
در این وبلاگ، تجربه همکاری تیمیمان در «Regression with an Abalone Dataset» در مجموعه مسابقات Kaggle را با شما به اشتراک میگذاریم. اگر دانشجو، دانشمند داده یا مهندس یادگیری ماشین هستید، در اینجا نکات کاربردی برای بهبود مهارتهای مدلسازی رگرسیون خواهید یافت و شاید شما هم تشویق شوید که با چالشهای مشابه روبرو شوید.
- 1. کار تیمی و یادگیری مستمر
- 2. شروع ماجرا: رقابت و توضیحات مجموعهداده Abalone
- 3. تحلیل اکتشافی دادهها
- 4. پیشپردازش دادهها
- 5. مهندسی ویژگیها
- 6. انتخاب مدل و آموزش
- 7. ارزیابی مدل
- 8. فرآیند ارسال خروجی پیشبینی در مسابقات Kaggle
- 9. درسهای کلیدی آموختهشده
- 10. نتیجهگیری
- 11. یادگیری ماشین لرنینگ را از امروز شروع کنید!
آیا تا به حال فکر کردهاید که در یک پروژه کلاسی، ناگهان به دنیایی پر از دادههای پیچیده و چالشبرانگیز وارد شوید؟ این دقیقاً تجربهای بود که چند هفته پیش برای من اتفاق افتاد. من و همتیمیهایم بهعنوان دانشجوی علم داده در کافه تدریس، تحت نظر استاد رضا شکرزاد در مسابقه Kaggle با موضوع پیشبینی سن صدف شرکت کردیم. در ابتدا فکر میکردیم که پیشبینی سن صدف کار سخت نباشد اما خیلی زود دریافتیم که این کار هم چالشبرانگیز و هم بسیار آموزنده است.
کار تیمی و یادگیری مستمر
ما هر هفته جلسات ایدهپردازی برگزار میکردیم که به من بیش از هر کتاب درسی، علم داده واقعی را یاد داد. شرکت در این مسابقات Kaggle برای ما بیش از یک تمرین عملی بود؛ یک ماجراجویی برای کشف و همکاری. ما با مجموعهداده Abalone کار کردیم، چالشها را پشت سر گذاشتیم و از دادهها به خروجی ارزشمندی رسیدیم. این تجربه به ما نشان داد که یادگیری واقعی از طریق کار عملی و تیمی اتفاق میافتد و فاصله بین دانش تئوری و کاربردهای واقعی را پر میکند.
اکنون، با ما همراه شوید تا ماجراجوییمان در تسلط بر مدلهای رگرسیون با مجموعهداده Abalone را مرور کنیم. از تحلیل اولیه دادهها تا تکنیکهای مدلسازی پیشرفته مرسوم در مسابقات Kaggle ، همه چیز را بررسی خواهیم کرد و درسهایی که در طول راه آموختیم را با شما به اشتراک میگذاریم.
شروع ماجرا: رقابت و توضیحات مجموعهداده Abalone
درباره رقابت و مسئله
در رقابت «Regression with an Abalone Dataset» هدف ما پیشبینی سن صدف بر اساس ویژگیهای فیزیکی آن است. این رقابت به دنبال سادهسازی فرآیندی پیچیده است که به طور سنتی برای تعیین سن صدف انجام میشده؛ فرآیندی که شامل برش، رنگآمیزی، و شمارش حلقههای پوسته زیر میکروسکوپ است. روشی که بسیار زمانبر و خستهکننده است. اکنون با استفاده از یادگیری ماشین و اندازهگیریهای سادهتر، این چالش به فرصتی برای تقویت تکنیکهای رگرسیون تبدیل شده است.
معیار اصلی سنجش ما در این رقابت، خطای ریشه میانگین مربعات لگاریتمی (RMSLE) است. این معیار عملکرد مدل را در مقیاس لگاریتمی میسنجد و به ارزیابی دقت نسبی پیشبینیها کمک میکند.
درک مجموعهداده
برای این رقابت، Kaggle یک نسخه تعدیلشده از مجموعهداده Abalone در UCI را ارائه کرده است. این نسخه جدید با استفاده از یک مدل یادگیری عمیق روی دادههای اصلی آموزش داده شده و ویژگیها کمی تفاوت دارند تا چالشی تازه و جذاب برای رقابت فراهم کند.
ویژگیهای (Features) این مجموعهداده عبارتند از:
شناسه (ID)، جنسیت (Sex)، طول (Length)، قطر (Diameter)، ارتفاع (Height)، وزن کل (Whole Weight)، وزن گوشت جدا شده (Shucked Weight)، وزن احشاء (Viscera Weight)، وزن پوسته (Shell Weight) و تعداد حلقهها (Rings، که بهاضافه ۱.۵ معادل سن صدف به سال است). متغیر هدف در این مجموعهداده، تعداد حلقههای درون پوسته است که بهطور مستقیم با سن صدف همبستگی دارد.
تجربه ما نشان داد که ترکیب مجموعهداده Kaggle با مجموعهداده اصلی UCI منجر به بهبود پیشبینیهای مدل شده و امتیازهای بالاتری به دست آوردیم. برای این ادغام، برخی ویژگیها را تغییر نام دادیم تا از تداخل دادهها جلوگیری کنیم و یکپارچگی اطلاعات حفظ شود.
تحلیل اکتشافی دادهها
در مرحله تحلیل اکتشافی دادهها (EDA)، از ابزارهای بصری مختلفی مانند نمودارهای توزیع داده ها (Distplot)، نمودارهای جعبهای (Boxplot) و برای نمایش ماتریس همبستگی (Correlation Matrix)، از Heatmap استفاده کردیم تا ساختار دادهها و روابط بین ویژگیها را بررسی کنیم. این ابزارها به ما کمک کردند تا دید واضحتری از ویژگیهای دادهها و الگوهای پنهان میان متغیرها به دست آوریم.
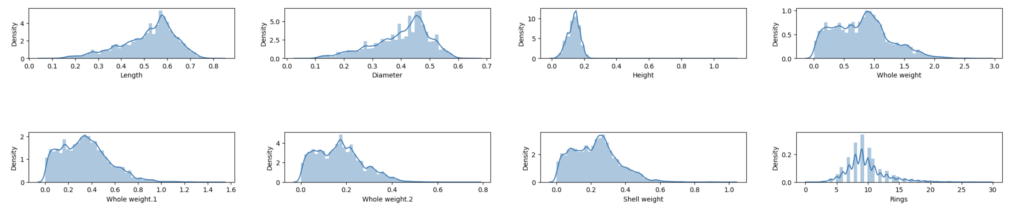
مشکل چولگی و وجود داده های پرت در متغیر هدف
با تحلیل توزیع متغیر هدف، یعنی تعداد حلقهها (Rings)، از طریق نمودارهای توزیع داده ها و جعبهای، متوجه شدیم که این متغیر دارای چولگی (Right Skewed) است و احتمالاً شامل داده های پرت (Outlier) میباشد. این وضعیت نشان میدهد که نیاز به دقت بیشتری در پیشپردازش دادهها داریم تا از اثرات منفی داده های پرت بر مدل جلوگیری کنیم.
روابط قوی بین ویژگیها و متغیر هدف
نمودار Heatmap نشان داد که برخی ویژگیها مانند طول (Length) و وزن کل (Whole Weight) همبستگیهای قوی با متغیر هدف (Rings) دارند. این همبستگیها نشان میدهد که این ویژگیها میتوانند در پیشبینی سن صدف بسیار مؤثر باشند و باید در مدلسازی به آنها توجه ویژهای شود.
اهمیت تحلیل اکتشافی دادهها
تحلیل اکتشافی دادهها (EDA) نقش مهمی در تعیین استراتژیهای ما برای آمادهسازی دادهها و توسعه مدلها ایفا کرد. به دلیل وجود چولگی و توزیع غیر نرمال «حلقهها»، به تکنیکهای پیشپردازش خاصی نیاز داریم تا دقت پیشبینیها بهینه شود. همچنین، شناسایی روابط قوی بین ویژگیها و متغیر هدف به ما کمک کرد تا جهتگیری بهتری در انتخاب و تنظیم مدلها داشته باشیم.
این تحلیل به ما کمک کرد تا درک عمیقتری از مجموعهداده Abalone پیدا کنیم و راهکارهای موثری برای بهبود عملکرد مدلها شناسایی کنیم.
پیشپردازش دادهها
مدیریت چولگی در متغیر هدف
درک و رفع چولگی
در حوزه یادگیری ماشین، توزیع متغیر هدف تاثیر چشمگیری بر عملکرد مدل دارد، بهخصوص در مسابقاتی که از معیارهایی مانند خطای ریشه میانگین مربعات لگاریتمی (RMSLE) استفاده میکنند. RMSLE به دلیل حساسیت به تفاوتهای نسبی و جریمه بیشتر پیشبینیهای کمتر از حد، نسبت به بیشتر از حد، برای مجموعهدادههایی با متغیر هدف چوله بسیار مناسب است. در مجموعهداده آبالون، متغیر هدف حلقهها (Rings) چولگی قابل توجهی دارد، که نشاندهنده وجود دادههای پرت و توزیع غیرنرمال است. این چولگی میتواند منجر به پیشبینیهای نامناسب، اختلال در درک مدل از روابط بین ویژگیها و کاهش عملکرد مدل شود.
راهحل ما: استفاده از تبدیل log1p برای رفع چولگی
برای مقابله با این چولگی و بهبود دقت مدل، از تبدیل np.log1p استفاده کردیم. این تبدیل لگاریتم طبیعی را با اضافه کردن یک به مقادیر (log(1 + x)) محاسبه میکند و به دلیل اضافه کردن ۱، بهخوبی با مقادیر صفر و نزدیک به صفر کار میکند، که به نرمالتر شدن توزیع متغیر هدف کمک میکند. این تبدیل باعث توزیع متعادلتر و متقارنتر متغیر هدف شد و اثر دادههای پرت را کاهش داد. همسو کردن متغیر هدف با فرضیات مدلهای رگرسیون، منجر به بهبود دقت و قابلیت اطمینان پیشبینیهای ما شد و در نهایت امتیاز ما را در رقابت با معیار (RMSLE) بهطور قابل توجهی افزایش داد.
چرا تبدیل log1p مفید است؟
- نرمالسازی توزیع: تبدیل log1p بهطور موثری چولگی توزیع دادهها را کاهش میدهد و توزیع را به نرمال نزدیکتر میکند. این امر برای الگوریتمهای رگرسیون که معمولاً با فرض توزیع نرمال کار میکنند، بسیار مفید است.
- برخورد مناسب با مقادیر صفر: این تبدیل با اضافه کردن ۱ به مقدار قبل از گرفتن لگاریتم، مقادیر صفر و نزدیک به صفر را بهخوبی مدیریت میکند، بدون اینکه باعث حذف یا تغییر نامطلوب آنها شود.
- کاهش اثر داده های پرت: با کاهش اثرداده های پرت، مدلها میتوانند اطلاعات معنادارتر و دقیقتری از دادهها استخراج کنند، که بهبود در پیشبینیها را به همراه دارد.
- افزایش عملکرد مدل: تنظیم توزیع دادهها به شکلی که مدلها بتوانند بهتر از آن یاد بگیرند، دقت و قابلیت اطمینان پیشبینیها را بهبود میبخشد. این موضوع بهویژه در مسابقات Kaggle با معیار RMSLE مؤثر است.
مدیریت مقادیر گمشده
شناسایی و جایگذاری مقادیر گمشده
یکی از مراحل حیاتی در پیشپردازش دادههای مجموعهداده Abalone، مدیریت مقادیر گمشده (Missing Value) بود. در ستون «ارتفاع» (Height)، با مقادیر صفر غیرواقعی مواجه شدیم که با توجه به دانش دامنهای این مسئله، غیرمنطقی به نظر میرسید. این مقادیر صفر را به عنوان دادههای گمشده شناسایی کردیم که نیاز به جایگذاری داشتند.
استراتژی جایگذاری مبتنی بر داده
به جای استفاده از روشهای ساده مانند میانگین یا میانه برای جایگذاری (Imputation)، تصمیم گرفتیم از رویکردی دادهمحور بهره ببریم تا دقت و یکپارچگی مجموعهداده را حفظ کنیم. ابتدا، ویژگی «قطر» (Diameter) را که بیشترین همبستگی با «ارتفاع» داشت، شناسایی کردیم. این همبستگی بالا (0.92) به ما این امکان را داد که به جایگذاری بهینه بپردازیم.
با استفاده از این همبستگی قوی، مقادیر گمشده «ارتفاع» را با محاسبه میانه «ارتفاع» در هر گروه «قطر» جایگزین کردیم. این روش تضمین کرد که مقادیر جایگزینشده به شکل بهتری منعکسکننده تخمینهای واقعی و منطبق بر ساختار دادهها باشند.
برای درک بهتر، در ادامه کد مربوط به این روش آورده شده است:
# Group by 'Diameter' and calculate the median 'Height' within each group
median_height_by_diameter = X_train.groupby('Diameter')['Height'].median()
# Create a function to impute zero values with median 'Height' based on 'Diameter'
def impute_height(row):
if row['Height'] == 0:
diameter_median_height = median_height_by_diameter.get(row['Diameter'])
if diameter_median_height is not None:
return diameter_median_height
return row['Height']
# Apply the function to impute missing 'Height' values
X_train['Height'] = X_train.apply(impute_height, axis=1)
یافتههای مهم
از این مرحله یاد گرفتیم که استفاده از همبستگیهای موجود در دادهها، برای انتخاب استراتژیهای جایگذاری، علاوه بر حفظ یکپارچگی مجموعه داده، روابط آماری مهم را برای مدلسازی دقیقتر برقرار نگه میدارد. تشخیص مقادیر نامناسب به عنوان داده گمشده (Missing Value)، یکی از نکات کلیدی بود که به ما کمک کرد تا پیشپردازش دادهها را به شکلی مؤثرتر انجام دهیم.
علاوه بر این، متوجه شدیم که مقادیر گمشده همیشه بهطور صریح به عنوان null یا NaN نشان داده نمیشوند. علاوه بر دادههای دنیای واقعی در برخی از مسابقات Kaggle نیز، مقادیر غیرمنطقی برای ویژگیهای خاص، مانند صفرها برای «ارتفاع»، باید به عنوان داده گمشده پنهان در نظر گرفته شوند. شناسایی این مقادیر نامناسب بر اساس دانش زمینهای دادهها، برای پیشپردازش دقیق و مؤثر ضروری است.
کدگذاری ویژگیهای دستهبندیشده
چالش: تبدیل ویژگیهای دستهبندیشده
مدیریت ویژگی های دستهبندیشده (Categorical) برای مدلهای رگرسیون که نیاز به ورودیهای عددی دارند، از اهمیت ویژهای برخوردار است. در مجموعهداده Abalone، ستون «جنسیت» (Sex) بهعنوان یک ویژگی دستهبندیشده، شامل مقادیر ‘M’ نر، ‘F’ ماده و ‘I’ نوزاد بود. برای تبدیل این ویژگی به فرمت عددی، از تکنیک کدگذاری One-Hot Encoding استفاده کردیم که امکان تفسیر دقیق دادههای دستهبندیشده را برای مدل فراهم میکرد.
استراتژی: استفاده از کدگذاری One-Hot Encoding با استفاده از تابع pd.get_dummies
برای تبدیل ستون «جنسیت» به فرمت عددی، از تابع pd.get_dummies در کتابخانه پانداس (pandas) استفاده کردیم. این روش ستونهای باینری جداگانهای برای هر دسته ایجاد میکند که به مدل اجازه میدهد به طور مؤثری از اطلاعات دستهبندیشده استفاده کند.
شناسایی و مدیریت دادههای پرت
شناسایی دادههای پرت
دادههای پرت (Outliers) میتوانند به دلیل وجود مقادیر افراطی در مجموعهداده، عملکرد مدلهای یادگیری ماشین را مختل کنند. برای شناسایی این دادههای پرت، از روش محدوده بینچارکی (IQR) استفاده کردیم. مقادیر خارج از این محدوده به عنوان دادههای پرت در نظر گرفته میشوند. کد محاسبه محدودههای پایینتر و بالاتر به شرح زیر است:
X_numerical_features = X_train.select_dtypes(include=[np.number])
# Define a function to find outliers based on IQR
def find_outliers(df):
outliers = {}
for col in df.columns:
v = df[col]
q1 = v.quantile(0.25)
q3 = v.quantile(0.75)
iqr = q3 - q1
lower_bound = q1 - 1.5 * iqr
upper_bound = q3 + 1.5 * iqr
outliers_count = ((v upper_bound)).sum() # Fixed the condition here
perc = outliers_count * 100.0 / len(df)
outliers[col] = (perc, outliers_count)
print(f"Column {col} outliers = {perc:.2f}% ({outliers_count} out of {len(df)})")
return outliers
# Find outliers in the DataFrame
outliers = find_outliers(X_numerical_features)
مدیریت دادههای پرت
برای مدیریت دادههای پرت، مقادیر خارج از محدوده IQR را با حداقل و حداکثر مرزهای تعیین شده جایگزین کردیم. این کار با استفاده از یک کلاس سفارشی انجام شد که به حفظ یکپارچگی دادهها و کاهش تأثیر مقادیر پرت کمک میکند. نمونه کد زیر نحوه اعمال این روش را نشان میدهد:
class OutlierBoundaryImputer(BaseEstimator, TransformerMixin):
def fit(self, X, y=None):
Q1 = np.percentile(X, 25, axis=0)
Q3 = np.percentile(X, 75, axis=0)
IQR = Q3 - Q1
self.lower_bound = Q1 - 1.5 * IQR
self.upper_bound = Q3 + 1.5 * IQR
return self
def transform(self, X):
X_outlier_imputed = np.where(X self.upper_bound,
self.upper_bound, X_outlier_imputed)
return X_outlier_imputed
این کلاس ابتدا با استفاده از متد fit محدوده پایینتر و بالاتر را برای ویژگی تعیین میکند و سپس با متد transform مقادیر پرت را با محدودههای تعیین شده جایگزین میکند.
مقیاسدهی ستونهای عددی
در تحلیلهای ما، استفاده از StandardScaler نسبت به MinMaxScaler برای آمادهسازی دادهها در مدلهای یادگیری ماشین عملکرد بهتری داشت. این ابزار مقیاسدهی، ویژگیها را به توزیعی با میانگین صفر و انحراف معیار یک تبدیل میکند که برای بسیاری از الگوریتمها بهینهتر است.
یکپارچهسازی پیشپردازش در یک پایپلاین
اهمیت استفاده از پایپلاین
پایپلاین (Pipeline) یادگیری ماشین، جریان کاری پیشپردازش و مدلسازی را سادهتر کرده و تضمین میکند که تمامی تبدیلها بهطور پیوسته روی مجموعههای آموزشی (train) و اعتبارسنجی (validation) اعمال میشوند. این پایپلاین شامل تمامی مراحل از مدیریت دادههای پرت و مقیاسدهی ویژگیها و برازش مدل است که تمامی مراحل را خودکار کرده و به بهبود کارایی و کاهش خطاها کمک میکند.
پیادهسازی در پروژه ما
در پروژه ما، مراحل پیشپردازشی که پیشتر توضیح داده شد را در یک پایپلاین یکپارچه کردیم. این مراحل شامل مدیریت دادههای پرت با استفاده از OutlierBoundaryImputer و مقیاسدهی ویژگیها با استفاده از StandardScaler بود. مهم است که در مجموعه آموزش (train) از fit_transform و در مجموعههای اعتبارسنجی و تست (validation & test) تنها از transform استفاده شود.
برای اطمینان از توسعه و ارزیابی دقیق مدل، از اعتبارسنجی متقابل پنجبخشی (fold cross-validation) استفاده کردیم که به کمک پایپلاین، تمامی مراحل بهدرستی اجرا شدند. کد زیر نحوه ساخت یک پایپلاین ساده را نشان میدهد:
pipeline_model = Pipeline(steps=[
('outlier_imputer', OutlierBoundaryImputer()),
('scaler', StandardScaler()),
('model', CatBoostRegressor())
])
این مثال نشان میدهد که چگونه میتوان یک پایپلاین ساخت که شامل تمامی مراحل پیشپردازش و مدلسازی باشد و نتایج پیوسته و قابل اعتمادی را ارائه دهد.
مهندسی ویژگیها
ایجاد ویژگیهای جدید و تبدیلها برای بهبود پیشبینیها
مهندسی ویژگیها مرحلهای کلیدی در فرآیند یادگیری ماشین است که هدف آن استخراج ویژگیهای جدید از ویژگیهای موجود به منظور افزایش دقت پیشبینی مدلها است. در تحلیل مجموعهداده Abalone، ما با بررسی و ایجاد ویژگیهای جدید از دادههای اولیه، تلاش کردیم روابط پیچیدهتری را شناسایی کرده و به بهبود دقت پیشبینی مدل کمک کنیم.
ابتدا فرض کردیم که برخی ویژگیها مانند حجم (Volume)، ضخامت پوسته (Shell Thickness)، چگالی (Density) و سطح پوسته (Shell surface area) میتوانند در پیشبینی سن صدفها مفید باشند. برای محاسبه حجم از ضرب طول، قطر و ارتفاع استفاده کردیم که نمایانگر اندازه کلی صدف است. ضخامت پوسته از تفاوت قطر و ارتفاع به دست آمد، با این فرض که صدفهای قدیمیتر دارای پوستههای ضخیمتری هستند. چگالی با تقسیم وزن کل بر حجم محاسبه شد، و سطح پوسته با استفاده از فرمول سطح جانبی یک استوانه تخمین زده شد. همچنین چند ویژگی نسبتسنجی (Ratio Features) را برای بررسی بیشتر انتخاب کردیم، مانند نسبتهای طول به وزن پوسته (Ratio of Length to Shell Weight)، وزن گوشت به وزن کل (Proportion of Shucked Weight to Whole Weight)، طول به قطر و ارتفاع به وزن کل، تا روابط بین جنبههای مختلف فیزیکی صدفها را بهتر درک کنیم.
با این حال، بررسی نتایج نشان داد که بیشتر این ویژگیهای جدید بهبود چشمگیری در عملکرد مدل ایجاد نکردند. پس از تحلیل اهمیت ویژگیها و ارزیابی مدل، تنها یک ویژگی جدید به طور مستمر باعث بهبود عملکرد پیشبینی مدل شد: نسبت وزن گوشت به وزن کل. این نسبت، شاخص معناداری از صدف فراهم کرد و نشان داد که چگونه توزیع گوشت نسبت به وزن کل میتواند با سن ارتباط داشته باشد. کد زیر برای تولید این ویژگی ارائه شده است:
# Feature Engineering
def Feature_Engineering(data):
# Proportion of Shucked Weight to Whole Weight
data['WholeW1_to_WholeW_Proportion'] = data['Whole weight.1'] / data['Whole weight']
return data
X_train = Feature_Engineering(X_train)
یافتههای مهم
مهمترین نتیجه این تجربه این است که همه ویژگیهایی که به صورت تئوری مفید به نظر میآیند، لزوماً به بهبود عملکرد مدل منجر نمیشوند. تأثیر هر ویژگی باید از طریق تحلیل اهمیت ویژگی (feature importance) و عملکرد مدل بهصورت تجربی بررسی شود. یافتههای ما بر اهمیت سادگی و ارتباط مؤثر تأکید دارند، به جای تولید تعداد زیادی از ویژگیهای جدید که ممکن است کارآمد نباشند. ایجاد طیف گستردهای از ویژگیهای جدید میتواند مفید باشد، اما اثربخشی واقعی آنها به تأثیر مثبتشان بر عملکرد پیشبینی مدل بستگی دارد. استراتژی مؤثر ما شامل استفاده از ویژگیهایی بود که به صورت شهودی و آماری با متغیر هدف همخوانی داشتند، مانند نسبت وزن گوشت به وزن کل. بنابراین، مهندسی ویژگیها باید براساس دادهها و دانش حوزهای انجام شود تا به پیشرفتهای معنادار در عملکرد مدل دست یابیم.
انتخاب مدل و آموزش
مقایسه مدلهای رگرسیون و تنظیم هایپرپارامترها برای عملکرد بهینه
انتخاب مدل مناسب، بخش حیاتی در فرآیند پیشبینی سن صدفها بود. برای یافتن مؤثرترین مدل، چندین مدل رگرسیون را مورد ارزیابی قرار دادیم. اینجا به بررسی دقیقتر فرآیند انتخاب مدل میپردازیم:
تست مدل ها و پایپلاین
برای تضمین ارزیابی دقیق، مدلهای مختلف رگرسیون را در یک پایپلاین یکپارچه قرار دادیم. این پایپلاین شامل مراحل پیشپردازش دادهها، مدیریت دادههای پرت، مقیاسبندی ویژگیها، و اجرای مدل نهایی بود. هر مدل با استفاده از اعتبارسنجی ۵-بخشی (fold cross validation) آزمایش شد تا عملکرد قابل اعتمادی را ارائه دهد. مدلهای مورد بررسی شامل:
- رگرسیون خطی (Linear Regression): به عنوان مدل پایه به دلیل سادگی و قابلیت تفسیر آن استفاده شد.
- رگرسیون lasso و ridge با ویژگیهای چندجملهای (Polynomial Features): برای شناسایی روابط غیرخطی، ویژگیهای چندجملهای افزوده شدند و lasso و ridge برای جلوگیری از بیشبرازش(overfitting) به کار رفتند.
- رگرسیون جنگل تصادفی (RandomForest Regressor): به دلیل تواناییاش در مدیریت تعاملات پیچیده بین ویژگیها بدون نیاز به مقیاسبندی انتخاب شد.
- XGBoost: به دلیل کارایی و عملکرد خوب در دادههای ساختارمند، از طریق تقویت گرادیان شناخته شده است.
- LightGBM: برای سرعت و توانایی مدیریت کارآمد مجموعه دادههای بزرگ انتخاب شد. استراتژی رشد درخت برگمحور(leaf-wise tree) LGBM به خوبی توانست الگوهای مهم و نکات ظریف در دادهها را ثبت کند.
- CatBoost: به دلیل توانایی مدیریت مستقیم متغیرهای دستهای و کاهش بیشبرازش (overfitting) با تکنیکهای boosting، مفید بود.
- رگرسیون گرادیان تقویتی (Regressor GradientBoosting): برای قابلیتاش در ساخت مدلهای پیشبینی قوی با ترکیب چندین یادگیرنده ضعیف به صورت تکراری، که به طور مؤثری روابط غیرخطی را ثبت میکند.
تنظیم هایپرپارامترها
تنظیم هایپرپارامترها (Hyperparameter Tuning) نقش کلیدی در بهینهسازی مدلها ایفا کرد. ما ازGridSearchCV برای جستجوی سیستماتیک بهترین هایپرپارامترها استفاده کردیم که شامل اعتبارسنجی متقابل پنجبخشی (fold cross-validation) بود. این روش تضمین کرد که ارزیابی هر مدل جامع باشد و از هرگونه بایاس احتمالی ناشی از تقسیمبندی ساده آموزش-آزمون (train-test-split) جلوگیری شود. تجربه ما نشان داد که تنظیم هایپرپارامترها برای بهبود عملکرد مدل ضروری است و کنترل دقیقتری بر رفتار و نتایج مدل فراهم میآورد.
روشهای ترکیبی: استفاده از مدلهای ترکیبی Stacking و Voting
پس از ارزیابی مدلهای بیان شده، LightGBM ،CatBoost و رگرسیون گرادیان تقویتی به عنوان بهترین مدلها انتخاب شدند. برای بهبود بیشتر عملکرد، روشهای ترکیبی زیر را به کار بردیم:
- Stacking Regressor : این رویکرد پیشبینیهای LightGBM، CatBoost، و رگرسیون گرادیان تقویتی را با استفاده از یک متا-مدل ترکیب کرد. متا-مدل از نقاط قوت هر مدل پایه استفاده کرد و بهبود چشمگیری در پیشبینی کلی ایجاد کرد.
- Voting Regressor: این روش با میانگینگیری از خروجیهای سه مدل برتر، پیشبینیها را تجمیع کرد. به هر مدل وزنهای مختلفی بر اساس عملکرد فردی آنها اختصاص یافت که امکان استفاده از نقاط قوت هر مدل را فراهم کرد و بهترین نتایج را در آزمونهای این رقابت ارائه داد.
برای هر مدل ترکیبی، یک پایپلاین کامل که شامل مدیریت دادههای پرت، مقیاسبندی ویژگیها، و مدل رگرسیون بود، ایجاد شد. تجربه ما نشان داد که روشهای ترکیبی Stacking و Voting با یکپارچه کردن نقاط قوت مدلهای تکی، به ارائه پیشبینیهای دقیقتر کمک میکنند.
ارزیابی مدل
ارزیابی عملکرد مدل: معیارها و تکنیکها برای رگرسیون
ارزیابی دقیق عملکرد مدلهای رگرسیونی بهویژه در پروژههای واقعی و مسابقات Kaggle بسیار حیاتی است. در این بخش، به شرح معیارها و روشهای ارزیابی مدل پرداختهایم:
معیارهای ارزیابی
ما از مجموعهای از معیارها برای سنجش اثربخشی مدل استفاده کردیم که هر یک از زاویهای خاص به تحلیل عملکرد کمک میکردند:
- خطای ریشه میانگین مربعات لگاریتمی (RMSLE): معیار اصلی برای ارزیابی مدل در این رقابت، RMSLE بود. این معیار نسبت به زیرپیشبینیها حساستر است و برای دادههایی که متغیر هدف به صورت لگاریتمی تبدیل شده است، مناسب میباشد. RMSLE خطای نسبی را محاسبه میکند، که برای سناریوهایی با دامنه وسیع متغیر هدف، مزیت دارد.
- امتیاز R² :R² نمایانگر درصد واریانس متغیر هدف که توسط ویژگیها توضیح داده شده است، میباشد. این معیار به ارزیابی توانایی مدل در پیشبینی دقیق متغیر هدف کمک میکند.
- خطای ریشه میانگین مربعات (RMSE): RMSE اندازهگیری مستقیمی از خطای پیشبینی را در همان واحدهای متغیر هدف ارائه میدهد. این معیار اهمیت خطاهای بزرگتر را برجسته میکند و میانگین بزرگی خطاها را نمایان میسازد.
- خطای میانگین مربعات لگاریتمی (MSLE): MSLE به بررسی تفاوتهای لگاریتمی بین مقادیر پیشبینیشده و واقعی میپردازد. این معیار مکمل RMSLE است و به تحلیل دقیقتری از خطای پیشبینی کمک میکند.
با توجه به اینکه متغیر هدف با استفاده از log1p تبدیل شده بود، در ارزیابی مدل از np.expm1 برای تبدیل مقادیر واقعی و پیشبینیشده به مقیاس اصلی استفاده کردیم. این تبدیل برای تفسیر دقیقتر معیارها و انعکاس صحیح توزیع دادههای اصلی ضروری بود.
یافتههای مهم
- انتخاب معیارها: استفاده از معیارهای مختلف به ما دید جامعی از عملکرد مدل داد. در حالی که RMSLE به عنوان معیار اصلی اهمیت داشت، RMSE و MSLE اطلاعات مکملی درباره ویژگیهای خطا ارائه کردند و R² کمک کرد تا قدرت توضیحی مدل (model’s explanatory power) را بهتر درک کنیم.
- تبدیل دادهها: تبدیل متغیر هدف با log1p و بازگرداندن این تبدیل در مرحله ارزیابی، برای تفسیر معنادار معیارها حیاتی بود. این تنظیم بهویژه برای RMSLE و MSLE که به مقیاس متغیر هدف حساس هستند، اهمیت داشت.
- اعتبارسنجی: استفاده از اعتبارسنجی متقابل پنجبخشی (fold cross-validation) در ارزیابی مدل، به کسب تخمین مقاوم از عملکرد کمک کرد. این روش، خطر بیشبرازش (overfitting) را کاهش داد و نمایانگر قابل اعتمادی از کارایی مدل در دادههای نادیده (unseen data) بود، که علاوه بر مسابقات Kaggle ، نشاندهنده پایداری آن برای کاربردهای دنیای واقعی است.
فرآیند ارسال خروجی پیشبینی در مسابقات Kaggle
از پیشبینی تا جدول امتیازات عمومی
پس از اتمام فرآیند آموزش و ارزیابی مدلها، نوبت به مرحلهی ارسال نتایج نهایی به مسابقات Kaggle رسید. برای این کار، مراحل زیر را انجام دادیم:
پیشبینیهای نهایی
ابتدا، کل پایپلاین آموزش خود را، که شامل پیشپردازش و مدلسازی بود، بر روی مجموعه دادههای آموزش کامل اعمال کردیم. سپس از این پایپلاین برای پیشبینی متغیر هدف بر روی مجموعه دادههای آزمایش استفاده کردیم. این پیشبینیها مطابق با فرمت sample_submission.csv ارائه شده توسط مسابقات Kaggle قالببندی شدند.
ارسال فایل
فایل submission.csv را در پلتفرم مسابقات Kaggle بارگذاری کردیم. امتیاز عمومی ما که بر اساس ۲۰٪ از دادههای آزمایشی تعیین میشود، بلافاصله به ما نشان داده شد. این امتیاز به ما دیدگاهی از عملکرد مدل در مقابل رقبا ارائه داد.
بهبود و ارسال مجدد
با تحلیل امتیاز عمومی، فرصتهای بهبود را شناسایی کرده و تغییرات لازم را در مدلهایمان اعمال کردیم. فرآیند ارسال مجدد تکرار شد تا به امتیاز بهینهتری دست یابیم.
تجربهی جمعی
شرکت در مسابقات Kaggle به ما این امکان را داد تا همکاری گروهی و فرآیند یادگیریمان را به سطح جدیدی ارتقا دهیم. هر یک از ما، با به اشتراکگذاری تجربیات و امتیازات فردی در جلسات منظم، به همدیگر کمک کردیم تا استراتژیهای بهینه را شناسایی کرده و درک عمیقتری از مدلها به دست آوریم. نتایج نخستین رقابت دوستانهی ما در تصویر زیر به خوبی نشاندهندهی تلاشهای مشترک و همبستگی گروهی ماست.
استاد راهنمای ما با راهنماییهای دقیق و صبورانه، ما را در این مسیر هدایت کرد و به شرکت در سایر مسابقات Kaggle و همچنین رقابتهای پیچیدهتر، از جمله رقابتهای پردازش زبان طبیعی (NLP) و پروژههای بینایی ماشین تشویق کرد. این تلاش جمعی، سنگ بنای موفقیت ما در مسابقه بود.
درسهای کلیدی آموختهشده
- استفاده از دادهها در تصمیمگیری: اتخاذ تصمیمات مبتنی بر دادهها، از مراحل اولیه پیشپردازش تا مهندسی ویژگیها، نقش کلیدی در موفقیت ما داشت. پرکردن مقادیر گمشده، انتخاب ویژگیهای مهم، و مدیریت دادههای پرت همگی بر پایه تحلیل دقیق دادهها انجام شدند.
- ارزشمندی ویژگیهای جدید: ایجاد ویژگیهای متعدد لزوماً به بهبود مدل منجر نشد. از بین ویژگیهای جدید ایجاد شده، تنها تعداد کمی به طور قابل توجهی عملکرد مدل را بهبود بخشیدند. این تجربه اهمیت تحلیل دقیق تأثیر هر ویژگی در مسابقات Kaggle و هر پروژه دیگری را نشان داد.
- کارایی روشهای ترکیبی: روشهای ترکیبی مانند Stacking و Voting بهتر از مدلهای تکی عمل کردند. این روشها با ترکیب نقاط قوت مدلهای مختلف، به بهبود پیشبینیها کمک کردند.
- اهمیت اعتبارسنجی: اعتبارسنجی متقابل پنجبخشی (fold cross-validation) به ما کمک کرد تا تخمین دقیقی از عملکرد مدل بر روی دادههای نادیده به دست آوریم و از بیشبرازش جلوگیری کنیم. این روش به نمایندگی قابل اعتمادی از کارایی مدل در کاربردهای واقعی منجر شد.
- قدرت همکاری: جلسات منظم تیمی و تبادل نظرها، تفکر جمعی را تقویت کرد و به شناسایی استراتژیهای بهینه و حل چالشهای پیچیده موجود در مسابقات Kaggle کمک کرد. همکاری در تیم نه تنها باعث یادگیری بیشتر شد، بلکه به بهبود مستمر مدلها نیز انجامید.
نتیجهگیری
مسابقات Kaggle تجربهای ارزشمند از ترکیب تئوری و عمل ارائه میدهد، جایی که دانش نظری به مهارتهای عملی تبدیل میشود. شرکت در مسابقات Kaggle نه تنها به ما امکان داد تا مفاهیم پیچیدهی یادگیری ماشین را در دنیای واقعی اعمال کنیم، بلکه به تقویت مهارتهای حل مسئله و کار تیمی ما نیز کمک کرد. در خلال این چالش، توانستیم با استفاده از دادههای واقعی، الگوریتمها و تکنیکهای متنوعی را پیادهسازی کنیم، نتایج آنها را با دقت ارزیابی کنیم، و از بازخوردهای مداوم برای بهبود مدلهای خود بهره ببریم.
این تجربه نشان داد که تکمیل فرایند یادگیری واقعی بعد از کلاس درس، در مواجهه با مشکلات واقعی و ایجاد راهحلهای خلاقانه برای آنها شکل میگیرد. در نهایت، درک این که دادهها همیشه با پیچیدگیهای خاص خود همراه هستند، ما را به استفادهی بهتر از ابزارها و رویکردهای مختلف هدایت کرد و ما را برای چالشهای بزرگتر در حوزه علوم داده آماده ساخت. امیدوارم این تجربهها الهامبخش دیگران باشد تا به چالشهای مشابه در دنیای یادگیری ماشین بپردازند و از مسیر یادگیری لذت ببرند. هر مجموعه داده داستانی برای گفتن دارد و وظیفه ما کشف این داستانها و تبدیل آنها به اطلاعات ارزشمند است. برای موفقیت در این مسیر، نیاز به یادگیری مستمر، همکاری و تعهد داریم.
قدردانی
از استاد شکرزاد برای خرد، صبر و راهنماییهای بیدریغشان سپاسگزاریم. نقش ایشان در موفقیت ما در این دسته مسابقات Kaggle اساسی بود و با تشویق مستمر خود، ما را ترغیب کردند تا مرزهای دانش و مهارتهای خود را پیوسته گسترش دهیم. همچنین، از تمامی شرکتکنندگان قدردانی میکنیم که با حمایت و مشارکت فعال خود، به غنای تجربهی جمعی ما افزودند.
در پستهای آینده داستانهای بیشتری از مسابقات Kaggle به اشتراک خواهم گذاشت. هر مسابقه یک ماجراجویی آموزشی است و مشتاقانه منتظر کاوش و بحث در مورد چالشهای پیچیدهتر یادگیری ماشین با شما هستم.
منابع
مسابقات Kaggle سری Playground – S4E4
کد کامل در Kaggle: لینک مخزن
کد کامل در GitHub: لینک مخزن
مقاله به زبان انگلیسی: لینک مقاله
یادگیری ماشین لرنینگ را از امروز شروع کنید!
دنیای دادهها جذاب است و دانستن علم داده، توانایی تحلیل داده، یا بازاریابی مبتنی بر داده، شما را برای فرصتهای شغلی بسیاری مناسب میکند. فارغ از رشته و پیشزمینه، میتوانید حالا شروع کنید و از سطح مقدماتی تا پیشرفته بیاموزید. اگر دوست دارید به این حوزه وارد شوید، پیشنهاد میکنیم با کلیک روی این لینک قدم اول را همین حالا بردارید.
مشاوران کافهتدریس به شما کمک میکنند مسیر یادگیری برای ورود به این حوزه را شروع کنید: