
پردازش صوت حوزهای است که بهسرعت در حال توسعه است. در این مطلب به اکتشاف ویژگیهای کلیدی صدا، از فرکانس و دامنه گرفته تا تکنیکهای نمونهبرداری و طیفنگاری، میپردازیم. هدف ما ارائه دیدگاهی عمیق درباره چگونگی تبدیل دادههای آنالوگ به دیجیتال و استفاده از این دادهها در مواردی نظیر تشخیص گفتار و طبقهبندی موسیقی است. این مطلب نقطه شروعی برای هر کسی است که به فناوری صوتی و پردازش صوت علاقهمند است و میخواهد درک بهتری از این حوزه پرچالش و پرکاربرد داشته باشد.
- 1. صوت چیست؟
- 2. پردازش صوت چطور انجام میشود و چطور صوت را به دادههای دیجیتالی تبدیل میکنیم؟
- 3. فرمت نهایی دادههای صوتی برای آموزش مدلهای ماشین لرنینگ
- 4. چه پروژههای دیگری میتوان در حوزه پردازش صوت انجام داد؟
- 5. فناوریهای کاربردی در پردازش صوت
- 6. خلاصه مطلب درباره پردازش صوت
-
7.
پرسشهای متداول
- 7.1. چرا نرخ نمونهبرداری (Sample Rate) در کیفیت فایلهای صوتی نقش مهمی دارد؟
- 7.2. طیفنگاری (Spectrography) چگونه میتواند در تحلیل صوتی به ما کمک کند؟
- 7.3. تفاوت میان پردازش صوت آنالوگ (Analog) و دیجیتال (Digital) در چیست و کدامیک برای مصارف خاص ترجیح داده میشود؟
- 7.4. چگونه فرمتهای مختلف صوتی مانند WAV و MP3 و WMA بر استفاده از فایلهای صوتی تأثیر میگذارند؟
- 7.5. کاربردهای یادگیری عمیق (Deep Learning) در پردازش صوتی چیست و چه نوآوریهایی را میتوان انتظار داشت؟
- 8. یادگیری دیتا ساینس و ماشین لرنینگ را از امروز شروع کنید!
صوت چیست؟
در یک نگاه ساده، صدا بر اثر تغییرات فشار هوا تولید میشود، اما در تعریف فیزیکی صوت یک موج مکانیکی طولی است که میتواند ازطریق ارتعاشات در محیطهای مختلف (مانند هوا، آب و جامدات) منتقل شود. امواج خصوصیاتی مانند طول موج، فرکانس و دامنه دارند که ویژگیهای صوت را تعیین میکنند. در ادامه هر یک از این خاصیتها را بررسی کردهایم.
طول موج (Wave length)
طول موج صوت فاصلهای است که یک موج صوتی در طی یک چرخه کامل ارتعاش طی میکند؛ بهعبارت دیگر، طول موج فاصله میان دو قله یا دو دره متوالی در آن موج است.
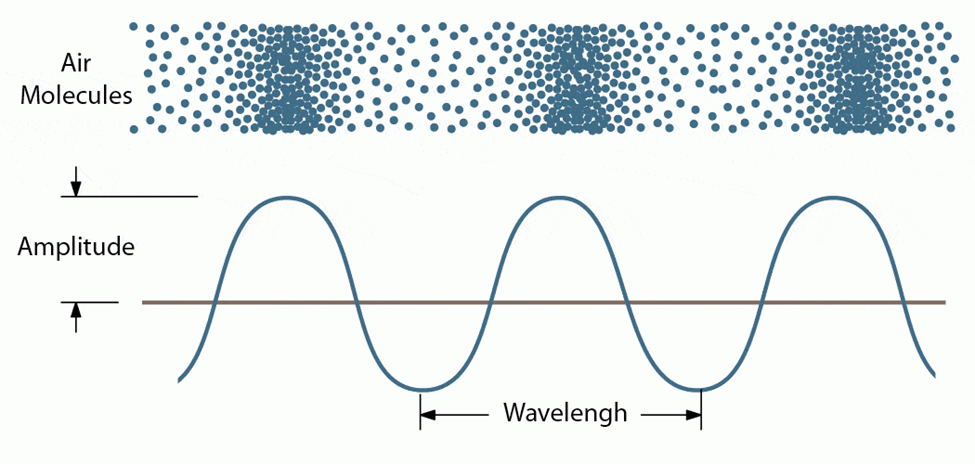
دامنه (Amplitude)
دامنه بیانگر ارتفاع حداکثری از نقطه میانی تا بالاترین یا پایینترین نقطه یک موج صوتی است. صداهای با دامنه بزرگتر بلندتر شنیده میشوند و صداهای با دامنه کوچکتر آرامتر به نظر میرسند.
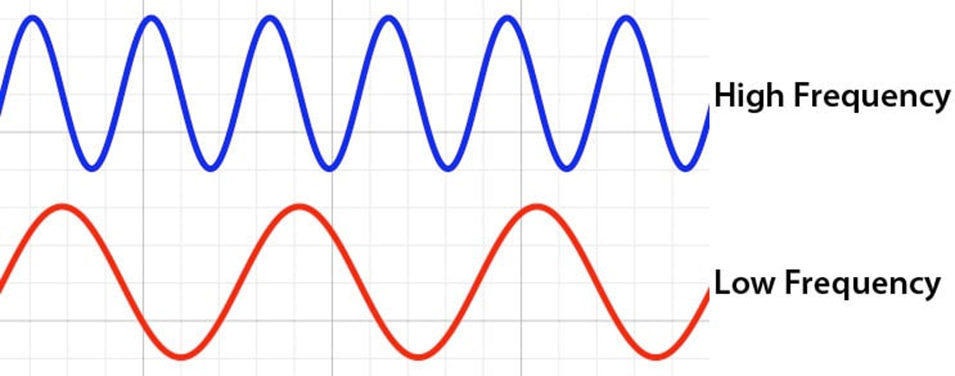
فرکانس (Frequency)
فرکانس موج صوتی به تعداد دفعاتی که آن موج در یک ثانیه تکرار میشود اشاره میکند و با واحد هرتز (Hz) اندازهگیری میشود؛ بهعبارت دیگر، فرکانس نشاندهنده سرعت ارتعاشاتی است که توسط منبع صدا ایجاد میشوند و مستقیماً بر ادراک ما از صدا تأثیر میگذارد؛ صداهایی با فرکانس بیشتر، زیر و صداهایی با فرکانس کمتر، بم شنیده میشوند. هر چه فرکانس یک صوت بیشتر باشد، انرژی آن نیز بیشتر است.
پردازش صوت آنالوگ درمقابل پردازش صوت دیجیتال
در پردازش صوت آنالوگ صوت بهصورت مستقیم و بدون تبدیل به دادههای دیجیتالی (یعنی بههمان حالت پیوسته که بود) پردازش میشود، اما در پردازش صوت دیجیتال ابتدا صوتها را به دادههای دیجیتال تبدیل میکنیم و بهاین ترتیب، امکان استفاده از الگوریتمهای پیچیدهتر فراهم میشود.
پردازش صوت چطور انجام میشود و چطور صوت را به دادههای دیجیتالی تبدیل میکنیم؟
برای دیجیتالیکردن یک موج صوتی باید سیگنال مدنظر را به یک سری عدد تبدیل کنیم تا بتوانیم آن را به مدلهای خود وارد کنیم. این کار با اندازهگیری دامنه صدا (بهعنوان نمایندهای از شدت آن) در فاصلههای زمانی ثابت انجام میشود. به این کار سمپلگیری (Sampling) میگویند.
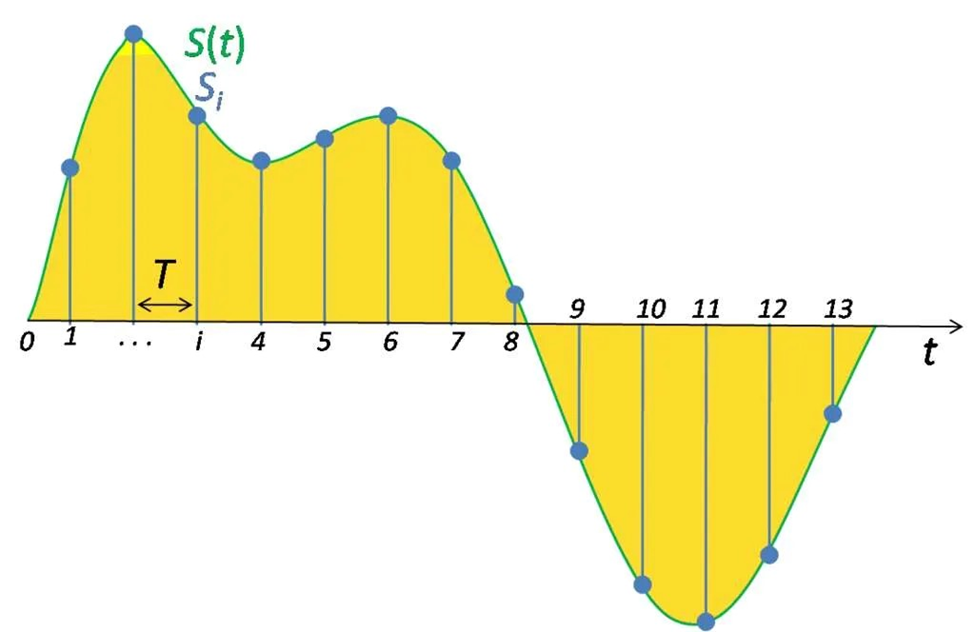
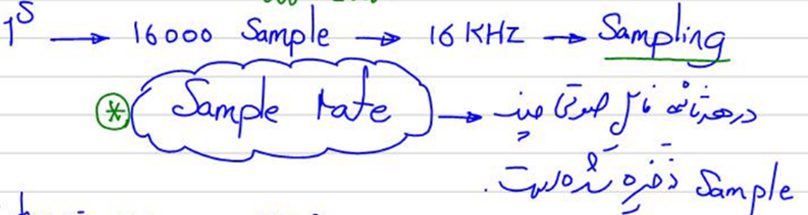
هر اندازهگیری از این نوع یک نمونه (Sample) نامیده میشود و نرخ نمونهبرداری (Sample Rate) تعداد نمونهها در هر ثانیه است. بهطور معمول، یک نمونهگیری حدود ۴۴۱۰۰ نمونه در هر ثانیه را شامل میشود؛ این یعنی مثلاً یک کلیپ موسیقی ۱۰ ثانیهای ۴۴۱۰۰۰ نمونه خواهد داشت. یک تعریف سادهتر از نرخ نمونهبرداری در جزوه پردازش صوت دوره علم داده ۲ استاد شکرزاد اینجا آمده است:
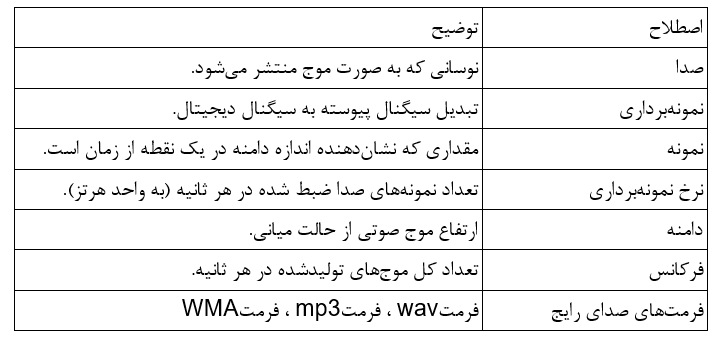
بهطور خلاصه، تمامی اصطلاحات رایج این حوزه را در این جدول جمعآوری کردهایم:
فرمت نهایی دادههای صوتی برای آموزش مدلهای ماشین لرنینگ
برای آموزش یک مدل یادگیری ماشین، چندین گزینه برای پیشپردازش و ارائه دادهها وجود دارد. نوع دادهای که باید به مدل داده شود، به هدف ما از آموزش مدل بستگی زیادی دارد؛ مثلاً اینکه تسک ما تشخیص گفتار (Speech recognition) است یا طبقهبندی (Music classification) موسیقی.
همچنین این موضوع به معماری مدل نیز بستگی دارد. در اینجا رایجترین انواع نمایشهای دادهای که در پردازش صوت برای یادگیری ماشین استفاده میشوند آورده شده است. برای فهم بیشتر روی یک فایل صوتی که کلمه Hello را تلفظ میکند کار میکنیم:
ابتدا کتابخانههای موردنیاز را فراخوانی میکنیم و فایل مدنظر را میخوانیم؛ سپس پسوند آن را به wav تغییر میدهیم. فرمت wav فایلهای صوتی را بهصورت خام و بدون فشردهسازی ذخیره میکند و این ویژگیها به این میانجامد که تجزیهوتحلیل صوتی دقیقتر و کارآمدتری داشته باشیم؛ بههمین دلیل، اغلب فرمت صوتی wav برای تحلیل دادهها ترجیح داده میشود.
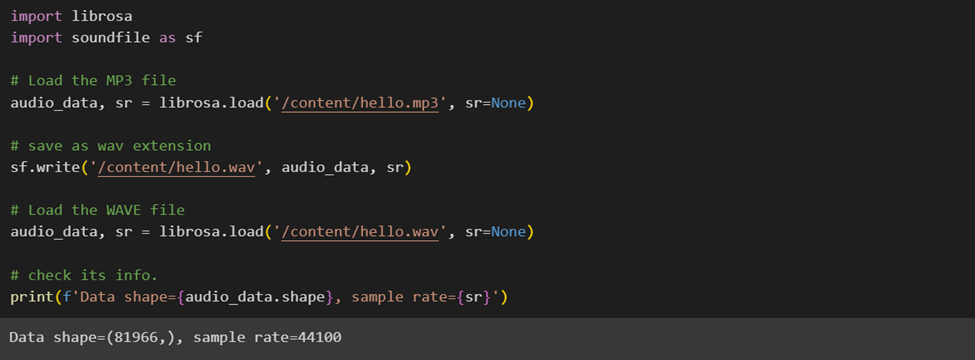
موجهای صوتی خام
گاهی میتوان بهطور مستقیم از نمونههای صوتی خام بهعنوان ورودی استفاده کرد. در این قسمت میخواهیم دامنه سیگنال را بهصورت تابعی از زمان رسم کنیم.
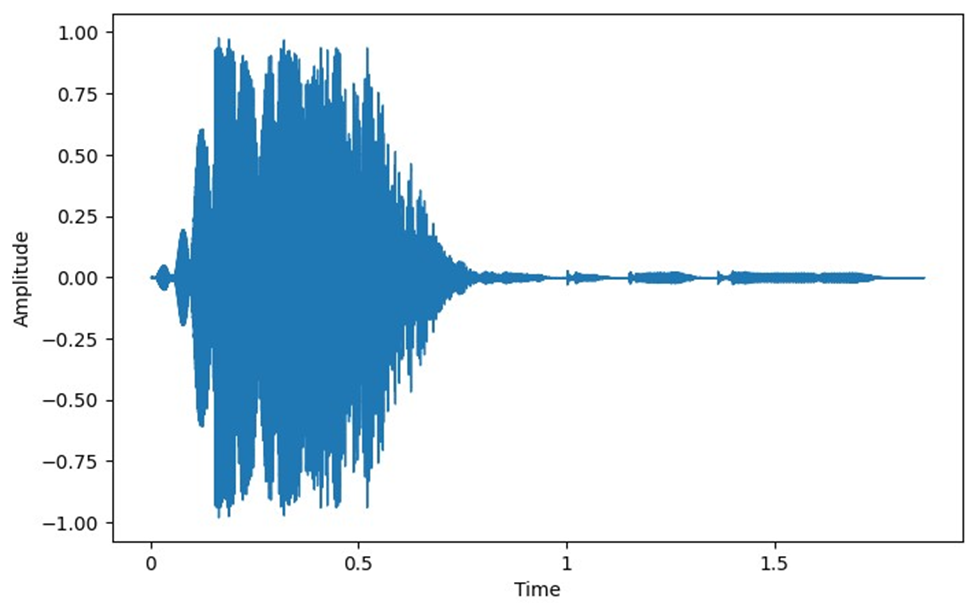
نمودار دامنه برحسب زمان صوت به ما اطلاعاتی درباره بلندی و زمان وقوع صداهای مختلف در طول فایل صوتی میدهد که برای تحلیل ساختار کلی صدا مفید است. خروجی کد بالا برای فایل صوتی ما بهاین شکل است:
برخی از معماریهای یادگیری عمیق قادر به یادگیری مستقیم از روی موج صوتی خام هستند که میتوانند داینامیکهای زمانی دقیق را درک کنند. شبکههای عصبی کانولوشنی یکبعدی (Conv1D) و برخی از انواع شبکههای عصبی بازگشتی (RNN) قادر به انجامدادن این کار هستند.
اما این نوع داده اطلاعات زیادی درباره فرکانسهای حاضر در صوت به ما نمیدهد و برای رفع این عیب میتوان طیفنگاری انجام داد. بیایید ابتدا درباره مفاهیمی چون طیف و طیفنگاری بیشتر بخوانیم.
طیف (Spectrum) چیست؟
طیف در پردازش صوتی به توزیع فرکانسی یک سیگنال صوتی اشاره میکند و یکی از مفاهیم کلیدی در تحلیل صدا به شمار میرود. هر سیگنال صوتی میتواند به مجموعهای از اجزای فرکانسی تجزیه شود که هر یک دامنه و فاز مخصوصبهخود را دارند. طیف به ما نشان میدهد که کدام فرکانسها در سیگنال وجود دارند و هر فرکانس چه شدتی دارد.
برای مثال، در موسیقی طیف میتواند به ما کمک کند تا صداهای مختلف مانند سازها و صدای خواننده را بهتر تفکیک کنیم. در تحلیل گفتار هم تجزیهوتحلیل طیف میتواند برای تشخیص ویژگیهای خاصی مانند تٌن صدا یا لهجه استفاده شود.
طیفنگاری چیست؟
طیفنگاری روشی است که نحوه تغییر فرکانسهای یک سیگنال صوتی را در طول زمان نمایش میدهد. بهبیان ساده، این نمودار مانند عکسی از صداهایی است که سیگنال در طول زمان تولید میکند. در طیفنگاری، زمان روی محور افقی (x) و فرکانس روی محور عمودی (y) قرار دارد؛ بنابراین میتوان دید که در هر لحظه از زمان چه فرکانسهایی در سیگنال وجود دارند و با چه شدتی.
رنگها در طیفنگاری نشاندهنده قدرت یا دامنه فرکانسها هستند؛ رنگهای روشنتر بهمعنای انرژی بیشتر و رنگهای تیرهتر بهمعنای انرژی کمتر است. هر بخش عمودی از نمودار که به آن برش گفته میشود، طیف سیگنال را در آن لحظه نشان میدهد و توزیع شدت فرکانسهای موجود در سیگنال را در آن زمان خاص به تصویر میکشد.
طیفنگاری چطور انجام میشود؟
طیفنگاریها با استفاده از فرایند تبدیل فوریه که یک تکنیک ریاضی برای تجزیهوتحلیل فرکانسهای مختلف درون یک سیگنال است تولید میشوند. این کار به ما کمک میکند تا سیگنالهای زمانمحور را به دادههای فرکانسمحور تبدیل کنیم. در مرحلههای تولید یک طیفنگاری، ابتدا سیگنال صوتی در بازههای زمانی کوتاه تقسیم میشود؛ سپس برای هر بخش تبدیل فوریه انجام میشود تا اطلاعات فرکانسی آن استخراج شود.
طیفنگارها
طیفنگارها (Spectrograms) اسپکتروگرام نمایش بصری از طیف فرکانسهای صداست که با گذشت زمان تغییر میکند. این نمایش با اعمال تبدیل فوریه روی سیگنال صوتی به دست میآید. درواقع طیفنگارها نمایش فشردهای از ویژگیهای زمان-فرکانس صدا را فراهم میکند.
البته اگر مثل من رابطه خوبی با تبدیل فوریه ندارید، نگران نباشید! برای پردازش و کارکردن با دادههای صوتی نیازی نیست تبدیل فوریه بلد باشید؛ چون پکیجهای پایتونی خود این کار را برایتان انجام میدهند. با استفاده از تابع specshow در کتابخانه Librosa میتوانیم طیفنگاره فایل صوتیمان را رسم میکنیم:
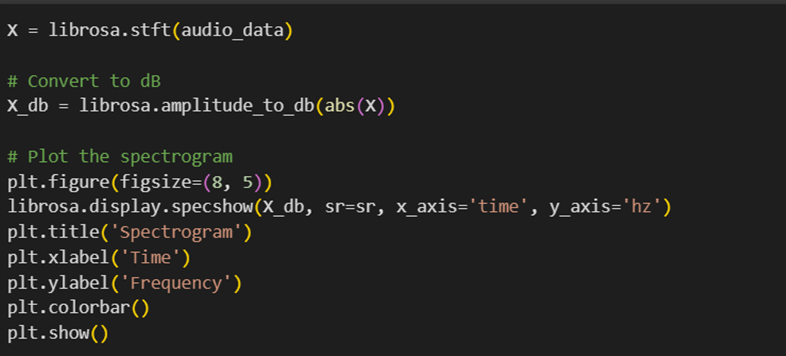
شایان ذکر است که تابع ()stft که مخفف Short-Time Fourier Transform است، یک ابزار اساسی در تجزیهوتحلیل سیگنالهای صوتی است. این تابع یک تبدیل فوریه معمولی را به قطعههای کوچکتر زمانی تقسیم میکند، بهاین معنی که بهجای درنظرگرفتن کل سیگنال صوتی برای محاسبه فرکانسها، فقط قسمتهای کوچکی از سیگنال را در هر بار محاسبه میکند. این روش به ما اجازه میدهد تا تغییرات فرکانسی در طول زمان را تشخیص دهیم. خروجی این کد را میتوانید در این شکل ببینید:
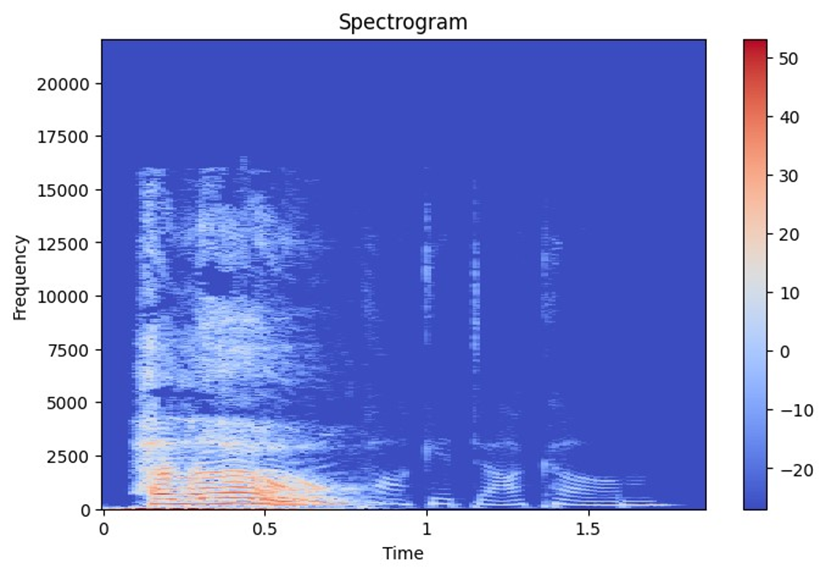
طیفنگارهی یک صوت را میتوان با استفاده از مدلهای شبکه عصبی کانولوشنی دوبعدی (Conv2D) تحلیل کرد؛ زیرا طیفنگارهها میتوانند شبیه به دادههای تصویری تلقی شوند.
طیفنگاره مقیاسشده
طیفنگارهی مقیاسشده (Mel-Spectrogram) نوعی از اسپکتروگرام است که در آن مقیاس فرکانس به مقیاس Mel تبدیل شده است که به نحوه درک صدا توسط انسان نزدیکتر است. این طیفنگاری با تقسیم فایل صوتی به قطعههای کوچک (مثلاً نیمثانیه) ساخته میشود و با استفاده از تبدیل فوریه، فرکانسهای هر قطعه تعیین میگردند تا میزان قوت هر فرکانس در آن دوره زمانی مشخص شود.
جالب است بدانید ما انسانها صداها را بهشکل خطی ادراک نمیکنیم، بهاین معنی که تفاوت میان صداهای با فرکانس پایین را راحتتر از صداهای با فرکانس بالا تشخیص میدهیم. برای اینکه طیفنگاری ما به ادراک انسانی نزدیکتر باشد، از یک مقیاس غیرخطی بهنام مقیاس Mel استفاده میکنیم. این کار به این میانجامد نمودار نهایی برای ما قابلفهمتر باشد. با استفاده از تابع specshow در کتابخانه Librosa میتوانیم طیفنگاره مقیاسشده فایل صوتیمان را رسم کنیم:
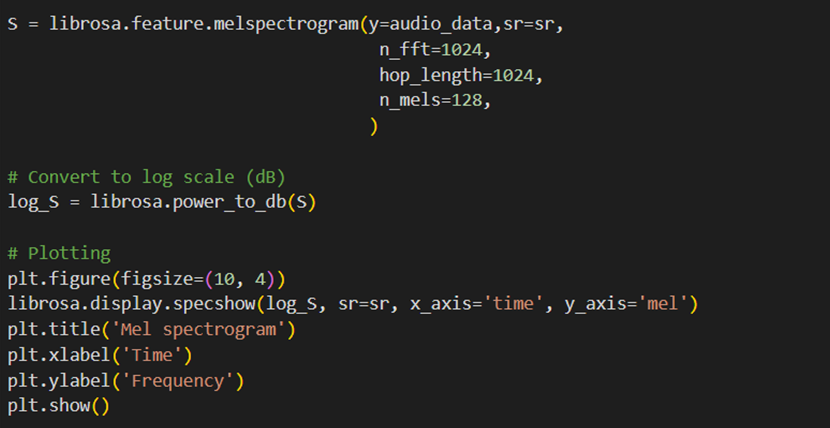
خروجی این کد را میتوانید در این شکل ببینید:

این نوع طیفنگاره را نیز میتوان با استفاده از مدلهای شبکه عصبی کانولوشنی دوبعدی (Conv2D) تحلیل کرد.
Mel-frequency cepstral coefficients
Mel-frequency cepstral coefficients در پردازش صوت، ضریب سپسترال فرکانس یا MFCC، نمایشی از طیف توان کوتاه مدت صداست. این نما بهگونهای طراحی شده است که شباهت بیشتری به نحوه درک صدا توسط گوش انسان داشته باشد. بهطور کلی، MFCC روشی کارآمد برای استخراج ویژگیهای مفید از سیگنالهای صوتی است که درک بهتری از محتوای صوتی برای ماشین فراهم میکند.
اولین گام تقسیمبندی سیگنال صوتی تقسیم آن به قطعههای کوچکتر است. این کار با استفاده از یک روش بهنام پنجرهگذاری انجام میشود که به کاهش تغییرات ناگهانی در دادهها کمک میکند و تجزیهوتحلیل دادهها را آسانتر میکند.
انجامدادن تبدیل فوریه گسسته (DFT) پس از پنجرهگذاری، برای هر قطعه، تبدیل فوریه گسسته انجام میشود. این تبدیل به شناسایی فرکانسهای موجود در هر قطعه و مشخصکردن شدت هر فرکانس کمک میکند.
محاسبه لگاریتم دامنهها پس از بهدستآوردن طیف فرکانسی هر قطعه لگاریتم دامنههای هر فرکانس گرفته میشود. این کار به تأکید بر تغییرات ریز در دامنهها کمک میکند و اطلاعات مهم برای تشخیص گفتار را در میآورد.
تغییر فرکانسها به مقیاس Mel فرکانسهای بهدستآمده در مرحله قبل تغییر مییابند تا به مقیاس Mel برسند. این مقیاس بهگونهای طراحی شده که نزدیک به نحوه ادراک فرکانس توسط گوش انسان است. انجامدادن تبدیل کسینوسی گسسته (DCT)، درنهایت، تبدیل کسینوسی گسسته روی لگاریتمهای دادههای مل انجام میشود. این مرحله به کاهش همبستگی میان نمونههای فرکانسی کمک میکند و اطلاعات مهم را در تعداد محدودتری از ضرایب متمرکز میکند. این امر درنهایت به بهبود تشخیص گفتار کمک میکند. با استفاده از تابع specshow در کتابخانه Librosa میتوانیم خروجی یک مقیاسشده فایل صوتیمان را رسم میکنیم:

خروجی این کد در این شکل قابلمشاهده است:
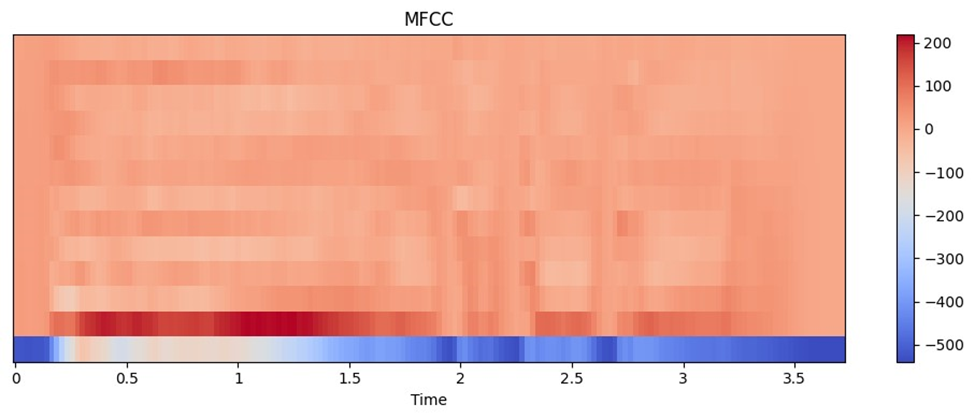
این روش اغلب با معماریهای شبکه عصبی ساده یا زمانی که منابع محاسباتی محدود هستند استفاده میشود.
همچنین برای دیدن محتوای داخل متغیر mfcc کد بالا میتوان بهاین ترتیب عمل کرد:
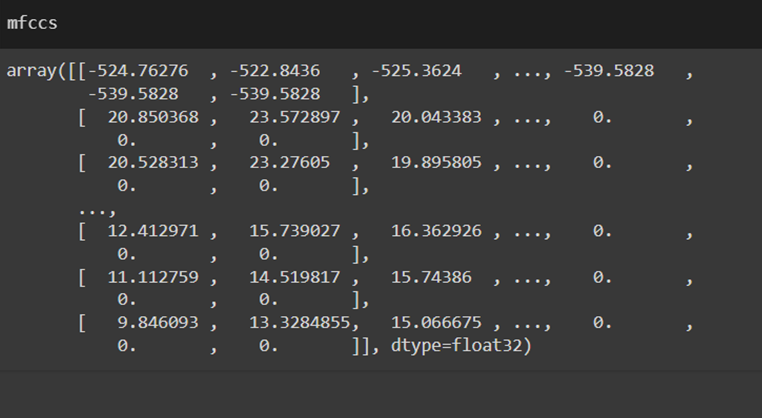
تفسیر خروجی MFCC
تعداد ضرایب هر سطر در ماتریس نمایشدهنده یک ضریب MFCC است. معمولاً اولین ضریب نشاندهنده انرژی کلی سیگنال در آن فریم زمانی است و باقی ضرایب جزئیات بیشتری درمورد طیف صوتی را ارائه میکنند.
تغییرات زمانی هر ستون به یک فریم زمانی خاص مربوط است. با توجه به این ستونها، میتوانید تغییرات ویژگیهای صوتی را در طول زمان ببینید. این اطلاعات برای تشخیص الگوهای گفتاری یا تغییرات در صدا مفید است.
رنگها و شدت در نمایش گرافیکی، رنگها شدت هر ضریب MFCC را در هر فریم زمانی نشان میدهند. رنگهای گرمتر (مانند قرمز) شدت بالاتری را نشان میدهند و رنگهای سردتر (مانند آبی) شدت پایینتری را نمایش میدهند.
تعیین جنسیت براساس صدا
یکی از رایجترین کاربردهای یادگیری عمیق در حوزه پردازش صوت طبقهبندی صداهاست. این فرایند شامل شناسایی و دستهبندی انواع صداها به چندین کلاس مختلف میشود؛ برای مثال، ممکن است در یک پروژه هدف تعیین نوع یا منبع صدا باشد، مانند تشخیص صدای خانمها و آقایان. در این قسمت میخواهیم یک نمونه از پروژههای مربوط به این تسک را اجرا کنیم.
ابتدا تمامی کتابخانههای موردنیاز را فراخوانی و سپس دادهها را دانلود میکنیم:
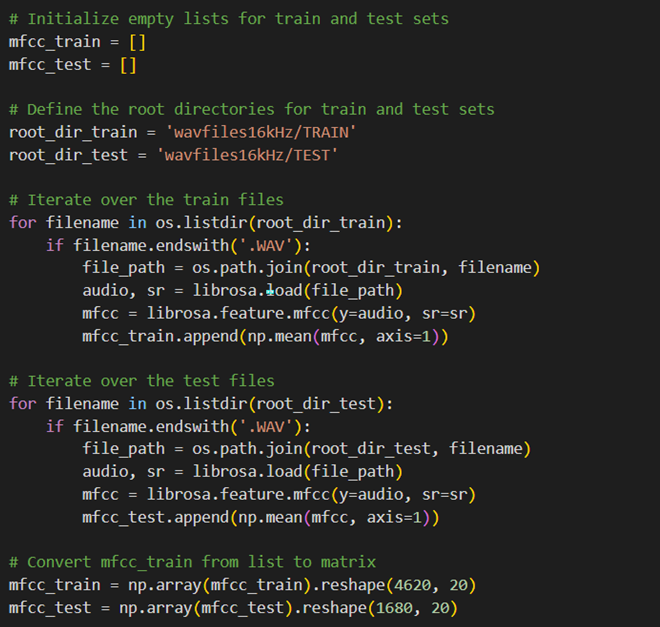
حال با استفاده از کد زیر دیتاست مدنظر را میسازیم. در این کد ابتدا دادههای خام صوتی در یک فهرست جمعآوری میشود و سپس با استفاده از تابع mfcc کتابخانه Librosa، Featureهای آن را استخراج میکنیم و در فهرستمان میریزیم.
از آنجا که خروجی یک فهرست بهاندازه تعداد صوتهای داده Trainمان است و خروجی mfcc شامل ۲۰ Value به عنوان تعداد Featureها، باید فهرست را ابتدا numpy array کرده و سپس آن را به یک ماتریس به ابعاد تعداد داده در تعداد Featureها تبدیل کنیم:
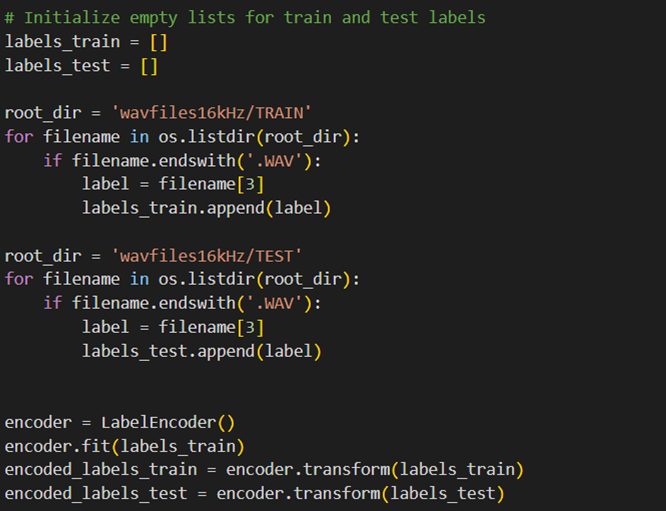
در ادامه فهرست Labelهای متناظر با هر صورت را بهاین شکل میسازیم:
در پایان مدل مدنظر را که یک پرسپترون چندلایه است میسازیم و آن را روی دادههای خود آموزش میدهیم:
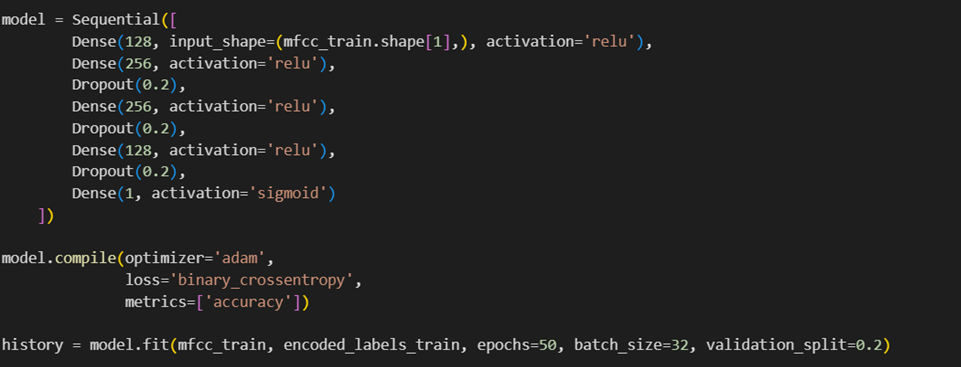
در مرحله ارزیابی دقت مدل ما برای تشخیص زنبودن یا مردبودن صاحب یک صدا با دقت ۹۶ درصد به دست آمد:

چه پروژههای دیگری میتوان در حوزه پردازش صوت انجام داد؟
صداها در محیطهای مختلف بهشکلهای گوناگونی یافت میشوند، ازجمله گفتار انسانها، موسیقی، صدای حیوانات و دیگر صداهای طبیعی یا صداهای ایجادشده توسط فعالیتهای انسانی مانند خودروها و ماشینآلات. در ادامه چگونگی بهرهگیری از یادگیری عمیق در پردازش و تحلیل انواع صداها را بررسی میکنیم:
جداسازی و تقطیع صدا
جداسازی صدا بهمعنای استخراج یک سیگنال خاص از مخلوطی از سیگنالها است تا بتوان آن را برای پردازشهای بیشتر استفاده کرد؛ برای مثال، ممکن است بخواهید صدای افراد مختلف را از پسزمینه پرسروصدا جدا کنید:
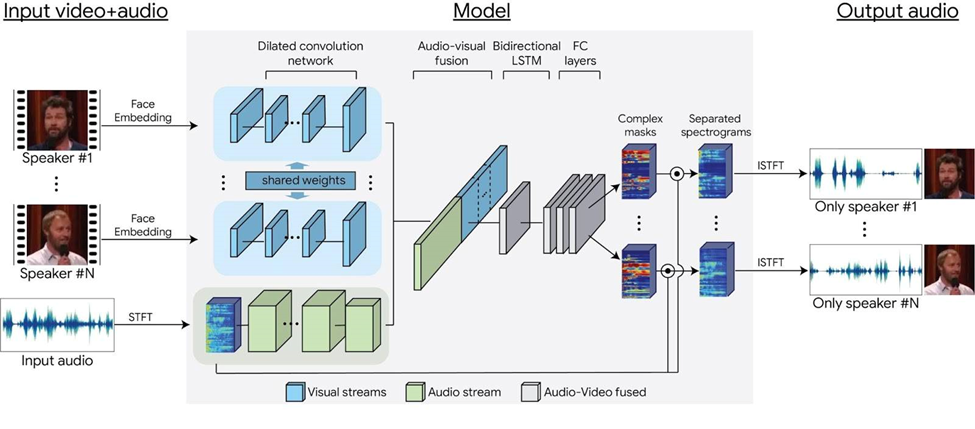
تقطیع صدا نیز بهمنظور برجستهسازی بخشهای مهم از جریان صدا استفاده میشود، مثلاً برای تشخیص تغییرات صدای قلب انسان بهمنظور تشخیص ناهنجاریها.
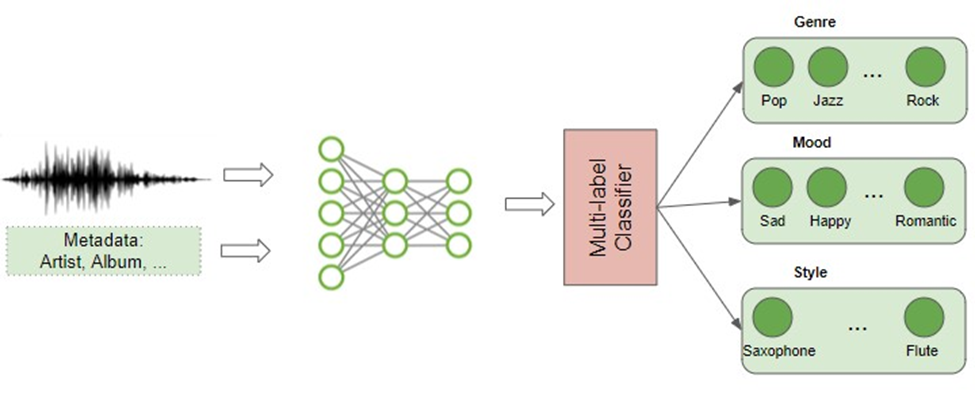
طبقهبندی ژانر موسیقی
با محبوبیت سرویسهای پخش موسیقی، طبقهبندی ژانر موسیقی نیز به یکی از کاربردهای رایج تبدیل شده است. این فرایند تحلیل محتوای موسیقی برای تعیین ژانر آن را شامل است. این مسئله یک مسئله طبقهبندی چندبرچسبی (Multi Label Classification) است؛ زیرا یک قطعه موسیقی ممکن است در چند ژانر مختلف قرار گیرد.
تولید موسیقی
امروزه همچنین استفاده از یادگیری عمیق برای تولید موسیقی را شاهد هستیم که میتواند مطابق با یک ژانر خاص، ساز یا سبک یک آهنگساز باشد.
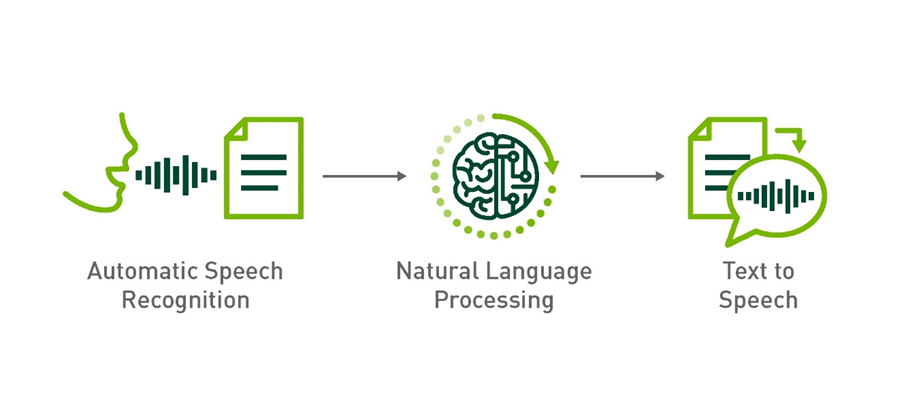
تبدیل گفتار به متن و برعکس
یکی دیگر از کاربردهای پیچیده تبدیل گفتار به متن و برعکس است. این فرایند، نهتنها تجزیهوتحلیل صدا را در بر میگیرد، به دانش پردازش زبان طبیعی (NLP) نیز نیاز دارد.
با استفاده از این فناوریها، میتوان کاربردهای متعددی را در زندگی کسبوکاری و شخصی فراهم آورد. دستیاران مجازی مانند Alexa، Siri و Google Home نمونههایی از محصولات مصرفی هستند که بر پایه این قابلیتها ساخته شدهاند. تواناییهای فراوان این فناوری تازه شروع به نمایانشدن کردهاند و افقهای جدیدی را در پیش روی ما قرار دادهاند.
فناوریهای کاربردی در پردازش صوت
تغییر صوت با استفاده از هوش مصنوعی یکی از جذابترین و درعینحال پیچیدهترین کاربردهای فناوریهای نوین است. این فناوری میتواند برای هدفهای مختلفی ازجمله سرگرمی، امنیت و تغییردادن نحوه ارتباط استفاده شود. در اینجا به برخی از بهترین ابزارهای موجود در این زمینه که با استفاده از هوش مصنوعی کار میکنند اشاره میکنیم.
Descript Overdub
Descript Overdub یکی از پیشرفتهترین ابزارها در زمینه تغییر صوت است. این نرمافزار به کاربران اجازه میدهد که با استفاده از فناوری هوش مصنوعی، صدای خود یا دیگران را تغییر دهند. این ابزار میتواند برای تولید محتوای صوتی، دوبله فیلم یا حتی تولید پادکست استفاده شود.
Respeecher
Respeecher یک ابزار قدرتمند برای تغییر صوت است که به کاربران این امکان میدهد صداها را بهشکلی واقعگرایانه تغییر دهند. این سرویس بهخصوص در صنعت سینما و تلویزیون برای بازسازی صدای بازیگرانی که دیگر در قید حیات نیستند یا جوانسازی صدای بازیگران مسنتر استفاده شده است.
Modulate.ai
Modulate یک ابزار تغییر صوت است که بهویژه برای استفاده در بازیهای ویدئویی و واقعیت مجازی طراحی شده است. این فناوری به بازیکنان اجازه میدهد تا صدای خود را بهصورت زنده تغییر دهند و یک تجربه ارتباطی منحصربهفرد ایجاد کنند.
iZotope RX
iZotope RX، نهتنها برای ترمیم و تصحیح فایلهای صوتی استفاده میشود، میتواند در تغییر و تعدیل صداها نیز کاربرد داشته باشد. این نرمافزار از پیشرفتهترین فناوریهای هوش مصنوعی برای تجزیهوتحلیل و تغییر دادههای صوتی بهره میبرد.
برای آشنایی با این سازوکار پیشنهاد میکنیم مطلب بهترین ابزارهای تغییر صدا با هوش مصنوعی را مطالعه کنید.
خلاصه مطلب درباره پردازش صوت
در این مطلب جنبههای مختلف پردازش صوت ازجمله خصوصیات اصلی امواج صوتی، روشهای پردازش آنالوگ و دیجیتال، تبدیلات فوریه و استفاده از طیفنگارهها را بررسی کردیم؛ علاوهبراین انواع فرمتهای صوتی و اهمیت نمونهبرداری و نرخ نمونهبرداری را هم توضیح دادیم. همچنین تکنیکهای مختلف تحلیل صوت مانند Mfcc و کاربردهای عملی آنها در تشخیص گفتار و طبقهبندی موسیقی را بررسی کنیم.
آنچه مشخص است امکان پیادهسازی فناوریهای پیچیدهتر و دقیقتر با پیشرفت در زمینه پردازش صوت است که میتواند در زمینههای گوناگونی مانند بهبود سیستمهای دستیار صوتی، تشخیص هویت ازطریق صوت و بهبود سیستمهای ارتباطی استفاده شود.

پرسشهای متداول
چرا نرخ نمونهبرداری (Sample Rate) در کیفیت فایلهای صوتی نقش مهمی دارد؟
در پردازش صوت نرخ نمونهبرداری نشاندهنده تعداد نمونههای صوتی است که در هر ثانیه ضبط میشود. این معیار بر دقت و وضوح صدای ضبط شده تأثیر مستقیمی میگذارد و در تعیین محدوده فرکانسهای قابل شنیدن صدا نیز نقش دارد.
طیفنگاری (Spectrography) چگونه میتواند در تحلیل صوتی به ما کمک کند؟
طیفنگاری تکنیکی است که توزیع فرکانسی (Frequency Distribution) یک سیگنال صوتی را در زمان نشان میدهد. این روش میتواند به تشخیص تغییرات صوتی در زمان و تفکیک صداهای مختلف موجود در یک نمونه صوتی کمک کند که برای تجزیهوتحلیلهای دقیق موسیقی یا گفتار بسیار مفید است.
تفاوت میان پردازش صوت آنالوگ (Analog) و دیجیتال (Digital) در چیست و کدامیک برای مصارف خاص ترجیح داده میشود؟
پردازش آنالوگ صوت را بهشکل مستقیم و بدون تغییر به دادههای دیجیتال میپذیرد، اما پردازش دیجیتال با تبدیل صوت به دادههای دیجیتالی اجازه استفاده از الگوریتمهای پیچیدهتر را میدهد. برای مواردی که به ویرایش دقیق و انجام پردازشهای پیچیده نیاز است، پردازش دیجیتال معمولاً ترجیح داده میشود.
چگونه فرمتهای مختلف صوتی مانند WAV و MP3 و WMA بر استفاده از فایلهای صوتی تأثیر میگذارند؟
هر فرمت صوتی خصوصیات خاص خود را دارد. فرمت WAV معمولاً برای کارهای حرفهای بهدلیل کیفیت بالا و نبود فشردهسازی ترجیح داده میشود، درحالیکه فرمتهای MP3 و WMA بهدلیل فشردهسازی و استفاده آسانتر در دستگاههای پخش موسیقی رایجتر هستند.
کاربردهای یادگیری عمیق (Deep Learning) در پردازش صوتی چیست و چه نوآوریهایی را میتوان انتظار داشت؟
یادگیری عمیق میتواند برای تشخیص گفتار، تولید موسیقی و طبقهبندی صداها استفاده شود. با پیشرفتهای جدید در این حوزه، انتظار میرود که دقت تشخیص گفتار بهبود یابد و سیستمهای پاسخگویی صوتی نیز قادر به درک و پاسخدهی بهتر به زبانهای مختلف و لهجهها باشند.
یادگیری دیتا ساینس و ماشین لرنینگ را از امروز شروع کنید!
دنیای دادهها جذاب است و دانستن علم داده، توانایی تحلیل داده، یا بازاریابی مبتنی بر داده و یادگیری ماشین شما را برای فرصتهای شغلی بسیاری مناسب میکند. فارغ از رشته تحصیلی و پیشزمینه شغلی، شما میتوانید یادگیری این دانش را همین امروز شروع کنید و آن را از سطح مقدماتی تا پیشرفته بیاموزید. اگر دوست دارید به این حوزه وارد شوید، پیشنهاد میکنیم با کلیک روی این لینک قدم اول را همین حالا بردارید.
مشاوران کافهتدریس به شما کمک میکنند مسیر یادگیری برای ورود به این حوزه را شروع کنید: