
در زمینههای رو به رشد یادگیری ماشین (ML) و یادگیری عمیق (DL)، بهینهسازی نقش حیاتی در بهبود عملکرد و کارایی مدلها ایفا میکند. بهینهسازی، شامل فرآیند دقیق یافتن بهترین راهحل از میان مجموعهای از راهحلهای ممکن است، که اغلب تحت مجموعهای از محدودیتها انجام میشود. این فرآیند در ML و DL بسیار مهم است زیرا بهطور مستقیم بر دقت، سرعت، و قابلیت اطمینان الگوریتمها تأثیر میگذارد. تکنیکهای بهینهسازی در علم داده ستون فقرات ML و DL هستند و فرآیندهای آموزش مدلها را با به حداقل رساندن یا به حداکثر رساندن توابع هدف، که معمولاً توابع زیان هستند، هدایت میکنند. این توابع میزان خطای پیشبینیهای مدل را در مقایسه با نتایج واقعی اندازهگیری میکنند.
- 1. مرور اجمالی یادگیری ماشین (ML) و یادگیری عمیق (DL)
- 2. اهمیت بهینهسازی
- 3. دامنه و اهداف مقاله
- 4. مبانی بهینهسازی در علم داده
- 5. الگوریتمهای بهینهسازی در یادگیری ماشین
- 6. بهینهسازی در یادگیری عمیق
- 7. مطالعات موردی و کاربردهای بهینهسازی در علم داده
- 8. ارزیابی تکنیکهای بهینهسازی
- 9. مسیرهای آینده در بهینهسازی برای ML و DL
- 10. جمعبندی
-
11.
پرسشهای متداول
- 11.1. تفاوتهای کلیدی بین مسائل بهینهسازی محدب و غیرمحدب در ML چیست؟
- 11.2. چرا از خطای میانگین مربعات (MSE) در وظایف رگرسیون استفاده میشود؟
- 11.3. بهینهساز Adam با روشهای گرادیان کاهشی چه تفاوتی دارد؟
- 11.4. چالشهای اصلی در بهینهسازی مدلهای یادگیری عمیق چیست؟
- 11.5. یادگیری فدرالی چگونه حفظ حریم خصوصی دادهها و مقیاسپذیری را بهبود میبخشد؟
- 12. یادگیری ماشین لرنینگ را از امروز شروع کنید!
مرور اجمالی یادگیری ماشین (ML) و یادگیری عمیق (DL)
یادگیری ماشین زیرمجموعهای از هوش مصنوعی (AI) است که بر توسعه الگوریتمهایی تمرکز دارد که به کامپیوترها اجازه میدهد از دادهها یاد بگیرند و بر اساس آنها تصمیمگیری کنند. تکنیکهای ML به طور کلی به یادگیری نظارتشده، یادگیری بدون نظارت، یادگیری نیمهنظارتشده و یادگیری تقویتی دستهبندی میشوند. یادگیری عمیق، زیرمجموعهای از ML، شبکههای عصبی با لایههای زیاد (از این رو “عمیق”) را به کار میگیرد تا الگوهای پیچیده در دادهها را مدلسازی کند. این مدلها در بسیاری از کاربردها، از جمله تشخیص تصویر، پردازش زبان طبیعی (NLP) و رانندگی خودکار، به عملکردهای پیشرفته دست یافتهاند.
اهمیت بهینهسازی
الگوریتمهای بهینهسازی برای آموزش مدلها به طور مؤثر و کارآمد، ضروری هستند. آنها تعیین میکنند که چگونه پارامترهای مدل بر اساس دادهها و هدف یادگیری تنظیم شوند و به طور مستقیم بر دقت و سرعت همگرایی مدل تأثیر میگذارند. بدون تکنیکهای بهینهسازی مؤثر، آموزش مدلهای یادگیری عمیق، بهویژه آنهایی که دارای میلیونها یا میلیاردها پارامتر هستند، بهطور عملی بسیار کند یا حتی غیرممکن خواهد بود. علاوه بر این، مدلهای بهخوبی بهینهشده، بهتر میتوانند از دادههای آموزشی به دادههای تست که هنوز دیده نشدهاند تعمیم یابند که برای کاربردهای دنیای واقعی، جایی که مدلها باید بهطور قابل اعتماد در ورودیهای جدید و غیرقابل پیشبینی عمل کنند، بسیار مهم است. روشهای پیشرفته بهینهسازی در علم داده همچنین به کاهش مشکلاتی مانند بیشبرازش و کمبرازش کمک میکنند و اطمینان میدهند که مدلها مقاوم هستند و میتوانند انواع مختلف دادهها و نویزها را مدیریت کنند.
دامنه و اهداف مقاله
این مقاله به اهداف زیر میپردازد:
- ارائه مرور کاملی از تکنیکهای بهینهسازی در ML و DL.
- بحث در مورد مبانی ریاضی و پیادهسازی عملی الگوریتمهای بهینهسازی مختلف.
- برجسته کردن چالشها و راهحلهای بهینهسازی مدلهای یادگیری عمیق.
- ارائه مطالعات موردی و کاربردهای واقعی بهینهسازی در علم داده.
- بررسی جهتگیریهای آینده و روندهای نوظهور در بهینهسازی برای ML و DL.
مبانی بهینهسازی در علم داده
تعاریف و انواع مسائل بهینهسازی
مسائل بهینهسازی در علم داده به منظور حل وظایف یادگیری ماشین (ML) بسیار حیاتی هستند زیرا شامل تعیین پارامترهای (وزنهای) بهینهای هستند که تابع هدف را به حداقل یا حداکثر میرسانند. این فرآیند برای بهبود عملکرد و دقت مدلهای یادگیری ماشین ضروری است. مسائل بهینهسازی در علم داده به طور کلی به دو نوع تقسیم میشوند:
بهینهسازی محدب (Convex Optimization)
در این مسائل، تابع هدف محدب است، به این معنی که هر کمینه محلی نیز یک کمینه سراسرس در فضای مسئله است. این ویژگی فرآیند حل مسئله را سادهتر میکند زیرا کمینههای دیگری برای در نظر گرفتن وجود ندارند و حل و تحلیل این مسائل را آسانتر میسازد.
بهینهسازی غیرمحدب (Non-Convex Optimization)
برخلاف بهینهسازی محدب، بهینهسازی غیرمحدب با توابع هدفی سروکار دارد که ممکن است دارای چندین کمینه و بیشینه محلی باشند. این پیچیدگی فرآیند بهینهسازی را چالشبرانگیزتر میکند زیرا الگوریتم ممکن است در کمینههای محلی گیر کند و نتواند کمینه سراسری را بیابد. حل چنین مسائلی نیازمند بهکارگیری تکنیکها و روشهای پیشرفتهتر است.
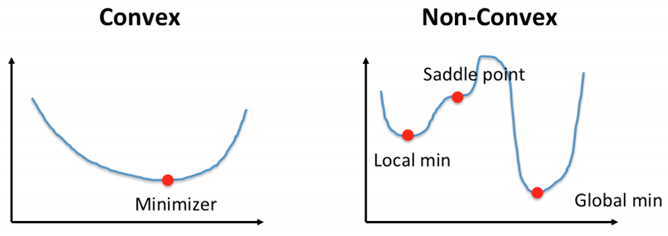
توابع هدف
یک تابع هدف، که اغلب به عنوان تابع زیان در ML شناخته میشود، خطای بین خروجیهای پیشبینی شده و خروجیهای واقعی را اندازهگیری میکند. توابع زیان رایج عبارتند از:
میانگین مربع خطا (MSE)
میانگین مربعات خطا (MSE) یک تابع هزینه معمول در وظایف رگرسیون است. این تابع میانگین مربعات خطاها را اندازهگیری میکند، که تفاوت بین مقادیر پیشبینی شده و واقعی است. به صورت ریاضی، به این شکل بیان میشود:

MSE کمتر نشاندهنده عملکرد بهتر مدل است زیرا نشان میدهد که مقادیر پیشبینی شده به مقادیر واقعی نزدیکتر هستند.
تابع هزینه کراس آنتروپی (Cross-Entropy)
تابع هزینه کراس-انتروپی، که به نام لاگ لاس نیز شناخته میشود، یک تابع هزینه است که عمدتاً در وظایف طبقهبندی، به ویژه در طبقهبندی دودویی و چندکلاسه استفاده میشود. این تابع عملکرد یک مدل طبقهبندی را که خروجی آن یک مقدار احتمالی بین 0 و 1 است، اندازهگیری میکند. تابع هزینه کراس-انتروپی برای یک مسئله طبقهبندی دودویی به این صورت تعریف میشود:
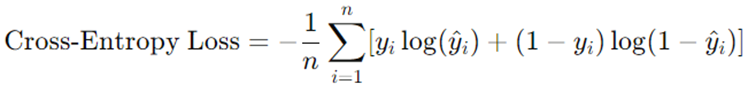
برای طبقهبندی چندکلاسه، فرمول بهگونهای گسترش مییابد که چندین کلاس را در نظر بگیرد. کراس-انتروپی کمتر نشاندهنده عملکرد بهتر مدل است زیرا نشاندهنده اطمینان بالاتر در پیشبینی کلاسهای صحیح است.
همچنین بخوانید: تابع هزینه یا Loss Function چیست؟ راهنمای جامع استفاده از توابع هزینه در ماشین لرنینگ
قیود و مناطق قابل قبول
قیود (محدودیتها) شرایطی را تعریف میکنند که راهحلها باید برآورده کنند. منطقه قابل قبول (شدنی) مجموعهای از تمام نقاطی است که این محدودیتها را برآورده میکنند. به طور ریاضی، یک مسئله بهینهسازی در علم داده میتواند به صورت زیر فرموله شود:
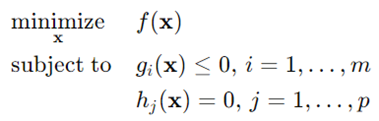
که f(x) تابع هدف، (x)gi محدودیت نامساوی و (x)hj محدودیت مساوی است.
الگوریتمهای بهینهسازی در یادگیری ماشین
گردایان کاهشی (Gradient Descent) و انواع آن
گرادیان کاهشی یک الگوریتم بهینهسازی مرتبه اول است که برای به حداقل رساندن تابع هزینه در مدلهای یادگیری ماشین استفاده میشود. این الگوریتم به صورت تکراری پارامترهای مدل را در جهت مخالف گرادیان تابع هزینه نسبت به پارامترها بهروزرسانی میکند.
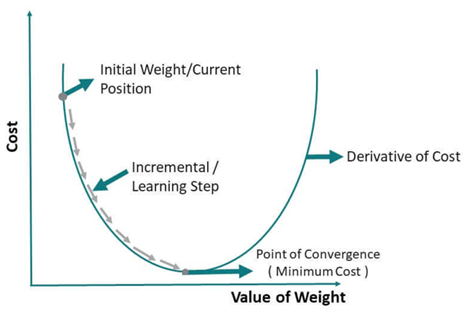
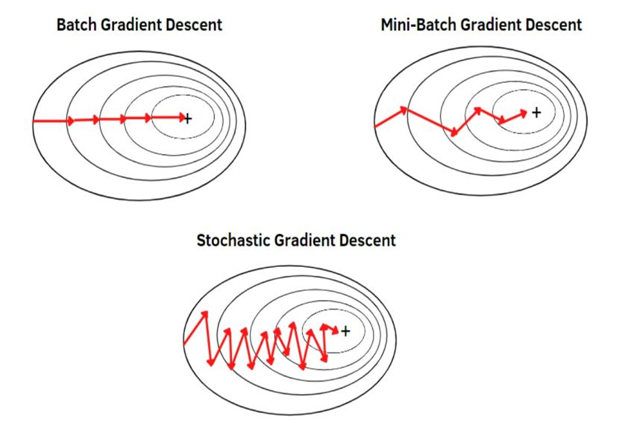
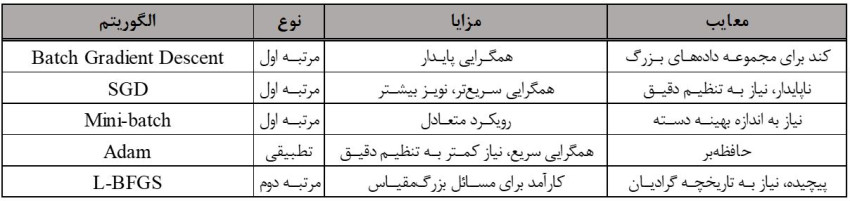
گرادیان کاهشی دستهای (Batch Gradient Descent)
گرادیان کاهشی دستهای گرادیان تابع هزینه را نسبت به کل مجموعه دادهها محاسبه میکند. این روش همگرایی پایدار و دقیقی را فراهم میکند اما میتواند برای مجموعه دادههای بزرگ از نظر محاسباتی گران باشد.
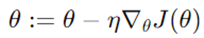
لذا میتوان گفت که گرادیان کاهشی دستهای، مشتق تابع زیان را با توجه به کل مجموعه دادهها محاسبه میکند. در رابطه فوق پارامتر (وزن) مدل میبایست پس از هر تکرار بهروز رسانی شود. مطابق این رابطه، نرخ یادگیری در تابع هزینه اثر گذارخواهد بود.
گرادیان کاهشی تصادفی (SGD)
گرادیان کاهشی تصادفی پارامترهای مدل را با استفاده از گرادیان محاسبه شده از یک نمونه آموزشی بهروزرسانی میکند. این روش با وجود اینکه سریعتر است و حافظه کمتری نیاز دارد، اما میتواند منجر به بهروزرسانیهای نویزی شود و ممکن است به طور هموار همگرا نشود.
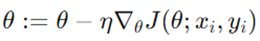
گرادیان کاهشی مینیبچ (Mini-batch Gradient Descent)
گرادیان کاهشی مینیبچ تعادلی بین گرادیان کاهشی دستهای و تصادفی ایجاد میکند. این امر با محاسبه گرادیان از زیرمجموعهای از دادههای آموزشی (مینیبچ) حاصل میشود. این روش همگرایی سریعتر و بهروزرسانیهای پایدارتر نسبت به SGD را فراهم میکند.
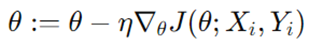
پس گرادیان کاهشی مینیبچ با استفاده از زیرمجموعهای از دادهها پارامترها را به روز میکند. در رابطه فوق Xi و Yi مینی بچهای دادهها هستند.
روشهای نرخ یادگیری تطبیقی
روشهای نرخ یادگیری تطبیقی نرخ یادگیری را در طول آموزش تنظیم میکنند، که این منجر به بهبود نرخهای همگرایی و پایداری مدل میشود. در ادامه سه نوع مشهور آنها را بیان میکنیم:
- AdaGrad
AdaGrad نرخ یادگیری را بر اساس گرادیانهای گذشته تنظیم میکند، بهروزرسانیهای بزرگتر برای پارامترهای نادر و بهروزرسانیهای کوچکتر برای پارامترهای مکرر فراهم میکند. این روش به ویژه برای دادههای پراکنده مفید است.

لذا میتوان گفت AdaGrad نرخ یادگیری را برای هر پارامتر تنظیم میکند که G در آن مجموع مربعات گرادیانهای گذشته است.
- RMSprop
RMSprop مشکل کاهش نرخ یادگیری AdaGrad را با استفاده از میانگین متحرک گرادیانهای مربعی برای نرمالسازی گرادیان حل میکند و همچنین نرخ یادگیری بیشتری را در طول آموزش حفظ میکند.
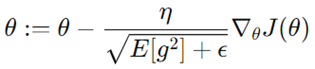
لذا طبق رابطه بالا میتوان گفت که RMSprop نرخ یادگیری را بر اساس میانگین متحرک گرادیانهای گذشته تنظیم میکند.
- Adam
Adam مزایای AdaGrad و RMSprop را با استفاده از میانگینهای متحرک هم از گرادیانها و هم از مربعات آنها ترکیب میکند. این روش به دلیل عملکرد کارآمد و تطبیقپذیریاش به طور گستردهای استفاده میشود.
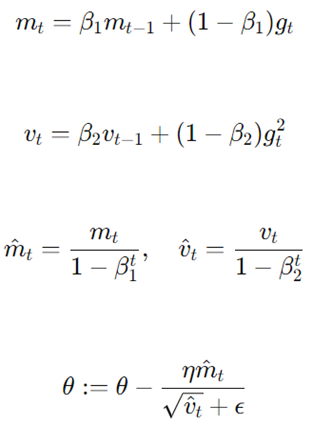
در ویدئو بالا گویهای سفید، سبز و آبی به ترتیب بیانگر بهینهسازهای RMSprop، AdaGrad و Adam هستند.
برای مطالعه بیشتر کلیک کنید: اهمیت نرخ یادگیری در یادگیری ماشین و یادگیری عمیق چیست؟
روشهای مرتبه دوم
روشهای مرتبه دوم از مشتقات مرتبه دوم (ماتریس هسین) برای بهینهسازی تابع هزینه استفاده میکنند و همگرایی سریعتری برای برخی مسائل فراهم میکنند. در ادامه به معرفی دو مورد از آنها میپردازیم:
روش نیوتن
روش نیوتن از ماتریس هسین برای یافتن نقاط ایستای یک تابع استفاده میکند. در حالی که سریع همگرا میشود، میتواند از نظر محاسباتی سنگین باشد و نیاز دارد که هسین معکوس پذیر باشد. لازم به ذکر است که روش نیوتن از بسط تیلور مرتبه دوم استفاده میکند.

در رابطه فوق H ماتریس هسین مشتقات دوم است.
روشهای شبهنیوتن (L-BFGS)
روشهای شبهنیوتن ماتریس هسین را تقریب میزنند و پیچیدگی محاسباتی را کاهش میدهند. L-BFGS (Limited-memory Broyden–Fletcher–Goldfarb–Shanno) یک روش محبوب است که به ویژه برای مسائل بهینهسازی در علم داده که دارای مقیاس بزرگ هستند، مفید است.
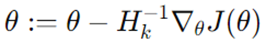
L-BFGS هسین را با استفاده از ارزیابی گرادیانها تقریب میزند. در رابطه فوق Hk تقریب از هسین است.
الگوریتمهای فراابتکاری
الگوریتمهای فراابتکاری برای حل مسائل بهینهسازی با کاوش در فضای مدل به طور گسترده عمل میکنند. از مهمترین مزایای آنها جلوگیری از کمینههای محلی است. در ادامه به معرفی سه روش مشهور در این زمینه میپردازیم:
الگوریتمهای ژنتیک
الگوریتمهای ژنتیک از انتخاب طبیعی و ژنتیک الهام گرفتهاند. آنها از عملیاتهایی مانند انتخاب، ترکیب و جهش برای تکامل جمعیت و گذر از راهحلهای مختلف به سمت راهحل بهینه استفاده میکنند.
بهینهسازی ازدحام ذرات (PSO)
بهینهسازی ازدحام ذرات رفتار اجتماعی پرندگان یا ماهیها را شبیهسازی میکند. هر ذره موقعیت خود را بر اساس تجربه خودش و تجربه ذرات همسایه تنظیم میکند و به سمت راهحل بهینه همگرا میشود.
Simulated Annealing
این روش از فرآیند بازپخت در متالورژی الهام گرفته شده است. این روش فضای راهحل را با پذیرش احتمالی راهحلهای بدتر در ابتدا کاوش میکند و به تدریج بر روی راهحلهای بهتر تمرکز میکند، که به آن اجازه میدهد از کمینههای محلی فرار کند.
همچنین بخوانید: عملکرد بهینه سازها در یادگیری عمیق چگونه است و کدامیک برای مدل شما بهتر است؟
بهینهسازی در یادگیری عمیق
چالشها در بهینهسازی یادگیری عمیق
بهینهسازی در علم داده و کاربرد آن در یادگیری عمیق به دلیل پیچیدگی شبکههای عصبی و ماهیت فرآیندهای آموزش آنها، چالشهای منحصر به فردی را ارائه میدهد. در ادامه به دو چالش متداول میپردازیم:
مدلهای غیرمحدب
مدلهای یادگیری عمیق اغلب دارای سطوح غیرمحدب هستند که دارای کمینههای محلی متعدد و نقاط زین اسبی هستند. نقاط زین اسبی نقاطی هستند که گرادیان صفر است، اما این نقاط حداقلهای محلی نیستند. پیچیدگی این سطوح بر ضرورت الگوریتمهای بهینهسازی قوی که قادر به پیمایش مؤثر در فضای غیرمحدب باشند، تأکید میکند.
محوشدگی یا انفجار گرادیانها
در شبکههای عمیق، گرادیانها میتوانند در طول پسانتشار به طور نمایی کاهش (محوشدگی) یا افزایش (انفجار) یابند، که منجر به همگرایی ضعیف و ناپایداری در فرآیند آموزش میشود. این مشکل به ویژه در شبکههای عصبی بازگشتی (RNNs) رایج است.
بهینهسازی شبکههای عصبی
الگوریتم پس انتشار (Backpropagation)
الگوریتم پسانتشار گرادیان تابع هزینه را نسبت به هر وزن در شبکه با استفاده از قانون مشتق زنجیرهای محاسبه میکند. این الگوریتم وزنها را به صورت تکراری بهروزرسانی میکند تا زیان را به حداقل برساند. این قاعده پایه و اساس آموزش شبکههای عصبی را تشکیل میدهد.
ویدئو بالا شماتیک عملیات پسانتشار در یک شبکه عصبی را نشان میدهد.
تکنیکهای Regularization
- L1- Regularization
این تکنیک قدر مطلق یا اندازه ضرایب را به عنوان یک عبارت جریمه به تابع زیان اضافه میکند:

این روش باعث کاهش تعداد پارامترهای مدل و جلوگیری از بیشبرازش میشود.
- L2-Regularization
این تکنیک مربع اندازه ضرایب را به عنوان یک عبارت جریمه به تابع زیان اضافه میکند:
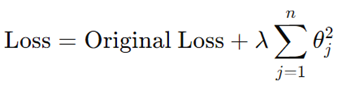
این روش از بزرگ شدن وزنها جلوگیری کرده و به تعمیم بهتر مدل کمک میکند.
- Dropout
Dropout به طور موقت یک زیرمجموعه تصادفی از نورونها را در طول آموزش حذف (صفر) میکند، که باعث میشود مدل به نورونهای خاصی وابسته نشود و از بیشبرازش جلوگیری شود.
تکنیکهای پیشرفته
نرمالسازی دستهای (Batch Normalization):
نرمالسازی دستهای ورودیهای هر لایه را نرمال میکند تا میانگین صفر و واریانس یک داشته باشند. این تثبیت به تسریع آموزش کمک کرده و مشکلاتی مانند گرادیانهای محو یا منفجر شونده را کاهش میدهد:
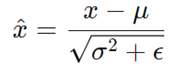
یادگیری انتقالی:
یادگیری انتقالی از مدلهای پیشآموزشدیده برای وظایف جدید استفاده میکند. با استفاده مجدد از مدلهای آموزشدیده بر روی مجموعه دادههای بزرگ، نیاز به دادههای گسترده و زمان آموزش کاهش مییابد و اغلب منجر به همگرایی سریعتر و عملکرد بهتر در وظیفه جدید میشود.
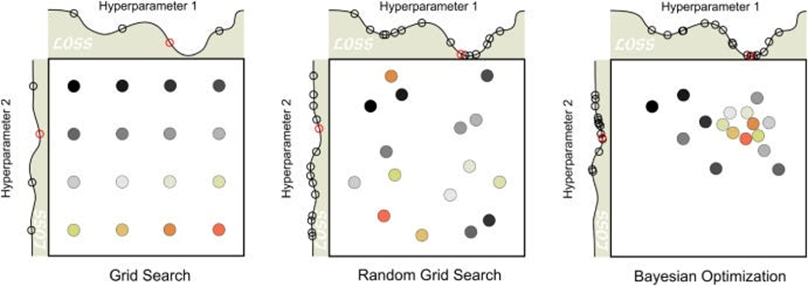
تنظیم هایپرپارامترها:
- جستجوی شبکهای (Grid Search): جستجوی جامع در فضای از پیش تعریف شده هایپرپارامترها، ارزیابی تمام ترکیبات ممکن برای یافتن بهترین تنظیمات.
- جستجوی تصادفی (Random Search): نمونهگیری تصادفی از ترکیبات مختلف هایپرپارامترها، ارائه یک اکتشاف کارآمدتر از فضای هایپرپارامترها نسبت به جستجوی شبکهای.
- بهینهسازی بیزی (Bayesian Optimization): مدلسازی عملکرد هایپرپارامترها و استفاده از این مدل برای هدایت جستجو جهت یافتن هایپرپارامترهای بهینه. این روش تعادل بین اکتشاف و بهرهبرداری برای یافتن تنظیمات با عملکرد بالا را به صورت کارآمد فراهم میکند.
مطالعات موردی و کاربردهای بهینهسازی در علم داده
بهینهسازی در بینایی ماشین
تکنیکهای بهینهسازی انقلابی در بینایی ماشین ایجاد کردهاند، که منجر به توسعه مدلهای با دقت بالا برای وظایف مختلف شدهاند. این وظایف شامل موارد زیر است:
- دستهبندی تصاویر: الگوریتمهای بهینهسازی به آموزش شبکههای عصبی عمیق کمک میکنند تا تصاویر را با دقت بالا به دستههای از پیش تعریف شده طبقهبندی کنند.
- تشخیص اشیا: تکنیکهایی مانند YOLO و SSD از بهینهسازی برای شناسایی و محلیسازی اشیا در یک تصویر به طور کارآمد استفاده میکنند.
- تقسیمبندی: بهینهسازی در وظایف طبقهبندی در سطح پیکسل، مانند تقسیمبندی معنایی و نمونهای، که در آن هر پیکسل یک تصویر به یک کلاس خاص طبقهبندی میشود، حیاتی است.
بهینهسازی پردازش زبان طبیعی (NLP)
در پردازش زبان طبیعی، بهینهسازی نقش حیاتی در بهبود عملکرد مدلها برای وظایف مختلف ایفا میکند، مانند:
- ترجمه زبان: الگوریتمهای بهینهسازی در علم داده دقت و روانی سیستمهای ترجمه ماشینی را بهبود میبخشند.
- تحلیل احساسات: تکنیکهای بهینهسازی طوری عملکرد مدلها را ارتقا میدهند تا بهتر احساسات دادههای متنی را درک و طبقهبندی کنند، که در وظایفی مانند استخراج نظرات و تحلیل رسانههای اجتماعی مفید است.
- تولید متن: بهینهسازی به تنظیم دقیق مدلها برای تولید متن منسجم و مرتبط با زمینه کمک میکند، که در برنامههایی مانند چتباتها و تولید محتوای خودکار استفاده میشود.
برای مطالعه بیشتر کلیک کنید: پردازش زبان طبیعی با پایتون چگونه انجام میشود و چه مراحلی دارد؟
بهینهسازی در یادگیری تقویتی
- الگوریتمهای بهینهسازی در علم داده در حوزه یادگیری تقویتی نیز حیاتی هستند، جایی که عوامل از طریق آزمون و خطا یاد میگیرند تا تصمیمات بهینه را بگیرند. کاربردهای کلیدی شامل موارد زیر است:
- بازیها: بهینهسازی به عوامل کمک میکند تا عملکردی فراتر از انسان در بازیهایی مانند Go، شطرنج و بازیهای ویدیویی داشته باشند.
- رباتیک: الگوریتمهای بهینهسازی به روباتها اجازه میدهند تا وظایف پیچیدهای مانند ناوبری، دستکاری و تعامل با محیط را یاد بگیرند و تطبیق یابند.
- وسایل نقلیه خودمختار: یادگیری تقویتی برای آموزش خودروهای خودران به تصمیمگیریهای ایمن و کارآمد به بهینهسازی متکی است.
بهینهسازی در دادههای پزشکی
تکنیکهای بهینهسازی در علم داده به طور قابل توجهی بر مراقبتهای بهداشتی تأثیر میگذارند، با بهبود مدلهای پیشبینی و فرآیندهای تصمیمگیری در چندین زمینه، از جمله:
- تشخیص بیماری: بهینهسازی دقت مدلهای تشخیصی را بهبود میبخشد و به تشخیص زودهنگام بیماریهایی مانند سرطان و بیماریهای قلبی کمک میکند.
- برنامهریزی درمان: الگوریتمهای بهینهسازی در توسعه برنامههای درمانی شخصیسازی شده، با در نظر گرفتن نیازها و شرایط خاص بیماران، کمک میکنند.
- مراقبت از بیماران: با بهینهسازی مدلهای پیشبینی، ارائهدهندگان مراقبتهای بهداشتی میتوانند نتایج فرآیند درمان بیماران را بهتر پیشبینی کنند و منجر به بهبود مراقبت و تخصیص منابع شوند.
ارزیابی تکنیکهای بهینهسازی
معیارهای عملکرد
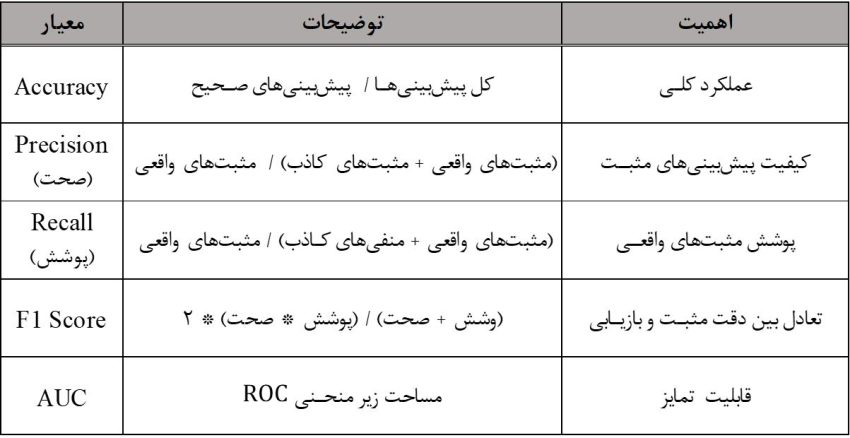
ارزیابی عملکرد تکنیکهای بهینهسازی در علم داده شامل استفاده از معیارهای گوناگون برای اندازهگیری جنبههای مختلف اثربخشی آنها است:
- دقت (Accuracy): نسبت پیشبینیهای صحیح به کل پیشبینیها، که یک اندازهگیری کلی از عملکرد را ارائه میدهد.
- صحت (Precision): نسبت پیشبینیهای مثبت درست به مجموع پیشبینیهای مثبت درست و مثبتهای کاذب، که کیفیت پیشبینیهای مثبت را نشان میدهد.
- درستی یا پوشش (Recall): نسبت پیشبینیهای مثبت درست به مجموع پیشبینیهای مثبت درست و منفیهای کاذب، که پوشش نمونههای مثبت واقعی را منعکس میکند.
- امتیاز F1: میانگین هارمونیک صحت و پوشش، که این دو معیار را متعادل میکند تا یک اندازهگیری عملکرد واحد را ارائه دهد.
- منطقه زیر منحنی (AUC): این معیار بیانگر ناحیه زیر نمودار مشخصه عملکرد (ROC) است که توانایی الگوریتم در تمایز بین کلاسها را اندازهگیری میکند.
برای وظایف رگرسیون، معیارهای اضافی شامل موارد زیر است:
- میانگین خطای مربعات (MSE): میانگین اختلاف مربعی بین مقادیر پیشبینی شده و واقعی، که دقت پیشبینی مدل را اندازهگیری میکند.
- میانگین خطای مطلق (MAE): میانگین اختلاف قدر مطلق بین مقادیر پیشبینی شده و واقعی، که یک اندازهگیری ساده از خطا ارائه میدهد.
- R-squared: نسبت واریانس در متغیر وابسته که توسط مدل توضیح داده میشود، که نشاندهنده تناسب خوب مدل است.
سرعت همگرایی
سرعت همگرایی الگوریتم بهینهسازی به یک راهحل، بسیار مهم است؛ به ویژه برای مسائل بزرگمقیاس. همگرایی سریعتر زمان و منابع محاسباتی را کاهش میدهد و امکان تکرار و تنظیمات سریعتر را فراهم میکند.
مقیاسپذیری و کارایی محاسباتی
الگوریتمهای بهینهسازی در علم داده به شرطی کارآمد هستند که با افزایش اندازه داده و پیچیدگی مدل به خوبی مقیاسپذیر باشند لذا میتوانند منابع محاسباتی مورد نیاز را به حداقل برسانند. مقیاسپذیری اطمینان حاصل میکند که الگوریتم با افزایش اندازه مسئله موثر باقی میماند.
مقاوم بودن و پایداری
الگوریتمهای قابل اعتماد در مجموعههای مختلف داده و تنظیمات گوناگون هایپرپارامترها به طور مداوم عمل میکنند و نتایج قابل اعتماد و پایدار را تضمین میکنند. پایداری برای کاربردهای عملی که شرایط و ورودیهای متنوعی رایج است، بسیار حیاتی است.
مسیرهای آینده در بهینهسازی برای ML و DL
روندهای پژوهشی در بهینهسازی
روندهای نوظهور در تحقیقات بهینهسازی، آینده یادگیری ماشینی و یادگیری عمیق را شکل میدهند. حوزههای کلیدی شامل موارد زیر است:
- توسعه الگوریتمهای بهینهسازی کارآمدتر: پژوهشگران به طور مداوم در حال ایجاد الگوریتمهایی هستند که بتوانند مشکلات بهینهسازی در علم داده را سریعتر و دقیقتر حل کنند، هزینههای محاسباتی را کاهش داده و عملکرد مدلها را بهبود بخشند.
- ادغام بهینهسازی با تکنیکهای دیگر هوش مصنوعی: ترکیب روشهای بهینهسازی با تکنیکهایی مانند یادگیری تقویتی، الگوریتمهای تکاملی و مدلهای احتمالی میتواند قابلیتهای سیستمهای هوش مصنوعی را افزایش دهد.
- کشف چارچوبهای ریاضی جدید: بررسی نظریهها و چارچوبهای ریاضی نوین میتواند به پیشرفتهای مهمی در حل مشکلات پیچیده بهینهسازی منجر شود.
بهینهسازی کوانتومی
محاسبات کوانتومی یک زمینه نوظهور است که پتانسیل انقلابی در بهینهسازی در علم داده را دارد. بهینهسازی کوانتومی از مکانیک کوانتومی برای حل مشکلات بهره میبرد که در قیاس با روشهای کلاسیک به شکل قابل توجهی از سرعت بیشتر برخوردار است. مزایای کلیدی شامل موارد زیر است:
- سرعت: الگوریتمهای کوانتومی میتوانند به طور بالقوه راهحلهایی در واحدهای زمانی گوناگون برای مشکلات پیدا میکنند که برای کامپیوترهای کلاسیک غیرقابل حل هستند.
- کارایی: بهینهسازی کوانتومی ممکن است راهحلهای کارآمدتری برای مشکلات بزرگمقیاس ارائه دهد و منابع محاسباتی مورد نیاز را به طور قابل توجهی کاهش دهد.
یادگیری فدرالی و بهینهسازی توزیعشده
یادگیری فدرالی و بهینهسازی توزیع شده فرآیند آموزش مدلها را با غیرمتمرکز کردن آن دگرگون میکنند. جنبههای کلیدی شامل موارد زیر است:
- یادگیری فدرالی: این رویکرد فرآیند آموزش را در میان دستگاههای مختلف با در نظر گرفتن اطمینان از حفظ حریم خصوصی دادهها و افزایش مقیاسپذیری توزیع میکند. هر دستگاه مدل محلی خود را با استفاده از دادههای خود آموزش میدهد و نتایج برای بهروزرسانی مدل سراسری تجمیع میشود.
- تکنیکهای بهینهسازی توزیع شده: این تکنیکها برای مدیریت ماهیت غیرمتمرکز یادگیری فدرالی بسیار حیاتی هستند و اطمینان از آموزش موثر و کارآمد مدلها در گرههای مختلف را فراهم میکنند.
ملاحظات اخلاقی و کاهش بایاس
با افزایش استفاده از سیستمهای هوش مصنوعی، پرداختن به ملاحظات اخلاقی و کاهش بایاس در فرآیندهای بهینهسازی ضروری است. این امر شامل موارد زیر میشود:
- عدالت: اطمینان از اینکه الگوریتمهای بهینهسازی بایاسهای موجود در دادهها را تقویت یا تشدید نمیکنند و منجر به نتایج عادلانه و منصفانه میشوند.
- شفافیت: این امر بیانگر شفافسازی فرآیندهای تصمیمگیری سیستمهای هوش مصنوعی برای ایجاد اعتماد و تسهیل پذیرش در کاربردهای دنیای واقعی است.
- پاسخگویی: این مورد اجرای مکانیسمهایی برای مسئولیتپذیری سیستمهای هوش مصنوعی برای اقدامات آنها، اطمینان از همخوانی با استانداردهای اخلاقی و ارزشهای اجتماعی را تبیین میکند.
جمعبندی
این مقاله به بررسی دقیق تکنیکهای بهینهسازی در علم داده پرداخته است. حوزههای کلیدی که پوشش داده شدهاند شامل موارد زیر است:
- مفاهیم بنیادی: درک کامل اصول بهینهسازی، از جمله بهینهسازی محدب و غیرمحدب و ارتباط آنها با ML و DL.
- الگوریتمها: بررسی عمیق الگوریتمهای بهینهسازی در علم داده مانند گرادیان کاهشی و انواع مختلف آن، روشهای مرتبه دوم و الگوریتمهای فراابتکاری.
- چالشها: بحث در مورد چالشهای رایج در بهینهسازی مانند فضاهای غیرمحدب، محو شدن و انفجار گرادیانها و نیاز به استراتژیهای بهینهسازی قوی در یادگیری عمیق.
- تکنیکهای پیشرفته: بررسی تکنیکهای پیشرفته بهینهسازی شامل نرخهای یادگیری تطبیقی، نرمالسازی دستهای، یادگیری انتقالی و تنظیم هایپرپارامترها.
بهینهسازی در موفقیت مدلهای ML و DL دارای نقش محوری است و به طور مستقیم بر عملکرد، کارایی و قابلیت اعمال آنها در حوزههای مختلف تاثیر میگذارد. تکنیکهای بهینهسازی موثر میتواند منجر به توسعه مدلهای دقیق و مقیاسپذیر شود که میتوانند مشکلات پیچیده دنیای واقعی را حل کنند. تحقیقات آینده باید بر توسعه تکنیکهای بهینهسازی قویتر، کارآمدتر و اخلاقیتر متمرکز شود تا نیازهای روزافزون کاربردهای هوش مصنوعی را برآورده کند. با پیشرفت در تکنیکهای بهینهسازی، پژوهشگران و فعالان میتوانند امکانهای جدیدی را در یادگیری ماشینی و یادگیری عمیق کشف کنند و راه را برای سیستمهای هوش مصنوعی هوشمندتر و توانمندتر هموار کنند.

پرسشهای متداول
تفاوتهای کلیدی بین مسائل بهینهسازی محدب و غیرمحدب در ML چیست؟
مسائل بهینهسازی محدب دارای توابع هدفی هستند که هر کمینه محلی، کمینه سراسری نیز میباشد و بنابراین حل و تحلیل آنها آسانتر است. در مقابل، مسائل بهینهسازی غیرمحدب ممکن است دارای چندین کمینه محلی باشند که فرآیند بهینهسازی را به دلیل پیچیدگی سطوح و فضای حل چالشبرانگیز میسازد.
چرا از خطای میانگین مربعات (MSE) در وظایف رگرسیون استفاده میشود؟
خطای میانگین مربعات (MSE) در وظایف رگرسیون استفاده میشود زیرا میانگین مربعات خطاهای بین مقادیر پیشبینیشده و واقعی را اندازهگیری میکند و نشاندهنده دقت پیشبینی است. MSE خطاهای بزرگتر را به شدت بیشتری جریمه میکند و آن را نسبت به نقاط پرت حساس میسازد و برای به حداقل رساندن انحرافات بزرگ در پیشبینیها مفید است.
بهینهساز Adam با روشهای گرادیان کاهشی چه تفاوتی دارد؟
بهینهساز Adam ترکیبی از مزایای دو بهینه ساز دیگر، یعنی AdaGrad و RMSprop است که با استفاده از هم مومنتوم و هم نرخهای یادگیری تطبیقی عمل میکند. این الگوریتم، نرخهای یادگیری تطبیقی را برای پارامترهای مختلف محاسبه میکند و نسبت به گرادیان کاهشی استاندارد، به ویژه در مدلهای یادگیری عمیق، سریعتر همگرا میشود.
چالشهای اصلی در بهینهسازی مدلهای یادگیری عمیق چیست؟
چالشهای اصلی شامل سطوح غیرمحدب با چندین کمینه محلی و نقاط زین اسبی، و مسائلی مانند محو شدن و انفجار گرادیانهاست که آموزش مؤثر را مختل میکنند. تکنیکهای پیشرفته مانند تنظیم دقیق وزنهای اولیه، روشهای نرمالسازی و بهینهسازهای تخصصی برای رفع این چالشها مورد نیاز است.
یادگیری فدرالی چگونه حفظ حریم خصوصی دادهها و مقیاسپذیری را بهبود میبخشد؟
یادگیری فدرالی حفظ حریم خصوصی دادهها را با غیرمتمرکز کردن فرآیند آموزش مدل در بین دستگاههای مختلف بهبود میبخشد، هر یک با استفاده از دادههای محلی خود. این رویکرد از به اشتراکگذاری مرکزی دادهها جلوگیری کرده و بنابراین حریم خصوصی را حفظ میکند. همچنین با توزیع بار محاسباتی، مقیاسپذیری را بهبود میبخشد و امکان استفاده از مجموعه دادههای بزرگ و متنوع را بدون جمعآوری مرکزی فراهم میکند.
یادگیری ماشین لرنینگ را از امروز شروع کنید!
دنیای دادهها جذاب است و دانستن علم داده، توانایی تحلیل داده، یا بازاریابی مبتنی بر داده، شما را برای فرصتهای شغلی بسیاری مناسب میکند. فارغ از رشته و پیشزمینه، میتوانید حالا شروع کنید و از سطح مقدماتی تا پیشرفته بیاموزید. اگر دوست دارید به این حوزه وارد شوید، پیشنهاد میکنیم با کلیک روی این لینک قدم اول را همین حالا بردارید.
مشاوران کافهتدریس به شما کمک میکنند مسیر یادگیری برای ورود به این حوزه را شروع کنید: