

در دنیای دیجیتال امروز یکی از ابزارهای قدرتمند که به طور فزایندهای توجه کاربران و کسبوکارها را به خود جلب کرده سیستمهای توصیهگر (Recommender Systems) است. این سیستمها، نهتنها تجربه کاربری را بهینه میکنند، در افزایش فروش و بهبود کارایی وبسایتها نیز نقش بسزایی دارند. در این مطلب عملکرد، انواع و مزایای سیستمهای توصیهگر را بررسی خواهیم کرد؛ همچنین دو نمونه از روشهای معمول پیادهسازی این سیستمها را آموزش میدهیم.
- 1. مقدمهای بر یادگیری ماشین و سیستمهای توصیهگر
- 2. سیستم توصیهگر چیست؟
- 3. انواع سیستمهای توصیهگر
- 4. روشهای محاسبه شباهت بین ذائقه کاربران در فیلترینگ مشارکتی
- 5. روشهای محاسبه شباهت بین ذائقه کابران در فیلترینگ مبتنی بر محتوا
- 6. مزایای استفاده از سیستمهای توصیهگر
- 7. نقش سیستمهای توصیهگر در تجارت الکترونیک بزرگ: از آمازون تا گوگل
- 8. جمعبندی
-
9.
پرسشهای متداول
- 9.1. سیستمهای توصیهگر چگونه به بهبود تجربه کاربری کمک میکنند؟
- 9.2. فیلترینگ مشارکتی و فیلترینگ مبتنی بر محتوا چه تفاوتهایی دارند؟
- 9.3. چه روشهایی برای محاسبه شباهت بین کاربران در سیستمهای توصیهگر استفاده میشود؟
- 9.4. در زمینه بهینهسازی سیستمهای توصیهگر، استفاده از SVD چه مزایایی دارد؟
- 9.5. نقش سیستمهای توصیهگر در افزایش تعامل کاربران و فروش چگونه است؟
- 10. یادگیری ماشین لرنینگ را از امروز شروع کنید!
مقدمهای بر یادگیری ماشین و سیستمهای توصیهگر
یادگیری ماشین یکی از شاخههای مهم و تأثیرگذار بر عرصه فناوری است که با پردازش و تحلیل دادهها ماشینها را قادر میکند تا بدون دخالت انسان، یاد بگیرند و تصمیمگیری کنند. در این میان سیستمهای توصیهگر، بهعنوان یکی از کاربردیترین ابزارهای یادگیری ماشین، نقش بسزایی در بهبود تجربه کاربری ایفا میکنند.
این سیستمها، با تحلیل عمیق دادههای کاربری، پیشنهادهای شخصیسازیشدهای را به کاربران ارائه میکنند که میتواند محصولات، سرویسها یا حتی محتوا را در بر گیرند.
سیستم توصیهگر چیست؟
سیستمهای توصیهگر ابزارهای هوشمندی هستند که با استفاده از الگوریتمهای پیشرفته، محصولات یا محتواهایی را به کاربران پیشنهاد میکنند که بیشترین ارتباط را با علاقهها و تاریخچه آنها دارند؛ برای مثال، یوتیوب (YouTube) ویدئوهایی را پیشنهاد میکند که مرتبط با سلیقه تماشایی کاربر است یا آمازون محصولاتی را نشان میدهد که ممکن است برای خریدار جذاب باشند.
چگونگی کارکرد سیستمهای توصیهگر
این سیستمها با جمعآوری و تجزیهوتحلیل دادههای کاربران شروعبهکار میکنند. این دادهها ممکن است امتیازات دادهشده به محصولات، بررسیهای کاربران، ویدئوهای پسندیدهشده (like) و نپسندیدهشده (dislike) و غیره را شامل باشد؛ سپس با استفاده از الگوریتمهای یادگیری ماشین و یادگیری عمیق، سیستم، پتانسیلها و الگوهای رفتاری مصرفکنندگان را شناسایی و پیشنهادهایی را براساس آن ارائه میکند.
بازخورد صریح و بازخورد ضمنی
یکی از مفهومهای کلیدی در سیستمهای توصیهگر جمعآوری بازخورد از کاربران است که ممکن است بهصورت ضمنی یا صریح باشد.
بازخورد صریح
بازخورد صریح (Explicit Feedback) به آن دسته از بازخوردهایی اطلاق میشود که کاربران به صورت آگاهانه و روشن، نظر خود را در مورد یک محصول یا محتوا ابراز میدارند، مانند امتیازدهی به محصولات. این نوع بازخورد اطلاعات دقیقی را در اختیار سیستم قرار میدهد، اما جمعآوری آن دشوار است چرا که بسیاری از کاربران تمایلی به نوشتن نظر یا امتیازدهی ندارند.
بازخورد ضمنی
بازخورد ضمنی (Implicit Feedback) در مقابل، از تعاملات کاربر با محصولات به دست میآید، مثل تاریخچه خرید یا فهرست آهنگهای گوش داده شده. این نوع بازخورد به وفور یافت میشود و اگرچه جزئیات کمتری دارد و ممکن است نویز بیشتری داشته باشد، ولی به دلیل حجم بالا برای سیستمهای توصیهگر بسیار ارزشمند است.


انواع سیستمهای توصیهگر
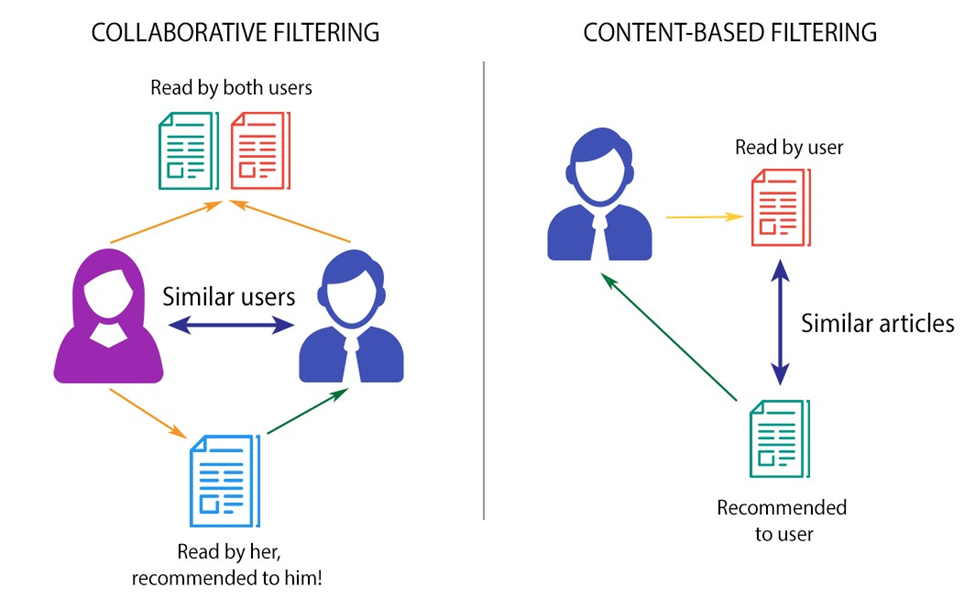
دو روش اصلی در سیستمهای توصیهگر وجود دارد: فیلترینگ مشارکتی و فیلترینگ مبتنی بر محتوا. روش سوم اما از ترکیب این دو رویکرد پدید میآید.
فیلترینگ مشارکتی (Collaborative Filtering)
این روش بر اساس شباهتهای بین کاربران و محصولات کار میکند. اگر کاربری محصولی را پسندیده، سایر کاربرانی که سلیقههای مشابهی دارند نیز ممکن است آن محصول را بپسندند. این روش میتواند به دو شکل مبتنی بر کاربر (User-Based Collaborative Filtering) و مبتنی بر محصول (Item-Based Collaborative Filtering) اجرا شود، که در هر دو مورد، محصولات یا کاربرانی با ویژگیها یا ترجیحات مشابه به یکدیگر معرفی میشوند.
فیلترینگ مبتنی بر محتوا (Content-Based Filtering)
این روش به بررسی محتوا و ویژگیهای محصولاتی که کاربر قبلا با آنها تعامل داشته، میپردازد و محصولات مشابه را پیشنهاد میدهد. این روش تلاش میکند محصولاتی با ویژگیهای مشابه به آنچه کاربر در گذشته برگزیده است را پیشنهاد دهد. فیلترینگ مبتنی بر محتوا عمدتاً بر پایهی ویژگیهایی مانند متن، تصاویر و دیگر جنبههای محتوایی محصولات است و نیازی به دادههای دیگر کاربران ندارد، بنابراین بسیار شخصیسازی شده و متناسب با سلیقهی فردی کاربر است.

فیلترینگ ترکیبی (Hybrid Filtering)
این روش ادغام دو روش قبلی است و مزایای هر دو را به کاربر ارائه میدهد تا دقت پیشنهادات را افزایش دهد. درواقع، فیلترینگ ترکیبی از ترکیب این روشها برای ارائه توصیههای دقیقتر و شخصیسازی شدهتر استفاده میکند. چند نوع رایج فیلترینگ ترکیبی شامل موارد زیر است:
- ترکیب توالی (Sequential Hybrid): در این روش، ابتدا یک روش (مانند فیلترینگ مبتنی بر محتوا) برای تولید یک لیست اولیه از توصیهها استفاده میشود و سپس روش دیگر (مانند فیلترینگ مشارکتی) برای تنظیم این لیست به کار میرود.
- ترکیب وزندهی (Weighted Hybrid): در این روش، نتایج چندین روش فیلترینگ با هم ترکیب میشوند، اما به هر روش وزنی اختصاص داده میشود که نشاندهنده اهمیت آن روش در ترکیب نهایی است.
- ترکیب تعویضی (Switching Hybrid): در این روش، سیستم بسته به شرایط یا مشخصات کاربر، بین روشهای مختلف جابجا میشود. به عنوان مثال، ممکن است برای کاربران جدید از فیلترینگ مبتنی بر محتوا استفاده شود، در حالی که برای کاربران قدیمیتر بیشتر از فیلترینگ مشارکتی استفاده شود.
هدف اصلی از استفاده از فیلترینگ ترکیبی در سیستمهای توصیهگر این است که دقت توصیهها افزایش یابد و مشکلاتی مانند سردی شروع (Cold Start)، مقیاسپذیری و تنوع بهبود یابد. این روشها با استفاده از اطلاعات و منابع مختلف، توانایی ارائه توصیههای دقیقتر و کارآمدتر را دارند.
روشهای محاسبه شباهت بین ذائقه کاربران در فیلترینگ مشارکتی
برای این منظور از رویکرد شباهت کسینوسی و تجزیه مقادیر منفرد استفاده میشود. هر دوی این روشها برای پیشبینی ترجیحات کاربران و ارائه توصیههایی مبتنی بر رفتار پیشین کاربران استفاده میشوند.
۱. شباهت کسینوسی
شباهت کسینوسی (Cosine Similarity) یکی از روشهای اندازهگیری شباهت بین دو بردار در فضای چندبعدی است. این روش کسینوس زاویه بین دو بردار را با استفاده از فرمول زیر محاسبه میکند تا میزان شباهت بین آنها را تعیین کند:
\cos(\theta) = \frac{\mathbf{A} \cdot \mathbf{B}}{|\mathbf{A}| |\mathbf{B}|}
کاربرد در سیستمهای توصیهگر
این روش برای محاسبه شباهت بین دو کاربر بر اساس امتیازاتی که به مجموعهای مشترک از محصولات (مانند فیلم، کتاب و …) دادهاند، استفاده میشود. شباهت کسینوسی، کسینوس زاویه بین دو بردار را در فضایی محاسبه میکند که هر بُعد آن متناظر با یک محصول است. مقدار کسینوس نزدیکتر به ۱ نشاندهنده شباهت بیشتر است. در اینجا هر بردار مجموعه امتیازات یک کاربر را نشان میدهد. در پایان امتیازی که ممکن است کاربر مورد نظر به فیلمی که هنوز آن را ندیده بدهد، بر اساس میانگین وزندار امتیازاتی که کاربران دیگر به آن فیلم دادهاند، محاسبه میشود.
منظور از میانگین وزندار چیست؟
در اینجا منظور از میانگین وزندار، ضرب میزان شباهت سلیقه کاربر مورد نظر و سایر کاربران (بر اساس شباهت کسینوسی) در امتیازی است که آن کاربران به آن فیلم دادهاند. این عبارت نهایتا تقسیم بر مجموع شباهت کسینوسی سایر کاربران و کاربر مورد نظر میشود و به این ترتیب امتیاز احتمالی کاربر مورد نظر به فیلمی که هنوز آن را تماشاش نکرده، بدست میآید. شکل زیر بخشی از دستنوشت کلاس علم داده ۲ رضا شکرزاد است که همین مفهوم را توضیح میدهد:


پیادهسازی کد سیستم توصیهگر بر مبنای شباهت کسینوسی
برای این کار ابتدا باید کتابخانههای مورد نیاز را فراخوانی کنیم:
import pandas as pd
import numpy as np
from tqdm.notebook import tqdm
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.metrics.pairwise import cosine_similarity
سپس مجموعه دادگان (Dataset) مورد نظر را دانلود و با استفاده از کتابخانه Pandas آن را میخوانیم:
ratings = pd.read_csv('/content/ratings.csv', encoding="ISO-8859-1")
movies = pd.read_csv('/content/movies.csv', encoding="ISO-8859-1")
tags = pd.read_csv('/content/tags.csv', encoding="ISO-8859-1")
rate_and_movie = ratings.merge(movies, on='movieId')
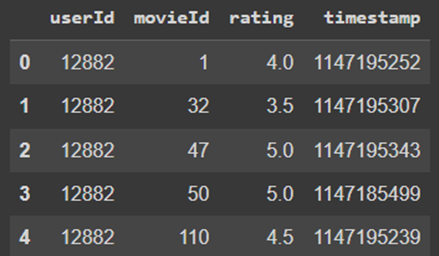
ratings.head()
خروجی کد بالا بهصورت زیر است:

همچنین جدول movies بهشکل زیر است:

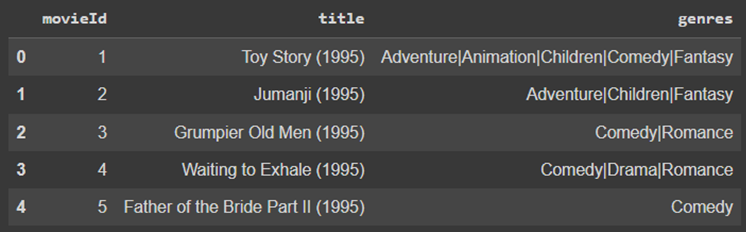
همانطور که پیدا است، جدول ratings نشاندهنده امتیازی است که کاربر با userId مشخص، به فیلمی با movieId مشخص داده است. جدول movies نیز نام و ژانر متناظر با هر movieId را نشان میدهد.
ساخت ماتریس امتیازات
حال باید ماتریس rating_matrix را با استفاده از تابع pivot_table بسازیم که در سطرهای آن userId، در ستونهای آن movieId و در هر خانه آن امتیازی قرار گرفته که هر کابر به هر فیلم داده است. در صورت عدم امتیازدهی به یک فیلم توسط یک کاربر، مقدار صفر در آن خانه قرار میگیرد:
rating_matrix = ratings.pivot_table(index=['userId'], columns=['movieId'], values=['rating'], fill_value=0)
rating_matrix.columns = rating_matrix.columns.droplevel(0)
rating_matrix.head()

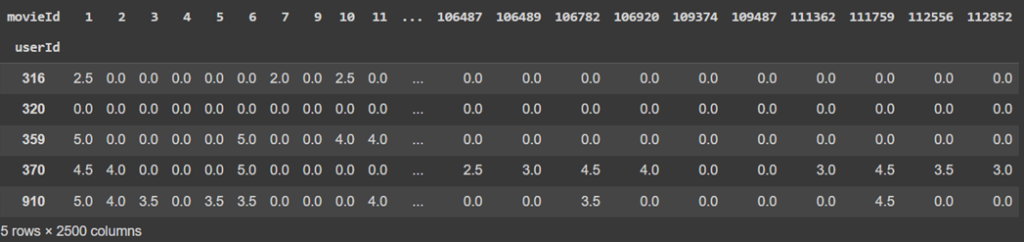
بعد برای محاسبه ماتریس شباهت که در آن شباهت بین دو کاربر بر اساس امتیازاتی که به فیلمها دادهاند مشخص میشود، از تابع cosine_similarity که در sklearn قرار دارد، استفاده میکنیم:
user_similarity = pd.DataFrame(cosine_similarity(rating_matrix), index=rating_matrix.index, columns=rating_matrix.index)
user_similarity.head()

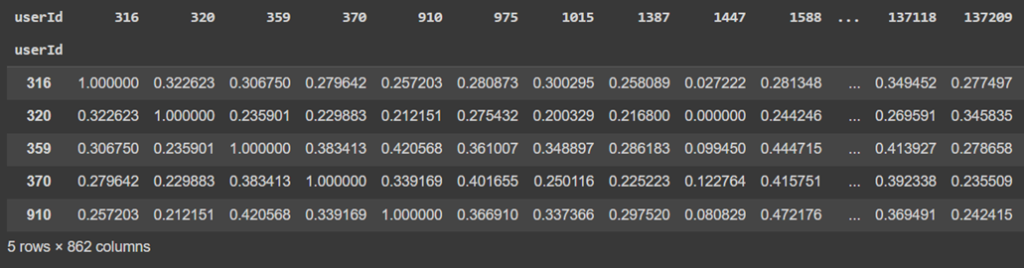
در ادامه یک لیست خالی به نام users_recom ایجاد میشود که قرار است فهرستی از فیلمهای توصیهشده برای هر کاربر در آن ذخیره شود. سپس با استفاده از یک حلقه for، برای هر user_id در سطرهای ماتریس شباهت کاربر (user_similarity.index) عملیات زیر انجام میشود:
- ایجاد متغیر curr_user که شباهتهای کاربر فعلی (user_id) با سایر کاربران را نگه میدارد.
- ایجاد متغیر sum_similarity که مجموع مطلق شباهتهای کاربر فعلی با دیگر کاربران را محاسبه میکند. این حاصل جمع بعدا برای مقیاسبندی امتیازات مورد استفاده قرار میگیرد.
- سپس برای هر کاربر، لیست خالیmovies_recom ایجاد میشود که قرار است امتیاز وزندار هر فیلم برای آن کاربر در آن ذخیره شود.
در حلقه داخلی، برای هر movie_id در ستونهای ماتریس امتیاز (rating_matrix.columns) کارهای زیر انجام میگردد:
- ایجاد متغیرother_users_rate شامل امتیازاتی است که سایر کاربران به فیلم مورد نظر دادهاند.
- محاسبه weighted_rate که با استفاده از فرمول زیر محاسبه میشود و نشاندهنده میانگین وزندار امتیازات است.
\text{weighted\_rate} = \frac{\text{np.dot(other\_users\_rate, curr\_user)}}{\text{sum\_similarity}}
- در این فرمول، ضرب داخلی (np.dot) بین امتیازات داده شده به فیلم توسط سایر کاربران و شباهتهای کاربر فعلی نسبت به آنها محاسبه میشود و سپس بر مجموع شباهتها تقسیم میشود تا امتیاز نهایی محاسبه شود.
- امتیازات وزندار محاسبه شده برای هر فیلم در لیست movies_recom ذخیره میشوند.
ساخت لیست امتیازات احتمالی کاربران
پس از پایان حلقه داخلی، movies_recom که حاوی امتیازات محاسبهشده برای هر فیلم به کاربر فعلی است، به لیست users_recom اضافه میشود. این فرایند برای هر کاربر تکرار میشود و در نهایت users_recom حاوی فهرستی از امتیازاتی خواهد بود که ممکن است کاربر مورد نظر به هر فیلم بدهد:
users_recom = []
for user_id in tqdm(user_similarity.index):
curr_user = user_similarity.loc[user_id]
sum_similarity = np.abs(curr_user.sum())
movies_recom = []
for movie_id in rating_matrix.columns:
other_users_rate = rating_matrix.loc[:, movie_id]
weighted_rate = (np.dot(other_users_rate, curr_user))/sum_similarity
movies_recom.append(weighted_rate)
users_recom.append(movies_recom)
با استفاده از کد زیر میتوان جدول شامل امتیازات هر کاربر به هر فیلم (حتی فیلمهایی که هنوز آنها را ندیده است) را ساخت:
users_recom_df = pd.DataFrame(users_recom)
users_recom_df.index = rating_matrix.index
users_recom_df.columns = rating_matrix.columns
users_recom_df = users_recom_df.T
users_recom_df.head()

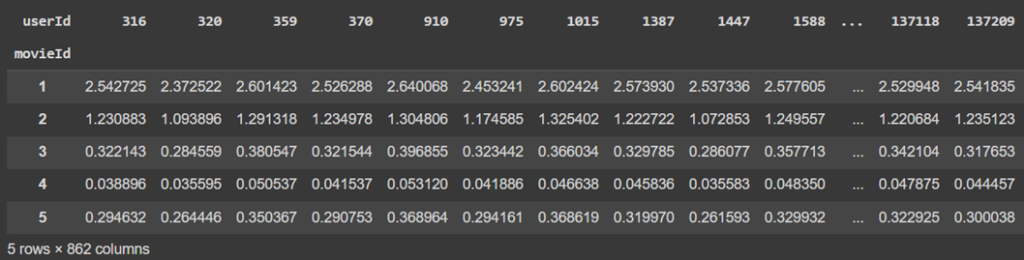
در ادامه تابعی تعریف میکنیم که برای یک کاربر مشخص، فیلمهای توصیهشده را بر اساس امتیازات پیشبینیشده و دادههای موجود در ماتریس امتیازها نمایش میدهد:
def recomm(user_id):
all_rates = users_recom_df[[user_id]].sort_values(by=user_id, ascending=False)
recommendations = {}
for movie_id in rating_matrix.columns:
if rating_matrix.loc[user_id, movie_id] == 0:
recommendations[movie_id] = all_rates.loc[movie_id, user_id]
recommendations = dict(sorted(recommendations.items(), key=lambda item: item[1]))
for movie_id in list(recommendations.keys())[-10:]:
recom = rate_and_movie[rate_and_movie['movieId']==movie_id]
movie = list(set(recom['title']))[0]
genre = list(set(recom['genres']))[0]
rate = recommendations[movie_id]
print(f'Recommended movie: {movie}, in genre: {genre}, with estimated rate: {round(rate, 2)}')
توضیحات مربوط به این تابع به شرح زیر است:
استخراج امتیازات
این تابع با نام recomm تعریف شده و یک شناسه کاربری (user_id) را به عنوان ورودی میگیرد. سپس امتیازاتی که برای کاربر مشخص شده را از دیتافریم users_recom_df استخراج میکند. این امتیازات بر اساس بیشترین به کمترین مرتب میشوند.
ایجاد فهرست توصیهها
سپس یک دیکشنری خالی به نام recommendations ایجاد میشود تا امتیازات فیلمهای توصیهشده که کاربر هنوز ندیده (یعنی امتیاز آنها در ماتریس امتیاز، صفر است) در آن ذخیره شود.
پر کردن دیکشنری
برای هر movie_id در ستونهای rating_matrix، بررسی میشود که آیا کاربر به آن فیلم امتیازی داده است یا خیر. اگر امتیاز داده نشده باشد، امتیاز پیشبینیشده از all_rates به دیکشنری recommendations اضافه میشود. آیتمها در دیکشنری recommendations بر اساس امتیاز، از کم به زیاد مرتب میشوند.
نمایش توصیهها
برای ده فیلم با بالاترین امتیاز توصیهشده، جزئیات بیشتری مانند نام فیلم، ژانر و امتیاز تخمینی نمایش داده میشود. این اطلاعات از دیتافریم rate_and_movie استخراج شده و چاپ میشوند. البته در شکل زیر تنها اطلاعات فیلمهای پیشنهادشده به یکی از کاربران قرار داده شده است:
user_ids = [359, 910, 138072]
for user_id in user_ids:
recomm(user_id)
print('*'*100)


۲. تجزیه مقادیر منفرد
تجزیه مقادیر منفرد (SVD) یک روش قدرتمند در جبر خطی است که برای تجزیه ماتریسها به کار میرود. در زمینه سیستمهای توصیهگر SVD برای پیدا کردن فاکتورهای پنهانی که رفتار کاربران و ویژگیهای محصولات را توصیف میکنند به کار برده میشود.
فرایند تجزیه
فرض کنید R ماتریس امتیازات کاربران به محصولات باشد که کاربران در سطرها و محصولات در ستونها قرار دارند. SVD ماتریس R را به سه ماتریس Σ ،U و VT تجزیه میکند:
R \approx U \Sigma V^T
که در آن:
- U (ماتریس کاربر) حاوی بردارهای ویژه سمت چپ و هر سطر آن نشاندهنده ویژگیهای پنهان کاربران است.
- Σ (ماتریس مقادیر منفرد) حاوی مقادیر منفرد است که اهمیت هر بعد پنهان را نشان میدهد.
- VT (ماتریس محصولات) حاوی بردارهای ویژه سمت راست و هر ستون آن نشاندهنده ویژگیهای پنهان محصولات است.
فرایند یادگیری
یادگیری در SVD بر پایه کمینه کردن تفاوت بین ماتریس امتیازات واقعی و ماتریس تخمینزدهشده است. برای این منظور، یک تابع هزینه (Cost Function) تعریف میشود که معمولاً میانگین خطای مربعات (MSE) است:
L = \sum_{(i,j) \in \kappa} (r_{ij} - \hat{r}_{ij})^2 + \lambda (\|U\|_F^2 + \|V\|_F^2)
که در آن:
- rij امتیاز واقعی کاربر i به محصول j است.
- r̂ij امتیاز تخمین زده شده است. r̂ij از ضرب دو ماتریس Ui.VjT بدست میآید که Ui نشاندهنده سطر iام از ماتریس U و Vj نشاندهنده ستون jام از ماتریس V است.
- κ مجموعه تمام جفتهای کاربر-محصول با امتیاز واقعی است.
- λ پارامتر تنظیمکننده برای جلوگیری از بیشبرازش (Overfitting) است.
- عبارت داخل پرانتز نیز مجموع مربعات تمام عناصر ماتریسهای U و V هستند که به عنوان جریمه (Regularization) به تابع هزینه اضافه میشوند.
بهینهسازی
فرایند بهینهسازی معمولاً با استفاده از الگوریتمهای گرادیان کاهشی، مانند ALS (کاهش گرادیان متناوب) انجام میشود. در هر تکرار، پارامترهای U و V بهروزرسانی میشوند تا تابع هزینه کاهش یابد. کاهش گرادیان متناوب (Alternating Least Squares – ALS) یک رویکرد متفاوت در بهینهسازی مدلهای تجزیه ماتریس است که برای تجزیههای بزرگ و پیچیدهتر مناسب است. در ALS، پارامترها (معمولاً ماتریسهای U و V در تجزیه ماتریس) به صورت متناوب و ثابت نگه داشته میشوند: ابتدا U ثابت نگه داشته شده و V بهینه میشود، سپس نقشها عوض شده و V ثابت نگه داشته شده و U بهینه میشود.
در هر تکرار از این الگوریتم، گرادیان تابع هزینه نسبت به پارامترها محاسبه میشود. گرادیان نشاندهنده جهت افزایش تابع است، بنابراین برای رسیدن به حداقل تابع، باید در جهت منفی گرادیان حرکت کرد. پارامترها (در اینجا U و V) با استفاده از مقدار گرادیان و نرخ یادگیری تنظیم میشوند:
U \leftarrow U - \alpha \cdot \frac{\partial L}{\partial U}
V \leftarrow V - \alpha \cdot \frac{\partial L}{\partial V}
که در آن α نرخ یادگیری است. دو گرادیان نیز مربوط به تابع هزینه نسبت به U و V هستند.
این فرایند بهینهسازی تا زمانی که معیاری از پیش تعیینشده برای توقف (مانند تعداد تکرارها، بهبود ناچیز در تابع هزینه، یا زمان اجرا) برآورده شود، ادامه مییابد.
خروجی مدل
خروجی مدلهای SVD شامل ماتریسی از امتیازات پیشبینیشده است که میتواند برای ارائه توصیههای دقیق به کاربران استفاده شود. همانطور که در بخش قبل گفتیم، این ماتریس از حاصل ضرب ماتریسهای U و V بدست میآید و به شما کمک میکند تا تعیین کنید که آیا یک محصول خاص برای یک کاربر مناسب است یا خیر.
پیادهسازی کد سیستم توصیهگر بر مبنای SVD
برای پیادهسازی یک سیستم توصیهگر به این روش، ابتدا باید کتابخانههای مورد نیاز را فراخوانی کنیم:
from surprise import SVD
from surprise import accuracy
from surprise import KNNWithMeans
from surprise.reader import Reader
from surprise.dataset import Dataset
from surprise.model_selection import train_test_split, RandomizedSearchCV
سپس به روش زیر مجموعه دادگان امتیاز کاربران به فیلمها را میخوانیم:
reader = Reader()
surprise_data = Dataset.load_from_df(ratings[['userId', 'movieId', 'rating']], reader)
trainset, testset = train_test_split(surprise_data)
در ادامه یک کلاس به نام RecommenderSystem تعریف میکنیم که بعد از train کردن مدل و predict کردن مجموعه دادگان تست توسط تابعی به نام recommended، بهکمک آن با گرفتن userId، ده تا از بهترین فیلمهایی را که میتوان به یک کاربر معرفی کرد، نمایش داده خواهد شد:
class RecommenderSystem:
def __init__(self, model, trainset, testset, rating_matrix, rate_and_movie):
self.model = model
self.trainset = trainset
self.testset = testset
self.rating_matrix = rating_matrix
self.rate_and_movie = rate_and_movie
def fit(self):
self.model.fit(self.trainset)
def rmse(self):
pred = self.model.test(self.testset)
rmse = round(accuracy.rmse(pred), 3)
def recommend(self, userid):
recommendations = {}
for itemid in self.rating_matrix.columns:
if rating_matrix.loc[userid, itemid] == 0:
recommendations[itemid] = self.model.predict(userid, itemid)[3]
recommendations = dict(sorted(recommendations.items(), key=lambda item: item[1], reverse=True))
movie = []
genre = []
est_rate = []
self.recommendations_df = pd.DataFrame()
for movie_id in list(recommendations.keys())[:10]:
recom = self.rate_and_movie[self.rate_and_movie['movieId']==movie_id]
movie.append(list(set(recom['title']))[0])
genre.append(list(set(recom['genres']))[0])
est_rate.append(recommendations[movie_id])
self.recommendations_df['userId'] = [userid for i in range(len(movie))]
self.recommendations_df['title'] = movie
self.recommendations_df['genres'] = genre
self.recommendations_df['est_rate'] = est_rate
display(self.recommendations_df)
جزئیات تعریف این کلاس و متدهای آن، در ادامه آمده است:
متد __init__: این متد سازنده کلاس است و برای ایجاد نمونههایی از کلاس RecommenderSystem استفاده میشود. پارامترهای ورودی آن موارد زیر را شامل میشود:
- model: مدلی که برای پیشبینی امتیازات استفاده میشود.
- trainset: دادههای آموزشی که برای آموزش مدل استفاده میشوند.
- testset: دادههای تست برای ارزیابی عملکرد مدل.
- rating_matrix: ماتریس امتیازات که شامل امتیازات کاربران به فیلمها است.
- rate_and_movie: اطلاعات مرتبط با فیلمها و امتیازات آنها.
متد fit: این متد، مدل را با استفاده از مجموعه دادههای آموزشی آموزش میدهد.
متد rmse: متدی برای محاسبه خطای میانگین مربعات ریشه که یک معیار مهم برای ارزیابی کیفیت پیشبینیهای مدل است. این متد ابتدا پیشبینیها را بر روی مجموعه دادههای تست انجام داده و سپس RMSE را محاسبه میکند.
متد recommend: این متد برای تولید توصیههای فیلم به کاربران بر اساس پیشبینیهای مدل استفاده میشود. فرایند کار به این صورت است:
- برای هر itemid در ستونهای rating_matrix، چک میکند که آیا کاربر به آن فیلم امتیاز داده است یا خیر.
- اگر کاربر به فیلم امتیاز نداده باشد، پیشبینی امتیاز را از مدل دریافت کرده و در دیکشنری recommendations قرار میدهد.
- امتیازات و فیلمهای پیشنهادی بر اساس امتیاز مرتب میشوند و ده فیلم برتر انتخاب میشوند.
- برای هر فیلم پیشنهادی، نام و ژانر آن را استخراج کرده و به همراه امتیاز پیشنهادی نمایش میدهد.
یافتن بهترین مدل
در ادامه کار، برای یافتن بهترین مدل از RandomizedSearchCV استفاده میکنیم. در این قسمت به منظور تنظیم پارامترها، یک دیکشنری تعریف میکنیم که در فرایند جستجوی تصادفی برای یافتن بهترین پارامترها مورد استفاده قرار میگیرد:
params= {"n_epochs": [5, 10, 15, 20], "lr_all": [0.002, 0.005], "reg_all": [0.4, 0.6]}
clf = RandomizedSearchCV(SVD, params, n_jobs=-1, measures=['rmse'])
clf.fit(surprise_data)
پس از پایان جستوجو و یافتن بهترین پارامترها، مدل با بهترین پارامترها را استخراج میکنیم. سپس، یک نمونه (Instance) از کلاس RecommenderSystem میسازیم که شامل مدل بهینه، دادههای آموزشی و تست، ماتریس امتیاز و دادههای ارتباطی بین امتیاز و فیلم است. recomm_system.fit فرایند آموزش مدل را با استفاده از مدل و دادههای موجود آغاز میکند:
model = clf.best_estimator['rmse']
recomm_system = RecommenderSystem(model, trainset, testset, rating_matrix, rate_and_movie)
recomm_system.fit()
سپس با استفاده از تابع recomm_system.rmse خطای مدل را بررسی میکنیم:
recomm_system.rmse()
RMSE: 0.8310
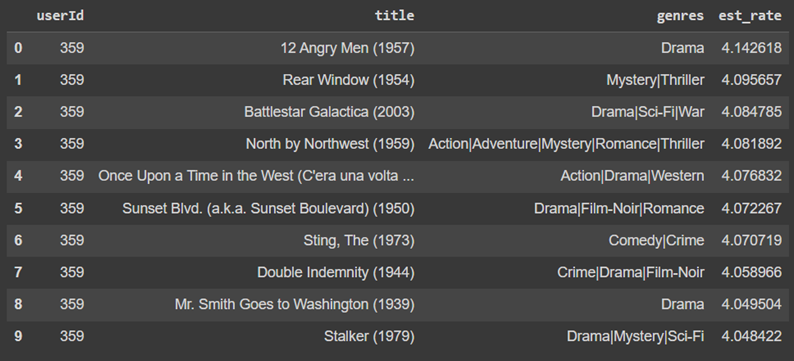
در نهایت با کمک تابع recomm_system.recommend فیلمهای پیشنهادی برای کاربران مورد نظر را چاپ میکنیم. البته در شکل زیر تنها اطلاعات فیلمهای پیشنهادشده به یکی از کاربران قرار داده شده است:
userids = [359, 910, 138072]
for userid in userids:
recomm_system.recommend(userid)
print('\n')

روشهای محاسبه شباهت بین ذائقه کابران در فیلترینگ مبتنی بر محتوا
در فیلترینگ مشارکتی، شباهت بین خود کاربران مورد بررسی قرار میگیرد اما در فیلترینگ مبتنی بر محتوا، تمرکز اصلی بر شباهت بین محصولاتی است که کاربران به آنها علاقهمند هستند. در فیلترینگ مبتنی بر محتوا، ابتدا ویژگیهای هر محصول (مانند فیلمها، کتابها و…) استخراج شده و سپس این ویژگیها برای یافتن شباهت بین محصولات مورد علاقه هر کاربر مورد استفاده قرار میگیرند. بیایید نگاهی دقیقتر به روشهای محاسبه این شباهتها بیندازیم:
استخراج ویژگیهای محصول
ابتدا باید ویژگیهای مرتبط با هر محصول استخراج شوند. این ویژگیها میتوانند متنی (مانند توضیحات، دستهبندیها، برچسبها)، صوتی یا تصویری (مانند جنس صدا، رنگها یا الگوهای تصویری) و متادیتا (مانند نام نویسنده، نام کارگردان، ژانر و سال انتشار) باشند.
محاسبه شباهت بین محصولات
پس از استخراج ویژگیها، میتوان شباهت بین محصولات را با استفاده از روشهای زیر محاسبه کرد:
- شباهت کسینوسی: این روش شباهت بین دو بردار ویژگی را با محاسبه کسینوس زاویه بین آنها تعیین میکند. این روش برای دادههای متنی که به صورت برداری از وزنها تبدیل شدهاند، بسیار مفید است.
- فاصله اقلیدسی: میزان فاصله مستقیم بین دو نقطه در فضای ویژگیهای محصولات را محاسبه میکند و میتواند برای دادههای عددی (مانند قیمت، سال تولید و …) مفید باشد.
- شاخص جاکارد: برای مقایسه مجموعههای ویژگیها استفاده میشود و نسبت تعداد ویژگیهای مشترک به کل ویژگیها را محاسبه میکند.
تطبیق شباهتها با ذائقه کاربر
پس از محاسبه شباهت بین محصولات، این شباهتها میتوانند برای توصیه آنها به کاربران استفاده شوند. برای هر کاربر، محصولاتی که بیشترین شباهت را به محصولاتی دارند که قبلاً توسط کاربر مورد تایید قرار گرفتهاند، انتخاب میشوند. این رویکرد اطمینان میدهد که محصولات پیشنهادی دارای ویژگیها و محتوای مشابه به آنچه کاربر ترجیح میدهد، هستند.
روشهای فیلترینگ مبتنی بر محتوا به واسطه تمرکز بر ویژگیهای خود محصولات و استفاده از متدهای محاسبه شباهت، امکان پیشبینی دقیق ترجیحات کاربران را فراهم میآورند. این تکنیکها به ویژه در مواردی که دادههای کافی در مورد تعاملات کاربران موجود نیست، بسیار مؤثر هستند.
مزایای استفاده از سیستمهای توصیهگر
- افزایش فروش: با ارائه محصولات و خدمات مناسب به کاربران، سیستمهای توصیهگر میتوانند تجربه کاربری را بهبود ببخشند و فروش را افزایش دهند.
- کاهش بار سیستم: با فیلتر کردن و ارائه محصولات مناسب به هر کاربر، این سیستمها به کاهش بار روی سرورها و کاهش هزینهها کمک میکنند.
- افزایش تعامل و رضایت کاربران: با ارائه مداوم محصولات و خدمات شخصیسازی شده، کاربران ترغیب میشوند تا با پلتفرم تعامل بیشتری داشته باشند.
نقش سیستمهای توصیهگر در تجارت الکترونیک بزرگ: از آمازون تا گوگل
در عصر اطلاعات، سیستمهای توصیهگر نقشی کلیدی در شکلدهی تجربیات کاربری دارند. این سیستمها، که به طور گسترده توسط شرکتهای بزرگی مانند آمازون، اسپاتیفای، فیسبوک، نتفلیکس و گوگل به کار گرفته میشوند، به بهبود تعامل کاربران و افزایش درآمدهای شرکتها کمک شایانی میکنند.
اسپاتیفای: کشف موسیقی جدید
اسپاتیفای، با تحلیل سلایق موسیقیایی کاربران خود، موسیقیهای جدیدی را به آنها پیشنهاد میدهد. این پلتفرم همچنین هر هفته پلیلیستی به نام کشف هفتگی تهیه میکند که به کاربران امکان میدهد موسیقیهای جدیدی که با سلیقهشان همخوانی دارد را کشف کنند.
نتفلیکس: بهینهسازی تجربه تماشا
نتفلیکس، که برای استفاده گسترده از سیستمهای توصیهگر شناخته شده است، بیش از ۸۰٪ از محتوای تماشا شده در پلتفرم خود را از طریق پیشنهادات الگوریتمی به دست میآورد.


این سیستمها نه تنها به افزایش درآمد کمک میکنند بلکه با ارزیابی نمایشها و فیلمهای محبوب توسط حسابهای جدید، در پیشبینی نمایشهای جدیدی که ممکن است مورد پسند واقع شوند نیز نقش دارند.
فیسبوک (متا): پیشنهادهای هدفمند
فیسبوک از سیستمهای توصیهگر متعددی در اپلیکیشن خود استفاده میکند که شامل پیشنهاد پستهای بعدی، پیشنهاد دوستان و مکانهای تبلیغاتی بر اساس سلیقهها، like/dislike و دوستان مشترک است.
آمازون: یافتن محصول مناسب در میان میلیونها گزینه
آمازون با داشتن میلیونها محصول، ممکن است کاربران را در انتخابهای خود دچار سردرگمی کند. سیستمهای توصیهگر آمازون با فیلتر کردن محصولات و ارائه گزینههایی که احتمالاً مورد پسند کاربران است، به آنها کمک میکنند تا تجربهای رضایتبخش داشته باشند.
گوگل و یوتیوب: بهینهسازی جستجو و پیشنهاد محتوا
گوگل، به عنوان یکی از محبوبترین موتورهای جستجو، به طور مداوم بر روی بهینهسازی و دقت سیستمهای توصیهگر خود سرمایهگذاری میکند.
یوتیوب، زیرمجموعهای از گوگل، با استفاده از فیلترهایی نظیر تعداد بازدیدها، لایکها و اشتراکها، محتوای پیشنهادی را شخصیسازی میکند.


با توجه به این مثالها، مشخص است که سیستمهای توصیهگر نه تنها در افزایش تعامل کاربران و رضایت آنها نقش دارند، بلکه به طور قابل توجهی به افزایش درآمد شرکتها کمک میکنند. این سیستمها با شناسایی دقیق نیازها و علایق کاربران، تجربهای شخصی و به یادماندنی را برای آنها فراهم میآورند.
جمعبندی
در دنیای دیجیتال کنونی، سیستمهای توصیهگر نقشی کلیدی در بهینهسازی تجربه کاربری ایفا میکنند و برای کسبوکارها مزایای فراوانی به همراه دارند. این سیستمها با تحلیل دادههای کاربران و استفاده از الگوریتمهای پیشرفته، پیشنهاداتی متناسب با سلیقه و نیازهای کاربران ارائه میدهند، که نه تنها به افزایش فروش و کاهش بار سرورها کمک میکند، بلکه موجب افزایش تعامل و رضایت کاربران میشود. استفاده از این سیستمها در پلتفرمهای بزرگی مانند آمازون، اسپاتیفای، فیسبوک، نتفلیکس و گوگل نشاندهنده اهمیت و تأثیرگذاری آنها در عرصه تجارت الکترونیک است. در نهایت، سیستمهای توصیهگر ابزارهای قدرتمندی هستند که با شناخت دقیق نیازها و علایق کاربران، میتوانند تجربهای شخصی و به یادماندنی را برای آنها فراهم آورند.


پرسشهای متداول
سیستمهای توصیهگر چگونه به بهبود تجربه کاربری کمک میکنند؟
سیستمهای توصیهگر با تحلیل دادههای کاربران و ارائه پیشنهادات شخصیسازیشده بر اساس علایق، رفتار و تاریخچه خرید آنها، به بهبود تجربه کاربری کمک میکنند. این سیستمها با فراهم آوردن محتوای مرتبط و جذاب، تعامل کاربران را افزایش داده و موجب رضایت بیشتر و وفاداری آنها میشوند.
فیلترینگ مشارکتی و فیلترینگ مبتنی بر محتوا چه تفاوتهایی دارند؟
فیلترینگ مشارکتی بر پایه شباهتهای بین کاربران کار میکند و پیشنهاداتی را بر اساس ترجیحات کاربرانی که رفتارهای مشابه داشتهاند، ارائه میدهد. در مقابل، فیلترینگ مبتنی بر محتوا بر ویژگیها و محتوای محصولاتی که کاربر قبلا با آنها تعامل داشته تمرکز دارد و محصولات مشابه را پیشنهاد میدهد.
چه روشهایی برای محاسبه شباهت بین کاربران در سیستمهای توصیهگر استفاده میشود؟
یکی از رایجترین روشها، شباهت کسینوسی است که میزان شباهت بین دو بردار را با محاسبه کسینوس زاویه بین آنها تعیین میکند. این روش برای ارزیابی شباهت بین سلایق کاربران بر اساس امتیازات داده شده به محصولات مشترک استفاده میشود.
در زمینه بهینهسازی سیستمهای توصیهگر، استفاده از SVD چه مزایایی دارد؟
SVD یا تجزیه مقادیر منفرد، به شناسایی عوامل پنهانی که ترجیحات کاربران و ویژگیهای محصولات را توصیف میکنند کمک میکند. این روش با کاهش ابعاد دادهها و حفظ اطلاعات مهم، به بهبود دقت پیشنهادات و کاهش پیچیدگی محاسباتی کمک میکند.
نقش سیستمهای توصیهگر در افزایش تعامل کاربران و فروش چگونه است؟
سیستمهای توصیهگر با ارائه پیشنهادات متناسب و جذاب، تعامل کاربران را با پلتفرمها افزایش داده و تجربه کاربری را بهینه میکنند. این امر نه تنها موجب افزایش رضایت و وفاداری کاربران میشود بلکه به طور مستقیم بر افزایش فروش و کاهش هزینههای بازاریابی تأثیر میگذارد.
یادگیری ماشین لرنینگ را از امروز شروع کنید!
دنیای دادهها جذاب است و دانستن علم داده، توانایی تحلیل داده، یا بازاریابی مبتنی بر داده، شما را برای فرصتهای شغلی بسیاری مناسب میکند. فارغ از رشته و پیشزمینه، میتوانید حالا شروع کنید و از سطح مقدماتی تا پیشرفته بیاموزید. اگر دوست دارید به این حوزه وارد شوید، پیشنهاد میکنیم با کلیک روی این لینک قدم اول را همین حالا بردارید.
مشاوران کافهتدریس به شما کمک میکنند مسیر یادگیری برای ورود به این حوزه را شروع کنید: