
معرفی SqueezeNet بهعنوان یکی از پیشرفتهای چشمگیر در حوزه یادگیری عمیق محسوب میشود. این معماری نشاندهنده تلاشهای مستمر برای بهبود کارایی و کاهش پیچیدگی در معماریهای شبکههای عصبی است. معماری SqueezeNet با بهکارگیری رویکردهای نوین در ساختار خود، امکان استخراج ویژگیهای دقیقتر از دادهها را فراهم میآورد و کاری میکند تا در طیف گستردهای از کاربردها قابلاستفاده باشد. SqueezeNet، نهتنها در زمینههای تحقیقاتی، در بسیاری از برنامههای کاربردی صنعتی و تجاری نیز بهعنوان یک راهحل اثربخش مطرح است. با اینکه معماری آن بر پایه کاهش پیچیدگی استوار است، توانسته است از نظر عملکرد نیز با استانداردهای بالایی رقابت کند.
- 1. معرفی معماری SqueezeNet
- 2. معماری SqueezeNet و پیشینیان آن
- 3. استراتژیهای طراحی معماری
- 4. معماری SqueezeNet
- 5. پیادهسازی SqueezeNet در Keras
- 6. مزایای معماری SqueezeNet
- 7. معایب معماری SqueezeNet
- 8. کاربردهای عملی SqueezeNet در صنعت
- 9. خلاصه مطلب درباره معماری SqueezeNet
-
10.
پرسشهای متداول
- 10.1. چرا معماری SqueezeNet به عنوان یک راهحل اثربخش برای دستگاههای با منابع محدود محسوب میشود؟
- 10.2. استراتژیهای کلیدی که در طراحی SqueezeNet برای کاهش پارامترها به کار رفتهاند چیست؟
- 10.3. ماژول آتش (Fire Module) در معماری SqueezeNet چگونه به بهبود کارایی کمک میکند؟
- 10.4. چرا استفاده از Global Average Pooling (میانگینگیری جهانی) بهجای لایههای کاملاً متصل درSqueezeNet مؤثر است؟
- 10.5. محدودیتهای اصلی معماری SqueezeNet در مقایسه با دیگر شبکههای عصبی پیچیدهتر چیست و چه زمینههایی برای بهبود آن وجود دارد؟
- 11. یادگیری دیتا ساینس و ماشین لرنینگ را از امروز شروع کنید!
معرفی معماری SqueezeNet
SqueezeNet یکی از معماریهای شبکه عصبی است که با هدف کاهش شدید تعداد پارامترهای لازم برای آموزش طراحی شده است. به این معماری در جوامع علمی و فنی، بهدلیل تواناییهای فراوان و کاربرد گستردهاش در دستگاههایی با منابع محدود، توجه شده است.

معماری SqueezeNet و پیشینیان آن
SqueezeNet، با بهرهگیری از معماری منحصربهفرد خود، توانسته است با استفاده از تعداد پارامترهای بسیار کمتر، در مقایسه با دیگر مدلهای شناختهشده، مانند AlexNet، دقت آن را حفظ کند. این موضوع نشاندهنده ظرفیت بالای SqueezeNet در پیشبرد تکنولوژیهای نوین و کاربردهای آینده است. در این جدول میتوانید بهراحتی این دو معماری را با یکدیگر مقایسه کنید:
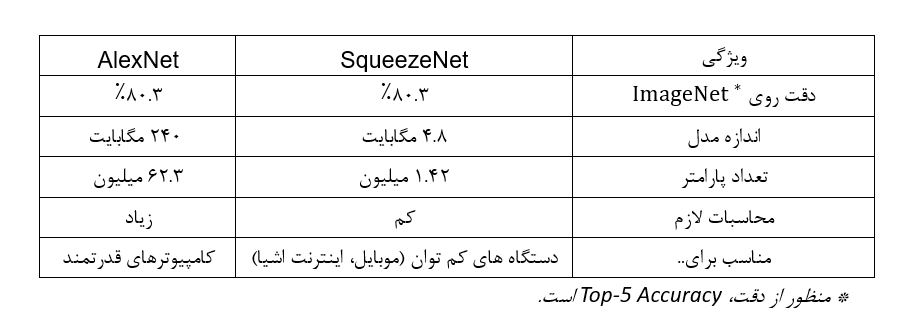
اگرچه شبکههای عصبی کانولوشنی سنتی مانند شبکه عصبی AlexNet و شبکه عصبی VGGNet دقت بالایی دارند، اما نیازمند قدرت محاسباتی قابلتوجهی برای آموزش هستند که استفاده از آنها در سیستمهای تعبیهشده (Embedded) یا دستگاههای موبایل را عملا ناممکن میکند. در این جدول میتوانید مقایسه SqueezeNet و VGGNet16 را ببینید:
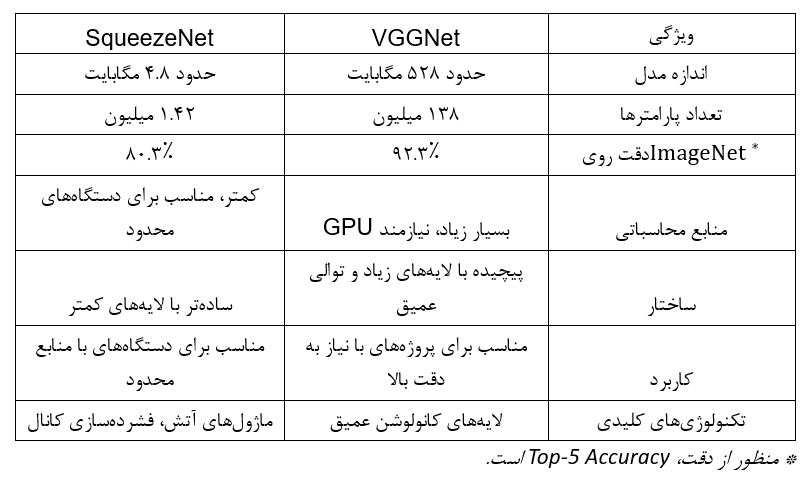
SqueezeNet همچنین میتواند بهعنوان یک استخراجکننده ویژگی (Feature Extraction) در دیگر خطوط پردازش یادگیری ماشین نیز استفاده شود که به دیگر مدلها امکان بهرهمندی از ویژگیهای آموختهشده توسط SqueezeNet را میدهد. این مدل به خاطر نوآوریهای معماریاش شناخته میشود و در دیگر معماریهای CNN استفاده شده و عملکرد آنها را بهبود بخشیده است.
استراتژیهای طراحی معماری
در طراحی SqueezeNet سه استراتژی اصلی به کار گرفته شده است تا تعداد پارامترهای شبکه کاهش یابد و درعینحال دقت شبکه حفظ شود:
جایگزینی فیلترهای ۳ در ۳ با ۱ در ۱
فیلترهای ۱x۱، پارامترهای کمتری در مقایسه با فیلترهای ۳x۳ دارند (۹ برابر کمتر). این بهمعنی استفاده از منابع کمتر برای یادگیری و ذخیرهسازی است.
کاهش تعداد کانالهای ورودی به فیلترهای ۳ در ۳
این کار با استفاده از لایههای فشردهسازی (squeeze layers) انجام میشود که تعداد کانالهای ورودی را کاهش میدهد و بهاین ترتیب، تعداد پارامترهای موردنیاز را کم میکند.
Down Sampling دیرهنگام در شبکه
این استراتژی بهاین معناست که عملیات کاهش اندازه تصاویر ورودی در لایههای بعدی شبکه انجام میگیرد تا لایهها بتوانند Feature Map های بزرگتری تولید کنند که میتواند به دقت بالاتر بینجامد.
دو استراتژی اول، با هدف حفظ دقت مدل، به کاهش هوشمندانه تعداد پارامترها در شبکههای CNN میپردازند، اما استراتژی سوم روی بیشینهکردن دقت مدل با توجه به تعداد کمتری پارامتر تمرکز میکند. در ادامه، ماژول Fire معرفی میشود که بهعنوان واحد اصلی معماریهای SqueezeNet به کار میرود. این ماژول امکان پیادهسازی موفقیتآمیز این استراتژیها را فراهم میآورد.
ماژول آتش (Fire)
ماژول Fire یکی از اجزای اصلی در معماری SqueezeNet است. این ماژول دو بخش را شامل است:
- لایه فشردهسازی (Squeeze layer): این لایه فقط از فیلترهای ۱x۱ استفاده میکند و تعداد کانالهای ورودی به لایه بعدی (Expand layer) را کاهش میدهد.
- لایه گسترش (Expand layer): این لایه از ترکیبی از فیلترهای ۱x۱ و ۳x۳ تشکیل شده است.
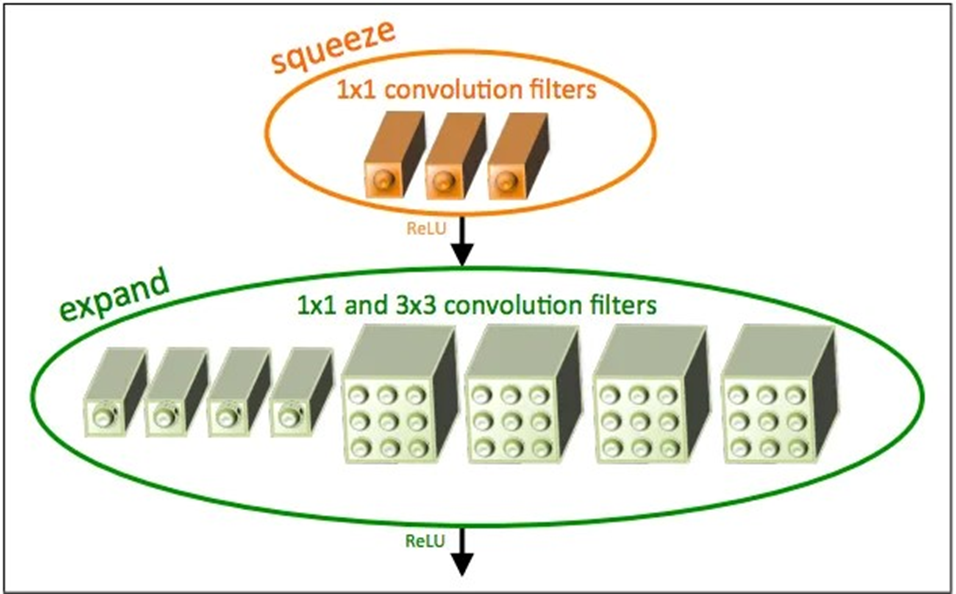
بهمنظور افزایش کارایی و کاهش تعداد پارامترها، تعداد فیلترهای لایه فشردهسازی (S1×1) از مجموع تعداد فیلترهای ۱x۱ (e3×3) و ۳x۳ (e3×3) در لایه گسترش کمتر تعیین میشود. این کار به لایه فشردهسازی اجازه میدهد که تعداد کانالهای ورودی به فیلترهای ۳x۳ را کاهش دهد که این امر با استراتژی ۲ نیز همخوانی دارد.
برای مثال، در این شکل لایه فشردهسازی از سه فیلتر (S1×1 = 3) و لایه گسترش از چهار فیلتر (e1×1 = 4) با کرنل اندازه ۱x۱ و چهار فیلتر (e3×3 = 4) با کرنل اندازه ۳x۳ استفاده شده است.
معماری SqueezeNet
SqueezeNet با یک لایه کانولوشن مستقل شروع میشود. سپس از چندین ماژول Fire پیروی میکند. در انتهای شبکه یک لایه کانولوشن دیگر قرار دارد. نمونهبرداری پایین در لایههای خاصی از شبکه انجام میشود تا مطابق با استراتژی سوم، نقشههای فعالسازی بزرگتری حاصل شود.
برای درک بهتر، برخی جزئیات و دلیل انتخابهای طراحی SqueezeNet را اینجا آوردهایم:
اعمال تابع فعالسازی (Relu)
تابع فعالسازی Relu (Rectified Linear Unit) به خروجیها از لایههای فشردهسازی و گسترش اعمال میشود. این تابع به مدل کمک میکند تا بهتر یاد بگیرد و بهینهسازی آن سادهتر باشد.
استفاده از Dropout
یک تکنیک بهنام Dropout با ضریب ۰.۵ پس از ماژول Fire ۹ اعمال میشود. این روش به جلوگیری از بیشبرازش (Overfitting) در شبکه کمک میکند، یعنی از یادگیری بیشازحد جزئیات دادههای آموزشی که ممکن است در دادههای جدید کارایی نداشته باشند جلوگیری میکند.
نبود وجود لایههای کاملاً متصل (Fully-connected)
در معماری SqueezeNet، بهجای استفاده از لایههای کاملاً متصل، از معماری شبکه در شبکه (Network in Network که بهصورت مخفف به آن NiN گفته میشود) الهام گرفته شده است. این انتخاب طراحی به کاهش تعداد پارامترها و نیازهای محاسباتی میانجامد.
استفاده از معماری شبکه در شبکه برای دستهبندی (Classification)
در معماری شبکه در شبکه، برخلاف شبکههای کانولوشنی سنتی که از لایههای کاملاً متصل برای دستهبندی نهایی استفاده میکنند، از تکنیکی بهنام میانگینگیری جهانی (Global Average Pooling) برای تولید خروجی شبکه استفاده میشود.
در این روش، بهجای یک لایه کاملاً متصل که تمامی مقادیر داخل Feature Map را بهصورت پشتسرهم به یکدیگر متصل میکند، از ترکیب کانولوشن ۱x۱ و Global Average Pooling استفاده میشود، بهاین صورت که ابتدا یک لایه کانولوشن که به تعداد کلاسها، فیلتر با کرنل اندازه ۱x۱ دارد قرار میدهیم؛ بهاین ترتیب ابعاد Feature Map تغییری نمیکند، اما عمق آن به تعداد کلاسهاست.
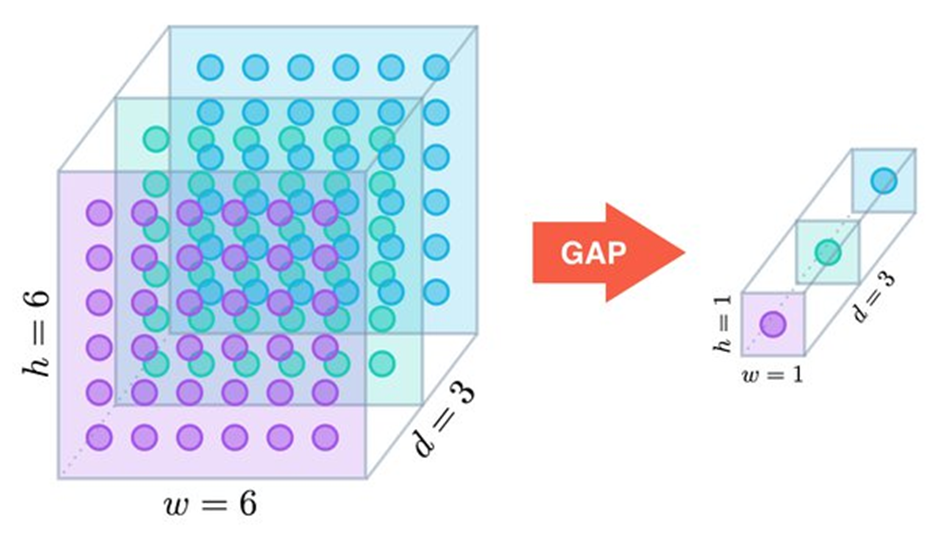
سپس با اعمال یک لایه Global Average Pooling، میانگین مقدارهای هر کرنل (صفحه) از Feature Map را بهصورت جداگانه محاسبه میکند؛ بهاین ترتیب، Logit مربوط به هر کلاس به دست میآید و با عبور از یک تابع فعالساز Sotfmax تعیین میشود که عکس مدنظر متعلق به کدام کلاس است.
نحوه پیادهسازی لایه گسترش
لایه گسترش با دو لایه کانولوشن جداگانه پیادهسازی شده است: یک لایه با فیلترهای ۱x۱ و یک لایه با فیلترهای ۳x۳. سپس خروجیهای این دو لایه در بعد کانالها به هم متصل (Concatenate) میشوند. این روش از لحاظ عددی معادل پیادهسازی یک لایه است که هر دو نوع فیلتر را دارند و بهاین ترتیب، امکان استفاده مؤثر از هر دو نوع فیلتر در یک لایه واحد فراهم میآید.
پیادهسازی SqueezeNet در Keras
در ادامه میتوانید یک شیوه پیادهسازی این معماری را با استفاده از کتابخانه Keras ببنید. توجه کنید که بلوکهای آتش (Fire) در این کد بههمان ترتیبی طراحی شده است که توضیح داده شد، یعنی ابتدا لایه فشردهسازی برای کاهش عمق Feature Map ورودی قرار داده شده و سپس لایه گسترش که شامل کانولوشنهای ۱x۱ و ۳x۳ است. تعداد فیلترهای این ماژول در قسمتهای مختلف مدل، با توجه به اعدادی که در مقاله اصلی SqueezeNet آمده است، تعیین میشود. این اعداد در جدول زیر قابلمشاهده هستند:
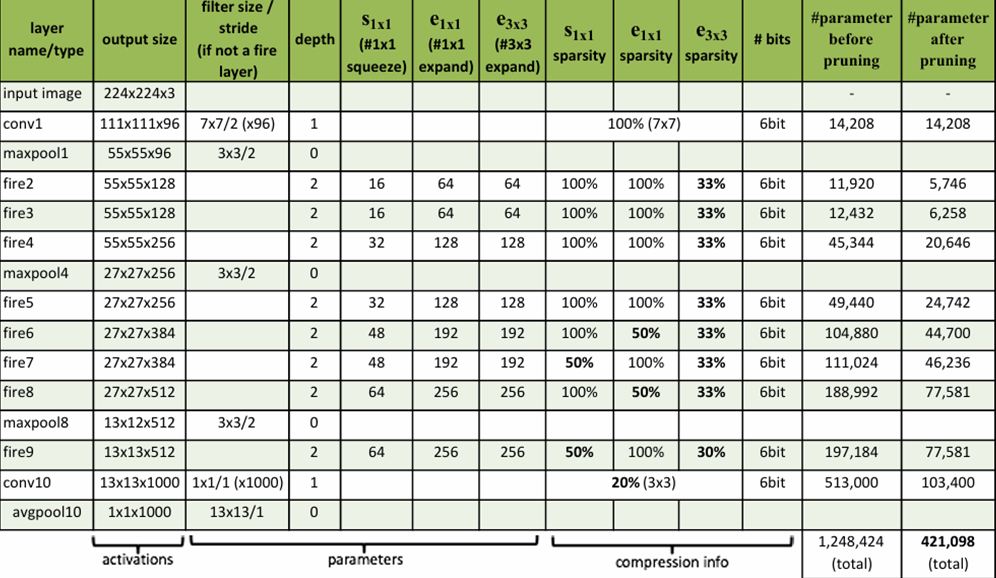
ابتدا کتابخانههای مدنظر را فراخوانی میکنیم:

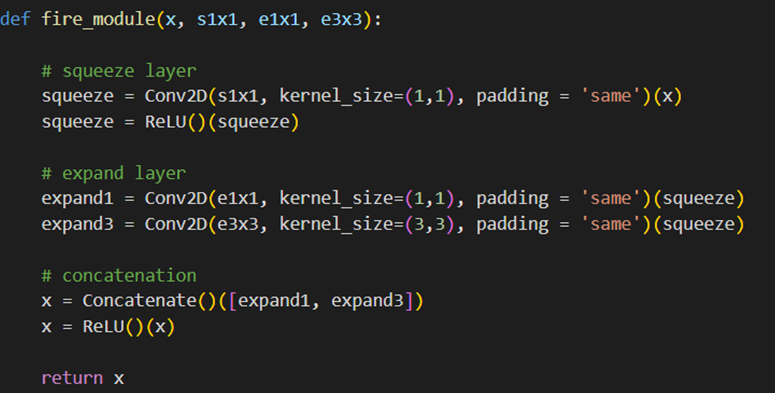
سپس باید ماژول آتش را بهنحوی که گفته شد بسازیم:
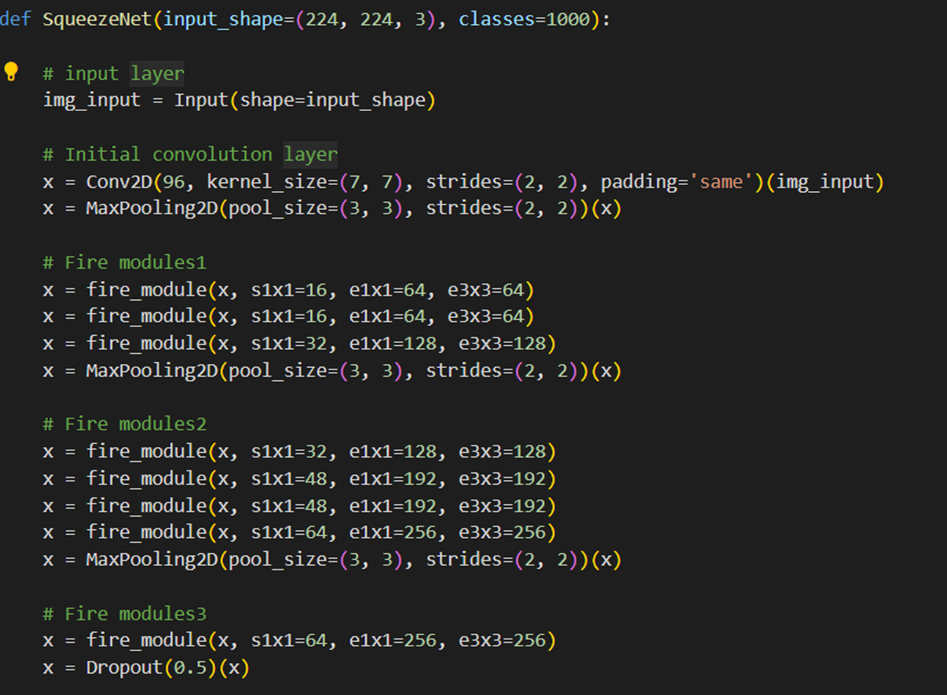
برای طراحی معماری SqueezeNet ابتدا یک لایه کانولوشن با ۹۶ فیلتر ۷x۷ میزنیم و پس از آن از MaxPooling2D جهت کاهش ابعاد Feature Map استفاده میکنیم؛ سپس ماژولها ساختهشده را فراخوانی و بعد از تعداد مشخصی از آن، مجدداً جهت کاهش ابعاد ازMaxPooling2D استفاده میکنیم. بعد از آخرین ماژول آتش نیز یک لایه Dropuot قرار میدهیم:
لایههای مربوط به Classify کردن عکس نیز همانطور که توضیح داده شد، با رویکرد NiN پیادهسازی میشود:
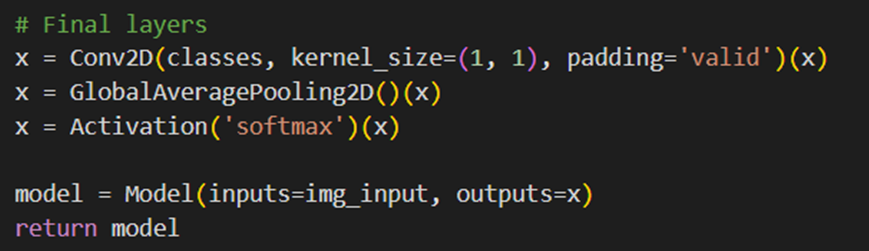
در پایان، مدل را با بهینهساز Adam و تابع هزینه Categorical Cross Entropy کامپایل و برای مشاهده تعداد پارامترهای قابلآموزش هر لایه از model.summary استفاده میکنیم:

بهعلت زیادبودن لایهها، فقط مجموع تعداد پارامترهای مدل را در این شکل نشان دادهایم:
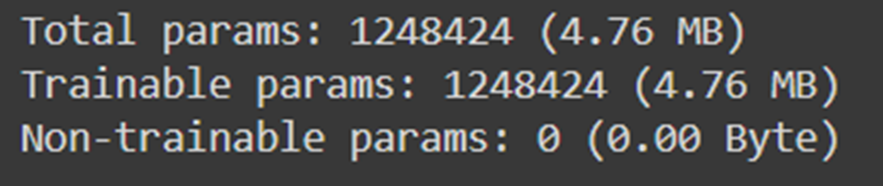
اگر میخواهید بدانید کدام مدل بهینهساز برای شما بهتر است پیشنهاد میکنیم مطلب عملکرد بهینه سازها در یادگیری عمیق را مطالعه کنید.
مزایای معماری SqueezeNet
این معماری، با وجود داشتن تعداد پارامترهای بسیار کمتر، توانسته است که کارایی برابر یا حتی بهتر از مدلهای قدیمیتر با تعداد پارامترهای بیشتر را ارائه کند. این امر، نهتنها در کاهش هزینههای محاسباتی، بر کاهش نیاز به حافظه و پردازش موثر بوده است. در این شکل مدتزمان موردنیاز برای اجرای معماریهای معروف ازجمله SqueezeNet را مشاهده کنید:
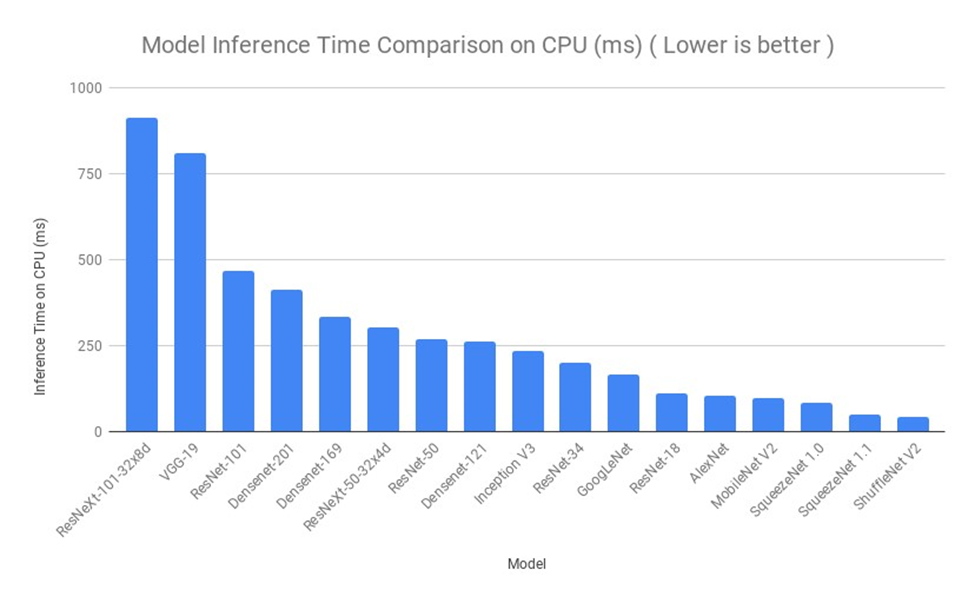
معایب معماری SqueezeNet
معماری SqueezeNet با وجود مزایایی که دارد، مانند دیگر معماریها، با چالشها و محدودیتهایی روبهرو است. یکی از اصلیترین چالشهای SqueezeNet دقت نهچندان بالای آن در مقایسه با مدلهای بزرگتر و پیچیدهتر است. SqueezeNet برای کارایی بالا و سرعت زیاد طراحی شده است، اما این مزیت بهقیمت کاهش در دقت به دست آمده است.
یکی دیگر از محدودیتهای SqueezeNet تعداد لایهها و فیلترهای آن است. معماری SqueezeNet نسبتاً ساده است و در مقایسه با دیگر معماریها تعداد لایه کمتری دارد. این مسئله میتواند توانایی آن را در یادگیری ویژگیها و نمایشهای پیچیده دادهها محدود کند.
علاوهبراین قابلیت مقیاسپذیری SqueezeNet کم است، بهاین معنا که ممکن است برای برنامههای کاربردی در مقیاس بزرگ که به قدرت محاسباتی بیشتری نیاز دارند مناسب نباشد. همچنین بهدلیل سازگاری محدود با دیگر معماریها، ممکن است با دیگر معماریها و مدلها سازگار نباشد؛ این مسئله میتواند کاربرد آن را در برخی برنامهها محدود کند.
کاربردهای عملی SqueezeNet در صنعت
بیایید به کاربرهای عملی و بالفعل معماری SqueezeNet در صنعت نگاهی بیندازیم:
تشخیص چهره دامها
معماری SqueezeNet، بهعنوان مدلی سبک و کمهزینه، در پروژههایی مانند تشخیص هویت دامها به کار رفته است؛ برای مثال، این معماری در تشخیص چهره گوسفندان استفاده شده و نتایج قابل توجهی از لحاظ دقت و سرعت پردازش به دست آمده است. این کاربرد نشاندهنده توانایی SqueezeNet در کاهش هزینهها و افزایش کارایی در صنایع کشاورزی است.

تشخیص شیءها در دستگاههای کوچک
همانطور که گفتیم، معماری SqueezeNet بهدلیل کارایی بالا در حافظه و محاسبات، برای استفاده در دستگاههای تلفنهمراه و سیستمهای تعبیهشده که منابع محدودی دارند مناسب است. این معماری در تشخیص اشیاه در چنین دستگاههایی میتواند بهطور مؤثری به کاهش مصرف انرژی و فضای حافظه کمک کند.

نظارت و امنیت
از معماری SqueezeNet در سیستمهای نظارتی و تشخیص تهدیدات امنیتی نیز استفاده میشود. بهخصوص در مکانهایی که به پردازش تصویر سریع و دقیق نیاز است، مانند فرودگاهها و منطقههای حساس دیگر، این معماری میتواند به تشخیص دقیق و بهموقع کمک کند، مثلاً استفاده از آن در شناسایی پهپادها و دیگر اشیای پرنده که ممکن است بهعنوان تهدیدات امنیتی در نظر گرفته شوند مطرح است.


تشخیص خودکار در صنعت خودرو
معماری SqueezeNet بهدلیل حجم کم و کارایی بالا در محاسبات، برای تشخیص خودکار در سیستمهای خودرویی مانند کمک به رانندگی و تشخیص موانع استفاده میشود. این کاربرد به بهبود امنیت در رانندگی و کاهش خطاهای انسانی کمک میکند؛ زیرا سیستمهای خودرویی نیاز به پاسخگویی سریع و دقیق دارند.
خلاصه مطلب درباره معماری SqueezeNet
SqueezeNet، با تأکید بر بهینهسازی منابع، نمونهای از پیشرفتها در زمینه شبکههای عصبی است که بدون ازدستدادن دقت، موفق به کاهش شدید تعداد پارامترها شده است. این ویژگیها امکان استفاده از معماریهای نسبتاً عمیق را در دستگاههایی با حافظه کم فراهم آورده و با این کار، دسترسی به فناوریهای پیشرفته را برای یک طیف گستردهتری از کاربران امکانپذیر کرده است.
با وجود این پیشرفتها معماری SqueezeNet در برخی سناریوها که نیازمند پردازش دادههای پیچیده و بزرگمقیاس هستند کمبودهایی دارد. این موارد باید در تصمیمگیریهای مربوط به انتخاب معماری مناسب برای برنامههای کاربردی خاص در نظر گرفته شود.
در پایان، معماری SqueezeNet گامی مهم در راستای افزایش کارآمدی شبکههای عصبی عمیق به شمار میرود و نشاندهنده توانایی علم مدرن در ایجاد راهحلهای نوآورانهای است که هم توانایی حل مشکلات عملی را دارند و هم به فرصتهای جدیدی برای پیشرفت فناوری دست یافتهاند.

پرسشهای متداول
چرا معماری SqueezeNet به عنوان یک راهحل اثربخش برای دستگاههای با منابع محدود محسوب میشود؟
SqueezeNet با کاهش شدید تعداد پارامترها و حفظ دقت مشابه با مدلهای بزرگتر، امکان استفاده از شبکههای عصبی پیچیده را در دستگاههایی با قدرت پردازشی و حافظه کم مانند موبایلها و دستگاههای اینترنت اشیا فراهم میآورد.
استراتژیهای کلیدی که در طراحی SqueezeNet برای کاهش پارامترها به کار رفتهاند چیست؟
جایگزینی فیلترهای بزرگتر با فیلترهای کوچکتر، کاهش تعداد کانالهای ورودی به فیلترها ازطریق لایههای فشردهسازی و تأخیر در عملیات کاهش نمونه (Down Sampling) برای افزایش تولید ویژگیها.
ماژول آتش (Fire Module) در معماری SqueezeNet چگونه به بهبود کارایی کمک میکند؟
ماژول آتش شامل دو بخش فشردهسازی و گسترش است که بهترتیب با فیلترهای ۱x۱ و ترکیبی از فیلترهای ۱x۱ و ۳x۳ کار میکند. این ساختار به کاهش شدید تعداد پارامترها کمک میکند، ضمن اینکه تنوع ویژگیهای استخراجشده از دادهها را حفظ میکند.
چرا استفاده از Global Average Pooling (میانگینگیری جهانی) بهجای لایههای کاملاً متصل درSqueezeNet مؤثر است؟
این تکنیک، با کاهش نیاز به پارامترهای اضافی معمولاً موردنیاز برای لایههای کاملاً متصل، به کاهش هزینههای محاسباتی و حافظه میانجامد، ضمن آنکه از بیشبرازش (Overfitting) جلوگیری میکند و بهطور مؤثری، توانایی شبکه را در تعمیم یافتهها به دادههای جدید افزایش میدهد.
محدودیتهای اصلی معماری SqueezeNet در مقایسه با دیگر شبکههای عصبی پیچیدهتر چیست و چه زمینههایی برای بهبود آن وجود دارد؟
درحالیکه معماری SqueezeNet در کاهش تعداد پارامترها و بهینهسازی منابع موفق است، این معماری ممکن است در دقت و قابلیت یادگیری ویژگیهای پیچیده در مقایسه با مدلهای بزرگتر مانند VGGNet کوتاهی کند. این امر میتواند با تغییراتی در تعداد و اندازه لایهها و فیلترها بهبود یابد.
یادگیری دیتا ساینس و ماشین لرنینگ را از امروز شروع کنید!
دنیای دادهها جذاب است و دانستن علم داده، توانایی تحلیل داده، یا بازاریابی مبتنی بر داده و یادگیری ماشین شما را برای فرصتهای شغلی بسیاری مناسب میکند. شما، فارغ از رشته تحصیلی و پیشزمینه شغلیتان، میتوانید یادگیری این دانش را همین امروز شروع کنید و آن را از سطح مقدماتی تا پیشرفته بیاموزید. اگر دوست دارید به این حوزه وارد شوید، پیشنهاد میکنیم با کلیک روی این لینک قدم اول را همین حالا بردارید.
مشاوران کافهتدریس به شما کمک میکنند مسیر یادگیری برای ورود به این حوزه را شروع کنید:
سلام چه مواقعی از mobilenet و چه مواقعی از squeeznet m پیشنهاد میشه که استفاده بشه؟
سلام و عرض ادب،
از MobileNet زمانی استفاده میشه که به مدلهای سبک و سریع برای کاربردهای موبایلی و توکار نیازه و دقت بالا هم مهمه. از SqueezeNet برای کاربردهایی استفاده میشه که به مدلهای کوچکتر با نیازمندیهای حافظه و محاسبات کمتر نیازه.