
یادگیری ماشین (Machine Learning) یکی از شاخههای هوش مصنوعی است که به مطالعه و ساخت روشهایی برای شبیهسازی یادگیری انسان میپردازد. سایکیدلرن (Scikit-Learn) یکی از محبوبترین کتابخانههای پایتون برای پیادهسازی مدلهای یادگیری ماشین است. این کتابخانه به کاربران اجازه میدهد تا با استفاده از واسطی یکپارچه، الگوریتمهای مختلف یادگیری نظارتی و غیرنظارتی را بهراحتی پیادهسازی کنند. در این آموزش، به بررسی مراحل مختلف چرخه یادگیری ماشین یعنی پیشپردازش (Preprocessing) داده، آموزش مدل (Training) و ارزیابی مدل (Evaluation) بهکمک سایکیدلرن میپردازیم.
- 1. انواع ماشین لرنینگ
- 2. سایکیدلرن چیست؟
- 3. چطور با سایکیدلرن کار کنیم؟
- 4. مدلهای طبقهبندی
- 5. مدلهای خوشهبندی
- 6. جمعبندی
-
7.
پرسشهای متداول
- 7.1. مراحل پیشپردازش دادهها در پروژههای یادگیری ماشین با استفاده از سایکیدلرن چیست؟
- 7.2. چه مدلهای رگرسیونی در کتابخانه سایکیدلرن موجود هستند و چه کاربردهایی دارند؟
- 7.3. چگونه میتوان مدلهای طبقهبندی را با استفاده از کتابخانه سایکیدلرن ارزیابی کرد؟
- 7.4. استفاده از دادههای مصنوعی در پروژههای یادگیری ماشین با سایکیدلرن چگونه امکانپذیر است؟
- 7.5. چگونه میتوان پارامترهای مدلهای یادگیری ماشین را با استفاده از GridSearchCV بهینهسازی کرد؟
- 8. یادگیری ماشین لرنینگ را از امروز شروع کنید!
انواع ماشین لرنینگ
یادگیری ماشین به کامپیوترها این امکان را میدهد که از دادهها یاد بگیرند و بدون برنامهنویسی صریح عملکردهای مختلف را بهبود بخشند. یادگیری ماشین به سه نوع اصلی تقسیم میشود:
یادگیری نظارتشده
یادگیری نظارتشده (Supervised Learning) متداولترین نوع یادگیری ماشین است که در آن مدل با استفاده از دادههای برچسبدار (Labelled data) آموزش میبیند. این دادهها شامل ورودیها و خروجیهای صحیح هستند. هدف این نوع یادگیری، یافتن یک رابطه یا تابعی است که بتواند ورودیهای جدید را به خروجیهای درست تبدیل کند. یادگیری نظارتشده به دو نوع اصلی تقسیم میشود:
- رگرسیون (Regression): در این روش، هدف پیشبینی مقدار عددی پیوسته است. به عنوان مثال، پیشبینی قیمت خانهها بر اساس ویژگیهای مختلف آنها.
- طبقهبندی (Classification): در این روش، هدف مدل، دستهبندی دادهها به کلاسهای مختلف است. به عنوان مثال، تشخیص ایمیلهای اسپم از غیر اسپم یا تشخیص بیماری در پزشکی.
یادگیری بدون نظارت
در یادگیری بدون نظارت (Unsupervised Learning)، مدل با استفاده از دادههای بدون برچسب (Unlabeled data) آموزش میبیند. هدف این نوع یادگیری، کشف الگوها و ساختارهای پنهان در دادهها بدون داشتن خروجیهای صحیح است. یادگیری بدون نظارت به دو نوع اصلی تقسیم میشود:
- خوشهبندی (Clustering): در این روش، مدل دادهها را به گروههای مشابه (خوشهها) تقسیم میکند. به عنوان مثال، تقسیم مشتریان به گروههای مختلف بر اساس رفتار خرید.
- کاهش ابعاد (Dimensionality Reduction): در این روش، مدل تلاش میکند ابعاد دادهها را کاهش دهد در حالی که اطلاعات مهم حفظ شود. به عنوان مثال، کاهش ابعاد تصاویر برای فشردهسازی دادهها یا تجسم دادهها.
یادگیری تقویتی
یادگیری تقویتی (Reinforcement Learning) نوعی از یادگیری ماشین است که در آن یک عامل نرمافزاری با تعامل با محیط خود یاد میگیرد تا اقداماتی را انجام دهد که منجر به حداکثر پاداش شود. در این نوع یادگیری، عامل به طور مداوم از محیط بازخورد میگیرد و تصمیمات خود را بر اساس این بازخوردها بهبود میبخشد. یادگیری تقویتی در مسائلی که شامل تصمیمگیریهای متوالی هستند، بسیار کاربردی است. به عنوان مثال، بازیهای ویدئویی، رباتیک و سیستمهای توصیهگر.
برای آشنایی بیشتر با یادگیری تقویتی، به این مقاله مراجعه کنید: یادگیری تقویتی یا Reinforcement Learning و کاربردهایش چیست؟
سایکیدلرن چیست؟
سایکیدلرن یک کتابخانه متنباز (Open Source) و قوی در پایتون است که برای سادهسازی فرآیند پیادهسازی مدلهای یادگیری ماشین طراحی شده است. این کتابخانه به متخصصان این امکان را میدهد که یک طیف وسیع از الگوریتمهای یادگیری ماشین نظارتشده و بدون نظارت را از طریق یک رابط کاربری سازگار پیادهسازی کنند. Sklearn بر پایه SciPy ساخته شده و با انواع دادههای عددی که به صورت آرایههای NumPy و سایر انواع دادههایی که میتوانند به آرایههای عددی تبدیل شوند (مانند DataFrameهای Pandas)، کار میکند.
چطور با سایکیدلرن کار کنیم؟
در ادامه میخواهیم نحوه استفاده از سایکیدلرن را طی اجرای چند پروژه ماشین لرنینگ در محیط Google Colab آموزش دهیم. برای انجام این کار لازم است ابتدا یک مجموعه داده متناسب با نوع پروژه ماشین لرنینگی که میخواهیم اجرا کنیم، داشته باشیم. جالب است بدانید سایکیدلرن فکر اینجا را هم کرده و برخی مجموعه دادههای استاندارد یادگیری ماشین را در کلاس datasets خود قرار داده است. این یعنی نیازی به دانلود داده از یک وبسایت یا پایگاه داده خارجی نیست. اما چطور میتوان به این مجموعه دادهها دسترسی پیدا کرد؟
بارگذاری دادهها
همانطور که گفتیم، میتوان از کلاس datasets از کتابخانه سایکیدلرن، داده موردنیاز برای انجام پروژه موردنظر را بارگذاری کرد. اما پیش از آن، باید بدانیم که میخواهیم چه پروژهای انجام بدهیم تا متناسب با آن، مجموعه داده خود را انتخاب کنیم. برای مثال، یکی از مجموعه دادههای سایکیدلرن که مناسب مدلهای رگرسیون میباشد، مجموعه داده دیابت است. در این قسمت بااستفاده از این دیتاست یک پروژه رگرسیون را اجرا خواهیم کرد. برای بارگذاری این دیتاست از کد زیر استفاده میکنیم:

این کد، دادهها را به صورت یک دیکشنری بارگذاری میکند. برای پردازش و تحلیل دادهها، میتوانیم آنها را به یک DataFrame تبدیل کنیم:

در نهایت، پنج سطر اول آن را نمایش میدهیم تا نگاهی سریع به دادهها داشته باشیم:
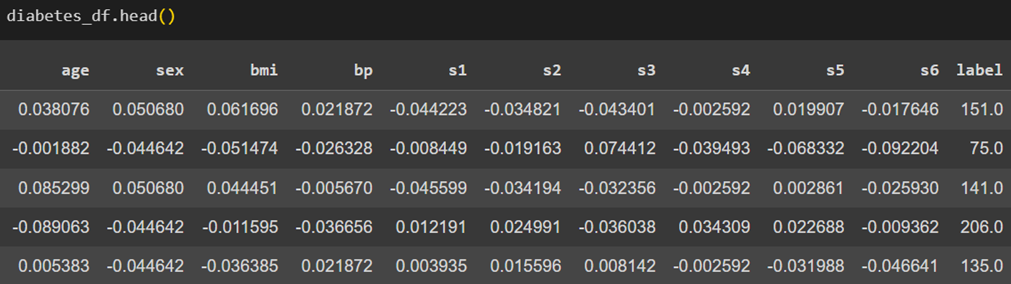
این دیتاست شامل اطلاعات مربوط به ۴۴۲ بیمار دیابتی است و همانطور که در تصویر بالا مشخص است، شامل ۱۰ ویژگی (Feature) و یک متغیر هدف (Label) میباشد. در ادامه توضیح مختصری از تعریف هریک از این ویژگیها و همچنین متغیر هدف آوردهشدهاست:
- age: سن بیمار
- sex: جنسیت بیمار
- BMI: شاخص توده بدنی بیمار یا همان نسبت وزن به کیلوگرم تقسیم بر (قد به متر بهتوان دو)
- BP: میانگین فشار خون بیمار
- S1: مقدار کلسترول موجود در سرم خون (بخشی از پلاسمای خون) بیمار
- S2: میزان لیپوپروتئینهای با چگالی کم بیمار
- S3: میزان لیپوپروتئینهای با چگالی بالا بیمار
- S4: میزان کلسترول کل بیمار
- S5: میزان تریگلیسرید سرم خون بیمار
- S6: سطح قند خون بیمار
- متغیر هدف: برچسب یا Label این مجموعه داده، یک معیار کمی از میزان پیشرفت بیماری است که با یک مقدار پیوسته نمایش داده میشود.
اکتشاف دادهها
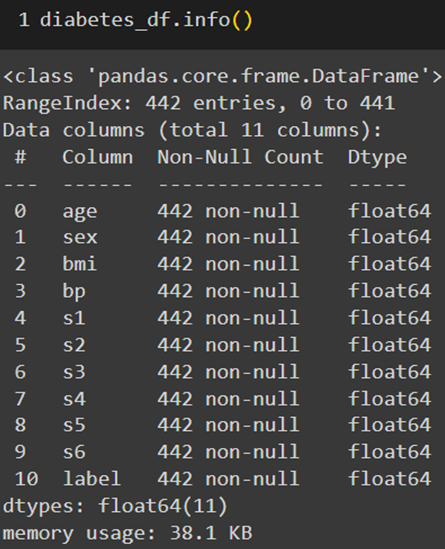
اکتشاف دادهها (Data exploration) مرحلهای مهم در هر پروژه ماشین لرنینگ است که به ما کمک میکند تا ساختار و ویژگیهای دادهها را بهتر بفهمیم. با استفاده از متدهای info و describe در پانداس، میتوانیم خلاصهای از دادهها و آمار توصیفی آنها را بهدست آوریم:
پیشپردازش دادهها
پیشپردازش (Preprocessing) دادهها شامل مراحل متعددی است. برخی از مهمترین این مراحل، حذف مقادیر گمشده (Missing values) و دادههای تکراری است. همانطور که در تصویر قبل مشخص است، مجموعه داده دیابت هیچ مقدارگمشدهای ندارد زیرا مقابل تمام فیچرها نوشتهشده که ۴۴۲ داده غیر خالی (non-null) داریم.
بررسی دادههای تکراری
بااستفاده از متد duplicated میتوان وجود دادههای تکراری در مجموعه داده را بررسی کرد. در اینجا بااستفاده از کد زیر مجموع تعداد دادههای تکراری را میتوان دید:
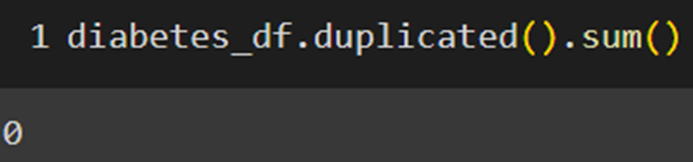
که خوشبختانه همانطور که میبینید، مجموعه داده ما داده تکراری هم ندارد.
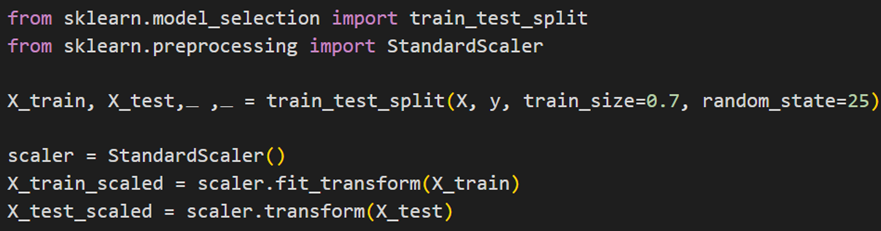
تقسیم دادهها به مجموعههای آموزشی و آزمایشی
پیش از انجام باقی مراحل پیشپردازش، بهتر است مجموعه دادهمان را به دو مجموعه آموزشی و آزمایشی تبدیل کنیم. این کار را میتوان بااستفاده از متد model_selection در سایکیدلرن بهصورت زیر انجام داد:

در این کد ابتدا از مجموعه داده کامل، ویژگیها را جدا کرده و در متغیر X میریزیم و برچسب را نیز در متغیر y. سپس باکمک تابع گفتهشده، دادهها را با نسبت ۸۵ درصد آموزشی و ۱۵ درصد آزمایشی تقسیم میکنیم.
استانداردسازی
یکی دیگر از کارهایی که میتوان در فاز پیشپردازش انجام داد استانداردسازی دادهها است. ما در کلاس preproseccing سایکیدلرن دو نوع استانداردسازی داریم:
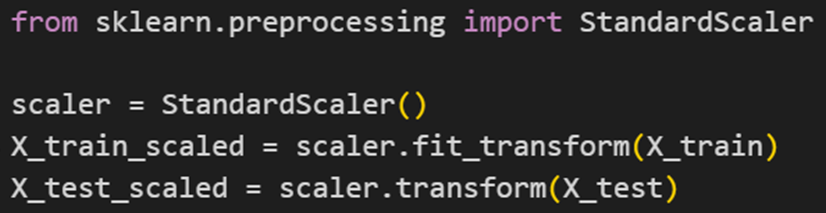
StandardScaler
StandardScaler یکی از ابزارهای موجود در کتابخانه سایکیدلرن است که برای استانداردسازی دادهها استفاده میشود. این ابزار دادهها را طوری مقیاسبندی میکند که میانگین هر ویژگی برابر با ۰ و انحراف معیار آن برابر با ۱ باشد. این کار باعث میشود تا ویژگیها با مقیاسهای مختلف، تأثیر یکسانی در مدلهای یادگیری ماشین داشته باشند. فرمول استفادهشده در این ابزار بهصورت زیر است:
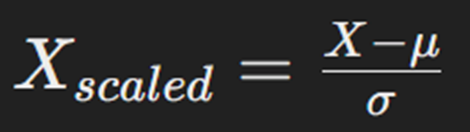
در این فرمول میانگین μ و انحراف معیار σ دادهها است.
نکته قابل توجه در نحوه استفاده از این تابع، این است که باید روی مجموعه داده آموزشی fit_transform و روی دادههای آزمایشی transform شود. درواقع برای استانداردسازی دادههای آموزشی ابتدا میانگین (μ_train) و انحراف معیار (σ_train) دادههای آموزش محاسبه میشود، سپس هر داده از مجموعه آموزش (X_train) از میانگین کسر شده و بر انحراف معیار تقسیم میشود. اما برای استانداردسازی دادههای آزمایشی (X_test)، از میانگین و انحراف معیار محاسبه شده از دادههای آموزش استفاده میشود. به عبارت دیگر، دادههای آزمایشی از میانگین دادههای آموزشی کسر شده و بر انحراف معیار دادههای آموزشی تقسیم میشوند.
توضیحات مربوط به این فرایند در کلاس علم داده استاد شکرزاد نیز مطرح شده است. در شکل زیر میتوانید دستنوشت استاد برای توضیح مبحث استانداردسازی را ببینید:

MinMaxScaler
MinMaxScaler یکی دیگر از ابزارهای موجود در کتابخانه سایکیدلرن است که برای استانداردسازی دادهها استفاده میشود. این ابزار دادهها را به یک بازه مشخص (بین ۰ و ۱) مقیاسبندی میکند. این کار باعث میشود تا مدلهای یادگیری ماشین سریعتر و با دقت بیشتری آموزش ببینند. فرمول استفادهشده در این ابزار بهصورت زیر است:
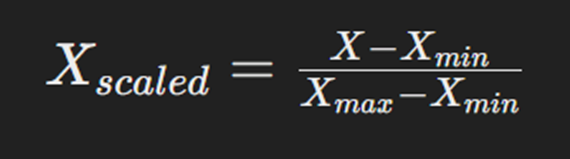
در این فرمول:
X مقدار اصلی ویژگی (Feature)، کمترین مقدار ویژگی در دادهها و بیشترین مقدار ویژگی در دادهها است.
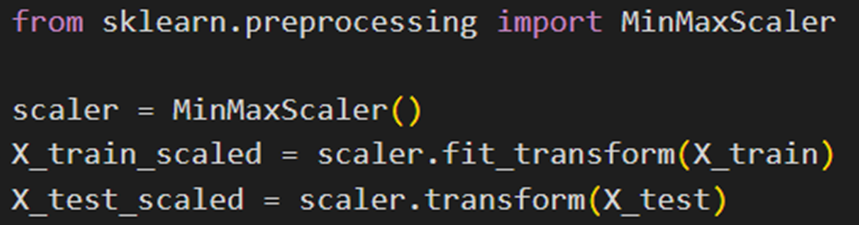
برای استفاده از این نوع استاندارسازی، ابتدا آن را از کلاس گفتهشده فراخوانی (import) میکنیم:

سپس یک نمونه (Instance) از آن میسازیم:

درپایان برای اعمال این تابع روی مجموعه دادههای آموزشی و آزمایشی بهصورتی که توضیح دادیم عمل میکنیم:
فراخوانی مدل
برای مرحله آموزش، ابتدا باید مدل موردنظر را انتخاب کنیم. سایکیدلرن مدلهای ماشین لرنینگ متنوعی دارد که برخی از آنها مربوط به پروژههای رگرسیون، برخی نیز مربوط به پروژههای طبقهبندی و برخی هم مربوط به پروژههای خوشهبندی است. ما در این قسمت از مدلهای رگرسیون این کتابخانه استفاده میکنیم.
برای این کار ابتدا باید این مدلها را از کلاسهای مربوطهشان فراخوانی کنیم:

مدلهای فراخوانیشده بهترتیب ماشین بردار پشتیبان، درخت تصمیم، K نزدیکترین همسایه، جنگل تصادفی، رگرسیونهای خطی، ریج، لاسو و الاستیک هستند. برای مطالعه تئوری هر یک از این مدلها، به لینک قراردادهشده مراجعه فرمایید.
برای مقایسه راحتتر عملکرد این مدلها بایکدیگر، ابتدا یک دیکشنری به اسم models تعریف میکنیم که شامل چندین مدل رگرسیون مختلف از کتابخانه سایکیدلرن است. هر کلید (key) در این دیکشنری نام مدل را نشان میدهد و هر مقدار (value) یک نمونه (Instance) از آن مدل است:

آموزش و ارزیابی عملکرد مدلها
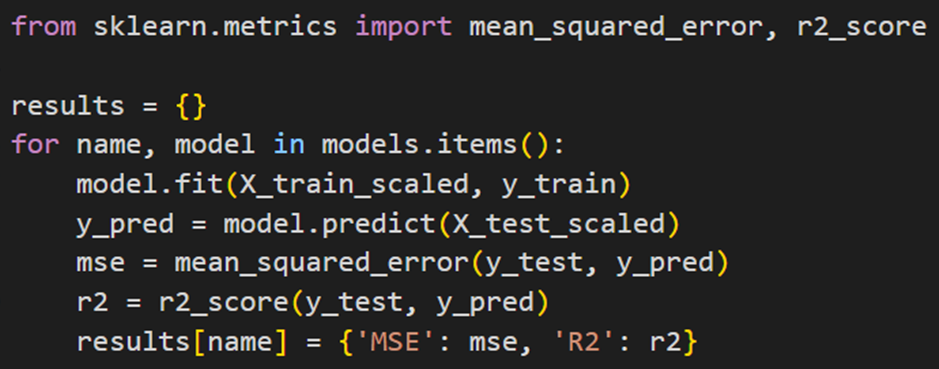
درقسمت بعد، دو تابع mean_squared_error و r2_score را از کتابخانه سایکیدلرن فراخوانی میکنیم که برای ارزیابی مدلها استفاده میشوند:

سپس یک دیکشنری خالی به نام results تعریف میکنیم تا نتایج ارزیابی مدلها را ذخیره کند:

درادامه یک حلقه for قرار میدهیم که برای هر مدل در دیکشنری models بهترتیب کارهای زیر را انجام میدهد:
- مدل روی دادههای آموزشی X_train_scaled و y_train آموزش داده میشود (model.fit).
- مدل بر روی دادههای آزمایشی X_test_scaled پیشبینی انجام میدهد (model.predict).
- سپس در فاز ارزیابی خطای میانگین مربعات (MSE) و امتیاز R² محاسبه میشود.
- نتایج ارزیابی مدل در دیکشنری results ذخیره میشود.
سپس بااستفاده از کد زیر میزان خطا و امتیاز عملکرد هر مدل را چاپ میکنیم:
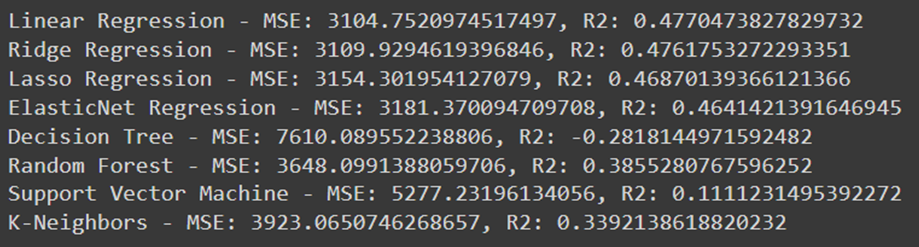
بعد از اجرای کدهای گفتهشده خروجی بهشکل زیر درخواهدآمد:
تفسیر نتایج
باتوجه به این اعداد میتوان فهمید مدل رگرسیون خطی با خطای ۳۱۰۴ و امتیاز ۰.۴۷ بهترین عملکرد را داشته است. رگرسیون Ridge عملکردی مشابه رگرسیون خطی دارد و تنها تفاوت اندکی در خطا و امتیاز نسبت به آن مشاهده میشود. رگرسیون Lasso، خطای بیشتری نسبت به دو مدل قبلی دارد اما هنوز هم عملکردش قابل قبول است. مدل رگرسیون Elasticnet نیز که ترکیبی از رگرسیونهای Ridge و Lasso است، نسبت به رگرسیون خطی و Ridge عملکرد کمی ضعیفتری دارد اما همچنان در حد متوسط است. با توجه بهMSE بسیار بالا و امتیاز R² منفی مدل درخت تصمیم، عملکرد این مدل بسیار ضعیف بهشمار میرود. مدل جنگل تصادفی عملکرد بهتری نسبت به درخت تصمیم دارد، اما هنوز هم MSE بیشتر وامتیاز R² پایینتری نسبت به مدلهای خطی نشان میدهد. عملکرد مدلهای ماشین بردار پشتیبان و KNN نیز چندان جالب نیست.
استفاده از GridSearchCV
برای تنظیم هایپر پارامترهای این مدلها و بهبود عملکرد هریک، میتوان از GridSearch استفاده کرد. برای این منظور ابتدا باید کتابخانه GridSearchCV را فراخوانی کنیم:

سپس یک دیکشنری تعریف میکنیم و پارامترهای مختلفی که برای هر مدل قرار است جستجو شوند را در آن قرار میدهیم. برای مثال، رگرسیونهای Ridge و Lasso دارای پارامتر alpha با مقادیر مختلف هستند. این پارامتر ضریب جمله تنظیم (Regularization term) را تعیین میکند:
حال باید مجددا مانند قسمت قبل، مدلها را در یک دیکشنری قرار دهیم. این دیکشنری، مدلهای مختلف رگرسیون را تعریف میکند که قرار است آموزش داده شوند. همچنین یک دیکشنری بهنام results برای ذخیره نتایج ارزیابی هر مدل ایجاد میکنیم:
سپس مانند حالت قبل یک حلقه for تعریف میکنیم که برای هر مدل در دیکشنری models کارهای زیر را انجام میدهد:
- برای هر مدل، ابتدا نام مدل چاپ میشود.
- یک GridSearchCV با استفاده از آن مدل و پارامترهای مربوطه ایجاد میشود (grid_search). این عملیات با ۵ فولد (cv=5) و خطای MSE و امتیاز R² برای ارزیابی انجام میشود.
- مدل با استفاده از دادههای آموزشی، آموزش داده میشود (grid_search.fit).
- بهترین مدل از جستجوی شبکه پارامترها انتخاب میشود (grid_search.best_estimator_).
- پیشبینیها برای دادههای آزمایشی بااستفاده از بهترین مدل انجام میشود (best_model.predict).
- MSE و R² برای پیشبینیهای انجام شده محاسبه میشود.
- نتایج در دیکشنری results ذخیره میشوند.
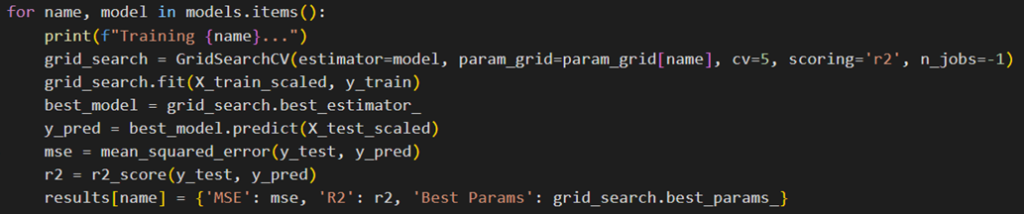
در نهایت، نتایج ارزیابی هر مدل شامل MSE، R² و بهترین پارامترهای تنظیمشده برای هریک چاپ میشوند:
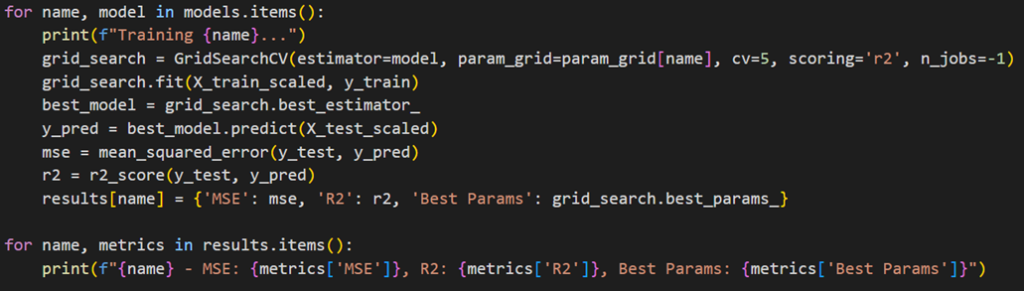
بهاینترتیب میتوان بهترین مدل و بهترین پارامترهای تنظیمشدهای که درطول فرآیند GridSearchCV آموزش دید را استخراج کرد. خروجی این کد را میتوانید در شکل زیر ببنید:
همانطور که میبینید در اغلب مدلها نسبت به حالت پایه، شاهد بهبود عملکرد هستیم. مقایسه عملکرد مدل پایه و تنظیمشده هر یک از مدلهای رگرسیون بالا را میتوانید در ادامه ببینید:
رگرسیون خطی
رگرسیون خطی به عنوان مدل پایه، خود عملکرد خوبی داشته و هیچ پارامتر اضافی برای تنظیم نداشته است.
رگرسیون Ridge
رگرسیون Ridge، که شامل منظمسازی L2 (L2 Regularization) برای جلوگیری از بیشبرازش است، در مدل پایه عملکرد کمی بهتر نسبت به مدل بهینه داشته است. این نشان میدهد که افزایش مقدار آلفا (ضریب جمله تنظیم) به ۱۰ در مدل بهینه ممکن است بیش از حد منظمسازی کرده و باعث کاهش کمی در عملکرد مدل شده باشد. بنابراین، انتخاب پارامترهای مناسب در این رگرسیون بسیار مهم است.
رگرسیون Lasso
رگرسیون Lasso با استفاده از منظمسازی L1 (L1 Regularization) برای تنظیم پارامترها عمل میکند. نتایج مدل پایه و مدل بهینه برای لاسو یکسان هستند که نشاندهنده عدم تغییر در تنظیم پارامترها است. این مدل میتواند ویژگیهای غیرمهم را به صفر برساند و مدل را سادهتر کند، اما به نظر میرسد که مقدار آلفا در هر دو حالت بهینه بوده است.
رگرسیون ElasticNet
رگرسیون ElasticNet ترکیبی از منظمسازیهای L1 و L2 را استفاده میکند و به طور قابل توجهی بهتر از مدل پایه عمل کرده است. این نشان میدهد که تنظیم پارامترهای آلفا و نسبت استفاده از L1 و L2 به ۰.۱ کمک کرده است تا مدل بهتر عمل کند. این مدل از هر دو نوع منظمسازی بهره میبرد و میتواند تعادلی مناسب بین آنها ایجاد کند.
درخت تصمیم
همانطور که بهخاطر دارید درخت تصمیم در مدل پایه عملکرد بسیار ضعیفی داشت، در حالی که تنظیم پارامترهای عمق درخت (max_depth) و حداقل نمونههای تقسیم (min_samples) بهبود چشمگیری ایجاد کرده است. این نشان میدهد که درخت تصمیم بدون تنظیمات مناسب ممکن است بهمشکل بیشبرازش (Overfitting) یا کمبرازش (Underfitting) دچار شوند، اما با تنظیمات مناسب میتوانند عملکرد بهتری داشته باشند.
جنگل تصادفی
جنگل تصادفی که مجموعهای از درختهای تصمیم است، در مدل بهینه کمی بهتر از مدل پایه عمل کرده است. تنظیم عمق درختها (max_depth) و تعداد درختها (n_estimators) به بهبود عملکرد کمک کرده است. این مدل به دلیل استفاده از چندین درخت، از استحکام و دقت بیشتری برخوردار است و تنظیمات مناسب میتواند این مزیت را افزایش دهد.
ماشین بردار پشتیبانی
مدل SVM در مدل پایه عملکرد بسیار ضعیفی داشته است، اما با تنظیم پارامترهای C و اپسیلون بهبود قابل توجهی پیدا کرده است. این نشان میدهد که SVM به شدت وابسته به تنظیم پارامترها است و با تنظیم مناسب میتواند عملکرد بسیار بهتری داشته باشد. این مدل به ویژه در مسائل پیچیده و غیرخطی کارآمد است.
K نزدیکترین همسایهها
مدل KNN در مدل بهینه عملکرد بهتری نسبت به مدل پایه داشته است. تنظیم تعداد همسایهها به ۱۰ کمک کرده است تا مدل پیشبینیهای دقیقتری داشته باشد. این مدل ساده اما موثر میتواند با تنظیم مناسب تعداد همسایهها بهبود یابد و عملکرد خوبی ارائه دهد.
به طور کلی، تنظیم پارامترها تأثیر قابل توجهی بر عملکرد مدلها دارد و در بسیاری از موارد میتواند به بهبود عملکرد کمک کند. انتخاب پارامترهای مناسب بر اساس دادههای موجود و روشهای بهینهسازی میتواند تفاوتهای عمدهای در دقت و کارایی مدلها ایجاد کند.
مدلهای طبقهبندی
حال که با sklearn آشنا شدیم، بیایید برای تمرین بیشتر یک پروژه طبقهبندی را هم بااستفاده از این کتابخانه انجام دهیم.
بارگذاری دادهها
مانند پروژه قبل، اینبار هم اولین مرحله بارگذاری دادهها است. برای این پروژه قصد داریم از مجموعه داده ارقام دستنوش استفاده کنیم. مجددا از کلاس datasets کتابخانه sklearn، مجموعه داده مورد نظر را بارگذاری میکنیم:
مانند بخش قبل، برای پردازش و تحلیل دادهها، میتوانیم این مجموعه داده را به یک DataFrame تبدیل کنیم:
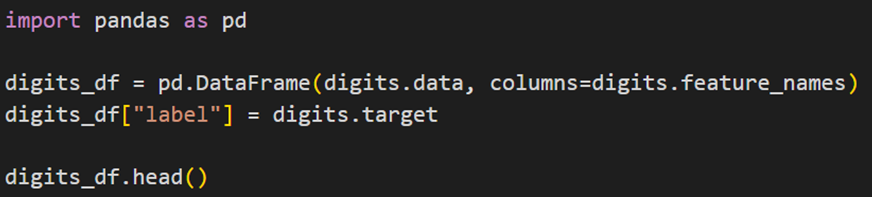
خروجی کد بالا را در شکل زیر میبینید:
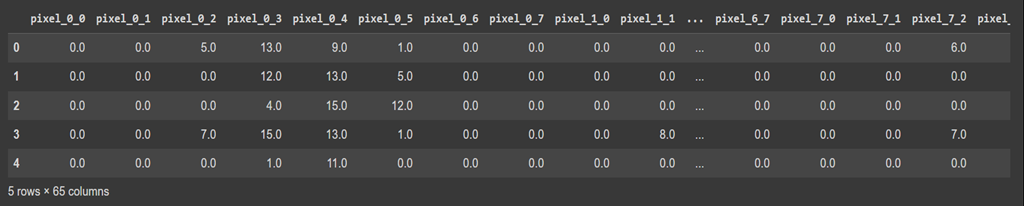
این مجموعه داده، یکی از مجموعه دادههای معروف در زمینه یادگیری ماشین است که برای آموزش مدلهای طبقهبندی مورد استفاده قرار میگیرد. این مجموعه داده شامل ۱۷۹۷ تصویر کوچک از ارقام دستنویس است که هرکدام با یک ماتریس ۸x۸ نشانداده میشوند. این ماتریسها بهصورت برداری در این مجموعه داده ذخیره شدهاند تا بتوانند بهراحتی در مدلهای یادگیری ماشین استفاده شوند. در مجموعه داده Digits:
- ابعاد هر تصویر ۸x۸ است و این یعنی هرعکس مجموعا ۶۴ پیکسل بهعنوان ویژگی (Features) دارد.
- هر یک از این ویژگیها در هر تصویر، بهعنوان یک مولفه از بردار ۶۴ بعدیای که با آن در دیتاست ذخیره شده، قرارگرفتهاست.
- تعداد کلاسها ۱۰تا است (اعداد ۰ تا ۹).
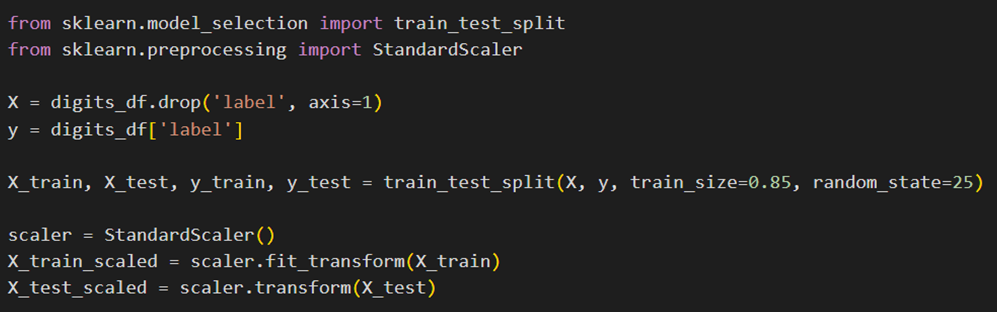
پیشپردازش دادهها
سپس مراحل پیشپردازش اعم از تقسیم دادهها به دو مجموعه آموزشی و آزمایشی و استانداردسازی انجام خواهد شد:
فراخوانی مدل
برای این کار ابتدا باید مدلهای طبقهبندی مورد نظر را از کلاسهای مربوطهشان در کتابخانه sklearn فراخوانی کنیم:
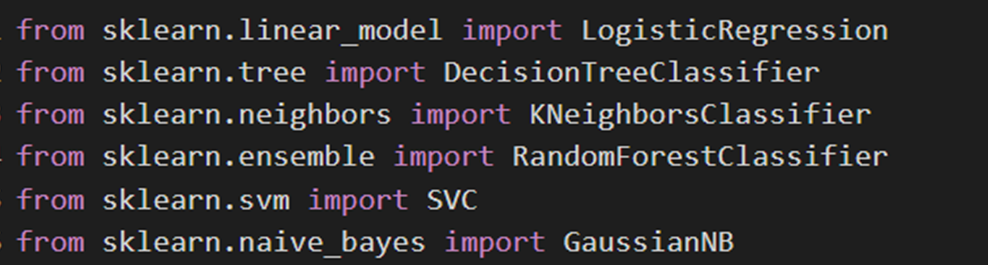
مدلهای فراخوانیشده بهترتیب رگرسیون لجستیک، درخت تصمیم، K نزدیکترین همسایه، جنگل تصادفی، ماشین بردار پشتیبان و بیز ساده هستند. برای مطالعه درمورد هریک از این مدلها بهلینک قراردادهشده مراجعه نمایید. لینک برخی از این مدلها که بین هر دو نوع یادگیری رگرسیون و طبقهبندی مشترک هستند، در همین بخش از پروژه قبلی قراردادهشدهاست.
مانند پروژه قبل، اینبار نیز برای مقایسه راحت این مدلها، یک دیکشنری تشکیل میدهیم:
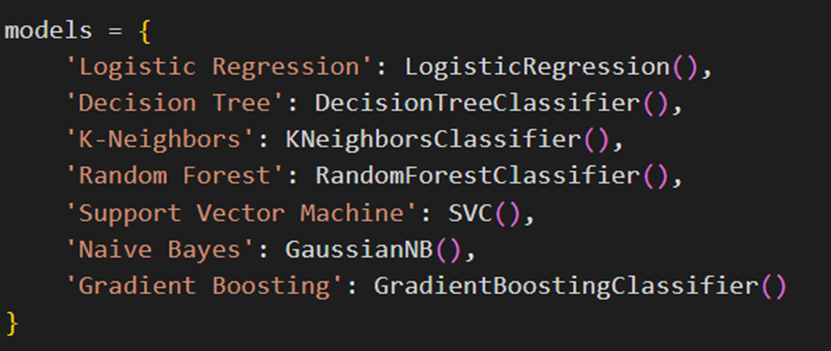
آموزش و ارزیابی عملکرد مدلها
ادامه کار در این مرحله مانند قسمت قبلی است و باید متریکهای مورد نظر برای ارزیابی را فراخوانی کنیم. سپس با یک حلقه for روی همه مدلهای دیکشنری بالا، آنها را آموزش داده و عملکردشان را ارزیابی میکنیم:
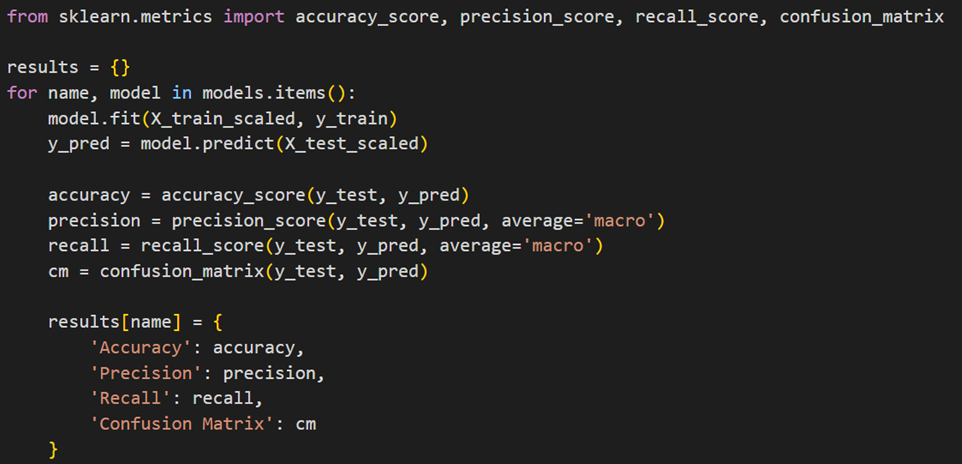
سپس با کد زیر نتایج را که شامل متریکهای ارزیابی دقت (Accuracy)، درستی (Precision) و یادآوری (Recall) است، چاپ میکنیم:

خروجی کد بالا به شرح زیر است:

تفسیر نتایج
همانطور که میبینید، در بین این مدلها ماشین بردار پشتیبان با دقت ۹۹ درصدی بهترین عملکرد را در بین همه مدلها دارد. درستی و بازیابی آن نیز تقریباً مشابه هستند، که نشان میدهد این مدل در دستهبندی نمونهها بسیار موفق بوده است.
رگرسیون لجستیک نیز با دقت ۹۶ درصد عملکرد خوبی داشته است. درستی و یادآوری آن نیز تقریباً مشابه هستند، که نشان میدهد این مدل در تشخیص نمونههای مثبت و منفی به خوبی و بهطور یکسان عمل کرده است.
درخت تصمیم با دقت ۸۷ درصدی همچنان عملکرد مناسبی دارد. دقت و یادآوری آن نیز نسبتا نزدیک هستند، که نشان میدهد این مدل در دستهبندی نمونههای مثبت و منفی بهطور مساوی خوب عمل کرده است.
KNN با دقت ۹۷ درصدی و جنگل تصادفی با دقت ۹۸ درصدی، از بهترین عملکردها در بین مدلها برخوردار هستند. در این مدلها نیز درستی و بازیابی بههم نزدیکاند و این یعنی بازهم نرخ تشخیص نمونههای مثبت (True positive) مدلهای نامبرده با نرخ اجتنابشان از تشخیص نادرست نمونههای منفی (False negative) برابر است.
بیز ساده اما با دقت ۸۰ درصدی پایینترین دقت را در بین تمام مدلها دارد. درستی آن نسبتاً بالا و ۸۵ درصد است، اما یادآوری آن ۷۹ درصد است که نشان میدهد مدل تعداد زیادی از نمونههای مثبت واقعی یا True positive را به عنوان منفی دستهبندی کرده است. به عبارت دیگر، تعداد زیادی False Negative وجود دارد. دلیل این امر ممکن است فرضیات سادهای باشد که این مدل استفاده میکند.
تفاوت متریکهای دقت، درستی و یادآوری
در ارزیابی عملکرد مدلهای دستهبندی، سه معیار مهم وجود دارد: دقت (Accuracy)، درستی (Precision) و یادآوری (Recall). هر یک از این معیارها کاربردها و معناهای خاص خود را دارند که در ادامه به توضیح داده و مقایسه آنها با یکدیگر میپردازیم. اگرچه دیتاست ما ۱۰ کلاسه بود اما برای درک راحتتر توضیحات را درمورد یک مسئله دوکلاسی بیان میکنیم.
دقت
دقت نشان میدهد که چه درصدی از پیشبینیها (هم درستهای مثبت و هم درستهای منفی) صحیح هستند. به عبارت دیگر، دقت نشان میدهد که مدل تا چه اندازه به درستی پیشبینی کرده است. فرمول محاسبه این معیار بهصورت زیر است:
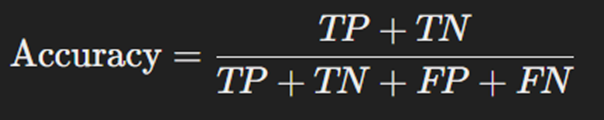
که در آن:
- TP یا True Positive نشاندهنده تعداد نمونههایی است که به درستی به عنوان مثبت پیشبینی شدهاند.
- TN یا False Negative نشاندهنده تعداد نمونههایی است که به درستی به عنوان منفی پیشبینی شدهاند.
- FP یا False Positive نشاندهنده تعداد نمونههایی است که به اشتباه به عنوان مثبت پیشبینی شدهاند.
- FN یا False Negative نشاندهنده تعداد نمونههایی است که به اشتباه به عنوان منفی پیشبینی شدهاند.
دقت معمولاً زمانی مهم است که تعداد نمونههای (Samples) با برچسب (Label) مثبت و منفی در دیتاست تقریباً برابر باشند. اگرچه این معیار بیانگر عملکرد کلی مدل است، اما در مواردی که دادهها نامتوازن باشند (تعداد نمونههای مثبت و منفی بسیار متفاوت باشد)، دقت بالا میتواند گمراهکننده باشد.
درستی
این معیار نشان میدهد چه درصدی از نمونههای مثبت پیشبینی شده واقعاً مثبت هستند. فرمول محاسبه این متریک بهصورت زیر است:
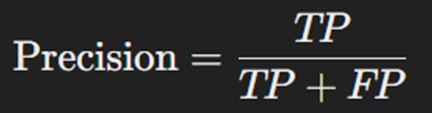
درستی به خصوص در مواردی که هزینهی پیشبینیهای مثبت اشتباه (False positive) بالا باشد، اهمیت دارد. دقت پیشبینی بالاتر به معنی خطای کمتر در پیشبینیهای مثبت است.
یادآوری
یادآوری یا بازیابی معیاری است که توانایی مدل را در شناسایی تمام نمونههای مثبت نشان میدهد. این معیار نشان میدهد چه درصدی از نمونههای مثبت واقعی به درستی شناسایی شدهاند. فرمول این متریک بهصورت زیر محاسبه میشود:
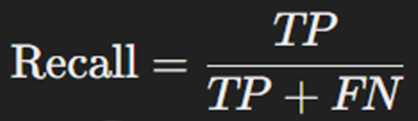
بازیابی بهخصوص در مواردی که عدم شناسایی نمونههای مثبت واقعی هزینهبر است (مانند تشخیص سرطان)، اهمیت دارد.
ماتریس درهمریختگی
ماتریس درهمریختگی یا Confusion matrix، یکی دیگر از معیارهای بررسی عملکرد مدلهای طبقهبندی است که بهصورت یک ماتریس نشانداده میشود. ماتریس درهمریختگی یا سردرگمی یک ابزار مهم در ارزیابی عملکرد مدلهای طبقهبندی است. این ماتریس نشان میدهد که مدل چگونه دستههای مختلف دادهها را پیشبینی کرده است. ماتریس درهمریختگی به صورت یک جدول مربعشکل نشان داده میشود که ردیفها نمایانگر دستههای واقعی و ستونها نمایانگر دستههای پیشبینی شده هستند.
همانطور که در کد دیدید، هنگام ساخت دیکشنری نتایج (results) ماتریس درهمریختگی نیز در آن ثبت شد. برای مشاهده ماتریس درهمریختگی هریک از مدلها بهصورت زیر عمل میکنیم:
بااستفاده از این کد میتوان ماتریس سردرگمی هر مدل را به صورت گرافیکی با استفاده از کتابخانههای matplotlib و seaborn نمایش داد. نتایج را برای هر یک مدلهای میتوانید در تصاویر زیر ببنید:
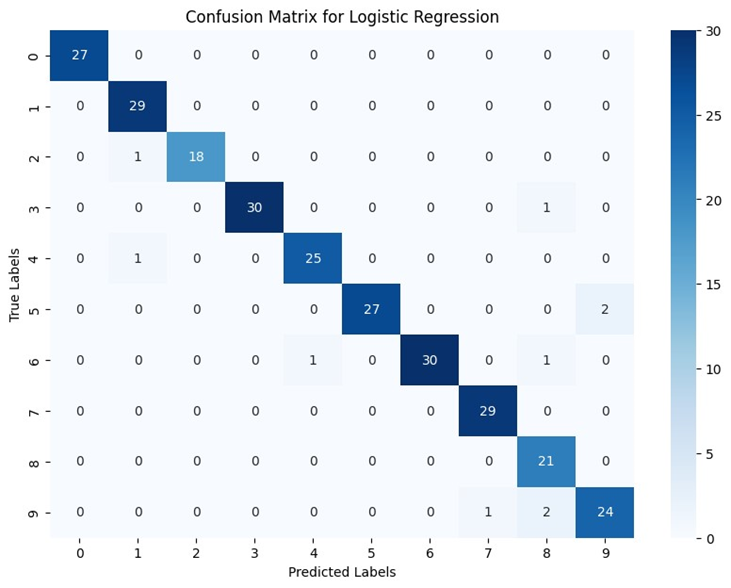
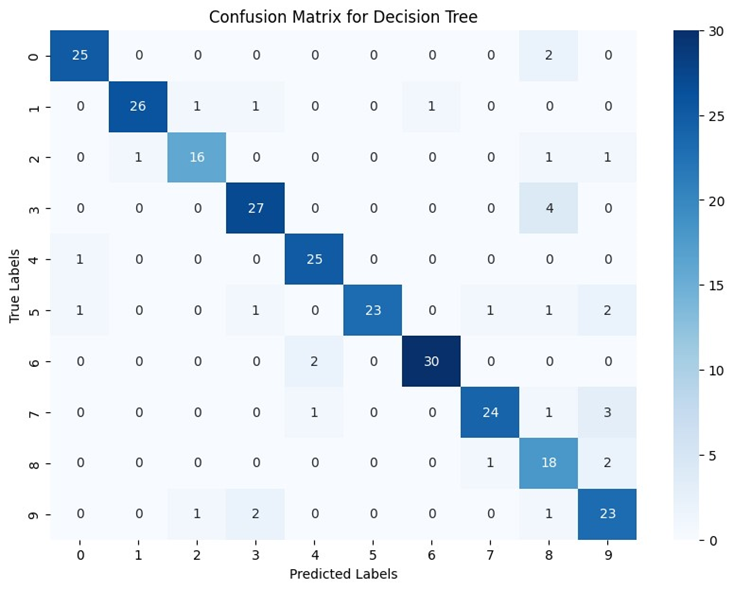
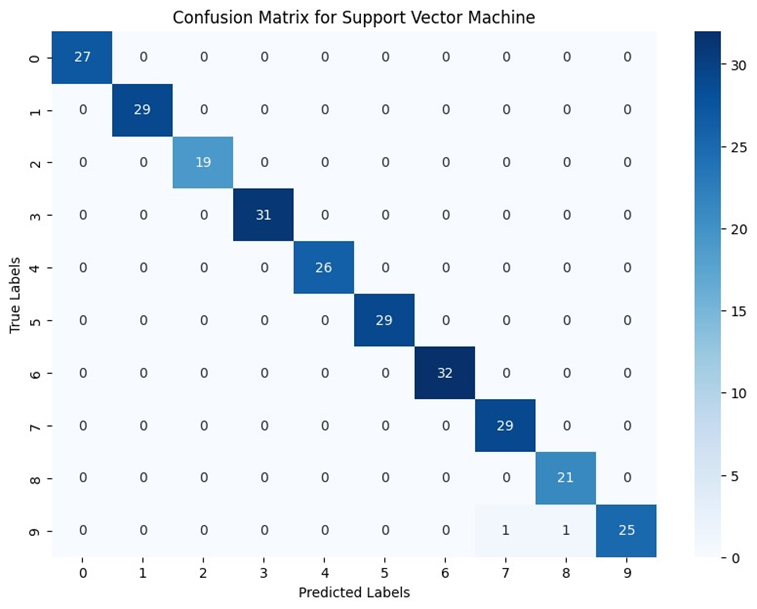
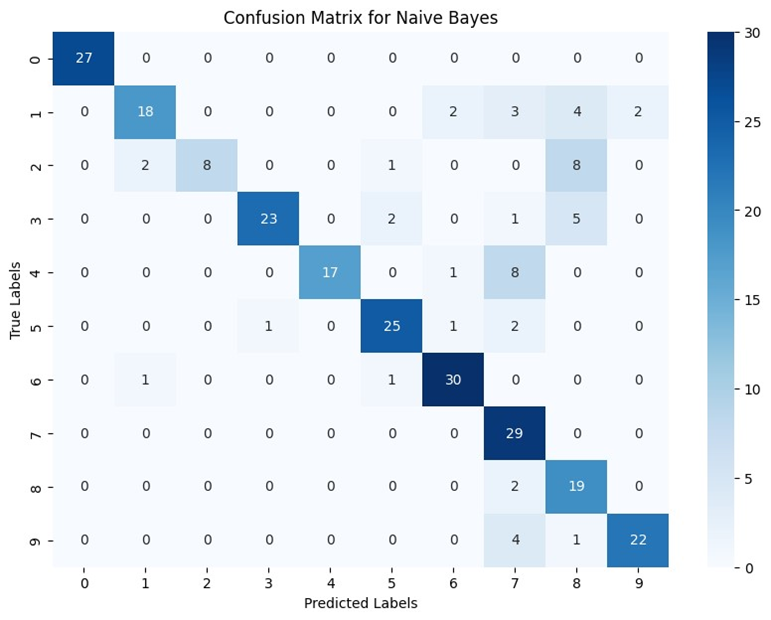
اعداد ۰ تا ۹ سطر و ستون این ماتریسها نشاندهنده لیبلهای ۰ تا ۹ در دیتاست هستند. بهطور کلی هرچه اعداد روی قطر ماتریس درهمریختگی بیشتر و اعداد سایر خانهها به صفر نزدیکتر باشد، یعنی عملکرد مدل بهتر است. زیرا نشاندهنده این است که مدل تعداد بیشتری از دادهها را در همان کلاسی که بهآن تعلق دارند، قراردادهاست.
مشابه پروژه رگرسیون، برای این بخش هم میتوان بااستفاده از GridsearchCV بهتنظیم پارامترهای این مدلها پرداخت و عملکردشان را بهبود بخشید.
مدلهای خوشهبندی
تاکنون با یادگرفتیم که چطور بااستفاده از کتابخانه سایکیدلرن، پروژههای بانظارت ماشین لرنینگ یعنی رگرسیون و کلاسبندی را انجام دهیم. حال میخواهیم نحوه استفاده از مدلهای خوشهبندی که یک روش یادگیری بدون نظارت است را با کمک کتابخانه سایکیدلرن بیاموزیم.
بارگذاری دادهها
کتابخانه sklearn علاوهبر مجموعه دادههای واقعیای که دارد، میتواند دادههای مصنوعی نیز بسازد. این کار را میتوان بااستفاده از متدهای make_classification، make_blobs یا make_moons کلاسِ datasets این کتابخانه انجام میشود. ما در این پروژه از تابع make_blobs استفاده میکنیم:
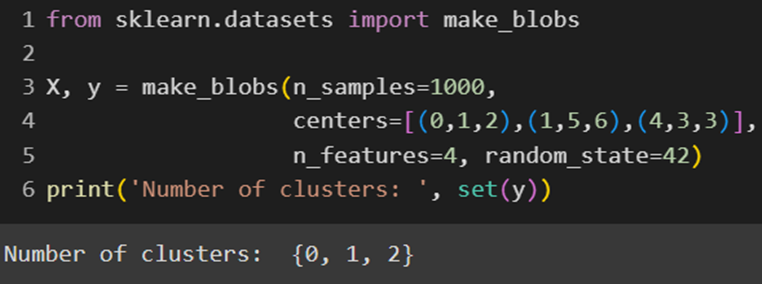
بهاینترتیب ما یک دیتاست با ۱۰۰۰ نمونهی سهکلاسی خواهیم داشت که هرکدام ۴ ویژگی (Feature) دارند. دقت کنید که چون پروژه ما خوشهبندی است و نیازی به برچسب ندارد، به لیبلی که این تابع برای هر نمونه داده مصنوعی تعبیه کرده است، نیازی نداریم.
پیشپردازش دادهها
بازهم میتوان نکاتی که در قسمتهای قبل برای پیشپردازش داده گفت را برای این مجموعه داده نیز اعمال کرد:
فراخوانی مدل
برای خوشهبندی این دادهها، ابتدا باید مدلهای موردنظر را از کتابخانه سایکیدلرن فراخوانی کرد:

مدلهای فراخوانیشده بهترتیب Kmeans ،DBSCAN و Agglomerative Clustering هستند. برای کسب اطلاعات بیشتر درمورد هر یک از این مدلها، به لینک مربوطه مراجعه کنید.
بازهم مثل دو قسمت قبلی، برای مقایسه راحتتر عملکرد این مدلها بایکدیگر، ابتدا یک دیکشنری به اسم models تعریف میکنیم که شامل سه مدل خوشهبندی مختلف از کتابخانه سایکیدلرن است:
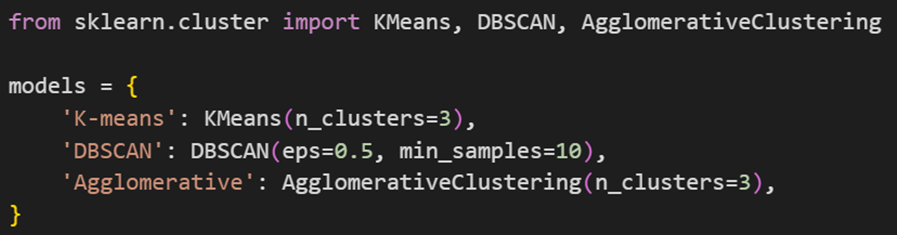
توجه کنید که میتوان برای تنظیم هایپر پارامترهای این مدلها هم از GridsearchCV استفاده کرد. برای اجتناب از تکرار مکررات، ما در این آموزش دیگر این کار را تکرار نخواهیم کرد اما شما برای تمرین بیشتر حتما این کار را انجام دهید. از آنجا که عملکرد مدلهای Kmeans و Agglomorative بهشدت به تعیین تعداد خوشهها بستگی دارد -و این پارامتر را هم بهعنوان ورودی تابع میگیرند- و همچنین عملکرد DBSCAN به پارامترهای ورودیاش بسیار وابسته است، ما این متغیرها را حین ساخت نمونه (Instance) در دیکشنری مدلها تعیین کردیم. دقت کنید که DBSCAN چون بر مبنای تراکم نمونهها درکنار یکدیگر کار میکند، ورودیای بهعنوان تعداد خوشهها دریافت نمیکند و خودش این عدد را پیدا میکند. البته تعیین دقیق تعداد خوشهها توسط مدل، حساسیت زیادی به پارامترهای eps و min_samples دارد.
آموزش و ارزیابی عملکرد مدلها
در ادامه مانند قبل باید متریکهای موردنظر را فراخوانی کنیم، یک دیکشنری برای ثبت نتایج ایجاد کنیم و سپس با یک حلقه for روی دیکشنری مدلها، آنها را آموزش دهیم و نتیجه ارزیابی عملکردشان را در دیکشنری results ثبت نماییم:
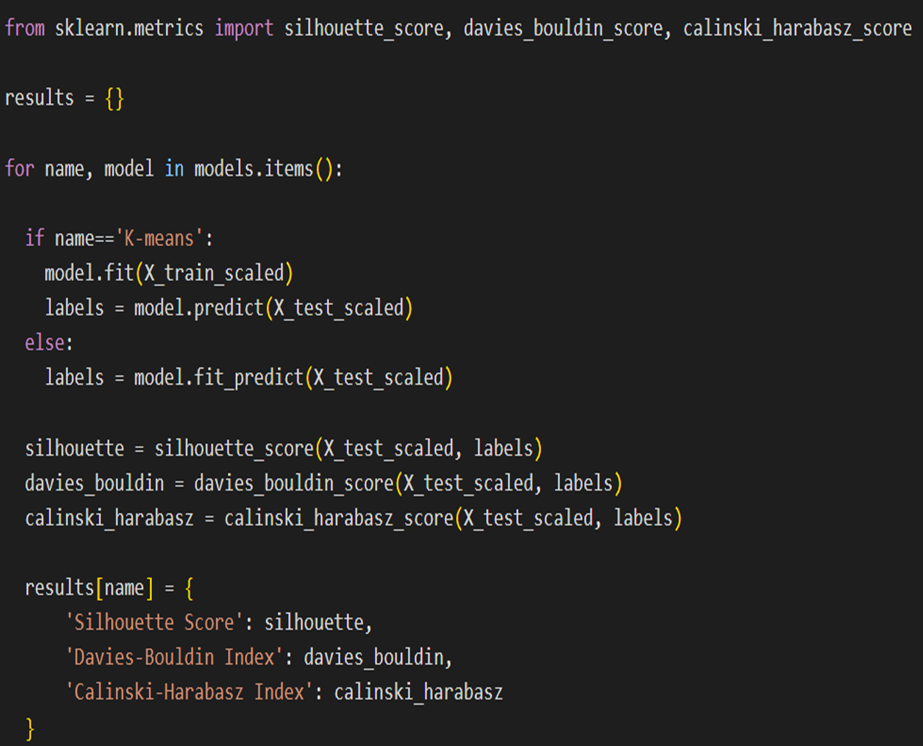
همانطور که در کد بالا میبینید، یک تفاوت جزئی در نحوه استفاده از الگوریتم خوشهبندی Kmeans کتابخانه سایکیدلرن و دو مدل دیگر وجود دارد. درواقع تفاوت در شیوه پیشبینی بین مدل Kmeans و سایر الگوریتمها به دلیل نحوه طراحی و استفاده آنها است. برای درک بهتر این تفاوت میتوان نحوه عملکرد این الگوریتمها را مرور کرد:
Kmeans
KMeans ابتدا مراکز خوشهها (centroids) را در مرحله آموزش با استفاده از دادههای آموزشی پیدا میکند. این مراکز خوشهها سپس برای پیشبینی برچسبهای دادههای جدید استفاده میشوند. KMeans معمولاً در مواقعی استفاده میشود که دادههای آموزشی و آزمایش جداگانه وجود دارد. به همین دلیل، این امکان وجود دارد که مدل ابتدا با دادههای آموزشی آموزش داده شود و سپس خوشه دادههای جدید را پیشبینی کند.
DBSCAN و AgglomerativeClustering
مدل Agglomerative همانطور که از نامش پیدا است، ماهیت سلسلهمراتبی دارد و DBSCAN نیز از جمله الگوریتمهای مبتنی بر چگالی است. DBSCAN به طور دینامیک (پویا) خوشهها را بر اساس چگالی نقاط دادهها تشکیل میدهد. اگر یک نقطه داده جدید به الگوریتم معرفی شود، نمیتوان به سادگی تصمیم گرفت که این نقطه به کدام خوشه تعلق دارد، زیرا با این کار این ممکن است ساختار چگالی دادهها را تغییر دهد و خوشههای جدیدی شکل بگیرد. بههمین دلیل برای اعمال پیشبینی نیاز است که الگوریتم از ابتدا بر روی کل دادهها اجرا شود تا خوشههای جدید پیدا شوند.
خوشهبندی سلسلهمراتبی بر اساس ساختار درختی انجام میشود که این ساختار در هر مرحله با ترکیب خوشهها تغییر میکند. در نتیجه، افزودن یک نقطه جدید میتواند به طور کامل ساختار درختی را تغییر دهد. بههمین دلیل برای اینکه بتوانیم پیشبینی کنیم که یک نقطه جدید به کدام خوشه تعلق دارد، باید الگوریتم را از ابتدا اجرا کنیم تا ساختار درختی بهروز شود و خوشههای جدید مشخص شوند.
بهعنوان سخن پایانی باید گفت که عدم وجود متد پیشبینی در این دو الگوریتم از کتابخانه سایکیدلرن به دلیل نیاز به بازسازی کامل خوشهها و ساختار آنها در مواجهه با دادههای جدید است. خوشهبندیهای این الگوریتمها به گونهای است که پیشبینی ساده برای نقاط جدید امکانپذیر نیست.
درادامه برای مقایسه و ارزیابی عملکرد این سه مدل روی مجموعه داده آزمایشی مطابق کد زیر، از دیکشنری نتایج استفاده میکنیم:
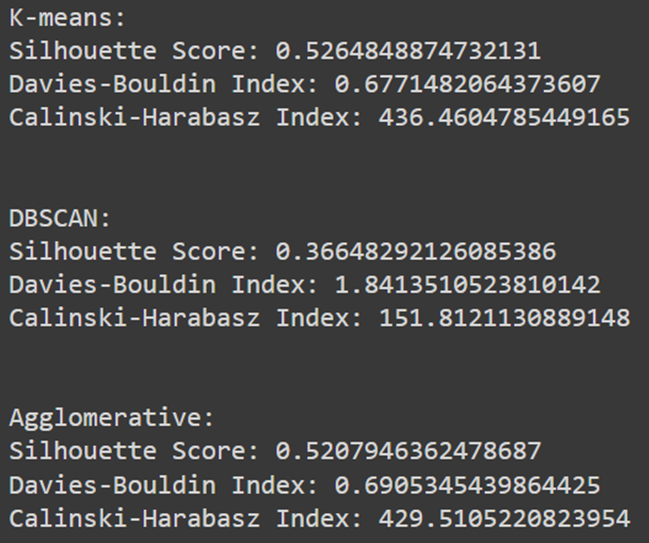
خروجی این کد بهصورت زیر چاپ میشود:
تفسیر نتایج
نمره سیلوئت (Silhouette Score) مدل K-means که ۰.۵۲ شده، نشاندهنده کیفیت نسبتا خوب این خوشهبندی است. شاخص دیویس-بولدین (Davies-Bouldin Index) نیز برای این مدل برابر با ۰.۶۷ است که نشاندهنده کیفیت خوب خوشهبندی است. شاخص کالینسکی-هاراباز (Calinski-Harabasz Index) الگوریتم K-means نیز برابر با ۴۳۶ است که تمایز خوب بین خوشهها را نشان میدهد.
نمره سیلوئت برای DBSCAN نسبتا پایین و برابر با ۰.۳۶ است. شاخص دیویس-بولدین برای این مدل برابر با ۱.۸ و شاخص کالینسکی-هاراباز آن برابر با ۱۵۱ است که هردو نشاندهنده تمایز ضعیف بین خوشهها است.
نمره سیلوئت برای خوشهبندی تجمعی نیز برابر با ۰.۵۲ است که نشاندهنده کیفیت نسبتا خوب این خوشهبندی است. شاخص دیویس-بولدین برابر با ۰.۶۹ و شاخص کالینسکی-هاراباز این مدل برابر با ۴۲۹ است که هردو نشاندهنده تمایز خوب بین خوشهها هستند.
هر یک از این معیارها چه میگویند؟
برای درک بهتر معنی این معیارها، هریک را به تفکیک توضیح میدهیم:
نمره سیلوئت
این معیار میزان شباهت یک نمونه به خوشه خود را نسبت به سایر خوشهها اندازهگیری میکند. نمره سیلوئت همواره عددی بین ۱- و ۱+ است. هرچه این عدد به یک نزدیکتر باشد، نشان میدهد که نمونهها به خوبی به اعضای خوشه خود نزدیک و از اعضای خوشههای دیگر دوراند. نمره نزدیک به ۰ نشان میدهد که برخی نمونهها در مرز بین خوشهها قرار دارند و نمره منفی نشان میدهد که نمونهها به خوشههای نادرست تخصیص یافتهاند.
شاخص دیویس-بولدین
این شاخص میانگین نسبت فشردگی درونخوشهای به جداسازی بینخوشهای را محاسبه میکند. شاخص دیویس-بولدین همواره عددی نامنفی است و هرچه مقدار آن کمتر باشد، خوشهبندی بهتر اتفاق افتاده است. به عبارت دیگر، شاخص پایین نشاندهنده فشردگی بیشتر خوشهها و جداسازی بهتر بین خوشهها است.
شاخص کالینسکی-هاراباز
این شاخص که نسبت مجموع فواصل بینخوشهای به مجموع فواصل درونخوشهای را محاسبه میکند، همواره عددی غیرمنفی است و هرچه مقدار آن بیشتر باشد، کیفیت خوشهبندی بهتر است. شاخص کالینسکی بالاتر، نشاندهنده تمایز بهتر بین خوشهها و فشردگی کمتر درون خوشهها است.
کاهش ابعاد و ترسیم نمودار
علاوهبر معیارهایی که در قسمت قبل به آنها اشاره کردیم، با رسم نمودار پراکندگی (Scatter plot) نمونههای کاهش بعدیافته این دیتاست و تعیین رنگ نقاط آن بهوسیله لیبلی که هر مدل به آنها نسبت داده است، میتوان بهصورت شهودی نیز عملکرد آنها را مورد بررسی قرارداد.
علت کاهش بعد نمونهها پیش از ترسیم، این است که ما تعداد ویژگیهای (Features) هر نمونه از این دیتاست را ۴ تعیین کردیم. یعنی اگر بخواهیم خود دیتاها را ترسیم کنیم، نیاز به نمودار ۴ بعدی داریم که میدانیم چنین چیزی ممکن نیست. بههمین دلیل باید آنها را به دو یا سهبعد کاهش داده و سپس رسم کرد.
برای این منظور ابتدا کتابخانههای مورد نیاز را فراخوانی میکنیم. matplotlib.pyplot برای رسم نمودار و PCA از sklearn.decomposition برای کاهش بعد استفاده میشود:

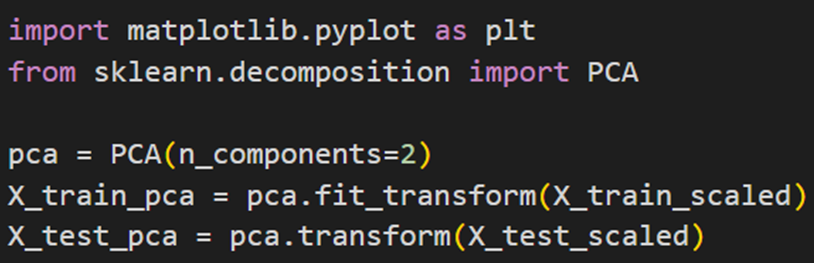
سپس یک شیء PCA با دو مولفه اصلی ساخته میشود. سپس دادههای آموزشی X_train_scaled و دادههای تست X_test_scaled به دو مولفه کاهش داده میشوند:
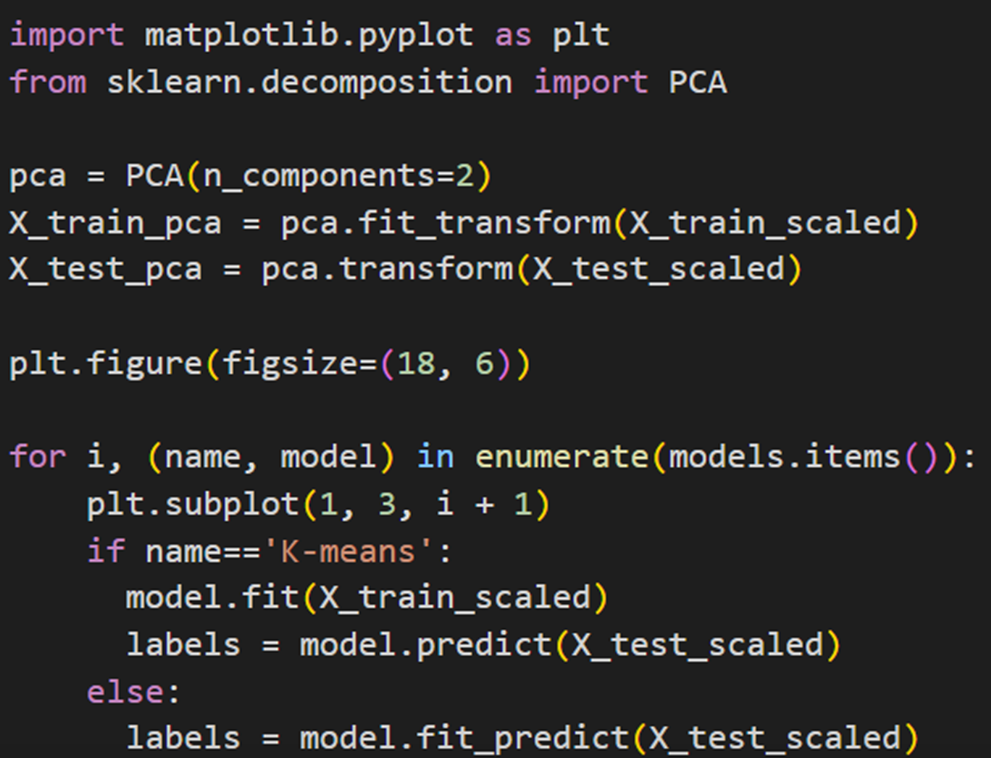
سپس یک حلقه for برای حرکت روی مدلهای مختلف خوشهبندی قرار میدهیم. در این حلقه، همانند قسمتهای قبل، اگر مدل K-means باشد، ابتدا بر روی دادههای آموزشی fit میشود و سپس بر روی دادههای تست predict میشود. برای سایر مدلها، دادههای تست مستقیماً fit_predict میشوند (علت این تفاوت قبلا توضیح داده شده است):
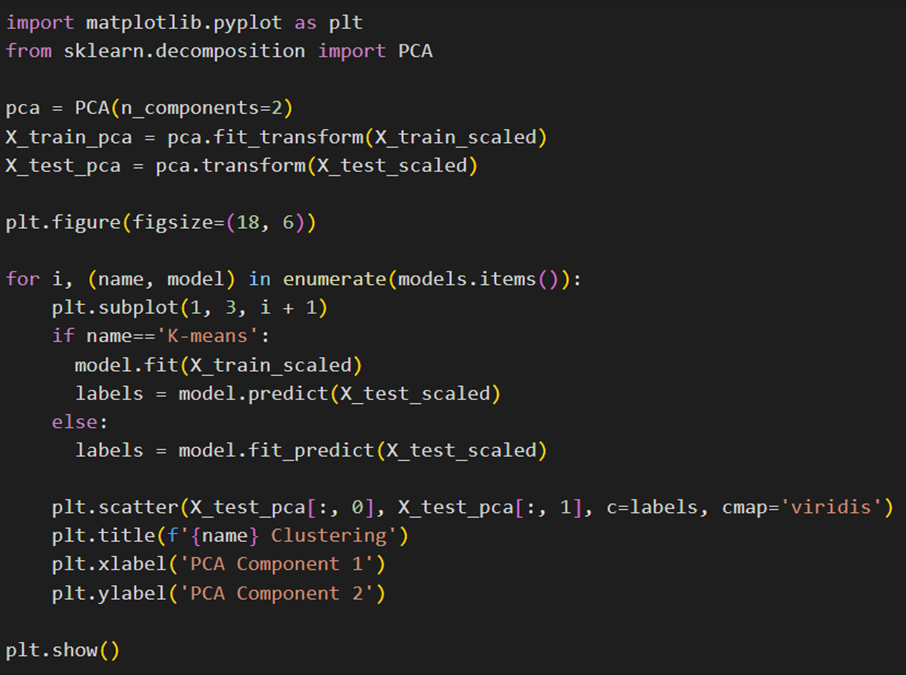
در پایان دادههای تست کاهشیافته به دو بعد رسم میشوند. نقاط دادهها بر اساس لیبلهای خوشهبندی رنگآمیزی میشوند:
خروجی این کد در شکل زیر نشانداده شدهاست:
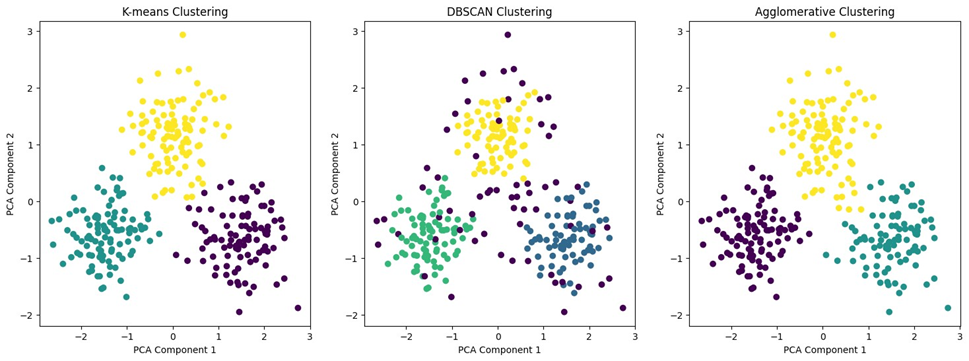
با توجه بهاین شکل، میفهمیم هر سه مدل خوشهبندی توانستهاند دادهها را بهدرستی به سه خوشه مختلف تقسیم کنند. K-means و Agglomerative Clustering نتایج نسبتا مشابهی با خوشههای مجزا و فشرده ارائه دادهاند. DBSCAN توانسته علاوهبر شکلهای مختلف خوشهها، نقاط نویز را نیز مشخص کند.
جمعبندی
در این مقاله، به بررسی مراحل مختلف پیادهسازی مدلهای یادگیری ماشین با استفاده از کتابخانه سایکیدلرن پرداختیم. از بارگذاری و پیشپردازش دادهها گرفته تا آموزش و ارزیابی مدلها، تمامی مراحل به تفصیل شرح داده شد. با استفاده از ابزارهای پیشرفتهای مانند GridSearchCV، بهینهسازی پارامترها و افزایش دقت مدلها امکانپذیر میشود. مدلهای نظارتی و غیرنظارتی مختلفی مانند رگرسیون، طبقهبندی و خوشهبندی معرفی شدند و کاربردهای هر یک در مسائل واقعی بررسی شد. این کتابخانه قدرتمند با رابط کاربری ساده و مستندات جامع، ابزاری مناسب برای متخصصان داده، پژوهشگران و علاقهمندان به یادگیری ماشین و هوش مصنوعی است. با مطالعه و استفاده از این مقاله، کاربران میتوانند دانش عملی و کاربردی خود را در زمینه یادگیری ماشین با سایکیدلرن بهبود بخشند و پروژههای موفقی را پیادهسازی کنند.

پرسشهای متداول
مراحل پیشپردازش دادهها در پروژههای یادگیری ماشین با استفاده از سایکیدلرن چیست؟
مراحل پیشپردازش دادهها شامل بارگذاری دادهها، حذف مقادیر گمشده و دادههای تکراری، تقسیم دادهها به مجموعههای آموزشی و آزمایشی، و استانداردسازی (Standardization) دادهها است. از ابزارهایی مانند MinMaxScaler و StandardScaler برای استانداردسازی استفاده میشود.
چه مدلهای رگرسیونی در کتابخانه سایکیدلرن موجود هستند و چه کاربردهایی دارند؟
کتابخانه سایکیدلرن شامل مدلهای رگرسیون متنوعی است که هر کدام کاربردهای خاص خود را دارند. برخی از مدلهای رایج عبارتند از: رگرسیون خطی (Linear Regression) برای پیشبینی متغیرهای پیوسته، رگرسیون Ridge و Lasso برای جلوگیری از بیشبرازش (Overfitting) با استفاده از منظمسازی (Regularization) و مدلهای رگرسیون پیچیدهتر مانند ماشین بردار پشتیبان (SVR). این مدلها برای مسائلی مانند پیشبینی قیمتها، تحلیل دادههای پزشکی و اقتصادی، و مدلسازی روابط بین متغیرها کاربرد دارند.
چگونه میتوان مدلهای طبقهبندی را با استفاده از کتابخانه سایکیدلرن ارزیابی کرد؟
برای ارزیابی مدلهای طبقهبندی، از معیارهایی مانند دقت (Accuracy)، درستی (Precision)، یادآوری (Recall) و ماتریس درهمریختگی (Confusion Matrix) استفاده کنید. این معیارها به شما کمک میکنند تا عملکرد مدل را در تشخیص دستههای مختلف دادهها بسنجید و نقاط قوت و ضعف آن را شناسایی کنید.
استفاده از دادههای مصنوعی در پروژههای یادگیری ماشین با سایکیدلرن چگونه امکانپذیر است؟
سایکیدلرن امکان تولید دادههای مصنوعی برای آموزش مدلهای یادگیری ماشین را فراهم میکند. با استفاده از توابعی مانند make_classification، make_blobs و make_moons، میتوانید مجموعه دادههای مصنوعی با ویژگیها و برچسبهای دلخواه خود ایجاد کنید و مدلهای مختلف را با آنها آزمایش کنید.
چگونه میتوان پارامترهای مدلهای یادگیری ماشین را با استفاده از GridSearchCV بهینهسازی کرد؟
برای بهینهسازی پارامترهای مدلهای یادگیری ماشین، ابتدا کتابخانه GridSearchCV را فراخوانی کنید و پارامترهای مختلفی که برای هر مدل قرار است جستجو شوند را در یک دیکشنری تعریف کنید. سپس مدلها را با استفاده از GridSearchCV و دادههای آموزشی، آموزش دهید. بهترین مدل و پارامترهای تنظیمشدهای که در طول فرآیند GridSearchCV آموزش دید را استخراج کنید و عملکرد آنها را ارزیابی نمایید.
یادگیری ماشین لرنینگ را از امروز شروع کنید!
دنیای دادهها جذاب است و دانستن علم داده، توانایی تحلیل داده، یا بازاریابی مبتنی بر داده، شما را برای فرصتهای شغلی بسیاری مناسب میکند. فارغ از رشته و پیشزمینه، میتوانید حالا شروع کنید و از سطح مقدماتی تا پیشرفته بیاموزید. اگر دوست دارید به این حوزه وارد شوید، پیشنهاد میکنیم با کلیک روی این لینک قدم اول را همین حالا بردارید.
مشاوران کافهتدریس به شما کمک میکنند مسیر یادگیری برای ورود به این حوزه را شروع کنید: