

یادگیری با ناظر (Supervised Learning) زیرمجموعهای از یادگیری ماشین (Machine Learning) است. این فرایند با یادگیری از روی دادههای برچسبدار (Labeled) به ما در تشخیص خروجی دادههایی کمک میکند که قبلاً دیده نشدهاند.
- 1. مقدمه
- 2. یادگیری ماشین چیست؟
- 3. یادگیری ماشین چگونه کار می کند؟
- 4. انواع مختلف مدل های یادگیری ماشین چیست؟
- 5. یادگیری با ناظر (Supervised Learning) چیست؟
- 6. زیرمجموعههای یادگیری با ناظر چیست؟
- 7. مزایای یادگیری با ناظر چیست؟
- 8. معایب یادگیری با ناظر چیست؟
- 9. خلاصهی مطالب
- 10. آموزش علم داده یا دیتا ساینس و یادگیری ماشین با کلاسهای آنلاین کافهتدریس
مقدمه
امروزه یادگیری با ناظر (Supervised Learning) متداولترین زیرشاخهی یادگیری ماشین (Machine Learning) است. بهطور معمول، تازهواردان به دنیای یادگیری ماشین سفر خود را با الگوریتمهای یادگیری با ناظر آغاز میکنند.
در این مطلب قصد داریم یادگیری با ناظر را معرفی کنیم، چگونگی کار آن را درک کنیم، دو زیرمجموعهی آن را بررسی کنیم و درنهایت با فواید و معایب آن آشنا شویم.
قبل از اینکه به سراغ یادگیری باناظر به عنوان یکی از زیرشاخههای یادگیری ماشین برویم، بهتر است ببینیم، یادگیری ماشین چیست و چطور کار میکند.
یادگیری ماشین چیست؟
یادگیری ماشین (ML) رشتهای از زیرمجموعههای هوش مصنوعی (AI) است که به ماشینها توانایی یادگیری خودکار از روی دادهها و تجربیات گذشته را میدهد و در عین حال الگوهایی را برای پیشبینی با کمترین مداخله انسانی شناسایی میکند. درواقع هدف از به کارگیری یادگیری ماشین فراهم کردن امکان یادگیری به ماشینها به همان شکلی است که انسانها یاد میگیرند. روشهای یادگیری ماشین، رایانهها را قادر میسازد تا بدون برنامهنویسی صریح به طور مستقل کار کنند. برنامه های کاربردی یادگیری ماشین با دادههای جدید تغذیه میشوند و می توانند به طور مستقل یاد بگیرند، رشد کنند، توسعه دهند و تطبیق دهند.
یادگیری ماشین با استفاده از الگوریتمها برای شناسایی الگوها و یادگیری در یک فرآیند تکراری، اطلاعات و بینش مفیدی را از حجم زیادی از داده به دست میآورد. الگوریتمهای ماشینلرنینگ از روشهای محاسباتی برای یادگیری مستقیم از دادهها استفاده میکنند. عملکرد الگوریتمهای ML به طور تطبیقی با افزایش تعداد نمونههای موجود در طول فرآیندهای “یادگیری” بهبود مییابد.
با وجود اینکه یادگیری ماشین مفهوم جدیدی نیست – قدمت آن به جنگ جهانی دوم برمیگردد، زمانی که Enigma Machine مورد استفاده قرار گرفت – توانایی اعمال محاسبات پیچیده ریاضی به طور خودکار برای حجم و انواع دادههای موجود در حال رشد، یک پیشرفت نسبتاً جدید است. امروزه، با ظهور کلان داده (Big Data)، اینترنت اشیا و محاسبات فراگیر، یادگیری ماشین برای حل مشکلات در بسیاری از زمینه ها مورد استفاده میگیرد. بعضی از این حوزهها عبارتند از:
- مالی محاسباتی (امتیاز اعتبار، معاملات الگوریتمی)
- بینایی کامپیوتر (تشخیص چهره، ردیابی حرکت، تشخیص اشیا)
- زیست شناسی محاسباتی (توالی یابی DNA، تشخیص تومور مغزی، کشف دارو)
- خودروسازی، هوافضا و تولید (تعمیر و نگهداری پیش بینی شده)
- پردازش زبان طبیعی (تشخیص گفتار یا تشخیص صدا، ترجمه متن)


یادگیری ماشین چگونه کار می کند؟
اینکه یادگیری ماشین چطور کار میکند، فوق العاده پیچیده است و نحوه عملکرد آن بسته به کار و الگوریتم مورد استفاده برای انجام آن متفاوت است. با این حال، به طور کلی میتوان گفت، یک مدل یادگیری ماشین کامپیوتری است که به دادهها برای شناسایی الگوها نگاه میکند و سپس از آن الگوها و بینشهایی که به دست آورده برای تکمیل بهتر وظایف محول شده خود استفاده میکند. هر کاری که بر مجموعهای از نقاط داده یا قوانین تکیه دارد، میتواند با استفاده از یادگیری ماشین خودکار شود، حتی کارهای پیچیدهتر مانند پاسخگویی به تماسهای خدمات مشتری و بررسی رزومه.
انواع مختلف مدل های یادگیری ماشین چیست؟
بسته به موقعیت، الگوریتمهای یادگیری ماشین با استفاده از مداخله کم و بیش انسانی عمل میکنند. چهار مدل اصلی یادگیری ماشین عبارتند از: یادگیری نظارتشده، یادگیری بدوننظارت، یادگیری نیمهنظارتی و یادگیری تقویتی.
با یادگیری نظارتشده (Supervised Learning)، رایانه با مجموعه ای برچسب گذاری شده از دادهها مواجه میشود که به آن امکان میدهد نحوه انجام یک کار انسانی را بیاموزد. در این حالت مدل یادگیری ماشین چ تلاش میکند تا یادگیری انسان را تکرار کند.
با یادگیری بدوننظارت (Unsupervised Learning)، کامپیوتر با داده های بدون برچسب مواجه می شود و الگوها یا بینشهای ناشناخته که از قبل مشخص نیستند را از آن استخراج میکند.
با یادگیری نیمهنظارتی (Semi-supervised Learning)، به کامپیوتر مجموعهای از دادههای دارای برچسب ارائه میشود و وظیفه خود را با استفاده از دادههای برچسب دار برای درک و تفسیر دادههای بدون برچسب انجام میدهد.
با یادگیری تقویتی (Reinforcement Learning)، کامپیوتر محیط خود را مشاهده میکند و از آن دادهها برای شناسایی رفتار ایدهآلی استفاده میکند که خطا را به حداقل می رساند و یا پاداش را به حداکثر میرساند. این یک رویکرد تکراری است که به نوعی سیگنال تقویتی نیاز دارد تا به رایانه کمک کند بهترین عملکرد خود را بهتر شناسایی کند.
برای آشنایی کامل با یادگیری ماشین این مطلب را بخوانید:
یادگیری ماشین (Machine Learning) چیست و چگونه کار میکند؟
حال که با یادگیری ماشین و نحوه کار آن آشنا شدیم، لازم است به سراغ یادگیری باناظر برویم.
یادگیری با ناظر (Supervised Learning) چیست؟
الگوریتمهای یادگیری ماشین با ناظر برای یادگیری از روی نمونهها طراحی شدهاند. نام یادگیری با ناظر هم از این ایده سرچشمه میگیرد که آموزش این نوع الگوریتمها مانند این است که یک معلم بر کل روند آموزش نظارت دارد.
هنگام آموزش الگوریتم یادگیری با ناظر دادههای آموزشی متشکل از ورودیهایی است که با خروجیهای صحیح جفت شدهاند؛ یعنی دادهها برچسب خروجیهای صحیح دارند. در حین آموزش، الگوریتم الگوهایی در دادهها را جستوجو میکند که با خروجیهای مدنظر ارتباط دارند و آن الگوها را یاد میگیرد.
پس از آموزش، الگوریتم یادگیری با ناظر ورودیهای جدیدی را میگیرد که خروجی مدنظر آنها مشخص نیست. براساس دادههای آموزشی قبلی تعیین میکند که ورودیهای جدید به کدام برچسب طبقهبندی شوند یا بهعبارت دیگر چه خروجی دارند.
هدف از یک مدل یادگیری با ناظر پیشبینی برچسب صحیح برای دادههای ورودی جدید است.
صورتبندی یادگیری با ناظر
در ابتداییترین شکل خود، یک الگوریتم یادگیری با ناظر را میتوان به فرم یک تابع نوشت: Y = F(x)
در این صورتبندی Y خروجی پیشبینی شده است که یک تابع نگاشت آن را تعیین میکند. این تابع یک کلاس (برچسب) را به مقدار ورودی x اختصاص میدهد. این تابع که برای اتصال یک ورودی به خروجی مدنظر است توسط الگوریتم یادگیری ماشین در حین آموزش ایجاد میشود.

زیرمجموعههای یادگیری با ناظر چیست؟
یادگیری با ناظر را میتوان به دو زیرمجموعه کلی طبقهبندی (Classification) و رگرسیون (Regression) تقسیم کرد. در ادامه با این دو بیشتر آشنا خواهیم شد.
طبقهبندی (Classification)
در طول آموزش، دادههایی به یک الگوریتم طبقهبندی وارد میشوند که هر یک از قبل در یک دسته یا کلاس خاصی طبقهبندی شدهاند. وظیفهی یک الگوریتم طبقهبندی این است که بعد از فرایند آموزش یک مقدار ورودی بگیرد و آن را به یک کلاس یا دسته اختصاص دهد که براساس چیزی که در حین آموزش یاد گرفته است، آن داده واقعاً در آن کلاس قرار بگیرد.
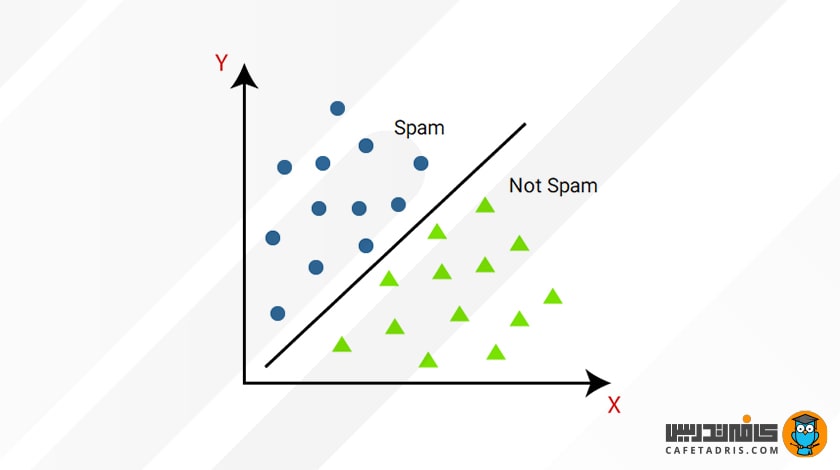
یکی از متداولترین نمونههای طبقهبندی تعیین اسپمبودن یا نبودن (Spam) ایمیل است. از آنجا که این مسئله دو کلاس برای انتخاب دارد (اسپمبودن یا نبودن)، آن را یک مسئلهی طبقهبندی باینری (Binary Classification) مینامند. در اینجا به الگوریتم دادههای آموزشی ما ایمیلهایی هستند که بعضی از آنها اسپم (Spam) هستند و بعضی دیگر خیر (Not Spam). سپس مدل ویژگیهای موجود در دادهها را در حین آموزش پیدا میکند که با هر دو کلاس مرتبط هستند و تابع نگاشت را ایجاد میکند که قبلاً به آن اشاره کردیم: Y = f (x). سپس، هنگامی که یک ایمیل جدید که از قبل دیده نشده است به الگوریتم ارائه میشود، مدل برای تعیین اسپمبودن یا نبودن این ایمیل از این تابع استفاده میکند.
الگوریتمهای متفاوتی برای حل مسائل طبقهبندی وجود دارند که طبق دادههای مسئله یکی از آنها را برای کارمان انتخاب میکنیم. برخی از الگوریتمهای معروف طبقهبندی عبارتاند از:
- طبقهبندیکنندههای خطی (Linear Classifiers)
- ماشینبردار پشتیبان (Support Vector Machines)
- درخت تصمیم (Decision Tree)
- K نزدیکترین همسایه (K-Nearest Neighbor)
- جنگل تصادفی (Random Forest)
رگرسیون (Regression)
رگرسیون یک فرایند آماری پیشبینیکننده است که در آن مدل سعی دارد رابطه مهم میان متغیرهای وابسته و مستقل را پیدا کند. هدف الگوریتم رگرسیون پیشبینی مقادیر پیوستهای، مانند مقدار فروش، درآمد و نمرات آزمون، است.
یک معادلهی رگرسیون خطی ساده میتواند بهاین شکل نوشته شود: ŷ = wx + b
در این معادله ŷ متغیر وابسته (که وابسته به متغیر x است) و x متغیر مستقل است. برای مسائل رگرسیون ساده، مانند مثال بالا، پیشبینی مدلها با یک خط نشان داده میشود. برای مدلهایی که دو ویژگی یا متغیر مستقل دارند، از سطح (Plane) استفاده میشود و برای مدلی که بیش از دو ویژگی یا متغیر مستقل دارد از یک هایپر پلین (Hyper Plane) استفاده میشود.
نمونهای برای رگرسیون
بیایید تصور کنیم میخواهیم براساس میزان ساعت مطالعه در هفته، نمرهی آزمون هر دانشآموز را تعیین کنیم. فرض میکنیم خطی که بهبهترین شکل دادههای موجود را نشان میدهد بهاین شکل است:
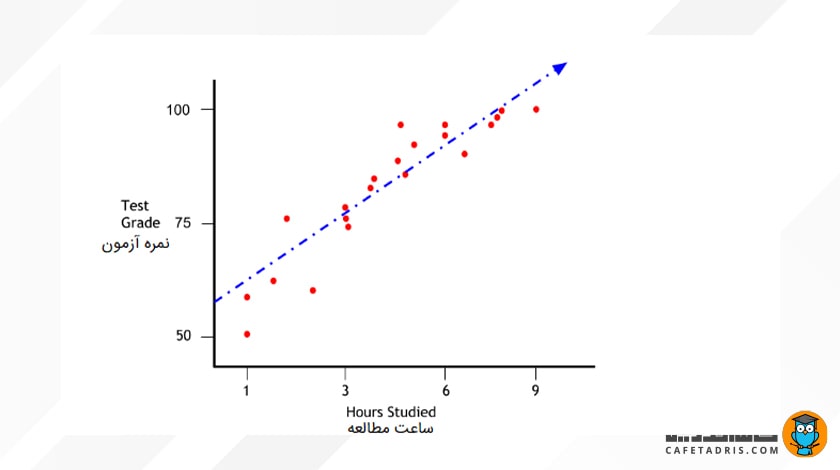
همانطور که مشخص است، میان ساعتهای مطالعهشده (متغیر مستقل) و نمرهی آزمون نهایی دانشآموزان (متغیر وابسته) همبستگی مثبت و واضحی وجود دارد؛ یعنی هر قدر که ساعت مطالعه بیشتر شود، نمرهی آزمون هم بالاتر میرود. بهاین شکل، میتوان ازطریق نقاط داده، بهترین خط ممکن را ترسیم کرد تا هنگام ورود دادهی جدید، پیشبینی مدل را نشان دهد؛ برای مثال، فرض کنیم میخواهیم بدانیم دانشآموزی با پنج ساعت مطالعه چه نمرهای میگیرد. میتوانیم از خطی که براساس عملکرد دیگر دانشآموزان ترسیم شده است برای پیشبینی نمرهی آزمون این دانشآموز استفاده کنیم.
الگوریتمهای رگرسیون زیادی وجود دارد که معروفترین آنها عبارتاند از:
- رگرسیون خطی (Linear Regression)
- رگرسیون لجستیک (Logistic Regression)
- رگرسیون چندجملهای (Polynomial Regression)
حال که با یادگیری با ناظر و دو زیرمجموعهی، آن یعنی طبقهبندی و رگرسیون، آشنا شدیم، بیایید نگاهی به مزایا و معایب آن بیندازیم.
برای آشنایی با یادگیری بدون ناظر این مطلب را مطالعه کنید:
یادگیری بدون ناظر (Unsupervised Learning) چیست؟
مزایای یادگیری با ناظر چیست؟
مزایای یادگیری با ناظر بهصورت کلی از این قرار است:
- یادگیری با ناظر به ما امکان میدهد با استفاده از تجربههایی که از دادههای قبلی به دست آوردهایم برای دادهی جدید خروجی مطلوب به دست آوریم.
- کمک میکند تا با استفاده از تجربههایی که در فرایند یادگیری از دادهها به دست آمده است عملکرد مدل را بهبود دهیم.
- یادگیری با ناظر امکان حل انواع مختلفی از مسائل محاسباتی را به ما میدهد که در دنیای واقعی با آنها روبهرو میشویم.
معایب یادگیری با ناظر چیست؟
با وجود مزایایی که در بخش قبل به آنها اشاره شد، یادگیری با ناظر معایبی هم دارد:
- درصورتیکه برای یک کلاس خاص نمونهای در مجموعهی آموزشی وجود نداشته باشد، مدل بهدرستی آموزش نمیبیند.
- باید برای هر کلاس نمونهی دادههای مناسب و با حجم مناسب داشته باشیم تا مدل بتواند درست آموزش ببیند.
- طبقهبندی کلانداده (Big Data) میتواند چالش باشد.
- آموزش یادگیری با ناظر به زمان محاسباتی زیادی نیاز دارد.
خلاصهی مطالب
در این مقاله یادگیری با ناظر (Supervised Learning) را معرفی کردیم و دیدیم در این نوع یادگیری ما ماشین را با استفاده از دادههایی که برچسبدارند، یعنی مشخص است که در کدام دسته یا کلاس قرار دارند، آموزش میدهیم تا درنهایت برای داده ورودی جدید پیشبینی درستی انجام دهند.
یادگیری با ناظر سادهترین زیرمجموعهی یادگیری ماشین است که بسیاری از متخصصان در شروع کار خود بهسراغ یادگیری آن میروند. درواقع این نوع یادگیری رایجترین شکل یادگیری ماشین است و با توجه به نتایج مطلوبی که داشته، ثابت کرده است که گزینهی بسیار خوبی برای حل مسائل مختلف در حوزهی هوش مصنوعی (Artificial Intelligence) و یادگیری ماشین است.
برای آشنایی بیشتر با یادگیری ماشین این مطلب را مطالعه کنید:
۹ کاربرد یادگیری ماشین در زندگی روزمره را بشناسید!
آموزش علم داده یا دیتا ساینس و یادگیری ماشین با کلاسهای آنلاین کافهتدریس
اگر به یادگیری علم داده و یادگیری ماشین علاقه دارید، کلاسهای آنلاین علم داده کافهتدریس به شما امکان میدهد این دانش را بهصورت مقدماتی و پیشرفته یاد بگیرید.
کلاسهای آنلاین آموزش علم داده کافهتدریس بهصورت کاملاً تعاملی و پویا برگزار میشود و مبتنی بر پروژههای واقعی دیتا ساینس است.
شما در کلاسهای آنلاین آموزش علم داده کافهتدریس به جامعترین و بهروزترین آموزش دیتا ساینس دسترسی خواهید داشت.
برای آشنایی بیشتر با کلاسهای آنلاین آموزش علم داده مقدماتی و پیشرفته کافهتدریس و مشاوره رایگان برای شروع یادگیری روی این لینک کلیک کنید: