
مشکل محوشدگی گرادیان (Vanishing Gradient) چگونه رخ میدهد؟ در یادگیری ماشین (Machine Learning) زمانیکه شبکهی عصبی را با استفاده از روشهای مبتنی بر گرادیان، مانند انتشار روبهعقب (Backpropagation)، آموزش میدهیم، با مشکل محوشدگی گرادیان مواجه میشویم. این مشکل امکان یادگیری و بهروزرسانی وزنها در لایههای اولیهی شبکه دشوار میکند؛ درواقع مشکل محوشدگی گرادیان یکی از رفتارهای ناپایدار شبکه است که هنگام آموزش شبکه ممکن است با آن مواجه شویم.
در این مطلب مشکل محوشدگی گرادیان (Vanishing Gradient)، دلیل ایجاد آن و راهحلهای موجود برای رفعش را شرح میدهیم.
محوشدگی گرادیان (Vanishing Gradient) چیست؟
محوشدگی گرادیان (Vanishing Gradient) موقعیتی را توصیف میکند که در آن یک شبکهی عصبی پیشخور عمیق (Deep Feed Forward Neural Network) یا یک شبکهی عصبی بازگشتی (RNN) تواند اطلاعات مفید گرادیان را از سمت لایهی خروجی بهسمت لایهی ورودی عبور دهد.
اما این به چه معناست؟ بهتر است با جزئیات بیشتری دربارهی آن صحبت کنیم. زمانیکه یک شبکهی عصبی که از توابع فعالساز خاصی، مانند تابع سیگموید (Sigmoid)، استفاده میکند، تعداد لایهها افزایش مییابد، مقدار گرادیان تابع زیان (Loss Function) به صفر نزدیک میشود و این آموزش شبکه را با مشکل مواجه میکند.

چرا مشکل محوشدگی گرادیان (Vanishing Gradient) اتفاق میافتد؟
برخی توابع فعالساز، مانند تابع سیگموید (Sigmoid)، مقادیر ورودی با مقیاس بزرگ را در یک بازهی کوچک میان صفر و 1 قرار میدهند؛ بنابراین زمانیکه یک تغییر بسیار بزرگ در مقدار ورودی تابع اتفاق میافتد، خروجی تابع تنها مقدار کمی تغییر میکند؛ این یعنی مقدار مشتق آن خیلی کوچک میشود.
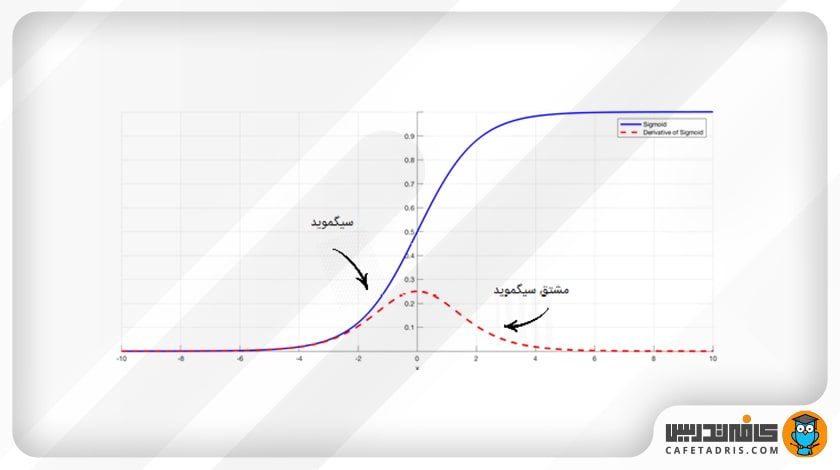
برای مثال، در شکل بالا تابع سیگموید را بههمراه مشتق آن مشاهده میکنیم. همانطور که میبینیم زمانیکه مقدار ورودی تابع بزرگ یا کوچک میشود، مقدار مشتق آن به صفر نزدیک میشود.
تا اینجا متوجه شدیم محوشدگی گرادیان زمانی اتفاق میافتد که مقدار مشتق ورودیها به صفر نزدیک شود، اما باید ببینیم این در شبکه چه اهمیتی دارد؟
چرا مشکل محوشدگی گرادیان اهمیت دارد؟
در شبکههای کمعمق که تعداد لایههای آنها کم است استفاده و از این توابع و مشکل محوشدگی گرادیان (Vanishing Gradient) خیلی اهمیت ندارد، اما زمانیکه تعداد لایههای شبکه زیاد باشد، این مشکل به این میانجامد که مقدار گرادیان در حدی کوچک شود که امکان آموزش شبکه وجود نداشته باشد.
درواقع گرادیان شبکه با فرایند انتشار روبهعقب محاسبه میشود. اگر بخواهیم سادهتر بگوییم، در فرایند انتشار روبهعقب مقدار مشتقهای شبکه با حرکت از سمت لایهی خروجی بهسمت لایهی ورودی به دست میآید؛ درواقع یک مشتق زنجیرهای از لایهی آخر بهسمت لایهی اول انجام میشود.
حال تصور کنیم که n لایه از تابعی مانند تابع سیگموید استفاده میکنند؛ این یعنی n مقدار مشتق کوچک در هم ضرب میشوند (مشتق زنجیرهای). این امر به این میانجامد که مقدار گرادیان در طول انتشار روبهعقب بهصورت نمایی کاهش یابد.
مقدار گرادیان کوچک بهمعنای این است که وزنهای لایههای اول بهدرستی بهروزرسانی نمیشوند. از آنجا که لایههای اول در شناسایی عناصر اصلی داده ورودی خیلی اهمیت دارند، این موضوع درنهایت کاری میکند که شبکهی خروجی قابلقبولی را ارائه نکند.
تا اینجا با مشکل محوشدگی گرادیان (Vanishing Gradient) آشنا شدیم و فهمیدیم چرا رفع آن اهمیت دارد، اما برای رفع آن چه راهحلهایی وجود دارد؟
در ادامه به چند مورد از راهحلهای موجود اشاره شده است.

راهحلهای رفع مشکل محوشدگی گرادیان
۱. اولین و سادهترین راه استفاده از توابع فعالسازی است که به مشتق با مقدار کوچک نمیانجامند؛ برای مثال، تابع واحد یکسوشدهی خطی (ReLU) جایگزین بسیار خوبی است.
۲. راهحل دوم استفاده از شبکههای باقیمانده (Residual networks) است. این شبکهها مجموعهای از اتصالات اضافی (Residual Connections) دارند که مستقیماً به لایههای اول وصل میشوند. همانطور که در شکل پایین مشخص است، یک اتصال اضافی (Residual Connection) مقدار x را از ابتدای بلاک مستقیماً به انتهای آن اضافه میکند (F(x)+x). روی این اتصال اضافی دیگر تابع فعالسازی اعمال نمیشود که مقدار مشتق را خیلی کوچک کند و به صفر نزدیک کند.

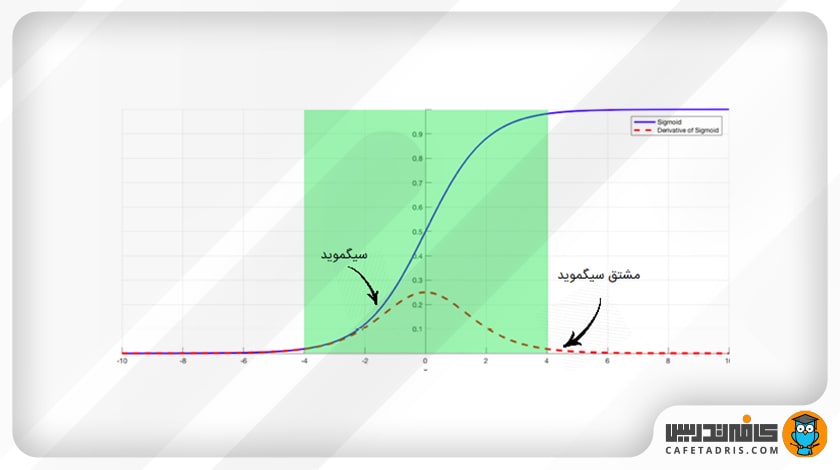
۳. راهحل آخر استفاده از لایههای عادیسازی دستهای (Batch Normalization Layers) است. همانطور که توضیح دادیم، مشکل زمانی ایجاد میشود که یک ورودی با مقیاس بزرگ در یک بازهی کوچک قرار میگیرد و به این میانجامد که مشتق بهقدری کوچک شود که کمکم به صفر برسد. عادیسازی دستهای، با عادیکردن مقدار ورودی، اجازه نمیدهد که مقدار ورودی به گوشههای تابع سیگموید برسد (در آنجا مشتق به صفر نزدیک میشود و از این راه به کاهش این مشکل کمک میکند). در شکل بعدی میبینیم که مقدار ورودی طوری نرمالسازی میشود که فقط در ناحیهی سبز رنگ قرار بگیرد، یعنی جایی که مقدار مشتق خیلی کوچک نیست.
خلاصه مطالب درباره محوشدگی گرادیان
در این مطلب مشکل محوشدگی گرادیان (Vanishing Gradient) را توضیح دادیم و با راهحلهای موجود برای رفع آن آشنا شدیم. یاد گرفتیم که محوشدگی گرادیان در آموزش شبکه مشکل ایجاد میکند و درنهایت شبکه نمیتواند خروجی مناسبی به دست دهد. دلیل این موضوع استفاده از توابعی مانند سیگموید (Sigmoid) است که مقادیر ورودی را در یک بازهی کوچک قرار میدهند که باعث میشود مقدار مشتق آن خیلی کوچک شود؛ همچنین اشاره شد که سادهترین راهحل استفاده از توابع فعالساز دیگری مانند ReLU است.
پیشنهاد میکنیم با یادگیری ماشین بیشتر آشنا شوید.
کلاسهای آنلاین آموزش علم داده کافهتدریس
کافهتدریس دورهی جامع آموزش علم داده را بهصورت آنلاین و پویا و کاملاً تعاملی برگزار میکند. این کلاسها در قالب مقدماتی و پیشرفته و بهصورت کارگاهی برگزار میشود و مبتنی بر کار روی پروژههای واقعی علم داده است.
شما به شرکت در کلاسهای آنلاین آموزش علم داده کافهتدریس از هر نقطهی جغرافیایی به بهروزترین و جامعترین آموزش دیتا ساینس دسترسی دارید.
برای آشنایی با کلاسهای آنلاین آموزش علم داده کافهتدریس و مشاورهی رایگان برای شروع یادگیری دیتا ساینس روی این لینک کلیک کنید:
خیلی خوب توضیح داده بود.
ممنون از توجه شما
من پایه ریاضی خوبی ندارم. برای شرکت تو دوره علم داده میخواستم یک پیش مطالعه ریاضی داشته باشم. چه مباحثی از ریاضی بیشتر در data science مطرح هست. آیا برای این مباحث ویدیوی آموزشی موجود دارید تا بتونم تهیه کنم؟
با ثبتنام در دورهها، ویدیوهای پیشمطالعه در مورد مباحث ریاضی و آمار و برنامهنویسی پایتون در اختیارتون قرار میگیره و جای نگرانی نیست. شما با مشاهدهی همون ویدیوها میتونین یادگیری علم داده رو شروع کنین.