
خوشهبندی (Clustering)، یکی از شیوههای کاربردی در حوزه یادگیری ماشین بدون نظارت است که از آن برای کشف ساختارها و الگوهای مخفی در مجموعههای بزرگ داده استفاده میشود. این فرایند، دادهها را بر اساس شباهتهای ذاتی به گروههایی تقسیم میکند که هر یک را یک خوشه مینامیم. خوشهبندی به عنوان ابزاری قدرتمند در دست تحلیلگران، امکان پذیرش تصمیمگیریهای دقیقتر و بهینهسازی استراتژیهای کسبوکار را فراهم میآورد. از بازاریابی گرفته تا پزشکی، توانایی خوشهبندی در تقسیمبندی مشتریان بر اساس نیازها، شناسایی الگوهای بیماریها و حتی تجزیه و تحلیل دادههای ژنتیکی، آن را به ابزاری چندمنظوره تبدیل کرده است. در این مقاله، با انواع روشهای خوشهبندی و کاربردهای آنها در صنایع مختلف آشنا خواهیم شد و نحوه پیادهسازی این الگوریتمها در پایتون را بررسی خواهیم کرد.
- 1. تعریف خوشهبندی
- 2. کاربردهای خوشهبندی در صنعت
- 3. انواع روشهای خوشهبندی
- 4. معیارهای ارزیابی خوشهبندی
- 5. چالشهای رایج در خوشهبندی
- 6. راه حلهای موجود برای مقابله با چالشهای خوشهبندی
-
7.
پرسشهای متداول
- 7.1. خوشهبندی چگونه به کسبوکارها کمک میکند تا به درک بهتری از مشتریان خود دست یابند؟
- 7.2. تفاوتهای اصلی بین خوشهبندی مبتنی بر مرکزیت و خوشهبندی مبتنی بر چگالی چیست؟
- 7.3. چه فنآوریهایی میتوانند در تکامل خوشهبندی نقش داشته باشند و چگونه؟
- 7.4. چالشهای رایج در پیادهسازی الگوریتمهای خوشهبندی چیست و چگونه میتوان این چالشها را مدیریت کرد؟
- 7.5. چگونه خوشهبندی در شناسایی و تحلیل الگوهای بیماریها در پزشکی مورد استفاده قرار میگیرد؟
- 8. یادگیری ماشین لرنینگ را از امروز شروع کنید!
تعریف خوشهبندی
خوشهبندی به فرایندی گفته میشود که طی آن دادهها بر اساس شباهتهای مشترک به گروههایی تقسیم میشوند. به هر یک از این گروهها یک خوشه (Cluster) میگویند. در یادگیری ماشین، این تکنیک به عنوان یک شیوه یادگیری بدون نظارت کاربرد دارد. زیرا مدلها بدون استفاده از برچسبهای (Labels) از پیش تعیین شده، ساختارهای موجود در دادهها را کشف میکنند.
کاربردهای خوشهبندی در صنعت
کاربردهای خوشهبندی در صنعت بسیار متنوع و گسترده هستند. خوشهبندی در حوزههای مختلف از جمله بازاریابی (Marketing) و پزشکی مورد استفاده قرار میگیرند. در ادامه، به تشریح بیشتر کاربردهای خوشهبندی در این دو حوزه خواهیم پرداخت:
کاربردهای خوشهبندی در بازاریابی
خوشهبندی یکی از ابزارهای کلیدی در استراتژیهای بازاریابی مدرن است. این روش به شرکتها کمک میکند تا مشتریان خود را بر اساس ویژگیهای مختلف مانند سن، جنسیت، درآمد، علایق و رفتار خرید به گروههای مختلف تقسیم کنند.
شرکت آمازون و تکنیکهای خوشهبندی
شرکت آمازون با استفاده از تکنیکهای خوشهبندی، مشتریان را بر اساس الگوهای خرید و ترجیحات محصول تقسیمبندی میکند تا پیشنهادات محصولات متناسبتری را به آنها ارائه دهد. این رویکرد به افزایش فروش و بهبود تجربه مشتریان کمک شایانی میکند.
کاربردهای خوشهبندی در پزشکی
در حوزه پزشکی، خوشهبندی امکان شناسایی گروههای بیماریهای با ویژگیهای مشابه را فراهم میآورد. به طور مثال، محققان در علم اپیدمیولوژی (Epidemiology) از خوشهبندی برای شناسایی الگوهای شیوع بیماریهای مسری استفاده میکنند.
خوشهبندی در کرونا
یک نمونه بارز استفاده از خوشهبندی، در همهگیری COVID-19 بود که خوشهبندی به تحلیل دادههای جمعآوریشده کمک کرد تا مناطق با شیوع بالای بیماری شناسایی شوند و اقدامات پیشگیرانه متناسب با نیازهای هر منطقه اتخاذ گردد.
خوشهبندی در علم ژنتیک
در ژنتیک، خوشهبندی به تحلیل و مقایسه الگوهای ژنتیکی مختلف کمک میکند که میتواند در شناسایی عوامل ژنتیکی مؤثر بر بیماریهای خاص یا پاسخهای دارویی مورد استفاده قرار گیرد.
انواع روشهای خوشهبندی
در یادگیری ماشین، روشهای خوشهبندی متنوعی وجود دارند. هر کدام از این روشها ویژگیها و کاربردهای مخصوص به خود را دارند. در اینجا چهار دسته اصلی خوشهبندی را با مثالها توضیح میدهیم:
خوشهبندی مبتنی بر مرکزیت
خوشهبندی مبتنی بر مرکزیت (Centroid-based Clustering)، دادهها را بر اساس فاصله آنها تا نقاط مرکزی خاصی که معمولاً به صورت میانگین نقاط درون هر خوشه تعیین میشوند، تقسیمبندی میکند. معروفترین مثال این نوع خوشهبندی، الگوریتم K-means است. در این روش، تعداد خوشهها (k) از قبل مشخص شده و الگوریتم سعی میکند مراکز خوشهها (centroidها) را طوری انتخاب کند که مجموع فواصل نقاط تا مرکز خوشههایشان به حداقل برسد.

برای آشنایی بیشتر با الگوریتم K-means، به این مقاله مراجعه کنید: معرفی الگوریتم K-means
خوشهبندی مبتنی بر چگالی
خوشهبندی مبتنی بر چگالی (Density-based Clustering)، خوشهها بر اساس مکانهایی که دارای تعداد بالایی از دادهها هستند شکل میگیرند. الگوریتم DBSCAN یکی از شناختهشدهترین مثالهای این نوع خوشهبندی است. DBSCAN خوشهها را بر اساس دو پارامتر مینیمم نقاط (min-samples) و شعاع (eps) تشکیل میدهد. این الگوریتم میتواند بدون داشتن تعداد آنها، خوشهها را در شکلها و اندازههای متفاوت تشخیص دهد. یکی دیگر از قابلیتهای قابل توجه DBSCAN، توانایی خوب آن در تشخیص دادههای پرت یا Outlierها است. در واقع DBSCAN وقتی میفهمد یک داده در مکانی قرار دارد که که تراکم دادههای اطرافش بسیار پایین و در حد صفر است، آن را به عنوان داده پرت برچسب میزند. این موضوع در شکل زیر قابل مشاهده است:
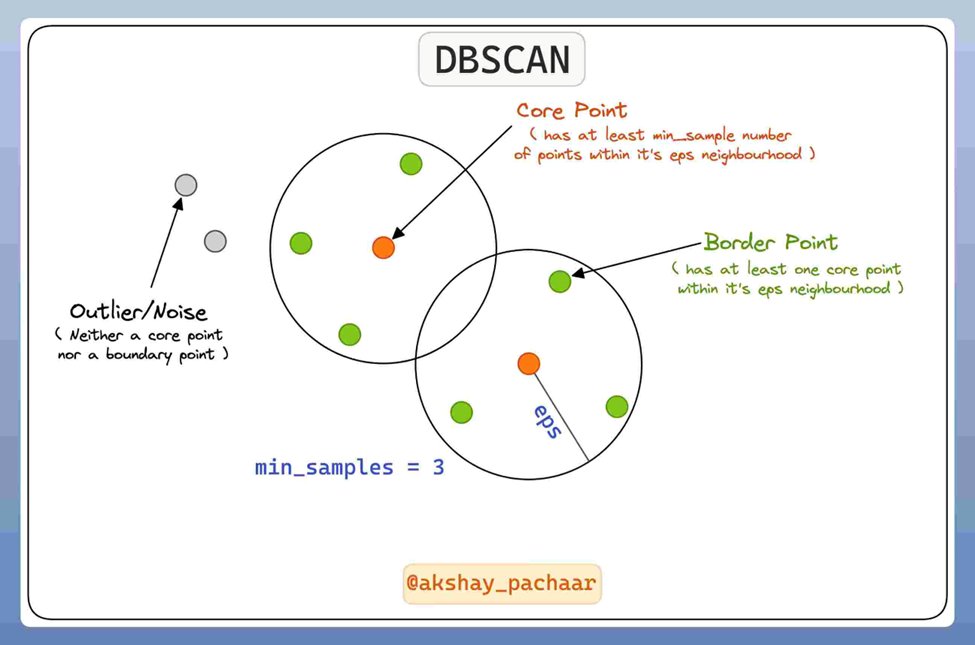
برای مطالعه بیشتر درمورد الگوریتم DBSCAN، این مطلب را بخوانید: با الگوریتم DBSCAN آشنا شوید!
خوشهبندی سلسلهمراتبی
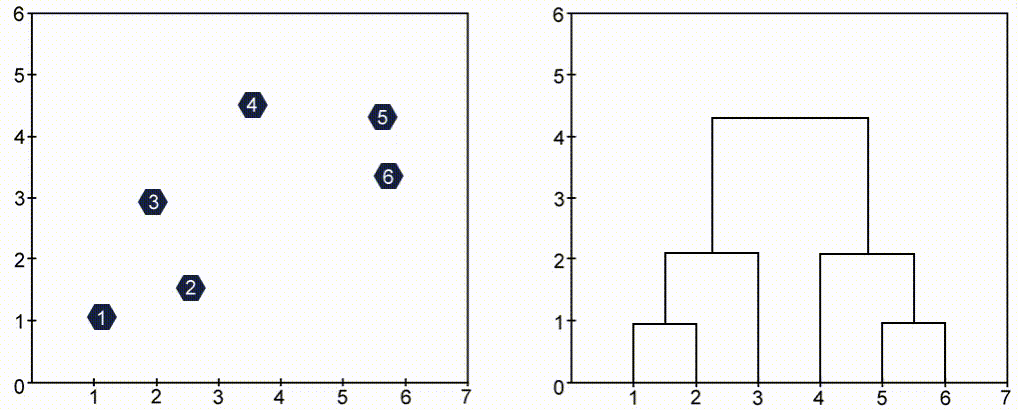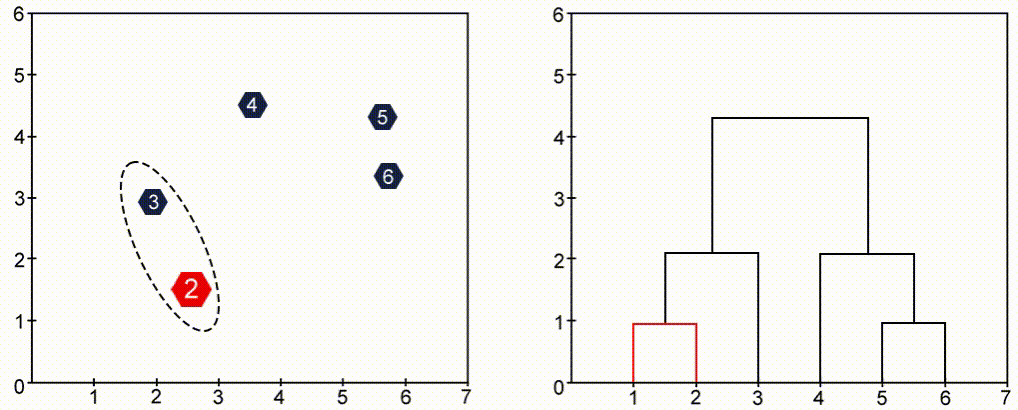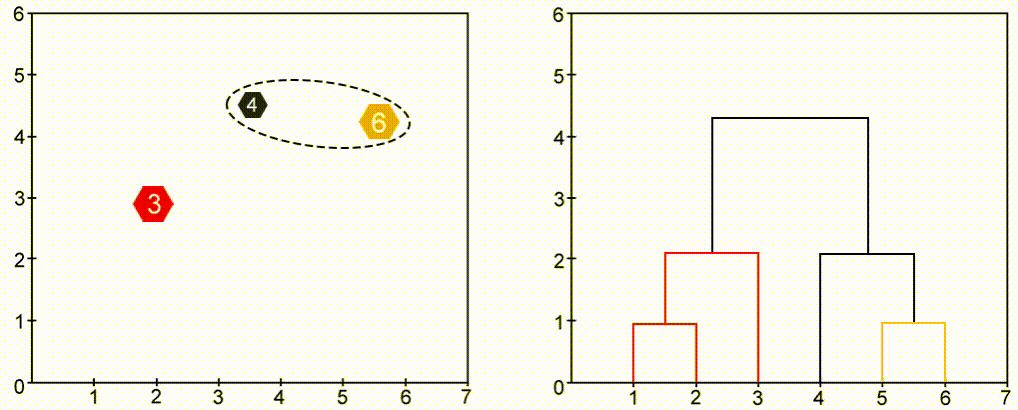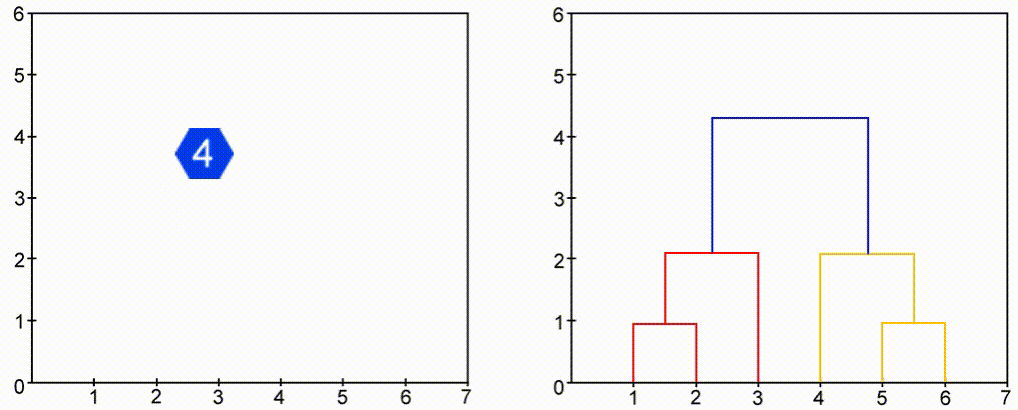
خوشهبندی سلسلهمراتبی (Hierarchical Clustering) یک درخت (ساختار سلسلهمراتبی) از خوشهها ایجاد میکند، که هر گره نشاندهنده یک خوشه است. درخت از یک خوشه واحد که شامل تمام نقاط است شروع شده و به تدریج به خوشههای کوچکتر تقسیم میشود. دو روش اصلی در این نوع خوشهبندی وجود دارد: Agglomerative (تجمیعی) که از پایین به بالا کار میکند و Divisive (تقسیمی) که از بالا به پایین عمل میکند. Agglomerative مدل معروفتری است. در این مدل، هر نقطه در ابتدا خود یک خوشه محسوب میشود و خوشهها به تدریج با یکدیگر ترکیب میشوند.
پیادهسازی در پایتون
در این قسمت نحوه استفاده از این الگوریتم را برای خوشهبندیAgglomerative مشتریان بر اساس درآمد سالانه و یک پارامتر خاص به نام امتیاز پرداخت، آموزش دادهایم.
برای این کار ابتدا کتابخانههای مورد نیاز را فراخوانی کردیم:
سپس مجموعه داده مورد نظر را با استفاده از پکیج pandas خواندیم:
در ادامه برای انتخاب ستونهای گفته شده و نیز مشاهده توزیع کلی مشتریان بر اساس این دو ویژگی از قطعه کد زیر استفاده کردیم:
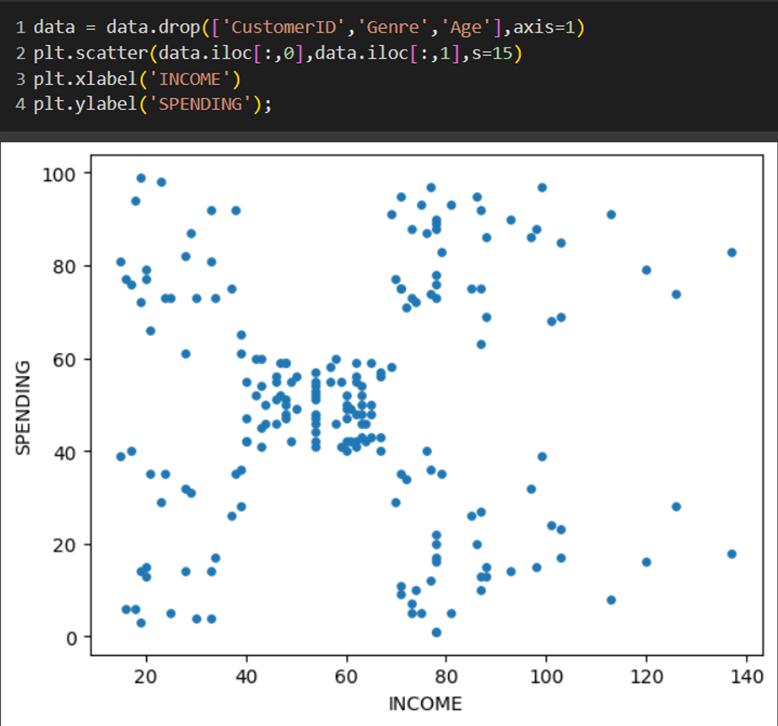
تنها نکته قابل توجه در این قسمت، این است که دو متغیر data.iloc[:,0] وdata.iloc[:,1] به ترتیب اولین و دومین ستون دادهها را از دیتافریم ما انتخاب میکنند. این دو ستون، به ترتیب به عنوان مقادیر محور افقی و عمودی نمودار در رسم نمودار پراکندگی (scatter plot) استفاده میشوند.
سپس برای استفاده راحتتر از این مجموعه دادگان، آن را به صورت برداری در آوردیم. به این ترتیب عنصر اول هر داده، درآمد و عنصر دوم آن امتیاز پرداخت را نشان میدهد:

در ادامه با استفاده از تابع AgglomerativeClustering از کتابخانه sklearn خوشهبندی را انجام میدهیم:

در این بخش، ابتدا یک شیء از کلاس AgglomerativeClustering ساختیم. پارامتر n_clusters=5 تعیین میکند که دادهها باید به ۵ خوشه (Cluster) تقسیم شوند. پارامتر affinity=euclidean مشخص میکند که برای محاسبه فاصله بین نقاط از فاصله اقلیدسی استفاده شود. پارامتر linkage=ward نشان میدهد که روش ward برای محاسبه فاصله بین خوشهها استفاده میشود. این روش به جستجوی خوشههایی با کمترین واریانس داخلی میپردازد.
در خط بعدی، متد fit_predict را روی مجموعه داده X اجرا کردیم. این متد الگوریتم خوشهبندی سلسله مراتبی را روی دادهها اعمال میکند و برچسبهای خوشههای پیشبینیشده را برای هر نمونه در آرایه X برمیگرداند. y_agg یک آرایه است که شامل برچسبهای خوشه برای هر نمونهی داده در X میباشد.
رسم نمودار پراکندگی خوشهبندیشده
در پایان برای دیدن خروجی کار، با استفاده از کد زیر، نمودار پراکندگی را به تفکیک خوشههای ایجاد شده توسط الگوریتم خوشهبندی رسم کردیم:
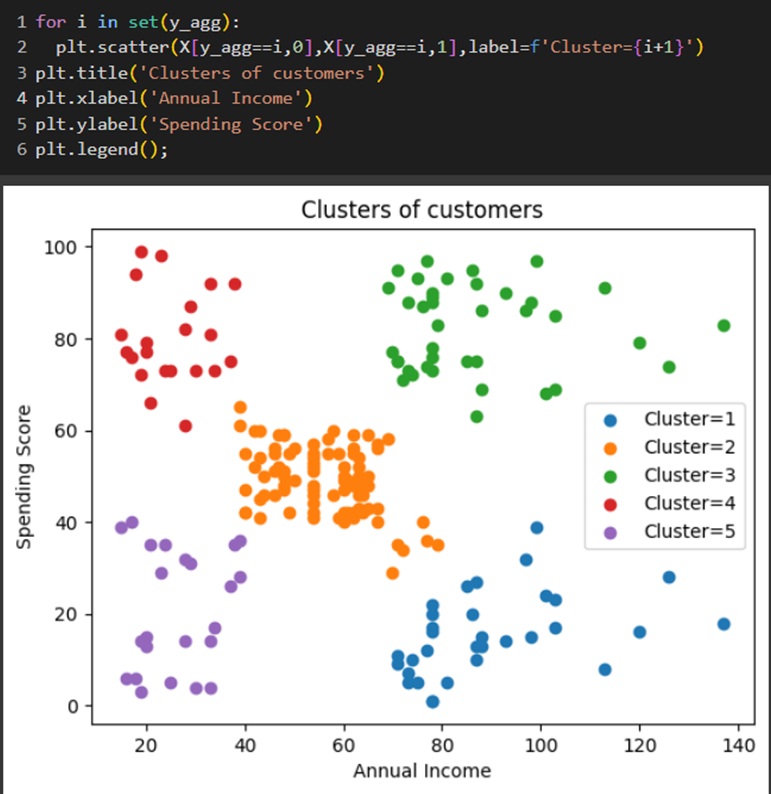
در این قسمت برای هر یک از خوشههای منحصربهفرد موجود در آرایه y_agg، حلقه for را اجرا کردیم. همچنین از تابع set(y_agg) برای برگرداندن تمام برچسبهای منحصربهفرد خوشهها استفاده کردیم. سپس درون حلقه، تابع plt.scatter را برای رسم نمودار پراکندگی فراخوانی کردیم، این تابع فقط دادههای متعلق به خوشه فعلی i را نمایش میدهد.
سپس با استفاده از X[y_agg==i,0] و X[y_agg==i,1] به ترتیب x و y مختصات نقاطی را که به خوشه i تعلق دارند، انتخاب کردیم.
خوشهبندی مبتنی بر توزیع
خوشهبندی مبتنی بر توزیع (Distribution-based Clustering) فرض میکند که دادهها از توزیعهای احتمالاتی خاصی پیروی میکنند. مثال بارز این دسته، الگوریتم Gaussian Mixture Models معروف به GMM است. در GMM، هر خوشه به عنوان یک توزیع گوسی (نرمال) مدلسازی میشود. سپس الگوریتم سعی میکند توزیعها و پارامترهای آنها را طوری تنظیم کند که به بهترین شکل دادهها را توصیف کنند.
پیادهسازی در پایتون
در این قسمت نحوه استفاده از این الگوریتم را برای خوشهبندی مشتریان بر اساس درآمد سالانه و یک پارامتر خاص به نام امتیاز پرداخت، آموزش دادهایم. روند کار مانند روش قبلی است با این تفاوت که خوشهبندی با استفاده از الگوریتم GMM انجام میشود.
کتابخانههای مورد نیاز این روش، همان کتابخانههای روش قبلی است فقط به جای تابع AgglomerativeClustering، تابع GaussianMixture را فراخوانی کردیم:
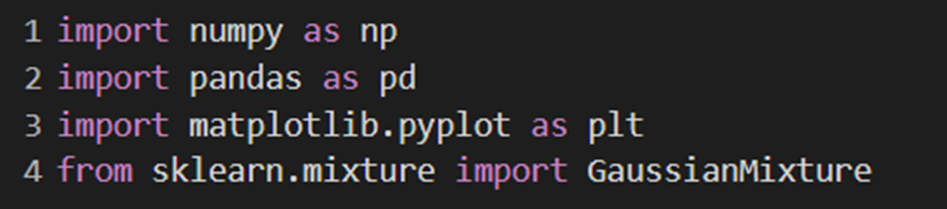
برای استفاده از این تابع، با قطعه کد زیر خوشهبندی مبتنی برتوزیع را انجام دادیم:

در خط اول، یک شیء از کلاس GaussianMixture را مقداردهی اولیه کردیم. پارامتر n_components=5 تعداد مؤلفهها یا خوشهها را در مدل مشخص میکند. این یعنی مدل به دنبال تقسیم دادهها به پنج دسته هستیم.
در خط بعدی متد fit_predict را روی دادهها اجرا کردیم. با fit کردن، مدل پارامترهای گوسی مانند میانگین و کوواریانس را بر اساس دادهها تنظیم میکند. سپس با predict، برچسب خوشهای برای هر نمونه داده در X بر اساس مدل برازششده پیشبینی میشود. y_gmm آرایهای است که برچسب خوشه (Cluster) هر نقطه داده (Data point) را در خود دارد.
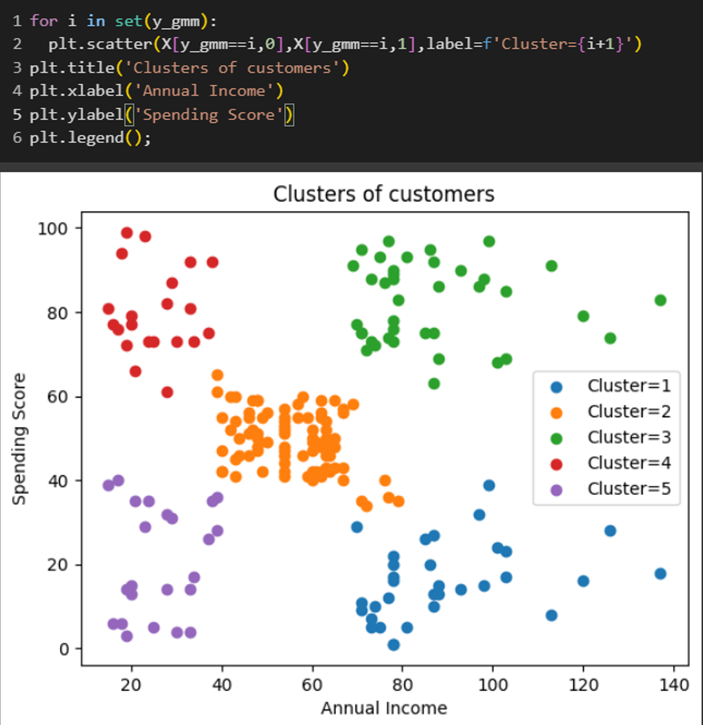
رسم نمودار پراکندگی خوشهبندیشده
نتیجه کار را همچون روش قبل، با استفاده از همان کد و این بار با لیبلهای روش توزیع گوسی رسم کردیم:
معیارهای ارزیابی خوشهبندی
از آنجا که خوشهبندی در یادگیری ماشین یک مدل بدون ناظر (Unsupervised) محسوب میشود، نمیتوان با معیارهای معمول، عملکرد مدل را ارزیابی کرد. برای بررسی کیفیت خوشهبندی، از معیارهای ویژهای استفاده میشود. این معیارها به ما کمک میکنند تا درک بهتری از چگونگی عملکرد الگوریتمهای خوشهبندی داشته باشیم. در اینجا شش معیار رایج خوشهبندی را شرح میدهیم:
مجموع مربعات درونخوشهای
مجموع مربعات درونخوشهای (Within-Cluster Sum of Squares) که به Inertia نیز معروف است، مجموع مربعات فواصل نقاط تا مرکز خوشههای مربوطه را محاسبه میکند.
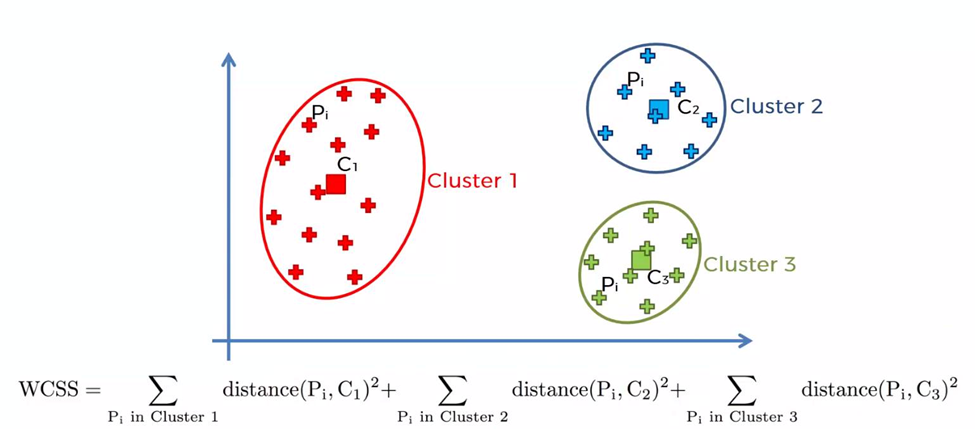
هدف از استفاده از WCSS این است که چگونگی تجمع دادهها درون خوشهها را ارزیابی کنیم. مقدار کمتر WCSS نشاندهنده آن است که نقاط درون یک خوشه نزدیکتر هستند. این یعنی خوشهبندی موثرتری داشتهایم.
ضریب سیلوئت
ضریب سیلوئت (Silhouette Coefficient) میزان تفکیکپذیری خوشهها را اندازهگیری میکند. این شاخص بر اساس تفاوت بین فاصله داخل خوشهای و نزدیکترین فاصله به خوشه دیگر محاسبه میشود. مقادیر ضریب سیلوئت بین ۱- و ۱+ متغیر است؛ مقدار نزدیک به ۱+ نشاندهنده خوشهبندی بهتر است، زیرا نشان میدهد نقاط درون خوشهها نزدیک هم و از سایر خوشهها دور هستند.
در شکل زیر میتوانید جزوه تدریس ضریب سیلوئت دوره جامع یادگیری ماشین استاد شکرزاد را مشاهده نمایید. همانطور که نوشته شده، در فرمول محاسبه این ضریب، پارامتر b میانگین فاصله یک نقطه از نقاط سایر خوشهها است و پارامتر a میانگین فاصله آن از نقاط خوشه خودش.

شاخص دیویس-بولدین
شاخص دیوس-بولدین (Davies-Bouldin Index) بر اساس میزان مشابهت بین خوشهها محاسبه میشود و شامل نسبت فاصله داخل خوشهای به فاصله بین خوشهها است. مقدار کمتر در شاخص دیویس-بولدین نشاندهنده خوشهبندی مؤثرتر است. کم بودن این عدد نشان میدهد خوشهها از یکدیگر مجزا و درون خود متراکم هستند.
شاخص کالینسکی-هاراباز
شاخص کالینسکی-هاراباز (Calinski-Harabasz Index) نسبت بین فاصله بین خوشهها به فاصله داخل خوشهها را اندازهگیری میکند. مقدار بالاتر در این شاخص نشاندهنده خوشهبندی با کیفیت بالاتر است، زیرا به این معنا است که خوشهها به خوبی از یکدیگر جدا شدهاند و درون خود متراکم هستند.
شاخص رند
شاخص رند (Rand Index) میزان صحت تقسیمبندی خوشهها را با مقایسه با یک تقسیمبندی مرجع ارزیابی میکند. شاخص رند مقادیری بین ۰ تا ۱ دارد، که مقدار ۱ به معنای تطابق کامل خوشهبندی با تقسیمبندی مرجع است.
اطلاعات متقابل تعدیلشده
شاخص متقابل تعدیلشده (Adjusted Mutual Informatio) میزان اطلاعات مشترک بین تقسیمبندی خوشهها و تقسیمبندی مرجع را، با تعدیل برای تصادفی بودن، اندازهگیری میکند. مقادیر بالاتر در AMI نشاندهنده همپوشانی بیشتر بین تقسیمبندی خوشهها و مرجع است که نشان میدهد که خوشهبندی به خوبی انجام شده است.
این معیارها به تحلیلگران و محققان کمک میکنند تا بهترین الگوریتمهای خوشهبندی را برای دادههای خاص خود انتخاب کنند و نتایج حاصل از خوشهبندی را به طور دقیقتری ارزیابی نمایند.
چالشهای رایج در خوشهبندی
تعیین تعداد مناسب خوشهها، تعیین معیار مناسب برای فاصله و کار با دادههایی که دارای نویز از مهمترین چالشهای الگوریتمهای خوشهبندی محسوب میشوند. در ادامه بیشتر به بررسی این موارد خواهیم پرداخت.
تعیین تعداد خوشهها
یکی از چالشهای اصلی در خوشهبندی، تعیین تعداد مناسب خوشهها است. این تعداد بسته به دادهها و هدف خوشهبندی متفاوت است و میتواند تأثیر زیادی بر کیفیت نهایی خوشهبندی داشته باشد. تعیین تعداد نادرست خوشهها میتواند به نتایج نامناسب منجر شود، به طوری که خوشههای بیش از حد بزرگ یا کوچک ایجاد شوند که باعث از دست رفتن اطلاعات مهم یا بیثمر شدن تجزیه و تحلیل میشود.
تعیین معیار مناسب برای فاصله
از آنجا که این معیار تأثیر مستقیمی بر ساختار خوشههای تشکیل شده دارد، تعیین معیار مناسب برای محاسبه فاصله بین نقاط داده در خوشهبندی بسیار حیاتی است. معیارهای فاصله متداول شامل فاصله اقلیدسی، منهتن و کسینوسی هستند. انتخاب معیار فاصله باید بر اساس نوع دادهها و هدف از تحلیل انجام گیرد. برای مثال، فاصله اقلیدسی برای دادههایی که در یک فضای اقلیدسی قرار دارند مناسب است، در حالی که فاصله کسینوسی برای مقایسه شباهت بین دو بردار در فضاهای برداری کاربرد دارد.
کار با دادههای دارای نویز
دادههای نویزی یا پراکنده میتوانند منجر به تشکیل خوشههای نامناسب و تفسیرهای غلط از دادهها شوند. برای حل این مشکل، استفاده از روشهای پیشپردازش داده بسیار کارآمد است.
راه حلهای موجود برای مقابله با چالشهای خوشهبندی
برای حل چالش تعیین تعداد مناسب خوشهها، میتوان از روش آرنج (Elbow Method) استفاده کرد. در این روش تغییرات WCSS (مجموع مربعات درونخوشهای) بررسی میشود تا نقطهای که افزایش خوشهها دیگر باعث بهبود معناداری در مدل نمیشود، شناسایی گردد.
روش استفاده از Elbow Method
برای آموزش روش تعیین تعداد خوشههای مناسب جهت خوشهبندی با تکنیک آرنج در پایتون، مراحل زیر را اجرا کردیم.
ابتدا کتابخانههای مورد نیاز را فراخوانی کردیم:
سپس یک مجموعه داده مصنوعی با استفاده از تابع make_blobs از کتابخانه sklearn ساختیم. همچنین برای درک بهتر نحوه توزیع دادهها، نمودار پراکندگی آن را هم رسم کردیم:
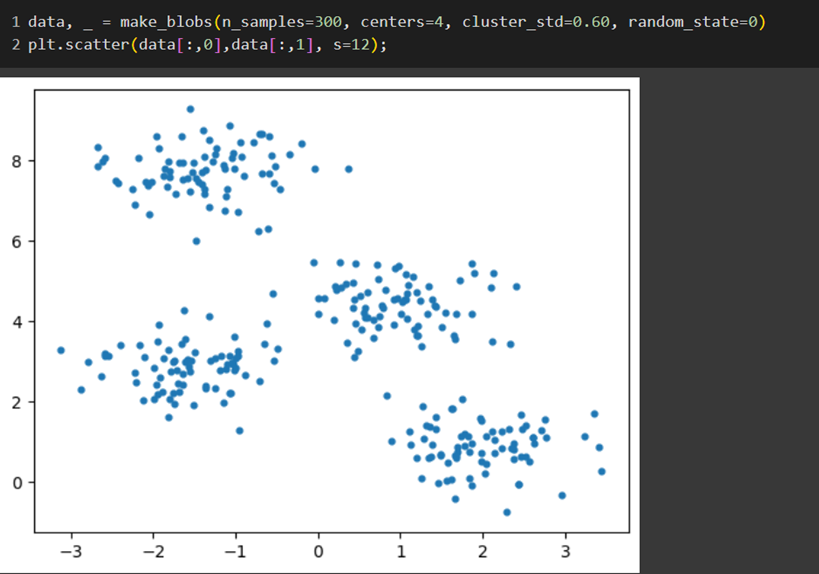
همانطور که با چشم قابل تشخیص است، این دادهها را میتوان به ۴ خوشه تقسیم کرد. اما این به واسطه ساده بودن داده ساختهشده است. در واقع در دنیای واقعی، هیچگاه نحوه توزیع دادهها به این شکل نخواهد بود. در این شرایط میتوان با استفاده از روش آرنج تعداد خوشههای مناسب را تعیین کرد. ما نیز برای پیادهسازی این روش از کد زیر استفاده کردیم:

در این قسمت، ابتدا یک لیست خالی به نام wcss ایجاد کردیم. این لیست برای ذخیرهسازی مقادیر مجموع مربعات فاصله داخل خوشهای برای هر تعداد خوشه استفاده میشود.
سپس یک حلقه for از ۱ تا ۱۰ قرار دادیم و در هر دوره پیشروی آن، یک مدل K-means با تعداد خوشه i ساختیم.
برای این کار یک شی از کلاس KMeans ساختیم. در این تابع، n_clusters را به تعداد i تنظیم کردیم. با قرار دادن ++init=k-means تعیین کردیم که اولین مرکز خوشه به صورت تصادفی از میان دادهها انتخاب شود. با n_init=10 تعداد دفعاتی را که الگوریتم با مراکز مختلف اولیه اجرا میشود، ۱۰ بار مشخص کردیم. در نهایت با kmeans.fit(data) مدل را آموزش دادیم.
با اضافه کردن مقدار kmeans.inertia_به لیست wcss، مجموع مربعات فاصلههای درون خوشهای متناظر با هر i ذخیره میگردد.
برای کشیدن نمودار میزان WCSS بر حسب تعداد کلاسترها، از کد زیر استفاده کردیم:
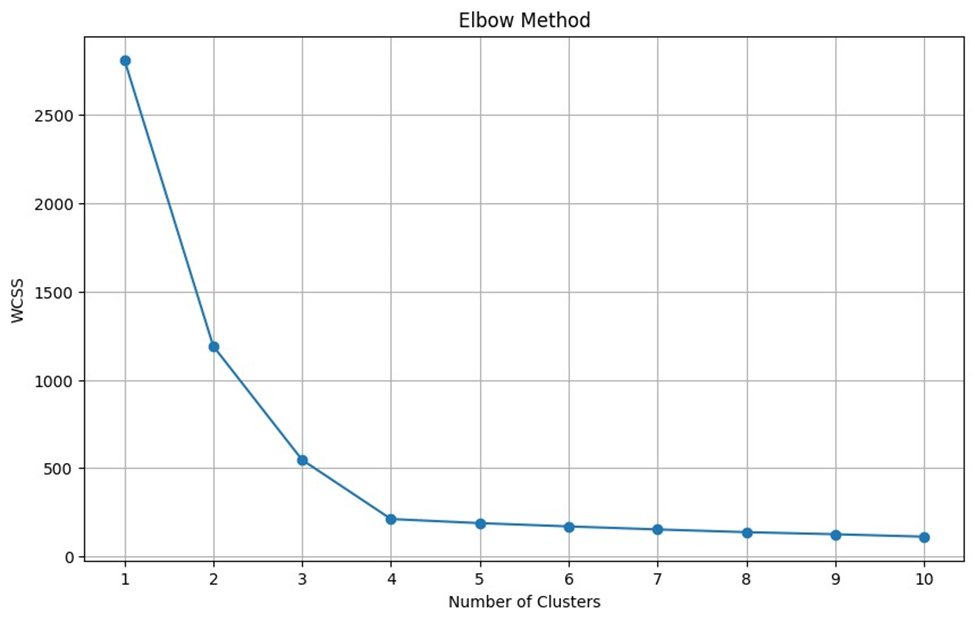
به این ترتیب، نمودار مربوطه به شکل زیر در آمد:
تفسیر نمودار
برای تفسیر نمودار روش آرنج که در نتیجه اجرای کد خوشهبندی K-means تولید میشود، باید به نکات زیر توجه کنید:
بررسی شکل نمودار
نمودار روش آرنج مجموع مربعات فاصلههای داخل خوشهای را بر حسب تعداد خوشهها نشان میدهد. در این نمودار، محور افقی تعداد خوشهها و محور عمودی مقدار WCSS را نشان میدهد.
یافتن نقطه آرنج
نقطه آرنج نقطهای در نمودار است که پس از آن، کاهش WCSS کمتر شدید است. به عبارت دیگر، این نقطه جایی است که منحنی نمودار از کاهش سریع WCSS به کاهش تدریجی یا ملایم تغییر میکند. نقطه آرنج به شما نشان میدهد که افزودن خوشههای بیشتر به کاهش مقدار WCSS کمک نمیکند. به این ترتیب، تعداد خوشههای ایدهآل را نشان میدهد.
تصمیمگیری برای تعداد خوشهها
تعداد خوشههایی که در نقطه آرنج قرار دارند، به عنوان تعداد بهینه خوشهها برای دادهها در نظر گرفته میشود. این به این دلیل است که افزایش تعداد خوشهها پس از این نقطه تأثیر چندانی در بهبود تفکیک خوشهها ندارد و صرفاً منجر به پیچیدگی بیشتر مدل میشود بدون اینکه کیفیت تفکیک را به طور معناداری افزایش دهد.
ارزیابی بصری و تنظیمات بیشتر
گاهی اوقات، نقطه آرنج ممکن است کاملاً واضح نباشد یا بین دو نقطه قرار گیرد. در این حالت، ممکن است لازم باشد با توجه به دانش موضوعی یا با استفاده از شاخصهای دیگر مانند شاخص سیلوئت برای ارزیابی کیفیت خوشهبندی، تجزیه و تحلیلهای بیشتری انجام دهید. این امر به شما کمک میکند تا تصمیم نهایی خود را در مورد تعداد خوشهها بهتر اتخاذ کنید.
با توجه به این نکات میتوان دریافت که بهترین تعداد خوشه برای داده ما، همانطور که انتظار داشتیم، ۴ خوشه است.
رویارویی با چالش تعیین معیار مناسب برای فاصله در خوشهبندی نیازمند درک دقیق از دادهها و هدف تحلیل است. در ادامه، روشهای مختلفی برای انتخاب بهترین معیار فاصله بر اساس نوع دادهها و کاربرد مورد نظر را ارائه دادیم.
درک ویژگیهای دادهها
بررسی و تحلیل دقیق دادهها برای شناسایی ویژگیهای کلیدی و ساختار آنها ضروری است. مثلاً، آیا دادهها برداری هستند، مقادیر عددی دارند، یا در فضای بُعدی خاصی توزیع شدهاند؟ این شناخت به انتخاب معیار فاصله مناسب کمک میکند.
انتخاب معیار فاصله بر اساس نوع دادهها
- فاصله اقلیدسی: معمولترین معیار فاصله است که به خوبی در فضاهای با ویژگیهای همگن کار میکند.
- فاصله منهتن: برای دادههایی که تفاوتهای مقیاس در آنها معنیدار است، مفید است.
- فاصله کسینوسی: برای مواردی که جهت دادهها مهمتر از اندازههای آنهاست، مثل بردارهای تعبیه (Embedding) در متن.
آزمایش با معیارهای مختلف
پس از انتخاب چند معیار فاصله، با هر کدام آزمایشهایی را انجام دهید تا ببینید کدام یک نتایج بهتری در مورد خوشهبندی ارائه میدهند. این کار میتواند شامل مقایسه نتایج خوشهبندی با معیارهای عینی مانند شاخص سیلوئت یا شاخص داویز-بولدین باشد.
برای رویارویی با چالش کار با دادههای دارای نویز، راهحلهای مختلفی وجود دارد که میتوان به کار برد تا تأثیر منفی این مسائل بر توانایی مدل کاهش یابد. در ادامه برخی از آنها را بررسی خواهیم کرد.
پیشپردازش دادهها
- نرمالسازی دادهها: برای اطمینان از اینکه هیچ یک از ویژگیها به دلیل مقیاس متفاوت، تأثیر نامتناسبی بر روی مدل ندارند.
- حذف نویز و دادههای پرت: استفاده از تکنیکهایی مانند فیلترینگ یا تکنیکهای آماری برای شناسایی و حذف نویز.
- کاهش بُعد: استفاده از تکنیکهایی مانند تحلیل مولفههای اصلی (PCA) برای کاهش تعداد ویژگیهای دادهها بدون از دست دادن اطلاعات مهم.
استفاده از DBSCAN
همانطور که گفتیم، این الگوریتم به خوبی با دادههای دارای نویز کار میکند، زیرا میتواند نواحی با تراکم بالا را شناسایی کند و دادههای پرت را نادیده بگیرد.

پرسشهای متداول
خوشهبندی چگونه به کسبوکارها کمک میکند تا به درک بهتری از مشتریان خود دست یابند؟
خوشهبندی امکان تقسیمبندی مشتریان را بر اساس نیازها، علایق و رفتارهای خرید مشابه فراهم میآورد. این تقسیمبندی به شرکتها اجازه میدهد تا استراتژیهای بازاریابی خود را به طور دقیقتری هدفگذاری کرده و پیشنهادات متناسب با نیازهای هر گروه از مشتریان ارائه دهند. این کار به نوبه خود منجر به افزایش رضایت مشتری و وفاداری آنها میشود.
تفاوتهای اصلی بین خوشهبندی مبتنی بر مرکزیت و خوشهبندی مبتنی بر چگالی چیست؟
خوشهبندی مبتنی بر مرکزیت، مانند الگوریتم K-means، دادهها را بر اساس فاصله به مراکز (centroidها) تعریف شده تقسیمبندی میکند و به دنبال کمینه کردن فواصل داخل خوشهای است. در مقابل، خوشهبندی مبتنی بر چگالی، مانند DBSCAN، خوشهها را بر اساس مناطقی با تراکم بالای دادهها شکل میدهد. این مدل قادر است خوشههای با اشکال نامنظم را تشخیص دهد و دادههای پرت (Outliers) را نیز شناسایی کند.
چه فنآوریهایی میتوانند در تکامل خوشهبندی نقش داشته باشند و چگونه؟
فناوریهایی مانند هوش مصنوعی (Artificial Intelligence) و یادگیری عمیق (Deep Learning) میتوانند به توسعه روشهای خوشهبندی پیشرفتهتر کمک کنند. این فناوریها امکان پردازش و تجزیه و تحلیل حجم عظیمی از دادهها را در زمان کمتر و با دقت بیشتری فراهم میآورند، که به بهبود توانایی شناسایی الگوها و ساختارهای پیچیده در دادهها منجر میشود.
چالشهای رایج در پیادهسازی الگوریتمهای خوشهبندی چیست و چگونه میتوان این چالشها را مدیریت کرد؟
یکی از چالشهای اصلی، تعیین تعداد مناسب خوشهها است. روشهایی مانند روش آرنج و شاخص سیلوئت میتوانند در تعیین تعداد ایدهآل خوشهها کمک کنند. همچنین، کار با دادههای دارای نویز یا خصوصیات نامتعارف میتواند دشوار باشد. استفاده از پیشپردازش دقیق دادهها و انتخاب الگوریتم مناسب برای نوع داده میتواند اثربخش باشد.
چگونه خوشهبندی در شناسایی و تحلیل الگوهای بیماریها در پزشکی مورد استفاده قرار میگیرد؟
این روش امکان میدهد تا محققان و پزشکان گروههای بیماری را بر اساس ویژگیهای کلینیکی و ژنتیکی مشابه شناسایی کنند، که این میتواند به تشخیص دقیقتر و سریعتر بیماریها کمک کند. همچنین، در ژنتیک، این تکنیک برای تحلیل و مقایسه الگوهای ژنتیکی افراد به کار رفته است، که میتواند در شناسایی عوامل ژنتیکی موثر بر بیماریها مفید باشد.
یادگیری ماشین لرنینگ را از امروز شروع کنید!
دنیای دادهها جذاب است و دانستن علم داده، توانایی تحلیل داده، یا بازاریابی مبتنی بر داده، شما را برای فرصتهای شغلی بسیاری مناسب میکند. فارغ از رشته و پیشزمینه، میتوانید حالا شروع کنید و از سطح مقدماتی تا پیشرفته بیاموزید. اگر دوست دارید به این حوزه وارد شوید، پیشنهاد میکنیم با کلیک روی این لینک قدم اول را همین حالا بردارید.
مشاوران کافهتدریس به شما کمک میکنند مسیر یادگیری برای ورود به این حوزه را شروع کنید:
دوره جامع دیتا ساینس و ماشین لرنینگ