

شبکه عصبی کانولوشنی (Convolutional Neural Network – CNN) یکی از تکنیکهای پیشرفته در حوزه یادگیری ماشین و بینایی ماشین است که بر بهبود دقت و کارایی مدلهای پردازش تصویر تأثیر بسزایی میگذارد. این روش به محققان و توسعهدهندگان این امکان را میدهد که با استفاده از ساختارهای چندلایه و پیچیده، ویژگیهای مختلف و مهم تصویرها را استخراج کنند و به تحلیل و طبقهبندی آنها بپردازند. PyTorch، نیز بهعنوان یکی از کتابخانههای مهم و پرکاربرد در یادگیری عمیق، نقشی حیاتی در پیادهسازی و آموزش شبکههای عصبی کانولوشنی ایفا میکند. این کتابخانه، با ارائه ابزارهای قدرتمند و انعطافپذیر، به کاربران اجازه میدهد تا بهراحتی مدلهای CNN خود را طراحی، آموزش و بهینهسازی کنند. در ادامه این مطلب شبکههای عصبی کانولوشنی و نحوه استفاده از شبکه عصبی کانولوشنی در PyTorch را بررسی میکنیم.
- 1. پایتورچ چیست؟
- 2. مقدمهای بر شبکههای عصبی کانولوشنی
- 3. چرا PyTorch برای پیادهسازی CNNها مناسب است؟
- 4. نکتههای کلیدی در پیادهسازی شبکه عصبی کانولوشنی در PyTorch
- 5. طبقهبندی ارقام دستنوشت با PyTorch
- 6. اصطلاحات تخصصی شبکههای عصبی کانولوشنی و PyTorch
- 7. جمعبندی پیادهسازی شبکه عصبی کانولوشنی در PyTorch
-
8.
پرسشهای متداول
- 8.1. چرا استفاده از شبکه عصبی کانولوشنی در پردازش تصاویر مؤثر است؟
- 8.2. استفاده از شبکه عصبی کانولوشنی در PyTorch چه مزیتهایی در مقایسه با دیگر کتابخانهها دارد؟
- 8.3. چگونه میتوان از تکنیکهای Regularization و Early Stopping برای جلوگیری از بیشبرازش در شبکه عصبی کانولوشنی در PyTorch استفاده کرد؟
- 8.4. چگونه میتوان Feature mapهای لایههای مختلف یک شبکه عصبی کانولوشنی در PyTorch را نمایش داد؟
- 9. یادگیری دیپ لرنینگ را از امروز شروع کنید!
پایتورچ چیست؟
پایتورچ (PyTorch) یک کتابخانه منبعباز یادگیری عمیق است که توسط فیسبوک توسعه یافته و به زبان پایتون نوشته شده است. این کتابخانه از تانسورها، ساختارهای دادهای چندبعدی مشابه numpy، برای انجام محاسبات استفاده میکند و قابلیت اجرای عملیات روی GPU را نیز دارد. پایتورچ به دلیل پشتیبانی از شبکههای عصبی دینامیک و محیطهای تعاملی مانند Jupyter Notebook، کار با مدلهای یادگیری عمیق را بسیار آسانتر میکند. این ابزار به دلیل سهولت استفاده و عملکرد قوی، به یکی از محبوبترین کتابخانهها در میان محققان و مهندسین حوزه یادگیری ماشین تبدیل شده است.
مقدمهای بر شبکههای عصبی کانولوشنی
شبکههای عصبی کانولوشنی ازجمله مدلهای یادگیری عمیق هستند که بهطور خاص برای پردازش دادههای تصویری طراحی شدهاند. این شبکهها، با استفاده از لایههای کانولوشنی و تجمعی، ویژگیهای پیچیده و جزئیات مهم تصویرها را استخراج میکنند. درواقع CNNها این توانایی را دارند تا ساختارهای مختلف موجود در تصویرها را شناسایی و آنها را درک کنند؛ بههمین دلیل، در کاربردهای مختلفی مانند تشخیص چهره، طبقهبندی تصویر و تشخیص اشیا استفاده میشوند.
برای آشنایی بیشتر با این شبکهها مطلب شبکه عصبی کانولوشنی (CNN) چیست؟ را مطالعه کنید.
چرا PyTorch برای پیادهسازی CNNها مناسب است؟
PyTorch، بهدلیل انعطافپذیری و سادگی در استفاده، یکی از محبوبترین کتابخانهها برای پیادهسازی و آموزش شبکههای عصبی است. این کتابخانه به محققان و توسعهدهندگان اجازه میدهد تا بهراحتی مدلهای خود را تعریف کنند، آموزش دهند و ارزیابی کنند. در ادامه به دلیلهای اصلی که PyTorch را به یک انتخاب مناسب برای پیادهسازی CNNها تبدیل کرده است پرداختهایم:
رابط کاربری پویا و انعطافپذیر
PyTorch از یک رابط کاربری پویا (Dynamic Computational Graph) بهره میبرد که امکان آزمایش و بهینهسازی مدلها را بهصورت سریع و کارآمد فراهم میکند. این ویژگی به محققان اجازه میدهد تا بهراحتی تغییرات مختلف را در مدل خود اعمال و نتایج آن را بلافاصله مشاهده کنند؛ بههمین دلیل، توسعه شبکه عصبی کانولوشنی در PyTorch بسیار سادهتر و سریعتر انجام میشود.
پشتیبانی از GPU
یکی از ویژگیهای مهم PyTorch پشتیبانی قوی از GPU است. با استفاده از PyTorch میتوانید مدلهای خود را بهراحتی روی کارتهای گرافیک مدرن اجرا کنید و از توان پردازشی بالای آنها بهره ببرید. این امر باعث میشود که فرایند آموزش مدلهای بزرگ و پیچیده بهطور چشمگیری سریعتر انجام شود.
جامعه کاربری فعال و منابع آموزشی
PyTorch یک جامعه کاربری فعال و پشتیبانی قوی دارد. این امر باعث میشود که منابع آموزشی و مستندات زیادی برای یادگیری و استفاده از PyTorch در دسترس باشد. وجود جامعه کاربری فعال بهاین معناست که در صورت مواجهه با هرگونه مشکل یا سؤال میتوانید بهراحتی از تجربههای دیگران بهرهمند شوید و راهحلهای مناسب را پیدا کنید.
سازگاری با کتابخانههای دیگر
PyTorch بهخوبی با دیگر کتابخانهها و ابزارهای محبوب یادگیری ماشین و علم داده سازگار است. این سازگاری به شما اجازه میدهد تا از ابزارهای مختلف در کنار PyTorch استفاده کنید و قابلیتهای پروژه خود را افزایش دهید؛ برای مثال، میتوانید از کتابخانههایی مانند NumPy ،SciPy ،Pandas برای پردازش دادهها و تحلیلهای آماری استفاده کنید.
قابلیت توسعه و سفارشیسازی
PyTorch امکان سفارشیسازی مدلها و توابع مختلف را فراهم میکند. با استفاده از PyTorch میتوانید مدلهای خود را بهصورت کاملاً سفارشی طراحی و بهینهسازی کنید. این ویژگی، بهویژه، برای محققانی که در حال کار بر روی پروژههای تحقیقاتی و نوآورانه هستند بسیار مفید است.
برای اینکه بیشتر با کتابخانه پایتورج آشنا شوید، پیشنهاد میکنیم مقاله آشنایی کامل با کتابخانه PyTorch را بخوانید.
نکتههای کلیدی در پیادهسازی شبکه عصبی کانولوشنی در PyTorch
با بهرهگیری از قابلیتهایPyTorch میتوان مدلهای CNN را بهطور مؤثری پیادهسازی، آموزش و ارزیابی کرد و به نتایج بهتری در پروژههای یادگیری عمیق دست یافت.
پیشپردازش دادهها
یکی از مهمترین مراحل در پیادهسازی شبکههای عصبی کانولوشنی آمادهسازی و پیشپردازش دادههاست. PyTorch ابزارهای مختلفی برای انجامدادن این کار دارد که میتوانند دادههای تصویری را به فرمتهای قابل استفاده برای شبکهها تبدیل کنند. نرمالسازی و افزایش دادهها ازجمله تکنیکهای مؤثر پیشپردازش هستند.
افزایش دادهها (Data Augmentation) نیز با ایجاد تغییرات کوچک در تصویرهای موجود مجموعه دادههای آموزشی را بزرگتر و متنوعتر میکند که به جلوگیری از بیشبرازش (Overfitting) میانجامد. این تغییرات میتوانند شامل چرخش، تغییر مقیاس، برش و تغییر شدت نور باشند. با این کار مدل با نمونههای بیشتری از دادهها مواجه میشود و درنتیجه، یادگیری بهتری خواهد داشت.
نرمالسازی یکی از تکنیکهای پایهای در پیشپردازش دادههاست که مقدارهای پیکسلها را در محدودهای مشخص قرار میدهد؛ برای مثال، اگر مقدارهای پیکسلها میان ۰ تا ۲۵۵ باشند، میتوان آنها را به محدوده ۰ تا ۱ یا -۱ تا ۱ نرمالسازی کرد. این کار کمک میکند تا مدل بتواند سریعتر و با دقت بیشتری آموزش ببیند؛ همچنین نرمالسازی به همگرایی (Convergence) بهتر و پایدارتر مدل کمک میکند.
تعریف مدل
با استفاده از PyTorch میتوان مدلهای CNN را بهسادگی تعریف و ساختار لایههای کانولوشنی و تجمعی را مشخص کرد. این کتابخانه امکان سفارشیسازی مدلها و افزودن لایههای مختلف را فراهم میکند. PyTorch از یک رابط کاربری پویا بهره میبرد که به محققان و توسعهدهندگان اجازه میدهد تا بهراحتی مدلهای خود را طراحی، تغییر و بهینهسازی کنند.
آموزش مدل
فرایند آموزش مدلهای CNN با PyTorch بسیار ساده و انعطافپذیر است. شما میتوانید با تنظیم پارامترهای مختلف مانند نرخ یادگیری (Learning rate) و تعداد epochها مدل خود را بهینهتر کنید. PyTorch ابزارهای متنوعی برای تنظیم و بهینهسازی پارامترهای مدل ارائه میکند. استفاده از توابع هزینه مختلف و بهینهسازهای متنوع میتواند به بهبود فرایند آموزش کمک کند؛ همچنین قابلیت اجرای مدل روی GPU باعث میشود که فرایند آموزش بسیار سریعتر و کارآمدتر باشد.
ارزیابی و بهبود مدل
پس از آموزش مدل نیاز است که عملکرد آن را با استفاده از دادههای تست ارزیابی کنیم. PyTorch ابزارهای متنوعی برای ارزیابی مدلها و تجزیهوتحلیل نتایج ارائه میکند. این متریکها به شما کمک میکنند تا عملکرد مدل را بهصورت جامعتری بررسی کنید و نقاط ضعف و قوت آن را شناسایی کنید؛ همچنین تکنیکهای بهینهسازی مانند Early Stopping، Regularization و استفاده از Learning Rate Scheduler میتوانند به بهبود عملکرد مدل کمک کنند.
Early Stopping
Early Stopping یک تکنیک برای جلوگیری از بیشبرازش (Overfitting) است که به شما اجازه میدهد آموزش مدل را زمانی که عملکرد آن روی دادههای اعتبارسنجی (validation) شروع به بدترشدن میکند متوقف کنید. برای پیادهسازی Early Stopping میتوان از کتابخانههای خارجی مانند torchtools استفاده کرد یا یک کلاس ساده نوشت.
Regularization
Regularization روشی است که بهمنظور جلوگیری از بیشبرازش استفاده میشود. دو نوع رایج Regularization شامل L2 و Dropout است. در PyTorch ،L2 Regularization با استفاده از پارامتر weight_decay در بهینهساز (Optimizer) پیادهسازی میشود. Dropout نیز یک لایه در کلاس torch.nn است که میتوان به مدل اضافه کرد.
Learning Rate Scheduler
Learning Rate Scheduler برای تنظیم نرخ یادگیری در طول آموزش استفاده میشود. این روش میتواند به بهبود همگرایی (Convergence) مدل کمک کند.
طبقهبندی ارقام دستنوشت با PyTorch
در این قسمت میخواهیم پروژه طبقهبندی (Classification) تصاویر مجموعه داده MNIST یا همان ارقام دستنوشت را در پایتورچ اجرا کنیم. ابتدا کتابخانههای موردنیاز را فراخوانی میکنیم:
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim.lr_scheduler import StepLR
from torchvision import datasets, transforms
from torch.utils.data import DataLoader, Dataset
import numpy as np
import matplotlib.pyplot as plt
پیشپردازش
اکنون لازم است یک شیء transform تعریف کنیم و بهکمک آن مرحلههای پیشپردازش را انجام دهیم:
transform = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(10),
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
در این کد تصویرهای ورودی با تابع RandomHorizontalFlip بهصورت تصادفی چرخش افقی یافته و با RandomRotation مجدداً بهصورت تصادفی تا ۱۰ درجه میچرخند که این امر افزایش تنوع دادهها و جلوگیری از بیشبرازش را رقم میزند.
همچنین در ادامه با استفاده از تابع ToTensor ابتدا مقدار پیکسلهای هر تصویر از بازه ۰ تا ۲۵۵ به ۰ تا ۱ تغییر مییابد و سپس با تابع Normalize که دو آرگومان ورودی دارد مقدار پیکسلهای هر تصویر را نرمالسازی میکنیم. این تابع دو آرگومان میگیرد:
- آرگومان اول میانگین است که مقادیری را تعیین میکند که پیکسلهای تصویر از آن کسر میشود.
- آرگومان دوم انحراف معیار است که مقدارهایی را تعیین میکند که پیکسلهای تصویر بر آن تقسیم میشوند.
ما در این کد هر دو آرگومان را برابر ۰.۵ قرار دادهایم. این بهمعنای آن است که ابتدا ۰.۵ واحد از هر پیکسل تصویر کسر میشود و سپس نتیجه بر ۰.۵ تقسیم میشود. چون از قبل با تابع ToTensor مقادیر پیکسلها را به بازه ۰ تا ۱ تغییر داده بودیم، با این کار اعداد درون هر پیکسل به محدوده ۱- و ۱+ میرود.
سپس مجموعه دادههای آموزشی و ارزیابی MNIST را بارگذاری و آنها را با استفاده از DataLoader، در دستههای ۶۴تایی برای استفاده در مدلهای یادگیری عمیق آماده میکنیم:
trainset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
train_loader = DataLoader(trainset, batch_size=64, shuffle=True)
valset = datasets.MNIST(root='./data', train=False, download=True, transform=transform)
val_loader = DataLoader(valset, batch_size=64, shuffle=False)
ساخت یک مدل شبکه عصبی کانولوشنی در PyTorch
برای ساخت یک شبکه عصبی کانولوشنی در PyTorch باید یک کلاس سفارشی ایجاد کنیم که از nn.Module ارثبری کند و دو متد اصلی __init__ و forward را داشته باشند. با این کد بههمین ترتیب میتوانیم یک مدل شبکه عصبی کانولوشنی (CNN) را برای دستهبندی تصویرهای MNIST تعریف کنیم:
class CNNModel(nn.Module):
def __init__(self):
super(CNNModel, self).__init__()
self.conv1 = nn.Conv2d(in_channels=1, out_channels=32, kernel_size=3, stride=1, padding=1)
self.relu1 = nn.ReLU()
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2, padding=0)
self.drop1 = nn.Dropout(0.3)
self.conv2 = nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, stride=1, padding=1)
self.relu2 = nn.ReLU()
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2, padding=0)
self.drop2 = nn.Dropout(0.2)
self.flatten = nn.Flatten()
self.fc1 = nn.Linear(64 * 7 * 7, 64)
self.drop3 = nn.Dropout(0.2)
self.fc2 = nn.Linear(64, 10)
که در آن:
- conv1 اولین لایه کانولوشنی با ورودی تککاناله (چون عکسهای MNIST سیاه و سفید و در نتیجه تککاناله هستند) و خروجی ۳۲ کاناله، کرنلی به ابعاد ۳x۳، گام (Stride) ۱ و پدینگ ۱ است.
- relu1 تابع فعالساز ReLU برای لایه اول است.
- pool1 لایه Maxpooling با ابعاد ۲x۲ و گام ۲ است.
- drop1 لایه دراپاوت با نرخ ۰.۳ و برای کاهش بیشبرازش است.
- conv2 دومین لایه کانولوشنی با ورودی ۳۲ کاناله (تعداد کانالهای خروجی لایه قبل) و خروجی ۶۴ کاناله، کرنلی به ابعاد ۳x۳، گام و پدینگ ۱ است.
- relu2 تابع فعالسازی ReLU برای لایه دوم است.
- Pool2 لایه Maxpooling با ابعاد ۲x۲ و گام ۲ است.
- drop2 دراپاوت با نرخ ۰.۲ برای کاهش بیشبرازش است.
- flatten لایهای برای تبدیل دادههای سهبعدی به یکبعدی است.
- fc1 اولین لایه کاملاً متصل (Fully Conected) با ۷*۷*۶۴ (ابعاد Feature map حاصل از لایههای کانولوشنی قبلی) نورون ورودی و ۶۴ نورون خروجی است.
- drop3 دراپآوت با نرخ ۰.۲ برای کاهش بیشبرازش است.
- fc2 دومین لایه کاملاً متصل با ۶۴ نورون ورودی و ۱۰ نورون خروجی است.
برای استفاده از معماری طراحیشده متد forward را در همان کلاس CNNModel بهشکل زیر طراحی میکنیم. این متد برای مشخصکردن توالی عملیات و تعاملات میان لایههای مختلف در مدل ضروری است:
def forward(self, x):
x = self.conv1(x) # input: 28x28x1, output: 28x28x32
x = self.relu1(x)
x = self.pool1(x) # input: 28x28x32, output: 14x14x32
x = self.drop1(x)
x = self.conv2(x) # input: 14x14x32, output: 14x14x64
x = self.relu2(x)
x = self.pool2(x) # input: 14x14x64, output: 7x7x64
x = self.drop2(x)
x = self.flatten(x)
x = self.fc1(x)
x = self.drop3(x)
x = self.fc2(x)
return x
در پایان یک نمونه (Instance) از مدل ساخته و آن را در متغیر مربوطه میریزیم:
model = CNNModel()
آموزش و ارزیابی مدل
برای آموزش این مدل نیاز به تعریف یک تابع هزینه و یک بهینهساز داریم. از آنجا که این مدل پیچیدگی زیادی دارد و حتما نیازمند اجراشدن روی GPU است، پیش از آغاز آموزش لازم است از انتقال مدل و دادهها به GPU مطمئن شویم؛ در غیر اینصورت فرایند آموزش بسیار طولانی خواهد بود.
با این کد ابتدا مدل را به GPU (در صورت موجودبودن) انتقال میدهیم:
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model.to(device)
سپس تابع هزینه CrossEntropyLoss و بهینهساز Adam را با نرخ یادگیری ۰.۰۰۱ تعریف میکنیم. همچنین از weight_decay برای اعمال L2 Regularization استفاده میکنیم تا از بیشبرازش جلوگیری شود. در این تابع weight_decay همان ضریب Regularization است. علاوه بر اینها، از StepLR برای تنظیم نرخ یادگیری در طول آموزش استفاده میکنیم. در این تابع پارامتر step_size تعیین میکند که هرچند epoch یک بار نرخ یادگیری کاهش یابد و gamma ضریب کاهش نرخ یادگیری را تعیین میکند:
criterion = nn.CrossEntropyLoss().to(device)
optimizer = optim.Adam(model.parameters(), lr=0.001, weight_decay=1e-5)
scheduler = StepLR(optimizer, step_size=10, gamma=0.1)
در اینجا از کلاس EarlyStopping که قبلا آن را تعریف کردیم نیز استفاده میکنیم که عملکرد مدل را در طول آموزش بررسی و در صورت بهبود نیافتن، آموزش را متوقف کنیم. این کلاس دو پارامتر patience (حداکثر تعداد epochهایی که بدون بهبود میتوان اجرا کرد) و delta (حداقل تغییر مورد نیاز برای بهبود) دارد:
early_stopping = EarlyStopping(patience=10, delta=0.001)
آموزش مدل
در ادامه فهرستهایی را برای ذخیره مقدار خطاهای آموزش و ارزیابی در طول دورههای آموزش ایجاد میکنیم و در هر epoch از مرحله آموزش، با استفاده از model.train مدل را در حالت آموزش قرار میدهیم و برای هر دسته از دادههای آموزشی، بهکمک optimizer.zero_grad ابتدا گرادیانها را صفر کرده، پیشبینی مدل را در outputs قرار داده و با استفاده از تابع هزینه گفتهشده، خطای بین مقدار پیشبینیشده و مقدار واقعی را محاسبه میکنیم. سپس عملیات پسانتشار (Backpropagate) را با استفاده از loss.backward انجام داده و با optimizer.step پارامترهای مدل را بهروزرسانی میکنیم. درپایان، خطای کل آموزشی برای هر epoch محاسبه و ذخیره میشود:
train_losses = []
val_losses = []
num_epochs = 50
for epoch in range(num_epochs):
model.train()
running_loss = 0.0
for inputs, labels in trainloader:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
scheduler.step()
train_loss = running_loss / len(trainloader)
train_losses.append(train_loss)
ارزیابی مدل
در فاز ارزیابی مدل را در حالت ارزیابی قرار میدهیم و دادههای ارزیابی را به GPU منتقل، خطاهای مدل بدون را بهروزرسانی گرادیانها محاسبه و بعد از هر ۱۰ epoch مقدار خطای آموزش و ارزیابی را چاپ میکنیم تا عملکرد مدل را در طول زمان بررسی نماییم. با هدف اجرای مکانیزم توقف زودهنگام (Early Stopping)، پس از هر epoch، عملکرد مدل روی دادههای ارزیابی بررسی میشود. اگر بهبودی در خطای ارزیابی مشاهده نشود، مقدار counter افزایش مییابد. اگر مقدار counter به patience برسد، آموزش متوقف میشود و بهترین مدل بازیابی میشود. دقت کنید که این کد باید در ادامه کد قبلی و داخل حلقه for اول اجرا شود:
val_loss = 0.0
model.eval()
with torch.no_grad():
for inputs, labels in valloader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
val_loss += loss.item()
val_loss = val_loss / len(valloader)
val_losses.append(val_loss)
if epoch % 5 == 0:
print(f'Epoch {epoch+1}/{num_epochs}, Train Loss: {train_loss:.4f}, Val Loss: {val_loss:.4f}')
early_stopping(val_loss, model)
if early_stopping.early_stop:
print("Early stopping")
model.load_state_dict(torch.load('checkpoint.pt'))
break
با این کد نیز میتوان نمودار تابع هزینه بر حسب epochها را رسم کرد:
# Set the figure size for the plot
plt.figure(figsize=(8, 5))
# Plot the training and validation losses
plt.plot(range(1, 17), train_losses, label='Training Loss')
plt.plot(range(1, 17), val_losses, label='Validation Loss')
# Add labels and title
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.show()
خروجی کد بالا بهاین صورت است:

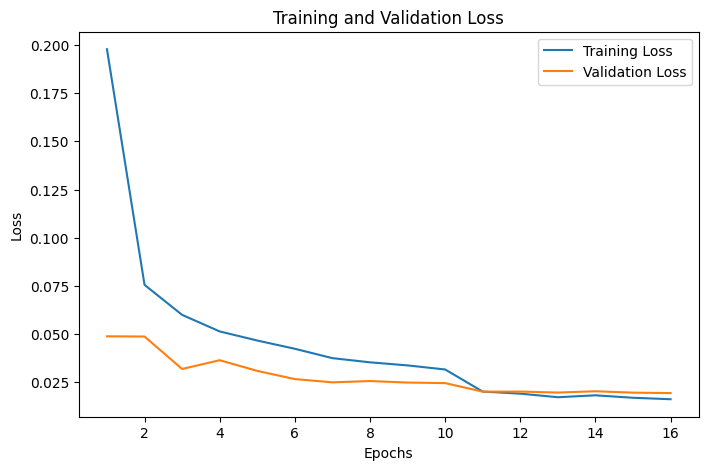
تفسیر نمودار
این نمودار نشان میدهد که مدل بهخوبی آموزش دیده است و میتواند عملکرد خوبی روی دادههای جدید داشته باشد. کاهش خطای آموزشی و ارزیابی بهطور همزمان نشاندهنده نبود بیشبرازش است؛ بهعبارت دیگر، مدل، نهتنها روی دادههای آموزشی، روی دادههای ارزیابی نیز عملکرد خوبی دارد؛ این یعنی پیادهسازی شبکه عصبی کانولوشنی در PyTorch میتواند نتایج خوبی داشته باشد.
رسم Feature mapها
یکی از کارهای جذابی که میتوانیم با مدلهای کانولوشنی در پایتورچ انجام دهیم رسم Feature mapهای لایههای مختلف مدلها است. برای این کار ابتدا یک تصویر از مجموعه دادههای آموزشی را انتخاب و به GPU منتقل میکنیم، سپس شکل آن را برای ورودی به مدل تغییر میدهیم.
سپس تصویر را به یک Tensor با نوع داده float32 تبدیل میکنیم. مدل را در حالت ارزیابی (eval) قرار داده و با استفاده از torch.no_grad، نقشههای ویژگیها استخراجشده از اولین و سپس دومین لایه کانولوشنی مدل را بدون بهروزرسانی گرادیانها محاسبه میکنیم؛ سپس این نقشههای ویژگیها را به CPU منتقل و به یک آرایه numpy تبدیل میکنیم:
# Load an image from the trainset and move to the device
X = trainset.data[5].to(device)
X = X.unsqueeze(0).unsqueeze(0)
X = torch.tensor(X, dtype=torch.float32)
# Pass through conv1 first to get the correct number of channels
model.eval()
with torch.no_grad():
feature_maps_conv1 = model.conv1(X)
feature_maps_conv2 = model.conv2(feature_maps_conv1)
# Move feature maps back to CPU and convert to numpy
feature_maps_conv1 = feature_maps_conv1.cpu().detach().numpy()
feature_maps_conv2 = feature_maps_conv2.cpu().detach().numpy()
درنهایت، یک شبکه از نمودارها با استفاده از Matplotlib ایجاد میکنیم و هر یک از ۳۲ کرنل نقشه ویژگی (Feature map) حاصل از لایه کانولوشنی اول را به صورت تصویری نمایش میدهیم:
# Plot the first conv feature maps
fig, ax = plt.subplots(4, 8, sharex=True, sharey=True, figsize=(16, 8))
for i in range(32):
row, col = i // 8, i % 8
ax[row][col].imshow(feature_maps_conv1[0][i], cmap='gray')
plt.show()


تحلیل Feature map حاصل از اولین لایه کانولولشنی
این تصویر، خروجی لایه کانولوشنی اول مدل CNN ما را برای طبقهبندی دیتاست MNIST نشان میدهد. هر یک از این تصویرها نمایانگر یک ویژگی استخراجشده از یک تصویر ورودی (که در این مثال عدد ۲ است) توسط یکی از فیلترهای لایه کانولوشنی اول است که در ادامه آنها را تحلیل میکنیم:
- ویژگیهای استخراجشده: هر تصویر در این ماتریس نشاندهنده ویژگیهایی است که توسط یک فیلتر مشخص استخراج شده است. این ویژگیها میتوانند شامل لبهها، خطوط، و دیگر الگوهای پایهای موجود در تصاویر ورودی باشند.
- فیلترهای مختلف: هر یک از تصویرهای خروجی نشاندهنده نتیجه اعمال یک فیلتر کانولوشنی روی تصویر ورودی است. این فیلترها به طور خودکار در طول فرایند آموزش یاد گرفته میشوند و هر یک سعی میکنند یک جنبه خاص از تصویر را استخراج کنند.
- تنوع ویژگیها: با نگاه به تصویرهای مختلف میتوان دید که فیلترهای مختلف به جنبههای مختلفی از تصویر حساس هستند. برخی از فیلترها ممکن است به لبههای عمودی حساس باشند، درحالیکه برخی دیگر به لبههای افقی یا الگوهای دیگر حساس هستند.
- تغییر روشنایی و کنتراست: برخی از تصویرهای خروجی ممکن است روشنتر یا تیرهتر از باقی باشند. این امر بهدلیل تنظیمات مختلف فیلترها و نحوه واکنش آنها به قسمتهای مختلف تصویر ورودی است.
- ویژگیهای سطح پایین: از آنجا که این تصاویر خروجی اولین لایه کانولوشنی هستند، معمولاً ویژگیهای سادهتری را نمایش میدهند. لایههای کانولوشنی بعدی ویژگیهای پیچیدهتری را استخراج میکنند.
همین کار را برای لایه کانولوشنی دوم نیز انجام میدهیم. فقط چون Feature map خروجی این لایه ۶۴ کرنل دارد، باید در بازه رسم مدنظر را به ۶۴ افزایش دهیم:
# Plot the second conv feature maps
fig, ax = plt.subplots(8, 8, sharex=True, sharey=True, figsize=(20, 10))
for i in range(64):
row, col = i // 8, i % 8
ax[row][col].imshow(feature_maps_conv2[0][i], cmap='gray')
plt.show()


تحلیل Feature map حاصل از دومین کانولولشنی
این تصویر خروجی لایه کانولوشنی دوم مدل CNN ما را برای طبقهبندی دیتاست MNIST نشان میدهد. هر یک از این تصاویر نمایانگر ویژگیهای استخراجشده توسط یکی از فیلترهای لایه کانولوشنی دوم است که در ادامه آنها را بررسی میکنیم:
- ویژگیهای پیچیدهتر: لایههای کانولوشنی عمیقتر در یک شبکه عصبی کانولوشنی، ویژگیهای پیچیدهتری را در مقایسه با لایههای اول استخراج میکنند. در این تصویرها میتوان مشاهده کردکه فیلترها به الگوهای پیچیدهتری از اعداد حساس هستند.
- ترکیب ویژگیها: فیلترهای این لایه معمولاً ترکیبی از ویژگیهای استخراجشده در لایههای قبلی را تحلیل میکنند؛ برای مثال، ممکن است یک فیلتر به لبهها و خطوط حساس باشد، درحالیکه فیلتر دیگر به بافتها یا الگوهای پیچیدهتر واکنش نشان دهد.
- تنوع بیشتر: تعداد و تنوع ویژگیهایی که توسط فیلترهای لایه دوم استخراج میشوند بیشتر از لایه اول است؛ این بهاین دلیل است که هر لایه جدید قابلیت استخراج ویژگیهای بیشتری از تصویرها را دارد.
- واکنش به ویژگیهای جزئیتر: برخی از فیلترها به ویژگیهای جزئیتر و دقیقتر تصاویر واکنش نشان میدهند که این امر به تشخیص دقیقتر و طبقهبندی بهتر تصاویر کمک میکند.
- افزایش دقت تشخیص: با افزایش تعداد لایههای کانولوشنی و عمق شبکه، مدل قادر میشود تا ویژگیهای پیچیدهتری را از تصاویر استخراج کند. این امر به افزایش دقت تشخیص و طبقهبندی میانجامد.
این Feature mapها چه فایدهای دارند؟
این ویژگیهای استخراجشده در مراحل بعدی شبکه عصبی استفاده میشوند تا مدل بتواند الگوهای پیچیدهتری را در دادهها شناسایی کند و درنهایت، به طبقهبندی دقیقتر اعداد دست یابد. این فرایند بهتدریج و با عبور از لایههای متعدد کانولوشنی و تجمعی، مدل را قادر میکند تا با دقت بیشتری تصاویر ورودی را تجزیهوتحلیل کند و کلاس مربوط به هر تصویر را تشخیص دهد.
مجموعه کامل کدهای بالا را میتوانید در این ریپازیتوری از گیتهاب مشاهده کنید.
اصطلاحات تخصصی شبکههای عصبی کانولوشنی و PyTorch
در این مطلب از اصطلاحات تخصصی زیادی درباره شبکههای عصبی کانولوشنی و PyTorch استفاده شد. در این قسمت واژهنامهای جامع از اصطلاحات کلیدی بهکاررفته در این مطلب را در اختیارتان قرار میدهیم. این واژهنامه به شما کمک میکند تا با مفهومهای اصلی این حوزه آشنا شوید و بتوانید از این دانش در پروژههای خود استفاده کنید.
واژنامه
| اصطلاح | تعریف |
| لایه کانولوشنی (Convolutional Layer) | لایهای در شبکه عصبی کانولوشنی که با استفاده از فیلترها (کرنلها) ویژگیهای مختلفی از تصاویر را استخراج میکند. این لایه به تشخیص الگوهای مختلف در تصاویر کمک میکند. |
| لایه تجمعی (Pooling Layer) | لایهای که اندازه دادههای خروجی از لایه کانولوشنی را کاهش میدهد و با این کار، ابعاد ویژگیها را کوچکتر میکند. این لایه باعث کاهش تعداد پارامترها و افزایش سرعت پردازش مدل میشود. |
| پیشپردازش دادهها (Data Preprocessing) | مجموعهای از تکنیکها و روشها برای آمادهسازی دادهها جهت استفاده در مدلهای یادگیری عمیق. این تکنیکها شامل نرمالسازی، افزایش دادهها (Data Augmentation) و تبدیل دادهها به فرمتهای مناسب میشود. |
| افزایش دادهها (Data Augmentation) | تکنیکی برای افزایش تنوع دادههای آموزشی با ایجاد تغییرات کوچک در تصاویر موجود، مانند چرخش، تغییر مقیاس، برش و تغییر شدت نور. این روش به جلوگیری از بیشبرازش کمک میکند. |
| نرمالسازی (Normalization) | فرایندی که در آن مقادیر پیکسلهای تصویر به محدودهای مشخص تبدیل میشوند تا مدل بتواند سریعتر و با دقت بیشتری آموزش ببیند. |
| بیشبرازش (Overfitting) | وضعیتی که در آن مدل به خوبی دادههای آموزشی را یاد میگیرد، اما عملکرد ضعیفی روی دادههای جدید (دادههای تست) دارد. این مسئله معمولاً به دلیل پیچیدگی بیش از حد مدل یا کمبود دادههای آموزشی رخ میدهد. |
| انتشار رو به عقب (Backpropagation) | الگوریتمی برای آموزش شبکههای عصبی که در آن گرادیانها محاسبه و پارامترهای مدل بهروزرسانی میشوند. این الگوریتم به مدل کمک میکند تا خطاها را کاهش دهد و به سمت بهینهسازی حرکت کند. |
| رابط کاربری پویا (Dynamic Computational Graph) | قابلیتی در PyTorch که به کاربران اجازه میدهد تا گراف محاسباتی مدل خود را در حین اجرا ایجاد و تغییر دهند. این ویژگی باعث انعطافپذیری بیشتر و سهولت در آزمایش و بهینهسازی مدلها میشود. |
جمعبندی پیادهسازی شبکه عصبی کانولوشنی در PyTorch
شبکههای عصبی کانولوشنی (CNN) یکی از مهمترین و مؤثرترین تکنیکهای یادگیری عمیق در پردازش تصاویر هستند. استفاده از PyTorch برای پیادهسازی این شبکهها به دلیل رابط کاربری پویا، پشتیبانی قوی از GPU و جامعه کاربری فعال، این فرایند را بسیار ساده و کارآمد میکند. با پیادهسازی تکنیکهای پیشپردازش دادهها، استفاده از تکنیکهای Regularization و Early Stopping و نمایش Feature mapها، میتوان به بهینهسازی و بهبود مدلهای CNN پرداخت. این اقدامات به پژوهشگران و توسعهدهندگان کمک میکند تا مدلهای دقیقتر و مؤثرتری برای تحلیل و طبقهبندی تصاویر بسازند.


پرسشهای متداول
چرا استفاده از شبکه عصبی کانولوشنی در پردازش تصاویر مؤثر است؟
شبکه عصبی کانولوشنی به دلیل قابلیت استخراج ویژگیهای پیچیده و مهم از تصویرها، بر پردازش و تحلیل دادههای تصویری بسیار مؤثر هستند. این شبکهها با استفاده از لایههای کانولوشنی و تجمعی، توانایی شناسایی الگوها و ساختارهای مختلف در تصویرها را دارند که باعث بهبود دقت مدلها در تشخیص و طبقهبندی میشود.
استفاده از شبکه عصبی کانولوشنی در PyTorch چه مزیتهایی در مقایسه با دیگر کتابخانهها دارد؟
PyTorch، بهدلیل رابط کاربری پویا و انعطافپذیر، پشتیبانی قوی از GPU، جامعه کاربری فعال و منابع آموزشی فراوان، یکی از محبوبترین کتابخانهها برای پیادهسازی و آموزش شبکههای عصبی کانولوشنی است؛ همچنین این کتابخانه امکان سفارشیسازی مدلها و استفاده از ابزارهای مختلف برای بهینهسازی را فراهم میکند.
چگونه میتوان از تکنیکهای Regularization و Early Stopping برای جلوگیری از بیشبرازش در شبکه عصبی کانولوشنی در PyTorch استفاده کرد؟
تکنیکهای Regularization مانند L2 و Dropout و استفاده از Early Stopping به شما کمک میکنند تا از بیشبرازش مدلهای CNN جلوگیری کنید. در PyTorch، میتوانید از پارامتر weight_decay در بهینهساز برای L2 Regularization و از لایه Dropout برای کاهش بیشبرازش استفاده کنید. Early Stopping نیز با متوقف کردن آموزش زمانی که عملکرد مدل روی دادههای اعتبارسنجی شروع به بدترشدن میکند، به جلوگیری از بیشبرازش کمک میکند.
چگونه میتوان Feature mapهای لایههای مختلف یک شبکه عصبی کانولوشنی در PyTorch را نمایش داد؟
برای نمایش Feature map های لایههای مختلف یک مدل CNN در PyTorch، ابتدا یک تصویر را انتخاب و به مدل وارد میکنید. سپس با استفاده از torch.no_grad، نقشههای ویژگیهای استخراج شده از لایههای کانولوشنی را محاسبه و به آرایههای numpy تبدیل کنید. با استفاده از Matplotlib میتوانید این نقشههای ویژگی را بهصورت تصویری نمایش دهید. این کار به درک بهتر نحوه استخراج ویژگیها توسط فیلترهای کانولوشنی کمک میکند.
چگونه میتوان عملکرد مدلهای CNN را با استفاده از تکنیکهای Ensemble بهبود بخشید؟
برای بهبود عملکرد مدلهای CNN میتوان از تکنیکهای Ensemble استفاده کرد. این روش شامل ترکیب چندین مدل مختلف برای ایجاد یک مدل نهایی است که عملکرد بهتری دارد. در این تکنیک، مدلهای مختلف میتوانند بهصورت موازی آموزش داده شوند و سپس پیشبینیهای آنها با هم ترکیب شود تا دقت و استحکام نهایی افزایش یابد. تکنیکهای Ensemble مانند Bagging و Boosting میتوانند برای این منظور استفاده شوند.
یادگیری دیپ لرنینگ را از امروز شروع کنید!
دنیای دادهها جذاب است و دانستن علم داده، توانایی تحلیل داده، یا بازاریابی مبتنی بر داده، شما را برای فرصتهای شغلی بسیاری مناسب میکند. فارغ از رشته و پیشزمینه، میتوانید حالا شروع کنید و از سطح مقدماتی تا پیشرفته بیاموزید. اگر دوست دارید به این حوزه وارد شوید، پیشنهاد میکنیم با کلیک روی این لینک قدم اول را همین حالا بردارید.
مشاوران کافهتدریس به شما کمک میکنند مسیر یادگیری برای ورود به این حوزه را شروع کنید: