

رگرسیون خطی (Linear Regression) روشی آماری برای یافتن رابطهی میان متغیرهای مستقل (Dependent Variables)و وابسته (Independent Variables)است. این روش در یادگیری ماشین با ناظر (Supervised Machine Learning) بسیار کاربرد دارد.

مقدمه
اخیراً هوش مصنوعی (Artificial Intelligence) بسیار مورد توجه قرار گرفته است و افراد در حوزههای مختلف سعی میکنند از هوش مصنوعی استفاده کنند تا کارهایشان بسیار راحتتر پیش رود؛ برای مثال، اقتصاددانان از هوش مصنوعی برای پیشبینی قیمت بازار در آینده برای کسب سود استفاده میکنند، پزشکان از هوش مصنوعی برای طبقهبندی بدخیم یا خوشخیمبودن تومور استفاده میکنند، هواشناسان برای پیشبینی آبوهوا از هوش مصنوعی استفاده میکنند، استخدامکنندگان منابع انسانی از هوش مصنوعی برای بررسی و تأیید و رد رزومهی متقاضیان استفاده میکنند.
برای آشنایی با هوش مصنوعی این مطلب را مطالعه کنید:
هوش مصنوعی چیست و چه کاربردهایی دارد؟
محرکی که در پشت پردهی چنین استفادهی همهگیری از هوش مصنوعی وجود دارد الگوریتمهای یادگیری ماشین (Machine Learning) است. الگوریتم سادهای که همهی علاقهمندان به یادگیری ماشین، یادگیری خود را با آن شروع میکنند الگوریتم رگرسیون خطی (Linear Regression) است. در این مطلب قصد داریم با این الگوریتم بیشتر آشنا شویم و ببینیم چطور کار میکند.
برای آشنایی با یادگیری ماشین این مطلب را مطالعه کنید:
یادگیری ماشین (Machine Learning) چیست و چگونه کار میکند؟
رگرسیون چیست؟
رگرسیون (Regression) نوعی تکنیک مدلسازی پیشبینی (Predictive Modelling) است که رابطهی میان یک متغیر وابسته و مستقل را بررسی میکند.
این تعریف درواقع تعریفی کتابی است؛ اگر بخواهیم سادهتر بگوییم، میتوانیم رگرسیون را اینگونه تعریف کنیم: «یافتن بهترین خط مناسب یا معادلهی رگرسیون با استفاده از رابطهی میان متغیرها که میتواند برای پیشبینی استفاده شود.»
انواع مختلفی از رگرسیون، مانند رگرسیون خطی (Linear Regression)، رگرسیون چندجملهای (Polynomial Regression) و رگرسیون لجستیک (Logistic Regression)، وجود دارد. در ادامه میخواهیم رگرسیون خطی را بررسی کنیم.
رگرسیون خطی (Linear Regression) چیست؟
رگرسیون خطی نوعی تجزیهوتحلیل اولیه و متداول است که معمولاً روی دادههای پیوسته کار میکند. در این رگرسیون ما قصد داریم بهترین خطی را که با نقاط دادههای موجود تناسب دارد انتخاب کنیم. درواقع میخواهیم بهترین معادلهی خطی را برای دادههای مدنظر داشته باشیم تا با استفاده از آن معادله بتوانیم خروجی مدنظر برای دادهی جدید را پیشبینی کنیم.
رگرسیون خطی ساده نوعی تحلیل رگرسیون است که در آن تعداد متغیرهای مستقل یک است و بین متغیر مستقل (x) و وابسته (y) رابطهی خطی وجود دارد؛ البته رگرسیون خطی چندمتغیره هم داریم که در آن تعداد متغیرهای مستقل بیشتر از یک است.
یک مثال: رگرسیون خطی (Linear Regression) و سابقهی کاری و حقوق
برای درک بهتر موضوع بهتر است با هم مثالی را بررسی کنیم: بیایید این مجموعهداده را با هم در نظر بگیریم. در جدول دادههای مربوط به سابقهی کاری یا همان سالهای تجربهی کاری و حقوقی که شخص بهازای سابقهی کاریاش میگیرد مشخص شده است. در این مثال ستون سالهای تجربه، متغیر مستقل و مقادیر ستون حقوق (واحد آن ۱۰۰۰ دلار است) متغیرهای وابسته هستند؛ اما چرا حقوق متغیر وابسته است؟ چون میتوانیم براساس سالهای تجربه، مقدار ستون حقوق (متغیرهای وابسته) را تعیین یا پیشبینی کنیم. اگر به دادهها نگاه کنیم، میبینیم که مقادیر ستون وابسته (حقوق) براساس سالهای تجربه افزایش یا کاهش مییابد؛ یعنی وقتی فردی سالهای بیشتری تجربه کاری داشته باشد، حقوق بیشتری دریافت کنیم و اگر سالهای کمتری تجربه داشته باشد، حقوقش هم کمتر خواهد بود.
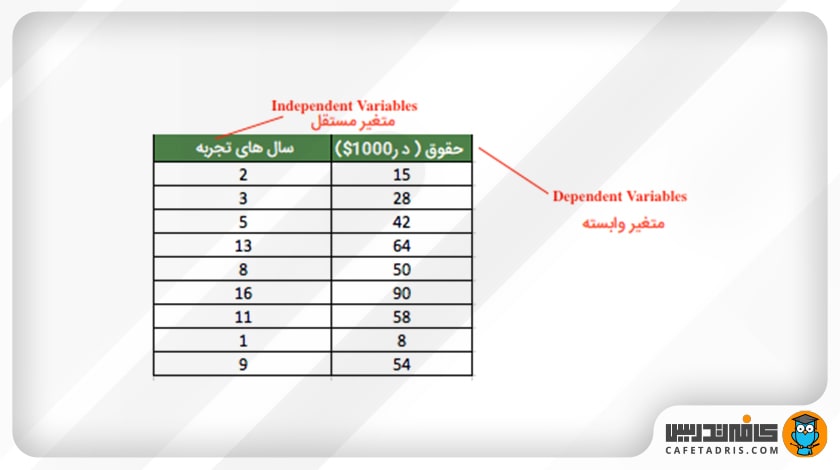
حال اگر این دادهها را در فضای ویژگی به نمایش بگذاریم، میبینیم که این دادهها تقریباً بهصورت یک خط در فضا قرار دارند.
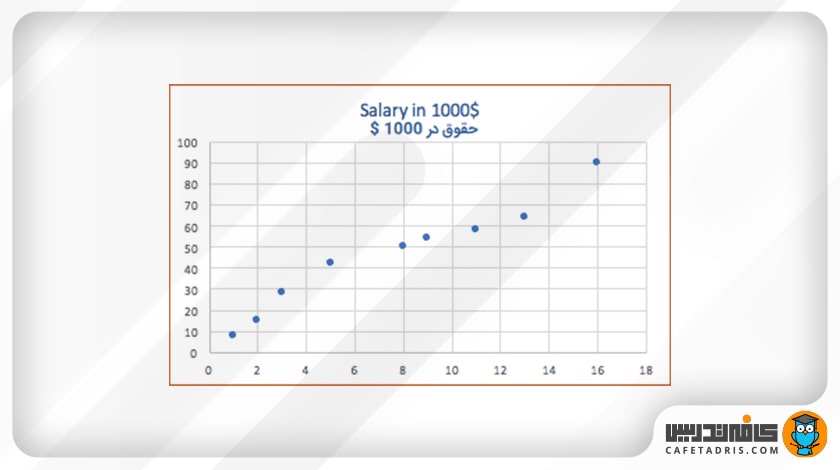
ما باید آن خطی را پیدا کنیم که بهبهترین شکل این دادهها را به نمایش میگذارد. درواقع این هدفی است که در رگرسیون خطی دنبال میکنیم.
بیایید ببینیم مراحل انجامدادن آن به چه شکل است.
مراحل رگرسیون خطی
رگرسیون خطی با رگرسیون خطی (Linear Regression) چند مرحله را شامل است:
- مقداردهی تصادفی پارامترها برای تابع فرضی؛ یعنی درواقع ابتدا یک معادلهی خطی با مقادیر رندوم را در نظر میگیریم.
- محاسبهی خطا با استفاده از یک تابع زیان (Cost Function) که در آن میبینیم خطی که بهصورت فرضی در نظر گرفتیم، چقدر با مقادیر واقعی فاصله دارد.
- در این مرحله لازم است پارامترها را با توجه به مشتقات جزئی و نرخ یادگیری بهروزرسانی کنیم که درواقع این کار را الگوریتم گرادیان نزولی (Gradient Descent) انجام میدهد.
- تکرار این روند تا بهحداقلرسیدن مقدار خطا.
همانطور که توضیح دادیم، هدف از رگرسیون خطی رسیدن به یک معادلهی خطی مناسب با کمترین خطاست. این معادله را میتوان بهاین شکل نشان داد:
y = mx + b
که در این معادله:
«m» شیب
«x» متغیر مستقل
«b» اینترسپت (Intercept) یا مقدار ثابت
«y» متغیر وابسته است.
دو پارامتر شیب (m) و مقدار ثابت (b) در این معادله در ابتدا بهصورت رندوم در نظر گرفته میشوند تا طبق مراحلی که توضیح داده شد، بهبهترین مقدار ممکن برسند.
همانطور که در مراحل رگرسیون خطی دیدیم، بعد از اینکه یک معادلهی خطی با پارامترهای رندوم ایجاد شد، لازم است با استفاده از تابع زیان (Cost Function) خطای موجود را به دست آوریم. در بخش بعد به یکی از معروفترین توابع زیان اشاره خواهیم کرد.
تابع زیان
بیایید بار دیگر مثالمان را در نظر بگیریم. بهمنظور بهدستآوردن بهترین خط میان نقاط موجود در دادهها، میتوانیم از معیاری بهنام «مجموع خطای مربع» (SSE/ Sum of Squared Error) استفاده کنیم تا با کاهش خطا بهترین تناسب را بیابیم. خطا مجموع تفاوت میان مقدار واقعی و مقدار پیشبینی شده است.
توابع زیان مختلفی برای محاسبهی خطا وجود دارد که ما در اینجا تابع SSE را بررسی میکنیم.
برای یافتن خطا باید از این فرمول استفاده کنیم.

بیایید فرض کنیم مقادیر رندومی که برای دو پارامتر شیب (m) و مقدار ثابت (b) در نظر گرفته شده بهاین صورت است:
y = 4.79x + 9.18
حال ما میخواهیم با استفاده از تابع زیان SSE مقدار خطای این معادله را بررسی کنیم:
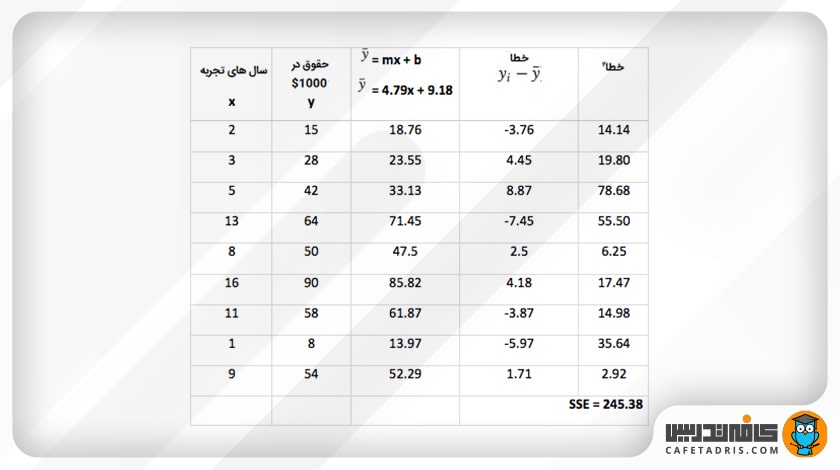
میبینیم که مقدار خطای SSE برابر با ۲۴۵/۳۸ است. طبق مراحل رگرسیون خطی ما باید بعد از مشخصکردن مقدار خطا، لازم است با استفاده از الگوریتم گرادیان نزولی (Gradient Descent) مقدار پارامترهای معادله را بهروزرسانی کنیم تا مقدار خطا کم شود و به خطی که بهبهترین شکل دادهها را به نمایش میگذارد بیشتر نزدیک شویم.
الگوریتم گرادیان نزولی
مفهوم مهم بعدی موردنیاز برای درک رگرسیون خطی گرادیان نزولی (Gradient Descent) است. گرادیان نزولی یک روش بهروزرسانی پارامترها برای کاهش تابع زیان است. همانطور که قبلاً هم اشاره کردیم، ما با مقادیر رندوم شروع میکنیم و سپس این مقادیر را بهطور مکرر تغییر میدهیم تا خطا کاهش یابد. گرادیان نزولی به ما در نحوهی تغییر مقدار این پارامترها کمک میکند.
برای درک بهتر، بیایید گودالی را بهشکل U تصور کنیم که در بالاترین نقطهی گودال ایستادهایم و هدف ما رسیدن به پایین گودال است، اما یک مشکل وجود دارد، آنهم این است که فقط میتوانید تعداد مشخصی گام جداگانه برای رسیدن به پایین گودال برداریم. اگر تصمیم بگیریم گامبهگام جلو برویم، درنهایت به انتهای گودال میرسیم، اما مدتزمان بیشتری طول میکشد. اگر هر بار قدمهای بلندتری برداریم، زودتر به آن میرسیم، اما این احتمال وجود دارد که از انتهای گودال فراتر برویم و از آن رد شویم. در الگوریتم گرادیان نزولی، تعداد گامهایی که برمیداریم برای رسیدن به خطای حداقل، نرخ یادگیری نامیده میشود. این مقدار تعیین میکند که الگوریتم با چه سرعتی به حداقل خطا برسد.

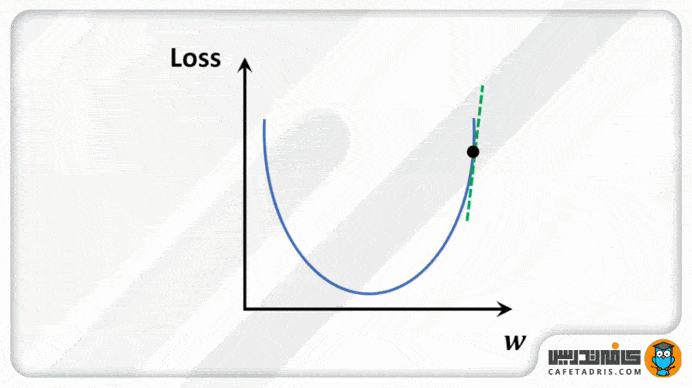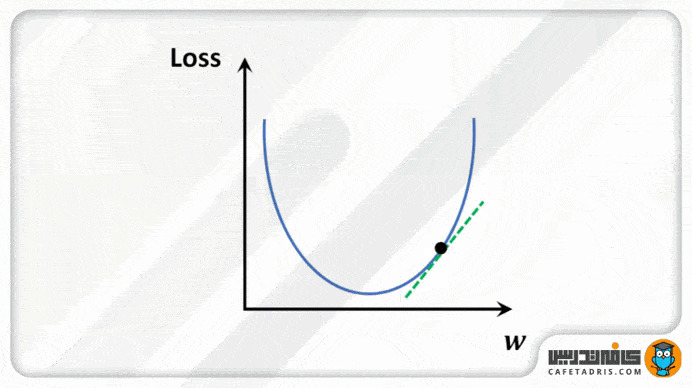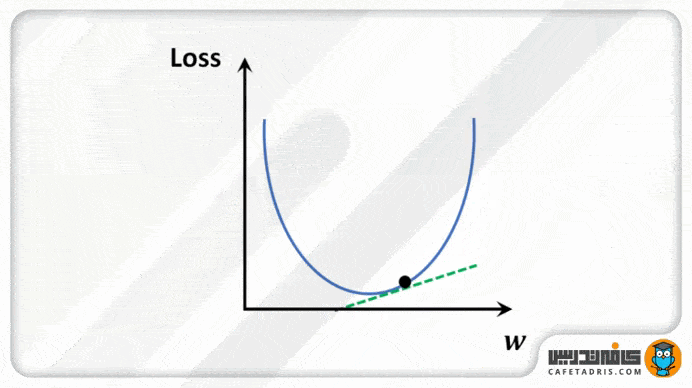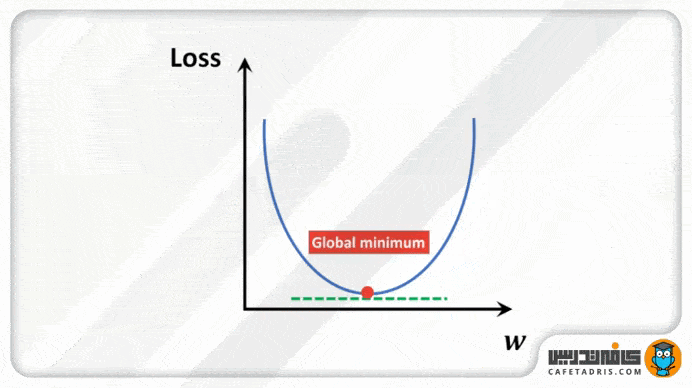
طرز کار با گرادیان نزولی برای بهروزرسانی پارامترهای معادله
شاید برایتان این سوال پیش آمده باشد که چگونه میتوان از گرادیان نزولی برای بهروزرسانی پارامترهای معادله استفاده کرد. برای بهروزرسانی پارامترها، گرادیان تابع زیان را محاسبه میکنیم. برای یافتن این گرادیان مشتقات جزئی را نسبت به دو پارامتر شیب و اینترسپت (Intercept) محاسبه میکنیم.
حال بیایید در نظر بگیریم که تابع زیان ما خطای میانگین مربع (MSE / Mean Squared Error) است. این تابع یکی دیگر از معروفترین توابع زیانی است که برای رگرسیون خطی استفاده میشود. در این تابع ما مربع اختلاف خطا را برای تمامی نقاط داده محاسبه میکنیم؛ سپس این مقادیر را با هم جمع و آن مقدار را بر تعداد کل نقاط داده تقسیم میکنیم. فرمول این تابع بهاین شکل است:

حال باید مشتق جزئی این تابع را در نسبت با پارامترهای معادلهی خطی به دست آوریم. این معادلهی خطی ماست:
y = a0 + a1 x
طبق فرمول تابع زیان (MSE)، مشتق جزئی این تابع در نسبت با دو پارامتر a0 و a1 بهاین شکل محاسبه میشود:

محاسبهی این مشتقات جزئی به دانش آمار و ریاضی نیاز دارد.
بعد از محاسبهی مشتقات جزئی، حال باید مقدار این دو پارامتر را با توجه به مشتقها بهروزرسانی کنیم:

مشتقات جزئی درواقع همان گرادیان هستند و از آنها برای بهروزرسانی مقادیر a0 و a_1 استفاده میشود. آلفا (α) نرخ یادگیری است که پیشتر دربارهی آن صحبت کردیم. Predi درواقع همان معادلهی خطی است که در هر مرحله پیشبینی میکنیم که با معادله قبلی مقایسه میشود.
مراحل رگرسیون چندین بار تکرار میشود تا درنهایت به کمترین خطای ممکن یا همان انتهاب گودال برسیم.
قسمتی از جزوه کلاس برای تدریس رگرسیون خطی
دوره جامع دیتا ساینس و ماشین لرنینگ


رگرسیون خطی در پایتون

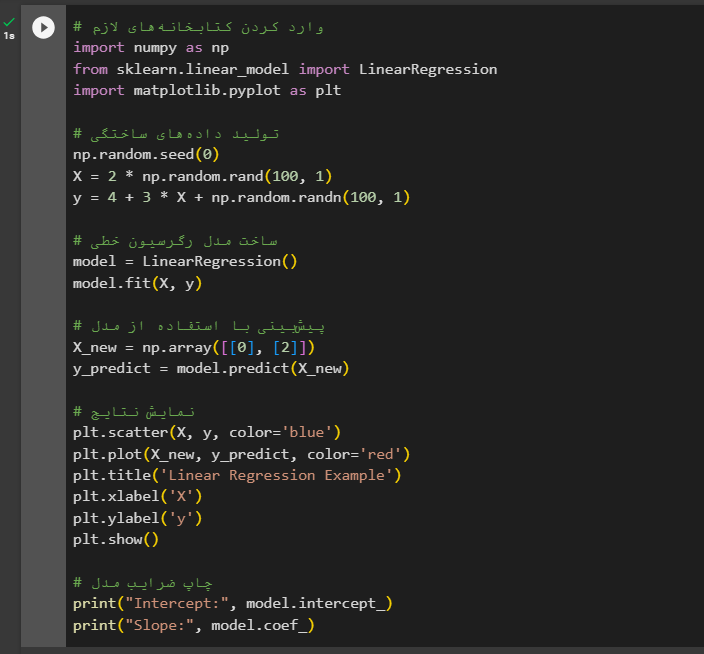
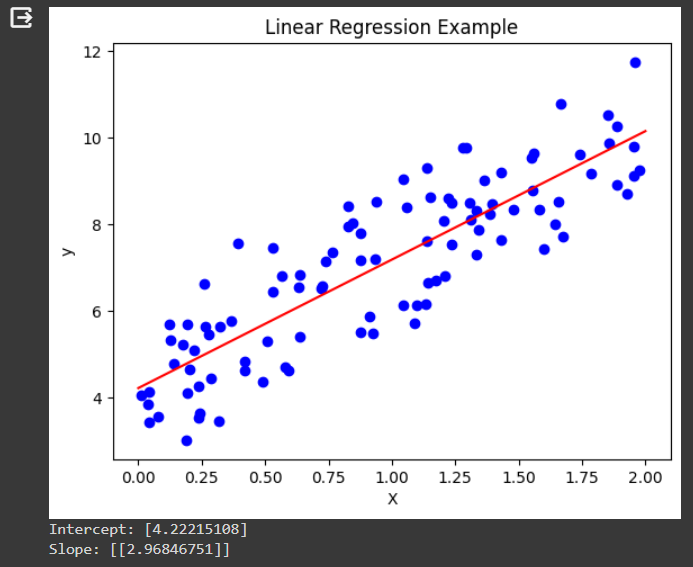
این قطعه کد یک نمونه ساده از رگرسیون خطی در پایتون است که با استفاده از کتابخانههای numpy برای تولید دادههای ساختگی، sklearn برای ایجاد و آموزش مدل رگرسیون، و matplotlib برای نمایش نتایج اجرا میشود. ابتدا دادههای تصادفی تولید میشوند و سپس یک مدل رگرسیون خطی با استفاده از این دادهها آموزش داده میشود. مدل برای پیشبینی مقادیر برای نمونههای جدید استفاده میشود و نتایج در یک نمودار نمایش داده میشوند که نشاندهنده تطابق خط رگرسیون با دادههای واقعی است. در نهایت، ضرایب مدل، یعنی شیب و عرض از مبدأ، چاپ میشوند که نشاندهنده رابطه خطی بین متغیرهای مستقل و وابسته است. در ادامه خروجی این مدل قابل مشاهد است.

جمعبندی مطالب دربارهی رگرسیون خطی (Linear Regression)
در این مطلب یکی از سادهترین الگوریتمهای یادگیری ماشین با ناظر یعنی رگرسیون خطی (Linear Regression) را معرفی کردیم. رگرسیون خطی الگوریتمی است که همهی علاقهمندان به یادگیری ماشین باید بدانند و همچنین مبدأ مناسبی برای شروع افرادی است که میخواهند یادگیری ماشین را بیاموزند. رگرسیون خطی یک الگوریتم ساده اما مفید است که در مواردی که میخواهیم کمیتی را براساس فاکتورهایی که میتوانند با یک خط مستقیم توصیف شوند، پیشبینی کنیم استفاده میشود.