
تصور کنید روی یک مسئله یادگیری ماشین از ابتدا تا انتها کار کردهاید و به بهترین راهحل با بهترین مدلها دست یافتهاید، اما هنگامی که کد خود را به تیم مهندسی ارسال میکنید، کدی که روی سیستم شما کار میکرد، روی سرورهای آنها که ممکن است سیستم عامل و نسخههای مختلفی از کتابخانهها داشته باشند کار نمیکند. با وجود دقت و سختکوشی شما، این اتفاق ناامیدکننده گاهی میتواند رخ دهد. اکثر توسعهدهندگان دستکم یک بار این را تجربه میکنند. راهحل چیست؟ اینجاست که داکر وارد میشود. با استفاده از داکر میتوانید محیطی دقیق و یکسان برای پروژه خود تعریف کنید و اطمینان حاصل کنید که کد شما بدون مشکل اجرا خواهد شد، بدون توجه به محیط و تنظیمات پیشین. این مطلب داکر در دیتا ساینس و مفهومهای مرتبط با آن را معرفی میکند و اهمیت آن را برای دانشمندان داده توضیح میدهد؛ علاوهبراین، این مطلب به شما کمک میکند ابزار را نصب و برای پروژه بعدی خود از آن استفاده کنید. درنهایت، شما با بهترین روشهای صنعت که هنگام استفاده از داکر باید رعایت کنید آشنا خواهید شد و به تمامی سوالات مربوط به داکر پاسخ داده خواهد شد.
- 1. داکر، کانتینرها و ایمیجها چیست؟
- 2. کانتینرهای داکر چگونه با ماشینهای مجازی متفاوت هستند؟
- 3. چرا از داکر در دیتا ساینس استفاده کنیم؟
- 4. آموزش استفاده از داکر در دیتا ساینس برای پروژه بعدی شما
- 5. آشنایی با دستورهای متداول داکر
- 6. داکرایزکردن یک برنامه ساده ماشین لرنینگ
- 7. بهترین روشهای صنعت یا Best Practices برای استفاده از داکر
- 8. نتیجهگیری
-
9.
پرسشهای متداول
- 9.1. آیا دیتا ساینتیستها باید داکر را یاد بگیرند و داکر در دیتا ساینس کاربرد دارد؟
- 9.2. چگونه میتوانم از Jupyter Notebook در یک کانتینر داکر استفاده کنم؟
- 9.3. چگونه میتوانم پروژههای علم داده خود را با استفاده از داکر به اشتراک بگذارم؟
- 9.4. چگونه میتوانم وابستگیهای پروژهام را در داکر مدیریت کنم؟
- 9.5. چگونه میتوانم عملکرد ایمیج داکر خود را بهینه کنم؟
- 10. یادگیری ماشین لرنینگ را از امروز شروع کنید!
داکر، کانتینرها و ایمیجها چیست؟
داکر یک پلتفرم برای ساخت، اجرا و ارسال برنامههاست.
کانتینرها بستههای سبک، مستقل و قابلاجرایی هستند که همه چیزهای لازم برای اجرای یک برنامه، ازجمله کد، زمان اجرا، کتابخانهها، متغیرهای محیطی و فایلهای پیکربندی، را در خود دارند.
یک ایمیج داکر یک فایل فقط خواندنی است که تمامی دستورعملهای لازم برای ایجاد یک کانتینر را در خود دارد. از ایمیجها برای ایجاد و راهاندازی کانتینرهای جدید در زمان اجرا استفاده میشود.
داکر به توسعهدهندگان کمک میکند تا برنامههای خود را همراه با وابستگیهایشان در یک کانتینر بستهبندی کنند؛ سپس میتواند روی هر ماشینی که داکر نصب شده است اجرا شود.
بهنوعی، مانند این است که شما برای یک پروژه جدید یک ماشین جدید دریافت کردهاید. پکیجهای موردنیاز را نصب میکنید، فایلهای مورنیاز را به ماشین کپی میکنید و اسکریپتها را اجرا میکنید؛ همچنین میتوانید این ماشین جدید را بهجای دیگری ارسال کنید.
کانتینرهای داکر چگونه با ماشینهای مجازی متفاوت هستند؟
بهمحض تعریف کانتینرها، ممکن است بپرسید که چگونه با ماشینهای مجازی متفاوت هستند؛ زیرا هر دو فناوری اجازه میدهند چندین محیط ایزوله بر روی یک ماشین فیزیکی اجرا شوند. به تفاوت معماری در این تصویر نگاه کنید و ببینید آیا میتوانید تفاوت را تشخیص دهید.
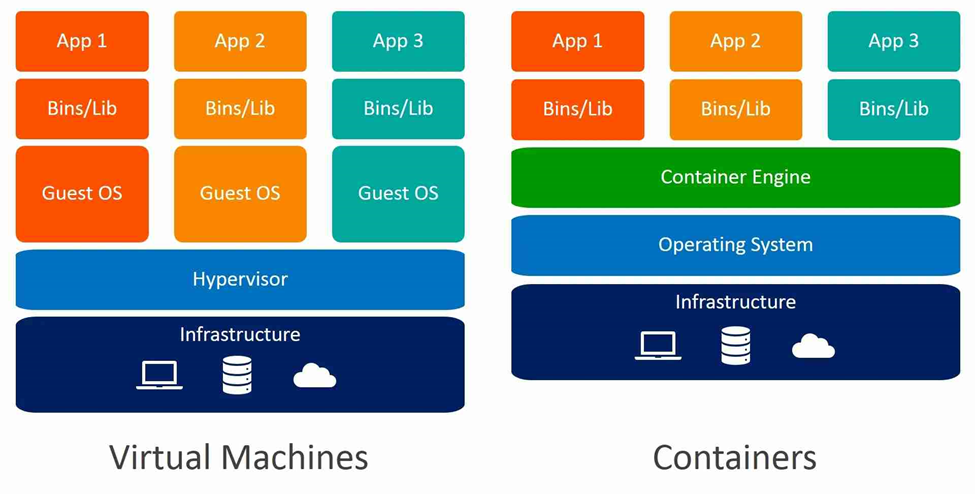
هر ماشین مجازی یک محیط ایزوله است که میتواند سیستمعاملها و تنظیمات مختلف را اجرا کند؛ همچنین این بهاین معناست که هر ماشین مجازی به یک کپی کامل از سیستمعامل نیاز دارد که میتواند منابع زیادی مصرف کند. از سوی دیگر، برنامههای کانتینری در یک محیط ایزوله اجرا میشوند بدون نیاز به یک کپی کامل از سیستمعامل که آنها را سبکتر و کارآمدتر میکند. درحالیکه ماشینهای مجازی مفید هستند، کانتینرها بهطور کلی کافی و ایدهآل برای ارسال برنامهها هستند.
چرا از داکر در دیتا ساینس استفاده کنیم؟
شاید از خود بپرسید چرا باید بهعنوان یک دانشمند داده داکر را یاد بگیرید. آیا تیمهای DevOps برای رسیدگی به زیرساختها وجود ندارند؟ سؤال خوبی است ، اما داکر در دیتا ساینس و برای دانشمندان داده بسیار مهم است، حتی اگر یک تیم DevOps وجود داشته باشد. بیایید بفهمیم چرا داکر اینقدر مفید است.
یکپارچگی با تیم DevOps
وجود یک تیم DevOps مزیتهای استفاده از داکر را نفی نمیکند، بلکه میتواند به پرکردن فاصله میان تیمهای توسعه و عملیات کمک کند. دانشمندان داده میتوانند از داکر برای بستهبندی کد خود و تحویل آن به تیم DevOps برای استقرار و مقیاسپذیری استفاده کنند. احتمالاً این را در یک تیم داده ساختاریافتهتر تجربه خواهید کرد.
محیط ثابت و تکرارپذیری
دانشمندان داده اغلب با وابستگیها و پیکربندیهای پیچیدهای کار میکنند که باید تنظیم و نگهداری شوند و برای دستیابی به نتایج مشابه، محیط باید ثابت بماند. داکر به دانشمندان داده اجازه میدهد تا یک محیط ثابت با همه وابستگیها و پیکربندیهای لازم ایجاد و به اشتراک بگذارند که دیگران بهراحتی میتوانند آن را تکرار کنند.
قابلحملبودن
کانتینرهای داکر میتوانند روی هر محیطی که داکر نصب شده است اجرا شوند، ازجمله لپتاپها، سرورها و پلتفرمهای ابری. این امر باعث میشود دانشمندان داده بتوانند کار خود را میان محیطهای مختلف منتقل کنند.
ایزولهکردن منابع
داکر به چندین کانتینر اجازه میدهد تا روی یک ماشین بهطور همزمان اجرا شوند، آنهم هر یک با منابع ایزوله خود. این میتواند به دانشمندان داده کمک کند تا منابع خود را بهطور کارآمدتر مدیریت و از تضاد با برنامههای دیگر جلوگیری کنند. وقتی چندین پروژه یادگیری ماشین دارید، این ویژگی میتواند نجاتبخش باشد.
ایجاد همکاری
داکر به دانشمندان داده اجازه میدهد تا کار خود را با هر کسی، ازجمله تیمهای راه دور، در کانتینرها به اشتراک بگذارند. همکاری بخش مهمی از کار بهعنوان یک تیم برای دانشمندان داده است و داکر این فرایند را ساده میکند.
اکثر دیتا ساینتیستهای باتجربه موافق هستند که با کمک داکر میتوانند روی کار خود تمرکز کنند، بدون آنکه درباره زیرساختها نگرانی داشته باشند.
آموزش استفاده از داکر در دیتا ساینس برای پروژه بعدی شما
از آنجا که نیاز به داکر برای یک دانشمند داده را ثابت کردهایم، بیایید بدون تلفکردن وقت با داکر در دیتا ساینس آشنا شویم. ابتدا باید داکر را روی ماشین خود نصب کنیم و با دستورهای متداول آن آشنا شویم.
نصب داکر روی ماشین یا سرور محلی شما
داکر برای همه سیستمعاملهای اصلی مانند لینوکس، ویندوز و مک در دسترس است؛ نصب آن ساده است و بهترین راهنماییها برای آن در مستندات رسمی یافت میشود.
- دستورعملهای نصب داکر برای لینوکس.
- دستورعملهای نصب داکر برای ویندوز.
- دستورعملهای نصب داکر برای مک.
اگر میخواهید ایمیجهای خود را ایجاد کنید و آنها را به Docker Hub منتقل کنید (همانطور که در برخی از دستورهای زیر نشان داده شده است)، باید در Docker Hub یک حساب کاربری ایجاد کنید. به Docker Hub بهعنوان یک مکان مرکزی فکر کنید که توسعهدهندگان میتوانند ایمیجهای داکر خود را ذخیره و به اشتراک بگذارند.
پیشنهاد میکنیم درباره مهندسی پرامپت هم مطالعه کنید.
آشنایی با دستورهای متداول داکر
پس از راهاندازی داکر روی ماشین (یا سرور) خود، مرحله بعدی آشنایی با برخی دستورهای داکر است. برای کمک به شروع شما، ۱۰ دستور متداول داکر را خلاصه کردهایم که بهاحتمال زیاد با آنها مواجه میشوید.
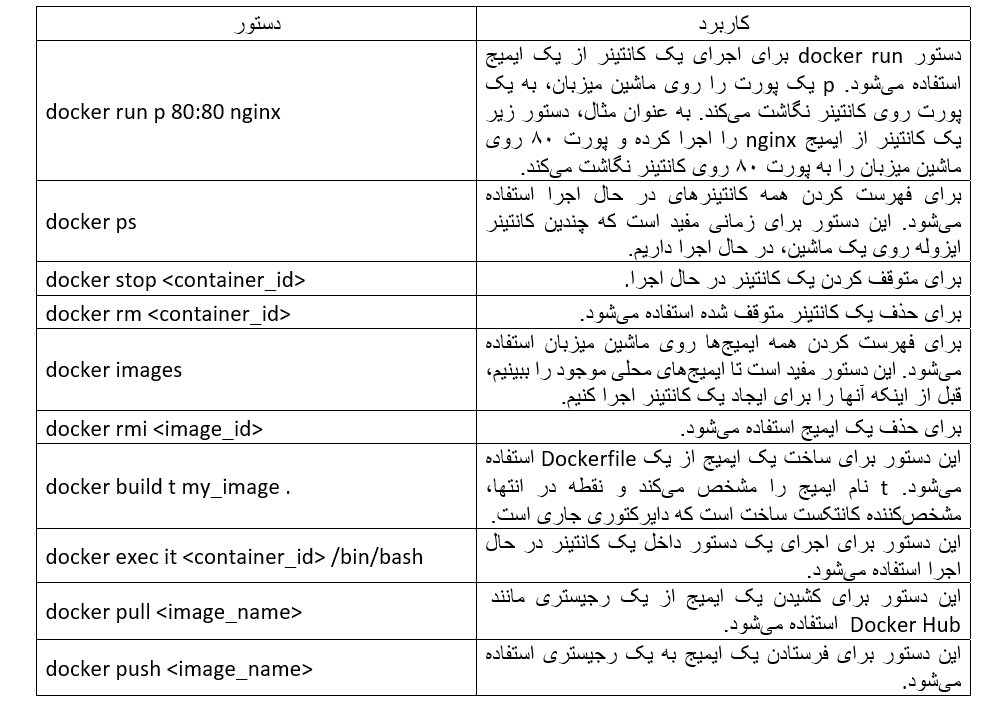
اکنون که یاد گرفتیم داکر را راهاندازی کنیم و با دستورهای متداول آن آشنا شدیم، هدف بعدی ما کاربرد داکر در دیتا ساینس و داکرایزکردن یک برنامه یادگیری ماشین است.
داکرایزکردن یک برنامه ساده ماشین لرنینگ
داکر در دیتا ساینس و داکریزهکردن هر برنامه ماشین لرنینگ آسانتر از آن چیزی است که فکر میکنید، بهشرطی که از یک رویکرد سهمرحلهای ساده پیروی کنید.
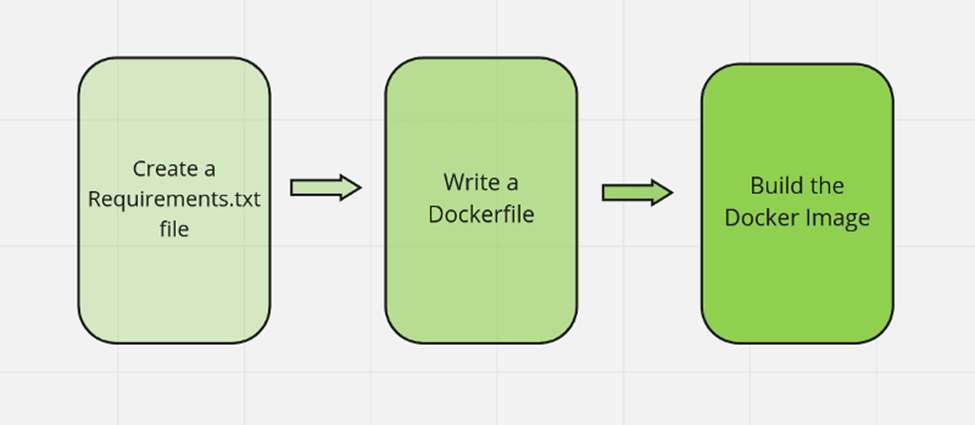
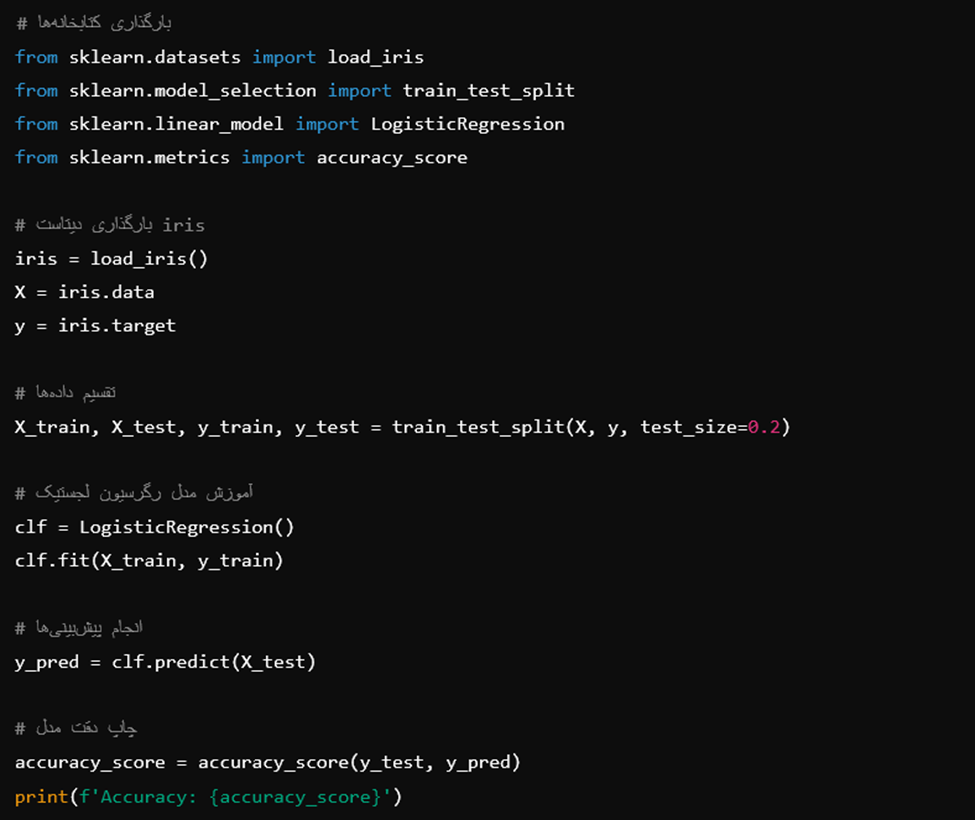
بیایید یک اسکریپت ماشین لرنینگ مبتدی را برای سادهنگهداشتن کار انتخاب کنیم؛ زیرا هدف ما نشاندادن نحوه داکریزهکردن یک اسکریپت است. مثالی که خواهیم دید یک مدل رگرسیون لجستیک ساده روی دیتاست iris میسازد.
تعریف محیط
شما باید دقیقاً محیط فعلی را بشناسید تا بتوانید آن را در مکان دیگری تکرار کنید. آسانترین و متداولترین راه این است که یک فایل requirements.txt ایجاد کنید که تمامی کتابخانههای مورداستفاده پروژه شما و نسخههای آنها را مشخص کند.
محتوای فایل بهاین صورت است: scikitlearn==1.2.0
توجه کنید که یک برنامه پیچیدهتر یادگیری ماشین ممکن است از کتابخانههای بیشتری مانند NumPy، pandas، matplotlib و غیره استفاده کند؛ بنابراین ایجاد فایل requirements.txt منطقیتر خواهد بود بهجای آنکه کتابخانه را نصب کنید (بیشتر در این مورد در بخش بهترین روشهای صنعت یا Best Practices توضیح داده خواهد شد).
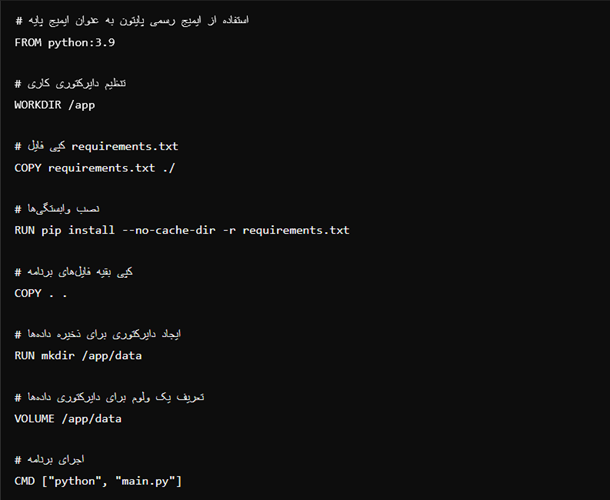
نوشتن یک Dockerfile
مرحله بعدی ایجاد فایلی بهنام Dockerfile است که میتواند محیط را ایجاد و برنامه ما را در آن اجرا کند. بهزبان ساده، این فایل مانند یک دفترچه راهنما برای داکر است که مشخص میکند محیط باید چگونه باشد، محتویات آن چه چیزهایی باشد و مراحل اجرایی دیگر. محتوای Dockerfile بهاین صورت است:
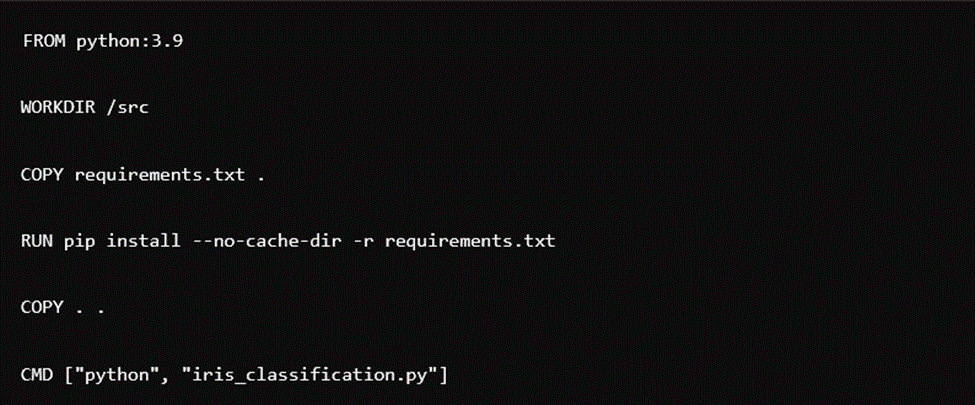
توضیحات خطبهخط کد از این قرار است:
- این یک Dockerfile است که محیط پایتون را برای اجرای یک اسکریپت به نام iris_classification.py راهاندازی میکند.
- خط اول: ایمیج پایه مورداستفاده را مشخص میکند که Python 3.9 است.
- خط دوم: دایرکتوری کاری را به /src قرار میدهد.
- خط سوم: فایل requirements.txt را به دایرکتوری کاری کپی میکند.
- خط چهارم: پکیجهای پایتون ذکرشده در requirements.txt را با استفاده از pip نصب میکند. nocachedir برای جلوگیری از کشکردن پکیجها استفاده میشود که میتواند فضای دیسک را ذخیره کند.
- خط پنجم: همه فایلها در دایرکتوری جاری را به دایرکتوری کاری کپی میکند.
- خط آخر: فرمانی را که هنگام شروع کانتینر اجرا میشود مشخص میکند که اجرای اسکریپت iris_classification.py با استفاده از مفسر پایتون است.
این Dockerfile از ایمیج رسمی پایتون بهعنوان پایه استفاده میکند، دایرکتوری کاری را تنظیم میکند، فایل requirements.txt را کپی میکند و وابستگیها را نصب میکند، کد برنامه را کپی میکند و دستور python iris_classification.py را برای شروع برنامه اجرا میکند.
ساختن ایمیج
مرحله نهایی برای ایجاد یک محیط قابل تکرار ساخت یک ایمیج است (که بهعنوان یک قالب نیز شناخته میشود) که میتواند اجرا شود تا هر تعداد کانتینر با همان تنظیمات ایجاد شود. شما میتوانید ایمیج را با اجرای این دستور در همان دایرکتوری که Dockerfile قرار دارد بسازید: <docker build -t <image-name
اکنون که برنامه ساده ماشین لرنینگ را داکریزه کردهایم، میتوانید از دستور docker run استفاده کنید، کانتینرها را ایجاد کنید و سپس آنها را متوقف کنید همانطور که قبلاً برخی از دستورهای متداول را پوشش دادیم.
بیایید اکنون دانش خود را از اصول و مباحث تئوری به انتظارات صنعت تبدیل کنیم.
پیشنهاد میکنیم درباره پردازش صوت هم مطالعه کنید.
بهترین روشهای صنعت یا Best Practices برای استفاده از داکر
درحالیکه درک اصول اولیه برای شروع کافی است، هنگام کار در صنعت، پیروی از بهترین روشها ضروری است.
کاهش تعداد لایهها
هر دستور در Dockerfile به ایجاد یک لایه جدید میانجامد. تعداد زیاد لایهها میتواند به این بینجامد که ایمیج بزرگ و کند شود. به نمونه این کد نگاه کنید:
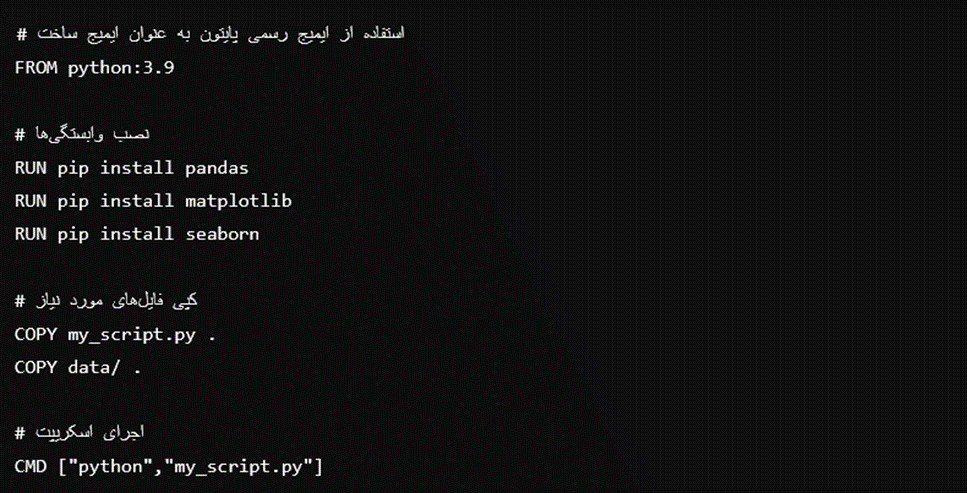
مشکل اینجا چیست؟ استفاده از چندین دستور RUN و COPY غیرضروری بود. در اینجا چگونگی اصلاح آن را مشاهده میکنید:
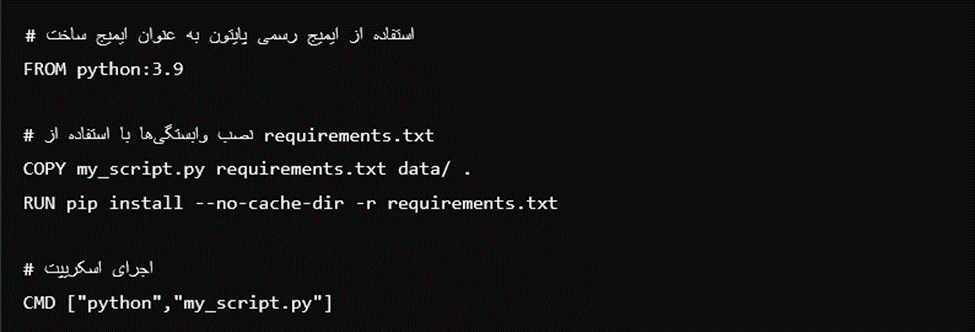
درحالیکه در یک فایل کوچک مانند این همهچیز واضح است. گروهبندی دستورهایی که کارهای مشابه انجام میدهند یا فایلهای مشابه را تغییر میدهند یک راه آسان برای کاهش لایهها در یک Dockerfile است.
استفاده از ایمیجهای رسمی
ایمیجهای رسمی ایمیجهایی هستند که ناشر ایمیج آنها را نگهداری و پشتیبانی میکنند. این ایمیجها معمولاً پایدارتر و امنتر از دیگر ایمیجها محسوب میشوند. گاهی در عجله برای انجامدادن سریعتر کار، با بیاحتیاطی از یک ایمیج غیررسمی استفاده میکنیم. زمانی که امکانپذیر است، از ایمیجهای رسمی بهعنوان پایه برای ایمیجهای خود استفاده کنید.
خروجی چندمرحلهای برای بهینهسازی عملکرد
خروجی چندمرحلهای در داکر به شما اجازه میدهد که از چند دستور FROM در یک Dockerfile استفاده کنید.
ما میتوانیم از یک ایمیج بزرگتر بهعنوان Build Image بهعنوان پایهواساس برنامه استفاده کنیم و سپس فایلهای ضروری را به یک ایمیج کوچکتر زمان اجرا کپی کنیم. با حذف فایلهای غیرضروری اندازه ایمیج نهایی را کاهش میدهیم که نهتنها عملکرد را بهینه میکند، برنامه را امنتر میکند. بیایید به یک مثال نگاه کنیم تا بهتر این موضوع را درک کنیم؛ زیرا این روش بهطور مکرر در صنعت استفاده میشود:
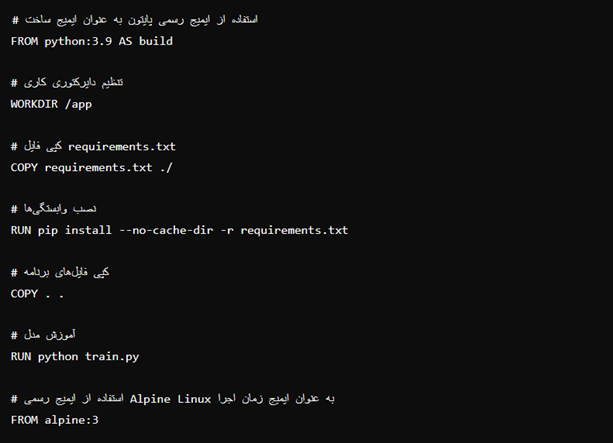
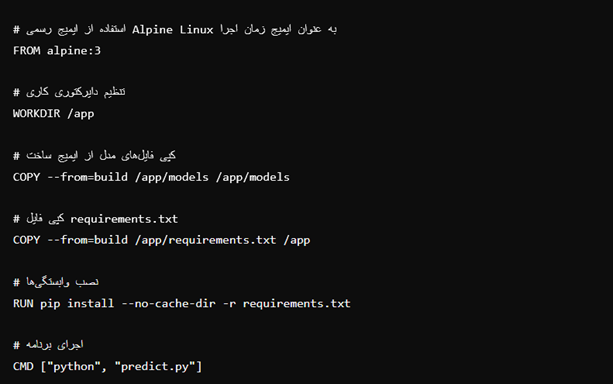
در این مثال ابتدا از ایمیج رسمی پایتون بهعنوان Build Image استفادهشده و تمامی وابستگیها در این مرحله نصب میشوند.
Build Image در داکر به ایمیجی اشاره میکند که در طول فرایند ساخت یک برنامه استفاده میشود. این ایمیج بهعنوان محیطی برای ایجاد، کامپایل یا آموزش برنامه به کار میرود. در این مرحله تمامی وابستگیها و ابزارهای موردنیاز برای ساخت برنامه نصب میشوند. پس از اتمام فرایند ساخت، تنها فایلهای ضروری (مانند مدلهای آموزشدادهشده یا باینریهای کامپایلشده) به ایمیج نهایی زمان اجرا (Runtime Image) منتقل میشوند.
بهعبارت دیگر، Build Image محیطی است که برای آمادهسازی و ساخت برنامه استفاده میشود، درحالیکه ایمیج زمان اجرا محیطی سبکتر و بهینهتر است که برای اجرای نهایی برنامه استفاده میشود. این روش به بهینهسازی اندازه ایمیج نهایی و افزایش امنیت و عملکرد برنامه کمک میکند.
پس از اجرای فایل train.py، فایلهای مدل تولیدشده و فایل requirements.txt را به یک ایمیج کوچکتر Alpine Linux برای زمان اجرا کپی میکنیم که از آن برای اجرای برنامه استفاده خواهیم کرد. با استفاده از یک ساخت چندمرحلهای و نگنجاندن وابستگیهای ساخت و مفسر پایتون در ایمیج نهایی، اندازه ایمیج نهایی را بهطور مؤثر کوچکتر کردهایم.
استفاده از Volumeها برای نگهداری دادهها
ولوم (Volume) در داکر به سازوکاری اشاره میکند که به شما امکان میدهد دادهها را خارج از چرخه عمر کانتینر ذخیره و مدیریت کنید؛ بهعبارت دیگر، دادههای ذخیرهشده در ولومها حتی پس از توقف یا حذف کانتینر نیز حفظ میشوند. ولومها به شما اجازه میدهند دادهها را میان کانتینرهای مختلف به اشتراک بگذارید و ازدسترفتن دادهها جلوگیری کنید.
Volumeها بهویژه در سناریوهایی که به ماندگاری دادهها و اشتراکگذاری میان چندین کانتینر نیاز دارید مفید هستند. استفاده از ولومها تضمین میکند که دادههای مهم از میان نمیروند و در دسترس باقی میمانند.
دادهها درون یک کانتینر پس از توقف و حذف آن در دسترس نیستند، اما گاهی شما به نتایج آزمایشها برای مراجعههای بعدی نیاز دارید؛ همچنین ممکن است بخواهید دادهها را میان چند کانتینر به اشتراک بگذارید. با استفاده از دستور volume شما اطمینان حاصل میکنید که دادهها در خارج از کانتینر ماندگار میشوند. در اینجا مثالی از نحوه انجامدادن این کار آمده است:
سازماندهی و نسخهبندی ایمیجهای داکر
هنگامی که با چندین ایمیج داکر کار میکنید، ممکن است مدیریت آنها گیجکننده شود و به سازماندهی نیاز پیدا کنید. اگرچه روشهای سازماندهی از یک سازمان به سازمان دیگر متفاوت است، اما میتوانیم برخی از روشهای متداول را برای سازماندهی ایمیجهای داکر معرفی کنیم:
- استفاده از نامگذاری ثابت: برای هر ایمیج یک نامگذاری ثابت داشته باشید؛ برای مثال، این قالب میتواند به شناسایی ایمیجها و نسخههای آنها در رجیستری کمک کند: <registry>/<organization>/<image>:<version>
- روشهای نسخهبندی: پیروی از روشهای نسخهبندی برای ایمیجها ضروری است، بهویژه اگر به بازگشت به نسخه قبلی (roll back) نیاز پیدا شود. نسخهبندی میتواند بهصورت نسخه اصلی.نسخه فرعی.نسخه پچ (Semantic Versioning: major version.minor version.patch version) انجام شود.
- برچسبگذاری معنیدار: برچسبگذاری ایمیجها با کلمات معنیدار مانند latest، staging، production به سازماندهی و مدیریت ایمیجها کمک میکند. این برچسبها به شما اجازه میدهند تا بهسرعت ایمیجهای مدنظر برای محیطها و مرحلههای مختلف خط تولید را شناسایی کنید.
توصیه میشود با سازمان خود هماهنگ شوید؛ انتظار میرود که کل تیم از همان نامگذاری پیروی کنند.
نتیجهگیری
در این مطلب به اهمیت ایجاد کدها و برنامههایی پرداختیم که با استفاده از ابزارهایی مانند داکر برای دانشمندان داده قابل تکرار هستند. از توضیح اهمیت داکر در دیتا ساینس داده تا دستورعملهای نصب و برخی از دستورهای متداول داکر شروع شد. در ادامه مطلب به چگونگی داکریزهکردن برنامههای ماشین لرنینگ با استفاده از کدهای نمونه و بهترین روشهای صنعتی پرداختیم که باید در استفاده از داکر رعایت شوند.
بیشتر دانشمندان داده روی مهارتهای اصلی مانند آمار، ریاضیات، یادگیری ماشین، یادگیری عمیق و کدنویسی تمرکز میکنند، اما یادگیری بهترین روشهای مهندسی نرمافزار را که در صنعت موردانتظار است فراموش میکنند.

پرسشهای متداول
آیا دیتا ساینتیستها باید داکر را یاد بگیرند و داکر در دیتا ساینس کاربرد دارد؟
یادگیری داکر میتواند برای دانشمندان داده مفید باشد؛ زیرا به آنان اجازه میدهد وابستگیها و محیطها را بهراحتی مدیریت کنند و اطمینان حاصل کنند که کدشان در سیستمهای مختلف بهطور یکسان اجرا میشود؛ همچنین این به اینمعناست که آنان مجبور نیستند فقط به تیم DevOps متکی باشند.
چگونه میتوانم از Jupyter Notebook در یک کانتینر داکر استفاده کنم؟
برای استفاده از Jupyter Notebook در یک کانتینر داکر، مشابه با آموزش بالا، میتوانید یک Dockerfile جدید ایجاد کرده و سپس از دستور RUN برای نصب Jupyter استفاده کنید؛ سپس از دستور CMD برای شروع سرور Jupyter Notebook استفاده کنید. بهطور جایگزین، میتوانید از ایمیجهای آماده در Docker Hub که Jupyter نصب شده است استفاده کنید. در اینجا یک راهنمای جامع برای استفاده از Jupyter Notebook، ازجمله ازطریق داکر آمده است.
چگونه میتوانم پروژههای علم داده خود را با استفاده از داکر به اشتراک بگذارم؟
میتوانید پروژههای علم داده خود را با استفاده از داکر به اشتراک بگذارید، با فشردن ایمیج خود به یک رجیستری کانتینر مانند Docker Hub. پس از آن، دیگران میتوانند ایمیج را بکشند و پروژه را در محیط خود اجرا کنند.
چگونه میتوانم وابستگیهای پروژهام را در داکر مدیریت کنم؟
برای مدیریت وابستگیهای پروژه در داکر شما میتوانید از یک فایل requirements.txt برای پروژههای پایتونی استفاده کنید. این فایل شامل فهرستی از تمامی کتابخانهها و نسخههای مورد نیاز پروژه است؛ سپس، در Dockerfile خود، میتوانید از دستور RUN pip install -r requirements.txt استفاده کنید تا تمامی وابستگیها بهطور خودکار نصب شوند.
چگونه میتوانم عملکرد ایمیج داکر خود را بهینه کنم؟
برای بهینهسازی عملکرد ایمیج داکر میتوانید از ساختهای چندمرحلهای (multi-stage builds) استفاده کنید. این روش به شما امکان میدهد که ایمیجهای ساخت و زمان اجرا را جدا کنید و فقط فایلهای ضروری را به ایمیج نهایی منتقل کنید. این کار اندازه ایمیج نهایی را کاهش میدهد و امنیت و کارایی آن را افزایش میدهد.
یادگیری ماشین لرنینگ را از امروز شروع کنید!
دنیای دادهها جذاب است و دانستن علم داده، توانایی تحلیل داده، یا بازاریابی مبتنی بر داده، شما را برای فرصتهای شغلی بسیاری مناسب میکند. فارغ از رشته و پیشزمینه، میتوانید حالا شروع کنید و از سطح مقدماتی تا پیشرفته بیاموزید. اگر دوست دارید به این حوزه وارد شوید، پیشنهاد میکنیم با کلیک روی این لینک قدم اول را همین حالا بردارید.
مشاوران کافهتدریس به شما کمک میکنند مسیر یادگیری برای ورود به این حوزه را شروع کنید: