

شبکه عصبی واحد بازگشتی گیتی (Gated Recurrent Unit) یا بهاختصار شبکه GRU نوع خاصی شبکه عصبی بازگشتی RNN است. این شبکه تا حد زیادی مشابه شبکه عصبی LSTM (حافظه کوتاه مدت طولانی) است؛ بهعبارت دیگر، شبکه GRU نوع پیشرفتهتری از شبکه عصبی بازگشتی RNN است و شبکه LSTM است. در این مطلب بهصورت مختصر دو شبکه RNN و LSTM را توضیح خواهیم داد و درنهایت با شبکه GRU آشنا خواهیم شد.
شبکه عصبی بازگشتی (Recurrent Neural Network / RNN)
شبکه عصبی RNN نوعی شبکه عصبی با حافظه داخلی است. این شبکه در ساختارش حلقهای دارد که از طریق آن در هر گام (Step) خروجی گام قبلی بههمراه ورودی جدید به شبکه وارد میشود. این حلقه به شبکه کمک میکند تا اطلاعات قبلی را در کنار اطلاعات جدید داشته باشد و بتواند براساس این اطلاعات خروجی مدنظر را ارائه کند. این ویژگی شبکه عصبی بازگشتی (RNN) امکان کار دادههای ترتیبی (Sequential Data)، مانند متن، صدا و غیره، را به ما میدهد.
مشکل اصلی شبکه RNN حافظه کوتاه آن است که در بلندمدت این شبکه توانایی یادگیری اطلاعاتی را که در گامهای زمانی بسیار قبلتر به شبکه شده است از دست میدهد. دلیل این موضوع مفهومی بهنام محوشدگی گرادیان (Vanishing Gradient) است.


شبکه (Long-Short Term Memory (LSTM
برای حل مشکل حافظه کوتاهمدت شبکه RNN نوع دیگری بهنام شبکه عصبی LSTM (حافظه کوتاهمدت طولانی) معرفی شد. شبکه LSTM مکانیسمهای داخلی بهنام گیت (Gate) دارد. این گیتها جریان اطلاعات را کنترل میکنند. این گیتها مشخص میکنند که چه دادههایی از توالی مهم هستند و باید همچنان حفظ شوند و چه دادههایی باید حذف شوند. بهاین شکل، شبکه اطلاعات مهم را در طول زنجیره توالی عبور میدهد تا خروجی مدنظر را داشته باشیم. در تصویر ۱ میبینیم که ساختار داخلی شبکه LSTM چندین عملیات مختلف دارد. این عملیات به شبکه LSTM کمک میکند اطلاعات را حفظ یا فراموش کند.

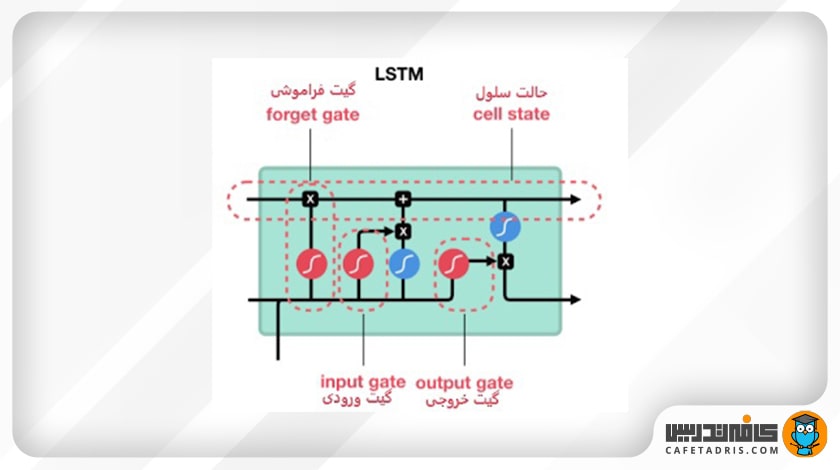
مهمترین بخش در ساختار شبکه LSTM حالت سلول (Cell State) است که میتوانیم آن را حافظه داخلی شبکه در نظر بگیریم. cell state اطلاعات را در شبکه منتقل میکند که این اطلاعات ساختارهایی بهنام گیت (Gate) آپدیت میشوند. شبکه LSTM سه گیت فراموشی (forget gate)، گیت ورودی (input gate) و گیت خروجی (output gate) است که هر یک وظایف خاص خود را در شبکه ایفا میکنند.
شبکه عصبی واحد بازگشتی گیتی (Gated Recurrent Unit / GRU)
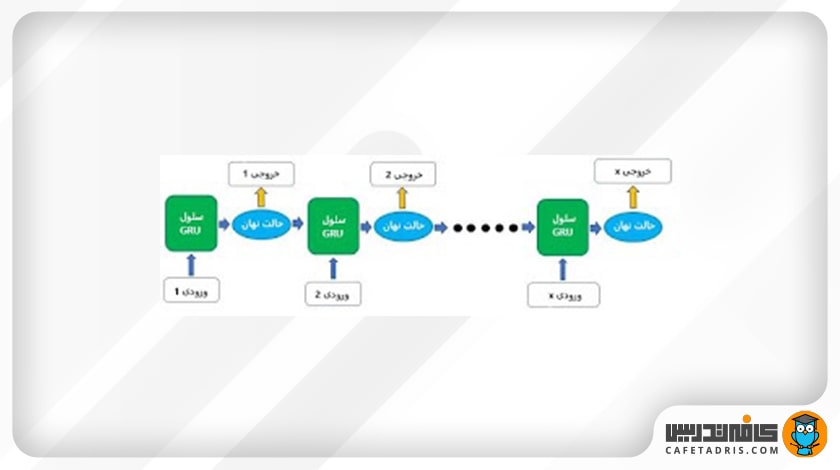
شبکه عصبی شبکه عصبی واحد بازگشتی گیتی یا GRU بسیار مشابه شبکه LSTM است، با این تفاوت که بهجای سه گیت، فقط دو گیت تنظیم مجدد (Reset Gate) و گیت بهروزرسانی (Update Gate) دارد؛ همچنین شبکه GRU چیزی بهنام حالت سلول (Cell State) ندارد و برای انتقال اطلاعات از حالت نهان (Hidden State) استفاده میکند. در تصویر ۲ ساختار یک شبکه GRU را مشاهده میکنیم.
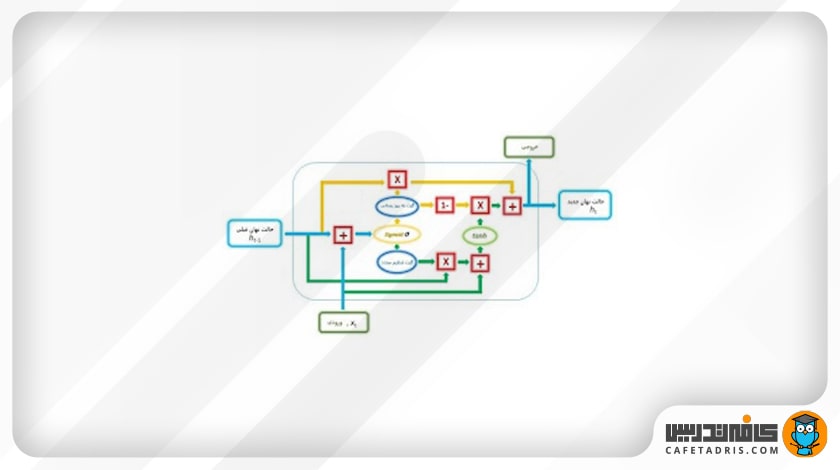
در تصویر ۳ یک سلول شبکه عصبی واحد بازگشتی گیتی با جزئیات آن مشخص شده است. همانطور که در تصویر میبینیم، در شبکه GRU هم مانند شبکه LSTM توابع سیگموید (Sigmoid) و تانژانت هایپربولیک (Tanh) وجود دارد.
بهتر است قبل از هر چیز با این توابع آشنا شویم.

تابع فعالساز تانژانت هایپربولیک (Tanh)
این تابع به تعدیل (regulate) مقادیری که در طول شبکه در جریان هستند کمک میکند. تابع Tanh تمام مقادیر را به بازه ۱- تا ۱ میبرد.

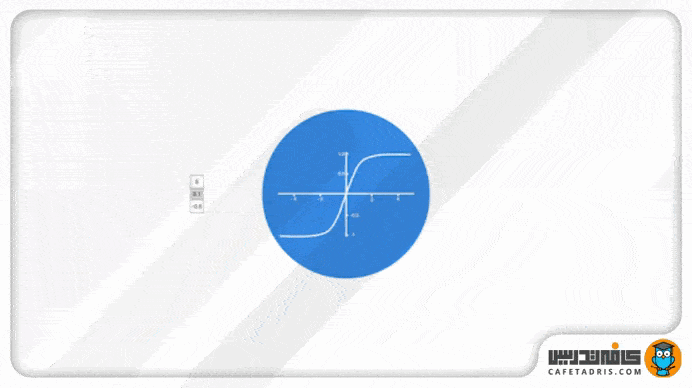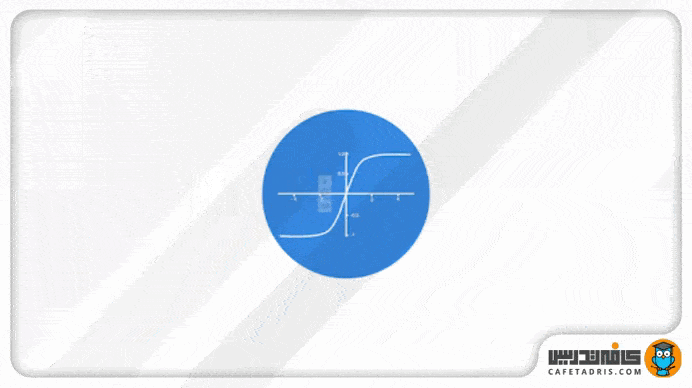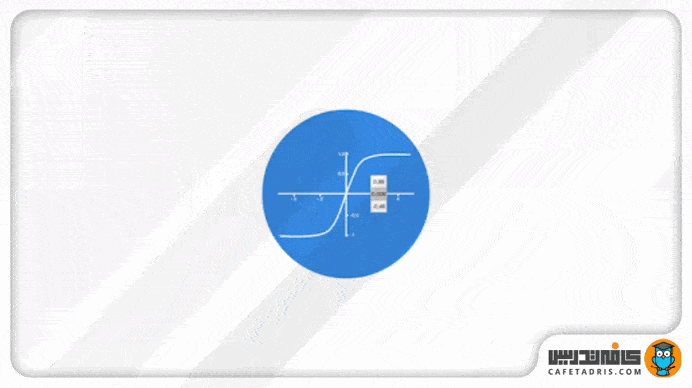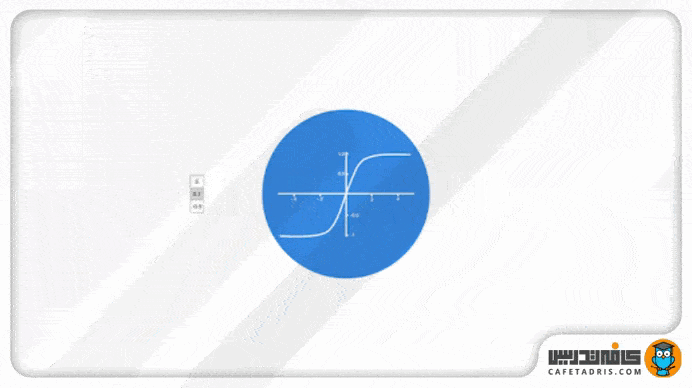
دلیل این کار این است که عملیات ریاضی مختلفی در طول شبکه روی بردارها انجام میشود؛ برای مثال، فکر کنیم اگر یک مقدار در طول شبکه بارها در عددی مانند ۳ ضرب شود، در این صورت میتوانیم فکر کنیم که مقادیر چقدر میتوانند بزرگ شوند.

تابع Tanh مقادیر شبکه را میان بازه ۱- تا ۱ قرار میدهد تا مقدار خروجی شبکه هم تعدیل شوند. همانطور که در تصویر ۶ میبینیم مقادیر با استفاده از تابع Tanh در یک بازه مشخصی (۱- تا ۱) باقی میمانند.
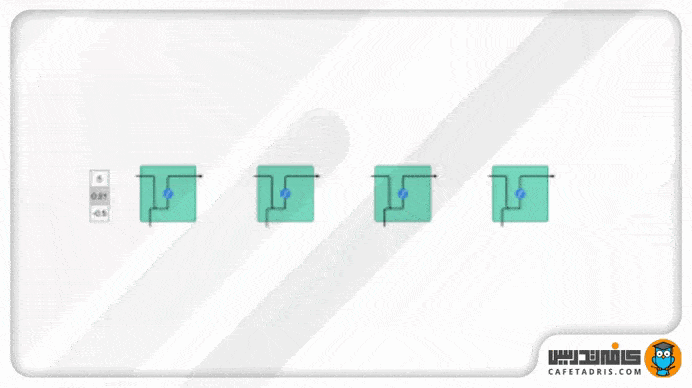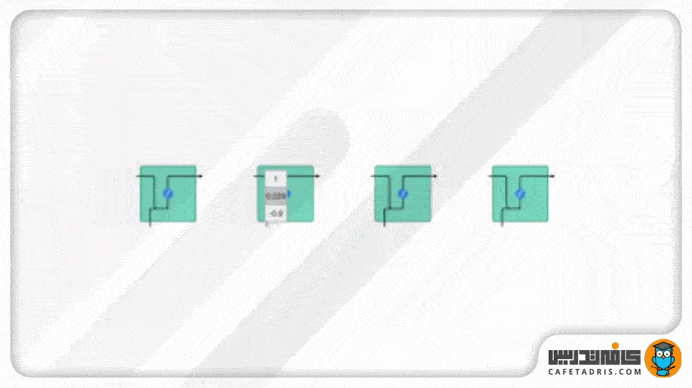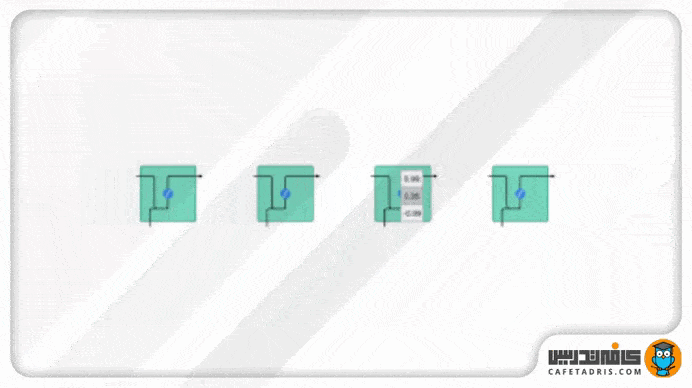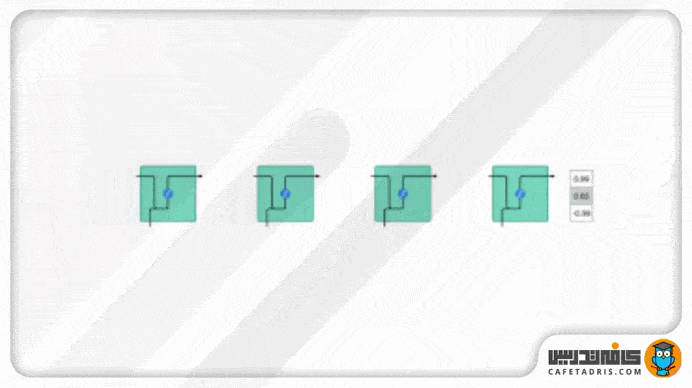
تابع فعالساز سیگموید (Sigmoid)
یکی دیگر از توابع فعالساز که در ساختار شبکه LSTM وجود دارد تابع Sigmoid است. این تابع مانند تابع Tanh عمل میکند، با این تفاوت که مقادیر را میان بازه صفر تا ۱ قرار میدهد. دلیل این کار این است که با بردن مقادیر در این بازه میتوانیم زمان آپدیتکردن یا فراموشکردن داده از آن استفاده کنیم؛ چون هر عددی که در صفر ضرب شود، نتیجه صفر میشود و این یعنی که این داده باید فراموش شود و هر عددی که در ۱ ضرب شود برابر با خودش میشود و این یعنی این داده باید حفظ شود؛ بهاین شکل، شبکه یاد میگیرد که کدام اطلاعات را فراموش و کدام را حفظ کند.
پیشنهاد میکنیم با توابع فعالساز (Activation Functions) بیشتر آشنا شوید.

حال وقت آن رسیده که با گیتهای موجود در ساختار شبکه GRU آشنا شویم: گیتهای تنظیم مجدد (Reset Gate) و گیت بهروزرسانی (Update Gate).
گیت بهروزرسانی (Update Gate)
این گیت دقیقاً مانند دو گیت فراموشی (Forget Gate) و ورودی (Input Gate) در شبکه LSTM عمل میکند. این گیت تصمیم میگیرد چه مقدار از اطلاعات گذشته، یعنی اطلاعاتی که در گامهای قبلی داشتیم، به شبکه اضافه شود. در این گیت مقدار ورودی جدید (xt) بههمراه مقدار حالت نهان گام قبلی (ht-1) در وزن متناظر خود ضرب و سپس با هم جمع میشوند و به یک تابع سیگموید وارد میشوند تا خروجی میان بازه صفر تا ۱ قرار بگیرد. در زمان آموزش شبکه این وزنها هر بار بهروزرسانی میشوند تا فقط اطلاعات مفید به شبکه اضافه شوند.
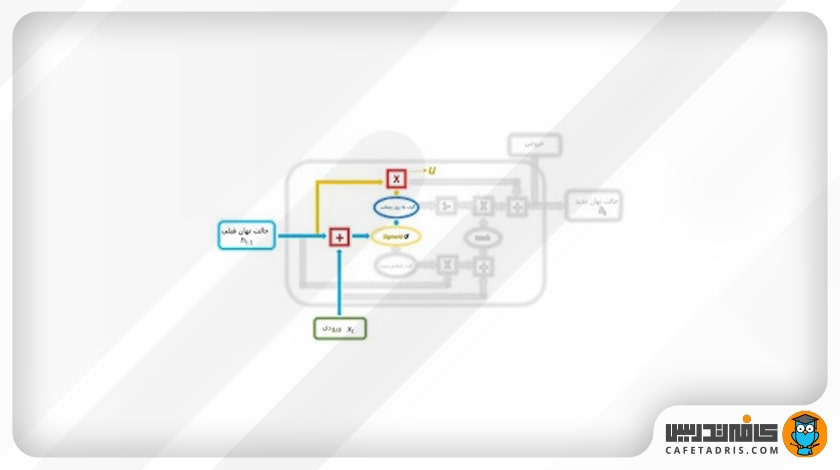
درنهایت خروجی گیت بهروزرسانی با حالت نهان گام قبلی ضرب نقطهای (pointwise multiplication) میشوند تا بعدها برای محاسبه خروجی استفاده شود.
گیت تنظیم مجدد (Reset Gate)
این گیت تصمیم میگیرد چه مقدار از اطلاعات گذشته، یعنی اطلاعات گامهای قبلی، فراموش شود. در اینجا هم مقدار ورودی جدید (xt)، بههمراه مقدار حالت نهان گام قبلی (ht-1)، در وزن متناظر خود ضرب و سپس با هم جمع میشوند و به یک تابع سیگموید وارد میشوند تا خروجی بین بازه صفر تا ۱ قرار بگیرد. تفاوتی که با گیت بهروزرسانی دارد این است که وزنهایی که مقدار ورودی و حالت نهان گام قبلی در آن ضرب میشوند متفاوت است و این یعنی بردارهای خروجی در اینجا با بردار خروجی که در گیت بهروزرسانی داریم متفاوت خواهد بود.
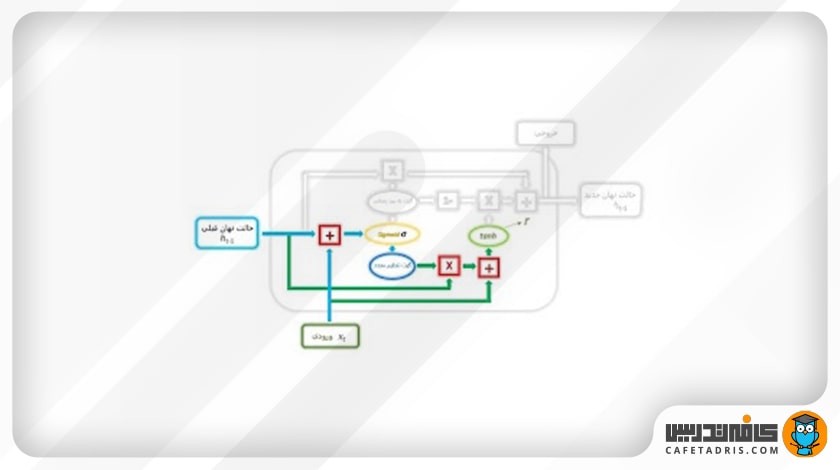
سپس خروجی گیت reset با حالت نهان گام قبلی ضرب نقطهای میشود؛ همچنین ورودی جدید ابتدا در یک وزن خاص ضرب و سپس با خروجی ضرب گیت reset با حالت نهان گام قبلی جمع میشود؛ درنهایت این بردار خروجی به یک تابع Tanh وارد میشود.
خروجی نهایی
در گام نهایی ما بار دیگر از بردار خروجی گیت بهروزرسانی برای به دست آوردن حالت نهایی جدید (new hidden state) استفاده میکنیم.

در این مرحله معکوس بردار (Element-Wise Inverse Version) خروجی گیت بهروزرسانی با خروجی که از تابع Tanh به دست آوردیم (r) ضرب نقطهای میشود. هدف این است که گیت بهروزرسانی تشخیص دهد چه اطلاعات جدیدی که در این گام به دست آمده است در حالت نهان جدید ذخیره شود. درنهایت خروجی این مرحله با خروجی ضرب نقطهای گیت بهروزرسانی با حالت نهان قبلی (u) جمع میشود و حالت نهان جدید را ایجاد میکند.
این حالت نهان میتواند بهعنوان خروجی نهایی (گام آخر) استفاده شود.
خلاصه مطالب درباره شبکه عصبی GRU
شبکه شبکه عصبی واحد بازگشتی گیتی برای حل مشکل محوشدگی گرادیان (Vanishing Gradient) که در شبکه عصبی بازگشتی (RNN) با آن مواجه بودیم معرفی شد. این نکته لازم به ذکر است که در حال حاضر شبکه عصبی بازگشتی و انواع خاص آن، یعنی شبکههای LSTM و GRU، در زمینههای مختلفی مانند پردازش زبانهای طبیعی با مدلهای انتقالی (Transformer) جایگزین شدهاند.
با کافهتدریس کلاس آنلاین علم داده را آسان بیاموزید!
اگر به علم داده علاقه دارید و دوست دارید بهصورت اصولی این شاخه را یاد بگیرید و در آن فعالیت کنید، کلاسهای آنلاین علم داده کافهتدریس فرصتی عالی برای شماست.
کلاسهای آنلاین علم داده کافهتدریس در ۱۶۰ ساعت و بهصورت کاملاً کارگاهی و در قالب کار روی پروژههای واقعی دیتاساینس برگزار میشود.
شما با شرکت در کلاسهای آنلاین علم داده کافهتدریس، نهتنها به جامعترین منابع آموزشی علم داده دسترسی دارید، هر جای ایران که هستید میتوانید علم داده را آسان یاد بگیرید.
برای آشنایی با کلاسهای آنلاین علم داده کافهتدریس روی این لینک کلیک کنید: