
فناوریهای بیگ دیتا برای پاسخگویی به چالشهای پردازش و تحلیل مجموعه دادههای بزرگ به صورت کارآمد به وجود آمدهاند. این فناوریها شامل چارچوبهایی مانند Apache Hadoop و Apache Spark میباشند که راهحلهای مقیاسپذیر و مقرونبهصرفهای برای مدیریت حجم عظیم دادهها ارائه میدهند. با بهرهگیری از این ابزارها، سازمانها میتوانند محاسبات پیچیده، تحلیلهای بلادرنگ و یادگیری ماشین را در مقیاس بزرگ انجام دهند. فناوریهای بیگ دیتا به کسبوکارها این امکان را میدهند که دادههای خام را به بینشهای قابل اجرا تبدیل کنند. در این مقاله با عمیقتر شدن در زمینههای Spark و Hadoop، بررسی خواهیم کرد که چگونه این فناوریها پردازش و تحلیل دادهها را متحول میکنند.
- 1. اهمیت کلان دادهها
- 2. مروری بر Spark و Hadoop
- 3. هدف مقاله
- 4. بیگ دیتا (Big Data)
- 5. مدلهای داده
- 6. تفاوتهای بین Spark و Hadoop
- 7. کاربردهای Spark و Hadoop
- 8. PySpark
- 9. تفاوت بین PySpark و Pandas
- 10. روندهای آینده در بیگ دیتا
- 11. جمعبندی
-
12.
پرسشهای متداول
- 12.1. چگونه میتوان از Apache Spark برای پردازش بلادرنگ (پردازش جریانی) دادهها استفاده کرد؟
- 12.2. تفاوتهای اصلی بین معماریهای Spark و Hadoop چیست؟
- 12.3. مزایای استفاده از دریاچه داده (Data Lake) در مقابل انبار داده (Data Warehouse) چیست؟
- 12.4. چرا سازمانها به جای Hadoop از Spark برای پردازش دادهها استفاده میکنند؟
- 12.5. چه کاربردهایی برای Spark و Hadoop در صنعت وجود دارد؟
- 13. یادگیری ماشین لرنینگ را از امروز شروع کنید!
اهمیت کلان دادهها
در عصر دیجیتال امروز، دادهها با سرعت بیسابقهای از منابع متعدد مانند شبکههای اجتماعی، حسگرها، سوابق تراکنشها و موارد دیگر تولید میشوند. این انفجار دادهها به ظهور مفهوم “کلانداده” یا “بیگ دیتا” منجر شده است که به مجموعه دادههای بسیار بزرگی اطلاق میشود که نمیتوان آنها را به راحتی با استفاده از ابزارهای سنتی پردازش داده، مدیریت یا پردازش کرد. اهمیت کلانداده در پتانسیل آن برای ارائه بینشهای ارزشمند و هدایت تصمیمگیری در صنایع مختلف از جمله بهداشت و درمان، امور مالی، خردهفروشی و حمل و نقل نهفته است.
مروری بر Spark و Hadoop
Apache Hadoop و Apache Spark دو چارچوب پرکاربرد برای مدیریت کلاندادهها هستند. Hadoop که در سال ۲۰۰۶ معرفی شد، با سیستم فایل توزیعشده خود (HDFS) و مدل برنامهنویسی MapReduce، ذخیرهسازی و پردازش دادهها را متحول کرد. با این حال، اتکای آن به پردازش مبتنی بر دیسک منجر به گلوگاههای عملکردی شد.
Spark که در سال ۲۰۰۹ توسط AMPLab در دانشگاه UC Berkeley توسعه یافت، به عنوان جایگزینی سریعتر و انعطافپذیرتر برای Hadoop ظهور کرد. Spark با بهرهگیری از پردازش در حافظه، عملکرد را برای الگوریتمهای تکراری و کوئریهای تعاملی به طور قابل توجهی افزایش میدهد. علاوه بر این، APIهای غنی Spark و پشتیبانی متنوع، از جمله پردازش دستهای (batch processing)، پردازش جریانهای دادههای زنده (Streaming)، یادگیری ماشینی (machine learning) و پردازش گراف (graph processing)، آن را به گزینهای محبوب برای برنامههای دادهمحور مدرن تبدیل کرده است.
هدف مقاله
این مقاله با هدف ارائه مقایسه جامع بین Spark و Hadoop، به بررسی تفاوتهای معماری، مدلهای داده، کاربردها و معیارهای عملکرد آنها میپردازد. با بررسی نقاط قوت و ضعف هر چارچوب، خوانندگان درک عمیقتری از این دو چارچوب خواهند یافت. علاوه بر این، مقاله به یکپارچهسازی انبارهای داده (data warehouses) و دریاچههای داده (data lakes) با این چارچوبها خواهد پرداخت و همچنین نمونه کدهای پایتون با استفاده از PySpark ارائه خواهد شد.
بیگ دیتا (Big Data)
تعریف و ویژگیها
بیگ دیتا با سه ویژگی اصلی شناخته میشود: حجم (Volume)، سرعت (Velocity) و تنوع (Variety). حجم به مقدار بسیار زیاد دادههای تولید شده اشاره دارد که میتواند از ترابایت تا پتابایت و فراتر از آن باشد. سرعت به سرعت تولید و پردازش دادهها، اغلب به صورت بلادرنگ یا زمان واقعی (real-time)، اشاره دارد. تنوع شامل انواع مختلف دادهها میشود که شامل فرمتهای ساختاریافته، نیمهساختاریافته و غیرساختاریافته مانند متن، تصاویر، ویدئوها و دادههای حسگرها است.
علاوه بر این سه ویژگی، دو ویژگی دیگر نیز اغلب در نظر گرفته میشوند: صحت (Veracity) و ارزش (Value). صحت به کیفیت و دقت دادهها اشاره دارد که ممکن است تحت تأثیر نویز و ناسازگاریها قرار گیرد. ارزش نمایانگر بینشها و مزایای بالقوهای است که میتوان از تحلیل کلاندادهها استخراج کرد.
همچنین بخوانید: بیگ دیتا (Big Data) چیست؟ مهمترین کاربردها و چالشهای آن کجاست؟
تکامل و رشد
مفهوم بیگ دیتا همراه با پیشرفتهای فناوری و قدرت محاسباتی تکامل یافته است. سیستمهای پردازش دادههای اولیه در مدیریت مجموعههای دادهای رو به رشد با مشکل مواجه بودند که این امر منجر به توسعه راهحلهای ذخیرهسازی و پردازش کارآمدتر شد. ظهور محاسبات توزیعشده (distributed computing) و فناوریهای ابری (cloud technologies) توانایی مدیریت و تحلیل کلاندادهها را تسریع کرده است و آن را برای سازمانهای با اندازههای مختلف قابل دسترس کرده است.
رشد بیگ دیتا توسط چندین عامل هدایت میشود، از جمله افزایش دستگاههای متصل به اینترنت (اینترنت اشیاء)، رشد پلتفرمهای شبکههای اجتماعی و دیجیتالیشدن بخشهای مختلف. در نتیجه، تقاضا برای چارچوبهای پردازش دادههای قوی مانند Spark و Hadoop افزایش یافته است و کسبوکارها را قادر ساخته تا از قدرت کلاندادهها برای مزیت رقابتی بهرهبرداری کنند.
تأثیر بر صنایع
کلانداده تأثیر تحولآفرینی بر صنایع مختلف داشته است و نحوه عملکرد و تصمیمگیری سازمانها را متحول کرده است. در بخش بهداشت و درمان، تحلیل کلاندادهها امکان مدلسازی پیشبینی بیماری، برنامههای درمان شخصیسازی شده و مدیریت کارآمد منابع را فراهم میکند. بخش مالی از بیگ دیتا برای تشخیص تقلب، ارزیابی ریسک و تجارت الگوریتمی بهره میبرد. خردهفروشان از کلانداده برای بهینهسازی مدیریت زنجیره تأمین، شخصیسازی تجربه مشتریان و پیشبینی تقاضا استفاده میکنند. در صنعت حمل و نقل، تحلیل بیگ دیتا به بهبود بهینهسازی مسیر، پیشبینی برنامههای نگهداری و مدیریت ناوگان کمک میکند. علاوه بر این، کلانداده نقش حیاتی در تحقیقات علمی، پایش محیط زیست و ابتکارات شهر هوشمند ایفا میکند که نشاندهنده تأثیرات گسترده آن است.
مدلهای داده
تعاریف و تفاوتها
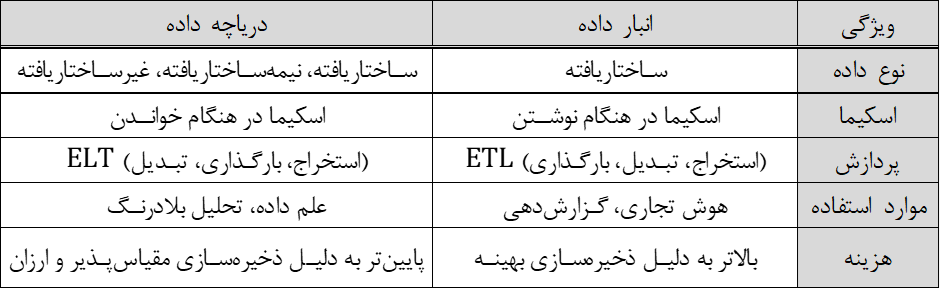
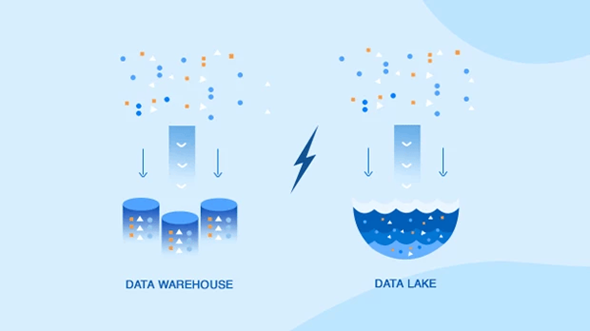
انبار داده (Data Warehouse)
انبار داده یک مخزن مرکزی است که برای ذخیرهسازی دادههای ساختاریافته از منابع مختلف طراحی شده است. این انبار از کوئریهای پیچیده، گزارشدهی و تحلیل داده پشتیبانی میکند. دادهها در انبار داده در قالب اسکیما یا طرحوارههای مشخص (مانند اسکیماهای ستارهای، برفدانهای و صورت فلکی) سازماندهی میشوند و برای عملیاتهای سنگین خواندنی بهینهسازی شدهاند. انبارهای داده سنتی از فرآیندهای ETL (استخراج، تبدیل، بارگذاری) برای پاکسازی، تبدیل و بارگذاری دادهها به انبار داده استفاده میکنند که به تضمین کیفیت و انسجام دادهها کمک میکند.
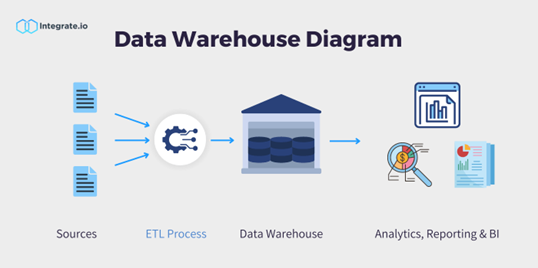
ویژگیهای کلیدی انبار داده:
- دادههای ساختاریافته: دادهها بسیار ساختاریافته و سازماندهی شده هستند.
- اسکیما در هنگام نوشتن (شمای نوشتنی): اسکیما داده قبل از ذخیرهسازی داده تعریف میشود. به این معنا که پیش از پیادهسازی انبار داده طراحی شده است.
- بهینهسازی شده برای کوئریها: طراحی شده برای کوئریهای پیچیده و کارهای تحلیلی.
- ذخیرهسازی دادههای تاریخی: حجمهای بزرگی از دادههای تاریخی را ذخیره میکند.
دریاچه داده (Data Lake)
دریاچه داده یک مخزن ذخیرهسازی است که حجم زیادی از دادههای خام را در فرمت اصلی خود تا زمانی که نیاز باشد نگهداری میکند. برخلاف انبار داده، دریاچه داده میتواند دادههای ساختاریافته، نیمهساختاریافته و غیرساختاریافته را ذخیره کند که آن را به راهحل انعطافپذیرتری تبدیل میکند. دریاچه داده از رویکرد ELT (استخراج، بارگذاری، تبدیل) استفاده میکنند و این امکان را میدهند که دادهها ابتدا بارگذاری شوند و سپس در صورت نیاز تبدیل شوند.
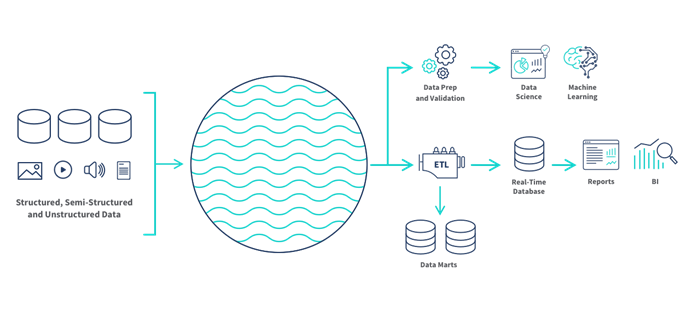
ویژگیهای کلیدی:
- دادههای غیرساختاریافته و نیمهساختاریافته: پشتیبانی از انواع مختلف دادهها.
- اسکیما در هنگام خواندن (شمای خواندنی): اسکیما داده هنگام خواندن داده اعمال میشود. به این معنا که هنگام تحلیل، طراحی و پردازش صورت میگیرد.
- مقیاسپذیری: به راحتی برای تطبیق با حجمهای در حال رشد دادهها مقیاسپذیر است.
- مقرونبهصرفه: اغلب به عنوان راهحلهای ذخیرهسازی ارزانتر شناخته میشود.
موارد استفاده و مزایا
موارد استفاده از انبار داده:
- هوش تجاری: پشتیبانی از ابزارهای گزارشدهی و داشبوردهای پیچیده.
- گزارشدهی عملیاتی: ارائه بینش در عملیات روزانه کسبوکار.
- تحلیل تاریخی: تسهیل تحلیل روندها و بررسی دادههای تاریخی.
- مطابقت قانونی: تضمین دقت و انسجام دادهها برای گزارشدهی قانونی.
مزایای انبار داده:
- عملکرد بالا: بهینهسازی شده برای عملکرد سریع کوئریها.
- انسجام داده: تضمین کیفیت دادهها از طریق فرآیندهای ETL.
- کاربرپسند: مناسب برای تحلیلگران کسبوکار و کاربران غیر فنی.
موارد استفاده از دریاچه داده:
- علم داده و یادگیری ماشین: ذخیره مجموعههای داده بزرگ برای آموزش مدلها.
- تحلیل بلادرنگ: پشتیبانی از بارگذاری و تحلیل بلادرنگ دادهها.
- اکتشاف داده: امکان اکتشاف دادههای خام توسط دانشمندان داده بدون اسکیماهای از پیشتعریفشده.
- دادههای اینترنت اشیا: جمعآوری و ذخیره دادهها از حسگرها و لاگها برای تحلیلهای بعدی.
مزایای دریاچه داده:
- انعطافپذیری: قابلیت مدیریت انواع دادهها و فرمتها.
- مقیاسپذیری: مقیاس پذیر بودن با رشد دادهها.
- ذخیرهسازی مقرونبهصرفه: استفاده از راهحلهای ذخیرهسازی کمهزینه.
- سازگار با نوع دادههای آینده: سازگاری با منابع داده جدید و انواع دادهها بدون نیاز به بازسازی.
یکپارچهسازی مدلهای داده با Spark و Hadoop
یکپارچهسازی با Hadoop
انبار داده: Hadoop میتواند به عنوان بکاند برای انبارهای داده سنتی عمل کند و از HDFS برای ذخیرهسازی مقیاسپذیر استفاده کند. ابزارهایی مانند Apache Hive امکان کوئریگیری مشابه SQL روی Hadoop را فراهم میکنند و آن را برای وظایف انبار داده مناسب میسازند.
دریاچه داده: Hadoop اغلب به عنوان پایه دریاچههای داده استفاده میشود. HDFS یک سیستم ذخیرهسازی توزیعشده فراهم میکند، در حالی که ابزارهایی مانند Apache Flink و Apache Kafka از بارگذاری و پردازش دادهها پشتیبانی میکنند.
یکپارچهسازی با Spark
انبار داده: Spark میتواند با ارائه پردازش سریع در حافظه برای وظایف ETL انبارهای داده را بهبود بخشد. Spark SQL با کوئریگیری، امکان یکپارچهسازی با راهحلهای موجود انبار داده را فراهم میکند.
دریاچه داده: Spark برای دریاچههای داده به دلیل توانایی آن در مدیریت انواع مختلف دادهها و فرمتها بسیار مناسب است. APIهای اسپارک از تبدیلهای پیچیده داده و تحلیلها پشتیبانی میکنند و آن را به ابزاری قدرتمند برای استخراج بینش از دریاچههای داده تبدیل میکند.
تفاوتهای بین Spark و Hadoop
در این بخش به معرفی دو چارچوب Spark و Hadoop و بیان تفاوتهای آنها میپردازیم
معماری
Hadoop:

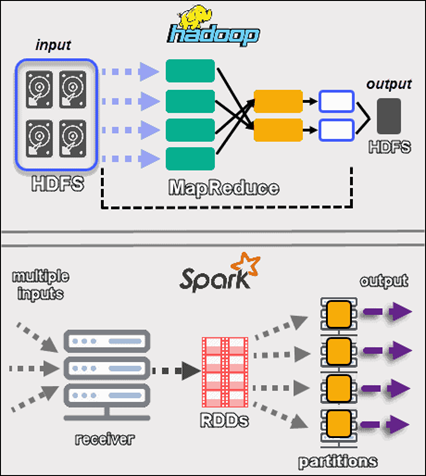
معماری Hadoop بر اساس دو مؤلفه اصلی است: سیستم فایل توزیعشده (HDFS) و مدل پردازشی MapReduce.
- HDFS: این لایه ذخیرهسازی Hadoop به شمار میآید که برای ذخیره حجمهای وسیعی داده در یک خوشه توزیعشده از ماشینها طراحی شده است و از طریق تکرار دادهها، اطمینان از قابلیت اطمینان و تحمل خطا را فراهم میکند.
- MapReduce: این لایه پردازشی Hadoop است که بر اساس اصل پردازش موازی عمل میکند، وظایف را به زیر وظایف کوچکتر تقسیم میکند که به صورت مستقل پردازش میشوند و سپس تجمیع میشوند.
Spark:

اسپارک با معماری متنوعتری طراحی شده است که میتواند انواع مختلف وظایف پردازش داده را انجام دهد.
- توزیع متغیرها (RDDs) (Resilient Distributed Datasets): RDDها نمایانگر مجموعههای توزیعشده و تغییرناپذیر اشیاء هستند که میتوانند به صورت موازی پردازش شوند.
- برنامهریز DAG (Directed Acyclic Graphs): اسپارک از گرافهای جهتدار غیرمدور (DAG) برای نمایش گردش کار محاسباتی استفاده میکند و طرح اجرای بهینه را فراهم میکند.
- محاسبات در حافظه: برخلاف Hadoop، اسپارک بیشتر عملیات خود را در حافظه انجام میدهد و به طور قابلتوجهی سرعت پردازش دادهها را افزایش میدهد.
مدلهای پردازشی
Hadoop:
- پردازش دستهای (Batch Processing): Hadoop عمدتاً برای پردازش دستهای طراحی شده است که شامل پردازش حجمهای بزرگ داده در یک اجرای واحد است. این مدل برای وظایفی مانند فرآیندهای ETL، انبار داده و تولید گزارش مناسب است.
Spark:
- پردازش دستهای (Batch Processing): اسپارک نیز از پردازش دستهای پشتیبانی میکند اما این کار را بسیار سریعتر از Hadoop به دلیل محاسبات در حافظه انجام میدهد.
- پردازش جریانی (Stream Processing): اسپارک استریمینگ امکان پردازش بلادرنگ دادهها را فراهم میکند و اجازه میدهد دادهها به صورت پیوسته بارگذاری و تحلیل شوند.
- پردازش تعاملی (Interactive Processing): با اسپارک، کاربران میتوانند کوئریهای تعاملی داده را با استفاده از Spark SQL انجام دهند که بینشهای سریع و تحلیلهای اکتشافی را فراهم میکند.
- پردازش گراف (Graph Processing): کتابخانه GraphX اسپارک از پردازش و تحلیل گراف پشتیبانی میکند و امکان محاسبات پیچیده گراف را فراهم میسازد.
عملکرد و مقیاسپذیری
Hadoop:
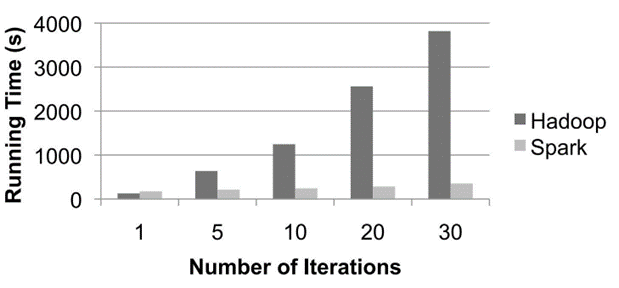
- ذخیرهسازی مبتنی بر دیسک: Hadoop دادهها را روی دیسک ذخیره میکند و برای پردازش از دیسک خوانده و نوشته میشود. این منجر به تأخیر بالاتر نسبت به پردازش در حافظه میشود.
- مقیاسپذیری: Hadoop بسیار مقیاسپذیر است و میتواند با اضافه کردن نودهای بیشتر به خوشه، دادههای با اندازه پتابایتهای را مدیریت کند. با این حال، عملکرد آن ممکن است با افزایش حجم دادهها به دلیل گلوگاههای I/O دیسک کاهش یابد.
Spark:
- پردازش در حافظه: پردازش در حافظه Hadoop عملکرد را به طور قابلتوجهی افزایش میدهد و برای برخی بارهای کاری تا ۱۰۰ برابر سریعتر از Hadoop است.
- مقیاسپذیری: Spark نیز بسیار مقیاسپذیر است و میتواند وظایف پردازش دادههای بزرگ را به طور کارآمد مدیریت کند. Spark میتواند از محیطهای درونسازمانی و ابری برای مقیاسپذیری استفاده کند.
تحمل خطا و قابلیت اطمینان
Hadoop:
- تکرار داده: HDFS با تکرار دادهها در نودهای متعدد، تحمل خطا را فراهم میکند. اگر یک نود از کار بیفتد، دادهها میتوانند از نود دیگری بازیابی شوند.
- تحمل خطا در MapReduce: کارهای MapReduce به وظایف کوچکتری تقسیم میشوند که در صورت بروز خطا میتوانند دوباره اجرا شوند، در این صورت قابلیت اطمینان سیستم فراهم میشود.
اسپارک:
- تحمل خطا در RDD: اسپارک فرآیند تحمل خطا را از طریق اطلاعات سلسلهمراتبی RDDها بدست میآورد. اگر یک پارتیشن از RDD گم شود، میتوان آن را با استفاده از گراف سلسلهمراتب مجدداً محاسبه کرد.
- نقطهگذاری (Checkpointing): برای برنامههای طولانیمدت، اسپارک نقطهگذاری را فراهم میکند تا RDDها را روی دیسک ذخیره کند، در این صورت از دسترفتن دادهها جلوگیری میشود.

کاربردهای Spark و Hadoop
پردازش دادههای بلادرنگ
Hadoop:
Hadoop عمدتاً بر پردازش دستهای تمرکز دارد و بهطور ذاتی برای پردازش دادههای بلادرنگ طراحی نشده است. با این حال، میتوان هدوپ را با ابزارهای پردازش دادههای بلادرنگ مانند Apache Storm یا Apache Flink ادغام کرد تا وظایف بلادرنگ را انجام دهد. این ابزارها با ارائه قابلیت پردازش و تحلیل دادهها به محض ورود، Hadoop را تکمیل میکنند، هرچند که این تنظیمات میتواند پیچیده و منابعبر باشد.
Spark:
اسپارک در پردازش دادههای بلادرنگ از طریق ماژول Spark Streaming برتری دارد. Spark Streaming امکان پردازش جریانهای داده بلادرنگ با مقیاسپذیری و تحمل خطا را فراهم میکند. اسپارک میتواند دادهها را از منابع مختلف مانند Apache Kafka، Flume و HDFS دریافت کند، به صورت زمان واقعی پردازش کند و بهصورت فوری نتایج را ارائه دهد. Spark Streaming دادهها را به ریزبچها تبدیل میکند که مناسب برای تحلیل بلادرنگ، سیستمهای پایش و هشداردهی است.
مثالهای مورد استفاده:
- خدمات مالی: تشخیص تقلب بلادرنگ و پایش تراکنشها.
- مخابرات: پایش عملکرد شبکه و تشخیص ناهنجاریها.
- صنایع مرتبط با خردهفروشی: مدیریت موجودی به صورت زمان واقعی و توصیههای شخصیسازی شده به مشتریان.
پردازش دستهای
Hadoop
پردازش دستهای تخصص Hadoop است که از مدل برنامهنویسی MapReduce بهره میبرد. MapReduce حجمهای بزرگ داده را با تقسیم وظایف به زیر وظایف مستقل پردازش میکند که به صورت موازی در یک خوشه توزیع شده پردازش میشوند. این مدل برای فرآیندهای ETL، تحلیل دادههای بزرگمقیاس و تولید گزارش مناسب است.
Spark
اسپارک نیز از پردازش دستهای پشتیبانی میکند، اما این کار را به دلیل قابلیتهای پردازش در حافظه کارآمدتر از Hadoop انجام میدهد. RDDها و DataFrameهای اسپارک امکان پردازش دادههای سریعتر و تغییرات پیچیده داده را فراهم میکنند. علاوه بر این، برنامهریز DAG اسپارک برنامه اجرای بهینه را فراهم میکند که منجر به عملکرد بهتر برای وظایف دستهای میشود.
مثالهای مورد استفاده:
- بهداشت و درمان: پردازش دستهای سوابق پزشکی برای مدیریت و پیشبینی سلامت جمعیت.
- امور مالی: پردازش دادههای مالی تاریخی برای ارزیابی ریسک و تطابق با مقررات.
- دولت: تحلیل دادههای بزرگ برای دادههای سرشماری و برنامهریزی سیاستهای عمومی.
یادگیری ماشین و هوش مصنوعی
Hadoop:
هدوپ میتواند از طریق ادغام با Apache Mahout، برای وظایف یادگیری ماشین استفاده شود. با این حال، Mahout عمدتاً به مدل MapReduce متکی است که برای الگوریتمهای یادگیری ماشین تکراری میتواند ناکارآمد باشد.
Spark:
اسپارک کتابخانه کامل یادگیری ماشین به نام MLlib را فراهم میکند که برای محاسبات توزیعشده بهینه شده است. MLlib شامل الگوریتمهایی برای طبقهبندی، رگرسیون، خوشهبندی و موارد دیگر است. مدل محاسبات در حافظه و تکراری اسپارک، آن را برای آموزش مدلهای یادگیری ماشین بزرگمقیاس ایدهآل میکند.
مثالهای مورد استفاده:
- تجارت الکترونیک: سیستمهای توصیهدهنده محصول و بخشبندی مشتریان.
- بهداشت و درمان: مدلسازی پیشبینی برای شیوع بیماریها و نتایج بیماری.
- بازاریابی: پیشبینی ریزش مشتری و کمپینهای بازاریابی هدفمند.
همچنین بخوانید: نقشهراه یادگیری هوش مصنوعی از پایه در سال ۲۰۲۴ چیست؟
تحلیل داده و هوش تجاری
Hadoop:
Hadoop از طریق ابزارهایی مانند Apache Hive و Pig از تحلیل داده و هوش تجاری پشتیبانی میکند. Hive رابطی مشابه SQL برای کوئریگیری و تحلیل دادههای بزرگ ذخیره شده در HDFS ارائه میدهد. Pig زبان اسکریپتنویسی سطح بالایی برای تغییر و تحلیل داده فراهم میکند. این ابزارها امکان استخراج بینش از حجمهای عظیم داده را برای کسبوکارها فراهم میکنند، هرچند عملکرد کوئریها ممکن است در مقایسه با اسپارک کندتر باشد.
Spark:
ماژول SQL اسپارک (Spark SQL) امکان کوئریگیری و تحلیل قدرتمند دادهها را فراهم میکند. این ماژول با دادههای ذخیره شده در HDFS، Hive و منابع داده مختلف دیگر بهطور یکپارچه ادغام میشود. Spark SQL از کوئریهای دستهای و تعاملی پشتیبانی میکند که امکان کاوش بلادرنگ داده و هوش تجاری را فراهم میکند. علاوه بر این، توانایی اسپارک در کش کردن دادهها در حافظه منجر به عملکرد سریعتر کوئریها میشود.
مثالهای مورد استفاده:
- خردهفروشی: تحلیل فروش، پیشبینی تقاضا و تحلیل رفتار مشتری.
- مالی: تحلیل بلادرنگ دادههای بازار و مدیریت پرتفوی.
- تولید: برنامههای تعمیر و نگهداری و تحلیل کنترل کیفیت.

برای مطالعه بیشتر کلیک کنید: هوش تجاری یا Business Intelligence چیست؟
PySpark
پایاسپارک API پایتون برای Apache Spark است که به توسعهدهندگان پایتون اجازه میدهد از قابلیتهای محاسبات توزیعشده اسپارک بهرهبرداری کنند. این ابزار ساده و کارآمد امکان پردازش دادههای بزرگمقیاس با استفاده از پایتون را فراهم میکند و به طور یکپارچه با عملکردهای اصلی اسپارک ادغام میشود. PySpark از اجزای مختلف اسپارک شامل Spark SQL، Spark Streaming، MLlib و GraphX پشتیبانی میکند و به کاربران پایتون امکان میدهد پردازش دستهای، تحلیل بلادرنگ، یادگیری ماشین و پردازش گراف را انجام دهند. با استفاده از PySpark، دانشمندان داده و مهندسان میتوانند برنامههای پردازش دادههای مقیاسپذیر را به زبان پایتون بنویسند و از عملکرد بالا و انعطافپذیری اسپارک بهرهمند شوند. در ادامه چند قطعه کد با بهرهگیری از این ابزار ارائه میشود:
برای درک بهتر به این ویدئو از پلی لیست PySpark مراجعه کنید.
تنظیم PySpark
برای شروع استفاده از PySpark، نیاز به نصب و پیکربندی محیط خود دارید. در اینجا یک راهنمای ساده برای راهاندازی آورده شده است:
# Install PySpark using pip
!pip install pyspark
# Set environment variables for Spark
!export SPARK_HOME=/path/to/spark
!export PATH=$SPARK_HOME/bin:$PATH
!export PYSPARK_PYTHON=python3
عملیات ابتدایی در PySpark
ایجاد یک جلسه در PySpark
برای شروع کار با PySpark لازم است که ابتدا یک جلسه (Session) مطابق کد زیر ایجاد شود:
from pyspark.sql import SparkSession
# Initialize a Spark session
spark = SparkSession.builder.appName("BasicOperations").getOrCreate()
بارگذاری مجموعه داده
ابتدا یک مجموعه داده ساده که بیانگر تراکنشهای یک فروشگاه است ایجاد میکنیم و سپس به کمک PySpark آن را بارگذاری میکنیم.
# Load the CSV file into a DataFrame
df = spark.read.csv("dataset.csv", header=True, inferSchema=True)
همچنین این ویدئو از پلی لیست PySpark را مشاهده کنید.
کار با دیتافریم
برای انجام عملیات ساده روی مجموعه داده نظیر مشاهده چند ردیف ابتدایی، دیتاتایپ ستونها، اعمال فیلتر و GroupBy میتوان مطابق قطعه کد زیر عمل کرد:
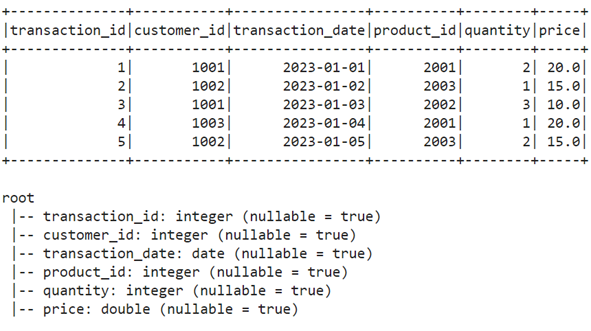
# Show the first 5 rows
df.show(5)
# Print schema of the DataFrame
df.printSchema()
# Select specific columns
df.select("transaction_id", "customer_id").show()
# Filter rows
df.filter(df["quantity"] > 1).show()
# Group by and aggregate
df.groupBy("product_id").count().show()
تصاویر زیر نماینگر خروجی قطعه کد بالا هستند:
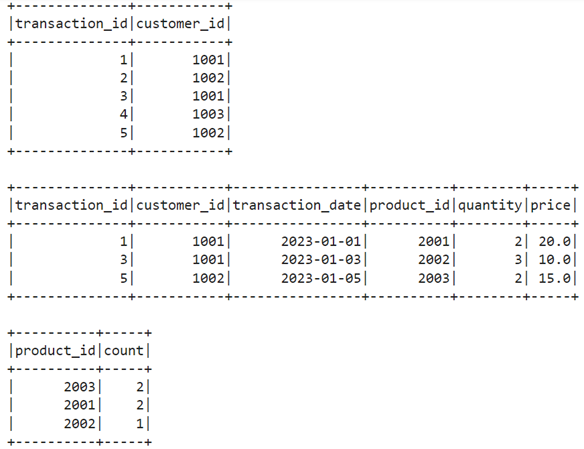
برای حذف، تغییرنام و یا ایجاد ستون جدید در PySpark نیز میتوان مطابق کد زیر عمل کرد:
# Add a new column for total amount
df = df.withColumn("total_amount", df["quantity"] * df["price"])
# Drop a column
df = df.drop("product_id")
# Rename a column
df = df.withColumnRenamed("transaction_date", "date")
برای درک بهتر به این ویدئو از پلی لیست PySpark مراجعه کنید.
پیادهسازی فرآیند یادگیری ماشین در PySpark
همانطور که در بخش پیشین اشاره شد، امکان پیادهسازی فرآیند یادگیری ماشین در Spark وجود دارد؛ قطعه کد زیر بیانگر کاربرد رگرسیون خطی برای این مجموعه داده نمونه میباشد:
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.regression import LinearRegression
# Feature engineering
assembler = VectorAssembler(inputCols=["quantity", "price"], outputCol="features")
data = assembler.transform(df)
# Split the data into training and test sets
train_data, test_data = data.randomSplit([0.8, 0.2])
# Initialize a linear regression model
lr = LinearRegression(featuresCol="features", labelCol="total_amount")
# Fit the model on training data
lr_model = lr.fit(train_data)
# Predict on test data
predictions = lr_model.transform(test_data)
predictions.select("total_amount", "prediction").show()
همچنین میتوانید این ویدئو را مشاهده کنید.
تفاوت بین PySpark و Pandas
در بخش قبل با مشاهده خروجی بخش مربوط به دیتافریم، احتمالا متوجه برخی شباهتهای pandas با PySpark شدیم. در حالی که pandas به دلیل سهولت استفاده و قابلیتهای قدرتمند در دستکاری دادهها در مجموعه دادههای کوچک تا متوسط معروف است، Spark در پردازش دادههای بزرگمقیاس و محاسبات توزیعشده برتری دارد. درک این تفاوتها برای دانشمندان داده و مهندسان در انتخاب ابزار مناسب برای نیازهای خاصشان، چه در تحلیل دادههای اکتشافی، پردازش دادههای بلادرنگ، یا وظایف یادگیری ماشین بزرگمقیاس، حیاتی است. لذا در این بخش به تفاوتهای این دو ابزار میپردازیم:
موارد استفاده
pandas:
- تحلیل دادهها: pandas برای تحلیل و دستکاری دادهها در محیطهای تک ماشینی طراحی شده و برای مجموعه دادههای کوچک تا متوسط مناسب است.
- تحلیل دادههای اکتشافی (EDA): به دلیل سهولت استفاده و عملکردهای گسترده در دستکاری دادهها، به طور گسترده برای EDA استفاده میشود.
- الگوی طراحی نمونه اولیه: ایدهآل برای نمونهسازی جریانهای کاری تحلیل داده قبل از مقیاسبندی.
Spark:
- پردازش دادههای بزرگ: Spark برای انجام وظایف پردازش دادههای بزرگ در محیطهای محاسبات توزیعشده طراحی شده است.
- کاربردهای تولیدی: مناسب برای بارهای کاری در سطح تولید که نیاز به مقیاسپذیری و عملکرد بالا دارند.
- پردازش بلادرنگ: پشتیبانی از پردازش و تحلیل دادههای بلادرنگ که pandas نمیتواند به طور مؤثر از عهده آن برآید.
قابلیتهای دستکاری و پردازش دادهها
pandas:
- DataFrames: ساختار داده اصلی در DataFrame، امکان دستکاری و تحلیل دادهها به صورت شهودی را فراهم میکند.
- توابع و عملیاتها: توابع گسترده برای پاکسازی، تبدیل و تحلیل دادهها.
- عملکرد: محدود به حافظه و توان پردازشی یک ماشین واحد.
Spark:
- DataFrames و Datasets: مشابه DataFrames در pandas اما توزیعشده در یک خوشه، امکان پردازش دادههای بزرگمقیاس را فراهم میکند.
- Spark SQL: ارائه قابلیتهای کوئرینویسی شبیه به SQL روی مجموعه دادههای بزرگ.
- عملکرد: بهینهشده برای محاسبات توزیعشده، عملکرد بسیار بهتری نسبت به pandas در مجموعه دادههای بزرگ دارد.
عملکرد و مقیاسپذیری
pandas:
- تک ماشینی: محدود به حافظه و CPU یک ماشین واحد.
- مقیاسپذیر نیست: در مجموعه دادههایی که از ظرفیت حافظه ماشین فراتر میروند، مشکل دارد.
- Spark:
- محاسبات توزیعشده: با استفاده از قدرت یک خوشه توزیعشده، دادههای بزرگ را پردازش میکند.
- مقیاسپذیر: با افزودن گرههای بیشتر به خوشه، میتوان مقیاس را افزایش داد که این امر Spark را ابزار مناسبی برای برنامههای دادههای بزرگ میکند.
ادغام با ابزارهای دیگر
pandas:
- به خوبی با کتابخانههای پایتون دیگر مانند NumPy، SciPy و scikit-learn برای تحلیل داده و یادگیری ماشین ادغام میشود.
- بصریسازی: به طور یکپارچه با کتابخانههای بصریسازی مانند Matplotlib و Seaborn کار میکند.
- Spark:
- اکوسیستم: بخشی از اکوسیستم بزرگتر Apache است و به خوبی با Hadoop، HDFS، Kafka و سایر ابزارهای دادههای بزرگ ادغام میشود.
- یادگیری ماشین: ارائه MLlib برای وظایف یادگیری ماشین که مقیاسپذیر و بهینهشده برای دادههای بزرگ است.
تصاویر زیر بیانگر تفاوتهای کدنویسی این دو ابزار را بیان میدارد:

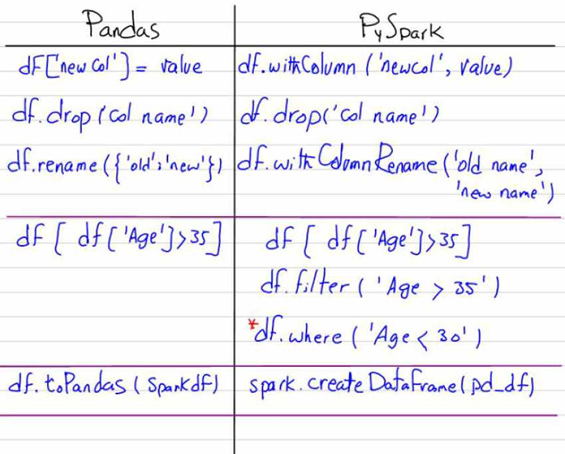

روندهای آینده در بیگ دیتا
با ادامه رشد حجم و پیچیدگی دادهها، تقاضا برای چارچوبهای پردازش داده کارآمد و مقیاسپذیر افزایش خواهد یافت. روندهای آینده در دادههای بزرگ احتمالاً شامل پیشرفت در پردازش دادههای بلادرنگ، الگوریتمهای یادگیری ماشین پیچیدهتر و یکپارچگی بیشتر با پلتفرمهای ابری خواهد بود. هر دو ابزار Spark و Hadoop به تکامل خود ادامه خواهند داد، با این احتمال که Spark همچنان به حفظ برتری خود در عملکرد و انعطافپذیری ادامه دهد.
جمعبندی
این مقاله مقایسهای بین Spark و Hadoop ارائه کرده است، تفاوتهای معماری، مدلهای داده و کاربردهای هر کدام را برجسته کرده است. ما نقاط قوت و ضعف هر چارچوب را بررسی کردهایم، با تمرکز ویژه بر اینکه چرا Spark اغلب برتر از Hadoop در نظر گرفته میشود. علاوه بر این، به یکپارچگی انبار داده و دریاچه داده با این چارچوبها و نمونههای کد عملی با استفاده از PySpark پرداختهایم.
در حالی که Hadoop به عنوان یک فناوری پایه در اکوسیستم دادههای بزرگ بوده است، Spark به عنوان یک جایگزین انعطافپذیرتر و کارآمدتر ظاهر شده است. توانایی آن در مدیریت بارهای کاری متنوع، همراه با قابلیتهای پردازش درون حافظه، Spark را به ابزاری قدرتمند برای کاربردهای دادههای مدرن تبدیل میکند. با این حال، انتخاب بین Spark و Hadoop در نهایت به موارد استفاده و نیازهای خاص بستگی دارد. با درک نقاط قوت و محدودیتهای هر چارچوب، سازمانها میتوانند تصمیمات آگاهانهای بگیرند که بهترین تطابق را با نیازهای پردازش داده آنها داشته باشد.
برای دسترسی به کد نوتبوک این بلاگ اینجا کلیک کنید.
برای دسترسی به نوتبوکهای بیشتر اینجا کلیک کنید.

پرسشهای متداول
چگونه میتوان از Apache Spark برای پردازش بلادرنگ (پردازش جریانی) دادهها استفاده کرد؟
Apache Spark از ابزارهایی مانند Spark Streaming استفاده میکند تا دادهها را به صورت پیوسته پردازش و تحلیل کند. این قابلیت باعث میشود که بتوان به صورت بلادرنگ دادههای ورودی را تحلیل و بینشهای سریع به دست آورد.
تفاوتهای اصلی بین معماریهای Spark و Hadoop چیست؟
Hadoop از معماری سیستم فایل توزیعشده (HDFS) و مدل پردازشی MapReduce استفاده میکند که پردازش را مبتنی بر دیسک انجام میدهد. در مقابل، Spark با استفاده از RDD (مجموعه دادههای توزیعشده انعطافپذیر) و پردازش در حافظه، سرعت پردازش را به طور قابلتوجهی افزایش میدهد.
مزایای استفاده از دریاچه داده (Data Lake) در مقابل انبار داده (Data Warehouse) چیست؟
دریاچه داده توانایی ذخیره حجم زیادی از دادههای خام و انواع مختلف دادهها را دارد که این امر انعطافپذیری بالایی به آن میبخشد. در مقابل، انبار داده برای ذخیره و تحلیل دادههای ساختاریافته و کوئریهای پیچیده بهینهسازی شده است.
چرا سازمانها به جای Hadoop از Spark برای پردازش دادهها استفاده میکنند؟
سازمانها به دلیل سرعت بالاتر پردازش در حافظه، توانایی پردازش بلادرنگ و تعاملی، و انعطافپذیری بیشتر Spark در مقایسه با Hadoop، اغلب از Spark استفاده میکنند. این مزایا باعث میشود که Spark برای کاربردهای دادهمحور مدرن مناسبتر باشد.
چه کاربردهایی برای Spark و Hadoop در صنعت وجود دارد؟
در صنعت بهداشت و درمان برای تحلیل پیشبینی بیماری، در بخش مالی برای تشخیص تقلب و ارزیابی ریسک، در خردهفروشی برای بهینهسازی مدیریت زنجیره تأمین و پیشبینی تقاضا، و در حمل و نقل برای بهینهسازی مسیر و مدیریت ناوگان از Spark و Hadoop استفاده میشود.
یادگیری ماشین لرنینگ را از امروز شروع کنید!
دنیای دادهها جذاب است و دانستن علم داده، توانایی تحلیل داده، یا بازاریابی مبتنی بر داده، شما را برای فرصتهای شغلی بسیاری مناسب میکند. فارغ از رشته و پیشزمینه، میتوانید حالا شروع کنید و از سطح مقدماتی تا پیشرفته بیاموزید. اگر دوست دارید به این حوزه وارد شوید، پیشنهاد میکنیم با کلیک روی این لینک قدم اول را همین حالا بردارید.
مشاوران کافهتدریس به شما کمک میکنند مسیر یادگیری برای ورود به این حوزه را شروع کنید: