
پیشبینی ریزش مشتری برای کسبوکارها که به دنبال حفظ پایگاه مشتریان و افزایش سودآوری هستند، حیاتی است. این مقاله به جنبههای مختلف پیشبینی ریزش پرداخته و اهمیت و کاربردهای آن را در صنایع مختلف از جمله مخابرات، بانکداری، خردهفروشی و خدمات اشتراکی بررسی میکند. با تحلیل یک مجموعه داده از یک شرکت مخابراتی، مراحل پردازش داده، تحلیل اکتشافی دادهها و آموزش مدل با استفاده از الگوریتمهای پیشرفته ماشین لرنینگ مانند XGBoost را نشان میدهیم. یافتههای ما ارائهدهنده بینشهای عملی و توصیههایی برای بهبود استراتژیهای حفظ مشتری است. تکنیکهای کلیدی مطرح شده شامل مهندسی ویژگی، مدیریت دادههای نامتوازن و تنظیم هایپرپارامترها است. این رویکرد جامع به کسبوکارها کمک میکند به صورت پیشگیرانه با ریزش مشتریان مقابله کرده و وفاداری مشتریان را تقویت کنند.
- 1. تعریف و اهمیت پیشبینی ریزش مشتری
- 2. کاربردهای پیشبینی ریزش مشتری در صنایع مختلف
- 3. مطالعه موردی: پیشبینی ریزش مشتری در صنعت مخابرات
- 4. تحلیل مجموعه داده
- 5. تحلیل داده اکتشافی (EDA)
- 6. پیشپردازش دادهها
- 7. آموزش و ارزیابی مدل
- 8. توصیههایی برای بهبود مدل ارائهشده پیشبینی ریزش مشتری
- 9. در نظر گرفتن سریهای زمانی در پیشبینی ریزش مشتری
- 10. جمعبندی
-
11.
پرسشهای متداول
- 11.1. تکنیکهای موثر برای پردازش و تمیز کردن دادهها در پیشبینی ریزش مشتری کدامند؟
- 11.2. چگونه الگوریتمهای جایگزین مانند CatBoost و LightGBM میتوانند در پیشبینی ریزش مشتری موثر باشند؟
- 11.3. نقش تحلیل دادههای اکتشافی (EDA) در بهبود دقت مدلهای پیشبینی ریزش مشتری چیست؟
- 11.4. چگونه میتوان با استفاده از روشهای ترکیبی (Ensemble Methods) دقت مدلهای پیشبینی ریزش مشتری را افزایش داد؟
- 11.5. مزایا و چالشهای استفاده از معماریهای RNN در پیشبینی ریزش مشتری چیست؟
- 12. یادگیری ماشین لرنینگ را از امروز شروع کنید!
تعریف و اهمیت پیشبینی ریزش مشتری
پیشبینی ریزش مشتری به فرآیند شناسایی مشتریانی اشاره دارد که احتمال دارد در یک بازه زمانی مشخص خدمات یا محصولی را ترک کنند. این امر برای کسبوکارها بسیار حیاتی است زیرا حفظ مشتریان فعلی اغلب بهمراتب مقرونبهصرفهتر از جذب مشتریان جدید است. توانایی پیشبینی ریزش مشتری به شرکتها این امکان را میدهد که اقدامات پیشگیرانهای برای بهبود رضایت و وفاداری مشتری انجام دهند، که در نهایت منجر به کاهش نرخ ریزش و افزایش سودآوری میشود.
مدلهای پیشبینی ریزش مشتری، دادههای مختلفی از مشتریان را تجزیه و تحلیل میکنند، از جمله اطلاعات جمعیتشناسی، الگوهای استفاده از خدمات و تاریخچه تراکنشها، تا روندها و رفتارهای نشاندهنده ریزش را شناسایی کنند. این بینشها به شرکتها اجازه میدهد تا کمپینهای بازاریابی هدفمند، پیشنهادات شخصیسازیشده و سایر اقدامات خدمات محور به مشتریان در معرض خطر ارائه دهند.

کاربردهای پیشبینی ریزش مشتری در صنایع مختلف
پیشبینی ریزش مشتری در طیف گستردهای از صنایع استفاده میشود و هر یک از آنها از این بینشها برای رفع چالشهای منحصر به فرد خود بهره میبرند:
- مخابرات: شرکتها از پیشبینی ریزش برای درک دلایل رویآوردن مشتریان به رقبا استفاده میکنند و به این ترتیب میتوانند کیفیت خدمات، استراتژیهای قیمتگذاری و پشتیبانی مشتری را بهبود بخشند.
- بانکداری و خدمات مالی: موسسات مالی، دادههای مشتری را تجزیه و تحلیل میکنند تا افرادی که در معرض خطر بستن حساب یا تغییر به رقبا هستند را شناسایی کنند. سپس استراتژیهایی برای ارائه محصولات مالی شخصیسازیشده و خدمات مشتری بهتر ارائه میدهند.
- خردهفروشی: خردهفروشان برای بهبود حفظ مشتری، تجربیات خرید را شخصیسازی میکنند، برنامههای وفاداری را بهینه میکنند و سیستمهای توصیهگر برای فروش محصول را بهبود میبخشند.
- خدمات اشتراکی: سرویسهای پخش، شرکتهای نرمافزار بهعنوان یک سرویس (SaaS) و سایر کسبوکارهای مبتنی بر اشتراک از پیشبینی ریزش برای حفظ ثبات پایه مشترکین استفاده میکنند و با بهبود محتوای ارائه شده و تجربه خدماتی، به این هدف میرسند.
همچنین بخوانید: هوش مصنوعی در صنعت خرده فروشی چگونه تحول ایجاد میکند؟
مطالعه موردی: پیشبینی ریزش مشتری در صنعت مخابرات
با رشد و تحول صنعت مخابرات، چالش حفظ مشتریان به طور فزایندهای پیچیده میشود. در کالیفرنیا، یک شرکت بزرگ مخابراتی در سهماهه دوم سال ۲۰۲۲ با نرخ بالای ریزش مشتریان مواجه شد که آنها را وادار کرد تا به طور عمیقتری به دادههای مشتریان خود بپردازند. با تحلیل این دادهها، آنها به دنبال کشف الگوها و عواملی بودند که به ریزش منجر میشوند تا بتوانند استراتژیهای مؤثری برای حفظ مشتریان خود اجرا کنند. این تحلیل جامع مراحل کاوش، پیشپردازش و مدلسازی این مجموعه داده را مشخص میکند و بینشهای حیاتی و توصیههای عملی برای کاهش ریزش ارائه میدهد. در ادامه به بررسی این مجموعه داده و ادغام آن با مفاهیم ماشین لرنینگ میپردازیم تا بتوانیم به درک مناسبی از پیش بینیریزش مشتری برسیم.
تحلیل مجموعه داده
فراخوانی کتابخانهها
به منظور اجرای کد، نیازمند فراخوانی کتابخانهها و پکیجهای موردنیاز برای پیشبینی ریزش مشتری هستیم:
!pip install imbalanced-learn
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import missingno as msno
from scipy.stats import trim_mean, kurtosis, skew
from sklearn.preprocessing import LabelEncoder, StandardScaler
from sklearn.impute import KNNImputer
from imblearn.combine import SMOTETomek
from sklearn.model_selection import train_test_split, GridSearchCV
import xgboost as xgb
from sklearn.metrics import classification_report, confusion_matrix, f1_score
from time import perf_counter
import warnings
warnings.filterwarnings('ignore')
بررسی اجمالی مجموعه داده
مجموعه داده مربوط به ریزش مشتریان را میتوان از سایت کگل دانلود کرد و آن را در یک دیتافریم از نوع pandas بارگذاری نمود.
data = pd.read_csv('dataset.csv')
این مجموعه داده شامل سوابق دقیق ۷۰۴۳ مشتری از یک شرکت مخابراتی در کالیفرنیا است که شامل ویژگیهای مختلف جمعیتشناسی، خدماتی و مالی میباشد.
دستور ()data.head مجموعه داده را نمایش میدهد و نگاهی اولیه به ساختار و محتوای دادهها فراهم میکند. این دیتافریم ویژگیهایی از قبیل شناسه مشتری، سن، جنسیت، مدت زمان عضویت، اشتراک خدمات و هزینههای ماهانه را شامل میشود.
خلاصه اطلاعات آماری
متد ()info خلاصهای مختصر از مجموعه داده ارائه میدهد که شامل تعداد مقادیر غیر خالی در هر ستون، انواع دادهها و استفاده از حافظه میشود. این اطلاعات برای درک کامل بودن و ساختار دادهها بسیار حیاتی است.
RangeIndex: 7043 entries, 0 to 7042
Data columns (total 38 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 customer_id 7043 non-null object
1 gender 7043 non-null object
2 age 7043 non-null int64
3 married 7043 non-null object
4 number_of_dependents 7043 non-null int64
5 city 7043 non-null object
6 zip_code 7043 non-null int64
7 latitude 7043 non-null float64
8 longitude 7043 non-null float64
9 number_of_referrals 7043 non-null int64
10 tenure_in_months 7043 non-null int64
11 offer 3166 non-null object
12 phone_service 7043 non-null object
13 avg_monthly_long_distance_charges 6361 non-null float64
14 multiple_lines 6361 non-null object
15 internet_service 7043 non-null object
16 internet_type 5517 non-null object
17 avg_monthly_gb_download 5517 non-null float64
18 online_security 5517 non-null object
19 online_backup 5517 non-null object
20 device_protection_plan 5517 non-null object
21 premium_tech_support 5517 non-null object
22 streaming_tv 5517 non-null object
23 streaming_movies 5517 non-null object
24 streaming_music 5517 non-null object
25 unlimited_data 5517 non-null object
26 contract 7043 non-null object
27 paperless_billing 7043 non-null object
28 payment_method 7043 non-null object
29 monthly_charge 7043 non-null float64
30 total_charges 7043 non-null float64
31 total_refunds 7043 non-null float64
32 total_extra_data_charges 7043 non-null int64
33 total_long_distance_charges 7043 non-null float64
34 total_revenue 7043 non-null float64
35 customer_status 7043 non-null object
36 churn_category 1869 non-null object
37 churn_reason 1869 non-null object
dtypes: float64(9), int64(6), object(23)
memory usage: 2.0+ MB
Some information about dataset: None
متد describe(include=’number’) اطلاعات آماری از ویژگیهای عددی ارائه میدهد که شامل تعداد، میانگین، انحراف معیار، حداقل و حداکثر مقادیر میشود. این متد کمک میکند تا گرایشهای مرکزی، پراکندگی و موارد استثنایی را شناسایی کنیم.
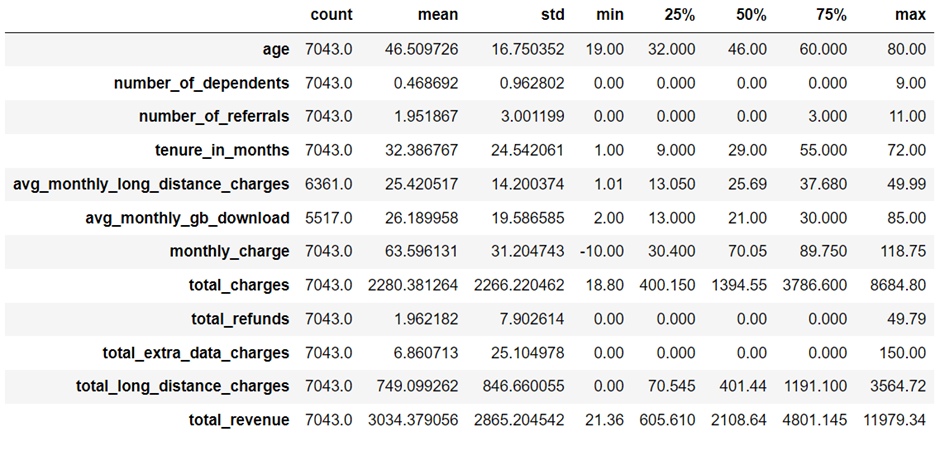
متد ()data.nunique مقادیر منحصر به فرد برای هر ویژگی را لیست میکند و تعداد دستههای هر کدام از متغیرها را مشخص میکند.
حذف ستونهای غیرضروری
با خروجی حاصل از متد قبلی، تعداد بالای دستهها در برخی ویژگیها نشاندهنده پتانسیل کم آنها جهت انتقال اطلاعات به مدلهای پیشبینی است. به عنوان مثال، شناسه مشتری و مختصات جغرافیایی، به دلیل عدم تأثیر قابل توجه در قدرت پیشبینی مدل میتوان آنها را حذف نمود.
data = data.drop(['customer_id', 'city', 'zip_code', 'latitude', 'longitude'], axis=1)
data = data.drop(['churn_category', 'churn_reason'], axis=1)
علاوه بر این، ویژگیهای “Churn Category” و “Churn Reason” از آنجایی که بیانگر علت ریزش مشتری و نوع ریزش هستند لذا فقط پس از خروج مشتریان در دسترس هستند. پس میتوانیم آنها را کنار بگذاریم.
تحلیل داده اکتشافی (EDA)
بصریسازی ویژگیهای غیر عددی
این قطعه کد نمودارهای میلهای برای هر ویژگی غیر عددی تولید میکند و توزیع و فراوانی هر دسته را نمایش میدهد. این تحلیل بصری به درک ترکیب ویژگیهای دستهبندی و شناسایی هرگونه عدم تعادل یا ناهنجاری کمک میکند.
warnings.filterwarnings("ignore")
fig, axes = plt.subplots(5, 4, figsize=(15, 20))
axes = axes.flatten()
for i, col in enumerate(data.select_dtypes(include=['object']).columns):
sns.countplot(x=col, data=data, ax=axes[i], palette='viridis')
axes[i].set_title(f'Distribution of {col}')
axes[i].set_xticklabels(axes[i].get_xticklabels(), rotation=20)
for p in axes[i].patches:
axes[i].annotate(f'{int(p.get_height())}', (p.get_x() + p.get_width() / 2., p.get_height()),
ha='center', va='center', fontsize=10, xytext=(0, 5),
textcoords='offset points')
plt.tight_layout()
plt.show()
تصویر زیر خروجی قطعه کد بالاست:
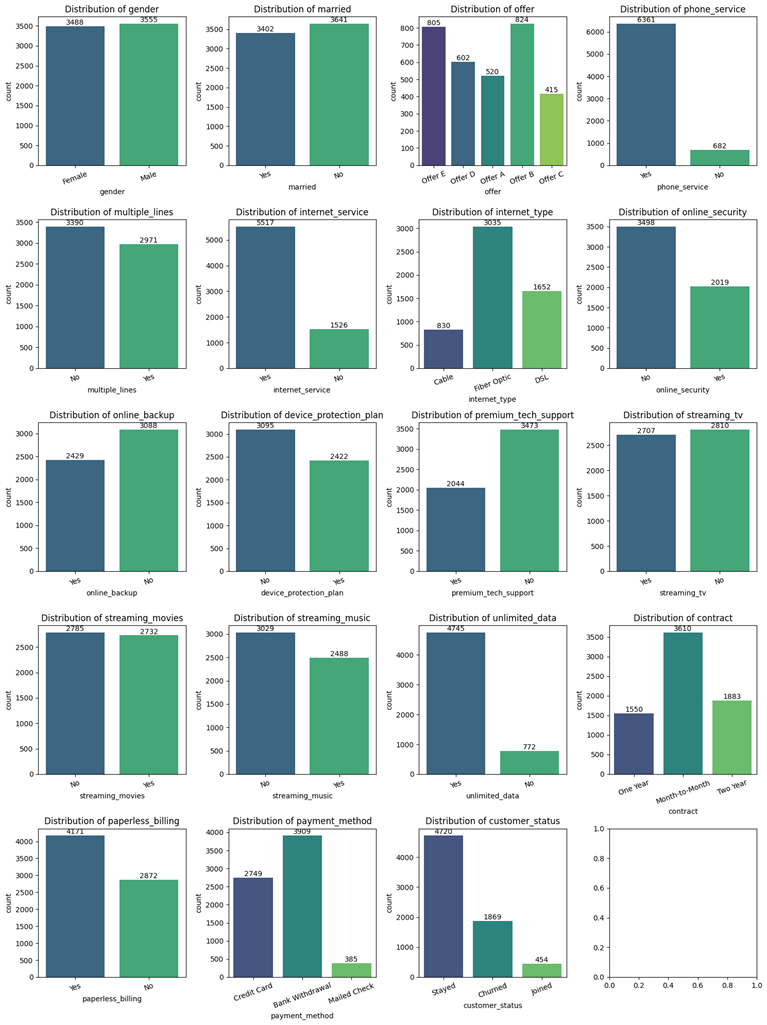
از این تصویر میتوان به بینشهای مختلفی دست یافت که مهمترین آنها عبارتند از:
- عدم تعادل در ستون هدف “وضعیت مشتری”: اکثر مشتریها در وضعیت ماندگار هستند. این عدم تعادل ممکن است نیاز به توجه ویژه در طول مدلسازی و ارزیابی مدل داشته باشد تا نتایج دقیقتری حاصل شود.
- توزیع متعادل جنسیتی: توزیع جنسیتی مشتریان نشان میدهد که نسبت جنسیتی مشتریان تقریباً متعادل است.
- استفاده گسترده از خدمات اینترنتی: خدمات اینترنتی یکی از ویژگیهایی است که به طور گسترده در میان مشتریان استفاده میشود.
این بینشها به ما کمک میکنند تا در مراحل بعدی مدلسازی و تحلیل، تصمیمات بهتری بگیریم.
بصریسازی ویژگیهای عددی
برای هر ویژگی عددی هیستوگرامها ترسیم میشوند تا توزیع آنها بصری شود. این کار به شناسایی چولگی، کشیدگی و موارد استثنایی بالقوه در دادهها کمک میکند که برای مراحل پیشپردازش مانند نرمالسازی ضروری هستند.
# visualization: distribution plot
fig, axs = plt.subplots(ncols=4, nrows=3, figsize=(25,15))
index = 0
axs = axs.flatten()
for k, v in data.select_dtypes(include=['number']).items():
sns.distplot(v, ax=axs[index])
index += 1
plt.tight_layout(pad=0.4, w_pad=0.5, h_pad=5)
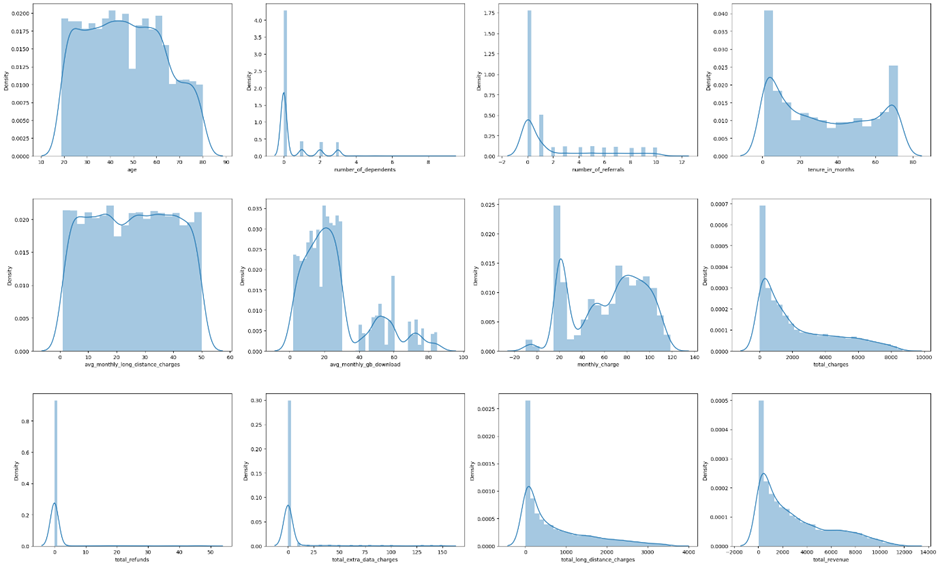
تحلیل چند متغیره
از طریق قطعه کد زیر میتوان هر کدام از متغیرهای غیرعددی را با در نظر گرفتن متغیر هدف مسئله ترسیم کرد. این امر کمک میکند تا بینشهای ارزشمندی جهت پیشبینی ریزش مشتری کسب کنیم:
warnings.filterwarnings("ignore")
fig, axes = plt.subplots(7, 3, figsize=(15, 25))
axes = axes.flatten()
for i, col in enumerate(data.select_dtypes(include=['object']).columns):
sns.countplot(x=col, data=data, hue='customer_status', ax=axes[i], palette='viridis')
axes[i].set_title(f'Distribution of {col}')
axes[i].set_xticklabels(axes[i].get_xticklabels(), rotation=20)
plt.tight_layout()
plt.show()
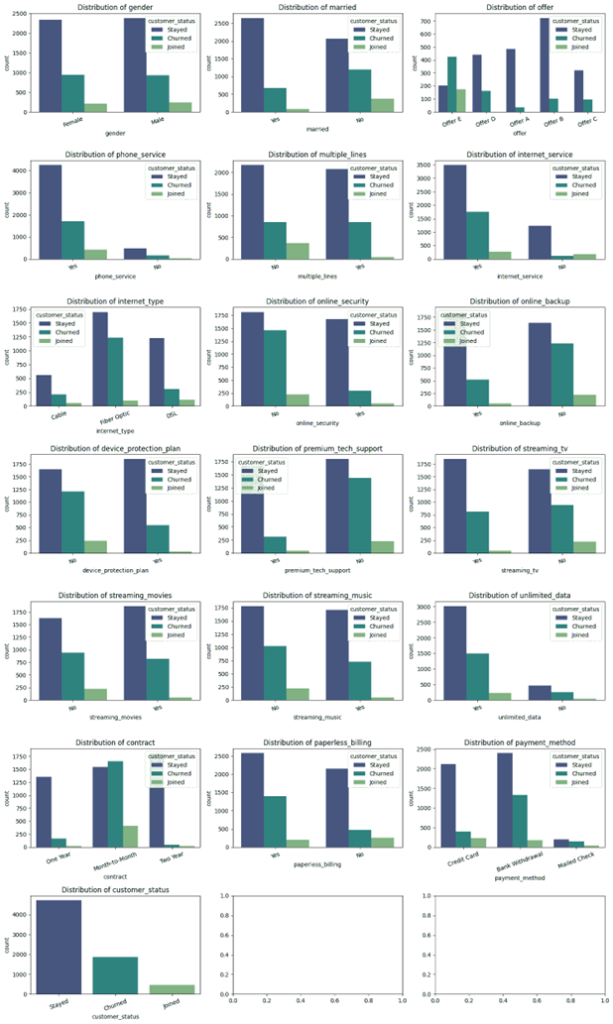
از این تصویر میتوان به بینشهای مختلفی دست یافت که مهمترین آنها عبارتند از:
- تأثیر پیشنهادها: پیشنهادهای A و B با حفظ مشتریان ارتباط بیشتری دارند، در حالی که پیشنهادهای D و E بیشتر به ترک مشتریان منجر شدهاند.
- نوع قرارداد: مشتریانی که قرارداد ماهانه دارند نرخ ترک بالاتری نسبت به قراردادهای بلندمدت دارند.
- نوع خدمات اینترنتی: مشتریانی که از اینترنت فیبر نوری استفاده میکنند احتمال ترک بیشتری نسبت به کسانی که از کابل استفاده میکنند، دارند.
- صورتحساب بدون کاغذ: درصد بیشتری از مشتریانی که گزینه صورتحساب بدون کاغذ را انتخاب کردهاند با خدمات باقی ماندهاند نسبت به کسانی که این گزینه را انتخاب نکردهاند.
همچنین از طریق groupby، میتوان بینشهای بیشتری از ارتباط ویژگیهای عددی با متغیر هدف کسب کرد:
# Define columns for groupby
groupby_columns = ['age', 'monthly_charge', 'total_charges', 'total_revenue', 'total_refunds']
# using groupby
groupby_result = data.groupby('customer_status')[groupby_columns].agg(lambda x: trim_mean(x, 0.05))
# Display the result
print("Groupby:")
groupby_result
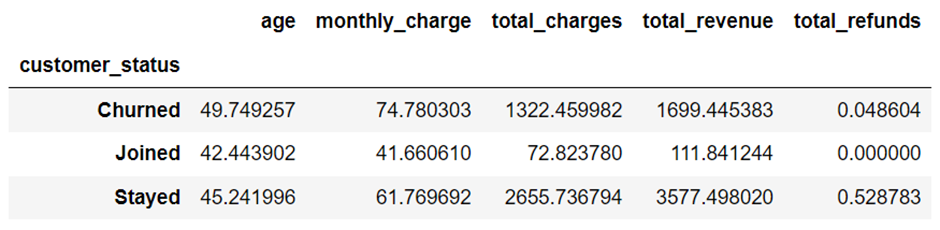
مهمترین بینشهای جدول فوق:
- عامل سن: مشتریان ترککرده بالاترین میانگین سن را دارند که تقریباً ۵۰ سال است.
- هزینههای ماهانه: مشتریان ترککرده بالاترین هزینههای ماهانه را دارند که به طور متوسط حدود ۷۴.۷۸ دلار است.
- کل هزینهها: مشتریانی که باقی ماندهاند بالاترین کل هزینهها را دارند که حدود ۲۶۵۵.۷۴ دلار است.
- کل درآمد: بالاترین درآمد از مشتریانی که باقی ماندهاند به دست میآید که مجموعاً حدود ۳۵۷۷.۵۰ دلار است.
- بازپرداختها: مشتریانی که باقی ماندهاند بالاترین بازپرداختها را دارند که به طور متوسط ۰.۵۳ دلار است.
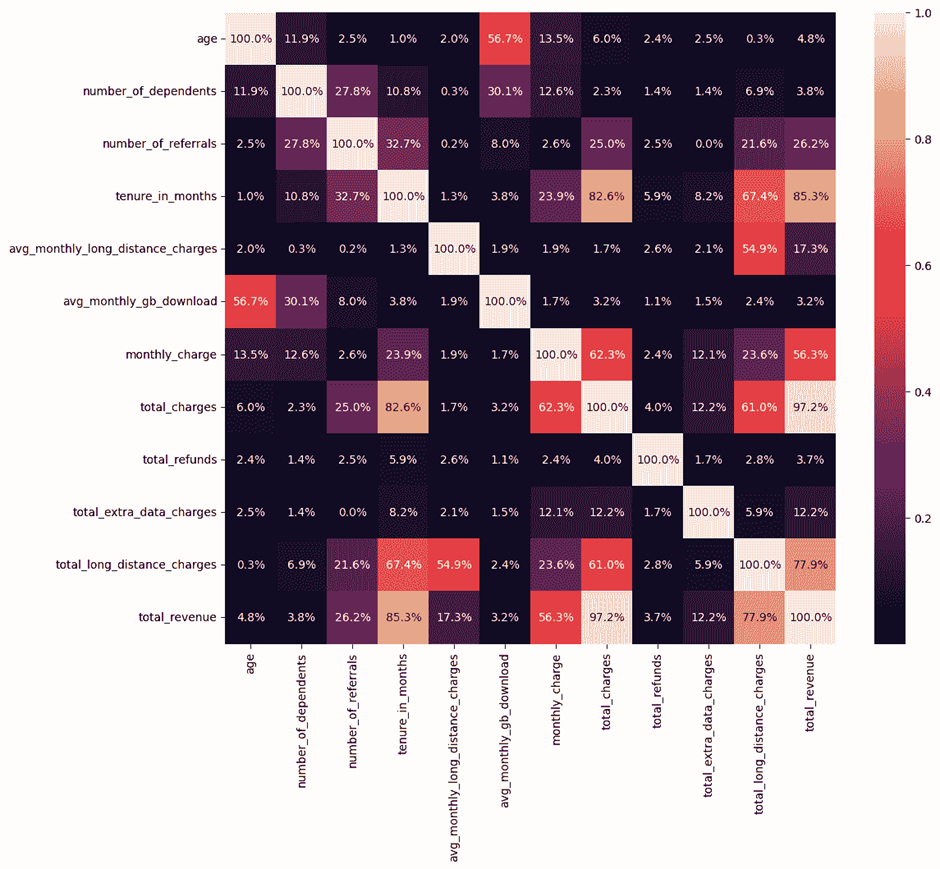
تحلیل همبستگی
یک نقشه حرارتی از ماتریس همبستگی برای ویژگیهای عددی ایجاد میشود تا روابط بین ویژگیها شناسایی شوند. با توجه به تصویر حاصل از این تحلیل، دو ویژگی “کل هزینهها” (total charges) و “کل درآمد” (total revenue) دارای همبستگی بالایی هستند. به عبارت دیگر، این دو ویژگی رابطه خطی قویای با یکدیگر دارند و هر دو به میزان تقریبا برابری در پیشبینی ریزش مشتری تأثیرگذار هستند. بنابراین، میتوان یکی از آنها را حذف کرد.
# heat map
corr_mat = data.select_dtypes(include=['number']).corr()
plt.figure(figsize=(12, 10))
sns.heatmap(corr_mat.abs(), annot=True, fmt=".1%")
print('The Highest Correlation among Features:')
for x in range(len(data.select_dtypes(include=['number']).columns)):
corr_mat.iloc[x,x] = 0.0
corr_mat.abs().idxmax()
پیشپردازش دادهها
مدیریت مقادیر از دست رفته
ویژگیهای غیرعددی
با اجرای قطعه کد زیر، مقادیر از دسترفته برای ویژگیهای غیرعددی مشخص میشوند:
# checking null values
print(f"null values in nominal features:\n{data.select_dtypes(include=['object']).isna().sum()}")
null values in nominal features:
gender 0
married 0
offer 3877
phone_service 0
multiple_lines 682
internet_service 0
internet_type 1526
online_security 1526
online_backup 1526
device_protection_plan 1526
premium_tech_support 1526
streaming_tv 1526
streaming_movies 1526
streaming_music 1526
unlimited_data 1526
contract 0
paperless_billing 0
payment_method 0
customer_status 0
dtype: int64
همانطور که در تصویر بخش بصریسازی ویژگیهای غیر عددی نشان داده شد، برخی ویژگیها وابسته به “اشتراک خدمات اینترنتی” (internet service) هستند. به عبارت دیگر، این ویژگیها هنگامی در دسترس هستند که مشتری به خدمات اینترنتی اشتراک داشته باشد. این ویژگیها شامل موارد زیر هستند:
- نوع اینترنت (Internet Type)
- امنیت آنلاین (Online Security)
- پشتیبانگیری آنلاین (Online Backup)
- طرح حفاظت از دستگاه (Device Protection Plan)
- پشتیبانی فنی پیشرفته (Premium Tech Support)
- پخش تلویزیونی (Streaming TV)
- پخش فیلم (Streaming Movies)
- پخش موسیقی (Streaming Music)
- دادههای نامحدود (Unlimited Data)
تعداد کل مشتریانی که به خدمات اینترنتی اشتراک دارند، ۵۵۱۷ نفر است. لذا براساس یافتههای مذکور، مشهود است که مشتریانی که به خدمات اینترنتی اشتراک ندارند، در ویژگیهای ذکر شده دارای مقادیر null هستند. بنابراین، برای حفظ سازگاری مجموعه داده میبایست مقادیر null در این ستونها با “no_internet_service” جایگزین شوند.
# filling null values
data['internet_type'] = data['internet_type'].apply(lambda x: 'no_internet_service' if pd.isnull(x) else x)
data['offer'] = data['offer'].apply(lambda x: 'no_offer' if pd.isnull(x) else x)
column_name = ['online_security', 'online_backup', 'device_protection_plan', 'premium_tech_support',
'streaming_tv', 'streaming_movies', 'streaming_music', 'unlimited_data']
for column in column_name:
data[column] = data[column].apply(lambda x: 'no_internet_service' if pd.isnull(x) else x)
ویژگیهای عددی
با اجرای قطعه کد زیر، مقادیر از دسترفته برای ویژگیهای عددی مشخص میشود:
print("null values in numerical features:\n",data.select_dtypes(include=['number']).isna().sum())
null values in numerical features:
age 0
tenure_in_months 0
avg_monthly_long_distance_charges 682
avg_monthly_gb_download 1526
monthly_charge 0
total_revenue 0
number_of_dependents_sqrt 0
number_of_referrals_sqrt 0
total_refunds_log 0
total_extra_data_charges_log 0
total_long_distance_charges_sqrt 0
dtype: int64
براساس تصویر بخش بصریسازی، مشخص است که ویژگی “میانگین حجم دانلود ماهانه (گیگابایت)” (Avg Monthly GB Download) وابسته به اشتراک خدمات اینترنتی است. به زبان ساده، این ویژگی زمانی فعال میشود که مشتری به خدمات اینترنتی اشتراک داشته باشد، در غیر این صورت مقادیر آن null خواهد بود. بنابراین، برای آمادهسازی دادهها باید مقادیر null در این ستون با صفر جایگزین شوند.
# filling null values
column_name = ['avg_monthly_long_distance_charges', 'avg_monthly_gb_download']
for column in column_name:
data[column] = data[column].apply(lambda x: 0 if pd.isnull(x) else x)
از طرفی، ویژگی “Avg Monthly Long Distance Charges” نشاندهنده میانگین هزینههای تماسهای بینالمللی مشتری تا پایان دوره مشخص است. اگر مشتری به خدمات تلفن خانگی اشتراک نداشته باشد، این مقدار به طور طبیعی صفر خواهد بود. بنابراین، در این ستون نیز باید مقادیر null با صفر جایگزین شوند.
این اقدامات ساده نه تنها به بهبود کیفیت دادهها کمک میکنند، بلکه تحلیلهای دقیقتر و پیشبینیهای بهتری را نیز ممکن میسازند. با اجرای این تغییرات، میتوان در فاز آمادهسازی دادهها یک گام رو به جلو برداریم!
همچنین بخوانید: نقش حیاتی پیشپردازش دادهها و مدیریت مقادیر گمشده در یادگیری ماشین
تبدیل ویژگیهای دارای چولگی
همانطور که میدانید، حضور ویژگیهای با چولگی زیاد میتواند منجر به بایاس در عملکرد مدلهای پیشبینی شود. برای جلوگیری از این مشکل، در یکی از مراحل پیشپردازش دادهها برای پیشبینی ریزش مشتری، باید چولگی ویژگیها مورد بررسی قرار گیرد. قطعه کد زیر، چولگی هر کدام از ویژگیهای عددی را نشان میدهد:
numeric_data = data.select_dtypes(include=['number'])
# Calculate skewness of numerical features
skewness = numeric_data.apply(skew)
print("Skewness of numerical features:")
print(skewness)
Skewness of numerical features:
age 0.162152
number_of_dependents 2.109483
number_of_referrals 1.445752
tenure_in_months 0.240491
avg_monthly_long_distance_charges NaN
avg_monthly_gb_download NaN
monthly_charge -0.275335
total_refunds 4.327595
total_extra_data_charges 4.090338
total_long_distance_charges 1.238018
total_revenue 0.919214
dtype: float64
براساس نتایج، ویژگیهای زیر دارای انحراف زیادی در توزیع خود هستند. برای رفع این مشکل، میتوانیم از توابع جذر یا لگاریتمی استفاده کنیم تا توزیع این ویژگیها را نرمال کنیم:
- “number_of_dependents”
- “number_of_referrals”
- “total_refunds”
- “total_extra_data_charges”
- “total_long_distance_charges”
# Define the columns to transform
columns_to_transform = ['number_of_dependents', 'number_of_referrals', 'total_refunds',
'total_extra_data_charges', 'total_long_distance_charges']
# Create new columns for sqrt and log transformations
for column in columns_to_transform:
data[f'{column}_sqrt'] = np.sqrt(data[column])
data[f'{column}_log'] = np.log1p(data[column])
# Calculate skewness before and after transformations
skewness_before = data[columns_to_transform].apply(skew)
skewness_after_sqrt = data[[f'{column}_sqrt' for column in columns_to_transform]].apply(skew)
skewness_after_log = data[[f'{column}_log' for column in columns_to_transform]].apply(skew)
# Print skewness before and after transformations
print("Skewness before transformation:")
print(skewness_before)
print("\nSkewness after square root transformation:")
print(skewness_after_sqrt)
print("\nSkewness after log transformation:")
print(skewness_after_log)
fig, axes = plt.subplots(nrows=5, ncols=3, figsize=(15, 20))
for i, column in enumerate(columns_to_transform):
sns.histplot(data[column], kde=True, ax=axes[i, 0])
axes[i, 0].set_title(f'Distribution of {column} (Before)')
sns.histplot(data[f'{column}_sqrt'], kde=True, ax=axes[i, 1])
axes[i, 1].set_title(f'Distribution of {column} (sqrt)')
sns.histplot(data[f'{column}_log'], kde=True, ax=axes[i, 2])
axes[i, 2].set_title(f'Distribution of {column} (log)')
plt.tight_layout()
plt.show()
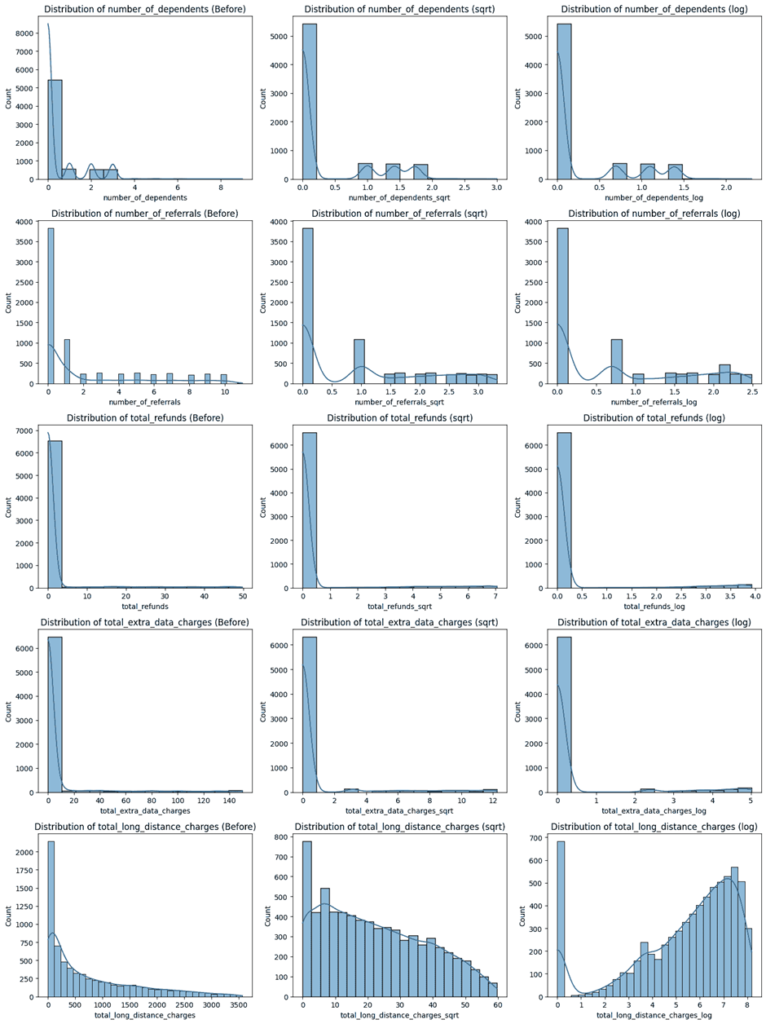
تصویر بالا، توزیع هر کدام از این ویژگیها را پس از اعمال این دو تابع نشان میدهد. با استفاده از قطعه کد زیر، ویژگیهایی با چولگی کمتر انتخاب و ویژگیهای با چولگی بالا حذف میشوند. این کار باعث بهبود عملکرد مدلهای یادگیری ماشین خواهد شد.
# drop redundunt columns
data = data.drop(['number_of_dependents', 'number_of_dependents_log',
'number_of_referrals', 'number_of_referrals_log',
'total_refunds', 'total_refunds_sqrt',
'total_extra_data_charges', 'total_extra_data_charges_sqrt',
'total_long_distance_charges', 'total_long_distance_charges_log'], axis=1)
کدگذاری متغیرهای غیر عددی
تبدیل ویژگیهای با ماهیت دسته بندی به صورت ویژگیهایی با مقادیر عددی اقدامی لازم در پیشپردازش دادههاست چراکه الگوریتمهای یادگیری ماشین نیاز به ورودی عددی دارند:
# first step:
conversion_dict = {"Yes": 1, "No": 0}
data['multiple_lines'] = data['multiple_lines'].map(conversion_dict)
# second step: labeling the target by using LabelEncoder
label_encoder = LabelEncoder()
data['customer_status'] = label_encoder.fit_transform(data['customer_status'])
# third step: using pd.get_dummies for other features
data = pd.get_dummies(data, drop_first=True)
برای ستون هدف مجموعه داده که بیانگر ریزش مشتری است از LabelEncoding بهره میبریم. همچنین، برای سایر ویژگیها با بیش از دو کلاس از متد ()pd.get_dummies استفاده میشود تا مدلسازی با فرآیند بهتری طی شود.
KNNImputing
در بخش مدیریت مقادیر از دست رفته، حتی با جایگذاری مقادیر جدید در ستونهای مربوطه، هنوز مقادیر null در ویژگی “multiple_lines” وجود دارند. یکی از روشهای موثر برای رفع این مشکل، بررسی نمونههای همسایه نزدیک به نمونهای است که مقدار null دارد. کد زیر با استفاده از تابع ()KNNImputer و در نظر گرفتن سه همسایه نزدیک، مقادیر null را با مقادیر مناسبی جایگزین میکند:
# Extract the label column before imputation
label_column = data['customer_status']
data = data.drop(columns=['customer_status'])
# the KNNImputer
imputer = KNNImputer(n_neighbors=3)
imputed_data = imputer.fit_transform(data)
# If we want to keep the DataFrame format:
data = pd.DataFrame(data=imputed_data, columns=data.columns)
# Round the imputed values for 'multiple_lines' to get the mode
data['multiple_lines'] = data['multiple_lines'].apply(lambda x: round(x))
# Reattach the label column
data['customer_status'] = label_column
این روش نه تنها دقت دادهها را بهبود میبخشد، بلکه باعث میشود تا تحلیلها و مدلهای ما دقیقتر و قابلاعتمادتر باشند.
برای مطالعه بیشتر کلیک کنید: با الگوریتم K نزدیک ترین همسایه (K-Nearest Neighbors) آشنا شوید!
Train-Test Split
برای ارزیابی بهتر مدل، مجموعه دادهها به دو بخش آموزشی و آزمایشی با نسبت ۸۰-۲۰ تقسیم میشوند. این تقسیمبندی با حفظ توزیع متغیر هدف انجام میشود تا دقت مدل روی دادههای جدید و دیدهنشده سنجیده شود.
X = data.drop(['customer_status'], axis=1)
y = data.loc[:, 'customer_status'].values
# Split Data into training and testing
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, shuffle=True, stratify=data.customer_status)
مدیریت دادههای پرت
برای مقابله با دادههای پرت در ویژگیهای عددی از روش محدوده بین چارکی (IQR) استفاده میکنیم. نمونههایی که دادههایشان از حدهای پایین و بالای تعیینشده تجاوز میکنند، با مقادیر مناسبی جایگزین میشوند. این قطعه کد تضمین میکند که تاثیر ناهنجاریها در پیشبینی ریزش مشتری کاهش یابد:
def handle_outliers(X_train, X_test, columns):
for col in columns:
Q1 = np.percentile(X_train[col], 25)
Q3 = np.percentile(X_train[col], 75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
# Handling outliers in X_train
X_train[col] = np.where(X_train[col] upper_bound, upper_bound, X_train[col])
# Handling outliers in X_test based on X_train IQR
X_test[col] = np.where(X_test[col] upper_bound, upper_bound, X_test[col])
return X_train, X_test
# Define the columns to apply outlier handling
columns_to_handle = ['avg_monthly_gb_download', 'total_revenue', 'number_of_dependents_sqrt',
'total_refunds_log', 'total_extra_data_charges_log']
# Apply the function to the specified columns
X_train, X_test = handle_outliers(X_train, X_test, columns_to_handle)
لازم به ذکر است برای اینکه تشخیص دهیم کدام ویژگیها دارای نقاط پرت هستند میتوان از رسم نمودار جعبهای برای ویژگیهای عددی استفاده کرد:
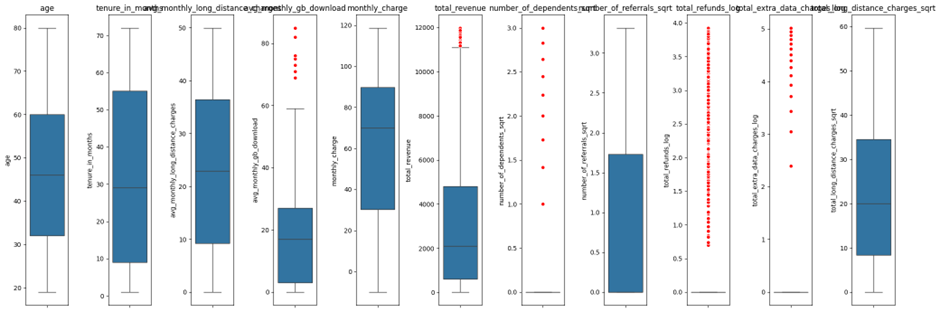
همانطور که از تصویر فوق پیداست، تنها ستونهای دارای نقاط پرت به تابع مدنظر اعمال شدهاند.
مقیاسبندی ویژگیها
برای نرمالسازی ویژگیهای عددی و اطمینان از قابل مقایسه بودن آنها، از StandardScaler استفاده میکنیم. این مرحله برای الگوریتمهایی که به مقیاسبندی ویژگیها حساس هستند ضروری است.
# Initialize the StandardScaler
scaler = StandardScaler()
# Fit the scaler on the training data and transform both training and test data
X_train[numerical_columns] = scaler.fit_transform(X_train[numerical_columns])
X_test[numerical_columns] = scaler.transform(X_test[numerical_columns])
مدیریت دادههای نامتوازن
در بخش بصریسازی مشاهده کردیم که ستون هدف مسئله پیشبینی ریزش مشتری دارای سه کلاس نامتوازن است. این نامتوازن بودن میتواند بر عملکرد مدلهای ماشین لرنینگ تاثیر بگذارد. برای رفع این چالش از تکنیک SMOTETomek که ترکیبی از نمونهبرداری بیش از حد و نمونهبرداری کمتر است، استفاده میکنیم. این تکنیک باعث بهبود یادگیری مدل از کلاسهای اقلیتی و افزایش دقت پیشبینی میشود:
# SMOTETomek
# Apply SMOTETomek to the training data
smote_tomek = SMOTETomek(random_state=42)
X_train_resampled, y_train_resampled = smote_tomek.fit_resample(X_train, y_train)
# Check the class distribution after resampling
print('Resampled training set shape:\n', pd.Series(y_train_resampled).value_counts())
Resampled training set shape:
1 3771
2 3729
0 3724
نکته حائز اهمیت در استفاده از این روش، اعمال آن تنها به دادههای مجموعه آموزشی و نه آزمایشی است.
آموزش و ارزیابی مدل
انتخاب مدل: XGBoost
XGBoost برای آموزش مدل استفاده میشود و تنظیمات هایپرپارامترها با استفاده از GridSearchCV انجام میشود. این فرآیند بهترین ترکیب پارامترها را شناسایی میکند و عملکرد و تعمیم مدل را بهبود میبخشد.
برای مطالعه بیشتر کلیک کنید: با الگوریتم XGBoost یکی از قدرتمندترین الگوریتمهای یادگیری ماشین آشنا شوید!
param_grid = {
'learning_rate': [0.01, 0.1, 0.2],
'n_estimators': [100, 200, 300],
'max_depth': [3, 4, 5],
'subsample': [0.8, 0.9, 1.0],
'colsample_bytree': [0.8, 0.9, 1.0]
}
# Initialize the XGBoost model
xgb_model = xgb.XGBClassifier(use_label_encoder=False)
# Instantiate the grid search model
grid_search_xgb = GridSearchCV(estimator=xgb_model, param_grid=param_grid, cv=5, n_jobs=-1, verbose=2, scoring='f1_macro')
# Fit the grid search to the data
grid_search_xgb.fit(X_train_resampled, y_train_resampled)
# Get the best parameters and the best score
best_params = grid_search_xgb.best_params_
best_score = grid_search_xgb.best_score_
print(f"Best parameters in XGBoost: {best_params}")
print(f"Best cross-validation score in XGBoost: {best_score}")
در قطعه کد بالا، با در نظر گرفتن امتیاز F1 به عنوان معیار امتیاز دهی به عملکرد مدل، فرآیند انتخاب بهترین هاپیرپارمترها انجام میشود. نتیجه حاصل از اجرای قطعه کد بالا:
Fitting 5 folds for each of 243 candidates, totalling 1215 fits
Best parameters in XGBoost: {'colsample_bytree': 0.8, 'learning_rate': 0.2, 'max_depth': 5, 'n_estimators': 300, 'subsample': 0.8}
Best cross-validation score in XGBoost: 0.9136815961552067
ارزیابی مدل
Confusion Matrix
ماتریس درهمریختگی عملکرد مدل را بر روی مجموعه آزمایشی ارزیابی میکند و تعداد مثبتهای واقعی، مثبتهای کاذب، منفیهای واقعی و منفیهای کاذب برای هر کلاس را نشان میدهد.
Classification Report
گزارش دستهبندی دقت (Accuracy)، پوشش (Recall)، صحت (Precision) و امتیازهای F1 را برای هر کلاس ارائه میدهد و ارزیابی دقیقی از عملکرد مدل را فراهم میکند. همانطور که پیشتر ذکر شد به دلیل ماهیت نامتوازن مجموعه داده، امتیاز F1 انتخاب مناسبی برای بیان عملکرد مدل است:
# Evaluate on the test set
best_model = grid_search_xgb.best_estimator_
y_pred = best_model.predict(X_test)
# Classification report and confusion matrix
target_names = {0: 'Churned', 1: 'Joined', 2: 'Stayed'}
print("Classification Report:")
print(classification_report(y_test, y_pred, target_names=[target_names[i] for i in sorted(target_names)]))
print("Confusion Matrix:")
print(confusion_matrix(y_test, y_pred))
Classification Report:
precision recall f1-score support
Churned 0.71 0.69 0.70 374
Joined 0.72 0.70 0.71 91
Stayed 0.90 0.92 0.91 944
accuracy 0.84 1409
macro avg 0.78 0.77 0.77 1409
weighted avg 0.84 0.84 0.84 1409
Confusion Matrix:
[[257 25 92]
[ 27 64 0]
[ 79 0 865]]
این نتایج نشان میدهد که مدل به ویژه در پیشبینی کلاس مشتریهای ماندگار عملکرد خوبی دارد. همچنین، عملکرد قابل قبولی در پیشبینی کلاسهای “ریزش” دارد. معیارهای کلی عملکرد نشان میدهند که این مدل برای پیشبینی ریزش مشتری در این مجموعه داده مناسب و مؤثر است.
توصیههایی برای بهبود مدل ارائهشده پیشبینی ریزش مشتری
تنظیمات پیشرفته هایپرپارامترها
تنظیم هایپرپارامترها برای بهینهسازی مدلهای یادگیری ماشین حیاتی است. روشهای سنتی مانند GridSearchCV که در تحلیل ما استفاده شد، میتوانند از نظر محاسباتی هزینهبر باشند. روشهای پیشرفتهتر میتوانند کارایی بهتری ارائه دهند و عملکرد مدل را بهبود بخشند:
جستجوی تصادفی (Randomized Search)
جستجوی تصادفی، زیرمجموعهای از فضای هایپرپارامتر را با انتخاب تصادفی ترکیبها برای آزمایش کاوش میکند. این روش نسبت به جستجوی شبکهای کمتر هزینهبر است و میتواند هایپرپارامترهای بهینه یا نزدیک به بهینه را سریعتر پیدا کند.
Optuna
Optuna یک چارچوب پیشرفته برای بهینهسازی هایپرپارامتر است که از تکنیکهایی مانند بهینهسازی بیزی استفاده میکند. این ابزار به طور کارآمد فضای هایپرپارامتر را با یادگیری از ارزیابیهای قبلی پیمایش میکند و تعداد تکرارهای لازم برای یافتن بهترین پارامترها را به طور قابل توجهی کاهش میدهد.
الگوریتمهای جایگزین
کاوش الگوریتمهای مختلف میتواند عملکرد بهتری برای پیشبینی ریزش مشتری ارائه دهد یا مزایای خاصی متناسب با ویژگیهای مجموعه داده داشته باشد. برخی از این الگوریتمها عبارتند از:
CatBoost
CatBoost یک الگوریتم توسعهیافته توسط Yandex است که به طور بومی با ویژگیهای دستهبندی سر و کار دارد و نیاز به پیشپردازش گسترده را کاهش میدهد. این الگوریتم نسبت به بیشبرازش مقاوم است و اغلب بر الگوریتمهای دیگر تقویت گرادیان در مجموعه دادههای با ویژگیهای دستهبندی زیاد برتری دارد.
برای مطالعه بیشتر کلیک کنید: مدل Catboost چیست؟ راهنمای کامل استفاده از Catboost در یادگیری ماشین
LightGBM
LightGBM، توسعهیافته توسط مایکروسافت، برای سرعت و کارایی بهینهسازی شده است. این الگوریتم با مجموعه دادههای بزرگ و دادههای با ابعاد بالا به خوبی کار میکند و آن را به یک انتخاب عالی برای سناریوهایی تبدیل میکند که منابع محاسباتی یا زمان محدود هستند.
روشهای ترکیبی (Ensemble Methods)
ترکیب مدلهای متعدد میتواند دقت پیشبینی و استحکام را با استفاده از نقاط قوت الگوریتمهای مختلف افزایش دهد. برخی از این ترکیبها شامل موارد زیر هستند:
Stacking Models
Stacking شامل آموزش چندین مدل و استفاده از پیشبینیهای آنها به عنوان ویژگیهای ورودی برای یک فرامدل نهایی است. این رویکرد میتواند با ترکیب بینشهای الگوریتمهای مختلف، عملکرد را بهبود بخشد و منجر به مدل دقیقتر و تعمیمپذیرتری شود.
Voting Methods
روشهای مبتنی بر Voting پیشبینیهای چندین مدل را برای اتخاذ یک تصمیم نهایی جمعآوری میکنند. دو نوع اصلی از روشهای مبتنی بر رأیگیری وجود دارد:
- Hard Voting: هر مدل پایه برای یک برچسب کلاس رأی میدهد و برچسبی که اکثریت آرا را دارد به عنوان پیشبینی نهایی انتخاب میشود. این روش ساده و مؤثر است وقتی که عملکرد مدلهای به صورت تکی در سطح مشابهی باشد.
- Soft Voting: هر مدل پایه یک توزیع احتمالی بر روی برچسبهای کلاس تولید میکند و پیشبینی نهایی بر اساس میانگین این احتمالات انجام میشود. رأیگیری نرم زمانی مفید است که مدلها تخمینهای احتمالی قابل اعتمادی ارائه دهند و این امکان را برای تصمیمگیریهای دقیقتر فراهم میکند.
هر دو روش Stacking و Voting میتوانند بهطور ترکیبی برای بهبود بیشتر استحکام و دقت مدلهای پیشبینی ریزش مشتری استفاده شوند. شما میتوانید با مراجعه به این لینک در سایت کگل به کد نوتبوک این پروژه دسترسی داشته باشید و هر کدام از این روشهای بهبود مدل را پیاده کنید.
در نظر گرفتن سریهای زمانی در پیشبینی ریزش مشتری
دادههای سری زمانی شامل مشاهداتی است که در فواصل زمانی منظم جمعآوری میشوند. در زمینه پیشبینی ریزش مشتری، تحلیل سری زمانی میتواند الگوها و روندهای زمانی را که تحلیل دادههای ایستا ممکن است از دست بدهد، شناسایی کند. این میتواند شامل فصلی بودن، تغییرات رفتار مشتری در طول زمان و تأثیر رویدادهای خارجی باشد.
معماریهای RNN برای پیشبینی ریزش مشتری
شبکههای عصبی بازگشتی (RNN) نوعی شبکه عصبی هستند که بهطور خاص برای کار با دادههای ترتیبی طراحی شدهاند. این شبکهها برای تحلیل سری زمانی بسیار موثر هستند زیرا میتوانند وابستگیها در زمان را ثبت کنند. شبکههای حافظه کوتاهمدت طولانی (LSTM)، که نوعی از RNN محسوب میشوند، بسیار مفید هستند زیرا میتوانند وابستگیهای بلندمدت را یاد بگیرند و کمتر به مشکلاتی مانند گرادیانهای ناپدید شونده دچار شوند.
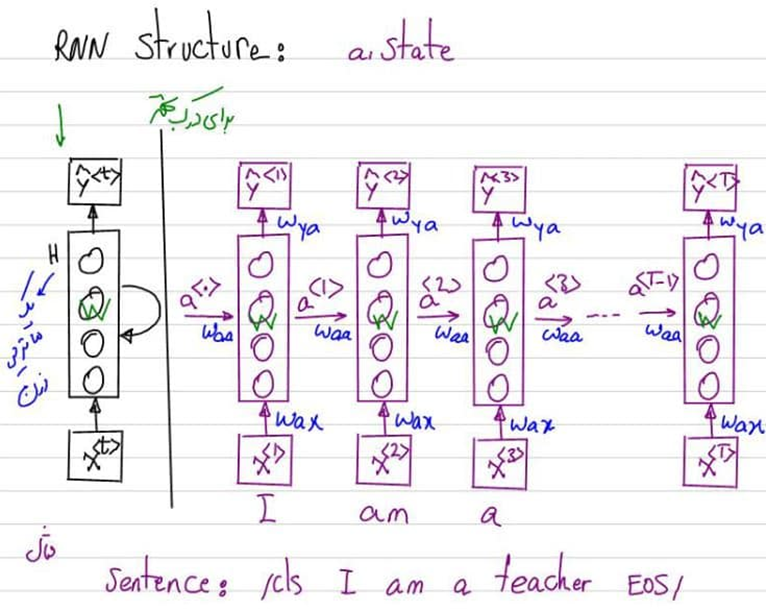
استفاده از RNNها برای پیشبینی ریزش مشتری شامل آموزش مدل بر روی توالیهای دادههای رفتاری مشتریان است. این میتواند شامل تاریخچه تراکنشها، الگوهای استفاده از خدمات و لاگهای تعامل باشد. RNN میتواند بر اساس این توالیها، احتمال ریزش آینده را پیشبینی کند.
مزایا و چالشها
مزایا:
- بینشهای زمانی: RNNها میتوانند الگوهای مربوط به زمان و توالی رویدادها را کشف کنند و بینشهای عمیقتری از رفتار مشتری ارائه دهند.
- بهبود دقت: با ثبت وابستگیهای زمانی، RNNها میتوانند دقت پیشبینی ریزش را بهبود بخشند.
- یادگیری تطبیقی: RNNها میتوانند به الگوهای تغییرات رفتار مشتری در طول زمان سازگار شوند و قدرت پیشبینی خود را با تغییر روندها حفظ کنند.
چالشها:
- آمادهسازی دادهها: دادههای سری زمانی نیاز به آمادهسازی دقیق دارند، از جمله مدیریت مقادیر از دسترفته و اطمینان از فواصل زمانی منظم.
- منابع محاسباتی: RNNها، بهویژه LSTMها، از نظر محاسباتی سنگین هستند و نیاز به منابع قابل توجهی برای آموزش دارند.
- پیچیدگی: طراحی و تنظیم معماریهای RNN میتواند پیچیده باشد و نیاز به تخصص در یادگیری عمیق و تحلیل سریهای زمانی دارد.
همچنین بخوانید: سفر به دنیای شبکه عصبی بازگشتی (RNN) با PyTorch
جمعبندی
تحلیل ما اثربخشی استفاده از XGBoost برای پیشبینی ریزش مشتری را نشان میدهد. با مدیریت دقیق مقادیر گمشده، رسیدگی به دادههای نامتوازن و انجام مقیاسبندی دقیق ویژگیها، مدل قویای توسعه دادیم که به دقت و عملکرد قابل قبولی در کلاسهای مختلف دست یافت. توانایی مدل در پیشبینی ریزش مشتری میتواند به کسبوکارها کمک کند تا استراتژیهای حفظ مشتری هدفمند را اجرا کنند، نرخ ریزش را کاهش دهند و وفاداری مشتریان را افزایش دهند.

پرسشهای متداول
تکنیکهای موثر برای پردازش و تمیز کردن دادهها در پیشبینی ریزش مشتری کدامند؟
تکنیکهای حذف دادههای از دسترفته، تبدیل متغیرها، نرمالسازی و استانداردسازی دادهها، و شناسایی و حذف نقاط پرت برای بهبود کیفیت دادهها موثر هستند.
چگونه الگوریتمهای جایگزین مانند CatBoost و LightGBM میتوانند در پیشبینی ریزش مشتری موثر باشند؟
الگوریتمهای CatBoost و LightGBM با توانایی پردازش دادههای نامتوازن و ارائه دقت بالاتر در پیشبینیها، میتوانند به عنوان جایگزینهای موثر در مدلهای پیشبینی ریزش مشتری استفاده شوند.
نقش تحلیل دادههای اکتشافی (EDA) در بهبود دقت مدلهای پیشبینی ریزش مشتری چیست؟
تحلیل دادههای اکتشافی (EDA) با شناسایی الگوها، همبستگیها و ویژگیهای مهم، به بهبود دقت و عملکرد مدلهای پیشبینی ریزش مشتری کمک میکند.
چگونه میتوان با استفاده از روشهای ترکیبی (Ensemble Methods) دقت مدلهای پیشبینی ریزش مشتری را افزایش داد؟
روشهای ترکیبی مانند بگینگ (Bagging)، بوستینگ (Boosting) و استکینگ (Stacking) با ترکیب چندین مدل، دقت و استحکام پیشبینی ریزش مشتری را افزایش میدهند.
مزایا و چالشهای استفاده از معماریهای RNN در پیشبینی ریزش مشتری چیست؟
معماریهای RNN با توانایی یادگیری از توالیهای زمانی، در پیشبینی رفتارهای مشتری مفید هستند، اما نیازمند محاسبات بیشتر و زمان آموزش طولانیتری هستند.
یادگیری ماشین لرنینگ را از امروز شروع کنید!
دنیای دادهها جذاب است و دانستن علم داده، توانایی تحلیل داده، یا بازاریابی مبتنی بر داده، شما را برای فرصتهای شغلی بسیاری مناسب میکند. فارغ از رشته و پیشزمینه، میتوانید حالا شروع کنید و از سطح مقدماتی تا پیشرفته بیاموزید. اگر دوست دارید به این حوزه وارد شوید، پیشنهاد میکنیم با کلیک روی این لینک قدم اول را همین حالا بردارید.
مشاوران کافهتدریس به شما کمک میکنند مسیر یادگیری برای ورود به این حوزه را شروع کنید: