
اتوانکدر یا Auto Encoder ازجمله مفاهیم بنیادین در حوزه یادگیری عمیق است که برای یادگیری ویژگیهای نهفته در دادهها و بازسازی اطلاعات با کاهش بعد به کار میروند. این تکنولوژی بهخصوص در مواردی که نیاز به کاهش ابعاد دادهها با حفظ اطلاعات مهم وجود دارد، کاربرد فراوانی دارد. این فناوری اجازه میدهد تا ماشینها ویژگیهای پیچیده و غیرقابل تشخیص برای انسانها را در دادهها شناسایی کنند و آنها را یاد بگیرند. برای پاسخ به این پرسش که اتوکندر چیست و آشنایی کامل با اتوانکدرها و بررسی جامع آنها این مطلب را تا انتها دنبال کنید.
- 1. اهمیت اتوانکدرها در یادگیری ماشین
- 2. درک ساختار اتوانکدرها
- 3. فرایند کدگذاری و کدگشایی
- 4. قطعه کد پایتون برای پیادهسازی اتوانکدر در کراس
- 5. کاربردهای اتوانکدرها
-
6.
انواع اتوانکدرها
- 6.1. Basic Auto Encoders (خودرمزگذارهای ساده)
- 6.2. Sparse Auto Encoders (خودرمزگذارهای تنک)
- 6.3. Denoising Auto Encoders (خودرمزگذارهای زداینده نویز)
- 6.4. Variational Auto Encoders (خودرمزگذارهای واریانسی)
- 6.5. Convolutional Auto Encoders (خودرمزگذارهای کانولوشنی)
- 6.6. Sequence-to-Sequence Auto Encoders (خودرمزگذارهای توالی به توالی)
- 7. جمعبندی
-
8.
پرسشهای متداول
- 8.1. نقش اتوانکدرها در کشف و استخراج ویژگیهای دادههای بزرگ چیست؟
- 8.2. چگونه اتوانکدرها با کاهش بعد دادهها به افزایش کارایی و سرعت مدلهای یادگیری کمک میکنند؟
- 8.3. چه روشهایی برای ارزیابی کارایی اتوانکدرها در بازسازی دادهها وجود دارد؟
- 8.4. اتوانکدرها چگونه در حذف نویز از دادهها به کار میروند؟
- 8.5. اتوانکدرها چه نقشی در بهبود مدلهای مولد دارند؟
- 9. یادگیری ماشین لرنینگ را از امروز شروع کنید!
اهمیت اتوانکدرها در یادگیری ماشین
چرا اتوانکدرها در ماشین لرنینگ اهمیت دارند؟ در اینجا به این پرسش پاسخ دادهایم و ابعاد مختلف آن را بررسی کردهایم.
کاهش بعد دادهها
یکی از مهمترین کاربردهای اتوانکدرها کاهش بعد دادههاست. این فرایند به حذف ویژگیهای اضافی و تمرکز روی آن بخش از دادهها که اطلاعات بیشتری دارند کمک میکند. کاهش بعد به این میآنجامد که مدلهای یادگیری ماشین با کارایی بیشتر و سرعت بالاتری کار کنند.
یادگیری ویژگیها
اتوانکدرها قادر هستند ویژگیهای معناداری را از دادهها استخراج کنند که این امر، بهویژه، در یادگیری بدون نظارت اهمیت زیادی دارد. آنها میتوانند به شناسایی الگوها و ساختارهای پنهان در دادهها کمک کنند؛ این کار زمینهساز فهم عمیقتر دادهها و کشف دانش جدید است.
بازسازی دادهها
اتوانکدرها در بازسازی دادهها نیز نقش مهمی دارند. آنها میتوانند دادههای ازدسترفته یا آسیبدیده را با استفاده از نمایشهای فشرده بازسازی کنند؛ این امر در مواردی مانند پردازش تصویر و صوت بسیار کاربردی است.
یادگیری نظارتنشده و نیمهنظارتی
در محیطهایی که دسترسی به دادههای برچسبدار محدود است، اتوانکدرها این امکان را فراهم میکنند تا از دادههای بدون برچسب بهمنظور یادگیری ویژگیهای مفید استفاده شود. این ویژگیها سپس میتوانند در مدلهای یادگیری نظارتشده یا نیمهنظارتی استفاده شوند.
ابتکار در مدلهای جدید
اتوانکدرها بهدلیل انعطافپذیری و کاربردهای متنوع، الهامبخش طراحی مدلهای جدید یادگیری عمیق هستند. آنها زمینهساز توسعه روشها و تکنیکهای نوآورانه در یادگیری ماشین میشوند و به پیشبرد دانش در این حوزه کمک شایانی میکنند.
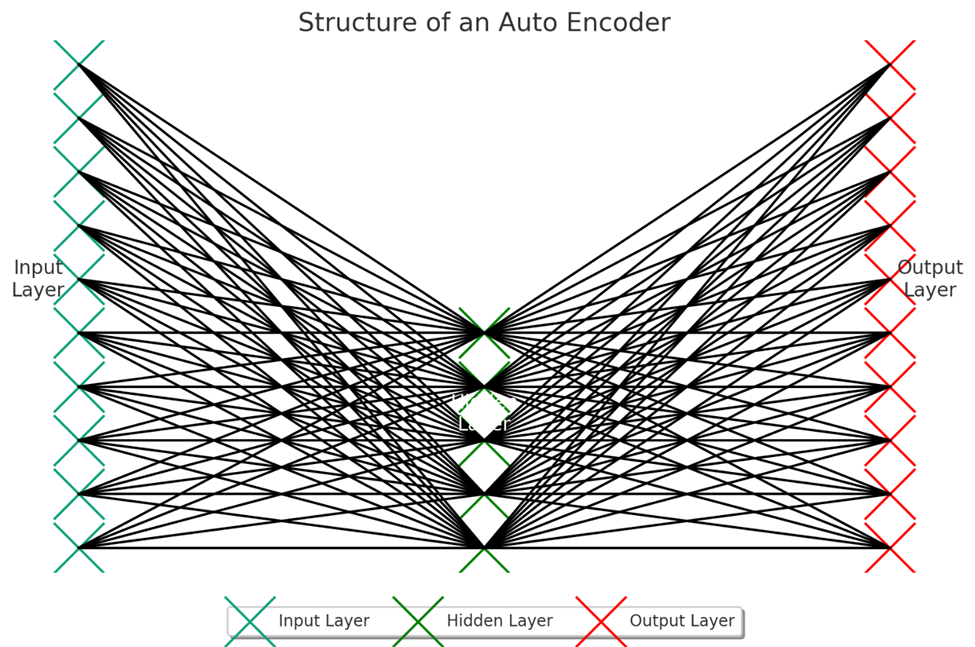
درک ساختار اتوانکدرها
ساختار اتوانکدرها براساس یک اصل ساده ولی قدرتمند در یادگیری عمیق شکل گرفته است: تلاش برای یادگیری یک نمایش فشرده و معنادار از دادهها بهگونهای که امکان بازسازی دادههای ورودی از روی این نمایش فراهم آید.
این فرایند از دو مرحله اصلی تشکیل شده است: کدگذاری (Encoding) و کدگشایی (Decoding). ساختار داخلی اتوانکدرها بهگونهای طراحی شده است که بهینهسازی و یادگیری این دو مرحله بهصورت همزمان انجام شود.
لایه ورودی
لایه ورودی در اتوانکدرها نقش پذیرش دادههای اولیه را بر عهده دارد. این لایه بهطور مستقیم با دادههای واقعی که قرار است مدل آنها را پردازش کند در تعامل است. اندازه این لایه متناسب با ابعاد دادههای ورودی تنظیم میشود تا بتواند تمامی ویژگیهای موردنیاز برای فرایند یادگیری را دریافت کند.
لایههای مخفی
لایههای مخفی در اتوانکدرها قلب تپندهی فرایند یادگیری هستند. این لایهها وظیفه دارند نمایش مختصر و معناداری از دادههای ورودی را یاد بگیرند. در فرایند کدگذاری، این لایهها دادهها را فشردهسازی میکنند و آنها را به نمایشهای کدگذاریشدهای تبدیل میکنند که اطلاعات کلیدی را در بر گرفتهاند. این نمایشها اغلب بهنسبت اندازه اصلی دادهها بسیار کوچکتر هستند؛ این امر به کاهش چشمگیر ابعاد و حذف اطلاعات اضافی کمک میکند.
لایه خروجی
لایه خروجی وظیفه بازسازی دادههای ورودی از روی نمایشهای مختصر یادگرفتهشده را دارد. این بخش از Auto Encoders تلاش میکند با استفاده از نمایشهای کدگذاریشده دادههایی را بازسازی کند که تا حد امکان شبیه به دادههای اصلی باشند. این فرایند نشاندهنده قابلیت مدل در یادگیری و بازیابی ویژگیهای مهم و کلیدی از دادههاست
فرایند کدگذاری و کدگشایی
فرایند کدگذاری تبدیل داده ورودی به نمایش مختصر و کدگذاریشدهای را شامل است که اطلاعات کلیدی داده اصلی را در بر میگیرد. پس از آن و در فرایند کدگشایی از این نمایش مختصر استفاده میشود تا دادهای شبیه به داده اصلی بازسازی شود. در ادامه هر بخش را بهتفضیل توضیح خواهیم داد:
کدگذاری (Encoding)
در مرحله کدگذاری دادههای ورودی از فضای اولیه خود به یک فضای نمایندگی فشردهتر (latent space) تبدیل میشوند. این فضای نمایندگی اغلب با ابعادی کمتر در مقایسه با دادههای اصلی توصیف میشود؛ این امر به حذف اطلاعات غیرضروری و تمرکز بر ویژگیهای مهم کمک میکند.
فرایند کدگذاری از لایههای مخفی مدل عبور میکند که در آن وزنها و بایاسهای شبکه بهنحوی تنظیم میشوند تا یک نمایش فشرده و معنادار از دادهها ایجاد شود.
این نمایش فشرده میتواند بهعنوان یک «خلاصه» از دادههای ورودی در نظر گرفته شود که اطلاعات ضروری و کلیدی برای بازسازی دادهها را در بر میگیرد.
کدگشایی (Decoding)
در مرحله کدگشایی نمایش فشرده تولیدشده توسط کدگذار مجدداً به فضای اولیه دادهها بازگردانده میشود. هدف از این فرایند بازسازی دادههای اصلی با استفاده از نمایش فشرده است.
بازسازی بهاین معناست که شبکه سعی میکند تا تصویر یا دادهای را که از نظر بصری یا مفهومی به داده اصلی نزدیک است تولید کند. این مرحله نشاندهنده توانایی شبکه در فهمیدن و بازیابی اطلاعات از نمایشهای فشرده است.

کیفیت بازسازی میتواند بهعنوان یک معیار برای سنجش کارایی Auto Encoder در نظر گرفته شود؛ زیرا نشان میدهد مدل تا چه حد توانسته ویژگیهای اساسی و معنادار دادهها را در نمایش فشرده خود حفظ کند.
بنابراین فرایند کدگذاری و کدگشایی در قلب عملکرد اتوانکدرها قرار دارد و برای فهم بهتر این مدلها درک دقیق این دو مرحله اساسی است. ازطریق این دو فرایند، اتوانکدرها قادر به یادگیری نمایشهای فشرده و معنادار از دادهها هستند که میتواند در کاربردهای متعددی مانند کاهش بعد، دستهبندی، تشخیص ناهنجاری و موارد دیگر به کار رود.
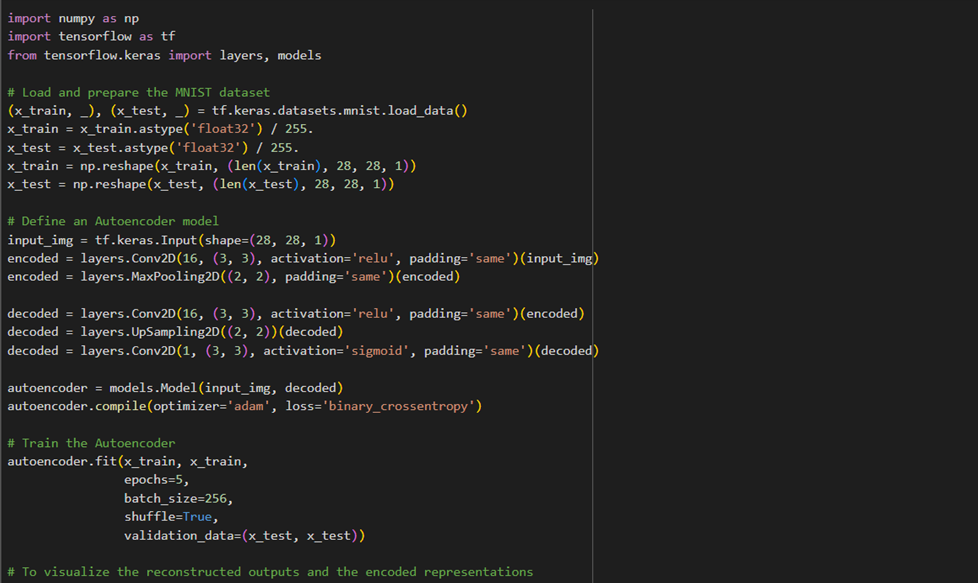
قطعه کد پایتون برای پیادهسازی اتوانکدر در کراس
در ادامه میتوانید قطعه کدی شامل پیادهسازی یک اتوانکدر در کراس را ببنید. این مدل دادهها دیتاست ارقام انگلیسی (MNIST) را بهعنوان ورودی میگیرد و در خروجی تلاش میکند چیزی مانند همان عکس را تولید کند:
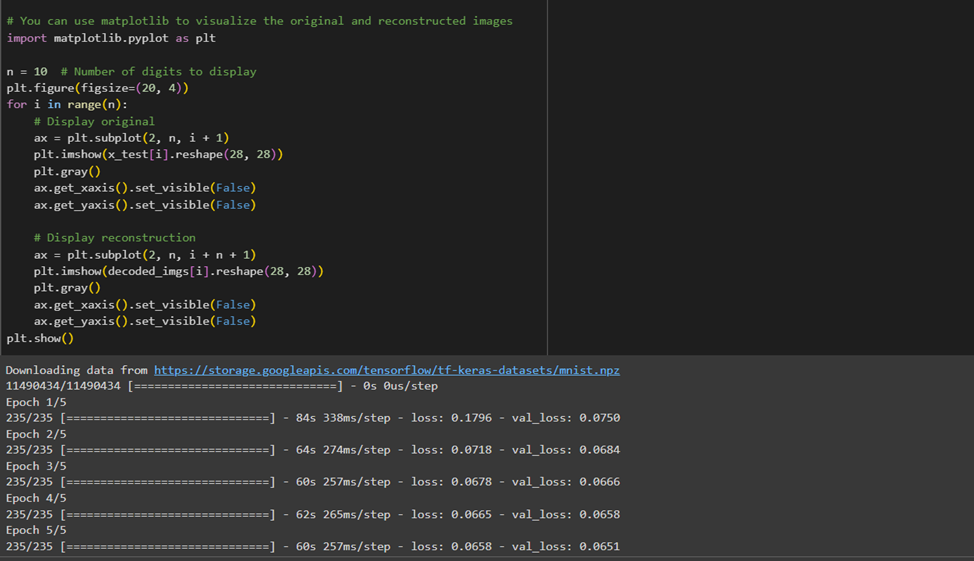
خروجی
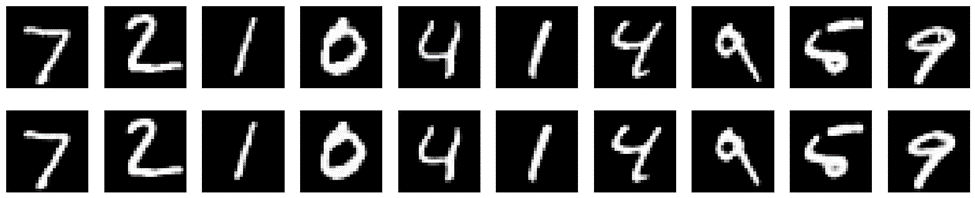
کاربردهای اتوانکدرها
اتوانکدرها در زمینههای مختلفی از یادگیری ماشین کاربرد دارند. بیایید برخی از مهمترین کاربردهای اتوانکدرها را با هم بررسی کنیم:
کاهش بعد (Dimensionality Reduction)
اتوانکدرها اغلب بهعنوان یک جایگزین برای روشهای کلاسیک کاهش بعد، مانند PCA (تجزیه به مؤلفههای اصلی)، استفاده میشوند. آنها میتوانند ویژگیهای غیرخطی دادهها را شناسایی و فشردهسازی کنند؛ امر به کاهش ابعاد دادهها با حفظ اطلاعات مهم کمک میکند.
پیشنهاد میکنیم درباره PCA یا بررسی دقیق تحلیل مؤلفههای اصلی هم مطالعه کنید.
یادگیری ویژگی (Feature Learning)
یادگیری ویژگیهای مفید و کاربردی از دادهها بدون نیاز به برچسبها یکی از مزایای عمده اتوانکدرهاست. این قابلیت آنها را به ابزاری قدرتمند برای یادگیری بدون نظارت تبدیل میکند که میتواند در بهبود دقت مدلهای یادگیری نظارتشده نیز به کار رود.
تشخیص ناهنجاری (Anomaly Detection)
در تشخیص ناهنجاری اتوانکدرها میتوانند به یادگیری توزیع دادههای عادی بپردازند و هنگامی که دادهای با توزیع متفاوت (ناهنجار) مواجه میشوند آن را شناسایی کنند. این کاربرد در حوزههای امنیتی، پزشکی، تولید صنعتی و مالی بسیار مهم است.
پیشنهاد میکنیم درباره ناهنجاری در یادگیری ماشین و روشهای تشخیص آن هم مطالعه کنید.
ازمیانبردن نویز (Denoising)
اتوانکدرها میتوانند برای حذف نویز از دادهها استفاده شوند. در این حالت دادههای نویزی بهعنوان ورودی به شبکه داده میشود و شبکه تلاش میکند تا نسخه پاکیزه دادهها را بازسازی کند. این فرایند، بهخصوص، در پردازش تصویر و صدا کاربردهای فراوانی دارد.
فشردهسازی دادهها (Data Compression)
با توجه به توانایی اتوانکدرها در یادگیری نمایشهای فشرده دادهها، آنها میتوانند در فشردهسازی دادهها برای ذخیرهسازی یا انتقال کارآمدتر استفاده شوند. این فرایند باید بهگونهای باشد که دادهها بتوانند با حداقل ازدستدادن اطلاعات بازیابی شوند.
بهبود مدلهای مولد (Improving Generative Models)
اتوانکدرها گاهی اوقات در ترکیب با مدلهای مولد دیگر مانند GANها (شبکههای مولد تقابلی) استفاده میشوند تا کیفیت تولید دادههای جدید را بهبود ببخشند. بهخصوص، Variational اتوانکدرها (VAEs) بهدلیل توانایی در مدلسازی توزیع دادهها، برای این منظور به کار میروند.
انواع اتوانکدرها
اتوانکدرها، با توجه به معماری و هدف استفاده، در انواع مختلفی طراحی و پیادهسازی میشوند. هر یک از این انواع به مسئلهای خاص را حل میکنند برخی از جنبههای کارایی را بهبود میبخشند:
Basic Auto Encoders (خودرمزگذارهای ساده)
این نوع از اتوانکدرها ساختار پایه و ابتدایی دارند و اغلب برای کاهش بعد و استخراج ویژگی (Feature Extraction) استفاده میشوند که شامل سه بخش اصلی هستند: لایه ورودی، لایههای مخفی برای کدگذاری و کدگشایی و همینطور لایه خروجی.
Sparse Auto Encoders (خودرمزگذارهای تنک)
این اتوانکدرها با اعمال محدودیتهای تنکسازی بر لایههای مخفی، فقط به تعداد محدودی از نورونها اجازه فعالیت میدهند. این کار به این میانجامد که مدل بر ویژگیهای مهم دادهها بیشتر تمرکز کند و درنتیجه، یادگیری مؤثرتری صورت گیرد.
Denoising Auto Encoders (خودرمزگذارهای زداینده نویز)
Denoising Auto Encoders با گرفتن دادههای دارای نویز، بهعنوان ورودی و یادگیری برای بازسازی دادههای بدون نویز، به بهبود کیفیت دادهها کمک میکنند. این نوع از اتوانکدرها در پردازش تصویر و صدا برای حذف نویز بسیار مفید هستند.
Variational Auto Encoders (خودرمزگذارهای واریانسی)
Variational Auto Encoders یک نوع پیشرفته از اتوانکدرها هستند که مبتنی بر اصول آماری و احتمالاتی طراحی شدهاند. آنها یک توزیع احتمالی را برای نمایشهای فشرده یاد میگیرند و در تولید دادههای جدید میتوانند بهعنوان مدلهای مولد استفاده شوند.
Convolutional Auto Encoders (خودرمزگذارهای کانولوشنی)
این نوع از اتوانکدرها برای دادههایی با ساختار فضایی مانند تصاویر طراحی شدهاند. آنها از لایههای کانولوشنی و لایههای Pooling در ساختار خود بهره میبرند تا بتوانند ویژگیهای فضایی دادهها را بهخوبی یاد بگیرند و بازسازی کنند.
Sequence-to-Sequence Auto Encoders (خودرمزگذارهای توالی به توالی)
این نوع از اتوانکدرها برای کار با دادههای توالی، مانند متن و گفتار، مناسب هستند. آنها معمولاً از شبکههای عصبی بازگشتی (RNN) یا واریانتهایی مانند LSTM یا GRU بهره میبرند تا وابستگیهای زمانی در دادهها را یاد بگیرند و بازسازی کنند.
جمعبندی
اتوانکدرها بهعنوان یکی از تکنیکهای کلیدی در حوزه یادگیری عمیق نقش مهمی در فهم و پردازش دادهها ایفا میکنند. از کاهش بعد و حذف اطلاعات غیرضروری گرفته تا یادگیری ویژگیهای معنادار و بازسازی دادهها، این ابزار قدرتمند به کاربردهای گوناگونی در بخشهای مختلف فناوری پرداخته است. انواع مختلف اتوانکدرها، ازجمله نسخههای تنک، زداینده نویز، واریانسی و کانولوشنی، هر یک قابلیتهای منحصربهفردی را در شناسایی و بازسازی دادهها ارائه میکنند.
همچنین توانایی این سیستمها در کار روی دادههای گوناگون و ارائه راهکارهای نوآورانه برای چالشهای پیچیده آنها را به یکی از ارکان اساسی در پیشرفت یادگیری ماشین و هوش مصنوعی تبدیل کرده است.
نهایتاً با پیشرفت فناوری و افزایش حجم دادهها، نقش اتوانکدرها در استخراج دانش و اطلاعات مفید از مجموعههای دادهای بزرگ اهمیت بیشتری مییابد و آینده روشنی را برای توسعه و کاربرد آنها در پروژههای متنوع پیشبینی میکند.

پرسشهای متداول
نقش اتوانکدرها در کشف و استخراج ویژگیهای دادههای بزرگ چیست؟
اتوانکدرها، با استفاده از ساختار کدگذاری و کدگشایی خود، قادر به ایجاد نمایشهای فشردهتری از دادهها هستند که ویژگیهای معنادار دادههای اصلی را حفظ میکنند. در مرحله کدگذاری، دادهها به نمایشهای کوچکتر تبدیل میشوند. این فرایند به حذف اطلاعات اضافی و تمرکز بر ویژگیهای اساسی کمک میکند. این امر، بهویژه، برای تحلیل و فهم عمیقتر دادههای بزرگ و پیچیده مفید است.
چگونه اتوانکدرها با کاهش بعد دادهها به افزایش کارایی و سرعت مدلهای یادگیری کمک میکنند؟
اتوانکدرها، با کاهش بعد دادهها، ازطریق فشردهسازی اطلاعات مهم و حذف ویژگیهای غیرضروری، به کاهش پیچیدگی محاسباتی مدلهای یادگیری کمک میکنند. این کاهش بعد باعث میشود دادهها سریعتر پردازش شوند و مدلها توانایی استفاده از دادههای فشرده برای آموزش سریعتر و کارآمدتر را داشته باشند. این فرایند به پیشگیری از بیشبرازش نیز کمک میکند.
چه روشهایی برای ارزیابی کارایی اتوانکدرها در بازسازی دادهها وجود دارد؟
کارایی اتوانکدرها در بازسازی دادهها میتواند ازطریق مقایسه دادههای ورودی و خروجی سنجیده شود. معیارهایی نظیر خطای میانگین مربعات (MSE) یا خطای مطلق میانگین (MAE) میتوانند برای اندازهگیری تفاوت میان دادههای اصلی و بازسازیشده به کار رود. کیفیت نمایشهای فشرده و توانایی آنها در حفظ اطلاعات کلیدی همچنین میتواند معیاری برای سنجش باشد. در پردازش تصویر از معیارهایی مانند SSIM برای ارزیابی توانایی اتوانکدرها در حفظ جزئیات و ساختار تصویر استفاده میشود.
اتوانکدرها چگونه در حذف نویز از دادهها به کار میروند؟
اتوانکدرها میتوانند دادههای دارای نویز را به عنوان ورودی دریافت کنند و نسخه پاکیزهی دادهها را بازسازی کنند. این فرایند بهویژه در پردازش تصویر و صدا برای حذف نویز مهم است و به بهبود کیفیت دادهها کمک میکند.
اتوانکدرها چه نقشی در بهبود مدلهای مولد دارند؟
اتوانکدرها گاهی در ترکیب با مدلهای مولد دیگر، مانند GANها، به کار میروند تا کیفیت تولید دادههای جدید را بهبود ببخشند. اتوانکدرهای واریانسی (VAEs)، بهدلیل توانایی در مدلسازی توزیع دادهها، بهخصوص برای این منظور مفید هستند و به ایجاد دادههای جدید با کیفیت بالاتر کمک میکنند.
یادگیری ماشین لرنینگ را از امروز شروع کنید!
دنیای دادهها جذاب است و دانستن علم داده، توانایی تحلیل داده یا بازاریابی مبتنی بر داده شما را برای فرصتهای شغلی بسیار در زمینه پرتقاضاترین حرفه قرن ۲۱ آماده میکند. فارغ از رشته و پیشزمینه شغلی و تحصیلی، میتوانید یادگیری این دانش را همین امروز شروع کنید و آن را از سطح مقدماتی تا پیشرفته بیاموزید. اگر دوست دارید به این حوزه وارد شوید، پیشنهاد میکنیم با سرزدن به این لینک قدم اول را همین حالا بردارید.
مشاوران کافهتدریس به شما کمک میکنند مسیر یادگیری برای ورود به این حوزه را شروع کنید: