسی جزئیات مراحل پیشپردازشی که برای پیشبینی سیل انجام دادیم، پرداختهایم.
مقیاسبندی و نرمالسازی
بمنظور مقیاسبندی و نرمالسازی (Scaling and Normalization)، با توجه به توزیع نزدیک به نرمال ویژگیها، از StandardScaler برای نرمالسازی داده استفاده کردیم. روش StandardScaler ویژگیها را به گونهای مقیاس میدهد که میانگین آنها صفر و انحراف معیار آنها یک باشد، که به ویژه برای مدلهای حساس به مقیاس ویژگیها مانند رگرسیون، بسیار مفید است.
مقادیر گمشده
در مجموعه داده، هیچ مقدار گمشدهای (Missing Values) وجود نداشت.
- نتیجه این بخش: هر مجموعه دادهای شاید دارای مقادیر گمشده نباشد، اما اهمیت اعتبارسنجی این موضوع قبل از ادامه کار بسیار حیاتی است تا از درستی دادهها اطمینان حاصل شود.
یکپارچگی عملیات با Pipeline
برای حفظ جریان کاری به صورت ساده، ما مراحل پیشپردازش را در یک Pipeline ادغام کردیم. این رویکرد باعث شد که نرمالسازی به صورت یکنواخت بر روی مجموعههای داده آموزش و آزمایش (train & test)، اعمال شود و یکپارچگی با مدل رگرسیون ما را ساده کند.
- نتیجه این بخش: Pipeline عملیات پیشپردازش ومدل پیشبینی را اتوماتیک میکند، که باعث کاهش خطاهای دستی و افزایش قابلیت انتقال در دیتاستهای مختلف میشود.
مهندسی ویژگی
مهندسی ویژگی (Feature Engineering) نقش کلیدی در تبدیل دادههای خام به ویژگیهای مفید دارد که دقت پیشبینی را به طور قابل توجهی افزایش میدهد. در پیشبینی سیل، ایجاد ویژگیهای جدید به ما کمک میکند تا روابط پیچیده بین عوامل محیطی و اجتماعی-اقتصادی را شناسایی کرده و توانایی مدل در پیشبینی احتمال وقوع سیل را بهبود بخشیم.
- نتیجه این بخش: مهندسی ویژگی به شناسایی و استخراج روابط پیچیده در دادهها کمک میکند و بهبود پیشبینی مدلها را تسهیل مینماید. با تمرکز بر این مرحله، میتوانیم ویژگیهایی را ایجاد کنیم که به مدل در پیشبینی دقیقتر احتمال وقوع سیل کمک کند.
ایجاد ویژگیهای جدید برای پیشبینی سیل
درک پیچیدگیهای عوامل ایجاد سیل نیازمند ویژگیهایی است که هم تأثیرات محیطی و هم انسانی را منعکس کنند. مجموعه دادههای ما شامل عوامل محیطی مانند شدت بارانهای موسمی، توپوگرافی (TopographyDrainage) و سیستمهای زهکشی (DrainageSystems)، و همچنین عوامل جمعیتی، اجتماعی و برنامهریزی مانند شهرنشینی، جنگلزدایی و آمادگی ناکافی برای بلایای طبیعی است. با استفاده از دانش تخصصی خود، ویژگیهای جدیدی ایجاد کردیم که تعامل بین این متغیرها را نشان میدهند.
تعاملات زیرساخت و اقلیم
خطرات سیل اغلب از تعامل بین کیفیت زیرساختها و عوامل اقلیمی (Infrastructure and Climate Interactions) ناشی میشود. برای به تصویر کشیدن این تعامل، دو ویژگی تعاملی (interaction) ایجاد کردیم:
- پیشگیری های مرتبط با زیرساخت (InfrastructurePreventionInteraction): این ویژگی از ضرب کیفیت سدها، سیستمهای زهکشی و زیرساختهای عمومی با عوامل مدیریت رودخانهها، آمادگی برای بلایا و برنامهریزی حاصل میشود. این ویژگی نشان میدهد که چگونه اقدامات زیرساختی و پیشگیرانه به صورت ترکیبی بر نتایج سیل تأثیر میگذارند.
- تعامل اقلیمی (ClimateAnthropogenicInteraction): این تعامل شدت بارانهای موسمی و تغییرات اقلیمی را با فعالیتهای انسانی مانند جنگلزدایی، شهرنشینی، فعالیتهای کشاورزی و تصرفات غیرقانونی ضرب میکند. این ویژگی نشان میدهد که چگونه تغییرات اقلیمی، هنگامی که با عوامل انسانی ترکیب میشوند، بر خطرات سیل تأثیر میگذارند.
نکته: برای جلوگیری از تقسیم بر صفر در هنگام ایجاد ویژگیهای جدید که شامل تقسیم میشوند، یک مقدار کوچک، اپسیلون (epsilon)، به مخرج اضافه کردیم. این امر تضمین میکند که حتی اگر برخی ویژگیها دارای مقادیر صفر باشند، از محاسبات غیرممکن که منجر به مقادیر NaN (Not a Number) میشوند، جلوگیری شود.
ویژگیهای آماری برای نتیجه بهتر
ویژگیهای آماری (Statistical Features) در مهندسی ویژگی، به ویژه برای مجموعه دادههای بزرگ، بسیار ارزشمند هستند. این اقدامات اطلاعات را خلاصه میکنند، تفاوتها را نشان میدهند و الگوهایی را که در دادههای خام آشکار نیستند، برجسته میسازند. در ادامه چگونگی استفاده ما از ویژگیهای آماری را توضیح میدهیم:
# Feature Engineering
def Feature_Engineering(data):
epsilon = 1e-9
# Statistical new Features:
data['mean'] = data[original_features].mean(axis=1)
data['std'] = data[original_features].std(axis=1)
data['max'] = data[original_features].max(axis=1)
data['min'] = data[original_features].min(axis=1)
data['median'] = data[original_features].median(axis=1)
data['ptp'] = data[original_features].values.ptp(axis=1)
data['q25'] = data[original_features].quantile(0.25, axis=1)
data['q75'] = data[original_features].quantile(0.75, axis=1)
# Infrastructure and Climate Interactions:
data['InfrastructurePreventionInteraction'] = (data['DamsQuality'] + \
data['DrainageSystems'] + data['DeterioratingInfrastructure'] ) * \
(data['RiverManagement'] + data['IneffectiveDisasterPreparedness'] + \
data['InadequatePlanning'])
data['ClimateAnthropogenicInteraction'] = (data['MonsoonIntensity'] + \
data['ClimateChange'] ) * (data['Deforestation'] + \
data['Urbanization'] + data['AgriculturalPractices'] + \
data['Encroachments'] )
return data
X_train = Feature_Engineering(X_train)
- میانگین (Mean) : نمایانگر مقدار میانگین در تمام ویژگیها برای هر نمونه است. این ویژگی به خصوص برای شناسایی گرایشهای مرکزی (central tendencies) در دادهها مفید است.
- انحراف معیار (Standard Deviation): میزان پراکندگی مقادیر ویژگیها را اندازهگیری میکند. انحراف معیار بالا نشاندهنده تنوع در مقادیر ویژگیها است، در حالی که انحراف معیار پایین یکنواختی را نشان میدهد.
- حداکثر/حداقل (Max/Min) : مقادیر حدی را که ممکن است نشاندهنده دادههای پرت یا آستانههای بحرانی باشند، نشان میدهد.
- میانه (Median) : نشاندهنده نقطه میانی است و به فهم تمایل توزیع کمک میکند.
- دامنه (Peak-to-Peak) : محدوده دادهها را اندازهگیری میکند و بر تنوع تأکید میکند.
- چارکها (Quantiles) : بازتاب پراکندگی دادهها هستند و در درک الگوهای توزیع نقش کلیدی دارند.
چرا ویژگیهای آماری؟
ویژگیهای آماری نقش حیاتی در سادهسازی و خلاصهسازی مجموعه دادههای پیچیده ایفا میکنند. آنها متغیرهای متنوع را به فرمهای قابل مدیریت تبدیل میکنند و بر الگوهای اساسی تمرکز میکنند به جای هر جزئیات کوچک. این خلاصهسازی کمک میکند تا از بیشبرازش (overfitting) جلوگیری شود و بر جنبههای مهم دادهها تمرکز شود، بدون اینکه نویزهایی که میتواند مدلهای پیشبینی را منحرف کند، مورد توجه قرار گیرند. در بررسی های ما، ویژگیهای آماری به طور موثری ساختار اصلی دادههای محیطی و اجتماعی-اقتصادی را به تصویر کشیدند که منجر به پیشبینیهای قویتر شد.
کاربرد آنها در کجا است؟
ویژگیهای آماری به ویژه در مجموعه دادههایی با محدودههای وسیع و توزیعهای متنوع ارزشمند هستند، مانند دادههای مرتبط با عوامل محیطی و اجتماعی-اقتصادی. این مجموعه دادهها اغلب حاوی تنوع و روندهای قابل توجهی هستند که در فرم خام آنها به راحتی قابل مشاهده نیستند. با استفاده از تکنیکهای آماری مانند میانگین، واریانس، میانه و همبستگیها (Correlation)، دادهها به خلاصههایی تبدیل میشوند که الگوها و روندهای کلیدی را برجسته میسازند.
چگونه پیشبینیهای ما را بهبود بخشیدند؟
در مسابقه پیشبینی سیل، ویژگیهای آماری عملکرد مدل را به طور قابل توجهی بهبود بخشیدند. آنها نمای کلی و مختصری از تنوع دادهها و گرایشهای مرکزی (central tendencies) فراهم کردند که باعث درک بهتر و پیشبینی احتمال وقوع سیل شدند. این ویژگیها بسیار مهم بودند زیرا دادههای پیچیده و با بعد بالا (high-dimensional) را به فرمهایی تبدیل کردند که الگوریتمهای پیشبینی ما به طور مؤثری میتوانستند پردازش کنند. دقت و قابلیت اطمینان پیشبینیهای ما به طور قابل توجهی بهبود یافت، که این امر اهمیت درک خصوصیات مجموعه دادهها را نشان میدهد.
کاربردهایی که در آنها ویژگیهای آماری میدرخشند
ویژگیهای آماری در انواع مختلفی از وظایف مبتنی بر دادهها به طور گسترده قابل استفاده هستند و در موارد زیر پراهمیت تر میشوند:
- تفسیر دادهها: سادهسازی تفسیر دادههای پیچیده با ارائه خلاصههای روشن از روندها.
- تشخیص الگو: شناسایی الگوها و روابط حیاتی که برای تحلیلهای پیشبینی و وظایف طبقهبندی ضروری هستند.
- کاهش نویز: کاهش تاثیر نویز در دادهها، که منجر به ورودیهای تمیزتر برای مدلها میشود.
- کاهش ابعاد: تسهیل در مصورسازی (visulization) و تحلیل سادهتر با کاهش پیچیدگی مجموعه داده.
تأثیرات و پیشنهادات
بررسی های ما نشان داد که ویژگیهای آماری، خلاصههای مختصری از الگوهای داده و گرایشهای مرکزی ارائه میدهند که به پیشبینیهای بهبود یافته منجر میشوند. این ویژگیها به طور مؤثری تنوع (variability) و روندها (trends) را به تصویر میکشند و عملکرد مدل را نسبت به استفاده از دادههای خام به تنهایی، افزایش میدهند.
در پایان این بخش، ما توصیه میکنیم که روشهای دیگری از مهندسی ویژگی را که ما استفاده نکردیم، بررسی کنید. در حالی که روشهای ما مؤثر بودند، راههای بسیاری برای ایجاد ویژگیهای جدید و ارزشمند وجود دارد که میتواند قدرت پیشبینی را بیشتر افزایش دهد.
انتخاب، آموزش و بهبود مدل با کتابخانه Optuna
در مسیر پیشبینی احتمال وقوع سیل برای مسابقه Kaggle Playground Series، انتخاب و تنظیم دقیق مدلهای رگرسیون یک گام حیاتی بود. ما چندین مدل پیشرفته را آزمایش کردیم تا بهترین مدل را برای مجموعه داده خود تعیین کنیم. در ادامه جزئیات فرآیند انتخاب مدل ما آمده است:
آزمایش مدل و ادغام در Pipeline
ما استراتژی مدلسازی خود را با دقت طراحی کردیم و مدلهای رگرسیون پیشرفته را در یک Pipeline که شامل مقیاسبندی دادهها از طریق StandardScaler و به دنبال آن مدل رگرسیون بود، ادغام کردیم. این رویکرد ساختارمند اطمینان حاصل کرد که دادههای ما به طور مداوم پیشپردازش شدهاند و منجر به نتایج قابل تکرار و قوی میشوند.
در ادامه چگونگی تناسب هر مدل با جریان کاری ما و دلایل انتخاب آنها آمده است:
XGBoost
- مزایا: موثر در مدیریت دادههای ساختاریافته/جدولی، به راحتی از پس دادههای گمشده بر میآید و با اعمال تنظیمات منظم به مقابله با بیشبرازش میپردازد.
- نکته کلیدی: تکنیک تقویت گرادیان (gradient boosting)XGBoost با ترکیب چندین یادگیرنده ضعیف، دقت مدل را افزایش میدهد و آن را به یک انتخاب مناسب برای سناریوهای داده پیچیده تبدیل میکند.
LightGBM
- مزایا: آموزش سریع، عالی برای مجموعه دادههای بزرگ و leaf-wise tree growth خاص آن (LightGBM) که الگوهای پیچیده را به خوبی شناسایی میکند.
- نکته کلیدی: کارآیی LightGBM در کاهش سریعتر خطا نسبت به الگوریتمهای سطحی سنتی میتواند در پروژههای حساس به زمان نقش تعیینکنندهای داشته باشد.
CatBoost
- مزایا: catboost توانایی برجسته در مدیریت متغیرهای دستهای بدون نیاز به پیشپردازش گسترده و کاهش بیشبرازش از طریق تقویت مرتبشده (ordered boosting) دارد.
- نکته کلیدی: تقویت مرتبشده CatBoost با استفاده از تغییرات دادهها، بهبود تعمیم مدل را فراهم میکند و آن را برای مجموعه دادههایی با تعاملات پیچیده دستهای (Categorical) ایدهآل میسازد.
برای مطالعه بیشتر کلیک کنید: مدل Catboost چیست؟ راهنمای کامل استفاده از Catboost در یادگیری ماشین
هر مدل با استفاده از یک تقسیمبندی آموزش-آزمایش (train-test-split) ارزیابی شد که به دلیل محدودیت زمانی ضروری بود. اگرچه این رویکرد برای نیازهای ما کافی بود، اما توصیه میکنیم برای ارزیابی جامعتر و دقیقتر از اعتبارسنجی متقاطع (cross validation) استفاده کنید. اعتبارسنجی متقاطع دادهها را به چندین بخش تقسیم میکند و هر بخش را به عنوان مجموعه اعتبارسنجی استفاده کرده و بر روی باقی ماندهها آموزش میدهد، و در نتیجه تخمین قابل اعتمادتر از عملکرد مدل ارائه میدهد.
شروع ساده
با مدلهای پایهای (basic models) برای تنظیم یک خط مبنا (baseline) برای عملکرد شروع کنید. ابتدا آنها را با مقادیر پیشفرض هایپرپارامترها اجرا کنید تا یک معیار پایهای ایجاد شود. در مراحل بعدی، هایپرپارامترها را تنظیم کنید و عملکرد را با خط مبنا مقایسه کنید. این رویکرد تکراری به شناسایی بهبودها کمک میکند و اطمینان میدهد که تلاشهای پیچیده برای انتخاب مدل و تنظیم هایپرپارامترها، بهبود واقعی در عملکرد را ایجاد میکنند.
تنظیم هایپرپارامتر با کتابخانه Optuna
تنظیم هایپرپارامتر نقش مهمی در بهینهسازی مدلهای ما ایفا کرد و برای این کار از کتابخانه Optuna استفاده کردیم. قابلیتهای پیشرفته کتابخانه Optuna راهی کارآمد و ساده برای شناسایی بهترین پارامترها فراهم کرد که با توجه به محدودیتهای زمانی ما بسیار حیاتی بود.
کتابخانه Optuna
کتابخانه Optuna یک چارچوب بهینهسازی هایپرپارامتر پیشرفته است که در تنظیم خودکار پارامترها برای بهبود عملکرد مدل برتری ویژه ای دارد. این ابزار از یک الگوریتم هوشمند به نام تخمینگر Parzen با ساختار درختی (TPE- Tree-structured Parzen Estimator) استفاده میکند تا به طور کارآمد فضای هایپرپارامترها را کاوش کند. کتابخانه Optuna مدلها را موثرتر از روشهای سنتی جستجوی شبکهای یا تصادفی (grid search & random search) بهینه میکند. در ادامه نگاهی دقیقتر به تجربه ما با کتابخانه Optuna و دلایلی که آن را به یک ابزار قدرتمند تبدیل میکند، داریم.
چرا کتابخانه Optuna یک ابزار قدرتمند است؟
مزایا:
- کارایی: الگوریتم TPE Optuna فضای جستجو را محدود کرده و بر روی امیدوارکنندهترین هایپرپارامترها تمرکز میکند و به طور قابل توجهی فرآیند بهینهسازی را تسریع میبخشد.
- انعطافپذیری: به راحتی با انواع چارچوبهای یادگیری ماشین ادغام میشود و اجازه سفارشیسازی گستردهای از فرآیند بهینهسازی را میدهد.
- کاربرپسند: API ساده آن، کتابخانه Optuna را برای هم مبتدیان و هم کاربران حرفهای قابل دسترسی میکند و فرآیند تنظیم را ساده میسازد.
- بصریسازی: ابزارهای بصریسازی غنی برای نظارت و تحلیل فرآیند جستجوی هایپرپارامترها فراهم میکند.
معایب:
- بار محاسباتی: میتواند برای مجموعه دادههای بسیار بزرگ یا مدلهای بسیار پیچیده، منابع زیادی مصرف کند.
- منحنی یادگیری شیبدار (steep learning curve): برای بهرهبرداری کامل از ویژگیهای پیشرفته و گزینههای سفارشیسازی نیاز به یادگیری دارد.
کاربردهای کتابخانه Optuna در پروژههای یادگیری ماشین
کتابخانه Optuna در جنبههای مختلف پروژههای یادگیری ماشین برتری دارد، از جمله:
انتخاب مدل: شناسایی بهترین ترکیب مدلها و هایپرپارامترها برای وظایفی مانند رگرسیون، طبقهبندی(classification) و خوشهبندی.
- مثال: استفاده از کتابخانه Optuna برای انتخاب بهترین مدل از بین گزینههای مختلف مانند جنگل تصادفی، XGBoost و LightGBM برای یک تسک طبقهبندی (classification).
- مقاله مرتبط: “Optuna: A Next-generation Hyperparameter Optimization Framework” by Akiba et al. (2019).
تنظیم پارامترها: بهینهسازی هایپرپارامترها برای الگوریتمهایی مانند gradient boosting، شبکههای عصبی و ماشینهای بردار پشتیبان(svm).
- مثال: تنظیم هایپرپارامترها برای یک شبکه عصبی با استفاده از کتابخانه Optuna.
- مقاله مرتبط: “Hyperparameter Optimization: A Spectral Approach” by Hazan et al. (2018)
بهینهسازیPipeline : ادغام و تنظیم کل خطوط پردازش ML شامل پیشپردازش، انتخاب ویژگی و مدلسازی.
- مثال: بهینهسازی یک Pipeline کامل ماشین لرنینگ شامل پیشپردازش، انتخاب ویژگی و مدلسازی.
- مقاله مرتبط: “Auto-Sklearn: Efficient and Robust Automated Machine Learning” by Feurer et al. (2015)
چقدر حرفهای است؟
کتابخانه Optuna به دلیل قابلیت اطمینان و کارایی خود، به طور گسترده در تحقیقات دانشگاهی و صنعت استفاده میشود. توانایی آن در مدیریت مسائل بهینهسازی در مقیاس بزرگ و ارائه نتایج کارآمد، آن را به انتخابی ترجیحی برای پروژههای حرفهای علوم داده و یادگیری ماشین تبدیل کرده است. برای مثال، شرکتهای بزرگ فناوری و مؤسسات مالی به کتابخانه Optuna متکی هستند تا مدلهای پیشبینی و سیستمهای تصمیمگیری خود را بهبود بخشند.
مثال خاص: محققان از تکنیکهای بهینهسازی هایپرپارامتر کتابخانه Optuna برای مدلهای تشخیص COVID-19 استفاده کردند و به طور قابلتوجهی سرعت و دقت تشخیص را بهبود بخشیدند. مقاله مرتبط: NCBI
کتابخانه Optuna چگونه کار میکند؟
کتابخانه Optuna با تعریف یک تابع هدف که هدف آن بهینهسازی است، عمل میکند. این تابع مجموعهای از هایپرپارامترها را با آموزش یک مدل و ارزیابی عملکرد آن بر روی یک مجموعه اعتبارسنجی ارزیابی میکند. الگوریتم TPE Sampler Optuna از نتایج برای پیشنهاد هایپرپارامترهای بهتر به صورت تکراری استفاده میکند و جستجو را بر اساس ارزیابیهای قبلی اصلاح میکند.
این ابزار همچنین میتواند با پارامترهای عددی و دستهای کار کند و آن را برای انواع وظایف یادگیری ماشین همهکاره میسازد. از تابع create_study Optuna با direction=’maximize’ یا direction=’minimize’ استفاده کنید تا بهینهسازی با معیارهای عملکرد مدل شما همسو شود.
در پروژه ما، از کتابخانه Optuna برای تنظیم هایپرپارامترهای مدلهای XGBoost ، LightGBM و CatBoost و همچنین برای یافتن بهترین وزنها برای Voting Regressor استفاده کردیم. علیرغم کمبود زمان برای اعتبارسنجی متقاطع (cross validation)، مکانیزم جستجوی کارآمد در کتابخانه Optuna به ما امکان داد از تقسیمبندی آموزش-آزمایش (train-test-split) به طور مؤثر استفاده کنیم و نتایج بهینه را در چارچوب محدودیتهای ما ارائه دهیم.
مثال کد برای تنظیم هایپرپارامتر:
# Objective function for each model
def objective(trial, model_class, X_train, y_train, X_test, y_test):
if model_class == XGBRegressor:
params = {
'n_estimators': trial.suggest_int('n_estimators', 600, 1000),
'learning_rate': trial.suggest_loguniform('learning_rate', 0.01, 0.1),
'reg_alpha': trial.suggest_loguniform('reg_alpha', 0.01, 1.0),
'reg_lambda': trial.suggest_loguniform('reg_lambda', 0.01, 1.0),
'max_depth': trial.suggest_int('max_depth', 3, 10),
'min_child_weight': trial.suggest_int('min_child_weight', 1, 10)
}
model = model_class(**params, random_state=42)
elif model_class == LGBMRegressor:
params = {
'n_estimators': trial.suggest_int('n_estimators', 600, 1000),
'learning_rate': trial.suggest_loguniform('learning_rate', 0.01, 0.1),
'max_depth': trial.suggest_int('max_depth', 3, 10),
'reg_alpha': trial.suggest_loguniform('reg_alpha', 0.01, 1.0),
'reg_lambda': trial.suggest_loguniform('reg_lambda', 0.01, 1.0)
}
model = model_class(**params, min_child_samples=114, force_col_wise=True,
num_leaves=183, random_state=42)
elif model_class == CatBoostRegressor:
params = {
'iterations': trial.suggest_int('iterations', 2000, 4000),
'learning_rate': trial.suggest_loguniform('learning_rate', 0.01, 0.1),
'depth': trial.suggest_int('depth', 3, 10),
'l2_leaf_reg': trial.suggest_loguniform('l2_leaf_reg', 1, 10)
}
model = model_class(**params, random_state=42, subsample=0.8, verbose=0)
# Create pipeline with StandardScaler and model
pipeline = Pipeline([
('scaler', StandardScaler()),
('model', model)
])
pipeline.fit(X_train, y_train)
y_pred = pipeline.predict(X_test)
return r2_score(y_test, y_pred)
# Function to tune hyperparameters
def tune_hyperparameters(X_train, y_train, X_test, y_test, model_class, n_trials=15):
study = optuna.create_study(direction='maximize', sampler=TPESampler())
study.optimize(lambda trial: objective(trial, model_class,
X_train, y_train, X_test, y_test), n_trials=n_trials)
return study.best_params
# Voting Regressor Tuning
def tune_voting_regressor(X_train, y_train, X_test, y_test,
xgb_params, lgbm_params, catboost_params, n_trials=15):
def objective(trial):
weight_xgb = trial.suggest_int('weight_xgb', 4, 10)
weight_lgbm = trial.suggest_int('weight_lgbm', 1, 4)
weight_catboost = trial.suggest_int('weight_catboost', 4, 10)
xgb_model = XGBRegressor(**xgb_params, random_state=42)
lgbm_model = LGBMRegressor(**lgbm_params, random_state=42)
catboost_model = CatBoostRegressor(**catboost_params, random_state=42,
verbose=0)
voting_reg = VotingRegressor(
estimators=[
('xgb', xgb_model),
('lgbm', lgbm_model),
('catboost', catboost_model)
],
weights=[weight_xgb, weight_lgbm, weight_catboost]
)
pipeline = Pipeline([
('scaler', StandardScaler()),
('model', voting_reg)
])
pipeline.fit(X_train, y_train)
y_pred = pipeline.predict(X_test)
return r2_score(y_test, y_pred)
study = optuna.create_study(direction='maximize', sampler=TPESampler())
study.optimize(objective, n_trials=n_trials)
return study.best_params
منابع بیشتر برای کتابخانه Optuna
- مستندات رسمی کتابخانه Optuna : برای راهنمای جامع استفاده از کتابخانه Optuna و ویژگیهای مختلف آن. مستندات کتابخانه Optuna
- مثالهایی از کتابخانه Optuna در GitHub : کدهای واقعی که نشان میدهند چگونه کتابخانه Optuna را با کتابخانهها و چارچوبهای مختلف ماسین لرنینگ یکپارچه کنید. مثالهای کتابخانه Optuna در GitHub
همچنین بخوانید: چگونه با چارچوب Optuna عملکرد مدلهای یادگیری ماشین خود را بهبود دهیم؟
روش ترکیبی Voting Regressor
پس از تنظیم مدلها، آنها را با استفاده از Voting Regressor ترکیب (Ensemble) کردیم که پیشبینیها را با میانگینگیری خروجیهای XGBoost ,LightGBM و CatBoost تجمیع میکند. این روش به ما اجازه میدهد از نقاط قوت هر مدل استفاده کنیم و به پیشبینیهای دقیقتری دست یابیم.
چرا Voting Regressor؟
مزایا:
- بهبود عملکرد پیشبینی با ترکیب مدلهای متنوع
- کاهش بیشبرازش (overfitting)
- شناسایی الگوهای داده با دامنه گستردهتر
نکته کلیدی: Voting Regressor از پیشبینیهای چندین مدل بهره میبرد و نقاط ضعف فردی آنها را هموار میکند و بر نقاط قوتشان تمرکز میکند تا عملکرد کلی بهتری را ارائه دهد.
بطور خلاصه، روش ما برای ترکیب XGBoost، LightGBM و CatBoost با استفاده از Voting Regressor و تنظیم دقیق آنها با کتابخانه Optuna، نتایج چشمگیری را به همراه داشت. اگرچه به دلیل محدودیتهای زمانی از تقسیم آموزش-آزمایش (train-test-split) به جای اعتبارسنجی متقاطع (cross validation) استفاده کردیم، اما توصیه میکنیم برای ارزیابی دقیقتر و قابلاعتمادتر مدل، از اعتبارسنجی متقاطع استفاده کنید. کاوش و بهکارگیری این تکنیکهای پیشرفته نه تنها پیشبینیهای ما را بهبود بخشید، بلکه درک ما از بهینهسازی مدل و یادگیری ترکیبی را نیز غنیتر کرد.
ارزیابی مدل: بررسی عمیق R² و RMSE
در این رقابت، ارزیابی بر اساس امتیاز R² انجام میشود که یک معیار بسیار استفادهشده برای مدل های رگرسیون است. با این حال، ما همچنین از خطای جذر میانگین مربعات (RMSE) برای کسب اطلاعات بیشتر در مورد عملکرد مدل خود استفاده کردیم. در ادامه توضیحات مربوط به این معیارها و برخی راهنماها برای استفاده مؤثر از آنها آورده شده است:
درک R²
امتیاز R² یا ضریب تعیین، اندازهگیری میکند که مدل رگرسیون ما چقدر خوب تغییرپذیری متغیر هدف را توضیح میدهد. این مقدار از 0 تا 1 متغیر است، که:
- 0 نشان میدهد که مدل هیچیک از تغییرپذیری دادههای پیشبینی شده را در اطراف میانگین خود نشان نمیدهد.
- 1 به معنای پیشبینی کامل است، جایی که مدل همه تغییرپذیری را توضیح میدهد.
استفاده از R² : از R² برای بررسی این که مدل شما چقدر خوب تغییرپذیری دادهها را توضیح میدهد استفاده کنید. اما به یاد داشته باشید، برای مجموعه دادههای کوچک یا الگوهای غیرخطی، R² ممکن است همیشه دقیق نباشد و گاهی اوقات نتایج گمراهکننده بدهد.
درک RMSE
خطای جذر میانگین مربعات (RMSE) اندازهگیری میکند که پیشبینیهای مدل چقدر به مقادیر واقعی نزدیک هستند. این مقدار جذر میانگین تفاوتهای مربعی بین مقادیر پیشبینیشده و واقعی است و به نوسانات حساس است.
استفاده از RMSE : از RMSE برای درک اندازه متوسط خطاهای پیشبینی استفاده کنید. از آنجا که RMSE در همان واحدهای متغیر هدف شماست، این کمک میکند تا ببینید چقدر خطا در پیشبینیهای خود انتظار دارید.
تعادل بین R² و RMSE
استفاده از هر دو معیار R² و RMSE نمای جامعتری از عملکرد مدل ارائه میدهد:
- R² به شما میگوید مدل شما چقدر خوب دادهها را تطبیق میدهد.
- RMSE به شما میگوید چقدر خطا در پیشبینیها میتوانید انتظار داشته باشید.
با تعادل این معیارها، میتوانید مدلهای قابل اعتمادتر و دقیقتری ایجاد کنید. به دنبال تعادلی باشید که در آن R² نسبتاً بالا و RMSE پایین باشد. این تعادل نشاندهنده مدلی است که دادهها را خوب توضیح میدهد و پیشبینیهای دقیقی میکند.
ارزیابی و مقایسه مدلها
با ارزیابی عملکرد مدل پایه خود با استفاده از R² و RMSE شروع کنید. هنگامی که با مدلها و تنظیمات مختلف هایپرپارامترها تکرار میکنید، بهبودها را با این پایه مقایسه کنید. این روش به شما کمک میکند بفهمید آیا پیچیدگی افزودهشده توسط مدلهای جدید یا تلاشهای تنظیم هایپرپارامترها بهبود عملکرد واقعی را به همراه دارد یا خیر.
فرآیند ارسال: راهبردهای موثر برای رقابت در Kaggle
شرکت در یک رقابت Kaggle تجربهای هیجانانگیز و چالشبرانگیز است. بر اساس تجربیات من، در ادامه چگونگی بهینهسازی استراتژی ارسال نتایج نهایی خود در طول یک ماه زمان مسابقه آمده است:
تابلو نتایج Kaggle:
شرکت در این رقابت Kaggle برای ما تجربهای پویا و پربار بود. همانطور که در تصویر زیر مشخص است، تلاشهای جمعی ما در تابلو نتایج Kaggle نشان داده شده است. این تصویر، منعکس کننده کار سخت، استراتژی و یادگیری هر تیم است. تابلو نتایج به عنوان یک سند از تجربه مشترک ما عمل کرد، که موفقیت، یادگیری و استقامت تیم ها را به تصویر میکشد.
استراتژی ارسال: بهینهسازی هر تلاش
در رقابتهای Kaggle Playground، شرکتکنندگان میتوانند پیشبینیهای خود را تا 5 بار در روز ارسال کنند. این محدودیت روزانه آزمایشات متفکرانه و بهبود مداوم را تشویق میکند. در ادامه نحوه مدیریت موثر این کار آورده شده است:
برنامهریزی ارسالها:
- برنامهریزی ارسالهای روزانه: از آنجا که میتوانید فقط 5 بار در روز ارسال کنید، با دقت از این فرصت ارسالها استفاده کنید. تعدادی را برای تست ایدههای جدید و تعدادی را برای بهبود مدلهای فعلی ذخیره کنید.
- ردیابی عملکرد: یک log از عملکرد هر ارسال و تغییرات ایجاد شده در مدل نگه دارید. این عمل به درک این که کدام تغییرات نتایج مثبتی به همراه دارند کمک میکند.
آزمایش و اصلاح:
- ارسالهای اولیه: از ارسالهای اولیه برای تست ایدههای بنیادی و مدلهای پایه استفاده کنید. این رویکرد به شما اجازه میدهد تا جهتهای امیدوارکننده را زودتر شناسایی کنید.
- بهبود تدریجی: با پیشرفت رقابت، بر بهینهسازی و تنظیم دقیق مدلهای خود تمرکز کنید. از نتایج ارسالهای قبلی برای هدایت بهبودهای تدریجی استفاده کنید.
تابلو نتایج عمومی در مقابل خصوصی:
- تابلو نتایج عمومی (Public Leaderboard): در طول رقابت، امتیاز شما در تابلو نتایج عمومی، عملکرد روی 20٪ از دادههای تست را منعکس میکند. این امتیاز یک نمای کلی ارائه میدهد اما ممکن است نمایانگر دقت کلی نباشد.
- تابلو نتایج خصوصی (Private Leaderboard): رتبهبندی نهایی، که پس از پایان رقابت اعلام میشود، بر اساس 80٪ باقیمانده از دادههای تست است. اجتناب از overfitting به تابلو نتایج عمومی ضروری است زیرا ممکن است بر روی تابلو نتایج خصوصی خوب عمل نکند.
زمانبندی استراتژیک:
- ارسالهای پایان روز: اگر تغییرات عمدهای اعمال میکنید، ارسال در پایان روز را در نظر بگیرید. این استراتژی حداکثر تلاشهای موجود را بهینه میکند و زمان برای تأمل و تنظیمات را فراهم میکند.
نتایج اعتبارسنجی متقاطع:
- کاهش overfitting : از اعتبارسنجی متقاطع برای سنجش پایداری مدل و کاهش خطر overfitting استفاده کنید. این رویکرد به هماهنگی عملکرد روی تابلو نتایج عمومی با نتایج احتمالی روی تابلو نتایج خصوصی کمک میکند.
همکاری تیمی:
- اشتراکگذاری یافتهها: با اعضای تیم برای بحث در مورد استراتژیها و یافتهها همکاری کنید. اشتراک دیدگاههای مختلف میتواند به راهحلهای نوآورانه و عملکرد بهتر منجر شود.
- ترکیب مدلها: ترکیب یا انباشتهسازی مدلها بر اساس ارسالهای اعضای تیم را در نظر بگیرید تا از نقاط قوت متنوع آنها استفاده کنید و پیشبینیها را بهبود بخشید.
با دنبال کردن این راهبردها، میتوانید اطمینان حاصل کنید که هر ارسال شما به طور موثری به بهبود مدلها و نتایج کلی شما کمک میکند.
تشویق و چشماندازهای آینده
شرکت ما در این رقابت با هدایت و حمایت استاد راهنمایمان، رضا شکرزاد، پربارتر شد. تخصص او در مواجهه با چالشهای پیچیده و ایجاد محیطی همکاریکننده نقش مهمی در تجربه ما ایفا کرد. این رقابت به عنوان یک سکوی پرتاب عمل کرد و ما را به پذیرش پروژههای بلندپروازانهتر در آینده ترغیب کرد.
مهارتها و استراتژیهای توسعهیافته در طول این رقابت ابزارهای ارزشمندی برای مواجهه با مشکلات جدید و هیجانانگیز علم داده خواهند بود. خواه آزمودن مدلهای مختلف باشد، خواه تنظیم پارامترها یا ابداع استراتژیهای موثر برای ارسال نتایج، در هر صورت درسهای آموخته شده در این مسابقات بدون شک شکلدهنده کارهای آینده ما خواهند بود.
درسهای کلیدی آموخته شده
- بهبود پیشبینیها با مهندسی ویژگیها: ایجاد ویژگیهای جدید مانند تعاملات و معیارهای آماری، الگوهای پیچیده دادهها را آشکار کرده و منجر به دقت بیشتر مدل میشود.
- بهینهسازی پارامترهای مدل: استفاده از ابزارهایی مانند کتابخانه Optuna برای تنظیم پارامترهای مدل میتواند به طور قابل توجهی عملکرد و کارایی مدل را بهبود بخشد.
- استفاده از معیارهای ارزیابی متعدد: مدل خود را با استفاده از معیارهای مختلف ارزیابی کنید تا تصویر کاملی از عملکرد آن به دست آورید و از نتیجهگیریهای گمراهکننده جلوگیری کنید.
- بهرهگیری از روشهای ترکیبی: مدلها را با هم ترکیب کنید تا از نقاط قوت آنها برای پیشبینیهای دقیقتر و پایدارتر بهرهمند شوید.
- آموزش از طریق رقابتها: در رقابتهای ماشین لرنینگ شرکت کنید تا تجربه عملی کسب کرده و از طریق یادگیری تکراری و بازخورد، مهارت هایتان بهبود یابد.
نتیجهگیری: یادگیری از طریق چالشهای علم داده
شرکت در سری رقابتهای Kaggle Playground برای تیم ما تجربهای بسیار آموزنده بوده است. چالش پیشبینی سیل به ما کمک کرد تا فراتر از انتظارات فکر کنیم و دانش خود در مورد رگرسیون را در مسائل واقعی به کار بگیریم. این کار باعث شد توانایی ما در مقابله با مسائل دنیای واقعی بهبود یابد.
ما مدلهای مختلفی را امتحان کردیم، عملکرد آنها را بررسی کردیم و رویکردمان را به طور مداوم بهبود بخشیدیم. این کار عملی به ما نشان داد که یادگیری واقعی زمانی رخ میدهد که دانش نظری را در عمل به کار بگیریم و روشهایمان را بهبود دهیم.
این رقابت نه تنها مهارتهای فنی ما را ارتقا داد، بلکه ارزش همکاری، پشتکار و تطبیق با شرایط جدید را نیز به ما آموخت. هر مشکلی که با آن مواجه شدیم و حل کردیم، ما را در درک علم داده بهتر کرد.
امیدوارم تجربهها و نکات ما به شما در پروژههای ماشین لرنینگ خودتان کمک کند. ایدههای جدید را امتحان کنید، از یکدیگر بیاموزید و از این تجربیات لذت ببرید. هر مجموعه دادهای داستانی دارد و هر چالشی فرصتی برای رشد است.
در مقالههای آینده، داستانهای بیشتری از این رقابتها با شما به اشتراک خواهیم گذاشت. هر یک از آنها یک ماجراجویی جدید در یادگیری هستند. منتظر مقاله بعدی از مجموعه مقالههای تجربیات ما در مسابقات Kaggle باشید!
منابع:
- مسابقه : Kaggle Playground Series — Season 4, Episode 5
- کد کامل در Kaggle : لینک
- کد کامل در : لینک مخزن
- مقاله به زبان انگلیسی : لینک مقاله.
یادگیری ماشین لرنینگ را از امروز شروع کنید!
دنیای دادهها جذاب است و دانستن علم داده، توانایی تحلیل داده، یا بازاریابی مبتنی بر داده، شما را برای فرصتهای شغلی بسیاری مناسب میکند. فارغ از رشته و پیشزمینه، میتوانید حالا شروع کنید و از سطح مقدماتی تا پیشرفته بیاموزید. اگر دوست دارید به این حوزه وارد شوید، پیشنهاد میکنیم با کلیک روی این لینک قدم اول را همین حالا بردارید.
مشاوران کافهتدریس به شما کمک میکنند مسیر یادگیری برای ورود به این حوزه را شروع کنید: