

شبکه عصبی رزنت (ResNet) یکی از پیشرفتهترین معماریهای شبکه عصبی عمیق است که توسط تیمی از محققان شرکت مایکروسافت یعنی شِیوکینگ رن (Shaoqing Ren)، کِیمینگ هی (Kaiming He)، ژان سان (Jian Sun) و زایانگیا ژوئنگ (Xiangyu Zhang) در سال ۲۰۱۵ معرفی شد. این معماری با بهرهگیری از واحدهای باقیمانده (Residual Blocks) و اتصالات کوتاه (Skip Connections) توانسته است چالشهای مرتبط با افزایش عمق شبکههای عصبی، به ویژه مشکل ناپدید شدن گرادیانها (Vanishing Gradient) را حل کند. شبکه عصبی رزنت در رقابت ImageNet 2015 با عملکرد برجسته خود توانست ضمن برنده شدن در مسابقه ImageNet 2015، رکوردهای این عرصه را نیز جابجا کند. در این مقاله، به بررسی جزئیات معماری رزنت و نحوه عملکرد آن در بهبود کارایی شبکههای عصبی عمیق میپردازیم.
- 1. مشکلات ناشی از افزایش تعداد لایهها
- 2. ResNet چگونه مشکل محو شدن گرادیان را حل میکند؟
- 3. نحوه حل مشکل عدم برابری ابعاد ورودی و خروجی یک واحد باقیمانده ResNet
- 4. پیادهسازی واحد باقیمانده در پایتون
- 5. بررسی تاثیر استفاده از واحدهای باقیمانده
- 6. مقایسه روش Identity Shortcut و Projection Shortcut
- 7. طراحی یک واحد باقیمانده بهینهتر
- 8. اتصالات کوتاه (Skip Connections) چطور به افزایش کارایی مدل کمک میکنند؟
- 9. جمعبندی
-
10.
پرسشهای متداول
- 10.1. رزنت (ResNet) چگونه به حل مشکل ناپدید شدن گرادیان در شبکههای عمیق کمک میکند؟
- 10.2. چه تفاوتی بین اتصالات کوتاه در معماری معماری شبکه عصبی رزنت (ResNet) و معماریهای شبکهی پیشین وجود دارد؟
- 10.3. نقش واحدهای باقیمانده (Residual Blocks) در بهبود دقت شبکههای عمیق چیست؟
- 10.4. چگونه میتوان کارایی مدلهای رزنت (ResNet) را در کاربردهای واقعی مانند شناسایی تصویر بهینه سازی کرد؟
- 10.5. آیا معماری رزنت (ResNet) در حوزههای دیگر غیر از شناسایی تصویر کاربرد دارد؟ چه تأثیراتی میتواند داشته باشد؟
- 11. یادگیری تحلیل داده را از امروز شروع کنید!

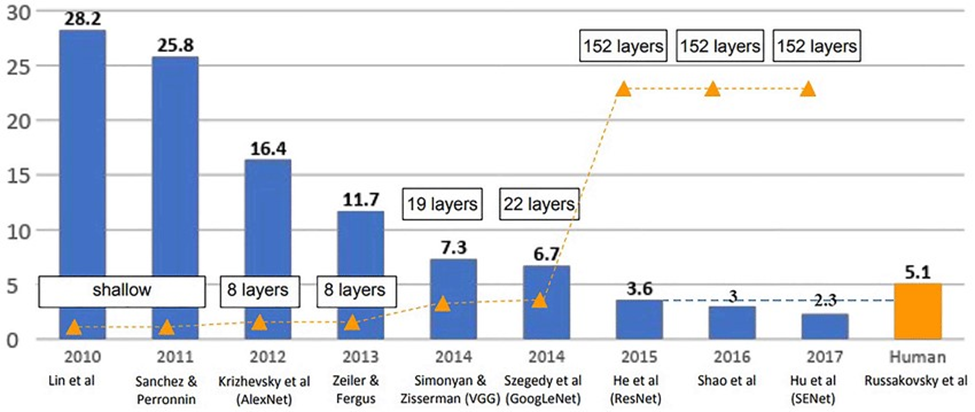
همانطور که در عکس بالا مشهود است، معماری ResNet علاوه بر کسب خطای کمتر در این رقابت، از تعداد لایههای بسیار بیشتری برخوردار است. سوال اصلی اینجاست که چرا هیچ یک از شرکتکنندگان قبلی، تعداد لایههای معماری شبکه عصبی خود را تا این حد بالا نبرده بودند؟ آیا آنها نمیدانستند که با بیشتر کردن تعداد لایهها، ظرفیت یادگیری مدل نیز افزایش یافته و به دنبال آن دقت بالاتری کسب خواهند کرد؟ این سوالی است که در این مطلب میتوانید پاسخ آن را بیابید.
مشکلات ناشی از افزایش تعداد لایهها
ماجرا از این قرار است که افزایش تعداد لایهها در یک شبکه عصبی لزوما باعث دستیابی به نتیجه بهتر نخواهد شد چرا که با افزایش عمق شبکه، مشکلاتی مانند ناپدید شدن و انفجار گرادیان (Vanishing and Exploding Gradient) میتوانند فرآیند آموزش را دشوار کنند.

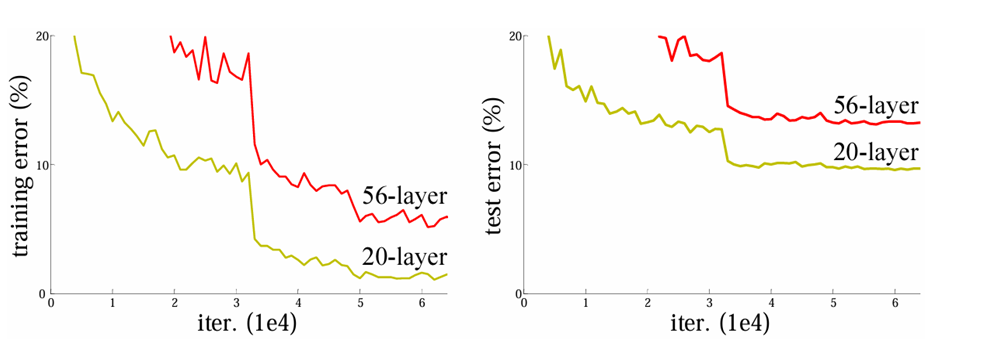
شکل بالا نتیجه آزمایشی را نشان میدهد که در مقاله ResNet برای اثبات این موضوع آورده شده است. همانطور که پیدا است، افزایش تعداد لایههای مدل از ۲۰ به ۵۶، نهتنها باعث کاهش خطا نشده، بلکه آن را افزایش نیز داده است. نکته دیگری که باید به آن اشاره کرد این است که خطای مدل ۵۶ لایه نسبت به ۲۰ لایه در هر دو فاز آموزش (Training) و ارزیابی (Test) بیشتر است و این یعنی مشکل اصلا بیشبرازش (Overfitting) نیست چرا که در آن صورت باید در فاز آموزش عملکرد بهتر و در فاز ارزیابی عملکرد ضعیفتری را مشاهده میکردیم.
معماری شبکه عصبی رزنت به عنوان یک رویکرد نوآورانه برای کاهش مشکلات ناشی از افزایش عمق شبکههای عصبی معرفی شده است. ResNet با استفاده از واحدهای باقیمانده (Residual Blocks) که شامل اتصالات کوتاه (Skip Connections) هستند، این مشکل را حل میکند. این اتصالات به گرادیانها اجازه میدهند تا بدون کاهش شدت در شبکه پخش شوند و از این طریق، امکان آموزش شبکههای بسیار عمیقتر را فراهم کنند.


ResNet چگونه مشکل محو شدن گرادیان را حل میکند؟
بیایید با یک مثال قابل درک شروع کنیم. فرض کنید که شما در حال حل یک مسئله پیچیده هستید. یکی از استراتژیها میتواند تقسیم کردن این مسئله به بخشهای کوچکتر، حل هر بخش و سپس ترکیب تمام راه حلهای کوچک برای به دست آوردن جواب نهایی باشد. حالا، اگر یکی از بخشهای کوچک از پیش حل شده باشد چه؟ به جای حل مجدد آن، شما سادهتر آن را جلو میبرید.
در شبکههای عصبی عمیق، بخصوص بدون اتصالات کوتاه (Skip Connections)، هر لایه سعی میکند داده ورودی خود را به نمایشی کمی انتزاعیتر و ترکیبیتر تبدیل کند. با افزودن لایههای بیشتر، توانایی شبکه برای تغییر دادهها افزایش مییابد، اما همانطور که گفتیم دشواری آموزش شبکه به دلیل مشکلاتی نظیر ناپدید شدن گرادیانها افزایش مییابد.
اتصالات کوتاه به لایههای شبکه این امکان را میدهند که سیگنالها و گرادیانهای خود را مستقیماً به لایههای دورتر منتقل کنند، بدون اینکه نیازی به تغییر یا تحول مجدد داشته باشند. در واقع، همانطور که در مثال ذکر شد، شما بخش حل شده را مستقیما در مراحل بعدی استفاده میکنید، اتصالات کوتاه نیز اجازه میدهند که اطلاعات بدون تغییر در شبکه منتقل شوند.
در معماری ResNet، به جای اینکه شبکه سعی کند به طور مستقیم نقشه کلی را یاد بگیرد، به شبکه کمک میکنیم تا فقط تفاوتها یا باقیماندهها را یاد بگیرد. این کار را میتوانیم با استفاده از اتصالات کوتاه انجام دهیم که به طور مستقیم بخشهایی از ورودی را به خروجی منتقل میکنند.
تعریف ریاضیاتی عملکرد اتصالات کوتاه
اگر بخواهیم مطالب بالا را با زبان ریاضیات تعریف کنیم، باید بگوییم که اگر نگاشت مورد نظر ما H(x) باشد، لایهها سعی میکنند تا F(x) = H(x) – x را یاد بگیرند. این کار به لایهها اجازه میدهد تا به جای یادگیری مستقیم H(x)، روی بدست آوردن تابعی (همان (x)F) تمرکز کند که باید به x اضافه شود تا (x)H حاصل گردد.
برای درک بهتر فرض کنید که در یک حالت خاص، بهترین عملکرد یک لایه حالتی باشد که هیچ تغییری روی خروجی لایه قبلی اعمال نشود، در این شرایط راحتتر است به شبکه یاد دهیم که این باقیمانده را به صفر میل دهد (F(x)=0) تا اینکه بخواهیم از اول همان خروجی لایه قبل را با لایههای پیچیده جدید بدست بیاوریم.

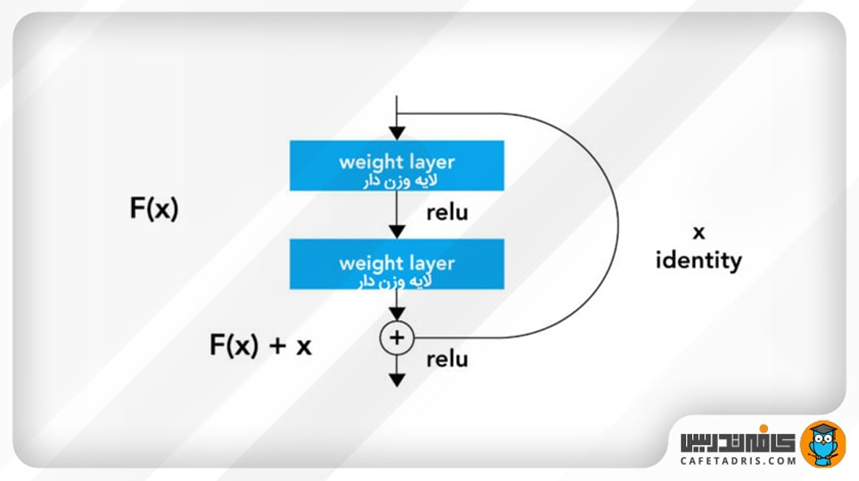
آیا استفاده از اتصالات کوتاه پیچیدگی مدل را افزایش میدهد؟
خیر، این اتصالات کوتاه نه هیچ پارامتر اضافهای به مدل تحمیل میکنند و نه پیچیدگی محاسباتی مدل را افزایش میدهند. چون با فرض داشتن یک مدل ساده (Plain در مقابل Residual) با تعداد لایههای برابر، به هر حال همین تعداد پارامتر باید آموزش میدیدند. این موضوع به سادگی در شکل زیر مشهود است:

برای داشتن درک بهتری از خروجی واحدهای باقیمانده میتوانید H(x) را به صورت تابع F(X, Wi) + X تصور کنید که Wiها همان وزن فیلترهای لایههای کانولوشنی درون هر واحد باقیمانده (Residual Blocks) هستند. به طور دقیقتر تابع F(X, Wi) برابر با W2σ(W1X) خواهد بود که در آن σ بیانگر تابع فعالساز ReLU است. حاصل F(X, Wi)+X نیز به صورت درایه به درایه روی Feature Mapهای ورودی (همان X در معادلات نوشته شده) و خروجی واحد باقیمانده، اعمال میشود. نکته ظریف اینجاست که این کار تنها در صورتی قابل انجام است که ابعاد Feature Map ورودی با خروجی برابر باشد در غیر این صورت باید به دنبال معادله دیگری برای توصیف رفتار یک واحد باقیمانده باشیم.

نحوه حل مشکل عدم برابری ابعاد ورودی و خروجی یک واحد باقیمانده ResNet
بعد از درک نحوه عملکرد اتصالات کوتاه در شبکه ResNet، حال وقت آن است که ببینیم اگر بخواهیم تعداد فیلترهای یک واحد را نسبت به واحد قبلی بیشتر کنیم، چطور باید Feature Map ورودی را با خروجی، که به واسطه افزایش تعداد فیلترها، عمق متفاوتی دارد جمع بزنیم. پیش از اینکه پاسخ این پرسش را بدهیم باید اشاره کنیم که منظور از تفاوت ابعاد ورودی و خروجی، صرفا تفاوت در عمق است چرا که سایر ابعاد (طول و عرض Feature Mapها) به واسطه استفاده از Padding یکسان میماند.
تولیدکنندگان مدل معماری شبکه عصبی رزنت برای حل مشکل اختلاف بعد در مقاله دو راه حل اصلی ارائه کردند: یک اینکه همچنان از روش قبلی (این روش در مقاله به عنوان Identity Shortcut معرفی شده است) استفاده کنیم اما با افزودن لایههای Padding Zero در عمق Feature Map ورودی این اختلاف را از بین ببریم که این روش باعث افزایش تعداد پارامترهای مدل نمیشود.
روش دوم این است که Feature Map ورودی را از یک لایه کانولوشنی 1×1 با تعداد فیلتر برابر با عمق Feature Map ورودی رد کرده و سپس با Feature Map خروجی جمع کنیم. این روش که در مقاله به عنوان Projection Shortcut معرفی شده، با معادله F(X, Wi)+WSX توصیف میشود که در آن WSوزن فیلترهای لایه کانولوشنی 1X1 گفته شده است.
پیادهسازی واحد باقیمانده در پایتون
در ادامه میتوانید نحوه پیادهسازی هر دو روش طراحی واحد باقیمانده یعنی Identity و Projection Shortcut را در فریم ورک کراس ببینید:

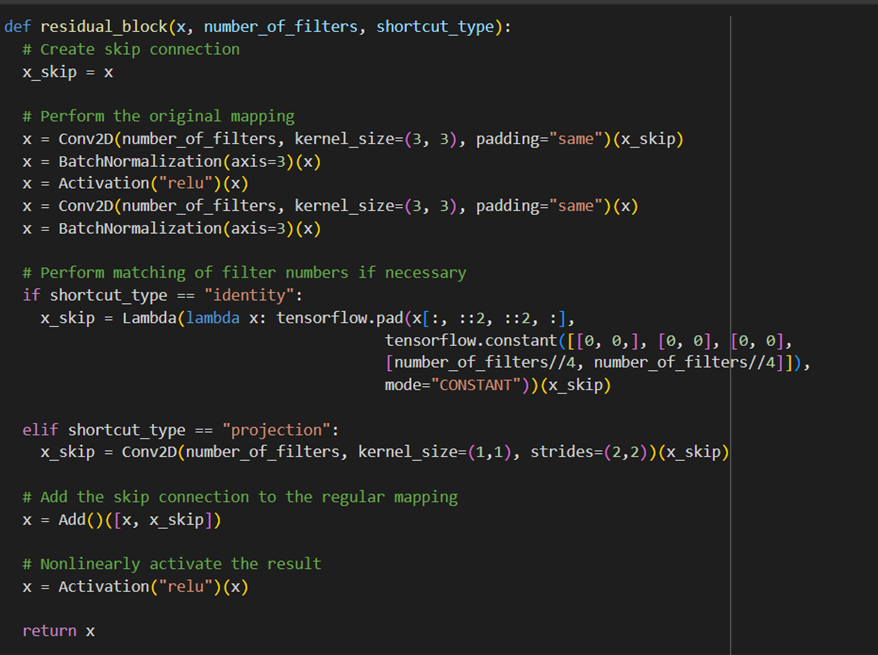
خط اول این تابع Feature Map ورودی (x) را در متغیر x_skip ذخیره میکند تا در انتهای واحد باقیمانده (Residual Block) آن را با خروجی حاصل از عبور x از دو لایه کانولوشنی 3×3 که همان F(x) است، جمع کند. برای حل مشکل اختلاف عمق x و x_skip، در شرایطی که این اختلاف وجود داشته باشد، بسته به نیاز از یکی دو روش Identity و Projection استفاده میشود. مشخص است که این اختلاف در صورتی پیش میآید که متغیر number_of_filters عددی متفاوت با عمق Feature Map خروجی واحد باقیمانده قبلی (که ورودی این واحد یا همان x است) باشد.
البته همانطور که در طرحواره معماری معماری شبکه عصبی رزنت مشخص است، در صورت نیاز به افزایش عمق، number_of_filters در واحد باقیمانده بعدی صرفا دو برابر میشود.
بررسی تاثیر استفاده از واحدهای باقیمانده

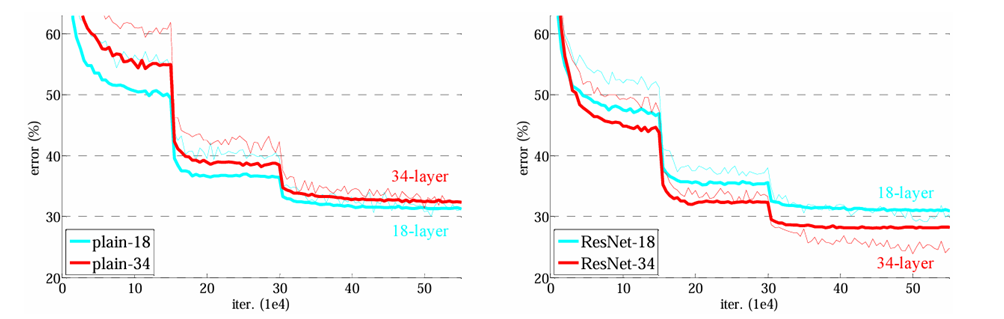


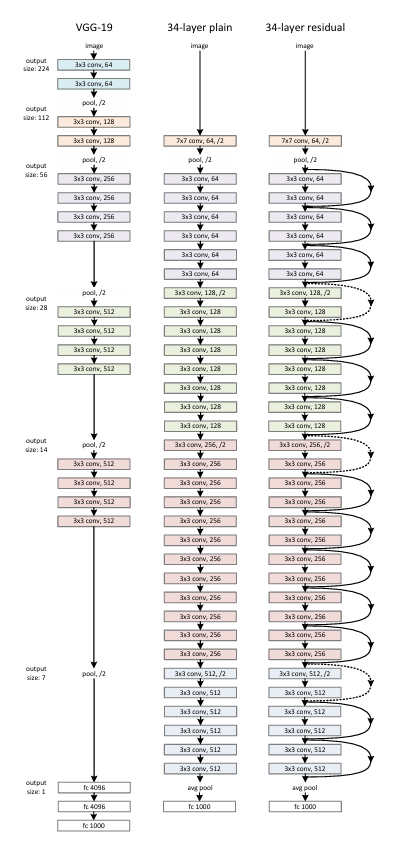
محققان این مقاله در گام نخست دو شبکه عصبی کانولوشنی ۱۸ و ۳۴ لایه ساده (Plain) را طراحی کرده و همانطور که میبینید طبق انتظار شبکه ۱۸ لایه عملکرد بهتری در هر دو فاز آموزش و ارزیابی داشت اما با تغییر این دو شبکه ساده به شبکههای باقیمانده (Residual Network) شاهد بهبود عملکرد هر دو مدل خواهیم بود. هرچند شبکه ۱۸ لایه Residual نسبت به ۱۸ لایه ساده بهبود چشمگیری نداشته اما سریعتر همگرا شده است.
نکته قابل توجه اما با مقایسه خطای مدل ۳۴ لایه Residual و ۱۸ لایه Residual بدست میآید. چرا که بر خلاف حالت ساده، مدل عمیقتر عملکرد بهتری ارائه کرده و این همان چیزی است که ما بدنبال آن بودیم. این یعنی تکنیک به کار رفته در ResNet مشکل محو شدن گرادیان را حل کرده و توانسته با تعداد لایه بیشتر، یادگیری بهتری هم داشته باشد، چیزی که پیشتر، بدون واحدهای باقیمانده به آن نرسیده بودیم.
نکته دیگر این است که در مدلهای Residual این فاز برای انتقال ورودیها از روش اول یعنی Identity Shortcut به همراه Zero Padding استفاده شده است که هیچ پارامتر اضافهای برای آموزش دیدن نسبت به روش ساده ندارد.
همچنین بخوانید: معماری U-Net چیست؟ معماری برتر برای پردازش تصاویر دیجیتال را بشناسید!
مقایسه روش Identity Shortcut و Projection Shortcut
در قسمت قبل دیدید که استفاده از واحدهای باقیمانده به روش اول توانست عملکرد مدل را بهبود ببخشد. در جدول زیر میتوانید عملکرد روش دوم را نیز ببنید:

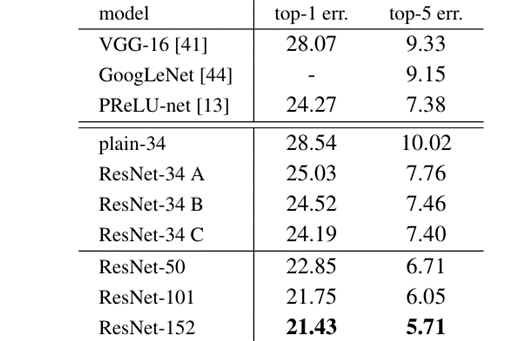
در این جدول عملکرد ۳ روش استفاده از واحدهای باقیمانده در ResNet ۳۴ لایه با یکدیگر مقایسه شده است:
- روش A که همان روش Identity Shortcut بود و دقت آن را هم در جدول قبل دیده بودید.
- روش B روشی است که تحت عنوان Projection Shortcut معرفی شده است که فقط در قسمتهای مورد نیاز یعنی وقتی که تعداد فیلترها از یک واحد به واحد دیگر، دو برابر میشود، از لایه کانولوشنی 1X1 استفاده میشود.
- روش C اما در تمامی Skip Connectionها از Projection Shortcut استفاده کرده است.
همانطور که میبینید هر سه روش نسبت به روش ساده ۳۴ لایه خطای کمتری داشتهاند. علت وضعیت بهتر شبکههای B و C نسبت به روش A این است که در این دو روش، مدل به واسطه لایههای Conv1x1 پارامترهای بیشتری برای یادگیری دارد. به طور خاص روش C نیز به واسطه داشتن سیزده Projection Shortcut بیشتر نسبت به روش B، از پارامترهای بیشتری برخوردار است (برای درک بهتر به شکل معماری شبکه زرنت ۳۴ لایه در ابتدای متن مراجعه کنید).
طراحی یک واحد باقیمانده بهینهتر
طراحان معماری معماری شبکه عصبی رزنت برای کسب دقت بالاتر روی دیتاست ImageNet مجبور به افزایش تعداد لایههای مدلشان بودند اما به دلیل افزایش زمان محاسبات، تصمیم به تبدیل واحدهای باقیمانده به واحدهای گلوگاه گرفتند، به این ترتیب که به جای ۲ لایه کانولوشن 3×3، از سه لایه به ترتیب با کانولوشنهای 1×1و 3×3 و مجددا 1×1 استفاده کردند. این لایهها به ترتیب مسئول کاهش و سپس افزایش ابعاد هستند. شکل زیر، یک مثال از این واحدهای گلوگاه را نشان میدهد. گفتنی است که هر دوی این طرحها دارای پیچیدگی زمانی مشابهی هستند.

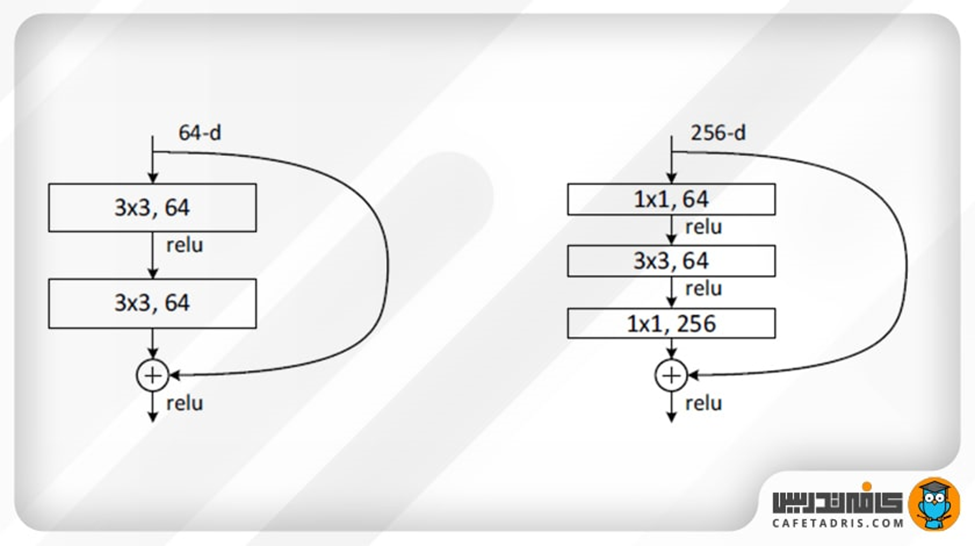
استفاده از اتصالات کوتاه Identity Shortcut به خصوص برای این واحدهای گلوگاه بسیار مهم است. اگر اتصال کوتاه Identity Shortcut با یک Projection جایگزین شود، پیچیدگی زمانی و اندازه مدل دو برابر میشود. بنابراین، استفاده از اتصالات کوتاه Identity منجر به مدلهای با کارایی بیشتر برای معماریهای دارای واحدهای گلوگاه میشود.
اتصالات کوتاه (Skip Connections) چطور به افزایش کارایی مدل کمک میکنند؟
تسهیل جریان اطلاعات
با اتصالات کوتاه، اطلاعات از لایههای اولیه میتوانند مستقیماً به لایههای بعدی جریان یابند بدون اینکه تغییری پیدا کنند. در مثال ما، این مانند انتقال مستقیم بخشی از راه حل به مرحله نهایی بدون تغییر است.
تسهیل آموزش
این اتصالات با فراهم آوردن مسیرهای اضافی، به جریان یافتن گرادیانها در شبکه کمک میکنند. در طی عملیات پسانتشار عقب (Backpropagation)، گرادیانها میتوانند از این مسیرهای مستقیم استفاده کنند تا به راحتی در تمام شبکه پخش شوند، که این به نوبه خود به آموزش مؤثرتر شبکههای عمیقتر کمک میکند.
با استفاده از این اتصالات کوتاه، یک لایه میتواند یاد بگیرد که باید تغییر کمی یا هیچ تغییری نسبت به ورودیهای خود ایجاد کند، که این برای لایههایی در یک شبکه بسیار عمیق که ممکن است وظیفه کمتری برای تغییر دادهها در لایههای میانی داشته باشند، بسیار مفید است. این مکانیزم به شبکه اجازه میدهد که عمق بیشتری داشته باشد و همزمان قابلیت آموزش خود را حفظ کند، بدون اینکه با مشکلاتی نظیر ناپدید شدن گرادیانها روبرو شود.
جمعبندی
مقالهای که در سال ۲۰۱۵ توسط محققان شرکت مایکروسافت منتشر شد، یک پیشرفت بزرگ در حوزه شناسایی تصویر به حساب میآید. این تحقیق، معماری جدیدی به نام معماری شبکه عصبی رزنت را معرفی کرد که با استفاده از واحدهای باقیمانده و اتصالات کوتاه توانست مشکلات مربوط به ناپدید شدن گرادیان را که در شبکههای عصبی عمیق با تعداد لایههای زیاد رخ میدهد، برطرف سازد. این ابتکار، شبکههای عصبی را قادر ساخت تا با عمق بیشتر، دقیقتر و مؤثرتر کار کنند.
اتصالات کوتاه به گرادیانها اجازه میدهند که بدون کاهش شدت در شبکه پخش شوند، که این امر منجر به آموزش پایدارتر و دقیقتر میشود. معماری معماری شبکه عصبی رزنت با افزایش قابل توجه تعداد لایهها توانست در مسابقه ImageNet 2015 برنده شود و استانداردهای جدیدی در دقت شناسایی تصویر ایجاد کند.
در نهایت، میتوان گفت که تکنیکهای معرفی شده در معماری ResNet، به ویژه استفاده از واحدهای باقیمانده و اتصالات کوتاه، گامهای بزرگی در بهبود شبکههای عصبی عمیق برداشتهاند و امکان پژوهشهای بیشتر در این زمینه را فراهم آوردهاند. این پیشرفتها نه تنها در شناسایی تصویر بلکه در بسیاری از زمینههای دیگر که به پردازش و تجزیه و تحلیل تصویر وابسته هستند، مؤثر واقع شده و آیندهی فناوریهای بینایی ماشین و یادگیری ماشین را تحت تأثیر قرار دادهاند.
پرسشهای متداول
رزنت (ResNet) چگونه به حل مشکل ناپدید شدن گرادیان در شبکههای عمیق کمک میکند؟
اتصالات کوتاه (Skip Connections) در معماری رزنت اجازه میدهند تا گرادیانها بدون کاهش شدت، در شبکه پخش شوند. این ویژگی به لایههای بسیار عمیق امکان میدهد تا یادگیری مؤثرتر و پایدارتری داشته باشند.
چه تفاوتی بین اتصالات کوتاه در معماری معماری شبکه عصبی رزنت (ResNet) و معماریهای شبکهی پیشین وجود دارد؟
در معماریهای پیشین، افزایش عمق شبکه معمولا با افزایش مشکلات آموزشی همراه بود. اما در رزنت، اتصالات کوتاه به شبکه امکان میدهند که سیگنالهای آموزشی و گرادیانها را به طور مستقیم و بدون تغییر به لایههای بعدی منتقل کنند.
نقش واحدهای باقیمانده (Residual Blocks) در بهبود دقت شبکههای عمیق چیست؟
واحدهای باقیمانده اجازه میدهند که لایهها تنها تفاوتها یا باقیماندهها را یاد بگیرند، نه کل تابع. این مکانیزم باعث میشود که آموزش شبکههای بسیار عمیقتر امکانپذیر و کارآمدتر شود.
چگونه میتوان کارایی مدلهای رزنت (ResNet) را در کاربردهای واقعی مانند شناسایی تصویر بهینه سازی کرد؟
بهینهسازی کارایی مدلهای رزنت میتواند از طریق تنظیم دقیق پارامترها، استفاده از تکنیکهای تقویت داده (Data Augmentation) و پیادهسازی معماریهای گلوگاه (Bottleneck Architectures) که کارایی محاسباتی را بهبود میبخشند، انجام گیرد.
آیا معماری رزنت (ResNet) در حوزههای دیگر غیر از شناسایی تصویر کاربرد دارد؟ چه تأثیراتی میتواند داشته باشد؟
بله، معماری رزنت در بسیاری از زمینههای دیگر مانند تحلیل ویدیو، شناسایی صدا و پردازش زبان طبیعی نیز کاربرد دارد. اتصالات کوتاه و واحدهای باقیمانده به این معماری اجازه میدهند تا در این حوزهها نیز به دقت و کارایی بالایی دست یابد.
یادگیری تحلیل داده را از امروز شروع کنید!
دنیای دادهها جذاب است و دانستن علم داده، توانایی تحلیل داده، یا بازاریابی مبتنی بر داده، شما را برای فرصتهای شغلی بسیاری مناسب میکند. فارغ از رشته و پیشزمینه، میتوانید حالا شروع کنید و از سطح مقدماتی تا پیشرفته بیاموزید. اگر دوست دارید به این حوزه وارد شوید، پیشنهاد میکنیم با کلیک روی این لینک قدم اول را همین حالا بردارید.
مشاوران کافهتدریس به شما کمک میکنند مسیر یادگیری برای ورود به این حوزه را شروع کنید: