
الکس نت (AlexNet) یک شبکهی عصبی عمیق است که Alex Krizhevsky، Ilya Sutskever و Geoffrey Hinton در سال 2012 ارائه کردند. این معماری بهمنظور طبقهبندی تصاویر مجموعهدادهی ImageNet در رقابت ILSVRC طراحی شد و توانست رتبهی اول را کسب کند.
- 1. شبکههای عصبی کانولوشنی و الکسنت (AlexNet)
- 2. معماری الکس نت (AlexNet) چگونه است؟
-
3.
لایهبندی شبکهی عصبی الکسنت (AlexNet)
- 3.1. لایهی اول (C1): اولین لایهی کانولوشن
- 3.2. لایهی دوم (S2): اولین لایهی ادغام (Max pooling)
- 3.3. لایهی سوم (C3): دومین لایهی کانولوشن
- 3.4. لایهی چهارم (S4): دومین لایهی ادغام (Max pooling)
- 3.5. لایهی پنجم (C5): سومین لایهی کانولوشن
- 3.6. لایهی ششم (C6): چهارمین لایهی کانولوشن
- 3.7. لایهی هفتم (C7): پنجمین لایهی کانولوشن
- 3.8. لایهی هشتم (S8): سومین لایهی ادغام (Max pooling)
- 3.9. لایهی نهم (F9): اولین لایهی کاملاً متصل (Fully Connected)
- 3.10. لایهی دهم (F10): دومین لایهی کاملاً متصل (Fully Connected)
- 3.11. لایهی یازدهم (F11): سومین لایهی کاملاً متصل (Fully Connected)
- 4. جمعبندی موارد گفتهشده دربارهی شبکهی الکسنت (AlexNet)
- 5. یادگیری دیتا ساینس و ماشین لرنینگ با کلاسهای آنلاین آموزش علم داده کافهتدریس

شبکههای عصبی کانولوشنی و الکسنت (AlexNet)
شبکههای عصبی کانولوشنی (CNNs / Convolutional Neural Networks) که نوعی شبکهی عصبی عمیق محسوب میشوند بهمنظور تقلید از فرایندهای بیولوژیکی بینایی انسان طراحی شدهاند. این شبکهها با استفاده از چندین لایه که بهروشهای مختلف مرتب شدهاند تا ساختارهای متمایز شبکه را تشکیل دهند. شبکههای عصبی کانولوشنی (CNNs) اغلب در شناسایی و طبقهبندی تصاویر استفاده میشوند.
الکس نت (AlexNet) یک شبکه عصبی کانولوشنی (CNN) است که یکی از بزرگترین شبکههای زمان خود محسوب میشود. این شبکه ۱۱ لایه را دربرمیگیرد. در ادامهی این مطلب جزئیات هر یک از این لایهها را توضیح خواهیم داد.
برای آشنایی با شبکهی عصبی گوگلنت این مطلب را مطالعه کنید:
گوگل نت (GoogleNet) چیست و از چه ساختاری تشکیل شده است؟
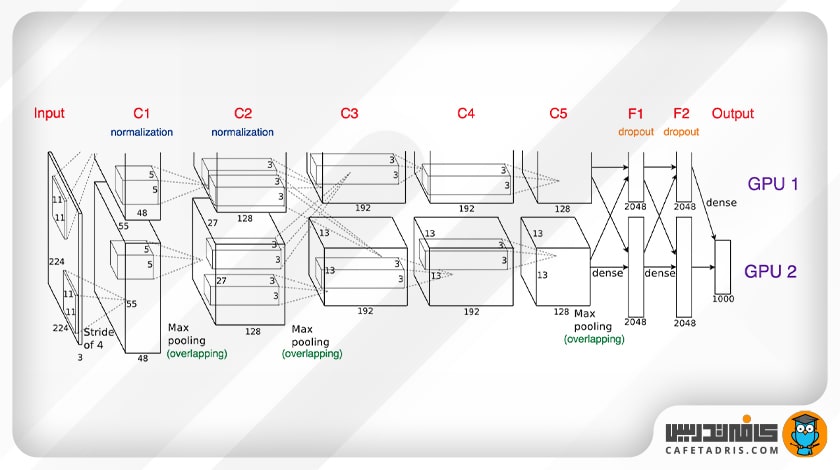
معماری الکس نت (AlexNet) چگونه است؟
الکس نت (AlexNet) یک شبکه عصبی کانولوشنی عمیق است که بهمنظور شناسایی و طبقهبندی تصاویر رنگی با سایز ۲۲۴x۲۲۴x۳ ارائه شده است. بهطور کلی این شبکهی عصبی ۶۲میلیون پارامتر یادگیری و ۱۱ لایه دارد. معماری AlexNet بهطور همزمان طی ۶ لایه روی دو GPU Nvidia Geforce GTX 580 آموزش دیده و بههمین دلیل، به دو بخش (Pipeline) تقسیم شده است.
لایهبندی شبکهی عصبی الکسنت (AlexNet)
بهتر است بهصورت کلی با هم به لایههای موجود در معماری الکس نت (AlexNet) نگاهی بیندازیم:
- لایهی اول (C1): ۹۶ لایه کانولوشن با سایز ۱۱×۱۱؛
- لایهی دوم (S2): لایهی ادغام (Max Pooling) با اندازهی ۳×۳؛
- لایهی سوم (C3): ۱۵۶ لایهی کانولوشن با اندازهی ۵×۵؛
- لایهی چهارم (S4): لایهی ادغام (Max Pooling) با اندازهی ۳×۳؛
- لایهی پنجم (C5): ۳۸۴ لایهی کانولوشن با اندازهی ۳×۳؛
- لایهی ششم (C6): ۳۸۴ لایهی کانولوشن با اندازهی ۳×۳؛
- لایهی هفتم (C7): ۲۵۶ لایهی کانولوشن با اندازهی ۳×۳؛
- لایهی هشتم (S8): لایهی ادغام (Max Pooling) با اندازهی ۳×۳؛
- لایهی نهم (F9): لایهی کاملاً متصل با اندازهی ۴۰۹۶؛
- لایهی دهم (F10): لایهی کاملاً متصل با اندازهی ۴۰۹۶؛
- لایهی یازدهم (F11): لایهی کاملاً متصل با سایز ۱۰۰۰.
این شکل لایهها را بهتر نشان میدهد:

حال که متوجه کلیات هر یک از ۱۱ لایه از معماری الکس نت (AlexNet) شدیم، جزئیات هر لایه را بررسی میکنیم.

لایهی اول (C1): اولین لایهی کانولوشن
لایهی اول شبکهی الکس نت (AlexNet) یک لایهی کانولوشن است که عکسی با اندازهی ۳×۲۲۴×۲۲۴ را بهعنوان ورودی دریافت میکند؛ سپس با استفاده از ۹۶ کرنل ۱۱×۱۱ با مقدار گام (Stride) ۴ و مقدار لایهگذاری (Padding) برابر ۲ عمل کانولوشن را روی عکس ورودی انجام میدهد. خروجی این لایه ۹۶ نقشهی ویژگی (Feature Map) به اندازهی ۵۵×۵۵ است که به یک تابع فعالساز واحد یکسوشدهی خطی (ReLU) وارد و به لایهی بعدی منتقل میشود. این لایه ۳۴۹۴۴ پارامتر یادگیری را دربردارد.
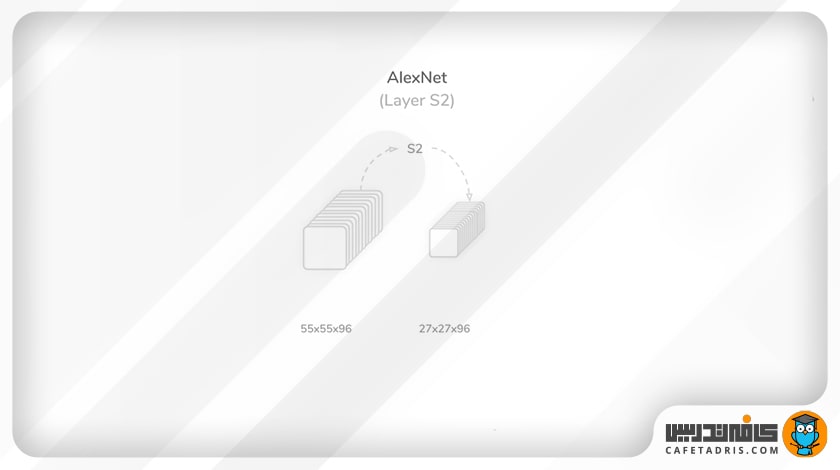
لایهی دوم (S2): اولین لایهی ادغام (Max pooling)
همانطور که در بخش قبل متوجه شدیم، خروجی لایهی اول ۹۶ نقشهی ویژگی (Feature Map) با اندازهی ۵۵×۵۵ است که در مرحلهی دوم به یک لایهی ادغام (Max pooling) وارد میشود. در این مرحله فرایند ادغام (Max pooling) با کرنلی به اندازهی ۳×۳، مقدار گام (Stride) ۲ و مقدار لایهگذاری (Padding) صفر انجام میشود. خروجی این لایهی ۹۶ نقشهی ویژگی (Feature Map) با اندازهی ۲۷×۲۷ است که به لایهی بعد انتقال مییابد.
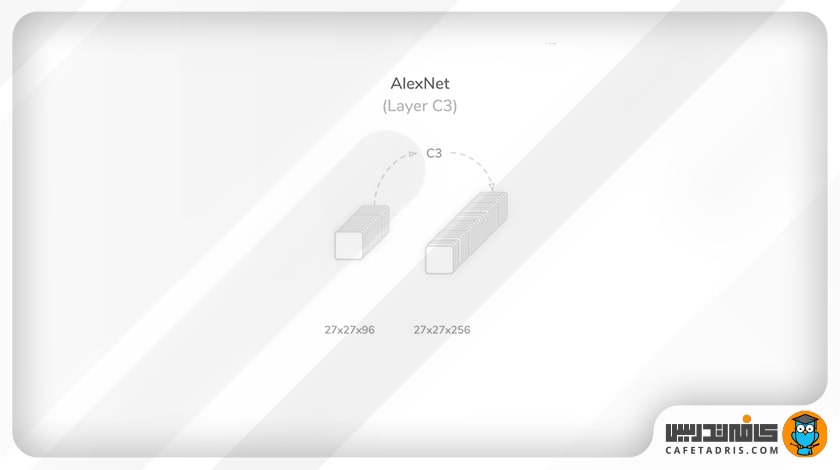
لایهی سوم (C3): دومین لایهی کانولوشن
در این مرحله بار دیگر خروجی مرحلهی قبل (لایهی دوم) که ۹۶ نقشهی ویژگی با اندازهی ۲۷×۲۷ است بهعنوان ورودی وارد میشود. در اینجا عملیات کانولوشن با ۲۵۶ کرنل ۵×۵، مقدار گام (Stride) ۱ و مقدار لایهگذاری (Padding) ۲ انجام میشود. این لایهی خروجی با اندازهی ۲۵۶×۲۷×۲۷ را تولید میکند که به یک تابع فعالساز واحد یکسوشدهی خطی (ReLU) وارد و به لایهی بعدی منتقل میشود. این لایه ۶۱۴۶۵۶ پارامتر یادگیری را دربردارد که مجموع آن با لایههای قبلی به ۶۴۹۶۰۰۰ میرسد.


لایهی چهارم (S4): دومین لایهی ادغام (Max pooling)
لایهی چهارم معماری شبکهی الکس نت (AlexNet) یک لایهی ادغام (Max pooling) است که خروجی لایهی قبلی را بهعنوان ورودی دریافت میکند. در اینجا هم مانند لایهی دوم فرایند ادغام (Max pooling) با کرنلی بهاندازهی ۳×۳، مقدار گام (Stride) ۲ و مقدار لایهگذاری (Padding) صفر انجام میشود. این لایه در خروجی ۲۵۶ نقشهی ویژگی (Feature Map) با اندازهی ۱۳×۱۳ میدهد که درنهایت یک تابع فعالساز واحد یکسوشدهی خطی (ReLU) بر روی آن اعمال و به لایهی بعد وارد میشود.
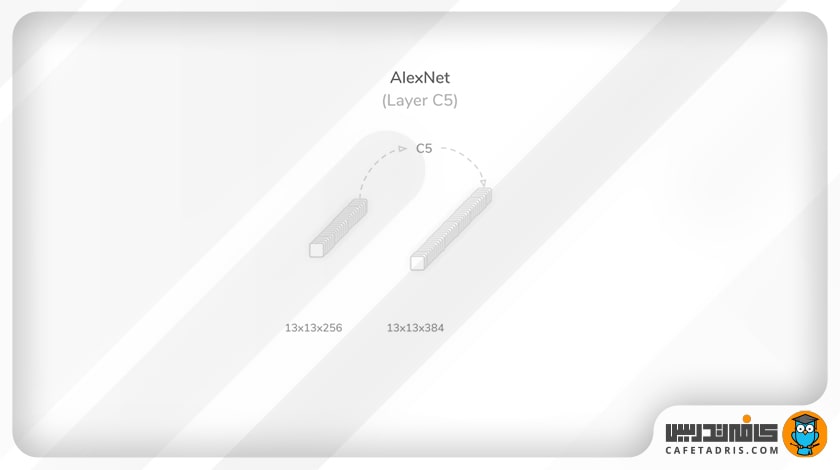
لایهی پنجم (C5): سومین لایهی کانولوشن
ورودی این لایه خروجی لایهی قبل، یعنی ۲۵۶ نقشهی ویژگی (Feature Map) با اندازهی ۱۳×۱۳، است. در این مرحله فرایند کانولوشن با استفاده از ۳۸۴ کرنل ۳×۳ و مقدار گام (Stride) و لایهگذاری (Padding) برابر با ۱ انجام میشود. این لایه در خروجی ۳۸۴ نقشهی ویژگی (Feature Map) با اندازهی ۳×۳ میدهد که درنهایت یک تابع فعالساز واحد یکسوشدهی خطی (ReLU) روی آن اعمال میشود تا به لایهی بعدی وارد شود.
این لایه ۸۸۵۱۲۰ پارامتر یادگیری است که بهطور کلی با لایههای شبکه تا الان ۱۵۳۴۷۲۰ پارامتر است.
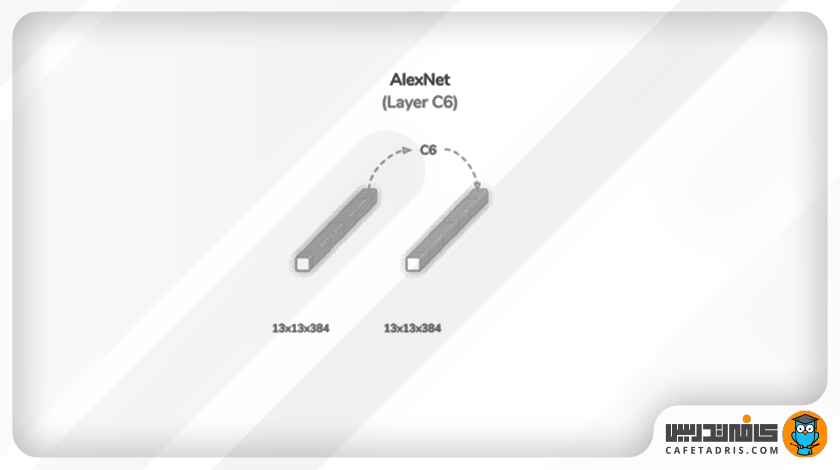
لایهی ششم (C6): چهارمین لایهی کانولوشن
بار دیگر فرایند کانولوشن در این مرحله روی خروجی لایهی کانولوشن قبلی اعمال میشود. فرایند کانولوشن در این مرحله کاملاً مشابه کانولوشن در لایهی 5 (C5) است؛ بنابراین اندازهی خروجی آن نیز یکسان خواهد بود. خروجی این لایه نیز مانند تمامی لایههای قبلی، به تابع فعالساز واحد یکسوشدهی خطی (ReLU) وارد میشود.
تعداد پارامترهای این لایه ۱۳۷۴۸۸ است که با جمع لایههای قبلی به ۲۸۶۲۲۰۸ میرسد.
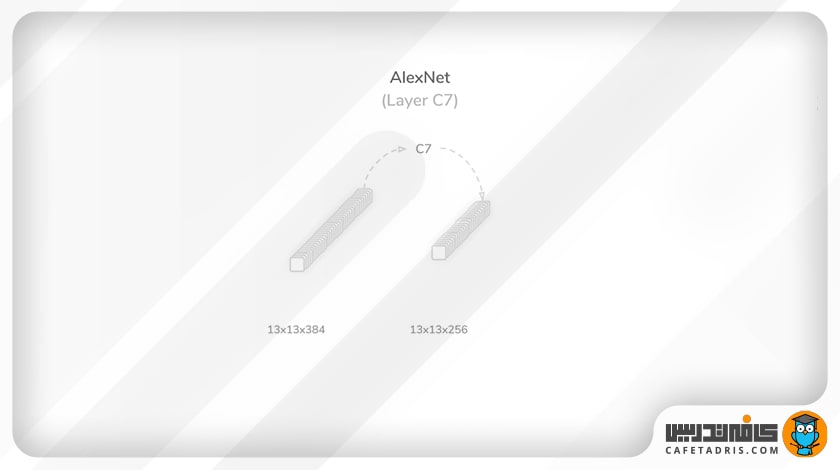
لایهی هفتم (C7): پنجمین لایهی کانولوشن
در این لایه عملیات کانولوشن با ۲۵۶ کرنل ۳×۳ و مقدار گام (Stride) و لایهگذاری (Padding) برابر با ۱ روی خروجی لایهی قبل انجام میشود. خروجی این لایه اندازهای برابر با ۲۵۶×۱۳×۱۳ دارد که مانند مراحل قبل از یک تابع فعالساز واحد یکسوشدهی خطی (ReLU) عبور میکند تا به لایهی بعدی برسد.
تعداد پارامترها در این لایه با ۸۸۴۹۹۲ برابر است و بهطور کلی شبکه تا این مرحله ۳۷۴۷۲۰۰ پارامتر یادگیری را دربرمیگیرد.
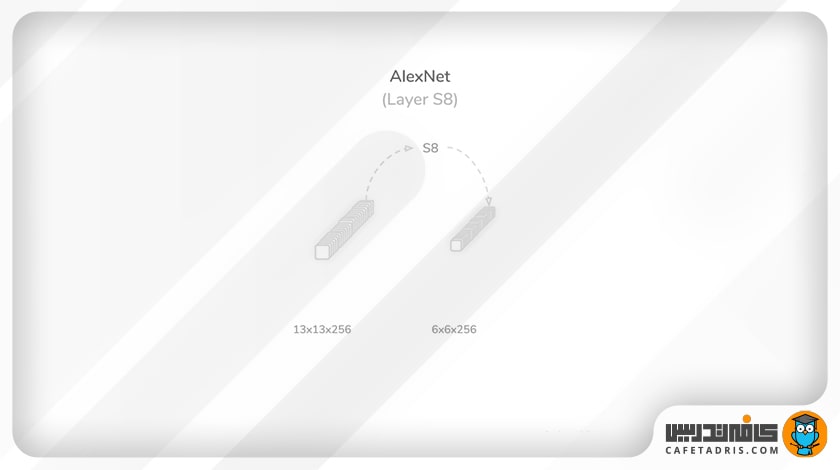
لایهی هشتم (S8): سومین لایهی ادغام (Max pooling)
همانطور که مشخص است، ورودی این لایه خروجی لایهی قبل، یعنی ۲۵۶ نقشهی ویژگی ۱۳×۱۳، است. در این مرحله فرایند ادغام (Max pooling) دقیقاً مانند لایهی دوم (S2) و چهارم (S4) با کرنلی به اندازهی ۳×۳، مقدار گام (Stride) ۲ و مقدار لایهگذاری (Padding) صفر انجام میشود. این لایه ۲۵۶ نقشهی ویژگی با اندازهی ۶×۶ را تولید میکند که به یک تابع فعالساز واحد یکسوشدهی خطی (ReLU) وارد میشود.
تا اینجا، یعنی لایهی هشتم، شبکه ۳۷۴۷۲۰۰ پارامتر یادگیری دارد و هنوز سه لایهی دیگر باقی مانده است. سه لایهی دیگر شبکه از نوع کاملاً متصل (Fully Connected) هستند. در ادامه با هم جزئیات این لایهها را بررسی میکنیم.
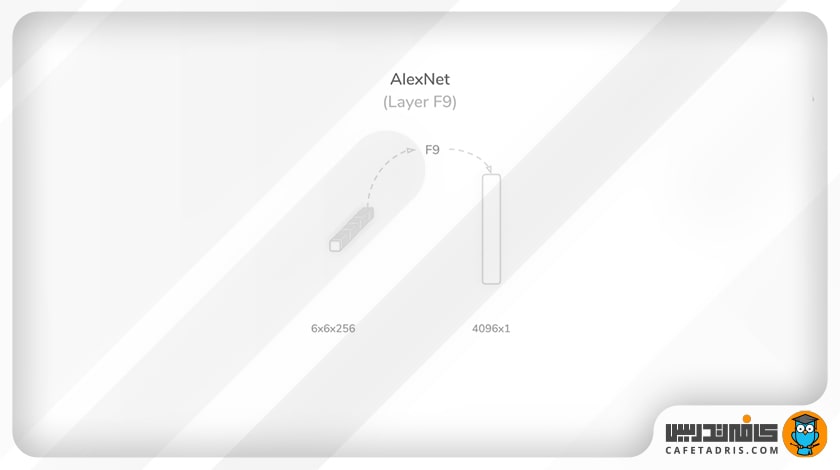
لایهی نهم (F9): اولین لایهی کاملاً متصل (Fully Connected)
این لایهی خروجی لایهی قبل را بهصورت مسطحشده (Flatten) دریافت میکند و جمع وزنی تمامی نودها را با مقدار بایاس (Bias) جمع میکند. اندازهی خروجی در این لایه برابر با ۴۰۹۶×۱ است که یک تابع فعالساز واحد یکسوشدهی خطی (ReLU) روی آن اعمال میشود. این لایه ۳۷۷۵۲۸۳۲ پارامتر یادگیری دارد و مجموع پارامترهای شبکه به ۴۱۵۰۰۰۳۲ رسیده است.
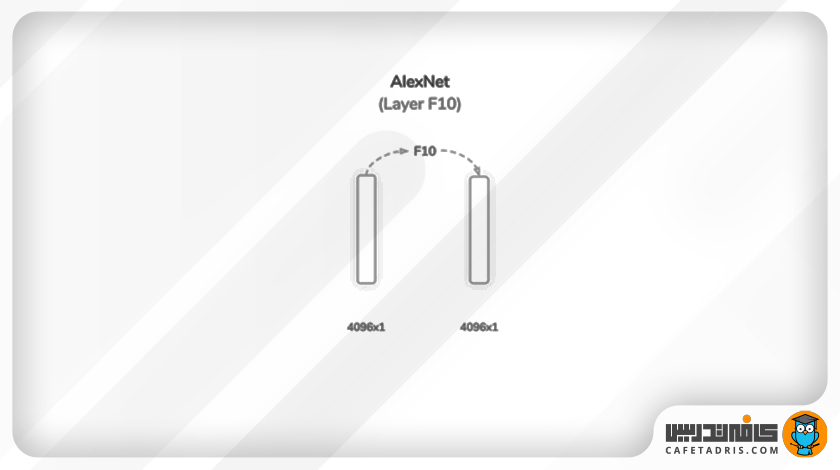
لایهی دهم (F10): دومین لایهی کاملاً متصل (Fully Connected)
همانطور که در شکل قبلی مشخص است، ورودی این لایه همان خروجی لایهی نهم (F9) است. در این مرحله همان فرایند لایهی قبلی روی ورودی اعمال میشود و بار دیگر خروجی به اندازهی ۴۰۹۶×۱ خواهیم داشت که به تابع فعالساز واحد یکسوشدهی خطی (ReLU) وارد میشود تا درنهایت به لایهی آخر منتقل شود.
تعداد پارامترهای یادگیری لایهی دهم برابر با ۶۷۸۱۳۱۲ است که مقدار کل پارامترهای شبکه را به ۵۸۲۸۱۳۴۴ میرساند.
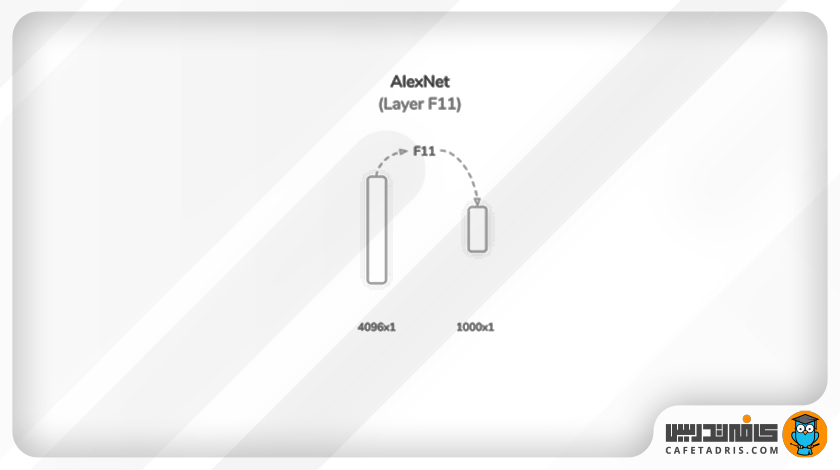
لایهی یازدهم (F11): سومین لایهی کاملاً متصل (Fully Connected)
لایهی نهایی شبکهی الکس نت (AlexNet) یا همان لایهی یازدهم (F11)، مانند دو لایهی قبلی، یعنی F10 و F9، عمل میکند و خروجیای بهاندازهی ۱۰۰۰×۱ را ارائه میکند. در این مرحله خروجی لایهی آخر به یک تابع فعالساز سافتمکس وارد میشود. خروجی تابع سافتمکس احتمال هر کلاس را نشان میدهد.
تعداد پارامترهای لایهی آخر برابر با ۴۰۹۷۰۰۰ است که نهایتاً مجموع پارامترهای شبکه را به ۶۲۳۷۸۳۴۴ میرساند.
حال که تمامی لایههای شبکهی الکس نت (AlexNet) را بررسی کردیم، بهتر است مطالب گفتهشده را با هم مرور کنیم.
جمعبندی موارد گفتهشده دربارهی شبکهی الکسنت (AlexNet)
شبکه الکس نت (AlexNet) یک شبکهی عصبی کانولوشنی عمیق است که روی مجموعهدادهی ImageNet رقابت ILSVRC سال ۲۰۱۰ آموزش داده شده است. این شبکه رتبهی اول رقابت 2012 ILSVRC را کسب کرد. شبکهی الکس نت (AlexNet) ۱۱ لایه دارد. در این جدول میتوانیم خلاصهای از ساختار این شبکه را مشاهده کنیم:
| تعداد فیلتر | گام | سایز کرنل | ابعاد خروجی | عملیات | لایهها |
| – | – | – | 227x227x3 | – | ورودی |
| 96 | 4 | 11×11 | 55x55x96 | کانولوشن (Convolution) | 1 |
| 96 | 2 | 3×3 | 27x27x96 | ادغام (Max pooling) | 2 |
| 256 | 1 | 5×5 | 27x27x256 | کانولوشن (Convolution) | 3 |
| 256 | 2 | 3×3 | 13x13x256 | ادغام (Max pooling) | 4 |
| 384 | 1 | 3×3 | 13x13x384 | کانولوشن (Convolution) | 5 |
| 384 | 1 | 3×3 | 13x13x384 | کانولوشن (Convolution) | 6 |
| 256 | 1 | 3×3 | 13x13x256 | کانولوشن (Convolution) | 7 |
| 256 | 2 | 3×3 | 6x6x256 | ادغام (Max pooling) | 8 |
| – | – | – | 4096 | کاملاً متصل (Fully Connected) | 9 |
| – | – | – | 4096 | کاملاً متصل (Fully Connected) | 10 |
| – | – | – | 1000 | کاملاً متصل (Fully Connected) | 11 |
یادگیری دیتا ساینس و ماشین لرنینگ با کلاسهای آنلاین آموزش علم داده کافهتدریس
اگه به یادگیری علم داده و یادگیری ماشین علاقهمند هستید، کلاسهای آنلاین آموزش علم داده کافهتدریس به شما امکان میدهد از هر نقطهی جغرافیایی به بهروزترین و جامعترین آموزش دسترسی داشته باشید.
کلاسهای آنلاین دیتا ساینس کافهتدریس در دورههای مقدماتی و پیشرفته برگزار میشود و مبتنی بر کار روی پروژههای واقعی علم داده است.
برای آشنایی با کلاسهای آنلاین آموزش علم داده کافهتدریس روی این لینک کلیک کنید:
به طور کلی الکس نت به شبکه کانولوشنی قوی است که در آن قوه قوی مانند قوه بینایی انسان تشکیل شده است و همانند او تقلید میکند و این دستگاه حدود ۶۰میلیون پارامتر یادگیری دارد و روی شبکه داده image net می افتند و با ۱۱لایه که هر کدام مار متمازی میکنند ساخته شده است و یکی از آنها 224در 224در 3 است هر یک از این لایه ها با کنار هم قرار گرفتن و وجود کانولوشن های شان شبکه را می سازند .
پاسخ سوال ۲
این لایه پس از پایان یافتن خروجی قبل ورودی خود را شروع میکند با اندازه نقشه feature map
55در 55است همچنین این لایه نقش ادغام یا pooling دارد و با نقشه 27در 27خارج میشود و ReLUتابع ساز فعال آن است
جواب پرسش آخر
لایه های fully connected از لایه نهم شروع میشوند و لایه قبلی به شکل مسطح شده flatten دریافت جمع وزنی نودها رو به شکل bias جمع میکنند که ویژگی آن ها به شمار می رود و سپس نسبت اندازه آنها با لایه های قبلی متفاوت بوده اندازه آنها بزرگ تر است و لایه های نهم و دهم 1در 4096و لایه آخر 1در 1000و پارامتر هم نسبت به قسمت های دیگر افزایش یافته به طوری که ۴۰۹۷۰۰۰پارامتر یادگیری دارد و در مجموع همه آنها ۶۲۳۷۸۳۴۴است .
الکسنت (AlexNet) چه نوع شبکهای است و چگونه با دیگر شبکههای عصبی متفاوت است؟
الکس نت (AlexNet) یک شبکه عصبی کانولوشنی عمیق است که بهمنظور شناسایی و طبقهبندی تصاویر رنگی با سایز ۲۲۴x۲۲۴x۳ ارائه شده است.
لایهی کانولوشن دوم در معماری الکسنت (AlexNet) با چه نامی شناخته میشود و چه کارکردی دارد؟
دومین لایهی ادغام (Max pooling)
چرا لایههای کاملاً متصل (Fully Connected) در معماری الکسنت (AlexNet) مهم هستند و لایهی کاملاً متصل سوم (F11) چه ویژگی خاصی دارد؟
لایهی نهایی شبکهی الکس نت (AlexNet) یا همان لایهی یازدهم (F11)، مانند دو لایهی قبلی، یعنی F10 و F9، عمل میکند و خروجیای بهاندازهی ۱۰۰۰×۱ را ارائه میکند.
چون کاملا متصل به لایه های دیگر است
مانند دو مرحله آخر عمل میکند
این مرحله خروجی لایهی آخر
به یک تابع فعالساز سافتمکس وارد میشود. خروجی تابع سافتمکس احتمال هر کلاس را نشان میدهد.
سایز۱٠٠٠
سوال ۲:
max pooling
خروجی لایهی اول ۹۶ نقشهی ویژگی (Feature Map) با اندازهی ۵۵×۵۵ است که در مرحلهی دوم به یک لایهی ادغام (Max pooling) وارد میشود. در این مرحله فرایند ادغام (Max pooling) با کرنلی به اندازهی ۳×۳، مقدار گام (Stride) ۲ و مقدار لایهگذاری (Padding) صفر انجام میشود. خروجی این لایهی ۹۶ نقشهی ویژگی (Feature Map) با اندازهی ۲۷×۲۷ است که به لایهی بعد انتقال مییابد.
سوال ۱:
الکس نت یک شبکه عصبی کانولوشن است که یکی از بزرگترین شبکههای زمان خود محسوب میشود. این شبکه ۱۱ لایه را دربرمیگیرد.
شبکه عصبی کانولوشنی عمیق است که بهمنظور شناسایی و طبقهبندی تصاویر رنگی با سایز ۲۲۴x۲۲۴x۳ ارائه شده است.
ممنون عالی بود
سلام
ممنون از توجه شما
عالی بود ینی هرچقدر تشکر کنم کمه واقعا چون خیلی راحت وروان می نویسین همراه با تصویر و اینفوگرافیک واین باعث میشه راحت یادگیری صورت بگسره
خوشحالیم که مفید بوده براتون.
ممنون واقعا خیلی خیلی داره بهم در یادگیری کمک میکنه خیلیم کامل عالیییی دستت درد نکه
ممنون دوست عزیز که نظرتون رو با ما به اشتراک میذارین.
Thank you for the useful lecture.. I sent you an email, could you please get back to me?
به چه آدرسی ایمیل دادین؟ اگه سوالی دارین، میتونین با ایدی ادمین کانال علمداده در ارتباط باشین. لینک کانال: https://t.me/DSLanders
در زمینه AlexNet سورس کامل تری هم برای تز پایان نامه ام دارید معرفی کنید ؟
بهترین سورس خود مقاله اصلی هست. بهتره به اون مراجعه کنین.
It was great. I’m sorry, I’m 11 years old and I’m very interested in datascience
ممنون از اشتراک نظرتون دوست عزیز. امیدواریم مسیر همواری پیشرو داشته باشین.
واقعا از شما ممنونم که مقالات تخصصی را برای ما رایگان میذارید مرسی از شما
سپاس از شما.