
شبکه عصبی کانولوشنی (CNN) چیست؟ از آنجا که استفاده از شبکههای عصبی تماممتصل (Fully connected) عمیق به قدرت محاسباتی (حافظه) بالایی نیاز دارد تا بتوان تعداد زیادی وزن و ضرب ماتریسی سنگین را مدیریت کرد، نوع جدیدی از شبکههای عصبی بهنام شبکه عصبی کانولوشنی (Convolutional Neural Network) معرفی شد. در میان شبکههای عصبی، شبکه عصبی کانولوشنی یکی از بهترینها برای حل مسائل حوزهی بینایی ماشین (Computer Vision)، مانند شناسایی تصاویر (Image Detection)، طبقهبندی تصاویر (Image Classification)، تشخیص چهره (Face Recognition) و غیره، است. در این مطلب قصد داریم این شبکهی بسیار پرکاربرد یعنی شبکه عصبی کانولوشنی (CNN) را توضیح دهیم.

آیا کامپیوتر هم عکسها را مانند انسان میبیند؟
در طبقهبندی تصاویر شبکهی CNN عکسی را بهعنوان ورودی دریافت میکند، آن را تجزیهوتحلیل و در گروههای خاصی، برای مثال، سگ، گربه، ببر، شیر و غیره، طبقهبندی میکند، اما نکته مهم این است که کامپیوتر عکس را بهشکلی نمیبیند که ما میبینیم. کامپیوتر عکس ورودی را بهشکل آرایهای از پیکسلها میبیند. درواقع کامپیوتر آرایهای بهشکل h×w×d میبیند که در آن h همان طول تصویر، w عرض تصویر و d ابعاد تصویر است؛ برای مثال، یک عکس با آرایهی ۳×۴×۴ بهاین معناست که طول و عرض آن ۴ پیکسل و تعداد کانال رنگ آن ۳ است (RGB) که در این شکل میتوان آن را مشاهده کرد:
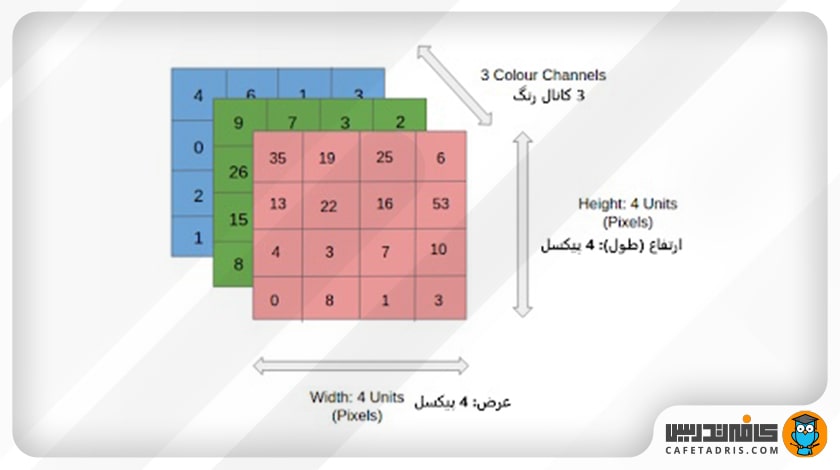
همچنین عکسی با آرایهی ۱×۶×۶ طول و عرض ۶ پیکسل و ۱ کانال رنگ دارد؛ بهاین معنا که عکس سیاهوسفید است، نه رنگی. هر یک از پیکسلها مقداری میان صفر تا ۲۵۵ دارند که درواقع این مقادیر شدت هر پیکسل را نشان میدهد؛ برای مثال، در یک عکس سیاهوسفید عدد صفر نشاندهندهی رنگ سیاه و عدد ۲۵۵ نشاندهندهی رنگ سفید است؛ اعداد میان این دو، هر قدر به صفر نزدیکتر باشند، تیرهتر هستند و برعکس. در این تصویر عکس سمت چپ چیزی است که ما میبینیم و عکس سمت راست چیزی است که کامپیوتر میبیند:

برای آشنایی با فرایند تشخیص چهره این مطلب را مطالعه کنید:
تشخیص چهره (Face Recognition) چیست و چطور کار میکند؟
ساختار شبکه عصبی کانولوشنی (CNN)
یک شبکه CNN از دو بخش کلی تشکیل شده است:
- استخراج ویژگی (Feature Extraction)
- طبقهبندی (Classification)
درواقع زمانیکه یک عکس به یک شبکهی CNN وارد میشود، ابتدا به مرحلهی استخراج ویژگی وارد میشود. در این مرحله هر عکس ورودی از چندین سری لایه کانولوشن (Convolution) و تابع فعالساز ReLU و لایهی pooling عبور میکند. سپس عکسهای ورودی به طبقهبندی وارد میشوند؛ در این مرحله ابتدا مسطحسازی (Flattening) صورت میگیرد و سپس به یک لایهی Fully Connected وارد میشوند و درنهایت یک تابع سافت مکس (Softmax) برای مسائل طبقهبندی چندکلاسه و یا تابع سیگموید (Sigmoid) برای مسائل طبقهبندی باینری روی آن اعمال میشود تا عکسها براساس مقادیر احتمالی میان صفر و یک طبقهبندی شوند.
در این شکل میتوانیم این فرایند را مشاهده کنیم:
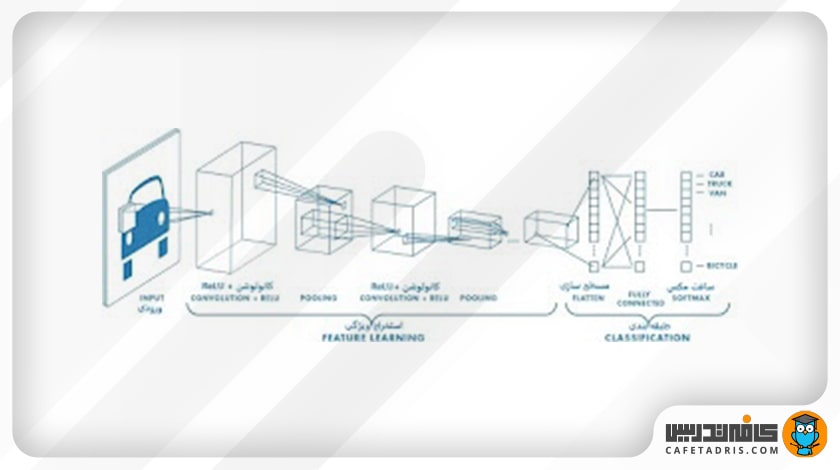
حال که بهطور کلی با فرایند طبقهبندی در یک شبکهی CNN آشنا شدیم، لازم است جزئیات هر بخش را بررسی کنیم.
مرحله اول: استخراج ویژگی (Feature Extraction)؛ لایه کانولوشن (Convolution)
این لایه اولین گام در استخراج ویژگی عکس ورودی است. در لایه کانولوشن، شبکه با استفاده از فیلترها (filter / kernel) که ماتریسهایی کوچک (معمولاً ۳×۳) هستند، ویژگیهای (feature) عکس را یاد میگیرد؛ اما این کار به چه شکلی انجام میشود؟
همانطور که گفتیم، کامپیوتر هر عکس ورودی را بهشکل ماتریسی از پیکسلها میبیند که هر یک از این پیکسلها مقداری بین صفر تا ۲۵۵ دارند؛ برای مثال، یک عکس ۵×۵ پیکسلی را در نظر میگیریم که در اینجا برای راحتی و درک بهتر مقدار هر پیکسل، بهجای صفر تا ۲۵۵، صفر یا یک است. این عکس ورودی ماست که در این شکل نمایی از ماتریس آن را مشاهده میکنیم:

در لایه کانولوشن مقدار پیکسلهای ماتریس عکس ورودی در یک فیلتر ضرب میشود. فیلتر یک ماتریس است که ممکن است مقادیر مختلفی داشته باشد.
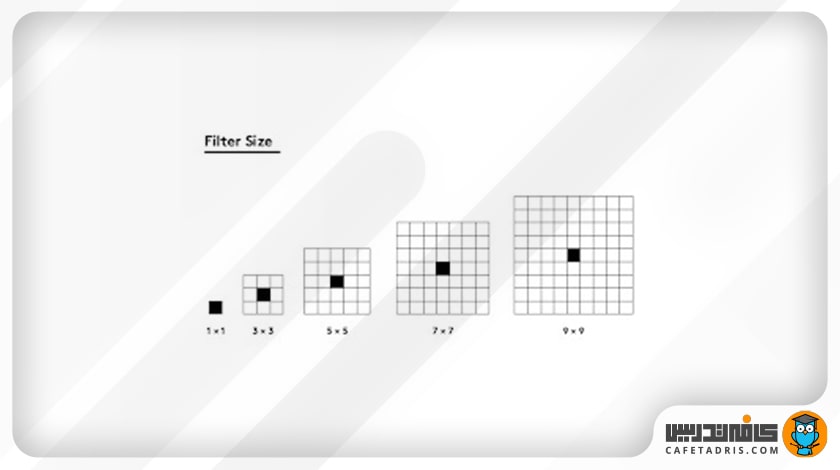
همچنین فیلترها در اندازههای مختلفی وجود دارند که در این شکل مشخص شده است:
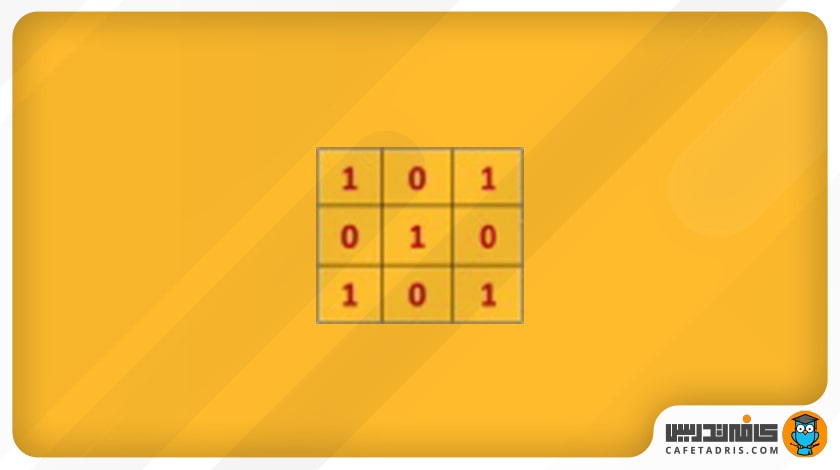
حال فرض میکنیم برای استخراج ویژگیهای عکس ورودی که ۵×۵ است، یک فیلتر ۳×۳ بهاین شکل داریم:
حال این فیلتر مثل یک پنجرهی کوچک روی عکس ورودی قرار میگیرد و بهعبارت دیگر، میتوانیم بگوییم این فیلتر با عکس ورودی ادغام (Convolve) میشود. این فیلتر روی هر بخش از عکس ورودی که قرار میگیرد مقدار هر پیکسل آن با مقدار پیکسل متناظرش در ماتریس عکس ورودی ضرب میشود؛ حاصلجمع ضرب تمامی پیکسلها با پیکسلهای متناظرشان ماتریس جدیدی را ایجاد میکند که به آن Convolved Layer / Convolutional Feature / Feature map / Filter map گفته میشود. در این شکل میتوانید این فرایند را مشاهده کنید:
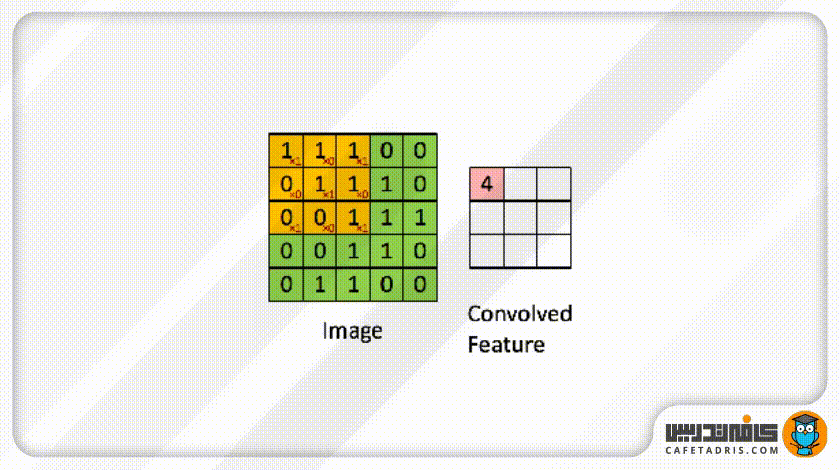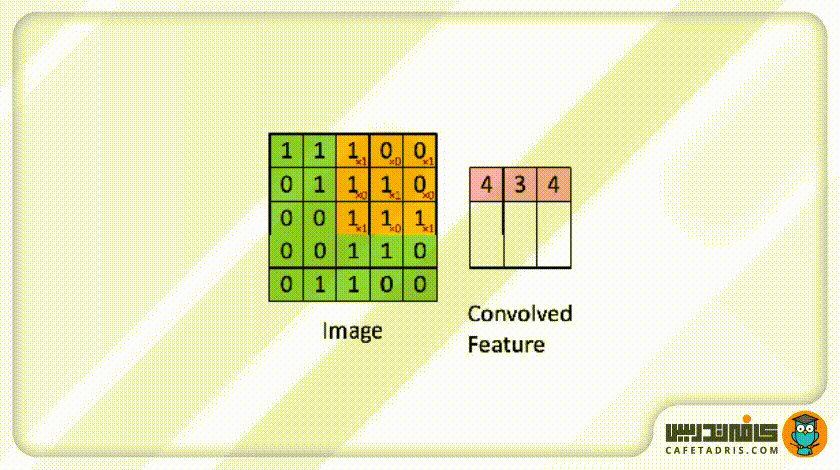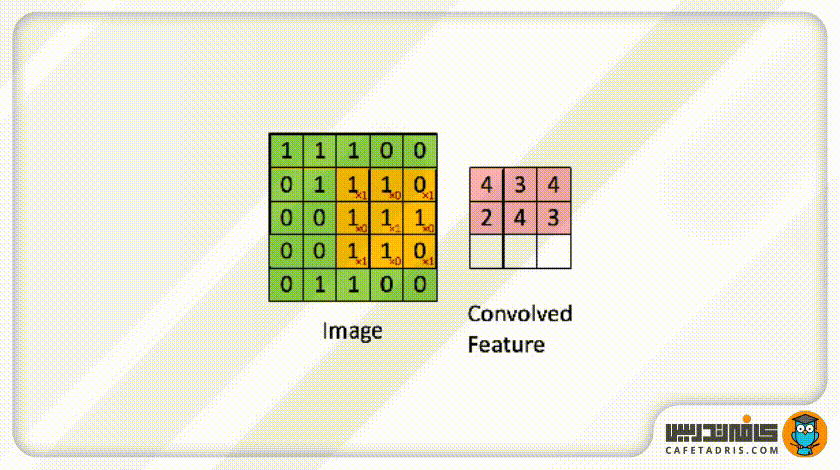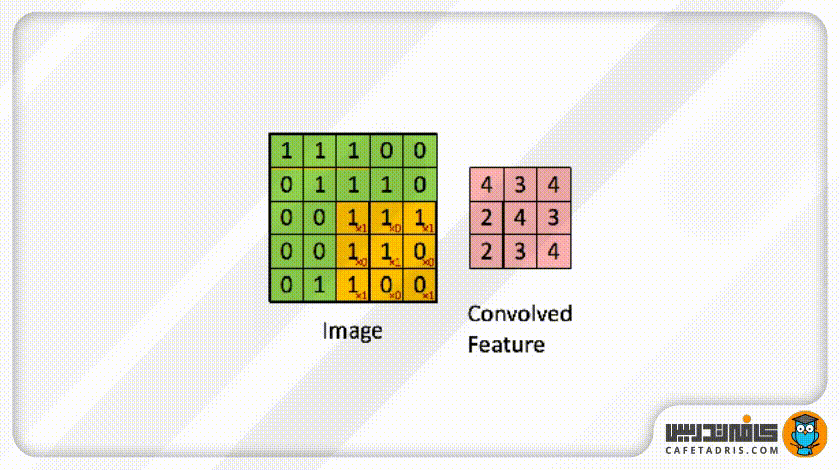
ممکن است با خود فکر کنیم این فیلتر هر بار باید چند پیکسل روی ماتریس عکس ورودی حرکت کند؟
پاسخ این سؤال در مفهوم گام (Stride) است.
(Stride) گام
گام یا Stride تعداد پیکسلهایی است که فیلتر روی ماتریس ورودی حرکت میکند. زمانیکه مقدار Stride را ۱ در نظر بگیریم، یعنی فیلتر هر بار ۱ پیکسل حرکت میکند و اگر ۲ در نظر بگیریم، یعنی فیلتر هر بار ۲ پیکسل حرکت میکند. در این شکل میتوانیم ببینیم فیلتر با مقدار Stride =۲ چطور حرکت میکند:
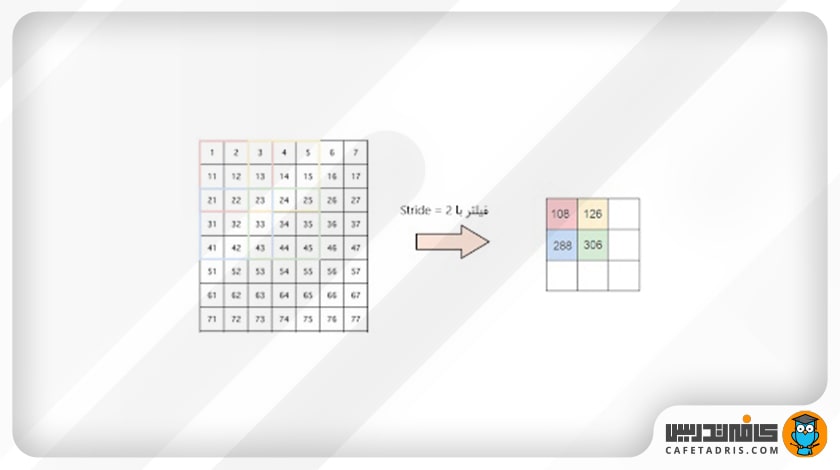
اما مسئله بعدی این است که اگر برای مثال ماتریس عکس ورودی ما ۹×۹ باشد و فیلتر ما ۲×۲ باشد، در این صورت با Stride =۱ فیلتر درنهایت به جایی میرسد که یک پیکسل بیشتر از تعداد پیکسلهای ماتریس ورودی دارد. در این مواقع که فیلتر با ماتریس عکس ورودی متناسب (fit) نیست چه کاری میتوانیم انجام دهیم؟
در این مواقع از Padding استفاده میکنیم.
Padding
در تکنیک Padding به ماتریس عکس ورودی صفر اضافه کنیم که به آن Zero-Padding گفته میشود. معمولاً مقدار Padding را ۱ در نظر میگیریم که در این شکل نمایش داده شده است:
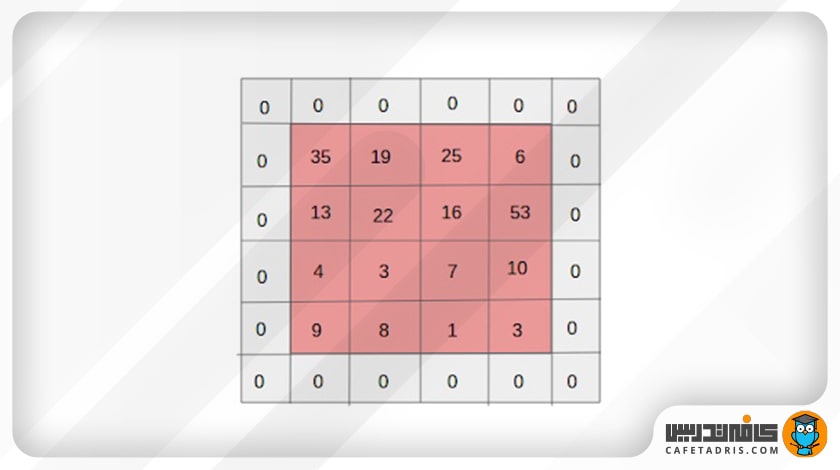
برای آشنایی با فرایند لایهگذاری (Padding) در شبکه عصبی کانولوشنی (CNN) این مطلب را مطالعه کنید:
فرایند لایهگذاری (Padding) در شبکه عصبی کانولوشنی چیست؟

تابع فعالساز ReLU (Rectified Linear Unit)
تا اینجا با لایهی کانولوشن و نحوهی کار آن آشنا شدیم. در مرحلهی استخراج ویژگی بعد از هر لایهی کانولوشن یک تابع فعالساز (معمولاً تابع ReLU) اعمال میشود.
ReLU یک تابع فعالساز برای عملیات غیرخطیکردن خروجی است. فرمول این تابع بهاین شکل است:
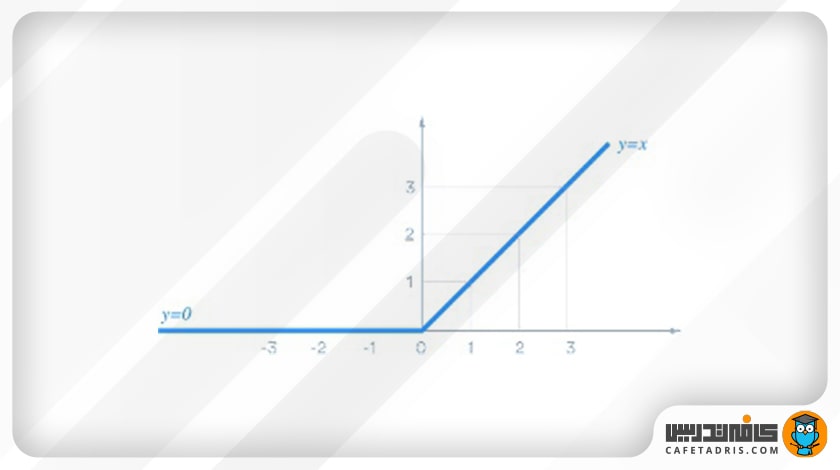
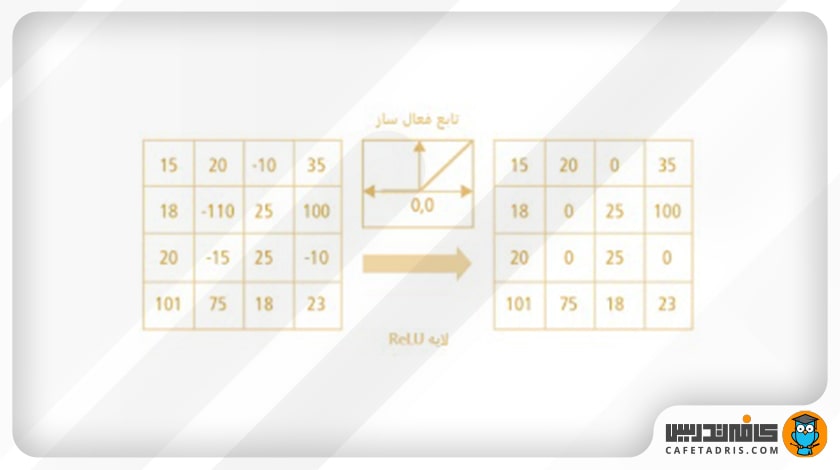
این تابع در خروجی اعداد منفی را صفر میکند و اعداد مثبت را بههمان شکل برمیگرداند.
اما به چه دلیل از تابع فعالساز استفاده میکنیم؟
زیرا میخواهیم در خروجی اعداد مثبت غیرخطی را داشته باشیم. در دنیای واقعی دادههای ما مثبت و غیرخطی هستند و از آنجا که عمل کانولوشن یک عمل خطی است، لازم است خروجی آن را غیرخطی کنیم؛ این همان کاری است که توابع فعالساز غیرخطی، مانند ReLU، انجام میدهند.
لایهی Pooling
گام بعدی در مرحله استخراج ویژگی لایهی Pooling است. در این مرحله هدف این است که ابعاد عکس ورودی را کاهش دهیم و فقط اطلاعات یا پیکسلهای مهم را نگه داریم و باقی را حذف کنیم. زمانیکه عکس ورودی اندازهی بسیار بزرگی دارد، میتوانیم با این کار اندازهی آن را تا حد زیادی کاهش دهیم. به این کار Downsampling یا Subsampling هم گفته میشود.
Pooling انواع مختلفی دارد:
- Max Pooling
- Average Pooling
- Sum Pooling
در بیشتر مواقع در شبکه عصبی کانولوشنی (CNN) از Max Pooling استفاده میشود. در Max Pooling پیکسلی که مقدار بزرگتری در مقایسه با باقی دارد در Average Pooling مقدار میانگین و در Sum Pooling جمع تمامی مقادیر در هر Feature Map انتخاب میشود. این شکل عملیات Max Pooling را نشان میدهد:
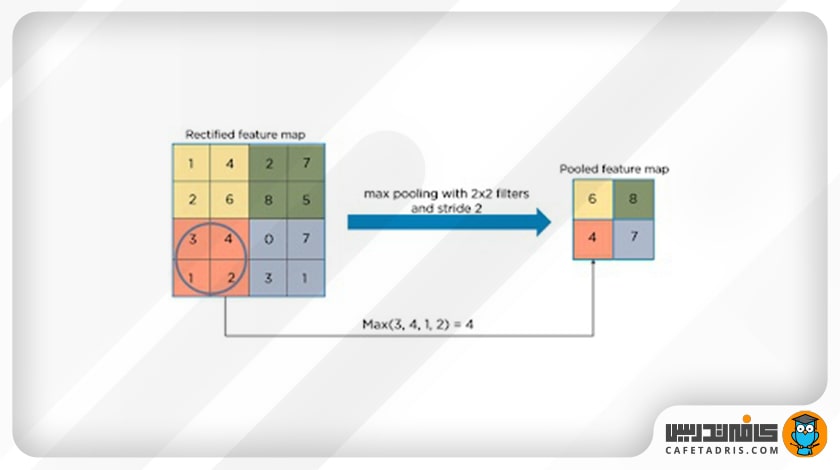
در اینجا مرحلهی اول، یعنی استخراج ویژگی، به پایان میرسد.
برای آشنایی بیشتر با لایه ادغام (Pooling Layer) در شبکه عصبی کانولوشنی (CNN) این مطلب را مطالعه کنید:
لایه ادغام (Pooling Layer) در شبکه عصبی کانولوشنی (CNN) چیست؟
مرحلهی دوم شبکهی عصبی کانولوشنی (CNN): طبقهبندی (Classification)
همانطور که قبلاً اشاره کردیم، در این مرحله از شبکهی عصبی کانولوشنی (CNN) ابتدا مسطحسازی (Flattening) صورت میگیرد. بهاین معنا که ماتریس خروجی از مرحلهی اول (استخراج ویژگی) باید به یک بردار تبدیل شود؛ یعنی اگر ماتریس ما ۳۰×۳۰ باشد، به یک بردار یا آرایه ۹۰۰تایی تبدیل میشود.
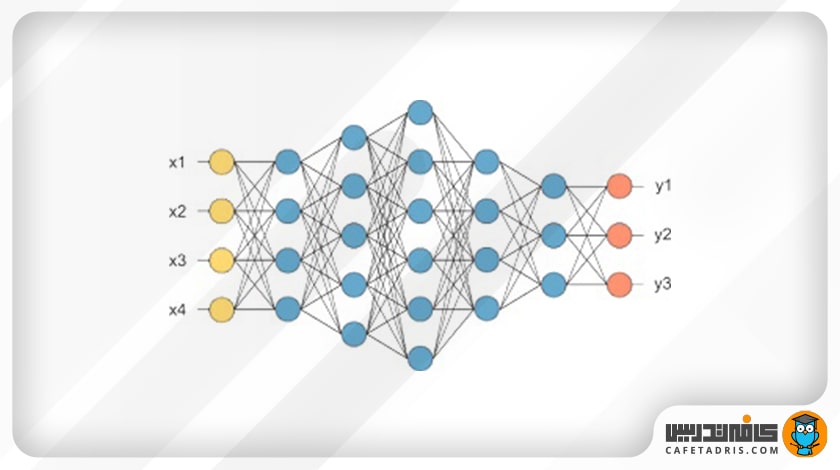
سپس این بردار به یک لایهی Fully Connected وارد میشود. یک لایهی Fully Connected درواقع یک پرسپترون چندلایه (MLP / Multi Layer Perceptron) است که در آن تمامی نودهای لایهی قبلی به تمامی نودهای لایهی بعدی متصل هستند. هدف از استفاده از لایهی Fully Connected این است که با توجه به ویژگیهایی که از مرحلهی اول دریافت کردهایم، عکسهای ورودی را در کلاسهای متفاوت طبقهبندی کنیم. درنهایت، یک تابع سافتمکس (Softmax) روی آن اعمال میشود تا احتمال تعلقداشتن عکس ورودی به هر کلاس (مثلاً گربه، سگ و غیره) در خروجی مشخص شود. جمع کل خروجیهای لایهی Fully Connected برابر با ۱ است. در این شکل تصویر یک لایهی Fully Connected را مشاهده میکنیم که ورودی آن بردار …,x1,x2,x3 است.
برای آشنایی با شبکه عصبی بازگشتی این مطلب را مطالعه کنید:
شبکه عصبی بازگشتی (RNN) چیست و چه کاربردهایی دارد؟
یادگیری دیتا ساینس و ماشین لرنینگ با کلاسهای آنلاین آموزش علم داده کافهتدریس
اگر به یادگیری دیتا ساینس یا ماشین لرنینگ علاقهمندید، پیشنهاد میکنیم شرکت در کلاسهای آنلاین آموزش علم داده کافهتدریس را از دست ندهید.
کلاسهای آنلاین آموزش علم داده کافهتدریس بهصورت مقدماتی و پیشرفته و بهشکلی پویا و تعاملی برگزار میشود. این کلاسها قالب کارگاهی دارد و مبتنی بر کار روی پروژههای واقعی علم داده است.
برای آشنایی بیشتر با کلاسهای آنلاین آموزش علم داده کافهتدریس و مشاورهی رایگان برای یادگیری دیتا ساینس و ماشین لرنینگ روی این لینک کلیک کنید:
شبکهی عصبی کانولوشنی (CNN) چگونه تصاویر را برای استخراج ویژگیها تجزیه و تحلیل میکند؟
درواقع زمانیکه یک عکس به یک شبکهی CNN وارد میشود، ابتدا به مرحلهی استخراج ویژگی وارد میشود. در این مرحله هر عکس ورودی از چندین سری لایهی کانولوشن (Convolution) و تابع فعالساز ReLU و لایهی pooling عبور میکند. سپس عکسهای ورودی به طبقهبندی وارد میشوند؛ در این مرحله ابتدا مسطحسازی (Flattening) صورت میگیرد و سپس به یک لایهی Fully Connected وارد میشوند و درنهایت یک تابع سافت مکس (Softmax) برای مسائل طبقهبندی چندکلاسه و یا تابع سیگموید (Sigmoid) برای مسائل طبقهبندی باینری روی آن اعمال میشود تا عکسها براساس مقادیر احتمالی میان صفر و یک طبقهبندی شوند.
لایهی کانولوشن در CNN چه نقشی دارد و چگونه به کمک Stride و Padding به استخراج ویژگیها کمک میکند؟
(Stride) گام
گام یا Stride تعداد پیکسلهایی است که فیلتر روی ماتریس ورودی حرکت میکند. زمانیکه مقدار Stride را ۱ در نظر بگیریم، یعنی فیلتر هر بار ۱ پیکسل حرکت میکند و اگر ۲ در نظر بگیریم، یعنی فیلتر هر بار ۲ پیکسل حرکت میکند
Padding
در تکنیک Padding به ماتریس عکس ورودی صفر اضافه کنیم که به آن Zero-Padding گفته میشود. معمولاً مقدار Padding را ۱ در نظر میگیریم
تابع فعالساز ReLU در فرآیند یادگیری شبکهی عصبی کانولوشنی چه کارکردی دارد و چرا در لایهی Pooling از آن استفاده میشود؟
در دنیای واقعی دادههای ما مثبت و غیرخطی هستند و از آنجا که عمل کانولوشن یک عمل خطی است، لازم است خروجی آن را غیرخطی کنیم؛ این همان کاری است که توابع فعالساز غیرخطی، مانند ReLU، انجام میدهند
سوال ۱:
در مرحلهی استخراج ویژگی بعد از هر لایهی کانولوشن یک تابع فعالساز (معمولاً تابع ReLU) اعمال میشود.
ReLU یک تابع فعالساز برای عملیات غیرخطیکردن خروجی است
pooling:
هدف این است که ابعاد عکس ورودی را کاهش دهیم و فقط اطلاعات یا پیکسلهای مهم را نگه داریم و باقی را حذف کنیم. زمانیکه عکس ورودی اندازهی بسیار بزرگی دارد، میتوانیم با این کار اندازهی آن را تا حد زیادی کاهش دهیم
سوال ۲:
گام یا Stride تعداد پیکسلهایی است که فیلتر روی ماتریس ورودی حرکت میکند. زمانیکه مقدار Stride را ۱ در نظر بگیریم، یعنی فیلتر هر بار ۱ پیکسل حرکت میکند و اگر ۲ در نظر بگیریم، یعنی فیلتر هر بار ۲ پیکسل حرکت میکند.
) گام
گام یا Stride تعداد پیکسلهایی است که فیلتر روی ماتریس ورودی حرکت میکند. زمانیکه مقدار Stride را ۱ در نظر بگیریم، یعنی فیلتر هر بار ۱ پیکسل حرکت میکند و اگر ۲ در نظر بگیریم، یعنی فیلتر هر بار ۲ پیکسل حرکت میکند.
سوال۱:
درواقع زمانیکه یک عکس به یک شبکهی CNN وارد میشود، ابتدا به مرحلهی استخراج ویژگی وارد میشود. در این مرحله هر عکس ورودی از چندین سری لایهی کانولوشن (Convolution) و تابع فعالساز ReLU و لایهی pooling عبور میکند. سپس عکسهای ورودی به طبقهبندی وارد میشوند؛ در این مرحله ابتدا مسطحسازی (Flattening) صورت میگیرد و سپس به یک لایهی Fully Connected وارد میشوند و درنهایت یک تابع سافت مکس (Softmax) برای مسائل طبقهبندی چندکلاسه و یا تابع سیگموید (Sigmoid)
برای مسائل طبقهبندی باینری روی آن اعمال میشود تا عکسها براساس مقادیر احتمالی میان صفر و یک طبقهبندی شوند
خیلی روان و عالی توضیح دادین
سپاس
مقاله تکمیلی در حوزه cnn دارید ؟
بله، مقاله معرفی شبکه عصبی کانولوشنی یا همون CNN رو از طریق این لینک مطالعه کنین: http://ctdrs.ir/ds0024
توابع فعالساز رو بهتر از هر منبع دیگری توضیح دادین….مررسی
تشکر از اینکه نظرتون رو با ما به اشتراک گذاشتین.
سلام خسته نباشید ممنون از توضیحتون برای تحصیل در رشته هوش مصنوعی مهندسی کامپیوتر خوند بهتره یا علوم کامپیوتر؟؟
برای تحصیل در ریاضیات هوش مصنوعی هم خیلی قوی باشه؟
سلام، اگه منظورتون تحصیل در مقطع کارشناسیه، هر کدوم از اینها میتونه شروع خوبی باشه. در مقطع ارشد میتونین هوشمصنوعی یا علوم داده رو انتخاب کنین. اگه درست متوجه سوال دومتون شده باشم پرسیدین که ریاضیات برای تحصیل در این حوزه باید قوی باشه، که جوابش مثبته. به طور کلی باید درک خوبی از مفاهیم ریاضی و آمار داشته باشین.
خیلی موضوعات خوبی رو راجب بهش مقاله می نویسی دست خوش !!!!! و خسته نباشید !!!!
ممنون از شما دوست عزیز.
با سلام و خسته نباشید میشه لطفا در مورد تفاوت بین javascript و python وهمچنین کدوم بهتره برای AI توضیح بدید؟
سلام. به طور کلی زبان برنامهنویسی پایتون با توجه به کتابخونههای مرتبط زیادی که برای حوزه هوش مصنوعی داره یکی از بهترین گزینهها محسوب میشه و معمولا برنامهنویسان این زبان رو ترجیح میدن. ما در مورد این دو مقالاتی رو منتشر کردیم که لینکشون رو قرار میدم، شاید بهتر بتونه کمکتون کنه: http://ctdrs.ir/ds0106 و http://ctdrs.ir/ds0100
فوق العاده بود . سپاس از شما
ممنون از توجه شما