
ماشین لرنینگ حوزهای است که به سرعت در حال رشد است که روش برخورد ما با مشکلات پیچیده در حوزههای مختلف از جمله مالی، مراقبتهای بهداشتی و امنیت سایبری را متحول کرده است. جنگل تصادفی یکی از قدرتمندترین و پرکاربردترین الگوریتمها در زمینه یادگیری ماشین است. در این پست، اینکه جنگل تصادفی یا Random Forest چیست، چگونه کار میکند و چرا بهتر از درختهای تصمیم است را بررسی میکنیم. همچنین برخی از کاربردهای جنگل تصادفی و مزایا و معایب آن را مورد بحث قرار خواهیم داد.
- 1. الگوریتم جنگل تصادفی یا Random Forest چیست؟
- 2. چرا جنگل تصادفی بهتر از درخت تصمیم است؟
- 3. مراحل الگوریتم جنگل تصادفی
- 4. کاربردهای الگوریتم جنگل تصادفی
- 5. مزایا و معایب الگوریتم جنگل تصادفی
- 6. مقایسه جنگل تصادفی با سایر الگوریتمهای یادگیری گروهی
- 7. قسمتی از جزوه کلاس برای آموزش الگوریتم Random Forest
- 8. قطعه کد جنگل تصادفی
- 9. خلاصهی مطالب
- 10. یادگیری ماشین لرنینگ را از امروز شروع کنید!
الگوریتم جنگل تصادفی یا Random Forest چیست؟
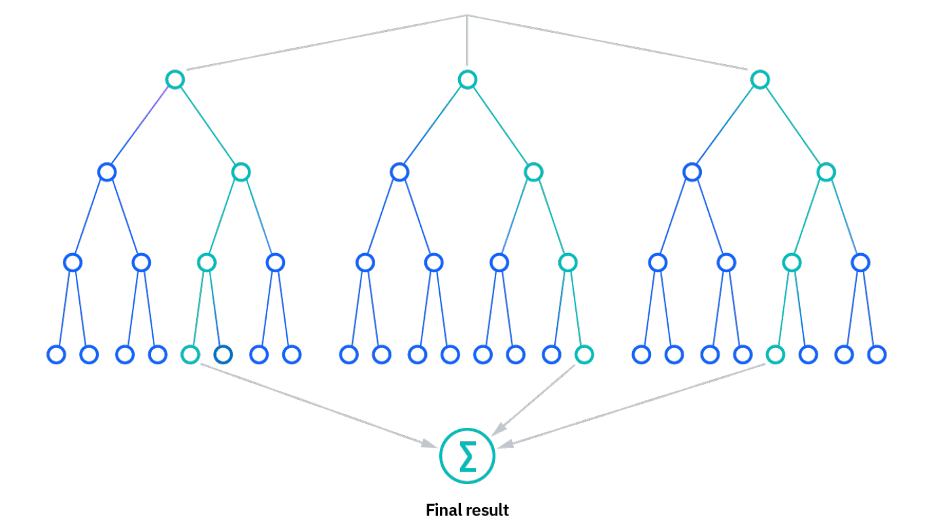
جنگل تصادفی یا Random Forest نوعی الگوریتم یادگیری گروهی (Ensemble Learning Algorithm) است که چندین درخت تصمیم را برای پیشبینی ترکیب میکند. هر درخت تصمیم در جنگل تصادفی بر روی یک زیر مجموعه تصادفی از دادههای آموزشی و یک زیر مجموعه تصادفی از فیچرها آموزش داده میشود. سپس خروجی جنگل تصادفی با تجمیع پیشبینیهای همه درختهای تصمیم تعیین میشود. این رویکرد به جنگل تصادفی اجازه میدهد تا بسیار دقیق و مقاوم در برابر مشکل بیشبرازش، یک مشکل رایج در یادگیری ماشین که در آن مدل در دادههای آموزشی خوب عمل میکند اما در دادههای جدید ضعیف است، باشد.
چرا جنگل تصادفی بهتر از درخت تصمیم است؟
Random Forest به چند دلیل بهتر از درخت تصمیم است. اول، درختان تصمیم مستعد مشکل بیشبرازش هستند، به خصوص زمانی که مجموعه داده پیچیده یا پر نویز باشد. جنگل تصادفی با ترکیب پیشبینیهای درختان تصمیمگیری چندگانه، مشکل بیشبرازش را کاهش میدهد. دوم، درختهای تصمیم به ساختار دادههای آموزشی بسیار حساس هستند، که میتواند منجر به ساخت درختهای مختلف برای زیر مجموعههای مختلف داده شود. جنگل تصادفی با استفاده از زیرمجموعه های تصادفی دادهها و فیچرهای آموزشی این تنوع را کاهش میدهد. در نهایت، درختهای تصمیم زمانی که فیچرهای ورودی زیادی وجود دارد، مؤثر نیستند، زیرا ممکن است بسیار پیچیده و تفسیر آنها دشوار باشد. جنگل تصادفی با انتخاب تنها یک زیرمجموعه تصادفی از آنها برای هر درخت می تواند تعداد زیادی فیچر را مدیریت کند.
پیشنهاد میکنیم درباره درخت تصمیم یا Decision Tree هم مطالعه کنید.
مراحل الگوریتم جنگل تصادفی
در اینجا مراحل اصلی در ساخت یک مدل Random Forest را بررسی میکنیم:
آماده سازی دادهها: اولین مرحله آماده سازی دادهها برای آموزش مدل است که شامل پاکسازی دادهها، حذف مقادیر از دست رفته و تبدیل متغیرهای طبقهبندی شده (Categorical) به متغیرهای عددی است. سپس داده ها به مجموعه های آموزشی و آزمایشی تقسیم می شوند.
انتخاب تصادفی زیر مجموعه: مرحله بعدی انتخاب تصادفی زیرمجموعه ای از فیچرها برای هر درخت در جنگل است. این کار برای کاهش بیشبرازش و افزایش تنوع درختان انجام میشود.
ساخت درخت: مرحله بعدی ساخت درختهای تصمیم با استفاده از زیرمجموعهای از فیچرهاست که به طور تصادفی انتخاب شدهاند. درختهای تصمیم با استفاده از یک الگوریتم تقسیم باینری بازگشتی ساخته میشوند، که در آن هر گره داخلی دادهها را بر اساس یک فیچر و مقدار آستانه انتخاب شده به دو زیر مجموعه تقسیم میکند.
رای گیری: هنگامی که تمام درخت های تصمیم ساخته شدند، مرحله بعدی پیش بینی مجموعه تست است. این کار با جمعآوری پیشبینیها از تمام درختان جنگل با استفاده از مکانیزم رایگیری انجام میشود. در تسکهای طبقهبندی، کلاسس که توسط اکثریت درختان به عنوان پیش بینی نهایی، پیشبینی شده انتخاب میشود. در تسکهای رگرسیون، میانگین پیشبینی درختان به عنوان پیش بینی نهایی انتخاب میشود.
ارزیابی مدل: در نهایت، عملکرد مدل با استفاده از معیارهای مختلفی مانند Accuracy، precision ، recall و F1 score ارزیابی میشود. اگر عملکرد مدل رضایت بخش باشد، میتوان از آن برای پیش بینی دادههای جدید استفاده کرد. این مراحل به صورت مکرر، با زیرمجموعههای مختلف فیچرها و زیرمجموعههای مختلف داده، تکرار میشوند تا به سطح مورد نظر از دقت دست پیدا کنند. Random Forest یک الگوریتم یادگیری ماشین قدرتمند است که میتواند وظایف پیچیده را انجام دهد و پیشبینیهای بسیار دقیقی را با حداقل بیشبرازش ایجاد کند.
کاربردهای الگوریتم جنگل تصادفی
جنگل تصادفی کاربردهای زیادی در حوزههای مختلف دارد، مانند:
- امور مالی: میتوان از آن برای کشف تقلب، امتیازدهی اعتباری و تحلیل بازار سهام استفاده کرد.
- مراقبتهای بهداشتی: میتوان از آن برای تشخیص بیماری، کشف دارو و تجزیه و تحلیل تصاویر پزشکی استفاده کرد.
- تجارت الکترونیک: میتوان از آن برای توصیه محصول، تقسیمبندی مشتری و پیشبینی تقاضا استفاده کرد.
- بازاریابی: میتوان از آن برای هدفگذاری کمپین، پیشبینی ریزش مشتری و تخمین ارزش طول عمر مشتری استفاده کرد.
- علوم محیطی: میتوان از آن برای پیشبینی آتش سوزی در جنگلها، پیشبینی کیفیت هوا و پیشبینی آب و هوا استفاده کرد.
- ورزش: میتوان از آن برای پیشبینی عملکرد بازیکن، انتخاب تیم و پیشبینی نتیجه بازی استفاده کرد.
- رسانههای اجتماعی: میتوان از آن برای تحلیل احساسات، تحلیل روند و تحلیل رفتار کاربر استفاده کرد. تطبیقپذیری جنگل تصادفی آن را به گزینه ای محبوب برای بسیاری از تسکهای یادگیری ماشین تبدیل میکند و با در دسترس قرار گرفتن دادههای بیشتر در حوزههای مختلف، کاربردهای آن به طور مداوم در حال گسترش است.
مزایا و معایب الگوریتم جنگل تصادفی
از مزایای جنگل تصادفی میتوان به دقت بالا، استحکام و توانایی مدیریت تعداد زیادی از فیچرها اشاره کرد. همچنین استفاده و تفسیر آن نسبتاً آسان است، زیرا درختان تصمیم را میتوان تجسم و درک کرد. با این حال، برخی از معایب هم وجود دارد، مانند پیچیدگی محاسباتی آن و امکان بیشبرازش در صورت زیاد بودن تعداد درختان. علاوه بر این، جنگل تصادفی ممکن است در مجموعه دادههای کوچک به خوبی عمل نکند، زیرا ممکن است دادههای کافی برای ایجاد زیرمجموعههای معنی دار برای هر درخت وجود نداشته باشد.
به صورت خلاصه میتوان محدودیتها و چالشهای الگوریتم جنگل تصادفی را به این صورت بیان کرد:
- پیچیدگی محاسباتی بالا: با افزایش تعداد درختان، زمان آموزش و پیشبینی افزایش مییابد، که میتواند در دادههای بسیار بزرگ به یک مشکل تبدیل شود.
- ممکن است برای دادههای با ابعاد بسیار کم مناسب نباشد: چون ممکن است دادههای کافی برای آموزش درختان متعدد وجود نداشته باشد.
- بیشبرازش: اگرچه جنگل تصادفی در مقایسه با یک درخت تصمیمگیری واحد در مقابل بیشبرازش مقاومتر است، اما با افزایش بیرویه تعداد درختان، میتواند به بیشبرازش منجر شود.
- تفسیر و تجسم دشوار: در مقایسه با یک درخت تصمیم ساده، تجسم و تفسیر نتایج میتواند دشوار باشد، زیرا ممکن است هزاران درخت در تصمیمگیری نقش داشته باشند.
- بهینهسازی پارامترها: تنظیم پارامترها میتواند چالشبرانگیز باشد، زیرا تعداد زیادی پارامتر مانند عمق درخت، تعداد فیچرها در هر تقسیم، و تعداد درختان باید در نظر گرفته شود.
مقایسه جنگل تصادفی با سایر الگوریتمهای یادگیری گروهی
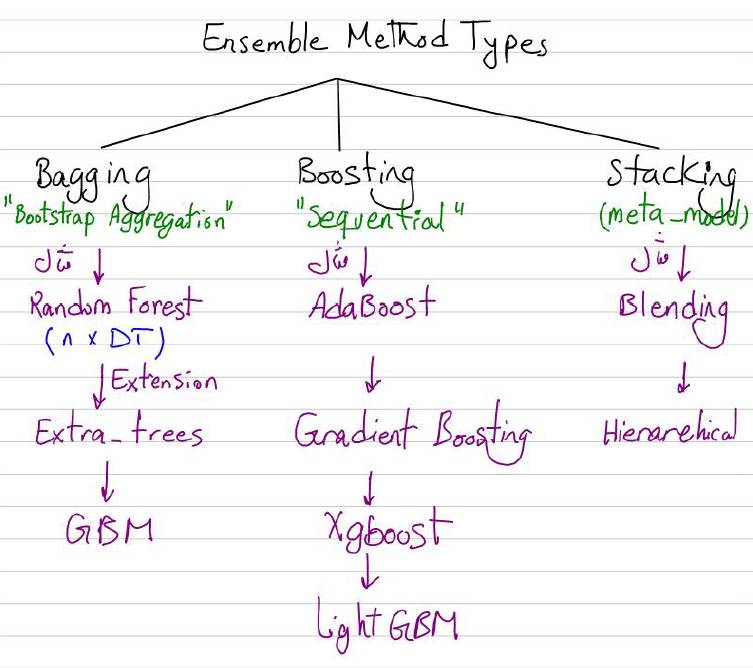
الگوریتمهای یادگیری گروهی، که به عنوان یادگیری ترکیبی نیز شناخته میشوند، از ترکیب چندین مدل پیشبینیکننده برای تولید یک پیشبینی نهایی دقیقتر استفاده میکنند. این رویکرد بر این باور استوار است که ترکیب چندین مدل تکی میتواند منجر به کاهش واریانس و بایاس شده و نتایج بهتری نسبت به استفاده از یک مدل تکی ارائه دهد. الگوریتمهای مختلف یادگیری گروهی میتوانند شامل تکنیکهای مختلفی مانند Boosting ، Bagging و Stacking باشند که هر کدام استراتژیهای متفاوتی برای ترکیب مدلها به کار میبرند.
جنگل تصادفی یکی از الگوریتمهای معروف یادگیری گروهی است که در کنار سایر روشهایی مثل Boosting و Stacking قرار میگیرد. جنگل تصادفی با استفاده از تعداد زیادی درخت تصمیم، به کاهش بیشبرازش و بهبود دقت کمک میکند. Boosting به طور متوالی مدلهای پیشبینیکننده ضعیف را بهبود بخشیده و روی خطاهای مدلهای پیشین تمرکز میکند. Stacking به ترکیب مدلهای مختلفی از الگوریتمها برای ساخت یک مدل قویتر میپردازد. انتخاب مناسبترین الگوریتم یادگیری گروهی بر اساس خصوصیات دادهها و مشکل مورد نظر، میتواند به بهبود عملکرد مدلهای پیشبینی کمک شایانی کند.
قسمتی از جزوه کلاس برای آموزش الگوریتم Random Forest
دوره جامع دیتا ساینس و ماشین لرنینگ
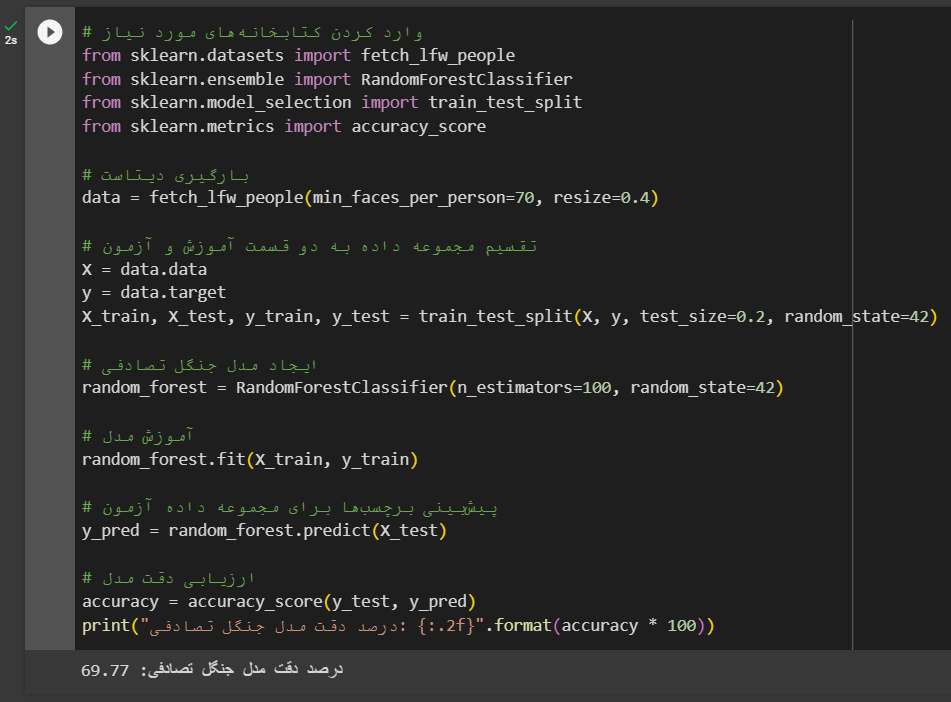
قطعه کد جنگل تصادفی
برای تمرین و آشنایی بیشتر با این الگوریتم، شما میتوانید کد زیر را در گوگل Colab اجرا کنید.
خلاصهی مطالب
به طور خلاصه، جنگل تصادفی یا Random Forest یک الگوریتم یادگیری گروهی قدرتمند و همه کاره است که به یک ابزار ضروری در زمینه یادگیری ماشین تبدیل شده است. توانایی آن در کاهش بیشبرازش، مدیریت تعداد زیادی از فیچرها و ارائه پیشبینیهای دقیق، آن را به انتخابی محبوب برای طیف گستردهای از برنامهها تبدیل میکند. با این حال، هنگام تصمیمگیری در مورد استفاده از آن برای یک کار خاص، مهم است که مزایا و معایب آن را در نظر بگیرید.
یادگیری ماشین لرنینگ را از امروز شروع کنید!
دنیای دادهها جذاب است و دانستن علم داده، توانایی تحلیل داده یا بازاریابی مبتنی بر داده و یادگیری ماشین شما را برای فرصتهای شغلی بسیاری مناسب میکند. شما، فارغ از رشته و پیشزمینه، میتوانید یادگیری این دانش را همین امروز شروع کنید و از سطح مقدماتی تا پیشرفته بیاموزید. اگر دوست دارید به این حوزه وارد شوید، پیشنهاد میکنیم با کلیک روی این لینک قدم اول را همین حالا بردارید.
مشاوران کافهتدریس به شما کمک میکنند مسیر یادگیری برای ورود به این حوزه را شروع کنید:
جنگل تصادفی به چه دلیلی نسبت به درخت تصمیم، ترجیح داده میشود؟
جنگل تصادفی با ترکیب پیشبینیهای درختان تصمیمگیری چندگانه، مشکل بیشبرازش را کاهش میدهد. دوم، درختهای تصمیم به ساختار دادههای آموزشی بسیار حساس هستند، که میتواند منجر به ساخت درختهای مختلف برای زیر مجموعههای مختلف داده شود. در نهایت، درختهای تصمیم زمانی که فیچرهای ورودی زیادی وجود دارد، مؤثر نیستند، زیرا ممکن است بسیار پیچیده و تفسیر آنها دشوار باشد. جنگل تصادفی با انتخاب تنها یک زیرمجموعه تصادفی از آنها برای هر درخت می تواند تعداد زیادی فیچر را مدیریت کند
دو مورد از کاربردهای الگوریتم جنگل تصادفی را نام ببرید.
امور مالی / مراقبتهای بهداشتی
یکی از مزایا و یکی از معایب الگوریتم جنگل تصادفی چیست؟
از مزایای جنگل تصادفی میتوان به دقت بالا، استحکام و توانایی مدیریت تعداد زیادی از فیچرها اشاره کرد.
پیچیدگی محاسباتی بالا: با افزایش تعداد درختان، زمان آموزش و پیشبینی افزایش مییابد، که میتواند در دادههای بسیار بزرگ به یک مشکل تبدیل شود.
سوال۳:
مزایای
جنگل تصادفی میتوان به دقت بالا، استحکام و توانایی مدیریت تعداد زیادی از فیچرها اشاره کرد. همچنین استفاده و تفسیر آن نسبتاً آسان است
معایب
ممکن است برای دادههای با ابعاد بسیار کم مناسب نباشد: چون ممکن است دادههای کافی برای آموزش درختان متعدد وجود نداشته باشد.
سوال ۲:
اموز مالی
ورزش
تجارت الکترونیک
مراقبتهای بهداشتی
سوال۱:
به چند دلیل بهتر از درخت تصمیم است. اول، درختان تصمیم مستعد مشکل بیشبرازش هستند، به خصوص زمانی که مجموعه داده پیچیده یا پر نویز باشد. جنگل تصادفی با ترکیب پیشبینیهای درختان تصمیمگیری چندگانه، مشکل بیشبرازش را کاهش میدهد. دوم، درختهای تصمیم به ساختار دادههای آموزشی بسیار حساس هستند، که میتواند منجر به ساخت درختهای مختلف برای زیر مجموعههای مختلف داده شود.