
در دامنه گسترده علم داده و یادگیری ماشین، گذر از دادههای خام تا پیشبینیهای دقیق نیازمند تکنیکهای پیشپردازش (Preprocessing) میباشد. مرحله پیشپردازش دادهها اهمیت بسیاری دارد چرا که پایهای برای آموزش موثر مدلها و پیشبینیهای قوی فراهم میکند. با تبدیل دادههای خام به یک فرمت ساختارمند و معنیدار، پیشپردازش کیفیت و قابلیت اعتماد مدلهای یادگیری ماشین را ارتقا میدهد که این امر موجب بهبود دقت مدلها برای دادههای تست میشود. در این مقاله با جزییات بیشتری روشهای مختلف پیشپردازش دادهها و مدیریت مقادیر گمشده را بررسی میکنیم.
- 1. اهمیت پیش پردازش دادهها
- 2. هدف مقاله
- 3. مقادیر نامعتبر و گمشده
- 4. نویز و دادههای پرت
- 5. دادههای با ابعاد بالا
- 6. دادههای نامتوازن
- 7. پیشبینی بایاسدار مدل
- 8. دادههای به شدت وابسته
- 9. رابطه غیر خطی بین فیچرها
- 10. جمعبندی
-
11.
پرسشهای متداول
- 11.1. روش KNN Imputer چگونه مقادیر گمشده را مدیریت میکند؟
- 11.2. روش Z-score چگونه به شناسایی دادههای پرت کمک میکند؟
- 11.3. مجموعهدادههای با ابعاد بالا چه چالشهایی ایجاد میکنند؟
- 11.4. Mutual Information چه کاربردی در پیشپردازش دادهها دارد؟
- 11.5. چرا مجموعهدادههای نامتوازن چالشبرانگیز هستند؟
- 12. یادگیری ماشین لرنینگ را از امروز شروع کنید!
اهمیت پیش پردازش دادهها
پیش پردازش دادهها در علم داده و یادگیری ماشین اهمیت بسیار بالایی دارد. این مرحله با تبدیل دادههای خام به فرمتی ساختارمند و معنیدار، کیفیت و قابلیت اعتماد مدلهای یادگیری ماشین را افزایش میدهد. دادههای خام معمولاً شامل مقادیر گمشده، نویز، دادههای پرت، و ابعاد بالا هستند که همگی میتوانند موجب کاهش دقت و کارایی مدلهای یادگیری شوند. با اعمال تکنیکهای مختلف پیش پردازش مانند مدیریت مقادیر گمشده، تشخیص و حذف دادههای پرت، و کاهش ابعاد، میتوان دادهها را به گونهای آماده کرد که مدلهای یادگیری ماشین بتوانند به بهترین نحو ممکن آموزش ببینند و پیشبینیهای دقیقی انجام دهند.
هدف مقاله
این مقاله به تشریح روشهایی میپردازد که از طریق آنها میتوان کیفیت دادهها را بهبود بخشید. از جمله موضوعات مورد بحث در این مقاله میتوان به مدیریت مقادیر گمشده و نامعتبر، تشخیص و مدیریت دادههای پرت، کاهش ابعاد، و مقابله با مشکلاتی همچون دادههای نامتوازن و همبستگی بالا اشاره کرد. هدف نهایی این است که با بهکارگیری این تکنیکهای پیشپردازش دادهها، مدلهای یادگیری ماشین بتوانند با دقت و کارایی بیشتری به پیشبینی و تحلیل دادهها بپردازند.
مقادیر نامعتبر و گمشده
یکی از ضروریترین مراحل پیشپردازش دادهها مدیریت مقادیر نامعتبر و گمشده (Missing Values or Null Values) به شمار میآید. حضور مقادیر گمشده یا نامعتبر در مجموعهدادهها میتواند منجر به مدلهای بایاسدار و پیشبینیهای نادرست شود. لذا در این راستا نحوه شناسایی و مدیریت کردن آنها بسیار اهمیت دارد.
نحوه تشخیص مقادیر نامتعبر و گمشده
چندین روش برای شناسایی مقادیر گمشده در مجموعهداده وجود دارد:
- روش ()isnull
این روش به ما امکان شناسایی مقادیر گمشده در یک دیتافریم (DataFrame) را میدهد. با اعمال این روش، میتوانیم یک دیتافریم بولینی بدست آوریم که در آن True مقادیر گمشده را نشان میدهد.
- روش ()info
این روش خلاصهای مختصر از دیتافریم را فراهم میکند که شامل تعداد مقادیر غیر گمشده برای هر ستون است. ستونهایی که تعداد مقادیر غیر گمشده آنها کمتر از تعداد کل ورودیها است احتمالاً شامل مقادیر گمشده هستند.
- سایر روشها
دیتافریمهایی وجود دارند که مقادیر گمشده آنها با استفاده از روشهای فوق قابل تشخیص نیستند چنین شرایطی نیازمند یک اپراتور است تا آنها را تشخیص دهد. به طور مثال یک مجموعهداده فرض کنید که دارای ویژگی قد اشخاص است. در چنین دیتافریمی اگر یک مقدار صفر حضور داشته باشد با روشهای فوق قابل تشخیص نیست بلکه شخص مهندسی که قرار است عملیات پیشپردازش را انجام دهد میداند که مقدار صفر برای قد افراد قابل استناد نیست و لذا میبایست به دنبال راه حلی برای مدیریت کردن این مقدار باشد.
مدیریت مقادیر گمشده
روشهای مختلفی برای برخورد با مقادیر گمشده در مرحله پیشپردازش دادهها وجود دارد که شامل موارد زیر میشوند:
- Dropna
اولین روش حذف ردیفهای دارای مقادیر گمشده است. این روش زمانی مناسب است که تعداد مقادیر گمشده نسبت به اندازه مجموعهداده به طور نسبی کم است.
- Fillna
روش دوم پر کردن مقادیر گمشده با میانگین، میانه، مد یا مقادیر خاص میباشد. این روش به حفظ اطلاعات ارزشمند کمک میکند.
- KNN Imputer
نهایتا تکمیل مقادیر گمشده بر اساس همسایگان نزدیک، یکی از پرکاربردترین روشهاست. KNN Imputer با در نظر گرفتن شباهتهای بین نقاط داده، به صورت دقیقتر مقادیر گمشده را تخمین میزند.
قطعه کد زیر بیانگر پر کردن مقادیر گم شده به روشهای مختلف است:
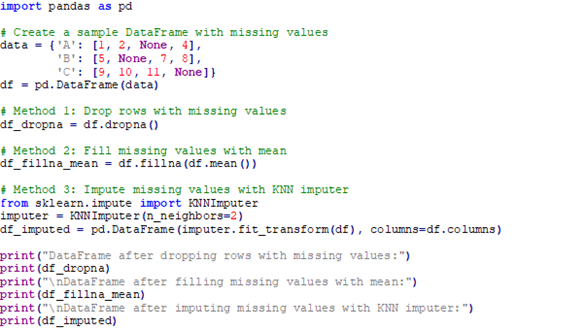
با استفاده از این روشها، مقادیر گمشده به طور موثر مدیریت میشوند و اطمینان حاصل میشود که سلامت و قابلیت اطمینان مجموعهداده برای وظایف یادگیری ماشین حفظ شده است.
نویز و دادههای پرت
نویز و نقاط ناهنجار در دادهها میتوانند بر عملکرد پیشبینی مدلهای یادگیری ماشین تأثیر قابل توجهی بگذارند. نویز به نوسانات تصادفی و خطاهای داده اشاره دارد، به عبارت دیگر، دادههای پرت، نقاط دادهای هستند که به طور قابل توجهی از بقیه مجموعهداده انحراف دارند.
تشخیص دادههای پرت
شناسایی دادههای پرت (Outlier Detection) و رفع نقاط دادهای که ممکن است تجزیه و تحلیل یا فرآیند مدلسازی را از هم بپاشانند، حیاتی است. چندین روش برای شناسایی نقاط ناهنجار در یک مجموعهداده مطرح شدهاست:
روشهای آماری
تکنیکهای آماری مانند Z-score میتوانند بر اساس انحراف دادهها از میانگین یا میانه توزیع داده، نقاط ناهنجار را شناسایی کنند. تصویر زیر درک شهودی مناسبی برای این منظور ارئه میدهد:
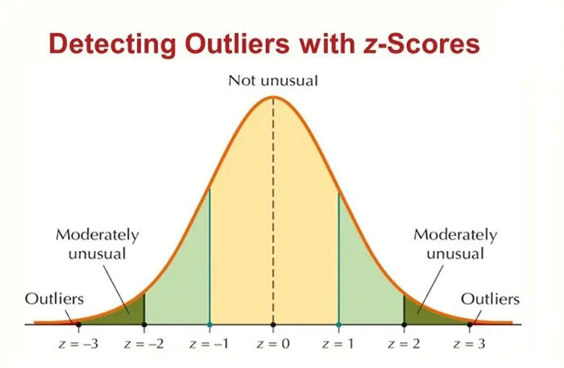
همانطور که از تصویر بالا پیداست، دادههایی که خارج از محدوده 3 برابری از انحراف معیار هستند، میتوان به عنوان داده پرت در نظر گرفت.
روشهای تصویرسازی
روشهای تصویرسازی مانند نمودار scatter plot و histogram میتوانند با نمایش توزیع نقاط داده و برجسته کردن هرگونه مقادیر بیشازحد، نقاط ناهنجار را آشکار کنند.
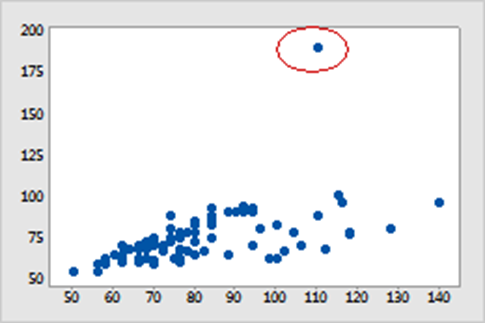
نمودار جعبهای
نمودار جعبهای (Box Plot)، یک ابزار تصویری قدرتمند برای شناسایی نقاط ناهنجار در مجموعهداده است. این نمودار شامل یک جعبه (box) است که محدوده بین چارکی (IQR) داده را نشان میدهد، میانه با یک خط در داخل جعبه نمایان میشود. شاخهها (whiskers) از جعبه در راستای حداقل و حداکثر مقادیر در یک محدوده خاص امتداد مییابند.
با مشاهده نمودار جعبهای، نقاط ناهنجار به عنوان نقاطی که خارج از شاخهها قرار دارند، به آسانی شناسایی میشوند. برای این منظور به شکل زیر دقت کنید:

مدیریت دادههای پرت
روشهای مختلفی برای مدیریت نقاط ناهنجار به منظور پیشپردازش دادهها مطرح شدهاند، در ادامه برخی از این روشها بیان میشوند:
روش محدوده بین چارکی
در این روش (IQR-Interquartile Range)، همانطور که در بخش پیشین توضیح دادهشد، دادههایی که خارج از محدوده شاخهها هستند، به عنوان نقاط ناهنجار مشخص میشوند. پس از شناسایی این دادهها میتوانیم دو رویکرد در مقابله با آنها اتخاذ کنیم؛ یکی حذف آنها و دیگری جایگزین کردن آنها با میانه، میانگین یا ماکزیمم و مینیمم مقدار قابل قبول. اگر رویکرد مدنظر حفظ اطلاعات باشد، جایگزینی میتواند انتخاب مناسبی باشد. قطعه کد زیر بیانگر این مسئله است:
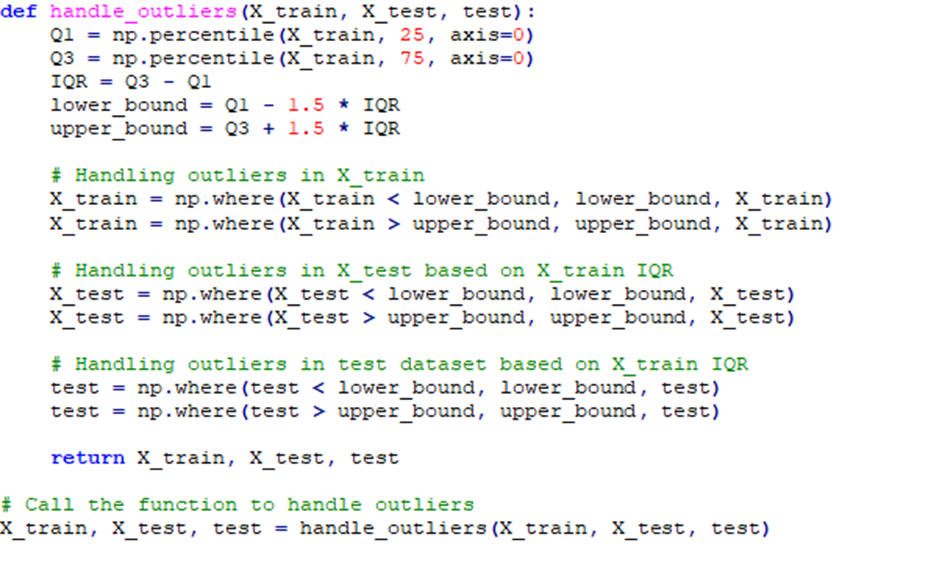
در تابع فوق بیشترین و کمترین مقدار ممکن بر اساس دادههای ترین شناسایی میشود و سپس به کمک این مقادیر، دادههای پرت در مجموعهداده تست و ترین جایگزین میشوند.
Isolation Forest (iForest)
علاوه بر روشهای سنتی، در مبحث یادگیری بدون نظارت روشهای مختلفی برای شناسایی دادههای پرت معرفی شدهاند. در این راستا، Isolation Forest یک الگوریتم یادگیری بدون نظارت است که با انتخاب تصادفی ویژگیها و تقسیم نقاط داده روی ویژگی با بیشترین واریانس، نقاط ناهنجار را جدا میکند. در این روش دادههای پرت نیاز به تقسیم (split) کمتری دارند تا از بقیه دادهها جدا شوند.
در ادامه سایر روشهای پیشپردازش جهت شناسایی دادههای پرت لیست شدهاند:
One-Class SVM (Support Vector Machine)
DBSCAN (Density-Based Spatial Clustering)
Local Outlier Factor (LOF)
Elliptic Envelope
Minimum Covariance Determinant (MCD)
Cluster-Based Local Outlier Factor (CBLOF)
Angle-Based Outlier Detection (ABOD)
همچنین بخوانید: ناهنجاری در یادگیری ماشین چیست و چه روشهای برای تشخیص ناهنجاری وجود دارد؟
دادههای با ابعاد بالا
مجموعهدادههای با ابعاد بالا (High Dimensionality) چالشهایی را از نظر منابع محاسباتی، پیچیدگی مدل و قابل تفسیر بودن در یادگیری ماشین و تجزیه و تحلیل داده ایجاد میکنند. این مجموعهدادهها در حوزههای مختلفی از جمله ژنتیک، پردازش تصویر، استخراج متن و اطلاعات حاصل از سنسورها ظاهر میشوند. به طور مثال، مجموعهدادههای CIFAR-10 و CIFAR-100 به ترتیب شامل تصاویر رنگی 32*32 پیکسل در ده و صد کلاس مختلف میباشند. هر تصویر توسط یک بردار از 3072 ویژگی (32*32*3) بیان میشود که این امر بیانگر ابعاد بالای دادهها است.
حل چالش ابعاد بالا
تکنیکهایی مانند انتخاب ویژگی (Feature Selection) و مهندسی ویژگی (Feature Engineering) میتوانند برای حل مشکلات مجموعهدادهها با ابعاد بالا به عنوان مرحله پیشپردازش استفاده شوند:
- انتخاب ویژگی: انتخاب زیرمجموعهای از ویژگیهای مرتبط.
- مهندسی ویژگی: ایجاد ویژگیهای جدید بر اساس دانش حوزه یا تبدیلهای ویژگیهای موجود.
دو روش فوق نیازمند خلاقیت مهندس یادگیری ماشین هستند که باید از دانش کافی در حوزه مورد مطالعه برخوردار باشد. اما روشهای دیگری برای کاهش ابعاد وجود دارند که در حیطه یادگیری بدون نظارت مطرح شدهاند..
تکنیکهای کاهش بعد (Dimensionality Reduction Techniques)
تجزیه مؤلفههای اصلی (PCA)، t-SNE و UMAP از جمله تکنیکهای محبوب کاهش بعد در حوزه یادگیری بدون نظارت هستند که روشهای مؤثری برای کاهش ابعاد مجموعهدادهها ارائه میدهند در حالی که ویژگیها و ساختارهای مهم را حفظ میکنند.
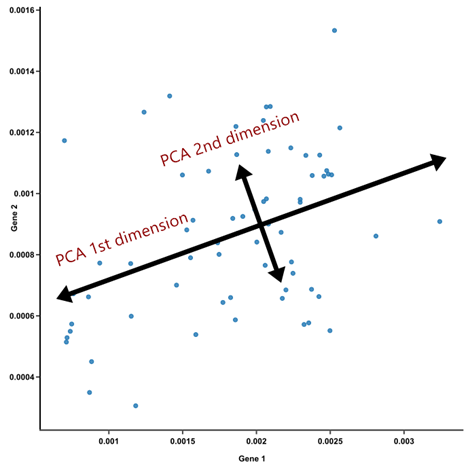
Principal Component Analysis
این روش که با نام PCA شناخته میشود با هدف کاهش بعد در حالی که پراکندگی دادهها را حفظ میکند، مطرح شده است.
برای مطالعه بیشتر کلیک کنید: صفر تا صد درباره PCA یا بررسی دقیق تحلیل مؤلفههای اصلی بدانید

t-Distributed Stochastic Neighbor Embedding
این روش که با نام t-SNE شناخته میشود برای کاهش بعد دادههای غیر خطی کاربرد دارد.
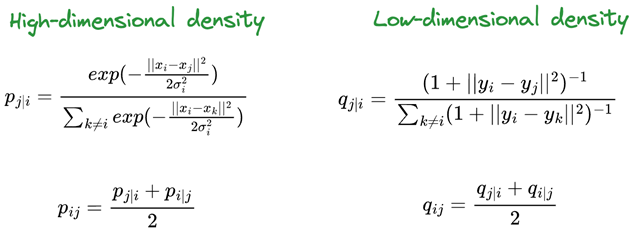
Uniform Manifold Approximation and Projection
این روش که با نام UMAP شناخته میشود با رویکرد حفظ ساختار محلی و سراسری داده، ابعاد را کاهش میدهد.

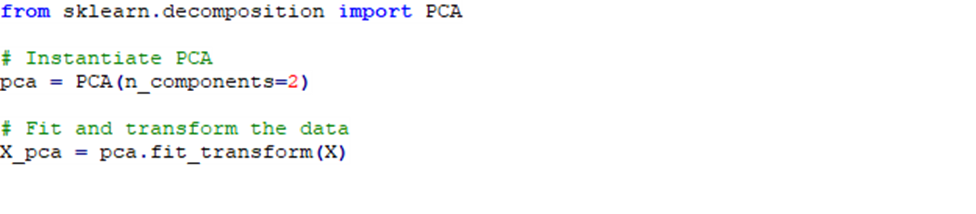
قطعه کد زیر نیز، نحوه فراخوانی PCA و اعمال آن به مجموعهداده را بیان میکند. در این کد ابعاد مجموعهداده به 2 کاهش مییابد.
دادههای نامتوازن
مجموعهدادههای نامتوازن یک چالش متداول در یادگیری ماشین هستند که در آن یک یا چند کلاس نسبت به دیگران به طور قابل توجهی نمایندهای ندارند. این نامتوازنی میتواند منجر به مدلهای بایاسدار شود که اولویت را برای کلاسهای اکثریت قائل میشوند، که منجر به پیشبینی ضعیف مدل برای کلاسهای اقلیتی میشود.
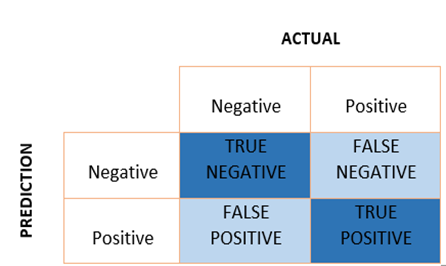
ارزیابی مجموعهدادههای نامتوازن
به منظور ارزیابی مدلهای آموزش دیده شده، معیارهای استاندارد مانند دقت (Accuracy) ممکن است به دلیل نامتوازنی کلاسها گمراهکننده باشند. زیرا همانطور که از فرمول آن پیداست به دلیل اثر گذاری دادههای اکثریت، پس احتمالا دقت مدل بیانگر عدد بالایی است. در زیر چندین معیار ارزیابی مرسوم که برای مجموعهدادههای نامتوازن مناسب هستند آورده شده است:

مدیریت مجموعهدادههای نامتوازن
برای حل چالش مجموعهدادههای نامتوازن، میتوان از چندین روش جهت پیشپردازش دادهها استفاده کرد که شامل موارد زیر میشود:
تکنیک افزایشنمونهبرداری (Over Sampling): افزایش نمونههای کلاسهای کمیت.
تکنینک کاهشنمونهبرداری (Down Sampling): کاهش نمونههای کلاسهای اکثریت.
SMOTE (تکنیک بالابردن مصنوعی کمیت): تولید نمونههای مصنوعی برای کلاسهای کمیت.
قطعه کد زیر بیانگر استفاده از تکنیک SMOTE است:

پیشبینی بایاسدار مدل
هنگامی که اکثریت دادهها در کلاس اکثریت قرار میگیرند، به طور کلی مدل جهت پیشبینی خروجی تمایل و سوق بیشتری در جهت آنها میگیرد. در سرتیتر قبلی بیان شد که یکی از علل این اتفاق، دادههای نامتوازن هستند. به طور کلی اگر در یک مجموعهداده، هر کدام از ویژگیها و لیبل از حالت توزیع نرمال خارج شوند و دچار چولگی (Skewness) شوند احتمال این رخداد افزایش مییابد.
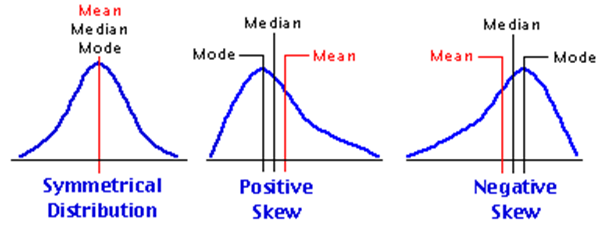
راهکارهای کاهش پیشبینی بایاسدار
- تنظیم وزن کلاسها
در این صورت میتوان برای کلاسهای با نمونه کمتر وزن و درجه اهمیت بیشتری تنظیم کرد تا به نحوی مجازات انتخاب اشتباه برای این کلاسها زیاد شود.
- اصلاح بایاس
استفاده از الگوریتمهایی که مدل را به حالت نرمال و متعادل نزدیک میکنند. به طور مثال اگر ویژگی و لیبل مجموعهداده پیوسته باشند و دارای چولگی زیادی باشند، استفاده از توابع جذر و لگاریتم میتواند انتخاب مناسبی برای حل این چالش باشد.
- تکنیکهای کاهش یا افزایش نمونه که در مبحث قبل مطرح شدند.
دادههای به شدت وابسته
وابستگی یا همبستگی (Correlation) بالا میان ویژگیهای مجموعهداده، انعطافپذیری مدل را کاهش میدهد که این امر میتواند منجر به ناکارآمدی مدلهای یادگیری ماشین شود. در این بخش، استراتژیهایی را برای حل این مسئله جهت پیشپردازش دادهها بررسی میکنیم.
تشخیص همبستگی زیاد
ماتریس وابستگی (Correlation Matrix): محاسبه ضرایب ارتباط بین جفت ویژگیها و تصویرسازی آنها با استفاده از نمودار حرارتی (Heat map). ویژگیهایی که ضرایب ارتباط نزدیک به 1 یا 1- دارند، به معنای وجود ارتباط بالا هستند و ممکن است نیاز به بررسی دقیقتر داشته باشند.

لازم به ذکر است که این فرمول رابطه خطی میان ویژگیها را بیان میدارد.
تکنیکهای مقابله با همبستگی بالا
- حذف ویژگی؛ اگر پس از رسم نمودار حرارتی متوجه رابطه بالا بین دو ویژگی شدیم، یکی از آنها را میتوان حذف کرد.
- استفاده از تکنیکهای کاهش ابعاد مسئله که در مباحث پیشین به آنها اشاره شد.
- انتخاب و مهندسی ویژگیها؛ این مورد به توانایی مهندس یادگیری ماشین و سطح تسلط او به مجموعهداده بستگی دارد.
نکته: در مواجه با مسائل رگرسیون، علاوه بر در نظرگرفتن همبستگی بالا میان ویژگیها، میبایست وابستگی خطی میان لیبل و تک تک ویژگیها بررسی شود. در چنین حالتی، اگر یک ویژگی رابطه خطی کمی با لیبل مسئله داشته باشد؛ میتوان آن را به شرطی که رابطه غیرخطی کمی نیز داشته باشد، حذف نمود. در بخش بعدی، نحوه محاسبه رابطه غیرخطی بیان خواهد شد.
رابطه غیر خطی بین فیچرها
رگرسیون خطی یک تکنیک اساسی در پیشپردازش دادهها است که برای مدلسازی رابطه بین متغیرهای وابسته و مستقل استفاده میشود. با این حال، این مدل همراه با چالشهایی است.
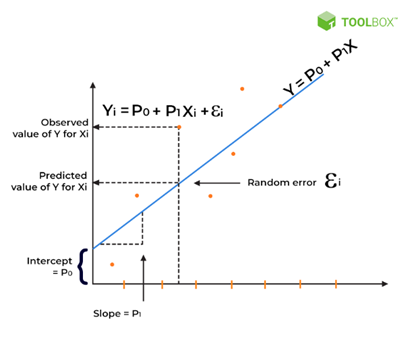
چالشهای رگرسیون خطی
- نقض فرضیات
رگرسیون خطی فرض میکند که روابط خطی، مستقل ازهم، و همبستگی یکنواختی بین ویژگیها وجود دارد. لذا نقض این فرضیات میتواند منجر به پیشبینیهای نادرست مدل در رگرسیون خطی شود.
- همبستگی غیرخطی بین ویژگیها
در مجموعهدادههای واقعی، رابطه بین ویژگیها و متغیر هدف ممکن است همیشه خطی نباشد. همبستگیهای غیرخطی یک چالش برای مدلهای رگرسیون خطی ایجاد میکنند.
مقابله با چالشهای رگرسیون خطی
برای رسیدگی به همبستگیهای غیرخطی بین ویژگیها در پیشپردازش دادهها، مدلهای جایگزینی وجود دارند؛ مانند:
رگرسیون چندجملهای (Polynomial Regression)
در این روش، ویژگیهای مجموعهداده تبدیل به ویژگیهای جدید و چند جملهای میشوند. قطعه کد زیر بیانگر این روش است:

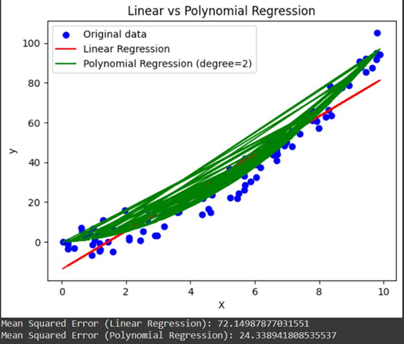
کد بالا بیانگر مقایسه دو روش رگرسیون خطی و چندجملهای است؛ همانطور که در شکل خروجی پیداست با تبدیل ویژگیهای متغیر مستقل به یک چندجملهای درجه دو، به وضوح عملکرد مدل در پیشبینی بهتر شدهاست.
الگوریتمهای Ensemble
روشهای Ensemble مانند جنگلهای تصادفی (Random Forest) و XGBoost به دلیل توانایی آنها در ثبت روابط غیرخطی و مدیریت مجموعهدادههای پیچیده، از جمله الگوریتمهای مشهور در این زمینه هستند. این مدلها پیشبینیهای چندین مدل را ترکیب میکنند تا عملکرد پیشبینی را بهبود بخشند. از مزایای این روشها، میتوان به Feature_Importance نام برد که به موجب آن هر مدل بعد از فرآیند یادگیری، مهمترین ویژگیها که بر مقدار لیبل اثر گذار هستند قابل نمایش میشوند. لذا می توان در پیشبینیهای بعدی فقط آن دسته از ویژگیها که حائز اهمیت بیشتری هستند لحاظ نمود.

قطعه کد بالا از بخشهای زیر تشکیل شدهاست:
- ایجاد مجموعه داده: ما از make_classification برای ایجاد یک مجموعه داده مصنوعی با ۱۰ ویژگی استفاده میکنیم.
- فرآیند یادگیری با کمک الگوریتم جنگل تصادفی
- نهایتا به کمک Feature_Importance، مهمترین ویژگیهای دیتافریم، استخراج و بصریسازی میشوند.
برای مطالعه بیشتر کلیک کنید: یادگیری گروهی در ماشین لرنینگ و روشهای آن را بهصورت کامل بشناسید!
روش Mutual Information
در دو روش ذکر شده، نیاز است که یک فرایند یادگیری روی دادهها انجام شود تا متوجه رابطه غیرخطی شویم. اما روشهای جایگزینی نیز وجود دارند که بدون نیاز به الگوریتمهای یادگیری مشهور، رابطه غیر خطی را محاسبه میکنند.
Mutual Information (MI) معیاری برای وابستگی متقابل بین دو متغیر است. در زمینه پیشپردازش دادهها، از آن برای ارزیابی رابطه بین ویژگیها و متغیر هدف (لیبل) استفاده میشود. MI یک معیار غیرخطی است و میتواند هر نوع رابطهای بین متغیرها را بهدست آورد، برخلاف همبستگی خطی. در مرحله مهندسی ویژگی، MI میتواند در انتخاب ویژگیهای مرتبطترین کمک کند و در نتیجه ابعاد را کاهش داده و عملکرد مدل را بهبود بخشد. همچنین میتواند برای شناسایی و حذف ویژگیهای زائد که اطلاعات جدیدی درباره متغیر هدف ارائه نمیدهند، استفاده شود.
نحوه کارکرد MI
نحوه کارکرد MI برای متغیرهای گسسته بر اساس توزیع احتمال مشترک متغیرها است. برای متغیرهای پیوسته، تخمین MI اغلب شامل گسستهسازی (discretization) یا استفاده از تکنیکهایی مانند تخمین چگالی کرنل (Kernel Density Estimation) است. خروجی MI نیز یک عدد غیر منفی است و مقادیر بالاتر نشاندهنده اطلاعات مشترک بیشتر بین دو متغیر هستند.
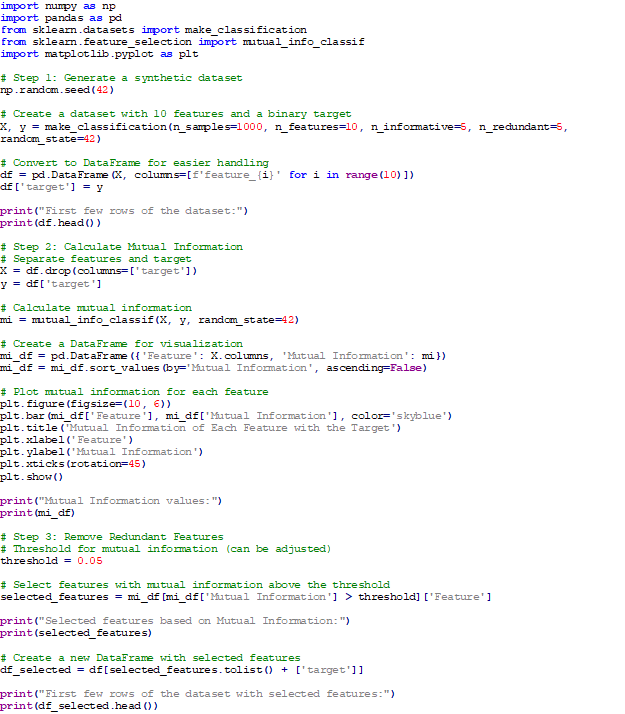
قطعه کد بیانگر کاربرد MI در یک دیتاست را نشان میدهد که از بخشهای زیر تشکیل شده است:
- ایجاد مجموعه داده: از make_classification برای ایجاد یک مجموعه داده با ۱۰ ویژگی که شامل ۵ ویژگی اصلی و ۵ ویژگی زائد است، استفاده میکنیم.
- محاسبه MI: از mutual_info_classif برای محاسبه همبستگی متقابل بین هر ویژگی و متغیر هدف استفاده میکنیم.
- تجسم نتایج حاصل از MI:
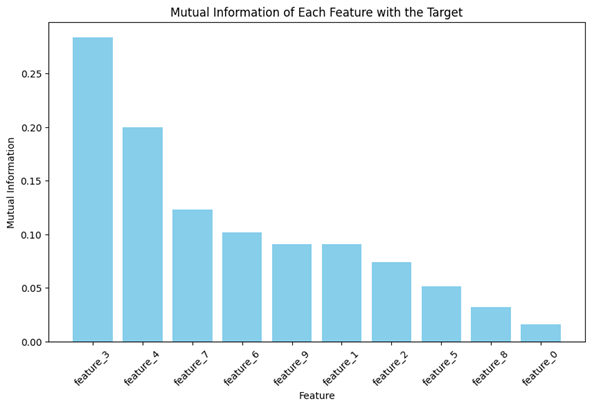
- تعیین آستانه و انتخاب ویژگیها: یک آستانه برای MI تعیین میکنیم (در اینجا ۰.۰5) و ویژگیهایی را که امتیاز آنها بالاتر از آستانه است انتخاب میکنیم و یک DataFrame جدید با آن ویژگیها ایجاد میکنیم.
برای دسترسی به کد نوتبوکهای این بلاگ روی این کلیک کنید.
جمعبندی
مسیر یادگیری علم داده و یادگیری ماشین همراه با چالشهای متنوع و البته راهحلهایی است. از تکنیکهای پیشپردازش دادهها تا رسیدگی به مجموعهدادههای نامتوازن، رسیدگی به ابعاد بالا، و مقابله با ارتباطات غیرخطی؛ در این مقاله بر اهمیت اتخاذ استراتژیهای مناسب تأکید گردید و مشاهده شد که با بهرهگیری روش مناسب، یک مهندس یادگیری ماشین میتواند مسیر را برای پیشبینیهای دقیقتر و بینشهای قابل اجرا هموار کند.

پرسشهای متداول
روش KNN Imputer چگونه مقادیر گمشده را مدیریت میکند؟
KNN Imputer با در نظر گرفتن شباهتهای بین نقاط داده، مقادیر گمشده را بر اساس همسایگان نزدیک تخمین میزند. این روش به تخمین دقیقتر مقادیر گمشده کمک میکند.
روش Z-score چگونه به شناسایی دادههای پرت کمک میکند؟
روش Z-score نقاط ناهنجار را بر اساس انحراف از میانگین یا میانه توزیع دادهها شناسایی میکند. دادههایی که خارج از محدوده 3 برابری انحراف معیار هستند، به عنوان داده پرت در نظر گرفته میشوند.
مجموعهدادههای با ابعاد بالا چه چالشهایی ایجاد میکنند؟
مجموعهدادههای با ابعاد بالا چالشهایی از نظر منابع محاسباتی، پیچیدگی مدل و قابل تفسیر بودن در یادگیری ماشین و تجزیه و تحلیل داده ایجاد میکنند.
Mutual Information چه کاربردی در پیشپردازش دادهها دارد؟
MI معیاری برای ارزیابی رابطه بین ویژگیها و متغیر هدف است که میتواند روابط غیرخطی را شناسایی کرده و در انتخاب ویژگیهای مرتبط کمک کند، در نتیجه ابعاد را کاهش داده و عملکرد مدل را بهبود میبخشد.
چرا مجموعهدادههای نامتوازن چالشبرانگیز هستند؟
مجموعهدادههای نامتوازن میتوانند منجر به مدلهای بایاسدار شوند که برای کلاسهای اکثریت اولویت قائل شده و پیشبینی ضعیفی برای کلاسهای اقلیتی دارند.
یادگیری ماشین لرنینگ را از امروز شروع کنید!
دنیای دادهها جذاب است و دانستن علم داده، توانایی تحلیل داده، یا بازاریابی مبتنی بر داده، شما را برای فرصتهای شغلی بسیاری مناسب میکند. فارغ از رشته و پیشزمینه، میتوانید حالا شروع کنید و از سطح مقدماتی تا پیشرفته بیاموزید. اگر دوست دارید به این حوزه وارد شوید، پیشنهاد میکنیم با کلیک روی این لینک قدم اول را همین حالا بردارید.
مشاوران کافهتدریس به شما کمک میکنند مسیر یادگیری برای ورود به این حوزه را شروع کنید: