
یادگیری انتقالی (Transfer Learning) یکی از رویکردهای پیشرفته در یادگیری ماشین است که توانسته تاثیر بسزایی در کاهش زمان و هزینههای آموزش مدلهای پیچیده داشته باشد. این روش به متخصصان یادگیری ماشین این امکان را میدهد که با استفاده از دانش و تجربیات مدلهای از پیشآموزشدیده توسط شرکتهای بزرگ و منابع سختافزاری قدرتمند، مدلهای جدیدی ایجاد کنند که نیاز نداشته باشند از ابتدا آموزش ببینند. PyTorch، به عنوان یک کتابخانه قدرتمند و انعطافپذیر یادگیری ماشین، نقش بسیار مهمی در این فرآیند ایفا میکند. این کتابخانه با ارائه ابزارها و امکانات متنوع، کمک میکند که به سادگی مدلهای پیشآموزشدیده را بارگذاری و آنها را با دادههای جدید تنظیم کنیم. در این مقاله، یادگیری انتقالی با PyTorch را بررسی و نحوه پیادهسازی آن را با جزئیات توضیح میدهیم.
- 1. پایتورچ چیست؟
- 2. یادگیری انتقالی چیست؟
- 3. روشهای استفاده از یادگیری انتقالی
- 4. مزایای استفاده از یادگیری انتقالی
- 5. مدلهای پیشآموزشدیده معروف
- 6. یادگیری انتقالی با PyTorch برای استخراج ویژگی
- 7. یادگیری انتقالی با PyTorch برای تنظیم دقیق مدل
- 8. کلام آخر درباره یادگیری انتقالی با PyTorch
-
9.
سؤالات متداول
- 9.1. یادگیری انتقالی با PyTorch چیست و چه مزایایی دارد؟
- 9.2. چرا PyTorch برای پیادهسازی یادگیری انتقالی انتخاب میشود؟
- 9.3. چه مدلهای پیشآموزشدیدهای برای یادگیری انتقالی مناسب هستند؟
- 9.4. یادگیری انتقالی چگونه زمان و منابع مورد نیاز برای آموزش مدلها را کاهش میدهد؟
- 9.5. تفاوت بین روشهای استخراج ویژگی (Feature Extraction) و تنظیم دقیق (Fine Tuning) در یادگیری انتقالی چیست؟
- 10. یادگیریماشین لرنینگ را از امروز شروع کنید!
پایتورچ چیست؟
پایتورچ (PyTorch) یک کتابخانه متنباز (Open Source) برای یادگیری ماشین و شبکههای عصبی است که توسط فیسبوک توسعه یافته است. این کتابخانه به دلیل سادگی و انعطافپذیری، به طور گستردهای در پژوهشها و پروژههای صنعتی استفاده میشود. پایتورچ امکانات زیادی برای ایجاد، آموزش و ارزیابی مدلهای یادگیری عمیق فراهم میکند و به کاربران اجازه میدهد تا به سرعت مدلهای پیچیده را پیادهسازی کنند.
یادگیری انتقالی چیست؟
یادگیری انتقالی به فرآیندی اشاره دارد که در آن یک مدل از تجربیات و دانش یک مدل دیگر بهره میبرد. این مفهوم زمانی به کار میرود که یک مدل بزرگ و قدرتمند با استفاده از دادههای گسترده آموزش دیده و سپس این دانش به مدلهای کوچکتر یا مخصوص به یک کار خاص منتقل میشود. در مقابل یادگیری سنتی که نیاز به دادههای بزرگ و زمان زیادی برای آموزش دارد، یادگیری انتقالی با استفاده از دانش از پیش کسبشده، فرآیند آموزش را سریعتر و کارآمدتر میکند.
برای آشنایی بیشتر با یادگیری انتقالی میتوانید مقاله یادگیری انتقالی (Transfer Learning) چیست و چطور کار میکند؟ را مطالعه نمایید.
روشهای استفاده از یادگیری انتقالی
بهطور کلی سه رویکرد برای استفاده از مدلهای ازپیشآموزشدیده وجود دارد و در همین راستا سه مدل، یادگیری انتقالی داریم: یادگیری انتقالی برای استخراج ویژگی (Feature Extraction)، یادگیری انتقالی برای تنظیم دقیق (Fine Tuning) مدل ازپیشآموزشدیده و یادگیری انتقالی چند مرحلهای. هر یک از این روشها مزایا و کاربردهای خاص خود را دارند و میتوانند به متخصصان یادگیری ماشین کمک کنند تا مدلهای کارآمدتر و دقیقتری ایجاد کنند. با استفاده از این روشها، میتوان زمان و منابع مورد نیاز برای آموزش مدلها را به طور قابل توجهی کاهش داد و به نتایج مطلوبتری دست یافت. در ادامه به بررسی این سه رویکرد استفاده از یادگیری انتقالی میپردازیم:
یادگیری انتقالی برای استخراج ویژگی
یادگیری انتقالی برای استخراج ویژگیها یکی از رایجترین انواع یادگیری انتقالی است که در آن از ویژگیهای استخراجشده توسط یک مدل پیشآموزشدیده استفاده میشود. در این روش، مدل اولیه (مدل پیشآموزشدیده) بر روی یک مجموعه داده بزرگ و جامع آموزش دیده است و توانسته ویژگیهای کلی و قدرتمندی را استخراج کند. این ویژگیها سپس به مدل جدید منتقل میشوند که برای حل یک مساله خاص استفاده میشود.
برای مثال،فرض کنید یک مدل پیشآموزشدیده بر روی مجموعه داده ImageNet آموزش دیده و توانسته ویژگیهای کلی تصاویر را به خوبی استخراج کند. این ویژگیها میتوانند به یک مدل جدید برای تشخیص انواع خاصی از حیوانات منتقل شوند. مدل جدید نیازی به آموزش از ابتدا ندارد و با استفاده از ویژگیهای استخراجشده توسط مدل اولیه، میتواند به سرعت و با دقت بالایی مساله را حل کند.
یادگیری انتقالی برای تنظیم دقیق
یادگیری انتقالی برای تنظیم دقیق روشی است که در آن علاوه بر استفاده از ویژگیهای استخراجشده توسط مدل پیشآموزشدیده، برخی از لایههای مدل نیز مجدداً آموزش داده میشوند. در این روش، ابتدا مدل پیشآموزشدیده بارگذاری میشود و سپس لایههای نهایی مدل با استفاده از دادههای جدید آموزش میبینند تا مدل بتواند به طور خاص برای مساله جدید بهینهسازی شود.
برای مثال، یک مدل پیشآموزشدیده بر روی دادههای عمومی تشخیص اشیا (Object Detection) آموزش دیده است. برای حل یک مساله خاص مانند تشخیص بیماریهای گیاهی از تصاویر برگ گیاهان، لایههای نهایی مدل با استفاده از دادههای جدید (تصاویر برگهای گیاهان بیمار و سالم) آموزش داده میشوند تا مدل بتواند با دقت بالایی بیماریهای گیاهی را تشخیص دهد.
یادگیری انتقالی چند مرحلهای
یادگیری انتقالی چندمرحلهای یکی از پیشرفتهترین روشهای یادگیری انتقالی است که در آن مدلها به صورت سلسله مراتبی آموزش دیده و دانش آنها به مدلهای پاییندست منتقل میشود. در این روش، ابتدا یک مدل بزرگ و عمومی آموزش دیده و سپس این مدل به عنوان پایهای برای آموزش مدلهای کوچکتر و خاصتر استفاده میشود. هر مدل به نوبه خود دانش خود را به مدلهای بعدی منتقل میکند تا در نهایت یک مدل بسیار دقیق و بهینه برای مساله خاص ایجاد شود.
برای مثال، در یک پروژه بزرگ تشخیص بیماریها از تصاویر پزشکی، ابتدا یک مدل عمومی بر روی دادههای گستردهای از تصاویر پزشکی آموزش دیده میشود. سپس این مدل به عنوان پایهای برای آموزش مدلهای خاصتر برای تشخیص بیماریهای خاص مانند سرطان، بیماریهای قلبی و غیره استفاده میشود. هر مدل تخصصی دانش خود را به مدلهای تخصصیتر انتقال میدهد تا در نهایت یک سیستم تشخیص دقیق و جامع ایجاد شود.
مقایسه سه روش
در جدول زیر میتوانید تعاریف، ویژگیها و کاربردهای هر یک از روشهای یادگیری انتقالی را ببینید:
| ویژگیها | استخراج ویژگی | تنظیم دقیق | چند مرحلهای |
| تعریف | استفاده از لایههای ازپیشآموزشدیده برای استخراج ویژگیهای مفید از دادهها | تنظیم دقیق کل مدل ازپیشآموزشدیده با استفاده از دادههای جدید | استفاده از چندین مرحله یادگیری انتقالی برای بهبود عملکرد مدل |
| کاربرد | زمانی که دادههای آموزشی محدود هستند. | زمانی که نیاز به بهبود عملکرد مدل در یک وظیفه خاص داریم. | زمانی که وظایف پیچیده هستند و نیاز به بهبود مرحلهای دارند. |
| زمان آموزش | نسبتاً کم | نسبتاً متوسط | نسبتاً زیاد |
| میزان دادههای مورد نیاز | متوسط | زیاد | بسیار زیاد |
| نیاز به تنظیم پارامترها | کم | متوسط تا زیاد | زیاد |
| کارایی در پروژههای جدید | نسبتا ضعیف | قابل قبول | عالی |
| پیچیدگی | کم | متوسط | زیاد |
مزایای استفاده از یادگیری انتقالی
استفاده از یادگیری انتقالی مزایای زیادی دارد که برخی از آنها عبارتند از:
- کاهش زمان آموزش مدل: با استفاده از مدلهای پیشآموزشدیده، زمان مورد نیاز برای آموزش مدلهای جدید به طور قابل توجهی کاهش مییابد.
- بهبود دقت مدل: انتقال ویژگیها از مدلهای قدرتمند به مدلهای جدید باعث افزایش دقت مدلها میشود.
- نیاز کمتر به دادههای بزرگ: یادگیری انتقالی به دلیل استفاده از دانش قبلی، نیاز به جمعآوری و پردازش دادههای بزرگ را کاهش میدهد.
مدلهای پیشآموزشدیده معروف
برخی از مدلهای معروف هستند که به طور گسترده در یادگیری انتقالی استفاده میشوند. این مدلها بر روی مجموعه دادههای بزرگ و متنوع آموزش دیدهاند و میتوانند ویژگیهای عمومی و مهمی را از دادهها استخراج کنند. در ادامه، به معرفی برخی از مدلهای معروف پیشآموزشدیده که به طور گسترده در یادگیری انتقالی استفاده میشوند، میپردازیم:
VGG
مدل VGG (Visual Geometry Group) توسط گروهی از محققان در دانشگاه آکسفورد توسعه یافته است. این مدل به دلیل سادگی و عمق زیاد، یکی از محبوبترین مدلهای تشخیص تصویر محسوب میشود. مدل VGG بر روی مجموعه داده ImageNet آموزش دیده است که شامل میلیونها تصویر و هزاران برچسب مختلف است. این مدل دارای معماری سادهای با لایههای کانولوشنی پشت سر هم است که توانسته است ویژگیهای قدرتمندی از تصاویر را استخراج کند.
برای آشنایی با معماری VGGNet مقاله با شبکه عصبی وی جی جی نت (VGGNet) آشنا شوید! را بخوانید.
ResNet
مدل ResNet (Residual Networks) توسط محققان شرکت مایکروسافت معرفی شد و توانست جایزه بهترین مقاله در کنفرانس CVPR 2015 را کسب کند. این مدل با استفاده از مفهوم شبکههای باقیمانده (Residual Networks) ساخته شده است که امکان ساخت شبکههای بسیار عمیقتر را فراهم میکند. در مدلهای عمیقتر، مشکلاتی مانند ناپایداری و کاهش دقت وجود دارد که ResNet با استفاده از بلوکهای باقیمانده این مشکلات را حل کرده است. این بلوکها اجازه میدهند که گرادیانها به صورت موثرتر به لایههای قبلی منتقل شوند و مدل با عمق بیشتری آموزش ببیند.
برای آشنایی بیشتر با این معماری مقاله شبکه عصبی رزنت (ResNet) چیست؟ را مطالعه نمایید.
Inception
مدل Inception که به نام GoogLeNet نیز شناخته میشود، توسط محققان گوگل توسعه یافته است. این مدل به دلیل استفاده از ساختارهای پیچیده و چندلایه برای استخراج ویژگیهای بیشتر از تصاویر، شناخته شده است. یکی از ویژگیهای بارز مدل Inception، استفاده از بلوکهای Inception است که در هر لایه، چندین فیلتر کانولوشن با اندازههای مختلف به صورت موازی اعمال میشوند. این امر باعث میشود که مدل بتواند ویژگیهای متنوعی از تصاویر را در مقیاسهای مختلف استخراج کند.
برای آشنایی با این مدل مقاله شبکه عصبی گوگل نت (GoogleNet) چیست و از چه ساختاری تشکیل شده است؟ را بخوانید.
مدلهای پیشآموزشدیده دیگری نیز هستند که برای طولانی نشدن بحث از اشاره به آنها خودداری میکنیم. در بخش بعدی میخواهیم نحوه استفاده از مدل ResNet را برای استخراج ویژگی و نیز تنظیم دقیق روی مجموعهداده CIFAR10 را گام به گام آموزش دهیم.
یادگیری انتقالی با PyTorch برای استخراج ویژگی
درادامه به بررسی استفاده از یادگیری انتقالی با PyTorch برای استخراج ویژگیهای عکس میپردازیم. برای این منظور، با استفاده از مدل پیشآموزشدیده ResNet، نحوه اعمال این روش را بر روی مجموعهداده CIFAR-10 به صورت عملی نشان میدهیم.
فراخوانی کتابخانهها
در بخش اول، کتابخانههای مورد نیاز PyTorch و torchvision و همچنین ابزارهای مربوط به تبدیل دادهها را بارگذاری میکنیم:
import numpy as np
import matplotlib.pyplot as plt
import torch
import torchvision
import torch.nn as nn
import torch.optim as optim
from torchvision import models
import torchvision.transforms as transforms
تعریف و آمادهسازی مجموعه دادهها
ابتدا، یک متغیر بهنام transform تعریف میکنیم (که از کلاس transform پایتورج گرفتهشده) و بهکمک آن تصاویر را به Tensor تبدیل کرده (بهاینترتیب مقادیر درون پیکسلهای هر تصویر بین ۰و ۱ قرار میگیرند) و آنها را با میانگین و انحراف معیار مشخص، نرمالسازی میکند:
transform = transforms.Compose([
transforms.Resize(224),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])
سپس، مجموعه داده CIFAR-10 را برای تمرین و تست دانلود و بارگذاری میکنیم. دادهها به صورت Batchهایی با اندازه ۳۲ بارگذاری میشوند و تابع transform را روی آن اعمال میکنیم:
# Load the CIFAR-10 training dataset, apply the transformations, and set up the DataLoader
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(trainset, batch_size=32, shuffle=True)
# Load the CIFAR-10 validation dataset, apply the same transformations, and set up the DataLoader
valset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
val_loader = torch.utils.data.DataLoader(valset, batch_size=32, shuffle=False)
تعریف مدل شبکه عصبی با استفاده از ResNet
در این بخش، مدل ResNet-18 که قبلا آموزشدیده را بارگذاری میکنیم:
model = models.resnet18(weights=True)
سپس، با استفاده از یک حلقه for، بهروزرسانی تمام پارامترهای مدل پیشآموزشدیده شده ResNet-18 را غیرفعال میکنیم تا گرادیانهای آنها در طول فاز آموزش بهروزرسانی نشوند. این کار باعث میشود که وزن لایههای اولیه مدل ثابت بمانند و تنها وزن لایههای جدید که اضافه میکنیم آموزش داده شوند. این تکنیک به کاهش زمان آموزش و جلوگیری از نیاز به دادههای بزرگ کمک میکند:
for param in model.parameters():
param.requires_grad = False
سپس تعداد ویژگیهای ورودی به آخرین لایه fully connected (که برای ResNet-18 برابر با ۵۱۲ است) را دریافت میکنیم. این مقدار نشاندهنده تعداد ویژگیهایی است که از لایههای قبلی به آخرین لایه کاملا متصل مدل رزنت وارد میشوند:
num_ftrs = model.fc.in_features
در بخش بعد، آخرین لایه کاملا متصل مدل را با یک مدل سفارشی که شامل چندین لایه است، تعویض میکنیم. این مدل سفارشی شامل:
- یک لایه nn.Linear است که تعداد ورودیها را از num_ftrs به ۵۱۲ تبدیل میکند.
- یک تابع فعالساز ReLU برای غیرخطی کردن مدل است.
- یک لایه Dropout با نرخ ۰.۴ برای کاهش overfitting است.
- یک لایه nn.Linear است که تعداد ویژگیها را از ۵۱۲ به ۲۵۶ کاهش میدهد.
- دوباره یک تابع فعالساز ReLU است.
- یک لایه nn.Linear نهایی که تعداد خروجیها را به تعداد کلاسهای (CIFAR-10) تبدیل میکند.
model.fc = nn.Sequential(
nn.Linear(num_ftrs, 512),
nn.ReLU(),
nn.Dropout(0.4),
nn.Linear(512, 256),
nn.ReLU(),
nn.Linear(256, 10)
)
این ساختار جدید به ما اجازه میدهد تا مدل ResNet-18 را برای تشخیص تصاویر مجموعه داده CIFAR-10 بهینهسازی کنیم و دقت آن را افزایش دهیم.
سپس مدل را به دستگاه مورد نظر (CPU یا GPU) منتقل میکنیم:
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model.to(device)
تعریف تابع هزینه و بهینهساز
سپس، تابع هزینه یا loss function را با استفاده از CrossEntropyLoss تعریف میکنیم. این تابع هزینه برای مسائل طبقهبندی چندکلاسی استفاده میشود و تفاوت بین خروجیهای مدل و برچسبهای واقعی را محاسبه میکند. همچنین، بهینهساز Adam را با نرخ یادگیری ۰.۰۰۱ تعریف میکنیم. این بهینهساز برای بهروزرسانی پارامترهای مدل در طول فرآیند آموزش استفاده میشود:
criterion = nn.CrossEntropyLoss().to(device)
optimizer = optim.Adam(model.fc.parameters(), lr=1e-4, weight_decay=1e-5)
آموزش مدل
در این بخش ابتدا دو لیست خالی برای ذخیره میزان خطای آموزش و ارزیابی ایجاد میکنیم:
train_losses = []
val_losses = []
سپس حلقه آموزشی مدل را برای ۲۰ دوره یا epoch تعریف میکنیم. مدل را در حالت آموزش قرار میدهیم و در هر تکرار، دادههای ورودی و برچسبها را دریافت کرده و سپس گرادیانهای پارامترهای مدل را صفر میکنیم تا برای بهروزرسانی آماده شوند. درادامه خروجیهای مدل را محاسبه میکنیم و تابع هزینه را بر اساس خروجیها و برچسبهای واقعی محاسبه میکنیم. با استفاده از loss.backward گرادیانها را محاسبه میکنیم و سپس بهینهساز را فراخوانی میکنیم تا پارامترهای مدل بهروزرسانی شوند. در نهایت نیز خطای میانگین دوره را محاسبه و چاپ میکنیم:
for epoch in range(20):
# Training phase
model.train()
epoch_train_loss = 0
# Get x, y of each batch
for X_train, y_train in train_loader:
X_train, y_train = X_train.to(device), y_train.to(device)
# Clear gradients
optimizer.zero_grad()
# Model predictions
outputs = model(X_train)
loss = criterion(outputs, y_train)
loss.backward()
# Update weights
optimizer.step()
epoch_train_loss += loss.item()
epoch_train_loss /= len(train_loader)
train_losses.append(epoch_train_loss)
ارزیابی مدل
کارهای بالا را برای دادههای ارزیابی نیز تکرار میکنیم. دقت کنید که همه این مراحل باید در ادامه حلقه for اصلی مرحله آموزش قرار گیرند:
# Validation phase
model.eval()
epoch_val_loss = 0
with torch.no_grad():
for X_val, y_val in val_loader:
X_val, y_val = X_val.to(device), y_val.to(device)
val_outputs = model(X_val)
loss = criterion(val_outputs, y_val)
epoch_val_loss += loss.item()
epoch_val_loss /= len(val_loader)
val_losses.append(epoch_val_loss)
if (epoch+1) % 5 == 0:
print(f'Epoch [{epoch+1}/20], Training Loss: {epoch_train_loss:.4f}, Validation Loss: {epoch_val_loss:.4f}')
ترسیم خطای آموزش و ارزیابی
در این بخش از کد، نموداری برای نمایش روند کاهش خطا در طول آموزش و ارزیابی مدل ترسیم میکنیم. این نمودار به ما کمک میکند تا مشاهده کنیم که مدل چگونه در طول زمان بهبود مییابد و همچنین میتوانیم تشخیص دهیم که آیا مدل دچار overfitting یا underfitting شده است یا خیر. برای این کار از تابع plt.plot استفاده میکنیم. محور x از ۱ تا ۲۰ (تعداد دورهها) و محور y مقادیر val_losses (لیستی از خطاهای ارزیابی در هر دوره) را نشان میدهد:
plt.figure(figsize=(8, 5))
plt.plot(range(1, 21), train_losses, label='Training Loss')
plt.plot(range(1, 21), val_losses, label='Validation Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.show()
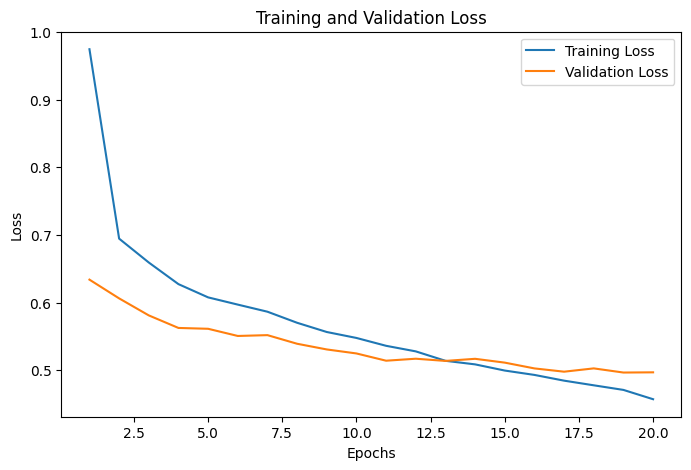
پیشبینی و محاسبه دقت مدل
برای این مرحله، مدل را در حالت ارزیابی قرار میدهیم. دقت مدل را بر روی دادههای تست بدون محاسبه گرادیانها حساب میکنیم. دادههای تست را بارگذاری، خروجیهای مدل را محاسبه و پیشبینیهای نهایی را تعیین میکنیم. تعداد کل برچسبهای درست پیشبینی شده را محاسبه میکنیم. در نهایت، دقت مدل را محاسبه و چاپ میکنیم:
# Lists to store all predictions and labels
all_predictions = []
all_labels = []
# Disable gradient calculation for evaluation
with torch.no_grad():
for X_test, y_test in val_loader:
X_test, y_test = X_test.to(device), y_test.to(device)
outputs = model(X_test)
# Apply softmax to get the class probabilities
probabilities = nn.functional.softmax(outputs, dim=1)
predicted_classes = torch.argmax(probabilities, dim=1)
all_predictions.extend(predicted_classes.cpu().numpy())
all_labels.extend(y_test.cpu().numpy())
# Calculate the number of correct predictions
correct_predictions = (np.array(all_predictions).flatten() == np.array(all_labels)).sum()
# Calculate the accuracy
accuracy = correct_predictions / len(all_labels)
print(f'Accuracy: {accuracy:.4f}')
مدل ما نهایتا توانست با دقت ۸۳ درصد کلاس مربوط به هر عکس مجموعهداده CIFAR10 را پیشبینی کند.
یادگیری انتقالی با PyTorch برای تنظیم دقیق مدل
در این بخش از مدل پیشآموزشدیده ResNet-18 برای یادگیری انتقالی بهمنظور تطبیق آن با دادههای جدید استفاده میکنیم. هدف اصلی این است که مدل ResNet-18 را که قبلا با استفاده از مجموعهداده ImageNet آموزشدیده شده است، بارگذاری کنیم، تمام لایههای آن را برای آموزش فعال کنیم و سپس لایه نهایی آن را با یک لایه جدید جایگزین کنیم تا بتواند کلاسهای جدید (در اینجا ۱۰ کلاس) را پیشبینی کند. این روش به ما اجازه میدهد تا از وزنهای مدل از پیش آموزشدیده، بهعنوان یک نقطه شروع استفاده کنیم و آن را برای یک مسئله خاص با دادههای جدید تطبیق دهیم.
چون این مدل را در ادامه همان مدل قبلی تعریف میکنیم، نیازی به فراخوانی مجدد کتابخانهها بارگذاری دوباره دادهها نداریم. تفاوت این مدل با مدل قبل از قسمت تعریف مدل شبکه عصبی با استفاده از ResNet آغاز میشود. ابتدا مدل ResNet-18 را با وزنهای تنظیمشده بر روی مجموعه داده ImageNet بارگذاری میکنیم. این کار به ما اجازه میدهد تا از ویژگیهای عمومی استخراج شده توسط مدل استفاده کنیم:
model = models.resnet18(weights=True)
سپس تمامی وزنهای مدل را فعال میکنیم تا گرادیانهای آنها در طول فاز آموزش بهروزرسانی شوند. این کار باعث میشود که تمامی لایههای مدل، شامل لایههای اولیه و میانی، برای مسئله جدید مجددا آموزش ببینند:
for param in model.parameters():
param.requires_grad = True
حال باید تعداد ویژگیهای ورودی به آخرین لایه کاملا متصل را دریافت کنیم. این مقدار نشاندهنده تعداد ویژگیهایی است که از لایههای قبلی به لایه نهایی وارد میشوند:
num_ftrs = model.fc.in_features
در آخر، لایه کاملا متصل نهایی مدل را با یک لایه جدید که تعداد ورودیها را از num_ftrs به ۱۰ (تعداد کلاسهای جدید) تبدیل میکند، تعویض میکنیم:
model.fc = nn.Linear(num_ftrs, 10)
مجددا باید مدل آماده خود را به GPU انتقال دهیم:
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model.to(device)
تعریف تابع هزینه و بهینهساز
تابع هزینه و بهینهساز را نیز مانند مدل قبلی تعریف میکنیم:
criterion = nn.CrossEntropyLoss().to(device)
optimizer = optim.Adam(model.fc.parameters(), lr=1e-4, weight_decay=1e-5)
آموزش مدل
روند آموزش این مدل نیز تقریبا مشابه مدل قبلی است اما از آنجا که میخواهیم تمامی لایههای رزنت را آموزش دهیم، به احتمال زیاد دچار بیشبرازش خواهیم شد که میتوان با ذخیره بهترین مدل در طول تمام دورههای آموزشی، جلوی این اتفاق را بگیریم. برای این منظور، ابتدا لیستهای train_losses و val_losses را برای ذخیره مقادیر خطای آموزش و ارزیابی در هر دوره تعریف میکنیم. سپس متغیر best_val_loss را برای ذخیره کمترین مقدار خطای ارزیابی و best_epoch را برای ذخیره شماره بهترین دوره تنظیم میکنیم:
train_losses = []
val_losses = []
best_val_loss = float('inf')
best_epoch = 0
سپس مدل را در حالت آموزش قرار میدهیم و متغیر epoch_train_loss را برای ذخیره مجموع خطای آموزش در هر دوره تعریف میکنیم. برای هر دسته از دادههای آموزشی، گرادیانهای بهینهساز صفر میشوند، خروجیهای مدل محاسبه میشوند و براساس آن خطای پیشبینی و گرادیانها محاسبه میشوند. سپس با optimizer.step وزنهای مدل بهروزرسانی میشوند. در نهایت، خطای مدل در پیشبینی هر دسته، به epoch_train_loss اضافه میشود و مجموع خطاهای هر دوره تقسیم بر تعداد دستهها محاسبه میشود تا میانگین خطا بدست آید. در پایان، این عدد به لیست train_losses اضافه میشود:
for epoch in range(30):
# Training phase
model.train()
epoch_train_loss = 0
# Get x, y of each batch
for X_train, y_train in train_loader:
# Transpose data to cuda
X_train, y_train = X_train.to(device), y_train.to(device)
# Clear gradients
optimizer.zero_grad()
# Model predictions
outputs = model(X_train)
# Calculate loss between preds and real values
loss = criterion(outputs, y_train)
# Backpropagation
loss.backward()
# Update weights
optimizer.step()
epoch_train_loss += loss.item()
epoch_train_loss /= len(train_loader)
train_losses.append(epoch_train_loss)
ارزیابی مدل
برای این مرحله، مدل در حالت ارزیابی قرار میگیرد. متغیر epoch_val_loss برای ذخیره مجموع خطای ارزیابی در هر دوره تعریف میشود. با استفاده از torch.no_grad محاسبه گرادیانها غیرفعال میشود تا حافظه کمتری مصرف شود. سپس برای هر دسته از دادههای ارزیابی، خروجیهای مدل محاسبه و میزان خطای پیشبینی بدست میآید. خطای دسته به epoch_val_loss اضافه میشود و خطای کل دوره تقسیم بر تعداد دستهها محاسبه و به لیست val_losses اضافه میشود:
# Validation phase
model.eval()
epoch_val_loss = 0
with torch.no_grad():
for X_val, y_val in val_loader:
X_val, y_val = X_val.to(device), y_val.to(device)
val_outputs = model(X_val)
loss = criterion(val_outputs, y_val)
epoch_val_loss += loss.item()
epoch_val_loss /= len(val_loader)
val_losses.append(epoch_val_loss)
if (epoch+1) % 5 == 0:
print(f'Epoch [{epoch+1}/30], Training Loss: {epoch_train_loss:.4f}, Validation Loss: {epoch_val_loss:.4f}')
ذخیره بهترین مدل
برای تشخیص بهترین مدل و ذخیره آن، اگر خطای ارزیابی بهتر از best_val_loss باشد، مقدار best_val_loss و best_epoch بهروزرسانی میشوند و آن مدل ذخیره میشود:
# Check if the validation loss improved for Early stopping
if epoch_val_loss < best_val_loss:
best_val_loss = epoch_val_loss
best_epoch = epoch
# Save the best model
torch.save(model.state_dict(), os.path.join(model_dir, 'best_model.pth'))
print(f'Best model saved at epoch {epoch + 1}')
رسم نمودار تابع هزینه
برای رسم نمودار تابع هزینه آموزش، از تابع plt.plot برای ترسیم خطای آموزش استفاده میکنیم. محور x از ۱ تا ۳۰ (تعداد دورهها) و محور y مقادیر train_losses (لیستی از خطاهای آموزش در هر دوره) را نشان میدهد. همین کار را برای خطای اریابی نیز انجام میدهیم:
plt.figure(figsize=(8, 5))
plt.plot(range(1, 31), train_losses, label='Training Loss')
plt.plot(range(1, 31), val_losses, label='Validation Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.show()
خروجی کد بالا بهصورت زیر است:
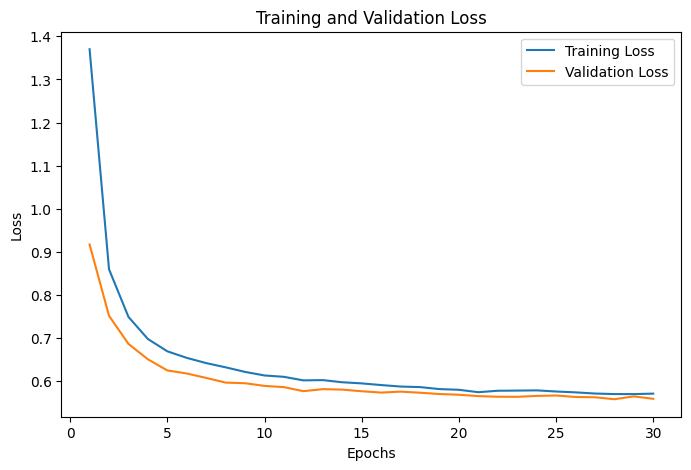
پیشبینی و محاسبه دقت مدل
این قسمت نیز تفاوت خاصی با مرحله متناظرش در مدل استخراج ویژگی ندارد و با همان کد میتوان دقت مدل را پیدا کرد:
# Lists to store all predictions and labels
all_predictions = []
all_labels = []
# Disable gradient calculation for evaluation
with torch.no_grad():
for X_test, y_test in val_loader:
X_test, y_test = X_test.to(device), y_test.to(device)
outputs = model(X_test)
# Apply softmax to get the class probabilities
probabilities = nn.functional.softmax(outputs, dim=1)
predicted_classes = torch.argmax(probabilities, dim=1)
all_predictions.extend(predicted_classes.cpu().numpy())
all_labels.extend(y_test.cpu().numpy())
# Calculate the number of correct predictions
correct_predictions = (np.array(all_predictions).flatten() == np.array(all_labels)).sum()
# Calculate the accuracy
accuracy = correct_predictions / len(all_labels)
print(f'Accuracy: {accuracy:.4f}')
دقت نهایی مدل ما در تشخیص کلاس مربوط به هر عکس، ۸۱ درصد شد. میتوان با افزایش تعداد دورهها، به دقت بهتری رسید.
رسم نقشه ویژگی لایههای مختلف
در پایان میتوانیم برای استخراج و ذخیره نقشههای ویژگی (Feature maps) از لایههای خاصی از مدل ResNet-16، خروجی لایههای خاصی را ذخیره کنیم تا بتوانیم آنچه ماشین برای پیشبینی از آن استفاده میکند را بهتر ببینیم. برای این کار، ابتدا یک دیکشنری به نام feature_maps تعریف میکنیم تا نقشههای ویژگی استخراج شده از لایههای مختلف مدل را در آن ذخیره کنیم. در این دیکشنری، کلیدها نام لایهها هستند و مقادیر، نقشههای ویژگی مربوط به آن لایهها:
feature_maps = {}
سپس یک تابع به نام get_feature_maps تعریف میکنیم که یک هوک برای مدل ایجاد میکند. این هوک خروجی یک لایه خاص را به عنوان نقشه ویژگی ذخیره میکند:
def get_feature_maps(name):
def hook(model, input, output):
feature_maps[name] = output.detach()
return hook
هوک (hook) در حوزه شبکههای عصبی، یک مکانیزم است که به ما اجازه میدهد تا در نقاط خاصی از اجرای یک مدل (مانند شروع یا پایان یک لایه خاص) کدی را اجرا کنیم.
حال هوکها را به لایههای کانولوشنی اول و آخر مدل ثبت میکنیم تا خروجی این لایهها در طول فرآیند پیشبینی ذخیره شوند. برای مثال، model.layer1[0].conv1 به اولین لایه کانولوشنی مدل اشاره دارد و هوک get_feature_maps(‘first_conv’) به آن اضافه میشود:
model.layer1[0].conv1.register_forward_hook(get_feature_maps('first_conv'))
model.layer4[1].conv2.register_forward_hook(get_feature_maps('last_conv'))
درادامه دو تابع تعریف میکنیم. تابع normalize_image تصویر ورودی را نرمالسازی میکند تا مقادیر آن در بازههای مشخصی قرار بگیرند:
def normalize_image(image):
if image.dtype == np.float32 or image.dtype == np.float64:
image = (image - image.min()) / (image.max() - image.min())
elif image.dtype == np.uint8:
image = 255 * (image - image.min()) / (image.max() - image.min())
return image
تابع plot_feature_maps نقشههای ویژگی استخراج شده از مدل را به همراه تصویر اصلی رسم میکند:
def plot_feature_maps(sample_image, feature_maps, title, num_channels=6):
feature_maps = feature_maps.cpu().detach().numpy()
sample_image = sample_image.cpu().detach().numpy().transpose(1, 2, 0)
sample_image = normalize_image(sample_image)
num_subplots = min(num_channels, feature_maps.shape[1]) + 1
fig, axes = plt.subplots(1, num_subplots, figsize=(20, 5))
fig.suptitle(title, fontsize=16)
# Plot the main image
axes[0].imshow(sample_image)
axes[0].axis('off')
axes[0].set_title('Original Image')
# Plot the feature maps
for i in range(1, num_subplots):
axes[i].imshow(feature_maps[0, i-1, :, :], cmap='viridis')
axes[i].axis('off')
axes[i].set_title(f'Feature Map {i}')
plt.show()
درنهایت بهکمک این توابع و با کد زیر، هر یک از نقشههای ویژگی استخراج شده را رسم میکنیم:
# Ensure the model is in evaluation mode
model.eval()
# Load a batch of data (you can use your validation or test data loader)
sample_inputs, _ = next(iter(val_loader)) # Using validation data as example
sample_inputs = sample_inputs.to(device)
# Perform a forward pass
with torch.no_grad():
_ = model(sample_inputs)
# As we defined above feature_maps is a dictionary where the keys are layer names
first_conv_features = feature_maps.get('first_conv')
last_conv_features = feature_maps.get('last_conv')
# Plot the first convolutional layer feature maps
if first_conv_features is not None:
plot_feature_maps(sample_inputs[0], first_conv_features, "First Convolutional Layer Feature Maps")
# Plot the last convolutional layer feature maps
if last_conv_features is not None:
plot_feature_maps(sample_inputs[0], last_conv_features, "Last Convolutional Layer Feature Maps")
خروجی کد بالا بهشکل زیر است:
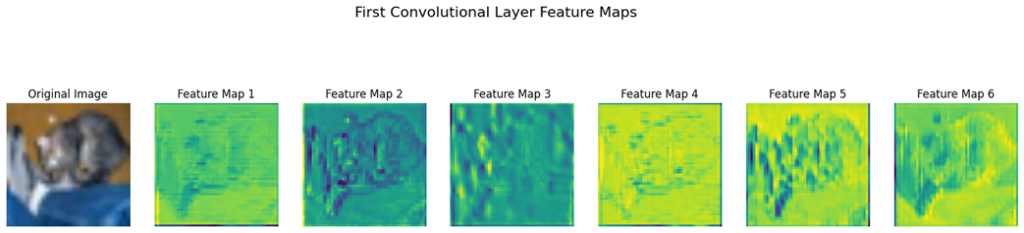
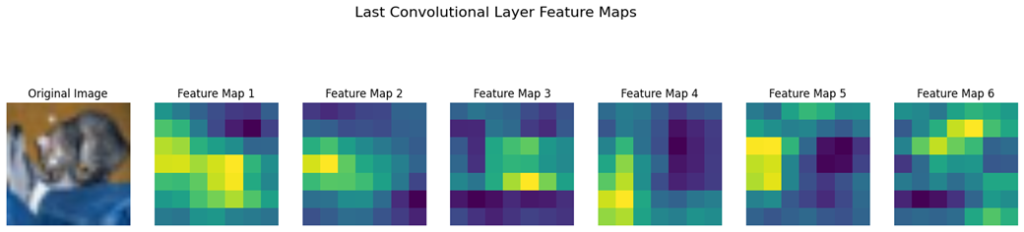
تفسیر نقشههای ویژگی اولین و آخرین لایه کانولوشنی
تصویر اول نقشههای ویژگی استخراجشده از اولین لایه کانولوشنی را نشان میدهد. این نقشهها نمایانگر ویژگیهای ساده و ابتداییای هستند که توسط فیلترهای این لایه تشخیص داده میشوند. در این مرحله، ویژگیها معمولاً شامل لبهها، بافتها و الگوهای ساده هستند. هر یک از نقشههای ویژگی، واکنش فیلترها به بخشهای مختلف تصویر ورودی را نمایش میدهد. شدت رنگها نشاندهنده سطح فعالسازی فیلترها است؛ رنگهای روشنتر بیانگر فعالسازی قویتر ویژگیها در آن نواحی میباشد.
تصویر دوم نقشههای ویژگی استخراجشده از آخرین لایه کانولوشنی را به نمایش میگذارد. این نقشهها بیانگر ویژگیهای پیچیدهتر و انتزاعیتری هستند که مدل در این مرحله استخراج کرده است. این نقشهها نشاندهنده توانایی مدل در شناسایی الگوها و جزئیات مشخصتر، مانند بخشهایی از صورت گربه میباشند.
تفاوت بین نقشههای ویژگی اولین و آخرین لایه کانولوشنی نشاندهنده پیشرفت مدل در شناسایی ویژگیها از ویژگیهای ساده و عمومی به ویژگیهای پیچیده و خاص میباشد. این پیشرفت از ویژگیهای ساده به ویژگیهای پیچیده در شبکههای عصبی کانولوشنی (CNN) برای کارهای تشخیص تصویر بسیار حیاتی است.
مجموعه کامل کدهای بالا را میتوانید در این ریپازیتوری از گیتهاب مشاهده نمایید.
کلام آخر درباره یادگیری انتقالی با PyTorch
یادگیری انتقالی با PyTorch یک ابزار قدرتمند برای کاهش زمان و هزینههای آموزش مدلهای پیچیده یادگیری عمیق است. این تکنیک با استفاده از مدلهای پیشآموزشدیده، به متخصصان یادگیری ماشین این امکان را میدهد که از دانش و تجربیات مدلهای قبلی بهرهبرداری کنند و مدلهای جدیدی با دقت بالا و کارآمد ایجاد کنند.
PyTorch با ارائه ابزارها و امکانات متنوع، فرآیند یادگیری انتقالی را سادهتر و مؤثرتر میکند. این کتابخانه با قابلیت بارگذاری مدلهای پیشآموزشدیده و تنظیم دقیق آنها برای مسائل خاص، به کاربران اجازه میدهد تا بدون نیاز به آموزش مدلها از ابتدا، نتایج بهتری را در زمان کوتاهتری به دست آورند.
در نتیجه، یادگیری انتقالی با PyTorch یک راه حل ایدهآل برای کاهش زمان و هزینههای آموزش مدلهای پیچیده است و به متخصصان یادگیری ماشین این امکان را میدهد که با استفاده از دانش موجود، مدلهای جدید و کارآمدی را برای مسائل خاص ایجاد کنند.

سؤالات متداول
یادگیری انتقالی با PyTorch چیست و چه مزایایی دارد؟
یادگیری انتقالی با PyTorch یک رویکرد پیشرفته در حوزه یادگیری ماشین است که با بهرهگیری از مدلهای از پیش آموزشدیده، فرآیند آموزش مدلهای جدید را تسریع و بهینه میکند. PyTorch به عنوان یک کتابخانه متنباز و قدرتمند یادگیری ماشین، ابزارها و امکانات متنوعی برای پیادهسازی یادگیری انتقالی فراهم میکند. مزایای این روش شامل کاهش زمان آموزش، بهبود دقت مدلها و کاهش نیاز به دادههای بزرگ است. با استفاده از PyTorch، میتوان به سادگی مدلهای پیشآموزشدیده را بارگذاری و آنها را با دادههای جدید تنظیم کرد، که این امر باعث میشود مدلهای جدید با دقت بالا و کارآمدی بیشتری به مسائل جدید پاسخ دهند.
چرا PyTorch برای پیادهسازی یادگیری انتقالی انتخاب میشود؟
PyTorch به دلیل سادگی و انعطافپذیری بالا، یکی از محبوبترین کتابخانههای یادگیری ماشین است. این کتابخانه با ارائه ابزارهای متنوع برای بارگذاری مدلهای پیشآموزشدیده و تنظیم دقیق آنها، فرآیند یادگیری انتقالی را سادهتر میکند و به کاربران امکان میدهد مدلهای پیچیده را به سرعت پیادهسازی و بهینهسازی کنند.
چه مدلهای پیشآموزشدیدهای برای یادگیری انتقالی مناسب هستند؟
برخی از مدلهای معروف پیشآموزشدیده شامل VGG، ResNet و Inception هستند. این مدلها بر روی مجموعه دادههای بزرگ و متنوع آموزش دیدهاند و میتوانند ویژگیهای عمومی و مهمی را از دادهها استخراج کنند. استفاده از این مدلها در یادگیری انتقالی باعث میشود که مدلهای جدید با دقت بالاتری مسائل را حل کنند.
یادگیری انتقالی چگونه زمان و منابع مورد نیاز برای آموزش مدلها را کاهش میدهد؟
با استفاده از مدلهای پیشآموزشدیده، ویژگیهای عمومی و قدرتمندی از دادهها استخراج میشود که نیاز به آموزش از ابتدا را کاهش میدهد. این ویژگیها به مدلهای جدید منتقل میشوند و باعث میشوند که مدلها با دادههای کمتر و در زمان کوتاهتری آموزش ببینند و به نتایج دقیقتری دست یابند.
تفاوت بین روشهای استخراج ویژگی (Feature Extraction) و تنظیم دقیق (Fine Tuning) در یادگیری انتقالی چیست؟
در روش استخراج ویژگی، از لایههای ازپیشآموزشدیده برای استخراج ویژگیهای مفید از دادهها استفاده میشود و لایههای نهایی مدل جدید آموزش داده میشوند. در روش تنظیم دقیق، علاوه بر استفاده از ویژگیهای استخراجشده، برخی از لایههای مدل پیشآموزشدیده نیز مجدداً آموزش داده میشوند تا مدل برای مسئله جدید بهینهسازی شود. این روش دقت بیشتری دارد اما نیاز به تنظیم پارامترها و دادههای بیشتری دارد.
یادگیریماشین لرنینگ را از امروز شروع کنید!
دنیای دادهها جذاب است و دانستن علم داده، توانایی تحلیل داده، یا بازاریابی مبتنی بر داده، شما را برای فرصتهای شغلی بسیاری مناسب میکند. فارغ از رشته و پیشزمینه، میتوانید حالا شروع کنید و از سطح مقدماتی تا پیشرفته بیاموزید. اگر دوست دارید به این حوزه وارد شوید، پیشنهاد میکنیم با کلیک روی این لینک قدم اول را همین حالا بردارید.
مشاوران کافهتدریس به شما کمک میکنند مسیر یادگیری برای ورود به این حوزه را شروع کنید: