

درخت تصمیم یا Decision Tree یک الگوریتم یادگیری ماشین محبوب است که برای حل مسائل طبقه بندی و رگرسیون استفاده میشود. درک و تفسیر آن آسان است و آن را به ابزاری ارزشمند برای متخصصان و غیرمتخصصان تبدیل میکند. در این پست وبلاگ، درباره چیستی درخت تصمیم، نحوه کار، انواع، مزایا و معایب و برخی کاربردهای رایج آن بحث خواهیم کرد.
- 1. الگوریتم درخت تصمیم چیست؟
- 2. الگوریتم درخت تصمیم چگونه کار میکند؟
- 3. شاخص جینی در الگوریتم درخت تصمیم
- 4. آنتروپی در درخت تصمیم
- 5. اجزای مختلف درخت تصمیم
- 6. فرآیند هرس کردن یا Pruning
- 7. انواع الگوریتم درخت تصمیم
- 8. مزایا و معایب الگوریتم درخت تصمیم
- 9. کاربردهای الگوریتم درخت تصمیم
- 10. قسمتی از جزوه کلاس برای آموزش الگوریتم درخت تصمیم
- 11. قطعه کد الگوریتم Decision Tree
- 12. خلاصه مطالب
- 13. یادگیری ماشین لرنینگ را از امروز شروع کنید!
الگوریتم درخت تصمیم چیست؟
درخت تصمیم یک مدل فلوچارت مانند است که با ترسیم مشاهدات در مورد یک آیتم تا نتیجهگیری در مورد متغیر هدف آن به پیش بینی نتایج کمک میکند. درخت شامل گرههایی است که ویژگیهای دادهها را نشان میدهد، شاخههایی که قوانین تصمیمگیری را نشان میدهند و برگهایی که نشاندهنده نتایج یا برچسبهای کلاس هستند.
به عبارت دیگر، یک الگوریتم درخت تصمیم، یک ساختار درختی از دادههای آموزشی ایجاد میکند که مجموعه ای از تصمیمات را نشان میدهد که منجر به پیشبینی متغیر هدف میشود. این الگوریتم با تقسیم بازگشتی دادهها به زیرمجموعهها بر اساس ویژگیهایی کار میکند که بیشترین اطلاعات را تا زمانی که پی بینی یا تصمیم نهایی گرفته شود، فراهم میکند.
الگوریتم درخت تصمیم چگونه کار میکند؟
الگوریتم درخت تصمیم در مراحل زیر کار میکند:
- با یک مجموعه داده شروع میشود و یک فیچر برای آزمایش انتخاب میشود.
- دادهها به زیر مجموعههایی تقسیم میشوند که مقدار یکسانی برای فیچر انتخاب شده دارند.
- آنتروپی زیر مجموعهها محاسبه میشود.
- با مقایسه آنتروپی قبل و بعد از پارتیشنبندی، بهره اطلاعاتی (Information gain) فیچر محاسبه میشود.
- فیچری با بالاترین بهره اطلاعاتی به عنوان گره بعدی درخت انتخاب میشود.
- مراحل 2-5 به صورت بازگشتی تکرار میشود تا زمانی که همه فیچرها استفاده شوند یا یک معیار توقف برآورده شود.
- یک برچسب کلاس به هر گره برگ درخت بر اساس اکثریت کلاس دادههای آموزشی که در آن گره برگ قرار میگیرند، اختصاص داده میشود.

شاخص جینی در الگوریتم درخت تصمیم
شاخص جینی (Gini index) یک معیار آماری است که برای اندازهگیری میزان پراکندگی دادهها در یک مجموعه استفاده میشود. این شاخص با استفاده از فرمول زیر محاسبه میشود:
Gini = 1 - Σ P^2
که در آن P احتمال وقوع یک کلاس خاص در مجموعه است.
در الگوریتم درخت تصمیم، شاخص جینی برای اندازهگیری میزان همگنی زیرمجموعههای ایجاد شده توسط یک ویژگی استفاده میشود. ویژگیای که شاخص جینی آن کمتر باشد، برای تقسیم دادهها به زیرمجموعههای همگنتر مناسبتر است.
مثال
فرض کنید مجموعه دادهای با 4 نمونه داریم که هر نمونه به یکی از دو کلاس A یا B تعلق دارد. اگر این نمونهها به صورت زیر توزیع شده باشند:
A: 1, 2, 3
B: 4
در این حالت، شاخص جینی مجموعه داده برابر با 0.75 خواهد بود. زیرا احتمال وقوع کلاس A برابر با 0.75 و احتمال وقوع کلاس B برابر با 0.25 است.
اگر اکنون این مجموعه داده را با استفاده از ویژگی “تعداد نمونههای A” تقسیم کنیم، به دو زیرمجموعه زیر خواهیم رسید:
زیرمجموعه 1: 1, 2
زیرمجموعه 2: 3, 4
شاخص جینی زیرمجموعه 1 برابر با 0 خواهد بود. زیرا تمام نمونههای این زیرمجموعه به کلاس A تعلق دارند. شاخص جینی زیرمجموعه 2 نیز برابر با 0.5 خواهد بود. زیرا احتمال وقوع کلاس A در این زیرمجموعه برابر با 0.5 و احتمال وقوع کلاس B برابر با 0.5 است.
بنابراین، ویژگی “تعداد نمونههای A” برای تقسیم دادههای این مجموعه به زیرمجموعههای همگنتر مناسبتر است.
الگوریتم درخت تصمیم از شاخص جینی برای انتخاب ویژگیای استفاده میکند که بیشترین کاهش را در شاخص جینی مجموعه ایجاد کند. این بدان معناست که ویژگی انتخاب شده، بیشترین میزان همگنی را در زیرمجموعههای ایجاد شده ایجاد میکند.
آنتروپی در درخت تصمیم
تعریف آنتروپی
آنتروپی، که گاهی به عنوان آنتروپی شانون شناخته میشود، یک مفهوم کلیدی در یادگیری ماشین و به خصوص در ساخت درخت تصمیم است. آنتروپی یک معیار برای اندازهگیری میزان ناپایداری یا پیشبینیناپذیری در یک مجموعه داده است. این مفهوم به ما امکان میدهد تا درک کنیم چگونه اطلاعات در یک مجموعه داده پراکنده هستند و چگونه میتوانیم از این اطلاعات برای تقسیم کارآمدتر دادهها در یک درخت تصمیم استفاده کنیم.
محاسبه آنتروپی
برای محاسبه آنتروپی، ابتدا باید احتمال وقوع هر کلاس در مجموعه دادهها را محاسبه کنیم. سپس، از این احتمالات برای محاسبه مجموع آنتروپی استفاده میشود، که از فرمول زیر پیروی میکند:

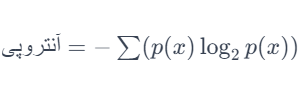
که در آن p(x) احتمال وقوع هر کلاس است. مقدار آنتروپی نشاندهنده میزان ناپایداری یا پیچیدگی موجود در دادهها است.
استفاده از آنتروپی در تصمیمگیری
در زمینه درخت تصمیم، آنتروپی برای انتخاب بهترین ویژگی برای تقسیم در هر گره استفاده میشود. هدف این است که ویژگیای را انتخاب کنیم که بیشترین کاهش را در آنتروپی ایجاد کند، به این معنی که دادههای تقسیم شده دارای پایداری بیشتری هستند و بهتر میتوانند پیشبینیهای دقیقتری را فراهم کنند.
مثال عملی
برای نمونه، در یک مجموعه داده شامل آب و هوا، ممکن است ویژگیهایی مانند دما، رطوبت، و وزش باد وجود داشته باشد. با محاسبه آنتروپی برای هر ویژگی، میتوان تصمیم گرفت که کدام یک بهترین تقسیم را برای پیشبینی بارش باران فراهم میکند. این انتخاب بر اساس کاهش آنتروپی که هر ویژگی ایجاد میکند، صورت میگیرد.
اجزای مختلف درخت تصمیم
گره ریشه: بالاترین گره درخت، که نشان دهنده نقطه شروع فرآیند تصمیم گیری است.
شاخهها: خطوطی که گرهها را به هم متصل میکنند و بیانگر تصمیمات یا انتخابهایی هستند که میتوان در هر مرحله از فرآیند تصمیم گیری انجام داد.
گرهها: نقاط تصمیمگیری در درخت که نشاندهنده نتایج یا حالتهای احتمالی سیستم مورد تجزیه و تحلیل است.
گرههای برگ: نتایج نهایی فرآیند تصمیم گیری که به عنوان نقاط انتهایی درخت نشان داده میشوند.
فرآیند هرس کردن یا Pruning
هرس فرآیند حذف شاخههایی است که برای عملکرد پیشبینی درخت تصمیم مفید نیستند. هدف از هرس بهبود توانایی تعمیم درخت با کاهش بیشبرازش برای دادههای آموزشی است. بیشبرازش زمانی اتفاق میافتد که مدل درختی به دادههای آموزشی خیلی نزدیک باشد و بیش از حد پیچیده شود، که میتواند منجر به عملکرد ضعیف در دادههای جدید و دیده نشده شود.
دو نوع روش هرس وجود دارد:
- پیش هرس (Pre-Pruning): در پیش هرس درخت تصمیم در حین ساخت هرس میشود. این شامل تعیین یک آستانه برای یک متریک خاص، مانند حداکثر عمق، حداقل تعداد نمونه در هر برگ، یا حداکثر کاهش ناخالصی (impurity) است. اگر شاخهای معیارهای آستانه را نداشته باشد، بیشتر گسترش نمییابد.
- پس هرس (Post-Pruning): در پسهرس درخت تصمیم پس از ساخت هرس میشود. این شامل حذف شاخههایی است که به دقت کلی درخت کمک نمیکند. یکی از روشهای متداول پس هرس، هرس با خطای کاهش یافته (REP) است که شامل حذف یک درخت فرعی و بررسی اینکه آیا دقت درخت هرس شده بهتر میشود یا خیر، میشود.
هرس میتواند به ساده سازی درخت تصمیم و کاهش اندازه آن کمک کند، که میتواند تفسیر و استفاده از آن را برای پیشبینی آسان تر کند. با این حال، ایجاد تعادل بین پیچیدگی و دقت، و اطمینان از اینکه درخت هرس شده هنوز به اندازه کافی دقیق است تا بتواند پیشبینیهای قابل اعتمادی را در مورد دادههای جدید انجام دهد، مهم است.
انواع الگوریتم درخت تصمیم
به طور عمده دو نوع درخت تصمیم وجود دارد:
درخت طبقهبندی: زمانی استفاده میشود که متغیر هدف طبقهبندی شده (Categorical) باشد. گرههای برگ درخت نشان دهنده برچسبهای کلاس هستند.
درخت رگرسیون: زمانی استفاده میشود که متغیر هدف پیوسته باشد. گرههای برگ درخت نشاندهنده مقادیر پیشبینی شده است.
مزایا و معایب الگوریتم درخت تصمیم
مزایا:
- درک و تفسیر درخت تصمیم آسان است.
- به حداقل پیش پردازش داده نیاز دارند و میتوانند دادههای طبقهبندی شده و عددی را مدیریت کنند.
- درخت تصمیم میتواند مقادیر از دست رفته را مدیریت کند.
- از نظر محاسباتی کارآمد است و برای مجموعه دادههای بزرگ مناسب است.
معایب:
- درخت تصمیم مستعد مشکل بیشبرازش یا است، به خصوص زمانی که درخت عمیق و پیچیده باشد.
- می تواند نسبت به فیچرهایی با سطوح یا مقادیر بیشتر تعصب داشته باشد.
- درخت تصمیم میتواند ناپایدار باشد، به این معنی که تغییرات کوچک در دادههای آموزشی میتواند منجر به تولید درختهای مختلف شود.
هنگامی که فیچرهای نامربوط یا اضافی در دادهها وجود داشته باشد، میتواند عملکرد ضعیفی داشته باشد.
کاربردهای الگوریتم درخت تصمیم
درختان تصمیم طیف وسیعی از کاربردها را دارند، از جمله:
- امتیازدهی اعتباری: از درختان تصمیم میتوان برای پیشبینی اینکه آیا وام گیرنده بر اساس سابقه اعتباری خود وام را برگشت میدهد یا خیر استفاده کرد.
- بازاریابی: درختان تصمیم را میتوان برای شناسایی بخشهای مشتری که به احتمال زیاد به یک کمپین بازاریابی پاسخ میدهند، استفاده کرد.
- تشخیص پزشکی: درختان تصمیم را میتوان برای کمک به تشخیص بیماریها بر اساس علائم بیمار و سابقه پزشکی استفاده کرد.
- تشخیص تقلب: درخت تصمیم را همچنین میتوان برای شناسایی تراکنشهای تقلبی در تراکنشهای مالی استفاده کرد.
- طبقهبندی تصاویر: از درختهای تصمیم میتوان برای طبقهبندی تصاویر بر اساس ویژگیهای آنها استفاده کرد.
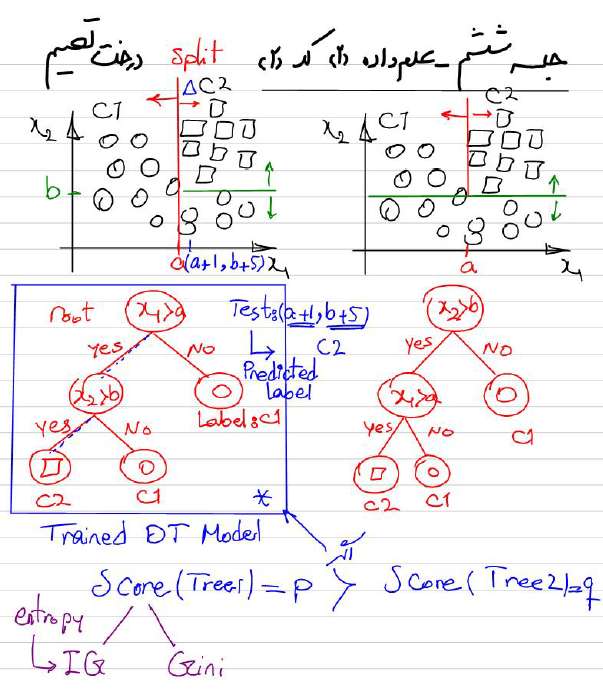
قسمتی از جزوه کلاس برای آموزش الگوریتم درخت تصمیم
دوره جامع دیتا ساینس و ماشین لرنینگ

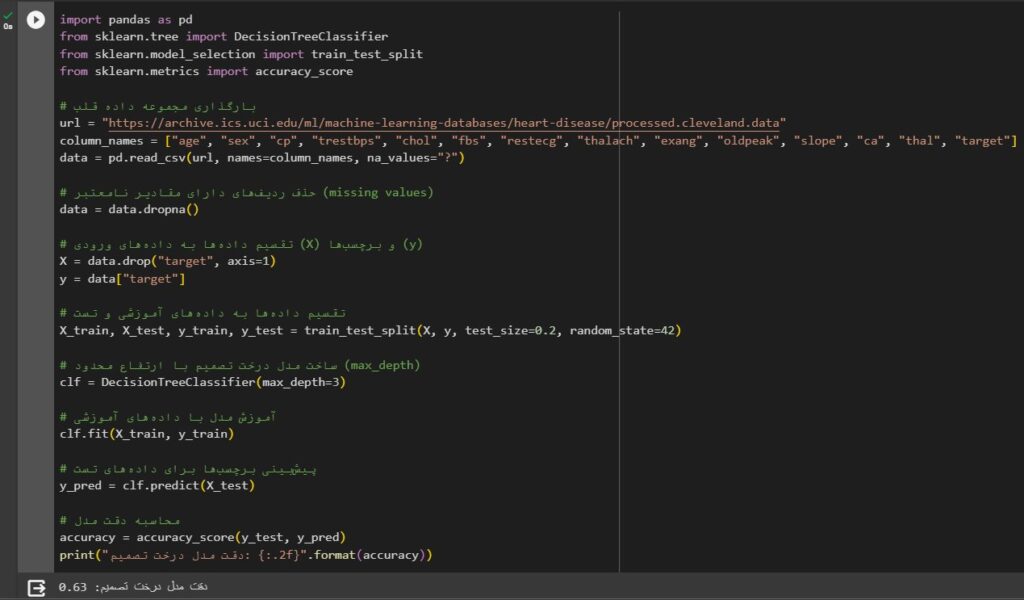
قطعه کد الگوریتم Decision Tree
برای تمرین و آشنایی بیشتر با این الگوریتم، شما میتوانید کد زیر را در گوگل Colab اجرا کنید.

خلاصه مطالب
درخت تصمیم یا Decision Tree یک نوع الگوریتم یادگیری ماشین ساده و قدرتمند هستند که میتوانند هم برای مسائل طبقهبندی و هم برای مسائل رگرسیون استفاده شوند. تفسیر آنها آسان است و میتوانند طیف گسترده ای از انواع دادهها را مدیریت کنند. با این حال، آنها مستعد مشکل بیشبرازش هستند و میتوانند ناپایدار باشند. علیرغم این محدودیتها، درختان تصمیم دارای کاربردهای گسترده ای در زمینههای مختلف هستند که آنها را به ابزاری ارزشمند برای تحلیل و پیشبینی دادهها تبدیل میکند.
یادگیری ماشین لرنینگ را از امروز شروع کنید!
دنیای دادهها جذاب است و دانستن علم داده، توانایی تحلیل داده یا بازاریابی مبتنی بر داده و یادگیری ماشین شما را برای فرصتهای شغلی بسیاری مناسب میکند. شما، فارغ از رشته و پیشزمینه، میتوانید یادگیری این دانش را همین امروز شروع کنید و از سطح مقدماتی تا پیشرفته بیاموزید. اگر دوست دارید به این حوزه وارد شوید، پیشنهاد میکنیم با کلیک روی این لینک قدم اول را همین حالا بردارید.
مشاوران کافهتدریس به شما کمک میکنند مسیر یادگیری برای ورود به این حوزه را شروع کنید: