
یادگیری تقویتی یا Reinforcement Learning چیست؟ در چشمانداز همیشه در حال تکامل هوش مصنوعی یادگیری تقویتی (RL) بهعنوان یک رویکرد پیشگامانه ظهور کرده است که ماشینها را قادر میکند ازطریق تعامل مستمر با محیط خود یاد بگیرند و تصمیم بگیرند. در این پست وبلاگ مفهوم یادگیری تقویتی (Reinforcement Learning)، رابطهی آن با یادگیری ماشین، نحوهی کارکرد، کاربردهای آن در حوزههای مختلف و محدودیتهای ذاتیاش را بررسی خواهیم کرد.
مروری کوتاه بر یادگیری ماشین
یادگیری ماشین (Machine Learing) زیرشاخهای از هوش مصنوعی است. این زیرشاخه بر توسعه الگوریتمها و مدلهایی تمرکز میکند که میتوانند بهطور خودکار از دادهها یاد بگیرند و عملکرد خود را در طول زمان بدون برنامهریزی صریح بهبود بخشند. یادگیری ماشین الگوهای یادگیری مختلف، ازجمله یادگیری تحت نظارت، یادگیری بدون نظارت و یادگیری تقویتی، را دربرمیگیرد.
یادگیری تقویتی یا Reinforcement Learning چیست؟
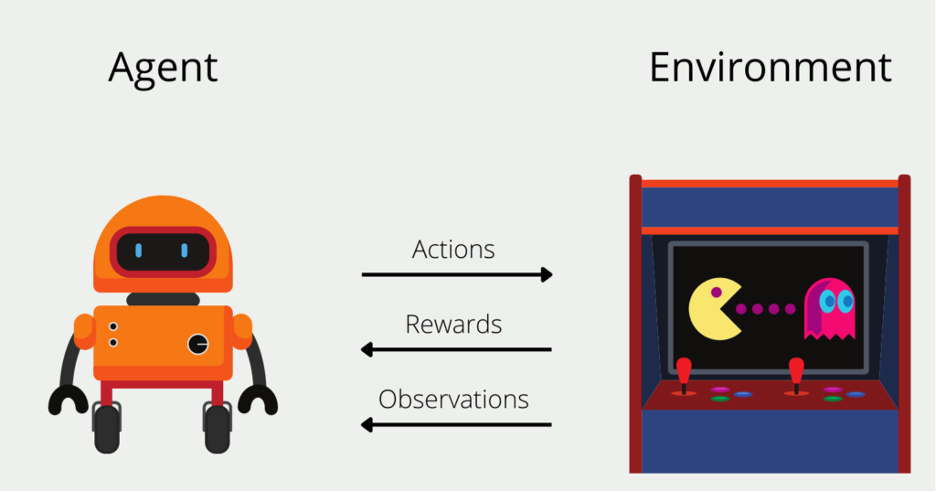
یادگیری تقویتی یا Reinforcement Learning نوعی یادگیری ماشین است که با فرایندهای تصمیمگیری متوالی سروکار دارد و شامل یک عامل (Agent)، یک محیط (Enivronment) و یک مکانیسم بازخورد برای هدایت اقدامات عامل است. عامل یاد میگیرد که اقداماتی را در محیط انجام دهد تا سیگنال پاداش تجمعی را به حداکثر برساند. این سیگانال پاداش جمعی بهعنوان نیروی محرکه برای یادگیری عمل میکند.
نحوهی عملکرد یادگیری تقویتی
یادگیری تقویتی را میتوان بهعنوان یک حلقه متشکل از اجزای زیر در نظر گرفت:
- عامل (Agent): یادگیرنده یا تصمیمگیرندهای که براساس مشاهدههای خود اقداماتی را انجام میدهد؛
- محیط (Environment): سیستم یا زمینهی خارجی که عامل در آن عمل میکند؛
- حالت (State): پیکربندی یا نمایش فعلی محیط در یک زمان معین؛
- اقدام (Action) : تصمیم یا انتخابی که عامل در پاسخ به یک حالت اتخاذ میکند؛
- پاداش (Reward): سیگنال بازخوردی که خوبی یا مطلوبیت عمل عامل را ارزیابی میکند؛
- خطمشی (Policy): استراتژی یا رویکردی که عامل برای انتخاب اقدامات براساس حالتهای مشاهدهشده به کار میگیرد.
یادگیری تقویتی (RL) یک الگوی یادگیری است که در آن یک عامل یاد میگیرد که با تعامل با یک محیط تصمیمهای متوالی بگیرد. عامل براساس اقدامات خود بازخوردی را در قالب پاداش یا جریمه دریافت میکند. هدف RL یادگیری یک خطمشی بهینه است که پاداشهای تجمعی را در طول زمان به حداکثر میرساند. عامل ازطریق آزمونوخطا محیط را بررسی میکند، اقداماتی را براساس وضعیت فعلی آن انجام میدهد و بازخورد دریافت میکند. از این بازخورد برای بهروزرسانی خطمشی خود و اتخاذ تصمیمهای بهتر در آینده استفاده میکند. الگوریتمهای RL اغلب از توابع یا value functions برای تخمین پاداشها یا مقادیر موردانتظار مرتبط با حالات و اقدامات مختلف استفاده میکنند که عامل را قادر میکند تواناییهای تصمیمگیری خود را یاد بگیرد و بهبود بخشد. با هر تعامل و یادگیری مکرر، خطمشی عامل بهتدریج بهسمت یک راهحل بهینه همگرا میشود و به رفتار هوشمندانه و سازگار در محیطهای پیچیده و پویا میانجامد.
کاربردهای یادگیری تقویتی
یادگیری تقویتی کاربردهای متعددی در حوزههای مختلف پیدا کرده است، از جمله:
- رباتیک: RL رباتها را قادر میکند تا عملها و حرکتهای خود را براساس آزمونوخطا یاد بگیرند و بهبود بخشند و به آنها اجازه میدهد در محیطهای پیچیده حرکت کنند یا اشیا را دستکاری کنند.
- بازی: الگوریتمهای RL در انجامدادن بازیهای پیچیده، مانند شطرنج، Go و بازیهای ویدئویی، به موفقیت چشمگیری دست یافتهاند و در برخی موارد از عملکرد انسان پیشی گرفتهاند.
- وسایل نقلیه خودمختار: تکنیکهای RL را میتوان برای آموزش خودروهای خودران برای تصمیمگیری بهینه در زمان واقعی به کار برد که به حملونقل ایمنتر و کارآمدتر میانجامد.
- مدیریت منابع: RL میتواند برای بهینهسازی تخصیص منابع، زمانبندی و تصمیمگیری در حوزههایی مانند مدیریت انرژی، لجستیک و ارتباطات استفاده شود.
محدودیتهای یادگیری تقویتی
درحالیکه یادگیری تقویتی قابلیتهای قدرتمندی را ارائه میکند، با محدودیتهای خاصی نیز همراه است:
- کارایی نمونه (Sample Efficiency): الگوریتمهای RL معمولاً به مقدار قابل توجهی از تعامل با محیط برای یادگیری سیاستهای بهینه نیاز دارند و از نظر محاسباتی گران و وقتگیر هستند.
- تریدآف اکتشاف و بهرهبرداری (Exploration-Exploitation Trade-off): ایجاد تعادل میان اکتشاف اقدامات جدید و بهرهبرداری از دانش آموختهشده چالشبرانگیز است؛ زیرا اکتشاف بیشازحد ممکن است تصمیمگیری بهینه را به تاخیر بیندازد و بهرهبرداری بیشازحد ممکن است به راهحلهای غیربهینه بینجامد.
- مهندسی پاداش (Reward Engineering): طراحی توابع پاداش مناسب که با رفتار مدنظر هماهنگ باشد میتواند پیچیده باشد و تعریف پاداشهایی که بهطور دقیق هدفهای عامل را نشان میدهند، یک کار غیرضروری است.
- ملاحظههای اخلاقی (Ethical Considerations): الگوریتمهای یادگیری تقویتی میتوانند رفتارهای نامطلوب یا مضر را بیاموزند، اگر بهدقت طراحی نشده باشند، بهطور بالقوه نگرانیهای اخلاقی و نیاز به نظارت دقیق را افزایش میدهند.
تفاوت یادگیری تقویتی با یادگیری تحت نظارت و بدون نظارت
یادگیری تقویتی (RL) با یادگیری تحت نظارت (Supervised Learning) و بدون نظارت (Unsupervised Learning) در چندین جنبه کلیدی متفاوت است:
پارادایم یادگیری
- یادگیری نظارتشده: در یادگیری نظارتشده الگوریتم از نمونههای برچسبگذاریشده یاد میگیرد، جایی که هر ورودی با یک برچسب هدف یا خروجی مربوطه مرتبط است. هدف نگاشت ورودیها به خروجیهای ازپیشتعریفشده براساس دادههای آموزشی ارائه شده است.
- یادگیری بدون نظارت: یادگیری بدون نظارت با دادههای بدون برچسب سروکار دارد و بر کشف الگوها، ساختارها یا رابطههای پنهان در دادهها تمرکز دارد. این الگوریتم ویژگیهای ذاتی دادهها را برای کشف اطلاعات معنادار بدون راهنمایی صریح بررسی میکند.
- یادگیری تقویتی: RL در محیطی عمل میکند که عامل ازطریق آزمونوخطا یاد میگیرد. با محیط تعامل میکند، اقداماتی انجام میدهد، بازخوردی را بهشکل پاداش یا جریمه دریافت میکند و رفتار خود را برای بهحداکثررساندن پاداشهای انباشته در طول زمان تنظیم میکند.
- بازخورد و آموزش
- یادگیری نظارتشده: در یادگیری نظارتشده الگوریتم بازخورد مستقیم را در قالب دادههای برچسبدار دریافت میکند. هدف آن بهحداقلرساندن اختلاف میان برچسبهای پیشبینیشده و واقعی، بهینهسازی عملکرد خطا یا ضرر ازپیشتعریفشده است.
- یادگیری بدون نظارت: یادگیری بدون نظارت بازخورد صریح یا برچسبهای حقیقی ندارد. این الگوریتم ساختار ذاتی دادهها را با خوشهبندی، کاهش ابعاد یا مدلسازی مولد بررسی میکند.
- یادگیری تقویتی: در RL عامل از بازخورد تأخیری و پراکنده در قالب پاداش میآموزد. عامل یک سیگنال پاداش براساس اقدامات خود دریافت میکند و هدف آن یادگیری سیاستی است که پاداش تجمعی بلندمدت را به حداکثر میرساند.
هدف
- یادگیری تحت نظارت: هدف از یادگیری تحت نظارت یادگیری یک تابع نگاشت است که برچسبهای هدف را برای ورودیهای جدید و نادیده بهطور دقیق پیشبینی میکند.
- یادگیری بدون نظارت: هدف یادگیری بدون نظارت کشف الگوها، ساختارها یا بازنماییهای زیربنایی در دادهها، ارائهی بینش درمورد سازمان یا ویژگیهای ذاتی دادههاست.
- یادگیری تقویتی: RL بر یادگیری یک خطمشی بهینه تمرکز میکند که پاداشهای تجمعی را در یک محیط تصمیمگیری پویا و متوالی به حداکثر میرساند. هدف یافتن بهترین اقدامها برای انجامدادن در حالتهای مختلف برای بهینهسازی نتیجههای بلندمدت است.
- دردسترسبودن دادهها
- یادگیری تحت نظارت: یادگیری تحت نظارت به دادههای آموزشی برچسبگذاریشده نیاز دارد، جایی که هر ورودی با برچسب هدف مربوطه مرتبط است. این فرایند برچسبزدن میتواند زمانبر و پرهزینه باشد.
- یادگیری بدون نظارت: یادگیری بدون نظارت میتواند با دادههای بدون برچسب کار کند که اغلب بهراحتی در دسترس هستند. از ساختار ذاتی یا رابطههای درون دادهها بدون تکیه بر حاشیهنویسیهای خارجی استفاده میکند.
- یادگیری تقویتی: RL در محیطی با سیگنالهای پاداش عمل میکند، جایی که عامل ازطریق تعامل با محیط یاد میگیرد. به دادههای برچسبگذاریشده صریح نیاز ندارد، اما درعوض از پیامدهای اعمال خود درس میگیرد.
پیشنهاد میکنیم درباره یادگیری باناظر و یادگیری بدون ناظر هم مطالعه کنید.
خلاصه مطالب
یادگیری تقویتی (Reinforcement Learning) به ماشینها قدرت میدهد تا از تجربیات بیاموزند و تصمیمهای هوشمندانه بگیرند. یادگیری تقویتی یک ابزار قدرتمند با کاربردهای گسترده است، از رباتیک گرفته تا بازی و مدیریت منابع. درک عملکرد و محدودیتهای آن برای استفاده موثر از پتانسیل آن بسیار مهم است. همانطور که محققان به اصلاح و پیشرفت الگوریتمهای یادگیری تقویتی ادامه میدهند، میتوانیم پیشرفتها و کاربردهای هیجانانگیزتری را در آینده پیشبینی کنیم.
یادگیری ماشین لرنینگ را از امروز شروع کنید!
دنیای دادهها جذاب است و دانستن علم داده، توانایی تحلیل داده یا بازاریابی مبتنی بر داده و یادگیری ماشین شما را برای فرصتهای شغلی بسیاری مناسب میکند. شما، فارغ از رشته و پیشزمینه، میتوانید یادگیری این دانش را همین امروز شروع کنید و از سطح مقدماتی تا پیشرفته بیاموزید. اگر دوست دارید به این حوزه وارد شوید، پیشنهاد میکنیم با کلیک روی این لینک قدم اول را همین حالا بردارید.
مشاوران کافهتدریس به شما کمک میکنند مسیر یادگیری برای ورود به این حوزه را شروع کنید:
یادگیری تقویتی چه محدودیتهایی دارد؟
کارایی نمونه (Sample Efficiency): الگوریتمهای RL معمولاً به مقدار قابل توجهی از تعامل با محیط برای یادگیری سیاستهای بهینه نیاز دارند و از نظر محاسباتی گران و وقتگیر هستند.
تریدآف اکتشاف و بهرهبرداری (Exploration-Exploitation Trade-off): ایجاد تعادل میان اکتشاف اقدامات جدید و بهرهبرداری از دانش آموختهشده چالشبرانگیز است؛ زیرا اکتشاف بیشازحد ممکن است تصمیمگیری بهینه را به تاخیر بیندازد و بهرهبرداری بیشازحد ممکن است به راهحلهای غیربهینه بینجامد.
مهندسی پاداش (Reward Engineering): طراحی توابع پاداش مناسب که با رفتار مدنظر هماهنگ باشد میتواند پیچیده باشد و تعریف پاداشهایی که بهطور دقیق هدفهای عامل را نشان میدهند، یک کار غیرضروری است.
ملاحظههای اخلاقی (Ethical Considerations): الگوریتمهای یادگیری تقویتی میتوانند رفتارهای نامطلوب یا مضر را بیاموزند، اگر بهدقت طراحی نشده باشند، بهطور بالقوه نگرانیهای اخلاقی و نیاز به نظارت دقیق را افزایش میدهند
دو کاربرد اصلی یادگیری تقویتی را نام ببرید.
وسایل نقلیه خودمختار
رباتیک
یادگیری تقویتی چگونه با دیگر انواع یادگیری ماشینی متفاوت است؟
یادگیری تقویتی یا Reinforcement Learning نوعی یادگیری ماشین است که با فرایندهای تصمیمگیری متوالی سروکار دارد و شامل یک عامل (Agent)، یک محیط (Enivronment) و یک مکانیسم بازخورد برای هدایت اقدامات عامل است. عامل یاد میگیرد که اقداماتی را در محیط انجام دهد تا سیگنال پاداش تجمعی را به حداکثر برساند. این سیگانال پاداش جمعی بهعنوان نیروی محرکه برای یادگیری عمل میکند.
سوال ۳:
هدف
بازخورد و آموزش
در دسترس بودن داه ها
سوال۲
بازی
رباتیک
مدیریت منابع
وسایل نقلیه خود مختار
سوال ۱:
کارایی نمونه (Sample Efficiency): الگوریتمهای RL معمولاً به مقدار قابل توجهی از تعامل با محیط برای یادگیری سیاستهای بهینه نیاز دارند و از نظر محاسباتی گران و وقتگیر هستند.
مهندسی پاداش (Reward Engineering): طراحی توابع پاداش مناسب که با رفتار مدنظر هماهنگ باشد میتواند پیچیده باشد و تعریف پاداشهایی که بهطور دقیق هدفهای عامل را نشان میدهند، یک کار غیرضروری است.
ملاحظههای اخلاقی (Ethical Considerations): الگوریتمهای یادگیری تقویتی میتوانند رفتارهای نامطلوب یا مضر را بیاموزند، اگر بهدقت طراحی نشده باشند، بهطور بالقوه نگرانیهای اخلاقی و نیاز به نظارت دقیق را افزایش میدهند