

در دنیای پیچیدهی یادگیری عمیق و پردازش تصویر، مدلهای مختلفی برای تشخیص و شناسایی اشیا در تصاویر توسعه یافتهاند که اولین آنها الگوریتم R-CNN است. بعد از این مدل که دقت قابل قبولی هم داشت، مدلهای Fast R-CNN و Faster R-CNN طراحی شدند تا نواقص R-CNN را رفع کنند. در این مقاله، به بررسی جزئیات فنی هر یک از این مدلها پرداخته و تفاوتها و بهبودهای ارائه شده در هر نسل را مورد بحث قرار خواهیم داد.
- 1. R-CNN چیست؟
- 2. Fast R-CNN چیست؟
- 3. Faster R-CNN چیست؟
- 4. مقایسه R-CNN و Faster R-CNN
- 5. نقاط قوت و ضعف Faster R-CNN
- 6. جمعبندی
-
7.
پرسشهای متداول
- 7.1. مدل R-CNN چگونه کار میکند و چه تفاوتی با Fast R-CNN و Faster R-CNN دارد؟
- 7.2. چه مشکلات و چالشهایی در استفاده از R-CNN وجود دارد؟
- 7.3. چرا Fast R-CNN نسبت به R-CNN بهینهتر است؟
- 7.4. تکنیک سرکوب غیر حداکثری در تشخیص اشیا چیست و چگونه عمل میکند؟
- 7.5. تفاوت اصلی بین شبکه ناحیه پیشنهادی و جستجوی انتخابی چیست؟
- 8. یادگیری تحلیل داده را از امروز شروع کنید!
مدل R-CNN به عنوان نخستین تلاش موفقیتآمیز در زمینه تشخیص اشیا (Object Detection)، توانست با استفاده از شبکههای عصبی کانولوشنی، مناطق مستطیلی احتمالی را که ممکن است حاوی اشیا باشند، شناسایی کند. این روش علیرغم دقت بالا، دارای معایبی چون زمان پردازش طولانی و نیاز به فضای ذخیرهسازی زیاد بود.
با معرفی Fast R-CNN، تلاش شد تا با استفاده از بهینهسازیهای مختلف، این مشکلات کاهش یابد. در این مدل، فرآیند استخراج ویژگیها و طبقهبندی به صورت موازی انجام میشود که بهبود قابل توجهی در سرعت و کارایی ایجاد میکند.
در نهایت، مدل Faster R-CNN با معرفی شبکههای ناحیه پیشنهادی (RPN یا Region Proposal Network) توانست به طور چشمگیری زمان پردازش را کاهش داده و دقت تشخیص را افزایش دهد. این شبکه با ایجاد نقاط پیشنهادی با دقت بالا، فرآیند شناسایی اشیا را به صورت یکپارچه و سریعتر انجام میدهد.


R-CNN چیست؟
در میان الگوریتمهای مختلف تشخیص اشیا، R-CNN (مخفف Region-based Convolutional Neural Network و به معنای شبکههای عصبی کانولوشنی مبتنی بر ناحیه) نام پرآوازهای است. این الگوریتم در سال ۲۰۱۴ توسط Girshick و همکارانش معرفی شد و با عملکرد فوقالعادهاش، توجه دنیای بینایی ماشین را به خود جلب کرد. میتوان R-CNN را یکی از پیشگامان حوزۀ تشخیص اشیاء بر پایه یادگیری عمیق به شمار آورد. اما R-CNN دقیقا چه کاری انجام میدهد؟


R-CNN به طور خاص برای تشخیص اشیا در تصاویر طراحی شده است. این الگوریتم با ترکیب شبکههای عصبی کانولوشنی با تکنیکهای شناسایی ناحیه، قابلیت تشخیص و طبقهبندی اشیا در تصاویر پیچیده را فراهم میکند. با استفاده از R-CNN، میتوان نواحی مختلف در یک تصویر را به دقت بررسی و اشیا موجود در آن را شناسایی کرد. درادامه مراحل اجرای الگوریتم R-CNN را بهترتیب بررسی خواهیم کرد.
تولید ناحیه پیشنهادی
مرحله اول شامل تولید ناحیه پیشنهادی (Region Proposal) است که به معنای جعبههای محدودکننده (Bounding Box) یا نواحی است که احتمالاً شامل اشیا مورد نظر ما در تصویر هستند. در مقاله R-CNN، از روش جستجوی انتخابی (Selective Search) برای این منظور استفاده میشود. جستجوی انتخابی از یک الگوریتم بخشبندی (Segmentation) برای ایجاد یک مجموعه اولیه از نواحی پیشنهادی استفاده میکند. این الگوریتم بهطور تکراری (Iterative) بخشهای تصویر را ترکیب میکند تا نواحی بزرگتری تشکیل دهد و سپس جعبههای محدودکنندهای را در اطراف این نواحی ترکیبی رسم میکند.
جستجوی انتخابی به این شکل کار میکند که ابتدا تصویر به قطعات کوچکتر تقسیم میشود. سپس این قطعات به طور تکراری ترکیب میشوند تا نواحی بزرگتری ایجاد شود که میتوانند اشیا را در بر گیرند. در پایان مرحله جستجوی انتخابی، ما ۲۰۰۰ ناحیه پیشنهادی برای هر عکس خواهیم داشت، که واقعا عدد قابل توجهی است. این نواحی پیشنهادی به عنوان ورودی مراحل بعدی مورد استفاده قرار میگیرند.
استخراج ویژگی از نواحی پیشنهادی
پس از تولید نواحی پیشنهادی، مرحله دوم شامل استخراج ویژگی (Feature Extraction) از هر ناحیه است. یک شبکه عصبی کانولوشنی (CNN) به طور مستقل به هر ناحیه پیشنهادی اعمال میشود تا Feature mapها را محاسبه کند. همانطور که گفتیم در R-CNN، از روش جستجوی انتخابی برای شناسایی نواحی مورد نظر استفاده میشود و در پایان، برای هر عکس حدود ۲۰۰۰ منطقه مختلف به دست میآید. این یعنی برای پردازش هر عکس، به ۲۰۰۰ شبکه CNN نیاز است.
نویسندگان مقاله اصلی R-CNN، از شبکه AlexNet به عنوان استخراجکننده ویژگی استفاده کردند، اما سایر معماریهای CNN نیز میتوانند برای این منظور مورد استفاده قرار گیرند. برای استفاده از AlexNet بهعنوان استخراجکننده ویژگی، کافی است لایه Softmax آخر این معماری را حذف کنیم. بهاینترتیب آخرین لایه شبکه استخراجکننده ویژگی ما یک لایه متصل با ۴۰۹۶ نورون است. این یعنی ویژگیهای (Features) ما ۴۰۹۶ بعدی هستند.
Warped Region
نکته دیگری که باید به آن توجه داشته باشیم این است که ابعاد ورودی AlexNet همیشه اندازه ثابتی دارد (۲۲۷ در ۲۲۷ در ۳). اما Region Proposalهای ما اشکال مختلفی دارند. بسیاری از آنها کوچکتر یا بزرگتر از اندازه گفتهشده هستند، بنابراین باید پیش از ورود به شبکه AlexNet، اندازه هر یک از آنها را تغییر دهیم و به ابعاد مشخص و یکسانی برسانیم. به نواحی پیشنهادی تغییراندازهیافته Warped Region گفته میشود.
Fine-Tune
همچنین با توجه به اینکه لزوما تعداد کلاسهای ما برابر با تعداد کلاسهای مجموعه داده ImageNet که شبکه AlexNet با آن آموزشدیدهاست نمیباشد، لازم است این شبکه طی آموزش مدل R-CNN یک بار روی داده مدنظر ما نیز Fine-Tune یا تنظیم دقیق شود. برای جدا کردن اشیا تصویر از پیشزمینه (Background) نیز لازم است تعداد کلاسهای مسئله یک واحد بیشتر از تعداد اشیا مختلف درنظرگرفته شود.
طبقهبندی
در مرحله نهایی، ویژگیهای استخراجشده از پیشنهادات ناحیه وارد یک لایه طبقهبند (Classifier) میشود. در مقاله اصلی R-CNN، از ماشین بردار پشتیبان (SVM) بهعنوان Classifier استفاده شده است. لایه Classifier آموزش داده میشود تا هر ناحیه پیشنهادی را در یکی از دستههای (Classes) اشیا از پیش تعریفشده قرار دهد.
ماشین بردار پشتیبان (SVM) یک الگوریتم یادگیری ماشین نظارتشده است که برای طبقهبندی و رگرسیون استفاده میشود. در R-CNN، SVM به گونهای آموزش داده میشود که بتواند ویژگیهای استخراجشده از هر ناحیه پیشنهادی را به دستههای مختلف اشیا نسبت دهد. این الگوریتم با استفاده از دادههای آموزشی، مرزهای تصمیمگیری را تعیین میکند که بتواند اشیا را با دقت بالا تشخیص دهد.
اصلاح جعبه محدودکننده
برای اینکه جعبههای محدودکننده یا همان Bounding Boxها بهدرستی اطراف شی مورد نظر قرار بگیرند، از رگرسیون جعبه محدودکننده (BBR یا Bounding Box Regressor) استفاده میشود که سعی میکند با کاهش تابع هزینه MSE روی مختصات جعبههای محدودکننده تعیینشده برای هر شی، پیشبینی دقیقی برای مکان قرارگیری هر شی در تصویر بدهد.
چطور باید یک مدل رگرسیون برای تعیین جعبههای محدودکننده آموزش دهیم؟
این فرآیند شامل تنظیم مختصات نواحی پیشنهادی (Region Proposal) برای تطابق بهتر با جعبههای هدف (Ground Truth) است. برای هر جعبه پیشنهادی اولیه با مختصات p=(px, py, pw, ph) و جعبه هدف با مختصات g=(gx, gy, gw, gh)که x و y بهترتیب مختصات افقی و عمودی مرکز جعبه w و h نشاندهنده طول و عرض جعبه هستند. مدل رگرسیون یاد میگیرد که تغییرات لازم را برای اصلاح جعبههای پیشنهادی محاسبه کند. این تغییرات شامل جابجایی افقی و عمودی و تغییر در ابعاد جعبهها است که به صورت زیر تعریف میشود:

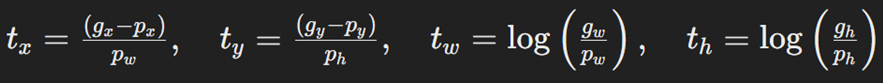
درواقع این نقاط نمایانگر تنظیمات لازم برای تبدیل جعبه پیشنهادی p به جعبه هدف g هستند. یعنی بعد از اینکه الگوریتم جستجوی انتخابی، ۲۰۰۰ ناحیه پیشنهادی را برای ما تولید کرد، باید با استفاده از فرمولهای بالا میزان جابهجایی لازم (t) برای قرارگیری هر ناحیه پیشنهادی روی جعبه هدف متناظرش را محاسبه کنیم. این t میشود برچسب یا Label مدل رگرسیون ما که دقیقا همان چیزی است که انتظار داریم آن را یاد بگیرد.
نهایتا تغییرات پیشبینیشده (t̂) روی جعبههای پیشنهادی اعمال میشود تا جعبههای بهبودیافته به دست آید. بهاینترتیب، مختصات نواحی پیشنهادی حاصل از جستجوی انتخابی اصلاحشده و بهشکل زیر درمیآیند تا جعبههای دقیقتری اطراف اشیا موجود در تصویر بسازند:

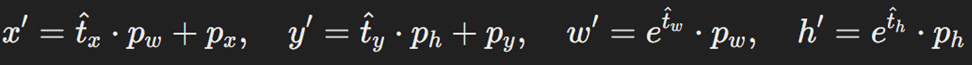
تابع هزینه رگرسیون جعبه محدودکننده چیست؟
پیش از هر چیز لازم است یادآوری کنیم که در R-CNN طبقهبندی اشیا موجود در تصویر و تعیین جعبه محدودکننده همزمان اتفاق میافتد. درنتیجه تابع هزینهای که باید برای آن درنظر گرفت، ترکیبی از توابع هزینه رگرسیون و کلسیفیکیشن (همان طبقهبندی) است:

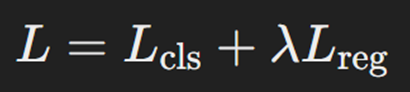
که در آن:
- Lcls تابع هزینه طبقهبندی (در اینجا Cross-Entropy) است.
- Lreg تابع هزینه رگرسیون (در اینجا Huber Loss) است.
- λ یک ضریب است که برای کنترل توازن بین دو تابع هزینه فوق استفاده میشود.
که تابع هزینه هوبر یا Smooth L1 Loss برای رگرسیون جعبه محدودکننده صورت زیر فرمولبندی میشود:

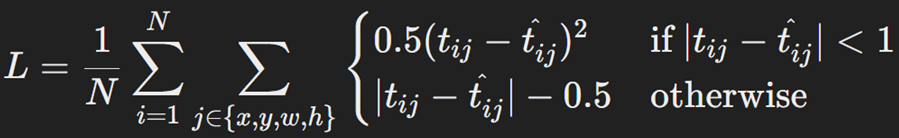
که در آن:
- t̂ij مقدار تغییر پیشبینیشده برای تنظیم مختصات jام (از بین x, y, w, h) ناحیه پیشنهادی iام تصویر مورد نظر است.
- tij مقدار تغییر واقعی برای تنظیم مختصات jام (از بین x, y, w, h) ناحیه پیشنهادی iام تصویر مورد نظر است.
- N تعداد نواحی پیشنهادی است که با الگوریتم جستجوی انتخابی برای هر عکس بدست آمده است.
در این قسمت خوب است یادآوری کنیم که گفتیم برای پردازش هر عکس، به ۲۰۰۰ شبکه CNN نیاز است. از آنجا که در R-CNN، Regressor Bounding Box همزمان با طبقهبندی اشیا هر جعبه انجام میشود، BBR نیز برای هر ناحیه پیشنهادی جداگانه اعمال میشود. این مفهوم را در شکل زیر میبینید:

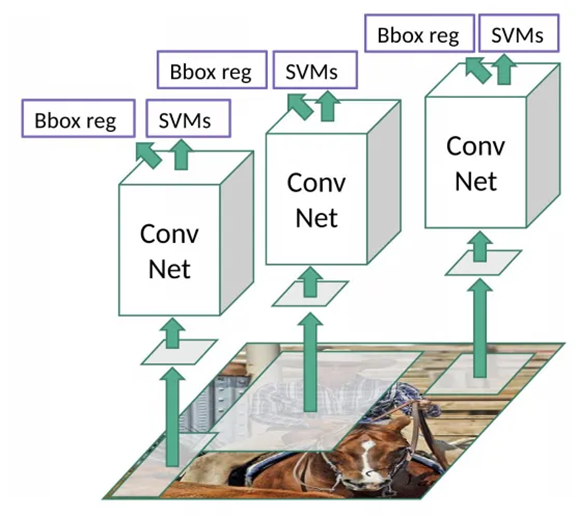
همچنین تغییر ابعاد Region Proposalها به یک مقدار ثابت و مشخص، پیش از ورود به یک شبکه عصبی کانولوشنی که در قسمتهای قبل علت آن را توضیح دادیم، در شکل مشخص است.
انتخاب نواحی پیشنهادی براساس IoU
تعیین دقیق اینکه هر یک از ۲۰۰۰ جعبه پیشنهادی یک تصویر در مجموعهداده آموزشی (Train dataset)، با کدام یک از جعبههای هدف موجود در آن متناظر میباشد، کار دشواری است. به صورت شهودی نیز این مشکل قابل فهم است، چرا که اگر یک ناحیه پیشنهادی بهطور قابل توجهی از تمامی جعبههای هدف که بهعنوان Label در مجموعهداده آموزشی قرارگرفتهاند دور باشد، تبدیل آن به یک جعبه محدودکننده منطقی نخواهد بود.
به همین دلیل، ما فقط در شرایطی از یک ناحیه پیشنهادی p استفاده میکنیم که بهاندازه کافی به یکی از جعبههای هدف g نزدیک باشد. این نزدیکی را با تخصیص p به جعبه هدفی که بیشترین همپوشانی IoU (Intersection over Union یا اشتراک تقسیم بر اجتماع) را با آن دارد تعریف میکنیم، آن هم بهشرطی که میزان همپوشانی بیشتر از یک حد آستانه باشد.

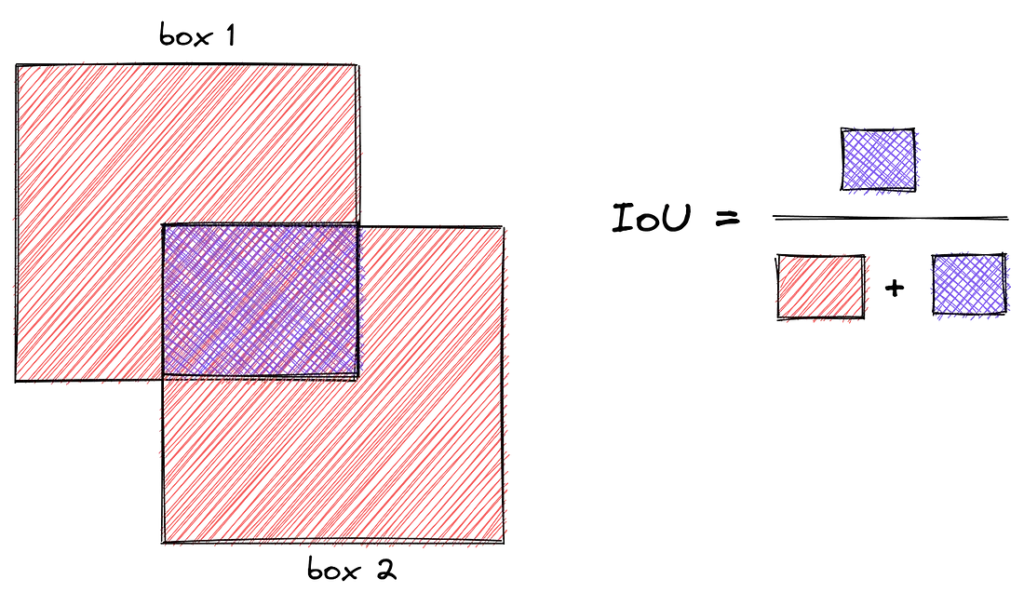
این آستانه در مقاله اصلی ۰.۶ تنظیم شده است. تمامی نواحی پیشنهادیای که به هیچ جعبه هدفی تخصیص نیافتهاند، کنار گذاشته میشوند و در فرآیند آموزش استفاده نمیشوند. این فرآیند را برای هر کلاس از اشیا بهصورت جداگانه انجام میدهیم تا دقت مدل بهبود یابد.
چرا به تفکیک کلاسها نیاز است؟
برای بهبود دقت مدل در تشخیص این اشیا، نیاز است که رگرسیون جعبه محدودکننده برای هر کلاس از اشیا بهصورت جداگانه انجام شود. هر کلاس ممکن است خصوصیات و ویژگیهای خاص خود را داشته باشد. برای مثال، شکل، اندازه، و موقعیت اشیاء مربوط به کلاس «ماشین» ممکن است بهطور قابل توجهی با کلاس «انسان» متفاوت باشد. اگر همه جعبههای محدود کننده را بدون توجه به کلاسهای اشیا با هم ترکیب کنیم، ممکن است مدل بهدرستی نتواند تفاوتها را یاد بگیرد و دقت آن کاهش یابد.
سرکوب غیر حداکثری
درپایان، تکنیک سرکوب غیر حداکثری (Non-Maximum Suppression) برای بدست آوردن نواحی درست استفاده میشود. با این تکنیک، جعبههای محدودکننده اصلاحشده به کمک BBR که امتیاز همپوشانی (IoU) بیش از ۰.۵ دارند حفظ شده و سایر جعبهها حذف میشوند. اگر بیش از یک جعبه محدودکننده با امتیاز بیش از ۰.۵ برای یک شی بدست آید، جعبهای که بالاترین امتیاز همپوشانی را دارد، پذیرفته میشود.
سرکوب غیر حداکثری (NMS) یک تکنیک پسپردازشی است که برای کاهش تعداد جعبههای محدودکننده استفاده میشود. این تکنیک با حذف جعبههایی که همپوشانی زیادی دارند و تنها نگه داشتن جعبهای که بالاترین امتیاز همپوشانی را دارد، به بهبود دقت تشخیص اشیا کمک میکند. NMS با این روش میتواند اطمینان حاصل کند که تنها جعبههای محدودکننده معتبر و دقیق باقی میمانند.
نقاط قوت و ضعف R-CNN
شبکههای عصبی عمیق R-CNN نیز مانند هر فناوری دیگری دارای نقاط قوت و ضعف خاص خود هستند. در این بخش، به بررسی این نقاط قوت و ضعف R-CNN پرداخته و دلایل موفقیت و محدودیتهای آن را تحلیل خواهیم کرد:
نقاط ضعف
- سرعت پایین: فرآیند استخراج ویژگی برای تک تک نواحی پیشنهادی باعث کندی الگوریتم میشد. این به دلیل نیاز به انجام چندین پیشبینی برای هر تصویر بود که به طور قابل توجهی زمان پردازش را افزایش میداد. در هر تصویر، الگوریتم انتخاب گزینشی حدود ۲۰۰۰ ناحیه پیشنهادی تولید میکند که هر یک نمایانگر یک منطقه ممکن است که اشیاء مورد نظر در آن قرار داشته باشند.
- حجم بالای محاسبات: به دلیل نیاز به پردازشهای سنگین، R-CNN برای اجرا به سخت افزارهای قدرتمندی احتیاج داشت. این امر نه تنها هزینهها را افزایش میداد، بلکه دسترسی به این تکنولوژی را محدود میکرد. برای هر تصویر، CNN باید ۲۰۰۰ بار برای هر ناحیه پیشنهادی مستقل اجرا شود که میتواند از نظر محاسباتی بسیار سنگین باشد.
- محدودیت در تشخیص بعضی اشیا: R-CNN در تشخیص اشیا کوچک یا اشیا با ظاهر مشابه، عملکرد ضعیفتری داشت. این به دلیل استفاده از نواحی پیشنهادی بود که ممکن بود به درستی اشیاء کوچک را تشخیص ندهند.
- نیاز به تصاویر با کیفیت: R-CNN برای عملکرد صحیح به تصاویر با کیفیت بالا نیاز داشت. تصاویر با وضوح پایین یا نویز زیاد میتوانستند دقت تشخیص را به شدت کاهش دهند.
- عدم انعطاف پذیری: R-CNN برای تشخیص اشیاء جدید نیاز به آموزش مجدد با مجموعه دادههای جدید داشت. این فرآیند زمانبر و پرهزینه بود و انعطافپذیری الگوریتم را کاهش میداد.
- حافظه بالا: به دلیل حجم بالای دادههای تولید شده در فرآیند استخراج ویژگی و نیاز به ذخیرهسازی آنها، استفاده از R-CNN نیازمند حافظه بالایی بود که ممکن بود برای برخی از سیستمها غیرقابل دسترسی باشد.
- پیچیدگی در آموزش: فرآیند آموزش R-CNN بسیار کند و پیچیده بود. الگوریتم پیشنهادی برای انتخاب ناحیه ثابت بود و بخشی از فرآیند آموزش نبود. استخراج ویژگیها، کلاسبندی با SVM و تنظیم جعبههای محدود کننده به صورت جداگانه آموزش داده میشدند و اشتراک محاسبات کمی داشتند.
نقاط قوت
- دقت بالا: R-CNN در مقایسه با الگوریتمهای قبلی خود، دقت بسیار بالاتری در تشخیص اشیاء ارائه میکرد. این دقت بالا باعث میشد که R-CNN برای بسیاری از کاربردهای عملی مورد توجه قرار گیرد.
- قابلیت تعمیم پذیری: R-CNN میتوانست برای تشخیص اشیاء در تصاویر مختلف با موضوعات مختلف آموزش داده شود. این ویژگی باعث میشد که الگوریتم در کاربردهای مختلفی قابل استفاده باشد.
- بستر مناسب برای تحقیقات: R-CNN به عنوان یک الگوریتم پیشگام، بستر مناسبی برای تحقیقات و توسعه الگوریتمهای جدید تشخیص اشیاء فراهم کرد. این الگوریتم مبنایی برای بسیاری از تحقیقات بعدی در حوزه یادگیری عمیق شد.
- تاثیرگذاری: R-CNN الهام بخش بسیاری از الگوریتمهای جدید تشخیص اشیا بر پایه یادگیری عمیق بوده است. الگوریتمهای پیشرفتهتری مانند Fast R-CNN و Faster R-CNN از اصول R-CNN استفاده کردند و بهبودهای قابل توجهی در کارایی و دقت داشتند.
- تطابق با تکنولوژیهای نوین: R-CNN با استفاده از شبکههای عصبی عمیق و تکنیکهای پیشرفته یادگیری ماشین، توانست تطابق خوبی با پیشرفتهای سریع در حوزه تکنولوژی داشته باشد و مبنای الگوریتمهای جدیدتر و کارآمدتر شود.
اما R-CNN پایان کار نبود و موفقیت آن باعث شد محققان به فکر بهبود و ارتقای این الگوریتم بیفتند؛ درنتیجه، شاهد ظهور نسلهای بعدی R-CNN با عملکرد بهتر و سریعتر بودیم.
Fast R-CNN چیست؟
اولین گام برای بهبود R-CNN، ارائه الگوریتم Fast R-CNN بود. این الگوریتم توانست سرعت R-CNN را به شکل قابل توجهی افزایش دهد. از آنجا که R-CNN برای هر تصویر حدود ۲۰۰۰ ناحیه پیشنهادی مختلف استخراج و برای هر ناحیه از شبکههای CNN جداگانهای استفاده میکند، زمان و منابع پردازشی زیادی برای آموزشدیدن نیاز دارد. Fast R-CNN اما به جای این کار، از یک شبکه عصبی واحد برای استخراج ویژگی از همه نواحی پیشنهادی به صورت همزمان استفاده میکند. شکل زیر نمای کلی یک مدل Fast R-CNN را نشان میدهد:

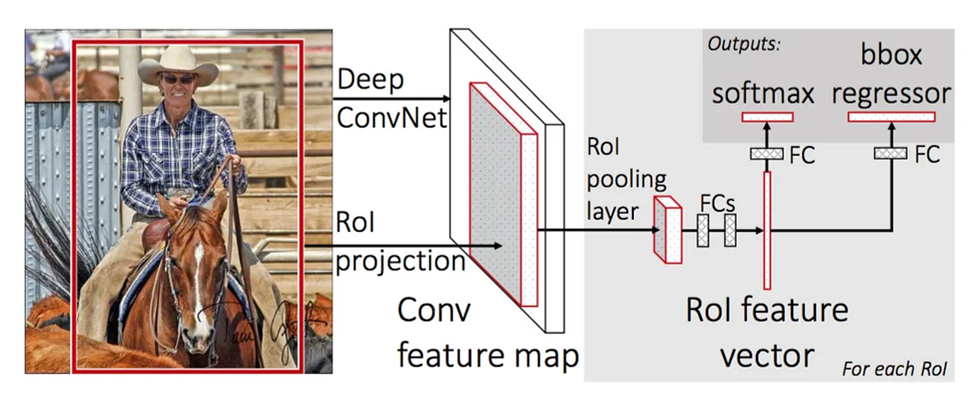
در این قسمت نحوه عملکرد Fast R-CNN را مرحله به مرحله توضیح خواهیم داد:
استخراج ویژگیها از کل تصویر
همانطور که در شکل بالا مشخص است، در این مدل ابتدا کل تصویر وارد یک شبکه CNN میشود تا نقشههای ویژگی یا همان Feature mapهای آن استخراج شود. این نقشه ویژگیها شامل تمام ویژگیهای مورد نیاز برای تشخیص اشیا در تصویر است.
استخراج نواحی پیشنهادی
در Fast R-CNN نیز مانند R-CNN، نواحی پیشنهادی (Region Proposals) توسط یک الگوریتم دیگر مانند جستجوی انتخابی (Selective Search) استخراج میشوند. این پیشنهادها نواحی مختلفی از تصویر هستند که ممکن است حاوی اشیا باشند. البته در مقاله اصلی Fast R-CNN بهجای Region Proposals از عبارت Object Proposal استفاده شده است.
RoI Projection
بعد از استخراج نواحی پیشنهادی بهکمک الگوریتم جستجوی انتخابی و نیز استخراج نقشههای ویژگی (Feature maps) از شبکه عصبی کانولوشنی، باتوجه به تفاوت ابعادشان لازم است مختصات مربوط به هر ناحیه پیشنهادی از تصویر ورودی به نقشه ویژگی متناظرش نگاشت شود. برای مثال اگر یک ناحیه پیشنهادی در تصویر اصلی دارای مختصات (x1, y1, x2, y2) باشد، پس از نگاشت به نقشه ویژگی، این مختصات تغییر میکنند تا با ابعاد نقشه ویژگی تطبیق یابند. به این فرآیند، RoI Projection (Region of Interest بهمعنای ناحیه مورد علاقه) میگوییم.
RoI Pooling
اگر بهشکل طراحی مدل Fast R-CNN توجه کنید، میبینید که پس از لایه RoI Pooling، یک شبکه عصبی Fully Connected وجود دارد. همانطور که میدانید شبکههای عصبی به ورودیهایی با اندازه ثابت نیاز دارند، در حالی که نواحی پیشنهادی نگاشتشده بر روی نقشههای ویژگی دارای اندازههای متفاوتی هستند. در مدل R-CNN برای حل این چالش، از تغییر ابعاد نواحی پیشنهادی به یک اندازه ثابت (Warped Region) استفاده کردیم. Fast R-CNN اما برای این منظور از تکنیک RoI pooling استفاده میکند. این تکنیک نواحی پیشنهادی نگاشتشده روی نقشههای ویژگی را که اندازههای مختلفی دارند، به ابعاد یکسان میرساند.
RoI Pooling هر ناحیه پیشنهادی با ابعاد h×w را به یک شبکه با ابعاد ثابت H×W از زیرشبکههایی با ابعاد h/H×w/W تبدیل میکند. سپس روی هر بخش یک لایه Max Pooling اعمال میکند تا برای هر ناحیه یک نقشه ویژگی با اندازه ثابت بهدست آید.
برای مثال فرض کنید یک ناحیه پیشنهادی با ابعاد ۶×۴ روی نقشه ویژگی یک عکس نگاشتشده و باید به یک شبکه ۳×۳ تقسیم میشود. برای تحقق این سازگاری، اندازه ابعاد ناحیه پیشنهادی باید به ۳ تقسیم شود تا زیرشبکههایی بهابعاد ۴/۳x۶/۳ بدست آید. که اگر مثل اینجا اعداد قابل تقسیم نباشند، اندازهها به اعداد صحیح نزدیکشان گرد میشوند تا در ماتریس قابل پردازش قرار گیرند. برای مثال ناحیه پیشنهادی مثال ما به زیرشبکههای ۱x۲ تقسیم میشود. در این فرآیند ممکن است برخی از دادهها ازدستبروند که در طرح زیر میتوانید تاثیر آن را ببینید:


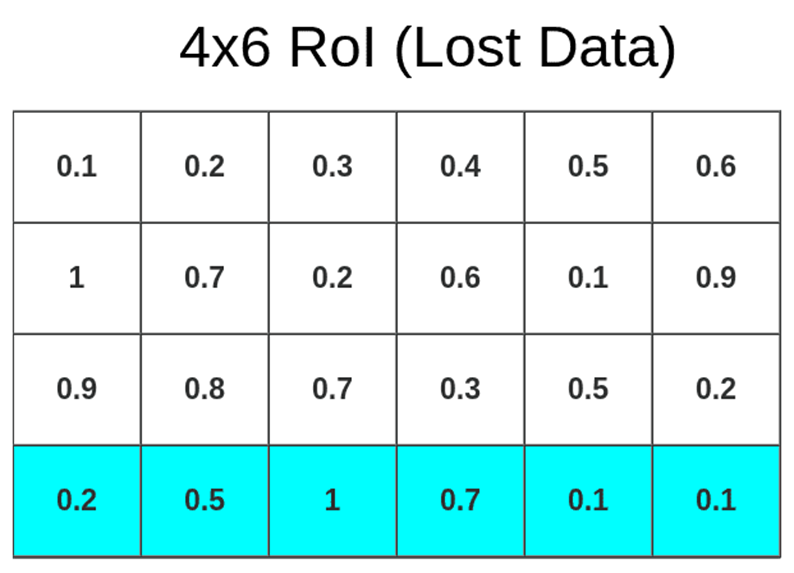
لایههای کاملاً متصل
پس از RoI pooling، نقشههای ویژگی نواحی پیشنهادی با اندازه ثابت به لایههای کاملاً متصل (Fully Connected Layers) ارسال میشوند. این لایهها ویژگیهای استخراجشده را به بردارهای ویژگی (Feature Vectors) تبدیل میکنند که برای طبقهبندی و رگرسیون جعبه محدودکننده استفاده میشوند.
طبقهبندی و رگرسیون جعبه محدودکننده
در مرحله بعدی بردارهای ویژگی بهدستآمده به دو شبکه جداگانه ارسال میشوند:
- یک شبکه برای طبقهبندی که نوع شی موجود در هر ناحیه را تشخیص میدهد.
- یک شبکه برای رگرسیون جعبه محدودکننده که موقعیت دقیق شی را در ناحیه تنظیم میکند.
تابع هزینه
مانند R-CNN، تابع هزینه در Fast R-CNN نیز شامل دو بخش است:
هزینه طبقهبندی
برای تشخیص نوع شی در هر ناحیه پیشنهادی از تابع هزینه Cross Entropy Loss استفاده میشود. فرض کنید u برچسب کلاس واقعی و p احتمال کلاس پیشبینی شده باشد. در آن صورت تابع هزینه طبقهبندی بهشکل خواهد بود:

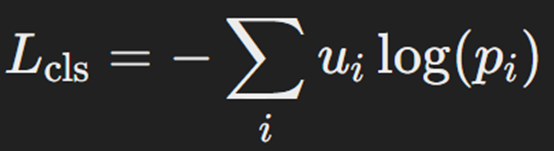
هزینه رگرسیون جعبه محدودکننده
مانند R-CNN برای تنظیم موقعیت شی در ناحیه پیشنهادی از تابع خطای هوبر یا همان Smooth L1 استفاده میشود. در این تابع مانند R-CNN مجددا tij و t̂ij بهترتیب میزان تغییر واقعی و پیشبینیشده برای تنظیم مختصات jام (از بین x, y, w, h) ناحیه پیشنهادی iام تصویر مورد نظر است:

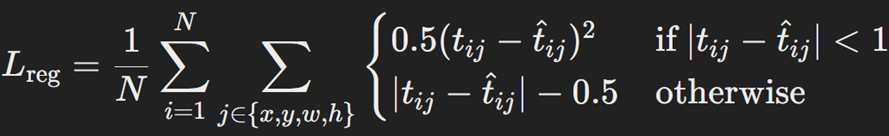
در تابع هزینه این مدل، برای مدیریت پسزمینه یا همان نواحی پیشنهادی فاقد شی، خطای پیشبینی جعبه محدود کننده را نادیده میگیریم. یک تابع هویت یا Identity این مورد را مدیریت میکند. بنابراین شکل کلی تابع هزینه Fast R-CNN بهشکل زیر خواهد بود:


که در آن تابع identity بهصورت زیر تعریف میشود:

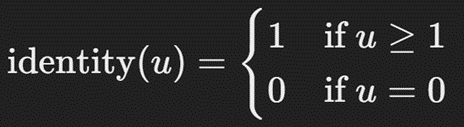
مقایسه Fast R-CNN و R-CNN
در جدول زیر میتوانید بهراحتی دو مدل تشخیص اشیا Fast R-CNN و R-CNN را با هم مقایسه کنید:
| ویژگی | R-CNN | Fast R-CNN |
| استخراج ویژگی | آموزش جداگانه CNN برای هر ناحیه | آموزش یک CNN برای کل تصویر |
| سرعت | کند | به طور قابل توجهی سریعتر |
| دقت | بالا | بالا |
نقاط قوت و ضعف Fast R-CNN
Fast R-CNN یک مدل یادگیری عمیق است که برای تشخیص اشیا در تصاویر استفاده میشود. این مدل، نسخهی بهبود یافتهای از R-CNN است و توانسته است سرعت و دقت را به طور چشمگیری افزایش دهد. در ادامه به نقاط قوت و ضعف Fast R-CNN میپردازیم:
نقاط ضعف
- نیاز به سختافزار قدرتمند: با وجود افزایش سرعت، Fast R-CNN همچنان به سختافزارهای قدرتمند مانند GPU نیاز دارد تا بتواند به صورت موثر و سریع عمل کند.
- پیچیدگی مدلFast R-CNN : نسبت به مدلهای سادهتر، پیچیدگی بیشتری دارد و این موضوع ممکن است موجب دشواری در درک و پیادهسازی آن برای تازهکاران شود.
- حساسیت به تنظیمات: مدل Fast R-CNN به تنظیمات مختلفی مانند اندازه ناحیه پیشنهادی، نرخ یادگیری و دیگر پارامترها حساس است و این موضوع میتواند تنظیم و بهینهسازی مدل را دشوار کند.
- عدم کارایی در تصاویر با رزولوشن بسیار بالا: در تصاویر با رزولوشن بسیار بالا، عملکرد Fast R-CNN ممکن است به دلیل نیاز به پردازش بیشتر کاهش یابد و سرعت و دقت مدل تحت تاثیر قرار گیرد.
نقاط قوت
- سرعت بالا: یکی از مهمترین مزایای Fast R-CNN سرعت بالای آن نسبت به R-CNN است. این مدل با استفاده از شبکههای عصبی کانولوشنی مشترک، قابلیت استخراج ویژگیها را به صورت سریعتر انجام میدهد و از اجرای مجدد شبکه برای هر ناحیه پیشنهادی جلوگیری میکند.
- دقت بالا:Fast R-CNN با استفاده از شبکههای عمیق، دقت بالایی در تشخیص اشیا دارد. این مدل میتواند اشیا را با دقت بیشتری نسبت به مدلهای قدیمیتر شناسایی کند.
- پیادهسازی آسانتر: پیادهسازی Fast R-CNN نسبت به R-CNN سادهتر است زیرا نیازی به محاسبات پیچیده و زمانبر برای استخراج ویژگیها و طبقهبندی نواحی پیشنهادی ندارد.
- بهینهسازی یادگیری: Fast R-CNN از الگوریتم یادگیری end-to-end استفاده میکند که باعث بهینهسازی همزمان همه مراحل یادگیری میشود و نیازی به مراحل جداگانه برای آموزش شبکهها ندارد.
اما Fast R-CNN پایان ماجرا نبود و گام بعدی برای بهبود الگوریتمهای تشخیص اشیا Faster R-CNN بود.
Faster R-CNN چیست؟
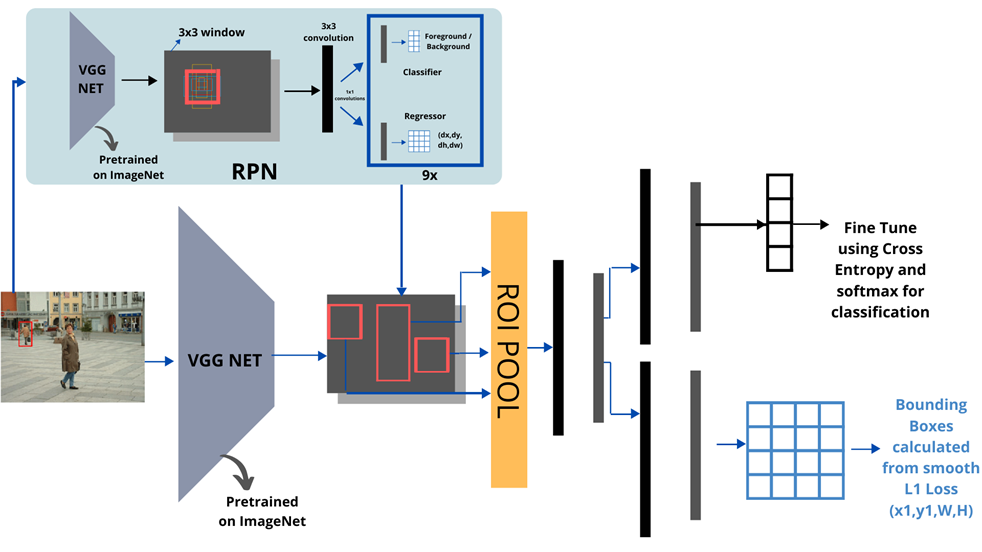
الگوریتم Faster R-CNN یکی دیگر از نسلهای تشخیص و شناسایی اشیا است که در سال ۲۰۱۵ توسط Girshick و همکارانش معرفی شد. هدف این الگوریتم افزایش سرعت و دقت در شناسایی اشیا است. Faster R-CNN با استفاده از یک شبکه ناحیه پیشنهادی (Region Proposal Network یا RPN) که یک شبکه عصبی تمام کانولوشنی (Fully Convolutional Neural Network) است، قادر است نواحی پیشنهادی را به طور مستقیم و در زمان کم از تصویر استخراج کند. این روش نه تنها سرعت پردازش را به طور قابل ملاحظهای افزایش میدهد، بلکه دقت بالاتری نیز در تشخیص و شناسایی اشیاء فراهم میکند. شکل زیر نمای کلی معماری مدل Faster R-CNN را نشان میدهد:

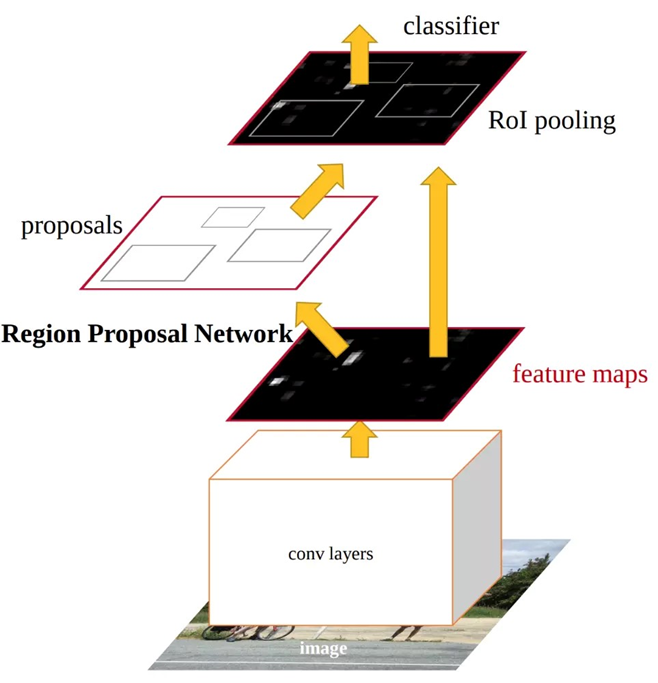
در ادامه مراحل اجرای مدل Faster R-CNN را توضیح خواهیم داد:
استخراج نقشه ویژگی
اولین گام این است که از یک شبکه عصبی از پیشآموزشدیده مانند VGG یا ResNet استفاده کنیم تا ویژگیهای مهم تصویر را استخراج کنیم. این شبکه، تصویر ورودی را به یک نقشه ویژگی (Feature Map) تبدیل میکند که شامل اطلاعات مهم دربارهی اشیا در تصویر است. به عبارتی، این نقشه ویژگی به ما میگوید که در هر بخش از تصویر چه چیزهایی وجود دارد، مثل لبهها، رنگها و الگوها. توجه داشته باشید که نقشه ویژگی روابط مکانی مهم بین اشیا را نیز حفظ میکند.
شبکهی ناحیه پیشنهادی
با اینکه Fast R-CNN با ادغام نواحی پیشنهادی در نقشههای ویژگی بهبود قابل توجهی در سرعت تشخیص اشیا ایجاد کرد، اما مرحله استخراج نواحی پیشنهادی در Fast R-CNN همچنان به الگوریتمهای مبتنی بر CPU مانند جستجوی انتخابی (Selective Search) وابسته بود که یادگیری در آن دخیل نبود و این امر باعث ایجاد بار محاسباتی قابل توجهی میشد. معرفی Faster R-CNN این محدودیت را با معرفی شبکه ناحیه پیشنهادی (RPN یا Region Proposal Network) برطرف کرد. RPN یک شبکه عصبی کاملا کانولوشنی است که نواحی پیشنهادی را مستقیماً از تصویر ورودی تولید میکند. Faster R-CNN با استفاده از RPN، زمان استخراج ناحیه پیشنهادی را از چند ثانیه به چند میلیثانیه کاهش داد و بهبود قابل توجهی در سرعت اجرا ایجاد کرد.
اما پیشبینی مختصات نواحی پیشنهادی توسط شبکههای عصبی معمول دو چالش اصلی دارد:
پیشبینی مستقیم مختصات نواحی پیشنهادی
پیشبینی مستقیم مختصات (x, y) ممکن است منجر به مقادیری شود که خارج از محدوده تصویر قرار میگیرند. این مسئله تفسیر و کاربرد این مختصات را دشوار میکند، زیرا نواحی پیشنهادی باید درون مرزهای تصویر باقی بمانند.
تضمین رعایت محدودیتها
اطمینان از این که مختصات پیشبینی شده معتبر باشند (مثلاً xmin<xmax و ymin<ymax) ضروری است. پیشبینی مستقیم مختصات این محدودیتها را به طور ذاتی تضمین نمیکند و ممکن است منجر به تولید جعبههای پیشنهادی نامعتبر شود.
Anchor Box
برای حل چالشهای بالا، Girshick و همکارانش، مفهومی به نام «Anchor Box» را معرفی کردند. Anchor Boxها، جعبههای محدودکننده ازپیشتعریفشده با اندازهها و نسبتهای مختلف هستند که به عنوان نقاط مرجع برای تشخیص اشیا در تصویر عمل میکنند. درواقع شبکه RPN، از Anchor Boxها به عنوان نقاط شروع استفاده کرده و با اعمال تغییراتی بر روی این جعبهها، نواحی پیشنهادی را تولید میکند. بدون این جعبههای ازپیشتعریفشده، RPN نمیتواند نواحی مناسبی تولید کند. همچنین استفاده ازAnchor ها، فرآیند تولید نواحی پیشنهادی را سادهتر و کارآمدتر میکند زیرا به جای جستجوی کامل تصویر، شبکه مذکور کارش را از تعداد محدودی Anchor Box شروع کرده و آنها را بهبود میبخشد.
Anchorها چطور انتخاب میشوند؟
Anchorها به صورت شبکهای روی نقشه ویژگی قرار میگیرند. برای هر پیکسل در نقشه ویژگی، چندین Anchor با اندازهها و نسبتهای مختلف تعریف میشوند:

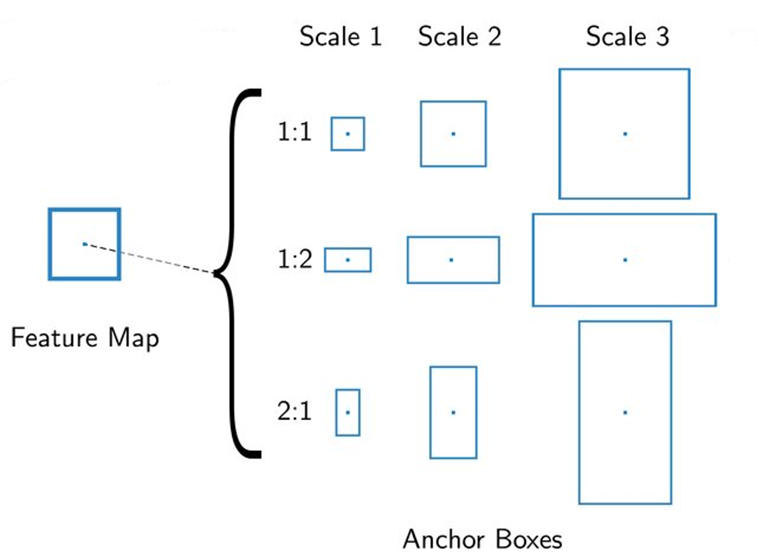
اگر اندازه نقشه ویژگی HxW باشد و تعداد Box Anchorهای هر پیکسل k باشد، در این صورت این k جعبه در هر پیکسل از نقشه ویژگی تولید میشوند و در نتیجه H*W*k، جعبه Anchor در هر Feature Map قرار میگیرد.
برای مثال اگر ابعاد Feature Map ما ۴x۶ باشد و برای هر پیکسل بخواهیم ۳ جعبه Anchor تعیین کنیم، مجموعا ۷۲ جعبه خواهیم داشت:


در مقاله اصلی k برابر ۹ درنظر گرفتهشدهاست، یعنی به مرکز هر پیکسل از نقشه ویژگی، ۹ تا Anchor Box تعریف میشود: سه مقیاس (Small, Medium, Large) هر کدام در سه اندازه مختلف (۱x۲، ۲x۱ و ۱x۱).
اختصاص برچسبهای دودویی به Anchor Boxها
به هر جعبه Anchor یک برچسب (Label) دودویی (به معنای حاوی شی بودن یا نبودن آن) اختصاص داده میشود. دو دسته از جعبههای Anchor برچسب مثبت دریافت میکنند: Box Anchorهایی که بالاترین میزان همپوشانی (Intersection over Union) را با یک جعبه محدودکننده واقعی دارند و Box Anchorهایی که میزان همپوشانی آنها با جعبه محدودکننده واقعی بیشتر از ۰.۷ باشد. Box Anchorهایی که برچسب مثبت ندارند، اگر میزان IoU آنها با تمامی جعبه محدودکننده واقعی کمتر از ۰.۳ باشد، برچسب منفی اختصاص داده میشود. جعبههای که نه برچسب مثبت داشته باشند و نه منفی، در آموزش شرکت داده نمیشوند.
شبکه RPN چطور کار میکند؟
حال که با هدف RPN و نیز مفهوم Anchor آشنا شدیم، وقت آن رسیده که بفهمیم آموزش شبکه RPN چطور منجر به پیشبینی جعبههای محدودکننده برای تشخیص اشیا هر تصویر میشود. درادامه مراحل آموزش یک شبکه RPN را شرح خواهیم داد:
لایه ورودی
ورودی RPN یک نقشه ویژگی است که از یک شبکه عصبی ازپیشآموزشدیده (مانند VGG یا ResNet) استخراج شده است.
لایههای کانولوشنی اولیه
درادامه روی نقشه ویژگی استخراجشده، یک پنجره لغزان ۳x۳ حرکت میکند تا نواحی مختلف تصویر را پوشش دهد. همانطور که گفتیم، برای هر پیکسل از نقشه ویژگی، ۹ Anchor Box با اندازهها و نسبتهای مختلف در نظر گرفته میشود. با حرکت پنجره لغزان روی نقشه ویژگی، یک لایه کانولوشنی ۳x۳ به طور مستقل روی Anchor Boxهای هر پیکسل اعمال میشود. این لایه ویژگیهای کلیدی را استخراج کرده و Feature Map خروجی آن در ادامه به دو لایه کانولوشنی دیگر داده میشود.

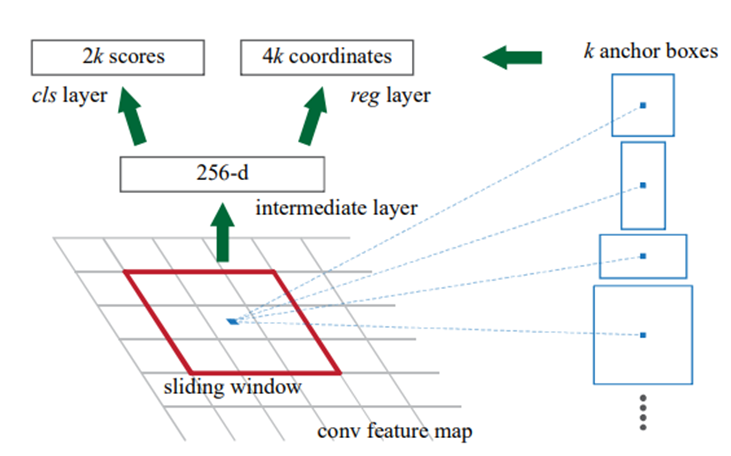
لایههای کانولوشنی ثانویه
خروجی لایه کانولوشنی اولیه به دو لایه کانولوشنی مختلف داده میشود:
- لایه طبقهبندی: این لایه برای تعیین اینکه آیا در Anchor Box مورد نظر شیای وجود دارد یا نه، استفاده میشود. این لایه، یک لایه کانولوشنی با ۱۸ کرنل باابعاد ۱x۱ است که یک طبقهبندی دودویی انجام میدهد و در آن ۱ به معنی Anchor Box مثبت و ۰ به معنی Anchor Box منفی است. در این لایه از تابع فعالساز سیگموید استفاده میشود. خروجی این لایه ابعادی بهاندازه (۲k) ۱۸ کرنل HxW دارد که H و W اندازه نقشه ویژگی حاصل از کانولوشن ۱x۱ را نشان میدهند و (۲x۹) ۱۸ احتمال وجود شی در هر یک از آن ۹ تا Anchor یا احتمال پیشزمینه بودن آن را نشان میدهد.
- لایه رگرسیون: این لایه مسئول پیشبینی مختصات جعبههای محدودکننده برای اشیا شناسایی شده در لایه طبقهبندی است. مختصات شامل چهار پارامتر tx, ty, tw, th است که تغییرات لازم برای تنظیم مختصاف افقی و عمودی مرکز جعبه، عرض و ارتفاع آن را نشان میدهد. این لایه، یک لایه کانولوشنی با ۳۶ کرنل باابعاد ۱x۱ است که یک مدل رگرسیون جعبه محدودکننده با هدف تنظیم مختصات نواحی پیشنهادی بهشمار میرود. خروجی این لایه ابعادی بهاندازه (۴k) ۳۶ کرنل HxW دارد که H و W اندازه نقشه ویژگی حاصل از کانولوشن ۱x۱ را نشان میدهند و (۴x۹) ۳۶ تعداد کانالهای خروجی این لایه خواهد بود که به میزان تغییر لازم برای تنظیم هر یک از ۴ مختصات گفتهشده از هر ۹ تا Anchor اشاره دارد.
RoI Pooling
لایه RoI Pooling طراحی شده است تا هر ناحیه پیشنهادی (که میتواند اندازههای متغیری داشته باشد) را به یک خروجی با اندازه ثابت (مثلا ۷x۷) تبدیل کند. این خروجی با اندازه ثابت میتواند برای پردازش در طبقهبندی و رگرسیون جعبه محدودکننده استفاده شود.
نحوه کار این لایه مانند RoI Pooling در الگوریتم Fast R-CNN است. دقت کنید که در Faster R-CNN مختصات نواحی پیشنهادی (که قبلا توسط RPN روی نقشه ویژگی تولید شدهاند) مستقیماً در نقشه ویژگی موجود هستند. به این ترتیب، نیازی به نگاشت Region Proposalها روی Feature Mapها نیست.
نمای دقیقتری از معماری مدل Faster R-CNN در شکل زیر آمده است:

تابع هزینه
تابع هزینه Faster R-CNN خطای طبقهبندی و رگرسیون را با هم ترکیب میکند. در ادامه فرمول تابع هزینه این مدل آمده است:


این تابع خطا شامل دو جزء اصلی است:
- خطای طبقهبندی که یک خطای لگاریتمی دو کلاسی (بودن یا نبودن شی در Anchor Box) است.
- خطای رگرسیون که مانند دو مدل قبلی، Huber Loss است. این تابع هزینه در اینجا به صورت Lreg(ti−ti*) تعریف شده و فقط برای Anchorهای مثبت فعال میشود.
نقاط مربوط به رگرسیون جعبه محدودکننده نیز به صورت زیر پارامترسازی میشود:

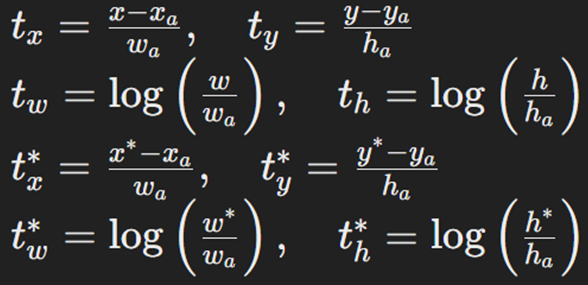
که در آن x ،y ،w و h مختصات مرکز جعبه پیشبینیشده و عرض و ارتفاع آن را نشان میدهند. متغیرهای xa، ya ،wa و ha مربوط به جعبه Anchor هستند و *x∗، y∗، w و *h مربوط به جعبه محدودکننده واقعی هستند.
مقایسه R-CNN و Faster R-CNN
در جدول زیر میتوانید بهراحتی دو مدل تشخیص اشیا R-CNN و Faster R-CNN را با هم مقایسه کنید:
| ویژگی | R-CNN | Faster R-CNN |
| سرعت | کند | به طور قابل توجهی سریعتر |
| دقت | بالا | بالا |
| شبکه پیشنهاد نواحی | Selective Search | Region Proposal Network |
نقاط قوت و ضعف Faster R-CNN
Faster R-CNN با طراحی یکپارچه و بهینهسازیهای قابل توجه، توانسته است به یکی از پرکاربردترین الگوریتمها در کاربردهای واقعی تبدیل شود. با این حال، مانند هر فناوری دیگری، این مدل نیز دارای نقاط قوت و ضعف خاص خود است که در ادامه به بررسی آنها خواهیم پرداخت.
نقاط ضعف
- پیچیدگی در پیادهسازی: علیرغم بهبودهای قابل توجه، Faster R-CNN همچنان دارای پیچیدگیهای خاص خود است. پیادهسازی و تنظیم پارامترهای مختلف این مدل نیازمند دانش تخصصی و تجربه کافی در حوزه یادگیری عمیق است.
- نیاز به تنظیم دقیق: برای دستیابی به عملکرد بهینه، مدل Faster R-CNN نیاز به تنظیم دقیق (Fine-tuning)) دارد. این فرآیند زمانبر و پیچیده است و نیازمند دادههای متنوع و با کیفیت بالا است.
- مصرف حافظه: علیرغم کاهش بار محاسباتی، مدل Faster R-CNN همچنان نیازمند حافظه بالایی برای پردازش و ذخیرهسازی نقشههای ویژگی و نواحی پیشنهادی است. این موضوع میتواند در سیستمهایی با محدودیت حافظه، مشکلساز باشد.
- حساسیت به پارامترها: عملکرد مدل Faster R-CNN به شدت به تنظیمات پارامترها مانند نرخ یادگیری، اندازه نواحی پیشنهادی و دیگر پارامترهای مرتبط حساس است. تنظیم نادرست این پارامترها میتواند دقت و کارایی مدل را کاهش دهد.
- عدم کارایی در تصاویر با رزولوشن بسیار بالا: در تصاویر با رزولوشن بسیار بالا، عملکرد Faster R-CNN ممکن است به دلیل نیاز به پردازش بیشتر کاهش یابد و سرعت و دقت مدل تحت تأثیر قرار گیرد. این موضوع میتواند در کاربردهای خاصی که نیازمند پردازش تصاویر با وضوح بالا هستند، مشکلساز باشد.
نقاط قوت
- سرعت بالا (High Speed): Faster R-CNN با استفاده از شبکه ناحیه پیشنهادی (RPN) به طور چشمگیری سرعت پردازش را افزایش داده است. این تکنیک با تولید نواحی پیشنهادی به صورت مستقیم از نقشه ویژگیها، نیاز به الگوریتمهای جستجوی انتخابی را برطرف کرده و زمان پردازش را به حداقل میرساند.
- دقت بالا: استفاده از RPN باعث افزایش دقت تشخیص اشیا شده است. با تولید نواحی پیشنهادی دقیقتر و بهینهتر، Faster R-CNN میتواند اشیا را با دقت بیشتری شناسایی کند و نرخ خطا را کاهش دهد.
- پیشرفت در یکپارچگی (Integrated Design): Faster R-CNN با طراحی یکپارچه خود، فرآیند تشخیص و طبقهبندی را به صورت همزمان و مؤثر انجام میدهد. این یکپارچگی باعث کاهش پیچیدگی و افزایش کارایی مدل میشود.
- قابلیت تطبیقپذیری: Faster R-CNN میتواند با شبکههای عصبی مختلف مانند VGG و ResNet استفاده شود. این قابلیت به مدل امکان میدهد تا با توجه به نیازهای خاص پروژه، بهترین شبکه عصبی را انتخاب کند و دقت و کارایی مطلوبی را ارائه دهد.
- کاهش بار محاسباتی: با استفاده از RPN، بار محاسباتی کاهش یافته و نیاز به سختافزارهای بسیار قدرتمند نیز کاهش یافته است. این امر باعث میشود که Faster R-CNN در محیطهای با منابع محدود نیز قابل استفاده باشد.
پیادهسازی در پایتون
برای استفاده از مدل Faster R-CNN در پایتون، ابتدا پکیج torchvision را نصب میکنیم:


سپس با کد زیر کتابخانههای لازم را فراخوانی میکنیم:

خط آخر کد بالا مدل ازپیشآموزشدیده Faster R-CNN را فراخوانی میکند که از شبکه Resnet بهعنوان استخراجکننده Feature map استفاده میکند. از آنجا که پیادهسازی این الگوریتم از ابتدا کار بسیار پیچیدهای است، ما از یک مدل آماده استفاده کردیم.
درادامه باید مدل گفتهشده را بخوانیم، در متغیر model بریزیم و آن را در حالت ارزیابی قرار دهیم:


سپس یک تابع تعریف میکنیم که تصویر ورودی را گرفته و با کمک مدل Faser R-CNN عملیات تشخیص اشیا را روی آن انجام دهد. برای این کار ابتدا تابع detect_objects را که سه ورودی (image_path: مسیر تصویر، model: مدل شناسایی اشیا و threshold: آستانه اطمینان، با مقدار پیشفرض ۰.۵) دارد، تعریف میکنیم:


بعد تصویر را از مسیر داده شده بارگذاری و آن را به فرمت RGB تبدیل میکنیم. سپس تصویر به تنسور تبدیل شده و بعد از آن، یک بعد اضافی به آن اضافه میشود:

درادامه باید عملیات شناسایی اشیا بدون محاسبات گرادیان (چون نمیخواهیم مدل را آموزش دهیم و صرفا قصد پیشبینی داریم) را انجام دهیم. با این کار مدل بر روی تنسور تصویر اعمال شده و نتایج پیشبینیها به دست میآید:


سپس برای استخراج اطلاعات مربوط به جعبهها (boxes)، برچسبها (labels) و نمرات (scores) از نتایج پیشبینی مدل استفاده میکنیم:

در پایان پیشبینیهایی که اطمینان کمتری از مقدار آستانه مشخصشده را دارند، فیلتر میکنیم. درواقع فقط جعبهها، برچسبها و نمراتی که بالاتر از آستانه اطمینان هستند حفظ و برگردانده میشوند:

بعد باید برای تفسیر سادهتر نتایج تشخیص، لیستی از برچسبهای دیتاست COCO را ذخیره کنیم:


در نهایت با قطعه کد زیر میتوان عملکرد مدل Faster R-CNN را روی تصاویر دلخواه مشاهده کرد:





برای مشاهده کامل کدهای فوق میتوانید به این ریپازیتوری از گیتهاب مراجعه نمایید.
جمعبندی
در این مقاله به بررسی مدلهای مختلفR-CNN ، Fast R-CNN و Faster R-CNN پرداخته و تاثیر آنها بر دنیای بینایی ماشین را تحلیل کردیم. با مروری بر جزئیات فنی و نقاط قوت و ضعف هر مدل، میتوان نتیجه گرفت که این تکنیکها، تحولات بزرگی در حوزه تشخیص اشیا ایجاد کردهاند. R-CNN با استفاده از شبکههای عصبی کانولوشنی، اولین گام را در جهت تشخیص دقیق اشیا برداشت. Fast R-CNN با بهبود سرعت و کارایی، این مسیر را هموارتر کرد و نهایتاً Faster R-CNN با معرفی شبکه ناحیه پیشنهادی (RPN) توانست به طور چشمگیری زمان پردازش را کاهش داده و دقت تشخیص را افزایش دهد. هر یک از این مدلها، با رفع محدودیتهای مدل قبلی، توانستند به یک پیشرفت قابل توجه دست یابند.

{kind=link}

پرسشهای متداول
مدل R-CNN چگونه کار میکند و چه تفاوتی با Fast R-CNN و Faster R-CNN دارد؟
مدل R-CNN (شبکههای عصبی کانولوشنی مبتنی بر ناحیه) برای تشخیص اشیا در تصاویر طراحی شده است. این مدل ابتدا نواحی پیشنهادی (Region Proposals) را با استفاده از الگوریتم جستجوی انتخابی تولید میکند و سپس ویژگیهای هر ناحیه را استخراج میکند. R-CNN در مرحله بعدی، این ویژگیها را به یک طبقهبند مانند ماشین بردار پشتیبان (SVM) ارسال میکند تا اشیا را شناسایی کند. تفاوت اصلی بین R-CNN و Fast R-CNN در این است که Fast R-CNN از یک شبکه عصبی واحد برای استخراج ویژگیهای همه نواحی پیشنهادی بهصورت همزمان استفاده میکند که باعث افزایش سرعت و کارایی میشود. مدل Faster R-CNN با معرفی شبکه ناحیه پیشنهادی (RPN)، فرآیند تولید نواحی پیشنهادی را بهبود بخشید و زمان پردازش را به طور چشمگیری کاهش داد.
چه مشکلات و چالشهایی در استفاده از R-CNN وجود دارد؟
یکی از مشکلات اصلی R-CNN سرعت پایین پردازش است. این مدل برای هر تصویر حدود ۲۰۰۰ ناحیه پیشنهادی تولید میکند که باید به صورت جداگانه پردازش شوند. چالش دیگر اما نیاز به سختافزارهای قدرتمند برای پردازش مدلهای R-CNN است. بهطور کلی پیادهسازی الگوریتم R-CNN کار دشواری است.
چرا Fast R-CNN نسبت به R-CNN بهینهتر است؟
Fast R-CNN با استفاده از یک شبکه عصبی واحد برای استخراج ویژگیها از کل تصویر و اجرای همزمان فرآیند استخراج ویژگی و طبقهبندی، سرعت و کارایی بالاتری را فراهم میکند.
تکنیک سرکوب غیر حداکثری در تشخیص اشیا چیست و چگونه عمل میکند؟
سرکوب غیر حداکثری (Non-Maximum Suppression) یک تکنیک پسپردازشی است که برای کاهش تعداد جعبههای محدودکننده استفاده میشود. در این تکنیک، جعبههای محدودکننده که همپوشانی زیادی دارند حذف میشوند و تنها جعبهای که بالاترین امتیاز همپوشانی IoU را دارد، نگه داشته میشود. این تکنیک باعث میشود تا تنها جعبههای محدودکننده معتبر و دقیق باقی بمانند و بهبود دقت تشخیص اشیا حاصل شود.
تفاوت اصلی بین شبکه ناحیه پیشنهادی و جستجوی انتخابی چیست؟
تفاوت اصلی بین شبکه ناحیه پیشنهادی و جستجوی انتخابی (Selective Search) در این است که RPN یک شبکه عصبی کانولوشنی است که نواحی پیشنهادی را مستقیماً از تصویر ورودی تولید میکند. این شبکه با استفاده از Anchor Boxها، نواحی پیشنهادی را با دقت بالا تولید میکند. در مقابل، جستجوی انتخابی یک الگوریتم مبتنی بر CPU است که با استفاده از تکنیکهای بخشبندی (Segmentation)، نواحی پیشنهادی را تولید میکند. RPN سرعت بیشتری دارد و دقت بالاتری در تولید نواحی پیشنهادی فراهم میکند.
یادگیری تحلیل داده را از امروز شروع کنید!
دنیای دادهها جذاب است و دانستن علم داده، توانایی تحلیل داده یا بازاریابی مبتنی بر داده شما را برای فرصتهای شغلی بسیاری مناسب میکند. فارغ از رشته و پیشزمینه تحصیلی یا شغلیتان، میتوانید یادگیری این دانش را همین امروز شروع کنید و از سطح مقدماتی تا پیشرفته آن را بیاموزید. اگر دوست دارید به این حوزه وارد شوید، پیشنهاد میکنیم با کلیک روی این لینک قدم اول را همین حالا بردارید.
مشاوران کافهتدریس به شما کمک میکنند مسیر یادگیری برای ورود به این حوزه را شروع کنید: