

امروز، پردازش زبان طبیعی به یکی از مهمترین و هیجانانگیزترین حوزههای تحقیقاتی تبدیل شده است. یکی از تکنیکهای پیشرفتهای که در این حوزه مورد استفاده قرار میگیرد، تعبیه کلمات Word2Vec است. این تکنیک به ما این امکان را میدهد که کلمات را به صورت عددی تحلیل و پردازش کنیم و به این ترتیب، معنای کلمات و روابط بین آنها را بهتر درک کنیم. در این مقاله، ما به بررسی معماری مدل و پیادهسازی این روش تعبیه کلمات (Word Embedding) خواهیم پرداخت و کاربردهای مختلف آن را مورد بررسی قرار خواهیم داد.
- 1. تاریخچه مختصری از شکلگیری تعبیه کلمات Word2Vec
- 2. چرا به Word2Vec نیاز داریم؟
- 3. تئوری تعبیه کلمات Word2Vec
- 4. معماری مدل Word2Vec
- 5. پیادهسازی Word2Vec در پایتون
- 6. کاربردهای Word2Vec
- 7. چالشها و محدودیتهای Word2Vec
- 8. آینده Word2Vec و پردازش زبان طبیعی
- 9. جمعبندی
-
10.
پرسشهای متداول
- 10.1. چرا Word2Vec نسبت به روشهای دیگر کدگذاری مانند One-Hot-Encoding و TF-IDF بهتر است؟
- 10.2. مدلهای Continuous Bag of Words (CBOW) و Skip-gram در Word2Vec چگونه کار میکنند و چه تفاوتهایی دارند؟
- 10.3. چگونه میتوانیم از Word2Vec در کاربردهای عملی مانند تحلیل احساسات و موتورهای جستجو استفاده کنیم؟
- 10.4. چالشها و محدودیتهای استفاده از Word2Vec چیست؟
- 10.5. چگونه میتوان از بردارهای Word2Vec برای انجام عملیات جبری معنایی استفاده کرد؟
- 11. یادگیری ماشین لرنینگ را از امروز شروع کنید!
تاریخچه مختصری از شکلگیری تعبیه کلمات Word2Vec
تعبیه کلمات Word2Vec اولین بار توسط تیم گوگل در سال ۲۰۱۳ معرفی شد و به سرعت تبدیل به یکی از ابزارهای محبوب در پردازش زبان طبیعی شد. این تکنیک به دلیل سادگی و کارآیی بالا، به سرعت جای خود را در بین محققان باز کرد و در بسیاری از پروژههای تحقیقاتی و کاربردهای صنعتی مورد استفاده قرار گرفت.
برای آشنایی بیشتر با نحوه انجام پروژههای پردازش زبان طبیعی بخوانید: پردازش زبان طبیعی با پایتون چگونه انجام میشود و چه مراحلی دارد؟
چرا به Word2Vec نیاز داریم؟
همانطور که میدانید ما برای اینکه بتوانیم کلمات را بهعنوان ورودی به مدلهای ماشین لرنینگ یا دیپ لرنینگ بدهیم، نیاز داریم آنها را بهصورت عددی نمایش دهیم. احتمالا اولین چیزی که برای این کار به ذهن شما میرسد این است که هر کلمه را با یک عدد نمایش دهیم اما با کمی تامل میتوانید بفهمید که این راه اصلا بهینه نیست. زیرا به این ترتیب ماشین نمیتواند معنای کلمات را درک کند. یکی دیگر از راههای مرسوم برای نمایش عددی کلمات، One-Hot-Encoding است. در این روش، هر کلمه به یک بردار دودویی (Binary) تبدیل میشود که در آن فقط یکی از بیتها مقدار ۱ دارد و بقیه بیتها مقدار ۰ دارند. برای مثال فرض کنید ما یک مجموعه کلمه داریم که شامل گربه، سگ و پرنده است. کدگذاری این کلمات به فرم One-Hot، بهصورت زیر درمیآید:
- گربه: [۱، ۰، ۰]
- سگ: [۰، ۱، ۰]
- پرنده: [۰، ۰، ۱]
اما محدودیتهای این روش نیز واضح است:
ابعاد بزرگ
برای مجموعه دادههای بزرگ با تعداد زیادی کلمه، بردارهای One-Hot میتوانند بسیار بزرگ شوند که باعث افزایش نیاز به حافظه و محاسبات میشود. درنتیجه این روش اصلا بهینه نیست.
عدم نمایش رابطه معنایی
در کدگذاری One-Hot، هیچ رابطه معنایی بین کلمات نمایش داده نمیشود. بهعنوان نمونه، در مثال بالا بردارهای گربه و سگ هیچ شباهت معنایی به هم ندارند، حتی اگر در واقعیت این دو کلمه از نظر معنایی به هم نزدیک باشند.
روش دیگری که میتوان برای نمایش عددی کلمات از آن استفاده کرد، TF-IDF است. TF-IDF روشی آماری است که برای ارزیابی اهمیت یک واژه در یک جمله نسبت به یک مجموعه جملات استفاده میشود. همانطور که از اسمش پیداست، TF-IDF از دو بخش تشکیل شده است:
- TF (Term Frequency): تعداد تکرار یک واژه در یک جمله
- IDF (Inverse Document Frequency): لگاریتم کسر تعداد کل جملات به تعداد جملات حاوی واژه مورد نظر.
در پایان TF-IDF برای هر جمله بسته به کلمات آن، یک بردار به طول کل کلمات منحصربهفرد مجموعه متون (Corpus) ارائه میدهد که مولفههای آن از حاصلضرب TF در IDF هر کلمه از آن جمله تشکیل شده است.
این روش نسبت به کدگذاری One-Hot اطلاعات بیشتری در مورد اهمیت واژهها ارائه میدهد اما همچنان قادر به درک روابط معنایی بین واژهها نیست. درواقع با هدف رفع مشکلات روشهای قبلی، محققان گوگل روش Word2Vec را ابداع کردند. حال سوالات اینجاست که Word2Vec چطور کار میکند؟
تئوری تعبیه کلمات Word2Vec
تعبیه کلمات Word2Vec یک روش برای تبدیل کلمات به بردارهای عددی است. این روش بر اساس شبکههای عصبی مصنوعی (Artificial Neural Networks) عمل میکند و دو مدل اصلی دارد:
- Continuous Bag of Words (کیسه کلمات پیوسته)
- Skip-gram (اسکیپگرام)
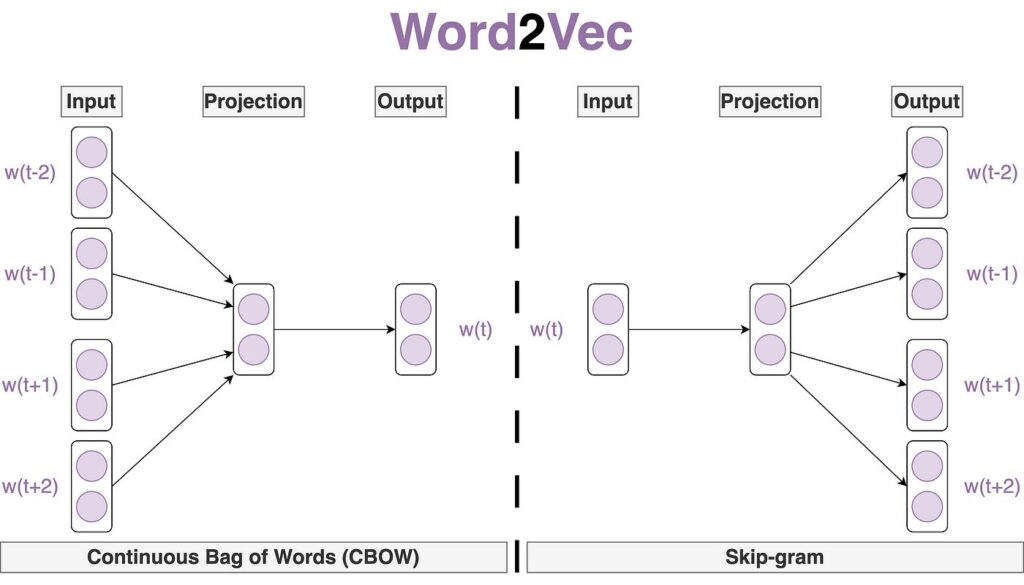
در مدل CBOW، هدف پیشبینی یک کلمه با توجه به کلمات اطراف آن است، در حالی که در مدل Skip-gram، هدف پیشبینی کلمات اطراف با توجه به یک کلمه خاص است. این دو مدل با استفاده از یک مجموعه بزرگ از متون آموزش داده میشوند تا بردارهایی تولید کنند که کلمات مشابه در متن را به صورت نزدیک به هم در فضای برداری نمایش دهند. به عنوان مثال، اگر بردار متناظر با کلمه پادشاه (king) را منهای بردار مرد (man) کنیم و سپس بردار متناظر با کلمه زن (woman) را به آن اضافه کنیم، نتیجه به بردار متناظر با کلمه ملکه (queen) نزدیک خواهد بود. بهاینترتیب تعبیه کلمات Word2Vec روابط معنایی و نحوی بین کلمات را حفظ میکنند.
معماری مدل Word2Vec
معماری Word2Vec یک شبکه عصبی کمعمق است که برای آموزش بردارهای تعبیه (Embedding) مناسب برای کلمات طراحی شده است. این مدل از یک مجموعه آموزشی شامل تمام متون موجود استفاده میکند. مدل Word2Vec شامل یک لایه ورودی، یک لایه پنهان و یک لایه خروجی است. در این مدل، لایه پنهان به عنوان فضایی برای یادگیری و ذخیره بردارهای تعبیه (Embedding) کلمات عمل میکند.
لایه ورودی
در این مدل برای نمایش اولیه کلمات بهعنوان ورودی، از One-Hot-Encoding استفاده میشود. یعنی هر کلمه به صورت یک بردار باینری نمایش داده میشود که تنها در یکی از مولفههایش مقدار یک و در بقیه مولفهها مقدار صفر دارد.
لایه پنهان
لایه پنهان، تعداد نورونهایی برابر با طول بردار تعبیه مورد نظر ما دارد. به عنوان مثال، اگر بخواهیم تمامی کلمات متنمان به بردارهایی با طول ۳۰۰ تبدیل شوند، لایه پنهان شامل ۳۰۰ نورون خواهد بود. فرآیند آموزش شبکه عصبی Word2Vec به گونهای است که در پایان، وزنهای لایه پنهان به عنوان بردار تعبیه کلمات استفاده میشوند. ماتریس وزن لایه پنهان در نهایت نمایش برداری کلمات را تشکیل میدهد.
لایه خروجی
خروجی این شبکه عصبی شامل احتمالهایی برای کلمه هدف است. به این معنا که با توجه به ورودی مدل، احتمال انتخاب کلمه مورد انتظار را به ما میدهد. درواقع بعد از عبور بردارهای One-Hot از لایههای پنهان شبکه عصبی، یک لایه Fully Connected با نورونهایی به تعداد کلمات منحصربهفرد مجموعه داده داریم. سپس یک تابع Softmax روی این لایه میزنیم تا احتمال انتخاب کلمه (درCBOW) یا کلمات (در Skip-gram) مورد نظر را از بین کل کلمات مجموعه داده، تعیین کند. در مسیر پسانتشار که طی آن وزن لایههای میانی بهروش گرادیان نزولی بهروزرسانی میشود، تابع هزینه در صورتی کمترین مقدار را خواهد داشت که کلمه انتخاب شده بهعنوان جواب، همان کلمهای باشد که انتظار داریم مدل آن را پیشبینی کند.
شبکههای عصبی معماری Word2Vec
CBOW و Skip-gram شبکههای عصبیای هستند که وظیفه بهدست آوردن وزن لایه پنهان، یعنی همان بردار متناظر به هر کلمه را دارند. همانطور که گفتیم این دو شبکه عصبی حین آموزش دیدن برای پیشبینی کلمه یا کلمات مورد نظر، وزنهای لایههای میانی یا پنهان را بهروزرسانی میکنند و با این کار در هر مرحله Embedding دقیقتری برای کلمات ساخته میشود.
CBOW چطور کار میکند؟
در روش CBOW، مدل به این صورت آموزش داده میشود که کلمه هدف را بر اساس کلمات اطراف پیشبینی کند. برای مثال، در جمله «کیک شکلاتی بود»، مدل تلاش میکند تا با استفاده از کلمات «شکلاتی» و «بود»، کلمه «کیک» را پیشبینی کند. در اینجا، بردارهای کلمات «شکلاتی» و «بود» بهصورت One-Hot-Encoding به لایه ورودی مدل داده میشود. سپس این بردارها از طریق وزنهای ضرب ماتریسی در ماتریس وزنهای لایه پنهان (W) به لایه پنهان منتقل میشوند تا به خروجی برسند. به این ترتیب لایه پنهان مقدارهای جدیدی دریافت میکند که نشاندهنده ویژگیهای کلمات ورودی هستند.
Skip-gram چطور کار میکند؟
در روش Skip-gram، فرآیند به صورت معکوس CBOW عمل میکند. در اینجا، یک کلمه ورودی مثلاً «کیک» به مدل داده میشود و مدل تلاش میکند تا کلماتی که احتمالاً در اطراف این کلمه قرار دارند، مثلاً «شکلاتی» و «بود» را پیشبینی کند. برای مثال، بردار کلمه «کیک» به لایه ورودی داده میشود و از طریق ضرب ماتریسی در ماتریس وزنهای لایه پنهان (W) به لایه پنهان منتقل میشود. سپس این بردار برای پیشبینی کلمات اطراف استفاده میشود.
همانطور که گفتیم وزنهای لایه پنهان همان بردارهای تعبیه (Embedding) کلمات هستند که در فرآیند آموزش یاد گرفته میشوند. در هر دو روش CBOW و Skip-gram، این وزنها به گونهای تنظیم میشوند که بتوانند به طور موثر کلمات را بر اساس روابط معنایی پیشبینی کنند. در CBOW، وزنهای لایه پنهان با استفاده از کلمات اطراف به روز میشوند تا کلمه هدف پیشبینی شود. در Skip-gram، وزنهای لایه پنهان با استفاده از کلمه هدف به روز میشوند تا کلمات اطراف پیشبینی شوند. در نهایت، این وزنها به عنوان بردارهای تعبیه نهایی کلمات استفاده میشوند و نمایش برداری کلمات را ایجاد میکنند.

چگونگی بهدست آوردن بردارهای تعبیه کلمات از وزنهای لایه پنهان
ماتریس وزنهای لایه پنهان یک ماتریس با ابعاد VxN است، که V تعداد کلمات منحصربهفرد مجموعه متون و N تعداد نورونهای لایه پنهان است. نتیجه این ضرب ماتریسی، یک بردار جدید به ابعاد N است که نشاندهنده مقادیر نورونهای لایه پنهان است. این بردار جدید، Embedding کلمه ورودی در فضای برداری N بعدی است.
برای درک بهتر فرض کنید تعداد کلمات منحصربهفرد متن ما شامل ۱۰ هزار کلمه باشد (۱۰۰۰۰=V) و طول بردارهای تعبیه (تعداد نورونهای لایه پنهان) ۳۰۰ باشد (۳۰۰=V). اگر کلمه ورودی «کیک» باشد، بردار One-Hot آن دارای ۱۰۰۰۰ مولفه خواهد بود که تنها در مولفه مربوط به کلمه «کیک» مقدار ۱ دارد و بقیه مولفههایش صفر هستند. این بردار با ماتریس وزنهای لایه پنهان W (که ابعاد آن ۱۰۰۰۰×۳۰۰ است) ضرب میشود و نتیجه یک بردار ۳۰۰ بعدی خواهد بود که نشاندهنده Embedding کلمه «کیک» در فضای برداری است.
توجه کنید که برای بهدست آوردن Embedding یک کلمه یا باید از شبکه عصبی CBOW استفاده کنیم یا Skip-gram.
پیادهسازی Word2Vec در پایتون
در این پروژه، ما از کتابخانه Gensim در پایتون برای پیادهسازی مدل تعبیه کلمات Word2Vec استفاده خواهیم کرد. Gensim یکی از کتابخانههای قدرتمند و محبوب در زمینه پردازش زبان طبیعی است که امکانات گستردهای برای ساخت و استفاده از مدلهای تعبیهسازی کلمات فراهم میکند.
فراخوانی کتابخانهها
برای پیادهسازی تعبیه کلمات Word2Vec در پایتون، ابتدا کتابخانههای مورد نظر را فراخوانی میکنیم:
import re
import pandas as pd
import numpy as np
from sklearn.decomposition import PCA
from sklearn.manifold import TSNE
from sklearn.metrics.pairwise import cosine_similarity
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
from tqdm import tqdm
tqdm.pandas()
import nltk
nltk.download('stopwords')
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizer
nltk.download("wordnet")
nltk.download('omw-1.4')
from nltk.corpus import wordnet as wn
nltk.download('punkt')
from nltk.tokenize import word_tokenize
from gensim.models import Word2Vec
کتابخانههای اصلی مثل Pandas و Numpy برای تجزیه و تحلیل دادهها و Matplotlib برای ترسیم نمودارها استفاده میشوند. کتابخانههای Scikit-learn برای تجزیه و تحلیلهای آماری و مدلهای یادگیری ماشین فراخوانی شده و کتابخانه NLTK برای پردازش زبان طبیعی. کتابخانه Gensim برای استفاده از مدل Word2Vec فراخوانی شده است وKeras برای ایجاد مدلهای یادگیری عمیق.
بارگذاری دادهها
در این بخش، مجموعه دادههای نظرات کاربران در IMDB را از منابع در دسترسر دانلود و بارگذاری میکنیم:
imdb = pd.read_csv('IMDB Dataset.csv')
پیشپردازش دادهها
در این قسمت توابعی برای پیشپردازش متن میسازیم و سپس آنها را روی دادهها اعمال میکنیم:
stop_lst = stopwords.words('english')
def normalize(sentence):
sentence = re.sub('^http', ' ', sentence)
sentence = re.sub('[^a-z A-Z]', ' ', sentence)
sentence = str(sentence).lower()
return sentence
def tokenize(sentence):
sentence = word_tokenize(sentence)
sentence = [token for token in sentence if len(token)>2]
return sentence
def stop_words(sentence):
sentence = [token for token in sentence if token not in stop_lst]
return sentence
def lemmatize(sentence):
sentence = [WordNetLemmatizer().lemmatize(token) for token in sentence]
return sentence
در این کد:
- تابع normalize (نرمالسازی) برای حذف کاراکترهای غیر از حروف اصلی انگلیسی و تبدیل متن به حروف کوچک است.
- تابع tokenize برای تبدیل جملات به لیستی از کلمات است.
- تابع stop_words برای حذف کلماتی است که ارزش اطلاعاتی کمی دارند (مانند the، a و …)
- تابع lemmatize برای تبدیل کلمات به ریشههای اصلیشان است.
برای اعمال این توابع روی مجموعه داده مورد نظر بهشکل زیر عمل میکنیم:
imdb = imdb.progress_apply(normalize)
imdb = imdb.progress_apply(tokenize)
imdb = imdb.progress_apply(stop_words)
imdb = imdb.progress_apply(lemmatize)
تبدیل کلمات به بردار با استفاده از Word2Vec
پیش از دادن مجموعه داده موردنظر به مدل Word2Vec و آموزش آن، نیاز است همه نظرات پیشپردازششده که اکنون بهصورت لیستی از tokenها درآمدهاند، در یک لیست جمعآوری شوند:
text = []
for i in imdb:
text.append(i)
درواقع لیست text در این کد، لیستی از لیست نظرات tokenizeشدهی کاربران است. بهاینترتیب میتوان این لیست را بهعنوان مجموعه جملات به مدل آماده Word2Vec داد که آن را از کتابخانه Gensim فراخوانی کردیم:
model = Word2Vec(sentences=text,
vector_size=256, sg=0,
min_count=2, window=5, workers=4)
هر پارامتر به چه معنا است؟
در این تابع، vector_size تعیینکننده طول بردار تعبیه هر کلمه و min_count نشاندهنده حداقل تکرار یک کلمه در متن برای استخراج یک بردار منحصربهفرد برای آن است. دقت کنید که این تابع بهطور پیشفرض از شبکه عصبی CBOW استفاده میکند و برای تغییر آن به Skip-gram باید پارامتر sg را که بهصورت پیشفرض به صفر مقداردهی شده است، برابر ۱ قرار دهید. بهاینترتیب پارامتر window تعیین میکند که مدل باید تا چند کلمه قبل و بعد یک کلمه مرکزی را به عنوان اطرافیان آن کلمه در نظر بگیرد (بهنحوه پیشبینی کلمه هدف توسط CBOW توجه کنید). پارامتر works نیز تعداد فرآیندهای موازی را مشخص میکند که میتوانند به صورت همزمان برای آموزش مدل روی مجموعه داده ما استفاده شوند.
بااجرای این قطعه کد، مدل ما train شده و میتوان بردار متناظر با هر کلمه را از متغیر model با متد wv بهدست آورد. درواقع خروجی model.wv، یک دیکشنری پایتونی شامل کلمات بهعنوان keys و بردار متناظر به آن بهعنوان values است.
یکی از توابعی که روی model.wv تعریف شده است، تابع most_similar است:
model.wv.most_similar('film')
[(‘movie’, 0.8418914079666138),
(‘flick’, 0.5352792739868164),
(‘cinema’, 0.475547730922699),
(‘documentary’, 0.46939778327941895),
(‘one’, 0.46168315410614014),
(‘picture’, 0.45609861612319946),
(‘certainly’, 0.4406309723854065),
(‘however’, 0.43780001997947693),
(‘thriller’, 0.4338338077068329),
(‘therefore’, 0.41475433111190796)]
همانطور که میبینید، تابع most_similar برای پیدا کردن کلماتی استفاده میشود که بیشترین شباهت را به کلمه موردنظر مشخصی دارند. این تابع از بردارهای کلمات استفاده میکند و با محاسبه فاصله کسینوسی (cosine similarity) بین بردارها، کلماتی را که به بردار کلمه ورودی نزدیکتر هستند، پیدا میکند. خروجی کد بالا نشان میدهد که بردار متناظر با کلماتی مانند movie ،cinema ،documentary و flick بیشترین شباهت را به بردار متناظر با کلمه film دارند.
خوشهبندی بردار کلمات
در این قسمت میخواهیم بردارهای کلمات مدل Word2Vec را به ۵ خوشه تقسیم کنیم، سپس با استفاده از PCA ابعاد بردارها را به ۳ بعد کاهش میدهد و در نهایت بردارهای کاهش یافته را در فضای سهبعدی رسم کنیم. این کار کمک میکند تا بتوانیم جایگاه بردارهای تعبیه کلمات نزدیکبههم را در فضای برداری بهصورت بصری درک کنیم.
برای این کار، ابتد، یک مدل خوشهبندی KMeans با تعداد ۵ خوشه (n_clusters=5) ایجاد میکنیم:
kmeans = KMeans(n_clusters=5)
KMeans یک الگوریتم خوشهبندی است که سعی میکند دادهها را به تعدادی خوشه تقسیم کند که دادههای درون هر خوشه بیشترین شباهت را به هم داشته باشند.
سپس مدل KMeans با استفاده از بردارهای کلمات (model.wv.vectors) آموزش داده میشود:
kmeans.fit(model.wv.vectors)
هدف از این مرحله این است که KMeans بردارهای کلمات را به ۵ خوشه تقسیم کند.
پس از آموزش مدل KMeans، برچسبهای (Labels) کلمات را در متغیر labels میریزیم:
labels = kmeans.labels_
این برچسبها نشان میدهند که هر کلمه به کدام یک از ۵ خوشه تعلق دارد.
نمایش بردار کلمات در سهبعد
برای نمایش بردار کلمات در سهبعد، از PCA استفاده میکنیم. بهاینمنظور یک مدل PCA با تعداد ۳ مؤلفه اصلی (n_components=3) ایجاد میکنیم:
pca = PCA(n_components=3)
vectors_3d = pca.fit_transform(model.wv.vectors)
PCA یا تحلیل مؤلفههای اصلی، یک روش کاهش ابعاد است که دادههای با ابعاد بالا را به ابعاد پایینتر تبدیل میکند. بهاینترتیب بردارهای کلمات (model.wv.vectors) به سه بعد (vectors_3d) کاهش مییابند.
برای نمایش بردارهای سهبعدی از قطعه کد زیر استفاده میکنیم:
fig = plt.figure(figsize=(15,10), dpi=100)
ax = fig.add_subplot(111, projection='3d')
ax.scatter(vectors_3d[0:80, 0], vectors_3d[0:80, 1], vectors_3d[0:80, 2], c=labels[0:80], s=50)
با این کد، نقاطی که بردارهای کاهشیافته به سهبعد به آن اشاره میکنند، برای اولین ۸۰ کلمه ترسیم میشوند. رنگ هر نقطه بر اساس برچسب خوشهاش تعیین میشود (c=labels[0:80).
سپس برچسب کلمات را به نقاط اضافه میکنیم:
for i, word in enumerate(words[0:80]):
ax.text(vectors_3d[i, 0], vectors_3d[i, 1], vectors_3d[i, 2]+0.25, word, fontsize=7)
بهاینترتیب هر کلمه در محلی که بردار متناظرش به آن اشاره میکند، در فضای سهبعدی نمایش داده میشود. خروجی کد بالا بهشکل زیر است:

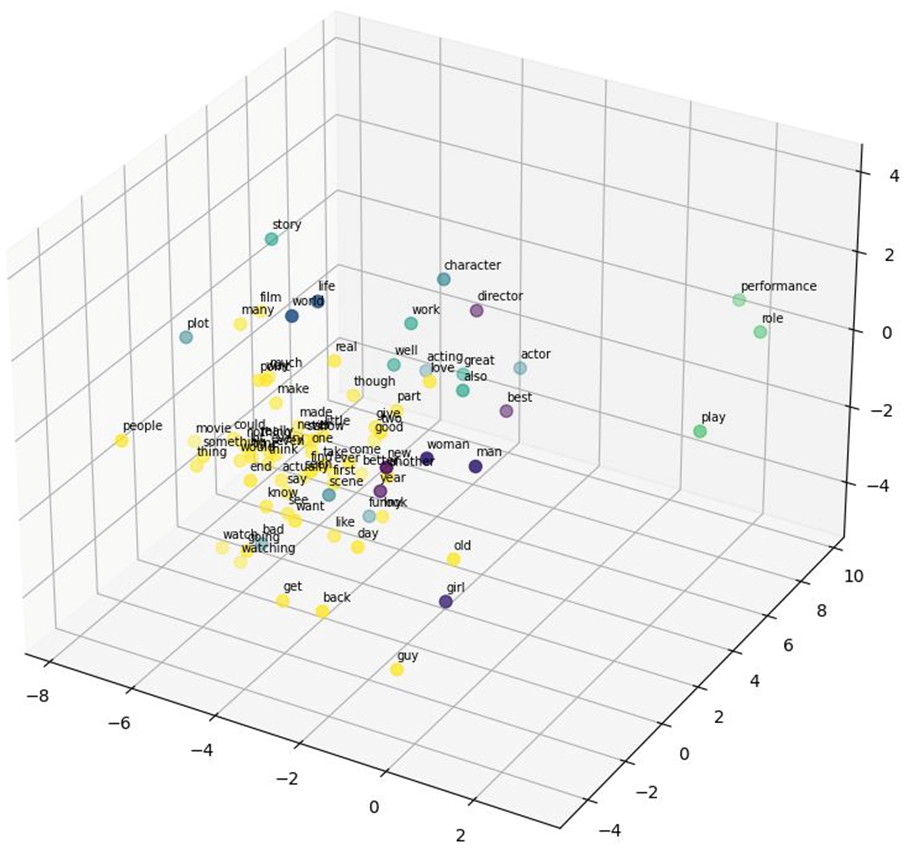
این نمودار کمک میکند تا بتوانیم شباهتهای معنایی بین کلمات را به صورت بصری بهتر درک کنیم و گروهبندیهای بین کلمات را مشاهده کنیم. برای مثال کلمات performance (نمایش)، play (بازی) و role (نقش) که تقریبا معنایی نزدیکی دارند، از نظر Label خوشهبندی یکسان هستند و در فضای سهبعدی موقعیت قرارگیری نزدیکی دارند.
درک شهودی حفظ روابط معنایی بین کلمات در Word2Vec
در این بخش میخواهیم بردارهای کلمات مدل Word2Vec را برای چهار کلمه man (مرد)، king (پادشاه)، woman (زن) و queen (ملکه) گرفته و آنها را به دو بعد کاهش دهیم تا بتوانیم آنها را در یک نمودار دو بعدی رسم کنیم. سپس روابط معنایی بین بردارهای این کلمات را با استفاده از نمایش برداری نشان دهیم.
پیادهسازی
برای این کار، چهار کلمه گفتهشده را در یک لیست قرار میدهیم:
words = ["man", "king", "woman", "queen"]
سپس بردارهای تعبیه مربوط به این کلمات را از مدل Word2Vec استخراج میکنیم:
vectors = [model.wv[i] for i in words]
در نهایت رنگهای مختلفی را برای نمایش این کلمات در نمودار انتخاب میکنیم:
new_labels = [labels[i] for i in range(len(model.wv)) if model.wv.index_to_key[i] in words]
سپس مانند قسمت قبل برای اینکه بتوانیم کلمات مورد نظر را بهتر ببینیم، باکمک PCA بردار متناظر با این چهار کلمه را به ۲ بعد کاهش میدهیم:
pca = PCA(n_components=2)
vectors_2d = pca.fit_transform(vectors)
دقت کنید که بردار اصلی تعبیهشده توسط این مدل طبق پارامتر vector_size در تابع Word2Vec، یک بردار ۲۵۶ بعدی است.
حال برای ترسیم نقاطی که بردارهای کاهشیافته متناظر با این چهار کلمه به آن اشاره میکنند، از کد زیر استفاده میکنیم. رنگ هر نقطه نیز بر اساس رنگهای مشخص شده در new_labels تعیین میشود:
fig = plt.figure(figsize=(10,8), dpi=90)
ax = fig.add_subplot(111)
ax.scatter(vectors_2d[:, 0], vectors_2d[:, 1], s=100, c=new_labels)
مانند قسمت قبل، با قطعه کد زیر، کلمات در محل مربوط به بردارهای دو بعدیشان قرار میگیرند:
for i, word in enumerate(words):
ax.text(vectors_2d[i, 0], vectors_2d[i, 1], word, fontsize=13)
در ادامه بردارهای دو بعدی مربوط به کلمات queen، woman و man را در یک دیکشنری ذخیره میکنیم و مختصات متناظر با بردار هر کلمه را جداگانه در متغیرهای مربوطهشان میریزیم:
points = {word: vectors_2d[i] for i, word in enumerate(words)}
queen_point = points['queen']
woman_point = points['woman']
man_point = points['man']
سپس بردار queen_woman را محاسبه میکنیم که نشاندهنده تفاضل بین بردارهای متناظر با کلمات queen و woman است:
queen_woman = queen_point - woman_point
همچنین بردار plus_man را محاسبه میکنیم که نشاندهنده جمع بردار queen_woman و بردار man است:
plus_man = queen_woman + man_point
حال میخواهیم نقاطی را که این دو بردار به آن اشاره میکنند، روی نمودار نشان دهیم و هر کلمه را در محل مربوط به بردارهای دو بعدیاش قرار دهیم. به این منظور در ادامه کد قبلی، از کد زیر استفاده میکنیم:
ax.scatter(plus_man[0], plus_man[1], s=100, c='green')
ax.text(plus_man[0], plus_man[1], 'queen - woman + man', fontsize=13)
ax.scatter(queen_woman[0], queen_woman[1], s=100, c='blue')
ax.text(queen_woman[0], queen_woman[1], 'queen-woman', fontsize=13, position=(10,1))
در پایان بااستفاده از کد زیر، پنج فلش از مبدا مختصات رسم میکنیم که هر کدام نشاندهنده یکی از بردارهای queen،woman ،man ،queen_woman و plus_man (که برابر بردار queen – woman + man است) میباشد:
ax.quiver(0, 0, queen_point[0], queen_point[1], angles='xy', scale_units='xy', scale=1, color='purple', linestyle='dotted')
ax.quiver(0, 0, woman_point[0], woman_point[1], angles='xy', scale_units='xy', scale=1, color='red', linestyle='dotted')
ax.quiver(0, 0, man_point[0], man_point[1], angles='xy', scale_units='xy', scale=1, color='#ffc60e', linestyle='dotted')
ax.quiver(0, 0, queen_woman[0], queen_woman[1], angles='xy', scale_units='xy', scale=1, color='blue', linestyle='dotted')
ax.quiver(0, 0, plus_man[0], plus_man[1], angles='xy', scale_units='xy', scale=1, color='green', linestyle='dotted')
نمایش خروجی
خروجی کدهای بالا به شکل زیر در میآید:

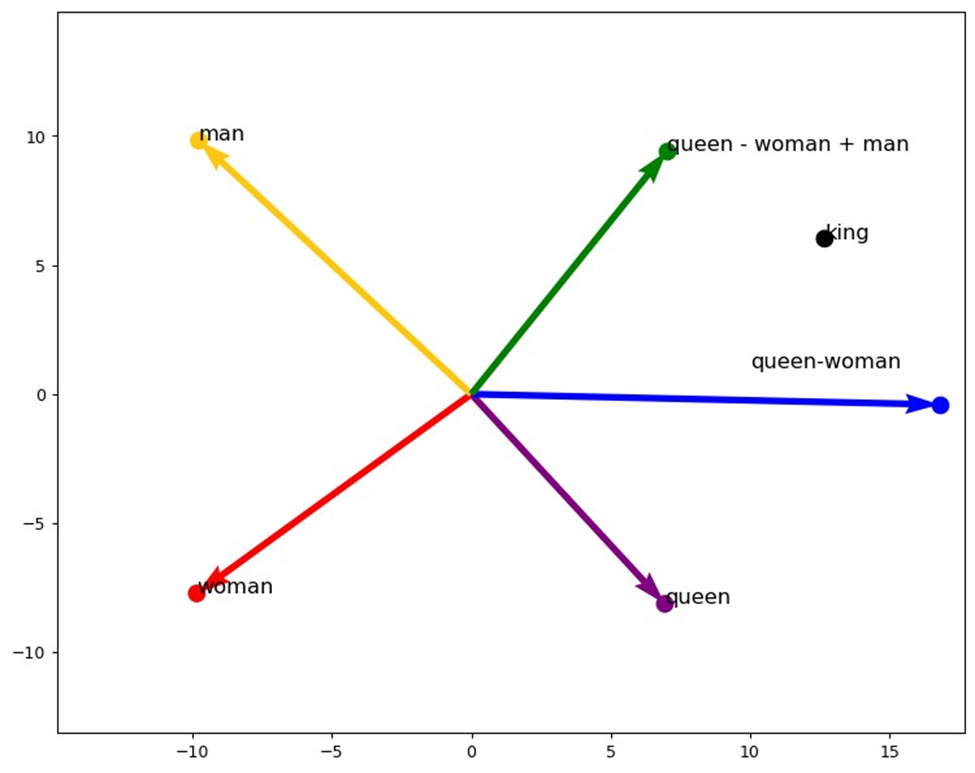
تفسیر نمودار
در این شکل بردار متناظر با کلمه woman با رنگ قرمز، queen با رنگ بنفش و man با رنگ زرد نشان داده شده است. بردار آبیرنگ، تفاضل بین بردار queen و woman را نشان میدهد و فلش سبز نشاندهنده بردار queen - woman + man است.
این نمودار نشان میدهد که با استفاده از بردارهای کلمات، میتوان عملیات جبری معنایی انجام داد. برای مثال در این شکل، بردار queen - woman + man به نقطهای که بردار king به آن اشاره میکند، نزدیک است که نشاندهنده قدرت Embedding کلمات در مدل Word2Vec برای فهمیدن روابط معنایی بینشان است.
کاربردهای Word2Vec
Word2Vec در بسیاری از زمینهها کاربرد دارد که در ادامه به برخی از آنها اشاره میکنیم:
تحلیل احساسات
Word2Vec میتواند به تحلیل احساسات در متنها کمک کند و نظرات مثبت و منفی را از یکدیگر تفکیک کند. این کاربرد در تحلیل نظرات کاربران در شبکههای اجتماعی و بررسی بازخوردهای مشتریان بسیار مفید است.
موتورهای جستجو
موتورهای جستجو میتوانند از Word2Vec برای بهبود دقت و ارتباط نتایج جستجو استفاده کنند. این تکنیک میتواند به درک بهتر پرسوجوهای کاربران و ارائه نتایج مرتبطتر کمک کند.
ترجمه ماشینی
در ترجمه ماشینی، Word2Vec میتواند به بهبود دقت ترجمهها و درک بهتر متنها کمک کند. این تکنیک میتواند به ترجمه معنایی دقیقتر و بهتر متنها کمک کند.
سیستمهای توصیهگر
سیستمهای توصیهگر نیز میتوانند از Word2Vec برای پیشنهاد محتوا و محصولات بهتر به کاربران استفاده کنند. این سیستمها با استفاده از روابط معنایی بین کلمات، میتوانند پیشنهادات دقیقتر و مرتبطتری ارائه دهند.
چالشها و محدودیتهای Word2Vec
با وجود مزایای زیاد، Word2Vec نیز با چالشها و محدودیتهایی مواجه است که باید در نظر گرفته شوند.
نیاز به دادههای بزرگ
یکی از بزرگترین چالشهای Word2Vec نیاز به دادههای بزرگ برای آموزش مدل است. بدون دادههای کافی، مدل نمیتواند به دقت مطلوب برسد.
مدیریت هممعنایی و چندمعنایی
Word2Vec در مدیریت هممعنایی و چندمعنایی کلمات ممکن است با مشکلاتی مواجه شود که باید به دقت بررسی شوند. این چالشها میتوانند به دقت مدل آسیب برسانند.
زمان محاسباتی
محاسبات مربوط به Word2Vec ممکن است زمانبر باشد و نیاز به منابع محاسباتی زیادی داشته باشد. این موضوع میتواند در پروژههای بزرگ مشکلساز باشد.
آینده Word2Vec و پردازش زبان طبیعی
پردازش زبان طبیعی همچنان در حال پیشرفت است و تکنیکهای جدیدی مانند BERT و GPT نیز به میدان آمدهاند که قابلیتهای بیشتری نسبت به Word2Vec دارند. با این حال، Word2Vec همچنان یکی از ابزارهای قدرتمند و پرکاربرد در این حوزه است.
جمعبندی
مدل Word2Vec یکی از تکنیکهای پیشرفته و کارآمد در حوزه پردازش زبان طبیعی (NLP) است که توسط تیم گوگل معرفی و توسعه داده شده است. این مدل با استفاده از شبکههای عصبی مصنوعی، کلمات را به بردارهای عددی تبدیل میکند که روابط معنایی و نحوی بین آنها را حفظ میکند. دو مدل اصلی Word2Vec، یعنی CBOW وSkip-gram، هر کدام با رویکردهای مختلفی به پیشبینی کلمات میپردازند و به کاربران امکان میدهند که با دقت بیشتری به تحلیل و پردازش متون بپردازند.
استفاده از Word2Vec برخلاف روشهای سنتی کدگذاری کلمات، امکان درک بهتر روابط معنایی بین کلمات را فراهم میکند. کاربردهای متنوع Word2Vec از جمله در تحلیل احساسات، بهبود موتورهای جستجو، ترجمه ماشینی و سیستمهای توصیهگر، نشان از قابلیتهای گسترده و مؤثر این مدل دارد.


پرسشهای متداول
چرا Word2Vec نسبت به روشهای دیگر کدگذاری مانند One-Hot-Encoding و TF-IDF بهتر است؟
Word2Vecنهتنها کلمات را به بردارهای عددی تبدیل میکند، بلکه روابط معنایی و نحوی بین کلمات را نیز حفظ میکند. این ویژگیها به مدلهای یادگیری ماشین کمک میکند تا ارتباطات معنایی بین کلمات را بهتر درک کنند. برخلاف One-Hot-Encoding که بردارهای بزرگ و غیرموثر ایجاد میکند و TF-IDF که تنها به فراوانی کلمات توجه دارد، Word2Vec میتواند کلمات مشابه را به صورت نزدیک به هم در فضای برداری نمایش دهد، که این باعث بهبود دقت مدلهای پردازش زبان طبیعی میشود.
مدلهای Continuous Bag of Words (CBOW) و Skip-gram در Word2Vec چگونه کار میکنند و چه تفاوتهایی دارند؟
در مدل CBOW، هدف پیشبینی یک کلمه هدف با توجه به کلمات اطراف آن است. به عبارت دیگر، این مدل از کلمات اطراف برای پیشبینی کلمه مرکزی استفاده میکند. در مقابل، مدل Skip-gram تلاش میکند تا با توجه به یک کلمه مرکزی، کلمات اطراف آن را پیشبینی کند. به طور کلی، مدل CBOW برای مجموعه دادههای بزرگ و مدل Skip-gram برای دادههای کوچک مناسبتر است.
چگونه میتوانیم از Word2Vec در کاربردهای عملی مانند تحلیل احساسات و موتورهای جستجو استفاده کنیم؟
Word2Vec در تحلیل احساسات، میتواند به کمک بردارهای کلمات، نظرات مثبت و منفی را از هم تفکیک کند و تحلیل دقیقی از احساسات کاربران ارائه دهد. در موتورهای جستجو، Word2Vec میتواند با فهمیدن بهتر پرسشهای کاربران و ارائه نتایج مرتبطتر، دقت و کارایی جستجو را بهبود بخشد. به عنوان مثال، اگر کاربر عبارتی را جستجو کند که شامل کلماتی با معنای مشابه است، موتور جستجو میتواند نتایج مرتبطتری را بر اساس بردارهای کلمات ارائه دهد.
چالشها و محدودیتهای استفاده از Word2Vec چیست؟
یکی از بزرگترین چالشهای Word2Vec نیاز به دادههای بزرگ برای آموزش مدل است. بدون دادههای کافی، مدل نمیتواند به دقت مطلوب برسد. همچنین، مدیریت هممعنایی (Synonymy) و چندمعنایی (Polysemy) کلمات در Word2Vec ممکن است با مشکلاتی مواجه شود که میتواند به دقت مدل آسیب برساند. همچنین، محاسبات مربوط به Word2Vec ممکن است زمانبر باشد و نیاز به منابع محاسباتی زیادی داشته باشد، که این موضوع میتواند در پروژههای بزرگ مشکلساز باشد.
چگونه میتوان از بردارهای Word2Vec برای انجام عملیات جبری معنایی استفاده کرد؟
یکی از ویژگیهای جذاب Word2Vec این است که میتوان با استفاده از بردارهایی که برای کلمات ایجاد میکند، عملیات جبری معنایی انجام داد. به عنوان مثال، اگر بردار کلمه پادشاه را منهای بردار مرد کنیم و سپس بردار زن را به آن اضافه کنیم، نتیجه به بردار ملکه نزدیک خواهد بود. این عملیات نشاندهنده قدرت Word2Vec در درک و نمایش روابط معنایی بین کلمات است.
یادگیری ماشین لرنینگ را از امروز شروع کنید!
دنیای دادهها جذاب است و دانستن علم داده، توانایی تحلیل داده، یا بازاریابی مبتنی بر داده، شما را برای فرصتهای شغلی بسیاری مناسب میکند. فارغ از رشته و پیشزمینه، میتوانید حالا شروع کنید و از سطح مقدماتی تا پیشرفته بیاموزید. اگر دوست دارید به این حوزه وارد شوید، پیشنهاد میکنیم با کلیک روی این لینک قدم اول را همین حالا بردارید.
مشاوران کافهتدریس به شما کمک میکنند مسیر یادگیری برای ورود به این حوزه را شروع کنید: