

تشخیص اشیا (Object Detection) چیست؟ حوزه بینایی ماشین (Computer Vision) بهطور قابلتوجهی پیشرفت کرده است، اما هنوز در تطبیق دقت ادراک انسان با چالش مواجه است. انسانها بهراحتی میتوانند اشیای موجود در یک تصویر را شناسایی کنند.
سیستم بینایی انسان سریع و دقیق است و میتواند کارهای پیچیدهای، مانند شناسایی اشیای متعدد و تشخیص موانع، را با تفکر آگاهانه کمی انجام دهد. با دردسترسبودن مقادیر زیادی داده، پردازندههای گرافیکی سریعتر و الگوریتمهای بهتر، اکنون میتوانیم بهراحتی رایانهها را برای شناسایی و طبقهبندی چندین شیء در یک تصویر با دقت بالا آموزش دهیم. با این نوع شناسایی و محلیسازی، میتوانیم از تشخیص اشیا برای شمارش آنها در یک عکس و تعیین و ردیابی مکانهای دقیقشان استفاده کنیم و درعینحال برچسبگذاری دقیق آنها را انجام دهیم.
در این مطلب به بینایی ماشین و یکی از تسکهای معروف آن بهنام تشخیص اشیا یا همان Object Detection میپردازیم. برای اینکه درمورد نحوه این کار بیشتر بدانید، در ادامه با ما همراه باشید.
تشخیص اشیا (Object Detection)
تشخیص اشیا یک تکنیک بینایی ماشین برای مکانیابی نمونههایی از اشیا در تصاویر یا فیلمهاست. انسانها بهراحتی میتوانند اشیای موجود در یک تصویر را شناسایی کنند، اما این کار در یک کامپیوتر چطور ممکن است؟ اجازه دهید این موضوع را با کمک تصویر ۱ کمی ساده کنیم.


بهجای طبقهبندی اینکه کدام نوع سگ در این تصویرها وجود دارد، باید فقط سگ را در تصویر پیدا کنیم؛ یعنی باید بفهمیم سگ در کجای تصویر حضور دارد، در مرکز است یا پایین سمت چپ و غیره؛ اما سوالی که به ذهن می رسد این است که چگونه میتوانیم کاری کنیم که کامپیوتر این کار را انجام دهد؟
میتوانیم دور سگی که در تصویر موجود است کادری ایجاد کنیم و مختصات x و y این کادر را مشخص کنیم.


در نظر بگیرید که مکان شیء در تصویر را میتوان بهشکل مختصات این کادر نشان داد. این کادر در اطراف جسم موجود در تصویر بهعنوان یک کادر محدودکننده یا Bounding Box شناخته میشود. اکنون، کاری که انجام شده مکانیابی تصویر یا Image Localization است که در آن مجموعهای از تصاویر به ما داده میشود و ما باید شناسایی کنیم که شیء موجود در تصویر کجاست. توجه کنید که در اینجا ما یک کلاس واحد داریم، اما اگر چند کلاس داشته باشیم چه؟ برای مثال:


در تصویر ۳ باید مکان اشیای موجود در تصویر را پیدا کنیم، اما توجه کنید که همهی اشیا سگ نیستند. اینجا ما یک سگ و یک ماشین داریم: بنابراین، نه تنها باید مکان اشیای موجود در تصویر را پیدا کنیم، باید شیء واقعشده را بهعنوان سگ یا ماشین طبقهبندی (Classify) کنیم. در این حالت تسکی که انجام میدهیم به تشخیص اشیا یا Object Detection تبدیل میشود.
درمورد تسک تشخیص اشیا (Object Detection)، ما باید اشیای موجود در تصویر را طبقهبندی کنیم و همچنین مکانهایی را که این اشیا در تصویر وجود دارند تعیین کنیم. این مسئله با مسئله طبقهبندی تصویر (Image Classification) متفاوت است که در آن تنها باید تصویرها را براساس اشیای موجود در آنها طبقهبندی یا Classify کنیم.
پیشنهاد میکنیم درباره Image Classification هم مطالعه کنید.
برای مثال، میتوانید در تصویر ۴سمت چپ را ببینید که در آن ما فقط کلاس هدف را پیشبینی میکنیم بهعنوان تسک طبقهبندی تصویر شناخته میشود. درحالیکه در حالت دوم که در سمت راست مشخص است همراه با پیشبینی کلاس هدف، باید کادر محدودکننده را نیز پیدا کنیم که مکان شیء را نشان میدهد. این همهی کاری است که در تسک تشخیص اشیا (Object Detection) صورت میگیرد.


بنابراین بهطور کلی ما سه وظیفه برای مسئلههای تشخیص اشیا یا object detection داریم:
- تشخیص اینکه آیا یک شیء در تصویر وجود دارد یا خیر؟
- این شیء در کجا قرار دارد؟
- این شیء چیست؟
تا کنون دربارهی مسئلهی تشخیص اشیا و تفاوت آن با مسئلهی طبقهبندی و مکانیابی تصویر بحث کردیم. اکنون در این بخش میفهمیم که دادهها برای یک تسک تشخیص اشیا به چه شکل هستند.
دادههای آموزشی برای تشخیص اشیا (Object Detection)
اجازه دهید ابتدا یک مثال از مسئلهی طبقهبندی بیاوریم. در تصویر ۵ یک تصویر ورودی و یک کلاس هدف برای هر یک از تصاویر ورودی داریم.


حال، فرض کنید تسکی که در دست است شناسایی خودروهای موجود در تصویر است. در این صورت، نهتنها یک تصویر ورودی، یک متغیرهدف یا Target variable خواهیم داشت. این متغیر هدف مختصات کادر محدودکننده دارد که مکان شیء را در تصویر نشان میدهد.


در این حالت این متغیر هدف پنج مقدار دارد که مقدار p نشاندهنده احتمال وجود یک شیء در تصویر است، درحالیکه چهار مقدار Xmin، Ymin، Xmax و Ymax نشاندهنده مختصات کادر محدودکننده هستند. حال اجازه دهید که بهتر بررسی کنیم که این مقادیر مختصات چگونه محاسبه میشوند.
محور x و محور y را در بالای تصویر همانطور که در تصویر ۶ میبینید در نظر بگیرید. در این صورت، Xmin و Ymin گوشه سمت چپ بالای کادر محدودکننده و Xmax و Ymax گوشه سمت راست پایین کادر محدودکننده خواهند بود. حال، توجه کنید که متغیر هدف فقط به دو سوال پاسخ میدهد:
۱. آیا شیء در تصویر وجود دارد؟
پاسخ: اگر شیء وجود نداشته باشد، p صفر و زمانی که شیء در تصویر وجود داشته باشد، p یک خواهد بود.
۲. اگر جسمی در تصویر وجود داشته باشد، آن شیء در کجا قرار دارد؟
پاسخ: با استفاده از مختصات کادر محدودکننده میتوان مکان شیء را پیدا کرد.
این در صورتی است که همهی تصویرهای یک کلاس واحد داشته باشند، مثلاً فقط ماشین باشد. حال چه اتفاقی میافتد وقتی کلاسهای بیشتری وجود داشته باشد؟ در آن صورت، متغیر هدف بهشکل تصویر ۷ خواهد بود.


بنابراین، اگر دو کلاس دارید که یک وسیله نقلیه اورژانس و یک وسیله نقلیه غیراورژانس هستند، دو مقدار اضافی c1 و c2 خواهید داشت که نشان میدهد شیء موجود در تصویر بالا به کدام کلاس تعلق دارد.
اگر مثال تصویر ۸ را در نظر بگیریم، ما Xmin، Ymin، Xmax و Ymax دادهشده را بهعنوان مختصات کادر محدودکننده داریم؛ همچنین مشخص شده که c1 برابر با ۱ است، زیرا این یک وسیله نقلیه اورژانس است و c2 بهدلیل اینکه یک وسیله نقلیه غیراورژانس در تصویر نداریم صفر خواهد بود.

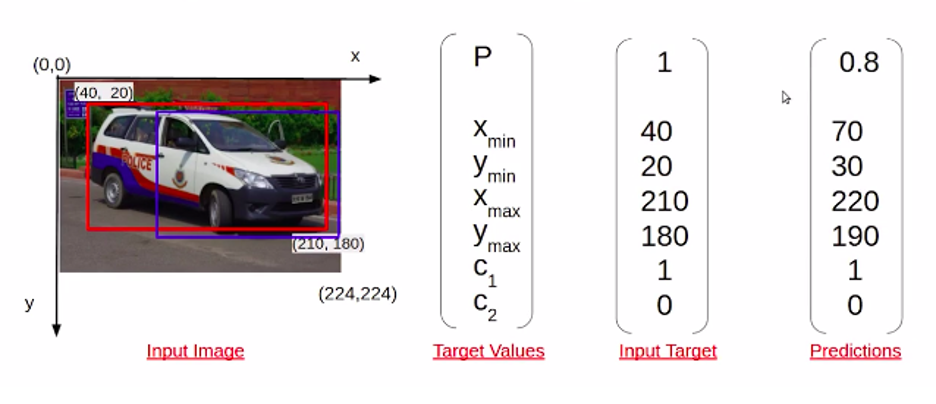
پس این همان شکلی است که دادههای آموزشی در تسک تشخیص اشیا (Object Detection) به مدل وارد میشوند.
حال فرض کنید ما یک مدل میسازیم و پیشبینیهایی را از مدل دریافت میکنیم. این خروجی مدل به چه شکل است؟ در تصویر ۸ میتوانید خروجی که ممکن است از یک مدل دریافت کنید ببینید. احتمال وجود یک شیء در این کادر محدودکننده ۰.۸ پیشبینی شده است، همچنین مختصات کادر محدودکننده آبی را دارید که مدل پیشبینی کرده است و درنهایت مقدار کلاس c1 و c2.
بنابراین اکنون میدانیم که یک مسئلهی تشخیص اشیا چیست و دادههای آموزشی برای آن چگونه به نظر میرسند.
حال باید چند مفهوم را درمورد تصویرها بدانیم ازجمله:
- چگونه می توان کار ارزیابی کادرمحدودکننده (Bounding Box Evaluation) را انجام داد؟
- چگونه IoU را محاسبه کنیم؟
- متریک ارزیابی چیست؟
بیایید با اولین مورد، یعنی Bounding Box Evaluation، شروع کنیم.
ارزیابی کادر محدودکننده – اشتراک روی اجتماع (IoU)
در این بخش قصد داریم به یک مفهوم بسیار جالب بپردازیم که همان اشتراک روی اجتماع یا Intersection on Union (IoU) است. ما قصد داریم از این برای تعیین متغیرهدف استفاده کنیم.

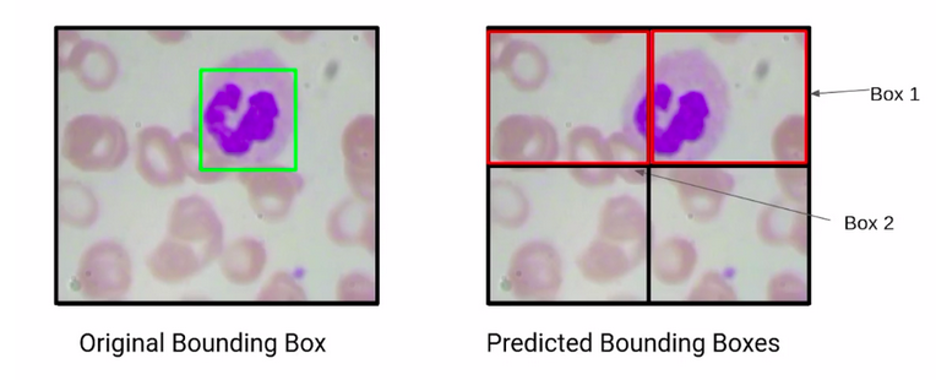
سناریوی زیر را در نظر بگیرید. در تصویر ۹ ما دو کادر محدودکننده داریم، box1 و box2. حال اگر از شما بپرسیم که کدامظیک از این دو کادر دقیق تر است، احتمالاً پاسخ شما box1 است.
چرا؟ زیرا بیشتر گلبول سفید خون یا همان WBC را دربرمیگیرد و WBC را بهدرستی تشخیص داده است، اما این پاسخ چشمی است، حال باید دید چگونه میتوانیم این موضوع را از نظر ریاضی کشف کنیم؟ یا بهعبارت دیگر، مدل چطور این موضوع را تشخیص میدهد؟
کاری که باید انجام دهیم این است که کادرهای محدودکنندهی اصلی و پیشبینیشده را مقایسه کنیم. اگر بتوانیم همپوشانی کادر محدودکنندهی واقعی و پیشبینیشده را دریابیم، میتوانیم تصمیم بگیریم که کدام کادر محدودکننده پیشبینی بهتری است.

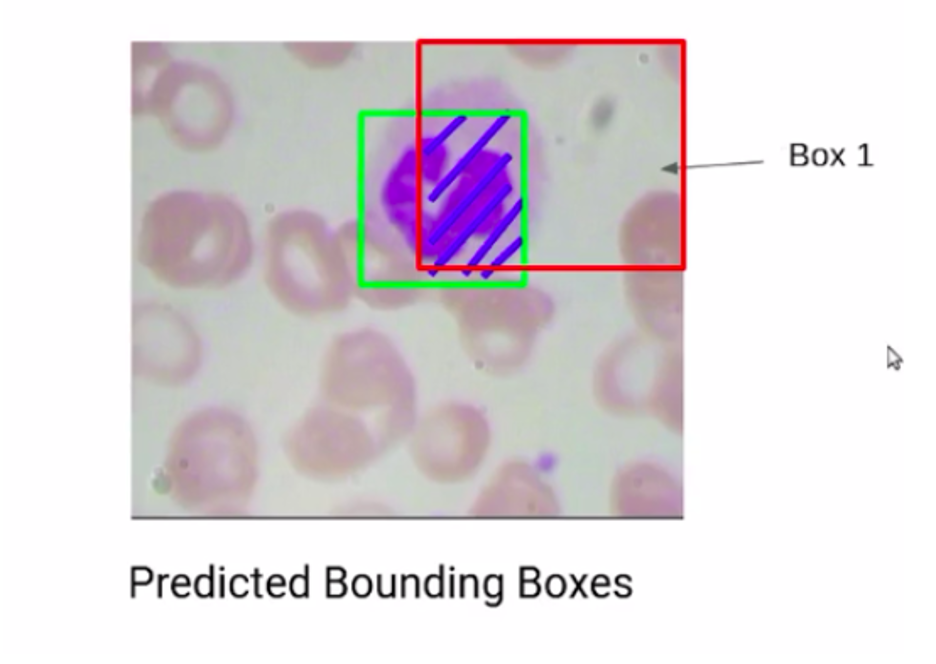
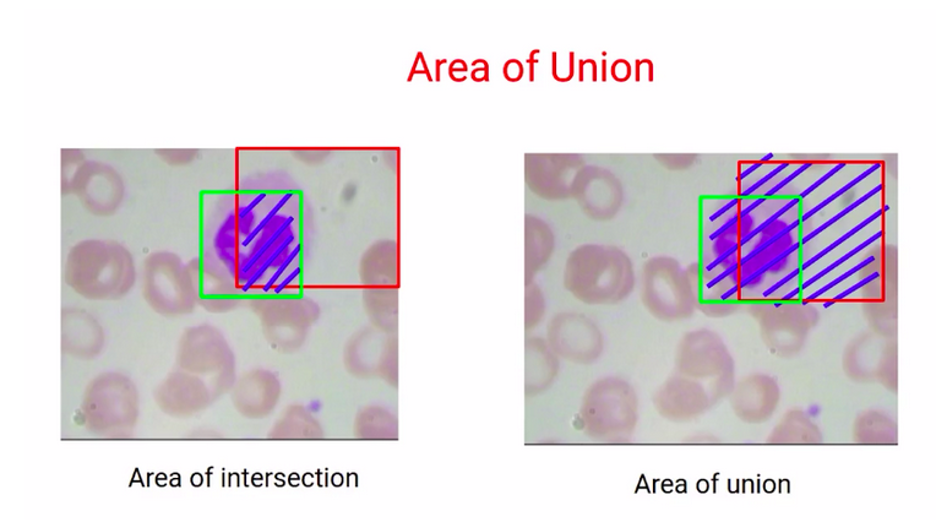
بنابراین کادر محدودکنندهای که همپوشانی بیشتری با کادر محدودکننده واقعی دارد پیشبینی بهتری است. به این همپوشانی ناحیه اشتراک می گویند که در تصویر ۱۰ همپوشانی box1 را با کادر اصلی میبینیم. میتوان گفت که مساحت اشتراک حدود ۷۰ درصد است. درحالیکه اگر box2 را در نظر بگیرید، مساحت اشتراک کادر محدودکننده دوم و کادر محدودکننده واقعی حدود ۲۰ درصد است.

بنابراین میتوانیم بگوییم که از میان این دو کادر بدیهی است که box1 پیشبینی بهتری است.
اما داشتن ناحیه اشتراک بهتنهایی کافی نیست. چرا؟ بیایید با هم به جواب برسیم.
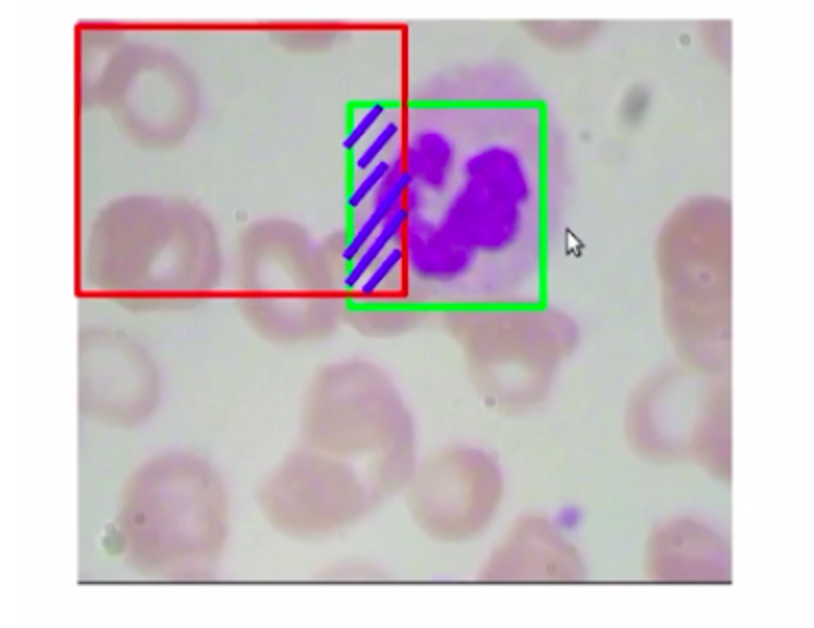
بیایید مثال دیگری را در نظر بگیریم؛ فرض کنید کادرهای محدودکننده با اندازههای مختلف ایجاد کردهایم.


در تصویر ۱۲، اشتراک کادر محدودکنندهی سمت چپ قطعاً ۱۰۰ درصد است، درحالیکه در تصویر سمت راست، اشتراک این کادر محدودکنندهی پیشبینیشده فقط ۷۰ درصد است. حالا میگویید که کادر محدودکنندهی سمت چپ پیشبینی بهتری است؟ بدیهی است که نه. کادر محدودکنندهی سمت راست دقیقتر است.
بنابراین، برای مقابله با چنین سناریوهایی ناحیه اجتماع را نیز در نظر میگیریم.


پس میتوان گفت هر قدر این ناحیهی اجتماع (ناحیهی بنقش) که در تصویر ۱۳ مشخص است بیشتر باشد، دقت کمتری در کادر محدودکننده پیشبینیشده خواهد بود. به این موضوع، اشتراک روی اجتماع (IoU) گفته میشود.
بنابراین چیزی که به آن میرسیم فرمول اشتراک روی اجتماع است که مساحت اشتراک تقسیم بر مساحت اجتماع است.

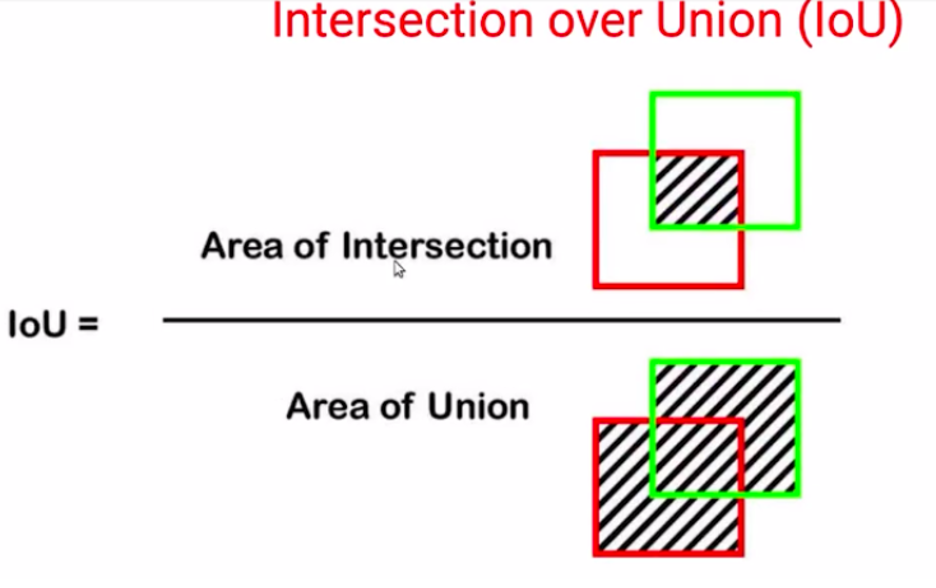
حالا، محدودهی اشتراک چقدر خواهد بود؟ بیایید چند سناریو افراطی را در نظر بگیریم.

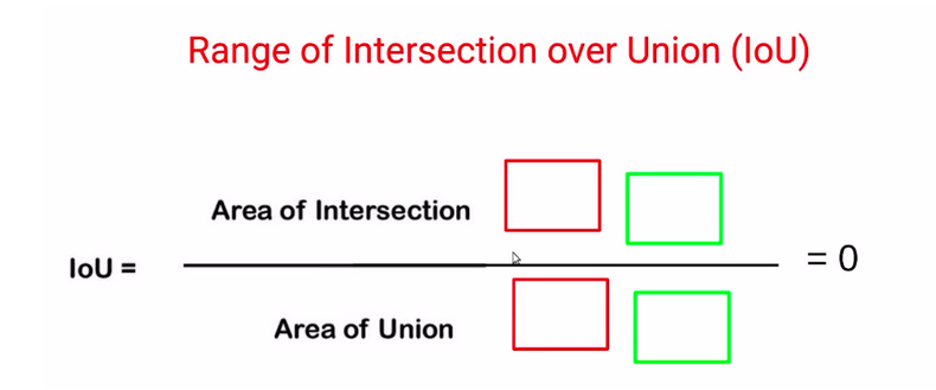
درصورتیکه ما کادر محدودکنندهی واقعی و کادر محدودکنندهی پیشبینیشدهی خود را داشته باشیم و اینها اصلاً همپوشانی نداشته باشند، در آن صورت، مساحت اشتراک صفر خواهد بود، درحالیکه مساحت اجتماع مجموع مساحت دو کادر خواهد بود؛ پس در این حالت مقدار IoU صفر خواهد بود.
سناریوی احتمالی دیگر میتواند زمانی باشد که کادر محدودکننده پیشبینیشده و کادر محدودکننده اصلی کاملاً همپوشانی داشته باشند.

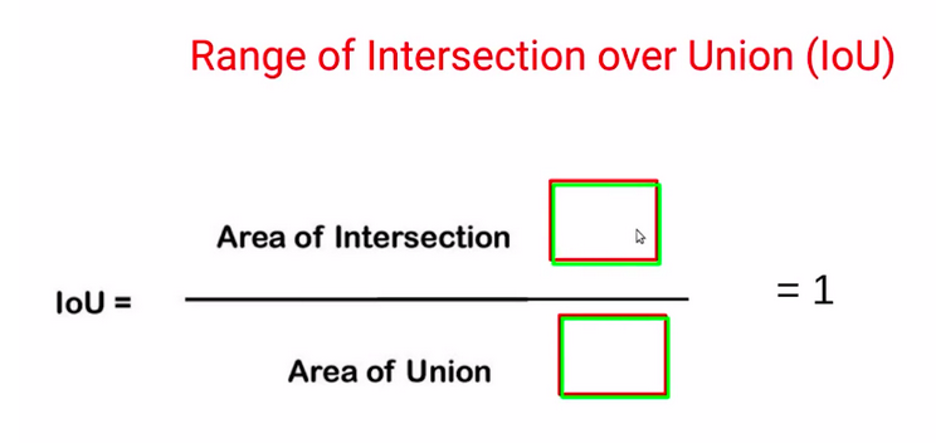
در این صورت مساحت اشتراک و مساحت اجتماع یکسان خواهد بود. از آنجا که صورت و مخرج در این مورد یکسان هستند، مقدار IoU برابر با ۱ خواهد بود. بنابراین اساساً محدوده IoU یا اشتراک روی اجتماع میان صفر و یک است.
ما اغلب یک آستانه را در نظر میگیریم تا تشخیص دهیم آیا کادر محدودکنندهی پیشبینیشده پیشبینی درستی است یا خیر؛ بنابراین اگر IoU بزرگتر از فرضا ۰.۵ باشد، در نظر خواهیم گرفت که کادر محدودکنندهی واقعی و کادر محدودکنندهی پیشبینیشده کاملاً مشابه هستند و در این صورت میگوییم پیشبینی خوبی بوده است.


درحالیکه اگر IoU کمتر از یک آستانه خاص باشد، مثلا ۰.۵ باشد، خواهیم گفت کادر محدودکننده پیشبینیشده به کادر محدودکننده واقعی اصلاً نزدیک نیست.

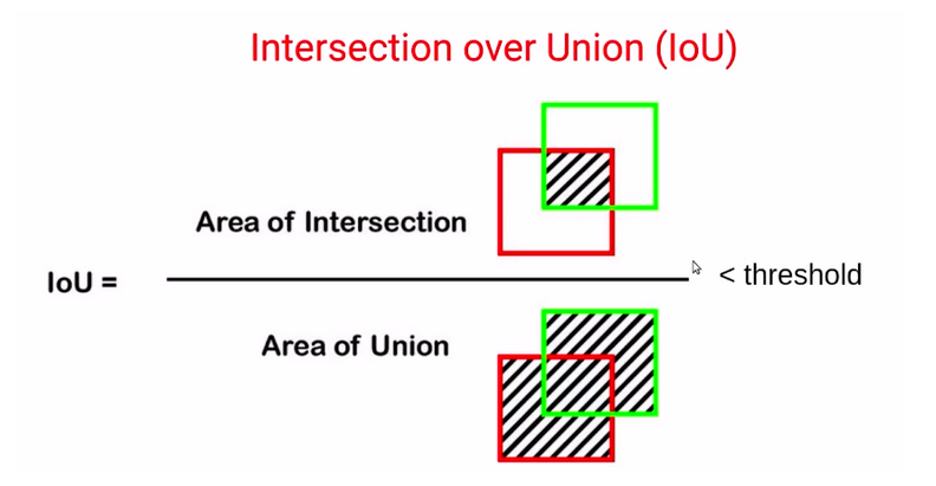
بدیهی است که ما آزادیم که این آستانه را خودمان تعیین کنیم.
از «IoU» میتوان برای انتخاب بهترین کادر محدودکننده و همچنین بهعنوان یک معیار ارزیابی استفاده کرد؛ زیرا از آنجا که اگر مقدار اشتراک روی اجتماع زیاد باشد، کادرهای محدودکنندهی پیشبینیشده نزدیک به کادر محدودکنندهی واقعی هستند، میتوان گفت که مدل عملکرد خوبی دارد.
از این رو «IoU» میتواند بهعنوان یک معیار ارزیابی استفاده شود. در بخش بعدی نحوهی محاسبهی IoU را برای کادرهای محدودکننده یاد خواهیم گرفت.
محاسبهی IoU
همانطور که در بخش قبل دیدیم، برای محاسبهی مقدار IoU به ناحیهی اشتراک و همچنین ناحیهی اجتماع نیاز داریم.

حال سؤال این است که چگونه این دو مقدار را به دست آوریم؟ برای پیبردن به مساحت اشتراک، به مساحت کادر بنفش که در تصویر ۱۹ مشخص شده است نیاز داریم. می توانیم با استفاده از مختصات کادر بنفش که در تصویر ۲۰ میبینیم، آن را محاسبه کنیم.

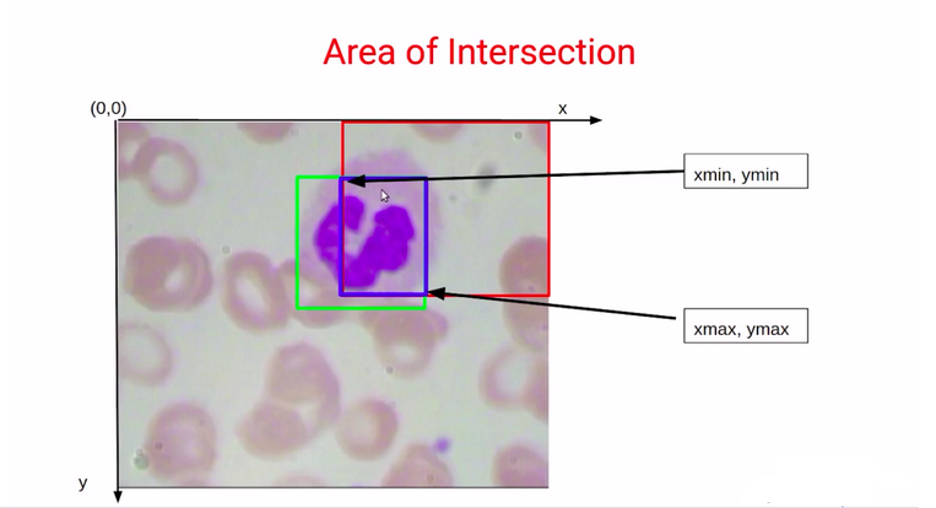
مختصات این کادر بنفش Xmin، Ymin، Xmax و Ymax خواهد بود که با استفاده از این مقدارها، بهراحتی قادر به محاسبهی مساحت اشتراک خواهیم بود.
بیایید ببینیم مقدار هر یک از اینها چطور محاسبه میشود.
برای اینکه مقدار Xmin را بفهمیم، از مقدارهای Xmin برای این دو کادرمحدودکننده استفاده میکنیم که بهصورت X1min و X2min نمایش داده میشود.

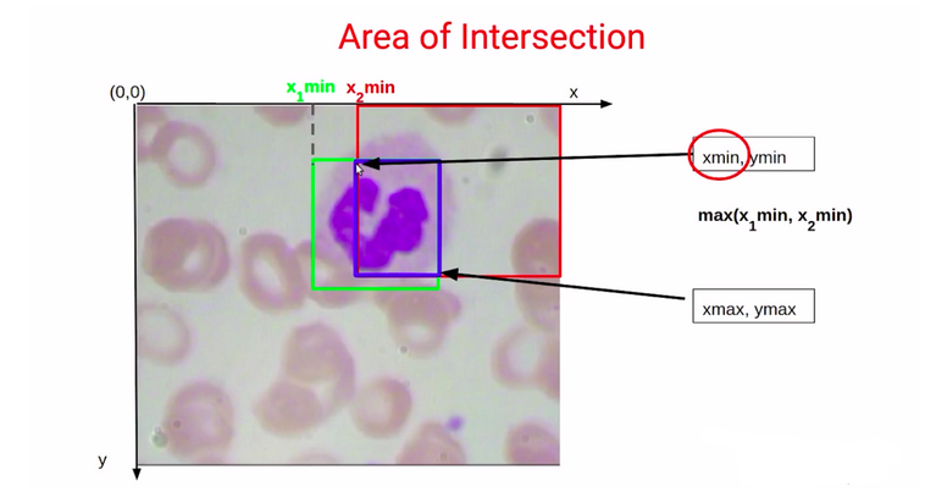
اکنون، همانطور که در بالای نمودار در تصویر ۲۱ میبینید، Xmin برای این کادر بنفش رنگ بهسادگی معادل X2min است؛ همچنین میتوان گفت که Xmin برای این کادر آبی همیشه حداکثر مقدار (ماکسیمم) از این دو مقدار X1min و X2min خواهد بود.
بههمین ترتیب، برای اینکه مقدار Xmax را برای این کادر بنفش رنگ مشخص کنیم، قصد داریم مقدارهای X1max و X2max را با هم مقایسه کنیم. میبینیم که Xmax برای این کادر بنفش رنگ معادل X1max است؛ همچنین میتوان آن را بهعنوان مینیمم X1max و X2max نوشت.
برای یافتن مقدار Ymin و Ymax بههمین شکل عمل میکنیم. قصد داریم Y1min و Y2min و Y1max و Y2max را با هم مقایسه کنیم. مقدار Ymin بهسادگی برابر با Y1min است یا بهعبارت دیگر برابر با ماکسیمم Y1min و Y2min خواهد بود.
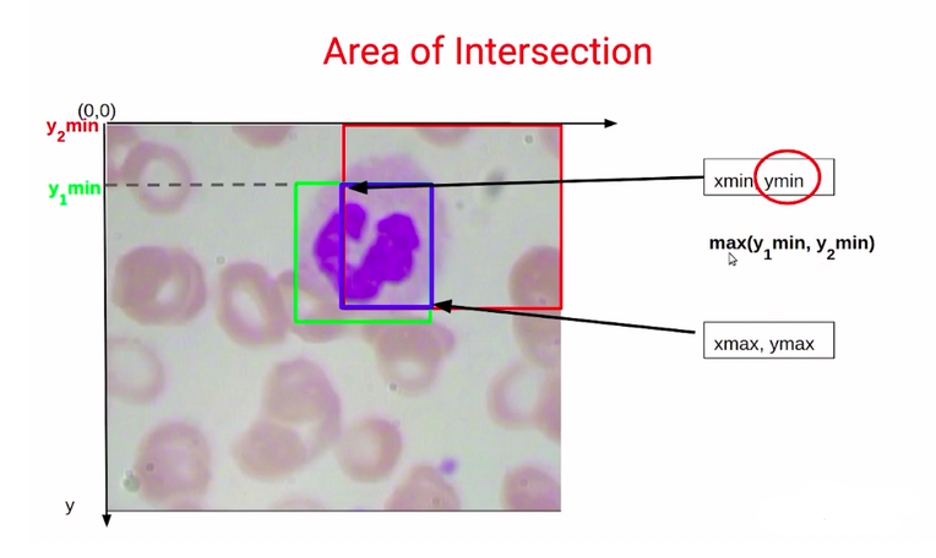
و بهطور مشابه، Ymax برابر با Y2max یا همان مینیمم Y1max و Y2max خواهد بود.

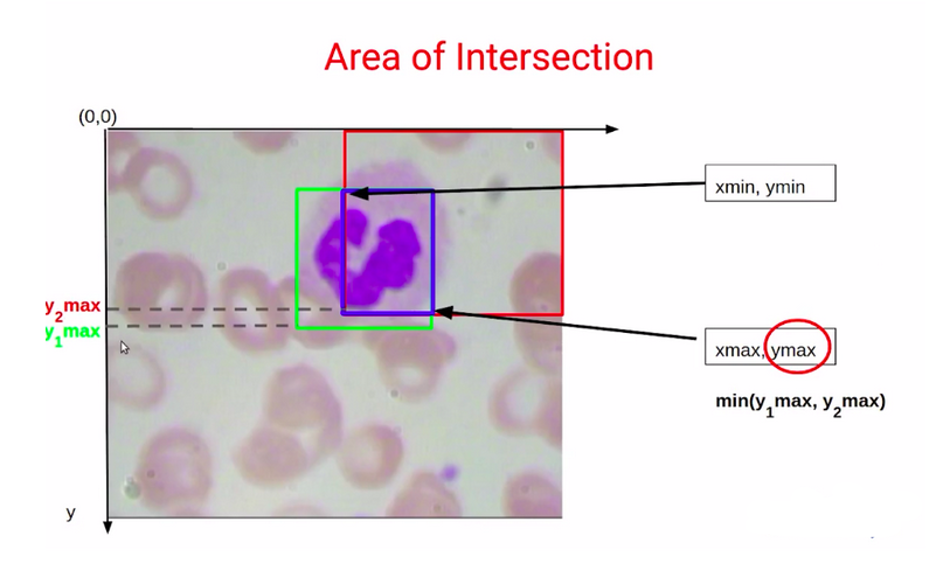
حالا که این چهار مقدار را داریم Xmin)، Ymin، Xmax و (Ymax، می توانیم مساحت اشتراک را با ضرب طول و عرض این مستطیل یا همان کادر بنفش که در تصویر ۲۳ میبینیم محاسبه کنیم.

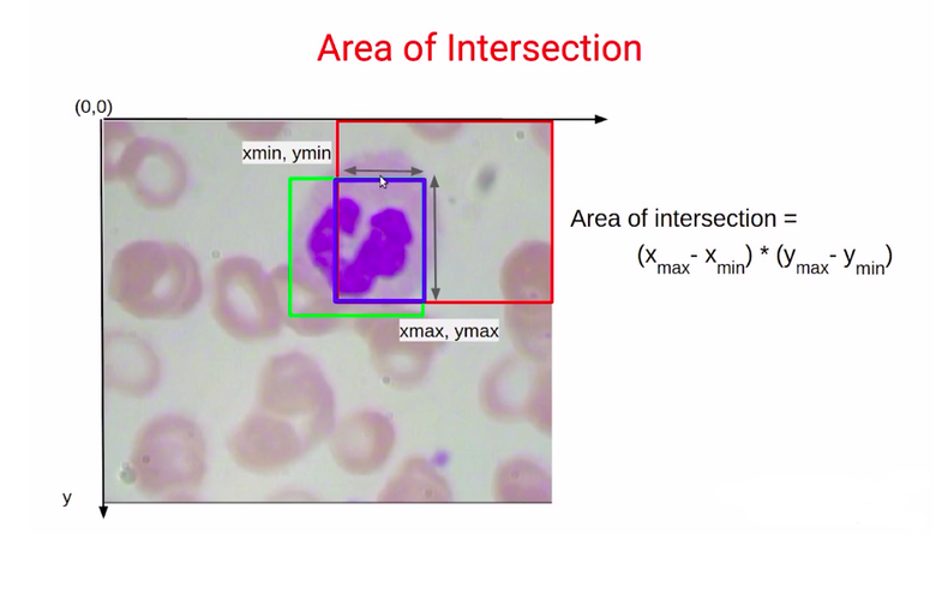
بنابراین برای فهمیدن طول مستطیل Xmin را از مقدار Xmax کم میکنیم. برای پیداکردن ارتفاع یا عرض مستطیل یا همان کادر بنفش، باید تفاوت میان Ymax و Ymin را پیدا کنیم، یعنی مقدارYmin را از Ymax کم کنیم. وقتی طول و عرض را داشته باشیم، مساحت اشتراک به سادگی برابر با ضرب طول در عرض خواهد بود؛ بنابراین اکنون میدانیم که چگونه مساحت اشتراک را محاسبه کنیم.
ناحیهی اجتماع
برای محاسبهی مساحت اجتماع میخواهیم از مقدارهای مختصات این دو کادر محدودکننده در تصویر شمارهی ۲۵ که کادر سبزرنگ و کادر قرمزرنگ هستند استفاده کنیم.


بنابراین اول از همه باید مساحت کادر ۱ را پیدا کنیم که این کادر محدودکنندهی سبز یا این منطقهی سایهدار سبز در تصویر ۲۶ است.



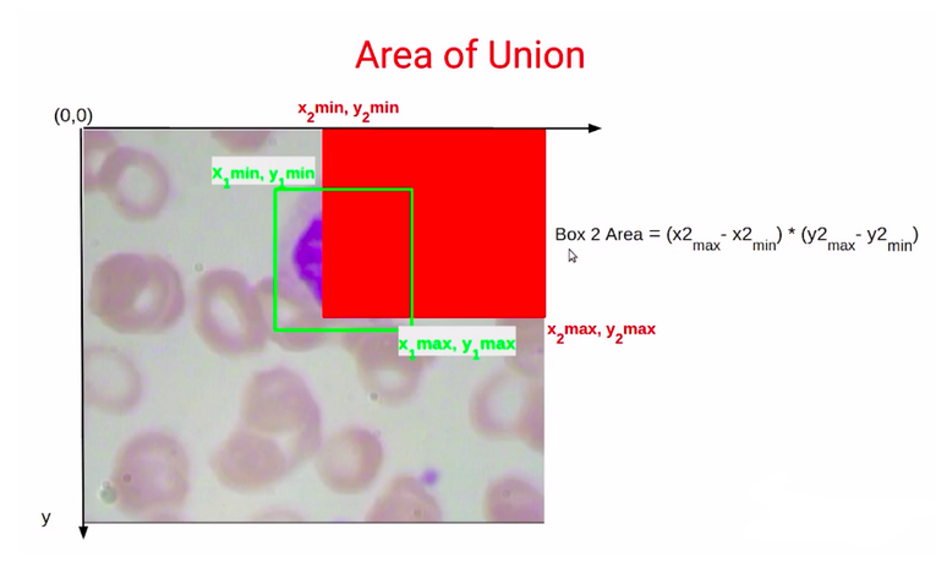
مساحت کادر قرمز را هم محاسبه میکنیم، اما توجه کنید که وقتی مساحتهای کادر ۱ و کادر ۲ را محاسبه میکنیم، درواقع ناحیهی بنفشرنگ در تصویر شمارهی ۲۸ را که همان ناحیهی اشتراک این دو است دو بار میشماریم. از آنجا که این قسمت دو بار شمرده میشود، باید آن را از مساحت کل کم کنیم تا مساحت اجتماع را به دست آوریم.

بنابراین اکنون مساحت اشتراک و اجتماع را برای دو کادر محدودکننده داریم. حالا میتوانیم بهسادگی مقدار اشتراک روی اجتماع یا همان IoU را محاسبه کنیم.


اکنون در بخش بعدی معیار ارزیابی را بررسی میکنیم.
متریک ارزیابی، میانگین دقت متوسط (Mean Average Precision)
اکنون قصد داریم درمورد برخی از معیارهای ارزیابی رایج مورداستفاده برای تشخیص اشیا (Object Detection) بحث کنیم.
معیارهای ارزیابی برای تشخیص اشیا از این قرار است:
- اشتراک روی اجتماع (IoU)
- میانگین دقت متوسط (mAP)
ما قبلاً درمورد اشتراک روی اجتماعی و چگونگی محاسبه آن بحث کردیم. یکی دیگر از معیارهای پرکاربرد میانگین دقت متوسط یا Mean Average Precision است. در این بخش متوجه خواهیم شد که میانگین دقت متوسط چیست و چگونه میتوان از آن استفاده کرد.
مطمئناً با متریک Precision آشنا هستید که بهسادگی تقسیم تعداد مثبتهای واقعی یا همان True Positive ها بر مثبتهای واقعی و مثبتهای کاذب (False Positives) است.
حالا بیایید مثالی بزنیم تا بفهمیم دقت چگونه محاسبه میشود؛ بیایید بگوییم که مجموعهای از پیشبینیهای کادر محدودکننده داریم. همراه با آن، امتیاز IoU را داریم که با مقایسهی این پیشبینیهای کادر محدودکننده با کادرهای محدودکنندهی واقعی محاسبه کردیم. حالا فرض کنید آستانهی ما ۰.۵ است.


با درنظرگرفتن آستانه میتوانیم این پیشبینیها را بهعنوان موارد مثبت واقعی و مثبت کاذب طبقهبندی کنیم. هنگامی که تعداد کل مثبتهای واقعی و مثبتهای کاذب را داشته باشیم، میتوانیم دقت یا همان Precision را محاسبه کنیم که در این مثال برابر با ۰.۶ است.
اکنون معیار دیگری وجود دارد که دقت متوسط یا Average Precision است. دقت متوسط اساساً میانگین مقادیر دقت را در سراسر دادهها محاسبه میکند.
بیایید نحوهی عملکرد آن را با مثالی درک کنیم.
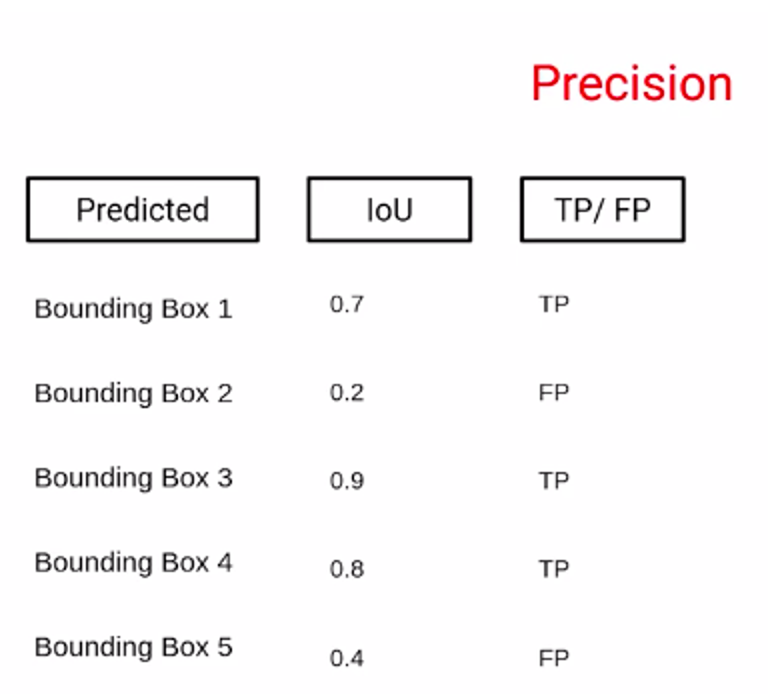
در مثال تصویر ۳۱، ما پنج کادر محدودکننده با امتیاز IoU آنها داریم و براساس امتیاز IoU میتوانیم تعریف کنیم که آیا این کادر محدودکنندهی مثبت واقعی است یا مثبت کاذب. اکنون ما دقت (Precision) را برای این سناریوی خاص محاسبه میکنیم که در آن فقط کادر محدودکننده ۱ را در نظر میگیریم.

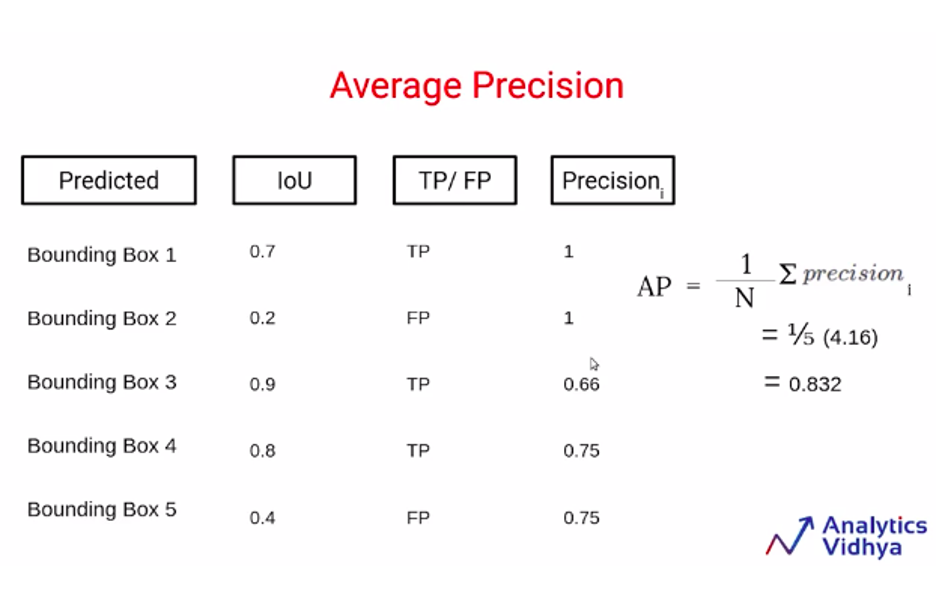
برای اولین کادر محدودکننده مثبت واقعی یک است و مخرج آن هم که مثبت واقعی بهاضافه مثبت کاذب است در این مورد برابر با یک است؛ از این رو، مقدار Precision برای اولین کادر محدودکننده یک است. زمانی که مثبت کاذب یا False Positive داریم، مقدار Precision را تغییر نمیدهیم؛ پس برای کادر دوم هم مقدار Precision برابر با ۱ است. برای کادر محدودکنندهی سوم مثبت واقعی داریم؛ بنابراین تعداد مثبتهای واقعی (Ture Positives) دو میشود و مجموع مثبتهای واقعی و مثبت کاذب ۳ میشود؛ بنابراین مقدار Precision در اینجا ۲ بر ۳ یا ۰.۶۶ خواهد بود. بهطور مشابه، ما برای تمامی کادرهای محدودکننده مقدار Precision را محاسبه میکنیم.
هنگامی که تمامی این مقدارها را برای کادرهای محدودکننده محاسبه میکنیم، میانگین این مقدارها را نیز محاسبه میکنیم که همان Average Precision است.
اکنون، میانگین دقت متوسط یا Mean Average Precision بهسادگی در تمامی کلاسها محاسبه میشود.
فرض کنید چندین کلاس داریم، مثلاً k کلاس داریم؛ سپس برای هر کلاس جداگانه این میانگین دقت را محاسبه میکنیم و میانگین یا همان Mean را در تمامی کلاسها میگیریم که مقدار میانگین دقت متوسط را میدهد. بهاین صورت است که میانگین دقت متوسط برای مسئلههای تشخیص اشیا محاسبه میشود و بهعنوان یک معیار ارزیابی برای مقایسه و ارزیابی عملکرد مدلهای تشخیص اشیا (Object Detection) استفاده میشود.
تئوری و مبانی تشخیص اشیای برای حل چالشهای تجاری و توسعه مدلهای موردنیاز لازم حیاتی است. ما در این مطلب سعی کردیم این تسک را که یکی از معروفترین تسکهای حوزهی بینایی ماشین یا Computer Vision است با جزییات کامل و بهسادهترین شکل توضیح دهیم.
پیشهاد میکنیم درباره بخشبندی تصویر یا Image Segmentation هم مطالعه کنید.
با کافهتدریس متخصص داده شوید!
کافهتدریس بهصورت تخصصی بهروزترین آموزشهای علم داده را در قالب کلاسهای آنلاین و ویدئوهای آموزشی در اختیار شما قرار میدهد. این آموزشها به شما کمک میکند در هر نقطهی جغرافیایی که هستید به کاملترین آموزش علم داده دسترسی داشته باشید و در مسیر تبدیلشدن به دیتا ساینتیست قدم بردارید.
برای آشنایی با کلاسهای آنلاین و ویدئوهای آموزشی علم داده روی این لینک کلیک کنید: