
آیا تابهحال فکر کردهاید که چگونه دستگاههای هوشمند توانایی تشخیص چهره را دارند یا چگونه خودروهای خودران میتوانند محیط اطراف خود را درک کنند؟ پاسخ این پرسشها در حوزهای بهنام پردازش تصویر (Image Processing) و بینایی کامپیوتر (Computer Vision) نهفته است. این دو حوزه که روزبهروز بر دامنه کاربرد آنها افزوده میشود، بهلطف ابزارهایی مانند OpenCV، امروزه راحتتر از همیشه در دسترس هستند. آماده باشید تا با هم به دنیای جذاب تصاویر دیجیتالی برویم و قابلیتهای ارزشمند OpenCV را کشف کنیم.
- 1. مفاهیم اولیه
- 2. کاربردهای بینایی کامپیوتر: چرا به آن نیاز داریم؟
- 3. OpenCV چیست؟
- 4. نحوه استفاده از OpenCV در پایتون
- 5. کلام آخر درباره پردازش تصویر
-
6.
پرسشهای متداول
- 6.1. چگونه میتوان OpenCV را با دیگر کتابخانههای محاسباتی ترکیب کرد تا کارایی برنامههای بینایی کامپیوتر بهبود یابد؟
- 6.2. در استفاده از الگوریتمهای تشخیص چهره درOpenCV، چه توصیههایی برای افزایش دقت و کارایی وجود دارد؟
- 6.3. برای کاهش پیچیدگی محاسباتی در پردازش تصاویر زنده چه روشهایی میتوان در OpenCV به کار برد؟
- 6.4. استفاده از OpenCV در سناریوهای پردازش تصویر Real Time چه محدودیتها و چالشهایی دارد؟
- 6.5. بخشبندی تصویر چیست و چه کاربردهایی دارد؟
- 7. یادگیری ماشین لرنینگ را از امروز شروع کنید!
مفاهیم اولیه
بیایید پیش از شروع کار با OpenCV با تعریف پردازش تصویر و بینایی کامپیوتر آشنا شویم و از این طریق تفاوت آنها را درک کنیم.
پردازش تصویر
فرایند پردازش تصویر به عملکرد تصفیه آب در یک تصفیهخانه شبیه است. همانطور که آب پیش از مصرف پاکسازی میشود، تصویرها نیز برای تحلیل و استفاده پردازش میشوند. این عمل ممکن است اعمال تغییراتی مانند تنظیم کنتراست، برش یا تغییر اندازه عکس را در بر بگیرد.
بینایی کامپیوتر
بینایی کامپیوتر، بهزبان ساده، چشم بینای ماشین است. این فناوری به دستگاهها این امکان را میدهد تا تصویرها را نهتنها ببینند، بفهمند. از این اطلاعات برای انجامدادن کارهای مختلف استفاده میشود. تصور کنید که یک روبات بتواند اشیا را در اتاق شناسایی کند و براساس آن تصمیم بگیرد؛ این دقیقاً همان کاری است که بینایی کامپیوتر انجام میدهد.
پیشنهاد میکنیم با بینایی کامپیوتری آشنا شوید.
کاربردهای بینایی کامپیوتر: چرا به آن نیاز داریم؟
در دنیایی که بینایی انسانی به نظر کاری ساده میآید، ممکن است سؤال شود که چرا به فناوریهای پردازش تصویر و بینایی کامپیوتر نیاز داریم؟
پاسخ اینجاست که مدلهای بینایی کامپیوتر قابلیت پردازش میلیونها داده را دارند و انسان قادر به انجامدادن این کار نیست. این فناوری میتواند بهطور مداوم و بدون خستگی کار کند، برخلاف انسانها!
علاوهبراین میتوان از بینایی کامپیوتر در حسگرها، دوربینها و دستگاههای هوشمند برای پردازش تصویر بهصورت زنده استفاده کرد. این امر در شرایطی بسیار مهم است که انسانها ممکن است خسته شوند یا از دیدن جزئیات غافل شوند.
در ادامه برخی از کاربردهای بینایی کامپیوتر در زندگی روزمره را بررسی میکنیم:
نظارت
کاربردهای بینایی کامپیوتر، مانند تشخیص اشیا و تخمین وضعیت، اغلب در دستگاههای امنیتی برای خودکارسازی نظارت انسانی به کار میروند. مدلهای تخمین وضعیت میتوانند زبان بدن افراد را تجزیهوتحلیل کنند تا بفهمند آیا شخصی در حال دزدی، ایجاد مزاحمت یاتجربه یک ایست قلبی است یا خیر.
خردهفروشی
مدلهای بینایی کامپیوتر در فروشگاهها برای ردیابی موقعیت چشم، زبان بدن و حرکتهای مشتریان استفاده میشوند. این الگوریتمها میتوانند به خردهفروشان درک بهتری از رفتار کاربران بدهند؛ بهاین ترتیب، فروشندگان میتوانند به سؤالاتی از این دست بهراحتی پاسخ دهند:
- کدام تبلیغات یا محصولات توجه مردم را جلب میکند و آنان را به داخل فروشگاه میکشاند؟
- مسیر معمول مشتریان داخل فروشگاه چگونه است؟
- کدام نوع قرارگیری محصول بیشترین توجه را به خود جلب میکند؟
- مشتریان چقدر با ابزار تبلیغاتی مانند بنرها و علائم تعامل دارند؟
این ۴ پرسش فقط نمونهای از پرسشهایی است که بینایی ماشین میتواند به رسیدن به پاسخ آنها کمک کند.
برای مطالعه درباره سایر کاربردهای هوش مصنوعی در این حوزه، مقاله هوش مصنوعی در صنعت خرده فروشی چگونه تحول ایجاد میکند؟ را بخوانید.
وسایل نقلیه خودران
بینایی کامپیوتر نقش مهمی در حوزه رانندگی خودکار ایفا میکند. مدلهای تشخیص اشیا در وسایل نقلیه به کار رفته تا عابران پیاده، وسایل نقلیه دیگر و حیوانات را شناسایی کنند؛ همچنین این فناوری میتواند علائم توقف و چراغهای راهنمایی را تفسیر کند، فاصله دقیق میان وسیله نقلیه و دیگر اشیا را تخمین بزند و از موانعی مانند چالهها اجتناب کند.
OpenCV چیست؟
حال که متوجه شدیم پردازش تصویر و بینایی کامپیوتر چقدر مفید است، بیایید یک ابزار محبوب را بررسی کنیم که برای پیادهسازی آن استفاده میشود.
OpenCV یک کتابخانه بینایی کامپیوتر است که زبانهای برنامهنویسی مانند Python و C++ و Java را پشتیبانی میکند. این بسته را اولین بار اینتل در سال ۱۹۹۹ ایجاد کرد و بعداً بهصورت منبعباز منتشر شد.
OpenCV به توسعهدهندگان و غیرریاضیدانان این امکان را میدهد تا بدون نیاز به نوشتن کدها سنگین، برنامههای بینایی کامپیوتر را با چند خط کد ساده بسازند. این کتابخانه بیش از ۲۵۰۰ الگوریتم دارد که به کاربران اجازه میدهد تا وظیفههایی مانند تشخیص چهره و تشخیص اشیا را انجام دهند.
نحوه استفاده از OpenCV در پایتون
در ادامه گامبهگام نحوه کار با این ابزار ارزشمند را آموزش دادهایم. در پایان نیز از OpenCV برای تشخیص چهره در Python استفاده کردهایم.
نصب و راهاندازی
برای کار با OpenCV اولین قدم نصب آن است. این کتابخانه برای اکثر سیستمهای عامل از جمله Windows ،MacOS و Linux در دسترس است. البته ما در این آموزش از محیط گوگل کلب برای اجرای کدها استفاده کردهایم. نصب OpenCV تنها چند دستور ساده را شامل میشود، اما امکانات بیشماری را برایتان فراهم میکند.
پیادهسازی
برای نصب OpenCV در گوگل کلب، دستور زیر را در آن اجرا میکنیم:
!pip install opencv-python
سپس کافی است کتابخانه cv2 را فراخوانی کنیم تا بتوانیم از امکانات آن استفاده نماییم. در ادامه برای نمایش عکس نیاز به کتابخانه matplotlib نیز داریم:
import cv2
import matplotlib.pyplot as plt
خواندن و نمایش تصویر
اولین تمرینها در OpenCV معمولاً بارگذاری و نمایش یک تصویر هستند. این کار شبیه فرآیند سادهای مانند باز کردن یک کتاب و خواندن صفحات آن است.
پیادهسازی
با استفاده از cv2.imread به شکل زیر میتوان عکس مورد نظر را خواند و سپس با استفاده از plt.imshow آن را نمایش داد:
img = cv2.imread('/content/my_image.jpg')
plt.imshow(img)
plt.show()
همانطور که میبینید عکس تناژ آبی دارد. علت این موضوع این است که وقتی تصاویر را با استفاده از OpenCV میخوانیم، به طور پیشفرض به فرمت BGR (آبی، سبز، قرمز) بارگذاری میشوند.
برای برگرداندن عکس به فرمت RGB کافی است کد زیر را اجرا کنیم:
rgb_img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
plt.imshow(rgb_img)
plt.show()

حال عکس ما به همان رنگی درآمد که برایمان آشناتر است.
ادامه کار را در تمامی مراحل با همین عکس یعنی با فرمت RGB انجام میدهیم. بیایید اندازه و ابعاد این عکس را نیز با هم ببینیم:
print(rgb_img.shape)
(413, 600, 3)
توجه کنید که عکس از دید کامپیوتر یک آرایه سهبعدی است. مقادیر این آرایه بهترتیب نشان دهنده ارتفاع، عرض و تعداد کانالهای تصویر هستند. چون این تصویر رنگی است، سه کانال دارد: قرمز، سبز و آبی (RGB).
تبدیل عکس رنگی به سیاه و سفید
گاهی اوقات برای بهبود کارایی محاسباتی، لازم است تصاویر را به سیاه و سفید تبدیل کنیم و سپس عملیات مورد نظر را اعمال کنیم.
پیادهسازی
در این قسمت میتوانید کد مربوط به انجام این کار را ببینید:
gray_image = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
print(gray_image.shape)
(675, 1200)
همانطور که میدانید عکس سیاه و سفید یا همان gray scale یک عکس دوُبعدی است که فقط طول و عرض دارد یا به عبارتی تککاناله است. به همین علت بعد از چاپ ابعاد این عکس با یک آرایه دوتایی مواجه شدیم.
تغییر اندازه تصویر
یکی دیگر از مهمترین مهارتها در پردازش تصویر، تغییر اندازه تصویر است. این کار شبیه به تغییر اندازه یک عکس در یک برنامه ویرایش عکس است. شما میتوانید بدون از دست دادن جزئیات، اندازه تصویر را کوچک یا بزرگ کنید. OpenCV این کار را با حفظ کیفیت تصویر امکانپذیر میسازد.
پیادهسازی
برای تغییر دادن سایز تصویر از cv2.resize به صورت زیر استفاده میکنیم و با همان دستورات قبلی آن را نمایش میدهیم:
height, width = 500, 500
resized_image = cv2.resize(rgb_img, dsize=(height, width))
plt.imshow(resized_image)
plt.show()

پارامترهای تابع
در این کد height و width طول و عرض مدنظر ما به عنوان ابعاد عکس تغییر سایز یافته است. این ابعاد به عنوان پارامتر dsize که مخفف destination size است، به تابع cv2.resize داده میشود. لازم است توجه داشته باشید که این تابع نیاز به گرفتن تعداد کانالهای عکس تغییر یافته ندارد و تعداد کانالهای عکس اصلی هرچه که باشد، عکس نهایی نیز به همان تعداد کانال خواهد داشت.
تارکردن تصویر
تارکردن تصویر (Image Blurring) یکی از روشهای پردازش تصویر است که در آن، تصاویر واضح به گونهای تغییر مییابند که جزئیات کمتری دارد و بیکیفیتتر به نظر میرسند. این کار اغلب با استفاده از کرنلهایی انجام میشود که مقادیر پیکسلهای یک تصویر را با میانگینگیری تغییر میدهند.
پیادهسازی
برای تارکردن عکس در OpenCV از تابع cv2.blur استفاده میکنیم:
kernel_width, kernel_height = 15, 15
blurred_image = cv2.blur(rgb_img, ksize=(kernel_width, kernel_height))
plt.imshow(blurred_image)
plt.show()

همانطور که میبینید عکس خروجی نسبت به عکس اصلی کمی تارتر دیده میشود. تابع cv2.blur از یک کرنل (ماتریس) استفاده میکند که عکس را پیمایش میکند و با محاسبه میانگین پیکسلهای زیر آن، نتیجه را در مرکز هر ناحیه قرار دهد. این روند برای کل تصویر تکرار میشود تا تصویر نهایی تار شود.
پارامترهای تابع
kernel_width یا عرض کرنل تعداد ستونهای کرنل را تعیین میکند. درواقع عددی که به این پارامتر داده میشود، مشخص میکند که هنگام میانگینگیری، چند پیکسل به صورت افقی تحت تأثیر قرار میگیرند. kernel_height ارتفاع کرنل تعداد ردیفهای کرنل را مشخص میکند. این دو پارامتر به عنوان اعضای تاپل ksize به معنای kernel size به تابع داده میشوند.
واضح است که اندازهی کرنل تأثیر زیادی بر میزان تاری نهایی دارد. کرنلهای بزرگتر تاری بیشتری ایجاد میکنند.
درواقع کرنلهای بزرگتر، بین تعداد بیشتری از پیکسلها میانگینگیری میکنند و نهایتا همگی را با یک پیکسل جایگزین میکنند. با توجه به خروجی کد زیر میتوان تاثیر سایز کرنل را در میزان تاری عکس مشاهده کرد:
kernels = [5, 15, 30]
plt.figure(figsize=(12, 5))
for i, k in enumerate(kernels):
blurred_image = cv2.blur(rgb_img, (k, k))
ax = plt.subplot(1, len(kernels), i + 1)
ax.imshow(blurred_image)
ax.set_title(f"Kernel size: {k}x{k}")
ax.axis('off')
plt.tight_layout()
plt.show()

این حلقه for برای هر مقدار در لیست kernels اجرا میشود که شامل اندازههای کرنل است. متغیر i شماره تکرار و k مقدار کرنل در آن تکرار است. برای هر کرنل، تصویر تار با استفاده از تابع cv2.blur ایجاد میشود. سپس، تصویر در یک زیرنمودار (subplot) قرار میگیرد. تابع imshow تصویر تار را نمایش میدهد.
تیزکردن تصویر
تیز کردن تصویر (Sharpening Images) یکی دیگر از تکنیکهای پردازش تصویر است که به منظور بهبود وضوح و جزئیات تصویر اعمال میشود. این عملیات به وسیلهی افزایش کنتراست بین پیکسلهای مجاور انجام میپذیرد. با این کار میتوان تصاویری که به دلایلی مانند حرکت یا نور کم، تار شدهاند را بهبود بخشید.
پیادهسازی
برای تیز کردن تصاویر در OpenCV معمولاً از فیلترهای کانولوشنی (Convolution Filters) استفاده میشود که کرنلهای خاصی برای این منظور طراحی شدهاند. با استفاده از تابع cv2.filter2D کرنل مورد نظر روی عکس اعمال خواهد شد. در کد زیر ما از کرنل شارپنینگ برای این کار استفاده کردهایم:
import numpy as np
kernel_sharpening = np.array([[-1, -1, -1],
[-1, 9, -1],
[-1, -1, -1]])
sharpened_image = cv2.filter2D(rgb_img, ddepth=-1, kernel=kernel_sharpening)
plt.imshow(sharpened_image)
plt.show()

همانطور که میبینید بعد از انجام این کار، تصویر ما واضحتر از تصویر اصلی شده است. این کاری است که کرنل شارپنینگ یا کرنلهای مشابه آن برای ما انجام میدهند.
پارامترهای تابع
ddepth که مخفف destination depth است، نوع داده تصویر خروجی را تعیین میکند. وقتی این مقدار برابر ۱- باشد، به این معنا است که عمق تصویر خروجی همانند تصویر ورودی خواهد بود.
کرنل ماتریسی است که تعریف میکند چگونه هر پیکسل و همسایههای آن برای تولید پیکسل جدید در تصویر خروجی ترکیب شوند. کرنل تیزکردن (kernel_sharpening) در این مورد یک ماتریس ۳x۳ است که با مقادیر خاص خود، باعث افزایش وضوح تصویر میشود.
تشخیص لبه
تشخیص لبه (Edge Detection) در تصاویر به خصوص در بخشهایی که نیاز به شناسایی و تحلیل ساختارها و اشکال در تصاویر وجود دارد، بسیار کاربردی است. این روش میتواند در زمینههای مختلف کمک کند تا اطلاعات بصری مهم را از پسزمینه یا دیگر عناصر ناخواسته جدا کنیم.
یکی از روشهای تشخیص لبه معروف الگوریتم کنی (Canny edge detector) است. این الگوریتم توسط جان اف. کنی در سال ۱۹۸۶ توسعه یافت و یک فرآیند چند مرحلهای است. الگوریتم کنی به خاطر دقت و قابلیت اطمینان بالایی که در شناسایی لبهها دارد، یکی از محبوبترین روشهای تشخیص لبه است. مراحل کار این الگوریتم به شرح زیر است:
کاهش نویز
ابتدا، تصویر اصلی هموار میشود تا نویز آن کاهش یابد. این کار معمولاً با استفاده از فیلتر گاوسی انجام میشود که به صاف کردن تصویر کمک میکند. هدف از این مرحله جلوگیری از اشتباه گرفته شدن نویز به عنوان لبه در مراحل بعدی است.
یافتن شدت و جهت لبهها
پس از کاهش نویز، از یک فیلتر خاص برای محاسبه گرادیان تصویر استفاده میشود. این گرادیانها شدت و جهت لبههای موجود در تصویر را نشان میدهند. شدت لبه نشاندهنده قدرت یا وضوح لبه در آن نقطه است، در حالی که جهت لبه جهت تغییر روشنایی را نشان میدهد.
نازکسازی لبهها
در این مرحله الگوریتم لبههایی که پیدا کرده را باریکتر میکند تا فقط قویترین و واضحترین لبهها باقی بمانند. این کار با حذف پیکسلهایی که در جهت لبه شدیدترین گرادیان نیستند، انجام میشود.
آستانهگذاری
در مرحله نهایی، الگوریتم دو آستانه تعریف میکند، یک آستانه بالا و یک آستانه پایین. پیکسلهایی که شدت آنها بالاتر از آستانه بالا است به عنوان لبههای واقعی در نظر گرفته میشوند و به طور مستقیم در تصویر نهایی لبهها نمایش داده میشوند.
پیکسلهایی که شدت گرادیان آنها بین آستانه بالا و پایین قرار دارد، به عنوان لبههای ضعیف شناخته شده و تنها زمانی به عنوان لبه قبول میشوند که به لبههای قوی متصل باشند.
پیادهسازی
این مدل را میتوانیم در OpenCV با تابع cv2.Canny پیاده کنیم:
edges = cv2.Canny(rgb_img, threshold1=50, threshold2=150)
plt.imshow(edges)
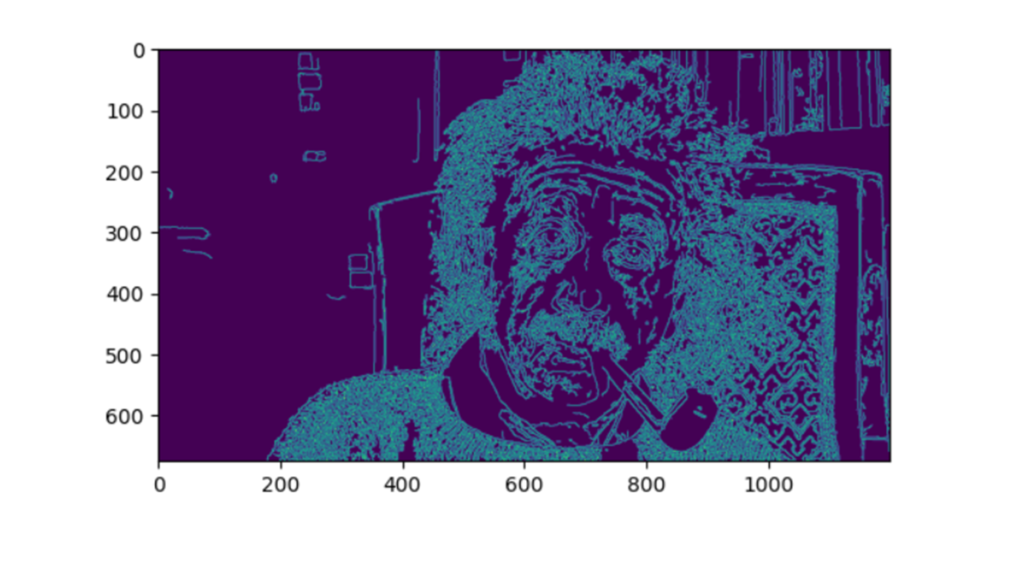
بهاینترتیب لبههای عکس ما به طور خاص و با الگوریتم گفته شده مشخص شد. احتمالا با توجه به توضیحات بالا میتوانید حدس بزنید نقش threshold1 و threshold2 چیست.
پارامترهای تابع
آستانه پایین (threshold1) تعیینکننده حداقل شدت گرادیان است که پیکسلهای زیرِ این مقدار به طور قطع به عنوان غیر لبه در نظر گرفته میشوند. آستانه بالا (threshold2) تعیینکننده حداکثر شدت گرادیان است که پیکسلهای بالاتر از این مقدار به طور قطع به عنوان لبه در نظر گرفته میشوند.
تشخیص چهره
تشخیص چهره (Face Detection) فرایندی است که در آن چهرهی یک فرد در تصویر یا ویدیو شناسایی میشود. این کار با تجزیه و تحلیل دادههای بصری انجام میشود تا مشخص شود آیا ویژگیهای چهرهی یک فرد در آن وجود دارد یا خیر.
چهرههای انسانی به دلیل تنوع بسیار بالا، مدلهای تشخیص چهره معمولاً نیاز به آموزش با حجم زیادی از دادههای ورودی دارند تا دقت لازم را کسب کنند. دیتاست آموزشی باید نمایندگی کافی از افرادی را داشته باشد که از پسزمینههای مختلف، جنسیتها و فرهنگهای متفاوت هستند.
این الگوریتمها همچنین باید نمونههای آموزشی متعددی را دریافت کنند که شامل نورپردازیهای مختلف، زوایا و جهتهای گوناگون باشد تا بتوانند در سناریوهای واقعی به درستی پیشبینی کنند.
این ظرافتها باعث میشوند که تشخیص چهره وظیفهای غیرساده و وقتگیر باشد که نیازمند ساعتها آموزش مدل و میلیونها نمونه داده است.
خوشبختانه، کتابخانه OpenCV شامل مدلهای از پیشآموزشدیده برای تشخیص چهره است. این یعنی ما برای تشخیص چهره نیازی به آموزش مدل نداریم. به طور خاصتر، این کتابخانه از یک رویکرد یادگیری ماشینی به نام Haar Cascade برای شناسایی در دادههای بصری استفاده میکند.
معرفی روش طبقهبندهای زنجیرهای Haar
روش طبقهبندهای زنجیرهای Haar برای اولین بار در مقالهای با عنوان «تشخیص سریع اشیاء با استفاده از زنجیرهای تقویتشده از ویژگیهای ساده»، نوشته شده توسط پل ویولا و مایکل جونز، معرفی شد. ایدهی پشت این تکنیک، استفاده از زنجیرهای از طبقهبندها برای تشخیص ویژگیهای مختلف در یک تصویر است. این طبقهبندها سپس در یک طبقهبند قوی ترکیب میشوند که قادر است به طور دقیق بین نمونههایی که حاوی چهره انسان هستند و آنهایی که نیستند، تمایز قائل شود.
طبقهبند Haar Cascade که در کتابخانه OpenCV تعبیه شده است، قبلاً روی مجموعهای بزرگ از چهرههای انسانی آموزش دیده است. بنابراین نیازی به آموزش دیدن ندارد.
ما تنها باید طبقهبند را از کتابخانه فراخوانی و از آن برای انجام تشخیص چهره روی تصویر ورودی استفاده کنیم. این روش به دلیل سرعت بالا و دقت مناسبش، یکی از پرکاربردترین تکنیکها در حوزه تشخیص چهره بهشمار میرود و در بسیاری از برنامههای کاربردی مورد استفاده قرار میگیرد.
پیادهسازی
برای استفاده از این مدل در OpenCV، لازم است ابتدا یک فایل XML به نام haarcascade_frontalface_default.xml را دریافت کنیم. با استفاده از کد زیر میتوانیم این کار را انجام دهیم:
clf = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_frontalface_default.xml')
این فایل حاوی دادههای ازپیشآموزشدادهشده برای تشخیص چهرههای تمامرخ (Frontal Faces) است. درواقع چنین فایلهایی شامل پارامترهایی هستند که مدل را قادر میسازند تا الگوهای خاصی از ویژگیهای چهره مانند چشمها، بینی و دهان را تشخیص دهد.
OpenCV همچنین مدلهای از پیش آموزش دیده دیگری دارد که از آنها برای تشخیص اشیاء مختلف در یک تصویر استفاده میشود – مانند تشخیص لبخند در چهره یا پلاک خودرو.
سپس با استفاده از تابع clf.detectMultiScale مختصات محدودههای مستطیلی را که چهرهها را دربرمیگیرند، بدست میآوریم:
coordinates = clf.detectMultiScale(rgb_img)
سپس با قطعه کد زیر ناحیه تشخیصدادهشده را در شکل مشخص میکنیم:1
for coordinate in coordinates:
x, y, width, height = coordinate
x2, y2 = x + width, y + height
cv2.rectangle(rgb_img, pt1=(x,y), pt2=(x2,y2), color=(255,0,0), thickness=3)
plt.imshow(rgb_img);

پارامترهای تابع
حلقه for در این قطعه کد برای هر عنصر در لیست coordinates اجرا میشود. هر عنصر در این لیست نشان دهنده مختصات و ابعاد یک مستطیل است که بر روی تصویر رسم خواهد شد.
در خط دوم متغیرهای x ،y ،width و height از هر عنصر coordinate استخراج می شوند. x و y نشان دهنده مختصات گوشه بالا و سمت چپ مستطیل هستند width و height نیز عرض و ارتفاع مستطیل را مشخص می کنند.
خط سوم مختصات گوشه پایین و سمت راست مستطیل با استفاده از مختصات ابتدایی و ابعاد مستطیل محاسبه و در متغیرهای x2 و y2 ذخیره میشوند.
در خط چهارم، از تابع cv2.rectangle برای رسم مستطیل بر روی تصویر استفاده میکند. این تابع ابتدا تصویر اصلی را دریافت میکند که در اینجا rgb_img است. سپس با پارامتر pt1، مختصات x و y را بهعنوان نقطه بالا-چپ و با پارامتر pt2 ،x2 و y2 را بهعنوان نقطه پایین-راست bounding boxای که قرار است روی تصویر بیاندازد، دریافت میکند.
پارامتر color رنگِ bounding box و thickness، ضخامت خطوط مستطیل را مشخص میکند.
بخشبندی تصویر
بخشبندی تصویر (Image Segmentation) یکی از فرایندهای کلیدی در بینایی کامپیوتر است که طی آن یک تصویر دیجیتال به چندین بخش یا مجموعهای از پیکسلها تقسیم میشود. این تقسیمبندی به دلیل کاهش قابل توجه پیچیدگی تصویر، اهمیت زیادی دارد. علت این است که تجزیه و تحلیل تصویر را سادهتر کرده و امکان استخراج اطلاعات معنادار از آن را فراهم میآورد. هر بخش معمولاً شامل پیکسلهایی با ویژگیهای مشابه مانند رنگ، شدت یا بافت است. این کار تجزیه و تحلیل دقیقتر و مشخصتر از قسمتهای مختلف تصویر را ممکن میسازد.
تکنیکهای بخشبندی تصویر
در زمینه بخشبندی تصویر، تکنیکهای مختلفی وجود دارد که عبارتند از:
- روش آستانهای
- بخشبندی مبتنی بر لبه
- بخشبندی مبتنی بر منطقه
- بخشبندی مبتنی بر خوشهبندی
- روش واترشد
- بخشبندی مبتنی بر شبکههای عصبی مصنوعی
در این میان، ما رویکرد بخشبندی مبتنی بر خوشهبندی را انتخاب کردهایم. این روشها، که الگوریتمهایی غیرنظارتی هستند و به کاربر اجازه میدهند بدون تعیین پیشفرض ویژگیها، کلاسها یا گروهها، اطلاعات پنهان و زیربنایی را کشف کنند. الگوریتمهایی مانند k-means به دلیل سادگی و کارایی بالا، در بین روشهای خوشهبندی رایج هستند. این الگوریتمها به تفکیک پیکسلها به گروههایی با ویژگیهای مشابه کمک میکنند.
پیادهسازی
برای بخشبندی تصویر زیر بهکمک OpenCV ابتدا باید آن را بخوانیم و بهفرمت RGB دربیاوریم:
image = cv2.imread('segment.jpg')
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
plt.imshow(image)
plt.show()

سپس برای پردازش تصویر باید آن را به یک آرایه دوبعدی تبدیل کنیم:
import numpy as np
pixel_values = image.reshape((-1, 3))
pixel_values = np.float32(pixel_values)
این کد تصویر را به یک آرایه دوبعدی تبدیل میکند. هر ردیف این آرایه نشاندهنده یک پیکسل با سه مولفه رنگی (RGB) است. تبدیل نوع دادههای آرایه به float32 برای سازگاری بیشتر با K-means است.
در ادامه لازم است پارامترهای الگوریتم K-means را مشخص و تابع cv2.kmeans را روی عکس پیشپردازششده اجرا کنیم:
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 100, 0.5)
_, labels, (centers) = cv2.kmeans(data=pixel_values, k=8, bestLabels=None,
criteria=criteria, attempts=10,
flags=cv2.KMEANS_RANDOM_CENTERS)
پارامترهای تابع
در این تابع k نشاندهنده تعداد خوشهها است. criteria یک تاپل سهتایی است که شرایط توقف الگوریتم K-means را تعیین میکند.
اولین عنصر این تاپل، type است و بهحالتی اشاره دارد که تحت آن الگوریتم دست از تکرار برمیدارد. این عنصر میتواند برابر cv2.TERM_CRITERIA_EPS باشد، که این بهمعنای حالتی است که الگوریتم با رسیدن به یک دقت مشخص (epsilon)، به کار خود پایان میدهد. همچنین میتوان آن را برابر با cv2.TERM_CRITERIA_MAX_ITER قرار داد که این یعنی الگوریتم باید پس از تعداد تکرار مشخصی (max_iter) متوقف شود. این حالت برای جلوگیری از اجرای نامحدود الگوریتم استفاده میشود، بهویژه در مواردی که ممکن است مدل به سرعت همگرا نشود. همچنین میتوان این عنصر را ترکیبی از هر دو این حالتها (مانند cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER) قرار داد.
عنصر دوم در criteria ،max_iter است که حداکثر تعداد تکرارهای الگوریتم را مشخص میکند.
نهایتا عنصر سوم epsilon است که دقت مورد نیاز را نشان میدهد. خروجی الگوریتم K-means در این کتابخانه، مراکز خوشهها (Centers) و برچسبهای (Labels) هر پیکسل است.
بخشبندی بااستفاده از لیبلها
در ادامه باید این مراکز را به نوع دادهای صحیح ۸ بیتی (unit8 data type) تبدیل کنیم. این عمل به منظور کاهش حجم دادهها و سازگاری با فرمتهای استاندارد تصویر انجام میشود:
centers = np.uint8(centers)
سپس با کد زیر برچسبها را به یک آرایه یکبعدی تبدیل و هر پیکسل را با مرکز خوشهای جایگزین میکنیم که به آن تعلق دارد:
segmented_image = centers[labels.flatten()]
در ادامه با کد زیر تصویر سگمنتشده را به شکل اصلی تصویر بازمیگردانیم. این کار به ما این اطمینان را میدهد که ابعاد تصویر سگمنتشده با تصویر ورودی مطابقت دارد:
segmented_image = segmented_image.reshape(image.shape)
در پایان خروجی کار را که یک تصویر بخشبندی شده است، نمایش میدهیم:
plt.imshow(segmented_image)
plt.title('Segmented Image')
plt.show()
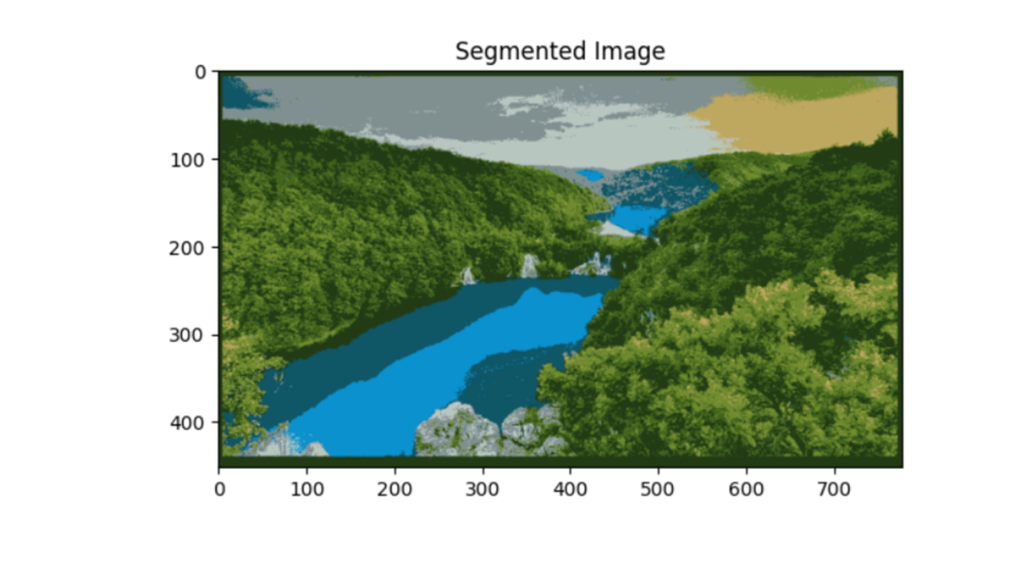
یکی از مهمترین ویژگیهای الگوریتمهای یادگیری ماشین مبتنی بر خوشهبندی این است که میتوانیم کیفیت بخشهایی که توسط آن تولید میشوند را با استفاده از چندین پارامتر آماری مانند ضریب سیلوئت، شاخص رند (RI) و غیره اندازهگیری کنیم.
همچنین بخوانید: کشف الگوهای پنهان در دادهها: معرفی جامع تکنیکهای خوشهبندی در یادگیری ماشین!
کلام آخر درباره پردازش تصویر
کتابخانه OpenCV به عنوان یک ابزار قدرتمند و منبع باز (Open Source)، امکانات گستردهای را برای توسعهدهندگان و محققان فراهم میآورد. در این مقاله علاوه بر ارائه اطلاعات درمورد تفاوت پردازش تصویر و بینایی کامپیوتر، کاربردهای این حوزه را در دنیای واقعی بررسی کردیم. در ادامه با هدف استفاده از تکنیکهای پیشرفتهی تشخیص چهره، تشخیص لبه و بخشبندی تصویر، مراحل انجام این کارها را با استفاده از OpenCV گامبهگام آموزش دادیم.

پرسشهای متداول
چگونه میتوان OpenCV را با دیگر کتابخانههای محاسباتی ترکیب کرد تا کارایی برنامههای بینایی کامپیوتر بهبود یابد؟
برای بهبود کارایی برنامههای بینایی کامپیوتر، میتوان OpenCV را با کتابخانههای محاسباتی مانند NumPy و SciPy ترکیب کرد. NumPy امکان مدیریت کارآمدتر آرایههای بزرگ دادهها را فراهم میکند که میتواند بهینهسازی پردازشها و محاسبات را تسهیل کند. SciPy مجموعهای از الگوریتمهای پیشرفته ریاضی و فنی را ارائه میدهد که میتواند در تحلیلهای پیچیدهتر مفید باشد.
در استفاده از الگوریتمهای تشخیص چهره درOpenCV، چه توصیههایی برای افزایش دقت و کارایی وجود دارد؟
برای افزایش دقت و کارایی در الگوریتمهای تشخیص چهره درOpenCV، استفاده از پیشپردازشهای مناسب مانند تصحیح نور و کنتراست میتواند به کاهش خطاها و بهبود تشخیص کمک کند. علاوه بر این، تنظیم دقیق پارامترهای الگوریتم مانند thresholdها و اندازه کرنلها برای تشخیص چهره نیز مهم است.
برای کاهش پیچیدگی محاسباتی در پردازش تصاویر زنده چه روشهایی میتوان در OpenCV به کار برد؟
برای کاهش پیچیدگی محاسباتی در پردازش تصاویر زنده، استفاده از الگوریتمهای سادهتر و کمهزینهتر مانند تشخیص لبهها با استفاده از فیلترهای Sobel یا Prewitt به جای الگوریتمهای پیچیدهتر مانند Canny میتواند مفید باشد. همچنین، کاهش وضوح تصویر ورودی و استفاده از تصاویر سیاه و سفید به جای رنگی میتواند به کاهش میزان دادههای مورد نیاز برای پردازش کمک کند.
استفاده از OpenCV در سناریوهای پردازش تصویر Real Time چه محدودیتها و چالشهایی دارد؟
یکی از چالشهای استفاده از OpenCV در پردازش تصویر Real Time، مدیریت منابع و تاخیر زمانی است که میتواند در پردازشهای پیچیده اتفاق بیفتد. برای مقابله با این محدودیتها، میتوان از پردازندههای قویتر استفاده کرد یا الگوریتمها را برای کارایی بهتر بهینهسازی کرد. استفاده از پردازش موازی و تکنولوژیهای GPU نیز میتواند به بهبود پاسخدهی و کاهش تاخیر کمک کند.
بخشبندی تصویر چیست و چه کاربردهایی دارد؟
بخشبندی تصویر یکی از فرآیندهای کلیدی در بینایی کامپیوتر است که طی آن یک تصویر دیجیتال به چندین بخش یا مجموعهای از پیکسلها تقسیم میشود که به آنها اشیاء تصویر گفته میشود. این تقسیمبندی به دلیل کاهش قابل توجه پیچیدگی تصویر، اهمیت زیادی دارد زیرا تجزیه و تحلیل تصویر را سادهتر کرده و امکان استخراج اطلاعات معنادار از آن را فراهم میآورد. هر بخش معمولاً شامل پیکسلهایی با ویژگیهای مشابه مانند رنگ، شدت یا بافت است. این امر تجزیه و تحلیل دقیقتر و مشخصتر از قسمتهای مختلف تصویر را ممکن میسازد.
یادگیری ماشین لرنینگ را از امروز شروع کنید!
دنیای دادهها جذاب است و دانستن علم داده، توانایی تحلیل داده، یا بازاریابی مبتنی بر داده، شما را برای فرصتهای شغلی بسیاری مناسب میکند. فارغ از رشته و پیشزمینه، میتوانید حالا شروع کنید و از سطح مقدماتی تا پیشرفته بیاموزید. اگر دوست دارید به این حوزه وارد شوید، پیشنهاد میکنیم با کلیک روی این لینک قدم اول را همین حالا بردارید.
مشاوران کافهتدریس به شما کمک میکنند مسیر یادگیری برای ورود به این حوزه را شروع کنید: