

شبکههای کاملاً کانولوشنی (Fully Convolutional Networks) (FCNs) چشمانداز بخشبندی تصویر (Image Segmentation) را متحول کردهاند و امکان پردازش دقیق و کارآمد دادههای بصری را فراهم آوردهاند. این مقاله یک مرور جامع از FCNs ارائه میدهد، سیر تکاملی آنها از شبکههای عصبی کانولوشنی (Convolutional Neural Networks) سنتی (CNNs) را دنبال کرده و معماری منحصر به فرد آنها را برجسته میکند. ما تکنیکهای آموزش، کاربردها و نتایج تجربی را بررسی کرده و نقاط قوت و محدودیتهای FCNs را برجسته میکنیم. یافتههای ما پتانسیل FCNs را در حوزههای مختلف، به ویژه در بخشبندی معنایی، تصویربرداری پزشکی، رانندگی خودکار و رباتیک نشان میدهد. همچنین پیشنهادهایی جهت سیر تحقیقاتی آینده برای رفع چالشهای کنونی و افزایش تواناییهای FCNs ارائه میشود.
- 1. پیشینه و انگیزه
- 2. اهمیت شبکههای کاملاً کانولوشنی
- 3. اهداف مقاله
- 4. شبکههای عصبی کانولوشنی سنتی (CNNs)
- 5. تکامل FCNها
- 6. مقایسه FCN با سایر روشهای بخشبندی
- 7. معماری شبکههای کاملاً کانولوشنی
- 8. تکنیکهای یادگیری مدل
- 9. معیارهای ارزیابی
- 10. کاربردهای FCNها
- 11. نتایج تجربی
- 12. مزایای شبکههای تمامکانولوشن (FCN)
- 13. محدودیتها و چالشها
- 14. جهتگیریهای تحقیقاتی آینده
- 15. نتیجهگیری
-
16.
پرسشهای متداول
- 16.1. چرا روشهای سنتی بخشبندی تصویر به دقت و مقیاسپذیری محدودی منجر میشدند؟
- 16.2. چرا CNNهای سنتی برای وظایف بخشبندی تصویر مناسب نیستند؟
- 16.3. FCNها چگونه چالشهای بخشبندی تصویر را حل میکنند؟
- 16.4. FCNها چگونه جزئیات فضایی و مکانی اشیاء را حفظ میکنند؟
- 16.5. معیارهای ارزیابی عملکرد FCNها شامل چه مواردی هستند؟
- 17. یادگیری ماشین لرنینگ را از امروز شروع کنید!
پیشینه و انگیزه
بخشبندی تصویر، که وظیفه تقسیم یک تصویر به نواحی معنادار را دارد، مدتهاست که یک مسئله چالشبرانگیز در بینایی کامپیوتر (Computer Vision) بوده است. روشهای سنتی اغلب به استخراج ویژگیهای دستی و قواعد اکتشافی متکی بودند، که منجر به دقت و مقیاسپذیری محدودی میشد. ظهور شبکههای عصبی کانولوشنی (CNNs) یک پیشرفت قابل توجه را در این زمینه رقم زد، که استخراج ویژگیها را خودکار کرده و موفقیت چشمگیری در وظایف مختلف بینایی ماشین به دست آورد. با این حال، علیرغم این پیشرفتها، نیاز به دقت پیکسلی (pixel-level precision) در بخشبندی تصویر همچنان یک مانع مهم باقی مانده بود.
اهمیت شبکههای کاملاً کانولوشنی
در حالی که CNNs در دستهبندی تصاویر (image classification) و تشخیص اشیا (object detection) بسیار کارآمد هستند، طراحی ذاتی آنها برای پیشبینیهای پیکسلی مورد نیاز در وظایف بخشبندی (Image segmentation) مناسب نیست. شبکههای کاملاً کانولوشنی (FCNs) این محدودیت را با جایگزینی لایههای کاملاً متصل (fully connected layers) با لایههای کانولوشنی (convolutional layers) برطرف میکنند، که به شبکه امکان میدهد نقشههای مکانی به جای امتیازهای کلاسی، خروجی دهد. این نوآوری به FCNs اجازه میدهد تا اطلاعات مکانی را حفظ کرده و نقشههای بخشبندی با وضوح بالا تولید کنند. اهمیت FCNs در توانایی آنها برای تبدیل بخشبندی تصویر به یک فرآیند خودکار، دقیق و مقیاسپذیر است، که برای کاربردهایی که نیاز به تحلیل تصویر دقیق و جزئی دارند، حیاتی است.

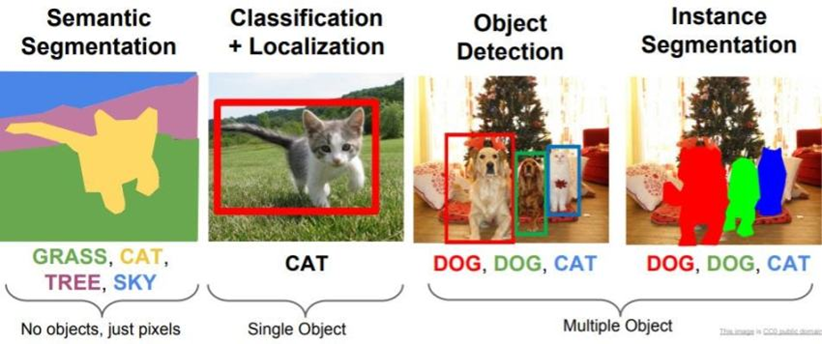
اهداف مقاله
این مقاله هدف دارد تا به طور جامع به بررسی FCNs بپردازد و جزئیات معماری، روشهای کارکرد این شبکهها و کاربردهای متنوع آنها را شرح دهد. ما همچنین نتایج تجربی را برای نشان دادن کارآیی FCNs ارائه میدهیم و نقاط قوت، محدودیتها و جهتهای تحقیقاتی آینده را مورد بحث قرار میدهیم. با ارائه یک تحلیل جامع، امیدواریم به پتانسیل تحولآفرین FCNs در زمینه بخشبندی تصویر پی ببریم و به تحقیق و نوآوری بیشتر در این زمینه الهام بخشیم.
شبکههای عصبی کانولوشنی سنتی (CNNs)
CNNها با استفاده از لایههای کانولوشنی برای یادگیری خودکار ویژگیها، پردازش تصویر را متحول کردهاند. با این حال، طراحی آنها که معمولاً شامل لایههای کاملاً متصل است، توانایی آنها را در انجام وظایفی که نیاز به پیشبینیهای متراکم پیکسلی دارند، محدود میکند. این محدودیت، نیاز به توسعه معماریهای تخصصیتر برای بخشبندی را ضروری کرد. CNNهای سنتی که عمدتاً برای دستهبندی تصاویر طراحی شدهاند، یک برچسب کلاسی واحد را به ازای هر تصویر، خروجی میدهند و اطلاعات فضایی یا مکانی مهمی که برای بخشبندی لازم است را از دست میدهند. تکنیکهایی مانند رویکردهای پنجره لغزان برای تطبیق CNNها با بخشبندی استفاده میشدند، اما این روشها از نظر محاسباتی پرهزینه و کمبازده بودند.

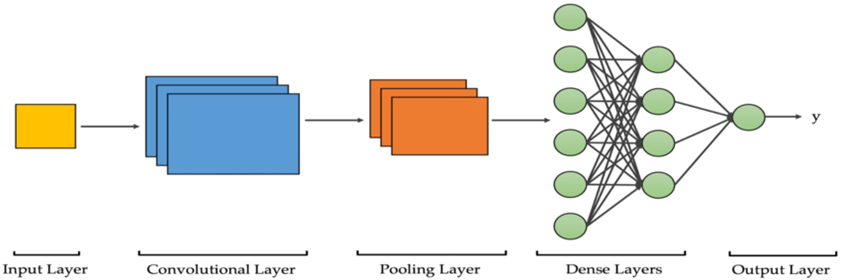
تکامل FCNها
FCNها به عنوان یک توسعه طبیعی از CNNها برای رفع چالشهای بخشبندی تصویر ظهور کردند. با تبدیل لایههای کاملاً متصل به لایههای کانولوشنی، FCNها قادر به تولید تصویر در خروجی هستند که با ابعاد ورودی مطابقت دارند. این معماری اطلاعات فضایی اشیا را در سراسر شبکه حفظ میکند و بخشبندی دقیق را تسهیل میکند. معرفی اتصالات پرشی (skip connections) که اطلاعات حاصل از ویژگیهای لایههای اولیه را به لایههای عمیقتر متصل میکند، عملکرد FCNها را بیشتر بهبود بخشید و به شبکه اجازه داد تا اطلاعات کلی و جزئی را با هم ترکیب کند، و بخشبندی دقیقتری در تصاویر تولید کند.

همچنین بخوانید: فرایند لایه گذاری در شبکه عصبی کانولوشنی چگونه است؟
مقایسه FCN با سایر روشهای بخشبندی
روشهای سنتی بخشبندی، مانند الگوریتمهای مبتنی بر ناحیه (region-based) و تشخیص لبه (edge-detection)، اغلب در برخورد با تصاویر پیچیده دچار مشکل میشوند و نیاز به پیشپردازش گسترده دارند. در مقابل، FCNها یادگیری End-to-End را ارائه میدهند، به طور خودکار با دیتاستهای متنوع تطبیق مییابند و عملکرد بهتری را به دست میآورند. در مقایسه با سایر روشهای مبتنی بر یادگیری عمیق، FCNها رویکردی سادهتر و کارآمدتر برای وظایف بخشبندی در مقیاس بزرگ ارائه میدهند. روشهای دیگر مبتنی بر یادگیری عمیق، مانند روشهای مبتنی بر تکهها (patch-based methods)، اغلب به دلیل اندازه تکهها و فقدان زمینه سراسری محدود هستند، در حالی که FCNها میتوانند از زمینه کل تصویر و ویژگیهای چند مقیاسی برای نتایج بهتر بخشبندی استفاده کنند.
معماری شبکههای کاملاً کانولوشنی
گذر از CNN به FCN
نوآوری کلیدی در FCNها جایگزینی لایههای کاملاً متصل با لایههای کانولوشنی است. این تغییر به شبکه اجازه میدهد تا ورودیهای با اندازههای مختلف را پردازش کرده و خروجیهایی از جنس تصویر با ابعاد مطابق با ورودی تولید کند. با استفاده از لایههای کانولوشنی و لایههای Pooling، FCNها سلسلهمراتب مکانی ویژگیها را در سراسر شبکه حفظ میکنند. این تغییر نه تنها FCNها را انعطافپذیرتر میکند بلکه تعداد پارامترها را کاهش میدهد، که باعث کاهش احتمال بیشبرازش (Overfitting) و افزایش کارایی یادگیری مدل میشود.
لایهها و اجزا
یک FCN معمولاً از یک رمزگذار (Encoder) و یک رمزگشا (Decoder) تشکیل شده است. رمزگذار، مشابه با CNNهای سنتی، ویژگیهای سلسلهمراتبی را از طریق لایههای کانولوشنی و Pooling متوالی استخراج میکند. رمزگشا، که شامل لایههای نمونهبرداری مجدد (Upsampling) و اتصالات پرشی (Skip Connections) است، نقشههای بخشبندی با وضوح بالا را از ویژگیهای رمزگذاری شده بازسازی میکند. اتصالات پرشی که ویژگیهای با وضوح بالاتر را از رمزگذار به رمزگشا متصل میکنند، نقش حیاتی در حفظ جزئیات فضایی و مکانی اشیاء دارند. ساختار رمزگذار-رمزگشا به شبکه اجازه میدهد تا ویژگی غنی را یاد بگیرد و همچنین بازسازی دقیق تصویر ورودی را انجام دهد که برای بخشبندی دقیق ضروری است.

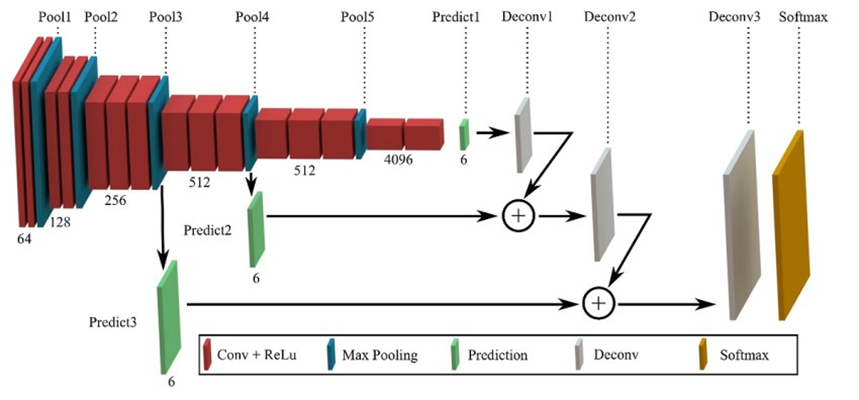
تکنیکهای یادگیری مدل
آمادهسازی دادهها
یادگیری موفقیتآمیز FCNها به دیتاستهای متنوع و خوب برچسبگذاری شده متکی است. تکنیکهای افزایش داده (Data Augmentation)، مانند چرخش، مقیاسبندی و وارونهسازی، به طور معمول برای افزایش پایداری شبکه و جلوگیری از بیشبرازش استفاده میشوند. افزایش داده نه تنها تنوع بیشتری از نمونههای آموزشی را فراهم میکند بلکه به شبکه کمک میکند تا بهتر با دادههای دیده نشده تطبیق پیدا کند. علاوه بر این، تکنیکهای نرمالسازی اعمال میشوند تا اطمینان حاصل شود که دادههای ورودی در محدودهای سازگار هستند که این امر منجر به یادگیری کارآمدتر میشود.
تابع هدف (Loss Function)
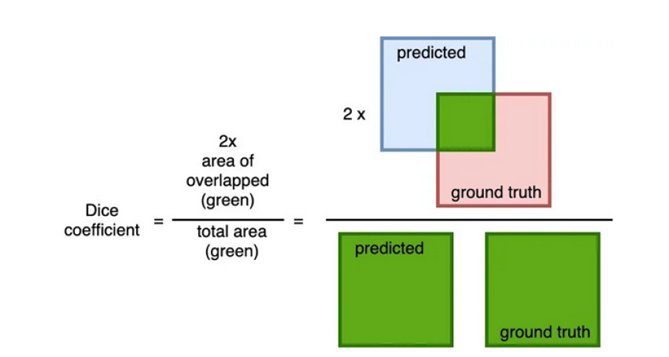
انتخاب Loss Function تأثیر قابل توجهی بر عملکرد FCNها دارد. توابع هدف رایج شامل cross-entropy برای بخشبندی دوتایی و چندکلاسه، و Dice coefficient برای تحلیل تصویر پزشکی هستند، چرا که در تصاویر پزشکی همپوشانی بین مناطق پیشبینی شده مدل و واقعی حیاتی است. علاوهبراین Dice در مقابله با عدم توازن کلاسها مؤثر است که یک مشکل رایج در دیتاستهای پزشکی است. توابع هدف پیشرفتهتر، مانند Jaccard و focal، نیز برای رفع چالشهای خاص در وظایف بخشبندی مورد بررسی قرار گرفتهاند و دقت و پایداری مدلها را بیشتر بهبود میبخشند.



الگوریتمهای بهینهسازی
الگوریتمهای بهینهسازی، مانند SGD و Adam، برای کمینهسازی تابع هدف استفاده میشوند. تنظیم نرخ یادگیری و تکنیکهای regularization و dropout نیز برای بهبود فرایند آموزش و اطمینان از همگرایی به کار میروند. انتخاب الگوریتم بهینهسازی و پارامترهای آن، مانند نرخ یادگیری و batch-size، میتواند به طور قابل توجهی بر دینامیک یادگیری و عملکرد نهایی مدل تأثیر بگذارد.
همچنین بخوانید: راهنمای جامع نحوه بهینهسازی در علم داده
معیارهای ارزیابی
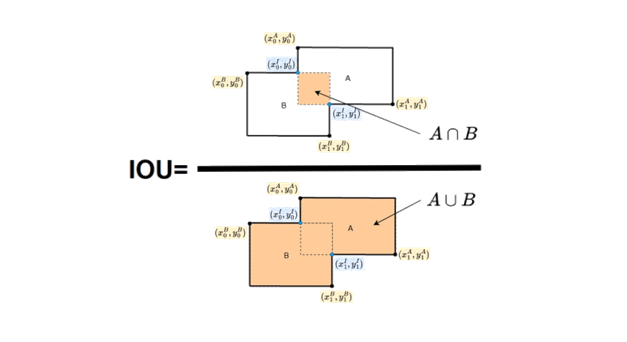
ارزیابی عملکرد FCNها شامل معیارهایی است که کیفیت بخشبندی را منعکس میکنند، مانند اشتراک بر اجتماع (IoU)، دقت پیکسلی و امتیاز F1. این معیارها بینشهایی در مورد توانایی شبکه برای تعیین دقیق مرزهای اشیا و بخشبندی نواحی مورد علاقه فراهم میکنند. IoU همپوشانی بین مناطق پیشبینی شده و واقعی را اندازهگیری میکند و نتیجهای قابل استناد از دقت بخشبندی ارائه میدهد. دقت پیکسلی، هرچند ساده، میتواند در موارد عدم توازن کلاس گمراهکننده باشد، بنابراین استفاده از ترکیبی از معیارها برای به دست آوردن ارزیابی جامع از عملکرد مدل اهمیت دارد.

برای مطالعه بیشتر کلیک کنید: پیادهسازی شبکه عصبی کانولوشنی (CNN) در PyTorch چگونه است؟
کاربردهای FCNها
بخشبندی معنایی
بخشبندی معنایی (Semantic Segmentation)، فرآیند دستهبندی هر پیکسل در یک تصویر به دستههای از پیش تعریف شده، یکی از کاربردهای اصلی FCNها است. توانایی آنها در تولید تصاویر بخشبندیشده با وضوح بالا، آنها را برای وظایفی که نیاز به درک دقیق از محتوای صحنه دارند، ایدهآل میکند. در برنامهریزی شهری، بخشبندی معنایی برای تحلیل تصاویر ماهوارهای به منظور شناسایی انواع پوششهای زمینی مانند ساختمانها، جادهها و پوشش گیاهی استفاده میشود. در پایش محیط زیست، به ردیابی تغییرات در اکوسیستمها، جنگلزدایی و گسترش شهری کمک میکند و بینشهای ارزشمندی برای سیاستگذاری و تلاشهای حفاظتی ارائه میدهد.
تحلیل تصویر پزشکی
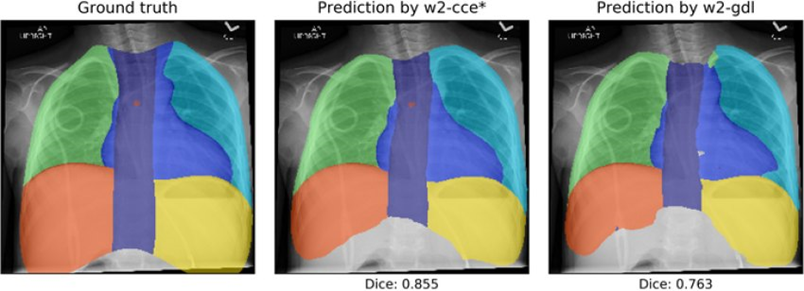
در تصویربرداری پزشکی، FCNها برای بخشبندی ساختارهای آناتومیک و تشخیص ناهنجاریها در MRI و سی تی اسکن استفاده میشوند. دقت و کارایی آنها امکان تشخیص و برنامهریزی درمان خودکار را فراهم میکند و به طور قابل توجهی فرآیندهای بالینی را بهبود میبخشد. به عنوان مثال، FCNها برای بخشبندی تومورهای مغزی به کار گرفته میشوند، و به رادیولوژیستها در تشخیص دقیق و برنامهریزی درمان کمک میکنند. بخشبندی خودکار اعضای بدن، مانند کبد و قلب، به برنامهریزی جراحی و پرتودرمانی کمک میکند و زمان و تلاش مورد نیاز برای تعیین دستی را کاهش میدهد.

رانندگی خودکار
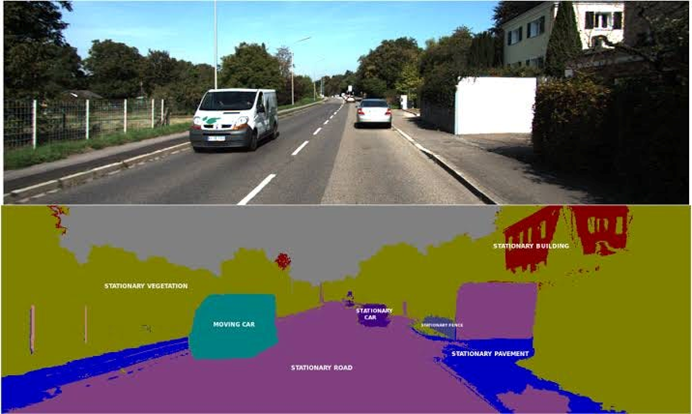
FCNها نقش حیاتی در رانندگی خودکار با بخشبندی صحنههای جاده برای شناسایی خطوط، وسایل نقلیه، عابران پیاده و سایر اشیاء مرتبط ایفا میکنند. این قابلیت بخشبندی بلادرنگ (real-time) برای ناوبری امن و تصمیمگیری در محیطهای پویا ضروری است. علاوه بر تشخیص خطوط و اشیا، FCNها برای بخشبندی مناطق قابل رانندگی و شناسایی موانع به کار گرفته میشوند، که آگاهی موقعیتی خودرو را افزایش داده و سیستمهای رانندگی خودکار را قابل اعتمادتر و ایمنتر میسازد. توانایی پردازش تصاویر با سرعت و همچنین وضوح بالا برای برنامههای بلادرنگ حیاتی است، و اطمینان حاصل میکند که خودرو خودران میتواند به تغییرات محیط به موقع واکنش نشان دهد.

رباتیک
در رباتیک، FCNها برای وظایفی مانند شناسایی اشیا، دستکاری و نقشهبرداری محیطی استفاده میشوند. توانایی آنها در ارائه اطلاعات مکانی دقیق، درک ربات از محیط اطراف را بهبود میبخشد و امکان تعامل مؤثرتر با اشیا و محیطها را فراهم میکند. به عنوان مثال، در جراحی رباتیک، FCNها به شناسایی و بخشبندی بافتها و اعضای بدن کمک میکنند و نمایهای واقعیت افزودهای را فراهم میکنند که دقت و ایمنی را افزایش میدهد. در اتوماسیون صنعتی، FCNها برای بازرسی کیفیت به کار میروند، که بخشبندی دقیق به شناسایی نقصها و اطمینان از کیفیت محصول کمک میکند.
نتایج تجربی
شرح مجموعه داده PASCAL VOC 2012
برای ارزیابی عملکرد شبکههای کاملاً کانولوشن (FCNs)، آزمایشاتی را بر روی مجموعه داده PASCAL VOC 2012 که یک معیار پرکاربرد برای وظایف تقسیمبندی تصویر است، انجام دادیم. این مجموعه داده شامل تصاویری با کلاسهای مختلف اشیا است و به صورت جامع پیکسلهای آن برچسب گذاری شدهاند که آن را برای ارزیابی مدلهای تقسیمبندی چندکلاسه مناسب میسازد.


جزئیات پیادهسازی
به منظور پیادهسازی FCNs، ما از یک شبکه VGG16 از پیش آموزشدیده استفاده کردیم. قبل از فرآیند آموزش مدل، مراحل پیش پردازش دادهها انجام شد و از بهینهساز Adam استفاده کردیم. شبکه در Google Colab با استفاده از یک GPU نوع T4 آموزش داده شد و از پردازش موازی برای مدیریت مجموعه داده بزرگ و کاهش زمان آموزش بهره بردیم.
مراحل زیر جهت تنظیمات فرآیند یادگیری انجام شد:
1. آمادهسازی داده: از TensorFlow Datasets (tfds) برای بارگذاری و پیشپردازش مجموعه داده PASCAL VOC 2012 استفاده کردیم. تصاویر به اندازه 224*224 پیکسل تغییر اندازه داده شدند و نرمالسازی داده اعمال شد.
2. معماری مدل: معماری VGG16 را اصلاح کردیم و لایههای کاملاً متصل را با لایههای upsampling جایگزین کردیم تا یک FCN ایجاد شود.
3. فرآیند آموزش: مدل برای 25 ایپاک با یک اندازه بچ 8 آموزش داده شد. از بهینهساز Adam و تابع هدف sparse categorical crossentropy برای آموزش استفاده شد.
قطعه کدهای زیر بیانگر این مراحل هستند:
آمادهسازی داده
!pip install tensorflow tensorflow_datasets matplotlib
import tensorflow as tf
import tensorflow_datasets as tfds
import matplotlib.pyplot as plt
# Load the PASCAL VOC 2012 dataset
dataset, info = tfds.load('voc/2012', with_info=True, as_supervised=True)
# Define the training and validation splits
train_dataset = dataset['train'].map(lambda x, y: (tf.image.resize(x, (224, 224)), tf.image.resize(y['segmentation'], (224, 224))))
val_dataset = dataset['validation'].map(lambda x, y: (tf.image.resize(x, (224, 224)), tf.image.resize(y['segmentation'], (224, 224))))
# Normalize the images
def normalize_image(image, label):
image = tf.cast(image, tf.float32) / 255.0
label = tf.cast(label, tf.int32)
return image, label
train_dataset = train_dataset.map(normalize_image).batch(8).prefetch(tf.data.experimental.AUTOTUNE)
val_dataset = val_dataset.map(normalize_image).batch(8).prefetch(tf.data.experimental.AUTOTUNE)
به کمک کد بالا میتوان مجموعهداده مدنظر را دانلود کرد و سپس پیشپردازشهای لازم را به آن اعمال نمود.
معماری مدل
اکنون میتوان با بهرهگیری معماری از پیش آموزش دیده VGG16، شبکه FCN را ایجاد نمود:
from tensorflow.keras.applications import VGG16
from tensorflow.keras.layers import Conv2D, Conv2DTranspose, Input, concatenate
from tensorflow.keras.models import Model
def create_fcn_model(input_shape=(224, 224, 3), num_classes=21):
# Load the VGG16 model pre-trained on ImageNet without the fully connected layers
vgg16 = VGG16(weights='imagenet', include_top=False, input_shape=input_shape)
# Get the output of the last convolutional block
c5 = vgg16.get_layer("block5_conv3").output
# Define the upsampling path
up6 = Conv2DTranspose(512, (3, 3), strides=(2, 2), padding="same")(c5)
up6 = concatenate([up6, vgg16.get_layer("block4_conv3").output], axis=3)
up7 = Conv2DTranspose(256, (3, 3), strides=(2, 2), padding="same")(up6)
up7 = concatenate([up7, vgg16.get_layer("block3_conv3").output], axis=3)
up8 = Conv2DTranspose(128, (3, 3), strides=(2, 2), padding="same")(up7)
up8 = concatenate([up8, vgg16.get_layer("block2_conv2").output], axis=3)
up9 = Conv2DTranspose(64, (3, 3), strides=(2, 2), padding="same")(up8)
up9 = concatenate([up9, vgg16.get_layer("block1_conv2").output], axis=3)
# Final upsampling layer to match the input size
up10 = Conv2DTranspose(num_classes, (3, 3), strides=(2, 2), padding="same")(up9)
outputs = Conv2D(num_classes, (1, 1), activation='softmax')(up10)
# Create the model
model = Model(inputs=vgg16.input, outputs=outputs)
return model
# Instantiate the model
fcn_model = create_fcn_model()
شبکه FCN به کار رفته در قطعه کد بالا از اجزای زیر تشکیل شدهاست:
1. مدل پایه: VGG16 – مدل FCN از یک مدل VGG16 از پیش آموزشدیده به عنوان بخش رمزگذار استفاده میکند و از قابلیتهای استخراج ویژگیهای آن بهره میبرد.
2. Skip Connections – مدل از این اتصالات برای ترکیب ویژگیهای سطح بالا با ویژگیهای سطح پایین از لایههای قبلی استفاده میکند.
3. Upsampling- از کانولوشنهای ترانسپوز برای افزایش سایز تصاویر استفاده میشود تا اینکه نهایتا ابعاد آنها به اندازه تصویر ورودی شود.
4. خروجی – لایه نهایی یک تصویر طبقهبندی پیکسلی برای تقسیمبندی معنایی خروجی میدهد.
به منظور تجزیه و تحلیل بصری، تصویر زیر به کمک visualkeras رسم شده است:

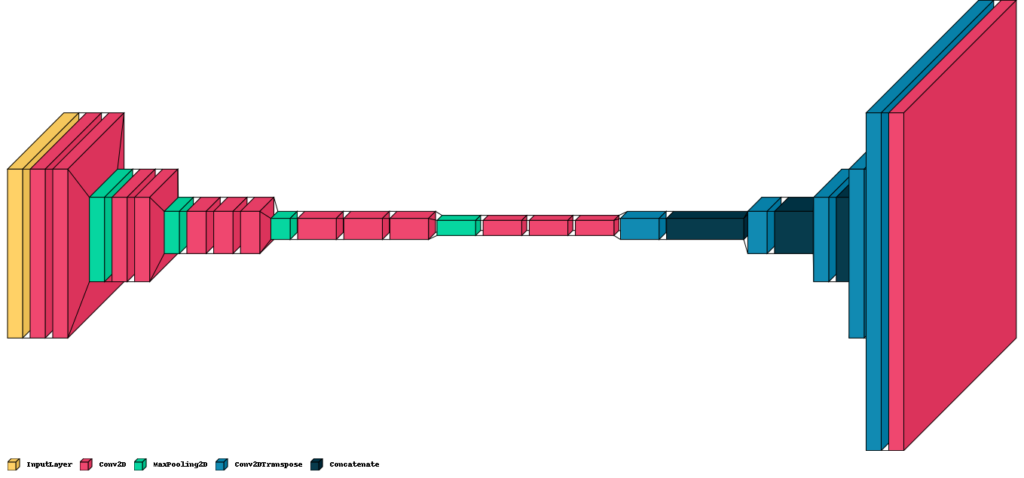
همانطور که از کد و شبکه ترسیم شده پیداست، مدل VGG16 بدون لایه طبقهبندی آخر آن بارگذاری میشود. همچنین لازم به ذکر است تصاویر ورودی در VGG میبایست به ابعاد 3*224*224 تنظیم شوند. آخرین لایه کانولوشنی VGG16 (block5_conv3) به عنوان نقطه شروع برای افزایش نمونه استفاده میشود.
لایهها و بخشهای Skip Connections بخش رمزگشا به شرح زیر هستند:
- لایه اول: خروجی غنیشده حاصل از block5_conv3 با استفاده از یک لایه Conv2DTranspose افزایش سایز میشود.
- Skip Connection 1: تصاویر (feature map) حاصل از لایه اول بخش رمزگشا با تصاویر block4_conv3 ترکیب میشوند.
- لایه دوم: دوباره فرآیند افزایش سایز در این بخش انجام میشود.
- Skip Connection 2: تصاویر حاصل با feature map خروجی از block3_conv3 ترکیب میشوند.
- لایه سوم: دوباره فرآیند افزایش سایز در این بخش انجام میشود.
- Skip Connection 3: تصاویر حاصل با feature map خروجی از block2_conv2 ترکیب میشوند.
- لایه چهارم: دوباره فرآیند افزایش سایز در این بخش انجام میشود..
- Skip Connection 3: تصاویر حاصل با feature map خروجی از block1_conv2 ترکیب میشوند.
- لایه پنجم: feature map ترکیبی حاصل از لایههای پیشین به اندازه ورودی اصلی افزایش نمونه داده میشود.
- لایه خروجی نهایی: یک لایه Conv2D با فعالسازی softmax برای تولید تصویر نهایی تقسیمبندی استفاده میشود که در آن هر پیکسل به یکی از تعداد کلاسها (num_classes) طبقهبندی میشود.
فرآیند آموزش
با قطعه کد زیر میتوان فرآیند کامپایل و یادگیری مدل را انجام داد.
fcn_model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# Train the model
history = fcn_model.fit(train_dataset,
validation_data=val_dataset,
epochs=25)
ارزیابی مدل
جهت ارزیابی مدل میتوان معیارهایی همچون Loss، Accuracy و IoU را در نظر گرفت. قطعه کد زیر برای این منظور روی دادههای تست، دقت مدل را ارزیابی میکند.
# Evaluate the model
val_loss, val_accuracy = fcn_model.evaluate(val_dataset)
print(f'Validation Loss: {val_loss}')
print(f'Validation Accuracy: {val_accuracy}')
def calculate_iou(y_true, y_pred, num_classes=21):
iou_list = []
y_true = y_true.flatten()
y_pred = y_pred.flatten()
for cls in range(num_classes):
intersection = np.sum((y_true == cls) & (y_pred == cls))
union = np.sum((y_true == cls) | (y_pred == cls))
if union == 0:
iou = float('nan') # If there is no ground truth, do not include in evaluation
else:
iou = intersection / union
iou_list.append(iou)
return np.nanmean(iou_list)
# Make predictions and calculate IoU
iou_scores = []
for images, labels in val_dataset:
preds = fcn_model.predict(images)
preds = np.argmax(preds, axis=-1)
for i in range(len(labels)):
iou = calculate_iou(labels[i].numpy(), preds[i], num_classes=21)
iou_scores.append(iou)
mean_iou = np.mean(iou_scores)
print(f'Mean IoU: {mean_iou}')
تحلیل عملکرد
نتایج تجربی ما نشان میدهد که FCNs به عملکرد پیشرفتهای بر روی مجموعه داده PASCAL VOC دست یافتهاند. FCN امتیاز 0.791 را برای معیار IoU به دست آورد که به طور قابل توجهی از روشهای سنتی بهتر است. توانایی شبکه حتی در تقسیمبندی دقیق اشیاء کوچک نشاندهنده قابلیت آن در مدیریت صحنههای متنوع و پیچیده در مجموعه داده است.
اعتبارسنجی مدل
در طول آموزش، عملکرد مدل بر روی مجموعه داده تست نظارت شد که به نتایج زیر منجر شد:
- Validation Loss: 0.2674
- Validation Accuracy: 87.34%
مقایسه با روشهای پیشرفته
تحلیل مقایسهای با سایر روشهای تقسیمبندی مانند U-Net و Mask R-CNN نشان میدهد که FCNها به طور قابل توجهی از نظر IoU و دقت پیکسلی برتر هستند. تقسیمبندی دقیق FCN و نیازهای محاسباتی کمتر، آن را برای برنامههای زمان واقعی (real-time) مناسبتر میسازد و برتری آن را در مدیریت دادههای پیچیده و با وضوح بالا بیشتر نشان میدهد. جدول زیر بیانگر عملکرد مدلهای مختلف برای وظایف تقسیمبندی تصاویر است:


همچنین بخوانید: با کانولوشن معکوس (Transposed Convolution) آشنا شوید!
مزایای شبکههای تمامکانولوشن (FCN)
شبکههای تمامکانولوشن چندین مزیت دارند، از جمله یادگیری End-to-End، خروجی با وضوح بالا و توانایی پردازش ورودیهایی با اندازههای مختلف. معماری کدگذار-رمزگشا، همراه با اتصالات پرشی، امکان بخشبندی دقیق و جزئی را فراهم میکند و آنها را در کاربردهای مختلف بسیار منعطف میسازد. توانایی استفاده از زمینه کل تصویر و ویژگیهای چندمقیاسی به FCNها اجازه میدهد تا روشهای مبتنی batch و region را پشت سر بگذارند و نتایج بخشبندی دقیقتر و کاملتری ارائه دهند. انعطافپذیری FCNها در تطبیق با اندازهها و نسبتهای ابعاد مختلف ورودی، بدون نیاز به پیشپردازش گسترده یا مهندسی ویژگیها، عملاً کاربرد آنها را بیشتر میکند.
محدودیتها و چالشها
با وجود مزایای خود، FCNها با چالشهایی مانند نیازمندیهای محاسباتی بالا و حساسیت به کیفیت دادههای آموزشی مواجه هستند. نیاز به مجموعههای دادهی بزرگ برچسب گذاریشده میتواند مانعی باشد و عملکرد آنها با دادههای نویزی کاهش مییابد. علاوه بر این، FCNها ممکن است در بخشبندی اشیاء بسیار کوچک یا جزئیات دقیق دچار مشکل شوند، به ویژه در مواردی که وضوح تصاویر ناکافی باشد. برای غلبه بر این محدودیتها، توسعه معماریهای کارآمدتر، ترکیب تکنیکهای پیشرفته افزایش داده و بررسی روشهای یادگیری نیمهنظارتی و بدون نظارت برای کاهش وابستگی به مجموعههای دادهی بزرگ برچسبخورده ضروری است.
جهتگیریهای تحقیقاتی آینده
تحقیقات آینده در زمینه FCNها میتواند بر رفع این چالشها با توسعه معماریهای کارآمدتر، ترکیب تکنیکهای یادگیری بدون نظارت و نیمهنظارتی و افزایش مقاومت آنها در برابر دادههای نویزی متمرکز شود. بررسی مدلهای هیبریدی که FCNها را با سایر رویکردهای یادگیری عمیق ترکیب میکند نیز میتواند به بهبود عملکرد و کاربردهای جدید منجر شود. به عنوان مثال، ادغام مکانیسمهای توجه و معماریهای ترنسفورمر با FCNها میتواند توانایی آنها را افزایش دهد و دقت و مقاومت بخشبندی را بهبود بخشد. توسعه مدلهای FCN سبک و بهینهشده برای دستگاهها و پلتفرمهای موبایل نیز کاربرد آنها را در محیطهای نیاز به پردازش زمان واقعی و البته منابع محدود گسترش خواهد داد.
نتیجهگیری
این مقاله مروری جامع بر شبکههای تمامکانولوشن (FCN) ارائه داده و به بررسی معماری، روشهای آموزشی و کاربردهای متنوع آنها پرداخته است. نتایج تجربی ما اثربخشی FCNها در وظایف مختلف بخشبندی را تأیید میکند و نشان میدهد که آنها توانایی پیشرفت در زمینه پردازش تصویر را دارند. توانایی FCNها در تولید تصاویر بخشبندی دقیق و با وضوح بالا، آنها را به ابزاری ارزشمند در حوزههای مختلف از جمله تصویربرداری پزشکی و رانندگی خودکار تبدیل کرده است که همهکاره بودن و تأثیرگذاری آنها را نشان میدهد.
موفقیت FCNها در بخشبندی معنایی، تصویربرداری پزشکی، رانندگی خودکار و رباتیک نشاندهنده تأثیر قابلتوجه آنها بر این حوزهها است. با ادامه تحقیقات، FCNها به احتمال زیاد نقش مهمتری در توسعه سیستمهای پیشرفته و هوشمند ایفا خواهند کرد. پذیرش گسترده FCNها میتواند صنایع مختلف را متحول کند و راهحلهای دقیقتر، کارآمدتر و خودکارتر برای وظایف پیچیده تحلیل تصویر ارائه دهد. پیشرفتهای مداوم در سختافزار و منابع محاسباتی نیز قابلیت اجرا و مقیاسپذیری FCNها را در کاربردهای واقعی بهبود میبخشد.
شبکههای تمامکانولوشن نمایانگر یک پیشرفت اساسی در یادگیری عمیق هستند و ابزاری قدرتمند برای بخشبندی دقیق تصویر ارائه میدهند. با رفع محدودیتهای فعلی و بررسی مسیرهای تحقیقاتی جدید، FCNها پتانسیل تحول بیشتر در زمینه بینایی کامپیوتر و فراتر از آن را دارند. تکامل مداوم FCNها، که توسط تحقیقات نوآورانه هدایت میشود، به احتمال زیاد منجر به مدلهای پیچیدهتر و توانمندتر خواهد شد و امکانات و کاربردهای جدیدی را در زمینه بخشبندی و تحلیل تصویر باز خواهد کرد.
برای دسترسی به کد نوتبوک این بلاگ اینجا کلیک کنید.


پرسشهای متداول
چرا روشهای سنتی بخشبندی تصویر به دقت و مقیاسپذیری محدودی منجر میشدند؟
روشهای سنتی بخشبندی تصویر به استخراج ویژگیهای دستی و قواعد اکتشافی متکی بودند، که این باعث محدودیت در دقت و مقیاسپذیری آنها میشد. این روشها نمیتوانستند به اندازه کافی با پیچیدگی و تنوع دادههای بصری مقابله کنند.
چرا CNNهای سنتی برای وظایف بخشبندی تصویر مناسب نیستند؟
CNNهای سنتی برای دستهبندی تصاویر طراحی شدهاند و با خروجی دادن یک برچسب کلاسی واحد به ازای هر تصویر، اطلاعات فضایی یا مکانی مهم برای بخشبندی را از دست میدهند. همچنین، استفاده از لایههای کاملاً متصل در این شبکهها توانایی آنها در انجام پیشبینیهای متراکم پیکسلی را محدود میکند.
FCNها چگونه چالشهای بخشبندی تصویر را حل میکنند؟
FCNها با تبدیل لایههای کاملاً متصل به لایههای کانولوشنی، قادر به تولید خروجی با ابعاد ورودی میشوند و اطلاعات فضایی را حفظ میکنند. این شبکهها با استفاده از اتصالات پرشی (skip connections) میتوانند اطلاعات کلی و جزئی را ترکیب کرده و بخشبندی دقیقی ایجاد کنند.
FCNها چگونه جزئیات فضایی و مکانی اشیاء را حفظ میکنند؟
FCNها با استفاده از ساختار رمزگذار-رمزگشا و اتصالات پرشی، جزئیات فضایی و مکانی اشیاء را حفظ میکنند. رمزگذار ویژگیهای سلسلهمراتبی را استخراج میکند و رمزگشا نقشههای بخشبندی با وضوح بالا را بازسازی میکند.
معیارهای ارزیابی عملکرد FCNها شامل چه مواردی هستند؟
معیارهای ارزیابی عملکرد FCNها شامل IoU، دقت پیکسلی و امتیاز F1 هستند. این معیارها کیفیت بخشبندی را منعکس کرده و بینشهایی در مورد توانایی شبکه برای تعیین دقیق مرزهای اشیا و بخشبندی نواحی مورد علاقه فراهم میکنند.
یادگیری ماشین لرنینگ را از امروز شروع کنید!
دنیای دادهها جذاب است و دانستن علم داده، توانایی تحلیل داده، یا بازاریابی مبتنی بر داده، شما را برای فرصتهای شغلی بسیاری مناسب میکند. فارغ از رشته و پیشزمینه، میتوانید حالا شروع کنید و از سطح مقدماتی تا پیشرفته بیاموزید. اگر دوست دارید به این حوزه وارد شوید، پیشنهاد میکنیم با کلیک روی این لینک قدم اول را همین حالا بردارید.
مشاوران کافهتدریس به شما کمک میکنند مسیر یادگیری برای ورود به این حوزه را شروع کنید: