
شبکه عصبی گوگل نت (GoogleNet) یک شبکه عصبی کانولوشن عمیق ۲۲ لایه است. این شبکه عصبی نسخهی تغییریافتهی شبکهی Inception است که یک شبکهی عصبی عمیق کانولوشن است و محققان Google آن را ساختهاند.
معماری شبکه عصبی گوگل نت در رقابت ILSVRC سال ۲۰۱۴ شرکت کرد و برندهی رقابت شد. امروزه از گوگلنت برای انجامدادن وظایف مختلف بینایی ماشین (Computer Vision) استفاده میکنند. در این مطلب بهصورت کامل شبکه عصبی گوگل نت (GoogleNet) را معرفی کردهایم.
- 1. با پیشینهی شبکه عصبی گوگل نت (GoogleNet) آشنا شوید!
- 2. معماری شبکه عصبی گوگل نت (GoogleNet) چگونه است؟
- 3. طبقهبندیکننده کمکی (Auxilary Classifier)
- 4. جمعبندی مطالب درباره معماری شبکه عصبی گوگل نت (GoogLeNet)
- 5. یادگیری دیتا ساینس با کلاسهای آنلاین آموزش علم داده کافهتدریس

با پیشینهی شبکه عصبی گوگل نت (GoogleNet) آشنا شوید!
پیش از معرفی کامل گوگل نت (GoogleNet) بد نیست با پیشینهی شبکههای عصبی آشنا شویم. در اینجا بهصورت مختصر تاریخچهای از شبکههای عصبی آوردهایم.
شبکههای عصبی لینت (LeNet-5) و الکسنت (AlexNet)
بهعنوان یک متخصص یادگیری عمیق، احتمالاً قبلاً با شبکههای عصبی لینت (LeNet-5) و الکسنت (AlexNet) روبهرو شدهاید. شبکهی عصبی کانولشنی لینت (LeNet-5) را در سال ۱۹۹۸ Yann LeCun معرفی کرد. لینت (LeNet-5) استفاده از شبکههای عصبی کانولوشنی (CNN) را برای وظیفهی طبقهبندی تصاویر (Image Classification) معرفی کرد.
الکسنت (AlexNet)
بعد از آن در سال ۲۰۱۲ الکسنت (AlexNet) یک ساختار شبکه عصبی کانولوشنی را معرفی کرد که ترکیبی از چندین لایهی کانولوشنی انباشتهشده پشتسرهم بود. سازندگان الکسنت (AlexNet) با استفاده از واحدهای پردازش گرافیکی (GPU) شبکه را آموزش دادند.
برای آشنایی با شبکهی عصبی الکسنت این مطلب را مطالعه کنید:
معماری الکس نت (AlexNet) را بهصورت کامل بشناسید!
شبکه کانولوشنی (CNN)
معرفی شبکه کانولوشنی (CNN) مجموعهی دادههای بزرگتر و منابع محاسباتی مناسب به توسعه سریع راهحلهای کارآمد برای وظایف حوزهی بینایی ماشین (Computer Vision) انجامید.
معماری GoogleNet
اینجا بود که محققان دریافتند که افزایش لایههای شبکه به افزایش عملکرد چشمگیر آن میانجامد، اما افزایش لایهها برای ایجاد شبکههای بزرگتر هزینه داشت. شبکههای بزرگ اغلب مستعد مشکل بیش برازش (Overfitting) هستند و با مشکل محوشدگی گرادیان(Vanishing Gradient) یا انفجار گرادیان (Exploding Gradient) مواجه هستند.
بههمین دلیل معماری GoogleNet معرفی شد که عمدتاً ازطریق استفاده از ماژول Inception بیشتر مشکلات شبکههای بزرگ را برطرف کرد.
ماژول Inception
ماژول Inception یک معماری شبکهی عصبی است که شناسایی ویژگی را در مقیاسهای مختلف از طریق لایههای کانولوشن با استفاده از فیلترهای مختلف انجام میدهد و هزینهی محاسباتی آموزش یک شبکه بزرگ را ازطریق کاهش ابعاد آن کاهش میدهد.
در ادامهی این مطلب با لایههای مختلف معماری گوگلنت آشنا میشویم و هر یک را توضیح میدهیم؛ سپس طبقهبندیکنندههای کمکی را بررسی میکنیم که در ساختار این معماری استفاده شدهاند.
معماری شبکه عصبی گوگل نت (GoogleNet) چگونه است؟
معماری گوگلنت (GoogleNet) از ۲۲ لایهی تشکیل شده است (با درنظرگرفتن لایههای ادغام (Pooling Layers)، ۲۷ لایه). از این تعداد ۹ لایهی آن ماژول Inception است.
معماری شبکه عصبی گوگل نت (GoogleNet)
معماری گوگلنت (GoogleNet) در این جدول آمده است:
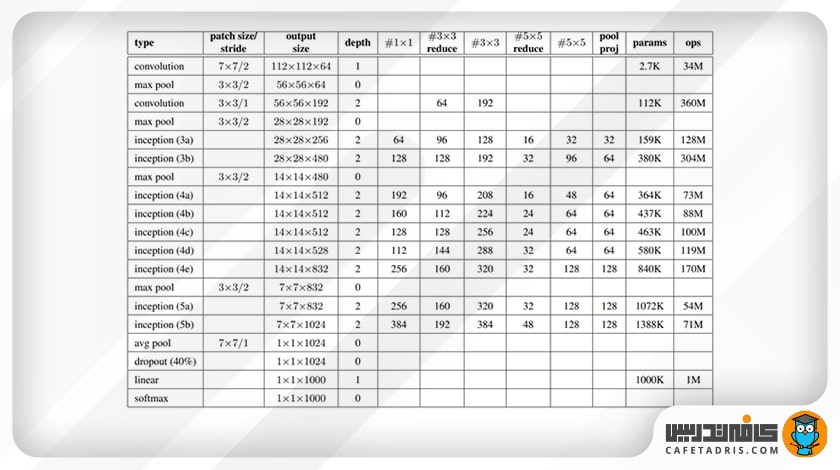
- Type: به اسم لایه مدنظر اشاره میکند؛
- Patch Size: منظور همان سایز فیلتر است؛
- Stride: به مقدار گام هر فیلتر اشاره میکند؛
- Output Size: اندازهی خروجی هر لایه را مشخص میکند؛
- Depth: تعداد لایههای هر عنصر این معماری را نشان میدهد؛
- #1×1 #3×3 #5×5: اندازهی فیلترهایی را نشان میدهد که در ماژول inception استفاده شده است؛
- #3X3 reduce #5×5: تعداد فیلترهای یک در یک را نشان میدهد که قبل از هر لایه کانولوشن به کار رفته است؛
- Pool Proj: تعداد فیلترهای یک در یک را نشان میدهد که بعد از هر لایهی ادغام در ماژول Inception استفاده شده است؛
- Params: تعداد پارامترهای یادگیری موجود در هر لایه را مشخص میکند؛
- Ops: تعداد عملیات ریاضی را نشان میدهد که در هر لایه انجام میشود.
لایههای تشکیلدهنده معماری گوگلنت (GoogleNet)
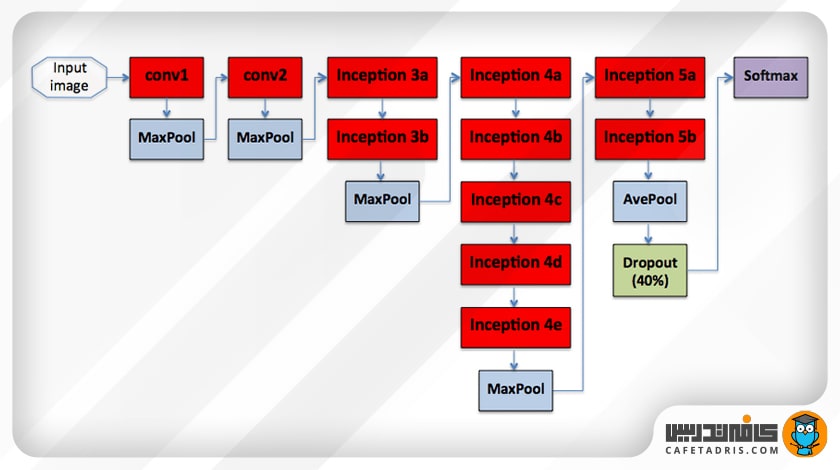
عکس ورودی شبکه اندازهای برابر با ۲۲۴ در ۲۲۴ دارد. در این شکل میتوانیم لایههای تشکیلدهندهی معماری گوگلنت (GoogleNet) را مشاهده کنیم:
لایهی کانولوشن
همانطور که در این شکل مشخص است اولین لایهی معماری گوگلنت(GoogleNet) یک کانولوشن است. این لایه از فیلتر با سایز ۷ در ۷ استفاده میکند که در مقایسه با فیلترهای دیگر شبکه، نسبتاً بزرگ است. هدف اصلی این لایه کاهش اندازهی تصویر ورودی بدون ازدستدادن اطلاعات فضایی (Spatial Information) است. در این لایه اندازهی تصویر ورودی نصف و برابر با ۱۱۲ در ۱۱۲ میشود.
لایهی ادغام حداکثر (Max pooling)
بعد از اولین لایهی کانولوشن یک لایهی ادغام حداکثر (Max pooling) داریم که اندازهی عکس را بار دیگر کوچک میکند و آن را به ۵۶ در ۵۶ میرساند.
بار دیگر یک لایه کانولوشن و ادغام حداکثر (Max pooling) داریم که اندازهی عکس را قبل از رسیدن به اولین لایهی Inception به ۸/۱ تبدیل میکند؛ البته نکتهی مهم این است که تعداد نقشهی ویژگیها با کوچکترشدن اندازهی تصویر بیشتر میشود؛ همانطور هم که در جدول اول آمده است، از ۶۴ در اولین لایهی کانولوشن به ۱۹۲ در دومین لایهی کانولوشن میرسد.
ماژولهای Inception در معماری گوگل نت (GoogleNet)
بعد از دو لایهی کانولوشن به ماژولهای Inception نوبت میرسد. معماری گوگلنت (GoogleNet) ۹ ماژول Inception را در برمیگیرد که در شکل اول نشان داده شده است.
باید این نکته را نیز اضافه کنیم که میان ماژولهای Inception دو لایهی ادغام حداکثر (Max pooling) داریم. هدف استفاده از این لایههای ادغام حداکثر (Max pooling) این است که اندازهی ورودی را در طول حرکت آن در شبکه کاهش دهیم. این کار با کاهش عرض و ارتفاع تصویر اتفاق میافتد.
علاوهبراین در داخل ماژولهای Inception نیز تصویر ورودی کاهش اندازه خواهد داشت. همهی اینها درنهایت به کاهش بار محاسباتی شبکه کمک بزرگی میکند.
لایهی ادغام میانگین (Average pooling)
همانطور که در شکل اول پیداست، بعد از ماژولهای Inception لایهی ادغام میانگین (Average pooling) را داریم. این لایه از تمامی نقشهی ویژگیهای ایجادشده بهدست ماژولهای inception میانگین میگیرد و عرض و ارتفاع ورودی را به ۱ در ۱ تبدیل میکند.
لایهی دراپاوت (Dropout)
درنهایت یک لایهی دارپاوت(Dropout) با نرخ چهل درصد قبل از لایهی خطی(Linear Layer) استفاده شده است. لایهی دراپاوتDropout) )، درواقع، یک تکنیک تنظیمسازی (Regularization technique) است که در حین آموزش شبکه استفاده میشود تا از مشکل بیش برازش (overfitting) در شبکه جلوگیری شود.
لایهی خطی
لایهی خطی ۱۰۰۰ نود را دربرمیگیرد که مطابق با ۱۰۰۰ کلاس موجود در مجموعهی داده ImageNet در نظر گرفته شده است.
لایهی سافتمکس (Softmax)
آخرین لایه یک لایهی سافتمکس (Softmax) است. این لایه از تابع سافتمکس (softmax) استفاده میکند، یک تابع فعالسازی برای استخراج توزیع احتمال مجموعهای از اعداد در یک بردار ورودی. خروجی یک تابع فعالسازی سافتمکس برداری است که در آن مجموعه مقادیر آن احتمال یک کلاس یا یک رخداد را نشان میدهد. مجموع تمامی مقادیر با هم برابر با ۱ است.
تا اینجا لایههای معماری گوگلنت (GoogleNet) را بررسی کردیم، اما هنوز کار تمام نشده است؛ لازم است دربارهی عنصر دیگری نیز صحبت کنیم که در این معماری استفاده شده است. عنصری که از آن صحبت میکنیم طبقهبندیکنندهی کمکی (Auxilary Classifier) نام دارد.
طبقهبندیکننده کمکی (Auxilary Classifier)
همانطور که پیشتر هم اشاره کردیم، یکی از مشکلات شبکههای بزرگ مشکل محوشدگی گرادیان (Vanishing Gradient) است. این مشکل هنگامی اتفاق میافتد که بهروزرسانی وزنهایی که ازطریق انتشار روبهعقب (Backpropagation) انجام میشود در لایههای اولیه بسیار ناچیز باشد و درنتیجه، مقدار گرادیان نسبتاً کوچک شود؛ اگر بخواهیم سادهتر بگوییم آموزش شبکه متوقف میشود.
بههمین جهت طبقهبندیهایکمکی (Auxilary Classifier) به لایههای میانی معماری، یعنی لایهی هشتم (Inception 4 (a)) و لایهی یازدهم (Inception4 (d))، اضافه میشوند.
عملکرد طبقهبندیکننده کمکی (Auxilary Classifier)
طبقهبندیهای کمکی فقط در حین آموزش به شبکه اضافه میشوند. کاری که این طبقهبندیکنندهها انجام میدهند طبقهبندی ورودی در لایههای میانی شبکه است که خطای (loss) محاسبهشده را نیز به خطای کلی(Total loss) شبکه اضافه میکنند. خطای بهدستآمده در طبقهبندیکنندههای کمکی (Auxilary Classifier) وزندار است و وزنی برابر با ۰/۳ دارد.
در شکل زیر نمایی از یک طبقهبندیکنندهی کمکی را میبینیم:
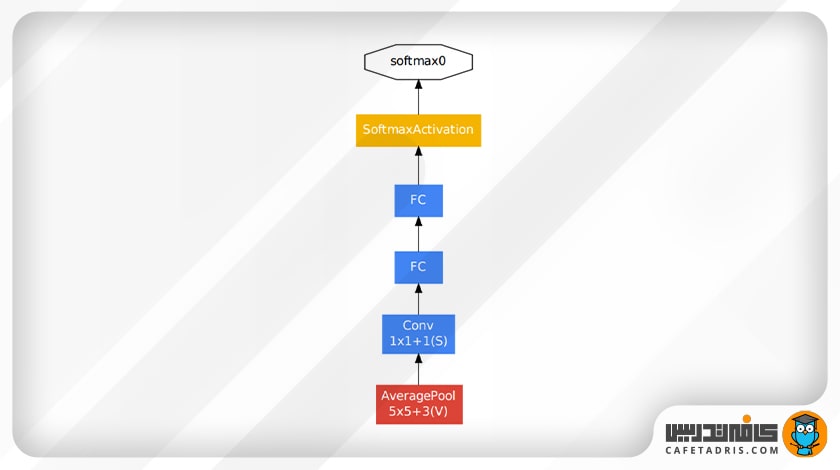
در این شکل مشخص است که یک طبقهبندیکننده کمکی لایهی ادغام میانگین (Average pooling layer)، دو لایهی کاملاً متصل (Fully Connected layer)، یک لایهی دراپاوت (dropout) با نرخ ۷۰ درصد و درنهایت یک لایهی خطی (Linear layer) و لایهی سافتمکس (softmax) دارد.
معماری کامل گوگلنت
حال که با تمامی جزئیات معماری گوگلنت (GoogLeNet) آشنا شدیم، بهتر است به شکل کلی این معماری نگاهی بیندازیم:

جمعبندی مطالب درباره معماری شبکه عصبی گوگل نت (GoogLeNet)
معماری شبکه عصبی گوگل نت (GoogLeNet) در چالش طبقهبندی ILSVRC 2014 در مقام اول قرار گرفت و عملکرد خوبی را از خود نشان داد. درک معماری GoogLeNet برای هر متخصص یادگیری عمیق که به دنبال درک شبکههای عمیق در حوزهی بینایی ماشین (Computer Vision) است بسیار اهمیت دارد.
شبکه عصبی گوگل نت (GoogLeNet) اکنون یک معماری اصلی در رایجترین کتابخانههای یادگیری ماشین (ML)، مانند TensorFlow، Keras، PyTorch و غیره، است.
در این مطلب جزئیات این معماری را بررسی کردیم و دیدیم که این معماری با ارائهی چندین عنصر جدید به حل مشکل اصلی شبکههای بزرگ، یعنی همان محوشدگی گرادیان (Vanishing Gradient)، پرداخته است.
یادگیری دیتا ساینس با کلاسهای آنلاین آموزش علم داده کافهتدریس
برای ورود به دنیای دیتا ساینس اولین قدم یادگیری است. کلاسهای آنلاین یکی از بهترین روشهای یادگیری علم داده است. کافهتدریس با برگزاری کلاسهای آنلاین آموزش علم داده به شما امکان میدهد از نقطهی جغرافیایی به بهروزترین و کاملترین آموزش دیتا ساینس دسترسی داشته باشید.
کلاسهای آنلاین آموزش علم داده کافهتدریس بهصورت کارگاهی و مبتنی بر کار روی پروژههای واقعی علم داده برگزار میشود.
برای آشنایی با کلاسهای مقدماتی و پیشرفته آموزش علم داده کافهتدریس و مشاورهی رایگان برای شروع یادگیری دیتا ساینس و ماشین لرنینگ روی این لینک کلیک کنید:
عال
با سلام و تشکر به جهت ارایه مقاله بسیار رسا جامع و خوبتون در حوزه گوگل نت
لذت بردم.
ممنون از شما
ممنون از اشتراک نظرتون.
خیلی خیلی ممنون خیلی مفیده و باورم نمیشه که به زبان فارسی هم مقالات موزشی به این تمیزی داریم هدف من آشنایی با کاربردهای گوگل نت هست و شما همراه خیلی خوبی بودید در این مسیر
خیلی خوشحالیم که مطالب براتون مفید واقع شده.
Thanks for sharing your knowledge
سپاس دوست عزیز.
خیلی عالی بود…
من با آموزش های غیررایگان نتونستم خوب یاد بگیرم ولی بعدش با این مقاله کاملا متوجه شدم
خیلی خوشحالیم که این اتفاق افتاده و براتون مفید بوده.
ممنون از این آموزش وقعا عالی شما خیلی قشنک و عالی است امیدوارم این آموزش های تان ادامه داشته باشد
تشکر از اشتراک نظرتون.
Very great ❤️.
سپاس دوست عزیز.
عزیز دمت گرم لطفا آموزشات های بعدی رو به صورت صوتی یا ویدیویی بذارید
ممنون از زحمات شما
آموزشهای وبلاگ به شکل نوشتاریه، اما در کانال علم داده میتونین به بعضی آموزشهای ویدیویی هم دسترسی داشته باشین.