
امروزه پردازش زبان طبیعی (Natural language processing) نهتنها فاصله میان انسان و ماشین را به شکل اعجابانگیزی کاهش داده، دروازههایی را بهسوی امکاناتی نوین گشوده است که پیشتر تصور آن دشوار بود. در این مطلب شما با اصول اساسی پردازش زبان و تحلیل متون آشنا خواهید شد. ما به شما نشان خواهیم داد که چگونه میتوان دادههای متنی را به برداری از اعداد تبدیل کرد که برای ماشین قابلدرک و تفسیرکردن باشد. برای یادگیری گامبهگام پردازش زبان طبیعی با پایتون با ما همراه باشید!
- 1. پردازش زبان طبیعی چیست؟
- 2. تاریخچه پردازش زبان طبیعی
- 3. اهمیت پایتون در پردازش زبان طبیعی
- 4. کاربردهای پردازش زبان طبیعی
- 5. مفاهیم اساسی حوزه پردازش زبان طبیعی
- 6. ابزارها و کتابخانههای پردازش زبان طبیعی با پایتون
- 7. پردازش زبان طبیعی در پایتون
- 8. پیادهسازی پروژه تشخیص توهین با پردازش متن
- 9. جمعبندی
-
10.
پرسشهای متداول
- 10.1. پردازش زبان طبیعی چه تاثیری بر توسعه دستیارهای صوتی میگذارد؟
- 10.2. از چه روشهایی برای تحلیل احساسات در متون با استفاده از NLP استفاده میشود و چه دقتی دارند؟
- 10.3. چگونه میتوان از پردازش زبان طبیعی در بهبود سیستمهای ترجمه ماشینی بهره برد؟
- 10.4. تأثیر پردازش زبان طبیعی در امنیت سایبری (Cybersecurity) چیست و چه چالشهایی در این زمینه وجود دارد؟
- 10.5. آینده پردازش زبان طبیعی چه تحولاتی را میتواند در صنعت خدمات مشتری ایجاد کند؟
- 11. یادگیری دیتا ساینس و ماشین لرنینگ را از امروز شروع کنید!
پردازش زبان طبیعی چیست؟
پردازش زبان طبیعی (Natural Language Processing)، بهعنوان یکی از جذابترین و کاربردیترین زمینههای هوش مصنوعی، راهی است برای برقراری ارتباط میان انسان و ماشین. اما چرا یادگیری این فناوری اهمیت دارد؟ پاسخ این پرسش خیلی ساده است؛ چون به رایانهها این امکان را میدهد زبان انسانی را درک و تفسیر کنند. این امر نهایتاً تعامل میان انسان و ماشین را سادهتر میکند و کاری میکند تا ما انسانها بتوانیم بیشتر و راحتتر از قبل از ماشینها خدمات بگیریم.
پیشنهاد میکنیم پیش از هر چیز با پردازش زبان طبیعی بیشتر آشنا شوید.
تاریخچه پردازش زبان طبیعی
پردازش زبان طبیعی (NLP) شاخهای از هوش مصنوعی است که به کامپیوترها توانایی درک و پردازش زبان انسان را میدهد. تاریخچه NLP به تلاشهای اولیه برای برقراری ارتباط بین انسان و ماشین در دهه ۱۹۵۰ باز میگردد. در آن زمان، محققان روی ترجمه ماشینی، تشخیص گفتار و درک زبان طبیعی تمرکز کردند.
در دهههای ۱۹۶۰ و ۱۹۷۰ پیشرفتهای قابلتوجهی در حوزه NLP حاصل شد. در آن مقطع مدلهای آماری برای ترجمه ماشینی و درک زبان طبیعی توسعه یافتند.
با ظهور رایانههای قدرتمندتر در دهه ۱۹۸۰ و ۱۹۹۰، روشهای یادگیری ماشین در NLP رواج پیدا کرد. شبکههای عصبی مصنوعی برای کارهای مختلفی ازجمله طبقهبندی متن، تشخیص احساسات و تولید زبان به کار گرفته شدند.
در قرن ۲۱ NLP، با توسعه مدلهای یادگیری عمیق، جهش قابل توجهی را تجربه کرد. این مدلها با حجم عظیمی از دادهها آموزش داده میشوند و میتوانند وظیفههای پیچیدهتری را در درک زبان انسان انجام دهند.
امروزه NLP در طیف گستردهای از کاربردها از جمله چتباتها، دستیارهای صوتی، ترجمه ماشینی دقیقتر و تحلیل احساسات متن استفاده میشود.
همچنین پیشنهاد میکنیم با دستیار شخصی مبتنی بر هوش مصنوعی و طرز کارشان آشنا شوید.
اهمیت پایتون در پردازش زبان طبیعی
امروزه پایتون، با کتابخانههای غنی و جامعه بزرگ توسعهدهندگان، به زبان اصلی برای کار با NLP تبدیل شده است. استفاده از پایتون، بهدلیل خوانایی بالا و ساختار سادهاش، یادگیری و پیادهسازی مفاهیم NLP را آسانتر میکند.
کاربردهای پردازش زبان طبیعی
پردازش زبان طبیعی در زمینههای مختلفی کاربرد دارد که به بهبود ارتباط بین انسان و ماشین کمک میکند. در اینجا به چند نمونه از کاربردهای مهم آن اشاره میکنیم:
- سیستمهای پاسخگویی خودکار: مانند روباتهای چت و دستیارهای صوتی که میتوانند به پرسشهای کاربران پاسخ دهند یا کمکهایی ارائه کنند.
- ترجمه ماشینی: ترجمه متون از یک زبان به زبان دیگر بهطور خودکار، مانند سرویسهایی مانند Google Translate.
- تحلیل احساسات: بررسی و تعیین احساسات موجود در متون، مانند تعیین نظرات مثبت یا منفی در نظرات کاربران.
- خلاصهسازی متن: ایجاد خلاصههای مختصر از متون طولانی برای ارائه اطلاعات کلیدی در زمان کمتر.
- تشخیص گفتار به متن: تبدیل گفتار انسانی به متن نوشتاری که در دستگاههای هوشمند و سیستمهای ناوبری استفاده میشود.
این کاربردها نشاندهنده توانایی NLP در فراهم آوردن راهحلهای مفید برای چالشهای روزمره است و تأثیر آن را بر تعامل میان انسان و فناوری برجسته میکند. برای کسب اطلاعات بیشتر در این مورد میتوانید ۱۱ کاربرد پردازش زبان طبیعی را بشناسید! را مطالعه کنید.
مفاهیم اساسی حوزه پردازش زبان طبیعی
پیش از ورود به دنیای جذاب پردازش متن، لازم است با مفاهیم اصلی آن آشنا شویم:
متن بهعنوان داده
در حوزه پردازش زبان طبیعی متن بهعنوان یکی از اشکال اصلی دادهها شناخته میشود که میتواند شامل هر نوع محتوای نوشتاری باشد. این دادهها میتوانند از منابع مختلفی مانند پیامهای متنی، ایمیلها، کتابها، مقالات، پستهای وبلاگ و شبکههای اجتماعی جمعآوری شوند.
این گستردگی در منابع متنی امکانات بیشماری را برای تحلیل و استفاده از اطلاعات موجود در آنها فراهم میآورد. تبدیل متن به دادههای قابل تحلیل در NLP این امکان را میدهد که ساختارها، الگوها و معانی موجود در متون را کشف کنیم.
مدلهای زبانی و یادگیری عمیق
یادگیری عمیق، بهعنوان یکی از پیشرفتهای مهم در عرصه هوش مصنوعی و یادگیری ماشین، نقش کلیدی در پیشبرد قابلیتهای پردازش زبان طبیعی داشته است. این فناوری با استفاده از شبکههای عصبی عمیق که از ساختارهای پیچیدهای از نورونها تشکیل شدهاند امکان مدلسازی زبانهای انسانی را با دقت بالا فراهم میکند. مدلهای زبانی مبتنی بر یادگیری عمیق قادر به درک مفاهیم پیچیده و تولید متونی هستند که بهطور قابلتوجهی طبیعی و رواناند.
این مدلها میتوانند از دادههای آموزشی عظیمی برای یادگیری نحوه تعامل واژهها، ساختار جملات و مفاهیم پشت آنها بهره ببرند. بهاین ترتیب، مدلهای زبانی توانایی پیشبینی و تولید متون جدید را با توجه به متن ورودی که به آنها داده شده است پیدا میکنند؛ برای مثال، مدلهایی مانند (Generative Pre- trained Transformer) GPT و (Bidirectional Encoder Representations from Transformers) BERT انقلابی در تولید و فهم متن ایجاد کردهاند و در کاربردهایی مانند ترجمه خودکار، خلاصهسازی متون و پاسخ به پرسشها به کار رفتهاند.
زبانشناسی محاسباتی
زبانشناسی محاسباتی (Computational linguistics)، بهعنوان یک حوزه تخصصی در میان علوم کامپیوتر و زبانشناسی، نقش بسزایی در توسعه و بهبود فناوریهای مرتبط با پردازش زبان طبیعی دارد. این رشته با استفاده از روشهای مبتنی بر الگوریتمها و مدلهای ریاضی زبانهای انسانی را تجزیهوتحلیل میکند و به ما امکان میدهد تا ساختار، معنا و تعاملات زبانی را بهطور دقیقتری درک کنیم.
تجزیهوتحلیل دستوری
تجزیهوتحلیل دستوری (Syntactic Analysis) شامل تحلیل ساختار دستوری جملات است. تجزیهوتحلیل دستوری نحوه سازماندهی و چینش کلمات در جملات برای انتقال معنا را تجزیهوتحلیل میکند. در این تحلیل اجزای مختلف جمله، مانند اسمها، فعلها، صفتها و غیره، شناسایی و نحوه ارتباط آنها با یکدیگر تعیین میشود؛ برای مثال، این تحلیل میتواند تعیین کند که کدام کلمه فاعل، فعل یا مفعول است که به سیستم کمک میکند تا ساختار ابتدایی زبان را درک کند.
تجزیهوتحلیل معنایی
تجزیهوتحلیل معنایی (Semantic Analysis) فراتر از ساختار جملات به تفسیر معنای آنها میپردازد. این شامل درک معانی کلمات فردی و چگونگی تغییر این معانی در زمینههای مختلف است. هدف آن درک پیام، مفاهیم و روابط بین کلمات در متن است. تجزیه و تحلیل معنایی برای وظایفی مانند ترجمه زبانها یا پاسخ به پرسشها حیاتی است. اینجا نیاز است که معنای دقیق و نیت پشت کلمهها بهدرستی درک شود.
استخراج اطلاعات
استخراج اطلاعات (Information Extraction) بخشهای خاصی از دادهها از یک متن را جمعآوری میکند. این تکنیک عناصر کلیدی مانند نامها، مکانها، تاریخها و دیگر مشخصات را شناسایی میکند؛ برای مثال، از یک مقاله خبری، الگوریتمهای استخراج اطلاعات میتوانند بهطور خودکار تشخیص دهند که چه کسی در یک داستان دخیل است، رویدادها کجا اتفاق میافتند و تاریخهای کلیدی چه زمانی هستند.
ابزارها و کتابخانههای پردازش زبان طبیعی با پایتون
بیایید با ابزارها و کتابخانههای پردازش زبان طبیعی با پایتون بیشتر آشنا شویم:
NLTK
NLTK که مخفف Natural Language Toolkit است امکانات وسیعی، ازجمله توکنسازی، برچسبزنی نقش دستوری، تجزیهگر نحوی، استخراج اطلاعات و دیگر ابزارهای پیشرفتهی پردازش متن، را فراهم میآورد. این کتابخانه، با داشتن مجموعهای از متون و منابع آموزشی، برای آموزش و تحقیق در حوزه NLP بسیار مفید است و به کاربران اجازه میدهد تا با اصول اولیهی پردازش زبان آشنا شوند.
SpaCy
SpaCy کتابخانهای مدرن و سریع برای پردازش زبان طبیعی است که بهخصوص برای برنامههای تجاری طراحی شده است. این کتابخانه برای تجزیهگری دقیق و سریع متون، تحلیل وابستگیهای نحوی و شناسایی نامدارها یا برچسبخوردهها طراحی شده است.
SpaCy، با پشتیبانی از بیش از ۱۰ زبان زنده دنیا و داشتن مدلهای زبانی ازپیشآموزشدیده، ابزاری قدرتمند برای توسعهدهندگان و متخصصان NLP محسوب میشود.
TensorFlow و PyTorch
TensorFlow و PyTorch، دو فریمورک اصلی در زمینهی یادگیری عمیق هستند که پشتیبانی قویای برای توسعه مدلهای پردازش زبان طبیعی ارائه میدهند. TensorFlow محصولی از Google و PyTorch محصولی از Facebookاست. هر دو این فریمورکها امکان ساخت مدلهای پیچیده عصبی، مانند شبکههای عصبی بازگشتی (RNN) و شبکههای عصبی مبتنی بر مکانیزم توجه (Attention Networks)، را فراهم میکنند که وظایفی مانند ترجمه ماشینی و تولید متن را بهتر از دیگر مدلها انجام میدهند.
پردازش زبان طبیعی در پایتون
در این بخش میخواهیم با استفاده از کتابخانه NLTK یک پروژه پردازش زبان طبیعی را اجرا کنیم. مانند تمامی پروژههای ماشین لرنینگ، اولین قدم در این پروژه نیز پیشپردازش است.
پیشپردازش متن
پیشپردازش متن یکی از مراحل اولیه و حیاتی در پردازش زبان طبیعی است که در آن متن خام پاکسازی و آمادهسازی میشود تا در کاربردهای مختلف NLP به کار رود. این فرایند شامل چند گام اساسی است که به حذف عناصر غیرضروری و کاهش پیچیدگی متن کمک میکند. مهمترین گامهای پیشپردازش در ادامه توضیح داده شده است:
توکنسازی
توکنسازی یکی از اولین و اساسیترین گامها در پیشپردازش متن برای پردازش زبان طبیعی است. این فرایند شامل تقسیم کردن متنهای طولانی به واحدهای کوچکتر، معمولاً کلمهها یا جملهها، میباشد که به این واحدها توکن گفته میشود. توکنها میتوانند شامل کلمات، عبارات یا حتی نمادهای علامتگذاری باشند. این فرایند به ما کمک میکند تا ساختار و معنای متن را بهتر درک کنیم و دادهها را برای تحلیلهای بعدی آماده سازیم.
توکنسازی میتواند در دو سطح انجام شود:
توکنسازی کلمه (Word Tokenization)
در این روش، متن به کلمات تقسیم میشود. این کار با جداکردن کلمات بر اساس فاصلهها و علائم نگارشی صورت میگیرد؛ برای مثال، جمله «سلام دوست من!» پس از توکنسازی به [“سلام، دوست، من، !] تبدیل میشود.
توکنسازی جمله (Sentence Tokenization)
در این روش متن به جملهها تقسیم میشود. این کار اغلب با شناسایی نقاط پایان جمله، مانند نقطه، علامت سؤال یا تعجب، انجام میگیرد؛ برای مثال، عبارت «سلام دوست من! حال شما چطور است؟ امیدوارم خوب باشید.» به سه جمله [سلام دوست من!، حال شما چطور است؟، امیدوارم خوب باشید.] تقسیم میشود.
نحوه حذف توکنسازی در پایتون
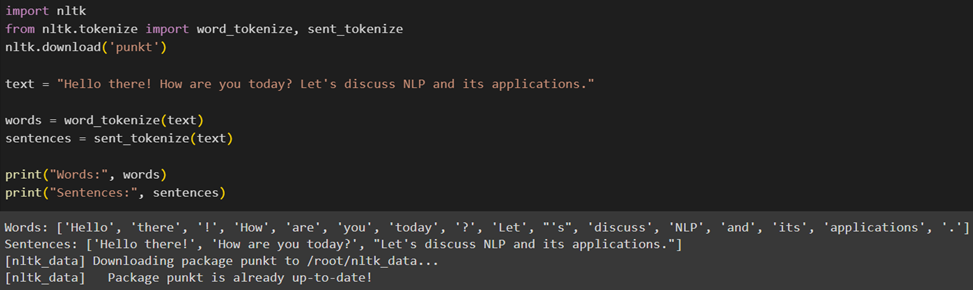
برای این منظور ابتدا باید کتابخانههای موردنیاز را فراخوانی کنیم؛ سپس پکیج punkt را که برای توکنسازی جملات و کلمات استفاده میشود دانلود میکنیم. این پکیج حاوی مدلهای ازپیشآموزشدیده برای تقسیم متن به جملهها و کلمههاست. در ادامه یک رشته متنی تعریف میکنیم که قرار است توکنسازی شود:

فرایند توکنسازی کلمات را با استفاده از توابع word_tokenize و sent_tokenize انجام میدهیم. این توابع متن ورودی را دریافت و آن را بهترتیب به توکنهای کلمه و جمله تقسیم میکنند:
حذف علائم نگارشی
حذف علائم نگارشی یکی از مراحل مهم در پیشپردازش متن است که به کاهش پیچیدگی و بهبود کیفیت دادههای متنی برای تحلیلهای بعدی کمک میکند. علائم نگارشی مانند نقطه، ویرگول، علامت سؤال و تعجب اغلب اطلاعات کمی برای مدلهای زبان طبیعی دارند و میتوانند در تحلیل معنایی متون اختلال ایجاد کنند؛ بنابراین حذف این عناصر از متن میتواند به تمرکز بیشتر روی کلمات کلیدی و معانی مهم موجود در متن کمک کند.
نحوه حذف علائم نگارشی در پایتون
برای حذف علائم نگارشی، ماژول string در پایتون را فراخوانی میکنیم که یک رشته از تمامی کاراکترهای نگارشی را شامل است؛ سپس با استفاده از یک حلقه و شرط، این کاراکترها را از متن حذف میکنیم:

در این کد، string.punctuation شامل تمام علائم نگارشی است و با استفاده از یکList comprehension، هر کاراکتر در متن اصلی که جزء علائم نگارشی نیست، انتخاب و به یک رشته جدید اضافه میشود. نتیجه خروجی متنی خواهد بود که از علائم نگارشی پاک شده است.
حذف کلمات اضافی
حذف کلمات اضافی یا کلمات توقف (Stopwords) یکی از مهمترین مراحل در پیشپردازش متن برای پردازش زبان طبیعی است. این کلمات که شامل حروف ربط، ضمایر و دیگر کلمات رایجی هستند که در زبان بهوفور یافت میشوند، معمولاً اطلاعات کمی درمورد محتوای اصلی متن ارائه میدهند؛ بنابراین در تحلیلهایی که بر درک عمیقتر متن متمرکز هستند کماهمیت شناخته میشوند.
چرا کلمات اضافی حذف میشوند؟
در بسیاری از کاربردهای NLP، مانند تجزیهوتحلیل احساسات، دستهبندی متن، یا مدلسازی موضوعی، حضور کلمات توقف میتواند نتایج را تحتتأثیر قرار دهد؛ زیرا:
- کاهش ابعاد دادهها: حذف این کلمهها به کاهش حجم دادههایی میانجامد که باید پردازش شوند، این امر صرفهجویی در منابع محاسباتی و زمان را رقم میزند.
- تمرکز بر کلمات معنادار: با حذف کلمههای توقف، الگوریتمهای تحلیل متن میتوانند تمرکز بیشتری روی کلماتی داشته باشند که واقعاً معنا و مفهوم مهمی را در متن حمل میکنند.
- بهبود دقت مدلها: مدلهایی که بر پایه متن تمرین داده میشوند دقت بهتری خواهند داشت؛ زیرا از پردازش دادههای غیرضروری پرهیز میکنند.
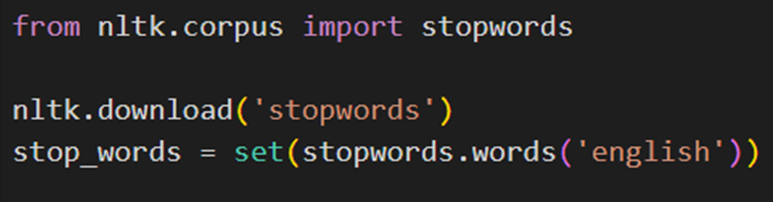
نحوه حذف کلمات اضافی در پایتون
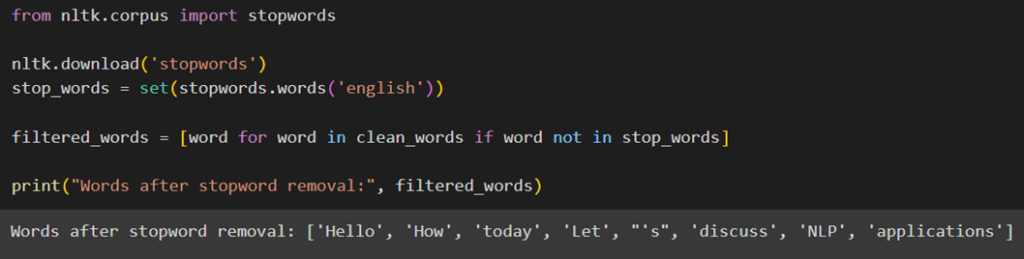
برای حذف کلمات اضافی در پایتون، از NLTK، ماژول stopwords را فراخوانی و سپس فهرست کلمههای اضافی انگلیسی را دانلود میکنیم:
سپس کلمههایی از متنمان را که در این فهرست هستند با استفاده از یک list comprehension حذف میکنیم:
ریشهیابی
ریشهیابی که به انگلیسی Stemming نامیده میشود، یکی از روشهای مهم در پردازش زبان طبیعی برای کاهش واژگان و تمرکز بر ساختار ریشهای کلمات است. در این فرایند، انتهای کلمات بریده میشود تا بهشکل سادهتر و پایهایتر خود درآیند. این کار به این میانجامد که واژههای مختلف با ریشه مشابه، مانند running، runner وran هر سه به یک شکل پایهای run تبدیل شوند. ریشهیابی، بهخصوص در مواردی که تعداد دادهها زیاد است و به کاهش پیچیدگی واژگان وجود نیاز دارد، مفید واقع میشود.
اهمیت ریشهیابی
ریشهیابی به کاهش تکرار و تنوع لغوی کمک میکند و این امر به کاهش ابعاد ماتریس ویژگیها در مدلهای یادگیری ماشین میانجامد. این فرایند، بهویژه در مواردی مانند جستوجوی متنی و دستهبندی متون که در آنها یکنواختسازی واژگان مهم است، کاربرد دارد.
چالشهای ریشهیابی
بااینحال ریشهیابی ممکن است همیشه دقیق نباشد؛ زیرا برخی کلمهها را ممکن است بیشازحد ساده کند یا بهشکل نادرستی ریشهیابی کند؛ برای مثال، کلمات university (دانشگاه) و universal (جهانی) ممکن است هر دو به univers تبدیل شوند، درحالیکه معنای بسیار متفاوتی دارند. این نوع خطاها را over-stemming مینامند.
روشهای ریشهیابی
متداولترین الگوریتم ریشهیابی که در کتابخانههای NLP مانند NLTK استفاده میشوند Porter Stemmer است. این الگوریتم یکی از قدیمیترین و محبوبترین روشهای ریشهیابی است که برای زبان انگلیسی طراحی شده است.
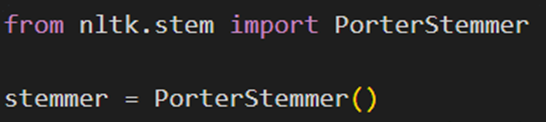
نحوه استفاده از الگوریتم Porter Stemmer در پایتون
برای این منظور کلاس PorterStemmer را از ماژول nltk.stem فراخوانی میکنیم؛ سپس یک نمونه (instance) از کلاس PorterStemmer ایجاد و در متغیر stemmer ذخیره میکنیم. از این نمونه برای اعمال عملیات ریشهیابی روی کلمات استفاده میکنیم:
در ادامه با استفاده از یک list comprehension هر کلمه را از فهرست filtered_words میگیریم و با استفاده از تابع stem موجود در شئ stemmer، آن را به ریشه خود تبدیل میکنیم. حاصل را در یک فهرست بهنام stemmed_words ذخیره و خروجی را چاپ میکنیم:
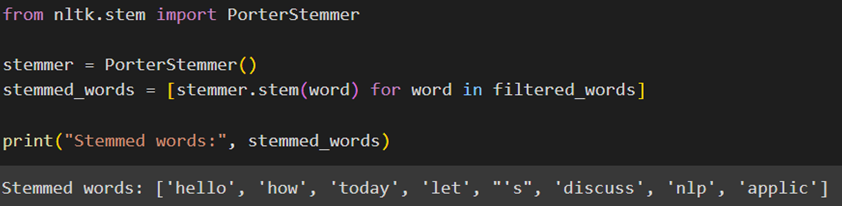
بیشترین تغییر در این فهرست روی کلمه applications دیده میشود که به ریشه applic تبدیل شده است.
واژهیابی
واژهیابی که به انگلیسی Lemmatization نامیده میشود یکی از روشهای پردازش متن در حوزه پردازش زبان طبیعی است که به کاهش کلمهها بهشکل دقیق و صحیح زبانیشان میپردازد. این روش، در مقایسه با ریشهیابی (Stemming) که فقط پسوندها را حذف میکند و ممکن است به شکلی ناقص کلمه را کاهش دهد، دقیقتر است.
اهمیت استفاده از واژهیابی
واژهیابی برای دستیابی به شکل اصلی کلمه با درنظرگرفتن زمینه زبانی و دستوری آن کلمه انجام میشود. این کار کمک میکند تا کلماتی که معانی مختلف دارند بتوانند به درستی تحلیل و مدیریت شوند؛ برای مثال، کلمه saw میتواند بهعنوان گذشته فعل see (دیدن) یا اسم (آره) شناخته شود. واژهیابی به تشخیص و کاهش این کلمه به “see” در صورت استفاده بهعنوان فعل کمک میکند.
فرایند واژهیابی
برای انجامدادن واژهیابی معمولاً از دیکشنریهای واژگان و الگوهای دستوری استفاده میشود تا فرم صحیح کلمه با توجه به کاربرد آن در جمله مشخص شود. این فرایند نیازمند دانش بیشتری نسبت به ریشهیابی است و اغلب به روشهای پیچیدهتری متکی است.
چالشها و محدودیتهای واژهیابی
واژهیابی ممکن است در مقایسه با ریشهیابی زمانبرتر باشد؛ زیرا نیازمند تجزیهوتحلیل دقیقتری است؛ علاوهبراین واژهیابی برای زبانهای با ساختار پیچیدهتر که قواعد دستوری متنوعی دارند میتواند چالشبرانگیز باشد.
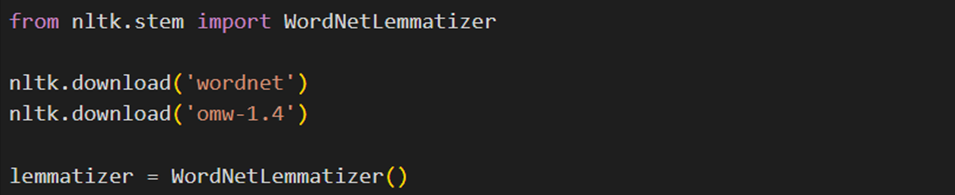
نحوه پیادهسازی واژهیابی در پایتون
برای انجامدادن واژهیابی میتوان از کتابخانه NLTK و کلاسWordNetLemmatizer استفاده کرد. برای این منظور، علاوه بر فراخوانی تابع WordNetLemmatizer، لازم است بسته wordnet را از NLTK دانلود کنیم.
wordnet یک پایگاه داده لغوی است که روابط معنایی میان کلمات را در بر میگیرد. علاوه بر اینها، omw-1.4 را که نسخهی ۱.۴ از Open Multilingual Wordnet است دانلود میکنیم. این پکیج نسخه چندزبانه wordnet است و به بهبود عملکرد واژهیابی کمک میکند.
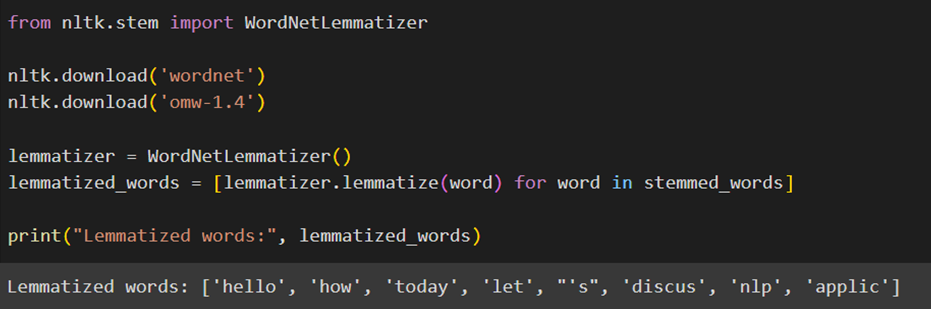
در ادامه یک نمونه از کلاس WordNetLemmatizer ایجاد و آن را در متغیری بهنام lemmatizer ذخیره میکنیم:
در پایان با استفاده از یکlist comprehension هر کلمه در فهرست stemmed_words را واژهیابی (Lemmatize) و نتیجه را در فهرست lemmatized_words ذخیره میکنیم:
مقایسه ریشهیابی و واژهیابی
در این جدول میتوانید تفاوتهای اصلی میان این دو روش را مشاهده کنید:
| ریشهیابی | واژهیابی | ویژگی |
| حذف پسوندها از کلمهها برای رسیدن به فرم اولیهی آنها، بدون توجه به مفهوم کلمه | استفاده از دانش لغوی و مفهومی برای تبدیل کلمه بهشکل اصلیاش که بهعنوان لم (lemma) شناخته میشود | تعریف |
| سریع و قوانین مبتنی بر متن | دقیق و مبتنی بر دانش لغوی | رویکرد |
| کمتر، ممکن است کلمات بهشکلهای نادرست تبدیل شوند | بیشتر، معمولاً شکل صحیح کلمه را بر میگرداند | دقت |
| معمولاً برای زبان انگلیسی و برخی دیگر | برای زبانهای دارای منابع کافی مانند انگلیسی | زبانها |
| محدود بهدلیل ساختار پیچیده زبان فارسی | بهتر، اما نیازمند دادههای بیشتر و دقیقتر | کاربرد در زبان فارسی |
اگرچه ما برای آموزش در این مقاله ابتدا از ریشهیابی و سپس از واژهیابی استفاده کردیم، میتوان این دو روش را با ترتیب برعکس استفاده کرد یا حتی فقط از یکی از آنها استفاده کرد. برای مشاهده تفاوت عملکرد این دو روش میتوان هر یک را جداگانه روی تعدادی واژه مشخص اجرا و خروجیها را بایکدیگر مقایسه کرد:
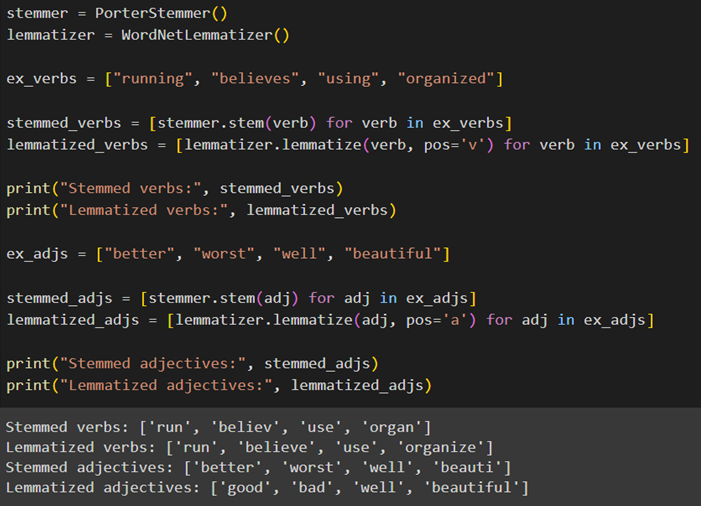
همانطور که میبینید این کد شامل دو مجموعه کلمه است: مجموعه فعلها و مجموعه صفتها. برای هر فعل و صفت، ابتدا نسخه ریشهیابیشده را به دست آوردیم و سپس نسخه واژهیابیشده را.
در خروجی این کد میتوانید تفاوت عملکرد این دو روش را مشاهده کنید. از آنجا که lemmatization این قابلیت را دارد که براساس نقش کلمه (برای مثال صفت یا فعل) آن را ساده میکند، اصولاً سادهسازی دقیقتری در مقایسه با ریشهیابی انجام میدهد.
تصمیم اینکه از کدام روش برای سادهسازی کلمات استفاده کنید به هدف و میزان حساسیت پروژهای بستگی دارد که انجام میدهید.
تبدیل دادههای متنی به بردار
TF و TF-IDF از تکنیکهای ابتدایی حوزه پردازش زبان طبیعی هستند که به مدلهای یادگیری ماشین این امکان را میدهند تا مفاهیم کلمات در یک فضای چندبعدی را درک کنند. در اینجا نحوه کار هر یک را شرح میدهیم:
TF (Term Frequency)
این مدل فقط تعداد دفعات تکرار هر کلمه در یک سند (مثلاً یک جمله) را حساب میکند. درواقع، برای هر کلمه در سند، یک مؤلفه در بردار متناظر با آن سند وجود دارد که تعداد دفعات ظهور آن کلمه را نشان میدهد.
این فرایند با توکنسازی متن شروع میشود که در آن متن به عناصر جداگانه، مانند کلمهها، تقسیم میشود. سپس واژهنامهای (Dictionary) از تمامی توکنهای منحصربهفرد موجود در مجموعه متون (Corpus) ساخته میشود. به هر توکن در واژهنامه یک ستون منحصربهفرد در ماتریس حاصل اختصاص داده میشود.
این روش هنگام تبدیل اسناد متنی به ماتریس، تعداد دفعات ظاهرشدن هر توکن را در هر سند (Document) شمارش میکند و این تعداد را در خانه متناظر ماتریس قرار میدهد. سطرهای ماتریس مربوط به اسناد در مجموعه متون هستند، درحالیکه ستونها متناظر با توکنها در واژهنامه است.
پیادهسازی در پایتون
CountVectorizer یکی از ماژولهای تعبیهشده در کتابخانه sklearn پایتون است که برای تبدیل متن به بردار از روش TF استفاده میکند. برای استفاده از این ماژول ابتداCountVectorizer را از ماژولsklearn.feature_extraction.text فراخوانی میکنیم؛ سپس مجموعه داده متنی خود را تعریف میکنیم. در این مجموعه هر جمله را یک سند درنظر میگیریم:
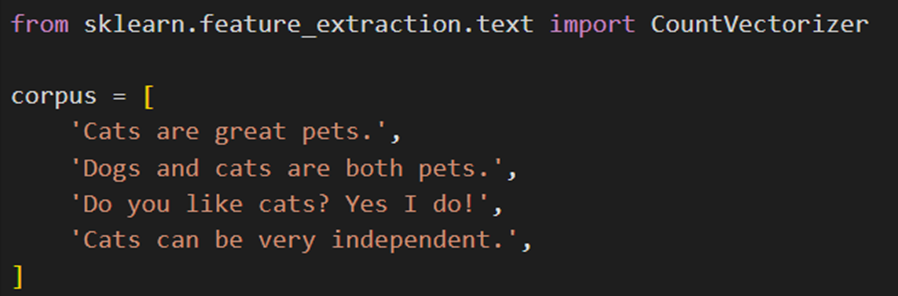
سپس یک نمونه از کلاس CountVectorizer میسازیم و آن را روی مجموعه متون خود fit_trnsfom میکنیم:
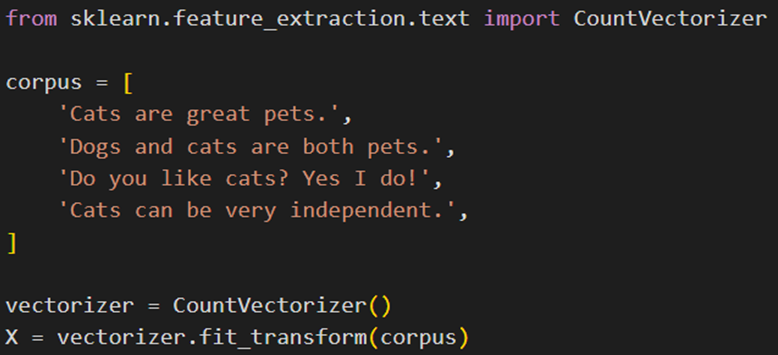
بهاینترتیب متن توکنسازی میشود. توجه کنید که به طور پیشفرض همه کلمات به حروف کوچک تبدیل میشوند تا کلماتی مانند Do و do به عنوان یک توکن یکسان در نظر گرفتهشوند. همچنینCountVectorizer تعداد تکرار هر توکن منحصر به فرد در هر سند را محاسبه میکند، که به صورت یک ماتریس خلوت (تنک) از اعداد صحیح درمیآید.
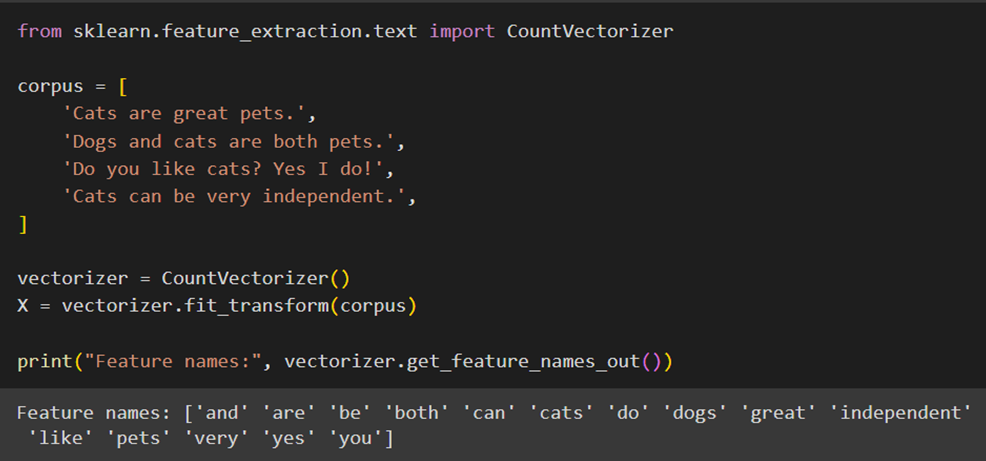
بعد از انجامدادن این مراحل با استفاده از متد get_feature_names_out که یک آرایه از توکنها یا همان واژهنامه را به ترتیب الفبایی برمیگرداند، فهرست تمامی کلمات درون متن را چاپ میکنیم:
سپس با X.toarray ماتریس خلوت تعداد توکنها را به یک آرایه numpy تبدیل میکنیم:
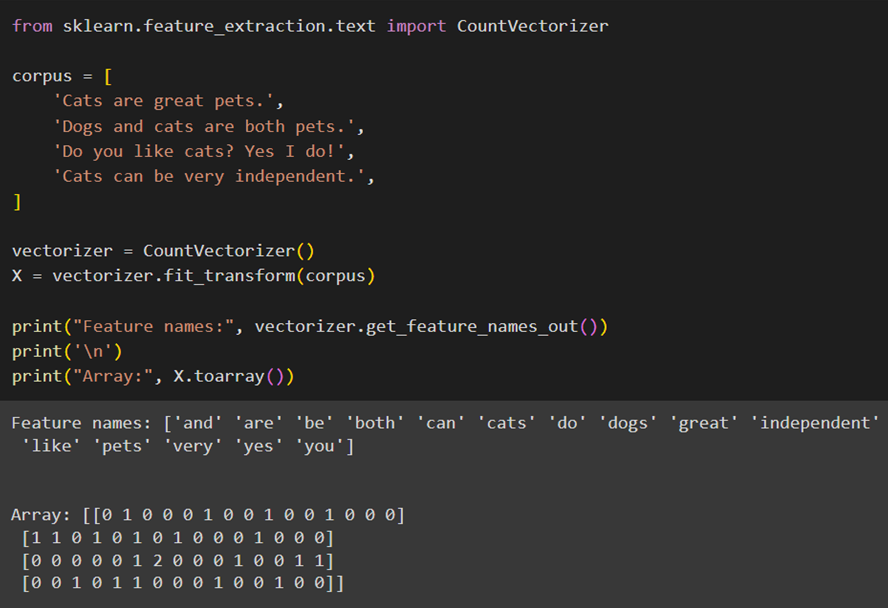
همانطور که گفتیم هر سطر از ماتریس X مربوط به یک سند (جمله) در مجموعه متون (Corpus) است و هر ستون نمایانگر یک کلمه منحصربهفرد در واژهنامهای است که از تمامی کلمات موجود در متون تشکیل شده است. عددهای درون ماتریس نشاندهنده تعداد دفعات ظاهرشدن هر کلمه در هر سند هستند؛ برای مثال، اگر در ستون دوم سطر اول عدد ۱ نوشته شده باشد، این بهاین معناست که کلمه are، یک بار در سند اول ظاهر شده است.
TF-IDF (Term Frequency-Inverse Document Frequency)
این مدل، علاوه بر اینکه از تکنیک محاسبه TF استفاده میکند، یک مؤلفه معکوس فراوانی اسناد (IDF) را هم در نظر میگیرد تا وزن کلماتی را که بیشازحد متداول هستند کاهش دهد و اهمیت کلمات نادرتر را افزایش دهد. مانند TF، در TF-IDF هر کلمه در یک سند به یک عدد تبدیل میشود که ترکیبی از تعداد دفعات تکرار و اهمیت نسبی آن کلمه در مجموعه متون (Corpus) است.
محاسبه TF-IDF
برای محاسبه TF-IDF، ابتدا فرکانس واژه (TF) را در لگاریتم معکوس فرکانس سند (IDF) ضرب میکنیم. این کار میزان اهمیت یک واژه را در یک سند خاص، با توجه به تعداد دفعات استفاده از آن واژه در کل مجموعه اسناد، مشخص میکند. فرمول محاسبه TF-IDF بهاین شکل است:
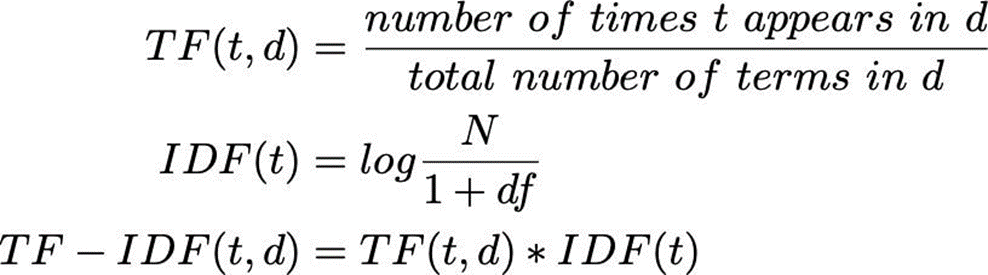
که در آن:
TF (Term Frequency) نشاندهنده تکرار یک توکن (t) در یک سند خاص (d) است و IDF (Inverse Document Frequency) نشاندهنده لگاریتم تعداد کل سندها (N) تقسیم بر تعداد سندهایی است که آن توکن در آنها به کار رفته است (df). مخرج کسر گفتهشده بهاین علت با یک جمع شده است که از صفرشدن آن جلوگیری کند.
پیادهسازی در پایتون
TfidfVectorizer یکی دیگر از ماژولهای تعبیهشده در sklearn است که برای تبدیل متن به بردار از روش TF-IDF استفاده میکند. برای استفاده از این ماژول TfidfVectorizer را از ماژول sklearn.feature_extraction.text فراخوانی میکنیم و ادامه کار را مانند قسمت قبل انجام میدهیم:
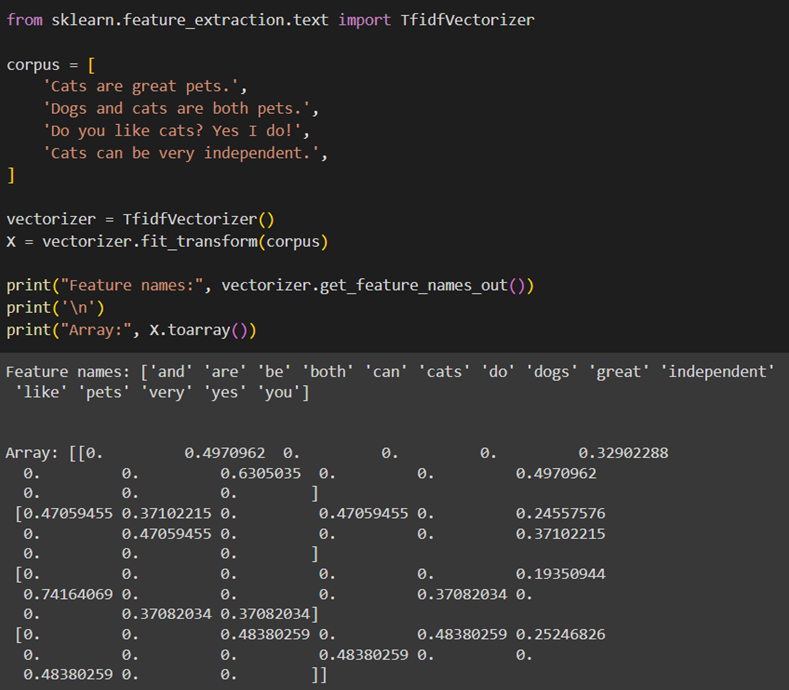
مانند CountVectorizer، هر سطر از آرایه X در این قسمت نمایانگر یک سند و هر ستون آن نمایانگر وزن TF-IDF یک توکن خاص در این مجموعه اسناد (یا مجموعه جملات) است. وزنها نشاندهنده اهمیت نسبی کلمات در هر سند هستند، که با توجه به تعداد تکرار آنها در سند مربوطه و کل مجموعه اسناد است.
با تبدیلشدن متن به یک نمایش عددی، حال، بهراحتی میتوان این دادهها را به ماشین داد و پروژههای مختلف پردازش متن را اجرا کرد.
پیادهسازی پروژه تشخیص توهین با پردازش متن
یکی از مرسومترین پروژههای حوزه پردازش متن تحلیل نظرات کاربران است. در این قسمت قصد داریم به ماشین یاد بدهیم که تشخیص دهد نظر یک کاربر شامل الفاظ رکیک، توهین، تهدید یا … بوده است یا خیر.
برای این منظور ابتدا مجموعه داده مدنظر را با کمک gdown از گوگل درایو دانلود میکنیم:

سپس کتابخانههای موردنیاز را فراخوانی میکنیم:
برای خواندن مجموعه دادهمان از pd.read_csv استفاده میکنیم:
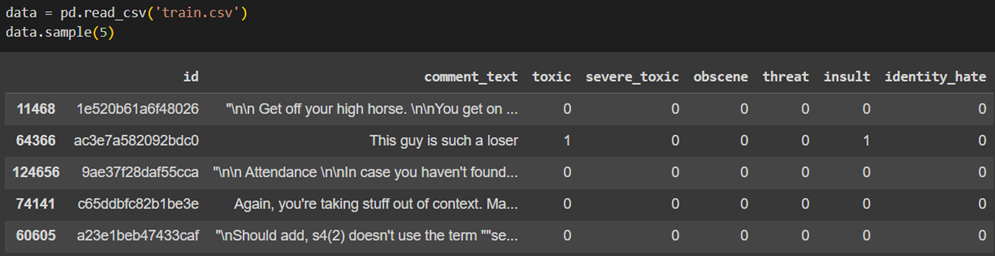
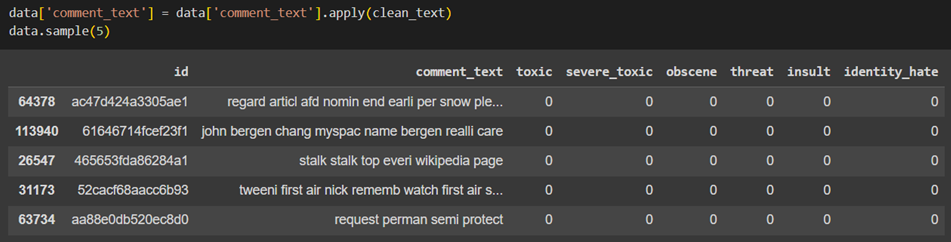
همانطور که در تصویر بالا میبینید مقابل هر یک از نظرات کاربران، ۶ ستون بهعنوان برچسب (Label) قرار گرفته است. یکبودن هر ستون بهاین معنی است که آن نظر، شامل آن برچسب خاص میشود.
پیشپردازش دادهها
مرحله بعدی ساخت یک تابع برای پاکسازی و آمادهسازی متن برای پردازش بهتر است؛ بهاین منظور با استفاده از روشهای پیشپردازش متنی که پیش از این آنها را توضیح دادیم، نظرات کاربران را به فرم سادهتری درمیآوریم:
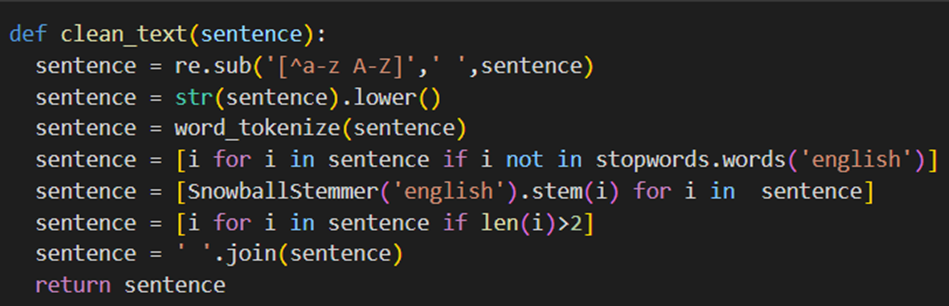
در این تابع ابتدا تمامی نویسههای غیرالفبایی با فضای خالی جایگزین میشوند تا فقط حروف انگلیسی باقی بمانند؛ سپس همه کلمات به حروف کوچک تبدیل میشود تا یکدستی دادهها حفظ شود. در ادامه متن به توکنها تقسیم میشود. در خط بعدی کلمات اضافی که اطلاعات محدودی دارند و بهطور معمول در زبان انگلیسی استفاده میشوند (مانند and و a و …) حذف میشوند. سپس با Stemming کلمات به ریشه خود تبدیل میشوند تا تنوع کلمات کاهش یابد. درنهایت نیز کلمات با طول کمتر از سه حرف حذف میشوند.
حال باید این تابع را روی مجموعه داده خود اعمال کنیم:
تبدیل دادهها به برداری از اعداد
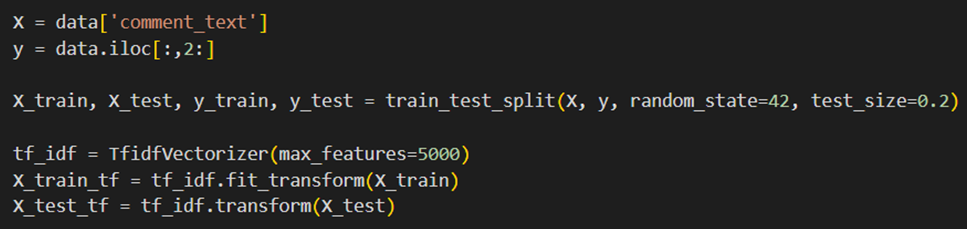
حال دادهها را به دو مجموعه آموزشی و ارزیابی تبدیل میکنیم و سپس از TfidfVectorizer برای تبدیل متنها به اعداد استفاده میکنیم:
آموزش مدل
اکنون که نظرات به بردارهایی از اعداد تبدیل شدند، میتوان بهراحتی آنها را به مدلهای ماشین لرنینگ کلاسبندی (Classification) داد تا برچسب آنها را مشخص کنند. از آنجا که این مجموعه داده ۶ لیبل مختلف دارند، لازم است از OneVsRestClassifier استفاده کنیم.
این تابع یک طبقهبندیکننده چندکلاسه را با استفاده از مدل انتخابی مثلا LogisticRegression آموزش میدهد و عملکرد آن را میسنجد. از متریک f1_score برای ارزیابی دقت مدل استفاده میشود:

جمعبندی
در پایان، پردازش زبان طبیعی، بهعنوان یکی از شاخههای مهم و تأثیرگذار هوش مصنوعی، قادر است تحولات بنیادینی در نحوه تعامل ما با دنیای دیجیتال ایجاد کند. از بهبود سیستمهای ترجمه ماشینی گرفته تا ارتقای امنیت سایبری و بهینهسازی خدمات مشتری، همه و همه، نشاندهنده پتانسیل بیپایان NLP در ساخت آیندهای هوشمندتر و واکنشپذیرتر هستند.
این فناوری، نهتنها قابلیتهای ماشینها را در درک و پردازش زبان انسانی افزایش میدهد، موجب بهبود کیفیت زندگی انسانها و افزایش کارآمدی در بخشهای مختلف صنعتی و خدماتی میشود. درنهایت، پردازش زبان طبیعی، با همه پیچیدگیها و چالشهای موجود، مسیری رو به جلو را برای ما ترسیم میکند و این وظیفه ماست که با درک بهتر و استفادهی بهینه از این فناوری آیندهای روشنتر را برای نسلهای آینده رقم بزنیم.

پرسشهای متداول
پردازش زبان طبیعی چه تاثیری بر توسعه دستیارهای صوتی میگذارد؟
پردازش زبان طبیعی به دستیارهای صوتی اجازه میدهد تا زبان انسانی را با دقت بیشتری درک کنند. این فناوری به دستیارهای صوتی کمک میکند تا دستورهای صوتی را تحلیل و پردازش و به آنها پاسخ مناسب ارائه کنند؛ بهعلاوه، بهبود تواناییهای تشخیص گفتار و تفسیر زبان طبیعی به افزایش کاربردپذیری و کارآمدی این دستگاهها در زندگی روزمره کمک میکند.
از چه روشهایی برای تحلیل احساسات در متون با استفاده از NLP استفاده میشود و چه دقتی دارند؟
تحلیل احساسات در متون عمدتاً از طریق مدلهای یادگیری ماشینی و عمیق صورت میگیرد که به تشخیص حالات مثبت، منفی، و بیطرف در متن میپردازند. دقت این روشها بسته به کیفیت دادههای آموزشی و پیچیدگی مدل متفاوت است. مدلهای جدیدتر مانند BERT و GPT در این زمینه به دقتهای بالایی دست یافتهاند.
چگونه میتوان از پردازش زبان طبیعی در بهبود سیستمهای ترجمه ماشینی بهره برد؟
پردازش زبان طبیعی به سیستمهای ترجمه ماشینی کمک میکند تا زبانهای مختلف را با درک بهتری از دستور زبان و معناشناسی ترجمه کنند. استفاده از مدلهای پیشرفته یادگیری عمیق، مانند شبکههای عصبی ترجمه ماشینی عصبی، میتواند دقت ترجمه را بهطور قابلتوجهی افزایش دهد و فهم متون را در سطح عمیقتری ممکن کند.
تأثیر پردازش زبان طبیعی در امنیت سایبری (Cybersecurity) چیست و چه چالشهایی در این زمینه وجود دارد؟
در امنیت سایبری پردازش زبان طبیعی میتواند برای تحلیل و شناسایی تهدیدات امنیتی استفاده شود، مانند تجزیهوتحلیل پیامهای مشکوک. چالشهای اصلی شامل تشخیص دقیق تهدیدات با توجه به تغییرات پیوسته در روشهای حمله و نیاز به دادههای آموزشی بسیار دقیق و بهروز است.
آینده پردازش زبان طبیعی چه تحولاتی را میتواند در صنعت خدمات مشتری ایجاد کند؟
پردازش زبان طبیعی انتظار میرود که نقش بزرگی در اتوماسیون پاسخگویی به مشتریان از طریق چتباتها و دستیاران هوشمند ایفا کند. این فناوری به شرکتها امکان میدهد تا درک بهتری از نیازها و احساسات مشتریان خود داشته باشند و به آنها پاسخهایی سریعتر و دقیقتر ارائه کنند. توسعه بیشتر در این زمینه میتواند به کاهش هزینهها و افزایش رضایت مشتری بینجامد.
یادگیری دیتا ساینس و ماشین لرنینگ را از امروز شروع کنید!
دنیای دادهها جذاب است و دانستن علم داده، توانایی تحلیل داده، یا بازاریابی مبتنی بر داده و یادگیری ماشین شما را برای فرصتهای شغلی بسیاری مناسب میکند. شما، فارغ از رشته تحصیلی و پیشزمینه شغلیتان، میتوانید یادگیری این دانش را از امروز شروع کنید و از سطح مقدماتی تا پیشرفته بیاموزید. اگر دوست دارید به این حوزه وارد شوید، پیشنهاد میکنیم با کلیک روی این لینک قدم اول را همین حالا بردارید.
مشاوران کافهتدریس به شما کمک میکنند مسیر یادگیری برای ورود به این حوزه را شروع کنید: