
منحنی یادگیری یا Learning Curve چیست؟ مدلهای یادگیری ماشین برای یادگیری الگوها در دادهها استفاده میشوند. بهترین مدلها آنها هستند که در صورت مواجهه با نمونههایی که از دادههای آموزشی اولیه نیستند، میتوانند بهخوبی تعمیم یابند. در طول فرایند پژوهش، آزمایشهای متعددی برای یافتن راهحلی بهبهترین شکل مشکل کسبوکار را حل کند و خطای ایجادشده توسط مدل را کاهش دهد انجام میشود. این خطا تفاوت میان پیشبینی مدل و مقدار واقعی تعریف میشود.
دلایل خطا در مدلهای یادگیری ماشین
بهصورت کلی دو دلیل برای بروز خطا در مدلهای یادگیری ماشین وجود دارد که از این قرار است:
- بایاس مدلی را توصیف میکند که فرضیات سادهشدهای را ایجاد میکند تا تابع هدف یا همان Target Function آسانتر به دست آید؛ برای مثال، یک مدل ممکن است یاد بگیرد هر مردی که قدش ۱۸۰ سانتیمتر است، سایزش مدیوم است که این موضوع دقیقاً همان بایاس است؛ زیرا لزوماً چنین چیزی درست نیست!
- واریانس تغییرپذیری در پیشبینی مدل را توصیف میکند؛ بهعبارت دیگر، زمانی که دادههای مورداستفاده برای آموزش آن را تغییر میدهیم، پیشبینی مدل تغییر میکند.
برای دستیابی به یک راهحل دقیقتر، ما به دنبال کاهش میزان بایاس و واریانس موجود در مدل خود هستیم. این کار اصلاً ساده نیست. بایاس و واریانس با یکدیگر در تضاد هستند؛ کاهش یکی دیگری را افزایش میدهد که به این موضوع تریدآف بایاسـواریانس (Bias-Variance tradeoff) گفته میشود.
قبل از اینکه دربارهی منحنی یادگیری صحبت کنیم، اجازه دهید ابتدا به موضوع تریدآف بایاسـواریانس عمیقتر بپردازیم.
نگاهی به تریدآف بایاس-واریانس در منحنی یادگیری Learning Curve
همه الگوریتمهای یادگیری باناظر یا همان Supervised Learning برای دستیابی به یک هدف تلاش میکنند: تخمین تابع هدف (f_hat) برای متغیر هدف (y) با توجه به تعدادی از دادههای ورودی (X). تابع هدف تابعی است که مدل یادگیری ماشین قصد دارد آن را به دست آورد.
تغییر دادههای ورودی مورداستفاده برای نزدیکترشدن به متغیر هدف به تولید تابع هدف متفاوتی میانجامد که ممکن است بر خروجیهای پیشبینیشدهی مدل تأثیر بگذارد. میزان تغییر تابع هدف ما با تغییر دادههای آموزشی بهعنوان واریانس یا variance شناخته میشود. ما نمیخواهیم مدل ما واریانس بالایی داشته باشد؛ زیرا با اینکه الگوریتم ما ممکن است در طول آموزش عملکرد بیعیبونقصی داشته باشد، نمیتواند بهدرستی به نمونههای دیدهنشده تعمیم یابد.
پیشنهاد میکنیم با مفهوم یادگیری با ناظر (Supervised Learning) هم آشنا شوید.
توضیح تریدآف بایاس-واریانس در منحنی یادگیری یا Learning Curve
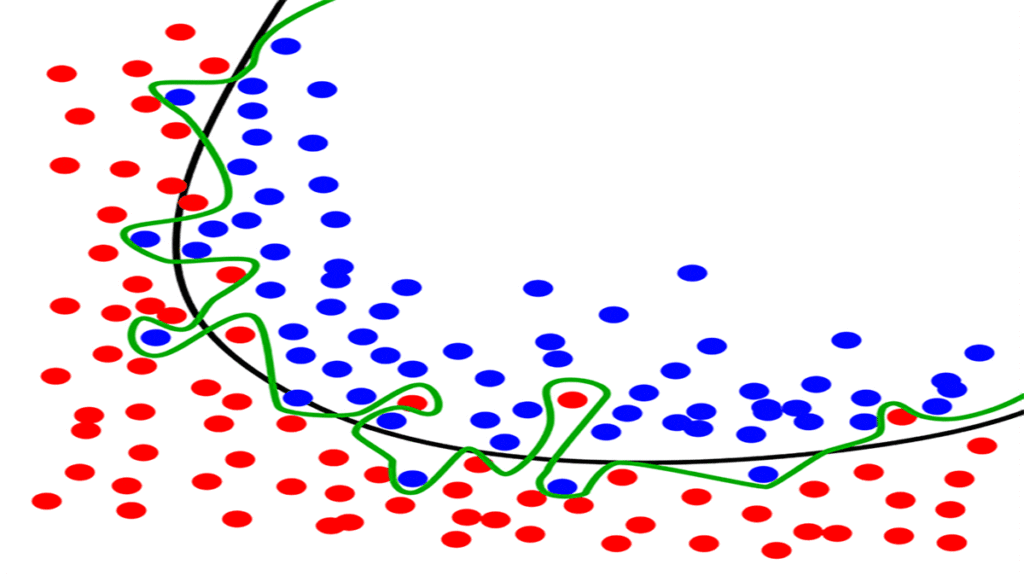
در این تصویر تابع هدف تقریبی خط سبز و خطی که بهترین حالت مدل را نشان میدهد یا بهعبارتی بهترین fit برای دادههاست بهرنگ مشکی است. توجه کنید که مدل چقدر دقیق دادههای آموزشی را با خط سبز یاد میگیرد. در این حالت مدل تمامی تلاش خود را میکند تا اطمینان حاصل شود که همهی نمونههای قرمز و آبی از هم جدا هستند. اگر این مدل را روی مشاهدههای جدید آموزش دهیم، یک تابع هدف کاملاً جدید را یاد میگیرد و سعی میکند همان رفتار را اعمال کند.
سناریویی را در نظر بگیرید که در آن از یک روش خطی مانند رگرسیون خطی (Linear Regression) برای بهدستآوردن تابع هدف استفاده میکنیم. اولین چیزی که درمورد رگرسیون خطی باید به آن توجه کرد این است که یک رابطهی خطی میان دادههای ورودی و هدفی را فرض میکند که میخواهیم پیش بینی کنیم؛ اما نکته اینجاست که رویدادهای دنیای واقعی بسیار پیچیدهتر هستند. این فرض ساده بهقیمت ازمیانبردن انعطافپذیری، یادگیری تابع هدف را بسیار سریعتر و درک آن را آسانتر میکند. ما از این پارادایم بهعنوان بایاس یاد میکنیم.
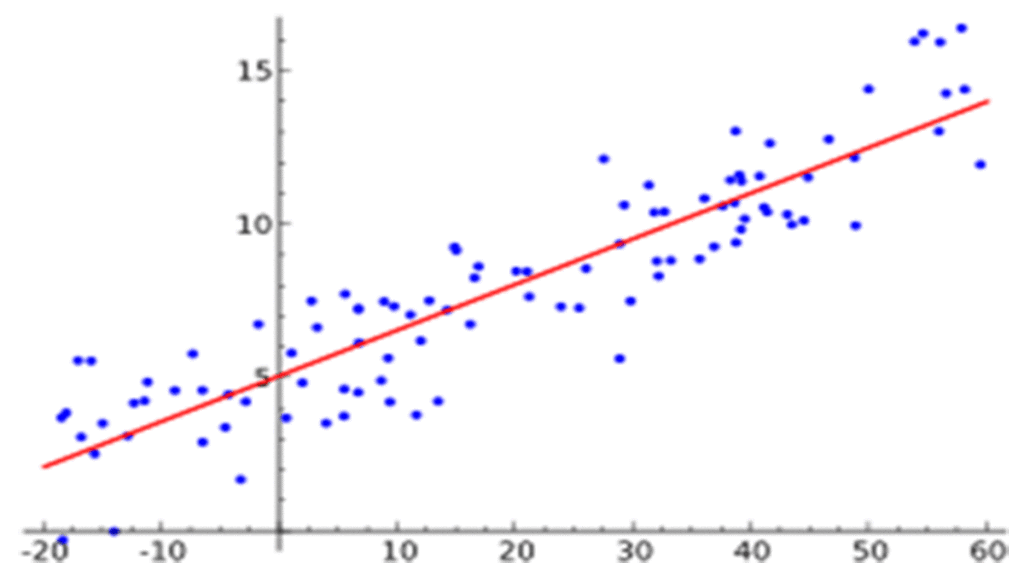
در این تصویر خط قرمز نشاندهندهی تابع هدف آموختهشده است. بسیاری از نمونهها با مقادیر پیشبینیشدهی مدل فاصلهی زیادی دارند.
ما میتوانیم با ایجاد انعطافپذیری بیشتر میزان بایاس مدل را کاهش دهیم، اما این کار به ایجاد واریانس میانجامد. از طرف دیگر، ما میتوانیم واریانس یک مدل را با سادهسازی آن کاهش دهیم، اما این کار خود باعث ایجاد بایاس میشود. هیچ راهی برای فرار از این رابطه وجود ندارد. بهترین راهحل این است که یک مدل را انتخاب کنید و آن را بهگونهای پیکربندی کنید که تعادلی میان میزان بایاس و واریانس برقرار کند.
خطای کاهشناپذیر
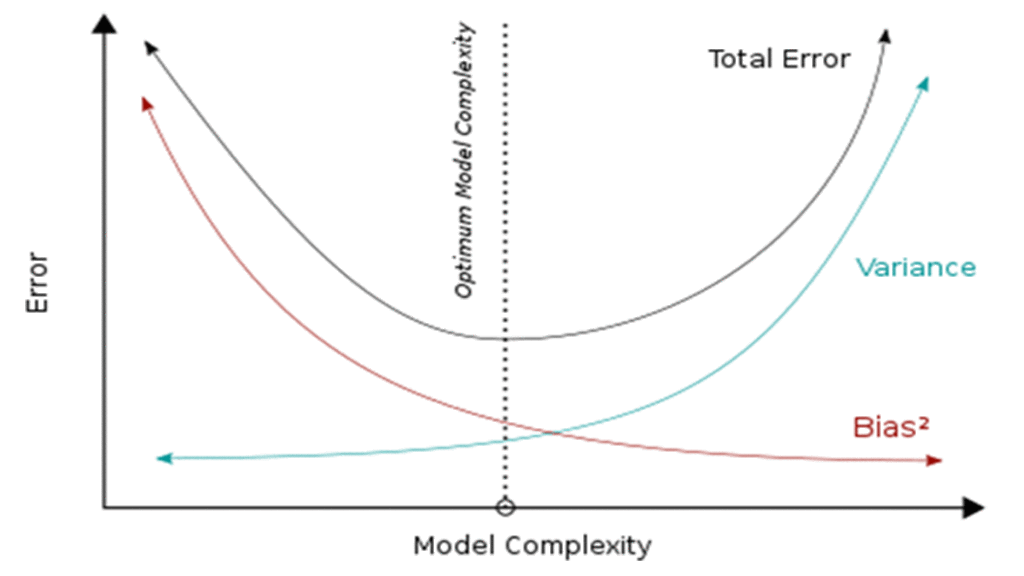
با توجه به عوامل ناشناختهی مؤثر بر تابع هدف، همیشه خطا در مدل وجود دارد که این خطا بهعنوان خطای کاهشناپذیر شناخته میشود. این را میتوان در تصویر بالا با توجه به مقدار خطای که در پایینترین نقطه نمودار خطای کل رخ میدهد مشاهده کرد. برای ساخت مدل ایدهآل باید تعادلی میان بایاس و واریانس پیدا کنیم که خطای کل به حداقل برسد که در شکل با خط نقطهچین بهنام پیچیدگی مدل بهینه نشان داده شده است.
حال بیایید با استفاده از منحنیهای یادگیری، بایاس و واریانس را بیشتر بررسی کنیم.
پیشنهاد میکنیم با رگرسیون خطی (Linear Regression) هم آشنا شوید.
آناتومی منحنی یادگیری
منحنیهای یادگیری نمودارهایی هستند که برای نشاندادن عملکرد یک مدل با افزایش اندازهی مجموعهی آموزشی استفاده میشوند. راه دیگری که میتوان از آن استفاده کرد نشاندادن عملکرد مدل در یک دورهی زمانی مشخص است. ما معمولاً از آنها برای بررسی الگوریتمهایی استفاده میکنیم که بهصورت تدریجی از دادهها آموزش میبینند. بهاین شکل که با ارزیابی یک مدل روی مجموعه دادههای آموزشی و اعتبارسنجی، عملکرد مدل را رسم میکنیم.
برای مثال، تصور کنید ما رابطهی میان برخی ورودیها و خروجیها را با استفاده از یک الگوریتم یادگیری ماشین مدلسازی کردهایم. ما با آموزش مدل با یک نمونه و اعتبارسنجی آن با صد نمونه شروع میکنیم. فکر میکنید چه اتفاقی می افتد؟ اگر حدس زدید که مدل دادههای آموزشی را بهخوبی یاد میگیرد، درست است؛ هیچ خطایی وجود نخواهد داشت.

توضیح آناتومی منحنی یادگیری
مدلکردن رابطهی یک ورودی با خروجی کار سختی نیست. تنها کاری که باید انجام دهید این است که آن رابطه را به خاطر بسپارید. بخش دشوار کار تلاش برای پیشبینی دقیق در صورت ارائهی نمونههای جدید و دیدهنشده است. از آنجا که مدل ما دادههای آموزشی را بهخوبی یاد گرفته است، تلاش برای تعمیم به دادههایی که قبلاً دیده نشدهاند عملکرد بسیار بدی خواهد داشت؛ درنتیجه، این مدل در دادههای اعتبارسنجی ما عملکرد ضعیفی خواهد داشت. این بهآن معناست که تفاوت زیادی میان عملکرد مدل ما در دادههای آموزشی و دادههای اعتبارسنجی وجود دارد. ما این تفاوت را خطای تعمیم مینامیم.
اگر قرار است الگوریتم ما شانسی برای پیشبینی بهتر در مجموعهی دادهی اعتبارسنجی داشته باشد، باید دادههای بیشتری اضافه کنیم. معرفی نمونههای جدید به دادههای آموزشی بهناچار تابع هدف مدل ما را تغییر میدهد. نحوهی عملکرد مدل در حین رشد مجموعهی دادهی آموزشی را میتوان نظارت و ترسیم کرد تا تکامل میزان خطای آموزش و اعتبارسنجی را آشکار کند.
بنابراین ما دو نمودار خواهیم داشت که دو نتیجهی متفاوت را باید نشان دهند:
- منحنی آموزش: منحنی محاسبهشده از دادههای آموزشی. برای اطلاع از چگونگی یادگیری یک مدل استفاده میشود.
- منحنی اعتبارسنجی: منحنی محاسبهشده از دادههای اعتبارسنجی. برای اطلاع از میزان تعمیم مدل به نمونههای دیدهنشده استفاده میشود.
این منحنیها به ما نشان میدهند با رشد دادهها مدل چقدر خوب عمل میکند؛ از این رو منحنی یادگیری نامیده میشوند.
پیشنهاد میکنیم با تفاوت یادگیری ماشین و یادگیری عمیق هم آشنا شوید.
خلاصهی مطالب دربارهی منحنی یادگیری یا Learning Curve
بهطور خلاصه، رفتار یک مدل را میتوان با استفاده از منحنیهای یادگیری مشاهده کرد. سناریوی ایدهآل هنگام ساخت مدلهای یادگیری ماشین این است که خطا را تا حد امکان پایین نگه دارید. دو عاملی که به خطای بالا میانجامند بایاس و واریانس هستند و توانایی ایجاد تعادل میان هر دو به یک مدل با عملکرد بهتر میانجامد.
یادگیری ماشین لرنینگ با کلاسهای آنلاین آموزش علم داده و یادگیری ماشین کافهتدریس
اگر به یادگیری ماشین و علم داده علاقه دارید و دوست دارید فرصتهای شغلی جذابی پیش روی خود داشته باشید، کلاسهای آنلاین آموزش علم داده و یادگیری ماشین کافهتدریس به شما کمک میکند از هر نقطهی جغرافیایی به بهروزترین و کاملترین آموزش دیتا ساینس و ماشین لرنینگ دسترسی داشته باشید.
کلاسهای آنلاین آموزش علم داده و یادگیری ماشین کافهتدریس در دورههای مقدماتی و پیشرفته برگزار میشود و شکل برگزاری آن کاملاً پویا و تعاملی و کارگاهی، مبتنی بر کار روی پروژههای واقعی علم داده، است.
برای آشنایی بیشتر با کلاسهای آنلاین آموزش علم داده کافهتدریس و مشاورهی رایگان برای شروع یادگیری دیتا ساینس و ماشین لرنینگ روی این لینک کلیک کنید:
برای ماشین لرنینگ
آیا مهمه که پایه ریاضی مون چطوریه؟
حوزه ماشین لرنینگ و دیتاساینس بر پایهی ریاضیات بنا شده، اما لزومی نداره حتما تو ریاضی نابغه باشین یا خیلی استعداد خاصی داشته باشین. یه سری مفاهیم اصلی ریاضی و آمار رو بدونین کفایت می کنه، اونم برای اینه که بدونین این مدلها چطور کار میکنن، چون تمام محاسبات توسط مدل انجام میشه. توی دوره علم داده کافه تدریس پیشنیازهای ریاضی و امار به شکل ویدیو در اختیارتون قرار میگیره.