
یادگیری تقویتی (RL) به یکی از ارکان هوش مصنوعی تبدیل شده است و به عوامل این امکان را میدهد که از طریق تعامل با محیطهای خود، رفتارهای بهینه را یاد بگیرند. این مقاله به بررسی عمیق مهمترین کتابخانههای یادگیری تقویتی میپردازد. ما تحلیل دقیقی از نقاط قوت و ضعف هر کتابخانه ارائه میدهیم تا به دانشمندان داده و محققان هوش مصنوعی در اتخاذ تصمیمات آگاهانه کمک کنیم. این مقاله با پیادهسازی عملی یک محیط، کاربرد چند کتابخانه برتر در این حوزه را نشان میدهد. این مرور جامع و مطالعه مقایسهای برای هر کسی که در حوزه یادگیری ماشین و هوش مصنوعی فعالیت دارد و به دنبال استفاده از بهترین ابزارهای RL است، ضروری است.
- 1. زمینه و اهمیت یادگیری تقویتی
- 2. هدف مقاله
- 3. مروری بر کتابخانههای یادگیری تقویتی
-
4.
تحلیل دقیق کتابخانههای یادگیری تقویتی
- 4.1. Gym
- 4.2. Baselines
- 4.3. Dopamine
- 4.4. TensorLayer
- 4.5. FinRL
- 4.6. Stable-Baselines
- 4.7. ReAgent
- 4.8. Acme
- 4.9. PARL
- 4.10. TF-Agents
- 4.11. TensorFlow
- 4.12. PyTorchRL
- 4.13. Keras-RL
- 4.14. Garage
- 4.15. TensorForce
- 4.16. RLax
- 4.17. Coach
- 4.18. RFRL
- 4.19. Rliable
- 4.20. ViZDoom
- 4.21. Ray RLlib
- 4.22. ChainerRL
- 4.23. MushroomRL
- 4.24. TRFL
- 4.25. CleanRL
- 5. پیادهسازی کتابخانههای یادگیری تقویتی در یک محیط نمونه
- 6. معیارهای ارزیابی عملکرد کتابخانههای یادگیری تقویتی
- 7. مسیرهای آینده یادگیری تقویتی
- 8. جمعبندی
-
9.
پرسشهای متداول
- 9.1. چگونه میتوانیم از یادگیری تقویتی در کاربردهای مالی استفاده کنیم؟
- 9.2. چرا پایداری و مقیاسپذیری در کتابخانههای یادگیری تقویتی مهم هستند؟
- 9.3. چگونه میتوان از یادگیری تقویتی در بهبود سیستمهای توصیهگر استفاده کرد؟
- 9.4. کدام یک از کتابخانههای یادگیری تقویتی برای آموزش رباتها کاربرد دارند؟
- 9.5. مزایای استفاده از گراف محاسباتی پویا در یادگیری تقویتی چیست؟
- 10. یادگیری ماشین لرنینگ را از امروز شروع کنید!
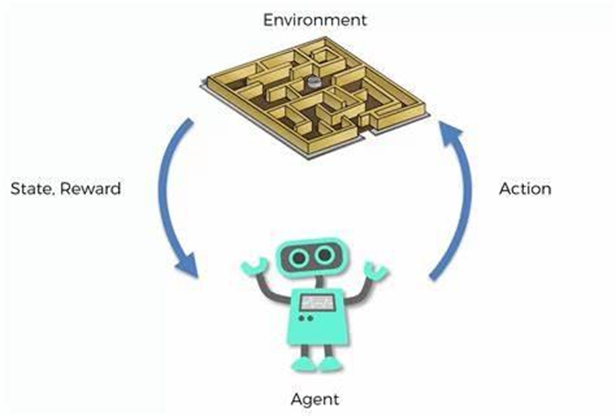
زمینه و اهمیت یادگیری تقویتی
یادگیری تقویتی (RL) به عنوان یک حوزه کلیدی در زمینه هوش مصنوعی (AI) ظهور کرده است که بر روی چگونگی انجام اقدامات توسط عوامل در یک محیط برای حداکثر کردن پاداشهای تجمعی تمرکز دارد. برخلاف یادگیری نظارتشده که مدل بر روی یک مجموعه داده ثابت آموزش داده میشود، RL شامل یادگیری از طریق تعامل با محیط است که آن را به ویژه برای وظایف پویا و پیچیده مانند رباتیک، بازیها، امور مالی و سیستمهای خودمختار مناسب میسازد. با ادامه تکامل RL، توسعه کتابخانههای یادگیری تقویتی برای تسریع تحقیقات و کاربردهای عملی ضروری است.
همچنین بخوانید: یادگیری با ناظر (Supervised Learning) چیست؟
هدف مقاله
هدف اصلی این مقاله ارائه یک مرور جامع از مهمترین کتابخانههای یادگیری تقویتی موجود است. با تحلیل و مقایسه این کتابخانهها، ما قصد داریم بینشهای ارزشمندی در مورد عملکردها، مزایا و محدودیتهای آنها ارائه دهیم و بدین ترتیب محققان و کارورزان را در انتخاب ابزارهای مناسب برای وظایف خاص RL خود راهنمایی کنیم. علاوه بر این، این مقاله مثالی عملی از یک محیط پیادهسازیشده با استفاده از کتابخانههای برتر RL را شامل میشود.
مروری بر کتابخانههای یادگیری تقویتی
معرفی کتابخانههای یادگیری تقویتی
کتابخانههای یادگیری تقویتی ابزارهای اساسی هستند که توسعه، آزمایش و استقرار الگوریتمهای RL را تسهیل میکنند. آنها محیطهای پیشساخته، الگوریتمهای آماده استفاده و ابزارهای مختلفی را ارائه میدهند که کل جریان کار RL را ساده میکنند. این کتابخانهها به کاهش پیچیدگی پیادهسازی RL از ابتدا کمک میکنند و به محققان و کارورزان امکان میدهند تا بیشتر بر نوآوری و آزمایش تمرکز کنند.
با افزایش علاقه به RL، کتابخانههای متعددی پدید آمدهاند که هر یک برای نیازها و ترجیحات مختلفی طراحی شدهاند. برخی کتابخانهها بر سادگی و سهولت استفاده تمرکز دارند و آنها را برای مبتدیان و اهداف آموزشی ایدهآل میسازند. برخی نیز برای عملکرد بالا و مقیاسپذیری طراحی شدهاند و برای کاربردهای صنعتی بزرگمقیاس مناسب هستند. درک نقاط قوت و ضعف این کتابخانهها برای انتخاب ابزار مناسب برای وظایف خاص RL بسیار مهم است.
برای مطالعه بیشتر کلیک کنید: یادگیری تقویتی یا Reinforcement Learning و کاربردهایش چیست؟
معیارهای انتخاب کتابخانه
انتخاب مناسبترین کتابخانه RL به عوامل مختلفی بستگی دارد، از جمله:
- سهولت استفاده: چقدر کتابخانه ساده و کاربرپسند است.
- عملکرد: کارایی و سرعت کتابخانه در آموزش و استقرار مدلهای RL.
- انعطافپذیری: توانایی سفارشیسازی و گسترش کتابخانه برای تطابق با نیازهای خاص.
- پشتیبانی: اندازه و فعالیت جامعه کاربران و همچنین در دسترس بودن مستندات و پشتیبانی.
- سازگاری: چقدر کتابخانه با ابزارها و چارچوبهای دیگر یکپارچه میشود.
در بخش بعدی، با استفاده از این معیارها، ما 25 مورد از مهمترین کتابخانههای یادگیری تقویتی موجود را معرفی و تلاش خواهیم کرد تا تحلیل دقیقی از هر کتابخانه منتخب، شامل توصیفات، مزایا و معایب، ارائه دهیم.
تحلیل دقیق کتابخانههای یادگیری تقویتی
Gym
Gym که توسط OpenAI توسعه داده شده است، یک ابزار برای توسعه و مقایسه الگوریتمهای یادگیری تقویتی است. این ابزار محیطهای مختلفی را از مسائل کنترل کلاسیک تا بازیهای Atari فراهم میکند که میتوان از آنها برای تست و ارزیابی الگوریتمهای RL استفاده کرد.
مزایا:
- مجموعه گستردهای از محیطها.
- مستندات جامع و استفاده آسان.
- جامعه بزرگ و فعال.
معایب:
- پشتیبانی محدود داخلی برای محیطهای سفارشی.
- برخی محیطها ممکن است به محاسبات سنگینی نیاز داشته باشند.
Baselines
Baselines که همچنین توسط OpenAI توسعه یافته است، پیادهسازیهای مختلف الگوریتمهای RL را با استفاده از محیطهای Gym فراهم میکند. این ابزار به عنوان یک مرجع و معیار برای مقایسه روشهای مختلف RL عمل میکند.
مزایا:
- پیادهسازیهای با کیفیت بالا با پشتیبانی از الگوریتمهای محبوب RL.
- ادغام با محیطهای Gym.
- جامعه فعال و بهروزرسانیهای مداوم.
معایب:
- تمرکز اصلی بر الگوریتمهای استاندارد، که امکان سفارشیسازی یا شخصیسازی را محدود میکند.
- ممکن است به منابع محاسباتی قابل توجهی نیاز داشته باشد.
Dopamine
Dopamine که توسط Google توسعه داده شده است، یک چارچوب تحقیقاتی برای نمونهسازی سریع الگوریتمهای RL است. این ابزار بر سادگی و سهولت استفاده تأکید دارد و برای تحقیق و آزمایش مناسب است.
مزایا:
- ساده و سبک.
- طراحی شده برای نمونهسازی سریع و آزمایش.
- تمرکز قوی بر قابلیت تکرار.
معایب:
- تعداد محدودی الگوریتم از پیش پیادهسازی شده.
- پشتیبانی کمتر از محیطهای پیچیده نسبت به سایر کتابخانهها.
TensorLayer
TensorLayer یک کتابخانه یادگیری عمیق و RL است که بر روی TensorFlow ساخته شده است. هدف این ابزار ارائه پلتفرمی کاربرپسند و کارآمد برای توسعه برنامههای یادگیری عمیق و RL است.
مزایا:
- API سطح بالا برای استفاده آسان.
- ادغام با TensorFlow.
- پشتیبانی از طیف گستردهای از وظایف یادگیری عمیق و RL.
معایب:
- ممکن است برای مبتدیان در این زمینه کمی پیچیده باشد. (منحنی یادگیری شیبدار)
- عملکرد آن ممکن است به دلیل نحوه کارکرد TensorFlow محدود شود.
FinRL
FinRL یکی دیگر از کتابخانههای یادگیری تقویتی است که بهطور خاص برای کاربردهای مالی طراحی شده است. این ابزار محیطها و ابزارهای مختلفی برای توسعه و تست الگوریتمهای RL در حوزه مالی فراهم میکند.
مزایا:
- متناسب با کاربردهای مالی.
- شامل دادهها و محیطهای مالی واقعی.
- تمرکز قوی بر قابلیت استفاده عملی در حوزه مالی.
معایب:
- محدود به کاربردهای مالی.
- ممکن است برای وظایف عمومی RL مناسب نباشد.
Stable-Baselines
Stable-Baselines مجموعهای از پیادهسازیهای بهبود یافته الگوریتمهای RL مبتنی بر OpenAI Baselines است. این کتابخانه بر عملکرد و سهولت استفاده تمرکز دارد و نسخههای پایدار و قابل اطمینانی از الگوریتمهای مختلف RL ارائه میدهد.
مزایا:
- عملکرد و پایداری بهبود یافته نسبت به Baselines.
- کاربرپسند و مستندات جامع.
- جامعه فعال و بهروزرسانیهای مکرر.
معایب:
- گزینههای سفارشیسازی محدود.
- تمرکز اصلی بر الگوریتمهای استاندارد.
ReAgent
ReAgent (که قبلاً با نام Horizon شناخته میشد) یک پلتفرم متنباز end-to-end برای یادگیری تقویتی است که توسط Facebook توسعه یافته است. این پلتفرم برای استقرار و مدیریت راهحلهای RL در محیطهای تولیدی طراحی شده است.
مزایا:
- پلتفرم جامع end-to-end.
- پشتیبانی قوی برای استقرار در تولید.
- یکپارچگی با ابزارها و چارچوبهای داخلی Facebook.
معایب:
- منحنی یادگیری شیبدار.
- در درجه اول برای برنامههای بزرگمقیاس طراحی شده است.
Acme
Acme که توسط DeepMind توسعه داده شده است، یکی دیگر از کتابخانههای یادگیری تقویتی است که برای ساخت و آموزش عوامل RL مورد استفاده قرار میگیرد. این ابزار چارچوبی انعطافپذیر و ماژولار برای توسعه الگوریتمهای جدید RL و مقیاسبندی آنها به سیستمهای توزیع شده بزرگ فراهم میکند.
مزایا:
- بسیار ماژولار و انعطافپذیر.
- طراحی شده برای مقیاسپذیری.
- توسعه یافته توسط محققان برجسته DeepMind.
معایب:
- ممکن است برای مبتدیان پیچیده باشد.
- نیاز به منابع محاسباتی قابل توجه برای کاربردهای بزرگمقیاس.
PARL
PARL یک چارچوب RL است که توسط Baidu توسعه داده شده و برای آموزش و استقرار کارآمد مدلهای RL طراحی شده است. این ابزار از وظایف RL تکعاملی و چندعاملی پشتیبانی میکند.
مزایا:
- کارآمد و مقیاسپذیر.
- پشتیبانی از طیف گستردهای از الگوریتمهای RL.
- تمرکز قوی بر کاربردهای صنعتی.
معایب:
- مستندات و پشتیبانی جامعه ممکن است محدود باشد.
- عمدتاً برای کاربردهای صنعتی طراحی شده است.
TF-Agents
TF-Agents یک کتابخانه متنباز RL است که بر روی TensorFlow ساخته شده است. این کتابخانه یک چارچوب انعطافپذیر و ماژولار برای ساخت و آزمایش الگوریتمهای RL ارائه میدهد و دارای یکپارچگی قوی با TensorFlow است.
مزایا:
- یکپارچگی بینقص با TensorFlow.
- طراحی ماژولار و قابل گسترش.
- مستندات و آموزشهای جامع.
معایب:
- کارکرد آن روی TensorFlow ممکن است بر عملکرد تأثیر بگذارد.
- منحنی یادگیری شیبدارتر برای کسانی که با TensorFlow آشنایی ندارند.
TensorFlow
TensorFlow یک چارچوب جامع یادگیری ماشین منبعباز است که توسط Google توسعه داده شده است. این چارچوب یک اکوسیستم قوی برای ساخت و استقرار مدلهای یادگیری ماشین فراهم میکند، شامل پشتیبانی از یادگیری تقویتی.
مزایا:
- اکوسیستم گسترده و پشتیبانی جامعه.
- عملکرد بالا و مقیاسپذیری.
- همهکاره، با پشتیبانی از وظایف مختلف یادگیری ماشین.
معایب:
- منحنی یادگیری شیبدار.
- ممکن است برای وظایف ساده RL بیش از حد باشد.
PyTorchRL
PyTorchRL از چارچوب PyTorch استفاده میکند تا پلتفرمی انعطافپذیر و شهودی برای توسعه الگوریتمهای RL فراهم کند. این ابزار از گراف محاسباتی پویا و سهولت استفاده PyTorch بهره میبرد.
مزایا:
- گراف محاسباتی پویا برای انعطافپذیری.
- پشتیبانی قوی جامعه.
- آسان برای یادگیری و استفاده.
معایب:
- اکوسیستم کمتر بالغ نسبت به TensorFlow.
- عملکرد ممکن است بسته به وظیفه متفاوت باشد.
Keras-RL
Keras-RL الگوریتمهای RL را با چارچوب یادگیری عمیق Keras یکپارچه میکند، و آن را برای کسانی که با Keras آشنا هستند، دسترسیپذیر و آسان برای استفاده میسازد.
مزایا:
- کاربرپسند و شهودی.
- یکپارچگی بینقص با Keras.
- مناسب برای نمونهسازی سریع.
معایب:
- محدود به الگوریتمهای پیادهسازی شده.
- ممکن است همه ویژگیهای پیشرفته RL را پشتیبانی نکند.
Garage
Garage یک ابزار برای توسعه و ارزیابی الگوریتمهای RL است که برای انعطافپذیری و قابلیت توسعه طراحی شده است. این ابزار از محیطها و پیادهسازیهای الگوریتمی مختلف پشتیبانی میکند.
مزایا:
- بسیار انعطافپذیر و قابل توسعه.
- پشتیبانی از طیف گستردهای از محیطها.
- تاکید قوی بر قابلیت تکرار.
معایب:
- مستندات ممکن است ناکافی باشد.
- منحنی یادگیری شیبدار برای تازهکاران.
TensorForce
TensorForce یکی دیگر از کتابخانههای یادگیری تقویتی سطح بالا است که بر روی TensorFlow ساخته شده و بر ماژولار بودن و قابلیت استفاده تاکید دارد. این ابزار به گونهای طراحی شده که به راحتی قابل گسترش و مناسب برای تحقیقات و کاربردهای عملی باشد.
مزایا:
- ماژولار و کاربرپسند.
- یکپارچگی قوی با TensorFlow.
- مناسب برای تحقیقات و تولید.
معایب:
- کارکرد آن روی TensorFlow ممکن است بر عملکرد تأثیر بگذارد.
- محدود به اکوسیستم TensorFlow.
RLax
RLax به عنوان یکی دیگر از کتابخانههای یادگیری تقویتی مبتنی بر JAX است که بلوکهای ساختاری برای عوامل RL ارائه میدهد. این کتابخانه به ارائه اجزای کارآمد و قابل ترکیب برای ایجاد الگوریتمهای RL سفارشی تمرکز دارد.
مزایا:
- بسیار کارآمد به دلیل بهینهسازیهای JAX.
- طراحی انعطافپذیر و قابل ترکیب.
- پشتیبانی قوی از توسعه الگوریتمهای سفارشی.
معایب:
- نیاز به آشنایی با JAX.
- جامعه کوچکتر نسبت به TensorFlow یا PyTorch.
Coach
Coach که توسط Intel AI Lab توسعه داده شده است، یک چارچوب تحقیقاتی RL است که از الگوریتمها و محیطهای مختلف پشتیبانی میکند. این کتابخانه برای تحقیقات علمی و کاربردهای عملی طراحی شده است.
مزایا:
- پشتیبانی گسترده از الگوریتمها.
- طراحی شده برای تحقیقات و تولید.
- مستندات جامع.
معایب:
- ممکن است برای مبتدیان پیچیده باشد.
- نیاز به منابع محاسباتی قابل توجه برای وظایف بزرگمقیاس.
RFRL
RFRL یک کتابخانه RL است که برای تحقیقات سریع و نمونهسازی طراحی شده است. این کتابخانه هدف دارد ابزارهای آسان برای توسعه و تست الگوریتمهای جدید RL فراهم کند.
مزایا:
- کاربرپسند و طراحی شده برای نمونهسازی سریع.
- پشتیبانی از وظایف مختلف RL.
- تمرکز قوی بر کاربردهای تحقیقاتی.
معایب:
- پشتیبانی محدود برای استقرار در تولید.
- جامعه کوچکتر و مستندات کمتر جامع.
Rliable
Rliable یک کتابخانه است که بر ارائه معیارها و ابزارهای ارزیابی قابل اطمینان برای تحقیقات RL تمرکز دارد. هدف این ابزار بهبود قابلیت تکرار و اطمینان در آزمایشات RL است.
مزایا:
- تاکید بر ارزیابی قابل اطمینان.
- ابزارهای مفید برای تحقیق و ارزیابی.
- کمک به بهبود قابلیت تکرار.
معایب:
- محدود به ارزیابی.
- یک چارچوب جامع RL ارائه نمیدهد.
ViZDoom
ViZDoom یکی دیگر از کتابخانههای یادگیری تقویتی است که از بازی کلاسیک Doom به عنوان محیطی برای آموزش عوامل RL استفاده میکند. این ابزار محیطی چالشبرانگیز و بصری غنی، برای تست الگوریتمهای RL فراهم میکند.
مزایا:
- محیط بصری غنی و چالشبرانگیز.
- مناسب برای وظایف پیچیده مبتنی بر بصری سازی.
- بهروزرسانی و پشتیبانی فعال.
معایب:
- محدود به محیط Doom.
- ممکن است به منابع محاسباتی قابل توجهی نیاز داشته باشد.
Ray RLlib
Ray RLlib یک کتابخانه RL مقیاسپذیر است که بر اساس چارچوب Ray ساخته شده است. این کتابخانه از آموزش توزیعشده و طیف گستردهای از الگوریتمهای RL پشتیبانی میکند و برای کاربردهای بزرگمقیاس مناسب است.
مزایا:
- مقیاسپذیر و کارآمد برای آموزش توزیعشده.
- پشتیبانی گسترده از الگوریتمها.
- جامعه قوی و مستندات جامع.
معایب:
- نیاز به آشنایی با چارچوب Ray.
- ممکن است برای وظایف کوچکتر پیچیده باشد.
ChainerRL
ChainerRL یکی دیگر از کتابخانههای یادگیری تقویتی است که بر روی چارچوب یادگیری عمیق Chainer ساخته شدهاست. این کتابخانه الگوریتمهای مختلف RL را فراهم میکند و برای انعطافپذیری و سهولت استفاده طراحی شده است.
مزایا:
- انعطافپذیر و کاربرپسند.
- یکپارچگی قوی با Chainer.
- مناسب برای تحقیق و آزمایش.
معایب:
- جامعه محدود نسبت به TensorFlow یا PyTorch.
- کاهش محبوبیت Chainer ممکن است بر پشتیبانی بلندمدت تأثیر بگذارد.
MushroomRL
MushroomRL یک کتابخانه پایتون است که برای ارائه یک رابط ساده، انعطافپذیر و سطح بالا برای RL طراحی شده است. این کتابخانه از طیف گستردهای از الگوریتمها و محیطهای RL پشتیبانی میکند.
مزایا:
- رابط ساده و شهودی.
- طراحی انعطافپذیر و قابل گسترش.
- پشتیبانی جامع از الگوریتمها.
معایب:
- جامعه و مستندات محدود.
- ممکن است برخی ویژگیهای پیشرفته را نداشته باشد.
TRFL
TRFL (TensorFlow Reinforcement Learning) یک کتابخانه است که توسط DeepMind توسعه داده شده و مجموعهای از الگوریتمها و اجزای کلیدی RL را فراهم میکند. این کتابخانه برای استفاده با TensorFlow طراحی شده است.
مزایا:
- توسعهیافته توسط DeepMind، تضمین پیادهسازیهای با کیفیت بالا.
- یکپارچگی بینقص با TensorFlow.
- مفید برای ساخت الگوریتمهای RL سفارشی.
معایب:
- محدود به اکوسیستم TensorFlow.
- ممکن است برای مبتدیان پیچیده باشد.
CleanRL
CleanRL یکی دیگر از کتابخانههای یادگیری تقویتی است که بر ارائه پیادهسازیهای ساده و کارآمد الگوریتمهای RL تمرکز دارد. هدف این کتابخانه این است که قابلیت تکرار و سهولت درک را تسهیل کند.
مزایا:
- پیادهسازیهای ساده و کارآمد.
- تاکید بر قابلیت تکرار.
- مناسب برای اهداف آموزشی.
معایب:
- محدود به الگوریتمهای پایه.
- جامعه کوچکتر و مستندات کمتر جامع.
پیادهسازی کتابخانههای یادگیری تقویتی در یک محیط نمونه
توضیحات محیط
برای طرح یک مسئله نمونه RL، ما یک محیط ساده به نام GridWorld ایجاد خواهیم کرد. در این محیط، یک عامل در یک شبکه ۵x۵ برای رسیدن به هدف حرکت میکند و باید از برخورد با موانع جلوگیری کند. عامل از یک موقعیت تصادفی شروع به حرکت میکند و هدف در یک مکان مشخص ثابت است. عامل میتواند به سمت بالا، پایین، چپ یا راست حرکت کند و برای رسیدن به هدف پاداش دریافت میکند و برای برخورد با موانع یا دیوارها جریمه میشود.
اهداف و مقاصد پیادهسازی
هدف اصلی برای عامل این است که یک سیاست بهینه برای رسیدن به هدف در کوتاهترین زمان ممکن یاد بگیرد و از موانع اجتناب کند. اهداف برای این وظیفه RL شامل موارد زیر است:
- کارایی یادگیری: عامل باید سیاست بهینه را با کمترین تعداد اپیزودهای آموزشی یاد بگیرد.
- عملکرد: عامل باید به طور مداوم به هدف برسد بدون حرکتهای غیرضروری یا برخوردها.
- تعمیمپذیری: عامل باید بتواند سیاست یادگرفتهشده خود را به تنظیمات شبکه مشابه تعمیم دهد.
جزئیات پیادهسازی
ما محیط GridWorld را با استفاده از رابط OpenAI Gym پیادهسازی خواهیم کرد تا با اکثر کتابخانههای یادگیری تقویتی سازگار باشد. محیط دارای ویژگیهای زیر خواهد بود:
- فضای حالت: یک شبکه ۵x۵ که به صورت آرایه دو بعدی نمایش داده میشود.
- فضای عمل: چهار عمل ممکن (بالا، پایین، چپ، راست).
- ساختار پاداش: 10+ برای رسیدن به هدف، 1- برای برخورد با موانع یا دیوارها، و 0.1- برای هر قدم برداشته شده.
پیش از اعمال کتابخانههای یادگیری تقویتی، لازم است محیط یادشده را فراهم کنیم، قطعه کد زیر بیانگر GridWorld است:

این کد یک محیط یادگیری تقویتی سفارشی با استفاده از کتابخانه gym تعریف میکند. این محیط شبکهای ایجاد میکند که در آن یک عامل سعی میکند به هدفی در موقعیت (۴, ۴) برسد و در عین حال از موانعی در موقعیتهای (۱, ۱)، (۲, ۲) و (۳, ۳) اجتناب کند. این محیط شامل متدهایی برای بازنشانی موقعیت عامل، بهروزرسانی حالت آن بر اساس اقدامات، و نمایش شبکه با شاخصهای بصری برای عامل، موانع و هدف با استفاده از matplotlib است.

این قطعه کد اضافی محیط یادشده را تحت شناسه ‘GridWorld-v0’ ثبت میکند. بلوک main، یک نمونه از محیط را ایجاد میکند، آن را بازنشانی میکند تا حالت اولیه را بگیرد و محیط را رندر میکند. سپس یک حلقه اجرا میشود که در آن ۱۰ عمل تصادفی نمونهبرداری شده از فضای حالت، انجام میدهد، محیط را با هر عمل بهروزرسانی میکند و بعد از هر گام محیط را رندر میکند، که اجازه مشاهده بصری حرکت و تعاملات عامل در محیط را میدهد.
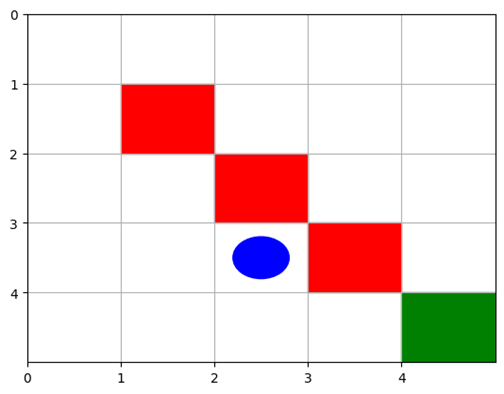
تصویر فوق محیط GridWorld نشان میدهد که خانه سبز رنگ و خانههای قرمز رنگ به ترتیب بیانگر هدف و موانع موجود در این فضای نمونه هستند. عامل با رنگ آبی در محیط مشخص شدهاست.
پیادهسازی فرآیند یادگیری تقویتی
در این بخش، نحوه استفاده از محیط GridWorld با انتخاب دو نمونه از کتابخانههای یادگیری تقویتی بیان خواهد شد. برای هر کتابخانه، قطعه کدی برای آموزش یک عامل برای حل مسئله GridWorld ارائه میشود.
- Stable-Baselines
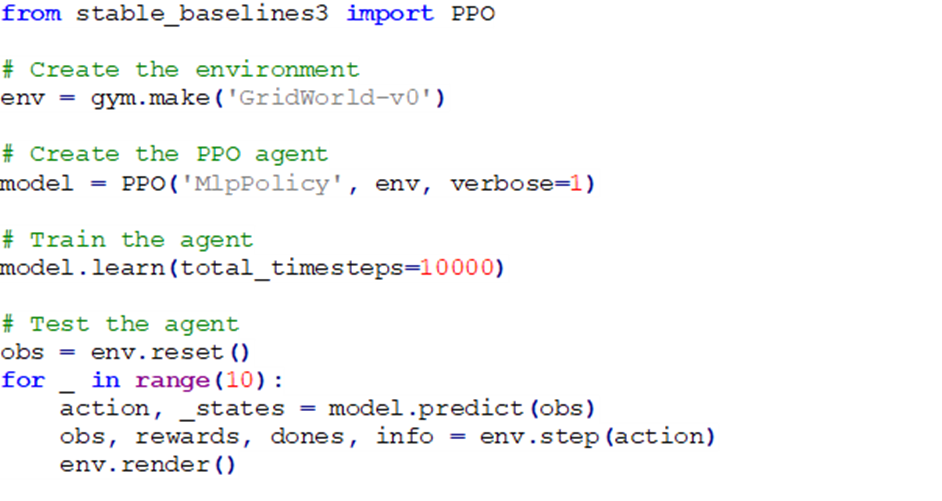
در کد فوق، ابتدا الگوریتم Proximal Policy Optimization (PPO) از کتابخانه Stable-Baselines3 فراخوانی میشود. سپس یک نمونه از محیط ‘GridWorld-v0’ با استفاده از کتابخانه Gym ایجاد میشود. در ادامه عامل PPO با یک سیاست شبکه عصبی چندلایه (MLP) مقداردهی اولیه میشود. پارامتر verbose=1 برای نمایش اطلاعات آموزشی، ثبت لاگ را فعال میکند. نهایتا model.learn() عامل PPO را بر روی محیط شبکهای برای مجموعاً ۱۰,۰۰۰ گام زمانی آموزش میدهد. بخش آخر کد، عامل آموزشدیده را تست میکند؛ که به موجب آن محیط را به حالت اولیه خود بازنشانی میکند و حلقهای را به مدت 10 مرحله اجرا میکند که شامل model.predict() و model.step() است این دو باعث میشوند عامل بر اساس مشاهده کنونی اقدام بعدی را پیشبینی و اجرا میکند. env.render() نیز، حالت کنونی محیط را برای مشاهده اقدامات عامل نمایش میدهد.
تصاویر زیر بیانگر حرکت عامل در طول این 10 مرحله هستند:
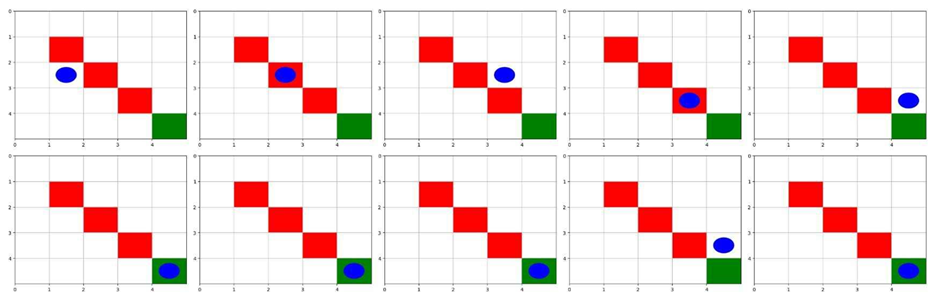
همانطور که از تصویر پیداست، عامل هنگام تست بعد از پنج گام به هدف مورد نظر میرسد.
- Ray RLlib

ابتدای کد ماژولهای مورد نیاز از کتابخانه Ray را فراخوانی میشوند، tune برای تنظیم هایپرپارامترها و PPO از RLlib Ray برای یادگیری تقویتی مورد استفاده قرار میگیرند. در ادامه ray.init() محیط زمان اجرای Ray را مقداردهی اولیه میکند. پارامتر ignore_reinit_error=True از بروز خطا در صورت از قبل مقداردهی اولیه شدن Ray جلوگیری میکند. سپس یک بلوک دیکشنری پیکربندی، برای الگوریتم PPO تعریف میشود که به موجب آن، محیط مورد مورد استفاده مشخص میشود و PyTorch به عنوان چارچوب یادگیری عمیق تنظیم میشود. tune.run() عامل PPO را با استفاده از پیکربندی تعریف شده قبلی آموزش میدهد. پارامتر stop={“timesteps_total”: 10000} مشخص میکند که آموزش باید پس از مجموعاً ۱۰,۰۰۰ گام زمانی متوقف شود. نهایتا ray.shutdown() محیط زمان اجرای Ray را برای آزادسازی منابع خاموش میکند.
همچنین بخوانید: با ۱۰ نرم افزار ماشین لرنینگ بهطور کامل آشنا شوید!
معیارهای ارزیابی عملکرد کتابخانههای یادگیری تقویتی
برای ارزیابی عملکرد کتابخانههای یادگیری تقویتی، مهمترین معیارهایی که میتوان در نظر گرفت شامل:
- زمان آموزش: میزان زمانی که برای آموزش عامل به منظور رسیدن به هدف نیاز است.
- نرخ همگرایی: تعداد اپیزودهایی که برای رسیدن مداوم عامل به هدف نیاز است.
- تجمع پاداش: پاداش تجمعی که عامل در طول دوره آموزش به دست میآورد.
- ثبات: میزان یکنواختی عملکرد عامل در طول اجرای مختلف فرایند ترین.
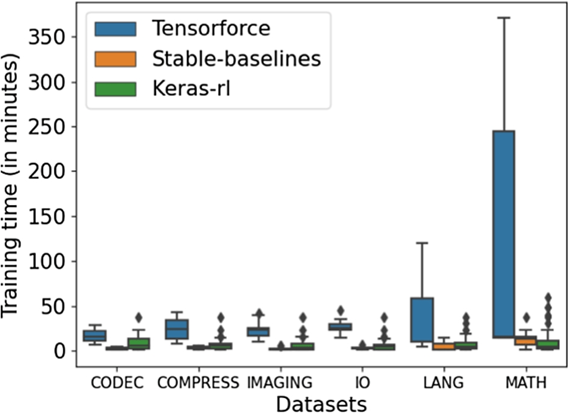
با مقایسه عملکرد کتابخانههای مختلف به منظور اجرای وظایف گوناگون، مشاهده شده که Ray RLlib، FinRL، Stable-Baselines، TensorLayer و Baselines با در نظر گرفتن تمامی معیارها عملکردی بهتری نسبت به بقیه داشتهاند.
جدول زیر ده نمونه از کتابخانههای یادگیری تقویتی در GitHub را مقایسه میکند.
| کتابخانه | توسعهدهنده | منبع باز؟ | ستارههای GitHub | تعداد مشارکتکنندگان |
| Stable-Baselines | Hill et al. | بله | ۴,۱۰۰ | ۱۲۰ |
| Ray RLlib | Ray Team | بله | ۳۲,۰۰۰ | ۹۸۰ |
| TF-Agents | TensorFlow | بله | ۲,۸۰۰ | ۱۳۰ |
| Gym | OpenAI | بله | ۳۴,۲۰۰ | ۳۷۰ |
| Baselines | OpenAI | بله | ۱۵,۵۰۰ | ۱۱۰ |
| Dopamine | بله | ۱۰,۴۰۰ | ۱۰ | |
| TensorLayer | TensorLayer Team | بله | ۷,۳۰۰ | ۹۰ |
| FinRL | Liu et al. | بله | ۹,۴۰۰ | ۱۱۰ |
| ReAgent | بله | ۳,۵۰۰ | ۹۰ | |
| Acme | DeepMind | بله | ۳,۴۰۰ | ۶۰ |
مسیرهای آینده یادگیری تقویتی
با ادامه تحول در زمینه RL، پژوهشهای آینده باید بر روی چندین حوزه کلیدی تمرکز کنند تا اثربخشی و کاربردپذیری کتابخانههای یادگیری تقویتی را بهبود بخشند:
توسعه الگوریتمهای کارآمدتر
- هدف: کاهش زمان آموزش و بهبود نرخ همگرایی.
- رویکرد: پژوهش و توسعه الگوریتمهای نوآورانه که از نظر محاسباتی کارآمدتر باشند و بتوانند سریعتر از دادههای محدود یاد بگیرند.
افزایش قابلیت تعامل کتابخانهها
- هدف: امکان ادغام کتابخانهها با ابزارهای دیگر یادگیری ماشین و پردازش داده.
- رویکرد: طراحی کتابخانهها با APIهای انعطافپذیر و رابطهای استاندارد برای اطمینان از سازگاری با چارچوبهای محبوب مانند TensorFlow، PyTorch، و کتابخانههای پیشپردازش داده.
گسترش دامنه محیطها
- هدف: پوشش دادن سناریوهای بیشتر در دنیای واقعی.
- رویکرد: توسعه و اضافه کردن محیطهای متنوعی که چالشهای دنیای واقعی مانند رانندگی خودران، رباتیک و بازارهای مالی پیچیده را شبیهسازی کنند.
با توجه به این مسیرهای آینده، جامعه RL میتواند به پیشرفت سطح فنی خود ادامه دهد و به کاربردهای پیچیدهتر و عملیتر یادگیری تقویتی بپردازد.
جمعبندی
در این مقاله، به بررسی ۲۵ کتابخانه مهم یادگیری تقویتی پرداختیم و توصیفات دقیق، مزایا و معایب هر یک را ارائه دادیم. یک محیط ساده GridWorld را پیادهسازی کردیم و نشان دادیم که چگونه از کتابخانههای یادگیری تقویتی برای آموزش عامل به منظور حل وظیفه استفاده کنیم. تحلیل عملکرد کتابخانههای مختلف به محققان و متخصصان در صنایع گوناگون کمک میکند که تصمیمات آگاهانهای بر اساس نیازهای خاص خود بگیرند.
برای مجریان پروژههای صنعتی، انتخاب مناسب از میان کتابخانههای یادگیری تقویتی میتواند تأثیر زیادی بر کارایی و موفقیت پروژههایشان داشته باشد. کتابخانههایی مانند Stable-Baselines و Ray RLlib عملکرد بالا و ثبات بالایی دارند و برای محیطهای تولیدی ایدهآل هستند. از سوی دیگر، محققان ممکن است به کتابخانههایی مانند Dopamine و ReAgent تمایل داشته باشند، زیرا این کتابخانهها سادگی و قابلیت نمونهسازی سریع را فراهم میکنند.
برای دسترسی به کدهای مقاله اینجا کلیک کنید.

پرسشهای متداول
چگونه میتوانیم از یادگیری تقویتی در کاربردهای مالی استفاده کنیم؟
یادگیری تقویتی میتواند در پیشبینی بازارهای مالی، مدیریت سبد سهام و استراتژیهای معاملهگری خودکار استفاده شود. کتابخانههایی مانند FinRL به طور خاص برای این کاربردها طراحی شدهاند و شامل دادهها و محیطهای مالی واقعی هستند که به تحقیقات و پیادهسازیهای عملی کمک میکنند.
چرا پایداری و مقیاسپذیری در کتابخانههای یادگیری تقویتی مهم هستند؟
پایداری به معنای عملکرد قابل اطمینان الگوریتمها در شرایط مختلف است، و مقیاسپذیری به توانایی الگوریتمها برای کار با حجم بالای داده و پردازشهای سنگین اشاره دارد. این ویژگیها برای کاربردهای صنعتی بزرگمقیاس ضروری هستند که کتابخانههایی مانند Stable-Baselines و Acme بر این جوانب تمرکز دارند.
چگونه میتوان از یادگیری تقویتی در بهبود سیستمهای توصیهگر استفاده کرد؟
یادگیری تقویتی میتواند در بهبود سیستمهای توصیهگر با تنظیم پیشنهادات بر اساس تعاملات کاربران و بازخوردهای آنها مؤثر باشد. کتابخانههایی مانند RecoGym و RLlib به صورت خاص برای این کاربردها طراحی شدهاند و ابزارهای مورد نیاز برای ساخت و ارزیابی الگوریتمهای توصیهگر را فراهم میکنند. این سیستمها میتوانند به بهبود تجربه کاربری و افزایش تعامل کاربران با پلتفرمها کمک کنند.
کدام یک از کتابخانههای یادگیری تقویتی برای آموزش رباتها کاربرد دارند؟
کتابخانههایی مانند Gym و Baselines، که شامل محیطهای شبیهسازی متنوعی هستند، ابزارهای مناسبی برای آموزش رباتها فراهم میکنند. این کتابخانهها به محققان امکان میدهند تا الگوریتمهای RL را در محیطهای کنترلشده تست و بهینهسازی کنند.
مزایای استفاده از گراف محاسباتی پویا در یادگیری تقویتی چیست؟
استفاده از گراف محاسباتی پویا در کتابخانههایی مانند PyTorchRL به توسعهدهندگان انعطافپذیری بیشتری در ساخت و آزمایش مدلها میدهد. این گرافها به راحتی قابل تغییر و تطبیق هستند، که به بهبود سرعت و کارایی تحقیقات کمک میکند.
یادگیری ماشین لرنینگ را از امروز شروع کنید!
دنیای دادهها جذاب است و دانستن علم داده، توانایی تحلیل داده، یا بازاریابی مبتنی بر داده، شما را برای فرصتهای شغلی بسیاری مناسب میکند. فارغ از رشته و پیشزمینه، میتوانید حالا شروع کنید و از سطح مقدماتی تا پیشرفته بیاموزید. اگر دوست دارید به این حوزه وارد شوید، پیشنهاد میکنیم با کلیک روی این لینک قدم اول را همین حالا بردارید.
مشاوران کافهتدریس به شما کمک میکنند مسیر یادگیری برای ورود به این حوزه را شروع کنید: