
شبکههای عصبی مولد متخاصم (GANs) بهدلیل ترکیب منحصربهفرد از یادگیری عمیق و رویکرد تخاصمی، یکی از پیچیدهترین دستاوردهای فناوری در حوزه هوش مصنوعی محسوب میشوند. در این سیستمها، دو شبکهی عصبی به طور همزمان آموزش داده میشوند: یکی به عنوان تولیدکننده (Generator) و دیگری به عنوان تشخیصدهنده (Discriminator). تولیدکننده وظیفه تولید نمونههای جدید و قانعکنندهای را دارد که هدف آن فریب تشخیصدهنده است. از طرف دیگر، تشخیصدهنده تلاش میکند تا بین نمونههای واقعی و تولیدی توسط تولیدکننده تفاوت قائل شود. این رقابت دائمی بین تولیدکننده و تشخیصدهنده موجب پیشرفت و بهبود مستمر در کیفیت تولیدات میشود.
- 1. کاربردهای GANs
- 2. تاریخچه GANs
- 3. معرفی ۱۰ مدل برتر استخراجشده از GANs
- 4. جمعبندی
-
5.
سوالات متداول
- 5.1. چه چالشهایی در توسعه و آموزش شبکههای عصبی مولد متخاصم (GAN) وجود دارد؟
- 5.2. چگونه GANs میتوانند در توسعه فناوریهای بینایی ماشین (Machine Vision) و پردازش تصویر کمک کنند؟
- 5.3. استفاده از GANs در شبیهسازی دادههای پزشکی چه مزایایی دارد؟
- 5.4. در کدام زمینههای نوآورانه میتوان از قابلیتهای GANs استفاده کرد؟
- 5.5. تأثیر GANs بر روی اخلاق و حریم خصوصی در تکنولوژی اطلاعات چیست؟
- 6. یادگیری ماشین لرنینگ را از امروز شروع کنید!
کاربردهای GANs
این فناوری قادر است تا تصاویری با دقت بالا، موسیقی با تنظیمات خلاقانه و حتی متونی که بهسختی میتوان آنها را از نوشتههای تولیدشده توسط انسان تمییز داد تولید کند. استفاده از GANs در ایجاد محتوای خلاق و نوآورانه بهویژه در حوزههایی مانند طراحی گرافیکی، مدلسازی سه بعدی و حتی خلق آثار هنری جدید، این حوزه را تحت تاثیر قرار داده است.
بهعلاوه، GANs بهدلیل تواناییهای منحصربهفرد خود در تولید نمونههای واقعگرایانه، در زمینههای پیچیدهتر مانند شبیهسازی دادههای پزشکی برای آموزش پزشکان، ایجاد سناریوهای متنوع برای آزمایش و تحقیق در هوش مصنوعی و یادگیری ماشین و حتی در مدلسازی تغییرات آب و هوایی استفاده میشوند. این تنوع کاربرد نشاندهنده قدرت و انعطافپذیری بینظیر GANها در حل مشکلات متنوع و پیچیده است.
تاریخچه GANs
شبکههای GAN اولین بار توسط ایان گودفلو (Ian Goodfellow) در سال ۲۰۱۴ معرفی شدند و از آن زمان تاکنون، پیشرفتهای چشمگیری داشتهاند. این تکنولوژی به سرعت در میان محققان و توسعهدهندگان AI محبوب شد و اکنون در زمینههای مختلفی از تصویرسازی دیجیتال گرفته تا پزشکی کاربرد دارد.
معرفی ۱۰ مدل برتر استخراجشده از GANs
در ادامه ۱۰ مدل برتر GAN که تحولات عمدهای در استفاده از این تکنولوژی داشتهاند معرفی کردهایم:
StyleGAN
این مدل بهخاطر تواناییهای بالا در تولید تصاویر با کیفیت و دقیق مشهور است و در تولید چهرههای واقعی و دیگر تصاویر پیچیده کاربرد فراوان دارد.
StyleGAN که بهطور خاص توسط تیمی در Nvidia توسعه یافته است یکی از پیشرفتهترین و محبوبترین مدلهای GAN است که به خصوص در زمینه تولید تصاویر چهرههای انسانی با کیفیت بسیار بالا شناخته شده است. این مدل براساس قابلیتهای خود در تنظیم دقیق ویژگیهای تصویر از طریق کنترلهای سطحبندیشده، بهنام استایلها، قادر است تصاویری را ایجاد کند که جزئیات دقیق و تنوع بالایی دارند.
ویژگی بارز StyleGAN در طراحی آن است که به شبکه اجازه میدهد تا ویژگیهای مختلف تصویر، مانند بافت پوست، مو، ویژگیهای چهره و حتی تاثیر نور و سایه را بهصورت مجزا کنترل کند. این امکان با استفاده از لایههای مختلف در شبکه تولیدکننده که هر یک مسئول ویژگیهای خاصی از تصویر هستند فراهم میشود؛ بهاین ترتیب، StyleGAN قادر است تصاویری با دقت فوقالعاده و تفاوتهای واقعگرایانه و دقیق تولید کند.
کاربردهای StyleGAN
یکی از کاربردهای مهم StyleGAN در صنعت مد و زیبایی است، جایی که این مدل میتواند تصاویر متنوعی از چهرهها با استایلهای مختلف را ایجاد کند، بدون نیاز به مدلهای واقعی این امر میتواند در طراحی محصولات آرایشی و مد به کار رود و به برندها این امکان را میدهد که تأثیر محصولات خود را روی طیف وسیعی از چهرهها نمایش دهند.
علاوهبراین، توانایی StyleGAN در تولید تصاویر با کیفیت بالا این امکان را به پژوهشگران میدهد که بدون نیاز به جمعآوری دیتاستهای وسیع و پیچیده، مطالعات و تحقیقات خود را در زمینه شناسایی چهره و پردازش تصویر پیش ببرند.
در راستای این بحث نمونه جالب توجهی را معرفی میکنیم؛ وبسایت www.thispersondoesnotexist.com به طور خودکار چهرههایی را تولید میکند که بسیار واقعی به نظر میرسند، اما هیچیک از این افراد در واقعیت وجود ندارند. این چهرهها توسط مدلهای StyleGAN تولید شدهاند که در آنها، شبکههای عصبی به تولید تصاویر جدید و دقیق از افراد غیرواقعی میپردازند. استفاده از این فناوری نشاندهنده قدرت و پتانسیل عظیم GANs در تولید محتوای بصری است که نهتنها در عرصه هنری، در بسیاری از زمینههای دیگر کاربرد دارد. نمونهای از تصاویر تولیدشده توسط StyleGAN را میتوانید در زیر ببینید. هیچیک از این افراد، وجود خارجی ندارند و صرفاً ساخته مدل GAN گفتهشده هستند:



StyleGAN یک ویژگی جالب دیگری بهنام ترکیب سبک (Style Mix) دارد که میتواند با استفاده از دو منبع تصویر A و B، تصویری جدید ایجاد کند که قسمتهای اصلی B و قسمتهای جزئی A را دارا باشد. این مورد در شکل زیر قابل مشاهده است:

پیشنهاد میکنیم درباره مدل مولد یا Generative Model بیشتر بدانید.
BigGAN
مدلی با قابلیتهای بسیار در تولید تصاویر با وضوح بالاست که بیشتر در پروژههای بزرگ تصویری به کار رفته است.
BigGAN که یکی از قویترین مدلهای شبکههای عصبی مولد متخاصم در زمینه تولید تصاویر با کیفیت بالاست. این مدل توسط تیمی در DeepMind توسعه یافته است. BigGan برای کار روی دیتاستهای بزرگ و پیچیده طراحی شده است و توانایی تولید تصاویر با جزئیات دقیق و رنگهای شفاف و زنده را دارد. BigGAN به توانایی خود در ایجاد تصاویر با وضوح بسیار بالا در میان توسعهدهندگان AI شناخته شده است.
ویژگیهای BigGAN
یکی از ویژگیهای کلیدی BigGAN استفاده از Batch های بزرگتر و نرخ یادگیری بالاتر در مقایسه با سایر مدلهای GAN است. این امر به مدل اجازه میدهد تا تصاویری با پیچیدگی بیشتر و کیفیت بهتر تولید کند؛ بهعلاوه، BigGAN با استفاده از تکنیکهای خاص تنظیم و بهینهسازی، قادر است تا در مقیاس بزرگ بسیار کارآمد عمل کند. این موضوع برای تولید تصاویر در مقیاس وسیع بسیار مهم است.
کاربردهای BigGAN
کاربرد BigGAN فقط به تولید تصاویر محدود نمیشود. این تکنولوژی در زمینههای مختلف دیگری نیز به کار رفته است، ازجمله در زمینههای تحقیقاتی برای بهبود مدلهای تشخیص تصویر و در صنعت بازی و سرگرمی برای ایجاد مناظر طبیعی و محیطهای خیالی با وضوح بسیار بالا. این تواناییها BigGAN را به یک ابزار قدرتمند در عرصههای تحقیقاتی تبدیل کردهاند.
علاوهبراین، استفاده از BigGAN در تولید دادههای آموزشی مصنوعی که برای تربیت مدلهای دیگر یادگیری ماشین استفاده میشود، نشاندهنده قابلیت انعطاف و گستردگی این مدل است. با استفاده از این دادهها، محققان میتوانند در شرایط کنترلشده، الگوریتمهای پیچیدهتر و دقیقتری را توسعه دهند؛ این بهنوبه خود دقت و کارایی سیستمهای هوش مصنوعی را افزایش میدهد.
CycleGAN
یک مدل پیشرفته در حوزه شبکههای عصبی مولد متخاصم است که قادر به انجامدادن تبدیلهای سبک تصویر بدون نیاز به دادههای جفتشده است؛ برای مثال به شکل زیر توجه کنید:

همانطور که میبینید عکس ورودی که تصویر یک اسب را نشان میدهد، در خروجی با طرحواره گورخر نمایش داده شده است. این دقیقاً کاری است که CycleGanها برای ما انجام میدهند.
CycleGAN یکی از مدلهای برجسته در زمینه شبکههای عصبی مولد متخاصم است که قابلیت تبدیل سبک تصاویر بدون نیاز به جفت دادههای مرتبط را دارد. این ویژگی به CycleGAN اجازه میدهد تا در کاربردهایی که دسترسی به دادههای جفت شده دشوار است، بهخوبی عمل کند.
ویژگی CycleGAN
ویژگی متمایزکننده CycleGAN این است که این مدل از معماری مبتنی بر دورهای (cyclic) استفاده میکند که شامل دو شبکه GAN مجزا است: یکی برای تبدیل از دامنه A به دامنه B و دیگری برای تبدیل معکوس از دامنه B به A. این دو شبکه بهطور همزمان آموزش داده میشوند تا اطمینان حاصل شود که تبدیلها دقیق و قابل بازگشت هستند، یعنی تصویر تولیدشده پس از دو تبدیل متوالی به تصویر اصلی نزدیک باشد.
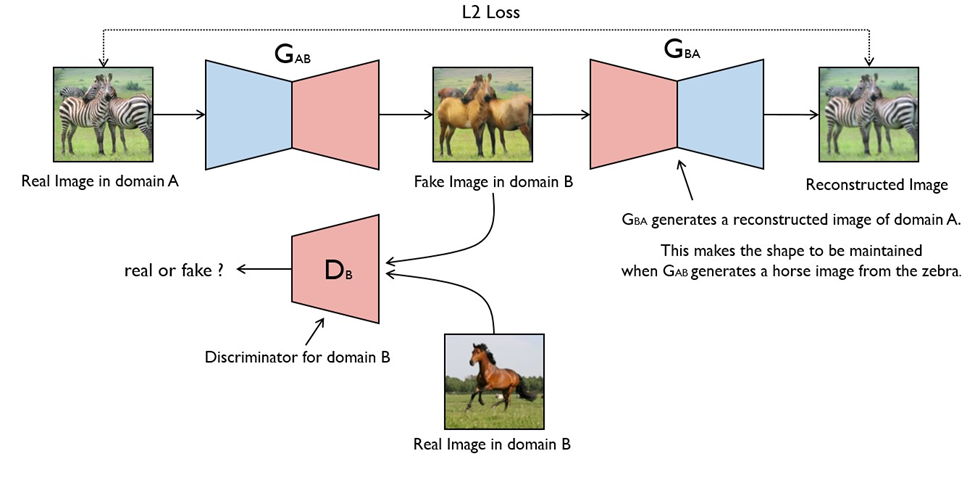
نکته کلیدی همین است که پس از دو تبدیل متوالی تصویر نهایی باید به تصویر اصلی خود بسیار نزدیک باشد. این فرایند تضمین میکند که تبدیلها قابلبازگشت و معتبر هستند. از این طریق دقت مدل در حفظ ویژگیهای اصلی تصاویر افزایش مییابد.
این قابلیت بازگشتپذیری مهم است؛ زیرا تضمین میکند هرگونه تغییری که توسط مدل ایجاد شده باشد، میتواند به صورت معکوس نیز صحت داشته باشد. این موضوع نشاندهنده ثبات و کارایی بالای مدل در تبدیل سبکها به شمار میرود.
کاربردهای CycleGAN
CycleGAN بدون آنکه به تنظیمات پیچیده و دادههای آموزشی عظیم نیاز داشته باشد، در تولید تصاویر با جزئیات و کیفیت بالا موفق عمل میکند. این امر آن را به ابزاری ارزشمند برای طراحان، هنرمندان و توسعهدهندگان میکند که میخواهند تصاویر خود را به سبکهای متفاوت بازآفرینی کنند.
بهعلاوه، CycleGAN بهدلیل قابلیتهای منحصربهفرد خود در تبدیلهای سبک بدون نیاز به مجموعهدادههای جفتشده، در پروژههای تحقیقاتی و کاربردی متعددی استفاده شده است. این شامل تبدیل ویژگیهای ژئوگرافیکی در تصاویر ماهوارهای، تغییرات آبوهوایی در تصاویر طبیعی و حتی ایجاد تصاویر آموزشی برای مقاصد علمی و آموزشی است. CycleGAN نمونهای بارز از چگونگی تاثیر فناوریهای نوین در گسترش دامنه خلاقیت و نوآوری در دنیای دیجیتال است.
یک نمونه از پیادهسازی CycleGAN در کلاس علم داده استاد شکرزاد را میتوانید در این ویدئو ببینید:
PGGAN
نسخهای پیشرفته از StyleGAN است که با رویکرد پرورش تدریجی، به تولید تصاویر با رزولوشن بالاتر و جزئیات دقیقتر دست مییابد.
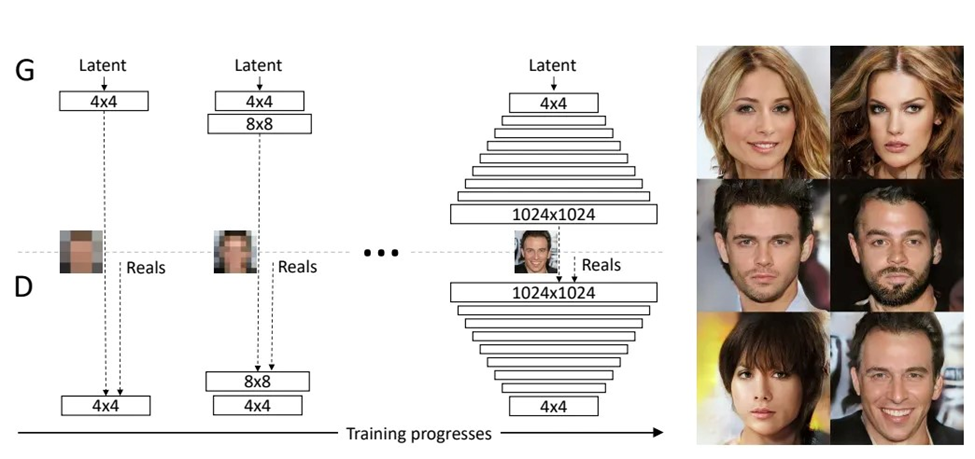
PGGAN یا شبکههای عصبی مولد پیشرونده (Progressive Growing of GANs) یک نوآوری مهم در حوزه شبکههای GAN است که توسط تیم تحقیقاتی Nvidia توسعه یافته است. این مدل به خصوص برای تولید تصاویر با رزولوشن بسیار بالا طراحی شده است.
رویکرد PGGAN
مکانیسم اصلی PGGAN در آن است که شبکه به صورت تدریجی و پیشرونده تصاویر را تولید میکند، شروعکننده با رزولوشنهای پایین و بهتدریج افزایشدهنده دقت تصاویر تا رسیدن به رزولوشنهای بسیار بالا. این رویکرد تدریجی به شبکه کمک میکند تا با کارآمدی بیشتری آموزش ببیند و به استحکام بیشتری در ساختارهای پیچیدهتر دست یابد.
با این روش، PGGAN قادر است تصاویری با جزئیات دقیق و طبیعیتر تولید کند؛ زیرا در هر مرحله از فرایند پیشرونده، شبکه فرصت دارد تا ویژگیهای سطح بالاتر و پیچیدهتری را یاد بگیرد؛ درنتیجه، تصویر نهایی دارای کیفیت بهتری خواهد بود.
کاربردهای PGGAN
PGGAN به ویژه در زمینههایی که نیازمند تولید تصاویر با دقت و وضوح فوقالعاده هستند، مانند شبیهسازیهای طبیعی و تصاویر پزشکی، کاربرد دارد.
این مدل همچنین در تولید چهرههای انسانی و مناظر طبیعی که در آنها جزئیات دقیق بسیار مهم هستند استفاده میشود.
DCGAN
DCGAN یکی از نخستین مدلهای موفق GAN است که از شبکههای عصبی کانولوشنال برای تولید تصاویر باکیفیت و واقعگرایانه استفاده میکند.
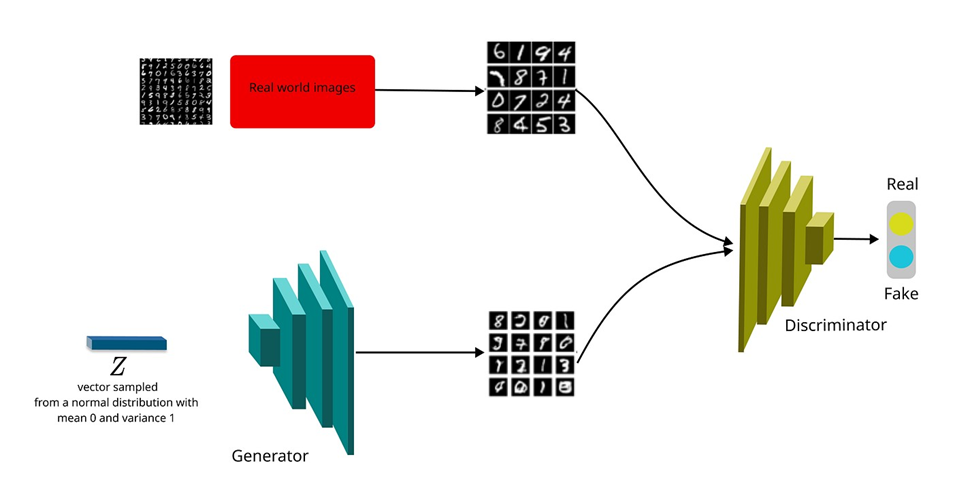
DCGAN، مخفف شبکههای عصبی مولد تمایزی عمیق (Deep Convolutional Generative Adversarial Networks)، یکی از انقلابهای بزرگ در حوزه شبکههای عصبی مولد متخاصم است. این مدل نخستین بار در سال ۲۰۱۵ معرفی شد. DCGAN با استفاده از لایههای کانولوشنی در هر دو شبکه تولیدکننده و تشخیصهنده خود، از آن بهعنوان یک راه قدرتمند برای تولید تصاویری با کیفیت بالا استفاده میکند.
ویژگی DCGAN
این مدل از لایههای کانولوشنی برخلاف لایههای کاملاً متصل استفاده میکند که به آن اجازه میدهد تا ویژگیهای تصویری را با دقت بیشتری بیاموزد و نتایجی واقعگرایانهتر تولید کند. DCGAN بهطور خاص برای بهبود پایداری آموزش شبکههای GAN طراحی شده است. این انر باعث شده که در تولید تصاویری که جزئیات غنی و وضوح بالا دارند موفقتر عمل کند.
کاربردهای DCGAN
یکی از دستاوردهای مهم DCGAN این است که آن مدل به تحقیقات بیشتر در زمینههای استفاده از شبکههای کانولوشنی در مدلهای GAN انجامیده است. از DCGAN در موارد متعددی ازجمله تولید تصاویر هنری، شبیهسازی چهرههای انسانی و حتی در تحقیقات پزشکی برای تولید تصاویر دادههای پزشکی مصنوعی استفاده میشود.
DCGAN، نهتنها در بهبود کیفیت تصاویر مولد کمک کرده، به پیشرفت در فهم ما از شبکههای تمایزی و آموزش مدلهای یادگیری عمیق نیز کمک شایانی کرده است. این مدل بهعنوان یکی از مبانی اصلی در توسعه نسلهای بعدی شبکههای GAN شناخته شده و تأثیر قابل توجهی در این حوزه داشته است.
نمونه پیادهسازی شده از DCGAN در کلاس علم داده ۲
در شکل زیر خروجی حاصل از کد ارائهشده در یکی از جلسات کلاس علم داده را میبینید. تصویر اول، نخستین عکسی است که Generator تولید کرده که تماماً نویز است. تصویر نهایی اما خروجی مدل بعد از بازخوردهای فراوان را نشان میدهد:


StarGAN
یک مدل یادگیری عمیق است که برای Image to image translation استفاده میشود. وظیفه ترجمه تصویر به تصویر این است که جنبه خاصی از یک تصویر داده شده را به جنبه دیگر تغییر دهد؛ برای مثال، تغییر حالت چهره یک فرد از خندان به غمگین.

مزیت StarGan
مدلهای دیگر GAN نیز میتواند ترجمه تصویر به تصویر انجام دهند، اما رویکردهایشان در مقیاسپذیری (Scalability) و مقاومت (Robustness) در برخورد با بیش از دو دامنه محدودیت دارند؛ زیرا باید برای هر جفت از دامنههای تصویر بهصورت جداگانه مدلهای مختلفی ساخته شوند.
مزیت عمده StarGAN در این است که میتواند با استفاده از یک مدل واحد و تنها یک Dataset چندین ویژگی مختلف را تغییر دهد. این امر باعث میشود که StarGAN بسیار کارآمدتر باشد. همچنین بتواند با تعداد دادههای کمتر به نتایج بهتری برسد.
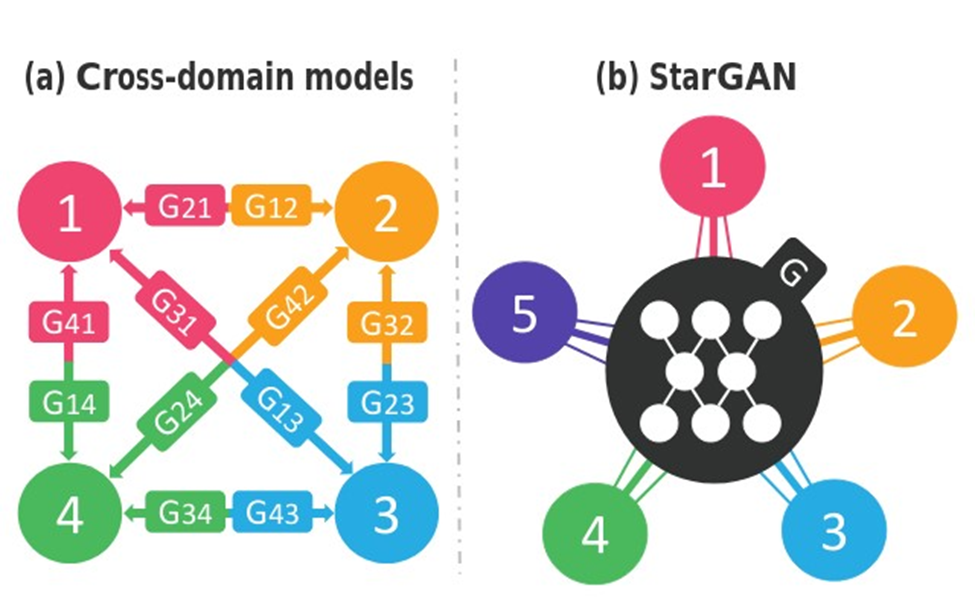
این امر همچنین منجر به کیفیت بیشتر تصاویر ترجمه شده توسط StarGAN در مقایسه با مدلهای موجود شده است. به علاوه اینکه توانایی جدیدی در ترجمهی تصویر ورودی به هر دامنهی مورد نظر را به ارمغان آورده است.
ویژگی StarGAN
از ویژگیهای برجسته StarGAN میتوان به توانایی آن در تولید تصاویر با جزئیات بسیار دقیق و حفظ هماهنگی عمومی ویژگیهای چهره اشاره کرد، که این امکان را به پژوهشگران میدهد تا تأثیرات واقعی تغییرات ویژگیها بر روی چهره انسانها را در محیطهای مجازی بررسی کنند.
علاوهبراین، استفاده از StarGAN در تولید تصاویر برای آموزش مدلهای تشخیص چهره و تجزیهوتحلیل بیانات چهره در زمینههای امنیتی و تبلیغاتی میتواند بسیار مؤثر واقع شود. این قابلیتها StarGAN را به یکی از کاربردیترین مدلهای GAN در عرصه فناوری تصویر تبدیل کردهاند.
نمونهای از کاربرد StarGAN

در تصویر بالا که مجموعهای از تصاویر صورت را نشان میدهد، StarGAN میتواند با دریافت تصویر ورودی اصلی و برچسبی که مشخص میکند کدام ویژگی باید تغییر کند (مثل موی بلوند)، تصویر جدیدی تولید کند که آن ویژگیها را منعکس کند. در هر ردیف، ابتدا تصویر اصلی و سپس چندین تصویر تغییر یافته با ویژگیهای مختلف نشان داده شده است. این روند نشاندهنده قابلیتهای StarGAN در تغییر موثر و واقعگرایانه ویژگیهای چهره است.
پیشنهاد میکنیم درباره الگوریتم GANs هم مطالعه کنید.
GauGAN
یک مدل شبکه عصبی مولد متخاصم است که از الگوریتمهای پیشرفته برای تولید تصاویر طبیعی بسیار واقعی استفاده میکند، که قابلیت تبدیل نقاشیهای ساده به مناظر طبیعی دقیق را دارد.

این مدل با تبدیل طرحهای اولیه ساده به مناظر طبیعی با جزئیات بسیار بالا، به طور چشمگیری در صنعت گرافیک و طراحی دیجیتالی تحول ایجاد کرده است. GauGAN برای طراحان، هنرمندان و معماران امکانات وسیعی را فراهم میآورد تا ایدههای خلاقانه خود را به تصاویر واقعگرایانه تبدیل کنند.
BEGAN
این شبکه مخفف Boundary Equilibrium Generative Adversarial Network، به معنای شبکه عصبی مولد متخاصم تعادل مرزی یکی از مدلهای متخاصم است. BEGAN با استفاده از مفهوم تعادل مرزی برای بهبود پایداری در فرایند آموزش شبکههای GAN طراحی شده است.
در BEGANها وظیفهی تولیدکننده (Generator) این است که نویز تصادفی را به عنوان ورودی بگیرد و نمونههای دادهای تولید کند که شبیه به دادههای آموزشی باشد. وظیفهی تشخیصدهنده (Discriminator) تمایز دادن نمونههای دادهی واقعی از مجموعه دادههای آموزشی و نمونههای جعلی تولید شده توسط تولیدکننده است.
در طول آموزش، مولد و تشخیصدهنده در یک بازی با حاصل جمع صفر (Zero sum) در مقابل هم قرار میگیرند. مولد سعی میکند توانایی خود را برای تولید نمونههای دادهی واقعی بهبود بخشد، در حالی که تشخیصدهنده سعی میکند توانایی خود را برای شناسایی نمونههای جعلی بهبود بخشد.
وجه تمایز BEGAN
BEGANها مشکلی که ممکن است در آموزش GANهای معمولی ایجاد شود را حل میکنند. در GANهای معمولی، تشخیصدهنده گاهی اوقات میتواند در ایجاد تمایز بین نمونههای واقعی و جعلی بیش از حد خوب عمل کند. این میتواند منجر به گیر افتادن مولد در حالتی شود که نتواند نمونههایی را تولید کند که بهاندازه کافی واقعی به نظر برسند تا تشخیصدهنده را فریب دهند یا بهعبارتی فرایند آموزش آن دچار مشکل میشود.
BEGANها تابع هزینه (loss function) جدیدی را معرفی میکنند که تشخیصدهنده را تشویق میکند تا درمورد واقعیبودن یک نمونه تصمیم خاصی بگیرد، بهجای اینکه فقط آن را واقعی یا جعلی طبقهبندی کند. این تابع اتلاف به جلوگیری از عملکرد بیشازحد خوب تشخیصدهنده کمک میکند و به تولیدکننده اجازه میدهد تا بهطور موثرتر یاد بگیرد.
روش کار BEGAN
در طول آموزش، تولیدکننده و تشخیصدهنده بهطور متناوب آموزش داده میشوند. هنگامی که تولیدکننده در حال آموزش است، وزنهای تشخیصدهنده ثابت نگه داشته میشوند. هدف تولیدکننده بهحداقلرساندن تابع هزینه است که معیاری از توانایی تشخیصدهنده در تشخیص بین نمونههای واقعی و جعلی است.
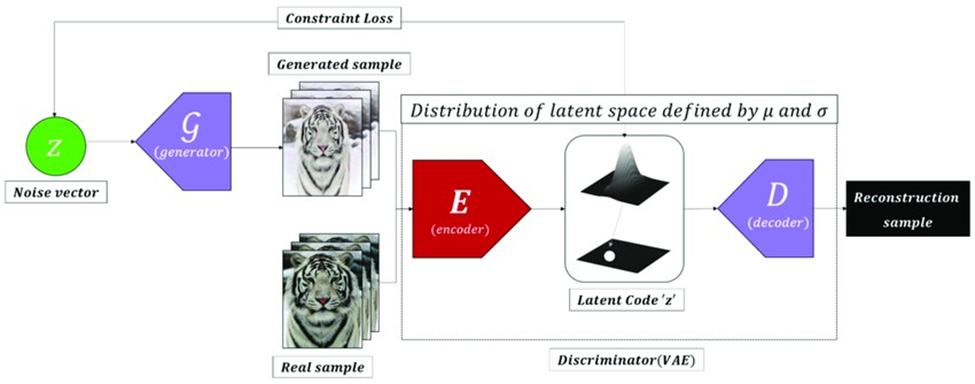
درواقع در BEGANها تشخیصدهنده بهعنوان یک خودرمزگذار عمل میکند و بهجای تمایزقائلشدن میان واقعی و جعلیبودن تصاویر، روی کمینهکردن خطای بازسازی تمرکز میکند.
تابع هزینه BEGAN
تابع هزینه BEGAN براساس مفهوم تعادل مرزی است. در تعادل مرزی، تشخیصدهنده صرفنظر از اینکه نمونه داده واقعی یا جعلی باشد، احتمال ۰.۵ را به تمامی نمونههای داده اختصاص میدهد (یعنی ۵۰ درصد احتمال میدهد همه عکسها واقعی هستند)؛ این بهآن معناست که تشخیصدهنده قادر به تشخیص بین نمونههای واقعی و جعلی نیست.
BEGANها تشخیصدهنده را با جریمهکردن آن بهخاطر اختصاصدادن احتمالاتی که خیلی از ۰.۵ فاصله دارند، بهسمت تعادل مرزی سوق میدهند. این به جلوگیری از عملکرد بیشازحد خوب تشخیصدهنده کمک میکند و به تولیدکننده اجازه میدهد تا به طور موثرتر یاد بگیرد.
InfoGAN
این مدل با استفاده از تکنیکهای اطلاعات متقابل بهمنظور کشف و مدلسازی ویژگیهای نهان و کلیدی دادهها بهطور خودکار طراحی شده است.
اطلاعات متقابل (Mutual Information)
اطلاعات متقابل یک مفهوم اساسی در نظریه اطلاعات است که میزان اطلاعات مشترک میان دو متغیر تصادفی را اندازهگیری میکند. بهزبان ساده، این معیار به ما میگوید که یادگیری درباره یک متغیر تصادفی چقدر اطلاعات درمورد متغیر تصادفی دیگر میدهد. این مفهوم برای تحلیل روابط بین دادهها در بسیاری از زمینههای علمی و فناوری بسیار مهم است.
فرمول اطلاعات متقابل
اطلاعات متقابل بین دو متغیر تصادفی (X) و (Y) با استفاده از انتروپی به شکل زیر محاسبه میشود:
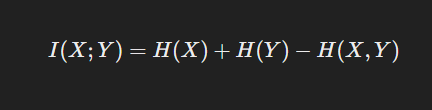
که در آن:
- H(X) انتروپی (X) است که نشاندهنده میزان نااطمینانی یا اطلاعات موجود در (X) است.
- H(Y) انتروپی (Y) است.
- H(X, Y) انتروپی مشترک بین (X) و (Y) است که میزان نااطمینانی کلی در هر دو متغیر را نشان میدهد.
کاربرد اطلاعات متقابل در InfoGAN
در زمینهی InfoGAN، اطلاعات متقابل برای کمک به شبکهی مولد استفاده میشود تا ویژگیهای معناداری از دادهها را شناسایی و بازنمایی کند. با این روش، شبکه سعی میکند تا کدهای نهانی که به آنها داده میشود را به گونهای تنظیم کند که بیشترین اطلاعات ممکن را در مورد دادههای تولیدی داشته باشند. این کار به شبکه اجازه میدهد تا تغییرات قابل تفسیر و معناداری را در دادههای تولیدی اعمال کند. مثلاً تغییر جزئیات خاص در تصویر چهره یا سایر انواع دادهها.
نحوه کار InfoGAN
در InfoGAN، مولد و تشخیصدهنده به شکل پیچیدهتری با هم کار میکنند تا ویژگیهای قابل تفسیرتری از دادهها را استخراج کنند. در ادامه به توضیح نحوه کار این مدل میپردازیم.
تولیدکننده در InfoGAN از دو نوع ورودی استفاده میکند:
- بردار نویز: این بردار معمولاً شامل دادههای تصادفی است که به عنوان منبع اولیه برای تولید دادههای جدید عمل میکند.
- بردار دستهبندی: این بردارها ویژگیهای کلیدی و قابل تفسیری را دربرمیگیرند که مدل قصد دارد آنها را در دادههای تولیدی خود بازنمایی کند. به طور مثال، در تولید تصاویر چهره، این بردار میتواند شامل ویژگیهایی مانند رنگ چشم، نوع مو و غیره باشد.
تشخیصدهنده در InfoGAN دو وظیفه دارد:
- تشخیص واقعیبودن: مانند GANهای معمولی، تشخیصدهنده سعی میکند بفهمد که آیا نمونهای که از مولد دریافت میکند واقعی است یا تولیدی.
- تشخیص دستهبندی نمونه: علاوه بر تشخیص واقعی بودن نمونهها، تشخیصدهنده در InfoGAN همچنین باید بتواند دستهبندی نهان مرتبط با هر نمونه را تشخیص دهد که این امر به مدل کمک میکند تا میزان اطلاعات متقابل بین بردار دستهبندی و نمونههای تولیدی را افزایش دهد.
فرآیند یادگیری
در طی فرایند یادگیری، مولد تلاش میکند نمونههایی تولید کند که نهتنها برای تشخیصدهنده واقعی به نظر برسند بلکه دستهبندیهای صحیح نهان را نیز داشته باشند. تشخیصدهنده با تلاش برای تشخیص صحیح هر دوی این ویژگیها، به تولیدکننده فشار میآورد تا کیفیت و دقت خود را افزایش دهد. این تعامل دوجانبه باعث میشود که تولیدکننده بتواند نمونههایی با ویژگیهای قابل تفسیر و معنیدار تولید کند.
Pix2Pix
یک شبکه عصبی مولد متخاصم است که برای تبدیل تصاویر از یک دامنه به دامنه دیگر طراحی شده است. این مدل از یادگیری ماشین استفاده میکند تا نقاشیها، طرحهای اولیه یا نقشههای سیاه و سفید را به تصاویر رنگی و واقعگرایانه تبدیل کند.
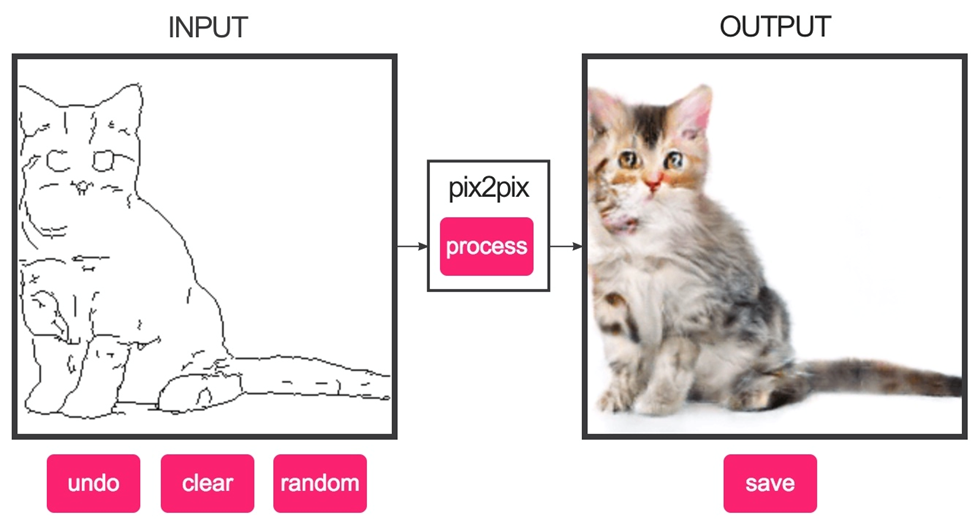
کاربردهای Pix2Pix
Pix2Pix برای کاربردهایی مانند تبدیل نقشههای معماری به تصاویر ساختمانهای واقعی، تبدیل طرحها به تابلوهای نقاشی و تغییر وضعیتهای مختلف تصاویر، مانند از روز به شب یا از تابستان به زمستان، بسیار مفید است. این توانایی تبدیل دقیق و موثر، Pix2Pix را به ابزاری ارزشمند در زمینه پردازش تصاویر و گرافیک کامپیوتری تبدیل کرده است.
جمعبندی
در این مقاله به بررسی کاربردهای فناوری شبکههای عصبی مولد متخاصم (GAN) پرداخته شد. GANs به دلیل تواناییهای بینظیرشان در تولید نمونههای واقعگرایانه و قابلیتهای خود در تقلید دادهها بدون نیاز به جمعآوری دیتاستهای بزرگ، اهمیت زیادی در پیشرفت هوش مصنوعی داشتهاند.
این تکنولوژی در زمینههای مختلفی مانند تولید تصاویر، موسیقی، متون، مدلسازی سهبعدی، شبیهسازیهای پزشکی و آب و هوایی مورد استفاده قرار گرفته است. تکنولوژی GAN با قابلیت تنظیم دقیق و کنترلهای سطح بندی شده، امکان خلق آثاری با جزئیات دقیق و تنوع بالا را فراهم میکند. این فناوری نشاندهنده قدرت و انعطافپذیری استثنایی در حل مشکلات پیچیده و متنوع است و در بسیاری از زمینههای دیگر نیز قابلیت کاربرد دارد.

سوالات متداول
چه چالشهایی در توسعه و آموزش شبکههای عصبی مولد متخاصم (GAN) وجود دارد؟
در توسعه و آموزش GANs، مواجهه با ناپایداری آموزشی یکی از چالشهای اصلی است. این ناپایداری معمولاً بهدلیل تفاوت سرعت یادگیری میان شبکههای تولیدکننده و تشخیصدهنده ایجاد میشود. این امر میتواند به مشکل میرایی گرادیان بینجامد. همچنین، اطمینان از اینکه تولیدکننده قادر به فریب دادن تشخیصدهنده با نمونههای کیفیت بالا است، نیازمند تنظیم دقیق پارامترها و آموزش کافی است.
چگونه GANs میتوانند در توسعه فناوریهای بینایی ماشین (Machine Vision) و پردازش تصویر کمک کنند؟
GANs با قابلیتهای پیشرفته در تولید و بازسازی تصاویر، میتوانند به بهبود سیستمهای بینایی ماشین و پردازش تصویر کمک کنند. بهویژه در تشخیص الگوها و تصحیح خودکار تصاویر، GANs میتوانند به افزایش دقت و کارایی این سیستمها منجر شوند. این قابلیت در کاربردهایی مانند تشخیص چهره و پردازش تصاویر پزشکی از اهمیت ویژهای برخوردار است.
استفاده از GANs در شبیهسازی دادههای پزشکی چه مزایایی دارد؟
استفاده از GANs در شبیهسازی دادههای پزشکی به پژوهشگران امکان میدهد بدون نیاز به دسترسی به دادههای واقعی، دادههای آموزشی واقعگرایانهای تولید کنند. این کاربرد در آموزش پزشکان و پژوهشگران برای شناسایی و درمان بیماریها بدون ریسک استفاده از دادههای حساس بیماران، ارزشمند است.
در کدام زمینههای نوآورانه میتوان از قابلیتهای GANs استفاده کرد؟
فراتر از کاربردهای متداول، GANs در تولید موسیقی و آثار هنری، تولید محتوای بازیهای ویدئویی و حتی در سناریوهای تولید محتوای تعلیمی و تربیتی کاربرد دارند. این تکنولوژی به خلاقان این امکان را میدهد که ایدههای نوآورانه خود را به شکلهای جدیدی بیان کنند و تجربیات کاربری غنیتری خلق کنند.
تأثیر GANs بر روی اخلاق و حریم خصوصی در تکنولوژی اطلاعات چیست؟
درحالیکه GANs فرصتهای زیادی برای نوآوری فراهم میکنند، نگرانیهای اخلاقی مهمی نیز به همراه دارند. تولید تصاویر جعلی و محتوای نادرست میتواند بر اعتماد عمومی و حریم خصوصی تأثیر منفی بگذارد؛ بنابراین ضروری است که در استفاده از این فناوریها دقت کافی به عمل آید و مقرراتی برای جلوگیری از سوء استفاده از آنها وضع شود.
یادگیری ماشین لرنینگ را از امروز شروع کنید!
دنیای دادهها جذاب است و دانستن علم داده، توانایی تحلیل داده، یا بازاریابی مبتنی بر داده، شما را برای فرصتهای شغلی بسیاری مناسب میکند. فارغ از رشته و پیشزمینه، میتوانید حالا شروع کنید و از سطح مقدماتی تا پیشرفته بیاموزید. اگر دوست دارید به این حوزه وارد شوید، پیشنهاد میکنیم با کلیک روی این لینک قدم اول را همین حالا بردارید.
مشاوران کافهتدریس به شما کمک میکنند مسیر یادگیری برای ورود به این حوزه را شروع کنید: