
{kind=link}
الگوریتم YOLO چیست و چه کاربردی در تشخیص اشیا دارد؟ در این مطلب بهصورت مفصل این الگوریتم را توضیح دادهایم؛ از پیشینهاش گفتهایم، عملکرد آن را براساس معیارهای مختلف بررسی کردهایم، طرز کار آن را شرح دادهایم و از کاربردهای مختلف آن گفتهایم.
الگوریتم YOLO
You Only Look Once یا YOLO یک الگوریتم پیشرفته تشخیص شیء بهشکل بلادرنگ است که در سال ۲۰۱۵ جوزف ردمون (Joseph Redmon)، سانتوش دیوالا (Santosh Divvala)، راس گیرشیک (Ross Girshick) و علی فرهادی (Ali Farhadi) در مقاله تحقیقاتی معروف “You Only Look Once, Unified, Real-Time Object Detection” آن را معرفی کردند.
نویسندگان با جداسازی فضایی کادرهای محدودکننده و اختصاص مقدار احتمال به هر یک از تصاویر شناساییشده با استفاده از یک شبکه عصبی کانولوشنی (CNN)، مسئلهی تشخیص شیء را بهعنوان یک تسک رگرسیونی (Regression) بهجای یک تسک طبقهبندی (Classification) مطرح میکنند.
الگوریتمهای مبتنی بر طبقهبندی در دو مرحله انجام میشوند. آنها با شناسایی مناطق مدنظر یا regions of interest در یک تصویر شروع میکنند. سپس از شبکه های عصبی کانولوشنی یا CNN برای طبقهبندی این مناطق استفاده میکنند. از آنجا که باید پیشبینیهایی را برای هر منطقه مشخصشده ارائه کنیم، این نوع الگوریتمها ممکن است کند باشند. شبکه عصبی کانولوشنی مبتنی بر منطقه یا Region-based CNN (RCNN) و Fast-RCNN، Faster-RCNN و Mask-RCNN نمونههای شناختهشدهای از این نوع الگوریتم هستند.
الگوریتمهای مبتنی بر رگرسیون کلاسها و کادرهای محدودکننده را برای کل تصویر در یک بار اجرای الگوریتم پیشبینی میکنند. الگوریتم های خانواده YOLO و SSD دو نمونه از شناختهشدهترین نمونههای این گروه هستند. آنها بهطور گسترده در زمینه تشخیص اشیا بهشکل بلادرنگ استفاده میشوند.
همانطور که در ابتدا گفتیم، در این مطلب قصد داریم الگوریتم YOLO را معرفی کنیم و ببینیم که این الگوریتم چطور کار میکند و چرا محبوب است؛ اما قبل از آنکه عمیقتر وارد بحث معرفی این الگوریتم شویم، بهتر است بدانیم تسکی که این الگوریتم برای آن شکل گرفته است، یعنی تشخیص شیء یا Object Detection، دقیقاً چیست؟
مقدمهای بر تشخیص اشیا
تشخیص اشیا یا Object Detection تکنیکی است که در بینایی ماشین (Computer Vision) برای شناسایی و مکانیابی اشیا در یک تصویر یا یک ویدئو استفاده میشود.
مکانیابی تصویر (Image Localization) فرایند شناسایی مکان صحیح یک یا چند شیء با استفاده از کادرهای محدودکننده (Bounding Box) است که درواقع همان شکلهای مستطیلی اطراف اشیا هستند.
گاهی این فرایند با طبقهبندی تصویر (Image Classification) یا تشخیص تصویر (Image Recognition) اشتباه گرفته میشود که هدف آن پیشبینی کلاس یک تصویر یا یک شیء در یک تصویر است.
تصویر ۱ تفاوت میان این سه تسک در حوزه بینایی ماشین را بهخوبی نشان میدهد. شیء شناساییشده در تصویر «شخص» است.

برای مطالعهی بیشتر درمورد تشخیص اشیا، پیشنهاد میکنیم حتماً مقالهی زیر را مطالعه کنید. ما در این مقاله بهطور مفصل و بهشکلی روان و قابل درک این مسئله را توضیح دادهایم:
چرا YOLO محبوب است؟
حال بهتر است برگردیم به موضوع اصلی، یعنی بررسی الگوریتم YOLO. اولین سؤالی که در اینجا مطرح است این است که چه چیزی YOLO را برای تسک تشخیص شیء محبوب میکند؟
پاسخ را باید در این ۴ عامل جستوجو کرد:
- سرعت (Speed)
- دقت تشخیص (Detection Accuracy)
- تعمیم خوب (Good Generalization)
- متنبازبودن (Open-scource)
بیایید این ۴ مورد را دقیقتر بررسی کنیم:
۱. سرعت
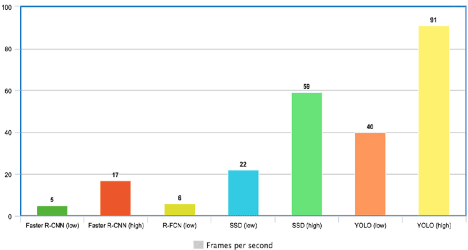
YOLO بسیار سریع است؛ زیرا با پایپلاین پیچیده سروکار ندارد. میتواند تصاویر را با سرعت ۴۵ فریم در ثانیه (FPS) پردازش کند؛ علاوهبراین، YOLO به بیش از دو برابر میانگین دقت متوسط (mAP) در مقایسه با دیگر سیستمهای بلادرنگ میرسد که آن را به یک کاندید عالی برای پردازش بلادرنگ تصاویر تبدیل میکند.
در تصویر ۲ مشاهده میکنیم که عملکرد YOLO بسیار فراتر از سایر مدلهای تشخیص شیء با 91 FPS است.
۲. دقت تشخیص بالا
YOLO از نظر دقت بسیار فراتر از دیگر مدلهای پیشرفته است و خطاهای پسزمینه (background errors) بسیار کمی دارد.
۳. تعمیم خوب
این امر بهویژه درمورد نسخههای جدید YOLO صادق است. با پیشرفتهای زیادی که در نسخههای جدید داشته است، YOLO با ارائه یک تعمیم خوب برای حوزههای جدید که به تشخیص سریع و قوی شیء متکی هستند عالی عمل میکند.
برای مثال، مقاله تشخیص خودکار ملانوم با شبکههای عصبی کانولوشنی عمیق Yolo نشان میدهد که نسخه اول YOLO یعنی YOLOv1 در مقایسه با YOLOv2 و YOLOv3 کمترین میانگین دقت را برای تشخیص خودکار بیماری ملانوم دارد.
۴. متنبازبودن
ساختن YOLO بهصورت متنباز به بهبود مستمر این مدل را رقم زده است؛ بههمین دلیل است که YOLO در چنین زمان محدودی چنین پیشرفتهای زیادی کرده است.
معماری YOLO
معماری YOLO مشابه GoogleNet است. همانطور که در تصویر ۳ نشان داده شده است، بهطور کلی ۲۴ لایه کانولوشن، چهار لایه max-pooling و دو لایه کاملاً متصل یا همان fully connected دارد.
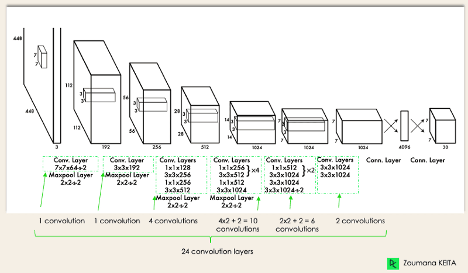
معماری YOLO بهاین شرح عمل میکند:
- اندازه تصویر ورودی را قبل از عبور از شبکه کانولوشن به ۴۴۸ در ۴۴۸ تغییر میدهد.
- یک کانولوشن ۱ در ۱ برای کاهش تعداد کانالها اعمال میشود و سپس یک کانولوشن ۳ در ۳ برای تولید یک خروجی مکعبی اعمال میشود.
- تابع فعالساز در آن ReLU است، البته بهجز لایهی نهایی که از تابع فعالساز خطی استفاده میکند.
- برخی از تکنیکهای اضافه، مانند نرمالسازی دستهای (batch normalization) و دراپاوت (dropout)، بهترتیب مدل را منظم (regularize) و از بیشبرازش یا همان overfitting جلوگیری میکنند.
الگوریتم تشخیص شیء YOLO چگونه کار میکند؟
اکنون که معماری YOLO را درک کردید، بیایید یک نمای کلی و سطح بالا از نحوه انجامدادن تشخیص شیء توسط الگوریتم YOLO داشته باشیم.
تصور کنید یک اپلیکیشن YOLO ساختهاید که بازیکنان و توپهای فوتبال را از روی یک تصویر مشخص تشخیص میدهد، اما چگونه میتوانید این روند را برای کسی توضیح دهید؟
حال، کل فرایند چگونگی انجامدادن تشخیص شیء را با استفاده از YOLO در اینجا درک خواهیم کرد که چطور طبق تصویر ۴، تصویر (B) از تصویر (A) در خروجی تولید میشود.
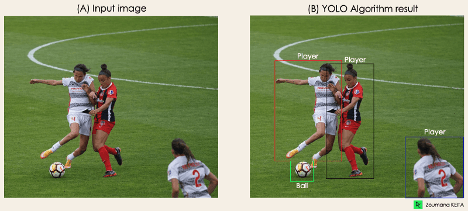
این الگوریتم براساس این چهار رویکرد کار میکند:
- بلوکهای رسوبی یا Residual blocks
- رگرسیون کادر محدودکننده یا Bounding box regression
- اشتراک روی اجتماع یا بهاختصار IOU
- سرکوب غیرحداکثری یا Non-Maximum Suppression
بیایید نگاهی دقیقتر به هر یک از آنها بیندازیم.
۱. بلوکهای رسوبی یا Residual Blocks
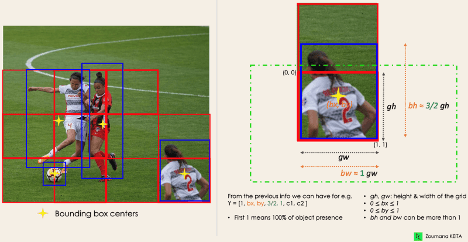
این مرحله با تقسیم تصویر اصلی (A) به سلولهای شبکهای (کادرها) NxN بهشکل مساوی شروع میشود. در مثال ما در تصویر ۵، N برابر با ۴ است که در تصویر سمت راست نشان داده شده است. هر سلول در شبکه مسئول مکانیابی و پیشبینی کلاس شیئی که پوشش میدهد، همراه با مقدار احتمال/اطمینان (Probability / Confidence value) است.

۲. رگرسیون کادر محدودکننده (Bounding Box Regression)
مرحله بعدی تعیین کادرهای محدودکننده است که همان مستطیلهایی است که اشیای موجود در تصویر را نشان میدهند. ما می توانیم به تعداد اشیای درون یک تصویر ارائه شده است کادرهای محدودکننده داشته باشیم.
YOLO با استفاده از یک ماژول رگرسیون منفرد در قالب زیر، ویژگیهای این کادرهای محدودکننده را تعیین میکند، بهطوری که Y نمایش بردار نهایی برای هر کادر محدودکننده است:
Y = [pc, bx, by, bh, bw, c1, c2]
این امر بهویژه در مرحله آموزش مدل بسیار مهم است، اما هر یک از این متغیرها نشاندهنده چه هستند؟
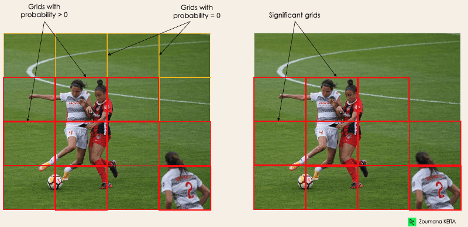
- pc احتمال این را که یک سلول (کادر محدودکننده) حاوی یک شیء باشد مشخص میکند؛ برای مثال، در تصویر ۶، تمامی کادرهای قرمز دارای امتیاز احتمالی بالاتر از صفر خواهند بود. تصویر سمت راست نسخه ساده شده است؛ زیرا احتمال هر سلول (کادر) زرد صفر یا ناچیز است.
- bx، با مختصات x و y مرکز کادر محدودکننده را نشان میدهد.
- bh، bw ارتفاع و عرض کادر محدودکننده را نشان میدهند.
- c1 و c2 مربوط به دو کلاس Player (بازیکن) و Ball (توپ) هستند. البته میتوانیم هر تعداد کلاس که مدنظرمان است و تسک ما نیاز دارد داشته باشیم. در اینجا هدف تشخیص این دو کلاس است.
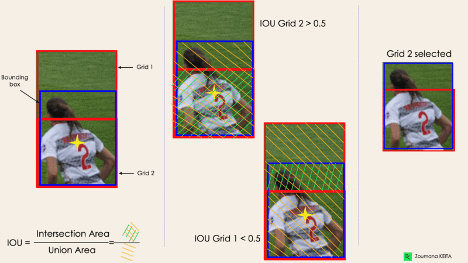
۳. اشتراک بر روی اجتماع یا IOU
اغلب اوقات، یک شیء منفرد در یک تصویر میتواند چندین نامزد کادر محدودکننده (یا همان سلولهایی که در ابتدا گفتیم) برای پیشبینی داشته باشد. هدف IOU (که مقدار آن بین ۰ و ۱ است) دورانداختن کادرهای محدودکنندهای است که مناسب نیستند و درواقع پیشبینی خوبی محسوب نمیشوند.
بهاین شکل که:
- کاربر حد آستانه IOU خود را تعریف میکند که برای مثال میتواند ۰.۵ باشد.
- سپس YOLO مقدار IOU هر کادر محدودکننده (سلول) را محاسبه میکند که مقدار ناحیه اشتراک تقسیم بر ناحیه اجتماع است.
- درنهایت، مدل کادرهای محدودکنندهی دارای IOU کمتر از حد آستانه را نادیده میگیرد و آنهایی را که IOU بیشتر از حد آستانه دارند در نظر میگیرد.
- در زیر تصویری از اعمال فرایند انتخاب سلول یا همان کادرمحدودکننده بر روی شیء پایین سمت چپ تصویر ارائه شده است. میتوانیم مشاهده کنیم که شیء در ابتدا دو نامزد کادر محدودکننده داشت، سپس در پایان فقط «کادر ۲» انتخاب شد.
۴. Non-Max Suppression یا NMS
نکتهای که اینجا باید در نظر بگیریم این است که تنظیم حد آستانه برای IOU همیشه کافی نیست؛ زیرا یک شیء میتواند چندین کادر با IOU بیشتر از حد آستانه داشته باشد و درنظرگرفتن همه آن کادرها ممکن است باعث اضافهکردن نویز شود. اینجاست که میتوانیم از NMS استفاده کنیم تا فقط کادرهایی را با بالاترین امتیاز احتمال تشخیص نگه داریم.
بنابراین بهاین شکل ما کادرهای محدودکنندهای را در خروجی خواهیم داشت که با احتمال بالا اشیای موجود در تصویر را شناسایی میکنند.
حال که با نحوه کار مدل YOLO آشنا شدیم، بهتر است به چند مورد از موارد کاربرد آن هم اشاره کنیم.
کاربردهای مدل YOLO
مدل تشخیص شیء YOLO کاربردهای متفاوتی در زندگی روزمره ما دارد. در این بخش به برخی از آنها در حوزههای پزشکی، کشاورزی، نظارت امنیتی و خودروهای خودران میپردازیم.
۱. پزشکی
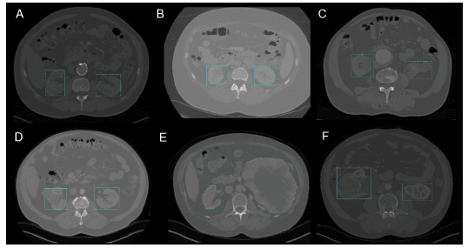
بهطور خاص در جراحی، مکانیابی (Localization) ارگانهای بدن بهشکل بلادرنگ، بهدلیل تنوع بیولوژیکی از یک بیمار به بیمار دیگر، میتواند چالشبرانگیز باشد. تشخیص کلیه در CT اسکن با استفاده از YOLOv3 برای تسهیل مکانیابی کلیهها بهصورت دوبعدی و سهبعدی از اسکنهای توموگرافی کامپیوتری (CT) نمونهای از این استفاده است.
۲. کشاورزی
هوش مصنوعی (AI) و رباتیک نقش مهمی در کشاورزی مدرن دارند. رباتهای برداشت محصول رباتهای مبتنی بر بینایی ماشین هستند که برای جایگزینی چیدن دستی میوهها و سبزیجات معرفی شدند. یکی از بهترین مدلها در این زمینه از YOLO استفاده میکند. در مقاله تشخیص گوجه فرنگی براساس فریمورک اصلاحشده YOLOv3، نویسندگان نحوه استفاده از YOLO را برای شناسایی انواع میوهها و سبزیجات برای برداشت مؤثر محصولات توصیف میکنند.

۳. نظارت امنیتی یا Security Surveillance
تشخیص اشیا یکی از بیشترین کاربردها را در نظارت امنیتی دارد. YOLOv3 در طول همهگیری کووید ۱۹ برای پیشبینی نقض فاصله اجتماعی میان افراد استفاده شده است. میتوانید درمورد این موضوع در مقاله یک فریمورک نظارت بر فاصله اجتماعی مبتنی بر یادگیری عمیق برای COVID-19 بیشتر بخوانید.
۴. خودروهای خودران
تشخیص اشیا بهشکل بلادرنگ بخشی از DNA سیستمهای خودروهای خودران (Autonomous Vehicles) است. این موضوع برای وسایل نقلیه خودران حیاتی است؛ زیرا آنها باید لاینهای صحیح جاده و تمامی اشیای اطراف و عابران پیاده را بهدرستی شناسایی کنند تا ایمنی جاده را افزایش دهند. جنبه بلادرنگ YOLO آن را در مقایسه با رویکردهای ساده بخشبندی تصویر (Image Segmentation) به کاندیدای بهتری تبدیل میکند.
پیشنهاد میکنیم درباره بخشبندی تصویر یا Image Segmentation هم مطالعه کنید.
یادگیری دیتا ساینس و ماشین لرنینگ را از امروز شروع کنید!
دنیای دادهها جذاب است و دانستن علم داده، توانایی تحلیل داده، یا بازاریابی مبتنی بر داده و یادگیری ماشین شما را برای فرصتهای شغلی بسیاری مناسب میکند. شما، فارغ از رشته تحصیلی و پیشزمینه شغلیتان، میتوانید یادگیری این دانش را از امروز شروع کنید و از سطح مقدماتی تا پیشرفته بیاموزید. اگر دوست دارید به این حوزه وارد شوید، پیشنهاد میکنیم با کلیک روی این لینک قدم اول را همین حالا بردارید.
مشاوران کافهتدریس به شما کمک میکنند مسیر یادگیری برای ورود به این حوزه را شروع کنید:
الگوریتم YOLO برای چه مقاصدی در زمینه تشخیص اشیا استفاده میشود؟
سرعت (Speed)
دقت تشخیص (Detection Accuracy)
تعمیم خوب (Good Generalization)
متنبازبودن (Open-scource)
الگوریتم YOLO چه ویژگیهایی دارد که آن را از سایر الگوریتمهای تشخیص شیء متمایز میکند؟
بلوکهای رسوبی یا Residual blocks
رگرسیون کادر محدودکننده یا Bounding box regression
اشتراک روی اجتماع یا بهاختصار IOU
سرکوب غیرحداکثری یا Non-Maximum Suppression
معماری YOLO را شرح دهید.
معماری YOLO بهاین شرح عمل میکند:
اندازه تصویر ورودی را قبل از عبور از شبکه کانولوشن به ۴۴۸ در ۴۴۸ تغییر میدهد.
یک کانولوشن ۱ در ۱ برای کاهش تعداد کانالها اعمال میشود و سپس یک کانولوشن ۳ در ۳ برای تولید یک خروجی مکعبی اعمال میشود.
تابع فعالساز در آن ReLU است، البته بهجز لایهی نهایی که از تابع فعالساز خطی استفاده میکند.
برخی از تکنیکهای اضافه، مانند نرمالسازی دستهای (batch normalization) و دراپاوت (dropout)، بهترتیب مدل را منظم (regularize) و از بیشبرازش یا همان overfitting جلوگیری میکنند.
سوال ۳:
اندازه تصویر ورودی را قبل از عبور از شبکه کانولوشن به ۴۴۸ در ۴۴۸ تغییر میدهد.
یک کانولوشن ۱ در ۱ برای کاهش تعداد کانالها اعمال میشود و سپس یک کانولوشن ۳ در ۳ برای تولید یک خروجی مکعبی اعمال میشود.
تابع فعالساز در آن ReLU است، البته بهجز لایهی نهایی که از تابع فعالساز خطی استفاده میکند.
برخی از تکنیکهای اضافه، مانند نرمالسازی دستهای (batch normalization) و دراپاوت (dropout)، بهترتیب مدل را منظم (regularize) و از بیشبرازش یا همان overfitting جلوگیری میکنند.
سوال ۱
پزشکی
کشاورزی
نظارت امنیتی
خودروهای خودران
سرعت (Speed)
سوال ۱:
دقت تشخیص (Detection Accuracy)
تعمیم خوب (Good Generalization)
متنبازبودن (Open-scource)