
ناهنجاریها در یادگیری ماشین که اغلب بهعنوان نقاط خارج از محدوده (outliers) شناخته میشوند نقاط دادهای هستند که بهطور چشمگیری از باقی دادهها متفاوتاند. این ناهنجاریها، بهدلیل اینکه میتوانند خطاهایی در جمعآوری دادهها، تغییرات در رفتار سیستم یا نقضهای امنیتی بالقوه را نشان دهند، اهمیت بسزایی دارند. ناهنجاریها ممکن است عمدی باشند، مانند تقلب یا حملات سایبری یا غیرعمدی، مانند اختلال در حسگر یا رویداد نادر. تشخیص ناهنجاری وظیفهای چالشبرانگیز است؛ زیرا نیاز به تمییزدادن میان نویز (تغییرات تصادفی در دادهها) و ناهنجاریهای واقعی دارد؛ علاوهبراین کمیابی و طبیعت غالباً غیرقابل پیشبینی ناهنجاریها پیچیدگیهای شناسایی آنها را افزایش میدهد. در این مطلب بهصورت کامل انواع روشهای تشخیص ناهنجاری را بررسی میکنیم.
- 1. تشخیص ناهنجاری چیست؟
- 2. اهمیت تشخیص ناهنجاری در یادگیری ماشین چیست؟
- 3. انواع ناهنجاریها
- 4. دستهبندیهای تشخیص ناهنجاری چیست؟
- 5. روشهای رایج در تشخیص ناهنجاریها چیست؟
- 6. چالشهای ارزیابی سیستمهای تشخیص ناهنجاری چیست؟
- 7. قسمتی از جزوه کلاس برای تدریس Anomaly Detection
- 8. قطعه کد پایتون برای تشخیص ناهنجاری
- 9. نتیجهگیری
-
10.
پرسشهای متداول
- 10.1. هدف اصلی تشخیص ناهنجاری در یادگیری ماشینی چیست؟
- 10.2. تکنیکهای یادگیری ماشینی چگونه به بهبود تشخیص ناهنجاری کمک میکنند؟
- 10.3. آیا صنایع خاصی وجود دارند که در آنها تشخیص ناهنجاری حیاتیتر است؟
- 10.4. آیا تشخیص ناهنجاری میتواند ناهنجاریهای آینده را پیشبینی کند؟
- 10.5. چگونه ظهور دادههای بزرگ (Big Data) بر تشخیص ناهنجاریها تأثیر میگذارد؟
- 11. یادگیری ماشین لرنینگ را از امروز شروع کنید!
تشخیص ناهنجاری چیست؟
تشخیص ناهنجاری (Anomaly Detection) که یک مفهوم اساسی در یادگیری ماشین است. این مفهوم به شناسایی الگوها، رفتارها یا مشاهدههای غیرعادی در دادهها که بهطور چشمگیری از حالت عادی منحرف میشوند اشاره میکند. این ناهنجاریها که اغلب بهعنوان نقاط خارج از محدوده نامیده میشوند، میتوانند نشاندهنده حوادث حیاتی، مانند شکستهای سیستمی، فعالیتهای تقلبی یا روندهای نوظهور (Novelty)، باشند.
در اصطلاحات فنی، تشخیص ناهنجاری شامل الگوریتمها و تکنیکهای آماری است که بینظمیها را درون مجموعه دادهها تشخیص میدهند. برخلاف تشخیص الگوی معمولی که هدف آن طبقهبندی (Classification) دادهها به دستههای از پیش تعیینشده است، تشخیص ناهنجاری بر روی شناسایی استثنائاتی که با الگوی مورد انتظار همخوانی ندارند متمرکز است.
اهمیت تشخیص ناهنجاری در یادگیری ماشین چیست؟
با رشد انفجاری دادهها در عصر دیجیتال، تشخیص ناهنجاری به بیش از یک ابزار برای شناسایی نقاط خارج از معمول تبدیل شده است، بلکه به یک دارایی راهبردی برای بهدستآوردن بینشها، تضمین امنیت و بهبود کارایی عملیاتی در بخشهای مختلف تبدیل شده است.
سیستم هشدار دهنده زودهنگام
در صنایع مختلف ناهنجاریها بهعنوان نشانههای هشداردهنده زودهنگام برای مشکلات بالقوه عمل میکنند؛ برای مثال، در حوزه مالی، تغییرات ناگهانی در الگوهای معاملات میتواند نشانهای از تقلب باشد، درحالیکه در حوزه بهداشت و درمان، دادههای غیرمعمول بیمار میتواند به یک شرایط پزشکی نیازمند توجه اشاره کند.
تضمین کیفیت دادهها
تشخیص ناهنجاری در حفظ یکپارچگی و کیفیت دادهها حیاتی است. با شناسایی نقاط خارج از معمول، سازمانها میتوانند مجموعه دادههای خود را پاکسازی کنند و اطمینان حاصل کنند که مدلهای یادگیری ماشین بر اساس دادههای دقیق و نماینده آموزش دیدهاند.
افزایش اقدامات امنیتی
در امنیت سایبری، الگوریتمهای تشخیص ناهنجاری در شناسایی نقضها، دستبردها یا فعالیتهای مخرب ازطریق نظارت بر ترافیک شبکه و رفتارهای کاربران که از حالت عادی منحرف شدهاند کلیدی هستند.
بهینهسازی کارایی عملیاتی
در تولید و مدیریت زنجیره تأمین، تشخیص ناهنجاریها در عملکرد سیستم یا فرایندهای تولید میتواند به مداخلات به موقع بینجامد؛ کاهش زمان تعطیلی و بهبود کارایی ازجمله آنهاست.
قابلیت انطباق و تکامل
همانطور که مدلهای یادگیری ماشین با دادههای جدید روبهرو میشوند، تشخیص ناهنجاری به انطباق این مدلها با الگوهای در حال تکامل کمک میکند و اطمینان میدهد که آنها برای مدت طولانی مؤثر باقی بمانند.
تحقیق و توسعه
تشخیص ناهنجاری در تحقیقات علمی کمک میکند با شناسایی پدیدههای نو و نادر، میتواند به کشفها و پیشرفتهای قابل توجه در زمینههای مختلف بینجامد.
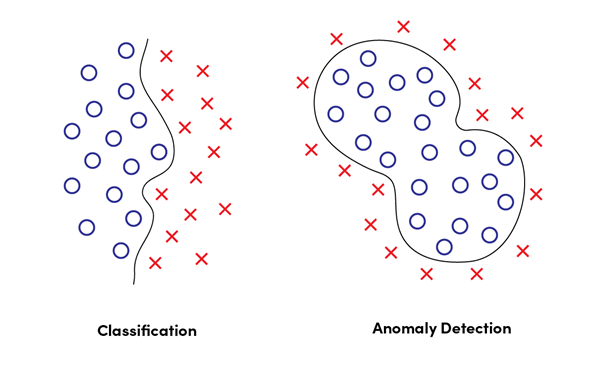
انواع ناهنجاریها
انواع ناهنجاریها را میتوان بهاین شکل صورتبندی کرد:
ناهنجاریهای نقطهای (Point Anomalies)
اینها نقاط دادهای هستند که بهطور قابل توجهی از باقی دادهها متفاوتاند؛ برای مثال، یک افزایش ناگهانی در تراکنشهای کارت اعتباری برای یک حساب خاص میتواند نشاندهنده فعالیت تقلبی باشد.
ناهنجاریهای زمینهای (Contextual Anomalies)
ناهنجاریهای زمینهای همچنین بهعنوان ناهنجاریهای شرایطی شناخته میشوند. این نقاط داده در یک زمینه خاص ناهنجار هستند، اما ممکن است در زمینهای دیگر بهعنوان نقاط خارج از محدوده در نظر گرفته نشوند؛ برای مثال، یک کاهش ناگهانی دما ممکن است در زمستان عادی باشد، اما در تابستان بهعنوان یک ناهنجاری در نظر گرفته شود.
ناهنجاریهای جمعی (Collective Anomalies)
این ناهنجاریها از مجموعهای از نقاط داده مرتبط تشکیل شدهاند که ناهنجار هستند، اما ممکن است هنگام بررسی بهصورت جداگانه بهعنوان ناهنجاریها در نظر گرفته نشوند؛ برای مثال، یک سری تراکنشها ممکن است هنگام بررسی بهصورت جداگانه عادی به نظر برسند، اما اگر این تراکنشها در یک الگوی غیرمعمول رخ دهند، مانند تعداد زیادی تراکنش در یک دوره کوتاه، میتوانند نشاندهنده تقلب باشند.
درک این انواع ناهنجاریها برای اعمال تکنیکهای تشخیص ناهنجاری صحیح حیاتی است. نوع ناهنجاری بر انتخاب روش تشخیص تأثیر میگذارد؛ برای مثال، روشهای آماری (statistical methods) ممکن است برای ناهنجاریهای نقطهای مؤثرتر باشند، درحالیکه رویکردهای یادگیری ماشین برای تشخیص ناهنجاریهای زمینهای و جمعی بهدلیل توانایی آنها در یادگیری الگوهای پیچیده مناسبتر هستند.

دستهبندیهای تشخیص ناهنجاری چیست؟
تشخیص ناهنجاری در یادگیری ماشین بهطور گسترده به سه نوع اصلی تقسیم میشود: تشخیص ناهنجاری نظارتشده (Supervised Anomaly Detection)، تشخیص ناهنجاری نیمهنظارتشده (Semi-supervised Anomaly Detection) و تشخیص ناهنجاری بدون نظارت (Unsupervised Anomaly Detection). هر دسته رویکرد منحصربهفرد خود را دارد و بسته به دسترسی و طبیعت دادهها، برای سناریوهای مختلف مناسب است.
تشخیص ناهنجاری نظارتشده
تشخیص ناهنجاری نظارتشده آموزش مدل یادگیری ماشین روی یک مجموعه داده برچسبدار را شامل است که در آن هم موارد عادی و هم موارد ناهنجار شناسایی شدهاند. این روش کمتر رایج است؛ زیرا ناهنجاریها نادر هستند و داشتن مجموعه دادهای کافی و متنوع از موارد ناهنجار برای آموزش دشوار است.
اصلیترین چالش در تشخیص ناهنجاری نظارتشده کمبود و عدم تعادل (Imbalanced) دادههای ناهنجار است؛ به دلیل ندرت ناهنجاریها، مجموعه داده ممکن است بهشدت بهسمت موارد عادی سوق داده شود که میتواند به مدلهای مغرضانهای بینجامد که در شناسایی ناهنجاریهای واقعی مؤثر نیستند.
تشخیص ناهنجاری نیمهنظارتی
در تشخیص ناهنجاری نیمهنظارتی مدل روی مجموعه دادهای آموزش داده میشود که تنها دادههای عادی در آن برچسبگذاری شدهاند. فرض بر این است که هرگونه انحراف از این رفتار تعریفشده «عادی» بهعنوان ناهنجاری در نظر گرفته میشود. این رویکرد در مقایسه با تشخیص باناظر رایجتر است؛ زیرا بهدستآوردن مجموعه دادهای از نمونههای عادی آسانتر است.
تشخیص ناهنجاری بدون نظارت
تشخیص ناهنجاری بدون نظارت (Unsupervised Anomaly Detection) رویکردی است که بیشترین استفاده را دارد و نیازی به دادههای برچسبدار ندارد. مدل فرض میکند که ناهنجاریها نادر و متمایز از الگوی معمولی در مجموعه دادهها هستند.
تکنیکها شامل روشهای مبتنی بر خوشهبندی (Cluster-based) میشوند، جایی که نقاط دادهای که خارج از خوشههای دادههای عادی قرار دارند، بهعنوان ناهنجاریها در نظر گرفته میشوند و روشهای مبتنی بر جداسازی مانند جنگلهای انزوا (Isolation Forests) که ناهنجاریها را به جای پروفایل کردن نقاط دادهی عادی، جدا میکنند. روشهای مبتنی بر تراکم مانند فاکتور بیرونزدگی محلی (Local Outlier Factor – LOF) نیز استفاده میشوند که با درنظرگرفتن تراکم محیط اطراف یک نقطه داده، ناهنجاریها را شناسایی میکنند.
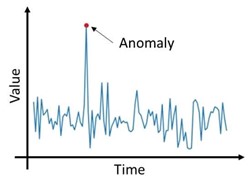
پیشنهاد میکنیم درباره یادگیری با ناظر (Supervised Learning) و همینطور یادگیری بدون ناظر (Unsupervised Learning) هم مطالعه کنید.
روشهای رایج در تشخیص ناهنجاریها چیست؟
مهمترین روشهای رایج در تشخصی ناهنجاریها را میتوان بهاین صورت دستهبندی کرد:
روشهای آماری
روشهای آماری پایهواساس تشخیص ناهنجاریها را تشکیل میدهند که در این میان، روش Z-Score یکی از سادهترین اما قدرتمندترین تکنیکهاست. این روش میزان انحراف استاندارد یک عنصر از میانگین را اندازهگیری میکند. در این زمینه یک Z-Score بالا نشاندهنده این است که نقطه داده بهطور قابل توجهی از بقیه دادهها متفاوت است که این امر نشاندهنده یک ناهنجاری است. این روش، بهویژه، برای شناسایی نقاط داده خارج از محدوده (Outliers) در مجموعههای دادهای که از توزیع گاوسی (Gaussian Distribution) پیروی میکنند مفید است.
تکنیکهای مبتنی بر تراکم (Density-Based Techniques)
تکنیکهای مبتنی بر تراکم از این قرار است:
عامل دورافتاده محلی (LOF – Local Outlier Factor)
الگوریتم عامل دورافتاده محلی (LOF) یک تکنیک مبتنی بر تراکم است که برای شناسایی ناهنجاریها به کار میرود. این الگوریتم با اندازهگیری انحراف تراکم محلی یک نقطه داده در مقایسه با همسایگان خود عمل میکند. درواقع، این الگوریتم تراکم اطراف یک نقطه را با تراکم اطراف همسایگان محلی آن مقایسه میکند. ناهنجاریها بهعنوان نقاطی شناسایی میشوند که تراکم قابل توجهی کمتری در مقایسه با همسایگان خود دارند.
جنگلهای ایزوله (Isolation Forests)
جنگلهای ایزوله روش دیگری مؤثر برای تشخیص ناهنجاریها هستند، بهویژه در مجموعههای داده با ابعاد بالا. این الگوریتم با انتخاب تصادفی یک ویژگی (Feature) و سپس انتخاب تصادفی یک مقدار تقسیم میان حداکثر و حداقل مقادیر ویژگی انتخابشده مشاهدات را جدا میکند. این روش بهدلیل اینکه ناهنجاریها را بهجای پروفایل کردن نقاط داده عادی از هم جدا میکند کارآمد است و به هزینههای محاسباتی پایینتر میانجامد، بهخصوص برای مجموعههای داده بزرگ.
دستگاههای بردار پشتیبان یککلاس (One-Class Support Vector Machines – OCSVM)
دستگاههای بردار پشتیبان یککلاس (OCSVM) یک انتخاب محبوب برای تشخیص ناهنجاریها در مواردی هستند که اطلاعات ما عمدتاً در مورد دادههای عادی است و اطلاعات بسیار کمی در مورد ناهنجاریها داریم. این روش، بهویژه، برای مجموعههای داده با بعد بالا مفید است. OCSVM با یافتن یک مرز تصمیمگیری که نقاط داده عادی را از تمامی ناهنجاریهای ممکن جدا میکند کار میکند.
شبکههای عصبی (Neural Networks) دو مورد
اتوانکودرها (Autoencoders)
اتوانکودرها، نوعی از شبکههای عصبی، برای تشخیص ناهنجاریها با یادگیری نمایش فشرده دادهها به کار گرفته میشوند. این شبکهها با رمزگذاری دادهها به فضایی با بُعد پایینتر و سپس بازسازی آنها به فضای اصلی کار میکنند. خطای بازسازی بهعنوان نشانگری برای تشخیص ناهنجاری استفاده میشود؛ هرچه خطا بیشتر باشد، احتمال ناهنجاری در نقطه داده بیشتر است.
LSTM (حافظه طولانی کوتاهمدت – Long Short-Term Memory)
شبکههای LSTM، نوعی از شبکههای عصبی بازگشتی، بهویژه برای تشخیص ناهنجاری در دادههای زمانمحور مناسب هستند. این شبکهها میتوانند الگوهایی را در طول زمان یاد بگیرند و قادر به شناسایی ناهنجاریها در دنبالههای دادهها هستند که این ویژگیها آنها را برای کاربردهایی مانند تشخیص تقلب در معاملات مالی یا نظارت بر ماشینآلات صنعتی ایدهآل میکند.
شبکههای بیزی (Bayesian Networks)
شبکههای بیزی مدلهای گرافیکی احتمالاتی هستند که مجموعهای از متغیرها و وابستگیهای شرطی آنها را ازطریق یک گراف بدون چرخه و جهتدار (DAG) نمایش میدهند. این شبکهها برای تشخیص ناهنجاریها با مدلسازی روابط احتمالاتی بین ویژگیهای مختلف در مجموعه دادهها استفاده میشوند. ناهنجاریها با مشاهده انحراف از توزیعهای احتمالاتی انتظاری قابل تشخیص هستند.
مدلهای مارکوف پنهان (HMMs)
مدلهای مارکوف پنهان مدلهای آماری هستند که دنبالهای از نمادها یا مقادیر را تولید میکنند. در تشخیص ناهنجاری، HMMها برای مدلسازی رفتار عادی و سپس تشخیص انحرافات از این رفتار به عنوان ناهنجاریها استفاده میشوند. این مدلها در سناریوهایی که دادهها دنبالهای و وابسته به زمان هستند، مانند شناسایی گفتار یا تجزیهوتحلیل توالیهای بیولوژیکی بسیار مؤثر هستند.
چالشهای ارزیابی سیستمهای تشخیص ناهنجاری چیست؟
برخی از چالشهای ارزیابی سیستمهای تشخیص ناهنجاری از این قرار است:
ناهمگنی دادهها
یکی از بزرگترین چالشها در ارزیابی سیستمهای تشخیص ناهنجاری (Anomaly Detection)، نابرابری ذاتی در مجموعه دادهها است. ناهنجاریها بهطور طبیعی رویدادهای نادری هستند، بهاین معنا که معمولاً مجموعه دادهها شامل تعداد زیادی مورد عادی و تعداد نسبتاً کمی ناهنجاری میباشند. این ناهمگنی میتواند به امتیاز دقت به طور گمراهکننده بالایی بینجامد که بهعنوان پارادوکس دقت (Accuracy Paradox) شناخته میشود.
تعریف و برچسبگذاری ناهنجاریها
تعریف و برچسبگذاری صحیح ناهنجاریها میتواند دشوار باشد، بهویژه در سناریوهای یادگیری بدون نظارت (Unsupervised Learning) که برچسبها در دسترس نیستند. ماهیت ذهنی آنچه که یک ناهنجاری را در زمینههای مختلف تشکیل میدهد به پیچیدگی افزوده میشود.
تغییرپذیری ناهنجاریها
ناهنجاریها میتوانند از نظر ماهیت و ظاهر بهشدت متفاوت باشند که این امر چالشبرانگیز است تا اطمینان حاصل شود که سیستم میتواند بهخوبی از یک ناهنجاری به ناهنجاری دیگر تعمیم یابد. این تغییرپذیری همچنین میتواند تنظیم آستانه مناسب برای تشخیص بدون افزایش نرخ مثبت کاذب (False Positive Rate) را دشوار کند.
دادههای پویا و جابهجایی مفهوم (Concept Drift)
در بسیاری از کاربردهای واقعی دادهها پویا هستند و با گذر زمان تحول مییابند. این بهآن معناست که یک سیستم تشخیص ناهنجاری که در یک نقطه از زمان بهخوبی عمل میکند، ممکن است در آینده همانقدر خوب عمل نکند؛ زیرا توزیع دادههای زیربنایی تغییر میکند.
ارزیابی حساس به هزینه
در بسیاری از کاربردها هزینههای مثبتهای کاذب و منفیهای کاذب میتواند بهطور قابل توجهی متفاوت باشد؛ برای مثال، در تشخیص تقلب یک منفی کاذب (ازدستدادن یک تراکنش تقلبی) ممکن است بسیار هزینهبرتر از یک مثبت کاذب (علامتگذاری یک تراکنش مشروع به عنوان تقلبی) باشد. ارزیابی سیستمها بهروشی که این تفاوتهای هزینهای را در نظر بگیرد، چالشبرانگیز اما ضروری است.
قسمتی از جزوه کلاس برای تدریس Anomaly Detection

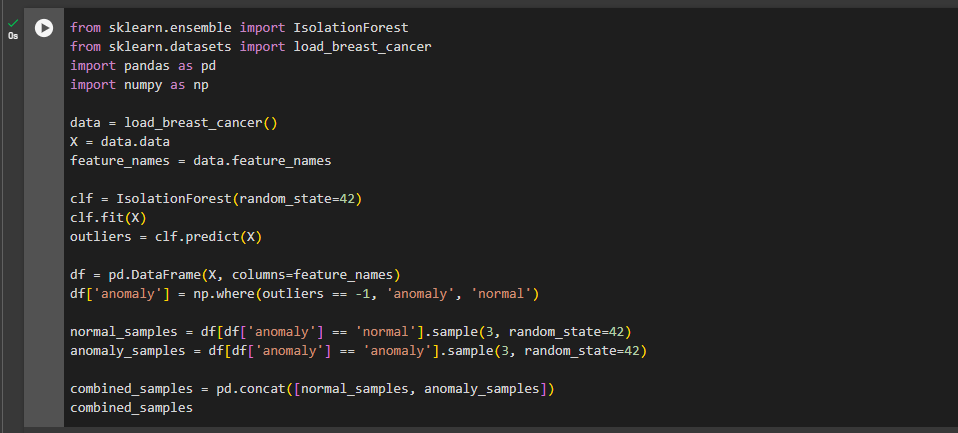
قطعه کد پایتون برای تشخیص ناهنجاری
این کد پایتون از مدل Isolation Forest برای تشخیص ناهنجاریها در دادههای مجموعه داده سرطان سینه استفاده میکند. ابتدا دادهها از کتابخانه sklearn.datasets بارگیری میشوند و سپس یک مدل جنگل انزوا با استفاده از این دادهها آموزش داده میشود. مدل به دادهها برچسبهایی میزند که نمایانگر نمونههای عادی (برچسب ۱) و ناهنجار (برچسب ۱-) است. در ادامه این برچسبها برای مشاهده به دادهها اضافه میشوند و دادهها در یک DataFrame پانداز قرار میگیرند تا بهراحتی قابل مشاهده و تجزیهوتحلیل باشند.

نتیجهگیری
در پایان، تشخیص ناهنجاری در یادگیری ماشین یک حوزه بسیار مهم است که فاصله میان الگوهای معمولی دادهها و رخدادهای غیرمنتظره را پر میکند. کاربردهای آن متنوع و حیاتی هستند و از امنیت سایبری گرفته تا بهداشت، مالی و فراتر از آن را دربرمیگیرند. روشها و تکنیکهای بهکاررفته در تشخیص ناهنجاری، مانند روشهای آماری (Statistical approaches)، تکنیکهای مبتنی بر تراکم (Density-based techniques) و مدلهای یادگیری ماشین (Machine learning models)، بهطور قابل توجهی تکامل یافتهاند و دقت و کارایی بیشتری ارائه میکنند.
چالشهای موجود در تشخیص ناهنجاری، بهویژه در زمینه کیفیت دادهها، انتخاب مدل و تعادل بین خطاهای مثبت و منفی کاذب، همچنان حوزههایی از تحقیق و توسعه فعال هستند؛ بااینحال پیشرفتهای مداوم در هوش مصنوعی (AI) و یادگیری ماشین امیدواریهایی برای بهبود تواناییهای تشخیص ناهنجاری ایجاد میکند، سیستمها را مقاومتر، هوشمندتر و قابل انطباقتر با تهدیدها و ناهنجاریهای نوظهور میکند.
در حرکت بهسوی آینده ادغام تشخیص ناهنجاری در بخشهای مختلف به طور فزایندهای ضروری خواهد شد، نهتنها بهعنوان ابزاری برای شناسایی خارج از الگوها، بهعنوان جنبهای اساسی در تحلیل پیشبینی و تصمیمگیری. اهمیت تشخیص ناهنجاری در حفظ یکپارچگی و امنیت سیستمها بیش از پیش روشن است و نقش آن در دوره دادههای بزرگ (Big data) و تحلیلهای پیشرفته روبهافزایش است.
دنیای دادهها جذاب است و دانستن علم داده، توانایی تحلیل داده، یا بازاریابی مبتنی بر داده، شما را برای فرصتهای شغلی بسیاری مناسب میکند. فارغ از رشته و پیشزمینه، میتوانید حالا شروع کنید و از سطح مقدماتی تا پیشرفته بیاموزید. اگر دوست دارید به این حوزه وارد شوید، پیشنهاد میکنیم با کلیک روی این لینک قدم اول را همین حالا بردارید.

پرسشهای متداول
هدف اصلی تشخیص ناهنجاری در یادگیری ماشینی چیست؟
هدف اصلی تشخیص ناهنجاری در یادگیری ماشینی (Machine Learning)، شناسایی الگوها یا نقاط دادهای است که بهطور قابل توجهی از اکثریت دادهها متفاوت هستند. این ناهنجاریها میتوانند نشانهای از حوادث حیاتی، مانند تقلب، خرابی سیستم یا مشکلات بهداشتی باشند که تشخیص به موقع آنها حیاتی است.
تکنیکهای یادگیری ماشینی چگونه به بهبود تشخیص ناهنجاری کمک میکنند؟
تکنیکهای یادگیری ماشینی (Machine Learning Techniques) با یادگیری از دادهها برای شناسایی الگوهای پیچیده و انحرافات ظریف، به بهبود تشخیص ناهنجاری کمک میکنند. این تکنیکها میتوانند به دادههای جدید وفق یابند، با گذشت زمان بهبود یابند و تشخیص دقیقتری نسبت به روشهای آماری سنتی ارائه کنند.
آیا صنایع خاصی وجود دارند که در آنها تشخیص ناهنجاری حیاتیتر است؟
تشخیص ناهنجاری در همه صنایع ارزشمند است، اما در بخشهایی مانند مالی برای تشخیص تقلب (Fraud Detection)، بهداشت برای نظارت بر بیماران، امنیت سایبری برای تشخیص تهدیدات، و تولید برای کنترل کیفیت، اهمیت بیشتری دارد.
آیا تشخیص ناهنجاری میتواند ناهنجاریهای آینده را پیشبینی کند؟
تشخیص ناهنجاری، بهویژه هنگامی که با تحلیل پیشبینیکننده (Predictive Analytics) ترکیب میشود، نهتنها میتواند ناهنجاریهای فعلی را شناسایی کند، براساس دادهها و روندهای تاریخی، امکان پیشبینی ناهنجاریهای بالقوه آینده را نیز فراهم میآورد. این توانایی پیشگویی برای اقدامات پیشگیرانه در بسیاری از کاربردها اساسی است.
چگونه ظهور دادههای بزرگ (Big Data) بر تشخیص ناهنجاریها تأثیر میگذارد؟
ظهور دادههای بزرگ تأثیر قابل توجهی بر تشخیص ناهنجاری داشته است؛ زیرا مجموعههای دادههای وسیعتری برای آموزش و تحلیل فراهم میآورد که این امر دقت و کارآمدی مدلهای تشخیصی را ارتقا میبخشد. بااینحال این موضوع چالشهایی را نیز از نظر قدرت پردازش و کنار آمدن با دادههای با ابعاد بالا (High-dimensional Data) به همراه دارد.
یادگیری ماشین لرنینگ را از امروز شروع کنید!
اگر به یادگیری ماشین لرنینگ علاقه دارید و دوست دارید به این دنیای جذاب وارد شوید، مشاوران کافهتدریس به شما کمک میکنند مسیر یادگیری برای ورود به این حوزه را شروع کنید:
تشخیص ناهنجاری در یادگیری ماشین چه اهمیتی دارد؟ ذکر دو مورد از اهمیتهای آن را بنویسید.
سیستم هشدار دهنده زودهنگام
تضمین کیفیت دادهها
ناهنجاریهای زمینهای چگونه ناهنجاریهایی هستند و چه تفاوتی با ناهنجاریهای نقطهای دارند؟
ناهنجاریهای نقطهای (Point Anomalies)
اینها نقاط دادهای هستند که بهطور قابل توجهی از باقی دادهها متفاوتاند؛ برای مثال، یک افزایش ناگهانی در تراکنشهای کارت اعتباری برای یک حساب خاص میتواند نشاندهنده فعالیت تقلبی باشد.
ناهنجاریهای زمینهای (Contextual Anomalies)
ناهنجاریهای زمینهای همچنین بهعنوان ناهنجاریهای شرایطی شناخته میشوند. این نقاط داده در یک زمینه خاص ناهنجار هستند، اما ممکن است در زمینهای دیگر بهعنوان نقاط خارج از محدوده در نظر گرفته نشوند؛ برای مثال، یک کاهش ناگهانی دما ممکن است در زمستان عادی باشد، اما در تابستان بهعنوان یک ناهنجاری در نظر گرفته شود.
یکی از روشهای رایج در تشخیص ناهنجاریها را نام ببرید و کاربرد آن را در یک جمله توضیح دهید.
جنگلهای ایزوله (Isolation Forests)
این الگوریتم با انتخاب تصادفی یک ویژگی (Feature) و سپس انتخاب تصادفی یک مقدار تقسیم میان حداکثر و حداقل مقادیر ویژگی انتخابشده مشاهدات را جدا میکند.
سوال ۳:
سه نوع اصلی تقسیم میشود: تشخیص ناهنجاری نظارتشده (Supervised Anomaly Detection)، تشخیص ناهنجاری نیمهنظارتشده (Semi-supervised Anomaly Detection) و تشخیص ناهنجاری بدون نظارت:
رویکردی است که بیشترین استفاده را دارد و نیازی به دادههای برچسبدار ندارد
ا
ناهنجاریهای زمینهای: این نقاط داده در یک زمینه خاص ناهنجار هستند، اما ممکن است در زمینهای دیگر بهعنوان نقاط خارج از محدوده در نظر گرفته نشوند؛ برای مثال، یک کاهش ناگهانی دما ممکن است در زمستان عادی باشد، اما در تابستان بهعنوان یک ناهنجاری در نظر گرفته شود
ناهنجاری نقطه ای:
اینها نقاط دادهای هستند که بهطور قابل توجهی از باقی دادهها متفاوتاند؛ برای مثال، یک افزایش ناگهانی در تراکنشهای کارت اعتباری برای یک حساب خاص میتواند نشاندهنده فعالیت تقلبی باشد
رشد انفجاری دادهها در عصر دیجیتال، تشخیص ناهنجاری به بیش از یک ابزار برای شناسایی نقاط خارج از معمول تبدیل شده است، بلکه به یک
دارایی راهبردی برای بهدست آوردن بینشها، تضمین امنیت و بهبود کارایی عملیاتی در بخشهای مختلف تبدیل شده است
قابلیت انطباق و تکامل
همانطور که مدلهای یادگیری ماشین با دادههای جدید روبهرو میشوند، تشخیص ناهنجاری به انطباق این مدلها با الگوهای در حال تکامل کمک میکند و اطمینان میدهد که آنها برای مدت طولانی مؤثر باقی بمانند.
تحقیق و توسعه
تشخیص ناهنجاری در تحقیقات علمی کمک میکند با شناسایی پدیدههای نو و نادر، میتواند به کشفها و پیشرفت های قابل توجه در زمینههای مختلف بینجامد.