
تعبیه کلمات GloVe یکی از روشهای محبوب و کارآمد در زمینه پردازش زبان طبیعی (NLP) است که برای تبدیل کلمات به بردارهای عددی استفاده میشود. این روش توسط محققان دانشگاه استنفورد توسعه یافته و به دلیل دقت و کارایی بالا، توجه بسیاری از پژوهشگران و مهندسان را به خود جلب کرده است. GloVe با استفاده از رویکردی منحصربهفرد که بر اساس ماتریس هموقوعی (Co-occurring) و بهینهسازی تابع هزینه بناشده، توانسته است به دقت بالایی در تعبیه کلمات دست یابد. در این مقاله به بررسی دقیق این روش و مزایا و چالشهای آن خواهیم پرداخت.
- 1. مفهوم تعبیه کلمات
- 2. اهمیت تعبیه کلمات در NLP
- 3. الگوریتمهای تعبیه کلمات
- 4. مدلهای مبتنی بر پیشبینی
- 5. مدلهای مبتنی بر شمارش
- 6. معرفی تعبیه کلمات GloVe
- 7. تاریخچه و توسعه
- 8. بررسی نحوه کار مدل GloVe
- 9. استفاده از تعبیه کلمات GloVe در پایتون
- 10. تحلیل احساس با استفاده از برداهای تعبیه کلمه GloVe
- 11. مزایای استفاده از تعبیه کلمات GloVe
- 12. محدودیتها و چالشهای تعبیه کلمات GloVe
- 13. کاربردهای عملی GloVe
- 14. تفاوت تعبیه کلمات در مدلهای Word2Vec و GloVe
- 15. جمعبندی
- 16. سوالات متداول
- 17. یادگیری ماشین لرنینگ را از امروز شروع کنید!
مفهوم تعبیه کلمات
تعبیه کلمات (Word Embedding) به فرآیندی اطلاق میشود که در آن کلمات به بردارهای عددی تبدیل میشوند. این بردارها نمایانگر ویژگیهای معنایی کلمات بوده و در الگوریتمهای مختلف NLP کاربرد دارند. به عبارت دیگر، تعبیه کلمات به ما کمک میکند تا معنای کلمات را به صورت عددی نمایش دهیم و از این نمایش برای تحلیل و پردازش متن استفاده کنیم. این فرآیند به مدلهای کامپیوتری امکان میدهد تا روابط پیچیده بین کلمات را درک کنند و نتایج دقیقتری ارائه دهند.
اهمیت تعبیه کلمات در NLP
تعبیه کلمات به دلیل توانایی درک روابط معنایی بین کلمات، نقش بسیار مهمی در پردازش زبان طبیعی دارد. بدون تعبیه کلمات، مدلهای NLP نمیتوانند معنای دقیق و روابط بین کلمات را به خوبی درک کنند. به عنوان مثال، کلمات گربه و سگ ممکن است در متون مختلف به صورت مجزا ظاهر شوند، اما تعبیه کلمات به مدل کمک میکند تا شباهت معنایی بین این دو کلمه را درک کند و آنها را به صورت بردارهای نزدیک به هم نمایش دهد. این ویژگی باعث میشود که مدلها بتوانند با دقت بیشتری متون را تحلیل کرده و به سوالات پیچیدهتر پاسخ دهند.
الگوریتمهای تعبیه کلمات
الگوریتمهای تعبیه کلمات به دو دسته اصلی تقسیم میشوند: مدلهای مبتنی بر پیشبینی و مدلهای مبتنی بر شمارش. هر یک از این مدلها روشها و مزایای خاص خود را دارند که در ادامه به بررسی آنها میپردازیم:
مدلهای مبتنی بر پیشبینی
این مدلها از شبکههای عصبی برای پیشبینی کلمه بعدی در یک جمله استفاده میکنند. Word2Vec یکی از معروفترین این مدلها است که توسط تیم پژوهشی گوگل توسعه یافته است. این مدل با استفاده از یک شبکه عصبی کوچک، بردارهای کلمات را بر اساس همسایگی آنها در جملات محاسبه میکند. مدلهای مبتنی بر پیشبینی به دلیل سادگی و دقت بالا، در بسیاری از کاربردهای NLP مورد استفاده قرار میگیرند.
مدلهای مبتنی بر شمارش
این مدلها بر اساس شمارش هموقوعی کلمات در یک متن بزرگ عمل میکنند. تعبیه کلمات GloVe نمونهای از این مدلها است که با استفاده از ماتریس هموقوعی کلمات، بردارهای کلمه را محاسبه میکند. مدلهای مبتنی بر شمارش بر اساس اطلاعات آماری از متون بزرگ، بردارهای دقیقتری از کلمات را تولید میکنند و میتوانند روابط معنایی پیچیدهتری را درک کنند.
معرفی تعبیه کلمات GloVe
GloVe که مخفف Global Vectors for Word Representation است، به دلیل استفاده از ماتریس هموقوعی و تابع هزینه منحصر به فرد، توانسته است به دقت بالایی در تعبیه کلمات دست یابد. تعبیه کلمات GloVe با استفاده از رویکردی تعمیمیافتهتر نسبت به سایر روشها، توانسته است نتایج بهتری در کاربردهای مختلف NLP ارائه دهد.
تاریخچه و توسعه
توسعه تعبیه کلمات GloVe از سال ۲۰۱۴ توسط محققان دانشگاه استنفورد آغاز شد و به سرعت در جامعه پژوهشی مورد استقبال قرار گرفت. این روش به دلیل رویکرد نوآورآنهاش در محاسبه بردارهای کلمه، توانست رقبای خود را پشت سر بگذارد. پژوهشگران استنفورد با بهرهگیری از مفاهیم آماری و بهینهسازی، تعبیه کلمات GloVe را به یکی از ابزارهای محبوب در تحلیل متن و پردازش زبان طبیعی تبدیل کردند.
بررسی نحوه کار مدل GloVe
پیش از بررسی نحوه آموزش مدل GloVe لازم است با چند تا از مفاهیم بهکاررفته در ساختار این مدل آشنا شویم:
ماتریس هموقوعی
ماتریس هموقوعی نشاندهنده تعداد دفعات همظهوری کلمات در یک متن بزرگ است. این ماتریس اطلاعات بسیار مفیدی درباره روابط بین کلمات فراهم میکند. به عنوان مثال، اگر دو کلمه در بسیاری از جملات به طور مکرر در کنار یکدیگر ظاهر شوند، ماتریس هموقوعی این همظهوری را ثبت میکند. با استفاده از این ماتریس، تعبیه کلمات GloVe میتواند بردارهای کلمه را محاسبه کند که روابط معنایی دقیقتری را نمایش میدهند.
ماتریس هموقوعی در GloVe به صورت یک ماتریس بزرگ و پراکنده ایجاد میشود که هر سطر و ستون آن نمایانگر یک کلمه در واژگان است. مقدار هر خانه در این ماتریس نشاندهنده تعداد دفعاتی است که کلمهای خاص با کلمهای دیگر (کلمه زمینه) در یک پنجره مشخص از کلمات همظهور شده است. این پنجره معمولاً شامل چند کلمه قبل و بعد از کلمه هدف است.
احتمال هموقوعی
ماتریس هموقوع که در قسمت قبل درباره آن توضیح دادیم، درادامه به یک توزیع احتمال تبدیل میشود. این توزیع نشان میدهد که احتمال وقوع یک کلمه در متن با توجه به وقوع کلمه دیگر چقدر است. به عبارتی، برای هر جفت کلمه i و j، احتمال وقوع Pij بهصورت زیر محاسبه میشود:
P_{ij} = \frac{X_{ij}}{X_i}
که در آن:
- Pij احتمال قرارگیری کلمه j درکنار کلمه i است.
- Xij تعداد دفعاتی است که کلمه j درکنار کلمه i ظاهر شده است.
- Xi تعداد دفعاتی است که هرکلمه دیگری درکنار کلمه i ظاهر شده است.
بررسی یک مثال برای درک احتمال هموقوعی
بیایید با شرح یک مثال ساده نشان دهیم که چگونه میتوان جنبههای خاصی از معنا را مستقیماً از احتمالات هموقوعی استخراج کرد. دو کلمه i و j را در نظر بگیرید که در آن i را به «یخ» و j را به «بخار» نسبت میدهیم. رابطه این کلمات را میتوان با مطالعه نسبت احتمالات هموقوعی آنها با کلمات مختلف (k) بررسی کرد.
برای کلماتی که به یخ مربوط هستند اما به بخار نه، مثلاً برای زمانی که k را به «جامد» نسبت میدهیم، انتظار داریم نسبت Pik به Pjk بزرگ باشد. به همین ترتیب، برای کلماتی که به بخار مربوط هستند اما به یخ نه، مثل «گاز»، این نسبت باید کوچک باشد. برای کلماتی مثل «آب» که هم به یخ مربوط هستند، هم به بخار یا مثل «مد» که به هیچکدام، مربوط نیستند این نسبت باید نزدیک به یک باشد. جدول زیر این احتمالات و نسبتهای آنها را برای یک مجموعه متنی بزرگ نشان میدهد و همانطور که میبینید، اعداد هم مطابق انتظار ما هستند:
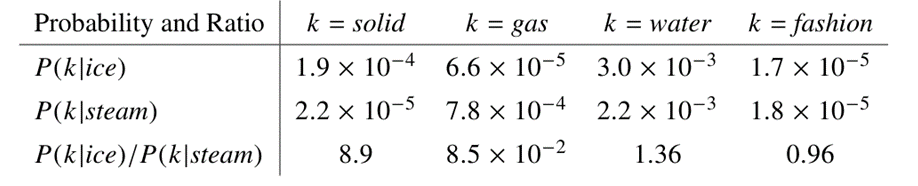
به این ترتیب، در مقایسه با احتمالات خام، نسبت احتمالات بهتر میتوانند کلمات مرتبط (جامد و گاز) را از کلمات نامربوط (آب و مد) تشخیص دهند و همچنین بهتر میتوانند بین دو کلمه مرتبط تمایز قائل شوند.
نسبت احتمالات هموقوع
استدلال فوق نشان میدهد که نقطه شروع مناسب برای یادگیری بردارهای کلمه نسبت احتمالات هموقوع است، نه خود احتمالات. این نسبتها توانایی بهتری در تمایز کلمات مرتبط از کلمات نامرتبط دارند. با توجه به اینکه نسبت Pik به Pjk به سه کلمه i، j و k بستگی دارد، این نسبت بهصورت عمومیتر بهصورت زیر نوشته میشود:
F(w_i, w_j, \widetilde{w}_k) = \frac{P_{ik}}{P_{jk}}
که در آن:
- Wi و Wj بردارهای متناظر با کلمات مربوطهشان هستند. این بردارها نمایانگر کلمات هدف در مجموعه متنی هستند. وقتی مدل در حال بررسی یک کلمه به عنوان هدف است، از این بردارها استفاده میکند.
- W̃k بردار زمینه مربوط به کلمه k است. این بردارها نمایانگر کلمات زمینه هستند. وقتی مدل در حال بررسی کلماتی است که در زمینه کلمه هدف ظاهر میشوند، از این بردارها استفاده میکند.
هدف اصلی داشتن دو مجموعه بردار W و W̃ این است که مدل بتواند تفاوتهای بین نقش کلمه به عنوان هدف و نقش کلمه به عنوان زمینه را به خوبی درک کند. این تفاوتها باعث میشود مدل بتواند روابط معنایی بین کلمات را بهتر نمایش دهد. برای درک بهتر و تطبیقدهی این شیوه نمایش بردارها با مثالی که پیشتر تعریف کردیم، فرض کنید i کلمه «یخ» باشد، در این صورت Wi بردار کلمهای است که نمایانگر «یخ» است. اگر j کلمه «بخار» باشد، باشد، Wj بردار کلمهای است که نمایانگر «بخار» است و اگر k کلمه «جامد» باشد، باشد، W̃k بردار کلمهای است که نمایانگر «جامد» است.
تابع F چیست؟
طرف راست معادله بالا از مجموعه دادگان متنی ما استخراج شدهاست و F ممکن است به برخی پارامترهایی که هنوز مشخص نیستند، وابسته باشد. توابع زیادی را میتوان به F نسبت داد اما با اعمال چند معیار خاص میتوانیم یک انتخاب منحصربهفرد برای F داشته باشیم. درواقع ما میخواهیم F اطلاعات موجود در نسبت احتمالات هموقوع را در فضای بردار کلمه رمزگذاری کند. از آنجایی که فضاهای برداری به طور ذاتی خطی هستند، بهترین روش برای مدلسازی این کار، استفاده از تفاضل بردارها است. دلیل این ادعا این است که اختلاف بردارها در فضای برداری خطی به سادگی میتواند رابطه بین کلمات را نمایش دهد. به عبارت دیگر، اختلاف بین دو بردار کلمه میتواند اطلاعات معنایی و روابط بین آنها را به شکلی ساده و قابل درک در فضای برداری خطی نشان دهد. پس معادله قبلی را به صورت زیر بازنویسی میکنیم:
F(\mathbf{w}_i - \mathbf{w}_j, \tilde{\mathbf{w}}_k) = \frac{P_{ik}}{P_{jk}}
واضح است که در این معادله، آرگومانهای تابع F برداری هستند در حالی که طرف راست معادله یک کمیت اسکالر (عددی) را نشان میدهد. اگرچه میتوان برای حل این مشکل، F را یک تابع پیچیده درنظرگرفت اما این کار باعث میشود ساختار خطی و سادگی مدل که بهدنبال آن هستیم، ازبینبرود.
راه حل بهتری که برای تبدیل سمت چپ معادله به یک کمیت اسکالر میتوان درنظرگرفت این است که بردارهای کلمات را در هم ضرب داخلی (Dot product) کنیم. این کار باعث میشود که هر دو سمت معادله از یک جنس (اسکالر) شوند:
F\left((\mathbf{w}_i - \mathbf{w}_j)^T \tilde{\mathbf{w}}_k\right) = \frac{P_{ik}}{P_{jk}}
این فرمول چه چیزی را نشان میدهد؟
این فرمول نشان میدهد که چگونه میتوان نسبت احتمالات هموقوع را با استفاده از تفاوت بردارهای کلمات هدف (Wi – Wj) و ضرب داخلی آن با بردار کلمه زمینه (W̃k)، مدلسازی کرد. در ماتریسهای هموقوع کلمه-کلمه، تفاوت بین یک کلمه و کلمه زمینه قابل چشمپوشی است و ما آزاد هستیم که نقش کلمات هدف و کلمات زمینه را تعویض کنیم. برای انجام این کار نهتنها W و W̃ بلکه X و XT را نیز باید بتوانیم بهراحتی تعویض کنیم. این یعنی مدل ما باید به تغییر نقشهای کلمات هدف و زمینه مقاوم باشد. برای این منظور، تابع F باید خاصیتی داشته باشد که تقارن بین گروههای مختلف ریاضی را حفظ کند. حفظ تقارن به این معنی است که اگر نقش کلمات (هدف یا زمینهای بودن) را تعویض کنیم، نتایج مدل نباید تغییر کند.
تابع F باید چه خاصیتی داشته باشد؟
تابع F باید همومورفیسم (همریخت) بین گروه اعداد حقیقی با عمل جمع (این گروه نشاندهنده بردارهای کلمه در فضای برداری است که با عمل جمع ترکیب میشوند) و گروه اعداد حقیقی مثبت با عمل ضرب (این گروه نشاندهنده احتمالات هموقوع کلمات است که با عمل ضرب ترکیب میشوند) باشد. با بازنویسی معادله بالا بهصورت زیر میتوانیم به این هدف دست پیدا کنیم:
F\left((\mathbf{w}_i - \mathbf{w}_j)^T \tilde{\mathbf{w}}_k\right) = \frac{F(\mathbf{w}_i^T \tilde{\mathbf{w}}_k)}{F(\mathbf{w}_j^T \tilde{\mathbf{w}}_k)}
این معادله تضمین میکند که مدل در برابر تغییر نقشهای کلمات هدف (W) و زمینه (W̃) مقاوم است و نتایج آن تغییر نمیکند. این ویژگی به مدل اجازه میدهد تا روابط معنایی را به صورت دقیق و پایدار نمایش دهد.
با توجه به خواصی که دارد، تابع نمایی (exponential) یک پاسخ مناسب برای تابع F بهشمار میرود. زیرا هم کار کردن با آن بسیار ساده است و هم دارای خاصیت همومورفیسم بین جمع (در نما) و ضرب (در پایه) است که با نیازهای مدل GloVe برای ترکیب احتمالات هموقوع، سازگار است. این انتخاب بهخاطر حفظ تعادل بین دقت ریاضی و کارایی محاسباتی است.
اثبات درستی انتخاب تابع نمایی بهعنوان پاسخ تابع F
با قراردادن e بهجای تابع F در معادله بالا، به رابطه زیر میرسیم:
e^{(\mathbf{w}_i - \mathbf{w}_j)^T \tilde{\mathbf{w}}_k} = \frac{e^{\mathbf{w}_i^T \tilde{\mathbf{w}}_k}}{e^{\mathbf{w}_j^T \tilde{\mathbf{w}}_k}}
سمت چپِ معادله بالا را میتوان به شکل زیر بازنویسی کرد:
e^{(\mathbf{w}_i - \mathbf{w}_j)^T \tilde{\mathbf{w}}_k} = e^{\mathbf{w}_i^T \tilde{\mathbf{w}}_k - \mathbf{w}_j^T \tilde{\mathbf{w}}_k}
اکنون لازم است یکی از ویژگیهای تابع نمایی (و البته سایر توابع توانی) را از ریاضیات مرور کنیم:
e^{a - b} = \frac{e^b}{e^a}
با استفاده از این ویژگی در معادله قبلی داریم:
e^{\mathbf{w}_i^T \tilde{\mathbf{w}}_k - \mathbf{w}_j^T \tilde{\mathbf{w}}_k} = \frac{e^{\mathbf{w}_i^T \tilde{\mathbf{w}}_k}}{e^{\mathbf{w}_j^T \tilde{\mathbf{w}}_k}}
بهاینترتیب فهمیدیم که از نظر ریاضی نیز تابع نمایی، پاسخ درستی برای F محسوب میشود و در معادله نسبت هموقوعیها صدق میکند.
طراحی تابع هزینه GloVe
تابع هزینه تعبیه کلمات GloVe به گونهای طراحی شده که فاصله بین بردارهای کلماتی که با هم هموقوعی بیشتری دارند، کمتر باشد. این تابع هزینه باعث میشود که بردارهای نهایی کلمات، نمایانگر روابط معنایی دقیقتری باشند. به عبارت دیگر، GloVe سعی میکند تا بردارهای کلماتی که در متون واقعی بیشتر با هم دیده میشوند، به هم نزدیکتر باشند.
استفاده از احتمال هموقوعیها برای ساخت تابع هزینه
باتوجه به رابطه تابع F و نسبت احتمال هموقوعیها، معادله زیر با جایگذاری بدست میآید:
F(\mathbf{w}_i^T \tilde{\mathbf{w}}_k) = P_{ik} = \frac{X_{ik}}{X_{i}}
این معادله نشان میدهد که تابع F که به ضرب داخلی بردار کلمه هدف Wi و بردار کلمه زمینه W̃k اعمال میشود، برابر با احتمال هموقوعی Pik است که برابر با نسبت Xik به Xi است، یعنی تعداد دفعاتی که کلمه k در زمینه کلمه i ظاهر شده به کل تعداد هموقوعیهای کلمه i با سایر کلمات.
دیدیم که F یک تابع نمایی است، پس با لگاریتم گرفتن از طرفین رابطه بالا خواهیم داشت:
\mathbf{w}_i^T \tilde{\mathbf{w}}_k = \log(P_{ik}) = \log(X_{ik}) - \log(X_i)
عبارت (log(Xi مستقل از k است، بنابراین میتواند بهصورت یک بایاس bi برای Wi نمایش داده شود:
\mathbf{w}_i^T \tilde{\mathbf{w}}_k + b_i + \tilde{b}_k = \log(X_{ik})
این معادله بهراحتی میتواند مبنای ساخت تابع هزینه کمترین مربعات خطا (MSE) برای یک مدل رگرسیون باشد. درواقع تابع هزینه ما میتواند بهشکل زیر نوشته شود:
\mathbf{w}_i^T \tilde{\mathbf{w}}_k + b_i + \tilde{b}_k - \log(X_{ik}) = 0
مشکل این تابع این است که به همه هموقوعات بهطور مساوی وزن میدهد، حتی بهآنهایی که بهندرت با هم ظاهر میشوند یا هرگز درکنارهم دیده نمیشوند. این هموقوعات نادر اطلاعات کمتری نسبت به هموقوعات متداول دارند و در نتیجه مدل نمیتواند به خوبی بین هموقوعات مفید و غیرمفید تمایز قائل شود. برای حل این مشکل طراحان مدل GloVe یک مدل جدید رگرسیون کمترین مربعات خطای وزندار با یک تابع وزندهی f(Xik) پیشنهاد کردند. بهاینترتیب تابع هزینه نهایتا بهشکل زیر درمیآید:
J = \sum_{i,k=1}^{V} f(X_{ik}) \left( \mathbf{w}_i^T \tilde{\mathbf{w}}_k + b_i + \tilde{b}_k - \log X_{ik} \right)^2
تابع هزینه GloVe چطور کار میکند؟
در فرمول تابع هزینه Glove که در قسمت قبل به آن رسیدیم، V تعداد واژگان مجموعهداده یا همان اندازه Vocabulary است. تابع هزینه J هدفش کمینه کردن اختلاف بین ضرب داخلی بردارهای کلمه (بههمراه بایاسها) و لگاریتم تعداد هموقوعیها است. این کار با وزندهی هر یک از هموقوعات انجام میشود تا تأثیر هموقوعات نادر و پر تکرار بهطور مناسبی مدیریت شود. برای تنظیم اهمیت هر هموقوع استفاده میشود. تابع f(Xik) کمک میکند تا هموقوعات نادر که اطلاعات کمتری دارند کمتر تأثیرگذار باشند و هموقوعات متداول که اطلاعات بیشتری دارند وزن بیشتری داشته باشند. بهاینترتیب این تابع باید سه ویژگی زیر را دارا باشد:
- f(0)=0: این شرط میگوید که تابع f در نقطه صفر باید صفر باشد. درواقع اگر f به عنوان یک تابع پیوسته در نظر گرفته شود، با نزدیک شدن x به صفر، باید به صفر میل کند که از آنجایی که لگاریتم صفر، بینهایت است، حد lim x→0 f(x)log(x2) محدود باشد و به بینهایت نرود.
- f(x) باید غیر کاهشی باشد: این شرط برای این منظور لحاظ میشود که هموقوعات نادر بهطور نامتناسبی وزندهی نشوند. اگر
f(x)کاهشی باشد، مقادیر کم x (هموقوعات نادر) ممکن است وزن بیشتری بگیرند که باعث عدم تعادل در مدل میشود. - f(x) باید برای مقادیر بزرگ x نسبتاً کوچک باشد: این شرط برای این منظور لحاظ میشود که هموقوعات متداول بهطور نامتناسبی وزندهی نشوند. اگر
f(x)برای مقادیر بزرگ x خیلی بزرگ باشد، هموقوعات متداول وزن بیشتری خواهند گرفت که میتواند تعادل مدل را به هم بزند و به ضرر هموقوعات نادر باشد.
اگرچه توابع صعودی زیادی میتوانند شروط گفتهشده را ارضا کنند اما یکی از توابعی که بهخوبی میتوان برای این مسئله آن را بهکار برد، تابع زیر است:
\large f(x) = \begin{cases} \left( \frac{x}{x_{\text{max}}} \right)^\alpha & \text{if } x \leq x_{max} \\ 1 & \text{otherwise} \end{cases}
وابستگی عملکرد مدل به مقدار Cutoff
عملکرد مدل با این تابع وزندهی به طور ضعیفی به مقدار cutoff یعنی Xmax وابسته است. بههمین دلیل نویسندگان مقاله GloVe این مقدار را برای همه آزمایشها برابر با ۱۰۰ در نظر گرفتند. این بدان معناست که هر هموقوعی که تعداد تکرار آن بیش از ۱۰۰ باشد، به ۱۰۰ محدود میشود. انتخاب مقدار برای Xmax به این دلیل است که از وزندهی نامتناسب هموقوعات بسیار متداول جلوگیری شود. با محدود کردن حداکثر تعداد هموقوعات به ۱۰۰، میتوان از تأثیرگذاری زیاد هموقوعات زیاد بر نتایج مدل جلوگیری کرد.
α دیگر پارامتری است که در تابع وزندهی استفاده میشود. تعیین مقدار کمتر از ۱ برای α به مدل اجازه میدهد که هموقوعیها را به طور غیرخطی وزندهی کند. این مقدار بهبود جزئیای نسبت به مقدار خطی (α=1) ایجاد میکند و نشان میدهد که یک تابع وزندهی غیرخطی میتواند بهینهتر باشد. در مقاله GloVe این پارامتر به ۳/۴ مقداردهی شده است.
شکل این نمودار برای α=3/4 بهصورت زیر است:
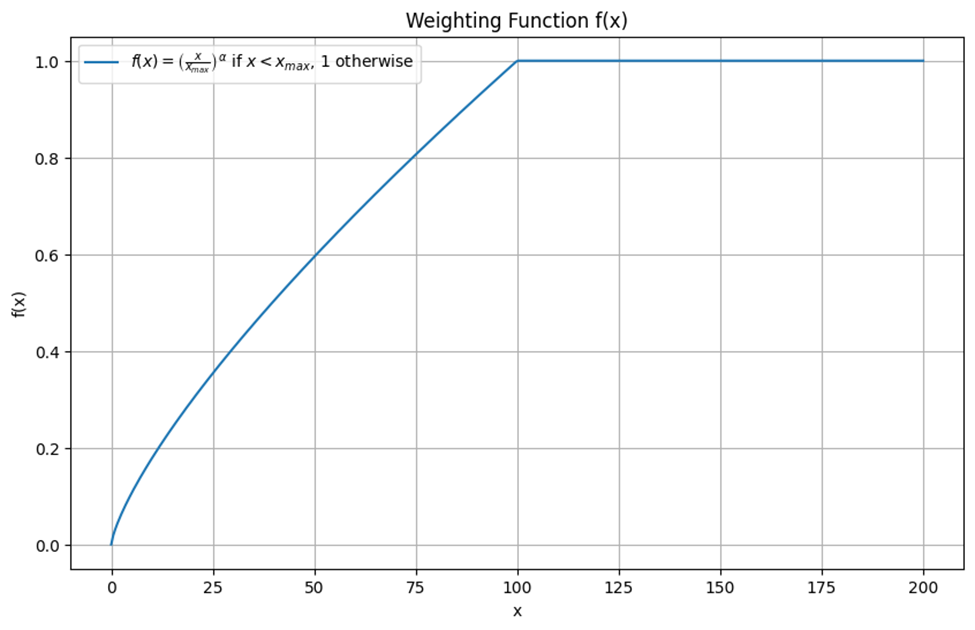
حال که با مفاهیم فوق آشنا شدید، میتوانید بهتر ساختار و نحوه آموزش مدل GloVe برای محاسبه بردارهای کلمات را درک کنید. در ادامه مراحل پیادهسازی GloVe را توضیح میدهیم.
مراحل پیادهسازی GloVe
پیادهسازی GloVe شامل سه مرحله اصلی است: پیشپردازش دادهها، محاسبه ماتریس هموقوعی و بهینهسازی مدل. این مراحل به ترتیب به آمادهسازی دادهها، استخراج اطلاعات هموقوعی و آموزش مدل منجر میشوند:
پیشپردازش دادهها
در این مرحله، متنهای ورودی برای آمادهسازی برای محاسبه ماتریس هموقوعی پردازش میشوند. این بخش شامل پاکسازی متنها از علائم نگارشی، حذف کلمات زائد و استانداردسازی کلمات است. همچنین، ممکن است کلمات به فرمت پایه خود (lemmatization) تبدیل شوند تا دقت مدل افزایش یابد.
ساخت ماتریس هموقوعی
این مرحله شامل شمارش دفعات همظهوری کلمات و ساخت ماتریس هموقوعی است. ماتریس هموقوعی یک ماتریس بزرگ و پراکنده است که هر سطر و ستون آن نمایانگر یک کلمه در واژگان است.
بهینهسازی مدل
در نهایت، مدل با استفاده از روشهایی مثل رگرسیون براساس معادلاتی که در قسمت قبل توضیح دادیم، آموزش داده میشود تا بردارهای نهایی کلمات محاسبه شوند. در این مرحله، با استفاده از تکنیکهای بهینهسازی مانند گرادیان نزولی، مدل GloVe سعی میکند تا بردارهای کلمات و بایاسها را به گونهای بهینه کند که تابع هزینه معرفی شده به حداقل برسد. هدف این است که فاصله بین بردارهای کلماتی که هموقوعی بیشتری دارند، کمتر شود و به این ترتیب، بردارهای نهایی نمایانگر روابط معنایی دقیقتری باشند.
استفاده از تعبیه کلمات GloVe در پایتون
در این قسمت میخواهیم با استفاده از بردارهای ازپیشآموزشدیده GloVe نحوه قرارگیری بردار متناظر با هر کلمه را در نمودار پراکندگی (Scatter Plot) ببینیم و همچنین با استفاده از روشهای بصریسازی، درک نسبی این روش از معنا و مفهوم کلمات را بفهیمیم. در پایان نیز با استفاده از این بردارها، یک پروژه تحلیل احساس روی مجموعهداده نظرات مردم درباره فیلمها در سایت IMDB با دو مدل KNN و شبکه عصبی بازگشتی اجرا میکنیم.
فراخوانی کتابخانههای مورد نیاز
برای این کار ابتدا باید کتابخانههای مورد نیاز را فراخوانی (Import) کنیم:
# general libraries
import re
import os
import zipfile
import numpy as np
import pandas as pd
from tqdm import tqdm
tqdm.pandas()
from scipy import spatial
from google.colab import files
# prevent warning
import warnings
warnings.filterwarnings('ignore')
# visualization libraries
import seaborn as sns
import matplotlib.pyplot as plt
# dimensionality reduction libraries
from sklearn.manifold import TSNE
from sklearn.decomposition import PCA
# ML models and metrics
from sklearn.cluster import KMeans
from sklearn.metrics import accuracy_score
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
# DL models
from tensorflow.keras import layers, optimizers
from tensorflow.keras.models import Sequential, Model
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
# nlp libraries
import nltk
nltk.download('punkt')
nltk.download('omw-1.4')
nltk.download("wordnet")
nltk.download('stopwords')
from nltk.corpus import stopwords
from nltk.corpus import wordnet as wn
from nltk.tokenize import word_tokenize
from nltk.stem import WordNetLemmatizer
دانلود بردارهای ازپیشآموزشدیده GloVe
سپس برای دانلود بردارهای ازپیشآموزشدیده GloVe یا همان تعبیه کلمات آماده این مدل، از کد زیر استفاده میکنیم:
# Download glove Embedding
!wget --no-check-certificate \
http://nlp.stanford.edu/data/glove.6B.zip \
-O /tmp/glove.6B.zip
with zipfile.ZipFile('/tmp/glove.6B.zip', 'r') as zip_ref:
# Extract all contents of the zip file
zip_ref.extractall('/tmp/glove')
f = open('/tmp/glove/glove.6B.100d.txt')
glove_embedding = {}
for line in f:
# Split each line into word and vector
values = line.split()
word = values[0]
# Convert the vector to a numpy array
vec = np.asarray(values[1:], dtype="float32")
glove_embedding[word] = vec
f.close()
دقت کنید که نسخههای متفاوتی از GloVe وجود دارد، برخی از آنها دارای بردارهای ۵۰ بعدی (یعنی هر کلمه را با یک بردار شامل ۵۰ مولفه نمایش میدهد)، برخی ۱۰۰ بعدی، ۲۰۰ بعدی و نهایتا برخی ۳۰۰ بعدی هستند که با کد بالا تمامی نسخههای آن دانلود میشوند اما ما در این آموزش تنها از بردارهای ۱۰۰ بعدی آن استفاده میکنیم.
نزدیکی بردارهای هممعنی در فضای تعبیه کلمات
در ادامه میخواهیم با استفاده از یک تابع، نزدیکترین بردارها را نسبت به یک بردار خاص در فضای تعبیه کلمات بدست آوریم:
# Define a function to find the closest words in the embedding space using Euclidean distance.
def find_closest_embeddings(embedding):
return sorted(glove_embedding.keys(), key=lambda word: spatial.distance.euclidean(glove_embedding[word], embedding))
# Find the closest embeddings for the vector representation of queen - woman + man, which typically results in "king".
find_closest_embeddings(glove_embedding['queen'] - glove_embedding['woman'] + glove_embedding['man'])[:3]
همانطور که در کد بالا پیدا است اگر از بردار کلمه ملکه (Queen) بردار کلمه زن (Woman) را کم کرده و به آن بردار کلمه مرد (Man) را اضافه کنیم، یکی از کلماتی که بردارش به آن نزدیک خواهد بود، کلمه پادشاه (King) است.
در این قسمت دو لیست جدا از بردارهای و کلمات و همچنین یک دیکشنری شامل کلمات و بردارهای متناظر با آن ها میسازیم:
# Create separate lists for the words and their corresponding vectors from the GloVe embeddings.
glove_words = list(glove_embedding.keys())[300:2500]
glove_vectors = list(glove_embedding.values())[300:2500]
# Make a dictionary includes above words as keys and their embedding vector as values
glove_embedding = {glove_words[i]:glove_vectors[i] for i in range(len(glove_words))}
حال با استفاده از روش خوشهبندی K-means بردار کلمات را به ۱۵ خوشه جداگانه تقسیم میکنیم و برچسبهای را برای کاربردهای بعدی در متغیر labels میریزیم:
# A k-means clustering method on word embeddings to cluster them into 15 categories
kmeans = KMeans(n_clusters=15)
kmeans.fit(glove_vectors)
labels = kmeans.labels_
سپس با کمک روش کاهش بعد PCA بردارها را به فضای ۲ یا ۳ بعدی کاهش میدهیم:
# A PCA to reduce glove vectors to 3D
pca = PCA(n_components=3)
vectors_3d = pca.fit_transform(glove_vectors)
# A PCA to reduce glove vectors to 2D
pca = PCA(n_components=2)
vectors_2d = pca.fit_transform(glove_vectors)
سپس با کد زیر میتوانیم این بردارهای کاهش بعد یافته را ترسیم کنیم:
# Extracting specific slices of the 3D vectors and corresponding labels and words for plotting
x = vectors_3d[200:500, 0]
y = vectors_3d[200:500, 1]
z = vectors_3d[200:500, 2]
colors = labels[200:500]
words = glove_words[200:500]
# Create the plot with specified size and resolution
fig = plt.figure(figsize=(18, 18), dpi=150)
ax = fig.add_subplot(111, projection='3d')
# Scatter plot with color coding based on labels
sc = ax.scatter(x, y, z, c=colors, s=50)
# Add text annotations for each point in the scatter plot
for i, word in enumerate(words):
ax.text(x[i], y[i], z[i], word, fontsize=7)
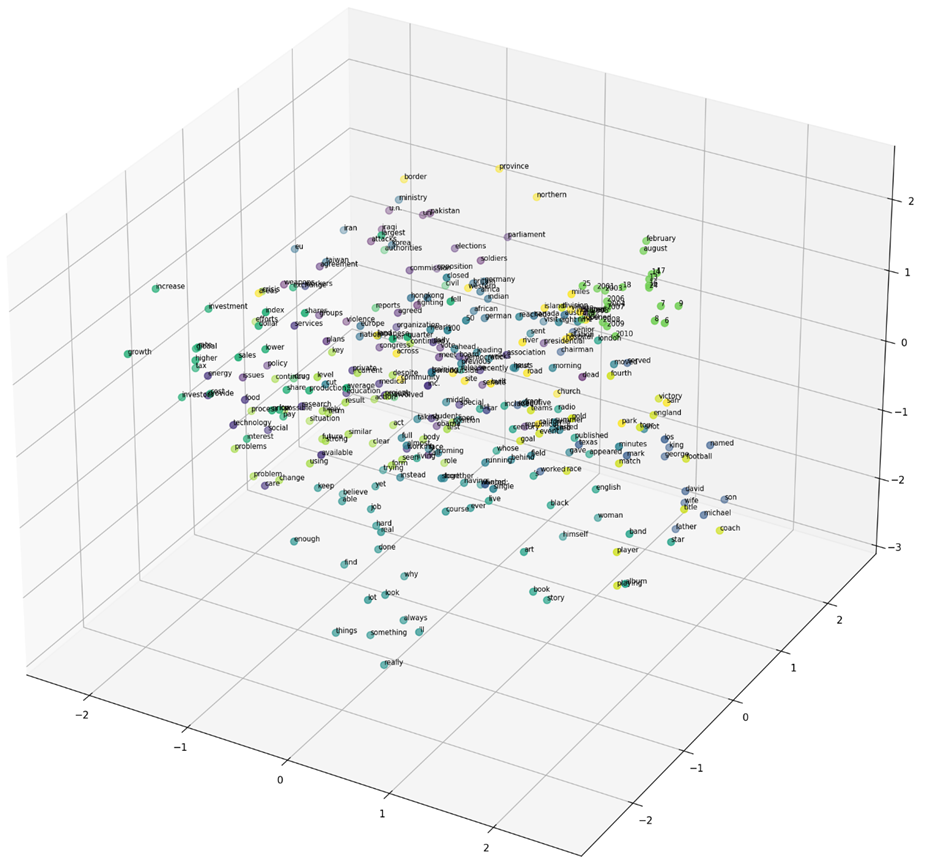
نمایش بردارهای کلمات و انجام عملیات برداری بین آنها
یکی دیگر از کارهایی که میتوان برای نشان دادن درک GloVe از معنای کلمات انجام داد، این است که بردارهای کلمات خاصی را از تعبیههای GloVe استخراج کرده و با استفاده از t-SNE به دو بُعد کاهش و سپس آنها را به صورت تصویری نمایش دهیم. با استفاده کد زیر میتوان این کار را انجام داد:
# Define a list of words to visualize
words = ["man", "king", "woman", "queen"]
# Extract the corresponding vectors for these words from the GloVe embeddings and convert to numpy array
vectors = np.array([glove_embedding[i] for i in words])
# Generate new labels for the selected words
new_labels = [labels[i] for i in range(len(glove_words)) if glove_words[i] in words]
# Perform t-SNE to reduce the dimensionality of the vectors to 2 components
tsne = TSNE(n_components=2, perplexity=2)
vectors_2d = tsne.fit_transform(vectors)
# Create a plot with specified size and resolution
fig = plt.figure(figsize=(10,8), dpi=90)
ax = fig.add_subplot(111)
# Scatter plot of the 2D vectors with color coding based on new labels
ax.scatter(vectors_2d[:, 0], vectors_2d[:, 1], s=50, c=new_labels)
# Add text annotations for each point in the scatter plot
for i, word in enumerate(words):
ax.text(vectors_2d[i, 0], vectors_2d[i, 1], word, fontsize=10)
خروجی بهشکل زیر خواهد بود. فاصلههای بین نقاط در این نمودار نشان میدهد که کلمات چقدر از نظر معنایی به یکدیگر نزدیک هستند. اگر دو نقطه (کلمه) به هم نزدیک باشند، به این معناست که آنها در فضای برداری GloVe نیز به هم نزدیک هستند و دارای معنای مشابهتری میباشند:

برای درک بهتر این روابط میتوانیم از عملیات برداری نیز استفاده کنیم. بهاین منظور ما بردارهای تعبیه شده کلمات انتخاب شده را در فضای دو بعدی با استفاده از PCA رسم میکنیم و عملیات برداری مانند queen - woman + man را بهتصویر میکشیم:
# Define a list of words to visualize
words = ["man", "king", "woman", "queen"]
# Extract the corresponding vectors for these words from the GloVe embeddings and convert to numpy array
vectors = np.array([glove_embedding[i] for i in words])
# Define new labels with specific colors for each word
new_labels = ['#ffc60e', 'black', 'red', 'purple']
# Perform PCA to reduce the dimensionality of the vectors to 2 components
pca = PCA(n_components=2)
vectors_2d = pca.fit_transform(vectors)
# Create a plot with specified size and resolution
fig = plt.figure(figsize=(10, 8), dpi=90)
ax = fig.add_subplot(111)
# Scatter plot of the 2D vectors with color coding based on new labels
ax.scatter(vectors_2d[:, 0], vectors_2d[:, 1], s=100, c=new_labels)
# Add text annotations for each point in the scatter plot
for i, word in enumerate(words):
ax.text(vectors_2d[i, 0], vectors_2d[i, 1], word, fontsize=13)
# Create a dictionary to store the 2D points for each word
points = {word: vectors_2d[i] for i, word in enumerate(words)}
queen_point = points['queen']
woman_point = points['woman']
man_point = points['man']
# Calculate the vector differences and additions
queen_woman = queen_point - woman_point
plus_man = queen_woman + man_point
# Plot the vectors using quiver with dotted lines
ax.quiver(0, 0, queen_point[0], queen_point[1], angles='xy', scale_units='xy', scale=1, color='purple', linestyle='dotted')
ax.quiver(0, 0, woman_point[0], woman_point[1], angles='xy', scale_units='xy', scale=1, color='red', linestyle='dotted')
ax.quiver(0, 0, man_point[0], man_point[1], angles='xy', scale_units='xy', scale=1, color='#ffc60e', linestyle='dotted')
ax.quiver(0, 0, queen_woman[0], queen_woman[1], angles='xy', scale_units='xy', scale=1, color='blue', linestyle='dotted')
ax.quiver(0, 0, plus_man[0], plus_man[1], angles='xy', scale_units='xy', scale=1, color='green', linestyle='dotted')
# Scatter and annotate the calculated points
ax.scatter(plus_man[0], plus_man[1], s=100, c='green')
ax.text(plus_man[0], plus_man[1], 'queen - woman + man', fontsize=13)
ax.scatter(queen_woman[0], queen_woman[1], s=100, c='blue')
ax.text(queen_woman[0], queen_woman[1], 'queen-woman', fontsize=13)
# Set the limits for the plot axes
ax.set_xlim(min(vectors_2d[:, 0]) - 3, max(vectors_2d[:, 0]) + 1)
ax.set_ylim(min(vectors_2d[:, 1]) - 3, max(vectors_2d[:, 1]) + 1)
نمودار خروجی این کد نکات مهمی دربردارد که در ادامه آنها را بررسی میکنیم:
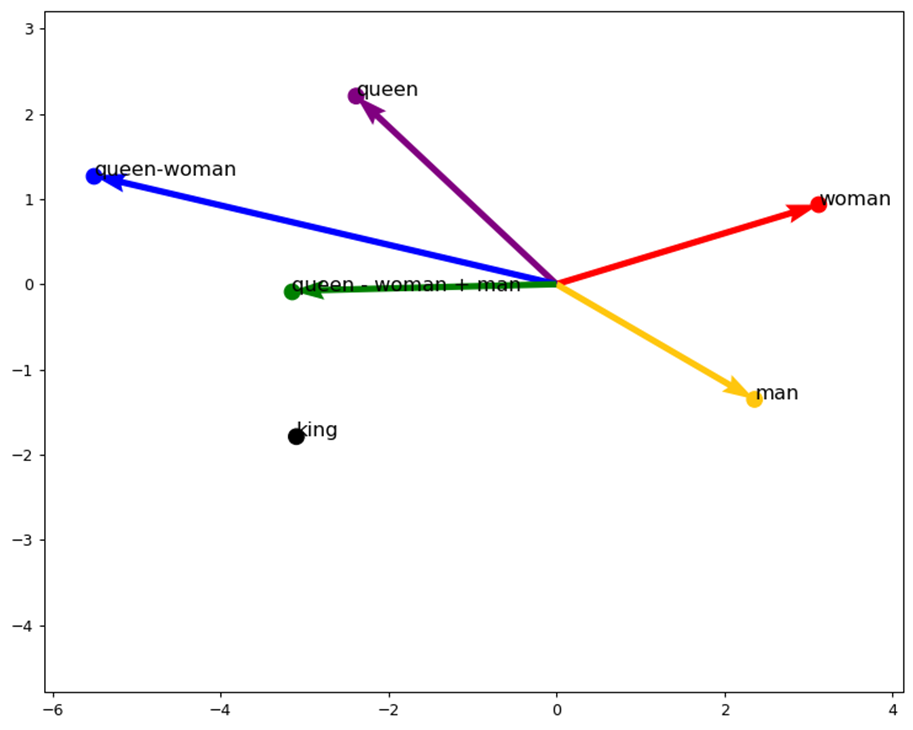
روابط بین بردارهای تعبیه کلمات
نمودار پراکندگی (Scatter plot) دو بعدی موقعیت کلمات انتخاب شده (man, king, woman, queen) را در فضای کاهش یافته نشان میدهد. این کاهش بیشترین واریانس ممکن را حفظ میکند و به ما اجازه میدهد که ببینیم چگونه این بردارهای کلمه با یکدیگر مرتبط هستند.
عملیات برداری
بردارهای مربوط به کلمات به عنوان نقاطی در فضای دو بعدی نمایش داده میشوند. با انجام عملیات حساب برداری (queen – woman + man)، نتیجه این عملیات را در زمینه تعبیهها تجسم میکنیم.
در نمودار، خطوط بردارها و عملیات آنها را نشان میدهند:
queen – womanبا خط آبی نشان داده شده است.queen - woman + manبا خط سبز نشان داده شده است.
این عملیات نشان میدهد که چگونه تعبیه کلمات میتواند روابط معنایی را ثبت کند. به عنوان مثال، نتیجه queen - woman + man نزدیک به king است که نشان میدهد مدل روابط معنایی را یاد گرفته است.
رنگبندی
هر کلمه با رنگ خاصی کدگذاری شده است تا از نظر بصری متفاوت باشد. به عنوان مثال، queen به رنگ بنفش (ترکیب رنگهای قرمز و آبی)، woman به رنگ قرمز، man به رنگ زرد و نتیجه عملیات برداری به رنگ سبز (ترکیب رنگهای آبی و زرد) است. که با عملیات برداری ما نیز تطبیق دارد. یعنی اگر از رنگ بنفش (کلمه ملکه) رنگ قرمز (کلمه زن) را کم کنیم و به حاصل که آبی است، رنگ زرد را اضافه کنیم نتیجه سبز خواهد بود.
تحلیل احساس با استفاده از برداهای تعبیه کلمه GloVe
یکی از پروژههای مرسوم حوزه NLP تشخیص احساس کابران در زمینههای مختلف است. برای مثال ما در این قسمت با استفاده از مجموعهداده نظرات کاربران در سایت IMDB با دو مدل KNN و شبکه عصبی بازگشتی تشخیص میدهیم که یک کاربر نظرش نسبت به فیلم مورد نظر مثبت بوده یا منفی.
دانلود و فراخوانی مجموعهداده نظرات
برای انجام این کار ابتدا با کد زیر و API حساب کاربری Kaggle خود، مجموعهداده نظرات را از این سایت دانلود میکنیم:
# request to kaggle
! pip install -q kaggle
files.upload()
! mkdir ~/.kaggle
! cp kaggle.json ~/.kaggle/
! chmod 600 ~/.kaggle/kaggle.json
# download dataset
! kaggle datasets download -d lakshmi25npathi/imdb-dataset-of-50k-movie-reviews
حال دادهها را unzip میکنیم:
# unzipping downloaded dataset
! unzip /content/imdb-dataset-of-50k-movie-reviews.zip
سپس باید با استفاده از کتابخانه pandas این دادهها را بخوانیم:
# Load the IMDB dataset from a CSV file
imdb = pd.read_csv('IMDB Dataset.csv')
# Convert the sentiment column to binary values: 1 for positive, 0 for negative
imdb['sentiment'] = [1 if i == 'positive' else 0 for i in imdb['sentiment']]
پیش پردازش
برای انجام مرحله پیشپردازش، حروف غیر انگلیسی را که تاثیر چندانی در القای حس بیننده ندارد، حذف و کلمات متداول (همان stop words) را پاک میکنیم. همچنین با استفاده از ریشهیابی Lemmatization کلمات مشتق را به ریشهشان بازمیگردانیم:
# Load the list of stopwords
stop_lst = stopwords.words('english')
# Function to normalize the sentence
def normalize(sentence):
sentence = re.sub('^http', ' ', sentence)
sentence = re.sub('[^a-zA-Z]', ' ', sentence)
sentence = str(sentence).lower()
return sentence
# Function to tokenize the sentence
def tokenize(sentence):
sentence = word_tokenize(sentence)
sentence = [token for token in sentence if len(token) > 2]
return sentence
# Function to remove stop words from the sentence
def stop_words(sentence):
sentence = [token for token in sentence if token not in stop_lst]
return sentence
# Function to lemmatize the tokens in the sentence
def lemmatize(sentence):
sentence = [WordNetLemmatizer().lemmatize(token) for token in sentence]
return sentence
برای آشنایی بیشتر با پروژههای پردازش زبان طبیعی و فهم بهتر این مراحل، پیشنهاد میکنیم مقاله پردازش زبان طبیعی با پایتون چگونه انجام میشود و چه مراحلی دارد؟ را مطالعه کنید.
حال توابع مربوط به پیشپردازش را روی دادهها اعمال میکنیم:
# Apply the normalization function to the 'review' column
imdb['review'] = imdb['review'].progress_apply(normalize)
# Apply the tokenization function to the 'review' column
imdb['review'] = imdb['review'].progress_apply(tokenize)
# Apply the stop words removal function to the 'review' column
imdb['review'] = imdb['review'].progress_apply(stop_words)
# Apply the lemmatization function to the 'review' column
imdb['review'] = imdb['review'].progress_apply(lemmatize)
ساخت ماتریس تعبیه کلمات GloVe
اگرچه یک بار پیش از این دیکشنری تعبیه کلمات GloVe را ساختیم اما چون تنها ۲۲۰۰ تا از کلمات آن را در آن ذخیره کردیم، لازم است برای انجام پروژه تحلیل احساس حتما تمامی کلمات را داشته باشیم:
# Extract the GloVe embeddings from the zip file
with zipfile.ZipFile('/tmp/glove.6B.zip', 'r') as zip_ref:
zip_ref.extractall('/tmp/glove')
# Open the extracted GloVe file
with open('/tmp/glove/glove.6B.100d.txt', 'r') as f:
glove_embedding = {}
# Read each line in the file and parse the word and its vector
for line in f:
values = line.split()
word = values[0]
vec = np.asarray(values[1:], dtype="float32")
glove_embedding[word] = vec
تقسیم مجموعهداده
حال باید دادهها را به مجموعههای آموزشی و آزمایشی تقسیم کنیم، سپس کلمات یکتای موجود در نظرات را استخراج و ذخیره نماییم. در نهایت، بیشینه طول هر نظر از نظر تعداد کلمات بهکاررفته در آن و اندازه واژگان را تعیین کنیم:
# Split the dataset into training and test sets
X_train, X_test, y_train, y_test = train_test_split(imdb['review'], imdb['sentiment'], random_state=12)
# Initialize an empty set to store unique words
unique_words = set()
# Tokenize the sentence and add each word to the set of unique words
for sent in X_train:
unique_words.add(word for word in sent)
# Define the maximum length of sequences
maxlen = 100
# Determine the vocabulary size based on the number of unique words
vocab_size = len(unique_words)
ایجاد Tokenizer
در قسمت بعد یک Tokenizer با اندازه واژگان مشخص مقداردهی اولیه و سپس بر روی دادههای متنی آموزش داده میشود تا بهکمک آن جملات را به توکنها تبدیل کنیم. درادامه، دادههای متنی آموزش و آزمون به توالیهایی از اعداد صحیح تبدیل شده و این توالیها پد میشوند تا طول یکسانی داشته باشند:
# Initialize and fit the tokenizer
tokenizer = Tokenizer(num_words=vocab_size)
tokenizer.fit_on_texts(X_train)
# Convert text data to sequences
X_train_sequences = tokenizer.texts_to_sequences(X_train)
X_train_padded = pad_sequences(X_train_sequences, maxlen=maxlen, padding='post')
X_test_sequences = tokenizer.texts_to_sequences(X_test)
X_test_padded = pad_sequences(X_test_sequences, maxlen=maxlen, padding='post')
دقت کنید که شی Tokenizer که با استفاده از tokenizer.fit_on_texts(X_train) بر روی دادههای متنی آموزش داده شده است، یک واژهنامه ایجاد میکند که هر کلمهی منحصربهفرد را به یک عدد منحصربهفرد نگاشت میکند. وقتی tokenizer.texts_to_sequences(X_train) فراخوانی میشود، هر کلمه در هر جمله از مجموعه نظرات X_train با شاخص عددی خود از واژهنامهی Tokenizer جایگزین میشود. این منجر به ایجاد یک لیست از توالیها میشود که هر توالی یک لیست از اعداد است که کلمات را در سند متناظر خود نشان میدهد.
تبدیل جملات به لیستی از بردارهای تعبیه کلمات
در ادامه از بردارهای آماده GloVe برای ایجاد یک ماتریس تعبیه برای کلمات بهکاررفته در نظرات مخاطبان استفاده میکنیم که تعداد سطرهای آن برابر با تعداد کلمات منحصربهفرد و تعداد ستونهای آن برابر با بیشینه طول کلمات یک جمله در مجموعه نظرات است. هر کلمه در مجموعه واژگان به یک بردار تعبیه نگاشت میشود که میتواند به عنوان ورودی برای یک مدل یادگیری عمیق مانند شبکههای عصبی مورد استفاده قرار گیرد:
# Define word index and embedding dimension
word_index = tokenizer.word_index
embedding_dim = 100
# Create an embedding matrix for the words in the IMDb dataset
embedding_matrix = np.zeros((vocab_size, embedding_dim))
for word, i in word_index.items():
if i < vocab_size:
embedding_vector = glove_embedding.get(word)
if embedding_vector is not None:
embedding_matrix[i] = embedding_vector
توجه کنید که word_index یک دیکشنری است که هر کلمه را به یک عدد منحصربهفرد در مجموعه نظرات نگاشت میکند.
در ادامه تابعی به نام get_average_embedding تعریف میکنیم که میانگین بردارهای تعبیهشده برای کلمات هر جمله (که اکنون به توالیای از اعداد تبدیل شده است) در مجموعه داده را محاسبه میکند. خروجی این قسمت فقط برای مدل KNN استفاده میشود:
# Define a function to get the average embedding for sequences
def get_average_embedding(sequences, embedding_matrix):
embeddings = []
for seq in sequences:
# Filter out words not in the embedding matrix and zero padding
embedded_seq = [embedding_matrix[word] for word in seq if word < embedding_matrix.shape[0] and word != 0]
if embedded_seq:
# Calculate the average embedding for the sequence
avg_embedding = np.mean(embedded_seq, axis=0)
else:
# If no valid words, use a zero vector of the same dimension as embeddings
avg_embedding = np.zeros(embedding_matrix.shape[1])
embeddings.append(avg_embedding)
return np.array(embeddings)
# Assuming X_train_padded and X_test_padded are the tokenized and padded versions of X_train and X_test
X_train_embed = get_average_embedding(X_train_padded, embedding_matrix)
X_test_embed = get_average_embedding(X_test_padded, embedding_matrix)
بهاینترتیب هر جمله به لیست واحدی از بردارهای متناظر با کلماتش تبدیل میشود. حال میتوان از این تعبیه کلمات بهعنوان ورودی یک مدل ماشین لرنینگ استفاده کرد.
آموزش مدل و بررسی دقت آن
KNN مدل موردنظر ما در این پروژه است تا بتواند براساس نظرات هر کاربر، احساس مثبت یا منفی بودن احساسش را نسبت به فیلم تعیین کند:
# Initialize the K-Nearest Neighbors classifier with 10 neighbors
knn = KNeighborsClassifier(n_neighbors=10)
# Fit the classifier on the training data
knn.fit(X_train_embed, y_train)
# Predict the labels for the test data
y_pred = knn.predict(X_test_embed)
# Calculate and print the accuracy of the model
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy}')
Accuracy: 0.73064
همانطور که میبینید دقت مدل مذکور برای تشخیص کلاس مثبت یا منفی ۷۳ درصد شده که نسبتا قابل قبول است. اما اگر دقت بهتری میخواهیم باید از مدلهای شبکه عصبی بازگشتی استفاده کنیم:
با کمک کد بالا یک مدل شبکه عصبی Sequential را تعریف میکنیم که شامل لایههای مختلفی از جمله لایه تعبیهسازی، LSTM دو جهته، لایههای چگال (Dense)، لایه Dropout و لایه خروجی با تابع فعالسازی سیگموئید است.
سپس مدل را با استفاده از دادههای آموزشی آموزش داده و از دادههای آزمایشی برای اعتبارسنجی و بررسی میزان دقت آن استفاده میکنیم:
# Define the Sequential model
model = Sequential()
# Add an embedding layer using the pre-trained embedding matrix
model.add(layers.Embedding(input_dim=embedding_matrix.shape[0],
output_dim=embedding_matrix.shape[1],
input_length=100,
weights=[embedding_matrix],
trainable=False))
# Add a bidirectional LSTM layer with 128 units
model.add(layers.Bidirectional(layers.LSTM(128, recurrent_dropout=0.1)))
model.add(layers.Dense(128))
model.add(layers.Reshape((1, 128)))
# Add a bidirectional LSTM layer with 256 units
model.add(layers.Bidirectional(layers.LSTM(256, recurrent_dropout=0.1)))
model.add(layers.Dense(64))
model.add(layers.Dropout(0.25))
model.add(layers.Dense(128))
model.add(layers.Dropout(0.3))
model.add(layers.Dense(256))
model.add(layers.Dense(1, activation='sigmoid'))

همانطور که میبینید دقت این مدل روی داده آزمایشی خیلی بهتر از دقت KNN است. البته این دقت تنها با ۵ ایپوک بدست آمده و طبیعتا با افزایش آن، مدل میتواند بهتر یاد بگیرد و به دقت بالاتری برسد.
مجموعه کامل کدهای استفاده شده در این مطلب، از گیتهاب ریپوزیتوری GloVe Embedding قابل دسترسی است.
مزایای استفاده از تعبیه کلمات GloVe
استفاده از تعبیه کلمات GloVe مزایای متعددی دارد که شامل دقت بالا، کارایی بیشتر نسبت به روشهای دیگر و توانایی درک روابط معنایی پیچیده میشود. این مزایا GloVe را به یکی از محبوبترین روشهای تعبیه کلمات در NLP تبدیل کردهاند.
دقت بالا در مدلهای زبانی
یکی از مهمترین مزایای Glove، دقت بالای آن در مدلهای زبانی است. با استفاده از ماتریس هموقوعی کلمات و تابع هزینه خاص خود، Glove میتواند روابط معنایی پیچیدهای بین کلمات را به خوبی بازنمایی کند. این ویژگی باعث میشود که مدلهای زبانی مبتنی بر Glove در بسیاری از وظایف پردازش زبان طبیعی مانند ترجمه ماشینی و تحلیل احساسات عملکرد بهتری داشته باشند.
توانایی درک روابط معنایی و قابلیت تفکیک معنایی بهتر
یکی از ویژگیهای برجسته GloVe، توانایی آن در درک روابط معنایی بین کلمات است که باعث میشود نتایج بهتری در کاربردهای مختلف NLP ارائه دهد. همچنین تعبیه کلمات Glove توانایی بالایی در تفکیک معنایی کلمات دارد. این ویژگی به دلیل استفاده از اطلاعات همرخدادی کلمات در کل مجموعه متنی است. با استفاده از این اطلاعات، Glove میتواند بردارهایی تولید کند که به طور دقیق معانی مختلف کلمات را بازنمایی کنند و در نتیجه تفکیک معنایی بهتری ارائه دهند.
محدودیتها و چالشهای تعبیه کلمات GloVe
با وجود مزایای زیاد، تعبیه کلمات GloVe نیز محدودیتها و چالشهایی دارد که شامل نیاز به حافظه بالا و پیچیدگی محاسباتی میشود. این چالشها ممکن است در کاربردهای عملی مشکلاتی ایجاد کنند.
نیاز به حافظه و حجم بالای داده
یکی از محدودیتهایGlove ، نیاز به حجم بالای داده برای ساخت ماتریس هموقوعی است. این ماتریس باید اطلاعات کاملی از همرخدادی کلمات در کل مجموعه متنی داشته باشد تا بتواند بردارهای دقیقی تولید کند. به همین دلیل، پیادهسازی Glove نیاز به حافظه بالایی دارد و ممکن است برای مجموعههای داده کوچک مناسب نباشد.
پیچیدگی محاسباتی
پیادهسازی و آموزش مدل GloVe نیاز به محاسبات پیچیدهای دارد که ممکن است زمانبر و هزینهبر باشد. این پیچیدگی محاسباتی میتواند برای پروژههایی با محدودیت زمانی و منابع مالی، مشکلساز باشد.
عدم پشتیبانی از کلمات جدید
تعبیه کلمات Glove نمیتواند به خوبی با کلمات جدیدی که در داده آموزشی وجود ندارند، کار کند. این محدودیت به دلیل استفاده از ماتریس هموقوعی کلمات است که فقط شامل کلمات موجود در داده آموزشی است. در نتیجه، در مواجهه با کلمات جدید، Glove نمیتواند بردارهای دقیقی تولید کند و عملکرد آن کاهش مییابد.
کاربردهای عملی GloVe
تعبیه کلمات GloVe در کاربردهای مختلفی از جمله تحلیل متن، سیستمهای توصیهگر و بهبود نتایج جستجوی اطلاعات مورد استفاده قرار میگیرد. این کاربردها نشاندهنده گستردگی و تنوع استفاده از GloVe در حوزههای مختلف هستند.
تحلیل متن و پردازش زبان طبیعی
یکی از کاربردهای اصلی GloVe، تحلیل متن و پردازش زبان طبیعی است که با استفاده از بردارهای دقیق کلمات، نتایج بهتری ارائه میدهد. این کاربرد در زمینههای مختلفی از جمله تحلیل احساسات، ترجمه ماشینی، طبقهبندی و خلاصهسازی متن مورد استفاده قرار میگیرد.
تحلیل احساسات
یکی از کاربردهای مهمGlove ، تحلیل احساسات در متون است. با استفاده از بردارهای کلمهای تولید شده توسط Glove، میتوان مدلهایی ساخت که بتوانند احساسات مختلف در متون را به خوبی تشخیص دهند و تحلیل کنند. این کاربرد در زمینههایی مانند تحلیل نظرات کاربران و بررسی احساسات مشتریان بسیار مفید است.
ترجمه ماشینی
Glove در ترجمه ماشینی نیز کاربرد دارد. با استفاده از بردارهای کلمهای Glove، میتوان مدلهای ترجمه ماشینی ساخت که دقت بالاتری در ترجمه متنها داشته باشند. این مدلها میتوانند روابط معنایی بین کلمات در زبآنهای مختلف را به خوبی بازنمایی کنند و ترجمههای دقیقتری ارائه دهند.
خلاصهسازی متن
Glove در خلاصهسازی متن نیز کاربرد دارد. با استفاده از بردارهای کلمهای Glove، میتوان مدلهای خلاصهسازی ساخت که دقت بالاتری در استخراج اطلاعات کلیدی از متون داشته باشند. این مدلها میتوانند با تحلیل روابط معنایی بین کلمات، جملات مهم را شناسایی کرده و نسخههای خلاصه و مفیدتری از متن اصلی ارائه دهند.
طبقهبندی متن
Glove میتواند در طبقهبندی متن نیز استفاده شود تا دقت و کارایی مدلهای طبقهبندی را افزایش دهد. این مدلها با استفاده از بردارهای کلمهای تولید شده توسط Glove، میتوانند روابط معنایی بین کلمات را بهتر درک کرده و متون را با دقت بیشتری در دستهبندیهای مختلف قرار دهند. این قابلیت در کاربردهایی مانند فیلتر کردن ایمیلهای اسپم، تشخیص نظرات مثبت و منفی، و تحلیل محتوا بسیار مفید است.
سیستمهای توصیهگر
GloVe میتواند در سیستمهای توصیهگر نیز استفاده شود تا پیشنهادات دقیقتری به کاربران ارائه دهد. این سیستمها با استفاده از بردارهای کلمهای که GloVe تولید میکند، میتوانند علاقهمندیهای کاربران را بهتر درک کرده و پیشنهادات شخصیسازیشدهتری ارائه دهند.
بهبود نتایج جستجوی اطلاعات
با استفاده از GloVe، نتایج جستجوی اطلاعات میتواند بهبود یابد زیرا این روش قادر به درک روابط معنایی بین کلمات است. این ویژگی باعث میشود که موتورهای جستجو نتایج مرتبطتری ارائه دهند و کاربران بتوانند به اطلاعات مورد نظر خود سریعتر دست یابند.
تفاوت تعبیه کلمات در مدلهای Word2Vec و GloVe
برخلاف مدل Word2Vec، مدل GloVe یک مدل شبکه عصبی نیست. در واقع Word2Vec از یک شبکه عصبی ساده برای یادگیری تعبیههای کلمه با پیشبینی کلمات زمینه (Context words) استفاده میکند اما GloVe یک ماتریس بزرگ هموقوعی کلمات را ایجاد کرده و سپس از تکنیکهای رگرسیون برای یادگیری تعبیههای کلمه استفاده میکند.
برای آشنایی با مدل Word2Vec این مقاله را بخوانید: تعبیه کلمات Word2Vec: روشی برای تبدیل معنادار کلمات به بردار
با وجود این تفاوتها، در هر دو مدل Word2Vec و GloVe، ما تعبیههای کلماتی را طراحی میکنیم که نشاندهنده احتمال دیدهشدن زوج کلمات بایکدیگر هستند. Word2Vec بر اساس حضور کلمات همسایه در یک پنجره متحرک عمل میکند. در روش Skipgram، ما مشاهده میکنیم که چه کلماتی در همسایگی یک کلمه معین در مجموعه ظاهر میشوند و درCBOW کلمه مرکزی را بر اساس همسایگانش پیدا میکنیم. نکته قابل توجه در Word2Vec این است که کلمات همسایه را چندین بار میبینیم زیرا برای هر کلمه مرکزی جدید، باید کلمات همسایه را مجدداً بررسی کنیم. این امر میتواند منجر به افزایش زمان و محاسبات مورد نیاز شود.
با هدف کاهش این بازبینیها، آموزش تعبیه کلمات GloVe با تشکیل یک ماتریس هموقوعی X شروع میشود که ورودی ijام آن تعداد دفعاتی است که کلمات در ردیف i و ستون j با هم ظاهر شدهاند. به طور خلاصه، در حالی که Word2Vec به دفعات کلمات همسایه را در یک پنجره متحرک پردازش میکند، GloVe از یک ماتریس هموقوعی که یک بار در کل مجموعه محاسبه میشود، استفاده میکند تا با استفاده از آن، حین آموزش بردارهای کلمه را بسازد.
مقایسه مدلهای تعبیه کلمات Word2Vec و GloVe
| مدل | Word2vec | GloVe |
| نام کامل | Word to Vector | Global Vectors for Word Representation |
| روش یادگیری | یادگیری عمیق | یادگیری ماشین |
| مبتنی بر | شبکههای عصبی Cbow و Skip-gram | ماتریس هموقوعی و گرادیان نزولی |
| پیچیدگی محاسباتی | کمتر | بیشتر |
| تفسیرپذیری | کمتر | بیشتر |
| دقت | به دادههای خاص حساستر | به دادههای گستردهتر حساستر |
| کاربردهای اصلی | پردازش زبان طبیعی، تحلیل احساسات | تحلیل معنایی، بازیابی اطلاعات |
جمعبندی
مدل GloVe (نمایههای جهانی برای نمایش کلمات) به عنوان یکی از روشهای قدرتمند و کارآمد در تعبیه کلمات در زمینه پردازش زبان طبیعی (NLP) شناخته میشود. این مدل توسط محققان دانشگاه استنفورد توسعه یافته است و به دلیل استفاده از ماتریس هموقوعی کلمات و تابع هزینه منحصر به فرد، توانسته است به دقت بالایی در تعبیه کلمات دست یابد.
GloVe با بهرهگیری از رویکرد آماری و تحلیل هموقوعی کلمات در متون بزرگ، قادر است بردارهای عددی دقیقی برای کلمات تولید کند که نشاندهنده روابط معنایی پیچیده بین کلمات هستند. این ویژگی باعث شده است که GloVe در بسیاری از کاربردهای NLP مانند تحلیل احساسات، ترجمه ماشینی، خلاصهسازی متن، و سیستمهای توصیهگر عملکرد بسیار خوبی داشته باشد.
با این حال، مدل GloVe نیز دارای چالشها و محدودیتهایی است. نیاز به حافظه بالا و پیچیدگی محاسباتی از جمله مشکلات این روش هستند که ممکن است در برخی کاربردهای عملی محدودیتهایی ایجاد کنند. همچنین، GloVe نمیتواند به خوبی با کلمات جدیدی که در داده آموزشی وجود ندارند، کار کند که این نیز یکی از محدودیتهای اصلی آن محسوب میشود.

سوالات متداول
GloVe چیست؟
تعبیه کلمات GloVe یک الگوریتم تعبیه کلمات است که کلمات را به بردارهای عددی تبدیل میکند و برای تحلیل متن و پردازش زبان طبیعی استفاده میشود. این روش به دلیل استفاده از ماتریس هموقوعی و تابع هزینه منحصر به فرد، توانسته است به دقت بالایی دست یابد.
GloVe چه مزایایی دارد؟
تعبیه کلمات GloVe دقت بالا، توانایی درک روابط معنایی و کارایی بهتر نسبت به روشهای دیگر را دارد. این مزایا GloVe را به یکی از محبوبترین روشهای تعبیه کلمات در NLP تبدیل کردهاند.
محدودیتهای GloVe چیست؟
نیاز به حافظه بالا و پیچیدگی محاسباتی از محدودیتهای تعبیه کلمات GloVe هستند. این محدودیتها ممکن است در کاربردهای عملی مشکلاتی ایجاد کنند.
کاربردهای عملی GloVe چیست؟
تعبیه کلمات GloVe در تحلیل متن، سیستمهای توصیهگر و بهبود نتایج جستجوی اطلاعات مورد استفاده قرار میگیرد. این کاربردها نشاندهنده گستردگی و تنوع استفاده از GloVe در حوزههای مختلف هستند.
یادگیری ماشین لرنینگ را از امروز شروع کنید!
دنیای دادهها جذاب است و دانستن علم داده، توانایی تحلیل داده، یا بازاریابی مبتنی بر داده، شما را برای فرصتهای شغلی بسیاری مناسب میکند. فارغ از رشته و پیشزمینه، میتوانید حالا شروع کنید و از سطح مقدماتی تا پیشرفته بیاموزید. اگر دوست دارید به این حوزه وارد شوید، پیشنهاد میکنیم با کلیک روی این لینک قدم اول را همین حالا بردارید.
مشاوران کافهتدریس به شما کمک میکنند مسیر یادگیری برای ورود به این حوزه را شروع کنید: