

بهینهساز یا Optimizer نقش محوری در توسعه و کارایی شبکههای عصبی ایفا میکند. این ابزارهای قدرتمند که با الهام از مکانیزمهای یادگیری مغز انسان طراحی شدهاند به مدلهای یادگیری ماشینی اجازه میدهند تا با کارایی بیشتر و سرعت بالاتر به اهداف یادگیری خود برسند. از گرادیان نزولی تصادفی (SGD) گرفته تا Adam و RMSprop، هر یک از این بهینهسازها استراتژیهای خاص خود را برای نوآوری و تطبیق با دادههای متغیر به کار میبرند. در این مطلب بهشکلی دقیق، به عملکرد بهینه سازها در یادگیری عمیق و طرز عمل آنها در شبکههای عصبی و تأثیرشان بر آنها نگاه میکنیم، آنها را تحلیل میکنیم و چگونگی بهبود عملکرد مدلها با استفاده از این ابزارها را بررسی میکنیم.
- 1. مقدمهای بر شبکههای عصبی
- 2. درک عملکرد بهینه سازها در یادگیری عمیق
- 3. انواع بهینهسازها در شبکههای عصبی
-
4.
پرسشهای متداول
- 4.1. بهینهساز SGD (Stochastic Gradient Descent) چگونه به کاهش خطای شبکههای عصبی کمک میکند و چه چالشهایی در استفاده از آن وجود دارد؟
- 4.2. بهینهساز Momentum چه مزیتی بر SGD دارد و در چه شرایطی کارایی بهتری ارائه میکند؟
- 4.3. بهینهساز Adagrad چگونه به بهبود یادگیری در دادههای پراکنده کمک میکند و چه محدودیتهایی دارد؟
- 4.4. RMSPROP در چه مواردی به عنوان یک بهینهساز ترجیح داده میشود و چه مزیتهایی بر Adagrad دارد؟
- 4.5. مزیت Adam در مقایسه با دیگر بهینهسازها چیست؟
- 5. یادگیری ماشین لرنینگ را از امروز شروع کنید!
مقدمهای بر شبکههای عصبی
شبکههای عصبی، بهعنوان بخشی اساسی از هوش مصنوعی، نقش پررنگی در فناوری مدرن ایفا میکنند. این سیستمها که از ساختار عصبی مغز انسان الهام گرفتهاند قادرند یادگیری، تطابق و پردازش اطلاعات پیچیده را بهبهترین شکل ممکن انجام دهند.
این شبکهها مجموعهای از واحدهای پردازشی یا نورونها را در خود جای دادهاند که بهصورت لایههای مختلف سازماندهی شدهاند. نورونها درون هر لایه میتوانند با نورونهای لایه بعدی از طریق اتصالاتی که وزن نامیده میشوند ارتباط برقرار کنند.
لایههای اصلی این شبکه عبارتاند از:
- لایه ورودی (Input Layer): این لایه نقطه ورود دادهها به شبکه است. هر نورون در این لایه نماینده یکی از ویژگیهای ورودی است.
- لایههای پنهان (Hidden Layers): این لایهها که میان لایه ورودی و خروجی قرار گرفتهاند قلب تپنده شبکه عصبی به شمار میروند. نورونها در این لایهها با استفاده از توابع فعالسازی، دادههای ورودی را پردازش و ویژگیهای معنادار را استخراج میکنند.
- لایه خروجی (Output Layer): لایه خروجی جایی است که پاسخ نهایی شبکه تولید میشود. تعداد نورونها در این لایه بستگی به مسئلهای دارد که شبکه قصد حل آن را دارد.
یادگیری در شبکههای عصبی ازطریق فرایندی بهنام «یادگیری ماشین» انجام میگیرد که در آن وزنهای میان نورونها به طور اتوماتیک تنظیم میشوند تا خروجی شبکه بهبهترین شکل به دادههای ورودی پاسخ دهد. این فرایند معمولاً ازطریق مجموعهای از دادههای آموزشی و با استفاده از الگوریتمهای بهینهسازی انجام میشود.
شبکههای عصبی در بسیاری از زمینهها کاربرد دارند، ازجمله در تشخیص گفتار، پردازش زبان طبیعی، پیشبینی مالی و بسیاری موارد دیگر. قابلیت انعطاف و توانایی یادگیری پیچیدهترین الگوها از دادهها شبکههای عصبی را به یکی از قدرتمندترین ابزارها در عرصه هوش مصنوعی تبدیل کرده است.
پیشنهاد میکنیم درباره پس انتشار یا عملیات انتشار روبهعقب در شبکههای عصبی هم مطالعه کنید.
درک عملکرد بهینه سازها در یادگیری عمیق
بهینهسازها در یادگیری عمیق روشهایی هستند که شبکههای عصبی را قادر میکنند تا بهطور هوشمندانهای به بهروزرسانی وزنها با هدف کمینهکردن تابع هزینه (Loss Function) بپردازند. اهمیت آنها در بهبود عملکرد و سرعت آموزش شبکههای عصبی بسیار حیاتی است.
معروفترین بهینهسازها SGD (گرادیان نزولی تصادفی)، Adam و RMSprop هستند که هر یک رویکردهای مختلفی برای بهروزرسانی وزنها در هر مرحله براساس دادههای ورودی ارائه میکنند.
بهینهسازها، نهتنها برای تسریع در فرایند یادگیری و بهروزرسانی کنترلشده وزنها مهم هستند، برای جلوگیری از بیشبرازش (overfitting) نیز اهمیت دارند. بیشبرازش زمانی رخ میدهد که مدل بیشازحد بر دادههای آموزشی (train) منطبق (fit) شود (بهتعبیری، بهجای آنکه دادههای train را یاد بگیرد، آنها را حفظ کند) و نتواند عملکرد خوبی روی دادههای جدید (test) نشان دهد.
استفاده از تکنیکهایی نظیر انطباق نرخ یادگیری و معماریهای مناسب بهینهساز میتواند بر کاهش این مشکل موثر باشد و به شبکه عصبی کمک کند تا تعمیم پذیری بهتری داشته باشد.

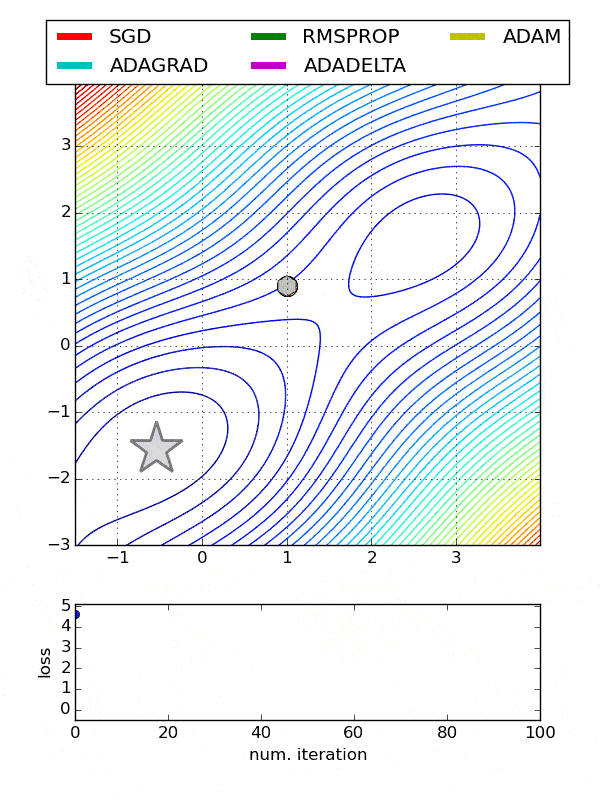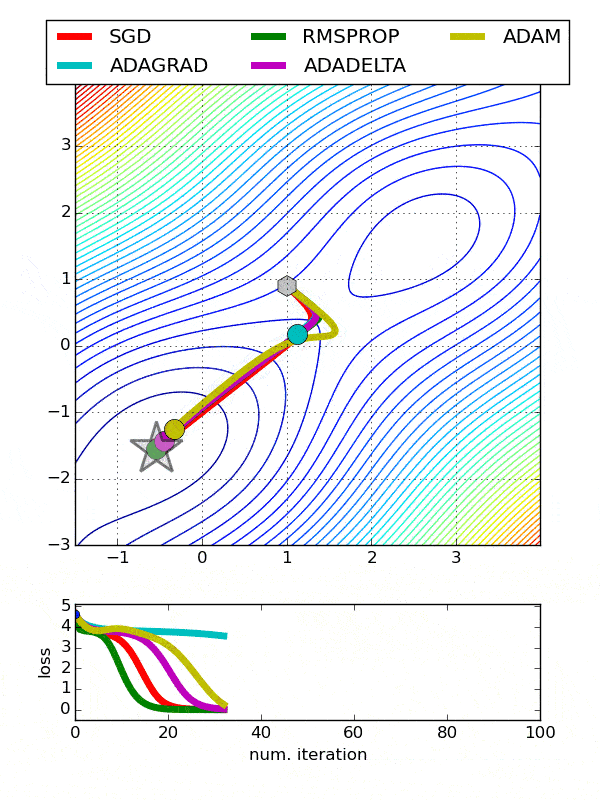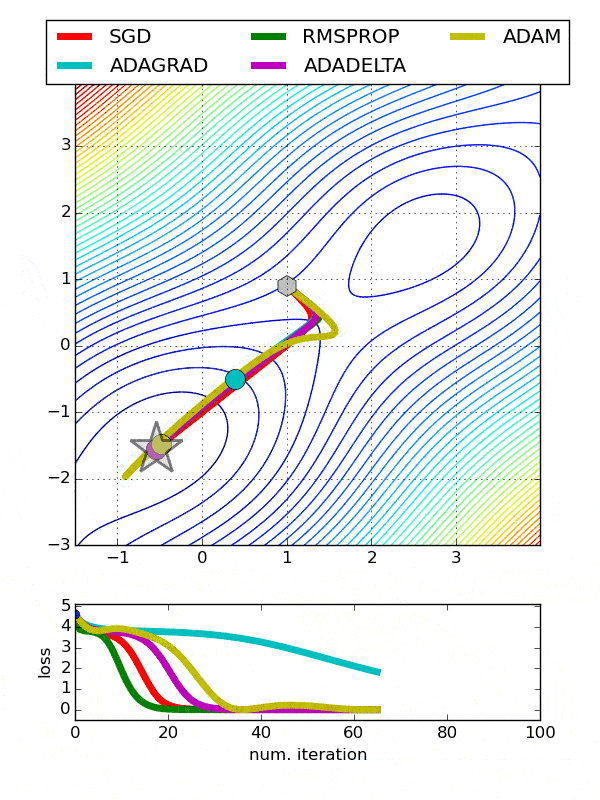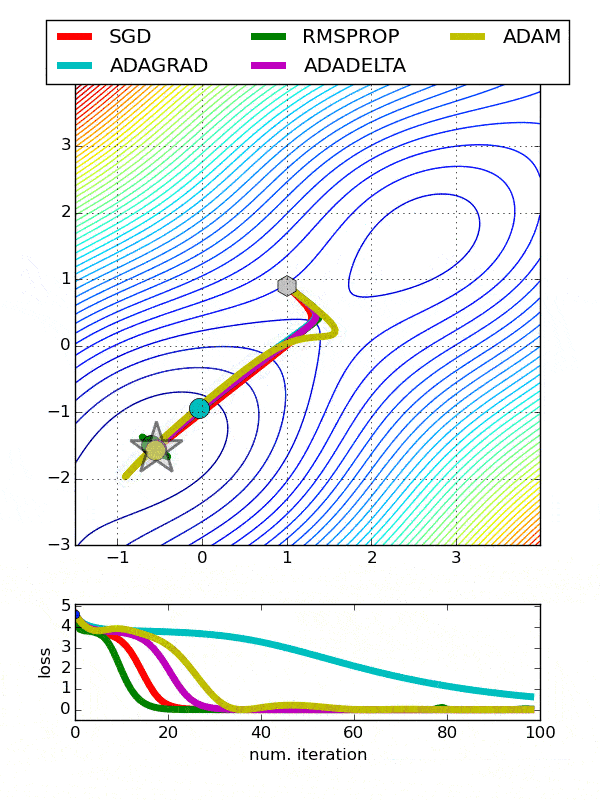
انواع بهینهسازها در شبکههای عصبی
در دنیای یادگیری عمیق بهینهسازها نقش حیاتی در تنظیم وزنهای شبکههای عصبی برای کاهش خطاها دارند. انواع مختلفی از بهینهسازها وجود دارد که هر یک ویژگیها و کاربردهای منحصربهفردی دارند. در ادامه با انواع آنها آشنا میشویم:
بهینهساز SGD (Stochastic Gradient Descent)
بهینهساز SGD یکی از سادهترین و درعینحال پرکاربردترین بهینهسازهاست. این روش، با گرفتن نمونههای تصادفی به جای کل دادهها، در هر گام بهروزرسانی وزنها را انجام میدهد.
درواقع آنچه در عمل بهعنوان SGD شناخته میشود minibatch GD است؛ بهاین معنی که برای آموزش، دادهها بهصورت دستهدسته به مدل داده میشوند.
Smoothنبودن تغییرات وزنها در هر گام از مشکلات اصلی این روش است که روش Momentum درصدد حل آن برامده است.
چگونگی کارکرد SGD
SGD با استفاده از گرادیان تابع هزینه نسبت به وزنها قدمهایی بهسمت کمینه محلی انجام میدهد. این بهینهساز با کاهش نوسانها و بهبود کارایی بهسمت بهینهسازی پیش میرود. نحوه بهروزرسانی وزنها و بایاس در این روش در این شکل آمده است:

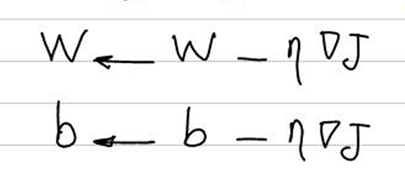
مزایا و معایب بهینهساز SGD
از مزایای اصلی SGD میتوان بهسادگی و سرعت بالا در آموزش اشاره کرد، اما معایبی مانند حساسیت به انتخاب نرخ یادگیری و احتمال گیرافتادن در کمینههای محلی وجود دارد.
در این قسمت میتوانید قطعه کدی شامل پیادهسازی این Optimizer و خروجی آن را ببنید. توجه کنید که قسمتهای مربوط به فراخوانی توابع و تعیین تابع هدف و مشتق آن برای کدهای بعدی نیز استفاده شده است:

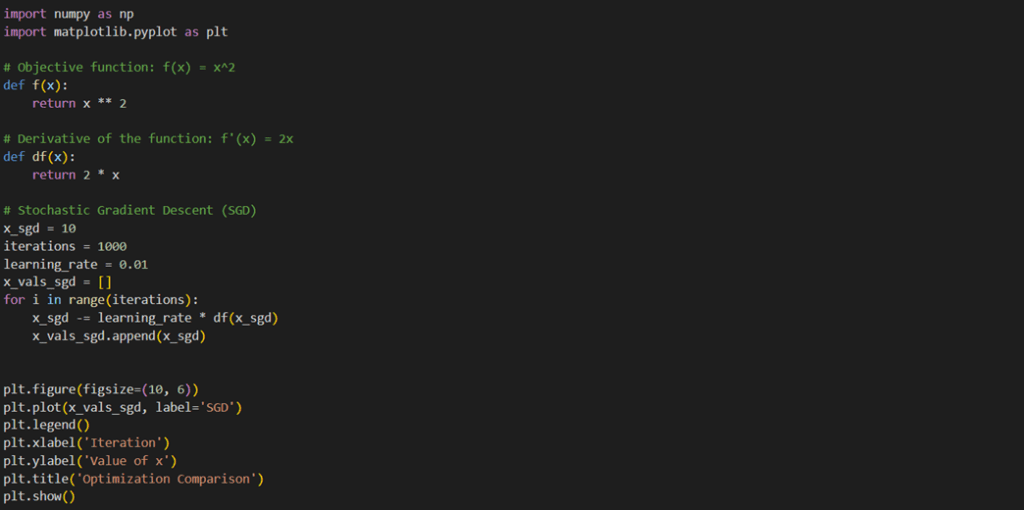

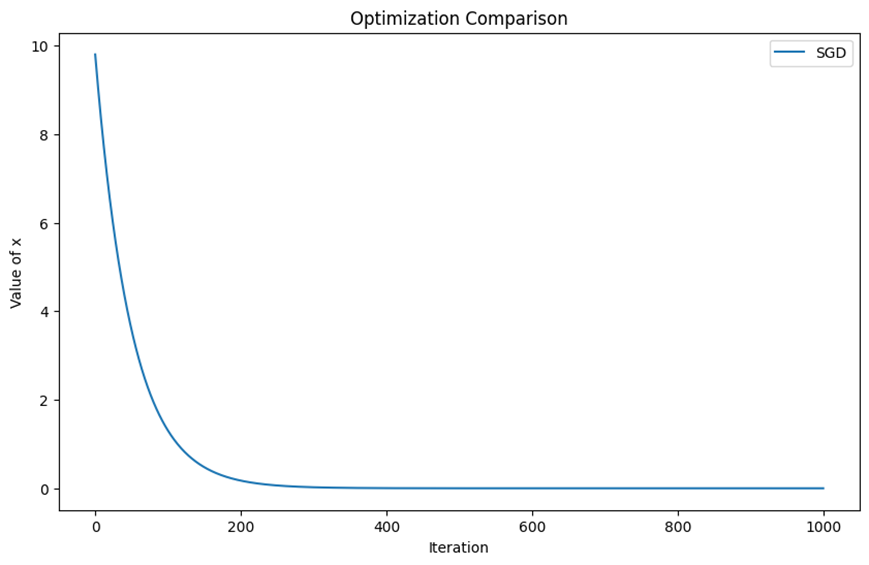
همانطور که در شکل میبینید، SGD بهراحتی توانسته است در کمتر از ۲۰۰ گام، بهینه سراسری (نقطه صفر) را پیدا کند. علت همگرایی سریع و بدون مشکل سادهبودن تابع هدف است. توجه کنید که این تابع (x^2) در واقع تابع هزینه (Loss Function) است که اختلاف مقدار پیشبینیشده توسط مدل و لیبلهای واقعی را نشان میدهد و باید به صفر میل کند.
بهینهساز تکانه (Momentum)
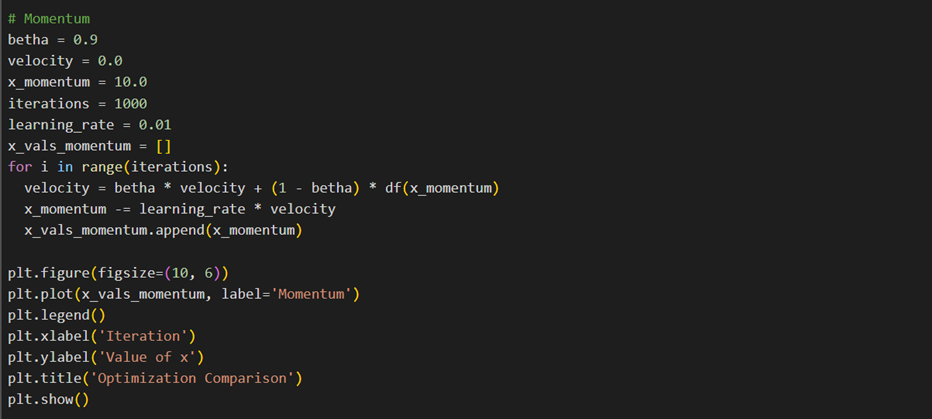
بهینهساز Momentum یا تکانه بهمنظور بهبود SGD طراحی شده است و با اضافهکردن جزئی حرکت به گرادیانها، بهروزرسانیها را طوری هدایت میکند که smooth باشد.
چگونگی کارکرد بهینهساز تکانه
این روش، با درنظرگرفتن گرادیانهای گذشته و حال، مسیر بهروزرسانی وزنها را تسهیل میبخشد. با این کار تنظیمات وزنی پایدارتر و سریعتر بهسمت کمینه سراسری حرکت میکنند. نحوه بهروزرسانی وزنها و بایاس در این روش در این شکل آمده است:

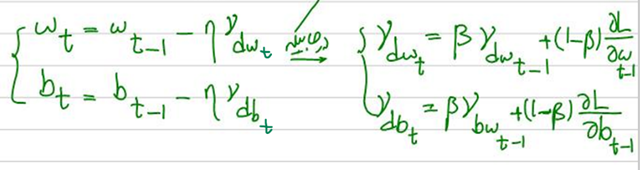
بهاین ترتیب، برای بهروزرسانی وزن فیچرها روش تکانه فقط به گرادیان دسته فعلی توجه نمیکند و اهمیتی هم به مقدار گرادیان همه دستههای قبل میدهد تا فرایند Convergence یا همگرایی به بهینه سراسری، روانتر اتفاق بیفتد.
مزایا و معایب بهینه ساز تکانه
Momentum، با کاهش نوسانها و جلوگیری از گیرافتادن در کمینههای محلی، کارایی را افزایش میدهد. این رویکرد، با استفاده از تاریخچه گرادیانها، به حرکت وزنها شتاب بیشتری میبخشد و به آنها کمک میکند از کمینههای محلی عبور کنند. این ویژگی خصوصاً در مدلهای پیچیده و با فرازوفرودهای متعدد بسیار مفید است.
بااینحال این بهینهساز نیز بدون عیب نیست. یکی از چالشهای اصلی استفاده از Momentum تنظیم پارامترهاست. اگر پارامتر حرکت بیشازحد بزرگ انتخاب شود، ممکن است بهجای نزدیکشدن به کمینه کلی، سیستم بیشازحد حرکت کند و از آن فراتر رود؛ همچنین درصورتیکه تنظیم نامناسبی برای نرخ یادگیری انجام شود، ممکن است بهینهساز بهسختی به کمینه بهینه برسد یا در زمان بسیار طولانی به آن دست یابد. روش Adam که در ادامه آن را توضیح میدهیم این مشکل را رفع کرده است.
بهطور خلاصه، درحالیکه Momentum میتواند سرعت همگرایی شبکه عصبی را بهطور چشمگیری افزایش دهد و از گیرافتادن در کمینههای محلی جلوگیری کند، باید بادقت و با درنظرگرفتن ویژگیهای مسئله مورداستفاده، پارامترهای آن تنظیم شود.
انتخاب دقیق این پارامترها مستلزم آزمونوخطا و تجربه است تا بهترین عملکرد را از شبکه عصبی خود کسب کنید.
در این قسمت میتوانید قطعه کدی شامل پیادهسازی این Optimizer را ببنید:


بهینهساز Adagrad (Adaptive Gradient)
همانطور که متوجه شدید، در روش SGD نرخ یادگیری (Learning Rtae) بهصورت Static یا ثابت تعیین میشود. مشکل اینجاست که وقتی به بهینه سراسری نزدیک میشویم، عموماً مقدار اولیه LR برای تغییرات مقدار W (وزنها) بسیار زیاد است و نوسان حول نقطه مدنظر را افزایش میدهد؛ بهاین ترتیب، ممکن است مدل همگرا نشود. حال باید به دنبال راهحلی باشیم که با نزدیکشدن به نقطه بهینه میزان نرخ یادگیری بهمرور و بهصورت داینامیک کم شود. به این راهکار کاهش نرخ یادگیری یا Learning Rate Decay میگویند.
Adagrad یکی از بهینهسازهای پیشرفته است که با تطبیقدادن نرخ یادگیری برای هر پارامتر، به خصوص در مواجهه با دادههای پراکنده و ویژگیهای (Features) مختلف مؤثر واقع میشود.
چگونگی کارکرد Adagard
Adagrad، با ارائه نرخ یادگیری متفاوت در هر گام، امکان پذیرش بهتری برای یادگیری در شرایط متفاوت را فراهم میکند. این بهینه ساز با جمعآوری پیاپی مجذور گرادیانها در یک متغیر به نام α (آلفا) و تقسیم نرخ یادگیری بر ریشه دوم این عدد، بهمروز زمان تغییر میکند؛ بنابراین هر چه جلوتر میرویم، تغییرات وزنها با شدت کمتری انجام شود. شیوه بهروزرسانی وزنها و بایاس در این روش در این شکل آمده است:

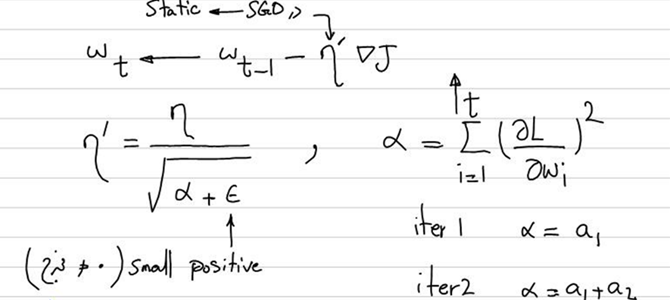
مزایا و معایب Adagrad
یکی از بزرگترین مزایای Adagrad این است که به تنظیم دستی نرخ یادگیری نیازی ندارد. این امر، بهویژه برای دادههایی با ویژگیهای دارای توزیعهای مختلف، مفید است.
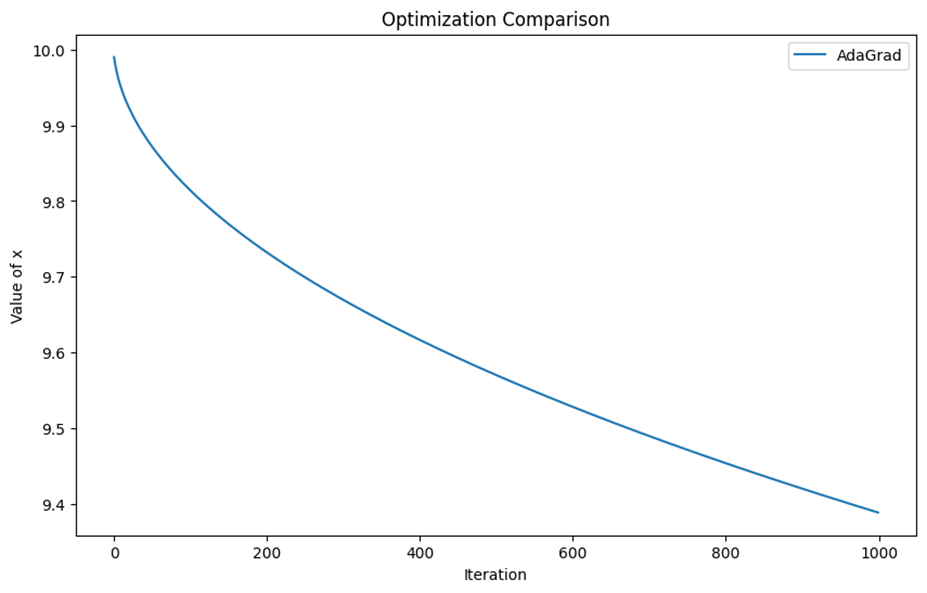
Adagrad میتواند در طولانیمدت با مشکل کاهش شدید نرخ یادگیری مواجه شود، بهاین معنی که الگوریتم ممکن است بهطور قابل توجهی کند شود و قبل از رسیدن به کمینه سراسری، بهروزرسانی وزنها را متوقف کند. علت این امر نیز در فرمول آن قابل دریافت است؛ زیرا هر چه جلوتر میرویم و به بهینه سراسری نزدیکتر میشویم، مقدار آلفا بهصورت تجمعی زیاد میشود و با زیادشدن مخرج کسر LR، این عدد بهمرور به صفر میل میکند و دیگر تغییری در مقدار وزنها مشاهده نمیشود.
درنهایت، Adagrad بهینهسازی است که در شرایط خاص، بهویژه زمانی که با دادههای نامتعادل و پراکنده سروکار داریم، بسیار مفید است؛ بااینحال در مواقعی که به ادامه تنظیمات و بهینهسازی پیوسته نیاز داریم، ممکن است به استراتژیهای متفاوتی هم برای جلوگیری از کاهش بیشازحد نرخ یادگیری نیاز داشته باشیم.
در این قسمت میتوانید قطعه کدی شامل پیادهسازی این Optimizer را ببنید:

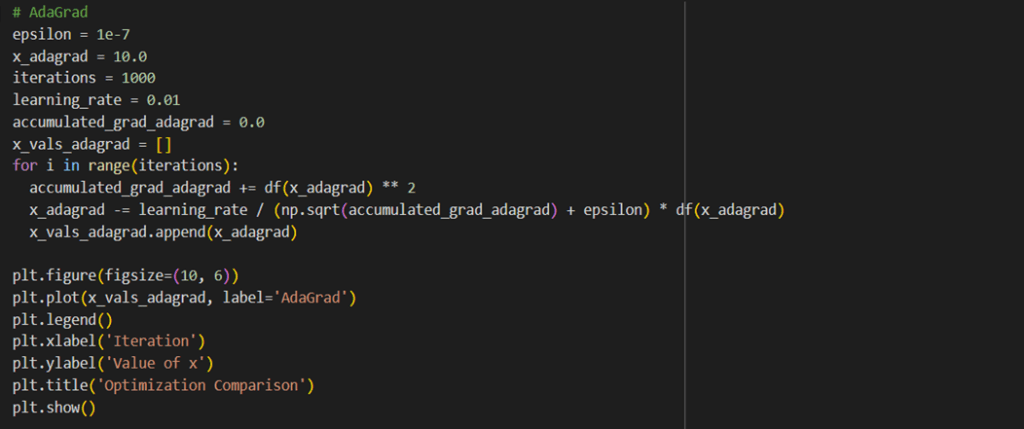

بهینهساز RMSprop
RMSprop که مخفف «Root Mean Square Propagation» است بهینهسازی است که برای حل برخی از مشکلات مربوط به کاهش سریع نرخ یادگیری در Adagrad طراحی شده است.
چگونگی کارکرد RMSprop
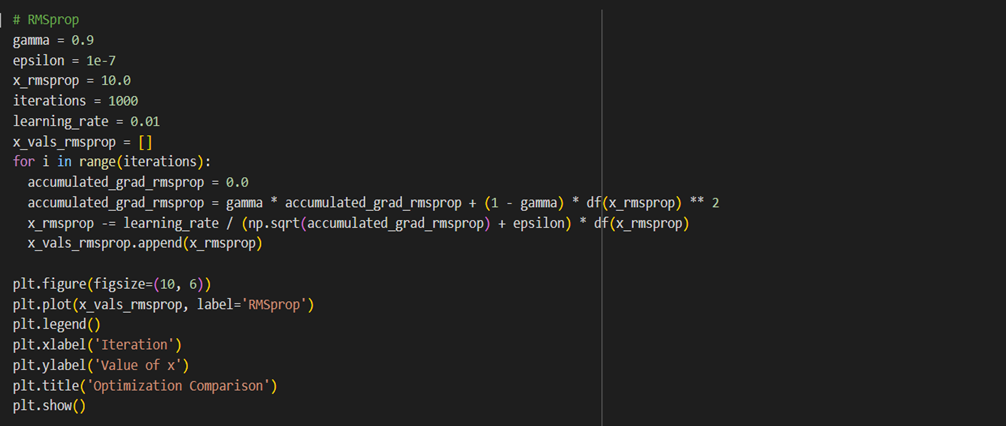
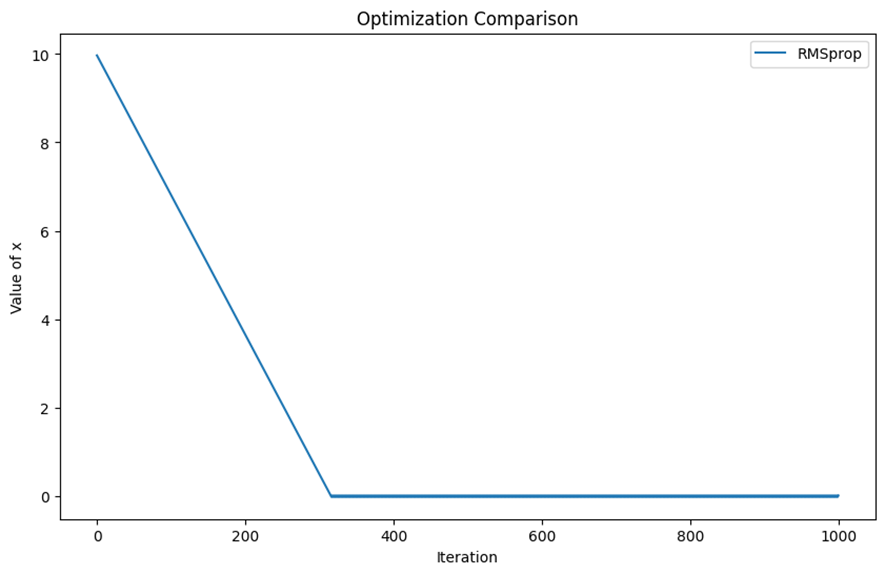
RMSprop، با تنظیم نرخ یادگیری برای هر پارامتر بر اساس میانگین مربعات گرادیانهای اخیر، از افت شدید و دائمی نرخ یادگیری در طول زمان جلوگیری میکند. این کار با محاسبه میانگین مربعات گرادیانها و تقسیم نرخ یادگیری بر ریشه دوم این میانگین انجام میشود.
درواقع این میانگینگیری با جلوگیری از افزایش بیشازحد مخرج کسر LR، کمک میکند بهروزرسانی وزنها در مرحلههای پایانی نیز ادامه یابد.
نحوه بروزرسانی وزنها RMSprop در این شکل آمده است:

مزایا و معایب RMSprop
یکی از مزایای بزرگ RMSprop این است که میتواند نرخ یادگیری را در حین بهینهسازی تطبیق دهد؛ بهاین ترتیب، یادگیری را در مقابله با مسائل متفاوت و ویژگیهای مختلف کارآمدتر میکند. این بهینهساز بهخصوص در مواردی که مسیر گرادیان تغییرات ناگهانی دارد بسیار مفید است.
همچنین یکی از نقاط ضعف RMSprop این است که ممکن است در برخی موارد که به تنظیمات دقیقتری نیاز است پاسخگو نباشد؛ علاوهبراین، همانند دیگر بهینهسازها، انتخاب درست پارامترها، مانند نرخ یادگیری اولیه و اندازه پنجره میانگین مربعات، برای کارایی این الگوریتم حیاتی است.
بهطور کلی، RMSprop ابزاری قدرتمند برای مواجهه با چالشهای مربوط به نرخهای یادگیری متغیر و محیطهای بهینهسازی ناپایدار است. این روش بهخصوص در شبکههای عصبی که با دادههای پراکنده و ویژگیهای متنوع سروکار دارند میتواند بسیار مؤثر باشد.
در این قسمت میتوانید قطعه کدی شامل پیادهسازی این Optimizer را ببنید:


بهینهساز Adam
Adam که مخفف «Adaptive Moment Estimation» است یکی از محبوبترین بهینهسازها در یادگیری عمیق است. این بهینهساز ویژگیهای هر دو بهینهساز RMSprop (برای تغییر داینامیک Learning Rate) و Momentum (برای رعایت شرط smoothing) را ترکیب میکند.
چگونگی کارکرد Adam
Adam نرخ یادگیری را با استفاده از میانگینهای محاسبهشده از گرادیانهای اول و دوم برای هر پارامتر بهصورت تطبیقی تنظیم میکند. این بهینهساز، با ترکیب این دو معیار، قابلیت بهبود سرعت و پایداری در فرایند یادگیری را فراهم میکند. نحوه کار این Optimizer در این شکل آمده است:

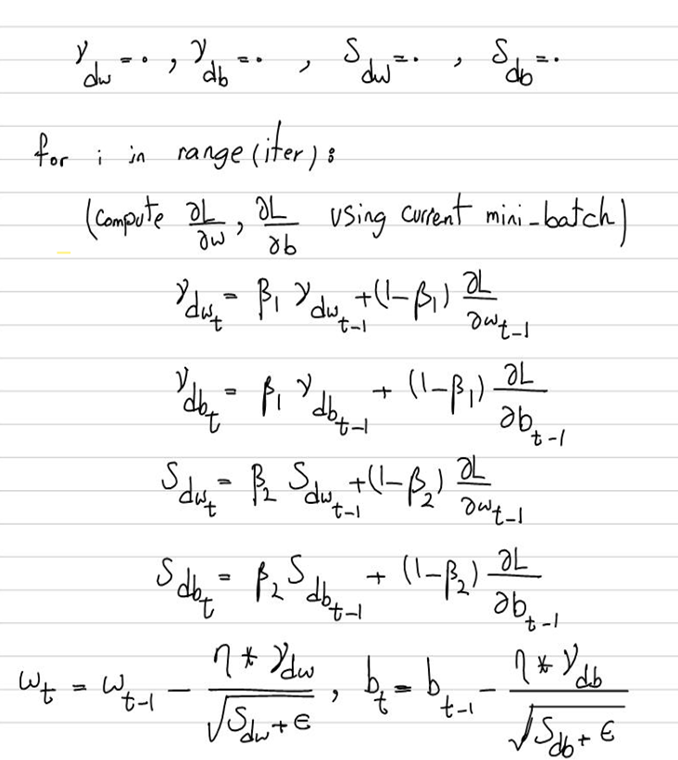
همانطور که در این شکل میبینید، برای جلوگیری از تغییرات غیر یکنواخت وزنها به واسطه تغییر دستهها (Batches) در هر گام، از همان ایده Momentum در صورت کسر عبارتی که وظیفه بروزرسانی وزنها را دارد و برای کاهش نرخ یادگیری در گامهای پایانی از ایده RMSprop در مخرج آن استفاده شده است.
مزایا و معایب Adam
یکی از بزرگترین مزایای Adam این است که نیاز کمتری به تنظیم دستی نرخ یادگیری دارد و در بسیاری از موارد، با تنظیمات پیشفرض نیز عملکرد بسیار خوبی ارائه میکند. Adam بهخوبی با دادههای متفاوت و در شرایط مختلف آموزشی سازگار است و توانایی آن در تطبیق نرخ یادگیری برای پارامترهای مختلف، بهخصوص در مواجهه با دادههای نامتعادل یا پراکنده، بسیار ارزشمند است.
بااینحال Adam ممکن است در برخی موارد خاص، بهویژه زمانی که دقت بسیار بالایی موردنیاز است، بهاندازه برخی روشهای دیگر کارآمد نباشد؛ همچنین اگرچه نسبتاً کمتر از دیگر بهینهسازها نیاز به تنظیم دارد، درک درست از عملکرد آن و انتخاب دقیق پارامترها همچنان میتواند به بهینهسازی بیشتر عملکرد کمک کند.
درنهایت، Adam، بهعنوان یک بهینهساز قدرتمند و انعطافپذیر، انتخاب محبوبی در میان محققان و مهندسان یادگیری عمیق است و در طیف وسیعی از شبکههای عصبی و دادههای مختلف کاربرد فراوانی دارد.
در این قسمت میتوانید قطعه کدی شامل پیادهسازی این Optimizer را ببنید:


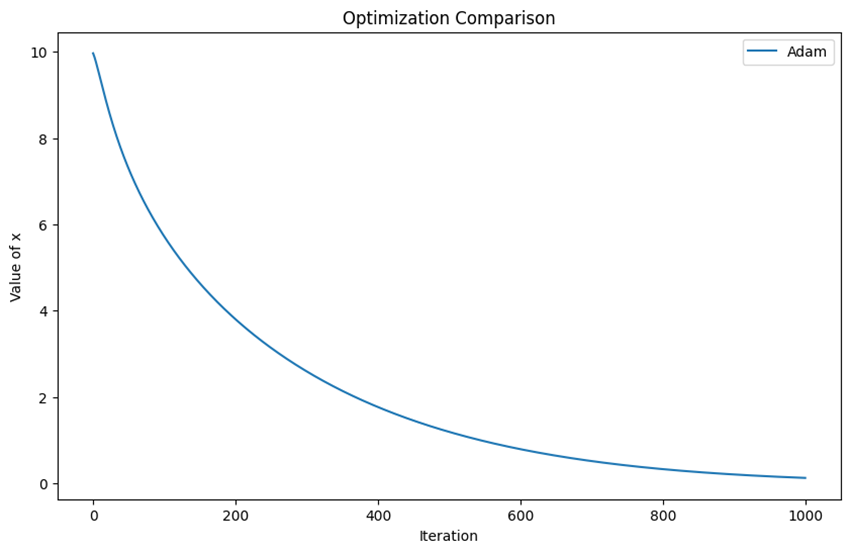
با مطالعه این پنج روش متوجه میشویم که تمامی مدلهای بررسیشده قادر به دستیابی به بهینه کلی تابع هدف مشخصشده هستند و تفاوت آنها صرفاً در زمانی است که به این بهینه سراسری میرسند.
پرسشهای متداول
بهینهساز SGD (Stochastic Gradient Descent) چگونه به کاهش خطای شبکههای عصبی کمک میکند و چه چالشهایی در استفاده از آن وجود دارد؟
بهینهساز SGD با بهروزرسانی وزنها براساس نمونههای تصادفی (نمونهبرداری تصادفی) از دادهها و حرکت بهسمت کمینه محلی به کاهش خطا کمک میکند. از چالشهای آن میتوان به حساسیت به انتخاب نرخ یادگیری (Learning Rate) و احتمال گیرافتادن در کمینههای محلی اشاره کرد.
بهینهساز Momentum چه مزیتی بر SGD دارد و در چه شرایطی کارایی بهتری ارائه میکند؟
بهینهساز Momentum با اضافهکردن جزئی حرکت (Momentum) به گرادیانها، تغییرات وزنها را پایدارتر و سریعتر میکند، بهخصوص در مسیرهایی که شیب کمی دارند. این روش در شرایطی که دادهها نوسانات و تغییرات گستردهای دارند کارایی بالاتری دارد.
بهینهساز Adagrad چگونه به بهبود یادگیری در دادههای پراکنده کمک میکند و چه محدودیتهایی دارد؟
Adagrad با تطبیق نرخ یادگیری برای هر پارامتر براساس تکرار آنها، به بهبود یادگیری در دادههای دارای توزیع نامتعادل کمک میکند. محدودیت اصلی آن کاهش شدید نرخ یادگیری در طول زمان است که میتواند به کندی پیشرفت بینجامد.
RMSPROP در چه مواردی به عنوان یک بهینهساز ترجیح داده میشود و چه مزیتهایی بر Adagrad دارد؟
RMSPROP در شرایطی که Adagrad با کاهش شدید نرخ یادگیری مواجه میشود ترجیح داده میشود؛ زیرا با استفاده از میانگین مربعات گرادیانها نرخ یادگیری را متعادلتر نگه میدارد.
مزیت Adam در مقایسه با دیگر بهینهسازها چیست؟
بهینهساز Adam یکی از الگوریتمهای بهینهسازی محبوب در یادگیری عمیق است که برخی مزیتهای مهم در مقایسه با دیگر بهینهسازها دارد:
- تنظیم خودکار نرخ یادگیری: Adam نرخ یادگیری را برای هر پارامتر بهطور جداگانه تنظیم میکند. این امر کمک میکند تا در مسائلی که دادهها و یا تابع هزینه پیچیدگیهای مختلفی دارند عملکرد بهتری داشته باشد.
- کارآمد در شرایط مختلف: Adam بهطور معمول در بسیاری از شرایط مختلف بهخوبی عمل میکند و به تنظیم دستی و دقیق پارامترها نیازی ندارد؛ این امر آن را برای کاربران کمتجربه مناسب میکند.
- داشتن ترکیبی از مزیتهای RMSprop و Momentum: بهطور همزمان از مزایای هر دو الگوریتم RMSprop (تنظیم نرخ یادگیری براساس آخرین گرادیانها) و Momentum (smoothing) بهره میبرد.
با وجود این مزیتها، استفاده از Adam در همه موقعیتها توصیه نمیشود. برخی تحقیقات نشان دادهاند که در موارد خاصی، مانند آموزش شبکههای بسیار عمیق یا مجموعهدادههای با نویز زیاد، ممکن است بهینهسازهای دیگری مانند SGD عملکرد بهتری داشته باشند.
یادگیری ماشین لرنینگ را از امروز شروع کنید!
دنیای دادهها جذاب است و دانستن دیتا ساینس توانایی تحلیل داده یا بازاریابی مبتنی بر داده شما را برای فرصتهای شغلی بسیاری مناسب میکند. فارغ از رشته و پیشزمینه تحصیلی یا شغلی، میتوانید یادگیری این دانش را همین امروز شروع کنید و از سطح مقدماتی تا پیشرفته آن را بیاموزید. اگر دوست دارید به این حوزه وارد شوید، پیشنهاد میکنیم با کلیک روی این لینک قدم اول را همین حالا بردارید.
مشاوران کافهتدریس به شما کمک میکنند مسیر یادگیری برای ورود به این حوزه را شروع کنید: